mirror of
https://github.com/qodo-ai/pr-agent.git
synced 2025-07-21 04:50:39 +08:00
Compare commits
1 Commits
v0.30
...
es/add_qm_
| Author | SHA1 | Date | |
|---|---|---|---|
| af351cada2 |
@ -1,4 +1,4 @@
|
||||
FROM public.ecr.aws/lambda/python:3.12 AS base
|
||||
FROM public.ecr.aws/lambda/python:3.12
|
||||
|
||||
RUN dnf update -y && \
|
||||
dnf install -y gcc python3-devel git && \
|
||||
@ -9,10 +9,4 @@ RUN pip install --no-cache-dir . && rm pyproject.toml
|
||||
RUN pip install --no-cache-dir mangum==0.17.0
|
||||
COPY pr_agent/ ${LAMBDA_TASK_ROOT}/pr_agent/
|
||||
|
||||
FROM base AS github_lambda
|
||||
CMD ["pr_agent.servers.github_lambda_webhook.lambda_handler"]
|
||||
|
||||
FROM base AS gitlab_lambda
|
||||
CMD ["pr_agent.servers.gitlab_lambda_webhook.lambda_handler"]
|
||||
|
||||
FROM github_lambda
|
||||
CMD ["pr_agent.servers.serverless.serverless"]
|
||||
|
||||
@ -1,83 +0,0 @@
|
||||
# Auto-approval 💎
|
||||
|
||||
`Supported Git Platforms: GitHub, GitLab, Bitbucket`
|
||||
|
||||
Under specific conditions, Qodo Merge can auto-approve a PR when a manual comment is invoked, or when the PR meets certain criteria.
|
||||
|
||||
**To ensure safety, the auto-approval feature is disabled by default.**
|
||||
To enable auto-approval features, you need to actively set one or both of the following options in a pre-defined _configuration file_:
|
||||
|
||||
```toml
|
||||
[config]
|
||||
enable_comment_approval = true # For approval via comments
|
||||
enable_auto_approval = true # For criteria-based auto-approval
|
||||
```
|
||||
|
||||
!!! note "Notes"
|
||||
- These flags above cannot be set with a command line argument, only in the configuration file, committed to the repository.
|
||||
- Enabling auto-approval must be a deliberate decision by the repository owner.
|
||||
|
||||
## **Approval by commenting**
|
||||
|
||||
To enable approval by commenting, set in the configuration file:
|
||||
|
||||
```toml
|
||||
[config]
|
||||
enable_comment_approval = true
|
||||
```
|
||||
|
||||
After enabling, by commenting on a PR:
|
||||
|
||||
```
|
||||
/review auto_approve
|
||||
```
|
||||
|
||||
Qodo Merge will approve the PR and add a comment with the reason for the approval.
|
||||
|
||||
## **Auto-approval when the PR meets certain criteria**
|
||||
|
||||
To enable auto-approval based on specific criteria, first, you need to enable the top-level flag:
|
||||
|
||||
```toml
|
||||
[config]
|
||||
enable_auto_approval = true
|
||||
```
|
||||
|
||||
There are two possible paths leading to this auto-approval - one via the `review` tool, and one via the `improve` tool. Each tool can independently trigger auto-approval.
|
||||
|
||||
### Auto-approval via the `review` tool
|
||||
|
||||
- **Review effort score criteria**
|
||||
|
||||
```toml
|
||||
[config]
|
||||
enable_auto_approval = true
|
||||
auto_approve_for_low_review_effort = X # X is a number between 1 and 5
|
||||
```
|
||||
|
||||
When the [review effort score](https://www.qodo.ai/images/pr_agent/review3.png) is lower than or equal to X, the PR will be auto-approved (unless ticket compliance is enabled and fails, see below).
