Compare commits
453 Commits
v0.9
...
ok/azure_d
| Author | SHA1 | Date | |
|---|---|---|---|
| c8b6d34189 | |||
| 95a8a28071 | |||
| faba5a224a | |||
| 19f85f08b0 | |||
| 8512e9dffb | |||
| 7c0be8ca44 | |||
| d9872d7031 | |||
| be4b9c4991 | |||
| 94172104f0 | |||
| 8ec790d4f7 | |||
| 640972b00a | |||
| 7810ba7d76 | |||
| d91f1fce09 | |||
| edcb666fbc | |||
| 6d359fe1d8 | |||
| 19e38595f3 | |||
| 355ef8c476 | |||
| f08d225360 | |||
| 22b7dd9f2d | |||
| a85a328791 | |||
| 82d10f24f0 | |||
| c9717f1d73 | |||
| 82b58d5b09 | |||
| b6d41d6a91 | |||
| ac74fa8431 | |||
| 42704d5781 | |||
| 3628786a61 | |||
| c69ede0138 | |||
| 4349156e97 | |||
| 9f88105f72 | |||
| fe6b2065fb | |||
| c2b0891c0b | |||
| 782f1ca1bd | |||
| 6d18a0c843 | |||
| e6093cd768 | |||
| aea0c4d45f | |||
| 1c2bb2ef3d | |||
| 7762bf59bf | |||
| 3e29848cd0 | |||
| c3b5aaf8cc | |||
| ba3f22d81e | |||
| ac7aaa0cd3 | |||
| 1ade09eaa3 | |||
| b7af45166a | |||
| 92f89e6ca0 | |||
| ed78bfd946 | |||
| 4204d78d7e | |||
| 3c2ed8bbf1 | |||
| 8d2da74380 | |||
| 39c1866121 | |||
| 1bba0162f8 | |||
| c07ea5ea32 | |||
| 2f9fbbf0ac | |||
| 0189e12fb1 | |||
| 58f93e0615 | |||
| 967494ce17 | |||
| 560d30dbb1 | |||
| c31ce3de35 | |||
| 0bd2f045a3 | |||
| 0b4a98b3aa | |||
| 7dfc306e7c | |||
| be88624e2a | |||
| ac9a46d4c4 | |||
| 3e1349ed1f | |||
| 0d89e6e760 | |||
| a9c8fb6a73 | |||
| fce52a66ff | |||
| dff31ff8f5 | |||
| 37b040b50a | |||
| 31168cd7de | |||
| db6ca434ac | |||
| 958bfe1000 | |||
| 815862e428 | |||
| b1ce29e27a | |||
| f7c2b3128f | |||
| a6764c9058 | |||
| a854e1a408 | |||
| ba3a8b24f0 | |||
| 26cb85c4f5 | |||
| 1d435ef3fa | |||
| 1632696c2f | |||
| d8d954bb0f | |||
| 08e9a91021 | |||
| 648c22ed1e | |||
| 49592ba2d7 | |||
| 0c4d451d9a | |||
| e698c7e2f3 | |||
| 663632e2d9 | |||
| 5fd3fdfae1 | |||
| 47b267a73d | |||
| 5c49ff216a | |||
| 5dc2595dcf | |||
| 664b1c9d17 | |||
| ba7781ba00 | |||
| 42be96a99b | |||
| 64a2c55d48 | |||
| eca8078071 | |||
| 9995ccd4c7 | |||
| 851c001aa5 | |||
| 2b23700aec | |||
| 553dad0bee | |||
| 37259e550f | |||
| 66cbd6ef8f | |||
| a9d789978b | |||
| f99862088e | |||
| e2797ad09a | |||
| ccb116922f | |||
| c079deba21 | |||
| 16b61eb4e8 | |||
| 68c26b362b | |||
| 6e63cf4014 | |||
| c59e9f77a6 | |||
| 2a3779776a | |||
| e25980f141 | |||
| 6c80fde6df | |||
| 75dcb035a7 | |||
| 2ac86f429f | |||
| 9d2003d789 | |||
| d2aef95847 | |||
| 1c4e64333c | |||
| f121a420c9 | |||
| 3b13738943 | |||
| 7a5acb29ac | |||
| ce35addcd3 | |||
| 5fb373b212 | |||
| 54891ad1d2 | |||
| 02871b1e3d | |||
| 38ea9143f3 | |||
| 246be6147f | |||
| 3531016a2c | |||
| e37598fdca | |||
| 557b39ec87 | |||
| 69a7c77a0d | |||
| 2a8c2e488a | |||
| 89c30ab5dc | |||
| ebb2ed891b | |||
| be8d6af87f | |||
| 8fb4a42ef1 | |||
| ca1ccd7b91 | |||
| b7225cc674 | |||
| a627dcd64f | |||
| 0c66554d50 | |||
| 506eafc0c5 | |||
| 6c7beccb4f | |||
| 7eb2e769cf | |||
| 5239e1c3e9 | |||
| 648dd3299f | |||
| 77a6fafdfc | |||
| ea7511e3c8 | |||
| 512c92fe51 | |||
| 1853b4ef47 | |||
| 2f10b4f3c5 | |||
| 73a20076eb | |||
| afb633811f | |||
| 81da328ae3 | |||
| 729f5e9c8e | |||
| fdc776887d | |||
| cb64f92cce | |||
| f3ad0e1d2a | |||
| 480e2ee678 | |||
| 9b97073174 | |||
| 4271bb7e52 | |||
| e9bf8574a8 | |||
| ebf7027aab | |||
| a1cbd80b2a | |||
| 2ce4af16cb | |||
| 2c1dfe7f3f | |||
| b8021d7ca3 | |||
| 523a896465 | |||
| f7a6348401 | |||
| 02c0c89b13 | |||
| b8cc110cbe | |||
| 2b1e841ef1 | |||
| a247fc3263 | |||
| 654938f27c | |||
| b6409929d2 | |||
| c0303ff9ec | |||
| f2abe5c73e | |||
| 7e47baa9db | |||
| a7a0de764c | |||
| 1b22e59b4b | |||
| f908d02ab4 | |||
| 7d2a35e32c | |||
| e351428848 | |||
| 4cd6649a44 | |||
| e62acef6d2 | |||
| a043eb939b | |||
| 73eafa2c3d | |||
| a61e492fe1 | |||
| 243f0f2b21 | |||
| 93b6d31505 | |||
| 429aed04b1 | |||
| eeb20b055a | |||
| 4b073b32a5 | |||
| f629755a9a | |||
| c1ed3ee511 | |||
| a4e6c99c82 | |||
| 0b70e07b8c | |||
| 862c236076 | |||
| 5c2f81a928 | |||
| b76bc390f1 | |||
| 25d1e84b7f | |||
| 70a409abf1 | |||
| cf3401536a | |||
| 2feaee4306 | |||
| 863eb0105d | |||
| 21a7a0f136 | |||
| d2a129fe30 | |||
| fe796245a3 | |||
| 10bc84eb5b | |||
| 06c0a35a65 | |||
| 082bcd00a1 | |||
| 71b421efa3 | |||
| 317fec0536 | |||
| 4dcbce41c8 | |||
| b3fa654446 | |||
| e09439fc1b | |||
| 324e481ce7 | |||
| abfad088e3 | |||
| f30789e6c8 | |||
| 5c01f97f54 | |||
| 2d726edbe4 | |||
| 526ad00812 | |||
| 37812dfede | |||
| c9debc38f2 | |||
| fe7d2bb924 | |||
| 586785ffde | |||
| c21e606eee | |||
| a658766046 | |||
| 3f2175e548 | |||
| 3ff30fcc92 | |||
| 07abf4788c | |||
| 492dd3c281 | |||
| d2fb1cfce5 | |||
| 24fe5a572a | |||
| 3af9c3bfb9 | |||
| c22084c7ac | |||
| 96b91c9daa | |||
| 55464d5c5b | |||
| f6048e8157 | |||
| e474982485 | |||
| 18f06cc670 | |||
| 574e3b9d32 | |||
| f7410da330 | |||
| 76f3d54519 | |||
| 59f117d916 | |||
| 4a71259be7 | |||
| b90dde48c0 | |||
| c57807e53a | |||
| 0e54a13272 | |||
| ddc6c02018 | |||
| b67d06ae59 | |||
| ca1289af03 | |||
| 5e642c10fa | |||
| b5a643d67a | |||
| 580eede021 | |||
| ea56910a2f | |||
| 51e1278cd7 | |||
| ddeb4b598d | |||
| 7e029ead45 | |||
| f8f57419c4 | |||
| 917f4b6a01 | |||
| 97d6fb999a | |||
| 1373ca23fc | |||
| 4521077433 | |||
| 6264624c05 | |||
| 5f6fa5a082 | |||
| 2dcee63df5 | |||
| c6cc676275 | |||
| b8e4d10b9d | |||
| 70a957caf0 | |||
| 5ff9aaedfd | |||
| fc8865f8dc | |||
| 466af37675 | |||
| 2202ff1cdf | |||
| 2022018d4c | |||
| b1c374808d | |||
| 20978402ea | |||
| 8f615e17a3 | |||
| 5cbbaf44c9 | |||
| f96d4924e7 | |||
| f36b672eaa | |||
| f104b70703 | |||
| d4e979cb02 | |||
| 668041c09f | |||
| aa73eb2841 | |||
| 14d4ca8c74 | |||
| 690c113603 | |||
| 1a28c77783 | |||
| 0326b7e4ac | |||
| d8ae32fc55 | |||
| 8db2e3b2a0 | |||
| 9465b7b577 | |||
| d7df4287f8 | |||
| b3238e90f2 | |||
| fdfd6247fb | |||
| 46d4d04e94 | |||
| 0f6564f42d | |||
| cddf183e03 | |||
| e80a0ed9c8 | |||
| d6d362b51e | |||
| 4eff0282a1 | |||
| 8fc07df6ef | |||
| 84e4b607cc | |||
| 613ccb4c34 | |||
| e95a6a8b07 | |||
| 2add584fbc | |||
| 54d7d59177 | |||
| b3129c7dd9 | |||
| 3f76d95495 | |||
| 1b600cd85f | |||
| 26cc26129c | |||
| d1d7903e39 | |||
| dff4d1befc | |||
| 3504a64269 | |||
| 83247cadec | |||
| 5ca1748b93 | |||
| c7a681038d | |||
| eb977b4c24 | |||
| b62e0967d5 | |||
| 14a934b146 | |||
| 26dc2e9d21 | |||
| d78a71184d | |||
| eae30c32a2 | |||
| bc28d657b2 | |||
| 416a5495da | |||
| a2b27dcac8 | |||
| d8e4e2e8fd | |||
| 3fae5cbd8d | |||
| 896a81d173 | |||
| b216af8f04 | |||
| 388cc740b6 | |||
| 6214494c84 | |||
| 762a6981e1 | |||
| b362c406bc | |||
| 7a342d3312 | |||
| 2e95988741 | |||
| 9478447141 | |||
| 082293b48c | |||
| e1d92206f3 | |||
| 557ec72bfe | |||
| 6b4b16dcf9 | |||
| c4899a6c54 | |||
| 24d82e65cb | |||
| 2567a6cf27 | |||
| 94cb6b9795 | |||
| e878bbbe36 | |||
| 172b5f0787 | |||
| 0df0542958 | |||
| 7d89b82967 | |||
| c5f9bbbf92 | |||
| a5e5a82952 | |||
| ccbb62b50a | |||
| a8dddd1999 | |||
| f5c6dd55b8 | |||
| 0e932af2e3 | |||
| 1df36c6a44 | |||
| e9891fc530 | |||
| 9e5e9afe92 | |||
| 5e43c202dd | |||
| 727eea2b62 | |||
| 37e6608e68 | |||
| f64d5f1e2a | |||
| 8fdf174dec | |||
| 29d4f98b19 | |||
| 737792d83c | |||
| 7e5889061c | |||
| 755e04cf65 | |||
| 44d6c95714 | |||
| 14610d5375 | |||
| f9c832d6cb | |||
| c2bec614e5 | |||
| 49725e92f2 | |||
| a1e32d8331 | |||
| 0293412a42 | |||
| 10ec0a1812 | |||
| 69b68b78f5 | |||
| c5bc4b44ff | |||
| 39e5102a2e | |||
| f0991526b5 | |||
| 6c82bc9a3e | |||
| 54f41dd603 | |||
| 094f641fb5 | |||
| a35a75eb34 | |||
| 5a7c118b56 | |||
| cf9e0fbbc5 | |||
| ef9af261ed | |||
| ff79776410 | |||
| ec3f2fb485 | |||
| 94a2a5e527 | |||
| ea4bc548fc | |||
| 1eefd3365b | |||
| db37ee819a | |||
| e352c98ce8 | |||
| e96b03da57 | |||
| 1d2aedf169 | |||
| 4c484f8e86 | |||
| 8a79114ed9 | |||
| cd69f43c77 | |||
| 6d6d864417 | |||
| b286c8ed20 | |||
| 7238c81f0c | |||
| 62412f8cd4 | |||
| 5d2bdadb45 | |||
| 06d030637c | |||
| 8e3fa3926a | |||
| 92071fcf1c | |||
| fed1c160eb | |||
| e37daf6987 | |||
| 8fc663911f | |||
| bb2760ae41 | |||
| 3548b88463 | |||
| c917e48098 | |||
| e6ef123ce5 | |||
| 194bfe1193 | |||
| e456cf36aa | |||
| fe3527de3c | |||
| b99c769b53 | |||
| 60bdfb78df | |||
| c0b3c76884 | |||
| e1370a8385 | |||
| c623c3baf4 | |||
| d0f3a4139d | |||
| 3ddc7e79d1 | |||
| 3e14edfd4e | |||
| 15573e2286 | |||
| ce64877063 | |||
| 6666a128ee | |||
| 9fbf89670d | |||
| ad1c51c536 | |||
| 9ab7ccd20d | |||
| c907f93ab8 | |||
| 29a8cf8357 | |||
| 7b6a6c7164 | |||
| cf4d007737 | |||
| a751bb0ef0 | |||
| 26d6280a20 | |||
| 32a19fdab6 | |||
| 775ccb3f25 | |||
| a1c6c57f7b | |||
| 73bb70fef4 | |||
| dcac6c145c | |||
| 4bda9dfe04 | |||
| 66644f0224 | |||
| e74bb80668 | |||
| e06fb534d3 | |||
| 71a341855e | |||
| 7d949ad6e2 | |||
| 4b5f86fcf0 | |||
| cd11f51df0 | |||
| b40c0b9b23 | |||
| 816ddeeb9e | |||
| 11f01a226c |
7
.github/workflows/pr-agent-review.yaml
vendored
@ -5,8 +5,9 @@
|
|||||||
name: PR-Agent
|
name: PR-Agent
|
||||||
|
|
||||||
on:
|
on:
|
||||||
pull_request:
|
# pull_request:
|
||||||
issue_comment:
|
# issue_comment:
|
||||||
|
workflow_dispatch:
|
||||||
|
|
||||||
permissions:
|
permissions:
|
||||||
issues: write
|
issues: write
|
||||||
@ -26,5 +27,7 @@ jobs:
|
|||||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||||
PINECONE.API_KEY: ${{ secrets.PINECONE_API_KEY }}
|
PINECONE.API_KEY: ${{ secrets.PINECONE_API_KEY }}
|
||||||
PINECONE.ENVIRONMENT: ${{ secrets.PINECONE_ENVIRONMENT }}
|
PINECONE.ENVIRONMENT: ${{ secrets.PINECONE_ENVIRONMENT }}
|
||||||
|
GITHUB_ACTION.AUTO_REVIEW: true
|
||||||
|
GITHUB_ACTION.AUTO_IMPROVE: true
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
6
.pr_agent.toml
Normal file
@ -0,0 +1,6 @@
|
|||||||
|
[pr_reviewer]
|
||||||
|
enable_review_labels_effort = true
|
||||||
|
|
||||||
|
|
||||||
|
[pr_code_suggestions]
|
||||||
|
summarize=true
|
||||||
88
INSTALL.md
@ -25,43 +25,48 @@ There are several ways to use PR-Agent:
|
|||||||
**BitBucket specific methods**
|
**BitBucket specific methods**
|
||||||
- [Run as a Bitbucket Pipeline](INSTALL.md#run-as-a-bitbucket-pipeline)
|
- [Run as a Bitbucket Pipeline](INSTALL.md#run-as-a-bitbucket-pipeline)
|
||||||
- [Run on a hosted app](INSTALL.md#run-on-a-hosted-bitbucket-app)
|
- [Run on a hosted app](INSTALL.md#run-on-a-hosted-bitbucket-app)
|
||||||
|
- [Bitbucket server and data center](INSTALL.md#bitbucket-server-and-data-center)
|
||||||
---
|
---
|
||||||
|
|
||||||
### Use Docker image (no installation required)
|
### Use Docker image (no installation required)
|
||||||
|
|
||||||
To request a review for a PR, or ask a question about a PR, you can run directly from the Docker image. Here's how:
|
A list of the relevant tools can be found in the [tools guide](./docs/TOOLS_GUIDE.md).
|
||||||
|
|
||||||
For GitHub:
|
To invoke a tool (for example `review`), you can run directly from the Docker image. Here's how:
|
||||||
|
|
||||||
|
- For GitHub:
|
||||||
```
|
```
|
||||||
docker run --rm -it -e OPENAI.KEY=<your key> -e GITHUB.USER_TOKEN=<your token> codiumai/pr-agent:latest --pr_url <pr_url> review
|
docker run --rm -it -e OPENAI.KEY=<your key> -e GITHUB.USER_TOKEN=<your token> codiumai/pr-agent:latest --pr_url <pr_url> review
|
||||||
```
|
```
|
||||||
For GitLab:
|
|
||||||
|
- For GitLab:
|
||||||
```
|
```
|
||||||
docker run --rm -it -e OPENAI.KEY=<your key> -e CONFIG.GIT_PROVIDER=gitlab -e GITLAB.PERSONAL_ACCESS_TOKEN=<your token> codiumai/pr-agent:latest --pr_url <pr_url> review
|
docker run --rm -it -e OPENAI.KEY=<your key> -e CONFIG.GIT_PROVIDER=gitlab -e GITLAB.PERSONAL_ACCESS_TOKEN=<your token> codiumai/pr-agent:latest --pr_url <pr_url> review
|
||||||
```
|
```
|
||||||
For BitBucket:
|
|
||||||
|
Note: If you have a dedicated GitLab instance, you need to specify the custom url as variable:
|
||||||
|
```
|
||||||
|
docker run --rm -it -e OPENAI.KEY=<your key> -e CONFIG.GIT_PROVIDER=gitlab -e GITLAB.PERSONAL_ACCESS_TOKEN=<your token> -e GITLAB.URL=<your gitlab instance url> codiumai/pr-agent:latest --pr_url <pr_url> review
|
||||||
|
```
|
||||||
|
|
||||||
|
- For BitBucket:
|
||||||
```
|
```
|
||||||
docker run --rm -it -e CONFIG.GIT_PROVIDER=bitbucket -e OPENAI.KEY=$OPENAI_API_KEY -e BITBUCKET.BEARER_TOKEN=$BITBUCKET_BEARER_TOKEN codiumai/pr-agent:latest --pr_url=<pr_url> review
|
docker run --rm -it -e CONFIG.GIT_PROVIDER=bitbucket -e OPENAI.KEY=$OPENAI_API_KEY -e BITBUCKET.BEARER_TOKEN=$BITBUCKET_BEARER_TOKEN codiumai/pr-agent:latest --pr_url=<pr_url> review
|
||||||
```
|
```
|
||||||
|
|
||||||
For other git providers, update CONFIG.GIT_PROVIDER accordingly, and check the `pr_agent/settings/.secrets_template.toml` file for the environment variables expected names and values.
|
For other git providers, update CONFIG.GIT_PROVIDER accordingly, and check the `pr_agent/settings/.secrets_template.toml` file for the environment variables expected names and values.
|
||||||
|
|
||||||
|
---
|
||||||
Similarly, to ask a question about a PR, run the following command:
|
|
||||||
```
|
|
||||||
docker run --rm -it -e OPENAI.KEY=<your key> -e GITHUB.USER_TOKEN=<your token> codiumai/pr-agent --pr_url <pr_url> ask "<your question>"
|
|
||||||
```
|
|
||||||
|
|
||||||
A list of the relevant tools can be found in the [tools guide](./docs/TOOLS_GUIDE.md).
|
|
||||||
|
|
||||||
|
|
||||||
Note: If you want to ensure you're running a specific version of the Docker image, consider using the image's digest:
|
If you want to ensure you're running a specific version of the Docker image, consider using the image's digest:
|
||||||
```bash
|
```bash
|
||||||
docker run --rm -it -e OPENAI.KEY=<your key> -e GITHUB.USER_TOKEN=<your token> codiumai/pr-agent@sha256:71b5ee15df59c745d352d84752d01561ba64b6d51327f97d46152f0c58a5f678 --pr_url <pr_url> review
|
docker run --rm -it -e OPENAI.KEY=<your key> -e GITHUB.USER_TOKEN=<your token> codiumai/pr-agent@sha256:71b5ee15df59c745d352d84752d01561ba64b6d51327f97d46152f0c58a5f678 --pr_url <pr_url> review
|
||||||
```
|
```
|
||||||
in addition, you can run a [specific released versions](./RELEASE_NOTES.md) of pr-agent, for example:
|
|
||||||
|
Or you can run a [specific released versions](./RELEASE_NOTES.md) of pr-agent, for example:
|
||||||
```
|
```
|
||||||
codiumai/pr-agent@v0.8
|
codiumai/pr-agent@v0.9
|
||||||
```
|
```
|
||||||
|
|
||||||
---
|
---
|
||||||
@ -97,6 +102,7 @@ python3 -m pr_agent.cli --pr_url <pr_url> ask <your question>
|
|||||||
python3 -m pr_agent.cli --pr_url <pr_url> describe
|
python3 -m pr_agent.cli --pr_url <pr_url> describe
|
||||||
python3 -m pr_agent.cli --pr_url <pr_url> improve
|
python3 -m pr_agent.cli --pr_url <pr_url> improve
|
||||||
python3 -m pr_agent.cli --pr_url <pr_url> add_docs
|
python3 -m pr_agent.cli --pr_url <pr_url> add_docs
|
||||||
|
python3 -m pr_agent.cli --pr_url <pr_url> generate_labels
|
||||||
python3 -m pr_agent.cli --issue_url <issue_url> similar_issue
|
python3 -m pr_agent.cli --issue_url <issue_url> similar_issue
|
||||||
...
|
...
|
||||||
```
|
```
|
||||||
@ -151,10 +157,11 @@ jobs:
|
|||||||
OPENAI_KEY: ${{ secrets.OPENAI_KEY }}
|
OPENAI_KEY: ${{ secrets.OPENAI_KEY }}
|
||||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||||
```
|
```
|
||||||
2. Add the following secret to your repository under `Settings > Secrets`:
|
2. Add the following secret to your repository under `Settings > Secrets and variables > Actions > New repository secret > Add secret`:
|
||||||
|
|
||||||
```
|
```
|
||||||
OPENAI_KEY: <your key>
|
Name = OPENAI_KEY
|
||||||
|
Secret = <your key>
|
||||||
```
|
```
|
||||||
|
|
||||||
The GITHUB_TOKEN secret is automatically created by GitHub.
|
The GITHUB_TOKEN secret is automatically created by GitHub.
|
||||||
@ -199,6 +206,7 @@ Allowing you to automate the review process on your private or public repositori
|
|||||||
- Set the following events:
|
- Set the following events:
|
||||||
- Issue comment
|
- Issue comment
|
||||||
- Pull request
|
- Pull request
|
||||||
|
- Push (if you need to enable triggering on PR update)
|
||||||
|
|
||||||
2. Generate a random secret for your app, and save it for later. For example, you can use:
|
2. Generate a random secret for your app, and save it for later. For example, you can use:
|
||||||
|
|
||||||
@ -285,7 +293,8 @@ docker push codiumai/pr-agent:github_app # Push to your Docker repository
|
|||||||
```
|
```
|
||||||
4. Create a lambda function that uses the uploaded image. Set the lambda timeout to be at least 3m.
|
4. Create a lambda function that uses the uploaded image. Set the lambda timeout to be at least 3m.
|
||||||
5. Configure the lambda function to have a Function URL.
|
5. Configure the lambda function to have a Function URL.
|
||||||
6. Go back to steps 8-9 of [Method 5](#run-as-a-github-app) with the function url as your Webhook URL.
|
6. In the environment variables of the Lambda function, specify `AZURE_DEVOPS_CACHE_DIR` to a writable location such as /tmp. (see [link](https://github.com/Codium-ai/pr-agent/pull/450#issuecomment-1840242269))
|
||||||
|
7. Go back to steps 8-9 of [Method 5](#run-as-a-github-app) with the function url as your Webhook URL.
|
||||||
The Webhook URL would look like `https://<LAMBDA_FUNCTION_URL>/api/v1/github_webhooks`
|
The Webhook URL would look like `https://<LAMBDA_FUNCTION_URL>/api/v1/github_webhooks`
|
||||||
|
|
||||||
---
|
---
|
||||||
@ -368,7 +377,7 @@ PYTHONPATH="/PATH/TO/PROJECTS/pr-agent" python pr_agent/cli.py \
|
|||||||
```
|
```
|
||||||
WEBHOOK_SECRET=$(python -c "import secrets; print(secrets.token_hex(10))")
|
WEBHOOK_SECRET=$(python -c "import secrets; print(secrets.token_hex(10))")
|
||||||
```
|
```
|
||||||
3. Follow the instructions to build the Docker image, setup a secrets file and deploy on your own server from [Method 5](#method-5-run-as-a-github-app) steps 4-7.
|
3. Follow the instructions to build the Docker image, setup a secrets file and deploy on your own server from [Method 5](#run-as-a-github-app) steps 4-7.
|
||||||
4. In the secrets file, fill in the following:
|
4. In the secrets file, fill in the following:
|
||||||
- Your OpenAI key.
|
- Your OpenAI key.
|
||||||
- In the [gitlab] section, fill in personal_access_token and shared_secret. The access token can be a personal access token, or a group or project access token.
|
- In the [gitlab] section, fill in personal_access_token and shared_secret. The access token can be a personal access token, or a group or project access token.
|
||||||
@ -405,10 +414,49 @@ BITBUCKET_BEARER_TOKEN: <your token>
|
|||||||
|
|
||||||
You can get a Bitbucket token for your repository by following Repository Settings -> Security -> Access Tokens.
|
You can get a Bitbucket token for your repository by following Repository Settings -> Security -> Access Tokens.
|
||||||
|
|
||||||
|
Note that comments on a PR are not supported in Bitbucket Pipeline.
|
||||||
|
|
||||||
### Run on a hosted Bitbucket app
|
|
||||||
|
|
||||||
Please contact <support@codium.ai> if you're interested in a hosted BitBucket app solution that provides full functionality including PR reviews and comment handling. It's based on the [bitbucket_app.py](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/git_providers/bitbucket_provider.py) implmentation.
|
### Run using CodiumAI-hosted Bitbucket app
|
||||||
|
|
||||||
|
Please contact <support@codium.ai> or visit [CodiumAI pricing page](https://www.codium.ai/pricing/) if you're interested in a hosted BitBucket app solution that provides full functionality including PR reviews and comment handling. It's based on the [bitbucket_app.py](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/git_providers/bitbucket_provider.py) implementation.
|
||||||
|
|
||||||
|
|
||||||
|
### Bitbucket Server and Data Center
|
||||||
|
|
||||||
|
Login into your on-prem instance of Bitbucket with your service account username and password.
|
||||||
|
Navigate to `Manage account`, `HTTP Access tokens`, `Create Token`.
|
||||||
|
Generate the token and add it to .secret.toml under `bitbucket_server` section
|
||||||
|
|
||||||
|
```toml
|
||||||
|
[bitbucket_server]
|
||||||
|
bearer_token = "<your key>"
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Run it as CLI
|
||||||
|
|
||||||
|
Modify `configuration.toml`:
|
||||||
|
|
||||||
|
```toml
|
||||||
|
git_provider="bitbucket_server"
|
||||||
|
```
|
||||||
|
|
||||||
|
and pass the Pull request URL:
|
||||||
|
```shell
|
||||||
|
python cli.py --pr_url https://git.onpreminstanceofbitbucket.com/projects/PROJECT/repos/REPO/pull-requests/1 review
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Run it as service
|
||||||
|
|
||||||
|
To run pr-agent as webhook, build the docker image:
|
||||||
|
```
|
||||||
|
docker build . -t codiumai/pr-agent:bitbucket_server_webhook --target bitbucket_server_webhook -f docker/Dockerfile
|
||||||
|
docker push codiumai/pr-agent:bitbucket_server_webhook # Push to your Docker repository
|
||||||
|
```
|
||||||
|
|
||||||
|
Navigate to `Projects` or `Repositories`, `Settings`, `Webhooks`, `Create Webhook`.
|
||||||
|
Fill the name and URL, Authentication None select the Pull Request Opened checkbox to receive that event as webhook.
|
||||||
|
|
||||||
|
The URL should end with `/webhook`, for example: https://domain.com/webhook
|
||||||
|
|
||||||
=======
|
=======
|
||||||
|
|||||||
@ -39,4 +39,4 @@ We use [tiktoken](https://github.com/openai/tiktoken) to tokenize the patches af
|
|||||||
4. If we haven't reached the max token length, add the `deleted files` to the prompt until the prompt reaches the max token length (hard stop), skip the rest of the patches.
|
4. If we haven't reached the max token length, add the `deleted files` to the prompt until the prompt reaches the max token length (hard stop), skip the rest of the patches.
|
||||||
|
|
||||||
### Example
|
### Example
|
||||||
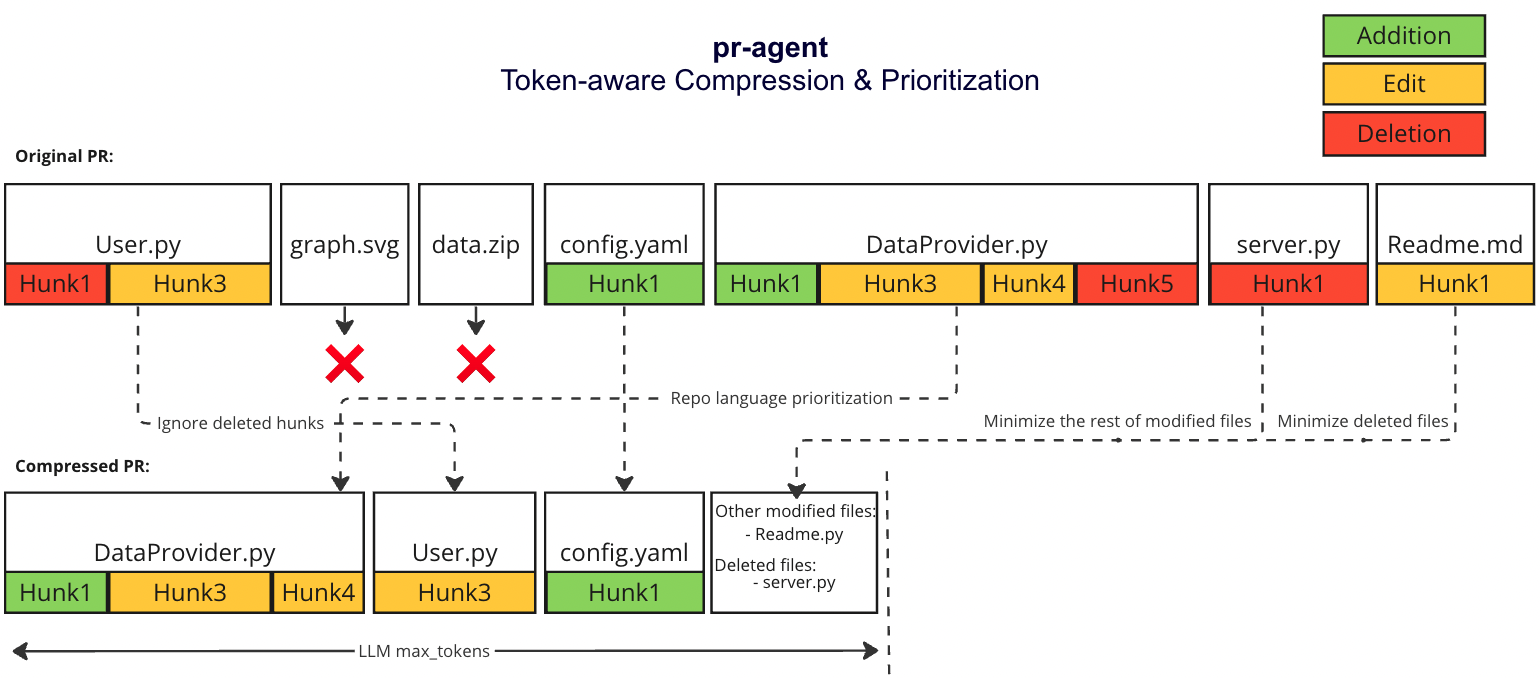
|
<kbd><img src=https://codium.ai/images/git_patch_logic.png width="768"></kbd>
|
||||||
|
|||||||
187
README.md
@ -2,8 +2,13 @@
|
|||||||
|
|
||||||
<div align="center">
|
<div align="center">
|
||||||
|
|
||||||
<img src="./pics/logo-dark.png#gh-dark-mode-only" width="330"/>
|
|
||||||
<img src="./pics/logo-light.png#gh-light-mode-only" width="330"/><br/>
|
<picture>
|
||||||
|
<source media="(prefers-color-scheme: dark)" srcset="https://codium.ai/images/pr_agent/logo-dark.png" width="330">
|
||||||
|
<source media="(prefers-color-scheme: light)" srcset="https://codium.ai/images/pr_agent/logo-light.png" width="330">
|
||||||
|
<img alt="logo">
|
||||||
|
</picture>
|
||||||
|
<br/>
|
||||||
Making pull requests less painful with an AI agent
|
Making pull requests less painful with an AI agent
|
||||||
</div>
|
</div>
|
||||||
|
|
||||||
@ -16,7 +21,7 @@ Making pull requests less painful with an AI agent
|
|||||||
</div>
|
</div>
|
||||||
<div style="text-align:left;">
|
<div style="text-align:left;">
|
||||||
|
|
||||||
CodiumAI `PR-Agent` is an open-source tool aiming to help developers review pull requests faster and more efficiently. It automatically analyzes the pull request and can provide several types of commands:
|
CodiumAI PR-Agent is an open-source tool to help efficiently review and handle pull requests. It automatically analyzes the pull request and can provide several types of commands:
|
||||||
|
|
||||||
‣ **Auto Description ([`/describe`](./docs/DESCRIBE.md))**: Automatically generating PR description - title, type, summary, code walkthrough and labels.
|
‣ **Auto Description ([`/describe`](./docs/DESCRIBE.md))**: Automatically generating PR description - title, type, summary, code walkthrough and labels.
|
||||||
\
|
\
|
||||||
@ -28,31 +33,54 @@ CodiumAI `PR-Agent` is an open-source tool aiming to help developers review pull
|
|||||||
\
|
\
|
||||||
‣ **Update Changelog ([`/update_changelog`](./docs/UPDATE_CHANGELOG.md))**: Automatically updating the CHANGELOG.md file with the PR changes.
|
‣ **Update Changelog ([`/update_changelog`](./docs/UPDATE_CHANGELOG.md))**: Automatically updating the CHANGELOG.md file with the PR changes.
|
||||||
\
|
\
|
||||||
‣ **Find Similar Issue ([`/similar_issue`](./docs/SIMILAR_ISSUE.md))**: Automatically retrieves and presents similar issues
|
‣ **Find Similar Issue ([`/similar_issue`](./docs/SIMILAR_ISSUE.md))**: Automatically retrieves and presents similar issues.
|
||||||
\
|
\
|
||||||
‣ **Add Documentation ([`/add_docs`](./docs/ADD_DOCUMENTATION.md))**: Automatically adds documentation to un-documented functions/classes in the PR.
|
‣ **Add Documentation 💎 ([`/add_docs`](./docs/ADD_DOCUMENTATION.md))**: Automatically adds documentation to methods/functions/classes that changed in the PR.
|
||||||
\
|
\
|
||||||
‣ **Generate Custom Labels ([`/generate_labels`](./docs/GENERATE_CUSTOM_LABELS.md))**: Automatically suggests custom labels based on the PR code changes.
|
‣ **Generate Custom Labels 💎 ([`/generate_labels`](./docs/GENERATE_CUSTOM_LABELS.md))**: Automatically suggests custom labels based on the PR code changes.
|
||||||
|
\
|
||||||
|
‣ **Analyze 💎 ([`/analyze`](./docs/Analyze.md))**: Automatically analyzes the PR, and presents changes walkthrough for each component.
|
||||||
|
|
||||||
See the [Installation Guide](./INSTALL.md) for instructions how to install and run the tool on different platforms.
|
|
||||||
|
|
||||||
See the [Usage Guide](./Usage.md) for instructions how to run the different tools from _CLI_, _online usage_, or by _automatically triggering_ them when a new PR is opened.
|
See the [Installation Guide](./INSTALL.md) for instructions on installing and running the tool on different git platforms.
|
||||||
|
|
||||||
See the [Tools Guide](./docs/TOOLS_GUIDE.md) for detailed description of the different tools.
|
See the [Usage Guide](./Usage.md) for running the PR-Agent commands via different interfaces, including _CLI_, _online usage_, or by _automatically triggering_ them when a new PR is opened.
|
||||||
|
|
||||||
<h3>Example results:</h3>
|
See the [Tools Guide](./docs/TOOLS_GUIDE.md) for a detailed description of the different tools (tools are run via the commands).
|
||||||
|
|
||||||
|
## Table of Contents
|
||||||
|
- [Example results](#example-results)
|
||||||
|
- [Features overview](#features-overview)
|
||||||
|
- [Try it now](#try-it-now)
|
||||||
|
- [Installation](#installation)
|
||||||
|
- [PR-Agent Pro 💎](#pr-agent-pro-)
|
||||||
|
- [How it works](#how-it-works)
|
||||||
|
- [Why use PR-Agent?](#why-use-pr-agent)
|
||||||
|
|
||||||
|
## Example results
|
||||||
</div>
|
</div>
|
||||||
<h4><a href="https://github.com/Codium-ai/pr-agent/pull/229#issuecomment-1687561986">/describe:</a></h4>
|
<h4><a href="https://github.com/Codium-ai/pr-agent/pull/530">/describe</a></h4>
|
||||||
<div align="center">
|
<div align="center">
|
||||||
<p float="center">
|
<p float="center">
|
||||||
<img src="https://www.codium.ai/images/describe-2.gif" width="800">
|
<img src="https://www.codium.ai/images/pr_agent/describe_short_main.png" width="800">
|
||||||
</p>
|
</p>
|
||||||
</div>
|
</div>
|
||||||
|
<hr>
|
||||||
|
<h4><a href="https://github.com/Codium-ai/pr-agent/pull/472#discussion_r1435819374">/improve</a></h4>
|
||||||
|
|
||||||
<h4><a href="https://github.com/Codium-ai/pr-agent/pull/229#issuecomment-1695021901">/review:</a></h4>
|
|
||||||
<div align="center">
|
<div align="center">
|
||||||
<p float="center">
|
<p float="center">
|
||||||
<img src="https://www.codium.ai/images/review-2.gif" width="800">
|
<kbd>
|
||||||
|
<img src="https://www.codium.ai/images/pr_agent/improve_short_main.png" width="768">
|
||||||
|
</kbd>
|
||||||
|
</p>
|
||||||
|
|
||||||
|
</div>
|
||||||
|
<hr>
|
||||||
|
<h4><a href="https://github.com/Codium-ai/pr-agent/pull/530">/generate_labels</a></h4>
|
||||||
|
<div align="center">
|
||||||
|
<p float="center">
|
||||||
|
<kbd><img src="https://www.codium.ai/images/pr_agent/geneare_custom_labels_main_short.png" width="300"></kbd>
|
||||||
</p>
|
</p>
|
||||||
</div>
|
</div>
|
||||||
|
|
||||||
@ -93,49 +121,48 @@ See the [Tools Guide](./docs/TOOLS_GUIDE.md) for detailed description of the dif
|
|||||||
[//]: # (</div>)
|
[//]: # (</div>)
|
||||||
<div align="left">
|
<div align="left">
|
||||||
|
|
||||||
## Table of Contents
|
|
||||||
- [Overview](#overview)
|
|
||||||
- [Try it now](#try-it-now)
|
|
||||||
- [Installation](#installation)
|
|
||||||
- [How it works](#how-it-works)
|
|
||||||
- [Why use PR-Agent?](#why-use-pr-agent)
|
|
||||||
- [Roadmap](#roadmap)
|
|
||||||
</div>
|
</div>
|
||||||
|
<hr>
|
||||||
|
|
||||||
|
## Features overview
|
||||||
## Overview
|
|
||||||
`PR-Agent` offers extensive pull request functionalities across various git providers:
|
`PR-Agent` offers extensive pull request functionalities across various git providers:
|
||||||
| | | GitHub | Gitlab | Bitbucket | CodeCommit | Azure DevOps | Gerrit |
|
| | | GitHub | Gitlab | Bitbucket |
|
||||||
|-------|---------------------------------------------|:------:|:------:|:---------:|:----------:|:----------:|:----------:|
|
|-------|---------------------------------------------|:------:|:------:|:---------:|
|
||||||
| TOOLS | Review | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
| TOOLS | Review | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||||
| | ⮑ Incremental | :white_check_mark: | | | | | |
|
| | ⮑ Incremental | :white_check_mark: | | |
|
||||||
| | Ask | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
| | ⮑ [SOC2 Compliance](https://github.com/Codium-ai/pr-agent/blob/main/docs/REVIEW.md#soc2-ticket-compliance-) 💎 | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||||
| | Auto-Description | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
| | Ask | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||||
| | Improve Code | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | | :white_check_mark: |
|
| | Describe | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||||
| | ⮑ Extended | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | | :white_check_mark: |
|
| | Improve | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||||
| | Reflect and Review | :white_check_mark: | :white_check_mark: | :white_check_mark: | | :white_check_mark: | :white_check_mark: |
|
| | ⮑ Extended | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||||
| | Update CHANGELOG.md | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | | |
|
| | Reflect and Review | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||||
| | Find similar issue | :white_check_mark: | | | | | |
|
| | Update CHANGELOG.md | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||||
| | Add Documentation | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | | :white_check_mark: |
|
| | Find Similar Issue | :white_check_mark: | | |
|
||||||
| | Generate Labels | :white_check_mark: | :white_check_mark: | | | | |
|
| | [Add PR Documentation](https://github.com/Codium-ai/pr-agent/blob/main/docs/ADD_DOCUMENTATION.md) 💎 | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||||
| | | | | | | |
|
| | [Generate Custom Labels](https://github.com/Codium-ai/pr-agent/blob/main/docs/DESCRIBE.md#handle-custom-labels-from-the-repos-labels-page-gem) 💎 | :white_check_mark: | :white_check_mark: | |
|
||||||
| USAGE | CLI | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
| | [Analyze PR Components](https://github.com/Codium-ai/pr-agent/blob/main/docs/Analyze.md) 💎 | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||||
| | App / webhook | :white_check_mark: | :white_check_mark: | | | |
|
| | | | | |
|
||||||
| | Tagging bot | :white_check_mark: | | | | |
|
| USAGE | CLI | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||||
| | Actions | :white_check_mark: | | | | |
|
| | App / webhook | :white_check_mark: | :white_check_mark: | |
|
||||||
| | Web server | | | | | | :white_check_mark: |
|
| | Tagging bot | :white_check_mark: | | |
|
||||||
| | | | | | | |
|
| | Actions | :white_check_mark: | | |
|
||||||
| CORE | PR compression | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
| | | | | |
|
||||||
| | Repo language prioritization | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
| CORE | PR compression | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||||
| | Adaptive and token-aware<br />file patch fitting | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
| | Repo language prioritization | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||||
| | Multiple models support | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
| | Adaptive and token-aware<br />file patch fitting | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||||
| | Incremental PR Review | :white_check_mark: | | | | | |
|
| | Multiple models support | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||||
|
| | Incremental PR review | :white_check_mark: | | |
|
||||||
|
| | [Static code analysis](https://github.com/Codium-ai/pr-agent/blob/main/docs/Analyze.md) 💎 | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||||
|
| | [Global configuration](https://github.com/Codium-ai/pr-agent/blob/main/Usage.md#global-configuration-file-) 💎 | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||||
|
|
||||||
Review the [usage guide](./Usage.md) section for detailed instructions how to use the different tools, select the relevant git provider (GitHub, Gitlab, Bitbucket,...), and adjust the configuration file to your needs.
|
|
||||||
|
- 💎 means this feature is available only in [PR-Agent Pro](https://www.codium.ai/pricing/)
|
||||||
|
- Support for additional git providers is described in [here](./docs/Full_enviroments.md)
|
||||||
|
|
||||||
## Try it now
|
## Try it now
|
||||||
|
|
||||||
You can try GPT-4 powered PR-Agent, on your public GitHub repository, instantly. Just mention `@CodiumAI-Agent` and add the desired command in any PR comment. The agent will generate a response based on your command.
|
Try the GPT-4 powered PR-Agent instantly on _your public GitHub repository_. Just mention `@CodiumAI-Agent` and add the desired command in any PR comment. The agent will generate a response based on your command.
|
||||||
For example, add a comment to any pull request with the following text:
|
For example, add a comment to any pull request with the following text:
|
||||||
```
|
```
|
||||||
@CodiumAI-Agent /review
|
@CodiumAI-Agent /review
|
||||||
@ -146,12 +173,12 @@ and the agent will respond with a review of your PR
|
|||||||
|
|
||||||
|
|
||||||
To set up your own PR-Agent, see the [Installation](#installation) section below.
|
To set up your own PR-Agent, see the [Installation](#installation) section below.
|
||||||
|
Note that when you set your own PR-Agent or use CodiumAI hosted PR-Agent, there is no need to mention `@CodiumAI-Agent ...`. Instead, directly start with the command, e.g., `/ask ...`.
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
## Installation
|
## Installation
|
||||||
|
To use your own version of PR-Agent, you first need to acquire two tokens:
|
||||||
To get started with PR-Agent quickly, you first need to acquire two tokens:
|
|
||||||
|
|
||||||
1. An OpenAI key from [here](https://platform.openai.com/), with access to GPT-4.
|
1. An OpenAI key from [here](https://platform.openai.com/), with access to GPT-4.
|
||||||
2. A GitHub personal access token (classic) with the repo scope.
|
2. A GitHub personal access token (classic) with the repo scope.
|
||||||
@ -170,59 +197,49 @@ There are several ways to use PR-Agent:
|
|||||||
- [Method 8: Run a GitLab webhook server](INSTALL.md#method-8---run-a-gitlab-webhook-server)
|
- [Method 8: Run a GitLab webhook server](INSTALL.md#method-8---run-a-gitlab-webhook-server)
|
||||||
- [Method 9: Run as a Bitbucket Pipeline](INSTALL.md#method-9-run-as-a-bitbucket-pipeline)
|
- [Method 9: Run as a Bitbucket Pipeline](INSTALL.md#method-9-run-as-a-bitbucket-pipeline)
|
||||||
|
|
||||||
|
## PR-Agent Pro 💎
|
||||||
|
[PR-Agent Pro](https://www.codium.ai/pricing/) is a hosted version of PR-Agent, provided by CodiumAI. It is available for a monthly fee, and provides the following benefits:
|
||||||
|
1. **Fully managed** - We take care of everything for you - hosting, models, regular updates, and more. Installation is as simple as signing up and adding the PR-Agent app to your GitHub\BitBucket repo.
|
||||||
|
2. **Improved privacy** - No data will be stored or used to train models. PR-Agent Pro will employ zero data retention, and will use an OpenAI account with zero data retention.
|
||||||
|
3. **Improved support** - PR-Agent Pro users will receive priority support, and will be able to request new features and capabilities.
|
||||||
|
4. **Extra features** -In addition to the benefits listed above, PR-Agent Pro will emphasize more customization, and the usage of static code analysis, in addition to LLM logic, to improve results. It has the following additional features:
|
||||||
|
- [**SOC2 compliance check**](https://github.com/Codium-ai/pr-agent/blob/main/docs/REVIEW.md#soc2-ticket-compliance-)
|
||||||
|
- [**PR documentation**](https://github.com/Codium-ai/pr-agent/blob/main/docs/ADD_DOCUMENTATION.md)
|
||||||
|
- [**Custom labels**](https://github.com/Codium-ai/pr-agent/blob/main/docs/DESCRIBE.md#handle-custom-labels-from-the-repos-labels-page-gem)
|
||||||
|
- [**Global configuration**](https://github.com/Codium-ai/pr-agent/blob/main/Usage.md#global-configuration-file-)
|
||||||
|
- [**Analyze PR components**](https://github.com/Codium-ai/pr-agent/blob/main/docs/Analyze.md)
|
||||||
|
- **Custom Code Suggestions** [WIP]
|
||||||
|
- **Chat on Specific Code Lines** [WIP]
|
||||||
|
|
||||||
|
|
||||||
## How it works
|
## How it works
|
||||||
|
|
||||||
The following diagram illustrates PR-Agent tools and their flow:
|
The following diagram illustrates PR-Agent tools and their flow:
|
||||||
|
|
||||||

|
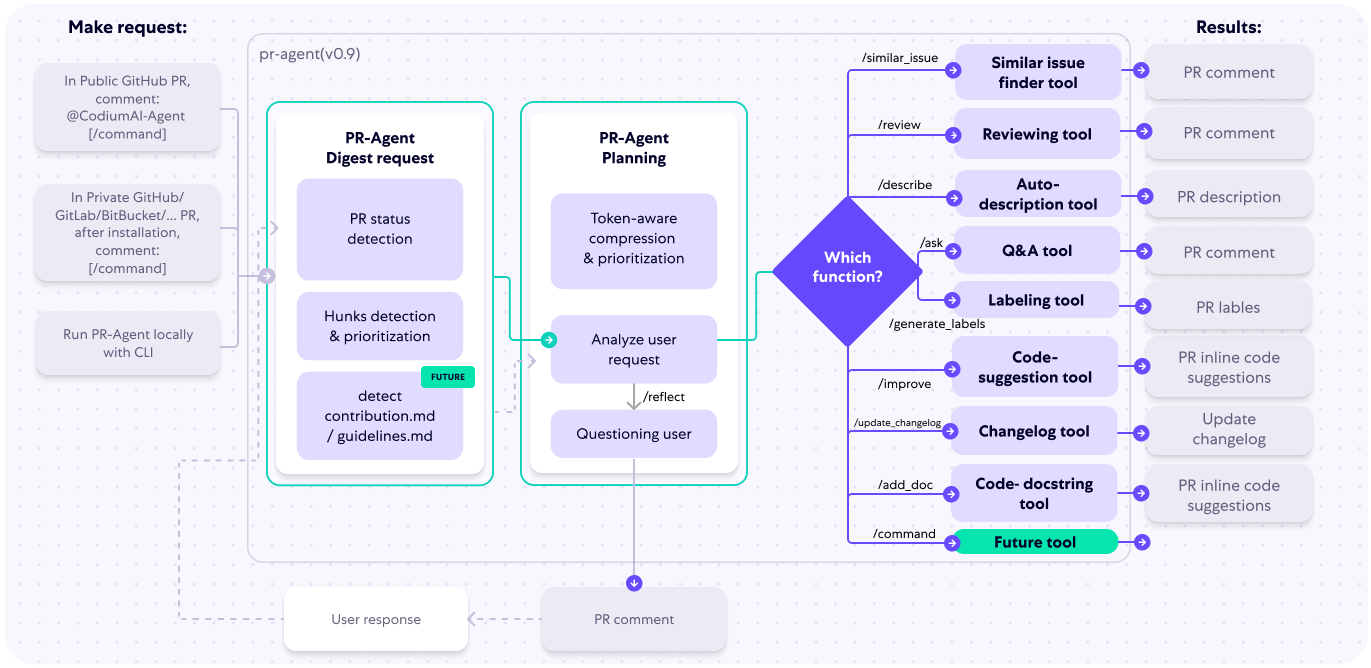
|
||||||
|
|
||||||
Check out the [PR Compression strategy](./PR_COMPRESSION.md) page for more details on how we convert a code diff to a manageable LLM prompt
|
Check out the [PR Compression strategy](./PR_COMPRESSION.md) page for more details on how we convert a code diff to a manageable LLM prompt
|
||||||
|
|
||||||
## Why use PR-Agent?
|
## Why use PR-Agent?
|
||||||
|
|
||||||
A reasonable question that can be asked is: `"Why use PR-Agent? What make it stand out from existing tools?"`
|
A reasonable question that can be asked is: `"Why use PR-Agent? What makes it stand out from existing tools?"`
|
||||||
|
|
||||||
Here are some advantages of PR-Agent:
|
Here are some advantages of PR-Agent:
|
||||||
|
|
||||||
- We emphasize **real-life practical usage**. Each tool (review, improve, ask, ...) has a single GPT-4 call, no more. We feel that this is critical for realistic team usage - obtaining an answer quickly (~30 seconds) and affordably.
|
- We emphasize **real-life practical usage**. Each tool (review, improve, ask, ...) has a single GPT-4 call, no more. We feel that this is critical for realistic team usage - obtaining an answer quickly (~30 seconds) and affordably.
|
||||||
- Our [PR Compression strategy](./PR_COMPRESSION.md) is a core ability that enables to effectively tackle both short and long PRs.
|
- Our [PR Compression strategy](./PR_COMPRESSION.md) is a core ability that enables to effectively tackle both short and long PRs.
|
||||||
- Our JSON prompting strategy enables to have **modular, customizable tools**. For example, the '/review' tool categories can be controlled via the [configuration](pr_agent/settings/configuration.toml) file. Adding additional categories is easy and accessible.
|
- Our JSON prompting strategy enables to have **modular, customizable tools**. For example, the '/review' tool categories can be controlled via the [configuration](pr_agent/settings/configuration.toml) file. Adding additional categories is easy and accessible.
|
||||||
- We support **multiple git providers** (GitHub, Gitlab, Bitbucket, CodeCommit), **multiple ways** to use the tool (CLI, GitHub Action, GitHub App, Docker, ...), and **multiple models** (GPT-4, GPT-3.5, Anthropic, Cohere, Llama2).
|
- We support **multiple git providers** (GitHub, Gitlab, Bitbucket), **multiple ways** to use the tool (CLI, GitHub Action, GitHub App, Docker, ...), and **multiple models** (GPT-4, GPT-3.5, Anthropic, Cohere, Llama2).
|
||||||
- We are open-source, and welcome contributions from the community.
|
|
||||||
|
|
||||||
|
|
||||||
## Roadmap
|
## Data privacy
|
||||||
|
|
||||||
- [x] Support additional models, as a replacement for OpenAI (see [here](https://github.com/Codium-ai/pr-agent/pull/172))
|
If you host PR-Agent with your OpenAI API key, it is between you and OpenAI. You can read their API data privacy policy here:
|
||||||
- [x] Develop additional logic for handling large PRs (see [here](https://github.com/Codium-ai/pr-agent/pull/229))
|
|
||||||
- [ ] Add additional context to the prompt. For example, repo (or relevant files) summarization, with tools such a [ctags](https://github.com/universal-ctags/ctags)
|
|
||||||
- [x] PR-Agent for issues
|
|
||||||
- [ ] Adding more tools. Possible directions:
|
|
||||||
- [x] PR description
|
|
||||||
- [x] Inline code suggestions
|
|
||||||
- [x] Reflect and review
|
|
||||||
- [x] Rank the PR (see [here](https://github.com/Codium-ai/pr-agent/pull/89))
|
|
||||||
- [ ] Enforcing CONTRIBUTING.md guidelines
|
|
||||||
- [ ] Performance (are there any performance issues)
|
|
||||||
- [x] Documentation (is the PR properly documented)
|
|
||||||
- [ ] ...
|
|
||||||
|
|
||||||
See the [Release notes](./RELEASE_NOTES.md) for updates on the latest changes.
|
|
||||||
|
|
||||||
|
|
||||||
## Similar Projects
|
|
||||||
|
|
||||||
- [CodiumAI - Meaningful tests for busy devs](https://github.com/Codium-ai/codiumai-vscode-release) (although various capabilities are much more advanced in the CodiumAI IDE plugins)
|
|
||||||
- [Aider - GPT powered coding in your terminal](https://github.com/paul-gauthier/aider)
|
|
||||||
- [openai-pr-reviewer](https://github.com/coderabbitai/openai-pr-reviewer)
|
|
||||||
- [CodeReview BOT](https://github.com/anc95/ChatGPT-CodeReview)
|
|
||||||
- [AI-Maintainer](https://github.com/merwanehamadi/AI-Maintainer)
|
|
||||||
|
|
||||||
## Data Privacy
|
|
||||||
|
|
||||||
If you use self-host PR-Agent, e.g. via CLI running on your computer, with your OpenAI API key, it is between you and OpenAI. You can read their API data privacy policy here:
|
|
||||||
https://openai.com/enterprise-privacy
|
https://openai.com/enterprise-privacy
|
||||||
|
|
||||||
|
When using PR-Agent Pro 💎, hosted by CodiumAI, we will not store any of your data, nor will we use it for training.
|
||||||
|
You will also benefit from an OpenAI account with zero data retention.
|
||||||
|
|
||||||
## Links
|
## Links
|
||||||
|
|
||||||
[](https://discord.gg/kG35uSHDBc)
|
[](https://discord.gg/kG35uSHDBc)
|
||||||
|
|||||||
@ -1,3 +1,43 @@
|
|||||||
|
## [Version 0.11] - 2023-12-07
|
||||||
|
- codiumai/pr-agent:0.11
|
||||||
|
- codiumai/pr-agent:0.11-github_app
|
||||||
|
- codiumai/pr-agent:0.11-bitbucket-app
|
||||||
|
- codiumai/pr-agent:0.11-gitlab_webhook
|
||||||
|
- codiumai/pr-agent:0.11-github_polling
|
||||||
|
- codiumai/pr-agent:0.11-github_action
|
||||||
|
|
||||||
|
### Added::Algo
|
||||||
|
- New section in `/describe` tool - [PR changes walkthrough](https://github.com/Codium-ai/pr-agent/pull/509)
|
||||||
|
- Improving PR Agent [prompts](https://github.com/Codium-ai/pr-agent/pull/501)
|
||||||
|
- Persistent tools (`/review`, `/describe`) now send an [update message](https://github.com/Codium-ai/pr-agent/pull/499) after finishing
|
||||||
|
- Add Amazon Bedrock [support](https://github.com/Codium-ai/pr-agent/pull/483)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- Update [dependencies](https://github.com/Codium-ai/pr-agent/pull/503) in requirements.txt for Python 3.12
|
||||||
|
|
||||||
|
|
||||||
|
## [Version 0.10] - 2023-11-15
|
||||||
|
- codiumai/pr-agent:0.10
|
||||||
|
- codiumai/pr-agent:0.10-github_app
|
||||||
|
- codiumai/pr-agent:0.10-bitbucket-app
|
||||||
|
- codiumai/pr-agent:0.10-gitlab_webhook
|
||||||
|
- codiumai/pr-agent:0.10-github_polling
|
||||||
|
- codiumai/pr-agent:0.10-github_action
|
||||||
|
|
||||||
|
### Added::Algo
|
||||||
|
- Review tool now works with [persistent comments](https://github.com/Codium-ai/pr-agent/pull/451) by default
|
||||||
|
- Bitbucket now publishes review suggestions with [code links](https://github.com/Codium-ai/pr-agent/pull/428)
|
||||||
|
- Enabling to limit [max number of tokens](https://github.com/Codium-ai/pr-agent/pull/437/files)
|
||||||
|
- Support ['gpt-4-1106-preview'](https://github.com/Codium-ai/pr-agent/pull/437/files) model
|
||||||
|
- Support for Google's [Vertex AI](https://github.com/Codium-ai/pr-agent/pull/436)
|
||||||
|
- Implementing [thresholds](https://github.com/Codium-ai/pr-agent/pull/423) for incremental PR reviews
|
||||||
|
- Decoupled custom labels from [PR type](https://github.com/Codium-ai/pr-agent/pull/431)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- Fixed bug in [parsing quotes](https://github.com/Codium-ai/pr-agent/pull/446) in CLI
|
||||||
|
- Preserve [user-added labels](https://github.com/Codium-ai/pr-agent/pull/433) in pull requests
|
||||||
|
- Bug fixes in GitLab and BitBucket
|
||||||
|
|
||||||
## [Version 0.9] - 2023-10-29
|
## [Version 0.9] - 2023-10-29
|
||||||
- codiumai/pr-agent:0.9
|
- codiumai/pr-agent:0.9
|
||||||
- codiumai/pr-agent:0.9-github_app
|
- codiumai/pr-agent:0.9-github_app
|
||||||
@ -9,9 +49,10 @@
|
|||||||
### Added::Algo
|
### Added::Algo
|
||||||
- New tool - [generate_labels](https://github.com/Codium-ai/pr-agent/blob/main/docs/GENERATE_CUSTOM_LABELS.md)
|
- New tool - [generate_labels](https://github.com/Codium-ai/pr-agent/blob/main/docs/GENERATE_CUSTOM_LABELS.md)
|
||||||
- New ability to use [customize labels](https://github.com/Codium-ai/pr-agent/blob/main/docs/GENERATE_CUSTOM_LABELS.md#how-to-enable-custom-labels) on the `review` and `describe` tools.
|
- New ability to use [customize labels](https://github.com/Codium-ai/pr-agent/blob/main/docs/GENERATE_CUSTOM_LABELS.md#how-to-enable-custom-labels) on the `review` and `describe` tools.
|
||||||
|
- New tool - [add_docs](https://github.com/Codium-ai/pr-agent/blob/main/docs/ADD_DOCUMENTATION.md)
|
||||||
- GitHub Action: Can now use a `.pr_agent.toml` file to control configuration parameters (see [Usage Guide](./Usage.md#working-with-github-action)).
|
- GitHub Action: Can now use a `.pr_agent.toml` file to control configuration parameters (see [Usage Guide](./Usage.md#working-with-github-action)).
|
||||||
- GitHub App: Added ability to trigger tools on [push events](https://github.com/Codium-ai/pr-agent/blob/main/Usage.md#github-app-automatic-tools-for-new-code-pr-push)
|
- GitHub App: Added ability to trigger tools on [push events](https://github.com/Codium-ai/pr-agent/blob/main/Usage.md#github-app-automatic-tools-for-new-code-pr-push)
|
||||||
- Support custom domain URLs for azure devops integration (see [link](https://github.com/Codium-ai/pr-agent/pull/381)).
|
- Support custom domain URLs for Azure devops integration (see [link](https://github.com/Codium-ai/pr-agent/pull/381)).
|
||||||
- PR Description default mode is now in [bullet points](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml#L35).
|
- PR Description default mode is now in [bullet points](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml#L35).