|
||||
|
||||
- **Ticket compliance criteria**
|
||||
|
||||
```toml
|
||||
[config]
|
||||
enable_auto_approval = true
|
||||
ensure_ticket_compliance = true # Default is false
|
||||
```
|
||||
|
||||
If `ensure_ticket_compliance` is set to `true`, auto-approval for the `review` toll path will be disabled if no ticket is linked to the PR, or if the PR is not fully compliant with a linked ticket. This ensures that PRs are only auto-approved if their associated tickets are properly resolved.
|
||||
|
||||
You can also prevent auto-approval if the PR exceeds the ticket's scope (see [here](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/#configuration-options)).
|
||||
|
||||
|
||||
### Auto-approval via the `improve` tool
|
||||
|
||||
PRs can be auto-approved when the `improve` tool doesn't find code suggestions.
|
||||
To enable this feature, set the following in the configuration file:
|
||||
|
||||
```toml
|
||||
[config]
|
||||
enable_auto_approval = true
|
||||
auto_approve_for_no_suggestions = true
|
||||
```
|
||||
|
||||
@ -1,8 +1,3 @@
|
||||
# Code Validation 💎
|
||||
|
||||
`Supported Git Platforms: GitHub, GitLab, Bitbucket`
|
||||
|
||||
|
||||
## Introduction
|
||||
|
||||
The Git environment usually represents the final stage before code enters production. Hence, Detecting bugs and issues during the review process is critical.
|
||||
|
||||
@ -1,8 +1,5 @@
|
||||
|
||||
`Supported Git Platforms: GitHub, GitLab, Bitbucket`
|
||||
|
||||
|
||||
## Overview
|
||||
## Overview - PR Compression Strategy
|
||||
|
||||
There are two scenarios:
|
||||
|
||||
|
||||
@ -1,5 +1,4 @@
|
||||
|
||||
`Supported Git Platforms: GitHub, GitLab, Bitbucket`
|
||||
## TL;DR
|
||||
|
||||
Qodo Merge uses an **asymmetric and dynamic context strategy** to improve AI analysis of code changes in pull requests.
|
||||
It provides more context before changes than after, and dynamically adjusts the context based on code structure (e.g., enclosing functions or classes).
|
||||
|
||||
@ -39,40 +39,17 @@ By understanding the reasoning and intent behind modifications, the LLM can offe
|
||||
Similarly to the `describe` tool, the `review` tool will use the ticket content to provide additional context for the code changes.
|
||||
|
||||
In addition, this feature will evaluate how well a Pull Request (PR) adheres to its original purpose/intent as defined by the associated ticket or issue mentioned in the PR description.
|
||||
Each ticket will be assigned a label (Compliance/Alignment level), Indicates the degree to which the PR fulfills its original purpose:
|
||||
|
||||
- Fully Compliant
|
||||
- Partially Compliant
|
||||
- Not Compliant
|
||||
- PR Code Verified
|
||||
Each ticket will be assigned a label (Compliance/Alignment level), Indicates the degree to which the PR fulfills its original purpose, Options: Fully compliant, Partially compliant or Not compliant.
|
||||
|
||||
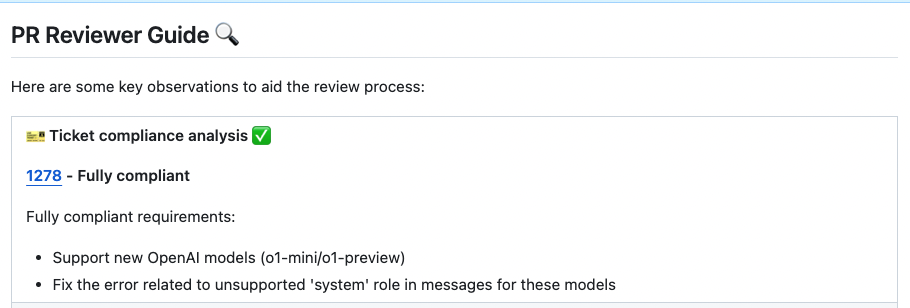{width=768}
|
||||
|
||||
A `PR Code Verified` label indicates the PR code meets ticket requirements, but requires additional manual testing beyond the code scope. For example - validating UI display across different environments (Mac, Windows, mobile, etc.).
|
||||
By default, the tool will automatically validate if the PR complies with the referenced ticket.
|
||||
If you want to disable this feedback, add the following line to your configuration file:
|
||||
|
||||
|
||||
#### Configuration options
|
||||
|
||||
-
|
||||
|
||||
By default, the tool will automatically validate if the PR complies with the referenced ticket.
|
||||
If you want to disable this feedback, add the following line to your configuration file:
|
||||
|
||||
```toml
|
||||
[pr_reviewer]
|
||||
require_ticket_analysis_review=false
|
||||
```
|
||||
|
||||
-
|
||||
|
||||
If you set:
|
||||
```toml
|
||||
[pr_reviewer]
|
||||
check_pr_additional_content=true
|
||||
```
|
||||
(default: `false`)
|
||||
|
||||
the `review` tool will also validate that the PR code doesn't contain any additional content that is not related to the ticket. If it does, the PR will be labeled at best as `PR Code Verified`, and the `review` tool will provide a comment with the additional unrelated content found in the PR code.
|
||||
```toml
|
||||
[pr_reviewer]
|
||||
require_ticket_analysis_review=false
|
||||
```
|
||||
|
||||
## GitHub Issues Integration
|
||||
|
||||
@ -392,7 +369,7 @@ To integrate with Jira, you can link your PR to a ticket using either of these m
|
||||
|
||||
**Method 1: Description Reference:**
|
||||
|
||||
Include a ticket reference in your PR description, using either the complete URL format `https://<JIRA_ORG>.atlassian.net/browse/ISSUE-123` or the shortened ticket ID `ISSUE-123` (without prefix or suffix for the shortened ID).
|
||||
Include a ticket reference in your PR description using either the complete URL format https://<JIRA_ORG>.atlassian.net/browse/ISSUE-123 or the shortened ticket ID ISSUE-123.
|
||||
|
||||
**Method 2: Branch Name Detection:**
|
||||
|
||||
@ -405,7 +382,6 @@ Name your branch with the ticket ID as a prefix (e.g., `ISSUE-123-feature-descri
|
||||
[jira]
|
||||
jira_base_url = "https://<JIRA_ORG>.atlassian.net"
|
||||
```
|
||||
Where `<JIRA_ORG>` is your Jira organization identifier (e.g., `mycompany` for `https://mycompany.atlassian.net`).
|
||||
|
||||
## Linear Integration 💎
|
||||
|
||||
|
||||
@ -1,6 +1,4 @@
|
||||
# Impact Evaluation 💎
|
||||
|
||||
`Supported Git Platforms: GitHub, GitLab, Bitbucket`
|
||||
# Overview - Impact Evaluation 💎
|
||||
|
||||
Demonstrating the return on investment (ROI) of AI-powered initiatives is crucial for modern organizations.
|
||||
To address this need, Qodo Merge has developed an AI impact measurement tools and metrics, providing advanced analytics to help businesses quantify the tangible benefits of AI adoption in their PR review process.
|
||||
|
||||
@ -2,7 +2,6 @@
|
||||
|
||||
Qodo Merge utilizes a variety of core abilities to provide a comprehensive and efficient code review experience. These abilities include:
|
||||
|
||||
- [Auto approval](https://qodo-merge-docs.qodo.ai/core-abilities/auto_approval/)
|
||||
- [Auto best practices](https://qodo-merge-docs.qodo.ai/core-abilities/auto_best_practices/)
|
||||
- [Chat on code suggestions](https://qodo-merge-docs.qodo.ai/core-abilities/chat_on_code_suggestions/)
|
||||
- [Code validation](https://qodo-merge-docs.qodo.ai/core-abilities/code_validation/)
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Interactivity 💎
|
||||
# Interactivity
|
||||
|
||||
`Supported Git Platforms: GitHub, GitLab`
|
||||
|
||||
|
||||
@ -1,6 +1,4 @@
|
||||
# Local and global metadata injection with multi-stage analysis
|
||||
|
||||
`Supported Git Platforms: GitHub, GitLab, Bitbucket`
|
||||
## Local and global metadata injection with multi-stage analysis
|
||||
|
||||
1\.