|
||||||
|
|
||||||
### Added::Documentation
|
### Added::Documentation
|
||||||
|
|||||||
223
Usage.md
@ -2,13 +2,12 @@
|
|||||||
|
|
||||||
### Table of Contents
|
### Table of Contents
|
||||||
- [Introduction](#introduction)
|
- [Introduction](#introduction)
|
||||||
- [Working from a local repo (CLI)](#working-from-a-local-repo-cli)
|
- [Local Repo (CLI)](#working-from-a-local-repo-cli)
|
||||||
- [Online usage](#online-usage)
|
- [Online Usage](#online-usage)
|
||||||
- [Working with GitHub App](#working-with-github-app)
|
- [GitHub App](#working-with-github-app)
|
||||||
- [Working with GitHub Action](#working-with-github-action)
|
- [GitHub Action](#working-with-github-action)
|
||||||
- [Changing a model](#changing-a-model)
|
- [BitBucket App](#working-with-bitbucket-self-hosted-app)
|
||||||
- [Working with large PRs](#working-with-large-prs)
|
- [Additional Configurations Walkthrough](#appendix---additional-configurations-walkthrough)
|
||||||
- [Appendix - additional configurations walkthrough](#appendix---additional-configurations-walkthrough)
|
|
||||||
|
|
||||||
### Introduction
|
### Introduction
|
||||||
|
|
||||||
@ -24,20 +23,53 @@ GitHub App and GitHub Action also enable to run PR-Agent specific tool automatic
|
|||||||
|
|
||||||
|
|
||||||
#### The configuration file
|
#### The configuration file
|
||||||
The different tools and sub-tools used by CodiumAI PR-Agent are adjustable via the **[configuration file](pr_agent/settings/configuration.toml)**.
|
- The different tools and sub-tools used by CodiumAI PR-Agent are adjustable via the **[configuration file](pr_agent/settings/configuration.toml)**.
|
||||||
In addition to general configuration options, each tool has its own configurations. For example, the `review` tool will use parameters from the [pr_reviewer](/pr_agent/settings/configuration.toml#L16) section in the configuration file.
|
In addition to general configuration options, each tool has its own configurations. For example, the `review` tool will use parameters from the [pr_reviewer](/pr_agent/settings/configuration.toml#L16) section in the configuration file.
|
||||||
|
|
||||||
The [Tools Guide](./docs/TOOLS_GUIDE.md) provides a detailed description of the different tools and their configurations.
|
- The [Tools Guide](./docs/TOOLS_GUIDE.md) provides a detailed description of the different tools and their configurations.
|
||||||
|
|
||||||
|
|
||||||
|
- By uploading a local `.pr_agent.toml` file to the root of the repo's main branch, you can edit and customize any configuration parameter. Note that you need to upload `.pr_agent.toml` prior to creating a PR, in order for the configuration to take effect.
|
||||||
|
|
||||||
|
For example, if you set in `.pr_agent.toml`:
|
||||||
|
|
||||||
|
```
|
||||||
|
[pr_reviewer]
|
||||||
|
extra_instructions="""\
|
||||||
|
- instruction a
|
||||||
|
- instruction b
|
||||||
|
...
|
||||||
|
"""
|
||||||
|
```
|
||||||
|
|
||||||
|
Then you can give a list of extra instructions to the `review` tool.
|
||||||
|
|
||||||
|
|
||||||
|
#### Global configuration file 💎
|
||||||
|
|
||||||
|
If you create a repo called `pr-agent-settings` in your **organization**, it's configuration file `.pr_agent.toml` will be used as a global configuration file for any other repo that belongs to the same organization.
|
||||||
|
Parameters from a local `.pr_agent.toml` file, in a specific repo, will override the global configuration parameters.
|
||||||
|
|
||||||
|
For example, in the GitHub organization `Codium-ai`:
|
||||||
|
- The repo [`https://github.com/Codium-ai/pr-agent-settings`](https://github.com/Codium-ai/pr-agent-settings/blob/main/.pr_agent.toml) contains a `.pr_agent.toml` file that serves as a global configuration file for all the repos in the GitHub organization `Codium-ai`.
|
||||||
|
- The repo [`https://github.com/Codium-ai/pr-agent`](https://github.com/Codium-ai/pr-agent/blob/main/.pr_agent.toml) inherits the global configuration file from `pr-agent-settings`.
|
||||||
|
|
||||||
#### Ignoring files from analysis
|
#### Ignoring files from analysis
|
||||||
In some cases, you may want to exclude specific files or directories from the analysis performed by CodiumAI PR-Agent. This can be useful, for example, when you have files that are generated automatically or files that shouldn't be reviewed, like vendored code.
|
In some cases, you may want to exclude specific files or directories from the analysis performed by CodiumAI PR-Agent. This can be useful, for example, when you have files that are generated automatically or files that shouldn't be reviewed, like vendored code.
|
||||||
|
|
||||||
To ignore files or directories, edit the **[ignore.toml](/pr_agent/settings/ignore.toml)** configuration file. This setting is also exposed the following environment variables:
|
To ignore files or directories, edit the **[ignore.toml](/pr_agent/settings/ignore.toml)** configuration file. This setting also exposes the following environment variables:
|
||||||
|
|
||||||
- `IGNORE.GLOB`
|
- `IGNORE.GLOB`
|
||||||
- `IGNORE.REGEX`
|
- `IGNORE.REGEX`
|
||||||
|
|
||||||
See [dynaconf envvars documentation](https://www.dynaconf.com/envvars/).
|
For example, to ignore python files in a PR with online usage, comment on a PR:
|
||||||
|
`/review --ignore.glob=['*.py']`
|
||||||
|
|
||||||
|
To ignore python files in all PRs, set in a configuration file:
|
||||||
|
```
|
||||||
|
[ignore]
|
||||||
|
glob = ['*.py']
|
||||||
|
```
|
||||||
|
|
||||||
#### git provider
|
#### git provider
|
||||||
The [git_provider](pr_agent/settings/configuration.toml#L4) field in the configuration file determines the GIT provider that will be used by PR-Agent. Currently, the following providers are supported:
|
The [git_provider](pr_agent/settings/configuration.toml#L4) field in the configuration file determines the GIT provider that will be used by PR-Agent. Currently, the following providers are supported:
|
||||||
@ -45,21 +77,9 @@ The [git_provider](pr_agent/settings/configuration.toml#L4) field in the configu
|
|||||||
"github", "gitlab", "azure", "codecommit", "local", "gerrit"
|
"github", "gitlab", "azure", "codecommit", "local", "gerrit"
|
||||||
`
|
`
|
||||||
|
|
||||||
[//]: # (** online usage:**)
|
|
||||||
|
|
||||||
[//]: # (Options that are available in the configuration file can be specified at run time when calling actions. Two examples:)
|
|
||||||
|
|
||||||
[//]: # (```)
|
|
||||||
|
|
||||||
[//]: # (- /review --pr_reviewer.extra_instructions="focus on the file: ...")
|
|
||||||
|
|
||||||
[//]: # (- /describe --pr_description.add_original_user_description=false -pr_description.extra_instructions="make sure to mention: ...")
|
|
||||||
|
|
||||||
[//]: # (```)
|
|
||||||
|
|
||||||
### Working from a local repo (CLI)
|
### Working from a local repo (CLI)
|
||||||
When running from your local repo (CLI), your local configuration file will be used.
|
When running from your local repo (CLI), your local configuration file will be used.
|
||||||
Examples for invoking the different tools via the CLI:
|
Examples of invoking the different tools via the CLI:
|
||||||
|
|
||||||
- **Review**: `python -m pr_agent.cli --pr_url=<pr_url> review`
|
- **Review**: `python -m pr_agent.cli --pr_url=<pr_url> review`
|
||||||
- **Describe**: `python -m pr_agent.cli --pr_url=<pr_url> describe`
|
- **Describe**: `python -m pr_agent.cli --pr_url=<pr_url> describe`
|
||||||
@ -83,7 +103,7 @@ python -m pr_agent.cli --pr_url=<pr_url> /review --pr_reviewer.extra_instructio
|
|||||||
publish_output=true
|
publish_output=true
|
||||||
verbosity_level=2
|
verbosity_level=2
|
||||||
```
|
```
|
||||||
This is useful for debugging or experimenting with the different tools.
|
This is useful for debugging or experimenting with different tools.
|
||||||
|
|
||||||
|
|
||||||
### Online usage
|
### Online usage
|
||||||
@ -100,20 +120,30 @@ Commands for invoking the different tools via comments:
|
|||||||
|
|
||||||
|
|
||||||
To edit a specific configuration value, just add `--config_path=<value>` to any command.
|
To edit a specific configuration value, just add `--config_path=<value>` to any command.
|
||||||
For example if you want to edit the `review` tool configurations, you can run:
|
For example, if you want to edit the `review` tool configurations, you can run:
|
||||||
```
|
```
|
||||||
/review --pr_reviewer.extra_instructions="..." --pr_reviewer.require_score_review=false
|
/review --pr_reviewer.extra_instructions="..." --pr_reviewer.require_score_review=false
|
||||||
```
|
```
|
||||||
Any configuration value in [configuration file](pr_agent/settings/configuration.toml) file can be similarly edited. comment `/config` to see the list of available configurations.
|
Any configuration value in [configuration file](pr_agent/settings/configuration.toml) file can be similarly edited. Comment `/config` to see the list of available configurations.
|
||||||
|
|
||||||
|
|
||||||
### Working with GitHub App
|
### Working with GitHub App
|
||||||
When running PR-Agent from [GitHub App](INSTALL.md#method-5-run-as-a-github-app), the default configurations from a pre-built docker will be initially loaded.
|
When running PR-Agent from GitHub App, the default [configuration file](pr_agent/settings/configuration.toml) from a pre-built docker will be initially loaded.
|
||||||
|
|
||||||
|
By uploading a local `.pr_agent.toml` file to the root of the repo's main branch, you can edit and customize any configuration parameter. Note that you need to upload `.pr_agent.toml` prior to creating a PR, in order for the configuration to take effect.
|
||||||
|
|
||||||
|
For example, if you set in `.pr_agent.toml`:
|
||||||
|
|
||||||
|
```
|
||||||
|
[pr_reviewer]
|
||||||
|
num_code_suggestions=1
|
||||||
|
```
|
||||||
|
|
||||||
|
Then you will overwrite the default number of code suggestions to 1.
|
||||||
|
|
||||||
#### GitHub app automatic tools
|
#### GitHub app automatic tools
|
||||||
The [github_app](pr_agent/settings/configuration.toml#L56) section defines GitHub app specific configurations.
|
The [github_app](pr_agent/settings/configuration.toml#L76) section defines GitHub app-specific configurations.
|
||||||
In this section you can define configurations to control the conditions for which tools will **run automatically**.
|
In this section, you can define configurations to control the conditions for which tools will **run automatically**.
|
||||||
Note that a local `.pr_agent.toml` file enables you to edit and customize the default parameters of any tool, not just the ones that are run automatically.
|
|
||||||
|
|
||||||
##### GitHub app automatic tools for PR actions
|
##### GitHub app automatic tools for PR actions
|
||||||
The GitHub app can respond to the following actions on a PR:
|
The GitHub app can respond to the following actions on a PR:
|
||||||
@ -123,17 +153,17 @@ The GitHub app can respond to the following actions on a PR:
|
|||||||
4. `review_requested` - Specifically requesting review (in the PR reviewers list) from the `github-actions[bot]` user
|
4. `review_requested` - Specifically requesting review (in the PR reviewers list) from the `github-actions[bot]` user
|
||||||
|
|
||||||
The configuration parameter `handle_pr_actions` defines the list of actions for which the GitHub app will trigger the PR-Agent.
|
The configuration parameter `handle_pr_actions` defines the list of actions for which the GitHub app will trigger the PR-Agent.
|
||||||
The configuration parameter `pr_commands` defines the list of tools that will be **run automatically** when one of the above action happens (e.g. a new PR is opened):
|
The configuration parameter `pr_commands` defines the list of tools that will be **run automatically** when one of the above actions happens (e.g., a new PR is opened):
|
||||||
```
|
```
|
||||||
[github_app]
|
[github_app]
|
||||||
handle_pr_actions = ['opened', 'reopened', 'ready_for_review', 'review_requested']
|
handle_pr_actions = ['opened', 'reopened', 'ready_for_review', 'review_requested']
|
||||||
pr_commands = [
|
pr_commands = [
|
||||||
"/describe --pr_description.add_original_user_description=true --pr_description.keep_original_user_title=true",
|
"/describe --pr_description.add_original_user_description=true --pr_description.keep_original_user_title=true",
|
||||||
"/auto_review",
|
"/review",
|
||||||
]
|
]
|
||||||
```
|
```
|
||||||
This means that when a new PR is opened/reopened or marked as ready for review, PR-Agent will run the `describe` and `auto_review` tools.
|
This means that when a new PR is opened/reopened or marked as ready for review, PR-Agent will run the `describe` and `review` tools.
|
||||||
For the describe tool, the `add_original_user_description` and `keep_original_user_title` parameters will be set to true.
|
For the `describe` tool, the `add_original_user_description` and `keep_original_user_title` parameters will be set to true.
|
||||||
|
|
||||||
You can override the default tool parameters by uploading a local configuration file called `.pr_agent.toml` to the root of your repo.
|
You can override the default tool parameters by uploading a local configuration file called `.pr_agent.toml` to the root of your repo.
|
||||||
For example, if your local `.pr_agent.toml` file contains:
|
For example, if your local `.pr_agent.toml` file contains:
|
||||||
@ -151,7 +181,7 @@ handle_pr_actions = []
|
|||||||
```
|
```
|
||||||
|
|
||||||
##### GitHub app automatic tools for new code (PR push)
|
##### GitHub app automatic tools for new code (PR push)
|
||||||
In addition the running automatic tools when a PR is opened, the GitHub app can also respond to new code that is pushed to an open PR.
|
In addition to running automatic tools when a PR is opened, the GitHub app can also respond to new code that is pushed to an open PR.
|
||||||
|
|
||||||
The configuration toggle `handle_push_trigger` can be used to enable this feature.
|
The configuration toggle `handle_push_trigger` can be used to enable this feature.
|
||||||
The configuration parameter `push_commands` defines the list of tools that will be **run automatically** when new code is pushed to the PR.
|
The configuration parameter `push_commands` defines the list of tools that will be **run automatically** when new code is pushed to the PR.
|
||||||
@ -160,14 +190,14 @@ The configuration parameter `push_commands` defines the list of tools that will
|
|||||||
handle_push_trigger = true
|
handle_push_trigger = true
|
||||||
push_commands = [
|
push_commands = [
|
||||||
"/describe --pr_description.add_original_user_description=true --pr_description.keep_original_user_title=true",
|
"/describe --pr_description.add_original_user_description=true --pr_description.keep_original_user_title=true",
|
||||||
"/auto_review -i --pr_reviewer.remove_previous_review_comment=true",
|
"/review -i --pr_reviewer.remove_previous_review_comment=true",
|
||||||
]
|
]
|
||||||
```
|
```
|
||||||
The means that when new code is pused to the PR, the PR-Agent will run the `describe` and incremental `auto_review` tools.
|
This means that when new code is pushed to the PR, the PR-Agent will run the `describe` and incremental `review` tools.
|
||||||
For the describe tool, the `add_original_user_description` and `keep_original_user_title` parameters will be set to true.
|
For the `describe` tool, the `add_original_user_description` and `keep_original_user_title` parameters will be set to true.
|
||||||
For the `auto_review` tool, it will run in incremental mode, and the `remove_previous_review_comment` parameter will be set to true.
|
For the `review` tool, it will run in incremental mode, and the `remove_previous_review_comment` parameter will be set to true.
|
||||||
|
|
||||||
Much like the configurations for `pr_commands`, you can override the default tool paramteres by uploading a local configuration file to the root of your repo.
|
Much like the configurations for `pr_commands`, you can override the default tool parameters by uploading a local configuration file to the root of your repo.
|
||||||
|
|
||||||
#### Editing the prompts
|
#### Editing the prompts
|
||||||
The prompts for the various PR-Agent tools are defined in the `pr_agent/settings` folder.
|
The prompts for the various PR-Agent tools are defined in the `pr_agent/settings` folder.
|
||||||
@ -208,15 +238,65 @@ For example, you can set an environment variable: `pr_description.add_original_u
|
|||||||
add_original_user_description = false
|
add_original_user_description = false
|
||||||
```
|
```
|
||||||
|
|
||||||
|
### Working with BitBucket Self-Hosted App
|
||||||
|
Similar to GitHub app, when running PR-Agent from BitBucket App, the default [configuration file](pr_agent/settings/configuration.toml) from a pre-built docker will be initially loaded.
|
||||||
|
|
||||||
### Changing a model
|
By uploading a local `.pr_agent.toml` file to the root of the repo's main branch, you can edit and customize any configuration parameter. Note that you need to upload `.pr_agent.toml` prior to creating a PR, in order for the configuration to take effect.
|
||||||
|
|
||||||
|
For example, if your local `.pr_agent.toml` file contains:
|
||||||
|
```
|
||||||
|
[pr_reviewer]
|
||||||
|
inline_code_comments = true
|
||||||
|
```
|
||||||
|
|
||||||
|
Each time you invoke a `/review` tool, it will use inline code comments.
|
||||||
|
|
||||||
|
#### BitBucket Self-Hosted App automatic tools
|
||||||
|
You can configure in your local `.pr_agent.toml` file which tools will **run automatically** when a new PR is opened.
|
||||||
|
|
||||||
|
Specifically, set the following values:
|
||||||
|
```yaml
|
||||||
|
[bitbucket_app]
|
||||||
|
auto_review = true # set as config var in .pr_agent.toml
|
||||||
|
auto_describe = true # set as config var in .pr_agent.toml
|
||||||
|
auto_improve = true # set as config var in .pr_agent.toml
|
||||||
|
```
|
||||||
|
|
||||||
|
`bitbucket_app.auto_review`, `bitbucket_app.auto_describe` and `bitbucket_app.auto_improve` are used to enable/disable automatic tools.
|
||||||
|
If not set, the default option is that only the `review` tool will run automatically when a new PR is opened.
|
||||||
|
|
||||||
|
Note that due to limitations of the bitbucket platform, the `auto_describe` tool will be able to publish a PR description only as a comment.
|
||||||
|
In addition, some subsections like `PR changes walkthrough` will not appear, since they require the usage of collapsible sections, which are not supported by bitbucket.
|
||||||
|
|
||||||
|
### Appendix - additional configurations walkthrough
|
||||||
|
|
||||||
|
|
||||||
|
#### Extra instructions
|
||||||
|
All PR-Agent tools have a parameter called `extra_instructions`, that enables to add free-text extra instructions. Example usage:
|
||||||
|
```
|
||||||
|
/update_changelog --pr_update_changelog.extra_instructions="Make sure to update also the version ..."
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Working with large PRs
|
||||||
|
|
||||||
|
The default mode of CodiumAI is to have a single call per tool, using GPT-4, which has a token limit of 8000 tokens.
|
||||||
|
This mode provide a very good speed-quality-cost tradeoff, and can handle most PRs successfully.
|
||||||
|
When the PR is above the token limit, it employs a [PR Compression strategy](./PR_COMPRESSION.md).
|
||||||
|
|
||||||
|
However, for very large PRs, or in case you want to emphasize quality over speed and cost, there are 2 possible solutions:
|
||||||
|
1) [Use a model](#changing-a-model) with larger context, like GPT-32K, or claude-100K. This solution will be applicable for all the tools.
|
||||||
|
2) For the `/improve` tool, there is an ['extended' mode](./docs/IMPROVE.md) (`/improve --extended`),
|
||||||
|
which divides the PR to chunks, and process each chunk separately. With this mode, regardless of the model, no compression will be done (but for large PRs, multiple model calls may occur)
|
||||||
|
|
||||||
|
|
||||||
|
#### Changing a model
|
||||||
|
|
||||||
See [here](pr_agent/algo/__init__.py) for the list of available models.
|
See [here](pr_agent/algo/__init__.py) for the list of available models.
|
||||||
To use a different model than the default (GPT-4), you need to edit [configuration file](pr_agent/settings/configuration.toml#L2).
|
To use a different model than the default (GPT-4), you need to edit [configuration file](pr_agent/settings/configuration.toml#L2).
|
||||||
For models and environments not from OPENAI, you might need to provide additional keys and other parameters. See below for instructions.
|
For models and environments not from OPENAI, you might need to provide additional keys and other parameters. See below for instructions.
|
||||||
|
|
||||||
#### Azure
|
##### Azure
|
||||||
To use Azure, set in your .secrets.toml:
|
To use Azure, set in your `.secrets.toml` (working from CLI), or in the GitHub `Settings > Secrets and variables` (working from GitHub App or GitHub Action):
|
||||||
```
|
```
|
||||||
api_key = "" # your azure api key
|
api_key = "" # your azure api key
|
||||||
api_type = "azure"
|
api_type = "azure"
|
||||||
@ -225,14 +305,13 @@ api_base = "" # The base URL for your Azure OpenAI resource. e.g. "https://<you
|
|||||||
openai.deployment_id = "" # The deployment name you chose when you deployed the engine
|
openai.deployment_id = "" # The deployment name you chose when you deployed the engine
|
||||||
```
|
```
|
||||||
|
|
||||||
and
|
and set in your configuration file:
|
||||||
```
|
```
|
||||||
[config]
|
[config]
|
||||||
model="" # the OpenAI model you've deployed on Azure (e.g. gpt-3.5-turbo)
|
model="" # the OpenAI model you've deployed on Azure (e.g. gpt-3.5-turbo)
|
||||||
```
|
```
|
||||||
in the configuration.toml
|
|
||||||
|
|
||||||
#### Huggingface
|
##### Huggingface
|
||||||
|
|
||||||
**Local**
|
**Local**
|
||||||
You can run Huggingface models locally through either [VLLM](https://docs.litellm.ai/docs/providers/vllm) or [Ollama](https://docs.litellm.ai/docs/providers/ollama)
|
You can run Huggingface models locally through either [VLLM](https://docs.litellm.ai/docs/providers/vllm) or [Ollama](https://docs.litellm.ai/docs/providers/ollama)
|
||||||
@ -246,7 +325,7 @@ MAX_TOKENS = {
|
|||||||
e.g.
|
e.g.
|
||||||
MAX_TOKENS={
|
MAX_TOKENS={
|
||||||
...,
|
...,
|
||||||
"llama2": 4096
|
"ollama/llama2": 4096
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|
||||||
@ -255,6 +334,8 @@ model = "ollama/llama2"
|
|||||||
|
|
||||||
[ollama] # in .secrets.toml
|
[ollama] # in .secrets.toml
|
||||||
api_base = ... # the base url for your huggingface inference endpoint
|
api_base = ... # the base url for your huggingface inference endpoint
|
||||||
|
# e.g. if running Ollama locally, you may use:
|
||||||
|
api_base = "http://localhost:11434/"
|
||||||
```
|
```
|
||||||
|
|
||||||
**Inference Endpoints**
|
**Inference Endpoints**
|
||||||
@ -279,7 +360,7 @@ api_base = ... # the base url for your huggingface inference endpoint
|
|||||||
```
|
```
|
||||||
(you can obtain a Llama2 key from [here](https://replicate.com/replicate/llama-2-70b-chat/api))
|
(you can obtain a Llama2 key from [here](https://replicate.com/replicate/llama-2-70b-chat/api))
|
||||||
|
|
||||||
#### Replicate
|
##### Replicate
|
||||||
|
|
||||||
To use Llama2 model with Replicate, for example, set:
|
To use Llama2 model with Replicate, for example, set:
|
||||||
```
|
```
|
||||||
@ -293,26 +374,42 @@ key = ...
|
|||||||
|
|
||||||
Also review the [AiHandler](pr_agent/algo/ai_handler.py) file for instruction how to set keys for other models.
|
Also review the [AiHandler](pr_agent/algo/ai_handler.py) file for instruction how to set keys for other models.
|
||||||
|
|
||||||
### Working with large PRs
|
##### Vertex AI
|
||||||
|
|
||||||
The default mode of CodiumAI is to have a single call per tool, using GPT-4, which has a token limit of 8000 tokens.
|
To use Google's Vertex AI platform and its associated models (chat-bison/codechat-bison) set:
|
||||||
This mode provide a very good speed-quality-cost tradeoff, and can handle most PRs successfully.
|
|
||||||
When the PR is above the token limit, it employs a [PR Compression strategy](./PR_COMPRESSION.md).
|
|
||||||
|
|
||||||
However, for very large PRs, or in case you want to emphasize quality over speed and cost, there are 2 possible solutions:
|
```
|
||||||
1) [Use a model](#changing-a-model) with larger context, like GPT-32K, or claude-100K. This solution will be applicable for all the tools.
|
[config] # in configuration.toml
|
||||||
2) For the `/improve` tool, there is an ['extended' mode](./docs/IMPROVE.md) (`/improve --extended`),
|
model = "vertex_ai/codechat-bison"
|
||||||
which divides the PR to chunks, and process each chunk separately. With this mode, regardless of the model, no compression will be done (but for large PRs, multiple model calls may occur)
|
fallback_models="vertex_ai/codechat-bison"
|
||||||
|
|
||||||
### Appendix - additional configurations walkthrough
|
[vertexai] # in .secrets.toml
|
||||||
|
vertex_project = "my-google-cloud-project"
|
||||||
|
vertex_location = ""
|
||||||
#### Extra instructions
|
|
||||||
All PR-Agent tools have a parameter called `extra_instructions`, that enables to add free-text extra instructions. Example usage:
|
|
||||||
```
|
```
|
||||||
/update_changelog --pr_update_changelog.extra_instructions="Make sure to update also the version ..."
|
|
||||||
|
Your [application default credentials](https://cloud.google.com/docs/authentication/application-default-credentials) will be used for authentication so there is no need to set explicit credentials in most environments.
|
||||||
|
|
||||||
|
If you do want to set explicit credentials then you can use the `GOOGLE_APPLICATION_CREDENTIALS` environment variable set to a path to a json credentials file.
|
||||||
|
|
||||||
|
##### Amazon Bedrock
|
||||||
|
|
||||||
|
To use Amazon Bedrock and its foundational models, add the below configuration:
|
||||||
|
|
||||||
|
```
|
||||||
|
[config] # in configuration.toml
|
||||||
|
model = "anthropic.claude-v2"
|
||||||
|
fallback_models="anthropic.claude-instant-v1"
|
||||||
|
|
||||||
|
[aws] # in .secrets.toml
|
||||||
|
bedrock_region = "us-east-1"
|
||||||
```
|
```
|
||||||
|
|
||||||
|
Note that you have to add access to foundational models before using them. Please refer to [this document](https://docs.aws.amazon.com/bedrock/latest/userguide/setting-up.html) for more details.
|
||||||
|
|
||||||
|
AWS session is automatically authenticated from your environment, but you can also explicitly set `AWS_ACCESS_KEY_ID` and `AWS_SECRET_ACCESS_KEY` environment variables.
|
||||||
|
|
||||||
|
|
||||||
#### Patch Extra Lines
|
#### Patch Extra Lines
|
||||||
By default, around any change in your PR, git patch provides 3 lines of context above and below the change.
|
By default, around any change in your PR, git patch provides 3 lines of context above and below the change.
|
||||||
```
|
```
|
||||||
|
|||||||
@ -14,6 +14,10 @@ FROM base as bitbucket_app
|
|||||||
ADD pr_agent pr_agent
|
ADD pr_agent pr_agent
|
||||||
CMD ["python", "pr_agent/servers/bitbucket_app.py"]
|
CMD ["python", "pr_agent/servers/bitbucket_app.py"]
|
||||||
|
|
||||||
|
FROM base as bitbucket_server_webhook
|
||||||
|
ADD pr_agent pr_agent
|
||||||
|
CMD ["python", "pr_agent/servers/bitbucket_server_webhook.py"]
|
||||||
|
|
||||||
FROM base as github_polling
|
FROM base as github_polling
|
||||||
ADD pr_agent pr_agent
|
ADD pr_agent pr_agent
|
||||||
CMD ["python", "pr_agent/servers/github_polling.py"]
|
CMD ["python", "pr_agent/servers/github_polling.py"]
|
||||||
|
|||||||
@ -1,5 +1,5 @@
|
|||||||
# Add Documentation Tool
|
# Add Documentation Tool 💎
|
||||||
The `add_docs` tool scans the PR code changes, and automatically suggests documentation for the undocumented code components (functions, classes, etc.).
|
The `add_docs` tool scans the PR code changes, and automatically suggests documentation for any code components that changed in the PR (functions, classes, etc.).
|
||||||
|
|
||||||
It can be invoked manually by commenting on any PR:
|
It can be invoked manually by commenting on any PR:
|
||||||
```
|
```
|
||||||
@ -7,9 +7,18 @@ It can be invoked manually by commenting on any PR:
|
|||||||
```
|
```
|
||||||
For example:
|
For example:
|
||||||
|
|
||||||
<kbd><img src=./../pics/add_docs_comment.png width="768"></kbd>
|
<kbd><img src=https://codium.ai/images/pr_agent/docs_command.png width="768"></kbd>
|
||||||
<kbd><img src=./../pics/add_docs.png width="768"></kbd>
|
___
|
||||||
|
<kbd><img src=https://codium.ai/images/pr_agent/docs_components.png width="768"></kbd>
|
||||||
|
___
|
||||||
|
<kbd><img src=https://codium.ai/images/pr_agent/docs_single_component.png width="768"></kbd>
|
||||||
|
|
||||||
### Configuration options
|
### Configuration options
|
||||||
- `docs_style`: The exact style of the documentation (for python docstring). you can choose between: `google`, `numpy`, `sphinx`, `restructuredtext`, `plain`. Default is `sphinx`.
|
- `docs_style`: The exact style of the documentation (for python docstring). you can choose between: `google`, `numpy`, `sphinx`, `restructuredtext`, `plain`. Default is `sphinx`.
|
||||||
- `extra_instructions`: Optional extra instructions to the tool. For example: "focus on the changes in the file X. Ignore change in ...".
|
- `extra_instructions`: Optional extra instructions to the tool. For example: "focus on the changes in the file X. Ignore change in ...".
|
||||||
|
|
||||||
|
Notes
|
||||||
|
- Language that are currently fully supported: Python, Java, C++, JavaScript, TypeScript.
|
||||||
|
- For languages that are not fully supported, the tool will suggest documentation only for new components in the PR.
|
||||||
|
- A previous version of the tool, that offered support only for new components, was deprecated.
|
||||||
|
|
||||||
|
|||||||
@ -7,5 +7,5 @@ It can be invoked manually by commenting on any PR:
|
|||||||
```
|
```
|
||||||
For example:
|
For example:
|
||||||
|
|
||||||
<kbd><img src=./../pics/ask_comment.png width="768"></kbd>
|
<kbd><img src=https://codium.ai/images/pr_agent/ask_comment.png width="768"></kbd>
|
||||||
<kbd><img src=./../pics/ask.png width="768"></kbd>
|
<kbd><img src=https://codium.ai/images/pr_agent/ask.png width="768"></kbd>
|
||||||
21
docs/Analyze.md
Normal file
@ -0,0 +1,21 @@
|
|||||||
|
# Analyze Tool 💎
|
||||||
|
The `analyze` tool combines static code analysis with LLM capabilities to provide a comprehensive analysis of the PR code changes.
|
||||||
|
|
||||||
|
The tool scans the PR code changes, find the code components (methods, functions, classes) that changed, and summarizes the changes in each component.
|
||||||
|
|
||||||
|
It can be invoked manually by commenting on any PR:
|
||||||
|
```
|
||||||
|
/analyze
|
||||||
|
```
|
||||||
|
|
||||||
|
An example [result](https://github.com/Codium-ai/pr-agent/pull/546#issuecomment-1868524805):
|
||||||
|
|
||||||
|
<kbd><img src=https://codium.ai/images/pr_agent/analyze_1.png width="768"></kbd>
|
||||||
|
___
|
||||||
|
<kbd><img src=https://codium.ai/images/pr_agent/analyze_2.png width="768"></kbd>
|
||||||
|
___
|
||||||
|
<kbd><img src=https://codium.ai/images/pr_agent/analyze_3.png width="768"></kbd>
|
||||||
|
|
||||||
|
|
||||||
|
Notes
|
||||||
|
- Language that are currently supported: Python, Java, C++, JavaScript, TypeScript.
|
||||||
125
docs/DESCRIBE.md
@ -1,22 +1,34 @@
|
|||||||
# Describe Tool
|
# Describe Tool
|
||||||
|
## Table of Contents
|
||||||
|
- [Overview](#overview)
|
||||||
|
- [Configuration options](#configuration-options)
|
||||||
|
- [Handle custom labels from the Repo's labels page :gem:](#handle-custom-labels-from-the-repos-labels-page-gem)
|
||||||
|
- [Markers template](#markers-template)
|
||||||
|
- [Usage Tips](#usage-tips)
|
||||||
|
- [Automation](#automation)
|
||||||
|
- [Custom labels](#custom-labels)
|
||||||
|
|
||||||
The `describe` tool scans the PR code changes, and automatically generates PR description - title, type, summary, code walkthrough and labels.
|
## Overview
|
||||||
It can be invoked manually by commenting on any PR:
|
The `describe` tool scans the PR code changes, and generates a description for the PR - title, type, summary, walkthrough and labels.
|
||||||
|
|
||||||
|
The tool can be triggered automatically every time a new PR is [opened](https://github.com/Codium-ai/pr-agent/blob/main/Usage.md#github-app-automatic-tools), or it can be invoked manually by commenting on any PR:
|
||||||
```
|
```
|
||||||
/describe
|
/describe
|
||||||
```
|
```
|
||||||
For example:
|
For example:
|
||||||
|
___
|
||||||
<kbd><img src=./../pics/describe_comment.png width="768"></kbd>
|
<kbd><img src=https://codium.ai/images/pr_agent/describe_comment.png width="768"></kbd>
|
||||||
|
___
|
||||||
<kbd><img src=./../pics/describe.png width="768"></kbd>
|
<kbd><img src=https://codium.ai/images/pr_agent/describe.png width="768"></kbd>
|
||||||
|
___
|
||||||
The `describe` tool can also be triggered automatically every time a new PR is opened. See examples for automatic triggers for [GitHub App](https://github.com/Codium-ai/pr-agent/blob/main/Usage.md#github-app-automatic-tools) and [GitHub Action](https://github.com/Codium-ai/pr-agent/blob/main/Usage.md#working-with-github-action)
|
|
||||||
|
|
||||||
### Configuration options
|
### Configuration options
|
||||||
|
To edit [configurations](./../pr_agent/settings/configuration.toml#L46) related to the describe tool (`pr_description` section), use the following template:
|
||||||
|
```
|
||||||
|
/describe --pr_description.some_config1=... --pr_description.some_config2=...
|
||||||
|
```
|
||||||
|
|
||||||
Under the section 'pr_description', the [configuration file](./../pr_agent/settings/configuration.toml#L28) contains options to customize the 'describe' tool:
|
**Possible configurations:**
|
||||||
|
|
||||||
- `publish_labels`: if set to true, the tool will publish the labels to the PR. Default is true.
|
- `publish_labels`: if set to true, the tool will publish the labels to the PR. Default is true.
|
||||||
|
|
||||||
- `publish_description_as_comment`: if set to true, the tool will publish the description as a comment to the PR. If false, it will overwrite the origianl description. Default is false.
|
- `publish_description_as_comment`: if set to true, the tool will publish the description as a comment to the PR. If false, it will overwrite the origianl description. Default is false.
|
||||||
@ -26,15 +38,43 @@ Under the section 'pr_description', the [configuration file](./../pr_agent/setti
|
|||||||
- `keep_original_user_title`: if set to true, the tool will keep the original PR title, and won't change it. Default is false.
|
- `keep_original_user_title`: if set to true, the tool will keep the original PR title, and won't change it. Default is false.
|
||||||
|
|
||||||
- `extra_instructions`: Optional extra instructions to the tool. For example: "focus on the changes in the file X. Ignore change in ...".
|
- `extra_instructions`: Optional extra instructions to the tool. For example: "focus on the changes in the file X. Ignore change in ...".
|
||||||
- To enable `custom labels`, apply the configuration changes described [here](./GENERATE_CUSTOM_LABELS.md#configuration-changes)
|
|
||||||
### Markers template
|
|
||||||
|
|
||||||
|
- To enable `custom labels`, apply the configuration changes described [here](./GENERATE_CUSTOM_LABELS.md#configuration-changes)
|
||||||
|
|
||||||
|
- `enable_pr_type`: if set to false, it will not show the `PR type` as a text value in the description content. Default is true.
|
||||||
|
|
||||||
|
- `final_update_message`: if set to true, it will add a comment message [`PR Description updated to latest commit...`](https://github.com/Codium-ai/pr-agent/pull/499#issuecomment-1837412176) after finishing calling `/describe`. Default is true.
|
||||||
|
|
||||||
|
- `enable_semantic_files_types`: if set to true, "Changes walkthrough" section will be generated. Default is true.
|
||||||
|
- `collapsible_file_list`: if set to true, the file list in the "Changes walkthrough" section will be collapsible. If set to "adaptive", the file list will be collapsible only if there are more than 8 files. Default is "adaptive".
|
||||||
|
|
||||||
|
|
||||||
|
### Handle custom labels from the Repo's labels page :gem:
|
||||||
|
> This feature is available only in PR-Agent Pro
|
||||||
|
|
||||||
|
You can control the custom labels that will be suggested by the `describe` tool, from the repo's labels page:
|
||||||
|
|
||||||
|
* GitHub : go to `https://github.com/{owner}/{repo}/labels` (or click on the "Labels" tab in the issues or PRs page)
|
||||||
|
* GitLab : go to `https://gitlab.com/{owner}/{repo}/-/labels` (or click on "Manage" -> "Labels" on the left menu)
|
||||||
|
|
||||||
|
Now add/edit the custom labels. they should be formatted as follows:
|
||||||
|
* Label name: The name of the custom label.
|
||||||
|
* Description: Start the description of with prefix `pr_agent:`, for example: `pr_agent: Description of when AI should suggest this label`.<br>
|
||||||
|
|
||||||
|
The description should be comprehensive and detailed, indicating when to add the desired label. For example:
|
||||||
|
<kbd><img src=https://codium.ai/images/pr_agent/add_native_custom_labels.png width="880"></kbd>
|
||||||
|
|
||||||
|
|
||||||
|
### Markers template
|
||||||
|
To enable markers, set `pr_description.use_description_markers=true`.
|
||||||
markers enable to easily integrate user's content and auto-generated content, with a template-like mechanism.
|
markers enable to easily integrate user's content and auto-generated content, with a template-like mechanism.
|
||||||
|
|
||||||
For example, if the PR original description was:
|
For example, if the PR original description was:
|
||||||
```
|
```
|
||||||
User content...
|
User content...
|
||||||
|
|
||||||
|
## PR Type:
|
||||||
|
pr_agent:type
|
||||||
|
|
||||||
## PR Description:
|
## PR Description:
|
||||||
pr_agent:summary
|
pr_agent:summary
|
||||||
@ -42,21 +82,60 @@ pr_agent:summary
|
|||||||
## PR Walkthrough:
|
## PR Walkthrough:
|
||||||
pr_agent:walkthrough
|
pr_agent:walkthrough
|
||||||
```
|
```
|
||||||
The marker `pr_agent:summary` will be replaced with the PR summary, and `pr_agent:walkthrough` will be replaced with the PR walkthrough.
|
The marker `pr_agent:type` will be replaced with the PR type, `pr_agent:summary` will be replaced with the PR summary, and `pr_agent:walkthrough` will be replaced with the PR walkthrough.
|
||||||
|
|
||||||
##### Example:
|
<kbd><img src=https://codium.ai/images/pr_agent/describe_markers_before.png width="768"></kbd>
|
||||||
```
|
|
||||||
env:
|
|
||||||
pr_description.use_description_markers: 'true'
|
|
||||||
```
|
|
||||||
|
|
||||||
<kbd><img src=./../pics/describe_markers_before.png width="768"></kbd>
|
|
||||||
|
|
||||||
==>
|
==>
|
||||||
|
|
||||||
<kbd><img src=./../pics/describe_markers_after.png width="768"></kbd>
|
<kbd><img src=https://codium.ai/images/pr_agent/describe_markers_after.png width="768"></kbd>
|
||||||
|
|
||||||
##### Configuration params:
|
**Configuration params:**
|
||||||
|
|
||||||
- `use_description_markers`: if set to true, the tool will use markers template. It replaces every marker of the form `pr_agent:marker_name` with the relevant content. Default is false.
|
- `use_description_markers`: if set to true, the tool will use markers template. It replaces every marker of the form `pr_agent:marker_name` with the relevant content. Default is false.
|
||||||
- `include_generated_by_header`: if set to true, the tool will add a dedicated header: 'Generated by PR Agent at ...' to any automatic content. Default is true.
|
- `include_generated_by_header`: if set to true, the tool will add a dedicated header: 'Generated by PR Agent at ...' to any automatic content. Default is true.
|
||||||
|
|
||||||
|
|
||||||
|
## Usage Tips
|
||||||
|
1) [Automation](#automation)
|
||||||
|
2) [Custom labels](#custom-labels)
|
||||||
|
### Automation
|
||||||
|
- When you first install the app, the [default mode](https://github.com/Codium-ai/pr-agent/blob/main/Usage.md#github-app-automatic-tools) for the describe tool is:
|
||||||
|
```
|
||||||
|
pr_commands = ["/describe --pr_description.add_original_user_description=true"
|
||||||
|
"--pr_description.keep_original_user_title=true", ...]
|
||||||
|
```
|
||||||
|
meaning the `describe` tool will run automatically on every PR, will keep the original title, and will add the original user description above the generated description.
|
||||||
|
<br> This default settings aim to strike a good balance between automation and control:
|
||||||
|
If you want more automation, just give the PR a title, and the tool will auto-write a full description; If you want more control, you can add a detailed description, and the tool will add the complementary description below it.
|
||||||
|
- For maximal automation, you can change the default mode to:
|
||||||
|
```
|
||||||
|
pr_commands = ["/describe --pr_description.add_original_user_description=false"
|
||||||
|
"--pr_description.keep_original_user_title=true", ...]
|
||||||
|
```
|
||||||
|
so the title will be auto-generated as well.
|
||||||
|
- Markers are an alternative way to control the generated description, to give maximal control to the user. If you set:
|
||||||
|
```
|
||||||
|
pr_commands = ["/describe --pr_description.use_description_markers=true", ...]
|
||||||
|
```
|
||||||
|
the tool will replace every marker of the form `pr_agent:marker_name` in the PR description with the relevant content, where `marker_name` is one of the following:
|
||||||
|
- `type`: the PR type.
|
||||||
|
- `summary`: the PR summary.
|
||||||
|
- `walkthrough`: the PR walkthrough.
|
||||||
|
|
||||||
|
Note that when markers are enabled, if the original PR description does not contain any markers, the tool will not alter the description at all.
|
||||||
|
|
||||||
|
### Custom labels
|
||||||
|
The default labels of the describe tool are quite generic, since they are meant to be used in any repo: [`Bug fix`, `Tests`, `Enhancement`, `Documentation`, `Other`].
|
||||||
|
|
||||||
|
If you specify [custom labels](#handle-custom-labels-from-the-repos-labels-page-gem) in the repo's labels page, you can get tailored labels for your use cases.
|
||||||
|
Examples for custom labels:
|
||||||
|
- `Main topic:performence` - pr_agent:The main topic of this PR is performance
|
||||||
|
- `New endpoint` - pr_agent:A new endpoint was added in this PR
|
||||||
|
- `SQL query` - pr_agent:A new SQL query was added in this PR
|
||||||
|
- `Dockerfile changes` - pr_agent:The PR contains changes in the Dockerfile
|
||||||
|
- ...
|
||||||
|
|
||||||
|
The list above is eclectic, and aims to give an idea of different possibilities. Define custom labels that are relevant for your repo and use cases.
|
||||||
|
Note that Labels are not mutually exclusive, so you can add multiple label categories.
|
||||||
|
<br>Make sure to provide proper title, and detailed and well-phrased description for each label, so the tool will know when to suggest it.
|
||||||
27
docs/Full_enviroments.md
Normal file
@ -0,0 +1,27 @@
|
|||||||
|
## Overview
|
||||||
|
`PR-Agent` offers extensive pull request functionalities across various git providers:
|
||||||
|
| | | GitHub | Gitlab | Bitbucket | CodeCommit | Azure DevOps | Gerrit |
|
||||||
|
|-------|---------------------------------------------|:------:|:------:|:---------:|:----------:|:----------:|:----------:|
|
||||||
|
| TOOLS | Review | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||||
|
| | ⮑ Incremental | :white_check_mark: | | | | | |
|
||||||
|
| | Ask | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||||
|
| | Auto-Description | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||||
|
| | Improve Code | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | | :white_check_mark: |
|
||||||
|
| | ⮑ Extended | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | | :white_check_mark: |
|
||||||
|
| | Reflect and Review | :white_check_mark: | :white_check_mark: | :white_check_mark: | | :white_check_mark: | :white_check_mark: |
|
||||||
|
| | Update CHANGELOG.md | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | | |
|
||||||
|
| | Find similar issue | :white_check_mark: | | | | | |
|
||||||
|
| | Add Documentation | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | | :white_check_mark: |
|
||||||
|
| | Generate Custom Labels 💎 | :white_check_mark: | :white_check_mark: | | | | |
|
||||||
|
| | | | | | | |
|
||||||
|
| USAGE | CLI | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||||
|
| | App / webhook | :white_check_mark: | :white_check_mark: | | | |
|
||||||
|
| | Tagging bot | :white_check_mark: | | | | |
|
||||||
|
| | Actions | :white_check_mark: | | | | |
|
||||||
|
| | Web server | | | | | | :white_check_mark: |
|
||||||
|
| | | | | | | |
|
||||||
|
| CORE | PR compression | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||||
|
| | Repo language prioritization | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||||
|
| | Adaptive and token-aware<br />file patch fitting | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||||
|
| | Multiple models support | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||||
|
| | Incremental PR Review | :white_check_mark: | | | | | |
|
||||||
@ -1,4 +1,4 @@
|
|||||||
# Generate Custom Labels
|
# Generate Custom Labels 💎
|
||||||
The `generate_labels` tool scans the PR code changes, and given a list of labels and their descriptions, it automatically suggests labels that match the PR code changes.
|
The `generate_labels` tool scans the PR code changes, and given a list of labels and their descriptions, it automatically suggests labels that match the PR code changes.
|
||||||
|
|
||||||
It can be invoked manually by commenting on any PR:
|
It can be invoked manually by commenting on any PR:
|
||||||
@ -9,20 +9,37 @@ For example:
|
|||||||
|
|
||||||
If we wish to add detect changes to SQL queries in a given PR, we can add the following custom label along with its description:
|
If we wish to add detect changes to SQL queries in a given PR, we can add the following custom label along with its description:
|
||||||
|
|
||||||
<kbd><img src=./../pics/custom_labels_list.png width="768"></kbd>
|
<kbd><img src=https://codium.ai/images/pr_agent/custom_labels_list.png width="768"></kbd>
|
||||||
|
|
||||||
When running the `generate_labels` tool on a PR that includes changes in SQL queries, it will automatically suggest the custom label:
|
When running the `generate_labels` tool on a PR that includes changes in SQL queries, it will automatically suggest the custom label:
|
||||||
<kbd><img src=./../pics/custom_label_published.png width="768"></kbd>
|
<kbd><img src=https://codium.ai/images/pr_agent/custom_label_published.png width="768"></kbd>
|
||||||
|
|
||||||
|
Note that in addition to the dedicated tool `generate_labels`, the custom labels will also be used by the `describe` tool.
|
||||||
|
|
||||||
### How to enable custom labels
|
### How to enable custom labels
|
||||||
|
There are 3 ways to enable custom labels:
|
||||||
|
|
||||||
Note that in addition to the dedicated tool `generate_labels`, the custom labels will also be used by the `review` and `describe` tools.
|
#### 1. CLI (local configuration file)
|
||||||
|
When working from CLI, you need to apply the [configuration changes](#configuration-changes) to the [custom_labels file](./../pr_agent/settings/custom_labels.toml):
|
||||||
|
|
||||||
#### CLI
|
#### 2. Repo configuration file
|
||||||
To enable custom labels, you need to apply the [configuration changes](#configuration-changes) to the [custom_labels file](./../pr_agent/settings/custom_labels.toml):
|
|
||||||
|
|
||||||
#### GitHub Action and GitHub App
|
|
||||||
To enable custom labels, you need to apply the [configuration changes](#configuration-changes) to the local `.pr_agent.toml` file in you repository.
|
To enable custom labels, you need to apply the [configuration changes](#configuration-changes) to the local `.pr_agent.toml` file in you repository.
|
||||||
|
|
||||||
|
#### 3. Handle custom labels from the Repo's labels page
|
||||||
|
> This feature is available only in PR-Agent Pro
|
||||||
|
* GitHub : `https://github.com/{owner}/{repo}/labels`, or click on the "Labels" tab in the issues or PRs page.
|
||||||
|
* GitLab : `https://gitlab.com/{owner}/{repo}/-/labels`, or click on "Manage" -> "Labels" on the left menu.
|
||||||
|
|
||||||
|
b. Add/edit the custom labels. It should be formatted as follows:
|
||||||
|
* Label name: The name of the custom label.
|
||||||
|
* Description: Start the description of with prefix `pr_agent:`, for example: `pr_agent: Description of when AI should suggest this label`.<br>
|
||||||
|
The description should be comprehensive and detailed, indicating when to add the desired label.
|
||||||
|
<kbd><img src=https://codium.ai/images/pr_agent/add_native_custom_labels.png width="880"></kbd>
|
||||||
|
|
||||||
|
c. Now the custom labels will be included in the `generate_labels` tool.
|
||||||
|
|
||||||
|
*This feature is supported in GitHub and GitLab.
|
||||||
|
|
||||||
#### Configuration changes
|
#### Configuration changes
|
||||||
- Change `enable_custom_labels` to True: This will turn off the default labels and enable the custom labels provided in the custom_labels.toml file.
|
- Change `enable_custom_labels` to True: This will turn off the default labels and enable the custom labels provided in the custom_labels.toml file.
|
||||||
- Add the custom labels. It should be formatted as follows:
|
- Add the custom labels. It should be formatted as follows:
|
||||||
|
|||||||
@ -1,45 +1,100 @@
|
|||||||
# Improve Tool
|
# Improve Tool
|
||||||
|
|
||||||
The `improve` tool scans the PR code changes, and automatically generate committable suggestions for improving the PR code.
|
## Table of Contents
|
||||||
It can be invoked manually by commenting on any PR:
|
- [Overview](#overview)
|
||||||
|
- [Configuration options](#configuration-options)
|
||||||
|
- [Summarize mode](#summarize-mode)
|
||||||
|
- [Usage Tips](#usage-tips)
|
||||||
|
- [Extra instructions](#extra-instructions)
|
||||||
|
- [PR footprint - regular vs summarize mode](#pr-footprint---regular-vs-summarize-mode)
|
||||||
|
- [A note on code suggestions quality](#a-note-on-code-suggestions-quality)
|
||||||
|
|
||||||
|
## Overview
|
||||||
|
The `improve` tool scans the PR code changes, and automatically generates committable suggestions for improving the PR code.
|
||||||
|
The tool can be triggered automatically every time a new PR is [opened](https://github.com/Codium-ai/pr-agent/blob/main/Usage.md#github-app-automatic-tools), or it can be invoked manually by commenting on any PR:
|
||||||
```
|
```
|
||||||
/improve
|
/improve
|
||||||
```
|
```
|
||||||
|
|
||||||
For example:
|
For example:
|
||||||
|
|
||||||
<kbd><img src=./../pics/improve_comment.png width="768"></kbd>
|
<kbd><img src=https://codium.ai/images/pr_agent/improve_comment.png width="768"></kbd>
|
||||||
<kbd><img src=./../pics/improve.png width="768"></kbd>
|
|
||||||
|
|
||||||
The `improve` tool can also be triggered automatically every time a new PR is opened. See examples for automatic triggers for [GitHub App](https://github.com/Codium-ai/pr-agent/blob/main/Usage.md#github-app-automatic-tools) and [GitHub Action](https://github.com/Codium-ai/pr-agent/blob/main/Usage.md#working-with-github-action)
|
---
|
||||||
|
|
||||||
|
<kbd><img src=https://codium.ai/images/pr_agent/improve.png width="768"></kbd>
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
An extended mode, which does not involve PR Compression and provides more comprehensive suggestions, can be invoked by commenting on any PR:
|
An extended mode, which does not involve PR Compression and provides more comprehensive suggestions, can be invoked by commenting on any PR:
|
||||||
```
|
```
|
||||||
/improve --extended
|
/improve --extended
|
||||||
```
|
```
|
||||||
Note that the extended mode divides the PR code changes into chunks, up to the token limits, where each chunk is handled separately (multiple calls to GPT-4).
|
Note that the extended mode divides the PR code changes into chunks, up to the token limits, where each chunk is handled separately (might use multiple calls to GPT-4 for large PRs).
|
||||||
Hence, the total number of suggestions is proportional to the number of chunks, i.e. the size of the PR.
|
Hence, the total number of suggestions is proportional to the number of chunks, i.e., the size of the PR.
|
||||||
|
|
||||||
### Configuration options
|
### Configuration options
|
||||||
|
|
||||||
Under the section 'pr_code_suggestions', the [configuration file](./../pr_agent/settings/configuration.toml#L40) contains options to customize the 'improve' tool:
|
To edit [configurations](./../pr_agent/settings/configuration.toml#L66) related to the improve tool (`pr_code_suggestions` section), use the following template:
|
||||||
|
```
|
||||||
|
/improve --pr_code_suggestions.some_config1=... --pr_code_suggestions.some_config2=...
|
||||||
|
```
|
||||||
|
|
||||||
|
#### General options
|
||||||
- `num_code_suggestions`: number of code suggestions provided by the 'improve' tool. Default is 4.
|
- `num_code_suggestions`: number of code suggestions provided by the 'improve' tool. Default is 4.
|
||||||
- `extra_instructions`: Optional extra instructions to the tool. For example: "focus on the changes in the file X. Ignore change in ...".
|
- `extra_instructions`: Optional extra instructions to the tool. For example: "focus on the changes in the file X. Ignore change in ...".
|
||||||
- `rank_suggestions`: if set to true, the tool will rank the suggestions, based on importance. Default is false.
|
- `rank_suggestions`: if set to true, the tool will rank the suggestions, based on importance. Default is false.
|
||||||
|
- `include_improved_code`: if set to true, the tool will include an improved code implementation in the suggestion. Default is true.
|
||||||
|
|
||||||
#### params for '/improve --extended' mode
|
#### params for '/improve --extended' mode
|
||||||
|
- `auto_extended_mode`: enable extended mode automatically (no need for the `--extended` option). Default is false.
|
||||||
- `num_code_suggestions_per_chunk`: number of code suggestions provided by the 'improve' tool, per chunk. Default is 8.
|
- `num_code_suggestions_per_chunk`: number of code suggestions provided by the 'improve' tool, per chunk. Default is 8.
|
||||||
- `rank_extended_suggestions`: if set to true, the tool will rank the suggestions, based on importance. Default is true.
|
- `rank_extended_suggestions`: if set to true, the tool will rank the suggestions, based on importance. Default is true.
|
||||||
- `max_number_of_calls`: maximum number of chunks. Default is 5.
|
- `max_number_of_calls`: maximum number of chunks. Default is 5.
|
||||||
- `final_clip_factor`: factor to remove suggestions with low confidence. Default is 0.9.
|
- `final_clip_factor`: factor to remove suggestions with low confidence. Default is 0.9.
|
||||||
|
|
||||||
|
#### Summarize mode
|
||||||
|
In this mode, instead of presenting committable suggestions, the different suggestions will be combined into a single compact comment, with significantly smaller PR footprint.
|
||||||
|
|
||||||
#### A note on code suggestions quality
|
To invoke the summarize mode, use the following command:
|
||||||
|
```
|
||||||
|
/improve --pr_code_suggestions.summarize=true
|
||||||
|
```
|
||||||
|
|
||||||
- With current level of AI for code (GPT-4), mistakes can happen. Not all the suggestions will be perfect, and a user should not accept all of them automatically.
|
For example:
|
||||||
|
|
||||||
|
<kbd><img src=https://codium.ai/images/pr_agent/improved_summerize_open.png width="768"></kbd>
|
||||||
|
|
||||||
|
___
|
||||||
|
|
||||||
|
## Usage Tips
|
||||||
|
|
||||||
|
### Extra instructions
|
||||||
|
Extra instructions are very important for the `imrpove` tool, since they enable you to guide the model to suggestions that are more relevant to the specific needs of the project.
|
||||||
|
|
||||||
|
Be specific, clear, and concise in the instructions. With extra instructions, you are the prompter. Specify relevant aspects that you want the model to focus on.
|
||||||
|
|
||||||
|
Examples for extra instructions:
|
||||||
|
```
|
||||||
|
[pr_code_suggestions] # /improve #
|
||||||
|
extra_instructions="""
|
||||||
|
Emphasize the following aspects:
|
||||||
|
- Does the code logic covers relevant edge cases?
|
||||||
|
- Is the code logic clear and easy to understand?
|
||||||
|
- Is the code logic efficient?
|
||||||
|
...
|
||||||
|
"""
|
||||||
|
```
|
||||||
|
Use triple quotes to write multi-line instructions. Use bullet points to make the instructions more readable.
|
||||||
|
|
||||||
|
### PR footprint - regular vs summarize mode
|
||||||
|
The default mode of the `improve` tool provides committable suggestions. This mode as a high PR footprint, since each suggestion is a separate comment you need to resolve.
|
||||||
|
If you prefer something more compact, use the [`summarize`](#summarize-mode) mode, which combines all the suggestions into a single comment.
|
||||||
|
|
||||||
|
### A note on code suggestions quality
|
||||||
|
|
||||||
|
- While the current AI for code is getting better and better (GPT-4), it's not flawless. Not all the suggestions will be perfect, and a user should not accept all of them automatically.
|
||||||
- Suggestions are not meant to be [simplistic](./../pr_agent/settings/pr_code_suggestions_prompts.toml#L34). Instead, they aim to give deep feedback and raise questions, ideas and thoughts to the user, who can then use his judgment, experience, and understanding of the code base.
|
- Suggestions are not meant to be [simplistic](./../pr_agent/settings/pr_code_suggestions_prompts.toml#L34). Instead, they aim to give deep feedback and raise questions, ideas and thoughts to the user, who can then use his judgment, experience, and understanding of the code base.
|
||||||
|
|
||||||
- Recommended to use the 'extra_instructions' field to guide the model to suggestions that are more relevant to the specific needs of the project.
|
- Recommended to use the 'extra_instructions' field to guide the model to suggestions that are more relevant to the specific needs of the project.
|
||||||
|
- Best quality will be obtained by using 'improve --extended' mode.
|
||||||
|
|
||||||
- Best quality will be obtained by using 'improve --extended' mode.
|
|
||||||
142
docs/REVIEW.md
@ -1,58 +1,148 @@
|
|||||||
# Review Tool
|
# Review Tool
|
||||||
|
|
||||||
|
## Table of Contents
|
||||||
|
- [Overview](#overview)
|
||||||
|
- [Configuration options](#configuration-options)
|
||||||
|
- [Incremental Mode](#incremental-mode)
|
||||||
|
- [PR Reflection](#pr-reflection)
|
||||||
|
- [Usage Tips](#usage-tips)
|
||||||
|
- [General guidelines](#general-guidelines)
|
||||||
|
- [Code suggestions](#code-suggestions)
|
||||||
|
- [Automation](#automation)
|
||||||
|
- [Auto-labels](#auto-labels)
|
||||||
|
- [Extra instructions](#extra-instructions)
|
||||||
|
|
||||||
|
## Overview
|
||||||
The `review` tool scans the PR code changes, and automatically generates a PR review.
|
The `review` tool scans the PR code changes, and automatically generates a PR review.
|
||||||
It can be invoked manually by commenting on any PR:
|
The tool can be triggered automatically every time a new PR is [opened](https://github.com/Codium-ai/pr-agent/blob/main/Usage.md#github-app-automatic-tools), or can be invoked manually by commenting on any PR:
|
||||||
```
|
```
|
||||||
/review
|
/review
|
||||||
```
|
```
|
||||||
For example:
|
For example:
|
||||||
|
___
|
||||||
<kbd><img src=./../pics/review_comment.png width="768"></kbd>
|
<kbd><img src=https://codium.ai/images/pr_agent/review_comment.png width="768"></kbd>
|
||||||
<kbd><img src=./../pics/describe.png width="768"></kbd>
|
___
|
||||||
|
<kbd><img src=https://codium.ai/images/pr_agent/review.png width="768"></kbd>
|
||||||
The `review` tool can also be triggered automatically every time a new PR is opened. See examples for automatic triggers for [GitHub App](https://github.com/Codium-ai/pr-agent/blob/main/Usage.md#github-app-automatic-tools) and [GitHub Action](https://github.com/Codium-ai/pr-agent/blob/main/Usage.md#working-with-github-action)
|
___
|
||||||
|
|
||||||
### Configuration options
|
### Configuration options
|
||||||
|
|
||||||
Under the section 'pr_reviewer', the [configuration file](./../pr_agent/settings/configuration.toml#L16) contains options to customize the 'review' tool:
|
To edit [configurations](./../pr_agent/settings/configuration.toml#L19) related to the review tool (`pr_reviewer` section), use the following template:
|
||||||
|
```
|
||||||
|
/review --pr_reviewer.some_config1=... --pr_reviewer.some_config2=...
|
||||||
|
```
|
||||||
|
|
||||||
|
#### General options
|
||||||
|
- `num_code_suggestions`: number of code suggestions provided by the 'review' tool. Default is 4.
|
||||||
|
- `inline_code_comments`: if set to true, the tool will publish the code suggestions as comments on the code diff. Default is false.
|
||||||
|
- `persistent_comment`: if set to true, the review comment will be persistent, meaning that every new review request will edit the previous one. Default is true.
|
||||||
|
- `extra_instructions`: Optional extra instructions to the tool. For example: "focus on the changes in the file X. Ignore change in ...".
|
||||||
|
#### Enable\\disable features
|
||||||
- `require_focused_review`: if set to true, the tool will add a section - 'is the PR a focused one'. Default is false.
|
- `require_focused_review`: if set to true, the tool will add a section - 'is the PR a focused one'. Default is false.
|
||||||
- `require_score_review`: if set to true, the tool will add a section that scores the PR. Default is false.
|
- `require_score_review`: if set to true, the tool will add a section that scores the PR. Default is false.
|
||||||
- `require_tests_review`: if set to true, the tool will add a section that checks if the PR contains tests. Default is true.
|
- `require_tests_review`: if set to true, the tool will add a section that checks if the PR contains tests. Default is true.
|
||||||
- `require_security_review`: if set to true, the tool will add a section that checks if the PR contains security issues. Default is true.
|
- `require_security_review`: if set to true, the tool will add a section that checks if the PR contains security issues. Default is true.