|
||||
Qodo Merge initially retrieves for each PR the following data:
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
`Supported Git Platforms: GitHub, GitLab, Bitbucket`
|
||||
## TL;DR
|
||||
|
||||
Qodo Merge implements a **self-reflection** process where the AI model reflects, scores, and re-ranks its own suggestions, eliminating irrelevant or incorrect ones.
|
||||
This approach improves the quality and relevance of suggestions, saving users time and enhancing their experience.
|
||||
|
||||
@ -1,14 +1,11 @@
|
||||
# Static Code Analysis 💎
|
||||
|
||||
` Supported Git Platforms: GitHub, GitLab, Bitbucket`
|
||||
|
||||
## Overview - Static Code Analysis 💎
|
||||
|
||||
By combining static code analysis with LLM capabilities, Qodo Merge can provide a comprehensive analysis of the PR code changes on a component level.
|
||||
|
||||
It scans the PR code changes, finds all the code components (methods, functions, classes) that changed, and enables to interactively generate tests, docs, code suggestions and similar code search for each component.
|
||||
|
||||
!!! note "Language that are currently supported:"
|
||||
Python, Java, C++, JavaScript, TypeScript, C#, Go.
|
||||
Python, Java, C++, JavaScript, TypeScript, C#.
|
||||
|
||||
## Capabilities
|
||||
|
||||
|
||||
@ -39,8 +39,6 @@ GITEA__PERSONAL_ACCESS_TOKEN=<personal_access_token>
|
||||
GITEA__WEBHOOK_SECRET=<webhook_secret>
|
||||
GITEA__URL=https://gitea.com # Or self host
|
||||
OPENAI__KEY=<your_openai_api_key>
|
||||
GITEA__SKIP_SSL_VERIFICATION=false # or true
|
||||
GITEA__SSL_CA_CERT=/path/to/cacert.pem
|
||||
```
|
||||
|
||||
8. Create a webhook in your Gitea project. Set the URL to `http[s]://<PR_AGENT_HOSTNAME>/api/v1/gitea_webhooks`, the secret token to the generated secret from step 3, and enable the triggers `push`, `comments` and `merge request events`.
|
||||
|
||||
@ -187,15 +187,14 @@ For example: `GITHUB.WEBHOOK_SECRET` --> `GITHUB__WEBHOOK_SECRET`
|
||||
2. Build a docker image that can be used as a lambda function
|
||||
|
||||
```shell
|
||||
# Note: --target github_lambda is optional as it's the default target
|
||||
docker buildx build --platform=linux/amd64 . -t codiumai/pr-agent:github_lambda --target github_lambda -f docker/Dockerfile.lambda
|
||||
docker buildx build --platform=linux/amd64 . -t codiumai/pr-agent:serverless -f docker/Dockerfile.lambda
|
||||
```
|
||||
|
||||
3. Push image to ECR
|
||||
|
||||
```shell
|
||||
docker tag codiumai/pr-agent:github_lambda <AWS_ACCOUNT>.dkr.ecr.<AWS_REGION>.amazonaws.com/codiumai/pr-agent:github_lambda
|
||||
docker push <AWS_ACCOUNT>.dkr.ecr.<AWS_REGION>.amazonaws.com/codiumai/pr-agent:github_lambda
|
||||
docker tag codiumai/pr-agent:serverless <AWS_ACCOUNT>.dkr.ecr.<AWS_REGION>.amazonaws.com/codiumai/pr-agent:serverless
|
||||
docker push <AWS_ACCOUNT>.dkr.ecr.<AWS_REGION>.amazonaws.com/codiumai/pr-agent:serverless
|
||||
```
|
||||
|
||||
4. Create a lambda function that uses the uploaded image. Set the lambda timeout to be at least 3m.
|
||||
|
||||
@ -61,12 +61,12 @@ git clone https://github.com/qodo-ai/pr-agent.git
|
||||
```
|
||||
|
||||
5. Prepare variables and secrets. Skip this step if you plan on setting these as environment variables when running the agent:
|
||||
1. In the configuration file/variables:
|
||||
- Set `config.git_provider` to "gitlab"
|
||||
1. In the configuration file/variables:
|
||||
- Set `config.git_provider` to "gitlab"
|
||||
|
||||
2. In the secrets file/variables:
|
||||
- Set your AI model key in the respective section
|
||||
- In the [gitlab] section, set `personal_access_token` (with token from step 2) and `shared_secret` (with secret from step 3)
|
||||
2. In the secrets file/variables:
|
||||
- Set your AI model key in the respective section
|
||||
- In the [gitlab] section, set `personal_access_token` (with token from step 2) and `shared_secret` (with secret from step 3)
|
||||
|
||||
6. Build a Docker image for the app and optionally push it to a Docker repository. We'll use Dockerhub as an example:
|
||||
|
||||
@ -88,63 +88,3 @@ OPENAI__KEY=<your_openai_api_key>
|
||||
8. Create a webhook in your GitLab project. Set the URL to `http[s]://<PR_AGENT_HOSTNAME>/webhook`, the secret token to the generated secret from step 3, and enable the triggers `push`, `comments` and `merge request events`.
|
||||
|
||||
9. Test your installation by opening a merge request or commenting on a merge request using one of PR Agent's commands.
|
||||
|
||||
## Deploy as a Lambda Function
|
||||
|
||||
Note that since AWS Lambda env vars cannot have "." in the name, you can replace each "." in an env variable with "__".<br>
|
||||
For example: `GITLAB.PERSONAL_ACCESS_TOKEN` --> `GITLAB__PERSONAL_ACCESS_TOKEN`
|
||||
|
||||
1. Follow steps 1-5 from [Run a GitLab webhook server](#run-a-gitlab-webhook-server).
|
||||
2. Build a docker image that can be used as a lambda function
|
||||
|
||||
```shell
|
||||
docker buildx build --platform=linux/amd64 . -t codiumai/pr-agent:gitlab_lambda --target gitlab_lambda -f docker/Dockerfile.lambda
|
||||
```
|
||||
|
||||
3. Push image to ECR
|
||||
|
||||
```shell
|
||||
docker tag codiumai/pr-agent:gitlab_lambda <AWS_ACCOUNT>.dkr.ecr.<AWS_REGION>.amazonaws.com/codiumai/pr-agent:gitlab_lambda
|
||||
docker push <AWS_ACCOUNT>.dkr.ecr.<AWS_REGION>.amazonaws.com/codiumai/pr-agent:gitlab_lambda
|
||||
```
|
||||
|
||||
4. Create a lambda function that uses the uploaded image. Set the lambda timeout to be at least 3m.
|
||||
5. Configure the lambda function to have a Function URL.
|
||||
6. In the environment variables of the Lambda function, specify `AZURE_DEVOPS_CACHE_DIR` to a writable location such as /tmp. (see [link](https://github.com/Codium-ai/pr-agent/pull/450#issuecomment-1840242269))
|
||||
7. Go back to steps 8-9 of [Run a GitLab webhook server](#run-a-gitlab-webhook-server) with the function url as your Webhook URL.