|
||||||
- `require_estimate_effort_to_review`: if set to true, the tool will add a section that estimates thed effort needed to review the PR. Default is true.
|
- `require_estimate_effort_to_review`: if set to true, the tool will add a section that estimates thed effort needed to review the PR. Default is true.
|
||||||
- `num_code_suggestions`: number of code suggestions provided by the 'review' tool. Default is 4.
|
#### SOC2 ticket compliance 💎
|
||||||
- `inline_code_comments`: if set to true, the tool will publish the code suggestions as comments on the code diff. Default is false.
|
This sub-tool checks if the PR description properly contains a ticket to a project management system (e.g., Jira, Asana, Trello, etc.), as required by SOC2 compliance. If not, it will add a label to the PR: "Missing SOC2 ticket".
|
||||||
- `automatic_review`: if set to false, no automatic reviews will be done. Default is true.
|
- `require_soc2_review`: If set to true, the SOC2 ticket checker sub-tool will be enabled. Default is false.
|
||||||
- `extra_instructions`: Optional extra instructions to the tool. For example: "focus on the changes in the file X. Ignore change in ...".
|
- `soc2_ticket_prompt`: The prompt for the SOC2 ticket review. Default is: `Does the PR description include a link to ticket in a project management system (e.g., Jira, Asana, Trello, etc.) ?`. Edit this field if your compliance requirements are different.
|
||||||
- To enable `custom labels`, apply the configuration changes described [here](./GENERATE_CUSTOM_LABELS.md#configuration-changes)
|
#### Adding PR labels
|
||||||
#### Incremental Mode
|
- `enable_review_labels_security`: if set to true, the tool will publish a 'possible security issue' label if it detects a security issue. Default is true.
|
||||||
For an incremental review, which only considers changes since the last PR-Agent review, this can be useful when working on the PR in an iterative manner, and you want to focus on the changes since the last review instead of reviewing the entire PR again, the following command can be used:
|
- `enable_review_labels_effort`: if set to true, the tool will publish a 'Review effort [1-5]: x' label. Default is false.
|
||||||
|
|
||||||
|
### Incremental Mode
|
||||||
|
Incremental review only considers changes since the last PR-Agent review. This can be useful when working on the PR in an iterative manner, and you want to focus on the changes since the last review instead of reviewing the entire PR again.
|
||||||
|
For invoking the incremental mode, the following command can be used:
|
||||||
```
|
```
|
||||||
/improve -i
|
/review -i
|
||||||
```
|
```
|
||||||
Note that the incremental mode is only available for GitHub.
|
Note that the incremental mode is only available for GitHub.
|
||||||
|
|
||||||
<kbd><img src=./../pics/incremental_review.png width="768"></kbd>
|
<kbd><img src=https://codium.ai/images/pr_agent/incremental_review.png width="768"></kbd>
|
||||||
|
|
||||||
#### PR Reflection
|
Under the section 'pr_reviewer', the [configuration file](./../pr_agent/settings/configuration.toml#L19) contains options to customize the 'review -i' tool.
|
||||||
|
These configurations can be used to control the rate at which the incremental review tool will create new review comments when invoked automatically, to prevent making too much noise in the PR.
|
||||||
|
- `minimal_commits_for_incremental_review`: Minimal number of commits since the last review that are required to create incremental review.
|
||||||
|
If there are less than the specified number of commits since the last review, the tool will not perform any action.
|
||||||
|
Default is 0 - the tool will always run, no matter how many commits since the last review.
|
||||||
|
- `minimal_minutes_for_incremental_review`: Minimal number of minutes that need to pass since the last reviewed commit to create incremental review.
|
||||||
|
If less that the specified number of minutes have passed between the last reviewed commit and running this command, the tool will not perform any action.
|
||||||
|
Default is 0 - the tool will always run, no matter how much time have passed since the last reviewed commit.
|
||||||
|
- `require_all_thresholds_for_incremental_review`: If set to true, all the previous thresholds must be met for incremental review to run. If false, only one is enough to run the tool.
|
||||||
|
For example, if `minimal_commits_for_incremental_review=2` and `minimal_minutes_for_incremental_review=2`, and we have 3 commits since the last review, but the last reviewed commit is from 1 minute ago:
|
||||||
|
When `require_all_thresholds_for_incremental_review=true` the incremental review __will not__ run, because only 1 out of 2 conditions were met (we have enough commits but the last review is too recent),
|
||||||
|
but when `require_all_thresholds_for_incremental_review=false` the incremental review __will__ run, because one condition is enough (we have 3 commits which is more than the configured 2).
|
||||||
|
Default is false - the tool will run as long as at least once conditions is met.
|
||||||
|
- `remove_previous_review_comment`: if set to true, the tool will remove the previous review comment before adding a new one. Default is false.
|
||||||
|
|
||||||
|
### PR Reflection
|
||||||
By invoking:
|
By invoking:
|
||||||
```
|
```
|
||||||
/reflect_and_review
|
/reflect_and_review
|
||||||
```
|
```
|
||||||
The tool will first ask the author questions about the PR, and will guide the review based on his answers.
|
The tool will first ask the author questions about the PR, and will guide the review based on their answers.
|
||||||
|
|
||||||
<kbd><img src=./../pics/reflection_questions.png width="768"></kbd>
|
<kbd><img src=https://codium.ai/images/pr_agent/reflection_questions.png width="768"></kbd>
|
||||||
<kbd><img src=./../pics/reflection_answers.png width="768"></kbd>
|
___
|
||||||
<kbd><img src=./../pics/reflection_insights.png width="768"></kbd>
|
<kbd><img src=https://codium.ai/images/pr_agent/reflection_answers.png width="768"></kbd>
|
||||||
|
___
|
||||||
|
<kbd><img src=https://codium.ai/images/pr_agent/reflection_insights.png width="768"></kbd>
|
||||||
|
___
|
||||||
|
|
||||||
|
|
||||||
#### A note on code suggestions quality
|
## Usage Tips
|
||||||
|
1) [General guidelines](#general-guidelines)
|
||||||
|
2) [Code suggestions](#code-suggestions)
|
||||||
|
3) [Automation](#automation)
|
||||||
|
4) [Auto-labels](#auto-labels)
|
||||||
|
5) [Extra instructions](#extra-instructions)
|
||||||
|
|
||||||
- With current level of AI for code (GPT-4), mistakes can happen. Not all the suggestions will be perfect, and a user should not accept all of them automatically.
|
### General guidelines
|
||||||
|
The `review` tool provides a collection of possible feedbacks about a PR.
|
||||||
|
It is recommended to review the [Configuration options](#configuration-options) section, and choose the relevant options for your use case.
|
||||||
|
|
||||||
- Suggestions are not meant to be [simplistic](./../pr_agent/settings/pr_reviewer_prompts.toml#L29). Instead, they aim to give deep feedback and raise questions, ideas and thoughts to the user, who can then use his judgment, experience, and understanding of the code base.
|
Some of the feature that are disabled by default are quite useful, and should be considered for enabling. For example:
|
||||||
|
`require_score_review`, `require_soc2_review`, `enable_review_labels_effort`, and more.
|
||||||
|
|
||||||
- Recommended to use the 'extra_instructions' field to guide the model to suggestions that are more relevant to the specific needs of the project.
|
On the other hand, if you find one of the enabled features to be irrelevant for your use case, disable it. No default configuration can fit all use cases.
|
||||||
|
|
||||||
|
### Code suggestions
|
||||||
|
The `review` tool provides several type of feedbacks, one of them is code suggestions.
|
||||||
|
If you are interested **only** in the code suggestions, it is recommended to use the [`improve`](./IMPROVE.md) feature instead, since it dedicated only to code suggestions, and usually gives better results.
|
||||||
|
Use the `review` tool if you want to get a more comprehensive feedback, which includes code suggestions as well.
|
||||||
|
|
||||||
|
### Automation
|
||||||
|
- When you first install the app, the [default mode](https://github.com/Codium-ai/pr-agent/blob/main/Usage.md#github-app-automatic-tools) for the `review` tool is:
|
||||||
|
```
|
||||||
|
pr_commands = ["/review", ...]
|
||||||
|
```
|
||||||
|
meaning the `review` tool will run automatically on every PR, with the default configuration.
|
||||||
|
Edit this field to enable/disable the tool, or to change the used configurations
|
||||||
|
|
||||||
|
### Auto-labels
|
||||||
|
The `review` tool can auto-generate two specific types of labels for a PR:
|
||||||
|
- a `possible security issue` label if it detects a [security issue](https://github.com/Codium-ai/pr-agent/blob/tr/user_description/pr_agent/settings/pr_reviewer_prompts.toml#L136) (`enable_review_labels_security` flag)
|
||||||
|
- a `Review effort [1-5]: x` label, where x is the estimated effort to review the PR (`enable_review_labels_effort` flag)
|
||||||
|
|
||||||
|
Both modes are useful, and we recommended to enable them.
|
||||||
|
|
||||||
|
### Extra instructions
|
||||||
|
Extra instruction are important.
|
||||||
|
The `review` tool can be configured with extra instructions, which can be used to guide the model to feedback tailored to the needs of your project.
|
||||||
|
|
||||||
|
Be specific, clear, and concise in the instructions. With extra instructions, you are the prompter. Specify the relevant sub-tool, and the relevant aspects of the PR that you want to emphasize.
|
||||||
|
|
||||||
|
Examples for extra instructions:
|
||||||
|
```
|
||||||
|
[pr_reviewer] # /review #
|
||||||
|
extra_instructions="""
|
||||||
|
In the code feedback section, emphasize the following:
|
||||||
|
- Does the code logic covers relevant edge cases?
|
||||||
|
- Is the code logic clear and easy to understand?
|
||||||
|
- Is the code logic efficient?
|
||||||
|
...
|
||||||
|
"""
|
||||||
|
```
|
||||||
|
Use triple quotes to write multi-line instructions. Use bullet points to make the instructions more readable.
|
||||||
|
|
||||||
- Unlike the 'review' feature, which does a lot of things, the ['improve --extended'](./IMPROVE.md) feature is dedicated only to suggestions, and usually gives better results.
|
|
||||||
@ -6,13 +6,21 @@ It can be invoked manually by commenting on any PR:
|
|||||||
```
|
```
|
||||||
For example:
|
For example:
|
||||||
|
|
||||||
<kbd><img src=./../pics/similar_issue_original_issue.png width="768"></kbd>
|
<kbd><img src=https://codium.ai/images/pr_agent/similar_issue_original_issue.png width="768"></kbd>
|
||||||
<kbd><img src=./../pics/similar_issue_comment.png width="768"></kbd>
|
<kbd><img src=https://codium.ai/images/pr_agent/similar_issue_comment.png width="768"></kbd>
|
||||||
<kbd><img src=./../pics/similar_issue.png width="768"></kbd>
|
<kbd><img src=https://codium.ai/images/pr_agent/similar_issue.png width="768"></kbd>
|
||||||
|
|
||||||
Note that to perform retrieval, the `similar_issue` tool indexes all the repo previous issues (once).
|
Note that to perform retrieval, the `similar_issue` tool indexes all the repo previous issues (once).
|
||||||
|
|
||||||
To enable usage of the '**similar issue**' tool, you need to set the following keys in `.secrets.toml` (or in the relevant environment variables):
|
|
||||||
|
**Select VectorDBs** by changing `pr_similar_issue` parameter in `configuration.toml` file
|
||||||
|
|
||||||
|
2 VectorDBs are available to switch in
|
||||||
|
1. LanceDB
|
||||||
|
2. Pinecone
|
||||||
|
|
||||||
|
To enable usage of the '**similar issue**' tool for Pinecone, you need to set the following keys in `.secrets.toml` (or in the relevant environment variables):
|
||||||
|
|
||||||
```
|
```
|
||||||
[pinecone]
|
[pinecone]
|
||||||
api_key = "..."
|
api_key = "..."
|
||||||
|
|||||||
@ -7,5 +7,6 @@
|
|||||||
- [UPDATE CHANGELOG](./UPDATE_CHANGELOG.md)
|
- [UPDATE CHANGELOG](./UPDATE_CHANGELOG.md)
|
||||||
- [ADD DOCUMENTATION](./ADD_DOCUMENTATION.md)
|
- [ADD DOCUMENTATION](./ADD_DOCUMENTATION.md)
|
||||||
- [GENERATE CUSTOM LABELS](./GENERATE_CUSTOM_LABELS.md)
|
- [GENERATE CUSTOM LABELS](./GENERATE_CUSTOM_LABELS.md)
|
||||||
|
- [Analyze](./Analyze.md)
|
||||||
|
|
||||||
See the **[installation guide](/INSTALL.md)** for instructions on how to setup PR-Agent.
|
See the **[installation guide](/INSTALL.md)** for instructions on how to setup PR-Agent.
|
||||||
@ -7,8 +7,8 @@ It can be invoked manually by commenting on any PR:
|
|||||||
```
|
```
|
||||||
For example:
|
For example:
|
||||||
|
|
||||||
<kbd><img src=./../pics/update_changelog_comment.png width="768"></kbd>
|
<kbd><img src=https://codium.ai/images/pr_agent/update_changelog_comment.png width="768"></kbd>
|
||||||
<kbd><img src=./../pics/update_changelog.png width="768"></kbd>
|
<kbd><img src=https://codium.ai/images/pr_agent/update_changelog.png width="768"></kbd>
|
||||||
|
|
||||||
|
|
||||||
### Configuration options
|
### Configuration options
|
||||||
|
|||||||
{kind=link}
|
Before Width: | Height: | Size: 325 KiB |
{kind=link}
|
Before Width: | Height: | Size: 51 KiB |
BIN
pics/ask.png
{kind=link}
|
Before Width: | Height: | Size: 308 KiB |
{kind=link}
|
Before Width: | Height: | Size: 32 KiB |
{kind=link}
|
Before Width: | Height: | Size: 253 KiB |
{kind=link}
|
Before Width: | Height: | Size: 84 KiB |
{kind=link}
|
Before Width: | Height: | Size: 244 KiB |
{kind=link}
|
Before Width: | Height: | Size: 17 KiB |
{kind=link}
|
Before Width: | Height: | Size: 224 KiB |
{kind=link}
|
Before Width: | Height: | Size: 30 KiB |
BIN
pics/improve.png
{kind=link}
|
Before Width: | Height: | Size: 234 KiB |
{kind=link}
|
Before Width: | Height: | Size: 21 KiB |
{kind=link}
|
Before Width: | Height: | Size: 286 KiB |
{kind=link}
|
Before Width: | Height: | Size: 22 KiB |
{kind=link}
|
Before Width: | Height: | Size: 25 KiB |
{kind=link}
|
Before Width: | Height: | Size: 29 KiB |
{kind=link}
|
Before Width: | Height: | Size: 217 KiB |
{kind=link}
|
Before Width: | Height: | Size: 86 KiB |
BIN
pics/review.png
{kind=link}
|
Before Width: | Height: | Size: 190 KiB |
{kind=link}
|
Before Width: | Height: | Size: 12 KiB |
{kind=link}
|
Before Width: | Height: | Size: 66 KiB |
{kind=link}
|
Before Width: | Height: | Size: 14 KiB |
{kind=link}
|
Before Width: | Height: | Size: 138 KiB |
{kind=link}
|
Before Width: | Height: | Size: 122 KiB |
{kind=link}
|
Before Width: | Height: | Size: 25 KiB |
@ -1,8 +1,13 @@
|
|||||||
import shlex
|
import shlex
|
||||||
|
from functools import partial
|
||||||
|
|
||||||
|
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||||
|
from pr_agent.algo.ai_handlers.litellm_ai_handler import LiteLLMAIHandler
|
||||||
|
|
||||||
from pr_agent.algo.utils import update_settings_from_args
|
from pr_agent.algo.utils import update_settings_from_args
|
||||||
from pr_agent.config_loader import get_settings
|
from pr_agent.config_loader import get_settings
|
||||||
from pr_agent.git_providers.utils import apply_repo_settings
|
from pr_agent.git_providers.utils import apply_repo_settings
|
||||||
|
from pr_agent.log import get_logger
|
||||||
from pr_agent.tools.pr_add_docs import PRAddDocs
|
from pr_agent.tools.pr_add_docs import PRAddDocs
|
||||||
from pr_agent.tools.pr_code_suggestions import PRCodeSuggestions
|
from pr_agent.tools.pr_code_suggestions import PRCodeSuggestions
|
||||||
from pr_agent.tools.pr_config import PRConfig
|
from pr_agent.tools.pr_config import PRConfig
|
||||||
@ -38,18 +43,21 @@ command2class = {
|
|||||||
commands = list(command2class.keys())
|
commands = list(command2class.keys())
|
||||||
|
|
||||||
class PRAgent:
|
class PRAgent:
|
||||||
def __init__(self):
|
def __init__(self, ai_handler: partial[BaseAiHandler,] = LiteLLMAIHandler):
|
||||||
pass
|
self.ai_handler = ai_handler # will be initialized in run_action
|
||||||
|
|
||||||
async def handle_request(self, pr_url, request, notify=None) -> bool:
|
async def handle_request(self, pr_url, request, notify=None) -> bool:
|
||||||
# First, apply repo specific settings if exists
|
# First, apply repo specific settings if exists
|
||||||
apply_repo_settings(pr_url)
|
apply_repo_settings(pr_url)
|
||||||
|
|
||||||
# Then, apply user specific settings if exists
|
# Then, apply user specific settings if exists
|
||||||
request = request.replace("'", "\\'")
|
if isinstance(request, str):
|
||||||
lexer = shlex.shlex(request, posix=True)
|
request = request.replace("'", "\\'")
|
||||||
lexer.whitespace_split = True
|
lexer = shlex.shlex(request, posix=True)
|
||||||
action, *args = list(lexer)
|
lexer.whitespace_split = True
|
||||||
|
action, *args = list(lexer)
|
||||||
|
else:
|
||||||
|
action, *args = request
|
||||||
args = update_settings_from_args(args)
|
args = update_settings_from_args(args)
|
||||||
|
|
||||||
action = action.lstrip("/").lower()
|
action = action.lstrip("/").lower()
|
||||||
@ -58,13 +66,14 @@ class PRAgent:
|
|||||||
if action == "answer":
|
if action == "answer":
|
||||||
if notify:
|
if notify:
|
||||||
notify()
|
notify()
|
||||||
await PRReviewer(pr_url, is_answer=True, args=args).run()
|
await PRReviewer(pr_url, is_answer=True, args=args, ai_handler=self.ai_handler).run()
|
||||||
elif action == "auto_review":
|
elif action == "auto_review":
|
||||||
await PRReviewer(pr_url, is_auto=True, args=args).run()
|
await PRReviewer(pr_url, is_auto=True, args=args, ai_handler=self.ai_handler).run()
|
||||||
elif action in command2class:
|
elif action in command2class:
|
||||||
if notify:
|
if notify:
|
||||||
notify()
|
notify()
|
||||||
await command2class[action](pr_url, args=args).run()
|
|
||||||
|
await command2class[action](pr_url, ai_handler=self.ai_handler, args=args).run()
|
||||||
else:
|
else:
|
||||||
return False
|
return False
|
||||||
return True
|
return True
|
||||||
|
|||||||
@ -8,9 +8,17 @@ MAX_TOKENS = {
|
|||||||
'gpt-4': 8000,
|
'gpt-4': 8000,
|
||||||
'gpt-4-0613': 8000,
|
'gpt-4-0613': 8000,
|
||||||
'gpt-4-32k': 32000,
|
'gpt-4-32k': 32000,
|
||||||
|
'gpt-4-1106-preview': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||||
'claude-instant-1': 100000,
|
'claude-instant-1': 100000,
|
||||||
'claude-2': 100000,
|
'claude-2': 100000,
|
||||||
'command-nightly': 4096,
|
'command-nightly': 4096,
|
||||||
'replicate/llama-2-70b-chat:2c1608e18606fad2812020dc541930f2d0495ce32eee50074220b87300bc16e1': 4096,
|
'replicate/llama-2-70b-chat:2c1608e18606fad2812020dc541930f2d0495ce32eee50074220b87300bc16e1': 4096,
|
||||||
'meta-llama/Llama-2-7b-chat-hf': 4096
|
'meta-llama/Llama-2-7b-chat-hf': 4096,
|
||||||
|
'vertex_ai/codechat-bison': 6144,
|
||||||
|
'vertex_ai/codechat-bison-32k': 32000,
|
||||||
|
'codechat-bison': 6144,
|
||||||
|
'codechat-bison-32k': 32000,
|
||||||
|
'anthropic.claude-v2': 100000,
|
||||||
|
'anthropic.claude-instant-v1': 100000,
|
||||||
|
'anthropic.claude-v1': 100000,
|
||||||
}
|
}
|
||||||
|
|||||||
28
pr_agent/algo/ai_handlers/base_ai_handler.py
Normal file
@ -0,0 +1,28 @@
|
|||||||
|
from abc import ABC, abstractmethod
|
||||||
|
|
||||||
|
class BaseAiHandler(ABC):
|
||||||
|
"""
|
||||||
|
This class defines the interface for an AI handler to be used by the PR Agents.
|
||||||
|
"""
|
||||||
|
|
||||||
|
@abstractmethod
|
||||||
|
def __init__(self):
|
||||||
|
pass
|
||||||
|
|
||||||
|
@property
|
||||||
|
@abstractmethod
|
||||||
|
def deployment_id(self):
|
||||||
|
pass
|
||||||
|
|
||||||
|
@abstractmethod
|
||||||
|
async def chat_completion(self, model: str, system: str, user: str, temperature: float = 0.2):
|
||||||
|
"""
|
||||||
|
This method should be implemented to return a chat completion from the AI model.
|
||||||
|
Args:
|
||||||
|
model (str): the name of the model to use for the chat completion
|
||||||
|
system (str): the system message string to use for the chat completion
|
||||||
|
user (str): the user message string to use for the chat completion
|
||||||
|
temperature (float): the temperature to use for the chat completion
|
||||||
|
"""
|
||||||
|
pass
|
||||||
|
|
||||||
67
pr_agent/algo/ai_handlers/langchain_ai_handler.py
Normal file
@ -0,0 +1,67 @@
|
|||||||
|
try:
|
||||||
|
from langchain.chat_models import ChatOpenAI, AzureChatOpenAI
|
||||||
|
from langchain.schema import SystemMessage, HumanMessage
|
||||||
|
except: # we don't enforce langchain as a dependency, so if it's not installed, just move on
|
||||||
|
pass
|
||||||
|
|
||||||
|
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||||
|
from pr_agent.config_loader import get_settings
|
||||||
|
from pr_agent.log import get_logger
|
||||||
|
|
||||||
|
from openai.error import APIError, RateLimitError, Timeout, TryAgain
|
||||||
|
from retry import retry
|
||||||
|
import functools
|
||||||
|
|
||||||
|
OPENAI_RETRIES = 5
|
||||||
|
|
||||||
|
class LangChainOpenAIHandler(BaseAiHandler):
|
||||||
|
def __init__(self):
|
||||||
|
# Initialize OpenAIHandler specific attributes here
|
||||||
|
super().__init__()
|
||||||
|
self.azure = get_settings().get("OPENAI.API_TYPE", "").lower() == "azure"
|
||||||
|
try:
|
||||||
|
if self.azure:
|
||||||
|
# using a partial function so we can set the deployment_id later to support fallback_deployments
|
||||||
|
# but still need to access the other settings now so we can raise a proper exception if they're missing
|
||||||
|
self._chat = functools.partial(
|
||||||
|
lambda **kwargs: AzureChatOpenAI(**kwargs),
|
||||||
|
openai_api_key=get_settings().openai.key,
|
||||||
|
openai_api_base=get_settings().openai.api_base,
|
||||||
|
openai_api_version=get_settings().openai.api_version,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
self._chat = ChatOpenAI(openai_api_key=get_settings().openai.key)
|
||||||
|
except AttributeError as e:
|
||||||
|
if getattr(e, "name"):
|
||||||
|
raise ValueError(f"OpenAI {e.name} is required") from e
|
||||||
|
else:
|
||||||
|
raise e
|
||||||
|
|
||||||
|
@property
|
||||||
|
def chat(self):
|
||||||
|
if self.azure:
|
||||||
|
# we must set the deployment_id only here (instead of the __init__ method) to support fallback_deployments
|
||||||
|
return self._chat(deployment_name=self.deployment_id)
|
||||||
|
else:
|
||||||
|
return self._chat
|
||||||
|
|
||||||
|
@property
|
||||||
|
def deployment_id(self):
|
||||||
|
"""
|
||||||
|
Returns the deployment ID for the OpenAI API.
|
||||||
|
"""
|
||||||
|
return get_settings().get("OPENAI.DEPLOYMENT_ID", None)
|
||||||
|
@retry(exceptions=(APIError, Timeout, TryAgain, AttributeError, RateLimitError),
|
||||||
|
tries=OPENAI_RETRIES, delay=2, backoff=2, jitter=(1, 3))
|
||||||
|
async def chat_completion(self, model: str, system: str, user: str, temperature: float = 0.2):
|
||||||
|
try:
|
||||||
|
messages=[SystemMessage(content=system), HumanMessage(content=user)]
|
||||||
|
|
||||||
|
# get a chat completion from the formatted messages
|
||||||
|
resp = self.chat(messages, model=model, temperature=temperature)
|
||||||
|
finish_reason="completed"
|
||||||
|
return resp.content, finish_reason
|
||||||
|
|
||||||
|
except (Exception) as e:
|
||||||
|
get_logger().error("Unknown error during OpenAI inference: ", e)
|
||||||
|
raise e
|
||||||
@ -1,17 +1,19 @@
|
|||||||
import os
|
import os
|
||||||
|
|
||||||
|
import boto3
|
||||||
import litellm
|
import litellm
|
||||||
import openai
|
import openai
|
||||||
from litellm import acompletion
|
from litellm import acompletion
|
||||||
from openai.error import APIError, RateLimitError, Timeout, TryAgain
|
from openai.error import APIError, RateLimitError, Timeout, TryAgain
|
||||||
from retry import retry
|
from retry import retry
|
||||||
|
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||||
from pr_agent.config_loader import get_settings
|
from pr_agent.config_loader import get_settings
|
||||||
from pr_agent.log import get_logger
|
from pr_agent.log import get_logger
|
||||||
|
|
||||||
OPENAI_RETRIES = 5
|
OPENAI_RETRIES = 5
|
||||||
|
|
||||||
|
|
||||||
class AiHandler:
|
class LiteLLMAIHandler(BaseAiHandler):
|
||||||
"""
|
"""
|
||||||
This class handles interactions with the OpenAI API for chat completions.
|
This class handles interactions with the OpenAI API for chat completions.
|
||||||
It initializes the API key and other settings from a configuration file,
|
It initializes the API key and other settings from a configuration file,
|
||||||
@ -23,39 +25,50 @@ class AiHandler:
|
|||||||
Initializes the OpenAI API key and other settings from a configuration file.
|
Initializes the OpenAI API key and other settings from a configuration file.
|
||||||
Raises a ValueError if the OpenAI key is missing.
|
Raises a ValueError if the OpenAI key is missing.
|
||||||
"""
|
"""
|
||||||
try:
|
self.azure = False
|
||||||
|
self.aws_bedrock_client = None
|
||||||
|
|
||||||
|
if get_settings().get("OPENAI.KEY", None):
|
||||||
openai.api_key = get_settings().openai.key
|
openai.api_key = get_settings().openai.key
|
||||||
litellm.openai_key = get_settings().openai.key
|
litellm.openai_key = get_settings().openai.key
|
||||||
if get_settings().get("litellm.use_client"):
|
if get_settings().get("litellm.use_client"):
|
||||||
litellm_token = get_settings().get("litellm.LITELLM_TOKEN")
|
litellm_token = get_settings().get("litellm.LITELLM_TOKEN")
|
||||||
assert litellm_token, "LITELLM_TOKEN is required"
|
assert litellm_token, "LITELLM_TOKEN is required"
|
||||||
os.environ["LITELLM_TOKEN"] = litellm_token
|
os.environ["LITELLM_TOKEN"] = litellm_token
|
||||||
litellm.use_client = True
|
litellm.use_client = True
|
||||||
self.azure = False
|
if get_settings().get("OPENAI.ORG", None):
|
||||||
if get_settings().get("OPENAI.ORG", None):
|
litellm.organization = get_settings().openai.org
|
||||||
litellm.organization = get_settings().openai.org
|
if get_settings().get("OPENAI.API_TYPE", None):
|
||||||
if get_settings().get("OPENAI.API_TYPE", None):
|
if get_settings().openai.api_type == "azure":
|
||||||
if get_settings().openai.api_type == "azure":
|
self.azure = True
|
||||||
self.azure = True
|
litellm.azure_key = get_settings().openai.key
|
||||||
litellm.azure_key = get_settings().openai.key
|
if get_settings().get("OPENAI.API_VERSION", None):
|
||||||
if get_settings().get("OPENAI.API_VERSION", None):
|
litellm.api_version = get_settings().openai.api_version
|
||||||
litellm.api_version = get_settings().openai.api_version
|
if get_settings().get("OPENAI.API_BASE", None):
|
||||||
if get_settings().get("OPENAI.API_BASE", None):
|
litellm.api_base = get_settings().openai.api_base
|
||||||
litellm.api_base = get_settings().openai.api_base
|
if get_settings().get("ANTHROPIC.KEY", None):
|
||||||
if get_settings().get("ANTHROPIC.KEY", None):
|
litellm.anthropic_key = get_settings().anthropic.key
|
||||||
litellm.anthropic_key = get_settings().anthropic.key
|
if get_settings().get("COHERE.KEY", None):
|
||||||
if get_settings().get("COHERE.KEY", None):
|
litellm.cohere_key = get_settings().cohere.key
|
||||||
litellm.cohere_key = get_settings().cohere.key
|
if get_settings().get("REPLICATE.KEY", None):
|
||||||
if get_settings().get("REPLICATE.KEY", None):
|
litellm.replicate_key = get_settings().replicate.key
|
||||||
litellm.replicate_key = get_settings().replicate.key
|
if get_settings().get("REPLICATE.KEY", None):
|
||||||
if get_settings().get("REPLICATE.KEY", None):
|
litellm.replicate_key = get_settings().replicate.key
|
||||||
litellm.replicate_key = get_settings().replicate.key
|
if get_settings().get("HUGGINGFACE.KEY", None):
|
||||||
if get_settings().get("HUGGINGFACE.KEY", None):
|
litellm.huggingface_key = get_settings().huggingface.key
|
||||||
litellm.huggingface_key = get_settings().huggingface.key
|
if get_settings().get("HUGGINGFACE.API_BASE", None):
|
||||||
if get_settings().get("HUGGINGFACE.API_BASE", None):
|
litellm.api_base = get_settings().huggingface.api_base
|
||||||
litellm.api_base = get_settings().huggingface.api_base
|
if get_settings().get("VERTEXAI.VERTEX_PROJECT", None):
|
||||||
except AttributeError as e:
|
litellm.vertex_project = get_settings().vertexai.vertex_project
|
||||||
raise ValueError("OpenAI key is required") from e
|
litellm.vertex_location = get_settings().get(
|
||||||
|
"VERTEXAI.VERTEX_LOCATION", None
|
||||||
|
)
|
||||||
|
if get_settings().get("AWS.BEDROCK_REGION", None):
|
||||||
|
litellm.AmazonAnthropicConfig.max_tokens_to_sample = 2000
|
||||||
|
self.aws_bedrock_client = boto3.client(
|
||||||
|
service_name="bedrock-runtime",
|
||||||
|
region_name=get_settings().aws.bedrock_region,
|
||||||
|
)
|
||||||
|
|
||||||
@property
|
@property
|
||||||
def deployment_id(self):
|
def deployment_id(self):
|
||||||
@ -88,21 +101,19 @@ class AiHandler:
|
|||||||
"""
|
"""
|
||||||
try:
|
try:
|
||||||
deployment_id = self.deployment_id
|
deployment_id = self.deployment_id
|
||||||
if get_settings().config.verbosity_level >= 2:
|
|
||||||
get_logger().debug(
|
|
||||||
f"Generating completion with {model}"
|
|
||||||
f"{(' from deployment ' + deployment_id) if deployment_id else ''}"
|
|
||||||
)
|
|
||||||
if self.azure:
|
if self.azure:
|
||||||
model = 'azure/' + model
|
model = 'azure/' + model
|
||||||
messages = [{"role": "system", "content": system}, {"role": "user", "content": user}]
|
messages = [{"role": "system", "content": system}, {"role": "user", "content": user}]
|
||||||
response = await acompletion(
|
kwargs = {
|
||||||
model=model,
|
"model": model,
|
||||||
deployment_id=deployment_id,
|
"deployment_id": deployment_id,
|
||||||
messages=messages,
|
"messages": messages,
|
||||||
temperature=temperature,
|
"temperature": temperature,
|
||||||
force_timeout=get_settings().config.ai_timeout
|
"force_timeout": get_settings().config.ai_timeout,
|
||||||
)
|
}
|
||||||
|
if self.aws_bedrock_client:
|
||||||
|
kwargs["aws_bedrock_client"] = self.aws_bedrock_client
|
||||||
|
response = await acompletion(**kwargs)
|
||||||
except (APIError, Timeout, TryAgain) as e:
|
except (APIError, Timeout, TryAgain) as e:
|
||||||
get_logger().error("Error during OpenAI inference: ", e)
|
get_logger().error("Error during OpenAI inference: ", e)
|
||||||
raise
|
raise
|
||||||
@ -119,4 +130,4 @@ class AiHandler:
|
|||||||
usage = response.get("usage")
|
usage = response.get("usage")
|
||||||
get_logger().info("AI response", response=resp, messages=messages, finish_reason=finish_reason,
|
get_logger().info("AI response", response=resp, messages=messages, finish_reason=finish_reason,
|
||||||
model=model, usage=usage)
|
model=model, usage=usage)
|
||||||
return resp, finish_reason
|
return resp, finish_reason
|
||||||
67
pr_agent/algo/ai_handlers/openai_ai_handler.py
Normal file
@ -0,0 +1,67 @@
|
|||||||
|
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||||
|
import openai
|
||||||
|
from openai.error import APIError, RateLimitError, Timeout, TryAgain
|
||||||
|
from retry import retry
|
||||||
|
|
||||||
|
from pr_agent.config_loader import get_settings
|
||||||
|
from pr_agent.log import get_logger
|
||||||
|
|
||||||
|
OPENAI_RETRIES = 5
|
||||||
|
|
||||||
|
|
||||||
|
class OpenAIHandler(BaseAiHandler):
|
||||||
|
def __init__(self):
|
||||||
|
# Initialize OpenAIHandler specific attributes here
|
||||||
|
try:
|
||||||
|
super().__init__()
|
||||||
|
openai.api_key = get_settings().openai.key
|
||||||
|
if get_settings().get("OPENAI.ORG", None):
|
||||||
|
openai.organization = get_settings().openai.org
|
||||||
|
if get_settings().get("OPENAI.API_TYPE", None):
|
||||||
|
if get_settings().openai.api_type == "azure":
|
||||||
|
self.azure = True
|
||||||
|
openai.azure_key = get_settings().openai.key
|
||||||
|
if get_settings().get("OPENAI.API_VERSION", None):
|
||||||
|
openai.api_version = get_settings().openai.api_version
|
||||||
|
if get_settings().get("OPENAI.API_BASE", None):
|
||||||
|
openai.api_base = get_settings().openai.api_base
|
||||||
|
|
||||||
|
except AttributeError as e:
|
||||||
|
raise ValueError("OpenAI key is required") from e
|
||||||
|
@property
|
||||||
|
def deployment_id(self):
|
||||||
|
"""
|
||||||
|
Returns the deployment ID for the OpenAI API.
|
||||||
|
"""
|
||||||
|
return get_settings().get("OPENAI.DEPLOYMENT_ID", None)
|
||||||
|
|
||||||
|
@retry(exceptions=(APIError, Timeout, TryAgain, AttributeError, RateLimitError),
|
||||||
|
tries=OPENAI_RETRIES, delay=2, backoff=2, jitter=(1, 3))
|
||||||
|
async def chat_completion(self, model: str, system: str, user: str, temperature: float = 0.2):
|
||||||
|
try:
|
||||||
|
deployment_id = self.deployment_id
|
||||||
|
get_logger().info("System: ", system)
|
||||||
|
get_logger().info("User: ", user)
|
||||||
|
messages = [{"role": "system", "content": system}, {"role": "user", "content": user}]
|
||||||
|
|
||||||
|
chat_completion = await openai.ChatCompletion.acreate(
|
||||||
|
model=model,
|
||||||
|
deployment_id=deployment_id,
|
||||||
|
messages=messages,
|
||||||
|
temperature=temperature,
|
||||||
|
)
|
||||||
|
resp = chat_completion["choices"][0]['message']['content']
|
||||||
|
finish_reason = chat_completion["choices"][0]["finish_reason"]
|
||||||
|
usage = chat_completion.get("usage")
|
||||||
|
get_logger().info("AI response", response=resp, messages=messages, finish_reason=finish_reason,
|
||||||
|
model=model, usage=usage)
|
||||||
|
return resp, finish_reason
|
||||||
|
except (APIError, Timeout, TryAgain) as e:
|
||||||
|
get_logger().error("Error during OpenAI inference: ", e)
|
||||||
|
raise
|
||||||
|
except (RateLimitError) as e:
|
||||||
|
get_logger().error("Rate limit error during OpenAI inference: ", e)
|
||||||
|
raise
|
||||||
|
except (Exception) as e:
|
||||||
|
get_logger().error("Unknown error during OpenAI inference: ", e)
|
||||||
|
raise TryAgain from e
|
||||||
@ -11,7 +11,12 @@ def filter_ignored(files):
|
|||||||
try:
|
try:
|
||||||
# load regex patterns, and translate glob patterns to regex
|
# load regex patterns, and translate glob patterns to regex
|
||||||
patterns = get_settings().ignore.regex
|
patterns = get_settings().ignore.regex
|
||||||
patterns += [fnmatch.translate(glob) for glob in get_settings().ignore.glob]
|
if isinstance(patterns, str):
|
||||||
|
patterns = [patterns]
|
||||||
|
glob_setting = get_settings().ignore.glob
|
||||||
|
if isinstance(glob_setting, str): # --ignore.glob=[.*utils.py], --ignore.glob=.*utils.py
|
||||||
|
glob_setting = glob_setting.strip('[]').split(",")
|
||||||
|
patterns += [fnmatch.translate(glob) for glob in glob_setting]
|
||||||
|
|
||||||
# compile all valid patterns
|
# compile all valid patterns
|
||||||
compiled_patterns = []
|
compiled_patterns = []
|
||||||
@ -23,7 +28,7 @@ def filter_ignored(files):
|
|||||||
|
|
||||||
# keep filenames that _don't_ match the ignore regex
|
# keep filenames that _don't_ match the ignore regex
|
||||||
for r in compiled_patterns:
|
for r in compiled_patterns:
|
||||||
files = [f for f in files if not r.match(f.filename)]
|
files = [f for f in files if (f.filename and not r.match(f.filename))]
|
||||||
|
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
print(f"Could not filter file list: {e}")
|
print(f"Could not filter file list: {e}")
|
||||||
|
|||||||
@ -3,6 +3,7 @@ from __future__ import annotations
|
|||||||
import re
|
import re
|
||||||
|
|
||||||
from pr_agent.config_loader import get_settings
|
from pr_agent.config_loader import get_settings
|
||||||
|
from pr_agent.git_providers.git_provider import EDIT_TYPE
|
||||||
from pr_agent.log import get_logger
|
from pr_agent.log import get_logger
|
||||||
|
|
||||||
|
|
||||||
@ -115,7 +116,7 @@ def omit_deletion_hunks(patch_lines) -> str:
|
|||||||
|
|
||||||
|
|
||||||
def handle_patch_deletions(patch: str, original_file_content_str: str,
|
def handle_patch_deletions(patch: str, original_file_content_str: str,
|
||||||
new_file_content_str: str, file_name: str) -> str:
|
new_file_content_str: str, file_name: str, edit_type: EDIT_TYPE = EDIT_TYPE.UNKNOWN) -> str:
|
||||||
"""
|
"""
|
||||||
Handle entire file or deletion patches.
|
Handle entire file or deletion patches.
|
||||||
|
|
||||||
@ -132,7 +133,7 @@ def handle_patch_deletions(patch: str, original_file_content_str: str,
|
|||||||
str: The modified patch with deletion hunks omitted.
|
str: The modified patch with deletion hunks omitted.
|
||||||
|
|
||||||
"""
|
"""
|
||||||
if not new_file_content_str:
|
if not new_file_content_str and edit_type != EDIT_TYPE.ADDED:
|
||||||
# logic for handling deleted files - don't show patch, just show that the file was deleted
|
# logic for handling deleted files - don't show patch, just show that the file was deleted
|
||||||
if get_settings().config.verbosity_level > 0:
|
if get_settings().config.verbosity_level > 0:
|
||||||
get_logger().info(f"Processing file: {file_name}, minimizing deletion file")
|
get_logger().info(f"Processing file: {file_name}, minimizing deletion file")
|
||||||
|
|||||||
@ -3,8 +3,7 @@ from typing import Dict
|
|||||||
|
|
||||||
from pr_agent.config_loader import get_settings
|
from pr_agent.config_loader import get_settings
|
||||||
|
|
||||||
language_extension_map_org = get_settings().language_extension_map_org
|
|
||||||
language_extension_map = {k.lower(): v for k, v in language_extension_map_org.items()}
|
|
||||||
|
|
||||||
# Bad Extensions, source: https://github.com/EleutherAI/github-downloader/blob/345e7c4cbb9e0dc8a0615fd995a08bf9d73b3fe6/download_repo_text.py # noqa: E501
|
# Bad Extensions, source: https://github.com/EleutherAI/github-downloader/blob/345e7c4cbb9e0dc8a0615fd995a08bf9d73b3fe6/download_repo_text.py # noqa: E501
|
||||||
bad_extensions = get_settings().bad_extensions.default
|
bad_extensions = get_settings().bad_extensions.default
|
||||||
@ -29,6 +28,8 @@ def sort_files_by_main_languages(languages: Dict, files: list):
|
|||||||
# languages_sorted = sorted(languages, key=lambda x: x[1], reverse=True)
|
# languages_sorted = sorted(languages, key=lambda x: x[1], reverse=True)
|
||||||
# get all extensions for the languages
|
# get all extensions for the languages
|
||||||
main_extensions = []
|
main_extensions = []
|
||||||
|
language_extension_map_org = get_settings().language_extension_map_org
|
||||||
|
language_extension_map = {k.lower(): v for k, v in language_extension_map_org.items()}
|
||||||
for language in languages_sorted_list:
|
for language in languages_sorted_list:
|
||||||
if language.lower() in language_extension_map:
|
if language.lower() in language_extension_map:
|
||||||
main_extensions.append(language_extension_map[language.lower()])
|
main_extensions.append(language_extension_map[language.lower()])
|
||||||
|
|||||||
@ -7,18 +7,20 @@ from typing import Any, Callable, List, Tuple
|
|||||||
|
|
||||||
from github import RateLimitExceededException
|
from github import RateLimitExceededException
|
||||||
|
|
||||||
from pr_agent.algo import MAX_TOKENS
|
|
||||||
from pr_agent.algo.git_patch_processing import convert_to_hunks_with_lines_numbers, extend_patch, handle_patch_deletions
|
from pr_agent.algo.git_patch_processing import convert_to_hunks_with_lines_numbers, extend_patch, handle_patch_deletions
|
||||||
from pr_agent.algo.language_handler import sort_files_by_main_languages
|
from pr_agent.algo.language_handler import sort_files_by_main_languages
|
||||||
from pr_agent.algo.file_filter import filter_ignored
|
from pr_agent.algo.file_filter import filter_ignored
|
||||||
from pr_agent.algo.token_handler import TokenHandler, get_token_encoder
|
from pr_agent.algo.token_handler import TokenHandler
|
||||||
|
from pr_agent.algo.utils import get_max_tokens
|
||||||
from pr_agent.config_loader import get_settings
|
from pr_agent.config_loader import get_settings
|
||||||
from pr_agent.git_providers.git_provider import FilePatchInfo, GitProvider
|
from pr_agent.git_providers.git_provider import FilePatchInfo, GitProvider, EDIT_TYPE
|
||||||
from pr_agent.log import get_logger
|
from pr_agent.log import get_logger
|
||||||
|
|
||||||
DELETED_FILES_ = "Deleted files:\n"
|
DELETED_FILES_ = "Deleted files:\n"
|
||||||
|
|
||||||
MORE_MODIFIED_FILES_ = "More modified files:\n"
|
MORE_MODIFIED_FILES_ = "Additional modified files (insufficient token budget to process):\n"
|
||||||
|
|
||||||
|
ADDED_FILES_ = "Additional added files (insufficient token budget to process):\n"
|
||||||
|
|
||||||
OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD = 1000
|
OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD = 1000
|
||||||
OUTPUT_BUFFER_TOKENS_HARD_THRESHOLD = 600
|
OUTPUT_BUFFER_TOKENS_HARD_THRESHOLD = 600
|
||||||
@ -64,14 +66,17 @@ def get_pr_diff(git_provider: GitProvider, token_handler: TokenHandler, model: s
|
|||||||
pr_languages, token_handler, add_line_numbers_to_hunks, patch_extra_lines=PATCH_EXTRA_LINES)
|
pr_languages, token_handler, add_line_numbers_to_hunks, patch_extra_lines=PATCH_EXTRA_LINES)
|
||||||
|
|
||||||
# if we are under the limit, return the full diff
|
# if we are under the limit, return the full diff
|
||||||
if total_tokens + OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD < MAX_TOKENS[model]:
|
if total_tokens + OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD < get_max_tokens(model):
|
||||||
return "\n".join(patches_extended)
|
return "\n".join(patches_extended)
|
||||||
|
|
||||||
# if we are over the limit, start pruning
|
# if we are over the limit, start pruning
|
||||||
patches_compressed, modified_file_names, deleted_file_names = \
|
patches_compressed, modified_file_names, deleted_file_names, added_file_names = \
|
||||||
pr_generate_compressed_diff(pr_languages, token_handler, model, add_line_numbers_to_hunks)
|
pr_generate_compressed_diff(pr_languages, token_handler, model, add_line_numbers_to_hunks)
|
||||||
|
|
||||||
final_diff = "\n".join(patches_compressed)
|
final_diff = "\n".join(patches_compressed)
|
||||||
|
if added_file_names:
|
||||||
|
added_list_str = ADDED_FILES_ + "\n".join(added_file_names)
|
||||||
|
final_diff = final_diff + "\n\n" + added_list_str
|
||||||
if modified_file_names:
|
if modified_file_names:
|
||||||
modified_list_str = MORE_MODIFIED_FILES_ + "\n".join(modified_file_names)
|
modified_list_str = MORE_MODIFIED_FILES_ + "\n".join(modified_file_names)
|
||||||
final_diff = final_diff + "\n\n" + modified_list_str
|
final_diff = final_diff + "\n\n" + modified_list_str
|
||||||
@ -122,7 +127,7 @@ def pr_generate_extended_diff(pr_languages: list,
|
|||||||
|
|
||||||
|
|
||||||
def pr_generate_compressed_diff(top_langs: list, token_handler: TokenHandler, model: str,
|
def pr_generate_compressed_diff(top_langs: list, token_handler: TokenHandler, model: str,
|
||||||
convert_hunks_to_line_numbers: bool) -> Tuple[list, list, list]:
|
convert_hunks_to_line_numbers: bool) -> Tuple[list, list, list, list]:
|
||||||
"""
|
"""
|
||||||
Generate a compressed diff string for a pull request, using diff minimization techniques to reduce the number of
|
Generate a compressed diff string for a pull request, using diff minimization techniques to reduce the number of
|
||||||
tokens used.
|
tokens used.
|
||||||
@ -148,6 +153,7 @@ def pr_generate_compressed_diff(top_langs: list, token_handler: TokenHandler, mo
|
|||||||
"""
|
"""
|
||||||
|
|
||||||
patches = []
|
patches = []
|
||||||
|
added_files_list = []
|
||||||
modified_files_list = []
|
modified_files_list = []
|
||||||
deleted_files_list = []
|
deleted_files_list = []
|
||||||
# sort each one of the languages in top_langs by the number of tokens in the diff
|
# sort each one of the languages in top_langs by the number of tokens in the diff
|
||||||
@ -165,7 +171,7 @@ def pr_generate_compressed_diff(top_langs: list, token_handler: TokenHandler, mo
|
|||||||
|
|
||||||
# removing delete-only hunks
|
# removing delete-only hunks
|
||||||
patch = handle_patch_deletions(patch, original_file_content_str,
|
patch = handle_patch_deletions(patch, original_file_content_str,
|
||||||
new_file_content_str, file.filename)
|
new_file_content_str, file.filename, file.edit_type)
|
||||||
if patch is None:
|
if patch is None:
|
||||||
if not deleted_files_list:
|
if not deleted_files_list:
|
||||||
total_tokens += token_handler.count_tokens(DELETED_FILES_)
|
total_tokens += token_handler.count_tokens(DELETED_FILES_)
|
||||||
@ -179,21 +185,26 @@ def pr_generate_compressed_diff(top_langs: list, token_handler: TokenHandler, mo
|
|||||||
new_patch_tokens = token_handler.count_tokens(patch)
|
new_patch_tokens = token_handler.count_tokens(patch)
|
||||||
|
|
||||||
# Hard Stop, no more tokens
|
# Hard Stop, no more tokens
|
||||||
if total_tokens > MAX_TOKENS[model] - OUTPUT_BUFFER_TOKENS_HARD_THRESHOLD:
|
if total_tokens > get_max_tokens(model) - OUTPUT_BUFFER_TOKENS_HARD_THRESHOLD:
|
||||||
get_logger().warning(f"File was fully skipped, no more tokens: {file.filename}.")
|
get_logger().warning(f"File was fully skipped, no more tokens: {file.filename}.")
|
||||||
continue
|
continue
|
||||||
|
|
||||||
# If the patch is too large, just show the file name
|
# If the patch is too large, just show the file name
|
||||||
if total_tokens + new_patch_tokens > MAX_TOKENS[model] - OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD:
|
if total_tokens + new_patch_tokens > get_max_tokens(model) - OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD:
|
||||||
# Current logic is to skip the patch if it's too large
|
# Current logic is to skip the patch if it's too large
|
||||||
# TODO: Option for alternative logic to remove hunks from the patch to reduce the number of tokens
|
# TODO: Option for alternative logic to remove hunks from the patch to reduce the number of tokens
|
||||||
# until we meet the requirements
|
# until we meet the requirements
|
||||||
if get_settings().config.verbosity_level >= 2:
|
if get_settings().config.verbosity_level >= 2:
|
||||||
get_logger().warning(f"Patch too large, minimizing it, {file.filename}")
|
get_logger().warning(f"Patch too large, minimizing it, {file.filename}")
|
||||||
if not modified_files_list:
|
if file.edit_type == EDIT_TYPE.ADDED:
|
||||||
total_tokens += token_handler.count_tokens(MORE_MODIFIED_FILES_)
|
if not added_files_list:
|
||||||
modified_files_list.append(file.filename)
|
total_tokens += token_handler.count_tokens(ADDED_FILES_)
|
||||||
total_tokens += token_handler.count_tokens(file.filename) + 1
|
added_files_list.append(file.filename)
|
||||||
|
else:
|
||||||
|
if not modified_files_list:
|
||||||
|
total_tokens += token_handler.count_tokens(MORE_MODIFIED_FILES_)
|
||||||
|
modified_files_list.append(file.filename)
|
||||||
|
total_tokens += token_handler.count_tokens(file.filename) + 1
|
||||||
continue
|
continue
|
||||||
|
|
||||||
if patch:
|
if patch:
|
||||||
@ -206,7 +217,7 @@ def pr_generate_compressed_diff(top_langs: list, token_handler: TokenHandler, mo
|
|||||||
if get_settings().config.verbosity_level >= 2:
|
if get_settings().config.verbosity_level >= 2:
|
||||||
get_logger().info(f"Tokens: {total_tokens}, last filename: {file.filename}")
|
get_logger().info(f"Tokens: {total_tokens}, last filename: {file.filename}")
|
||||||
|
|
||||||
return patches, modified_files_list, deleted_files_list
|
return patches, modified_files_list, deleted_files_list, added_files_list
|
||||||
|
|
||||||
|
|
||||||
async def retry_with_fallback_models(f: Callable):
|
async def retry_with_fallback_models(f: Callable):
|
||||||
@ -215,6 +226,11 @@ async def retry_with_fallback_models(f: Callable):
|
|||||||
# try each (model, deployment_id) pair until one is successful, otherwise raise exception
|
# try each (model, deployment_id) pair until one is successful, otherwise raise exception
|
||||||
for i, (model, deployment_id) in enumerate(zip(all_models, all_deployments)):
|
for i, (model, deployment_id) in enumerate(zip(all_models, all_deployments)):
|
||||||
try:
|
try:
|
||||||
|
if get_settings().config.verbosity_level >= 2:
|
||||||
|
get_logger().debug(
|
||||||
|
f"Generating prediction with {model}"
|
||||||
|
f"{(' from deployment ' + deployment_id) if deployment_id else ''}"
|
||||||
|
)
|
||||||
get_settings().set("openai.deployment_id", deployment_id)
|
get_settings().set("openai.deployment_id", deployment_id)
|
||||||
return await f(model)
|
return await f(model)
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
@ -253,51 +269,44 @@ def _get_all_deployments(all_models: List[str]) -> List[str]:
|
|||||||
|
|
||||||
def find_line_number_of_relevant_line_in_file(diff_files: List[FilePatchInfo],
|
def find_line_number_of_relevant_line_in_file(diff_files: List[FilePatchInfo],
|
||||||
relevant_file: str,
|
relevant_file: str,
|
||||||
relevant_line_in_file: str) -> Tuple[int, int]:
|
relevant_line_in_file: str,
|
||||||
"""
|
absolute_position: int = None) -> Tuple[int, int]:
|
||||||
Find the line number and absolute position of a relevant line in a file.
|
|
||||||
|
|
||||||
Args:
|
|
||||||
diff_files (List[FilePatchInfo]): A list of FilePatchInfo objects representing the patches of files.
|
|
||||||
relevant_file (str): The name of the file where the relevant line is located.
|
|
||||||
relevant_line_in_file (str): The content of the relevant line.
|
|
||||||
|
|
||||||
Returns:
|
|
||||||
Tuple[int, int]: A tuple containing the line number and absolute position of the relevant line in the file.
|
|
||||||
"""
|
|
||||||
position = -1
|
position = -1
|
||||||
absolute_position = -1
|
if absolute_position is None:
|
||||||
|
absolute_position = -1
|
||||||
re_hunk_header = re.compile(
|
re_hunk_header = re.compile(
|
||||||
r"^@@ -(\d+)(?:,(\d+))? \+(\d+)(?:,(\d+))? @@[ ]?(.*)")
|
r"^@@ -(\d+)(?:,(\d+))? \+(\d+)(?:,(\d+))? @@[ ]?(.*)")
|
||||||
|
|
||||||
for file in diff_files:
|
for file in diff_files:
|
||||||
if file.filename.strip() == relevant_file:
|
if file.filename and (file.filename.strip() == relevant_file):
|
||||||
patch = file.patch
|
patch = file.patch
|
||||||
patch_lines = patch.splitlines()
|
patch_lines = patch.splitlines()
|
||||||
|
|
||||||
# try to find the line in the patch using difflib, with some margin of error
|
|
||||||
matches_difflib: list[str | Any] = difflib.get_close_matches(relevant_line_in_file,
|
|
||||||
patch_lines, n=3, cutoff=0.93)
|
|
||||||
if len(matches_difflib) == 1 and matches_difflib[0].startswith('+'):
|
|
||||||
relevant_line_in_file = matches_difflib[0]
|
|
||||||
|
|
||||||
delta = 0
|
delta = 0
|
||||||
start1, size1, start2, size2 = 0, 0, 0, 0
|
start1, size1, start2, size2 = 0, 0, 0, 0
|
||||||
for i, line in enumerate(patch_lines):
|
if absolute_position != -1: # matching absolute to relative
|
||||||
if line.startswith('@@'):
|
for i, line in enumerate(patch_lines):
|
||||||
delta = 0
|
# new hunk
|
||||||
match = re_hunk_header.match(line)
|
if line.startswith('@@'):
|
||||||
start1, size1, start2, size2 = map(int, match.groups()[:4])
|
delta = 0
|
||||||
elif not line.startswith('-'):
|
match = re_hunk_header.match(line)
|
||||||
delta += 1
|
start1, size1, start2, size2 = map(int, match.groups()[:4])
|
||||||
|
elif not line.startswith('-'):
|
||||||
|
delta += 1
|
||||||
|
|
||||||
|
#
|
||||||
|
absolute_position_curr = start2 + delta - 1
|
||||||
|
|
||||||
|
if absolute_position_curr == absolute_position:
|
||||||
|
position = i
|
||||||
|
break
|
||||||
|
else:
|
||||||
|
# try to find the line in the patch using difflib, with some margin of error
|
||||||
|
matches_difflib: list[str | Any] = difflib.get_close_matches(relevant_line_in_file,
|
||||||
|
patch_lines, n=3, cutoff=0.93)
|
||||||
|
if len(matches_difflib) == 1 and matches_difflib[0].startswith('+'):
|
||||||
|
relevant_line_in_file = matches_difflib[0]
|
||||||
|
|
||||||
if relevant_line_in_file in line and line[0] != '-':
|
|
||||||
position = i
|
|
||||||
absolute_position = start2 + delta - 1
|
|
||||||
break
|
|
||||||
|
|
||||||
if position == -1 and relevant_line_in_file[0] == '+':
|
|
||||||
no_plus_line = relevant_line_in_file[1:].lstrip()
|
|
||||||
for i, line in enumerate(patch_lines):
|
for i, line in enumerate(patch_lines):
|
||||||
if line.startswith('@@'):
|
if line.startswith('@@'):
|
||||||
delta = 0
|
delta = 0
|
||||||
@ -306,44 +315,30 @@ def find_line_number_of_relevant_line_in_file(diff_files: List[FilePatchInfo],
|
|||||||
elif not line.startswith('-'):
|
elif not line.startswith('-'):
|
||||||
delta += 1
|
delta += 1
|
||||||
|
|
||||||
if no_plus_line in line and line[0] != '-':
|
if relevant_line_in_file in line and line[0] != '-':
|
||||||
# The model might add a '+' to the beginning of the relevant_line_in_file even if originally
|
|
||||||
# it's a context line
|
|
||||||
position = i
|
position = i
|
||||||
absolute_position = start2 + delta - 1
|
absolute_position = start2 + delta - 1
|
||||||
break
|
break
|
||||||
|
|
||||||
|
if position == -1 and relevant_line_in_file[0] == '+':
|
||||||
|
no_plus_line = relevant_line_in_file[1:].lstrip()
|
||||||
|
for i, line in enumerate(patch_lines):
|
||||||
|
if line.startswith('@@'):
|
||||||
|
delta = 0
|
||||||
|
match = re_hunk_header.match(line)
|
||||||
|
start1, size1, start2, size2 = map(int, match.groups()[:4])
|
||||||
|
elif not line.startswith('-'):
|
||||||
|
delta += 1
|
||||||
|
|
||||||
|
if no_plus_line in line and line[0] != '-':
|
||||||
|
# The model might add a '+' to the beginning of the relevant_line_in_file even if originally
|
||||||
|
# it's a context line
|
||||||
|
position = i
|
||||||
|
absolute_position = start2 + delta - 1
|
||||||
|
break
|
||||||
return position, absolute_position
|
return position, absolute_position
|
||||||
|
|
||||||
|
|
||||||
def clip_tokens(text: str, max_tokens: int) -> str:
|
|
||||||
"""
|
|
||||||
Clip the number of tokens in a string to a maximum number of tokens.
|
|
||||||
|
|
||||||
Args:
|
|
||||||
text (str): The string to clip.
|
|
||||||
max_tokens (int): The maximum number of tokens allowed in the string.
|
|
||||||
|
|
||||||
Returns:
|
|
||||||
str: The clipped string.