|
||||
The Webhook URL would look like `https://<LAMBDA_FUNCTION_URL>/webhook`
|
||||
|
||||
### Using AWS Secrets Manager
|
||||
|
||||
For production Lambda deployments, use AWS Secrets Manager instead of environment variables:
|
||||
|
||||
1. Create individual secrets for each GitLab webhook with this JSON format (e.g., secret name: `project-webhook-secret-001`)
|
||||
|
||||
```json
|
||||
{
|
||||
"gitlab_token": "glpat-xxxxxxxxxxxxxxxxxxxxxxxx",
|
||||
"token_name": "project-webhook-001"
|
||||
}
|
||||
```
|
||||
|
||||
2. Create a main configuration secret for common settings (e.g., secret name: `pr-agent-main-config`)
|
||||
|
||||
```json
|
||||
{
|
||||
"openai.key": "sk-proj-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
|
||||
}
|
||||
```
|
||||
|
||||
3. Set these environment variables in your Lambda:
|
||||
|
||||
```bash
|
||||
CONFIG__SECRET_PROVIDER=aws_secrets_manager
|
||||
AWS_SECRETS_MANAGER__SECRET_ARN=arn:aws:secretsmanager:us-east-1:123456789012:secret:pr-agent-main-config-AbCdEf
|
||||
```
|
||||
|
||||
4. In your GitLab webhook configuration, set the **Secret Token** to the **Secret name** created in step 1:
|
||||
- Example: `project-webhook-secret-001`
|
||||
|
||||
**Important**: When using Secrets Manager, GitLab's webhook secret must be the Secrets Manager secret name.
|
||||
|
||||
5. Add IAM permission `secretsmanager:GetSecretValue` to your Lambda execution role
|
||||
@ -27,9 +27,7 @@ Qodo Merge for GitHub cloud is available for installation through the [GitHub Ma
|
||||
|
||||
### GitHub Enterprise Server
|
||||
|
||||
To use Qodo Merge on your private GitHub Enterprise Server, you will need to [contact](https://www.qodo.ai/contact/#pricing) Qodo for starting an Enterprise trial.
|
||||
|
||||
(Note: The marketplace app is not compatible with GitHub Enterprise Server. Installation requires creating a private GitHub App instead.)
|
||||
To use Qodo Merge application on your private GitHub Enterprise Server, you will need to [contact](https://www.qodo.ai/contact/#pricing) Qodo for starting an Enterprise trial.
|
||||
|
||||
### GitHub Open Source Projects
|
||||
|
||||
|
||||
@ -2,231 +2,200 @@
|
||||
|
||||
## Methodology
|
||||
|
||||
Qodo Merge PR Benchmark evaluates and compares the performance of Large Language Models (LLMs) in analyzing pull request code and providing meaningful code suggestions.
|
||||
Qodo Merge PR Benchmark evaluates and compares the performance of two Large Language Models (LLMs) in analyzing pull request code and providing meaningful code suggestions.
|
||||
Our diverse dataset comprises of 400 pull requests from over 100 repositories, spanning various programming languages and frameworks to reflect real-world scenarios.
|
||||
|
||||
- For each pull request, we have pre-generated suggestions from [11](https://qodo-merge-docs.qodo.ai/pr_benchmark/#models-used-for-generating-the-benchmark-baseline) different top-performing models using the Qodo Merge `improve` tool. The prompt for response generation can be found [here](https://github.com/qodo-ai/pr-agent/blob/main/pr_agent/settings/code_suggestions/pr_code_suggestions_prompts_not_decoupled.toml).
|
||||
- For each pull request, two distinct LLMs process the same prompt using the Qodo Merge `improve` tool, each generating two sets of responses. The prompt for response generation can be found [here](https://github.com/qodo-ai/pr-agent/blob/main/pr_agent/settings/code_suggestions/pr_code_suggestions_prompts_not_decoupled.toml).