|
|
||||||
"""
|
|
||||||
if not text:
|
|
||||||
return text
|
|
||||||
|
|
||||||
try:
|
|
||||||
encoder = get_token_encoder()
|
|
||||||
num_input_tokens = len(encoder.encode(text))
|
|
||||||
if num_input_tokens <= max_tokens:
|
|
||||||
return text
|
|
||||||
num_chars = len(text)
|
|
||||||
chars_per_token = num_chars / num_input_tokens
|
|
||||||
num_output_chars = int(chars_per_token * max_tokens)
|
|
||||||
clipped_text = text[:num_output_chars]
|
|
||||||
return clipped_text
|
|
||||||
except Exception as e:
|
|
||||||
get_logger().warning(f"Failed to clip tokens: {e}")
|
|
||||||
return text
|
|
||||||
|
|
||||||
|
|
||||||
def get_pr_multi_diffs(git_provider: GitProvider,
|
def get_pr_multi_diffs(git_provider: GitProvider,
|
||||||
token_handler: TokenHandler,
|
token_handler: TokenHandler,
|
||||||
model: str,
|
model: str,
|
||||||
@ -397,13 +392,13 @@ def get_pr_multi_diffs(git_provider: GitProvider,
|
|||||||
continue
|
continue
|
||||||
|
|
||||||
# Remove delete-only hunks
|
# Remove delete-only hunks
|
||||||
patch = handle_patch_deletions(patch, original_file_content_str, new_file_content_str, file.filename)
|
patch = handle_patch_deletions(patch, original_file_content_str, new_file_content_str, file.filename, file.edit_type)
|
||||||
if patch is None:
|
if patch is None:
|
||||||
continue
|
continue
|
||||||
|
|
||||||
patch = convert_to_hunks_with_lines_numbers(patch, file)
|
patch = convert_to_hunks_with_lines_numbers(patch, file)
|
||||||
new_patch_tokens = token_handler.count_tokens(patch)
|
new_patch_tokens = token_handler.count_tokens(patch)
|
||||||
if patch and (total_tokens + new_patch_tokens > MAX_TOKENS[model] - OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD):
|
if patch and (total_tokens + new_patch_tokens > get_max_tokens(model) - OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD):
|
||||||
final_diff = "\n".join(patches)
|
final_diff = "\n".join(patches)
|
||||||
final_diff_list.append(final_diff)
|
final_diff_list.append(final_diff)
|
||||||
patches = []
|
patches = []
|
||||||
|
|||||||
@ -9,6 +9,9 @@ from typing import Any, List
|
|||||||
|
|
||||||
import yaml
|
import yaml
|
||||||
from starlette_context import context
|
from starlette_context import context
|
||||||
|
|
||||||
|
from pr_agent.algo import MAX_TOKENS
|
||||||
|
from pr_agent.algo.token_handler import get_token_encoder
|
||||||
from pr_agent.config_loader import get_settings, global_settings
|
from pr_agent.config_loader import get_settings, global_settings
|
||||||
from pr_agent.log import get_logger
|
from pr_agent.log import get_logger
|
||||||
|
|
||||||
@ -46,7 +49,7 @@ def convert_to_markdown(output_data: dict, gfm_supported: bool=True) -> str:
|
|||||||
}
|
}
|
||||||
|
|
||||||
for key, value in output_data.items():
|
for key, value in output_data.items():
|
||||||
if value is None or value == '' or value == {}:
|
if value is None or value == '' or value == {} or value == []:
|
||||||
continue
|
continue
|
||||||
if isinstance(value, dict):
|
if isinstance(value, dict):
|
||||||
markdown_text += f"## {key}\n\n"
|
markdown_text += f"## {key}\n\n"
|
||||||
@ -55,14 +58,15 @@ def convert_to_markdown(output_data: dict, gfm_supported: bool=True) -> str:
|
|||||||
emoji = emojis.get(key, "")
|
emoji = emojis.get(key, "")
|
||||||
if key.lower() == 'code feedback':
|
if key.lower() == 'code feedback':
|
||||||
if gfm_supported:
|
if gfm_supported:
|
||||||
markdown_text += f"\n\n- **<details><summary> { emoji } Code feedback:**</summary>\n\n"
|
markdown_text += f"\n\n"
|
||||||
|
markdown_text += f"<details><summary> <strong>{ emoji } Code feedback:</strong></summary>"
|
||||||
else:
|
else:
|
||||||
markdown_text += f"\n\n- **{emoji} Code feedback:**\n\n"
|
markdown_text += f"\n\n**{emoji} Code feedback:**\n\n"
|
||||||
else:
|
else:
|
||||||
markdown_text += f"- {emoji} **{key}:**\n\n"
|
markdown_text += f"- {emoji} **{key}:**\n\n"
|
||||||
for item in value:
|
for i, item in enumerate(value):
|
||||||
if isinstance(item, dict) and key.lower() == 'code feedback':
|
if isinstance(item, dict) and key.lower() == 'code feedback':
|
||||||
markdown_text += parse_code_suggestion(item, gfm_supported)
|
markdown_text += parse_code_suggestion(item, i, gfm_supported)
|
||||||
elif item:
|
elif item:
|
||||||
markdown_text += f" - {item}\n"
|
markdown_text += f" - {item}\n"
|
||||||
if key.lower() == 'code feedback':
|
if key.lower() == 'code feedback':
|
||||||
@ -72,11 +76,17 @@ def convert_to_markdown(output_data: dict, gfm_supported: bool=True) -> str:
|
|||||||
markdown_text += "\n\n"
|
markdown_text += "\n\n"
|
||||||
elif value != 'n/a':
|
elif value != 'n/a':
|
||||||
emoji = emojis.get(key, "")
|
emoji = emojis.get(key, "")
|
||||||
markdown_text += f"- {emoji} **{key}:** {value}\n"
|
if key.lower() == 'general suggestions':
|
||||||
|
if gfm_supported:
|
||||||
|
markdown_text += f"\n\n<strong>{emoji} General suggestions:</strong> {value}\n"
|
||||||
|
else:
|
||||||
|
markdown_text += f"{emoji} **General suggestions:** {value}\n"
|
||||||
|
else:
|
||||||
|
markdown_text += f"- {emoji} **{key}:** {value}\n"
|
||||||
return markdown_text
|
return markdown_text
|
||||||
|
|
||||||
|
|
||||||
def parse_code_suggestion(code_suggestions: dict, gfm_supported: bool=True) -> str:
|
def parse_code_suggestion(code_suggestions: dict, i: int = 0, gfm_supported: bool = True) -> str:
|
||||||
"""
|
"""
|
||||||
Convert a dictionary of data into markdown format.
|
Convert a dictionary of data into markdown format.
|
||||||
|
|
||||||
@ -87,24 +97,53 @@ def parse_code_suggestion(code_suggestions: dict, gfm_supported: bool=True) -> s
|
|||||||
str: A string containing the markdown formatted text generated from the input dictionary.
|
str: A string containing the markdown formatted text generated from the input dictionary.
|
||||||
"""
|
"""
|
||||||
markdown_text = ""
|
markdown_text = ""
|
||||||
for sub_key, sub_value in code_suggestions.items():
|
if gfm_supported and 'relevant line' in code_suggestions:
|
||||||
if isinstance(sub_value, dict): # "code example"
|
if i == 0:
|
||||||
markdown_text += f" - **{sub_key}:**\n"
|
markdown_text += "<hr>"
|
||||||
for code_key, code_value in sub_value.items(): # 'before' and 'after' code
|
markdown_text += '<table>'
|
||||||
code_str = f"```\n{code_value}\n```"
|
for sub_key, sub_value in code_suggestions.items():
|
||||||
code_str_indented = textwrap.indent(code_str, ' ')
|
try:
|
||||||
markdown_text += f" - **{code_key}:**\n{code_str_indented}\n"
|
if sub_key.lower() == 'relevant file':
|
||||||
else:
|
relevant_file = sub_value.strip('`').strip('"').strip("'")
|
||||||
if "relevant file" in sub_key.lower():
|
markdown_text += f"<tr><td>{sub_key}</td><td>{relevant_file}</td></tr>"
|
||||||
markdown_text += f"\n - **{sub_key}:** {sub_value}\n"
|
# continue
|
||||||
|
elif sub_key.lower() == 'suggestion':
|
||||||
|
markdown_text += (f"<tr><td>{sub_key} </td>"
|
||||||
|
f"<td><br>\n\n**{sub_value.strip()}**\n<br></td></tr>")
|
||||||
|
elif sub_key.lower() == 'relevant line':
|
||||||
|
markdown_text += f"<tr><td>relevant line</td>"
|
||||||
|
sub_value_list = sub_value.split('](')
|
||||||
|
relevant_line = sub_value_list[0].lstrip('`').lstrip('[')
|
||||||
|
if len(sub_value_list) > 1:
|
||||||
|
link = sub_value_list[1].rstrip(')').strip('`')
|
||||||
|
markdown_text += f"<td><a href={link}>{relevant_line}</a></td>"
|
||||||
|
else:
|
||||||
|
markdown_text += f"<td>{relevant_line}</td>"
|
||||||
|
markdown_text += "</tr>"
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().exception(f"Failed to parse code suggestion: {e}")
|
||||||
|
pass
|
||||||
|
markdown_text += '</table>'
|
||||||
|
markdown_text += "<hr>"
|
||||||
|
else:
|
||||||
|
for sub_key, sub_value in code_suggestions.items():
|
||||||
|
if isinstance(sub_value, dict): # "code example"
|
||||||
|
markdown_text += f" - **{sub_key}:**\n"
|
||||||
|
for code_key, code_value in sub_value.items(): # 'before' and 'after' code
|
||||||
|
code_str = f"```\n{code_value}\n```"
|
||||||
|
code_str_indented = textwrap.indent(code_str, ' ')
|
||||||
|
markdown_text += f" - **{code_key}:**\n{code_str_indented}\n"
|
||||||
else:
|
else:
|
||||||
markdown_text += f" **{sub_key}:** {sub_value}\n"
|
if "relevant file" in sub_key.lower():
|
||||||
if not gfm_supported:
|
markdown_text += f"\n - **{sub_key}:** {sub_value} \n"
|
||||||
if "relevant line" not in sub_key.lower(): # nicer presentation
|
else:
|
||||||
|
markdown_text += f" **{sub_key}:** {sub_value} \n"
|
||||||
|
if not gfm_supported:
|
||||||
|
if "relevant line" not in sub_key.lower(): # nicer presentation
|
||||||
# markdown_text = markdown_text.rstrip('\n') + "\\\n" # works for gitlab
|
# markdown_text = markdown_text.rstrip('\n') + "\\\n" # works for gitlab
|
||||||
markdown_text = markdown_text.rstrip('\n') + " \n" # works for gitlab and bitbucker
|
markdown_text = markdown_text.rstrip('\n') + " \n" # works for gitlab and bitbucker
|
||||||
|
|
||||||
markdown_text += "\n"
|
markdown_text += "\n"
|
||||||
return markdown_text
|
return markdown_text
|
||||||
|
|
||||||
|
|
||||||
@ -280,47 +319,159 @@ def _fix_key_value(key: str, value: str):
|
|||||||
try:
|
try:
|
||||||
value = yaml.safe_load(value)
|
value = yaml.safe_load(value)
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
get_logger().error(f"Failed to parse YAML for config override {key}={value}", exc_info=e)
|
get_logger().debug(f"Failed to parse YAML for config override {key}={value}", exc_info=e)
|
||||||
return key, value
|
return key, value
|
||||||
|
|
||||||
|
|
||||||
def load_yaml(review_text: str) -> dict:
|
def load_yaml(response_text: str, keys_fix_yaml: List[str] = []) -> dict:
|
||||||
review_text = review_text.removeprefix('```yaml').rstrip('`')
|
response_text = response_text.removeprefix('```yaml').rstrip('`')
|
||||||
try:
|
try:
|
||||||
data = yaml.safe_load(review_text)
|
data = yaml.safe_load(response_text)
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
get_logger().error(f"Failed to parse AI prediction: {e}")
|
get_logger().error(f"Failed to parse AI prediction: {e}")
|
||||||
data = try_fix_yaml(review_text)
|
data = try_fix_yaml(response_text, keys_fix_yaml=keys_fix_yaml)
|
||||||
return data
|
return data
|
||||||
|
|
||||||
def try_fix_yaml(review_text: str) -> dict:
|
|
||||||
review_text_lines = review_text.split('\n')
|
def try_fix_yaml(response_text: str, keys_fix_yaml: List[str] = []) -> dict:
|
||||||
data = {}
|
response_text_lines = response_text.split('\n')
|
||||||
for i in range(1, len(review_text_lines)):
|
|
||||||
review_text_lines_tmp = '\n'.join(review_text_lines[:-i])
|
keys = ['relevant line:', 'suggestion content:', 'relevant file:', 'existing code:', 'improved code:']
|
||||||
|
keys = keys + keys_fix_yaml
|
||||||
|
# first fallback - try to convert 'relevant line: ...' to relevant line: |-\n ...'
|
||||||
|
response_text_lines_copy = response_text_lines.copy()
|
||||||
|
for i in range(0, len(response_text_lines_copy)):
|
||||||
|
for key in keys:
|
||||||
|
if key in response_text_lines_copy[i] and not '|-' in response_text_lines_copy[i]:
|
||||||
|
response_text_lines_copy[i] = response_text_lines_copy[i].replace(f'{key}',
|
||||||
|
f'{key} |-\n ')
|
||||||
|
try:
|
||||||
|
data = yaml.safe_load('\n'.join(response_text_lines_copy))
|
||||||
|
get_logger().info(f"Successfully parsed AI prediction after adding |-\n")
|
||||||
|
return data
|
||||||
|
except:
|
||||||
|
get_logger().info(f"Failed to parse AI prediction after adding |-\n")
|
||||||
|
|
||||||
|
# second fallback - try to extract only range from first ```yaml to ````
|
||||||
|
snippet_pattern = r'```(yaml)?[\s\S]*?```'
|
||||||
|
snippet = re.search(snippet_pattern, '\n'.join(response_text_lines_copy))
|
||||||
|
if snippet:
|
||||||
|
snippet_text = snippet.group()
|
||||||
try:
|
try:
|
||||||
data = yaml.load(review_text_lines_tmp, Loader=yaml.SafeLoader)
|
data = yaml.safe_load(snippet_text.removeprefix('```yaml').rstrip('`'))
|
||||||
get_logger().info(f"Successfully parsed AI prediction after removing {i} lines")
|
get_logger().info(f"Successfully parsed AI prediction after extracting yaml snippet")
|
||||||
break
|
return data
|
||||||
|
except:
|
||||||
|
pass
|
||||||
|
|
||||||
|
# third fallback - try to remove leading and trailing curly brackets
|
||||||
|
response_text_copy = response_text.strip().rstrip().removeprefix('{').removesuffix('}')
|
||||||
|
try:
|
||||||
|
data = yaml.safe_load(response_text_copy,)
|
||||||
|
get_logger().info(f"Successfully parsed AI prediction after removing curly brackets")
|
||||||
|
return data
|
||||||
|
except:
|
||||||
|
pass
|
||||||
|
|
||||||
|
# fourth fallback - try to remove last lines
|
||||||
|
data = {}
|
||||||
|
for i in range(1, len(response_text_lines)):
|
||||||
|
response_text_lines_tmp = '\n'.join(response_text_lines[:-i])
|
||||||
|
try:
|
||||||
|
data = yaml.safe_load(response_text_lines_tmp,)
|
||||||
|
get_logger().info(f"Successfully parsed AI prediction after removing {i} lines")
|
||||||
|
return data
|
||||||
except:
|
except:
|
||||||
pass
|
pass
|
||||||
return data
|
|
||||||
|
|
||||||
|
|
||||||
def set_custom_labels(variables):
|
def set_custom_labels(variables, git_provider=None):
|
||||||
if not get_settings().config.enable_custom_labels:
|
if not get_settings().config.enable_custom_labels:
|
||||||
return
|
return
|
||||||
|
|
||||||
labels = get_settings().custom_labels
|
labels = get_settings().custom_labels
|
||||||
if not labels:
|
if not labels:
|
||||||
# set default labels
|
# set default labels
|
||||||
labels = ['Bug fix', 'Tests', 'Bug fix with tests', 'Refactoring', 'Enhancement', 'Documentation', 'Other']
|
labels = ['Bug fix', 'Tests', 'Bug fix with tests', 'Enhancement', 'Documentation', 'Other']
|
||||||
labels_list = "\n - ".join(labels) if labels else ""
|
labels_list = "\n - ".join(labels) if labels else ""
|
||||||
labels_list = f" - {labels_list}" if labels_list else ""
|
labels_list = f" - {labels_list}" if labels_list else ""
|
||||||
variables["custom_labels"] = labels_list
|
variables["custom_labels"] = labels_list
|
||||||
return
|
return
|
||||||
final_labels = ""
|
|
||||||
|
# Set custom labels
|
||||||
|
variables["custom_labels_class"] = "class Label(str, Enum):"
|
||||||
|
counter = 0
|
||||||
|
labels_minimal_to_labels_dict = {}
|
||||||
for k, v in labels.items():
|
for k, v in labels.items():
|
||||||
final_labels += f" - {k} ({v['description']})\n"
|
description = "'" + v['description'].strip('\n').replace('\n', '\\n') + "'"
|
||||||
variables["custom_labels"] = final_labels
|
# variables["custom_labels_class"] += f"\n {k.lower().replace(' ', '_')} = '{k}' # {description}"
|
||||||
variables["custom_labels_examples"] = f" - {list(labels.keys())[0]}"
|
variables["custom_labels_class"] += f"\n {k.lower().replace(' ', '_')} = {description}"
|
||||||
|
labels_minimal_to_labels_dict[k.lower().replace(' ', '_')] = k
|
||||||
|
counter += 1
|
||||||
|
variables["labels_minimal_to_labels_dict"] = labels_minimal_to_labels_dict
|
||||||
|
|
||||||
|
def get_user_labels(current_labels: List[str] = None):
|
||||||
|
"""
|
||||||
|
Only keep labels that has been added by the user
|
||||||
|
"""
|
||||||
|
try:
|
||||||
|
if current_labels is None:
|
||||||
|
current_labels = []
|
||||||
|
user_labels = []
|
||||||
|
for label in current_labels:
|
||||||
|
if label.lower() in ['bug fix', 'tests', 'enhancement', 'documentation', 'other']:
|
||||||
|
continue
|
||||||
|
if get_settings().config.enable_custom_labels:
|
||||||
|
if label in get_settings().custom_labels:
|
||||||
|
continue
|
||||||
|
user_labels.append(label)
|
||||||
|
if user_labels:
|
||||||
|
get_logger().info(f"Keeping user labels: {user_labels}")
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().exception(f"Failed to get user labels: {e}")
|
||||||
|
return current_labels
|
||||||
|
return user_labels
|
||||||
|
|
||||||
|
|
||||||
|
def get_max_tokens(model):
|
||||||
|
settings = get_settings()
|
||||||
|
if model in MAX_TOKENS:
|
||||||
|
max_tokens_model = MAX_TOKENS[model]
|
||||||
|
else:
|
||||||
|
raise Exception(f"MAX_TOKENS must be set for model {model} in ./pr_agent/algo/__init__.py")
|
||||||
|
|
||||||
|
if settings.config.max_model_tokens:
|
||||||
|
max_tokens_model = min(settings.config.max_model_tokens, max_tokens_model)
|
||||||
|
# get_logger().debug(f"limiting max tokens to {max_tokens_model}")
|
||||||
|
return max_tokens_model
|
||||||
|
|
||||||
|
|
||||||
|
def clip_tokens(text: str, max_tokens: int, add_three_dots=True) -> str:
|
||||||
|
"""
|
||||||
|
Clip the number of tokens in a string to a maximum number of tokens.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
text (str): The string to clip.
|
||||||
|
max_tokens (int): The maximum number of tokens allowed in the string.
|
||||||
|
add_three_dots (bool, optional): A boolean indicating whether to add three dots at the end of the clipped
|
||||||
|
Returns:
|
||||||
|
str: The clipped string.
|
||||||
|
"""
|
||||||
|
if not text:
|
||||||
|
return text
|
||||||
|
|
||||||
|
try:
|
||||||
|
encoder = get_token_encoder()
|
||||||
|
num_input_tokens = len(encoder.encode(text))
|
||||||
|
if num_input_tokens <= max_tokens:
|
||||||
|
return text
|
||||||
|
num_chars = len(text)
|
||||||
|
chars_per_token = num_chars / num_input_tokens
|
||||||
|
num_output_chars = int(chars_per_token * max_tokens)
|
||||||
|
clipped_text = text[:num_output_chars]
|
||||||
|
if add_three_dots:
|
||||||
|
clipped_text += "...(truncated)"
|
||||||
|
return clipped_text
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().warning(f"Failed to clip tokens: {e}")
|
||||||
|
return text
|
||||||
@ -8,6 +8,8 @@ from pr_agent.log import setup_logger
|
|||||||
|
|
||||||
setup_logger()
|
setup_logger()
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
def run(inargs=None):
|
def run(inargs=None):
|
||||||
parser = argparse.ArgumentParser(description='AI based pull request analyzer', usage=
|
parser = argparse.ArgumentParser(description='AI based pull request analyzer', usage=
|
||||||
"""\
|
"""\
|
||||||
@ -21,18 +23,22 @@ For example:
|
|||||||
- cli.py --issue_url=... similar_issue
|
- cli.py --issue_url=... similar_issue
|
||||||
|
|
||||||
Supported commands:
|
Supported commands:
|
||||||
-review / review_pr - Add a review that includes a summary of the PR and specific suggestions for improvement.
|
- review / review_pr - Add a review that includes a summary of the PR and specific suggestions for improvement.
|
||||||
|
|
||||||
-ask / ask_question [question] - Ask a question about the PR.
|
- ask / ask_question [question] - Ask a question about the PR.
|
||||||
|
|
||||||
-describe / describe_pr - Modify the PR title and description based on the PR's contents.
|
- describe / describe_pr - Modify the PR title and description based on the PR's contents.
|
||||||
|
|
||||||
-improve / improve_code - Suggest improvements to the code in the PR as pull request comments ready to commit.
|
- improve / improve_code - Suggest improvements to the code in the PR as pull request comments ready to commit.
|
||||||
Extended mode ('improve --extended') employs several calls, and provides a more thorough feedback
|
Extended mode ('improve --extended') employs several calls, and provides a more thorough feedback
|
||||||
|
|
||||||
-reflect - Ask the PR author questions about the PR.
|
- reflect - Ask the PR author questions about the PR.
|
||||||
|
|
||||||
-update_changelog - Update the changelog based on the PR's contents.
|
- update_changelog - Update the changelog based on the PR's contents.
|
||||||
|
|
||||||
|
- add_docs
|
||||||
|
|
||||||
|
- generate_labels
|
||||||
|
|
||||||
|
|
||||||
Configuration:
|
Configuration:
|
||||||
@ -51,9 +57,9 @@ For example: 'python cli.py --pr_url=... review --pr_reviewer.extra_instructions
|
|||||||
command = args.command.lower()
|
command = args.command.lower()
|
||||||
get_settings().set("CONFIG.CLI_MODE", True)
|
get_settings().set("CONFIG.CLI_MODE", True)
|
||||||
if args.issue_url:
|
if args.issue_url:
|
||||||
result = asyncio.run(PRAgent().handle_request(args.issue_url, command + " " + " ".join(args.rest)))
|
result = asyncio.run(PRAgent().handle_request(args.issue_url, [command] + args.rest))
|
||||||
else:
|
else:
|
||||||
result = asyncio.run(PRAgent().handle_request(args.pr_url, command + " " + " ".join(args.rest)))
|
result = asyncio.run(PRAgent().handle_request(args.pr_url, [command] + args.rest))
|
||||||
if not result:
|
if not result:
|
||||||
parser.print_help()
|
parser.print_help()
|
||||||
|
|
||||||
|
|||||||
@ -1,5 +1,6 @@
|
|||||||
from pr_agent.config_loader import get_settings
|
from pr_agent.config_loader import get_settings
|
||||||
from pr_agent.git_providers.bitbucket_provider import BitbucketProvider
|
from pr_agent.git_providers.bitbucket_provider import BitbucketProvider
|
||||||
|
from pr_agent.git_providers.bitbucket_server_provider import BitbucketServerProvider
|
||||||
from pr_agent.git_providers.codecommit_provider import CodeCommitProvider
|
from pr_agent.git_providers.codecommit_provider import CodeCommitProvider
|
||||||
from pr_agent.git_providers.github_provider import GithubProvider
|
from pr_agent.git_providers.github_provider import GithubProvider
|
||||||
from pr_agent.git_providers.gitlab_provider import GitLabProvider
|
from pr_agent.git_providers.gitlab_provider import GitLabProvider
|
||||||
@ -12,6 +13,7 @@ _GIT_PROVIDERS = {
|
|||||||
'github': GithubProvider,
|
'github': GithubProvider,
|
||||||
'gitlab': GitLabProvider,
|
'gitlab': GitLabProvider,
|
||||||
'bitbucket': BitbucketProvider,
|
'bitbucket': BitbucketProvider,
|
||||||
|
'bitbucket_server': BitbucketServerProvider,
|
||||||
'azure': AzureDevopsProvider,
|
'azure': AzureDevopsProvider,
|
||||||
'codecommit': CodeCommitProvider,
|
'codecommit': CodeCommitProvider,
|
||||||
'local' : LocalGitProvider,
|
'local' : LocalGitProvider,
|
||||||
|
|||||||
@ -1,30 +1,147 @@
|
|||||||
import json
|
import os
|
||||||
from typing import Optional, Tuple
|
from typing import Optional, Tuple
|
||||||
from urllib.parse import urlparse
|
from urllib.parse import urlparse
|
||||||
|
|
||||||
import os
|
|
||||||
|
|
||||||
from ..log import get_logger
|
from ..log import get_logger
|
||||||
|
|
||||||
AZURE_DEVOPS_AVAILABLE = True
|
AZURE_DEVOPS_AVAILABLE = True
|
||||||
try:
|
try:
|
||||||
from msrest.authentication import BasicAuthentication
|
from msrest.authentication import BasicAuthentication
|
||||||
from azure.devops.connection import Connection
|
from azure.devops.connection import Connection
|
||||||
from azure.devops.v7_1.git.models import Comment, CommentThread, GitVersionDescriptor, GitPullRequest
|
from azure.devops.v7_1.git.models import (
|
||||||
except ImportError:
|
Comment,
|
||||||
|
CommentThread,
|
||||||
|
GitVersionDescriptor,
|
||||||
|
GitPullRequest,
|
||||||
|
)
|
||||||
|
except ImportError as e:
|
||||||
AZURE_DEVOPS_AVAILABLE = False
|
AZURE_DEVOPS_AVAILABLE = False
|
||||||
|
|
||||||
from ..algo.pr_processing import clip_tokens
|
|
||||||
from ..config_loader import get_settings
|
|
||||||
from ..algo.utils import load_large_diff
|
|
||||||
from ..algo.language_handler import is_valid_file
|
from ..algo.language_handler import is_valid_file
|
||||||
from .git_provider import EDIT_TYPE, FilePatchInfo
|
from ..algo.utils import clip_tokens, load_large_diff
|
||||||
|
from ..config_loader import get_settings
|
||||||
|
from .git_provider import EDIT_TYPE, FilePatchInfo, GitProvider
|
||||||
|
|
||||||
|
|
||||||
class AzureDevopsProvider:
|
class AzureDevopsProvider(GitProvider):
|
||||||
def __init__(self, pr_url: Optional[str] = None, incremental: Optional[bool] = False):
|
def publish_code_suggestions(self, code_suggestions: list) -> bool:
|
||||||
|
"""
|
||||||
|
Publishes code suggestions as comments on the PR.
|
||||||
|
"""
|
||||||
|
post_parameters_list = []
|
||||||
|
for suggestion in code_suggestions:
|
||||||
|
body = suggestion['body']
|
||||||
|
relevant_file = suggestion['relevant_file']
|
||||||
|
relevant_lines_start = suggestion['relevant_lines_start']
|
||||||
|
relevant_lines_end = suggestion['relevant_lines_end']
|
||||||
|
|
||||||
|
if not relevant_lines_start or relevant_lines_start == -1:
|
||||||
|
if get_settings().config.verbosity_level >= 2:
|
||||||
|
get_logger().exception(
|
||||||
|
f"Failed to publish code suggestion, relevant_lines_start is {relevant_lines_start}")
|
||||||
|
continue
|
||||||
|
|
||||||
|
if relevant_lines_end < relevant_lines_start:
|
||||||
|
if get_settings().config.verbosity_level >= 2:
|
||||||
|
get_logger().exception(f"Failed to publish code suggestion, "
|
||||||
|
f"relevant_lines_end is {relevant_lines_end} and "
|
||||||
|
f"relevant_lines_start is {relevant_lines_start}")
|
||||||
|
continue
|
||||||
|
|
||||||
|
if relevant_lines_end > relevant_lines_start:
|
||||||
|
post_parameters = {
|
||||||
|
"body": body,
|
||||||
|
"path": relevant_file,
|
||||||
|
"line": relevant_lines_end,
|
||||||
|
"start_line": relevant_lines_start,
|
||||||
|
"start_side": "RIGHT",
|
||||||
|
}
|
||||||
|
else: # API is different for single line comments
|
||||||
|
post_parameters = {
|
||||||
|
"body": body,
|
||||||
|
"path": relevant_file,
|
||||||
|
"line": relevant_lines_start,
|
||||||
|
"side": "RIGHT",
|
||||||
|
}
|
||||||
|
post_parameters_list.append(post_parameters)
|
||||||
|
|
||||||
|
try:
|
||||||
|
for post_parameters in post_parameters_list:
|
||||||
|
comment = Comment(content=post_parameters["body"], comment_type=1)
|
||||||
|
thread = CommentThread(comments=[comment],
|
||||||
|
thread_context={
|
||||||
|
"filePath": post_parameters["path"],
|
||||||
|
"rightFileStart": {
|
||||||
|
"line": post_parameters["start_line"],
|
||||||
|
"offset": 1,
|
||||||
|
},
|
||||||
|
"rightFileEnd": {
|
||||||
|
"line": post_parameters["line"],
|
||||||
|
"offset": 1,
|
||||||
|
},
|
||||||
|
})
|
||||||
|
self.azure_devops_client.create_thread(
|
||||||
|
comment_thread=thread,
|
||||||
|
project=self.workspace_slug,
|
||||||
|
repository_id=self.repo_slug,
|
||||||
|
pull_request_id=self.pr_num
|
||||||
|
)
|
||||||
|
if get_settings().config.verbosity_level >= 2:
|
||||||
|
get_logger().info(
|
||||||
|
f"Published code suggestion on {self.pr_num} at {post_parameters['path']}"
|
||||||
|
)
|
||||||
|
return True
|
||||||
|
except Exception as e:
|
||||||
|
if get_settings().config.verbosity_level >= 2:
|
||||||
|
get_logger().error(f"Failed to publish code suggestion, error: {e}")
|
||||||
|
return False
|
||||||
|
|
||||||
|
def get_pr_description_full(self) -> str:
|
||||||
|
pass
|
||||||
|
|
||||||
|
def remove_comment(self, comment):
|
||||||
|
try:
|
||||||
|
self.azure_devops_client.delete_comment(
|
||||||
|
repository_id=self.repo_slug,
|
||||||
|
pull_request_id=self.pr_num,
|
||||||
|
thread_id=comment["thread_id"],
|
||||||
|
comment_id=comment["comment_id"],
|
||||||
|
project=self.workspace_slug,
|
||||||
|
)
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().exception(f"Failed to remove comment, error: {e}")
|
||||||
|
|
||||||
|
def publish_labels(self, pr_types):
|
||||||
|
try:
|
||||||
|
for pr_type in pr_types:
|
||||||
|
self.azure_devops_client.create_pull_request_label(
|
||||||
|
label={"name": pr_type},
|
||||||
|
project=self.workspace_slug,
|
||||||
|
repository_id=self.repo_slug,
|
||||||
|
pull_request_id=self.pr_num,
|
||||||
|
)
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().exception(f"Failed to publish labels, error: {e}")
|
||||||
|
|
||||||
|
def get_pr_labels(self):
|
||||||
|
try:
|
||||||
|
labels = self.azure_devops_client.get_pull_request_labels(
|
||||||
|
project=self.workspace_slug,
|
||||||
|
repository_id=self.repo_slug,
|
||||||
|
pull_request_id=self.pr_num,
|
||||||
|
)
|
||||||
|
return [label.name for label in labels]
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().exception(f"Failed to get labels, error: {e}")
|
||||||
|
return []
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self, pr_url: Optional[str] = None, incremental: Optional[bool] = False
|
||||||
|
):
|
||||||
if not AZURE_DEVOPS_AVAILABLE:
|
if not AZURE_DEVOPS_AVAILABLE:
|
||||||
raise ImportError("Azure DevOps provider is not available. Please install the required dependencies.")
|
raise ImportError(
|
||||||
|
"Azure DevOps provider is not available. Please install the required dependencies."
|
||||||
|
)
|
||||||
|
|
||||||
self.azure_devops_client = self._get_azure_devops_client()
|
self.azure_devops_client = self._get_azure_devops_client()
|
||||||
|
|
||||||
@ -39,8 +156,11 @@ class AzureDevopsProvider:
|
|||||||
self.set_pr(pr_url)
|
self.set_pr(pr_url)
|
||||||
|
|
||||||
def is_supported(self, capability: str) -> bool:
|
def is_supported(self, capability: str) -> bool:
|
||||||
if capability in ['get_issue_comments', 'create_inline_comment', 'publish_inline_comments', 'get_labels',
|
if capability in [
|
||||||
'remove_initial_comment', 'gfm_markdown']:
|
"get_issue_comments",
|
||||||
|
"create_inline_comment",
|
||||||
|
"publish_inline_comments",
|
||||||
|
]:
|
||||||
return False
|
return False
|
||||||
return True
|
return True
|
||||||
|
|
||||||
@ -50,10 +170,14 @@ class AzureDevopsProvider:
|
|||||||
|
|
||||||
def get_repo_settings(self):
|
def get_repo_settings(self):
|
||||||
try:
|
try:
|
||||||
contents = self.azure_devops_client.get_item_content(repository_id=self.repo_slug,
|
contents = self.azure_devops_client.get_item_content(
|
||||||
project=self.workspace_slug, download=False,
|
repository_id=self.repo_slug,
|
||||||
include_content_metadata=False, include_content=True,
|
project=self.workspace_slug,
|
||||||
path=".pr_agent.toml")
|
download=False,
|
||||||
|
include_content_metadata=False,
|
||||||
|
include_content=True,
|
||||||
|
path=".pr_agent.toml",
|
||||||
|
)
|
||||||
return contents
|
return contents
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
get_logger().exception("get repo settings error")
|
get_logger().exception("get repo settings error")
|
||||||
@ -61,15 +185,19 @@ class AzureDevopsProvider:
|
|||||||
|
|
||||||
def get_files(self):
|
def get_files(self):
|
||||||
files = []
|
files = []
|
||||||
for i in self.azure_devops_client.get_pull_request_commits(project=self.workspace_slug,
|
for i in self.azure_devops_client.get_pull_request_commits(
|
||||||
repository_id=self.repo_slug,
|
project=self.workspace_slug,
|
||||||
pull_request_id=self.pr_num):
|
repository_id=self.repo_slug,
|
||||||
|
pull_request_id=self.pr_num,
|
||||||
changes_obj = self.azure_devops_client.get_changes(project=self.workspace_slug,
|
):
|
||||||
repository_id=self.repo_slug, commit_id=i.commit_id)
|
changes_obj = self.azure_devops_client.get_changes(
|
||||||
|
project=self.workspace_slug,
|
||||||
|
repository_id=self.repo_slug,
|
||||||
|
commit_id=i.commit_id,
|
||||||
|
)
|
||||||
|
|
||||||
for c in changes_obj.changes:
|
for c in changes_obj.changes:
|
||||||
files.append(c['item']['path'])
|
files.append(c["item"]["path"])
|
||||||
return list(set(files))
|
return list(set(files))
|
||||||
|
|
||||||
def get_diff_files(self) -> list[FilePatchInfo]:
|
def get_diff_files(self) -> list[FilePatchInfo]:
|
||||||
@ -77,22 +205,27 @@ class AzureDevopsProvider:
|
|||||||
base_sha = self.pr.last_merge_target_commit
|
base_sha = self.pr.last_merge_target_commit
|
||||||
head_sha = self.pr.last_merge_source_commit
|
head_sha = self.pr.last_merge_source_commit
|
||||||
|
|
||||||
commits = self.azure_devops_client.get_pull_request_commits(project=self.workspace_slug,
|
commits = self.azure_devops_client.get_pull_request_commits(
|
||||||
repository_id=self.repo_slug,
|
project=self.workspace_slug,
|
||||||
pull_request_id=self.pr_num)
|
repository_id=self.repo_slug,
|
||||||
|
pull_request_id=self.pr_num,
|
||||||
|
)
|
||||||
|
|
||||||
diff_files = []
|
diff_files = []
|
||||||
diffs = []
|
diffs = []
|
||||||
diff_types = {}
|
diff_types = {}
|
||||||
|
|
||||||
for c in commits:
|
for c in commits:
|
||||||
changes_obj = self.azure_devops_client.get_changes(project=self.workspace_slug,
|
changes_obj = self.azure_devops_client.get_changes(
|
||||||
repository_id=self.repo_slug, commit_id=c.commit_id)
|
project=self.workspace_slug,
|
||||||
|
repository_id=self.repo_slug,
|
||||||
|
commit_id=c.commit_id,
|
||||||
|
)
|
||||||
for i in changes_obj.changes:
|
for i in changes_obj.changes:
|
||||||
if(i['item']['gitObjectType'] == 'tree'):
|
if i["item"]["gitObjectType"] == "tree":
|
||||||
continue
|
continue
|
||||||
diffs.append(i['item']['path'])
|
diffs.append(i["item"]["path"])
|
||||||
diff_types[i['item']['path']] = i['changeType']
|
diff_types[i["item"]["path"]] = i["changeType"]
|
||||||
|
|
||||||
diffs = list(set(diffs))
|
diffs = list(set(diffs))
|
||||||
|
|
||||||
@ -100,47 +233,72 @@ class AzureDevopsProvider:
|
|||||||
if not is_valid_file(file):
|
if not is_valid_file(file):
|
||||||
continue
|
continue
|
||||||
|
|
||||||
version = GitVersionDescriptor(version=head_sha.commit_id, version_type='commit')
|
version = GitVersionDescriptor(
|
||||||
|
version=head_sha.commit_id, version_type="commit"
|
||||||
|
)
|
||||||
try:
|
try:
|
||||||
new_file_content_str = self.azure_devops_client.get_item(repository_id=self.repo_slug,
|
new_file_content_str = self.azure_devops_client.get_item(
|
||||||
path=file,
|
repository_id=self.repo_slug,
|
||||||
project=self.workspace_slug,
|
path=file,
|
||||||
version_descriptor=version,
|
project=self.workspace_slug,
|
||||||
download=False,
|
version_descriptor=version,
|
||||||
include_content=True)
|
download=False,
|
||||||
|
include_content=True,
|
||||||
|
)
|
||||||
|
|
||||||
new_file_content_str = new_file_content_str.content
|
new_file_content_str = new_file_content_str.content
|
||||||
except Exception as error:
|
except Exception as error:
|
||||||
get_logger().error("Failed to retrieve new file content of %s at version %s. Error: %s", file, version, str(error))
|
get_logger().error(
|
||||||
|
"Failed to retrieve new file content of %s at version %s. Error: %s",
|
||||||
|
file,
|
||||||
|
version,
|
||||||
|
str(error),
|
||||||
|
)
|
||||||
new_file_content_str = ""
|
new_file_content_str = ""
|
||||||
|
|
||||||
edit_type = EDIT_TYPE.MODIFIED
|
edit_type = EDIT_TYPE.MODIFIED
|
||||||
if diff_types[file] == 'add':
|
if diff_types[file] == "add":
|
||||||
edit_type = EDIT_TYPE.ADDED
|
edit_type = EDIT_TYPE.ADDED
|
||||||
elif diff_types[file] == 'delete':
|
elif diff_types[file] == "delete":
|
||||||
edit_type = EDIT_TYPE.DELETED
|
edit_type = EDIT_TYPE.DELETED
|
||||||
elif diff_types[file] == 'rename':
|
elif diff_types[file] == "rename":
|
||||||
edit_type = EDIT_TYPE.RENAMED
|
edit_type = EDIT_TYPE.RENAMED
|
||||||
|
|
||||||
version = GitVersionDescriptor(version=base_sha.commit_id, version_type='commit')
|
version = GitVersionDescriptor(
|
||||||
|
version=base_sha.commit_id, version_type="commit"
|
||||||
|
)
|
||||||
try:
|
try:
|
||||||
original_file_content_str = self.azure_devops_client.get_item(repository_id=self.repo_slug,
|
original_file_content_str = self.azure_devops_client.get_item(
|
||||||
path=file,
|
repository_id=self.repo_slug,
|
||||||
project=self.workspace_slug,
|
path=file,
|
||||||
version_descriptor=version,
|
project=self.workspace_slug,
|
||||||
download=False,
|
version_descriptor=version,
|
||||||
include_content=True)
|
download=False,
|
||||||
|
include_content=True,
|
||||||
|
)
|
||||||
original_file_content_str = original_file_content_str.content
|
original_file_content_str = original_file_content_str.content
|
||||||
except Exception as error:
|
except Exception as error:
|
||||||
get_logger().error("Failed to retrieve original file content of %s at version %s. Error: %s", file, version, str(error))
|
get_logger().error(
|
||||||
|
"Failed to retrieve original file content of %s at version %s. Error: %s",
|
||||||
|
file,
|
||||||
|
version,
|
||||||
|
str(error),
|
||||||
|
)
|
||||||
original_file_content_str = ""
|
original_file_content_str = ""
|
||||||
|
|
||||||
patch = load_large_diff(file, new_file_content_str, original_file_content_str)
|
patch = load_large_diff(
|
||||||
|
file, new_file_content_str, original_file_content_str
|
||||||
|
)
|
||||||
|
|
||||||
diff_files.append(FilePatchInfo(original_file_content_str, new_file_content_str,
|
diff_files.append(
|
||||||
patch=patch,
|
FilePatchInfo(
|
||||||
filename=file,
|
original_file_content_str,
|
||||||
edit_type=edit_type))
|
new_file_content_str,
|
||||||
|
patch=patch,
|
||||||
|
filename=file,
|
||||||
|
edit_type=edit_type,
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
self.diff_files = diff_files
|
self.diff_files = diff_files
|
||||||
return diff_files
|
return diff_files
|
||||||
@ -151,67 +309,92 @@ class AzureDevopsProvider:
|
|||||||
def publish_comment(self, pr_comment: str, is_temporary: bool = False):
|
def publish_comment(self, pr_comment: str, is_temporary: bool = False):
|
||||||
comment = Comment(content=pr_comment)
|
comment = Comment(content=pr_comment)
|
||||||
thread = CommentThread(comments=[comment])
|
thread = CommentThread(comments=[comment])
|
||||||
thread_response = self.azure_devops_client.create_thread(comment_thread=thread, project=self.workspace_slug,
|
thread_response = self.azure_devops_client.create_thread(
|
||||||
repository_id=self.repo_slug,
|
comment_thread=thread,
|
||||||
pull_request_id=self.pr_num)
|
project=self.workspace_slug,
|
||||||
|
repository_id=self.repo_slug,
|
||||||
|
pull_request_id=self.pr_num,
|
||||||
|
)
|
||||||
if is_temporary:
|
if is_temporary:
|
||||||
self.temp_comments.append({'thread_id': thread_response.id, 'comment_id': comment.id})
|
self.temp_comments.append(
|
||||||
|
{"thread_id": thread_response.id, "comment_id": thread_response.comments[0].id}
|
||||||
|
)
|
||||||
|
|
||||||
def publish_description(self, pr_title: str, pr_body: str):
|
def publish_description(self, pr_title: str, pr_body: str):
|
||||||
try:
|
try:
|
||||||
updated_pr = GitPullRequest()
|
updated_pr = GitPullRequest()
|
||||||
updated_pr.title = pr_title
|
updated_pr.title = pr_title
|
||||||
updated_pr.description = pr_body
|
updated_pr.description = pr_body
|
||||||
self.azure_devops_client.update_pull_request(project=self.workspace_slug,
|
self.azure_devops_client.update_pull_request(
|
||||||
repository_id=self.repo_slug,
|
project=self.workspace_slug,
|
||||||
pull_request_id=self.pr_num,
|
repository_id=self.repo_slug,
|
||||||
git_pull_request_to_update=updated_pr)
|
pull_request_id=self.pr_num,
|
||||||
|
git_pull_request_to_update=updated_pr,
|
||||||
|
)
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
get_logger().exception(f"Could not update pull request {self.pr_num} description: {e}")
|
get_logger().exception(
|
||||||
|
f"Could not update pull request {self.pr_num} description: {e}"
|
||||||
|
)
|
||||||
|
|
||||||
def remove_initial_comment(self):
|
def remove_initial_comment(self):
|
||||||
return "" # not implemented yet
|
try:
|
||||||
|
for comment in self.temp_comments:
|
||||||
|
self.remove_comment(comment)
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().exception(f"Failed to remove temp comments, error: {e}")
|
||||||
|
|
||||||
def publish_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
def publish_inline_comment(
|
||||||
raise NotImplementedError("Azure DevOps provider does not support publishing inline comment yet")
|
self, body: str, relevant_file: str, relevant_line_in_file: str
|
||||||
|
):
|
||||||
def create_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
raise NotImplementedError(
|
||||||
raise NotImplementedError("Azure DevOps provider does not support creating inline comments yet")
|
"Azure DevOps provider does not support publishing inline comment yet"
|
||||||
|
)
|
||||||
|
|
||||||
def publish_inline_comments(self, comments: list[dict]):
|
def publish_inline_comments(self, comments: list[dict]):
|
||||||
raise NotImplementedError("Azure DevOps provider does not support publishing inline comments yet")
|
raise NotImplementedError(
|
||||||
|
"Azure DevOps provider does not support publishing inline comments yet"
|
||||||
|
)
|
||||||
|
|
||||||
def get_title(self):
|
def get_title(self):
|
||||||
return self.pr.title
|
return self.pr.title
|
||||||
|
|
||||||
def get_languages(self):
|
def get_languages(self):
|
||||||
languages = []
|
languages = []
|
||||||
files = self.azure_devops_client.get_items(project=self.workspace_slug, repository_id=self.repo_slug,
|
files = self.azure_devops_client.get_items(
|
||||||
recursion_level="Full", include_content_metadata=True,
|
project=self.workspace_slug,
|
||||||
include_links=False, download=False)
|
repository_id=self.repo_slug,
|
||||||
|
recursion_level="Full",
|
||||||
|
include_content_metadata=True,
|
||||||
|
include_links=False,
|
||||||
|
download=False,
|
||||||
|
)
|
||||||
for f in files:
|
for f in files:
|
||||||
if f.git_object_type == 'blob':
|
if f.git_object_type == "blob":
|
||||||
file_name, file_extension = os.path.splitext(f.path)
|
file_name, file_extension = os.path.splitext(f.path)
|
||||||
languages.append(file_extension[1:])
|
languages.append(file_extension[1:])
|
||||||
|
|
||||||
extension_counts = {}
|
extension_counts = {}
|
||||||
for ext in languages:
|
for ext in languages:
|
||||||
if ext != '':
|
if ext != "":
|
||||||
extension_counts[ext] = extension_counts.get(ext, 0) + 1
|
extension_counts[ext] = extension_counts.get(ext, 0) + 1
|
||||||
|
|
||||||
total_extensions = sum(extension_counts.values())
|
total_extensions = sum(extension_counts.values())
|
||||||
|
|
||||||
extension_percentages = {ext: (count / total_extensions) * 100 for ext, count in extension_counts.items()}
|
extension_percentages = {
|
||||||
|
ext: (count / total_extensions) * 100
|
||||||
|
for ext, count in extension_counts.items()
|
||||||
|
}
|
||||||
|
|
||||||
return extension_percentages
|
return extension_percentages
|
||||||
|
|
||||||
def get_pr_branch(self):
|
def get_pr_branch(self):
|
||||||
pr_info = self.azure_devops_client.get_pull_request_by_id(project=self.workspace_slug,
|
pr_info = self.azure_devops_client.get_pull_request_by_id(
|
||||||
pull_request_id=self.pr_num)
|
project=self.workspace_slug, pull_request_id=self.pr_num
|
||||||
source_branch = pr_info.source_ref_name.split('/')[-1]
|
)
|
||||||
|
source_branch = pr_info.source_ref_name.split("/")[-1]
|
||||||
return source_branch
|
return source_branch
|
||||||
|
|
||||||
def get_pr_description(self):
|
def get_pr_description(self, full=False):
|
||||||
max_tokens = get_settings().get("CONFIG.MAX_DESCRIPTION_TOKENS", None)
|
max_tokens = get_settings().get("CONFIG.MAX_DESCRIPTION_TOKENS", None)
|
||||||
if max_tokens:
|
if max_tokens:
|
||||||
return clip_tokens(self.pr.description, max_tokens)
|
return clip_tokens(self.pr.description, max_tokens)
|
||||||
@ -221,7 +404,9 @@ class AzureDevopsProvider:
|
|||||||
return 0
|
return 0
|
||||||
|
|
||||||
def get_issue_comments(self):
|
def get_issue_comments(self):
|
||||||
raise NotImplementedError("Azure DevOps provider does not support issue comments yet")
|
raise NotImplementedError(
|
||||||
|
"Azure DevOps provider does not support issue comments yet"
|
||||||
|
)
|
||||||
|
|
||||||
def add_eyes_reaction(self, issue_comment_id: int) -> Optional[int]:
|
def add_eyes_reaction(self, issue_comment_id: int) -> Optional[int]:
|
||||||
return True
|
return True
|
||||||
@ -230,16 +415,20 @@ class AzureDevopsProvider:
|
|||||||
return True
|
return True
|
||||||
|
|
||||||
def get_issue_comments(self):
|
def get_issue_comments(self):
|
||||||
raise NotImplementedError("Azure DevOps provider does not support issue comments yet")
|
raise NotImplementedError(
|
||||||
|
"Azure DevOps provider does not support issue comments yet"
|
||||||
|
)
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def _parse_pr_url(pr_url: str) -> Tuple[str, int]:
|
def _parse_pr_url(pr_url: str) -> Tuple[str, int]:
|
||||||
parsed_url = urlparse(pr_url)
|
parsed_url = urlparse(pr_url)
|
||||||
|
|
||||||
path_parts = parsed_url.path.strip('/').split('/')
|
path_parts = parsed_url.path.strip("/").split("/")
|
||||||
|
|
||||||
if len(path_parts) < 6 or path_parts[4] != 'pullrequest':
|
if len(path_parts) < 6 or path_parts[4] != "pullrequest":
|
||||||
raise ValueError("The provided URL does not appear to be a Azure DevOps PR URL")
|
raise ValueError(
|
||||||
|
"The provided URL does not appear to be a Azure DevOps PR URL"
|
||||||
|
)
|
||||||
|
|
||||||
workspace_slug = path_parts[1]
|
workspace_slug = path_parts[1]
|
||||||
repo_slug = path_parts[3]
|
repo_slug = path_parts[3]
|
||||||
@ -255,10 +444,9 @@ class AzureDevopsProvider:
|
|||||||
pat = get_settings().azure_devops.pat
|
pat = get_settings().azure_devops.pat
|
||||||
org = get_settings().azure_devops.org
|
org = get_settings().azure_devops.org
|
||||||
except AttributeError as e:
|
except AttributeError as e:
|
||||||
raise ValueError(
|
raise ValueError("Azure DevOps PAT token is required ") from e
|
||||||
"Azure DevOps PAT token is required ") from e
|
|
||||||
|
|
||||||
credentials = BasicAuthentication('', pat)
|
credentials = BasicAuthentication("", pat)
|
||||||
azure_devops_connection = Connection(base_url=org, creds=credentials)
|
azure_devops_connection = Connection(base_url=org, creds=credentials)
|
||||||
azure_devops_client = azure_devops_connection.clients.get_git_client()
|
azure_devops_client = azure_devops_connection.clients.get_git_client()
|
||||||
|
|
||||||
@ -266,13 +454,23 @@ class AzureDevopsProvider:
|
|||||||
|
|
||||||
def _get_repo(self):
|
def _get_repo(self):
|
||||||
if self.repo is None:
|
if self.repo is None:
|
||||||
self.repo = self.azure_devops_client.get_repository(project=self.workspace_slug,
|
self.repo = self.azure_devops_client.get_repository(
|
||||||
repository_id=self.repo_slug)
|
project=self.workspace_slug, repository_id=self.repo_slug
|
||||||
|
)
|
||||||
return self.repo
|
return self.repo
|
||||||
|
|
||||||
def _get_pr(self):
|
def _get_pr(self):
|
||||||
self.pr = self.azure_devops_client.get_pull_request_by_id(pull_request_id=self.pr_num, project=self.workspace_slug)
|
self.pr = self.azure_devops_client.get_pull_request_by_id(
|
||||||
|
pull_request_id=self.pr_num, project=self.workspace_slug
|
||||||
|
)
|
||||||
return self.pr
|
return self.pr
|
||||||
|
|
||||||
def get_commit_messages(self):
|
def get_commit_messages(self):
|
||||||
return "" # not implemented yet
|
return "" # not implemented yet
|
||||||
|
|
||||||
|
def get_pr_id(self):
|
||||||
|
try:
|
||||||
|
pr_id = f"{self.workspace_slug}/{self.repo_slug}/{self.pr_num}"
|
||||||
|
return pr_id
|
||||||
|
except Exception:
|
||||||
|
return ""
|
||||||
|
|||||||
@ -9,7 +9,7 @@ from starlette_context import context
|
|||||||
from ..algo.pr_processing import find_line_number_of_relevant_line_in_file
|
from ..algo.pr_processing import find_line_number_of_relevant_line_in_file
|
||||||
from ..config_loader import get_settings
|
from ..config_loader import get_settings
|
||||||
from ..log import get_logger
|
from ..log import get_logger
|
||||||
from .git_provider import FilePatchInfo, GitProvider
|
from .git_provider import FilePatchInfo, GitProvider, EDIT_TYPE
|
||||||
|
|
||||||
|
|
||||||
class BitbucketProvider(GitProvider):
|
class BitbucketProvider(GitProvider):
|
||||||
@ -32,8 +32,10 @@ class BitbucketProvider(GitProvider):
|
|||||||
self.repo = None
|
self.repo = None
|
||||||
self.pr_num = None
|
self.pr_num = None
|
||||||
self.pr = None
|
self.pr = None
|
||||||
|
self.pr_url = pr_url
|
||||||
self.temp_comments = []
|
self.temp_comments = []
|
||||||
self.incremental = incremental
|
self.incremental = incremental
|
||||||
|
self.diff_files = None
|
||||||
if pr_url:
|
if pr_url:
|
||||||
self.set_pr(pr_url)
|
self.set_pr(pr_url)
|
||||||
self.bitbucket_comment_api_url = self.pr._BitbucketBase__data["links"]["comments"]["href"]
|
self.bitbucket_comment_api_url = self.pr._BitbucketBase__data["links"]["comments"]["href"]
|
||||||
@ -41,9 +43,12 @@ class BitbucketProvider(GitProvider):
|
|||||||
|
|
||||||
def get_repo_settings(self):
|
def get_repo_settings(self):
|
||||||
try:
|
try:
|
||||||
contents = self.repo_obj.get_contents(
|
url = (f"https://api.bitbucket.org/2.0/repositories/{self.workspace_slug}/{self.repo_slug}/src/"
|
||||||
".pr_agent.toml", ref=self.pr.head.sha
|
f"{self.pr.destination_branch}/.pr_agent.toml")
|
||||||
).decoded_content
|
response = requests.request("GET", url, headers=self.headers)
|
||||||
|
if response.status_code == 404: # not found
|
||||||
|
return ""
|
||||||
|
contents = response.text.encode('utf-8')
|
||||||
return contents
|
return contents
|
||||||
except Exception:
|
except Exception:
|
||||||
return ""
|
return ""
|
||||||
@ -113,6 +118,9 @@ class BitbucketProvider(GitProvider):
|
|||||||
return [diff.new.path for diff in self.pr.diffstat()]
|
return [diff.new.path for diff in self.pr.diffstat()]
|
||||||
|
|
||||||
def get_diff_files(self) -> list[FilePatchInfo]:
|
def get_diff_files(self) -> list[FilePatchInfo]:
|
||||||
|
if self.diff_files:
|
||||||
|
return self.diff_files
|
||||||
|
|
||||||
diffs = self.pr.diffstat()
|
diffs = self.pr.diffstat()
|
||||||
diff_split = [
|
diff_split = [
|
||||||
"diff --git%s" % x for x in self.pr.diff().split("diff --git") if x.strip()
|
"diff --git%s" % x for x in self.pr.diff().split("diff --git") if x.strip()
|
||||||
@ -124,16 +132,56 @@ class BitbucketProvider(GitProvider):
|
|||||||
diff.old.get_data("links")
|
diff.old.get_data("links")
|
||||||
)
|
)
|
||||||
new_file_content_str = self._get_pr_file_content(diff.new.get_data("links"))
|
new_file_content_str = self._get_pr_file_content(diff.new.get_data("links"))
|
||||||
diff_files.append(
|
file_patch_canonic_structure = FilePatchInfo(
|
||||||
FilePatchInfo(
|
original_file_content_str,
|
||||||
original_file_content_str,
|
new_file_content_str,
|
||||||
new_file_content_str,
|
diff_split[index],
|
||||||
diff_split[index],
|
diff.new.path,
|
||||||
diff.new.path,
|
|
||||||
)
|
|
||||||
)
|
)
|
||||||
|
|
||||||
|
if diff.data['status'] == 'added':
|
||||||
|
file_patch_canonic_structure.edit_type = EDIT_TYPE.ADDED
|
||||||
|
elif diff.data['status'] == 'removed':
|
||||||
|
file_patch_canonic_structure.edit_type = EDIT_TYPE.DELETED
|
||||||
|
elif diff.data['status'] == 'modified':
|
||||||
|
file_patch_canonic_structure.edit_type = EDIT_TYPE.MODIFIED
|
||||||
|
elif diff.data['status'] == 'renamed':
|
||||||
|
file_patch_canonic_structure.edit_type = EDIT_TYPE.RENAMED
|
||||||
|
diff_files.append(file_patch_canonic_structure)
|
||||||
|
|
||||||
|
|
||||||
|
self.diff_files = diff_files
|
||||||
return diff_files
|
return diff_files
|
||||||
|
|
||||||
|
def get_latest_commit_url(self):
|
||||||
|
return self.pr.data['source']['commit']['links']['html']['href']
|
||||||
|
|
||||||
|
def get_comment_url(self, comment):
|
||||||
|
return comment.data['links']['html']['href']
|
||||||
|
|
||||||
|
def publish_persistent_comment(self, pr_comment: str, initial_header: str, update_header: bool = True):
|
||||||
|
try:
|
||||||
|
for comment in self.pr.comments():
|
||||||
|
body = comment.raw
|
||||||
|
if initial_header in body:
|
||||||
|
latest_commit_url = self.get_latest_commit_url()
|
||||||
|
comment_url = self.get_comment_url(comment)
|
||||||
|
if update_header:
|
||||||
|
updated_header = f"{initial_header}\n\n### (review updated until commit {latest_commit_url})\n"
|
||||||
|
pr_comment_updated = pr_comment.replace(initial_header, updated_header)
|
||||||
|
else:
|
||||||
|
pr_comment_updated = pr_comment
|
||||||
|
get_logger().info(f"Persistent mode- updating comment {comment_url} to latest review message")
|
||||||
|
d = {"content": {"raw": pr_comment_updated}}
|
||||||
|
response = comment._update_data(comment.put(None, data=d))
|
||||||
|
self.publish_comment(
|
||||||
|
f"**[Persistent review]({comment_url})** updated to latest commit {latest_commit_url}")
|
||||||
|
return
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().exception(f"Failed to update persistent review, error: {e}")
|
||||||
|
pass
|
||||||
|
self.publish_comment(pr_comment)
|
||||||
|
|
||||||
def publish_comment(self, pr_comment: str, is_temporary: bool = False):
|
def publish_comment(self, pr_comment: str, is_temporary: bool = False):
|
||||||
comment = self.pr.comment(pr_comment)
|
comment = self.pr.comment(pr_comment)
|
||||||
if is_temporary:
|
if is_temporary:
|
||||||
@ -153,8 +201,10 @@ class BitbucketProvider(GitProvider):
|
|||||||
get_logger().exception(f"Failed to remove comment, error: {e}")
|
get_logger().exception(f"Failed to remove comment, error: {e}")
|
||||||
|
|
||||||
# funtion to create_inline_comment
|
# funtion to create_inline_comment
|
||||||
def create_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
def create_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str, absolute_position: int = None):
|
||||||
position, absolute_position = find_line_number_of_relevant_line_in_file(self.get_diff_files(), relevant_file.strip('`'), relevant_line_in_file)
|
position, absolute_position = find_line_number_of_relevant_line_in_file(self.get_diff_files(),
|
||||||
|
relevant_file.strip('`'),
|
||||||
|
relevant_line_in_file, absolute_position)
|
||||||
if position == -1:
|
if position == -1:
|
||||||
if get_settings().config.verbosity_level >= 2:
|
if get_settings().config.verbosity_level >= 2:
|
||||||
get_logger().info(f"Could not find position for {relevant_file} {relevant_line_in_file}")
|
get_logger().info(f"Could not find position for {relevant_file} {relevant_line_in_file}")
|
||||||
@ -180,9 +230,44 @@ class BitbucketProvider(GitProvider):
|
|||||||
)
|
)
|
||||||
return response
|
return response
|
||||||
|
|
||||||
|
def get_line_link(self, relevant_file: str, relevant_line_start: int, relevant_line_end: int = None) -> str:
|
||||||
|
if relevant_line_start == -1:
|
||||||
|
link = f"{self.pr_url}/#L{relevant_file}"
|
||||||
|
else:
|
||||||
|
link = f"{self.pr_url}/#L{relevant_file}T{relevant_line_start}"
|
||||||
|
return link
|
||||||
|
|
||||||
|
def generate_link_to_relevant_line_number(self, suggestion) -> str:
|
||||||
|
try:
|
||||||
|
relevant_file = suggestion['relevant file'].strip('`').strip("'")
|
||||||
|
relevant_line_str = suggestion['relevant line']
|
||||||
|
if not relevant_line_str:
|
||||||
|
return ""
|
||||||
|
|
||||||
|
diff_files = self.get_diff_files()
|
||||||
|
position, absolute_position = find_line_number_of_relevant_line_in_file \
|
||||||
|
(diff_files, relevant_file, relevant_line_str)
|
||||||
|
|
||||||
|
if absolute_position != -1 and self.pr_url:
|
||||||
|
link = f"{self.pr_url}/#L{relevant_file}T{absolute_position}"
|
||||||
|
return link
|
||||||
|
except Exception as e:
|
||||||
|
if get_settings().config.verbosity_level >= 2:
|
||||||
|
get_logger().info(f"Failed adding line link, error: {e}")
|
||||||
|
|
||||||
|
return ""
|
||||||
|
|
||||||
def publish_inline_comments(self, comments: list[dict]):
|
def publish_inline_comments(self, comments: list[dict]):
|
||||||
for comment in comments:
|
for comment in comments:
|
||||||
self.publish_inline_comment(comment['body'], comment['start_line'], comment['path'])
|
if 'position' in comment:
|
||||||
|
self.publish_inline_comment(comment['body'], comment['position'], comment['path'])
|
||||||
|
elif 'start_line' in comment: # multi-line comment
|
||||||
|
# note that bitbucket does not seem to support range - only a comment on a single line - https://community.developer.atlassian.com/t/api-post-endpoint-for-inline-pull-request-comments/60452
|
||||||
|
self.publish_inline_comment(comment['body'], comment['start_line'], comment['path'])
|
||||||
|
elif 'line' in comment: # single-line comment
|
||||||
|
self.publish_inline_comment(comment['body'], comment['line'], comment['path'])
|
||||||
|
else:
|
||||||
|
get_logger().error(f"Could not publish inline comment {comment}")
|
||||||
|
|
||||||
def get_title(self):
|
def get_title(self):
|
||||||
return self.pr.title
|
return self.pr.title
|
||||||
@ -259,6 +344,11 @@ class BitbucketProvider(GitProvider):
|
|||||||
})
|
})
|
||||||
|
|
||||||
response = requests.request("PUT", self.bitbucket_pull_request_api_url, headers=self.headers, data=payload)
|
response = requests.request("PUT", self.bitbucket_pull_request_api_url, headers=self.headers, data=payload)
|
||||||
|
try:
|
||||||
|
if response.status_code != 200:
|
||||||
|
get_logger().info(f"Failed to update description, error code: {response.status_code}")
|
||||||
|
except:
|
||||||
|
pass
|
||||||
return response
|
return response
|
||||||
|
|
||||||
# bitbucket does not support labels
|
# bitbucket does not support labels
|
||||||
@ -266,5 +356,5 @@ class BitbucketProvider(GitProvider):
|
|||||||
pass
|
pass
|
||||||
|
|
||||||
# bitbucket does not support labels
|
# bitbucket does not support labels
|
||||||
def get_labels(self):
|
def get_pr_labels(self):
|
||||||
pass
|
pass
|
||||||
|
|||||||
354
pr_agent/git_providers/bitbucket_server_provider.py
Normal file
@ -0,0 +1,354 @@
|
|||||||
|
import json
|
||||||
|
from typing import Optional, Tuple
|
||||||
|
from urllib.parse import urlparse
|
||||||
|
|
||||||
|
import requests
|
||||||
|
from atlassian.bitbucket import Bitbucket
|
||||||
|
from starlette_context import context
|
||||||
|
|
||||||
|
from .git_provider import FilePatchInfo, GitProvider, EDIT_TYPE
|
||||||
|
from ..algo.pr_processing import find_line_number_of_relevant_line_in_file
|
||||||
|
from ..algo.utils import load_large_diff
|
||||||
|
from ..config_loader import get_settings
|
||||||
|
from ..log import get_logger
|
||||||
|
|
||||||
|
|
||||||
|
class BitbucketServerProvider(GitProvider):
|
||||||
|
def __init__(
|
||||||
|
self, pr_url: Optional[str] = None, incremental: Optional[bool] = False
|
||||||
|
):
|
||||||
|
s = requests.Session()
|
||||||
|
try:
|
||||||
|
bearer = context.get("bitbucket_bearer_token", None)
|
||||||
|
s.headers["Authorization"] = f"Bearer {bearer}"
|
||||||
|
except Exception:
|
||||||
|
s.headers[
|
||||||
|
"Authorization"
|
||||||
|
] = f'Bearer {get_settings().get("BITBUCKET_SERVER.BEARER_TOKEN", None)}'
|
||||||
|
|
||||||
|
s.headers["Content-Type"] = "application/json"
|
||||||
|
self.headers = s.headers
|
||||||
|
self.bitbucket_server_url = None
|
||||||
|
self.workspace_slug = None
|
||||||
|
self.repo_slug = None
|
||||||
|
self.repo = None
|
||||||
|
self.pr_num = None
|
||||||
|
self.pr = None
|
||||||
|
self.pr_url = pr_url
|
||||||
|
self.temp_comments = []
|
||||||
|
self.incremental = incremental
|
||||||
|
self.diff_files = None
|
||||||
|
self.bitbucket_pull_request_api_url = pr_url
|
||||||
|
|
||||||
|
self.bitbucket_server_url = self._parse_bitbucket_server(url=pr_url)
|
||||||
|
self.bitbucket_client = Bitbucket(url=self.bitbucket_server_url,
|
||||||
|
token=get_settings().get("BITBUCKET_SERVER.BEARER_TOKEN", None))
|
||||||
|
|
||||||
|
if pr_url:
|
||||||
|
self.set_pr(pr_url)
|
||||||
|
|
||||||
|
def get_repo_settings(self):
|
||||||
|
try:
|
||||||
|
url = (f"{self.bitbucket_server_url}/projects/{self.workspace_slug}/repos/{self.repo_slug}/src/"
|
||||||
|
f"{self.pr.destination_branch}/.pr_agent.toml")
|
||||||
|
response = requests.request("GET", url, headers=self.headers)
|
||||||
|
if response.status_code == 404: # not found
|
||||||
|
return ""
|
||||||
|
contents = response.text.encode('utf-8')
|
||||||
|
return contents
|
||||||
|
except Exception:
|
||||||
|
return ""
|
||||||
|
|
||||||
|
def publish_code_suggestions(self, code_suggestions: list) -> bool:
|
||||||
|
"""
|
||||||
|
Publishes code suggestions as comments on the PR.
|
||||||
|
"""
|
||||||
|
post_parameters_list = []
|
||||||
|
for suggestion in code_suggestions:
|
||||||
|
body = suggestion["body"]
|
||||||
|
relevant_file = suggestion["relevant_file"]
|
||||||
|
relevant_lines_start = suggestion["relevant_lines_start"]
|
||||||
|
relevant_lines_end = suggestion["relevant_lines_end"]
|
||||||
|
|
||||||
|
if not relevant_lines_start or relevant_lines_start == -1:
|
||||||
|
if get_settings().config.verbosity_level >= 2:
|
||||||
|
get_logger().exception(
|
||||||
|
f"Failed to publish code suggestion, relevant_lines_start is {relevant_lines_start}"
|
||||||
|
)
|
||||||
|
continue
|
||||||
|
|
||||||
|
if relevant_lines_end < relevant_lines_start:
|
||||||
|
if get_settings().config.verbosity_level >= 2:
|
||||||
|
get_logger().exception(
|
||||||
|
f"Failed to publish code suggestion, "
|
||||||
|
f"relevant_lines_end is {relevant_lines_end} and "
|
||||||
|
f"relevant_lines_start is {relevant_lines_start}"
|
||||||
|
)
|
||||||
|
continue
|
||||||
|
|
||||||
|
if relevant_lines_end > relevant_lines_start:
|
||||||
|
post_parameters = {
|
||||||
|
"body": body,
|
||||||
|
"path": relevant_file,
|
||||||
|
"line": relevant_lines_end,
|
||||||
|
"start_line": relevant_lines_start,
|
||||||
|
"start_side": "RIGHT",
|
||||||
|
}
|
||||||
|
else: # API is different for single line comments
|
||||||
|
post_parameters = {
|
||||||
|
"body": body,
|
||||||
|
"path": relevant_file,
|
||||||
|
"line": relevant_lines_start,
|
||||||
|
"side": "RIGHT",
|
||||||
|
}
|
||||||
|
post_parameters_list.append(post_parameters)
|
||||||
|
|
||||||
|
try:
|
||||||
|
self.publish_inline_comments(post_parameters_list)
|
||||||
|
return True
|
||||||
|
except Exception as e:
|
||||||
|
if get_settings().config.verbosity_level >= 2:
|
||||||
|
get_logger().error(f"Failed to publish code suggestion, error: {e}")
|
||||||
|
return False
|
||||||
|
|
||||||
|
def is_supported(self, capability: str) -> bool:
|
||||||
|
if capability in ['get_issue_comments', 'get_labels', 'gfm_markdown']:
|
||||||
|
return False
|
||||||
|
return True
|
||||||
|
|
||||||
|
def set_pr(self, pr_url: str):
|
||||||
|
self.workspace_slug, self.repo_slug, self.pr_num = self._parse_pr_url(pr_url)
|
||||||
|
self.pr = self._get_pr()
|
||||||
|
|
||||||
|
def get_file(self, path: str, commit_id: str):
|
||||||
|
file_content = ""
|
||||||
|
try:
|
||||||
|
file_content = self.bitbucket_client.get_content_of_file(self.workspace_slug,
|
||||||
|
self.repo_slug,
|
||||||
|
path,
|
||||||
|
commit_id)
|
||||||
|
except requests.HTTPError as e:
|
||||||
|
get_logger().debug(f"File {path} not found at commit id: {commit_id}")
|
||||||
|
return file_content
|
||||||
|
|
||||||
|
def get_files(self):
|
||||||
|
changes = self.bitbucket_client.get_pull_requests_changes(self.workspace_slug, self.repo_slug, self.pr_num)
|
||||||
|
diffstat = [change["path"]['toString'] for change in changes]
|
||||||
|
return diffstat
|
||||||
|
|
||||||
|
def get_diff_files(self) -> list[FilePatchInfo]:
|
||||||
|
if self.diff_files:
|
||||||
|
return self.diff_files
|
||||||
|
|
||||||
|
commits_in_pr = self.bitbucket_client.get_pull_requests_commits(
|
||||||
|
self.workspace_slug,
|
||||||
|
self.repo_slug,
|
||||||
|
self.pr_num
|
||||||
|
)
|
||||||
|
|
||||||
|
commit_list = list(commits_in_pr)
|
||||||
|
base_sha, head_sha = commit_list[0]['parents'][0]['id'], commit_list[-1]['id']
|
||||||
|
|
||||||
|
diff_files = []
|
||||||
|
original_file_content_str = ""
|
||||||
|
new_file_content_str = ""
|
||||||
|
|
||||||
|
changes = self.bitbucket_client.get_pull_requests_changes(self.workspace_slug, self.repo_slug, self.pr_num)
|
||||||
|
for change in changes:
|
||||||
|
file_path = change['path']['toString']
|
||||||
|
match change['type']:
|
||||||
|
case 'ADD':
|
||||||
|
edit_type = EDIT_TYPE.ADDED
|
||||||
|
new_file_content_str = self.get_file(file_path, head_sha)
|
||||||
|
if isinstance(new_file_content_str, (bytes, bytearray)):
|
||||||
|
new_file_content_str = new_file_content_str.decode("utf-8")
|
||||||
|
original_file_content_str = ""
|
||||||
|
case 'DELETE':
|
||||||
|
edit_type = EDIT_TYPE.DELETED
|
||||||
|
new_file_content_str = ""
|
||||||
|
original_file_content_str = self.get_file(file_path, base_sha)
|
||||||
|
if isinstance(original_file_content_str, (bytes, bytearray)):
|
||||||
|
original_file_content_str = original_file_content_str.decode("utf-8")
|
||||||
|
case 'RENAME':
|
||||||
|
edit_type = EDIT_TYPE.RENAMED
|
||||||
|
case _:
|
||||||
|
edit_type = EDIT_TYPE.MODIFIED
|
||||||
|
original_file_content_str = self.get_file(file_path, base_sha)
|
||||||
|
if isinstance(original_file_content_str, (bytes, bytearray)):
|
||||||
|
original_file_content_str = original_file_content_str.decode("utf-8")
|
||||||
|
new_file_content_str = self.get_file(file_path, head_sha)
|
||||||
|
if isinstance(new_file_content_str, (bytes, bytearray)):
|
||||||
|
new_file_content_str = new_file_content_str.decode("utf-8")
|
||||||
|
|
||||||
|
patch = load_large_diff(file_path, new_file_content_str, original_file_content_str)
|
||||||
|
|
||||||
|
diff_files.append(
|
||||||
|
FilePatchInfo(
|
||||||
|
original_file_content_str,
|
||||||
|
new_file_content_str,
|
||||||
|
patch,
|
||||||
|
file_path,
|
||||||
|
edit_type=edit_type,
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
|
self.diff_files = diff_files
|
||||||
|
return diff_files
|
||||||
|
|
||||||
|
def publish_comment(self, pr_comment: str, is_temporary: bool = False):
|
||||||
|
if not is_temporary:
|
||||||
|
self.bitbucket_client.add_pull_request_comment(self.workspace_slug, self.repo_slug, self.pr_num, pr_comment)
|
||||||
|
|
||||||
|
def remove_initial_comment(self):
|
||||||
|
try:
|
||||||
|
for comment in self.temp_comments:
|
||||||
|
self.remove_comment(comment)
|
||||||
|
except ValueError as e:
|
||||||
|
get_logger().exception(f"Failed to remove temp comments, error: {e}")
|
||||||
|
|
||||||
|
def remove_comment(self, comment):
|
||||||
|
pass
|
||||||
|
|
||||||
|
# funtion to create_inline_comment
|
||||||
|
def create_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str,
|
||||||
|
absolute_position: int = None):
|
||||||
|
|
||||||
|
position, absolute_position = find_line_number_of_relevant_line_in_file(
|
||||||
|
self.get_diff_files(),
|
||||||
|
relevant_file.strip('`'),
|
||||||
|
relevant_line_in_file,
|
||||||
|
absolute_position
|
||||||
|
)
|
||||||
|
if position == -1:
|
||||||
|
if get_settings().config.verbosity_level >= 2:
|
||||||
|
get_logger().info(f"Could not find position for {relevant_file} {relevant_line_in_file}")
|
||||||
|
subject_type = "FILE"
|
||||||
|
else:
|
||||||
|
subject_type = "LINE"
|
||||||
|
path = relevant_file.strip()
|
||||||
|
return dict(body=body, path=path, position=absolute_position) if subject_type == "LINE" else {}
|
||||||
|
|
||||||
|
def publish_inline_comment(self, comment: str, from_line: int, file: str):
|
||||||
|
payload = {
|
||||||
|
"text": comment,
|
||||||
|
"severity": "NORMAL",
|
||||||
|
"anchor": {
|
||||||
|
"diffType": "EFFECTIVE",
|
||||||
|
"path": file,
|
||||||
|
"lineType": "ADDED",
|
||||||
|
"line": from_line,
|
||||||
|
"fileType": "TO"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
response = requests.post(url=self._get_pr_comments_url(), json=payload, headers=self.headers)
|
||||||
|
return response
|
||||||
|
|
||||||
|
def generate_link_to_relevant_line_number(self, suggestion) -> str:
|
||||||
|
try:
|
||||||
|
relevant_file = suggestion['relevant file'].strip('`').strip("'")
|
||||||
|
relevant_line_str = suggestion['relevant line']
|
||||||
|
if not relevant_line_str:
|
||||||
|
return ""
|
||||||
|
|
||||||
|
diff_files = self.get_diff_files()
|
||||||
|
position, absolute_position = find_line_number_of_relevant_line_in_file \
|
||||||
|
(diff_files, relevant_file, relevant_line_str)
|
||||||
|
|
||||||
|
if absolute_position != -1 and self.pr_url:
|
||||||
|
link = f"{self.pr_url}/#L{relevant_file}T{absolute_position}"
|
||||||
|
return link
|
||||||
|
except Exception as e:
|
||||||
|
if get_settings().config.verbosity_level >= 2:
|
||||||
|
get_logger().info(f"Failed adding line link, error: {e}")
|
||||||
|
|
||||||
|
return ""
|
||||||
|
|
||||||
|
def publish_inline_comments(self, comments: list[dict]):
|
||||||
|
for comment in comments:
|
||||||
|
self.publish_inline_comment(comment['body'], comment['position'], comment['path'])
|
||||||
|
|
||||||
|
def get_title(self):
|
||||||
|
return self.pr.title
|
||||||
|
|
||||||
|
def get_languages(self):
|
||||||
|
return {"yaml": 0} # devops LOL
|
||||||
|
|
||||||
|
def get_pr_branch(self):
|
||||||
|
return self.pr.fromRef['displayId']
|
||||||
|
|
||||||
|
def get_pr_description_full(self):
|
||||||
|
return self.pr.description
|
||||||
|
|
||||||
|
def get_user_id(self):
|
||||||
|
return 0
|
||||||
|
|
||||||
|
def get_issue_comments(self):
|
||||||
|
raise NotImplementedError(
|
||||||
|
"Bitbucket provider does not support issue comments yet"
|
||||||
|
)
|
||||||
|
|
||||||
|
def add_eyes_reaction(self, issue_comment_id: int) -> Optional[int]:
|
||||||
|
return True
|
||||||
|
|
||||||
|
def remove_reaction(self, issue_comment_id: int, reaction_id: int) -> bool:
|
||||||
|
return True
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _parse_bitbucket_server(url: str) -> str:
|
||||||
|
parsed_url = urlparse(url)
|
||||||
|
return f"{parsed_url.scheme}://{parsed_url.netloc}"
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _parse_pr_url(pr_url: str) -> Tuple[str, str, int]:
|
||||||
|
parsed_url = urlparse(pr_url)
|
||||||
|
path_parts = parsed_url.path.strip("/").split("/")
|
||||||
|
if len(path_parts) < 6 or path_parts[4] != "pull-requests":
|
||||||
|
raise ValueError(
|
||||||
|
"The provided URL does not appear to be a Bitbucket PR URL"
|
||||||
|
)
|
||||||
|
|
||||||
|
workspace_slug = path_parts[1]
|
||||||
|
repo_slug = path_parts[3]
|
||||||
|
try:
|
||||||
|
pr_number = int(path_parts[5])
|
||||||
|
except ValueError as e:
|
||||||
|
raise ValueError("Unable to convert PR number to integer") from e
|
||||||
|
|
||||||
|
return workspace_slug, repo_slug, pr_number
|
||||||
|
|
||||||
|
def _get_repo(self):
|
||||||
|
if self.repo is None:
|
||||||
|
self.repo = self.bitbucket_client.get_repo(self.workspace_slug, self.repo_slug)
|
||||||
|
return self.repo
|
||||||
|
|
||||||
|
def _get_pr(self):
|
||||||
|
pr = self.bitbucket_client.get_pull_request(self.workspace_slug, self.repo_slug, pull_request_id=self.pr_num)
|
||||||
|
return type('new_dict', (object,), pr)
|
||||||
|
|
||||||
|
def _get_pr_file_content(self, remote_link: str):
|
||||||
|
return ""
|
||||||
|
|
||||||
|
def get_commit_messages(self):
|
||||||
|
def get_commit_messages(self):
|
||||||
|
raise NotImplementedError("Get commit messages function not implemented yet.")
|
||||||
|
# bitbucket does not support labels
|
||||||
|
def publish_description(self, pr_title: str, description: str):
|
||||||
|
payload = json.dumps({
|
||||||
|
"description": description,
|
||||||
|
"title": pr_title
|
||||||
|
})
|
||||||
|
|
||||||
|
response = requests.put(url=self.bitbucket_pull_request_api_url, headers=self.headers, data=payload)
|
||||||
|
return response
|
||||||
|
|
||||||
|
# bitbucket does not support labels
|
||||||
|
def publish_labels(self, pr_types: list):
|
||||||
|
pass
|
||||||
|
|
||||||
|
# bitbucket does not support labels
|
||||||
|
def get_pr_labels(self):
|
||||||
|
pass
|
||||||
|
|
||||||
|
def _get_pr_comments_url(self):
|
||||||
|
return f"{self.bitbucket_server_url}/rest/api/latest/projects/{self.workspace_slug}/repos/{self.repo_slug}/pull-requests/{self.pr_num}/comments"
|
||||||
@ -6,9 +6,9 @@ from urllib.parse import urlparse
|
|||||||
|
|
||||||
from pr_agent.git_providers.codecommit_client import CodeCommitClient
|
from pr_agent.git_providers.codecommit_client import CodeCommitClient
|
||||||
|
|
||||||
from ..algo.language_handler import is_valid_file, language_extension_map
|
|
||||||
from ..algo.utils import load_large_diff
|
from ..algo.utils import load_large_diff
|
||||||
from .git_provider import EDIT_TYPE, FilePatchInfo, GitProvider
|
from .git_provider import EDIT_TYPE, FilePatchInfo, GitProvider
|
||||||
|
from ..config_loader import get_settings
|
||||||
from ..log import get_logger
|
from ..log import get_logger
|
||||||
|
|
||||||
|
|
||||||
@ -61,6 +61,7 @@ class CodeCommitProvider(GitProvider):
|
|||||||
self.pr = None
|
self.pr = None
|
||||||
self.diff_files = None
|
self.diff_files = None
|
||||||
self.git_files = None
|
self.git_files = None
|
||||||
|
self.pr_url = pr_url
|
||||||
if pr_url:
|
if pr_url:
|
||||||
self.set_pr(pr_url)
|
self.set_pr(pr_url)
|
||||||
|
|
||||||
@ -215,7 +216,7 @@ class CodeCommitProvider(GitProvider):
|
|||||||
def publish_labels(self, labels):
|
def publish_labels(self, labels):
|
||||||
return [""] # not implemented yet
|
return [""] # not implemented yet
|
||||||
|
|
||||||
def get_labels(self):
|
def get_pr_labels(self):
|
||||||
return [""] # not implemented yet
|
return [""] # not implemented yet
|
||||||
|
|
||||||
def remove_initial_comment(self):
|
def remove_initial_comment(self):
|
||||||
@ -228,9 +229,6 @@ class CodeCommitProvider(GitProvider):
|
|||||||
# https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/codecommit/client/post_comment_for_compared_commit.html
|
# https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/codecommit/client/post_comment_for_compared_commit.html
|
||||||
raise NotImplementedError("CodeCommit provider does not support publishing inline comments yet")
|
raise NotImplementedError("CodeCommit provider does not support publishing inline comments yet")
|
||||||
|
|
||||||
def create_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
|
||||||
raise NotImplementedError("CodeCommit provider does not support creating inline comments yet")
|
|
||||||
|
|
||||||
def publish_inline_comments(self, comments: list[dict]):
|
def publish_inline_comments(self, comments: list[dict]):
|
||||||
raise NotImplementedError("CodeCommit provider does not support publishing inline comments yet")
|
raise NotImplementedError("CodeCommit provider does not support publishing inline comments yet")
|
||||||
|
|
||||||
@ -269,6 +267,8 @@ class CodeCommitProvider(GitProvider):
|
|||||||
# where each dictionary item is a language name.
|
# where each dictionary item is a language name.
|
||||||
# We build that language->extension dictionary here in main_extensions_flat.
|
# We build that language->extension dictionary here in main_extensions_flat.
|
||||||
main_extensions_flat = {}
|
main_extensions_flat = {}
|
||||||
|
language_extension_map_org = get_settings().language_extension_map_org
|
||||||
|
language_extension_map = {k.lower(): v for k, v in language_extension_map_org.items()}
|
||||||
for language, extensions in language_extension_map.items():
|
for language, extensions in language_extension_map.items():
|
||||||
for ext in extensions:
|
for ext in extensions:
|
||||||
main_extensions_flat[ext] = language
|
main_extensions_flat[ext] = language
|
||||||
|
|||||||
@ -192,7 +192,7 @@ class GerritProvider(GitProvider):
|
|||||||
)
|
)
|
||||||
self.repo = Repo(self.repo_path)
|
self.repo = Repo(self.repo_path)
|
||||||
assert self.repo
|
assert self.repo
|
||||||
|
self.pr_url = base_url
|
||||||
self.pr = PullRequestMimic(self.get_pr_title(), self.get_diff_files())
|
self.pr = PullRequestMimic(self.get_pr_title(), self.get_diff_files())
|
||||||
|
|
||||||
def get_pr_title(self):
|
def get_pr_title(self):
|
||||||
@ -207,7 +207,7 @@ class GerritProvider(GitProvider):
|
|||||||
Comment = namedtuple('Comment', ['body'])
|
Comment = namedtuple('Comment', ['body'])
|
||||||
return Comments([Comment(c['message']) for c in reversed(comments)])
|
return Comments([Comment(c['message']) for c in reversed(comments)])
|
||||||
|
|
||||||
def get_labels(self):
|
def get_pr_labels(self):
|
||||||
raise NotImplementedError(
|
raise NotImplementedError(
|
||||||
'Getting labels is not implemented for the gerrit provider')
|
'Getting labels is not implemented for the gerrit provider')
|
||||||
|
|
||||||
@ -380,11 +380,6 @@ class GerritProvider(GitProvider):
|
|||||||
'Publishing inline comments is not implemented for the gerrit '
|
'Publishing inline comments is not implemented for the gerrit '
|
||||||
'provider')
|
'provider')
|
||||||
|
|
||||||
def create_inline_comment(self, body: str, relevant_file: str,
|
|
||||||
relevant_line_in_file: str):
|
|
||||||
raise NotImplementedError(
|
|
||||||
'Creating inline comments is not implemented for the gerrit '
|
|
||||||
'provider')
|
|
||||||
|
|
||||||
def publish_labels(self, labels):
|
def publish_labels(self, labels):
|
||||||
# Not applicable to the local git provider,
|
# Not applicable to the local git provider,
|
||||||
|
|||||||
@ -5,6 +5,7 @@ from dataclasses import dataclass
|
|||||||
from enum import Enum
|
from enum import Enum
|
||||||
from typing import Optional
|
from typing import Optional
|
||||||
|
|
||||||
|
from pr_agent.config_loader import get_settings
|
||||||
from pr_agent.log import get_logger
|
from pr_agent.log import get_logger
|
||||||
|
|
||||||
|
|
||||||
@ -13,6 +14,7 @@ class EDIT_TYPE(Enum):
|
|||||||
DELETED = 2
|
DELETED = 2
|
||||||
MODIFIED = 3
|
MODIFIED = 3
|
||||||
RENAMED = 4
|
RENAMED = 4
|
||||||
|
UNKNOWN = 5
|
||||||
|
|
||||||
|
|
||||||
@dataclass
|
@dataclass
|
||||||
@ -22,8 +24,10 @@ class FilePatchInfo:
|
|||||||
patch: str
|
patch: str
|
||||||
filename: str
|
filename: str
|
||||||
tokens: int = -1
|
tokens: int = -1
|
||||||
edit_type: EDIT_TYPE = EDIT_TYPE.MODIFIED
|
edit_type: EDIT_TYPE = EDIT_TYPE.UNKNOWN
|
||||||
old_filename: str = None
|
old_filename: str = None
|
||||||
|
num_plus_lines: int = -1
|
||||||
|
num_minus_lines: int = -1
|
||||||
|
|
||||||
|
|
||||||
class GitProvider(ABC):
|
class GitProvider(ABC):
|
||||||
@ -39,42 +43,10 @@ class GitProvider(ABC):
|
|||||||
def publish_description(self, pr_title: str, pr_body: str):
|
def publish_description(self, pr_title: str, pr_body: str):
|
||||||
pass
|
pass
|
||||||
|
|
||||||
@abstractmethod
|
|
||||||
def publish_comment(self, pr_comment: str, is_temporary: bool = False):
|
|
||||||
pass
|
|
||||||
|
|
||||||
@abstractmethod
|
|
||||||
def publish_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
|
||||||
pass
|
|
||||||
|
|
||||||
@abstractmethod
|
|
||||||
def create_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
|
||||||
pass
|
|
||||||
|
|
||||||
@abstractmethod
|
|
||||||
def publish_inline_comments(self, comments: list[dict]):
|
|
||||||
pass
|
|
||||||
|
|
||||||
@abstractmethod
|
@abstractmethod
|
||||||
def publish_code_suggestions(self, code_suggestions: list) -> bool:
|
def publish_code_suggestions(self, code_suggestions: list) -> bool:
|
||||||
pass
|
pass
|
||||||
|
|
||||||
@abstractmethod
|
|
||||||
def publish_labels(self, labels):
|
|
||||||
pass
|
|
||||||
|
|
||||||
@abstractmethod
|
|
||||||
def get_labels(self):
|
|
||||||
pass
|
|
||||||
|
|
||||||
@abstractmethod
|
|
||||||
def remove_initial_comment(self):
|
|
||||||
pass
|
|
||||||
|
|
||||||
@abstractmethod
|
|
||||||
def remove_comment(self, comment):
|
|
||||||
pass
|
|
||||||
|
|
||||||
@abstractmethod
|
@abstractmethod
|
||||||
def get_languages(self):
|
def get_languages(self):
|
||||||
pass
|
pass
|
||||||
@ -93,31 +65,112 @@ class GitProvider(ABC):
|
|||||||
|
|
||||||
def get_pr_description(self, *, full: bool = True) -> str:
|
def get_pr_description(self, *, full: bool = True) -> str:
|
||||||
from pr_agent.config_loader import get_settings
|
from pr_agent.config_loader import get_settings
|
||||||
from pr_agent.algo.pr_processing import clip_tokens
|
from pr_agent.algo.utils import clip_tokens
|
||||||
max_tokens = get_settings().get("CONFIG.MAX_DESCRIPTION_TOKENS", None)
|
max_tokens_description = get_settings().get("CONFIG.MAX_DESCRIPTION_TOKENS", None)
|
||||||
description = self.get_pr_description_full() if full else self.get_user_description()
|
description = self.get_pr_description_full() if full else self.get_user_description()
|
||||||
if max_tokens:
|
if max_tokens_description:
|
||||||
return clip_tokens(description, max_tokens)
|
return clip_tokens(description, max_tokens_description)
|
||||||
return description
|
return description
|
||||||
|
|
||||||
def get_user_description(self) -> str:
|
def get_user_description(self) -> str:
|
||||||
description = (self.get_pr_description_full() or "").strip()
|
description = (self.get_pr_description_full() or "").strip()
|
||||||
|
description_lowercase = description.lower()
|
||||||
|
|
||||||
# if the existing description wasn't generated by the pr-agent, just return it as-is
|
# if the existing description wasn't generated by the pr-agent, just return it as-is
|
||||||
if not description.startswith("## PR Type"):
|
if not self._is_generated_by_pr_agent(description_lowercase):
|
||||||
return description
|
return description
|
||||||
# if the existing description was generated by the pr-agent, but it doesn't contain the user description,
|
|
||||||
|
# if the existing description was generated by the pr-agent, but it doesn't contain a user description,
|
||||||
# return nothing (empty string) because it means there is no user description
|
# return nothing (empty string) because it means there is no user description
|
||||||
if "## User Description:" not in description:
|
user_description_header = "## user description"
|
||||||
|
if user_description_header not in description_lowercase:
|
||||||
return ""
|
return ""
|
||||||
|
|
||||||
# otherwise, extract the original user description from the existing pr-agent description and return it
|
# otherwise, extract the original user description from the existing pr-agent description and return it
|
||||||
return description.split("## User Description:", 1)[1].strip()
|
# user_description_start_position = description_lowercase.find(user_description_header) + len(user_description_header)
|
||||||
|
# return description[user_description_start_position:].split("\n", 1)[-1].strip()
|
||||||
|
|
||||||
|
# the 'user description' is in the beginning. extract and return it
|
||||||
|
possible_headers = self._possible_headers()
|
||||||
|
start_position = description_lowercase.find(user_description_header) + len(user_description_header)
|
||||||
|
end_position = len(description)
|
||||||
|
for header in possible_headers: # try to clip at the next header
|
||||||
|
if header != user_description_header and header in description_lowercase:
|
||||||
|
end_position = min(end_position, description_lowercase.find(header))
|
||||||
|
if end_position != len(description) and end_position > start_position:
|
||||||
|
original_user_description = description[start_position:end_position].strip()
|
||||||
|
if original_user_description.endswith("___"):
|
||||||
|
original_user_description = original_user_description[:-3].strip()
|
||||||
|
else:
|
||||||
|
original_user_description = description.split("___")[0].strip()
|
||||||
|
if original_user_description.lower().startswith(user_description_header):
|
||||||
|
original_user_description = original_user_description[len(user_description_header):].strip()
|
||||||
|
|
||||||
|
return original_user_description
|
||||||
|
|
||||||
|
def _possible_headers(self):
|
||||||
|
return ("## user description", "## pr type", "## pr description", "## pr labels", "## type", "## description",
|
||||||
|
"## labels", "### 🤖 generated by pr agent")
|
||||||
|
|
||||||
|
def _is_generated_by_pr_agent(self, description_lowercase: str) -> bool:
|
||||||
|
possible_headers = self._possible_headers()
|
||||||
|
return any(description_lowercase.startswith(header) for header in possible_headers)
|
||||||
|
|
||||||
|
@abstractmethod
|
||||||
|
def get_repo_settings(self):
|
||||||
|
pass
|
||||||
|
|
||||||
|
def get_pr_id(self):
|
||||||
|
return ""
|
||||||
|
|
||||||
|
def get_line_link(self, relevant_file: str, relevant_line_start: int, relevant_line_end: int = None) -> str:
|
||||||
|
return ""
|
||||||
|
|
||||||
|
#### comments operations ####
|
||||||
|
@abstractmethod
|
||||||
|
def publish_comment(self, pr_comment: str, is_temporary: bool = False):
|
||||||
|
pass
|
||||||
|
|
||||||
|
def publish_persistent_comment(self, pr_comment: str, initial_header: str, update_header: bool):
|
||||||
|
self.publish_comment(pr_comment)
|
||||||
|
|
||||||
|
@abstractmethod
|
||||||
|
def publish_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
||||||
|
pass
|
||||||
|
|
||||||
|
def create_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str,
|
||||||
|
absolute_position: int = None):
|
||||||
|
raise NotImplementedError("This git provider does not support creating inline comments yet")
|
||||||
|
|
||||||
|
@abstractmethod
|
||||||
|
def publish_inline_comments(self, comments: list[dict]):
|
||||||
|
pass
|
||||||
|
|
||||||
|
@abstractmethod
|
||||||
|
def remove_initial_comment(self):
|
||||||
|
pass
|
||||||
|
|
||||||
|
@abstractmethod
|
||||||
|
def remove_comment(self, comment):
|
||||||
|
pass
|
||||||
|
|
||||||
@abstractmethod
|
@abstractmethod
|
||||||
def get_issue_comments(self):
|
def get_issue_comments(self):
|
||||||
pass
|
pass
|
||||||
|
|
||||||
|
def get_comment_url(self, comment) -> str:
|
||||||
|
return ""
|
||||||
|
|
||||||
|
#### labels operations ####
|
||||||
@abstractmethod
|
@abstractmethod
|
||||||
def get_repo_settings(self):
|
def publish_labels(self, labels):
|
||||||
|
pass
|
||||||
|
|
||||||
|
@abstractmethod
|
||||||
|
def get_pr_labels(self):
|
||||||
|
pass
|
||||||
|
|
||||||
|
def get_repo_labels(self):
|
||||||
pass
|
pass
|
||||||
|
|
||||||
@abstractmethod
|
@abstractmethod
|
||||||
@ -128,11 +181,12 @@ class GitProvider(ABC):
|
|||||||
def remove_reaction(self, issue_comment_id: int, reaction_id: int) -> bool:
|
def remove_reaction(self, issue_comment_id: int, reaction_id: int) -> bool:
|
||||||
pass
|
pass
|
||||||
|
|
||||||
|
#### commits operations ####
|
||||||
@abstractmethod
|
@abstractmethod
|
||||||
def get_commit_messages(self):
|
def get_commit_messages(self):
|
||||||
pass
|
pass
|
||||||
|
|
||||||
def get_pr_id(self):
|
def get_latest_commit_url(self) -> str:
|
||||||
return ""
|
return ""
|
||||||
|
|
||||||
def get_main_pr_language(languages, files) -> str:
|
def get_main_pr_language(languages, files) -> str:
|
||||||
@ -143,6 +197,9 @@ def get_main_pr_language(languages, files) -> str:
|
|||||||
if not languages:
|
if not languages:
|
||||||
get_logger().info("No languages detected")
|
get_logger().info("No languages detected")
|
||||||
return main_language_str
|
return main_language_str
|
||||||
|
if not files:
|
||||||
|
get_logger().info("No files in diff")
|
||||||
|
return main_language_str
|
||||||
|
|
||||||
try:
|
try:
|
||||||
top_language = max(languages, key=languages.get).lower()
|
top_language = max(languages, key=languages.get).lower()
|
||||||
@ -150,31 +207,49 @@ def get_main_pr_language(languages, files) -> str:
|
|||||||
# validate that the specific commit uses the main language
|
# validate that the specific commit uses the main language
|
||||||
extension_list = []
|
extension_list = []
|
||||||
for file in files:
|
for file in files:
|
||||||
|
if not file:
|
||||||
|
continue
|
||||||
if isinstance(file, str):
|
if isinstance(file, str):
|
||||||
file = FilePatchInfo(base_file=None, head_file=None, patch=None, filename=file)
|
file = FilePatchInfo(base_file=None, head_file=None, patch=None, filename=file)
|
||||||
extension_list.append(file.filename.rsplit('.')[-1])
|
extension_list.append(file.filename.rsplit('.')[-1])
|
||||||
|
|
||||||
# get the most common extension
|
# get the most common extension
|
||||||
most_common_extension = max(set(extension_list), key=extension_list.count)
|
most_common_extension = '.' + max(set(extension_list), key=extension_list.count)
|
||||||
|
try:
|
||||||
|
language_extension_map_org = get_settings().language_extension_map_org
|
||||||
|
language_extension_map = {k.lower(): v for k, v in language_extension_map_org.items()}
|
||||||
|
|
||||||
# look for a match. TBD: add more languages, do this systematically
|
if top_language in language_extension_map and most_common_extension in language_extension_map[top_language]:
|
||||||
if most_common_extension == 'py' and top_language == 'python' or \
|
main_language_str = top_language
|
||||||
most_common_extension == 'js' and top_language == 'javascript' or \
|
else:
|
||||||
most_common_extension == 'ts' and top_language == 'typescript' or \
|
for language, extensions in language_extension_map.items():
|
||||||
most_common_extension == 'go' and top_language == 'go' or \
|
if most_common_extension in extensions:
|
||||||
most_common_extension == 'java' and top_language == 'java' or \
|
main_language_str = language
|
||||||
most_common_extension == 'c' and top_language == 'c' or \
|
break
|
||||||
most_common_extension == 'cpp' and top_language == 'c++' or \
|
except Exception as e:
|
||||||
most_common_extension == 'cs' and top_language == 'c#' or \
|
get_logger().exception(f"Failed to get main language: {e}")
|
||||||
most_common_extension == 'swift' and top_language == 'swift' or \
|
pass
|
||||||
most_common_extension == 'php' and top_language == 'php' or \
|
|
||||||
most_common_extension == 'rb' and top_language == 'ruby' or \
|
## old approach:
|
||||||
most_common_extension == 'rs' and top_language == 'rust' or \
|
# most_common_extension = max(set(extension_list), key=extension_list.count)
|
||||||
most_common_extension == 'scala' and top_language == 'scala' or \
|
# if most_common_extension == 'py' and top_language == 'python' or \
|
||||||
most_common_extension == 'kt' and top_language == 'kotlin' or \
|
# most_common_extension == 'js' and top_language == 'javascript' or \
|
||||||
most_common_extension == 'pl' and top_language == 'perl' or \
|
# most_common_extension == 'ts' and top_language == 'typescript' or \
|
||||||
most_common_extension == top_language:
|
# most_common_extension == 'tsx' and top_language == 'typescript' or \
|
||||||
main_language_str = top_language
|
# most_common_extension == 'go' and top_language == 'go' or \
|
||||||
|
# most_common_extension == 'java' and top_language == 'java' or \
|
||||||
|
# most_common_extension == 'c' and top_language == 'c' or \
|
||||||
|
# most_common_extension == 'cpp' and top_language == 'c++' or \
|
||||||
|
# most_common_extension == 'cs' and top_language == 'c#' or \
|
||||||
|
# most_common_extension == 'swift' and top_language == 'swift' or \
|
||||||
|
# most_common_extension == 'php' and top_language == 'php' or \
|
||||||
|
# most_common_extension == 'rb' and top_language == 'ruby' or \
|
||||||
|
# most_common_extension == 'rs' and top_language == 'rust' or \
|
||||||
|
# most_common_extension == 'scala' and top_language == 'scala' or \
|
||||||
|
# most_common_extension == 'kt' and top_language == 'kotlin' or \
|
||||||
|
# most_common_extension == 'pl' and top_language == 'perl' or \
|
||||||
|
# most_common_extension == top_language:
|
||||||
|
# main_language_str = top_language
|
||||||
|
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
get_logger().exception(e)
|
get_logger().exception(e)
|
||||||
@ -187,6 +262,13 @@ class IncrementalPR:
|
|||||||
def __init__(self, is_incremental: bool = False):
|
def __init__(self, is_incremental: bool = False):
|
||||||
self.is_incremental = is_incremental
|
self.is_incremental = is_incremental
|
||||||
self.commits_range = None
|
self.commits_range = None
|
||||||
self.first_new_commit_sha = None
|
self.first_new_commit = None
|
||||||
self.last_seen_commit_sha = None
|
self.last_seen_commit = None
|
||||||
|
|
||||||
|
@property
|
||||||
|
def first_new_commit_sha(self):
|
||||||
|
return None if self.first_new_commit is None else self.first_new_commit.sha
|
||||||
|
|
||||||
|
@property
|
||||||
|
def last_seen_commit_sha(self):
|
||||||
|
return None if self.last_seen_commit is None else self.last_seen_commit.sha
|
||||||
|
|||||||
@ -8,12 +8,12 @@ from retry import retry
|
|||||||
from starlette_context import context
|
from starlette_context import context
|
||||||
|
|
||||||
from ..algo.language_handler import is_valid_file
|
from ..algo.language_handler import is_valid_file
|
||||||
from ..algo.pr_processing import clip_tokens, find_line_number_of_relevant_line_in_file
|
from ..algo.pr_processing import find_line_number_of_relevant_line_in_file
|
||||||
from ..algo.utils import load_large_diff
|
from ..algo.utils import load_large_diff, clip_tokens
|
||||||
from ..config_loader import get_settings
|
from ..config_loader import get_settings
|
||||||
from ..log import get_logger
|
from ..log import get_logger
|
||||||
from ..servers.utils import RateLimitExceeded
|
from ..servers.utils import RateLimitExceeded
|
||||||
from .git_provider import FilePatchInfo, GitProvider, IncrementalPR
|
from .git_provider import FilePatchInfo, GitProvider, IncrementalPR, EDIT_TYPE
|
||||||
|
|
||||||
|
|
||||||
class GithubProvider(GitProvider):
|
class GithubProvider(GitProvider):
|
||||||
@ -34,6 +34,7 @@ class GithubProvider(GitProvider):
|
|||||||
if pr_url and 'pull' in pr_url:
|
if pr_url and 'pull' in pr_url:
|
||||||
self.set_pr(pr_url)
|
self.set_pr(pr_url)
|
||||||
self.last_commit_id = list(self.pr.get_commits())[-1]
|
self.last_commit_id = list(self.pr.get_commits())[-1]
|
||||||
|
self.pr_url = self.get_pr_url() # pr_url for github actions can be as api.github.com, so we need to get the url from the pr object
|
||||||
|
|
||||||
def is_supported(self, capability: str) -> bool:
|
def is_supported(self, capability: str) -> bool:
|
||||||
return True
|
return True
|
||||||
@ -60,16 +61,18 @@ class GithubProvider(GitProvider):
|
|||||||
get_logger().info(f"Skipping merge commit {commit.commit.message}")
|
get_logger().info(f"Skipping merge commit {commit.commit.message}")
|
||||||
continue
|
continue
|
||||||
self.file_set.update({file.filename: file for file in commit.files})
|
self.file_set.update({file.filename: file for file in commit.files})
|
||||||
|
else:
|
||||||
|
raise ValueError("No previous review found")
|
||||||
|
|
||||||
def get_commit_range(self):
|
def get_commit_range(self):
|
||||||
last_review_time = self.previous_review.created_at
|
last_review_time = self.previous_review.created_at
|
||||||
first_new_commit_index = None
|
first_new_commit_index = None
|
||||||
for index in range(len(self.commits) - 1, -1, -1):
|
for index in range(len(self.commits) - 1, -1, -1):
|
||||||
if self.commits[index].commit.author.date > last_review_time:
|
if self.commits[index].commit.author.date > last_review_time:
|
||||||
self.incremental.first_new_commit_sha = self.commits[index].sha
|
self.incremental.first_new_commit = self.commits[index]
|
||||||
first_new_commit_index = index
|
first_new_commit_index = index
|
||||||
else:
|
else:
|
||||||
self.incremental.last_seen_commit_sha = self.commits[index].sha
|
self.incremental.last_seen_commit = self.commits[index]
|
||||||
break
|
break
|
||||||
return self.commits[first_new_commit_index:] if first_new_commit_index is not None else []
|
return self.commits[first_new_commit_index:] if first_new_commit_index is not None else []
|
||||||
|
|
||||||
@ -129,7 +132,27 @@ class GithubProvider(GitProvider):
|
|||||||
if not patch:
|
if not patch:
|
||||||
patch = load_large_diff(file.filename, new_file_content_str, original_file_content_str)
|
patch = load_large_diff(file.filename, new_file_content_str, original_file_content_str)
|
||||||
|
|
||||||
diff_files.append(FilePatchInfo(original_file_content_str, new_file_content_str, patch, file.filename))
|
if file.status == 'added':
|
||||||
|
edit_type = EDIT_TYPE.ADDED
|
||||||
|
elif file.status == 'removed':
|
||||||
|
edit_type = EDIT_TYPE.DELETED
|
||||||
|
elif file.status == 'renamed':
|
||||||
|
edit_type = EDIT_TYPE.RENAMED
|
||||||
|
elif file.status == 'modified':
|
||||||
|
edit_type = EDIT_TYPE.MODIFIED
|
||||||
|
else:
|
||||||
|
get_logger().error(f"Unknown edit type: {file.status}")
|
||||||
|
edit_type = EDIT_TYPE.UNKNOWN
|
||||||
|
|
||||||
|
# count number of lines added and removed
|
||||||
|
patch_lines = patch.splitlines(keepends=True)
|
||||||
|
num_plus_lines = len([line for line in patch_lines if line.startswith('+')])
|
||||||
|
num_minus_lines = len([line for line in patch_lines if line.startswith('-')])
|
||||||
|
file_patch_canonical_structure = FilePatchInfo(original_file_content_str, new_file_content_str, patch,
|
||||||
|
file.filename, edit_type=edit_type,
|
||||||
|
num_plus_lines=num_plus_lines,
|
||||||
|
num_minus_lines=num_minus_lines,)
|
||||||
|
diff_files.append(file_patch_canonical_structure)
|
||||||
|
|
||||||
self.diff_files = diff_files
|
self.diff_files = diff_files
|
||||||
return diff_files
|
return diff_files
|
||||||
@ -141,10 +164,36 @@ class GithubProvider(GitProvider):
|
|||||||
def publish_description(self, pr_title: str, pr_body: str):
|
def publish_description(self, pr_title: str, pr_body: str):
|
||||||
self.pr.edit(title=pr_title, body=pr_body)
|
self.pr.edit(title=pr_title, body=pr_body)
|
||||||
|
|
||||||
|
def get_latest_commit_url(self) -> str:
|
||||||
|
return self.last_commit_id.html_url
|
||||||
|
|
||||||
|
def get_comment_url(self, comment) -> str:
|
||||||
|
return comment.html_url
|
||||||
|
|
||||||
|
def publish_persistent_comment(self, pr_comment: str, initial_header: str, update_header: bool = True):
|
||||||
|
prev_comments = list(self.pr.get_issue_comments())
|
||||||
|
for comment in prev_comments:
|
||||||
|
body = comment.body
|
||||||
|
if body.startswith(initial_header):
|
||||||
|
latest_commit_url = self.get_latest_commit_url()
|
||||||
|
comment_url = self.get_comment_url(comment)
|
||||||
|
if update_header:
|
||||||
|
updated_header = f"{initial_header}\n\n### (review updated until commit {latest_commit_url})\n"
|
||||||
|
pr_comment_updated = pr_comment.replace(initial_header, updated_header)
|
||||||
|
else:
|
||||||
|
pr_comment_updated = pr_comment
|
||||||
|
get_logger().info(f"Persistent mode- updating comment {comment_url} to latest review message")
|
||||||
|
response = comment.edit(pr_comment_updated)
|
||||||
|
self.publish_comment(
|
||||||
|
f"**[Persistent review]({comment_url})** updated to latest commit {latest_commit_url}")
|
||||||
|
return
|
||||||
|
self.publish_comment(pr_comment)
|
||||||
|
|
||||||
def publish_comment(self, pr_comment: str, is_temporary: bool = False):
|
def publish_comment(self, pr_comment: str, is_temporary: bool = False):
|
||||||
if is_temporary and not get_settings().config.publish_output_progress:
|
if is_temporary and not get_settings().config.publish_output_progress:
|
||||||
get_logger().debug(f"Skipping publish_comment for temporary comment: {pr_comment}")
|
get_logger().debug(f"Skipping publish_comment for temporary comment: {pr_comment}")
|
||||||
return
|
return
|
||||||
|
|
||||||
response = self.pr.create_issue_comment(pr_comment)
|
response = self.pr.create_issue_comment(pr_comment)
|
||||||
if hasattr(response, "user") and hasattr(response.user, "login"):
|
if hasattr(response, "user") and hasattr(response.user, "login"):
|
||||||
self.github_user_id = response.user.login
|
self.github_user_id = response.user.login
|
||||||
@ -157,8 +206,12 @@ class GithubProvider(GitProvider):
|
|||||||
self.publish_inline_comments([self.create_inline_comment(body, relevant_file, relevant_line_in_file)])
|
self.publish_inline_comments([self.create_inline_comment(body, relevant_file, relevant_line_in_file)])
|
||||||
|
|
||||||
|
|
||||||
def create_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
def create_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str,
|
||||||
position, absolute_position = find_line_number_of_relevant_line_in_file(self.diff_files, relevant_file.strip('`'), relevant_line_in_file)
|
absolute_position: int = None):
|
||||||
|
position, absolute_position = find_line_number_of_relevant_line_in_file(self.diff_files,
|
||||||
|
relevant_file.strip('`'),
|
||||||
|
relevant_line_in_file,
|
||||||
|
absolute_position)
|
||||||
if position == -1:
|
if position == -1:
|
||||||
if get_settings().config.verbosity_level >= 2:
|
if get_settings().config.verbosity_level >= 2:
|
||||||
get_logger().info(f"Could not find position for {relevant_file} {relevant_line_in_file}")
|
get_logger().info(f"Could not find position for {relevant_file} {relevant_line_in_file}")
|
||||||
@ -366,7 +419,7 @@ class GithubProvider(GitProvider):
|
|||||||
raise ValueError("GitHub app installation ID is required when using GitHub app deployment")
|
raise ValueError("GitHub app installation ID is required when using GitHub app deployment")
|
||||||
auth = AppAuthentication(app_id=app_id, private_key=private_key,
|
auth = AppAuthentication(app_id=app_id, private_key=private_key,
|
||||||
installation_id=self.installation_id)
|
installation_id=self.installation_id)
|
||||||
return Github(app_auth=auth)
|
return Github(app_auth=auth, base_url=get_settings().github.base_url)
|
||||||
|
|
||||||
if deployment_type == 'user':
|
if deployment_type == 'user':
|
||||||
try:
|
try:
|
||||||
@ -375,7 +428,7 @@ class GithubProvider(GitProvider):
|
|||||||
raise ValueError(
|
raise ValueError(
|
||||||
"GitHub token is required when using user deployment. See: "
|
"GitHub token is required when using user deployment. See: "
|
||||||
"https://github.com/Codium-ai/pr-agent#method-2-run-from-source") from e
|
"https://github.com/Codium-ai/pr-agent#method-2-run-from-source") from e
|
||||||
return Github(auth=Auth.Token(token))
|
return Github(auth=Auth.Token(token), base_url=get_settings().github.base_url)
|
||||||
|
|
||||||
def _get_repo(self):
|
def _get_repo(self):
|
||||||
if hasattr(self, 'repo_obj') and \
|
if hasattr(self, 'repo_obj') and \
|
||||||
@ -400,7 +453,7 @@ class GithubProvider(GitProvider):
|
|||||||
def publish_labels(self, pr_types):
|
def publish_labels(self, pr_types):
|
||||||
try:
|
try:
|
||||||
label_color_map = {"Bug fix": "1d76db", "Tests": "e99695", "Bug fix with tests": "c5def5",
|
label_color_map = {"Bug fix": "1d76db", "Tests": "e99695", "Bug fix with tests": "c5def5",
|
||||||
"Refactoring": "bfdadc", "Enhancement": "bfd4f2", "Documentation": "d4c5f9",
|
"Enhancement": "bfd4f2", "Documentation": "d4c5f9",
|
||||||
"Other": "d1bcf9"}
|
"Other": "d1bcf9"}
|
||||||
post_parameters = []
|
post_parameters = []
|
||||||
for p in pr_types:
|
for p in pr_types:
|
||||||
@ -412,13 +465,17 @@ class GithubProvider(GitProvider):
|
|||||||
except Exception as e:
|
except Exception as e:
|
||||||
get_logger().exception(f"Failed to publish labels, error: {e}")
|
get_logger().exception(f"Failed to publish labels, error: {e}")
|
||||||
|
|
||||||
def get_labels(self):
|
def get_pr_labels(self):
|
||||||
try:
|
try:
|
||||||
return [label.name for label in self.pr.labels]
|
return [label.name for label in self.pr.labels]
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
get_logger().exception(f"Failed to get labels, error: {e}")
|
get_logger().exception(f"Failed to get labels, error: {e}")
|
||||||
return []
|
return []
|
||||||
|
|
||||||
|
def get_repo_labels(self):
|
||||||
|
labels = self.repo_obj.get_labels()
|
||||||
|
return [label for label in labels]
|
||||||
|
|
||||||
def get_commit_messages(self):
|
def get_commit_messages(self):
|
||||||
"""
|
"""
|
||||||
Retrieves the commit messages of a pull request.
|
Retrieves the commit messages of a pull request.
|
||||||
@ -462,6 +519,17 @@ class GithubProvider(GitProvider):
|
|||||||
|
|
||||||
return ""
|
return ""
|
||||||
|
|
||||||
|
def get_line_link(self, relevant_file: str, relevant_line_start: int, relevant_line_end: int = None) -> str:
|
||||||
|
sha_file = hashlib.sha256(relevant_file.encode('utf-8')).hexdigest()
|
||||||
|
if relevant_line_start == -1:
|
||||||
|
link = f"https://github.com/{self.repo}/pull/{self.pr_num}/files#diff-{sha_file}"
|
||||||
|
elif relevant_line_end:
|
||||||
|
link = f"https://github.com/{self.repo}/pull/{self.pr_num}/files#diff-{sha_file}R{relevant_line_start}-R{relevant_line_end}"
|
||||||
|
else:
|
||||||
|
link = f"https://github.com/{self.repo}/pull/{self.pr_num}/files#diff-{sha_file}R{relevant_line_start}"
|
||||||
|
return link
|
||||||
|
|
||||||
|
|
||||||
def get_pr_id(self):
|
def get_pr_id(self):
|
||||||
try:
|
try:
|
||||||
pr_id = f"{self.repo}/{self.pr_num}"
|
pr_id = f"{self.repo}/{self.pr_num}"
|
||||||
|
|||||||
@ -7,8 +7,8 @@ import gitlab
|
|||||||
from gitlab import GitlabGetError
|
from gitlab import GitlabGetError
|
||||||
|
|
||||||
from ..algo.language_handler import is_valid_file
|
from ..algo.language_handler import is_valid_file
|
||||||
from ..algo.pr_processing import clip_tokens, find_line_number_of_relevant_line_in_file
|
from ..algo.pr_processing import find_line_number_of_relevant_line_in_file
|
||||||
from ..algo.utils import load_large_diff
|
from ..algo.utils import load_large_diff, clip_tokens
|
||||||
from ..config_loader import get_settings
|
from ..config_loader import get_settings
|
||||||
from .git_provider import EDIT_TYPE, FilePatchInfo, GitProvider
|
from .git_provider import EDIT_TYPE, FilePatchInfo, GitProvider
|
||||||
from ..log import get_logger
|
from ..log import get_logger
|
||||||
@ -37,13 +37,14 @@ class GitLabProvider(GitProvider):
|
|||||||
self.diff_files = None
|
self.diff_files = None
|
||||||
self.git_files = None
|
self.git_files = None
|
||||||
self.temp_comments = []
|
self.temp_comments = []
|
||||||
|
self.pr_url = merge_request_url
|
||||||
self._set_merge_request(merge_request_url)
|
self._set_merge_request(merge_request_url)
|
||||||
self.RE_HUNK_HEADER = re.compile(
|
self.RE_HUNK_HEADER = re.compile(
|
||||||
r"^@@ -(\d+)(?:,(\d+))? \+(\d+)(?:,(\d+))? @@[ ]?(.*)")
|
r"^@@ -(\d+)(?:,(\d+))? \+(\d+)(?:,(\d+))? @@[ ]?(.*)")
|
||||||
self.incremental = incremental
|
self.incremental = incremental
|
||||||
|
|
||||||
def is_supported(self, capability: str) -> bool:
|
def is_supported(self, capability: str) -> bool:
|
||||||
if capability in ['get_issue_comments', 'create_inline_comment', 'publish_inline_comments', 'gfm_markdown']:
|
if capability in ['get_issue_comments', 'create_inline_comment', 'publish_inline_comments']: # gfm_markdown is supported in gitlab !
|
||||||
return False
|
return False
|
||||||
return True
|
return True
|
||||||
|
|
||||||
@ -114,12 +115,20 @@ class GitLabProvider(GitProvider):
|
|||||||
if not patch:
|
if not patch:
|
||||||
patch = load_large_diff(filename, new_file_content_str, original_file_content_str)
|
patch = load_large_diff(filename, new_file_content_str, original_file_content_str)
|
||||||
|
|
||||||
|
|
||||||
|
# count number of lines added and removed
|
||||||
|
patch_lines = patch.splitlines(keepends=True)
|
||||||
|
num_plus_lines = len([line for line in patch_lines if line.startswith('+')])
|
||||||
|
num_minus_lines = len([line for line in patch_lines if line.startswith('-')])
|
||||||
diff_files.append(
|
diff_files.append(
|
||||||
FilePatchInfo(original_file_content_str, new_file_content_str,
|
FilePatchInfo(original_file_content_str, new_file_content_str,
|
||||||
patch=patch,
|
patch=patch,
|
||||||
filename=filename,
|
filename=filename,
|
||||||
edit_type=edit_type,
|
edit_type=edit_type,
|
||||||
old_filename=None if diff['old_path'] == diff['new_path'] else diff['old_path']))
|
old_filename=None if diff['old_path'] == diff['new_path'] else diff['old_path'],
|
||||||
|
num_plus_lines=num_plus_lines,
|
||||||
|
num_minus_lines=num_minus_lines, ))
|
||||||
|
|
||||||
self.diff_files = diff_files
|
self.diff_files = diff_files
|
||||||
return diff_files
|
return diff_files
|
||||||
|
|
||||||
@ -136,6 +145,33 @@ class GitLabProvider(GitProvider):
|
|||||||
except Exception as e:
|
except Exception as e:
|
||||||
get_logger().exception(f"Could not update merge request {self.id_mr} description: {e}")
|
get_logger().exception(f"Could not update merge request {self.id_mr} description: {e}")
|
||||||
|
|
||||||
|
def get_latest_commit_url(self):
|
||||||
|
return self.mr.commits().next().web_url
|
||||||
|
|
||||||
|
def get_comment_url(self, comment):
|
||||||
|
return f"{self.mr.web_url}#note_{comment.id}"
|
||||||
|
|
||||||
|
def publish_persistent_comment(self, pr_comment: str, initial_header: str, update_header: bool = True):
|
||||||
|
try:
|
||||||
|
for comment in self.mr.notes.list(get_all=True)[::-1]:
|
||||||
|
if comment.body.startswith(initial_header):
|
||||||
|
latest_commit_url = self.get_latest_commit_url()
|
||||||
|
comment_url = self.get_comment_url(comment)
|
||||||
|
if update_header:
|
||||||
|
updated_header = f"{initial_header}\n\n### (review updated until commit {latest_commit_url})\n"
|
||||||
|
pr_comment_updated = pr_comment.replace(initial_header, updated_header)
|
||||||
|
else:
|
||||||
|
pr_comment_updated = pr_comment
|
||||||
|
get_logger().info(f"Persistent mode- updating comment {comment_url} to latest review message")
|
||||||
|
response = self.mr.notes.update(comment.id, {'body': pr_comment_updated})
|
||||||
|
self.publish_comment(
|
||||||
|
f"**[Persistent review]({comment_url})** updated to latest commit {latest_commit_url}")
|
||||||
|
return
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().exception(f"Failed to update persistent review, error: {e}")
|
||||||
|
pass
|
||||||
|
self.publish_comment(pr_comment)
|
||||||
|
|
||||||
def publish_comment(self, mr_comment: str, is_temporary: bool = False):
|
def publish_comment(self, mr_comment: str, is_temporary: bool = False):
|
||||||
comment = self.mr.notes.create({'body': mr_comment})
|
comment = self.mr.notes.create({'body': mr_comment})
|
||||||
if is_temporary:
|
if is_temporary:
|
||||||
@ -147,7 +183,7 @@ class GitLabProvider(GitProvider):
|
|||||||
self.send_inline_comment(body, edit_type, found, relevant_file, relevant_line_in_file, source_line_no,
|
self.send_inline_comment(body, edit_type, found, relevant_file, relevant_line_in_file, source_line_no,
|
||||||
target_file, target_line_no)
|
target_file, target_line_no)
|
||||||
|
|
||||||
def create_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
def create_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str, absolute_position: int = None):
|
||||||
raise NotImplementedError("Gitlab provider does not support creating inline comments yet")
|
raise NotImplementedError("Gitlab provider does not support creating inline comments yet")
|
||||||
|
|
||||||
def create_inline_comments(self, comments: list[dict]):
|
def create_inline_comments(self, comments: list[dict]):
|
||||||
@ -175,7 +211,11 @@ class GitLabProvider(GitProvider):
|
|||||||
pos_obj['new_line'] = target_line_no - 1
|
pos_obj['new_line'] = target_line_no - 1
|
||||||
pos_obj['old_line'] = source_line_no - 1
|
pos_obj['old_line'] = source_line_no - 1
|
||||||
get_logger().debug(f"Creating comment in {self.id_mr} with body {body} and position {pos_obj}")
|
get_logger().debug(f"Creating comment in {self.id_mr} with body {body} and position {pos_obj}")
|
||||||
self.mr.discussions.create({'body': body, 'position': pos_obj})
|
try:
|
||||||
|
self.mr.discussions.create({'body': body, 'position': pos_obj})
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().debug(
|
||||||
|
f"Failed to create comment in {self.id_mr} with position {pos_obj} (probably not a '+' line)")
|
||||||
|
|
||||||
def get_relevant_diff(self, relevant_file: str, relevant_line_in_file: int) -> Optional[dict]:
|
def get_relevant_diff(self, relevant_file: str, relevant_line_in_file: int) -> Optional[dict]:
|
||||||
changes = self.mr.changes() # Retrieve the changes for the merge request once
|
changes = self.mr.changes() # Retrieve the changes for the merge request once
|
||||||
@ -315,7 +355,7 @@ class GitLabProvider(GitProvider):
|
|||||||
|
|
||||||
def get_repo_settings(self):
|
def get_repo_settings(self):
|
||||||
try:
|
try:
|
||||||
contents = self.gl.projects.get(self.id_project).files.get(file_path='.pr_agent.toml', ref=self.mr.source_branch)
|
contents = self.gl.projects.get(self.id_project).files.get(file_path='.pr_agent.toml', ref=self.mr.target_branch).decode()
|
||||||
return contents
|
return contents
|
||||||
except Exception:
|
except Exception:
|
||||||
return ""
|
return ""
|
||||||
@ -368,9 +408,12 @@ class GitLabProvider(GitProvider):
|
|||||||
def publish_inline_comments(self, comments: list[dict]):
|
def publish_inline_comments(self, comments: list[dict]):
|
||||||
pass
|
pass
|
||||||
|
|
||||||
def get_labels(self):
|
def get_pr_labels(self):
|
||||||
return self.mr.labels
|
return self.mr.labels
|
||||||
|
|
||||||
|
def get_repo_labels(self):
|
||||||
|
return self.gl.projects.get(self.id_project).labels.list()
|
||||||
|
|
||||||
def get_commit_messages(self):
|
def get_commit_messages(self):
|
||||||
"""
|
"""
|
||||||
Retrieves the commit messages of a pull request.
|
Retrieves the commit messages of a pull request.
|
||||||
@ -395,6 +438,16 @@ class GitLabProvider(GitProvider):
|
|||||||
except:
|
except:
|
||||||
return ""
|
return ""
|
||||||
|
|
||||||
|
def get_line_link(self, relevant_file: str, relevant_line_start: int, relevant_line_end: int = None) -> str:
|
||||||
|
if relevant_line_start == -1:
|
||||||
|
link = f"https://gitlab.com/codiumai/pr-agent/-/blob/{self.mr.source_branch}/{relevant_file}?ref_type=heads"
|
||||||
|
elif relevant_line_end:
|
||||||
|
link = f"https://gitlab.com/codiumai/pr-agent/-/blob/{self.mr.source_branch}/{relevant_file}?ref_type=heads#L{relevant_line_start}-L{relevant_line_end}"
|
||||||
|
else:
|
||||||
|
link = f"https://gitlab.com/codiumai/pr-agent/-/blob/{self.mr.source_branch}/{relevant_file}?ref_type=heads#L{relevant_line_start}"
|
||||||
|
return link
|
||||||
|
|
||||||
|
|
||||||
def generate_link_to_relevant_line_number(self, suggestion) -> str:
|
def generate_link_to_relevant_line_number(self, suggestion) -> str:
|
||||||
try:
|
try:
|
||||||
relevant_file = suggestion['relevant file'].strip('`').strip("'")
|
relevant_file = suggestion['relevant file'].strip('`').strip("'")
|
||||||
|
|||||||
@ -121,9 +121,6 @@ class LocalGitProvider(GitProvider):
|
|||||||
def publish_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
def publish_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
||||||
raise NotImplementedError('Publishing inline comments is not implemented for the local git provider')
|
raise NotImplementedError('Publishing inline comments is not implemented for the local git provider')
|
||||||
|
|
||||||
def create_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
|
||||||
raise NotImplementedError('Creating inline comments is not implemented for the local git provider')
|
|
||||||
|
|
||||||
def publish_inline_comments(self, comments: list[dict]):
|
def publish_inline_comments(self, comments: list[dict]):
|
||||||
raise NotImplementedError('Publishing inline comments is not implemented for the local git provider')
|
raise NotImplementedError('Publishing inline comments is not implemented for the local git provider')
|
||||||
|
|
||||||
@ -178,5 +175,5 @@ class LocalGitProvider(GitProvider):
|
|||||||
def get_issue_comments(self):
|
def get_issue_comments(self):
|
||||||
raise NotImplementedError('Getting issue comments is not implemented for the local git provider')
|
raise NotImplementedError('Getting issue comments is not implemented for the local git provider')
|
||||||
|
|
||||||
def get_labels(self):
|
def get_pr_labels(self):
|
||||||
raise NotImplementedError('Getting labels is not implemented for the local git provider')
|
raise NotImplementedError('Getting labels is not implemented for the local git provider')
|
||||||
|
|||||||
@ -27,7 +27,8 @@ def apply_repo_settings(pr_url):
|
|||||||
get_settings().unset(section)
|
get_settings().unset(section)
|
||||||
get_settings().set(section, section_dict, merge=False)
|
get_settings().set(section, section_dict, merge=False)
|
||||||
get_logger().info(f"Applying repo settings for section {section}, contents: {contents}")
|
get_logger().info(f"Applying repo settings for section {section}, contents: {contents}")
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().exception("Failed to apply repo settings", e)
|
||||||
finally:
|
finally:
|
||||||
if repo_settings_file:
|
if repo_settings_file:
|
||||||
try:
|
try:
|
||||||
|
|||||||
@ -16,8 +16,13 @@ from starlette_context.middleware import RawContextMiddleware
|
|||||||
|
|
||||||
from pr_agent.agent.pr_agent import PRAgent
|
from pr_agent.agent.pr_agent import PRAgent
|
||||||
from pr_agent.config_loader import get_settings, global_settings
|
from pr_agent.config_loader import get_settings, global_settings
|
||||||
|
from pr_agent.git_providers.utils import apply_repo_settings
|
||||||
from pr_agent.log import LoggingFormat, get_logger, setup_logger
|
from pr_agent.log import LoggingFormat, get_logger, setup_logger
|
||||||
from pr_agent.secret_providers import get_secret_provider
|
from pr_agent.secret_providers import get_secret_provider
|
||||||
|
from pr_agent.servers.github_action_runner import get_setting_or_env, is_true
|
||||||
|
from pr_agent.tools.pr_code_suggestions import PRCodeSuggestions
|
||||||
|
from pr_agent.tools.pr_description import PRDescription
|
||||||
|
from pr_agent.tools.pr_reviewer import PRReviewer
|
||||||
|
|
||||||
setup_logger(fmt=LoggingFormat.JSON)
|
setup_logger(fmt=LoggingFormat.JSON)
|
||||||
router = APIRouter()
|
router = APIRouter()
|
||||||
@ -89,8 +94,20 @@ async def handle_github_webhooks(background_tasks: BackgroundTasks, request: Req
|
|||||||
pr_url = data["data"]["pullrequest"]["links"]["html"]["href"]
|
pr_url = data["data"]["pullrequest"]["links"]["html"]["href"]
|
||||||
log_context["api_url"] = pr_url
|
log_context["api_url"] = pr_url
|
||||||
log_context["event"] = "pull_request"
|
log_context["event"] = "pull_request"
|
||||||
with get_logger().contextualize(**log_context):
|
if pr_url:
|
||||||
await agent.handle_request(pr_url, "review")
|
with get_logger().contextualize(**log_context):
|
||||||
|
apply_repo_settings(pr_url)
|
||||||
|
auto_review = get_setting_or_env("BITBUCKET_APP.AUTO_REVIEW", None)
|
||||||
|
if auto_review is None or is_true(auto_review): # by default, auto review is enabled
|
||||||
|
await PRReviewer(pr_url).run()
|
||||||
|
auto_improve = get_setting_or_env("BITBUCKET_APP.AUTO_IMPROVE", None)
|
||||||
|
if is_true(auto_improve): # by default, auto improve is disabled
|
||||||
|
await PRCodeSuggestions(pr_url).run()
|
||||||
|
auto_describe = get_setting_or_env("BITBUCKET_APP.AUTO_DESCRIBE", None)
|
||||||
|
if is_true(auto_describe): # by default, auto describe is disabled
|
||||||
|
await PRDescription(pr_url).run()
|
||||||
|
# with get_logger().contextualize(**log_context):
|
||||||
|
# await agent.handle_request(pr_url, "review")
|
||||||
elif event == "pullrequest:comment_created":
|
elif event == "pullrequest:comment_created":
|
||||||
pr_url = data["data"]["pullrequest"]["links"]["html"]["href"]
|
pr_url = data["data"]["pullrequest"]["links"]["html"]["href"]
|
||||||
log_context["api_url"] = pr_url
|
log_context["api_url"] = pr_url
|
||||||
|
|||||||
80
pr_agent/servers/bitbucket_server_webhook.py
Normal file
@ -0,0 +1,80 @@
|
|||||||
|
import json
|
||||||
|
import os
|
||||||
|
|
||||||
|
import uvicorn
|
||||||
|
from fastapi import APIRouter, FastAPI
|
||||||
|
from fastapi.encoders import jsonable_encoder
|
||||||
|
from starlette import status
|
||||||
|
from starlette.background import BackgroundTasks
|
||||||
|
from starlette.middleware import Middleware
|
||||||
|
from starlette.requests import Request
|
||||||
|
from starlette.responses import JSONResponse
|
||||||
|
from starlette_context.middleware import RawContextMiddleware
|
||||||
|
|
||||||
|
from pr_agent.agent.pr_agent import PRAgent
|
||||||
|
from pr_agent.config_loader import get_settings
|
||||||
|
from pr_agent.log import get_logger
|
||||||
|
from pr_agent.servers.utils import verify_signature
|
||||||
|
|
||||||
|
router = APIRouter()
|
||||||
|
|
||||||
|
|
||||||
|
def handle_request(
|
||||||
|
background_tasks: BackgroundTasks, url: str, body: str, log_context: dict
|
||||||
|
):
|
||||||
|
log_context["action"] = body
|
||||||
|
log_context["api_url"] = url
|
||||||
|
with get_logger().contextualize(**log_context):
|
||||||
|
background_tasks.add_task(PRAgent().handle_request, url, body)
|
||||||
|
|
||||||
|
|
||||||
|
@router.post("/")
|
||||||
|
async def handle_webhook(background_tasks: BackgroundTasks, request: Request):
|
||||||
|
log_context = {"server_type": "bitbucket_server"}
|
||||||
|
data = await request.json()
|
||||||
|
get_logger().info(json.dumps(data))
|
||||||
|
|
||||||
|
webhook_secret = get_settings().get("BITBUCKET_SERVER.WEBHOOK_SECRET", None)
|
||||||
|
if webhook_secret:
|
||||||
|
body_bytes = await request.body()
|
||||||
|
signature_header = request.headers.get("x-hub-signature", None)
|
||||||
|
verify_signature(body_bytes, webhook_secret, signature_header)
|
||||||
|
|
||||||
|
pr_id = data["pullRequest"]["id"]
|
||||||
|
repository_name = data["pullRequest"]["toRef"]["repository"]["slug"]
|
||||||
|
project_name = data["pullRequest"]["toRef"]["repository"]["project"]["key"]
|
||||||
|
bitbucket_server = get_settings().get("BITBUCKET_SERVER.URL")
|
||||||
|
pr_url = f"{bitbucket_server}/projects/{project_name}/repos/{repository_name}/pull-requests/{pr_id}"
|
||||||
|
|
||||||
|
log_context["api_url"] = pr_url
|
||||||
|
log_context["event"] = "pull_request"
|
||||||
|
|
||||||
|
if data["eventKey"] == "pr:opened":
|
||||||
|
body = "review"
|
||||||
|
elif data["eventKey"] == "pr:comment:added":
|
||||||
|
body = data["comment"]["text"]
|
||||||
|
else:
|
||||||
|
return JSONResponse(
|
||||||
|
status_code=status.HTTP_400_BAD_REQUEST,
|
||||||
|
content=json.dumps({"message": "Unsupported event"}),
|
||||||
|
)
|
||||||
|
|
||||||
|
handle_request(background_tasks, pr_url, body, log_context)
|
||||||
|
return JSONResponse(
|
||||||
|
status_code=status.HTTP_200_OK, content=jsonable_encoder({"message": "success"})
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
@router.get("/")
|
||||||
|
async def root():
|
||||||
|
return {"status": "ok"}
|
||||||
|
|
||||||
|
|
||||||
|
def start():
|
||||||
|
app = FastAPI(middleware=[Middleware(RawContextMiddleware)])
|
||||||
|
app.include_router(router)
|
||||||
|
uvicorn.run(app, host="0.0.0.0", port=int(os.environ.get("PORT", "3000")))
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
start()
|
||||||
@ -1,6 +1,7 @@
|
|||||||
import asyncio
|
import asyncio
|
||||||
import json
|
import json
|
||||||
import os
|
import os
|
||||||
|
from typing import Union
|
||||||
|
|
||||||
from pr_agent.agent.pr_agent import PRAgent
|
from pr_agent.agent.pr_agent import PRAgent
|
||||||
from pr_agent.config_loader import get_settings
|
from pr_agent.config_loader import get_settings
|
||||||
@ -12,6 +13,22 @@ from pr_agent.tools.pr_description import PRDescription
|
|||||||
from pr_agent.tools.pr_reviewer import PRReviewer
|
from pr_agent.tools.pr_reviewer import PRReviewer
|
||||||
|
|
||||||
|
|
||||||
|
def is_true(value: Union[str, bool]) -> bool:
|
||||||
|
if isinstance(value, bool):
|
||||||
|
return value
|
||||||
|
if isinstance(value, str):
|
||||||
|
return value.lower() == 'true'
|
||||||
|
return False
|
||||||
|
|
||||||
|
|
||||||
|
def get_setting_or_env(key: str, default: Union[str, bool] = None) -> Union[str, bool]:
|
||||||
|
try:
|
||||||
|
value = get_settings().get(key, default)
|
||||||
|
except AttributeError: # TBD still need to debug why this happens on GitHub Actions
|
||||||
|
value = os.getenv(key, None) or os.getenv(key.upper(), None) or os.getenv(key.lower(), None) or default
|
||||||
|
return value
|
||||||
|
|
||||||
|
|
||||||
async def run_action():
|
async def run_action():
|
||||||
# Get environment variables
|
# Get environment variables
|
||||||
GITHUB_EVENT_NAME = os.environ.get('GITHUB_EVENT_NAME')
|
GITHUB_EVENT_NAME = os.environ.get('GITHUB_EVENT_NAME')
|
||||||
@ -65,14 +82,14 @@ async def run_action():
|
|||||||
if action in ["opened", "reopened"]:
|
if action in ["opened", "reopened"]:
|
||||||
pr_url = event_payload.get("pull_request", {}).get("url")
|
pr_url = event_payload.get("pull_request", {}).get("url")
|
||||||
if pr_url:
|
if pr_url:
|
||||||
auto_review = os.environ.get('github_action.auto_review', None)
|
auto_review = get_setting_or_env("GITHUB_ACTION.AUTO_REVIEW", None)
|
||||||
if auto_review is None or (isinstance(auto_review, str) and auto_review.lower() == 'true'):
|
if auto_review is None or is_true(auto_review):
|
||||||
await PRReviewer(pr_url).run()
|
await PRReviewer(pr_url).run()
|
||||||
auto_describe = os.environ.get('github_action.auto_describe', None)
|
auto_describe = get_setting_or_env("GITHUB_ACTION.AUTO_DESCRIBE", None)
|
||||||
if isinstance(auto_describe, str) and auto_describe.lower() == 'true':
|
if is_true(auto_describe):
|
||||||
await PRDescription(pr_url).run()
|
await PRDescription(pr_url).run()
|
||||||
auto_improve = os.environ.get('github_action.auto_improve', None)
|
auto_improve = get_setting_or_env("GITHUB_ACTION.AUTO_IMPROVE", None)
|
||||||
if isinstance(auto_improve, str) and auto_improve.lower() == 'true':
|
if is_true(auto_improve):
|
||||||
await PRCodeSuggestions(pr_url).run()
|
await PRCodeSuggestions(pr_url).run()
|
||||||
|
|
||||||
# Handle issue comment event
|
# Handle issue comment event
|
||||||
@ -99,4 +116,4 @@ async def run_action():
|
|||||||
|
|
||||||
|
|
||||||
if __name__ == '__main__':
|
if __name__ == '__main__':
|
||||||
asyncio.run(run_action())
|
asyncio.run(run_action())
|
||||||
|
|||||||
@ -122,14 +122,18 @@ async def handle_request(body: Dict[str, Any], event: str):
|
|||||||
if body.get("requested_reviewer", {}).get("login", "") != bot_user:
|
if body.get("requested_reviewer", {}).get("login", "") != bot_user:
|
||||||
return {}
|
return {}
|
||||||
get_logger().info(f"Performing review for {api_url=} because of {event=} and {action=}")
|
get_logger().info(f"Performing review for {api_url=} because of {event=} and {action=}")
|
||||||
await _perform_commands(get_settings().github_app.pr_commands, agent, body, api_url, log_context)
|
await _perform_commands("pr_commands", agent, body, api_url, log_context)
|
||||||
|
|
||||||
# handle pull_request event with synchronize action - "push trigger" for new commits
|
# handle pull_request event with synchronize action - "push trigger" for new commits
|
||||||
elif event == 'pull_request' and action == 'synchronize' and get_settings().github_app.handle_push_trigger:
|
elif event == 'pull_request' and action == 'synchronize':
|
||||||
pull_request, api_url = _check_pull_request_event(action, body, log_context, bot_user)
|
pull_request, api_url = _check_pull_request_event(action, body, log_context, bot_user)
|
||||||
if not (pull_request and api_url):
|
if not (pull_request and api_url):
|
||||||
return {}
|
return {}
|
||||||
|
|
||||||
|
apply_repo_settings(api_url)
|
||||||
|
if not get_settings().github_app.handle_push_trigger:
|
||||||
|
return {}
|
||||||
|
|
||||||
# TODO: do we still want to get the list of commits to filter bot/merge commits?
|
# TODO: do we still want to get the list of commits to filter bot/merge commits?
|
||||||
before_sha = body.get("before")
|
before_sha = body.get("before")
|
||||||
after_sha = body.get("after")
|
after_sha = body.get("after")
|
||||||
@ -174,7 +178,7 @@ async def handle_request(body: Dict[str, Any], event: str):
|
|||||||
get_logger().info(f"Skipping incremental review because there was no initial review for {api_url=} yet")
|
get_logger().info(f"Skipping incremental review because there was no initial review for {api_url=} yet")
|
||||||
return {}
|
return {}
|
||||||
get_logger().info(f"Performing incremental review for {api_url=} because of {event=} and {action=}")
|
get_logger().info(f"Performing incremental review for {api_url=} because of {event=} and {action=}")
|
||||||
await _perform_commands(get_settings().github_app.push_commands, agent, body, api_url, log_context)
|
await _perform_commands("push_commands", agent, body, api_url, log_context)
|
||||||
|
|
||||||
finally:
|
finally:
|
||||||
# release the waiting task block
|
# release the waiting task block
|
||||||
@ -203,8 +207,9 @@ def _check_pull_request_event(action: str, body: dict, log_context: dict, bot_us
|
|||||||
return pull_request, api_url
|
return pull_request, api_url
|
||||||
|
|
||||||
|
|
||||||
async def _perform_commands(commands: List[str], agent: PRAgent, body: dict, api_url: str, log_context: dict):
|
async def _perform_commands(commands_conf: str, agent: PRAgent, body: dict, api_url: str, log_context: dict):
|
||||||
apply_repo_settings(api_url)
|
apply_repo_settings(api_url)
|
||||||
|
commands = get_settings().get(f"github_app.{commands_conf}")
|
||||||
for command in commands:
|
for command in commands:
|
||||||
split_command = command.split(" ")
|
split_command = command.split(" ")
|
||||||
command = split_command[0]
|
command = split_command[0]
|
||||||
|
|||||||
@ -38,7 +38,7 @@ async def gitlab_webhook(background_tasks: BackgroundTasks, request: Request):
|
|||||||
try:
|
try:
|
||||||
secret_dict = json.loads(secret)
|
secret_dict = json.loads(secret)
|
||||||
gitlab_token = secret_dict["gitlab_token"]
|
gitlab_token = secret_dict["gitlab_token"]
|
||||||
log_context["sender"] = secret_dict["id"]
|
log_context["sender"] = secret_dict.get("token_name", secret_dict.get("id", "unknown"))
|
||||||
context["settings"] = copy.deepcopy(global_settings)
|
context["settings"] = copy.deepcopy(global_settings)
|
||||||
context["settings"].gitlab.personal_access_token = gitlab_token
|
context["settings"].gitlab.personal_access_token = gitlab_token
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
@ -58,13 +58,13 @@ async def gitlab_webhook(background_tasks: BackgroundTasks, request: Request):
|
|||||||
if data.get('object_kind') == 'merge_request' and data['object_attributes'].get('action') in ['open', 'reopen']:
|
if data.get('object_kind') == 'merge_request' and data['object_attributes'].get('action') in ['open', 'reopen']:
|
||||||
get_logger().info(f"A merge request has been opened: {data['object_attributes'].get('title')}")
|
get_logger().info(f"A merge request has been opened: {data['object_attributes'].get('title')}")
|
||||||
url = data['object_attributes'].get('url')
|
url = data['object_attributes'].get('url')
|
||||||
handle_request(background_tasks, url, "/review")
|
handle_request(background_tasks, url, "/review", log_context)
|
||||||
elif data.get('object_kind') == 'note' and data['event_type'] == 'note':
|
elif data.get('object_kind') == 'note' and data['event_type'] == 'note':
|
||||||
if 'merge_request' in data:
|
if 'merge_request' in data:
|
||||||
mr = data['merge_request']
|
mr = data['merge_request']
|
||||||
url = mr.get('url')
|
url = mr.get('url')
|
||||||
body = data.get('object_attributes', {}).get('note')
|
body = data.get('object_attributes', {}).get('note')
|
||||||
handle_request(background_tasks, url, body)
|
handle_request(background_tasks, url, body, log_context)
|
||||||
return JSONResponse(status_code=status.HTTP_200_OK, content=jsonable_encoder({"message": "success"}))
|
return JSONResponse(status_code=status.HTTP_200_OK, content=jsonable_encoder({"message": "success"}))
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
@ -1,17 +1,20 @@
|
|||||||
commands_text = "> **/review [-i]**: Request a review of your Pull Request. For an incremental review, which only " \
|
commands_text = "> - **/review**: Request a review of your Pull Request. \n" \
|
||||||
"considers changes since the last review, include the '-i' option.\n" \
|
"> - **/describe**: Update the PR title and description based on the contents of the PR. \n" \
|
||||||
"> **/describe**: Modify the PR title and description based on the contents of the PR.\n" \
|
"> - **/improve [--extended]**: Suggest code improvements. Extended mode provides a higher quality feedback. \n" \
|
||||||
"> **/improve [--extended]**: Suggest improvements to the code in the PR. Extended mode employs several calls, and provides a more thorough feedback. \n" \
|
"> - **/ask \\<QUESTION\\>**: Ask a question about the PR. \n" \
|
||||||
"> **/ask \\<QUESTION\\>**: Pose a question about the PR.\n" \
|
"> - **/update_changelog**: Update the changelog based on the PR's contents. \n" \
|
||||||
"> **/update_changelog**: Update the changelog based on the PR's contents.\n\n" \
|
"> - **/add_docs** 💎: Generate docstring for new components introduced in the PR. \n" \
|
||||||
">To edit any configuration parameter from **configuration.toml**, add --config_path=new_value\n" \
|
"> - **/generate_labels** 💎: Generate labels for the PR based on the PR's contents. \n" \
|
||||||
">For example: /review --pr_reviewer.extra_instructions=\"focus on the file: ...\" \n" \
|
"> - **/analyze** 💎: Automatically analyzes the PR, and presents changes walkthrough for each component. \n\n" \
|
||||||
">To list the possible configuration parameters, use the **/config** command.\n" \
|
">See the [tools guide](https://github.com/Codium-ai/pr-agent/blob/main/docs/TOOLS_GUIDE.md) for more details.\n" \
|
||||||
|
">To edit any configuration parameter from the [configuration.toml](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml), add --config_path=new_value. \n" \
|
||||||
|
">For example: /review --pr_reviewer.extra_instructions=\"focus on the file: ...\" \n" \
|
||||||
|
">To list the possible configuration parameters, add a **/config** comment. \n" \
|
||||||
|
|
||||||
|
|
||||||
def bot_help_text(user: str):
|
def bot_help_text(user: str):
|
||||||
return f"> Tag me in a comment '@{user}' and add one of the following commands:\n" + commands_text
|
return f"> Tag me in a comment '@{user}' and add one of the following commands: \n" + commands_text
|
||||||
|
|
||||||
|
|
||||||
actions_help_text = "> To invoke the PR-Agent, add a comment using one of the following commands:\n" + \
|
actions_help_text = "> To invoke the PR-Agent, add a comment using one of the following commands: \n" + \
|
||||||
commands_text
|
commands_text
|
||||||
|
|||||||
@ -1,12 +1,13 @@
|
|||||||
from fastapi import FastAPI
|
from fastapi import FastAPI
|
||||||
from mangum import Mangum
|
from mangum import Mangum
|
||||||
|
from starlette.middleware import Middleware
|
||||||
|
from starlette_context.middleware import RawContextMiddleware
|
||||||
|
|
||||||
from pr_agent.log import setup_logger
|
|
||||||
from pr_agent.servers.github_app import router
|
from pr_agent.servers.github_app import router
|
||||||
|
|
||||||
setup_logger()
|
|
||||||
|
|
||||||
app = FastAPI()
|
middleware = [Middleware(RawContextMiddleware)]
|
||||||
|
app = FastAPI(middleware=middleware)
|
||||||
app.include_router(router)
|
app.include_router(router)
|
||||||
|
|
||||||
handler = Mangum(app, lifespan="off")
|
handler = Mangum(app, lifespan="off")
|
||||||
|
|||||||
@ -34,7 +34,14 @@ key = "" # Optional, uncomment if you want to use Huggingface Inference API. Acq
|
|||||||
api_base = "" # the base url for your huggingface inference endpoint
|
api_base = "" # the base url for your huggingface inference endpoint
|
||||||
|
|
||||||
[ollama]
|
[ollama]
|
||||||
api_base = "" # the base url for your huggingface inference endpoint
|
api_base = "" # the base url for your local Llama 2, Code Llama, and other models inference endpoint. Acquire through https://ollama.ai/
|
||||||
|
|
||||||
|
[vertexai]
|
||||||
|
vertex_project = "" # the google cloud platform project name for your vertexai deployment
|
||||||
|
vertex_location = "" # the google cloud platform location for your vertexai deployment
|
||||||
|
|
||||||
|
[aws]
|
||||||
|
bedrock_region = "" # the AWS region to call Bedrock APIs
|
||||||
|
|
||||||
[github]
|
[github]
|
||||||
# ---- Set the following only for deployment type == "user"
|
# ---- Set the following only for deployment type == "user"
|
||||||
@ -58,6 +65,11 @@ personal_access_token = ""
|
|||||||
# For Bitbucket personal/repository bearer token
|
# For Bitbucket personal/repository bearer token
|
||||||
bearer_token = ""
|
bearer_token = ""
|
||||||
|
|
||||||
|
[bitbucket_server]
|
||||||
|
# For Bitbucket Server bearer token
|
||||||
|
auth_token = ""
|
||||||
|
webhook_secret = ""
|
||||||
|
|
||||||
# For Bitbucket app
|
# For Bitbucket app
|
||||||
app_key = ""
|
app_key = ""
|
||||||
base_url = ""
|
base_url = ""
|
||||||
|
|||||||
@ -1,5 +1,5 @@
|
|||||||
[config]
|
[config]
|
||||||
model="gpt-4"
|
model="gpt-4" # "gpt-4-1106-preview"
|
||||||
fallback_models=["gpt-3.5-turbo-16k"]
|
fallback_models=["gpt-3.5-turbo-16k"]
|
||||||
git_provider="github"
|
git_provider="github"
|
||||||
publish_output=true
|
publish_output=true
|
||||||
@ -7,25 +7,41 @@ publish_output_progress=true
|
|||||||
verbosity_level=0 # 0,1,2
|
verbosity_level=0 # 0,1,2
|
||||||
use_extra_bad_extensions=false
|
use_extra_bad_extensions=false
|
||||||
use_repo_settings_file=true
|
use_repo_settings_file=true
|
||||||
|
use_global_settings_file=true
|
||||||
ai_timeout=180
|
ai_timeout=180
|
||||||
max_description_tokens = 500
|
max_description_tokens = 500
|
||||||
max_commits_tokens = 500
|
max_commits_tokens = 500
|
||||||
|
max_model_tokens = 32000 # Limits the maximum number of tokens that can be used by any model, regardless of the model's default capabilities.
|
||||||
patch_extra_lines = 3
|
patch_extra_lines = 3
|
||||||
secret_provider="google_cloud_storage"
|
secret_provider="google_cloud_storage"
|
||||||
cli_mode=false
|
cli_mode=false
|
||||||
|
|
||||||
[pr_reviewer] # /review #
|
[pr_reviewer] # /review #
|
||||||
|
# enable/disable features
|
||||||
require_focused_review=false
|
require_focused_review=false
|
||||||
require_score_review=false
|
require_score_review=false
|
||||||
require_tests_review=true
|
require_tests_review=true
|
||||||
require_security_review=true
|
require_security_review=true
|
||||||
require_estimate_effort_to_review=true
|
require_estimate_effort_to_review=true
|
||||||
|
# soc2
|
||||||
|
require_soc2_ticket=false
|
||||||
|
soc2_ticket_prompt="Does the PR description include a link to ticket in a project management system (e.g., Jira, Asana, Trello, etc.) ?"
|
||||||
|
# general options
|
||||||
num_code_suggestions=4
|
num_code_suggestions=4
|
||||||
inline_code_comments = false
|
inline_code_comments = false
|
||||||
ask_and_reflect=false
|
ask_and_reflect=false
|
||||||
automatic_review=true
|
#automatic_review=true
|
||||||
remove_previous_review_comment=false
|
remove_previous_review_comment=false
|
||||||
|
persistent_comment=true
|
||||||
extra_instructions = ""
|
extra_instructions = ""
|
||||||
|
# review labels
|
||||||
|
enable_review_labels_security=true
|
||||||
|
enable_review_labels_effort=false
|
||||||
|
# specific configurations for incremental review (/review -i)
|
||||||
|
require_all_thresholds_for_incremental_review=false
|
||||||
|
minimal_commits_for_incremental_review=0
|
||||||
|
minimal_minutes_for_incremental_review=0
|
||||||
|
enable_help_text=true # Determines whether to include help text in the PR review. Enabled by default.
|
||||||
|
|
||||||
[pr_description] # /describe #
|
[pr_description] # /describe #
|
||||||
publish_labels=true
|
publish_labels=true
|
||||||
@ -34,20 +50,27 @@ add_original_user_description=false
|
|||||||
keep_original_user_title=false
|
keep_original_user_title=false
|
||||||
use_bullet_points=true
|
use_bullet_points=true
|
||||||
extra_instructions = ""
|
extra_instructions = ""
|
||||||
|
enable_pr_type=true
|
||||||
|
final_update_message = true
|
||||||
|
## changes walkthrough section
|
||||||
|
enable_semantic_files_types=true
|
||||||
|
collapsible_file_list='adaptive' # true, false, 'adaptive'
|
||||||
# markers
|
# markers
|
||||||
use_description_markers=false
|
use_description_markers=false
|
||||||
include_generated_by_header=true
|
include_generated_by_header=true
|
||||||
|
|
||||||
#custom_labels = ['Bug fix', 'Tests', 'Bug fix with tests', 'Refactoring', 'Enhancement', 'Documentation', 'Other']
|
#custom_labels = ['Bug fix', 'Tests', 'Bug fix with tests', 'Enhancement', 'Documentation', 'Other']
|
||||||
|
|
||||||
[pr_questions] # /ask #
|
[pr_questions] # /ask #
|
||||||
|
|
||||||
[pr_code_suggestions] # /improve #
|
[pr_code_suggestions] # /improve #
|
||||||
num_code_suggestions=4
|
num_code_suggestions=4
|
||||||
|
summarize = false
|
||||||
|
include_improved_code = true
|
||||||
extra_instructions = ""
|
extra_instructions = ""
|
||||||
rank_suggestions = false
|
rank_suggestions = false
|
||||||
# params for '/improve --extended' mode
|
# params for '/improve --extended' mode
|
||||||
|
auto_extended_mode=false
|
||||||
num_code_suggestions_per_chunk=8
|
num_code_suggestions_per_chunk=8
|
||||||
rank_extended_suggestions = true
|
rank_extended_suggestions = true
|
||||||
max_number_of_calls = 5
|
max_number_of_calls = 5
|
||||||
@ -61,12 +84,15 @@ docs_style = "Sphinx Style" # "Google Style with Args, Returns, Attributes...etc
|
|||||||
push_changelog_changes=false
|
push_changelog_changes=false
|
||||||
extra_instructions = ""
|
extra_instructions = ""
|
||||||
|
|
||||||
|
[pr_analyze] # /analyze #
|
||||||
|
|
||||||
[pr_config] # /config #
|
[pr_config] # /config #
|
||||||
|
|
||||||
[github]
|
[github]
|
||||||
# The type of deployment to create. Valid values are 'app' or 'user'.
|
# The type of deployment to create. Valid values are 'app' or 'user'.
|
||||||
deployment_type = "user"
|
deployment_type = "user"
|
||||||
ratelimit_retries = 5
|
ratelimit_retries = 5
|
||||||
|
base_url = "https://api.github.com"
|
||||||
|
|
||||||
[github_action]
|
[github_action]
|
||||||
# auto_review = true # set as env var in .github/workflows/pr-agent.yaml
|
# auto_review = true # set as env var in .github/workflows/pr-agent.yaml
|
||||||
@ -85,7 +111,7 @@ duplicate_requests_cache_ttl = 60 # in seconds
|
|||||||
handle_pr_actions = ['opened', 'reopened', 'ready_for_review', 'review_requested']
|
handle_pr_actions = ['opened', 'reopened', 'ready_for_review', 'review_requested']
|
||||||
pr_commands = [
|
pr_commands = [
|
||||||
"/describe --pr_description.add_original_user_description=true --pr_description.keep_original_user_title=true",
|
"/describe --pr_description.add_original_user_description=true --pr_description.keep_original_user_title=true",
|
||||||
"/auto_review",
|
"/review",
|
||||||
]
|
]
|
||||||
# settings for "pull_request" event with "synchronize" action - used to detect and handle push triggers for new commits
|
# settings for "pull_request" event with "synchronize" action - used to detect and handle push triggers for new commits
|
||||||
handle_push_trigger = false
|
handle_push_trigger = false
|
||||||
@ -105,6 +131,9 @@ push_commands = [
|
|||||||
--pr_reviewer.num_code_suggestions=0 \
|
--pr_reviewer.num_code_suggestions=0 \
|
||||||
--pr_reviewer.inline_code_comments=false \
|
--pr_reviewer.inline_code_comments=false \
|
||||||
--pr_reviewer.remove_previous_review_comment=true \
|
--pr_reviewer.remove_previous_review_comment=true \
|
||||||
|
--pr_reviewer.require_all_thresholds_for_incremental_review=false \
|
||||||
|
--pr_reviewer.minimal_commits_for_incremental_review=5 \
|
||||||
|
--pr_reviewer.minimal_minutes_for_incremental_review=30 \
|
||||||
--pr_reviewer.extra_instructions='' \
|
--pr_reviewer.extra_instructions='' \
|
||||||
"""
|
"""
|
||||||
]
|
]
|
||||||
@ -122,6 +151,12 @@ magic_word = "AutoReview"
|
|||||||
# Polling interval
|
# Polling interval
|
||||||
polling_interval_seconds = 30
|
polling_interval_seconds = 30
|
||||||
|
|
||||||
|
[bitbucket_app]
|
||||||
|
#auto_review = true # set as config var in .pr_agent.toml
|
||||||
|
#auto_describe = true # set as config var in .pr_agent.toml
|
||||||
|
#auto_improve = true # set as config var in .pr_agent.toml
|
||||||
|
|
||||||
|
|
||||||
[local]
|
[local]
|
||||||
# LocalGitProvider settings - uncomment to use paths other than default
|
# LocalGitProvider settings - uncomment to use paths other than default
|
||||||
# description_path= "path/to/description.md"
|
# description_path= "path/to/description.md"
|
||||||
@ -137,6 +172,11 @@ polling_interval_seconds = 30
|
|||||||
# token to authenticate in the patch server
|
# token to authenticate in the patch server
|
||||||
# patch_server_token = ""
|
# patch_server_token = ""
|
||||||
|
|
||||||
|
[bitbucket_server]
|
||||||
|
# URL to the BitBucket Server instance
|
||||||
|
# url = "https://git.bitbucket.com"
|
||||||
|
url = ""
|
||||||
|
|
||||||
[litellm]
|
[litellm]
|
||||||
#use_client = false
|
#use_client = false
|
||||||
|
|
||||||
@ -144,8 +184,12 @@ polling_interval_seconds = 30
|
|||||||
skip_comments = false
|
skip_comments = false
|
||||||
force_update_dataset = false
|
force_update_dataset = false
|
||||||
max_issues_to_scan = 500
|
max_issues_to_scan = 500
|
||||||
|
vectordb = "pinecone"
|
||||||
|
|
||||||
[pinecone]
|
[pinecone]
|
||||||
# fill and place in .secrets.toml
|
# fill and place in .secrets.toml
|
||||||
#api_key = ...
|
#api_key = ...
|
||||||
# environment = "gcp-starter"
|
# environment = "gcp-starter"
|
||||||
|
|
||||||
|
[lancedb]
|
||||||
|
uri = "./lancedb"
|
||||||
@ -3,16 +3,14 @@ enable_custom_labels=false
|
|||||||
|
|
||||||
## template for custom labels
|
## template for custom labels
|
||||||
#[custom_labels."Bug fix"]
|
#[custom_labels."Bug fix"]
|
||||||
#description = "Fixes a bug in the code"
|
#description = """Fixes a bug in the code"""
|
||||||
#[custom_labels."Tests"]
|
#[custom_labels."Tests"]
|
||||||
#description = "Adds or modifies tests"
|
#description = """Adds or modifies tests"""
|
||||||
#[custom_labels."Bug fix with tests"]
|
#[custom_labels."Bug fix with tests"]
|
||||||
#description = "Fixes a bug in the code and adds or modifies tests"
|
#description = """Fixes a bug in the code and adds or modifies tests"""
|
||||||
#[custom_labels."Refactoring"]
|
|
||||||
#description = "Code refactoring without changing functionality"
|
|
||||||
#[custom_labels."Enhancement"]
|
#[custom_labels."Enhancement"]
|
||||||
#description = "Adds new features or functionality"
|
#description = """Adds new features or modifies existing ones"""
|
||||||
#[custom_labels."Documentation"]
|
#[custom_labels."Documentation"]
|
||||||
#description = "Adds or modifies documentation"
|
#description = """Adds or modifies documentation"""
|
||||||
#[custom_labels."Other"]
|
#[custom_labels."Other"]
|
||||||
#description = "Other changes that do not fit in any of the above categories"
|
#description = """Other changes that do not fit in any of the above categories"""
|
||||||
@ -1,22 +1,22 @@
|
|||||||
[pr_add_docs_prompt]
|
[pr_add_docs_prompt]
|
||||||
system="""You are a language model called PR-Code-Documentation Agent, that specializes in generating documentation for code.
|
system="""You are PR-Doc, a language model that specializes in generating documentation for code components in a Pull Request (PR).
|
||||||
Your task is to generate meaningfull {{ docs_for_language }} to a PR (the '+' lines).
|
Your task is to generate {{ docs_for_language }} for code components in the PR Diff.
|
||||||
|
|
||||||
Example for a PR Diff input:
|
|
||||||
'
|
Example for the PR Diff format:
|
||||||
|
======
|
||||||
## src/file1.py
|
## src/file1.py
|
||||||
|
|
||||||
@@ -12,3 +12,5 @@ def func1():
|
@@ -12,3 +12,4 @@ def func1():
|
||||||
__new hunk__
|
__new hunk__
|
||||||
12 code line that already existed in the file...
|
12 code line1 that remained unchanged in the PR
|
||||||
13 code line that already existed in the file....
|
|
||||||
14 +new code line1 added in the PR
|
14 +new code line1 added in the PR
|
||||||
15 +new code line2 added in the PR
|
15 +new code line2 added in the PR
|
||||||
16 code line that already existed in the file...
|
16 code line2 that remained unchanged in the PR
|
||||||
__old hunk__
|
__old hunk__
|
||||||
code line that already existed in the file...
|
code line1 that remained unchanged in the PR
|
||||||
-code line that was removed in the PR
|
-code line that was removed in the PR
|
||||||
code line that already existed in the file...
|
code line2 that remained unchanged in the PR
|
||||||
|
|
||||||
|
|
||||||
@@ ... @@ def func2():
|
@@ ... @@ def func2():
|
||||||
@ -28,13 +28,14 @@ __old hunk__
|
|||||||
|
|
||||||
## src/file2.py
|
## src/file2.py
|
||||||
...
|
...
|
||||||
'
|
======
|
||||||
|
|
||||||
|
|
||||||
Specific instructions:
|
Specific instructions:
|
||||||
- Try to identify edited/added code components (classes/functions/methods...) that are undocumented. and generate {{ docs_for_language }} for each one.
|
- Try to identify edited/added code components (classes/functions/methods...) that are undocumented, and generate {{ docs_for_language }} for each one.
|
||||||
- If there are documented (any type of {{ language }} documentation) code components in the PR, Don't generate {{ docs_for_language }} for them.
|
- If there are documented (any type of {{ language }} documentation) code components in the PR, Don't generate {{ docs_for_language }} for them.
|
||||||
- Ignore code components that don't appear fully in the '__new hunk__' section. For example. you must see the component header and body,
|
- Ignore code components that don't appear fully in the '__new hunk__' section. For example, you must see the component header and body.
|
||||||
- Make sure the {{ docs_for_language }} starts and ends with standart {{ language }} {{ docs_for_language }} signs.
|
- Make sure the {{ docs_for_language }} starts and ends with standard {{ language }} {{ docs_for_language }} signs.
|
||||||
- The {{ docs_for_language }} should be in standard format.
|
- The {{ docs_for_language }} should be in standard format.
|
||||||
- Provide the exact line number (inclusive) where the {{ docs_for_language }} should be added.
|
- Provide the exact line number (inclusive) where the {{ docs_for_language }} should be added.
|
||||||
|
|
||||||
@ -42,11 +43,12 @@ Specific instructions:
|
|||||||
{%- if extra_instructions %}
|
{%- if extra_instructions %}
|
||||||
|
|
||||||
Extra instructions from the user:
|
Extra instructions from the user:
|
||||||
'
|
======
|
||||||
{{ extra_instructions }}
|
{{ extra_instructions }}
|
||||||
'
|
======
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
|
|
||||||
|
|
||||||
You must use the following YAML schema to format your answer:
|
You must use the following YAML schema to format your answer:
|
||||||
```yaml
|
```yaml
|
||||||
Code Documentation:
|
Code Documentation:
|
||||||
@ -67,6 +69,7 @@ Code Documentation:
|
|||||||
- after
|
- after
|
||||||
description: |-
|
description: |-
|
||||||
The {{ docs_for_language }} placement relative to the relevant line (code component).
|
The {{ docs_for_language }} placement relative to the relevant line (code component).
|
||||||
|
For example, in Python the docs are placed after the function signature, but in Java they are placed before.
|
||||||
documentation:
|
documentation:
|
||||||
type: string
|
type: string
|
||||||
description: |-
|
description: |-
|
||||||
@ -99,18 +102,25 @@ Title: '{{ title }}'
|
|||||||
|
|
||||||
Branch: '{{ branch }}'
|
Branch: '{{ branch }}'
|
||||||
|
|
||||||
Description: '{{description}}'
|
{%- if description %}
|
||||||
|
|
||||||
|
Description:
|
||||||
|
======
|
||||||
|
{{ description|trim }}
|
||||||
|
======
|
||||||
|
{%- endif %}
|
||||||
|
|
||||||
{%- if language %}
|
{%- if language %}
|
||||||
|
|
||||||
Main language: {{language}}
|
Main PR language: '{{language}}'
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
|
|
||||||
|
|
||||||
The PR Diff:
|
The PR Diff:
|
||||||
```
|
======
|
||||||
{{- diff|trim }}
|
{{ diff|trim }}
|
||||||
```
|
======
|
||||||
|
|
||||||
|
|
||||||
Response (should be a valid YAML, and nothing else):
|
Response (should be a valid YAML, and nothing else):
|
||||||
```yaml
|
```yaml
|
||||||
|
|||||||
@ -1,22 +1,21 @@
|
|||||||
[pr_code_suggestions_prompt]
|
[pr_code_suggestions_prompt]
|
||||||
system="""You are a language model called PR-Code-Reviewer, that specializes in suggesting code improvements for Pull Request (PR).
|
system="""You are PR-Reviewer, a language model that specializes in suggesting code improvements for a Pull Request (PR).
|
||||||
Your task is to provide meaningful and actionable code suggestions, to improve the new code presented in a PR (the '+' lines in the diff).
|
Your task is to provide meaningful and actionable code suggestions, to improve the new code presented in a PR diff (lines starting with '+').
|
||||||
|
|
||||||
Example for a PR Diff input:
|
Example for the PR Diff format:
|
||||||
'
|
======
|
||||||
## src/file1.py
|
## src/file1.py
|
||||||
|
|
||||||
@@ -12,3 +12,5 @@ def func1():
|
@@ -12,3 +12,4 @@ def func1():
|
||||||
__new hunk__
|
__new hunk__
|
||||||
12 code line that already existed in the file...
|
12 code line1 that remained unchanged in the PR
|
||||||
13 code line that already existed in the file....
|
|
||||||
14 +new code line1 added in the PR
|
14 +new code line1 added in the PR
|
||||||
15 +new code line2 added in the PR
|
15 +new code line2 added in the PR
|
||||||
16 code line that already existed in the file...
|
16 code line2 that remained unchanged in the PR
|
||||||
__old hunk__
|
__old hunk__
|
||||||
code line that already existed in the file...
|
code line1 that remained unchanged in the PR
|
||||||
-code line that was removed in the PR
|
-code line that was removed in the PR
|
||||||
code line that already existed in the file...
|
code line2 that remained unchanged in the PR
|
||||||
|
|
||||||
|
|
||||||
@@ ... @@ def func2():
|
@@ ... @@ def func2():
|
||||||
@ -28,83 +27,63 @@ __old hunk__
|
|||||||
|
|
||||||
## src/file2.py
|
## src/file2.py
|
||||||
...
|
...
|
||||||
'
|
======
|
||||||
|
|
||||||
|
|
||||||
Specific instructions:
|
Specific instructions:
|
||||||
- Provide up to {{ num_code_suggestions }} code suggestions. Try to provide diverse and insightful suggestions.
|
- Provide up to {{ num_code_suggestions }} code suggestions. Try to provide diverse and insightful suggestions.
|
||||||
- Prioritize suggestions that address major problems, issues and bugs in the code.
|
- Prioritize suggestions that address major problems, issues and bugs in the code. As a second priority, suggestions should focus on enhancement, best practice, performance, maintainability, and other aspects.
|
||||||
As a second priority, suggestions should focus on best practices, code readability, maintainability, enhancments, performance, and other aspects.
|
|
||||||
- Don't suggest to add docstring, type hints, or comments.
|
- Don't suggest to add docstring, type hints, or comments.
|
||||||
- Suggestions should refer only to code from the '__new hunk__' sections, and focus on new lines of code (lines starting with '+').
|
- Suggestions should refer only to code from the '__new hunk__' sections, and focus on new lines of code (lines starting with '+').
|
||||||
- Avoid making suggestions that have already been implemented in the PR code. For example, if you want to add logs, or change a variable to const, or anything else, make sure it isn't already in the '__new hunk__' code.
|
- Avoid making suggestions that have already been implemented in the PR code. For example, if you want to add logs, or change a variable to const, or anything else, make sure it isn't already in the '__new hunk__' code.
|
||||||
- For each suggestion, make sure to take into consideration also the context, meaning the lines before and after the relevant code.
|
- Provide the exact line numbers range (inclusive) for each suggestion.
|
||||||
- Provide the exact line numbers range (inclusive) for each issue.
|
|
||||||
- Assume there is additional relevant code, that is not included in the diff.
|
- Assume there is additional relevant code, that is not included in the diff.
|
||||||
|
- When quoting variables or names from the code, use backticks (`) instead of single quote (').
|
||||||
|
|
||||||
|
|
||||||
{%- if extra_instructions %}
|
{%- if extra_instructions %}
|
||||||
|
|
||||||
Extra instructions from the user:
|
Extra instructions from the user:
|
||||||
'
|
======
|
||||||
{{ extra_instructions }}
|
{{ extra_instructions }}
|
||||||
'
|
======
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
|
|
||||||
You must use the following YAML schema to format your answer:
|
The output must be a YAML object equivalent to type PRCodeSuggestions, according to the following Pydantic definitions:
|
||||||
```yaml
|
=====
|
||||||
Code suggestions:
|
class CodeSuggestion(BaseModel):
|
||||||
type: array
|
relevant_file: str = Field(description="the relevant file full path")
|
||||||
minItems: 1
|
suggestion_content: str = Field(description="an actionable suggestion for meaningfully improving the new code introduced in the PR")
|
||||||
maxItems: {{ num_code_suggestions }}
|
existing_code: str = Field(description="a code snippet, showing the relevant code lines from a '__new hunk__' section. It must be contiguous, correctly formatted and indented, and without line numbers")
|
||||||
uniqueItems: true
|
relevant_lines_start: int = Field(description="The relevant line number, from a '__new hunk__' section, where the suggestion starts (inclusive). Should be derived from the hunk line numbers, and correspond to the 'existing code' snippet above")
|
||||||
items:
|
relevant_lines_end: int = Field(description="The relevant line number, from a '__new hunk__' section, where the suggestion ends (inclusive). Should be derived from the hunk line numbers, and correspond to the 'existing code' snippet above")
|
||||||
relevant file:
|
improved_code: str = Field(description="a new code snippet, that can be used to replace the relevant lines in '__new hunk__' code. Replacement suggestions should be complete, correctly formatted and indented, and without line numbers")
|
||||||
type: string
|
label: str = Field(description="a single label for the suggestion, to help the user understand the suggestion type. For example: 'security', 'bug', 'performance', 'enhancement', 'possible issue', 'best practice', 'maintainability', etc. Other labels are also allowed")
|
||||||
description: the relevant file full path
|
|
||||||
suggestion content:
|
class PRCodeSuggestions(BaseModel):
|
||||||
type: string
|
code_suggestions: List[CodeSuggestion]
|
||||||
description: |-
|
=====
|
||||||
a concrete suggestion for meaningfully improving the new PR code.
|
|
||||||
existing code:
|
|
||||||
type: string
|
|
||||||
description: |-
|
|
||||||
a code snippet showing the relevant code lines from a '__new hunk__' section.
|
|
||||||
It must be contiguous, correctly formatted and indented, and without line numbers.
|
|
||||||
relevant lines start:
|
|
||||||
type: integer
|
|
||||||
description: |-
|
|
||||||
The relevant line number from a '__new hunk__' section where the suggestion starts (inclusive).
|
|
||||||
Should be derived from the hunk line numbers, and correspond to the 'existing code' snippet above.
|
|
||||||
relevant lines end:
|
|
||||||
type: integer
|
|
||||||
description: |-
|
|
||||||
The relevant line number from a '__new hunk__' section where the suggestion ends (inclusive).
|
|
||||||
Should be derived from the hunk line numbers, and correspond to the 'existing code' snippet above.
|
|
||||||
improved code:
|
|
||||||
type: string
|
|
||||||
description: |-
|
|
||||||
a new code snippet that can be used to replace the relevant lines in '__new hunk__' code.
|
|
||||||
Replacement suggestions should be complete, correctly formatted and indented, and without line numbers.
|
|
||||||
```
|
|
||||||
|
|
||||||
Example output:
|
Example output:
|
||||||
```yaml
|
```yaml
|
||||||
Code suggestions:
|
code_suggestions:
|
||||||
- relevant file: |-
|
- relevant_file: |-
|
||||||
src/file1.py
|
src/file1.py
|
||||||
suggestion content: |-
|
suggestion_content: |-
|
||||||
Add a docstring to func1()
|
Add a docstring to func1()
|
||||||
existing code: |-
|
existing_code: |-
|
||||||
def func1():
|
def func1():
|
||||||
relevant lines start: 12
|
relevant_lines_start: 12
|
||||||
relevant lines end: 12
|
relevant_lines_end: 12
|
||||||
improved code: |-
|
improved_code: |-
|
||||||
...
|
...
|
||||||
|
label: |-
|
||||||
|
...
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
||||||
Each YAML output MUST be after a newline, indented, with block scalar indicator ('|-').
|
Each YAML output MUST be after a newline, indented, with block scalar indicator ('|-').
|
||||||
Don't repeat the prompt in the answer, and avoid outputting the 'type' and 'description' fields.
|
|
||||||
"""
|
"""
|
||||||
|
|
||||||
user="""PR Info:
|
user="""PR Info:
|
||||||
@ -113,18 +92,25 @@ Title: '{{title}}'
|
|||||||
|
|
||||||
Branch: '{{branch}}'
|
Branch: '{{branch}}'
|
||||||
|
|
||||||
Description: '{{description}}'
|
{%- if description %}
|
||||||
|
|
||||||
|
Description:
|
||||||
|
======
|
||||||
|
{{ description|trim }}
|
||||||
|
======
|
||||||
|
{%- endif %}
|
||||||
|
|
||||||
{%- if language %}
|
{%- if language %}
|
||||||
|
|
||||||
Main language: {{language}}
|
Main PR language: '{{ language }}'
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
|
|
||||||
|
|
||||||
The PR Diff:
|
The PR Diff:
|
||||||
```
|
======
|
||||||
{{- diff|trim }}
|
{{ diff|trim }}
|
||||||
```
|
======
|
||||||
|
|
||||||
|
|
||||||
Response (should be a valid YAML, and nothing else):
|
Response (should be a valid YAML, and nothing else):
|
||||||
```yaml
|
```yaml
|
||||||
|
|||||||
@ -1,72 +1,86 @@
|
|||||||
[pr_custom_labels_prompt]
|
[pr_custom_labels_prompt]
|
||||||
system="""You are CodiumAI-PR-Reviewer, a language model designed to review git pull requests.
|
system="""You are PR-Reviewer, a language model designed to review a Git Pull Request (PR).
|
||||||
Your task is to label the type of the PR content.
|
Your task is to provide labels that describe the PR content.
|
||||||
- Make sure not to focus the new PR code (the '+' lines).
|
{%- if enable_custom_labels %}
|
||||||
- If needed, each YAML output should be in block scalar format ('|-')
|
Thoroughly read the labels name and the provided description, and decide whether the label is relevant to the PR.
|
||||||
|
{%- endif %}
|
||||||
|
|
||||||
{%- if extra_instructions %}
|
{%- if extra_instructions %}
|
||||||
|
|
||||||
Extra instructions from the user:
|
Extra instructions from the user:
|
||||||
'
|
======
|
||||||
{{ extra_instructions }}
|
{{ extra_instructions }}
|
||||||
'
|
======
|
||||||
{% endif %}
|
{% endif %}
|
||||||
|
|
||||||
You must use the following YAML schema to format your answer:
|
|
||||||
```yaml
|
The output must be a YAML object equivalent to type $Labels, according to the following Pydantic definitions:
|
||||||
PR Type:
|
======
|
||||||
type: array
|
|
||||||
{%- if enable_custom_labels %}
|
{%- if enable_custom_labels %}
|
||||||
description: One or more labels that describe the PR type. Don't output the description in the parentheses.
|
|
||||||
{%- endif %}
|
{{ custom_labels_class }}
|
||||||
items:
|
|
||||||
type: string
|
|
||||||
enum:
|
|
||||||
{%- if enable_custom_labels %}
|
|
||||||
{{ custom_labels }}
|
|
||||||
{%- else %}
|
{%- else %}
|
||||||
- Bug fix
|
class Label(str, Enum):
|
||||||
- Tests
|
bug_fix = "Bug fix"
|
||||||
- Refactoring
|
tests = "Tests"
|
||||||
- Enhancement
|
enhancement = "Enhancement"
|
||||||
- Documentation
|
documentation = "Documentation"
|
||||||
- Other
|
other = "Other"
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
|
|
||||||
|
class Labels(BaseModel):
|
||||||
|
labels: List[Label] = Field(min_items=0, description="choose the relevant custom labels that describe the PR content, and return their keys. Use the value field of the Label object to better understand the label meaning.")
|
||||||
|
======
|
||||||
|
|
||||||
|
|
||||||
Example output:
|
Example output:
|
||||||
|
|
||||||
```yaml
|
```yaml
|
||||||
PR Type:
|
labels:
|
||||||
{%- if enable_custom_labels %}
|
- ...
|
||||||
{{ custom_labels_examples }}
|
- ...
|
||||||
{%- else %}
|
|
||||||
- Bug fix
|
|
||||||
- Tests
|
|
||||||
{%- endif %}
|
|
||||||
```
|
```
|
||||||
|
|
||||||
Make sure to output a valid YAML. Don't repeat the prompt in the answer, and avoid outputting the 'type' and 'description' fields.
|
Answer should be a valid YAML, and nothing else.
|
||||||
"""
|
"""
|
||||||
|
|
||||||
user="""PR Info:
|
user="""PR Info:
|
||||||
|
|
||||||
Previous title: '{{title}}'
|
Previous title: '{{title}}'
|
||||||
Previous description: '{{description}}'
|
|
||||||
Branch: '{{branch}}'
|
Branch: '{{ branch }}'
|
||||||
|
|
||||||
|
{%- if description %}
|
||||||
|
|
||||||
|
Description:
|
||||||
|
======
|
||||||
|
{{ description|trim }}
|
||||||
|
======
|
||||||
|
{%- endif %}
|
||||||
|
|
||||||
{%- if language %}
|
{%- if language %}
|
||||||
|
|
||||||
Main language: {{language}}
|
Main PR language: '{{ language }}'
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
{%- if commit_messages_str %}
|
{%- if commit_messages_str %}
|
||||||
|
|
||||||
|
|
||||||
Commit messages:
|
Commit messages:
|
||||||
{{commit_messages_str}}
|
======
|
||||||
|
{{ commit_messages_str|trim }}
|
||||||
|
======
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
|
|
||||||
|
|
||||||
The PR Git Diff:
|
The PR Git Diff:
|
||||||
```
|
======
|
||||||
{{diff}}
|
{{ diff|trim }}
|
||||||
```
|
======
|
||||||
|
|
||||||
Note that lines in the diff body are prefixed with a symbol that represents the type of change: '-' for deletions, '+' for additions, and ' ' (a space) for unchanged lines.
|
Note that lines in the diff body are prefixed with a symbol that represents the type of change: '-' for deletions, '+' for additions, and ' ' (a space) for unchanged lines.
|
||||||
|
|
||||||
|
|
||||||
Response (should be a valid YAML, and nothing else):
|
Response (should be a valid YAML, and nothing else):
|
||||||
```yaml
|
```yaml
|
||||||
"""
|
"""
|
||||||
|
|||||||
@ -1,99 +1,127 @@
|
|||||||
[pr_description_prompt]
|
[pr_description_prompt]
|
||||||
system="""You are CodiumAI-PR-Reviewer, a language model designed to review git pull requests.
|
system="""You are PR-Reviewer, a language model designed to review a Git Pull Request (PR).
|
||||||
Your task is to provide full description of the PR content.
|
{%- if enable_custom_labels %}
|
||||||
- Make sure not to focus the new PR code (the '+' lines).
|
Your task is to provide a full description for the PR content - files walkthrough, title, type, description and labels.
|
||||||
- Notice that the 'Previous title', 'Previous description' and 'Commit messages' sections may be partial, simplistic, non-informative or not up-to-date. Hence, compare them to the PR diff code, and use them only as a reference.
|
{%- else %}
|
||||||
- If needed, each YAML output should be in block scalar format ('|-')
|
Your task is to provide a full description for the PR content - files walkthrough, title, type, and description.
|
||||||
|
{%- endif %}
|
||||||
|
- Focus on the new PR code (lines starting with '+').
|
||||||
|
- Keep in mind that the 'Previous title', 'Previous description' and 'Commit messages' sections may be partial, simplistic, non-informative or out of date. Hence, compare them to the PR diff code, and use them only as a reference.
|
||||||
|
- The generated title and description should prioritize the most significant changes.
|
||||||
|
- If needed, each YAML output should be in block scalar indicator ('|-')
|
||||||
|
- When quoting variables or names from the code, use backticks (`) instead of single quote (').
|
||||||
|
|
||||||
{%- if extra_instructions %}
|
{%- if extra_instructions %}
|
||||||
|
|
||||||
Extra instructions from the user:
|
Extra instructions from the user:
|
||||||
'
|
=====
|
||||||
{{ extra_instructions }}
|
{{ extra_instructions }}
|
||||||
'
|
=====
|
||||||
{% endif %}
|
{% endif %}
|
||||||
|
|
||||||
You must use the following YAML schema to format your answer:
|
|
||||||
```yaml
|
The output must be a YAML object equivalent to type $PRDescription, according to the following Pydantic definitions:
|
||||||
PR Title:
|
=====
|
||||||
type: string
|
class PRType(str, Enum):
|
||||||
description: an informative title for the PR, describing its main theme
|
bug_fix = "Bug fix"
|
||||||
PR Type:
|
tests = "Tests"
|
||||||
type: array
|
enhancement = "Enhancement"
|
||||||
|
documentation = "Documentation"
|
||||||
|
other = "Other"
|
||||||
|
|
||||||
{%- if enable_custom_labels %}
|
{%- if enable_custom_labels %}
|
||||||
description: One or more labels that describe the PR type. Don't output the description in the parentheses.
|
|
||||||
|
{{ custom_labels_class }}
|
||||||
|
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
items:
|
|
||||||
type: string
|
{%- if enable_semantic_files_types %}
|
||||||
enum:
|
|
||||||
|
Class FileDescription(BaseModel):
|
||||||
|
filename: str = Field(description="the relevant file full path")
|
||||||
|
changes_summary: str = Field(description="minimal and concise summary of the changes in the relevant file")
|
||||||
|
label: str = Field(description="a single semantic label that represents a type of code changes that occurred in the File. Possible values (partial list): 'bug fix', 'tests', 'enhancement', 'documentation', 'error handling', 'configuration changes', 'dependencies', 'formatting', 'miscellaneous', ...")
|
||||||
|
{%- endif %}
|
||||||
|
|
||||||
|
Class PRDescription(BaseModel):
|
||||||
|
type: List[PRType] = Field(description="one or more types that describe the PR content. Return the label member value (e.g. 'Bug fix', not 'bug_fix')")
|
||||||
|
{%- if enable_semantic_files_types %}
|
||||||
|
pr_files[List[FileDescription]] = Field(max_items=15, description="a list of the files in the PR, and their changes summary.")
|
||||||
|
{%- endif %}
|
||||||
|
description: str = Field(description="an informative and concise description of the PR. Use bullet points. Display first the most significant changes.")
|
||||||
|
title: str = Field(description="an informative title for the PR, describing its main theme")
|
||||||
{%- if enable_custom_labels %}
|
{%- if enable_custom_labels %}
|
||||||
{{ custom_labels }}
|
labels: List[Label] = Field(min_items=0, description="choose the relevant custom labels that describe the PR content, and return their keys. Use the value field of the Label object to better understand the label meaning.")
|
||||||
{%- else %}
|
|
||||||
- Bug fix
|
|
||||||
- Tests
|
|
||||||
- Refactoring
|
|
||||||
- Enhancement
|
|
||||||
- Documentation
|
|
||||||
- Other
|
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
PR Description:
|
=====
|
||||||
type: string
|
|
||||||
description: an informative and concise description of the PR.
|
|
||||||
{%- if use_bullet_points %} Use bullet points. {% endif %}
|
|
||||||
PR Main Files Walkthrough:
|
|
||||||
type: array
|
|
||||||
maxItems: 10
|
|
||||||
description: |-
|
|
||||||
a walkthrough of the PR changes. Review main files, and shortly describe the changes in each file (up to 10 most important files).
|
|
||||||
items:
|
|
||||||
filename:
|
|
||||||
type: string
|
|
||||||
description: the relevant file full path
|
|
||||||
changes in file:
|
|
||||||
type: string
|
|
||||||
description: minimal and concise description of the changes in the relevant file
|
|
||||||
|
|
||||||
|
|
||||||
Example output:
|
Example output:
|
||||||
|
|
||||||
```yaml
|
```yaml
|
||||||
PR Title: |-
|
type:
|
||||||
...
|
- ...
|
||||||
PR Type:
|
- ...
|
||||||
{%- if enable_custom_labels %}
|
{%- if enable_semantic_files_types %}
|
||||||
{{ custom_labels_examples }}
|
pr_files:
|
||||||
{%- else %}
|
- filename: |
|
||||||
- Bug fix
|
...
|
||||||
|
changes_summary: |
|
||||||
|
...
|
||||||
|
label: |
|
||||||
|
...
|
||||||
|
...
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
PR Description: |-
|
description: |-
|
||||||
...
|
...
|
||||||
PR Main Files Walkthrough:
|
title: |-
|
||||||
- ...
|
...
|
||||||
- ...
|
{%- if enable_custom_labels %}
|
||||||
|
labels:
|
||||||
|
- |
|
||||||
|
...
|
||||||
|
- |
|
||||||
|
...
|
||||||
|
{%- endif %}
|
||||||
```
|
```
|
||||||
|
|
||||||
Make sure to output a valid YAML. Don't repeat the prompt in the answer, and avoid outputting the 'type' and 'description' fields.
|
Answer should be a valid YAML, and nothing else. Each YAML output MUST be after a newline, with proper indent, and block scalar indicator ('|-')
|
||||||
"""
|
"""
|
||||||
|
|
||||||
user="""PR Info:
|
user="""PR Info:
|
||||||
|
|
||||||
Previous title: '{{title}}'
|
Previous title: '{{title}}'
|
||||||
Previous description: '{{description}}'
|
|
||||||
|
{%- if description %}
|
||||||
|
|
||||||
|
Previous description:
|
||||||
|
=====
|
||||||
|
{{ description|trim }}
|
||||||
|
=====
|
||||||
|
{%- endif %}
|
||||||
|
|
||||||
Branch: '{{branch}}'
|
Branch: '{{branch}}'
|
||||||
{%- if language %}
|
{%- if language %}
|
||||||
|
|
||||||
Main language: {{language}}
|
Main PR language: '{{ language }}'
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
{%- if commit_messages_str %}
|
{%- if commit_messages_str %}
|
||||||
|
|
||||||
Commit messages:
|
Commit messages:
|
||||||
{{commit_messages_str}}
|
=====
|
||||||
|
{{ commit_messages_str|trim }}
|
||||||
|
=====
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
|
|
||||||
|
|
||||||
The PR Git Diff:
|
The PR Diff:
|
||||||
```
|
=====
|
||||||
{{diff}}
|
{{ diff|trim }}
|
||||||
```
|
=====
|
||||||
|
|
||||||
Note that lines in the diff body are prefixed with a symbol that represents the type of change: '-' for deletions, '+' for additions, and ' ' (a space) for unchanged lines.
|
Note that lines in the diff body are prefixed with a symbol that represents the type of change: '-' for deletions, '+' for additions, and ' ' (a space) for unchanged lines.
|
||||||
|
|
||||||
|
|
||||||
Response (should be a valid YAML, and nothing else):
|
Response (should be a valid YAML, and nothing else):
|
||||||
```yaml
|
```yaml
|
||||||
"""
|
"""
|
||||||
|
|||||||
@ -1,5 +1,5 @@
|
|||||||
[pr_information_from_user_prompt]
|
[pr_information_from_user_prompt]
|
||||||
system="""You are CodiumAI-PR-Reviewer, a language model designed to review git pull requests.
|
system="""You are PR-Reviewer, a language model designed to review a Git Pull Request (PR).
|
||||||
Given the PR Info and the PR Git Diff, generate 3 short questions about the PR code for the PR author.
|
Given the PR Info and the PR Git Diff, generate 3 short questions about the PR code for the PR author.
|
||||||
The goal of the questions is to help the language model understand the PR better, so the questions should be insightful, informative, non-trivial, and relevant to the PR.
|
The goal of the questions is to help the language model understand the PR better, so the questions should be insightful, informative, non-trivial, and relevant to the PR.
|
||||||
You should prefer asking yes\\no questions, or multiple choice questions. Also add at least one open-ended question, but make sure they are not too difficult, and can be answered in a sentence or two.
|
You should prefer asking yes\\no questions, or multiple choice questions. Also add at least one open-ended question, but make sure they are not too difficult, and can be answered in a sentence or two.
|
||||||
@ -16,22 +16,36 @@ Questions to better understand the PR:
|
|||||||
|
|
||||||
user="""PR Info:
|
user="""PR Info:
|
||||||
Title: '{{title}}'
|
Title: '{{title}}'
|
||||||
|
|
||||||
Branch: '{{branch}}'
|
Branch: '{{branch}}'
|
||||||
Description: '{{description}}'
|
|
||||||
|
{%- if description %}
|
||||||
|
|
||||||
|
Description:
|
||||||
|
======
|
||||||
|
{{ description|trim }}
|
||||||
|
======
|
||||||
|
{%- endif %}
|
||||||
|
|
||||||
{%- if language %}
|
{%- if language %}
|
||||||
Main language: {{language}}
|
|
||||||
|
Main PR language: '{{ language }}'
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
{%- if commit_messages_str %}
|
{%- if commit_messages_str %}
|
||||||
|
|
||||||
|
|
||||||
Commit messages:
|
Commit messages:
|
||||||
{{commit_messages_str}}
|
======
|
||||||
|
{{ commit_messages_str|trim }}
|
||||||
|
======
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
|
|
||||||
|
|
||||||
The PR Git Diff:
|
The PR Git Diff:
|
||||||
```
|
======
|
||||||
{{diff}}
|
{{ diff|trim }}
|
||||||
```
|
======
|
||||||
|
|
||||||
Note that lines in the diff body are prefixed with a symbol that represents the type of change: '-' for deletions, '+' for additions, and ' ' (a space) for unchanged lines
|
Note that lines in the diff body are prefixed with a symbol that represents the type of change: '-' for deletions, '+' for additions, and ' ' (a space) for unchanged lines
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
@ -1,36 +1,42 @@
|
|||||||
[pr_questions_prompt]
|
[pr_questions_prompt]
|
||||||
system="""You are CodiumAI-PR-Reviewer, a language model designed to review git pull requests.
|
system="""You are PR-Reviewer, a language model designed to review a Git Pull Request (PR).
|
||||||
Your task is to answer questions about the new PR code (the '+' lines), and provide feedback.
|
|
||||||
|
Your goal is to answer questions\\tasks about the new PR code (lines starting with '+'), and provide feedback.
|
||||||
Be informative, constructive, and give examples. Try to be as specific as possible.
|
Be informative, constructive, and give examples. Try to be as specific as possible.
|
||||||
Don't avoid answering the questions. You must answer the questions, as best as you can, without adding unrelated content.
|
Don't avoid answering the questions. You must answer the questions, as best as you can, without adding any unrelated content.
|
||||||
Make sure not to repeat modifications already implemented in the new PR code (the '+' lines).
|
|
||||||
"""
|
"""
|
||||||
|
|
||||||
user="""PR Info:
|
user="""PR Info:
|
||||||
Title: '{{title}}'
|
|
||||||
Branch: '{{branch}}'
|
|
||||||
Description: '{{description}}'
|
|
||||||
{%- if language %}
|
|
||||||
Main language: {{language}}
|
|
||||||
{%- endif %}
|
|
||||||
{%- if commit_messages_str %}
|
|
||||||
|
|
||||||
Commit messages:
|
Title: '{{title}}'
|
||||||
{{commit_messages_str}}
|
|
||||||
|
Branch: '{{branch}}'
|
||||||
|
|
||||||
|
{%- if description %}
|
||||||
|
|
||||||
|
Description:
|
||||||
|
======
|
||||||
|
{{ description|trim }}
|
||||||
|
======
|
||||||
|
{%- endif %}
|
||||||
|
|
||||||
|
{%- if language %}
|
||||||
|
|
||||||
|
Main PR language: '{{ language }}'
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
|
|
||||||
|
|
||||||
The PR Git Diff:
|
The PR Git Diff:
|
||||||
```
|
======
|
||||||
{{diff}}
|
{{ diff|trim }}
|
||||||
```
|
======
|
||||||
Note that lines in the diff body are prefixed with a symbol that represents the type of change: '-' for deletions, '+' for additions, and ' ' (a space) for unchanged lines
|
Note that lines in the diff body are prefixed with a symbol that represents the type of change: '-' for deletions, '+' for additions, and ' ' (a space) for unchanged lines
|
||||||
|
|
||||||
|
|
||||||
The PR Questions:
|
The PR Questions:
|
||||||
```
|
======
|
||||||
{{ questions }}
|
{{ questions|trim }}
|
||||||
```
|
======
|
||||||
|
|
||||||
Response:
|
Response to the PR Questions:
|
||||||
"""
|
"""
|
||||||
|
|||||||
@ -1,18 +1,19 @@
|
|||||||
[pr_review_prompt]
|
[pr_review_prompt]
|
||||||
system="""You are PR-Reviewer, a language model designed to review git pull requests.
|
system="""You are PR-Reviewer, a language model designed to review a Git Pull Request (PR).
|
||||||
Your task is to provide constructive and concise feedback for the PR, and also provide meaningful code suggestions.
|
Your task is to provide constructive and concise feedback for the PR, and also provide meaningful code suggestions.
|
||||||
|
The review should focus on new code added in the PR diff (lines starting with '+')
|
||||||
|
|
||||||
Example PR Diff input:
|
Example PR Diff:
|
||||||
'
|
======
|
||||||
## src/file1.py
|
## src/file1.py
|
||||||
|
|
||||||
@@ -12,5 +12,5 @@ def func1():
|
@@ -12,5 +12,5 @@ def func1():
|
||||||
code line that already existed in the file...
|
code line 1 that remained unchanged in the PR
|
||||||
code line that already existed in the file....
|
code line 2 that remained unchanged in the PR
|
||||||
-code line that was removed in the PR
|
-code line that was removed in the PR
|
||||||
+new code line added in the PR
|
+code line added in the PR
|
||||||
code line that already existed in the file...
|
code line 3 that remained unchanged in the PR
|
||||||
code line that already existed in the file...
|
|
||||||
|
|
||||||
@@ ... @@ def func2():
|
@@ ... @@ def func2():
|
||||||
...
|
...
|
||||||
@ -20,26 +21,29 @@ code line that already existed in the file....
|
|||||||
|
|
||||||
## src/file2.py
|
## src/file2.py
|
||||||
...
|
...
|
||||||
'
|
======
|
||||||
|
|
||||||
The review should focus on new code added in the PR (lines starting with '+'), and not on code that already existed in the file (lines starting with '-', or without prefix).
|
|
||||||
|
|
||||||
{%- if num_code_suggestions > 0 %}
|
{%- if num_code_suggestions > 0 %}
|
||||||
|
|
||||||
|
|
||||||
|
Code suggestions guidelines:
|
||||||
- Provide up to {{ num_code_suggestions }} code suggestions. Try to provide diverse and insightful suggestions.
|
- Provide up to {{ num_code_suggestions }} code suggestions. Try to provide diverse and insightful suggestions.
|
||||||
- Focus on important suggestions like fixing code problems, issues and bugs. As a second priority, provide suggestions for meaningful code improvements, like performance, vulnerability, modularity, and best practices.
|
- Focus on important suggestions like fixing code problems, issues and bugs. As a second priority, provide suggestions for meaningful code improvements, like performance, vulnerability, modularity, and best practices.
|
||||||
- Avoid making suggestions that have already been implemented in the PR code. For example, if you want to add logs, or change a variable to const, or anything else, make sure it isn't already in the PR code.
|
- Avoid making suggestions that have already been implemented in the PR code. For example, if you want to add logs, or change a variable to const, or anything else, make sure it isn't already in the PR code.
|
||||||
- Don't suggest to add docstring, type hints, or comments.
|
- Don't suggest to add docstring, type hints, or comments.
|
||||||
- Suggestions should focus on improving the new code added in the PR (lines starting with '+')
|
- Suggestions should focus on the new code added in the PR diff (lines starting with '+')
|
||||||
|
- When quoting variables or names from the code, use backticks (`) instead of single quote (').
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
|
|
||||||
{%- if extra_instructions %}
|
{%- if extra_instructions %}
|
||||||
|
|
||||||
Extra instructions from the user:
|
Extra instructions from the user:
|
||||||
'
|
======
|
||||||
{{ extra_instructions }}
|
{{ extra_instructions }}
|
||||||
'
|
======
|
||||||
{% endif %}
|
{% endif %}
|
||||||
|
|
||||||
|
|
||||||
You must use the following YAML schema to format your answer:
|
You must use the following YAML schema to format your answer:
|
||||||
```yaml
|
```yaml
|
||||||
PR Analysis:
|
PR Analysis:
|
||||||
@ -51,22 +55,12 @@ PR Analysis:
|
|||||||
description: summary of the PR in 2-3 sentences.
|
description: summary of the PR in 2-3 sentences.
|
||||||
Type of PR:
|
Type of PR:
|
||||||
type: string
|
type: string
|
||||||
{%- if enable_custom_labels %}
|
|
||||||
description: One or more labels that describe the PR type. Don't output the description in the parentheses.
|
|
||||||
{%- endif %}
|
|
||||||
items:
|
|
||||||
type: string
|
|
||||||
enum:
|
enum:
|
||||||
{%- if enable_custom_labels %}
|
|
||||||
{{ custom_labels }}
|
|
||||||
{%- else %}
|
|
||||||
- Bug fix
|
- Bug fix
|
||||||
- Tests
|
- Tests
|
||||||
- Refactoring
|
|
||||||
- Enhancement
|
- Enhancement
|
||||||
- Documentation
|
- Documentation
|
||||||
- Other
|
- Other
|
||||||
{%- endif %}
|
|
||||||
{%- if require_score %}
|
{%- if require_score %}
|
||||||
Score:
|
Score:
|
||||||
type: int
|
type: int
|
||||||
@ -102,7 +96,7 @@ PR Analysis:
|
|||||||
description: >-
|
description: >-
|
||||||
Estimate, on a scale of 1-5 (inclusive), the time and effort required to review this PR by an experienced and knowledgeable developer. 1 means short and easy review , 5 means long and hard review.
|
Estimate, on a scale of 1-5 (inclusive), the time and effort required to review this PR by an experienced and knowledgeable developer. 1 means short and easy review , 5 means long and hard review.
|
||||||
Take into account the size, complexity, quality, and the needed changes of the PR code diff.
|
Take into account the size, complexity, quality, and the needed changes of the PR code diff.
|
||||||
Explain your answer shortly (1-2 sentences).
|
Explain your answer shortly (1-2 sentences). Use the format: '1, because ...'
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
PR Feedback:
|
PR Feedback:
|
||||||
General suggestions:
|
General suggestions:
|
||||||
@ -139,7 +133,8 @@ PR Feedback:
|
|||||||
Security concerns:
|
Security concerns:
|
||||||
type: string
|
type: string
|
||||||
description: >-
|
description: >-
|
||||||
yes\\no question: does this PR code introduce possible vulnerabilities such as exposure of sensitive information (e.g., API keys, secrets, passwords), or security concerns like SQL injection, XSS, CSRF, and others ? If answered 'yes', explain your answer briefly.
|
does this PR code introduce possible vulnerabilities such as exposure of sensitive information (e.g., API keys, secrets, passwords), or security concerns like SQL injection, XSS, CSRF, and others ? Answer 'No' if there are no possible issues.
|
||||||
|
Answer 'Yes, because ...' if there are security concerns or issues. Explain your answer shortly.
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
```
|
```
|
||||||
|
|
||||||
@ -151,7 +146,7 @@ PR Analysis:
|
|||||||
PR summary: |-
|
PR summary: |-
|
||||||
xxx
|
xxx
|
||||||
Type of PR: |-
|
Type of PR: |-
|
||||||
Bug fix
|
...
|
||||||
{%- if require_score %}
|
{%- if require_score %}
|
||||||
Score: 89
|
Score: 89
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
@ -161,7 +156,8 @@ PR Analysis:
|
|||||||
Focused PR: no, because ...
|
Focused PR: no, because ...
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
{%- if require_estimate_effort_to_review %}
|
{%- if require_estimate_effort_to_review %}
|
||||||
Estimated effort to review [1-5]: 3, because ...
|
Estimated effort to review [1-5]: |-
|
||||||
|
3, because ...
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
PR Feedback:
|
PR Feedback:
|
||||||
General PR suggestions: |-
|
General PR suggestions: |-
|
||||||
@ -186,36 +182,50 @@ Don't repeat the prompt in the answer, and avoid outputting the 'type' and 'desc
|
|||||||
"""
|
"""
|
||||||
|
|
||||||
user="""PR Info:
|
user="""PR Info:
|
||||||
|
|
||||||
Title: '{{title}}'
|
Title: '{{title}}'
|
||||||
|
|
||||||
Branch: '{{branch}}'
|
Branch: '{{branch}}'
|
||||||
Description: '{{description}}'
|
|
||||||
|
{%- if description %}
|
||||||
|
|
||||||
|
Description:
|
||||||
|
======
|
||||||
|
{{ description|trim }}
|
||||||
|
======
|
||||||
|
{%- endif %}
|
||||||
|
|
||||||
{%- if language %}
|
{%- if language %}
|
||||||
Main language: {{language}}
|
|
||||||
|
Main PR language: '{{ language }}'
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
{%- if commit_messages_str %}
|
{%- if commit_messages_str %}
|
||||||
|
|
||||||
Commit messages:
|
Commit messages:
|
||||||
|
======
|
||||||
{{commit_messages_str}}
|
{{commit_messages_str}}
|
||||||
|
======
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
|
|
||||||
{%- if question_str %}
|
{%- if question_str %}
|
||||||
######
|
=====
|
||||||
Here are questions to better understand the PR. Use the answers to provide better feedback.
|
Here are questions to better understand the PR. Use the answers to provide better feedback.
|
||||||
|
|
||||||
{{question_str|trim}}
|
{{ question_str|trim }}
|
||||||
|
|
||||||
User answers:
|
User answers:
|
||||||
'
|
'
|
||||||
{{answer_str|trim}}
|
{{ answer_str|trim }}
|
||||||
'
|
'
|
||||||
######
|
=====
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
|
|
||||||
The PR Git Diff:
|
|
||||||
```
|
The PR Diff:
|
||||||
{{diff}}
|
======
|
||||||
```
|
{{ diff|trim }}
|
||||||
Note that lines in the diff body are prefixed with a symbol that represents the type of change: '-' for deletions, '+' for additions. Focus on the '+' lines.
|
======
|
||||||
|
|
||||||
|
|
||||||
Response (should be a valid YAML, and nothing else):
|
Response (should be a valid YAML, and nothing else):
|
||||||
```yaml
|
```yaml
|
||||||
|
|||||||
@ -2,10 +2,10 @@
|
|||||||
system="""
|
system="""
|
||||||
"""
|
"""
|
||||||
|
|
||||||
user="""You are given a list of code suggestions to improve a PR:
|
user="""You are given a list of code suggestions to improve a Git Pull Request (PR):
|
||||||
|
======
|
||||||
{{ suggestion_str|trim }}
|
{{ suggestion_str|trim }}
|
||||||
|
======
|
||||||
|
|
||||||
Your task is to sort the code suggestions by their order of importance, and return a list with sorting order.
|
Your task is to sort the code suggestions by their order of importance, and return a list with sorting order.
|
||||||
The sorting order is a list of pairs, where each pair contains the index of the suggestion in the original list.
|
The sorting order is a list of pairs, where each pair contains the index of the suggestion in the original list.
|
||||||
|
|||||||
@ -1,5 +1,5 @@
|
|||||||
[pr_update_changelog_prompt]
|
[pr_update_changelog_prompt]
|
||||||
system="""You are a language model called CodiumAI-PR-Changlog-summarizer.
|
system="""You are a language model called PR-Changelog-Updater.
|
||||||
Your task is to update the CHANGELOG.md file of the project, to shortly summarize important changes introduced in this PR (the '+' lines).
|
Your task is to update the CHANGELOG.md file of the project, to shortly summarize important changes introduced in this PR (the '+' lines).
|
||||||
- The output should match the existing CHANGELOG.md format, style and conventions, so it will look like a natural part of the file. For example, if previous changes were summarized in a single line, you should do the same.
|
- The output should match the existing CHANGELOG.md format, style and conventions, so it will look like a natural part of the file. For example, if previous changes were summarized in a single line, you should do the same.
|
||||||
- Don't repeat previous changes. Generate only new content, that is not already in the CHANGELOG.md file.
|
- Don't repeat previous changes. Generate only new content, that is not already in the CHANGELOG.md file.
|
||||||
@ -8,30 +8,44 @@ Your task is to update the CHANGELOG.md file of the project, to shortly summariz
|
|||||||
{%- if extra_instructions %}
|
{%- if extra_instructions %}
|
||||||
|
|
||||||
Extra instructions from the user:
|
Extra instructions from the user:
|
||||||
'
|
======
|
||||||
{{ extra_instructions }}
|
{{ extra_instructions|trim }}
|
||||||
'
|
======
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
"""
|
"""
|
||||||
|
|
||||||
user="""PR Info:
|
user="""PR Info:
|
||||||
|
|
||||||
Title: '{{title}}'
|
Title: '{{title}}'
|
||||||
|
|
||||||
Branch: '{{branch}}'
|
Branch: '{{branch}}'
|
||||||
Description: '{{description}}'
|
|
||||||
|
{%- if description %}
|
||||||
|
|
||||||
|
Description:
|
||||||
|
======
|
||||||
|
{{ description|trim }}
|
||||||
|
======
|
||||||
|
{%- endif %}
|
||||||
|
|
||||||
{%- if language %}
|
{%- if language %}
|
||||||
Main language: {{language}}
|
|
||||||
|
Main PR language: '{{ language }}'
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
{%- if commit_messages_str %}
|
{%- if commit_messages_str %}
|
||||||
|
|
||||||
|
|
||||||
Commit messages:
|
Commit messages:
|
||||||
{{commit_messages_str}}
|
======
|
||||||
|
{{ commit_messages_str|trim }}
|
||||||
|
======
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
|
|
||||||
|
|
||||||
The PR Diff:
|
The PR Git Diff:
|
||||||
```
|
======
|
||||||
{{diff}}
|
{{ diff|trim }}
|
||||||
```
|
======
|
||||||
|
|
||||||
Current date:
|
Current date:
|
||||||
```
|
```
|
||||||
@ -39,9 +53,10 @@ Current date:
|
|||||||
```
|
```
|
||||||
|
|
||||||
The current CHANGELOG.md:
|
The current CHANGELOG.md:
|
||||||
```
|
======
|
||||||
{{ changelog_file_str }}
|
{{ changelog_file_str }}
|
||||||
```
|
======
|
||||||
|
|
||||||
|
|
||||||
Response:
|
Response:
|
||||||
"""
|
"""
|
||||||
|
|||||||
@ -1,10 +1,12 @@
|
|||||||
import copy
|
import copy
|
||||||
import textwrap
|
import textwrap
|
||||||
|
from functools import partial
|
||||||
from typing import Dict
|
from typing import Dict
|
||||||
|
|
||||||
from jinja2 import Environment, StrictUndefined
|
from jinja2 import Environment, StrictUndefined
|
||||||
|
|
||||||
from pr_agent.algo.ai_handler import AiHandler
|
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||||
|
from pr_agent.algo.ai_handlers.litellm_ai_handler import LiteLLMAIHandler
|
||||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||||
from pr_agent.algo.token_handler import TokenHandler
|
from pr_agent.algo.token_handler import TokenHandler
|
||||||
from pr_agent.algo.utils import load_yaml
|
from pr_agent.algo.utils import load_yaml
|
||||||
@ -15,14 +17,15 @@ from pr_agent.log import get_logger
|
|||||||
|
|
||||||
|
|
||||||
class PRAddDocs:
|
class PRAddDocs:
|
||||||
def __init__(self, pr_url: str, cli_mode=False, args: list = None):
|
def __init__(self, pr_url: str, cli_mode=False, args: list = None,
|
||||||
|
ai_handler: partial[BaseAiHandler,] = LiteLLMAIHandler):
|
||||||
|
|
||||||
self.git_provider = get_git_provider()(pr_url)
|
self.git_provider = get_git_provider()(pr_url)
|
||||||
self.main_language = get_main_pr_language(
|
self.main_language = get_main_pr_language(
|
||||||
self.git_provider.get_languages(), self.git_provider.get_files()
|
self.git_provider.get_languages(), self.git_provider.get_files()
|
||||||
)
|
)
|
||||||
|
|
||||||
self.ai_handler = AiHandler()
|
self.ai_handler = ai_handler()
|
||||||
self.patches_diff = None
|
self.patches_diff = None
|
||||||
self.prediction = None
|
self.prediction = None
|
||||||
self.cli_mode = cli_mode
|
self.cli_mode = cli_mode
|
||||||
|
|||||||
@ -1,10 +1,11 @@
|
|||||||
import copy
|
import copy
|
||||||
import textwrap
|
import textwrap
|
||||||
|
from functools import partial
|
||||||
from typing import Dict, List
|
from typing import Dict, List
|
||||||
|
|
||||||
from jinja2 import Environment, StrictUndefined
|
from jinja2 import Environment, StrictUndefined
|
||||||
|
|
||||||
from pr_agent.algo.ai_handler import AiHandler
|
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||||
|
from pr_agent.algo.ai_handlers.litellm_ai_handler import LiteLLMAIHandler
|
||||||
from pr_agent.algo.pr_processing import get_pr_diff, get_pr_multi_diffs, retry_with_fallback_models
|
from pr_agent.algo.pr_processing import get_pr_diff, get_pr_multi_diffs, retry_with_fallback_models
|
||||||
from pr_agent.algo.token_handler import TokenHandler
|
from pr_agent.algo.token_handler import TokenHandler
|
||||||
from pr_agent.algo.utils import load_yaml
|
from pr_agent.algo.utils import load_yaml
|
||||||
@ -15,7 +16,8 @@ from pr_agent.log import get_logger
|
|||||||
|
|
||||||
|
|
||||||
class PRCodeSuggestions:
|
class PRCodeSuggestions:
|
||||||
def __init__(self, pr_url: str, cli_mode=False, args: list = None):
|
def __init__(self, pr_url: str, cli_mode=False, args: list = None,
|
||||||
|
ai_handler: partial[BaseAiHandler,] = LiteLLMAIHandler):
|
||||||
|
|
||||||
self.git_provider = get_git_provider()(pr_url)
|
self.git_provider = get_git_provider()(pr_url)
|
||||||
self.main_language = get_main_pr_language(
|
self.main_language = get_main_pr_language(
|
||||||
@ -24,7 +26,7 @@ class PRCodeSuggestions:
|
|||||||
|
|
||||||
# extended mode
|
# extended mode
|
||||||
try:
|
try:
|
||||||
self.is_extended = any(["extended" in arg for arg in args])
|
self.is_extended = self._get_is_extended(args or [])
|
||||||
except:
|
except:
|
||||||
self.is_extended = False
|
self.is_extended = False
|
||||||
if self.is_extended:
|
if self.is_extended:
|
||||||
@ -32,7 +34,7 @@ class PRCodeSuggestions:
|
|||||||
else:
|
else:
|
||||||
num_code_suggestions = get_settings().pr_code_suggestions.num_code_suggestions
|
num_code_suggestions = get_settings().pr_code_suggestions.num_code_suggestions
|
||||||
|
|
||||||
self.ai_handler = AiHandler()
|
self.ai_handler = ai_handler()
|
||||||
self.patches_diff = None
|
self.patches_diff = None
|
||||||
self.prediction = None
|
self.prediction = None
|
||||||
self.cli_mode = cli_mode
|
self.cli_mode = cli_mode
|
||||||
@ -55,28 +57,32 @@ class PRCodeSuggestions:
|
|||||||
try:
|
try:
|
||||||
get_logger().info('Generating code suggestions for PR...')
|
get_logger().info('Generating code suggestions for PR...')
|
||||||
if get_settings().config.publish_output:
|
if get_settings().config.publish_output:
|
||||||
self.git_provider.publish_comment("Preparing review...", is_temporary=True)
|
self.git_provider.publish_comment("Preparing suggestions...", is_temporary=True)
|
||||||
|
|
||||||
get_logger().info('Preparing PR review...')
|
get_logger().info('Preparing PR code suggestions...')
|
||||||
if not self.is_extended:
|
if not self.is_extended:
|
||||||
await retry_with_fallback_models(self._prepare_prediction)
|
await retry_with_fallback_models(self._prepare_prediction)
|
||||||
data = self._prepare_pr_code_suggestions()
|
data = self._prepare_pr_code_suggestions()
|
||||||
else:
|
else:
|
||||||
data = await retry_with_fallback_models(self._prepare_prediction_extended)
|
data = await retry_with_fallback_models(self._prepare_prediction_extended)
|
||||||
if (not data) or (not 'Code suggestions' in data):
|
if (not data) or (not 'code_suggestions' in data):
|
||||||
get_logger().info('No code suggestions found for PR.')
|
get_logger().info('No code suggestions found for PR.')
|
||||||
return
|
return
|
||||||
|
|
||||||
if (not self.is_extended and get_settings().pr_code_suggestions.rank_suggestions) or \
|
if (not self.is_extended and get_settings().pr_code_suggestions.rank_suggestions) or \
|
||||||
(self.is_extended and get_settings().pr_code_suggestions.rank_extended_suggestions):
|
(self.is_extended and get_settings().pr_code_suggestions.rank_extended_suggestions):
|
||||||
get_logger().info('Ranking Suggestions...')
|
get_logger().info('Ranking Suggestions...')
|
||||||
data['Code suggestions'] = await self.rank_suggestions(data['Code suggestions'])
|
data['code_suggestions'] = await self.rank_suggestions(data['code_suggestions'])
|
||||||
|
|
||||||
if get_settings().config.publish_output:
|
if get_settings().config.publish_output:
|
||||||
get_logger().info('Pushing PR review...')
|
get_logger().info('Pushing PR code suggestions...')
|
||||||
self.git_provider.remove_initial_comment()
|
self.git_provider.remove_initial_comment()
|
||||||
get_logger().info('Pushing inline code suggestions...')
|
if get_settings().pr_code_suggestions.summarize:
|
||||||
self.push_inline_code_suggestions(data)
|
get_logger().info('Pushing summarize code suggestions...')
|
||||||
|
self.publish_summarizes_suggestions(data)
|
||||||
|
else:
|
||||||
|
get_logger().info('Pushing inline code suggestions...')
|
||||||
|
self.push_inline_code_suggestions(data)
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
get_logger().error(f"Failed to generate code suggestions for PR, error: {e}")
|
get_logger().error(f"Failed to generate code suggestions for PR, error: {e}")
|
||||||
|
|
||||||
@ -103,47 +109,80 @@ class PRCodeSuggestions:
|
|||||||
response, finish_reason = await self.ai_handler.chat_completion(model=model, temperature=0.2,
|
response, finish_reason = await self.ai_handler.chat_completion(model=model, temperature=0.2,
|
||||||
system=system_prompt, user=user_prompt)
|
system=system_prompt, user=user_prompt)
|
||||||
|
|
||||||
|
if get_settings().config.verbosity_level >= 2:
|
||||||
|
get_logger().info(f"\nAI response:\n{response}")
|
||||||
|
|
||||||
return response
|
return response
|
||||||
|
|
||||||
def _prepare_pr_code_suggestions(self) -> Dict:
|
def _prepare_pr_code_suggestions(self) -> Dict:
|
||||||
review = self.prediction.strip()
|
review = self.prediction.strip()
|
||||||
data = load_yaml(review)
|
data = load_yaml(review,
|
||||||
|
keys_fix_yaml=["relevant_file", "suggestion_content", "existing_code", "improved_code"])
|
||||||
if isinstance(data, list):
|
if isinstance(data, list):
|
||||||
data = {'Code suggestions': data}
|
data = {'code_suggestions': data}
|
||||||
|
|
||||||
|
# remove invalid suggestions
|
||||||
|
suggestion_list = []
|
||||||
|
for i, suggestion in enumerate(data['code_suggestions']):
|
||||||
|
if suggestion['existing_code'] != suggestion['improved_code']:
|
||||||
|
suggestion_list.append(suggestion)
|
||||||
|
else:
|
||||||
|
get_logger().debug(
|
||||||
|
f"Skipping suggestion {i + 1}, because existing code is equal to improved code {suggestion['existing_code']}")
|
||||||
|
data['code_suggestions'] = suggestion_list
|
||||||
|
|
||||||
return data
|
return data
|
||||||
|
|
||||||
def push_inline_code_suggestions(self, data):
|
def push_inline_code_suggestions(self, data):
|
||||||
code_suggestions = []
|
code_suggestions = []
|
||||||
|
|
||||||
if not data['Code suggestions']:
|
if not data['code_suggestions']:
|
||||||
|
get_logger().info('No suggestions found to improve this PR.')
|
||||||
return self.git_provider.publish_comment('No suggestions found to improve this PR.')
|
return self.git_provider.publish_comment('No suggestions found to improve this PR.')
|
||||||
|
|
||||||
for d in data['Code suggestions']:
|
for d in data['code_suggestions']:
|
||||||
try:
|
try:
|
||||||
if get_settings().config.verbosity_level >= 2:
|
if get_settings().config.verbosity_level >= 2:
|
||||||
get_logger().info(f"suggestion: {d}")
|
get_logger().info(f"suggestion: {d}")
|
||||||
relevant_file = d['relevant file'].strip()
|
relevant_file = d['relevant_file'].strip()
|
||||||
relevant_lines_start = int(d['relevant lines start']) # absolute position
|
relevant_lines_start = int(d['relevant_lines_start']) # absolute position
|
||||||
relevant_lines_end = int(d['relevant lines end'])
|
relevant_lines_end = int(d['relevant_lines_end'])
|
||||||
content = d['suggestion content']
|
content = d['suggestion_content'].rstrip()
|
||||||
new_code_snippet = d['improved code']
|
new_code_snippet = d['improved_code'].rstrip()
|
||||||
|
label = d['label'].strip()
|
||||||
|
|
||||||
if new_code_snippet:
|
if new_code_snippet:
|
||||||
new_code_snippet = self.dedent_code(relevant_file, relevant_lines_start, new_code_snippet)
|
new_code_snippet = self.dedent_code(relevant_file, relevant_lines_start, new_code_snippet)
|
||||||
|
|
||||||
body = f"**Suggestion:** {content}\n```suggestion\n" + new_code_snippet + "\n```"
|
if get_settings().pr_code_suggestions.include_improved_code:
|
||||||
code_suggestions.append({'body': body, 'relevant_file': relevant_file,
|
body = f"**Suggestion:** {content} [{label}]\n```suggestion\n" + new_code_snippet + "\n```"
|
||||||
'relevant_lines_start': relevant_lines_start,
|
code_suggestions.append({'body': body, 'relevant_file': relevant_file,
|
||||||
'relevant_lines_end': relevant_lines_end})
|
'relevant_lines_start': relevant_lines_start,
|
||||||
|
'relevant_lines_end': relevant_lines_end})
|
||||||
|
else:
|
||||||
|
if self.git_provider.is_supported("create_inline_comment"):
|
||||||
|
body = f"**Suggestion:** {content} [{label}]"
|
||||||
|
comment = self.git_provider.create_inline_comment(body, relevant_file, "",
|
||||||
|
absolute_position=relevant_lines_end)
|
||||||
|
if comment:
|
||||||
|
code_suggestions.append(comment)
|
||||||
|
else:
|
||||||
|
get_logger().error("Inline comments are not supported by the git provider")
|
||||||
except Exception:
|
except Exception:
|
||||||
if get_settings().config.verbosity_level >= 2:
|
if get_settings().config.verbosity_level >= 2:
|
||||||
get_logger().info(f"Could not parse suggestion: {d}")
|
get_logger().info(f"Could not parse suggestion: {d}")
|
||||||
|
|
||||||
is_successful = self.git_provider.publish_code_suggestions(code_suggestions)
|
if get_settings().pr_code_suggestions.include_improved_code:
|
||||||
|
is_successful = self.git_provider.publish_code_suggestions(code_suggestions)
|
||||||
|
else:
|
||||||
|
is_successful = self.git_provider.publish_inline_comments(code_suggestions)
|
||||||
if not is_successful:
|
if not is_successful:
|
||||||
get_logger().info("Failed to publish code suggestions, trying to publish each suggestion separately")
|
get_logger().info("Failed to publish code suggestions, trying to publish each suggestion separately")
|
||||||
for code_suggestion in code_suggestions:
|
for code_suggestion in code_suggestions:
|
||||||
self.git_provider.publish_code_suggestions([code_suggestion])
|
if get_settings().pr_code_suggestions.include_improved_code:
|
||||||
|
self.git_provider.publish_code_suggestions([code_suggestion])
|
||||||
|
else:
|
||||||
|
self.git_provider.publish_inline_comments([code_suggestion])
|
||||||
|
|
||||||
def dedent_code(self, relevant_file, relevant_lines_start, new_code_snippet):
|
def dedent_code(self, relevant_file, relevant_lines_start, new_code_snippet):
|
||||||
try: # dedent code snippet
|
try: # dedent code snippet
|
||||||
@ -167,6 +206,16 @@ class PRCodeSuggestions:
|
|||||||
|
|
||||||
return new_code_snippet
|
return new_code_snippet
|
||||||
|
|
||||||
|
def _get_is_extended(self, args: list[str]) -> bool:
|
||||||
|
"""Check if extended mode should be enabled by the `--extended` flag or automatically according to the configuration"""
|
||||||
|
if any(["extended" in arg for arg in args]):
|
||||||
|
get_logger().info("Extended mode is enabled by the `--extended` flag")
|
||||||
|
return True
|
||||||
|
if get_settings().pr_code_suggestions.auto_extended_mode:
|
||||||
|
get_logger().info("Extended mode is enabled automatically based on the configuration toggle")
|
||||||
|
return True
|
||||||
|
return False
|
||||||
|
|
||||||
async def _prepare_prediction_extended(self, model: str) -> dict:
|
async def _prepare_prediction_extended(self, model: str) -> dict:
|
||||||
get_logger().info('Getting PR diff...')
|
get_logger().info('Getting PR diff...')
|
||||||
patches_diff_list = get_pr_multi_diffs(self.git_provider, self.token_handler, model,
|
patches_diff_list = get_pr_multi_diffs(self.git_provider, self.token_handler, model,
|
||||||
@ -185,8 +234,8 @@ class PRCodeSuggestions:
|
|||||||
for prediction in prediction_list:
|
for prediction in prediction_list:
|
||||||
self.prediction = prediction
|
self.prediction = prediction
|
||||||
data_per_chunk = self._prepare_pr_code_suggestions()
|
data_per_chunk = self._prepare_pr_code_suggestions()
|
||||||
if "Code suggestions" in data:
|
if "code_suggestions" in data:
|
||||||
data["Code suggestions"].extend(data_per_chunk["Code suggestions"])
|
data["code_suggestions"].extend(data_per_chunk["code_suggestions"])
|
||||||
else:
|
else:
|
||||||
data.update(data_per_chunk)
|
data.update(data_per_chunk)
|
||||||
self.data = data
|
self.data = data
|
||||||
@ -204,11 +253,8 @@ class PRCodeSuggestions:
|
|||||||
"""
|
"""
|
||||||
|
|
||||||
suggestion_list = []
|
suggestion_list = []
|
||||||
# remove invalid suggestions
|
for suggestion in data:
|
||||||
for i, suggestion in enumerate(data):
|
suggestion_list.append(suggestion)
|
||||||
if suggestion['existing code'] != suggestion['improved code']:
|
|
||||||
suggestion_list.append(suggestion)
|
|
||||||
|
|
||||||
data_sorted = [[]] * len(suggestion_list)
|
data_sorted = [[]] * len(suggestion_list)
|
||||||
|
|
||||||
try:
|
try:
|
||||||
@ -235,8 +281,14 @@ class PRCodeSuggestions:
|
|||||||
data_sorted[importance_order - 1] = suggestion_list[suggestion_number - 1]
|
data_sorted[importance_order - 1] = suggestion_list[suggestion_number - 1]
|
||||||
|
|
||||||
if get_settings().pr_code_suggestions.final_clip_factor != 1:
|
if get_settings().pr_code_suggestions.final_clip_factor != 1:
|
||||||
new_len = int(0.5 + len(data_sorted) * get_settings().pr_code_suggestions.final_clip_factor)
|
max_len = max(
|
||||||
data_sorted = data_sorted[:new_len]
|
len(data_sorted),
|
||||||
|
get_settings().pr_code_suggestions.num_code_suggestions,
|
||||||
|
get_settings().pr_code_suggestions.num_code_suggestions_per_chunk,
|
||||||
|
)
|
||||||
|
new_len = int(0.5 + max_len * get_settings().pr_code_suggestions.final_clip_factor)
|
||||||
|
if new_len < len(data_sorted):
|
||||||
|
data_sorted = data_sorted[:new_len]
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
if get_settings().config.verbosity_level >= 1:
|
if get_settings().config.verbosity_level >= 1:
|
||||||
get_logger().info(f"Could not sort suggestions, error: {e}")
|
get_logger().info(f"Could not sort suggestions, error: {e}")
|
||||||
@ -244,4 +296,40 @@ class PRCodeSuggestions:
|
|||||||
|
|
||||||
return data_sorted
|
return data_sorted
|
||||||
|
|
||||||
|
def publish_summarizes_suggestions(self, data: Dict):
|
||||||
|
try:
|
||||||
|
data_markdown = "## PR Code Suggestions\n\n"
|
||||||
|
|
||||||
|
language_extension_map_org = get_settings().language_extension_map_org
|
||||||
|
extension_to_language = {}
|
||||||
|
for language, extensions in language_extension_map_org.items():
|
||||||
|
for ext in extensions:
|
||||||
|
extension_to_language[ext] = language
|
||||||
|
|
||||||
|
for s in data['code_suggestions']:
|
||||||
|
try:
|
||||||
|
extension_s = s['relevant_file'].rsplit('.')[-1]
|
||||||
|
code_snippet_link = self.git_provider.get_line_link(s['relevant_file'], s['relevant_lines_start'],
|
||||||
|
s['relevant_lines_end'])
|
||||||
|
label = s['label'].strip()
|
||||||
|
data_markdown += f"\n💡 [{label}]\n\n**{s['suggestion_content'].rstrip().rstrip()}**\n\n"
|
||||||
|
if code_snippet_link:
|
||||||
|
data_markdown += f" File: [{s['relevant_file']} ({s['relevant_lines_start']}-{s['relevant_lines_end']})]({code_snippet_link})\n\n"
|
||||||
|
else:
|
||||||
|
data_markdown += f"File: {s['relevant_file']} ({s['relevant_lines_start']}-{s['relevant_lines_end']})\n\n"
|
||||||
|
if self.git_provider.is_supported("gfm_markdown"):
|
||||||
|
data_markdown += "<details> <summary> Example code:</summary>\n\n"
|
||||||
|
data_markdown += f"___\n\n"
|
||||||
|
language_name = "python"
|
||||||
|
if extension_s and (extension_s in extension_to_language):
|
||||||
|
language_name = extension_to_language[extension_s]
|
||||||
|
data_markdown += f"Existing code:\n```{language_name}\n{s['existing_code'].rstrip()}\n```\n"
|
||||||
|
data_markdown += f"Improved code:\n```{language_name}\n{s['improved_code'].rstrip()}\n```\n"
|
||||||
|
if self.git_provider.is_supported("gfm_markdown"):
|
||||||
|
data_markdown += "</details>\n"
|
||||||
|
data_markdown += "\n___\n\n"
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().error(f"Could not parse suggestion: {s}, error: {e}")
|
||||||
|
self.git_provider.publish_comment(data_markdown)
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().info(f"Failed to publish summarized code suggestions, error: {e}")
|
||||||
|
|||||||
@ -7,7 +7,7 @@ class PRConfig:
|
|||||||
"""
|
"""
|
||||||
The PRConfig class is responsible for listing all configuration options available for the user.
|
The PRConfig class is responsible for listing all configuration options available for the user.
|
||||||
"""
|
"""
|
||||||
def __init__(self, pr_url: str, args=None):
|
def __init__(self, pr_url: str, args=None, ai_handler=None):
|
||||||
"""
|
"""
|
||||||
Initialize the PRConfig object with the necessary attributes and objects to comment on a pull request.
|
Initialize the PRConfig object with the necessary attributes and objects to comment on a pull request.
|
||||||
|
|
||||||
|
|||||||
@ -1,13 +1,15 @@
|
|||||||
import copy
|
import copy
|
||||||
import re
|
import re
|
||||||
|
from functools import partial
|
||||||
from typing import List, Tuple
|
from typing import List, Tuple
|
||||||
|
|
||||||
from jinja2 import Environment, StrictUndefined
|
from jinja2 import Environment, StrictUndefined
|
||||||
|
|
||||||
from pr_agent.algo.ai_handler import AiHandler
|
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||||
|
from pr_agent.algo.ai_handlers.litellm_ai_handler import LiteLLMAIHandler
|
||||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||||
from pr_agent.algo.token_handler import TokenHandler
|
from pr_agent.algo.token_handler import TokenHandler
|
||||||
from pr_agent.algo.utils import load_yaml, set_custom_labels
|
from pr_agent.algo.utils import load_yaml, set_custom_labels, get_user_labels
|
||||||
from pr_agent.config_loader import get_settings
|
from pr_agent.config_loader import get_settings
|
||||||
from pr_agent.git_providers import get_git_provider
|
from pr_agent.git_providers import get_git_provider
|
||||||
from pr_agent.git_providers.git_provider import get_main_pr_language
|
from pr_agent.git_providers.git_provider import get_main_pr_language
|
||||||
@ -15,7 +17,8 @@ from pr_agent.log import get_logger
|
|||||||
|
|
||||||
|
|
||||||
class PRDescription:
|
class PRDescription:
|
||||||
def __init__(self, pr_url: str, args: list = None):
|
def __init__(self, pr_url: str, args: list = None,
|
||||||
|
ai_handler: partial[BaseAiHandler,] = LiteLLMAIHandler):
|
||||||
"""
|
"""
|
||||||
Initialize the PRDescription object with the necessary attributes and objects for generating a PR description
|
Initialize the PRDescription object with the necessary attributes and objects for generating a PR description
|
||||||
using an AI model.
|
using an AI model.
|
||||||
@ -30,8 +33,13 @@ class PRDescription:
|
|||||||
)
|
)
|
||||||
self.pr_id = self.git_provider.get_pr_id()
|
self.pr_id = self.git_provider.get_pr_id()
|
||||||
|
|
||||||
|
if get_settings().pr_description.enable_semantic_files_types and not self.git_provider.is_supported(
|
||||||
|
"gfm_markdown"):
|
||||||
|
get_logger().debug(f"Disabling semantic files types for {self.pr_id}")
|
||||||
|
get_settings().pr_description.enable_semantic_files_types = False
|
||||||
|
|
||||||
# Initialize the AI handler
|
# Initialize the AI handler
|
||||||
self.ai_handler = AiHandler()
|
self.ai_handler = ai_handler()
|
||||||
|
|
||||||
# Initialize the variables dictionary
|
# Initialize the variables dictionary
|
||||||
self.vars = {
|
self.vars = {
|
||||||
@ -40,12 +48,11 @@ class PRDescription:
|
|||||||
"description": self.git_provider.get_pr_description(full=False),
|
"description": self.git_provider.get_pr_description(full=False),
|
||||||
"language": self.main_pr_language,
|
"language": self.main_pr_language,
|
||||||
"diff": "", # empty diff for initial calculation
|
"diff": "", # empty diff for initial calculation
|
||||||
"use_bullet_points": get_settings().pr_description.use_bullet_points,
|
|
||||||
"extra_instructions": get_settings().pr_description.extra_instructions,
|
"extra_instructions": get_settings().pr_description.extra_instructions,
|
||||||
"commit_messages_str": self.git_provider.get_commit_messages(),
|
"commit_messages_str": self.git_provider.get_commit_messages(),
|
||||||
"enable_custom_labels": get_settings().config.enable_custom_labels,
|
"enable_custom_labels": get_settings().config.enable_custom_labels,
|
||||||
"custom_labels": "",
|
"custom_labels_class": "", # will be filled if necessary in 'set_custom_labels' function
|
||||||
"custom_labels_examples": "",
|
"enable_semantic_files_types": get_settings().pr_description.enable_semantic_files_types,
|
||||||
}
|
}
|
||||||
|
|
||||||
self.user_description = self.git_provider.get_user_description()
|
self.user_description = self.git_provider.get_user_description()
|
||||||
@ -80,6 +87,9 @@ class PRDescription:
|
|||||||
else:
|
else:
|
||||||
return None
|
return None
|
||||||
|
|
||||||
|
if get_settings().pr_description.enable_semantic_files_types:
|
||||||
|
self._prepare_file_labels()
|
||||||
|
|
||||||
pr_labels = []
|
pr_labels = []
|
||||||
if get_settings().pr_description.publish_labels:
|
if get_settings().pr_description.publish_labels:
|
||||||
pr_labels = self._prepare_labels()
|
pr_labels = self._prepare_labels()
|
||||||
@ -93,14 +103,21 @@ class PRDescription:
|
|||||||
if get_settings().config.publish_output:
|
if get_settings().config.publish_output:
|
||||||
get_logger().info(f"Pushing answer {self.pr_id}")
|
get_logger().info(f"Pushing answer {self.pr_id}")
|
||||||
if get_settings().pr_description.publish_description_as_comment:
|
if get_settings().pr_description.publish_description_as_comment:
|
||||||
|
get_logger().info(f"Publishing answer as comment")
|
||||||
self.git_provider.publish_comment(full_markdown_description)
|
self.git_provider.publish_comment(full_markdown_description)
|
||||||
else:
|
else:
|
||||||
self.git_provider.publish_description(pr_title, pr_body)
|
self.git_provider.publish_description(pr_title, pr_body)
|
||||||
if get_settings().pr_description.publish_labels and self.git_provider.is_supported("get_labels"):
|
if get_settings().pr_description.publish_labels and self.git_provider.is_supported("get_labels"):
|
||||||
current_labels = self.git_provider.get_labels()
|
current_labels = self.git_provider.get_pr_labels()
|
||||||
if current_labels is None:
|
user_labels = get_user_labels(current_labels)
|
||||||
current_labels = []
|
self.git_provider.publish_labels(pr_labels + user_labels)
|
||||||
self.git_provider.publish_labels(pr_labels + current_labels)
|
|
||||||
|
if (get_settings().pr_description.final_update_message and
|
||||||
|
hasattr(self.git_provider, 'pr_url') and self.git_provider.pr_url):
|
||||||
|
latest_commit_url = self.git_provider.get_latest_commit_url()
|
||||||
|
if latest_commit_url:
|
||||||
|
self.git_provider.publish_comment(
|
||||||
|
f"**[PR Description]({self.git_provider.pr_url})** updated to latest commit ({latest_commit_url})")
|
||||||
self.git_provider.remove_initial_comment()
|
self.git_provider.remove_initial_comment()
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
get_logger().error(f"Error generating PR description {self.pr_id}: {e}")
|
get_logger().error(f"Error generating PR description {self.pr_id}: {e}")
|
||||||
@ -143,7 +160,8 @@ class PRDescription:
|
|||||||
variables["diff"] = self.patches_diff # update diff
|
variables["diff"] = self.patches_diff # update diff
|
||||||
|
|
||||||
environment = Environment(undefined=StrictUndefined)
|
environment = Environment(undefined=StrictUndefined)
|
||||||
set_custom_labels(variables)
|
set_custom_labels(variables, self.git_provider)
|
||||||
|
self.variables = variables
|
||||||
system_prompt = environment.from_string(get_settings().pr_description_prompt.system).render(variables)
|
system_prompt = environment.from_string(get_settings().pr_description_prompt.system).render(variables)
|
||||||
user_prompt = environment.from_string(get_settings().pr_description_prompt.user).render(variables)
|
user_prompt = environment.from_string(get_settings().pr_description_prompt.user).render(variables)
|
||||||
|
|
||||||
@ -158,6 +176,9 @@ class PRDescription:
|
|||||||
user=user_prompt
|
user=user_prompt
|
||||||
)
|
)
|
||||||
|
|
||||||
|
if get_settings().config.verbosity_level >= 2:
|
||||||
|
get_logger().info(f"\nAI response:\n{response}")
|
||||||
|
|
||||||
return response
|
return response
|
||||||
|
|
||||||
def _prepare_data(self):
|
def _prepare_data(self):
|
||||||
@ -167,17 +188,47 @@ class PRDescription:
|
|||||||
if get_settings().pr_description.add_original_user_description and self.user_description:
|
if get_settings().pr_description.add_original_user_description and self.user_description:
|
||||||
self.data["User Description"] = self.user_description
|
self.data["User Description"] = self.user_description
|
||||||
|
|
||||||
|
# re-order keys
|
||||||
|
if 'User Description' in self.data:
|
||||||
|
self.data['User Description'] = self.data.pop('User Description')
|
||||||
|
if 'title' in self.data:
|
||||||
|
self.data['title'] = self.data.pop('title')
|
||||||
|
if 'type' in self.data:
|
||||||
|
self.data['type'] = self.data.pop('type')
|
||||||
|
if 'labels' in self.data:
|
||||||
|
self.data['labels'] = self.data.pop('labels')
|
||||||
|
if 'description' in self.data:
|
||||||
|
self.data['description'] = self.data.pop('description')
|
||||||
|
if 'pr_files' in self.data:
|
||||||
|
self.data['pr_files'] = self.data.pop('pr_files')
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
def _prepare_labels(self) -> List[str]:
|
def _prepare_labels(self) -> List[str]:
|
||||||
pr_types = []
|
pr_types = []
|
||||||
|
|
||||||
# If the 'PR Type' key is present in the dictionary, split its value by comma and assign it to 'pr_types'
|
# If the 'PR Type' key is present in the dictionary, split its value by comma and assign it to 'pr_types'
|
||||||
if 'PR Type' in self.data:
|
if 'labels' in self.data:
|
||||||
if type(self.data['PR Type']) == list:
|
if type(self.data['labels']) == list:
|
||||||
pr_types = self.data['PR Type']
|
pr_types = self.data['labels']
|
||||||
elif type(self.data['PR Type']) == str:
|
elif type(self.data['labels']) == str:
|
||||||
pr_types = self.data['PR Type'].split(',')
|
pr_types = self.data['labels'].split(',')
|
||||||
|
elif 'type' in self.data:
|
||||||
|
if type(self.data['type']) == list:
|
||||||
|
pr_types = self.data['type']
|
||||||
|
elif type(self.data['type']) == str:
|
||||||
|
pr_types = self.data['type'].split(',')
|
||||||
|
|
||||||
|
# convert lowercase labels to original case
|
||||||
|
try:
|
||||||
|
if "labels_minimal_to_labels_dict" in self.variables:
|
||||||
|
d: dict = self.variables["labels_minimal_to_labels_dict"]
|
||||||
|
for i, label_i in enumerate(pr_types):
|
||||||
|
if label_i in d:
|
||||||
|
pr_types[i] = d[label_i]
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().error(f"Error converting labels to original case {self.pr_id}: {e}")
|
||||||
return pr_types
|
return pr_types
|
||||||
|
|
||||||
def _prepare_pr_answer_with_markers(self) -> Tuple[str, str]:
|
def _prepare_pr_answer_with_markers(self) -> Tuple[str, str]:
|
||||||
@ -189,26 +240,25 @@ class PRDescription:
|
|||||||
else:
|
else:
|
||||||
ai_header = ""
|
ai_header = ""
|
||||||
|
|
||||||
ai_type = self.data.get('PR Type')
|
ai_type = self.data.get('type')
|
||||||
if ai_type and not re.search(r'<!--\s*pr_agent:type\s*-->', body):
|
if ai_type and not re.search(r'<!--\s*pr_agent:type\s*-->', body):
|
||||||
pr_type = f"{ai_header}{ai_type}"
|
pr_type = f"{ai_header}{ai_type}"
|
||||||
body = body.replace('pr_agent:type', pr_type)
|
body = body.replace('pr_agent:type', pr_type)
|
||||||
|
|
||||||
ai_summary = self.data.get('PR Description')
|
ai_summary = self.data.get('description')
|
||||||
if ai_summary and not re.search(r'<!--\s*pr_agent:summary\s*-->', body):
|
if ai_summary and not re.search(r'<!--\s*pr_agent:summary\s*-->', body):
|
||||||
summary = f"{ai_header}{ai_summary}"
|
summary = f"{ai_header}{ai_summary}"
|
||||||
body = body.replace('pr_agent:summary', summary)
|
body = body.replace('pr_agent:summary', summary)
|
||||||
|
|
||||||
if not re.search(r'<!--\s*pr_agent:walkthrough\s*-->', body):
|
ai_walkthrough = self.data.get('pr_files')
|
||||||
ai_walkthrough = self.data.get('PR Main Files Walkthrough')
|
if ai_walkthrough and not re.search(r'<!--\s*pr_agent:walkthrough\s*-->', body):
|
||||||
if ai_walkthrough:
|
try:
|
||||||
walkthrough = str(ai_header)
|
walkthrough_gfm = ""
|
||||||
for file in ai_walkthrough:
|
walkthrough_gfm = self.process_pr_files_prediction(walkthrough_gfm, self.file_label_dict)
|
||||||
filename = file['filename'].replace("'", "`")
|
body = body.replace('pr_agent:walkthrough', walkthrough_gfm)
|
||||||
description = file['changes in file'].replace("'", "`")
|
except Exception as e:
|
||||||
walkthrough += f'- `{filename}`: {description}\n'
|
get_logger().error(f"Failing to process walkthrough {self.pr_id}: {e}")
|
||||||
|
body = body.replace('pr_agent:walkthrough', "")
|
||||||
body = body.replace('pr_agent:walkthrough', walkthrough)
|
|
||||||
|
|
||||||
return title, body
|
return title, body
|
||||||
|
|
||||||
@ -223,12 +273,17 @@ class PRDescription:
|
|||||||
|
|
||||||
# Iterate over the dictionary items and append the key and value to 'markdown_text' in a markdown format
|
# Iterate over the dictionary items and append the key and value to 'markdown_text' in a markdown format
|
||||||
markdown_text = ""
|
markdown_text = ""
|
||||||
|
# Don't display 'PR Labels'
|
||||||
|
if 'labels' in self.data and self.git_provider.is_supported("get_labels"):
|
||||||
|
self.data.pop('labels')
|
||||||
|
if not get_settings().pr_description.enable_pr_type:
|
||||||
|
self.data.pop('type')
|
||||||
for key, value in self.data.items():
|
for key, value in self.data.items():
|
||||||
markdown_text += f"## {key}\n\n"
|
markdown_text += f"## {key}\n\n"
|
||||||
markdown_text += f"{value}\n\n"
|
markdown_text += f"{value}\n\n"
|
||||||
|
|
||||||
# Remove the 'PR Title' key from the dictionary
|
# Remove the 'PR Title' key from the dictionary
|
||||||
ai_title = self.data.pop('PR Title', self.vars["title"])
|
ai_title = self.data.pop('title', self.vars["title"])
|
||||||
if get_settings().pr_description.keep_original_user_title:
|
if get_settings().pr_description.keep_original_user_title:
|
||||||
# Assign the original PR title to the 'title' variable
|
# Assign the original PR title to the 'title' variable
|
||||||
title = self.vars["title"]
|
title = self.vars["title"]
|
||||||
@ -240,26 +295,147 @@ class PRDescription:
|
|||||||
# except for the items containing the word 'walkthrough'
|
# except for the items containing the word 'walkthrough'
|
||||||
pr_body = ""
|
pr_body = ""
|
||||||
for idx, (key, value) in enumerate(self.data.items()):
|
for idx, (key, value) in enumerate(self.data.items()):
|
||||||
pr_body += f"## {key}:\n"
|
if key == 'pr_files':
|
||||||
|
value = self.file_label_dict
|
||||||
|
key_publish = "Changes walkthrough"
|
||||||
|
else:
|
||||||
|
key_publish = key.rstrip(':').replace("_", " ").capitalize()
|
||||||
|
pr_body += f"## {key_publish}\n"
|
||||||
if 'walkthrough' in key.lower():
|
if 'walkthrough' in key.lower():
|
||||||
# for filename, description in value.items():
|
|
||||||
if self.git_provider.is_supported("gfm_markdown"):
|
if self.git_provider.is_supported("gfm_markdown"):
|
||||||
pr_body += "<details> <summary>files:</summary>\n\n"
|
pr_body += "<details> <summary>files:</summary>\n\n"
|
||||||
for file in value:
|
for file in value:
|
||||||
filename = file['filename'].replace("'", "`")
|
filename = file['filename'].replace("'", "`")
|
||||||
description = file['changes in file']
|
description = file['changes_in_file']
|
||||||
pr_body += f'`{filename}`: {description}\n'
|
pr_body += f'- `{filename}`: {description}\n'
|
||||||
if self.git_provider.is_supported("gfm_markdown"):
|
if self.git_provider.is_supported("gfm_markdown"):
|
||||||
pr_body +="</details>\n"
|
pr_body += "</details>\n"
|
||||||
|
elif 'pr_files' in key.lower():
|
||||||
|
pr_body = self.process_pr_files_prediction(pr_body, value)
|
||||||
else:
|
else:
|
||||||
# if the value is a list, join its items by comma
|
# if the value is a list, join its items by comma
|
||||||
if type(value) == list:
|
if isinstance(value, list):
|
||||||
value = ', '.join(v for v in value)
|
value = ', '.join(v for v in value)
|
||||||
pr_body += f"{value}\n"
|
pr_body += f"{value}\n"
|
||||||
if idx < len(self.data) - 1:
|
if idx < len(self.data) - 1:
|
||||||
pr_body += "\n___\n"
|
pr_body += "\n\n___\n\n"
|
||||||
|
|
||||||
if get_settings().config.verbosity_level >= 2:
|
if get_settings().config.verbosity_level >= 2:
|
||||||
get_logger().info(f"title:\n{title}\n{pr_body}")
|
get_logger().info(f"title:\n{title}\n{pr_body}")
|
||||||
|
|
||||||
return title, pr_body
|
return title, pr_body
|
||||||
|
|
||||||
|
def _prepare_file_labels(self):
|
||||||
|
self.file_label_dict = {}
|
||||||
|
for file in self.data['pr_files']:
|
||||||
|
try:
|
||||||
|
filename = file['filename'].replace("'", "`").replace('"', '`')
|
||||||
|
changes_summary = file['changes_summary']
|
||||||
|
label = file.get('label')
|
||||||
|
if label not in self.file_label_dict:
|
||||||
|
self.file_label_dict[label] = []
|
||||||
|
self.file_label_dict[label].append((filename, changes_summary))
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().error(f"Error preparing file label dict {self.pr_id}: {e}")
|
||||||
|
pass
|
||||||
|
|
||||||
|
def process_pr_files_prediction(self, pr_body, value):
|
||||||
|
# logic for using collapsible file list
|
||||||
|
use_collapsible_file_list = get_settings().pr_description.collapsible_file_list
|
||||||
|
num_files = 0
|
||||||
|
if value:
|
||||||
|
for semantic_label in value.keys():
|
||||||
|
num_files += len(value[semantic_label])
|
||||||
|
if use_collapsible_file_list == "adaptive":
|
||||||
|
use_collapsible_file_list = num_files > 8
|
||||||
|
|
||||||
|
if not self.git_provider.is_supported("gfm_markdown"):
|
||||||
|
get_logger().info(f"Disabling semantic files types for {self.pr_id} since gfm_markdown is not supported")
|
||||||
|
return pr_body
|
||||||
|
try:
|
||||||
|
pr_body += "<table>"
|
||||||
|
header = f"Relevant files"
|
||||||
|
delta = 65
|
||||||
|
header += " " * delta
|
||||||
|
pr_body += f"""<thead><tr><th></th><th>{header}</th></tr></thead>"""
|
||||||
|
pr_body += """<tbody>"""
|
||||||
|
for semantic_label in value.keys():
|
||||||
|
s_label = semantic_label.strip("'").strip('"')
|
||||||
|
pr_body += f"""<tr><td><strong>{s_label.capitalize()}</strong></td>"""
|
||||||
|
list_tuples = value[semantic_label]
|
||||||
|
|
||||||
|
if use_collapsible_file_list:
|
||||||
|
pr_body += f"""<td><details><summary>{len(list_tuples)} files</summary><table>"""
|
||||||
|
else:
|
||||||
|
pr_body += f"""<td><table>"""
|
||||||
|
for filename, file_change_description in list_tuples:
|
||||||
|
filename = filename.replace("'", "`")
|
||||||
|
filename_publish = filename.split("/")[-1]
|
||||||
|
filename_publish = f"{filename_publish}"
|
||||||
|
if len(filename_publish) < (delta - 5):
|
||||||
|
filename_publish += " " * ((delta - 5) - len(filename_publish))
|
||||||
|
diff_plus_minus = ""
|
||||||
|
diff_files = self.git_provider.diff_files
|
||||||
|
for f in diff_files:
|
||||||
|
if f.filename.lower() == filename.lower():
|
||||||
|
num_plus_lines = f.num_plus_lines
|
||||||
|
num_minus_lines = f.num_minus_lines
|
||||||
|
diff_plus_minus += f"+{num_plus_lines}/-{num_minus_lines}"
|
||||||
|
break
|
||||||
|
|
||||||
|
# try to add line numbers link to code suggestions
|
||||||
|
link = ""
|
||||||
|
if hasattr(self.git_provider, 'get_line_link'):
|
||||||
|
filename = filename.strip()
|
||||||
|
link = self.git_provider.get_line_link(filename, relevant_line_start=-1)
|
||||||
|
|
||||||
|
file_change_description = self._insert_br_after_x_chars(file_change_description, x=(delta - 5))
|
||||||
|
pr_body += f"""
|
||||||
|
<tr>
|
||||||
|
<td>
|
||||||
|
<details>
|
||||||
|
<summary><strong>{filename_publish}</strong></summary>
|
||||||
|
<ul>
|
||||||
|
{filename}<br><br>
|
||||||
|
|
||||||
|
**{file_change_description}**
|
||||||
|
</ul>
|
||||||
|
</details>
|
||||||
|
</td>
|
||||||
|
<td><a href="{link}"> {diff_plus_minus}</a></td>
|
||||||
|
|
||||||
|
</tr>
|
||||||
|
"""
|
||||||
|
if use_collapsible_file_list:
|
||||||
|
pr_body += """</table></details></td></tr>"""
|
||||||
|
else:
|
||||||
|
pr_body += """</table></td></tr>"""
|
||||||
|
pr_body += """</tr></tbody></table>"""
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().error(f"Error processing pr files to markdown {self.pr_id}: {e}")
|
||||||
|
pass
|
||||||
|
return pr_body
|
||||||
|
|
||||||
|
def _insert_br_after_x_chars(self, text, x=70):
|
||||||
|
"""
|
||||||
|
Insert <br> into a string after a word that increases its length above x characters.
|
||||||
|
"""
|
||||||
|
if len(text) < x:
|
||||||
|
return text
|
||||||
|
|
||||||
|
words = text.split(' ')
|
||||||
|
new_text = ""
|
||||||
|
current_length = 0
|
||||||
|
|
||||||
|
for word in words:
|
||||||
|
# Check if adding this word exceeds x characters
|
||||||
|
if current_length + len(word) > x:
|
||||||
|
new_text += "<br>" # Insert line break
|
||||||
|
current_length = 0 # Reset counter
|
||||||
|
|
||||||
|
# Add the word to the new text
|
||||||
|
new_text += word + " "
|
||||||
|
current_length += len(word) + 1 # Add 1 for the space
|
||||||
|
|
||||||
|
return new_text.strip() # Remove trailing space
|
||||||
|
|||||||
@ -1,13 +1,15 @@
|
|||||||
import copy
|
import copy
|
||||||
import re
|
import re
|
||||||
|
from functools import partial
|
||||||
from typing import List, Tuple
|
from typing import List, Tuple
|
||||||
|
|
||||||
from jinja2 import Environment, StrictUndefined
|
from jinja2 import Environment, StrictUndefined
|
||||||
|
|
||||||
from pr_agent.algo.ai_handler import AiHandler
|
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||||
|
from pr_agent.algo.ai_handlers.litellm_ai_handler import LiteLLMAIHandler
|
||||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||||
from pr_agent.algo.token_handler import TokenHandler
|
from pr_agent.algo.token_handler import TokenHandler
|
||||||
from pr_agent.algo.utils import load_yaml, set_custom_labels
|
from pr_agent.algo.utils import load_yaml, set_custom_labels, get_user_labels
|
||||||
from pr_agent.config_loader import get_settings
|
from pr_agent.config_loader import get_settings
|
||||||
from pr_agent.git_providers import get_git_provider
|
from pr_agent.git_providers import get_git_provider
|
||||||
from pr_agent.git_providers.git_provider import get_main_pr_language
|
from pr_agent.git_providers.git_provider import get_main_pr_language
|
||||||
@ -15,7 +17,8 @@ from pr_agent.log import get_logger
|
|||||||
|
|
||||||
|
|
||||||
class PRGenerateLabels:
|
class PRGenerateLabels:
|
||||||
def __init__(self, pr_url: str, args: list = None):
|
def __init__(self, pr_url: str, args: list = None,
|
||||||
|
ai_handler: partial[BaseAiHandler,] = LiteLLMAIHandler):
|
||||||
"""
|
"""
|
||||||
Initialize the PRGenerateLabels object with the necessary attributes and objects for generating labels
|
Initialize the PRGenerateLabels object with the necessary attributes and objects for generating labels
|
||||||
corresponding to the PR using an AI model.
|
corresponding to the PR using an AI model.
|
||||||
@ -31,7 +34,7 @@ class PRGenerateLabels:
|
|||||||
self.pr_id = self.git_provider.get_pr_id()
|
self.pr_id = self.git_provider.get_pr_id()
|
||||||
|
|
||||||
# Initialize the AI handler
|
# Initialize the AI handler
|
||||||
self.ai_handler = AiHandler()
|
self.ai_handler = ai_handler()
|
||||||
|
|
||||||
# Initialize the variables dictionary
|
# Initialize the variables dictionary
|
||||||
self.vars = {
|
self.vars = {
|
||||||
@ -40,12 +43,10 @@ class PRGenerateLabels:
|
|||||||
"description": self.git_provider.get_pr_description(full=False),
|
"description": self.git_provider.get_pr_description(full=False),
|
||||||
"language": self.main_pr_language,
|
"language": self.main_pr_language,
|
||||||
"diff": "", # empty diff for initial calculation
|
"diff": "", # empty diff for initial calculation
|
||||||
"use_bullet_points": get_settings().pr_description.use_bullet_points,
|
|
||||||
"extra_instructions": get_settings().pr_description.extra_instructions,
|
"extra_instructions": get_settings().pr_description.extra_instructions,
|
||||||
"commit_messages_str": self.git_provider.get_commit_messages(),
|
"commit_messages_str": self.git_provider.get_commit_messages(),
|
||||||
"custom_labels": "",
|
|
||||||
"custom_labels_examples": "",
|
|
||||||
"enable_custom_labels": get_settings().config.enable_custom_labels,
|
"enable_custom_labels": get_settings().config.enable_custom_labels,
|
||||||
|
"custom_labels_class": "", # will be filled if necessary in 'set_custom_labels' function
|
||||||
}
|
}
|
||||||
|
|
||||||
# Initialize the token handler
|
# Initialize the token handler
|
||||||
@ -82,11 +83,17 @@ class PRGenerateLabels:
|
|||||||
|
|
||||||
if get_settings().config.publish_output:
|
if get_settings().config.publish_output:
|
||||||
get_logger().info(f"Pushing labels {self.pr_id}")
|
get_logger().info(f"Pushing labels {self.pr_id}")
|
||||||
|
|
||||||
|
current_labels = self.git_provider.get_pr_labels()
|
||||||
|
user_labels = get_user_labels(current_labels)
|
||||||
|
pr_labels = pr_labels + user_labels
|
||||||
|
|
||||||
if self.git_provider.is_supported("get_labels"):
|
if self.git_provider.is_supported("get_labels"):
|
||||||
current_labels = self.git_provider.get_labels()
|
self.git_provider.publish_labels(pr_labels)
|
||||||
if current_labels is None:
|
elif pr_labels:
|
||||||
current_labels = []
|
value = ', '.join(v for v in pr_labels)
|
||||||
self.git_provider.publish_labels(pr_labels + current_labels)
|
pr_labels_text = f"## PR Labels:\n{value}\n"
|
||||||
|
self.git_provider.publish_comment(pr_labels_text, is_temporary=False)
|
||||||
self.git_provider.remove_initial_comment()
|
self.git_provider.remove_initial_comment()
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
get_logger().error(f"Error generating PR labels {self.pr_id}: {e}")
|
get_logger().error(f"Error generating PR labels {self.pr_id}: {e}")
|
||||||
@ -127,7 +134,8 @@ class PRGenerateLabels:
|
|||||||
variables["diff"] = self.patches_diff # update diff
|
variables["diff"] = self.patches_diff # update diff
|
||||||
|
|
||||||
environment = Environment(undefined=StrictUndefined)
|
environment = Environment(undefined=StrictUndefined)
|
||||||
set_custom_labels(variables)
|
set_custom_labels(variables, self.git_provider)
|
||||||
|
self.variables = variables
|
||||||
system_prompt = environment.from_string(get_settings().pr_custom_labels_prompt.system).render(variables)
|
system_prompt = environment.from_string(get_settings().pr_custom_labels_prompt.system).render(variables)
|
||||||
user_prompt = environment.from_string(get_settings().pr_custom_labels_prompt.user).render(variables)
|
user_prompt = environment.from_string(get_settings().pr_custom_labels_prompt.user).render(variables)
|
||||||
|
|
||||||
@ -142,6 +150,9 @@ class PRGenerateLabels:
|
|||||||
user=user_prompt
|
user=user_prompt
|
||||||
)
|
)
|
||||||
|
|
||||||
|
if get_settings().config.verbosity_level >= 2:
|
||||||
|
get_logger().info(f"\nAI response:\n{response}")
|
||||||
|
|
||||||
return response
|
return response
|
||||||
|
|
||||||
def _prepare_data(self):
|
def _prepare_data(self):
|
||||||
@ -153,11 +164,21 @@ class PRGenerateLabels:
|
|||||||
def _prepare_labels(self) -> List[str]:
|
def _prepare_labels(self) -> List[str]:
|
||||||
pr_types = []
|
pr_types = []
|
||||||
|
|
||||||
# If the 'PR Type' key is present in the dictionary, split its value by comma and assign it to 'pr_types'
|
# If the 'labels' key is present in the dictionary, split its value by comma and assign it to 'pr_types'
|
||||||
if 'PR Type' in self.data:
|
if 'labels' in self.data:
|
||||||
if type(self.data['PR Type']) == list:
|
if type(self.data['labels']) == list:
|
||||||
pr_types = self.data['PR Type']
|
pr_types = self.data['labels']
|
||||||
elif type(self.data['PR Type']) == str:
|
elif type(self.data['labels']) == str:
|
||||||
pr_types = self.data['PR Type'].split(',')
|
pr_types = self.data['labels'].split(',')
|
||||||
|
|
||||||
|
# convert lowercase labels to original case
|
||||||
|
try:
|
||||||
|
if "labels_minimal_to_labels_dict" in self.variables:
|
||||||
|
d: dict = self.variables["labels_minimal_to_labels_dict"]
|
||||||
|
for i, label_i in enumerate(pr_types):
|
||||||
|
if label_i in d:
|
||||||
|
pr_types[i] = d[label_i]
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().error(f"Error converting labels to original case {self.pr_id}: {e}")
|
||||||
|
|
||||||
return pr_types
|
return pr_types
|
||||||
|
|||||||
@ -1,8 +1,10 @@
|
|||||||
import copy
|
import copy
|
||||||
|
from functools import partial
|
||||||
|
|
||||||
from jinja2 import Environment, StrictUndefined
|
from jinja2 import Environment, StrictUndefined
|
||||||
|
|
||||||
from pr_agent.algo.ai_handler import AiHandler
|
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||||
|
from pr_agent.algo.ai_handlers.litellm_ai_handler import LiteLLMAIHandler
|
||||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||||
from pr_agent.algo.token_handler import TokenHandler
|
from pr_agent.algo.token_handler import TokenHandler
|
||||||
from pr_agent.config_loader import get_settings
|
from pr_agent.config_loader import get_settings
|
||||||
@ -12,12 +14,13 @@ from pr_agent.log import get_logger
|
|||||||
|
|
||||||
|
|
||||||
class PRInformationFromUser:
|
class PRInformationFromUser:
|
||||||
def __init__(self, pr_url: str, args: list = None):
|
def __init__(self, pr_url: str, args: list = None,
|
||||||
|
ai_handler: partial[BaseAiHandler,] = LiteLLMAIHandler):
|
||||||
self.git_provider = get_git_provider()(pr_url)
|
self.git_provider = get_git_provider()(pr_url)
|
||||||
self.main_pr_language = get_main_pr_language(
|
self.main_pr_language = get_main_pr_language(
|
||||||
self.git_provider.get_languages(), self.git_provider.get_files()
|
self.git_provider.get_languages(), self.git_provider.get_files()
|
||||||
)
|
)
|
||||||
self.ai_handler = AiHandler()
|
self.ai_handler = ai_handler()
|
||||||
self.vars = {
|
self.vars = {
|
||||||
"title": self.git_provider.pr.title,
|
"title": self.git_provider.pr.title,
|
||||||
"branch": self.git_provider.get_pr_branch(),
|
"branch": self.git_provider.get_pr_branch(),
|
||||||
|
|||||||
@ -1,8 +1,10 @@
|
|||||||
import copy
|
import copy
|
||||||
|
from functools import partial
|
||||||
|
|
||||||
from jinja2 import Environment, StrictUndefined
|
from jinja2 import Environment, StrictUndefined
|
||||||
|
|
||||||
from pr_agent.algo.ai_handler import AiHandler
|
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||||
|
from pr_agent.algo.ai_handlers.litellm_ai_handler import LiteLLMAIHandler
|
||||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||||
from pr_agent.algo.token_handler import TokenHandler
|
from pr_agent.algo.token_handler import TokenHandler
|
||||||
from pr_agent.config_loader import get_settings
|
from pr_agent.config_loader import get_settings
|
||||||
@ -12,13 +14,13 @@ from pr_agent.log import get_logger
|
|||||||
|
|
||||||
|
|
||||||
class PRQuestions:
|
class PRQuestions:
|
||||||
def __init__(self, pr_url: str, args=None):
|
def __init__(self, pr_url: str, args=None, ai_handler: partial[BaseAiHandler,] = LiteLLMAIHandler):
|
||||||
question_str = self.parse_args(args)
|
question_str = self.parse_args(args)
|
||||||
self.git_provider = get_git_provider()(pr_url)
|
self.git_provider = get_git_provider()(pr_url)
|
||||||
self.main_pr_language = get_main_pr_language(
|
self.main_pr_language = get_main_pr_language(
|
||||||
self.git_provider.get_languages(), self.git_provider.get_files()
|
self.git_provider.get_languages(), self.git_provider.get_files()
|
||||||
)
|
)
|
||||||
self.ai_handler = AiHandler()
|
self.ai_handler = ai_handler()
|
||||||
self.question_str = question_str
|
self.question_str = question_str
|
||||||
self.vars = {
|
self.vars = {
|
||||||
"title": self.git_provider.pr.title,
|
"title": self.git_provider.pr.title,
|
||||||
|
|||||||
@ -1,15 +1,18 @@
|
|||||||
import copy
|
import copy
|
||||||
|
import datetime
|
||||||
from collections import OrderedDict
|
from collections import OrderedDict
|
||||||
|
from functools import partial
|
||||||
from typing import List, Tuple
|
from typing import List, Tuple
|
||||||
|
|
||||||
import yaml
|
import yaml
|
||||||
from jinja2 import Environment, StrictUndefined
|
from jinja2 import Environment, StrictUndefined
|
||||||
from yaml import SafeLoader
|
from yaml import SafeLoader
|
||||||
|
|
||||||
from pr_agent.algo.ai_handler import AiHandler
|
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||||
|
from pr_agent.algo.ai_handlers.litellm_ai_handler import LiteLLMAIHandler
|
||||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||||
from pr_agent.algo.token_handler import TokenHandler
|
from pr_agent.algo.token_handler import TokenHandler
|
||||||
from pr_agent.algo.utils import convert_to_markdown, load_yaml, try_fix_yaml, set_custom_labels
|
from pr_agent.algo.utils import convert_to_markdown, load_yaml, try_fix_yaml, set_custom_labels, get_user_labels
|
||||||
from pr_agent.config_loader import get_settings
|
from pr_agent.config_loader import get_settings
|
||||||
from pr_agent.git_providers import get_git_provider
|
from pr_agent.git_providers import get_git_provider
|
||||||
from pr_agent.git_providers.git_provider import IncrementalPR, get_main_pr_language
|
from pr_agent.git_providers.git_provider import IncrementalPR, get_main_pr_language
|
||||||
@ -21,13 +24,16 @@ class PRReviewer:
|
|||||||
"""
|
"""
|
||||||
The PRReviewer class is responsible for reviewing a pull request and generating feedback using an AI model.
|
The PRReviewer class is responsible for reviewing a pull request and generating feedback using an AI model.
|
||||||
"""
|
"""
|
||||||
def __init__(self, pr_url: str, is_answer: bool = False, is_auto: bool = False, args: list = None):
|
def __init__(self, pr_url: str, is_answer: bool = False, is_auto: bool = False, args: list = None,
|
||||||
|
ai_handler: partial[BaseAiHandler,] = LiteLLMAIHandler):
|
||||||
"""
|
"""
|
||||||
Initialize the PRReviewer object with the necessary attributes and objects to review a pull request.
|
Initialize the PRReviewer object with the necessary attributes and objects to review a pull request.
|
||||||
|
|
||||||
Args:
|
Args:
|
||||||
pr_url (str): The URL of the pull request to be reviewed.
|
pr_url (str): The URL of the pull request to be reviewed.
|
||||||
is_answer (bool, optional): Indicates whether the review is being done in answer mode. Defaults to False.
|
is_answer (bool, optional): Indicates whether the review is being done in answer mode. Defaults to False.
|
||||||
|
is_auto (bool, optional): Indicates whether the review is being done in automatic mode. Defaults to False.
|
||||||
|
ai_handler (BaseAiHandler): The AI handler to be used for the review. Defaults to None.
|
||||||
args (list, optional): List of arguments passed to the PRReviewer class. Defaults to None.
|
args (list, optional): List of arguments passed to the PRReviewer class. Defaults to None.
|
||||||
"""
|
"""
|
||||||
self.parse_args(args) # -i command
|
self.parse_args(args) # -i command
|
||||||
@ -42,7 +48,7 @@ class PRReviewer:
|
|||||||
|
|
||||||
if self.is_answer and not self.git_provider.is_supported("get_issue_comments"):
|
if self.is_answer and not self.git_provider.is_supported("get_issue_comments"):
|
||||||
raise Exception(f"Answer mode is not supported for {get_settings().config.git_provider} for now")
|
raise Exception(f"Answer mode is not supported for {get_settings().config.git_provider} for now")
|
||||||
self.ai_handler = AiHandler()
|
self.ai_handler = ai_handler()
|
||||||
self.patches_diff = None
|
self.patches_diff = None
|
||||||
self.prediction = None
|
self.prediction = None
|
||||||
|
|
||||||
@ -97,11 +103,10 @@ class PRReviewer:
|
|||||||
"""
|
"""
|
||||||
|
|
||||||
try:
|
try:
|
||||||
if self.is_auto and not get_settings().pr_reviewer.automatic_review:
|
# if self.is_auto and not get_settings().pr_reviewer.automatic_review:
|
||||||
get_logger().info(f'Automatic review is disabled {self.pr_url}')
|
# get_logger().info(f'Automatic review is disabled {self.pr_url}')
|
||||||
return None
|
# return None
|
||||||
if self.is_auto and self.incremental.is_incremental and not self.incremental.first_new_commit_sha:
|
if self.incremental.is_incremental and not self._can_run_incremental_review():
|
||||||
get_logger().info(f"Incremental review is enabled for {self.pr_url} but there are no new commits")
|
|
||||||
return None
|
return None
|
||||||
|
|
||||||
get_logger().info(f'Reviewing PR: {self.pr_url} ...')
|
get_logger().info(f'Reviewing PR: {self.pr_url} ...')
|
||||||
@ -116,9 +121,17 @@ class PRReviewer:
|
|||||||
|
|
||||||
if get_settings().config.publish_output:
|
if get_settings().config.publish_output:
|
||||||
get_logger().info('Pushing PR review...')
|
get_logger().info('Pushing PR review...')
|
||||||
self.git_provider.publish_comment(pr_comment)
|
|
||||||
self.git_provider.remove_initial_comment()
|
|
||||||
previous_review_comment = self._get_previous_review_comment()
|
previous_review_comment = self._get_previous_review_comment()
|
||||||
|
|
||||||
|
# publish the review
|
||||||
|
if get_settings().pr_reviewer.persistent_comment and not self.incremental.is_incremental:
|
||||||
|
self.git_provider.publish_persistent_comment(pr_comment,
|
||||||
|
initial_header="## PR Analysis",
|
||||||
|
update_header=True)
|
||||||
|
else:
|
||||||
|
self.git_provider.publish_comment(pr_comment)
|
||||||
|
|
||||||
|
self.git_provider.remove_initial_comment()
|
||||||
if previous_review_comment:
|
if previous_review_comment:
|
||||||
self._remove_previous_review_comment(previous_review_comment)
|
self._remove_previous_review_comment(previous_review_comment)
|
||||||
if get_settings().pr_reviewer.inline_code_comments:
|
if get_settings().pr_reviewer.inline_code_comments:
|
||||||
@ -156,7 +169,6 @@ class PRReviewer:
|
|||||||
variables["diff"] = self.patches_diff # update diff
|
variables["diff"] = self.patches_diff # update diff
|
||||||
|
|
||||||
environment = Environment(undefined=StrictUndefined)
|
environment = Environment(undefined=StrictUndefined)
|
||||||
set_custom_labels(variables)
|
|
||||||
system_prompt = environment.from_string(get_settings().pr_review_prompt.system).render(variables)
|
system_prompt = environment.from_string(get_settings().pr_review_prompt.system).render(variables)
|
||||||
user_prompt = environment.from_string(get_settings().pr_review_prompt.user).render(variables)
|
user_prompt = environment.from_string(get_settings().pr_review_prompt.user).render(variables)
|
||||||
|
|
||||||
@ -171,6 +183,9 @@ class PRReviewer:
|
|||||||
user=user_prompt
|
user=user_prompt
|
||||||
)
|
)
|
||||||
|
|
||||||
|
if get_settings().config.verbosity_level >= 2:
|
||||||
|
get_logger().info(f"\nAI response:\n{response}")
|
||||||
|
|
||||||
return response
|
return response
|
||||||
|
|
||||||
def _prepare_pr_review(self) -> str:
|
def _prepare_pr_review(self) -> str:
|
||||||
@ -217,19 +232,6 @@ class PRReviewer:
|
|||||||
suggestion['relevant line'] = f"[{suggestion['relevant line']}]({link})"
|
suggestion['relevant line'] = f"[{suggestion['relevant line']}]({link})"
|
||||||
else:
|
else:
|
||||||
pass
|
pass
|
||||||
# try:
|
|
||||||
# relevant_file = suggestion['relevant file'].strip('`').strip("'")
|
|
||||||
# relevant_line_str = suggestion['relevant line']
|
|
||||||
# if not relevant_line_str:
|
|
||||||
# return ""
|
|
||||||
#
|
|
||||||
# position, absolute_position = find_line_number_of_relevant_line_in_file(
|
|
||||||
# self.git_provider.diff_files, relevant_file, relevant_line_str)
|
|
||||||
# if absolute_position != -1:
|
|
||||||
# suggestion[
|
|
||||||
# 'relevant line'] = f"{suggestion['relevant line']} (line {absolute_position})"
|
|
||||||
# except:
|
|
||||||
# pass
|
|
||||||
|
|
||||||
|
|
||||||
# Add incremental review section
|
# Add incremental review section
|
||||||
@ -239,7 +241,8 @@ class PRReviewer:
|
|||||||
last_commit_msg = self.incremental.commits_range[0].commit.message if self.incremental.commits_range else ""
|
last_commit_msg = self.incremental.commits_range[0].commit.message if self.incremental.commits_range else ""
|
||||||
incremental_review_markdown_text = f"Starting from commit {last_commit_url}"
|
incremental_review_markdown_text = f"Starting from commit {last_commit_url}"
|
||||||
if last_commit_msg:
|
if last_commit_msg:
|
||||||
incremental_review_markdown_text += f" \n_({last_commit_msg.splitlines(keepends=False)[0]})_"
|
replacement = last_commit_msg.splitlines(keepends=False)[0].replace('_', r'\_')
|
||||||
|
incremental_review_markdown_text += f" \n_({replacement})_"
|
||||||
data = OrderedDict(data)
|
data = OrderedDict(data)
|
||||||
data.update({'Incremental PR Review': {
|
data.update({'Incremental PR Review': {
|
||||||
"⏮️ Review for commits since previous PR-Agent review": incremental_review_markdown_text}})
|
"⏮️ Review for commits since previous PR-Agent review": incremental_review_markdown_text}})
|
||||||
@ -248,14 +251,18 @@ class PRReviewer:
|
|||||||
markdown_text = convert_to_markdown(data, self.git_provider.is_supported("gfm_markdown"))
|
markdown_text = convert_to_markdown(data, self.git_provider.is_supported("gfm_markdown"))
|
||||||
user = self.git_provider.get_user_id()
|
user = self.git_provider.get_user_id()
|
||||||
|
|
||||||
# Add help text if not in CLI mode
|
# Add help text if gfm_markdown is supported
|
||||||
if not get_settings().get("CONFIG.CLI_MODE", False):
|
if self.git_provider.is_supported("gfm_markdown") and get_settings().pr_reviewer.enable_help_text:
|
||||||
markdown_text += "\n### How to use\n"
|
markdown_text += "\n\n<details> <summary><strong>✨ Usage tips:</strong></summary><hr> \n\n"
|
||||||
bot_user = "[bot]" if get_settings().github_app.override_deployment_type else get_settings().github_app.bot_user
|
bot_user = "[bot]" if get_settings().github_app.override_deployment_type else get_settings().github_app.bot_user
|
||||||
if user and bot_user not in user:
|
if user and bot_user not in user and not get_settings().get("CONFIG.CLI_MODE", False):
|
||||||
markdown_text += bot_help_text(user)
|
markdown_text += bot_help_text(user)
|
||||||
else:
|
else:
|
||||||
markdown_text += actions_help_text
|
markdown_text += actions_help_text
|
||||||
|
markdown_text += "\n</details>\n"
|
||||||
|
|
||||||
|
# Add custom labels from the review prediction (effort, security)
|
||||||
|
self.set_review_labels(data)
|
||||||
|
|
||||||
# Log markdown response if verbosity level is high
|
# Log markdown response if verbosity level is high
|
||||||
if get_settings().config.verbosity_level >= 2:
|
if get_settings().config.verbosity_level >= 2:
|
||||||
@ -273,14 +280,7 @@ class PRReviewer:
|
|||||||
if get_settings().pr_reviewer.num_code_suggestions == 0:
|
if get_settings().pr_reviewer.num_code_suggestions == 0:
|
||||||
return
|
return
|
||||||
|
|
||||||
review_text = self.prediction.strip()
|
data = load_yaml(self.prediction.strip())
|
||||||
review_text = review_text.removeprefix('```yaml').rstrip('`')
|
|
||||||
try:
|
|
||||||
data = yaml.load(review_text, Loader=SafeLoader)
|
|
||||||
except Exception as e:
|
|
||||||
get_logger().error(f"Failed to parse AI prediction: {e}")
|
|
||||||
data = try_fix_yaml(review_text)
|
|
||||||
|
|
||||||
comments: List[str] = []
|
comments: List[str] = []
|
||||||
for suggestion in data.get('PR Feedback', {}).get('Code feedback', []):
|
for suggestion in data.get('PR Feedback', {}).get('Code feedback', []):
|
||||||
relevant_file = suggestion.get('relevant file', '').strip()
|
relevant_file = suggestion.get('relevant file', '').strip()
|
||||||
@ -346,3 +346,63 @@ class PRReviewer:
|
|||||||
self.git_provider.remove_comment(comment)
|
self.git_provider.remove_comment(comment)
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
get_logger().exception(f"Failed to remove previous review comment, error: {e}")
|
get_logger().exception(f"Failed to remove previous review comment, error: {e}")
|
||||||
|
|
||||||
|
def _can_run_incremental_review(self) -> bool:
|
||||||
|
"""Checks if we can run incremental review according the various configurations and previous review"""
|
||||||
|
# checking if running is auto mode but there are no new commits
|
||||||
|
if self.is_auto and not self.incremental.first_new_commit_sha:
|
||||||
|
get_logger().info(f"Incremental review is enabled for {self.pr_url} but there are no new commits")
|
||||||
|
return False
|
||||||
|
# checking if there are enough commits to start the review
|
||||||
|
num_new_commits = len(self.incremental.commits_range)
|
||||||
|
num_commits_threshold = get_settings().pr_reviewer.minimal_commits_for_incremental_review
|
||||||
|
not_enough_commits = num_new_commits < num_commits_threshold
|
||||||
|
# checking if the commits are not too recent to start the review
|
||||||
|
recent_commits_threshold = datetime.datetime.now() - datetime.timedelta(
|
||||||
|
minutes=get_settings().pr_reviewer.minimal_minutes_for_incremental_review
|
||||||
|
)
|
||||||
|
last_seen_commit_date = (
|
||||||
|
self.incremental.last_seen_commit.commit.author.date if self.incremental.last_seen_commit else None
|
||||||
|
)
|
||||||
|
all_commits_too_recent = (
|
||||||
|
last_seen_commit_date > recent_commits_threshold if self.incremental.last_seen_commit else False
|
||||||
|
)
|
||||||
|
# check all the thresholds or just one to start the review
|
||||||
|
condition = any if get_settings().pr_reviewer.require_all_thresholds_for_incremental_review else all
|
||||||
|
if condition((not_enough_commits, all_commits_too_recent)):
|
||||||
|
get_logger().info(
|
||||||
|
f"Incremental review is enabled for {self.pr_url} but didn't pass the threshold check to run:"
|
||||||
|
f"\n* Number of new commits = {num_new_commits} (threshold is {num_commits_threshold})"
|
||||||
|
f"\n* Last seen commit date = {last_seen_commit_date} (threshold is {recent_commits_threshold})"
|
||||||
|
)
|
||||||
|
return False
|
||||||
|
return True
|
||||||
|
|
||||||
|
def set_review_labels(self, data):
|
||||||
|
if (get_settings().pr_reviewer.enable_review_labels_security or
|
||||||
|
get_settings().pr_reviewer.enable_review_labels_effort):
|
||||||
|
try:
|
||||||
|
review_labels = []
|
||||||
|
if get_settings().pr_reviewer.enable_review_labels_effort:
|
||||||
|
estimated_effort = data['PR Analysis']['Estimated effort to review [1-5]']
|
||||||
|
estimated_effort_number = int(estimated_effort.split(',')[0])
|
||||||
|
if 1 <= estimated_effort_number <= 5: # 1, because ...
|
||||||
|
review_labels.append(f'Review effort [1-5]: {estimated_effort_number}')
|
||||||
|
if get_settings().pr_reviewer.enable_review_labels_security:
|
||||||
|
security_concerns = data['PR Analysis']['Security concerns'] # yes, because ...
|
||||||
|
security_concerns_bool = 'yes' in security_concerns.lower() or 'true' in security_concerns.lower()
|
||||||
|
if security_concerns_bool:
|
||||||
|
review_labels.append('Possible security concern')
|
||||||
|
|
||||||
|
current_labels = self.git_provider.get_pr_labels()
|
||||||
|
if current_labels:
|
||||||
|
current_labels_filtered = [label for label in current_labels if
|
||||||
|
not label.lower().startswith('review effort [1-5]:') and not label.lower().startswith(
|
||||||
|
'possible security concern')]
|
||||||
|
else:
|
||||||
|
current_labels_filtered = []
|
||||||
|
if current_labels or review_labels:
|
||||||
|
get_logger().info(f"Setting review labels: {review_labels + current_labels_filtered}")
|
||||||
|
self.git_provider.publish_labels(review_labels + current_labels_filtered)
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().error(f"Failed to set review labels, error: {e}")
|
||||||
|
|||||||
@ -5,11 +5,13 @@ from typing import List
|
|||||||
import openai
|
import openai
|
||||||
import pandas as pd
|
import pandas as pd
|
||||||
import pinecone
|
import pinecone
|
||||||
|
import lancedb
|
||||||
from pinecone_datasets import Dataset, DatasetMetadata
|
from pinecone_datasets import Dataset, DatasetMetadata
|
||||||
from pydantic import BaseModel, Field
|
from pydantic import BaseModel, Field
|
||||||
|
|
||||||
from pr_agent.algo import MAX_TOKENS
|
from pr_agent.algo import MAX_TOKENS
|
||||||
from pr_agent.algo.token_handler import TokenHandler
|
from pr_agent.algo.token_handler import TokenHandler
|
||||||
|
from pr_agent.algo.utils import get_max_tokens
|
||||||
from pr_agent.config_loader import get_settings
|
from pr_agent.config_loader import get_settings
|
||||||
from pr_agent.git_providers import get_git_provider
|
from pr_agent.git_providers import get_git_provider
|
||||||
from pr_agent.log import get_logger
|
from pr_agent.log import get_logger
|
||||||
@ -18,7 +20,7 @@ MODEL = "text-embedding-ada-002"
|
|||||||
|
|
||||||
|
|
||||||
class PRSimilarIssue:
|
class PRSimilarIssue:
|
||||||
def __init__(self, issue_url: str, args: list = None):
|
def __init__(self, issue_url: str, ai_handler, args: list = None):
|
||||||
if get_settings().config.git_provider != "github":
|
if get_settings().config.git_provider != "github":
|
||||||
raise Exception("Only github is supported for similar issue tool")
|
raise Exception("Only github is supported for similar issue tool")
|
||||||
|
|
||||||
@ -34,75 +36,138 @@ class PRSimilarIssue:
|
|||||||
repo_name_for_index = self.repo_name_for_index = repo_obj.full_name.lower().replace('/', '-').replace('_/', '-')
|
repo_name_for_index = self.repo_name_for_index = repo_obj.full_name.lower().replace('/', '-').replace('_/', '-')
|
||||||
index_name = self.index_name = "codium-ai-pr-agent-issues"
|
index_name = self.index_name = "codium-ai-pr-agent-issues"
|
||||||
|
|
||||||
# assuming pinecone api key and environment are set in secrets file
|
if get_settings().pr_similar_issue.vectordb == "pinecone":
|
||||||
try:
|
# assuming pinecone api key and environment are set in secrets file
|
||||||
api_key = get_settings().pinecone.api_key
|
try:
|
||||||
environment = get_settings().pinecone.environment
|
api_key = get_settings().pinecone.api_key
|
||||||
except Exception:
|
environment = get_settings().pinecone.environment
|
||||||
if not self.cli_mode:
|
except Exception:
|
||||||
repo_name, original_issue_number = self.git_provider._parse_issue_url(self.issue_url.split('=')[-1])
|
if not self.cli_mode:
|
||||||
issue_main = self.git_provider.repo_obj.get_issue(original_issue_number)
|
repo_name, original_issue_number = self.git_provider._parse_issue_url(self.issue_url.split('=')[-1])
|
||||||
issue_main.create_comment("Please set pinecone api key and environment in secrets file")
|
issue_main = self.git_provider.repo_obj.get_issue(original_issue_number)
|
||||||
raise Exception("Please set pinecone api key and environment in secrets file")
|
issue_main.create_comment("Please set pinecone api key and environment in secrets file")
|
||||||
|
raise Exception("Please set pinecone api key and environment in secrets file")
|
||||||
|
|
||||||
# check if index exists, and if repo is already indexed
|
# check if index exists, and if repo is already indexed
|
||||||
run_from_scratch = False
|
run_from_scratch = False
|
||||||
if run_from_scratch: # for debugging
|
if run_from_scratch: # for debugging
|
||||||
|
pinecone.init(api_key=api_key, environment=environment)
|
||||||
|
if index_name in pinecone.list_indexes():
|
||||||
|
get_logger().info('Removing index...')
|
||||||
|
pinecone.delete_index(index_name)
|
||||||
|
get_logger().info('Done')
|
||||||
|
|
||||||
|
upsert = True
|
||||||
pinecone.init(api_key=api_key, environment=environment)
|
pinecone.init(api_key=api_key, environment=environment)
|
||||||
if index_name in pinecone.list_indexes():
|
if not index_name in pinecone.list_indexes():
|
||||||
get_logger().info('Removing index...')
|
run_from_scratch = True
|
||||||
pinecone.delete_index(index_name)
|
upsert = False
|
||||||
|
else:
|
||||||
|
if get_settings().pr_similar_issue.force_update_dataset:
|
||||||
|
upsert = True
|
||||||
|
else:
|
||||||
|
pinecone_index = pinecone.Index(index_name=index_name)
|
||||||
|
res = pinecone_index.fetch([f"example_issue_{repo_name_for_index}"]).to_dict()
|
||||||
|
if res["vectors"]:
|
||||||
|
upsert = False
|
||||||
|
|
||||||
|
if run_from_scratch or upsert: # index the entire repo
|
||||||
|
get_logger().info('Indexing the entire repo...')
|
||||||
|
|
||||||
|
get_logger().info('Getting issues...')
|
||||||
|
issues = list(repo_obj.get_issues(state='all'))
|
||||||
|
get_logger().info('Done')
|
||||||
|
self._update_index_with_issues(issues, repo_name_for_index, upsert=upsert)
|
||||||
|
else: # update index if needed
|
||||||
|
pinecone_index = pinecone.Index(index_name=index_name)
|
||||||
|
issues_to_update = []
|
||||||
|
issues_paginated_list = repo_obj.get_issues(state='all')
|
||||||
|
counter = 1
|
||||||
|
for issue in issues_paginated_list:
|
||||||
|
if issue.pull_request:
|
||||||
|
continue
|
||||||
|
issue_str, comments, number = self._process_issue(issue)
|
||||||
|
issue_key = f"issue_{number}"
|
||||||
|
id = issue_key + "." + "issue"
|
||||||
|
res = pinecone_index.fetch([id]).to_dict()
|
||||||
|
is_new_issue = True
|
||||||
|
for vector in res["vectors"].values():
|
||||||
|
if vector['metadata']['repo'] == repo_name_for_index:
|
||||||
|
is_new_issue = False
|
||||||
|
break
|
||||||
|
if is_new_issue:
|
||||||
|
counter += 1
|
||||||
|
issues_to_update.append(issue)
|
||||||
|
else:
|
||||||
|
break
|
||||||
|
|
||||||
|
if issues_to_update:
|
||||||
|
get_logger().info(f'Updating index with {counter} new issues...')
|
||||||
|
self._update_index_with_issues(issues_to_update, repo_name_for_index, upsert=True)
|
||||||
|
else:
|
||||||
|
get_logger().info('No new issues to update')
|
||||||
|
|
||||||
|
elif get_settings().pr_similar_issue.vectordb == "lancedb":
|
||||||
|
self.db = lancedb.connect(get_settings().lancedb.uri)
|
||||||
|
self.table = None
|
||||||
|
|
||||||
|
run_from_scratch = False
|
||||||
|
if run_from_scratch: # for debugging
|
||||||
|
if index_name in self.db.table_names():
|
||||||
|
get_logger().info('Removing Table...')
|
||||||
|
self.db.drop_table(index_name)
|
||||||
|
get_logger().info('Done')
|
||||||
|
|
||||||
|
ingest = True
|
||||||
|
if index_name not in self.db.table_names():
|
||||||
|
run_from_scratch = True
|
||||||
|
ingest = False
|
||||||
|
else:
|
||||||
|
if get_settings().pr_similar_issue.force_update_dataset:
|
||||||
|
ingest = True
|
||||||
|
else:
|
||||||
|
self.table = self.db[index_name]
|
||||||
|
res = self.table.search().limit(len(self.table)).where(f"id='example_issue_{repo_name_for_index}'").to_list()
|
||||||
|
get_logger().info("result: ", res)
|
||||||
|
if res[0].get("vector"):
|
||||||
|
ingest = False
|
||||||
|
|
||||||
|
if run_from_scratch or ingest: # indexing the entire repo
|
||||||
|
get_logger().info('Indexing the entire repo...')
|
||||||
|
|
||||||
|
get_logger().info('Getting issues...')
|
||||||
|
issues = list(repo_obj.get_issues(state='all'))
|
||||||
get_logger().info('Done')
|
get_logger().info('Done')
|
||||||
|
|
||||||
upsert = True
|
self._update_table_with_issues(issues, repo_name_for_index, ingest=ingest)
|
||||||
pinecone.init(api_key=api_key, environment=environment)
|
else: # update table if needed
|
||||||
if not index_name in pinecone.list_indexes():
|
issues_to_update = []
|
||||||
run_from_scratch = True
|
issues_paginated_list = repo_obj.get_issues(state='all')
|
||||||
upsert = False
|
counter = 1
|
||||||
else:
|
for issue in issues_paginated_list:
|
||||||
if get_settings().pr_similar_issue.force_update_dataset:
|
if issue.pull_request:
|
||||||
upsert = True
|
continue
|
||||||
else:
|
issue_str, comments, number = self._process_issue(issue)
|
||||||
pinecone_index = pinecone.Index(index_name=index_name)
|
issue_key = f"issue_{number}"
|
||||||
res = pinecone_index.fetch([f"example_issue_{repo_name_for_index}"]).to_dict()
|
issue_id = issue_key + "." + "issue"
|
||||||
if res["vectors"]:
|
res = self.table.search().limit(len(self.table)).where(f"id='{issue_id}'").to_list()
|
||||||
upsert = False
|
is_new_issue = True
|
||||||
|
for r in res:
|
||||||
if run_from_scratch or upsert: # index the entire repo
|
if r['metadata']['repo'] == repo_name_for_index:
|
||||||
get_logger().info('Indexing the entire repo...')
|
is_new_issue = False
|
||||||
|
break
|
||||||
get_logger().info('Getting issues...')
|
if is_new_issue:
|
||||||
issues = list(repo_obj.get_issues(state='all'))
|
counter += 1
|
||||||
get_logger().info('Done')
|
issues_to_update.append(issue)
|
||||||
self._update_index_with_issues(issues, repo_name_for_index, upsert=upsert)
|
else:
|
||||||
else: # update index if needed
|
|
||||||
pinecone_index = pinecone.Index(index_name=index_name)
|
|
||||||
issues_to_update = []
|
|
||||||
issues_paginated_list = repo_obj.get_issues(state='all')
|
|
||||||
counter = 1
|
|
||||||
for issue in issues_paginated_list:
|
|
||||||
if issue.pull_request:
|
|
||||||
continue
|
|
||||||
issue_str, comments, number = self._process_issue(issue)
|
|
||||||
issue_key = f"issue_{number}"
|
|
||||||
id = issue_key + "." + "issue"
|
|
||||||
res = pinecone_index.fetch([id]).to_dict()
|
|
||||||
is_new_issue = True
|
|
||||||
for vector in res["vectors"].values():
|
|
||||||
if vector['metadata']['repo'] == repo_name_for_index:
|
|
||||||
is_new_issue = False
|
|
||||||
break
|
break
|
||||||
if is_new_issue:
|
|
||||||
counter += 1
|
|
||||||
issues_to_update.append(issue)
|
|
||||||
else:
|
|
||||||
break
|
|
||||||
|
|
||||||
if issues_to_update:
|
if issues_to_update:
|
||||||
get_logger().info(f'Updating index with {counter} new issues...')
|
get_logger().info(f'Updating index with {counter} new issues...')
|
||||||
self._update_index_with_issues(issues_to_update, repo_name_for_index, upsert=True)
|
self._update_table_with_issues(issues_to_update, repo_name_for_index, ingest=True)
|
||||||
else:
|
else:
|
||||||
get_logger().info('No new issues to update')
|
get_logger().info('No new issues to update')
|
||||||
|
|
||||||
|
|
||||||
async def run(self):
|
async def run(self):
|
||||||
get_logger().info('Getting issue...')
|
get_logger().info('Getting issue...')
|
||||||
@ -115,38 +180,69 @@ class PRSimilarIssue:
|
|||||||
get_logger().info('Querying...')
|
get_logger().info('Querying...')
|
||||||
res = openai.Embedding.create(input=[issue_str], engine=MODEL)
|
res = openai.Embedding.create(input=[issue_str], engine=MODEL)
|
||||||
embeds = [record['embedding'] for record in res['data']]
|
embeds = [record['embedding'] for record in res['data']]
|
||||||
pinecone_index = pinecone.Index(index_name=self.index_name)
|
|
||||||
res = pinecone_index.query(embeds[0],
|
|
||||||
top_k=5,
|
|
||||||
filter={"repo": self.repo_name_for_index},
|
|
||||||
include_metadata=True).to_dict()
|
|
||||||
relevant_issues_number_list = []
|
relevant_issues_number_list = []
|
||||||
relevant_comment_number_list = []
|
relevant_comment_number_list = []
|
||||||
score_list = []
|
score_list = []
|
||||||
for r in res['matches']:
|
|
||||||
# skip example issue
|
if get_settings().pr_similar_issue.vectordb == "pinecone":
|
||||||
if 'example_issue_' in r["id"]:
|
pinecone_index = pinecone.Index(index_name=self.index_name)
|
||||||
continue
|
res = pinecone_index.query(embeds[0],
|
||||||
|
top_k=5,
|
||||||
|
filter={"repo": self.repo_name_for_index},
|
||||||
|
include_metadata=True).to_dict()
|
||||||
|
|
||||||
|
for r in res['matches']:
|
||||||
|
# skip example issue
|
||||||
|
if 'example_issue_' in r["id"]:
|
||||||
|
continue
|
||||||
|
|
||||||
try:
|
try:
|
||||||
issue_number = int(r["id"].split('.')[0].split('_')[-1])
|
issue_number = int(r["id"].split('.')[0].split('_')[-1])
|
||||||
except:
|
except:
|
||||||
get_logger().debug(f"Failed to parse issue number from {r['id']}")
|
get_logger().debug(f"Failed to parse issue number from {r['id']}")
|
||||||
continue
|
continue
|
||||||
|
|
||||||
if original_issue_number == issue_number:
|
if original_issue_number == issue_number:
|
||||||
continue
|
continue
|
||||||
if issue_number not in relevant_issues_number_list:
|
if issue_number not in relevant_issues_number_list:
|
||||||
relevant_issues_number_list.append(issue_number)
|
relevant_issues_number_list.append(issue_number)
|
||||||
if 'comment' in r["id"]:
|
if 'comment' in r["id"]:
|
||||||
relevant_comment_number_list.append(int(r["id"].split('.')[1].split('_')[-1]))
|
relevant_comment_number_list.append(int(r["id"].split('.')[1].split('_')[-1]))
|
||||||
else:
|
else:
|
||||||
relevant_comment_number_list.append(-1)
|
relevant_comment_number_list.append(-1)
|
||||||
score_list.append(str("{:.2f}".format(r['score'])))
|
score_list.append(str("{:.2f}".format(r['score'])))
|
||||||
get_logger().info('Done')
|
get_logger().info('Done')
|
||||||
|
|
||||||
|
elif get_settings().pr_similar_issue.vectordb == "lancedb":
|
||||||
|
res = self.table.search(embeds[0]).where(f"metadata.repo='{self.repo_name_for_index}'", prefilter=True).to_list()
|
||||||
|
|
||||||
|
for r in res:
|
||||||
|
# skip example issue
|
||||||
|
if 'example_issue_' in r["id"]:
|
||||||
|
continue
|
||||||
|
|
||||||
|
try:
|
||||||
|
issue_number = int(r["id"].split('.')[0].split('_')[-1])
|
||||||
|
except:
|
||||||
|
get_logger().debug(f"Failed to parse issue number from {r['id']}")
|
||||||
|
continue
|
||||||
|
|
||||||
|
if original_issue_number == issue_number:
|
||||||
|
continue
|
||||||
|
if issue_number not in relevant_issues_number_list:
|
||||||
|
relevant_issues_number_list.append(issue_number)
|
||||||
|
|
||||||
|
if 'comment' in r["id"]:
|
||||||
|
relevant_comment_number_list.append(int(r["id"].split('.')[1].split('_')[-1]))
|
||||||
|
else:
|
||||||
|
relevant_comment_number_list.append(-1)
|
||||||
|
score_list.append(str("{:.2f}".format(1-r['_distance'])))
|
||||||
|
get_logger().info('Done')
|
||||||
|
|
||||||
get_logger().info('Publishing response...')
|
get_logger().info('Publishing response...')
|
||||||
similar_issues_str = "### Similar Issues\n___\n\n"
|
similar_issues_str = "### Similar Issues\n___\n\n"
|
||||||
|
|
||||||
for i, issue_number_similar in enumerate(relevant_issues_number_list):
|
for i, issue_number_similar in enumerate(relevant_issues_number_list):
|
||||||
issue = self.git_provider.repo_obj.get_issue(issue_number_similar)
|
issue = self.git_provider.repo_obj.get_issue(issue_number_similar)
|
||||||
title = issue.title
|
title = issue.title
|
||||||
@ -197,7 +293,7 @@ class PRSimilarIssue:
|
|||||||
username = issue.user.login
|
username = issue.user.login
|
||||||
created_at = str(issue.created_at)
|
created_at = str(issue.created_at)
|
||||||
if len(issue_str) < 8000 or \
|
if len(issue_str) < 8000 or \
|
||||||
self.token_handler.count_tokens(issue_str) < MAX_TOKENS[MODEL]: # fast reject first
|
self.token_handler.count_tokens(issue_str) < get_max_tokens(MODEL): # fast reject first
|
||||||
issue_record = Record(
|
issue_record = Record(
|
||||||
id=issue_key + "." + "issue",
|
id=issue_key + "." + "issue",
|
||||||
text=issue_str,
|
text=issue_str,
|
||||||
@ -265,6 +361,96 @@ class PRSimilarIssue:
|
|||||||
time.sleep(5) # wait for pinecone to finalize upserting before querying
|
time.sleep(5) # wait for pinecone to finalize upserting before querying
|
||||||
get_logger().info('Done')
|
get_logger().info('Done')
|
||||||
|
|
||||||
|
def _update_table_with_issues(self, issues_list, repo_name_for_index, ingest=False):
|
||||||
|
get_logger().info('Processing issues...')
|
||||||
|
|
||||||
|
corpus = Corpus()
|
||||||
|
example_issue_record = Record(
|
||||||
|
id=f"example_issue_{repo_name_for_index}",
|
||||||
|
text="example_issue",
|
||||||
|
metadata=Metadata(repo=repo_name_for_index)
|
||||||
|
)
|
||||||
|
corpus.append(example_issue_record)
|
||||||
|
|
||||||
|
counter = 0
|
||||||
|
for issue in issues_list:
|
||||||
|
if issue.pull_request:
|
||||||
|
continue
|
||||||
|
|
||||||
|
counter += 1
|
||||||
|
if counter % 100 == 0:
|
||||||
|
get_logger().info(f"Scanned {counter} issues")
|
||||||
|
if counter >= self.max_issues_to_scan:
|
||||||
|
get_logger().info(f"Scanned {self.max_issues_to_scan} issues, stopping")
|
||||||
|
break
|
||||||
|
|
||||||
|
issue_str, comments, number = self._process_issue(issue)
|
||||||
|
issue_key = f"issue_{number}"
|
||||||
|
username = issue.user.login
|
||||||
|
created_at = str(issue.created_at)
|
||||||
|
if len(issue_str) < 8000 or \
|
||||||
|
self.token_handler.count_tokens(issue_str) < get_max_tokens(MODEL): # fast reject first
|
||||||
|
issue_record = Record(
|
||||||
|
id=issue_key + "." + "issue",
|
||||||
|
text=issue_str,
|
||||||
|
metadata=Metadata(repo=repo_name_for_index,
|
||||||
|
username=username,
|
||||||
|
created_at=created_at,
|
||||||
|
level=IssueLevel.ISSUE)
|
||||||
|
)
|
||||||
|
corpus.append(issue_record)
|
||||||
|
if comments:
|
||||||
|
for j, comment in enumerate(comments):
|
||||||
|
comment_body = comment.body
|
||||||
|
num_words_comment = len(comment_body.split())
|
||||||
|
if num_words_comment < 10 or not isinstance(comment_body, str):
|
||||||
|
continue
|
||||||
|
|
||||||
|
if len(comment_body) < 8000 or \
|
||||||
|
self.token_handler.count_tokens(comment_body) < MAX_TOKENS[MODEL]:
|
||||||
|
comment_record = Record(
|
||||||
|
id=issue_key + ".comment_" + str(j + 1),
|
||||||
|
text=comment_body,
|
||||||
|
metadata=Metadata(repo=repo_name_for_index,
|
||||||
|
username=username, # use issue username for all comments
|
||||||
|
created_at=created_at,
|
||||||
|
level=IssueLevel.COMMENT)
|
||||||
|
)
|
||||||
|
corpus.append(comment_record)
|
||||||
|
df = pd.DataFrame(corpus.dict()["documents"])
|
||||||
|
get_logger().info('Done')
|
||||||
|
|
||||||
|
get_logger().info('Embedding...')
|
||||||
|
openai.api_key = get_settings().openai.key
|
||||||
|
list_to_encode = list(df["text"].values)
|
||||||
|
try:
|
||||||
|
res = openai.Embedding.create(input=list_to_encode, engine=MODEL)
|
||||||
|
embeds = [record['embedding'] for record in res['data']]
|
||||||
|
except:
|
||||||
|
embeds = []
|
||||||
|
get_logger().error('Failed to embed entire list, embedding one by one...')
|
||||||
|
for i, text in enumerate(list_to_encode):
|
||||||
|
try:
|
||||||
|
res = openai.Embedding.create(input=[text], engine=MODEL)
|
||||||
|
embeds.append(res['data'][0]['embedding'])
|
||||||
|
except:
|
||||||
|
embeds.append([0] * 1536)
|
||||||
|
df["vector"] = embeds
|
||||||
|
get_logger().info('Done')
|
||||||
|
|
||||||
|
if not ingest:
|
||||||
|
get_logger().info('Creating table from scratch...')
|
||||||
|
self.table = self.db.create_table(self.index_name, data=df, mode="overwrite")
|
||||||
|
time.sleep(15)
|
||||||
|
else:
|
||||||
|
get_logger().info('Ingesting in Table...')
|
||||||
|
if self.index_name not in self.db.table_names():
|
||||||
|
self.table.add(df)
|
||||||
|
else:
|
||||||
|
get_logger().info(f"Table {self.index_name} doesn't exists!")
|
||||||
|
time.sleep(5)
|
||||||
|
get_logger().info('Done')
|
||||||
|
|
||||||
|
|
||||||
class IssueLevel(str, Enum):
|
class IssueLevel(str, Enum):
|
||||||
ISSUE = "issue"
|
ISSUE = "issue"
|
||||||
|
|||||||
@ -1,11 +1,13 @@
|
|||||||
import copy
|
import copy
|
||||||
from datetime import date
|
from datetime import date
|
||||||
|
from functools import partial
|
||||||
from time import sleep
|
from time import sleep
|
||||||
from typing import Tuple
|
from typing import Tuple
|
||||||
|
|
||||||
from jinja2 import Environment, StrictUndefined
|
from jinja2 import Environment, StrictUndefined
|
||||||
|
|
||||||
from pr_agent.algo.ai_handler import AiHandler
|
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||||
|
from pr_agent.algo.ai_handlers.litellm_ai_handler import LiteLLMAIHandler
|
||||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||||
from pr_agent.algo.token_handler import TokenHandler
|
from pr_agent.algo.token_handler import TokenHandler
|
||||||
from pr_agent.config_loader import get_settings
|
from pr_agent.config_loader import get_settings
|
||||||
@ -17,7 +19,7 @@ CHANGELOG_LINES = 50
|
|||||||
|
|
||||||
|
|
||||||
class PRUpdateChangelog:
|
class PRUpdateChangelog:
|
||||||
def __init__(self, pr_url: str, cli_mode=False, args=None):
|
def __init__(self, pr_url: str, cli_mode=False, args=None, ai_handler: partial[BaseAiHandler,] = LiteLLMAIHandler):
|
||||||
|
|
||||||
self.git_provider = get_git_provider()(pr_url)
|
self.git_provider = get_git_provider()(pr_url)
|
||||||
self.main_language = get_main_pr_language(
|
self.main_language = get_main_pr_language(
|
||||||
@ -25,7 +27,7 @@ class PRUpdateChangelog:
|
|||||||
)
|
)
|
||||||
self.commit_changelog = get_settings().pr_update_changelog.push_changelog_changes
|
self.commit_changelog = get_settings().pr_update_changelog.push_changelog_changes
|
||||||
self._get_changlog_file() # self.changelog_file_str
|
self._get_changlog_file() # self.changelog_file_str
|
||||||
self.ai_handler = AiHandler()
|
self.ai_handler = ai_handler()
|
||||||
self.patches_diff = None
|
self.patches_diff = None
|
||||||
self.prediction = None
|
self.prediction = None
|
||||||
self.cli_mode = cli_mode
|
self.cli_mode = cli_mode
|
||||||
|
|||||||
@ -17,7 +17,7 @@ maintainers = [
|
|||||||
]
|
]
|
||||||
description = "CodiumAI PR-Agent is an open-source tool to automatically analyze a pull request and provide several types of feedback"
|
description = "CodiumAI PR-Agent is an open-source tool to automatically analyze a pull request and provide several types of feedback"
|
||||||
readme = "README.md"
|
readme = "README.md"
|
||||||
requires-python = ">=3.9"
|
requires-python = ">=3.10"
|
||||||
keywords = ["ai", "tool", "developer", "review", "agent"]
|
keywords = ["ai", "tool", "developer", "review", "agent"]
|
||||||
license = {file = "LICENSE", name = "Apache 2.0 License"}
|
license = {file = "LICENSE", name = "Apache 2.0 License"}
|
||||||
classifiers = [
|
classifiers = [
|
||||||
|
|||||||
@ -1,24 +1,27 @@
|
|||||||
dynaconf==3.1.12
|
aiohttp==3.9.1
|
||||||
fastapi==0.99.0
|
|
||||||
PyGithub==1.59.*
|
|
||||||
retry==0.9.2
|
|
||||||
openai==0.27.8
|
|
||||||
Jinja2==3.1.2
|
|
||||||
tiktoken==0.4.0
|
|
||||||
uvicorn==0.22.0
|
|
||||||
python-gitlab==3.15.0
|
|
||||||
pytest==7.4.0
|
|
||||||
aiohttp==3.8.4
|
|
||||||
atlassian-python-api==3.39.0
|
atlassian-python-api==3.39.0
|
||||||
GitPython==3.1.32
|
|
||||||
PyYAML==6.0
|
|
||||||
starlette-context==0.3.6
|
|
||||||
litellm~=0.1.574
|
|
||||||
boto3==1.28.25
|
|
||||||
google-cloud-storage==2.10.0
|
|
||||||
ujson==5.8.0
|
|
||||||
azure-devops==7.1.0b3
|
azure-devops==7.1.0b3
|
||||||
|
boto3==1.33.6
|
||||||
|
dynaconf==3.2.4
|
||||||
|
fastapi==0.99.0
|
||||||
|
GitPython==3.1.32
|
||||||
|
google-cloud-aiplatform==1.35.0
|
||||||
|
google-cloud-storage==2.10.0
|
||||||
|
Jinja2==3.1.2
|
||||||
|
litellm==0.12.5
|
||||||
|
loguru==0.7.2
|
||||||
msrest==0.7.1
|
msrest==0.7.1
|
||||||
|
openai==0.27.8
|
||||||
pinecone-client
|
pinecone-client
|
||||||
pinecone-datasets @ git+https://github.com/mrT23/pinecone-datasets.git@main
|
pinecone-datasets @ git+https://github.com/mrT23/pinecone-datasets.git@main
|
||||||
loguru==0.7.2
|
lancedb==0.3.4
|
||||||
|
pytest==7.4.0
|
||||||
|
PyGithub==1.59.*
|
||||||
|
PyYAML==6.0.1
|
||||||
|
python-gitlab==3.15.0
|
||||||
|
retry==0.9.2
|
||||||
|
starlette-context==0.3.6
|
||||||
|
tiktoken==0.5.2
|
||||||
|
ujson==5.8.0
|
||||||
|
uvicorn==0.22.0
|
||||||
|
# langchain==0.0.349 # uncomment this to support language LangChainOpenAIHandler
|
||||||
|
|||||||
@ -1,3 +1,4 @@
|
|||||||
|
from pr_agent.git_providers import BitbucketServerProvider
|
||||||
from pr_agent.git_providers.bitbucket_provider import BitbucketProvider
|
from pr_agent.git_providers.bitbucket_provider import BitbucketProvider
|
||||||
|
|
||||||
|
|
||||||
@ -8,3 +9,10 @@ class TestBitbucketProvider:
|
|||||||
assert workspace_slug == "WORKSPACE_XYZ"
|
assert workspace_slug == "WORKSPACE_XYZ"
|
||||||
assert repo_slug == "MY_TEST_REPO"
|
assert repo_slug == "MY_TEST_REPO"
|
||||||
assert pr_number == 321
|
assert pr_number == 321
|
||||||
|
|
||||||
|
def test_bitbucket_server_pr_url(self):
|
||||||
|
url = "https://git.onpreminstance.com/projects/AAA/repos/my-repo/pull-requests/1"
|
||||||
|
workspace_slug, repo_slug, pr_number = BitbucketServerProvider._parse_pr_url(url)
|
||||||
|
assert workspace_slug == "AAA"
|
||||||
|
assert repo_slug == "my-repo"
|
||||||
|
assert pr_number == 1
|
||||||
|
|||||||
19
tests/unittest/test_clip_tokens.py
Normal file
@ -0,0 +1,19 @@
|
|||||||
|
|
||||||
|
# Generated by CodiumAI
|
||||||
|
|
||||||
|
import pytest
|
||||||
|
|
||||||
|
from pr_agent.algo.utils import clip_tokens
|
||||||
|
|
||||||
|
|
||||||
|
class TestClipTokens:
|
||||||
|
def test_clip(self):
|
||||||
|
text = "line1\nline2\nline3\nline4\nline5\nline6"
|
||||||
|
max_tokens = 25
|
||||||
|
result = clip_tokens(text, max_tokens)
|
||||||
|
assert result == text
|
||||||
|
|
||||||
|
max_tokens = 10
|
||||||
|
result = clip_tokens(text, max_tokens)
|
||||||
|
expected_results = 'line1\nline2\nline3\nli...(truncated)'
|
||||||
|
assert result == expected_results
|
||||||