|
||||
|
||||
- To benchmark a model, we generate its suggestions for the same pull requests and ask a high-performing judge model to **rank** the new model's output against the 11 pre-generated baseline suggestions. We utilize OpenAI's `o3` model as the judge, though other models have yielded consistent results. The prompt for this ranking judgment is available [here](https://github.com/Codium-ai/pr-agent-settings/tree/main/benchmark).
|
||||
- Subsequently, a high-performing third model (an AI judge) evaluates the responses from the initial two models to determine the superior one. We utilize OpenAI's `o3` model as the judge, though other models have yielded consistent results. The prompt for this comparative judgment is available [here](https://github.com/Codium-ai/pr-agent-settings/tree/main/benchmark).
|
||||
|
||||
- We aggregate ranking outcomes across all pull requests, calculating performance metrics for the evaluated model. We also analyze the qualitative feedback from the judge to identify the model's comparative strengths and weaknesses against the established baselines.
|
||||
- We aggregate comparison outcomes across all the pull requests, calculating the win rate for each model. We also analyze the qualitative feedback (the "why" explanations from the judge) to identify each model's comparative strengths and weaknesses.
|
||||
This approach provides not just a quantitative score but also a detailed analysis of each model's strengths and weaknesses.
|
||||
|
||||
- For each model we build a "Model Card", comparing it against others. To ensure full transparency and enable community scrutiny, we also share the raw code suggestions generated by each model, and the judge's specific feedback. See example for the full output [here](https://github.com/Codium-ai/pr-agent-settings/blob/main/benchmark/sonnet_37_vs_gemini-2.5-pro-preview-05-06.md)
|
||||
|
||||
[//]: # (Note that this benchmark focuses on quality: the ability of an LLM to process complex pull request with multiple files and nuanced task to produce high-quality code suggestions.)
|
||||
Note that this benchmark focuses on quality: the ability of an LLM to process complex pull request with multiple files and nuanced task to produce high-quality code suggestions.
|
||||
Other factors like speed, cost, and availability, while also relevant for model selection, are outside this benchmark's scope.
|
||||
|
||||
[//]: # (Other factors like speed, cost, and availability, while also relevant for model selection, are outside this benchmark's scope. We do specify the thinking budget used by each model, which can be a factor in the model's performance.)
|
||||
## TL;DR
|
||||
|
||||
[//]: # ()
|
||||
Here's a summary of the win rates based on the benchmark:
|
||||
|
||||
## Results
|
||||
[//]: # (| Model A | Model B | Model A Win Rate | Model B Win Rate |)
|
||||
|
||||
[//]: # (|:-------------------------------|:-------------------------------|:----------------:|:----------------:|)
|
||||
|
||||
[//]: # (| Gemini-2.5-pro-preview-05-06 | GPT-4.1 | 70.4% | 29.6% |)
|
||||
|
||||
[//]: # (| Gemini-2.5-pro-preview-05-06 | Sonnet 3.7 | 78.1% | 21.9% |)
|
||||
|
||||
[//]: # (| GPT-4.1 | Sonnet 3.7 | 61.0% | 39.0% |)
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th style="text-align:left;">Model Name</th>
|
||||
<th style="text-align:left;">Version (Date)</th>
|
||||
<th style="text-align:left;">Thinking budget tokens</th>
|
||||
<th style="text-align:center;">Score</th>
|
||||
</tr>
|
||||
<th style="text-align:left;">Model A</th>
|
||||
<th style="text-align:left;">Model B</th>
|
||||
<th style="text-align:center;">Model A Win Rate</th> <th style="text-align:center;">Model B Win Rate</th> </tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td style="text-align:left;">o3</td>
|
||||
<td style="text-align:left;">2025-04-16</td>
|
||||
<td style="text-align:left;">'medium' (<a href="https://ai.google.dev/gemini-api/docs/openai">8000</a>)</td>
|
||||
<td style="text-align:center;"><b>62.5</b></td>
|
||||
</tr>
|
||||
<td style="text-align:left;">Gemini-2.5-pro-preview-05-06</td>
|
||||
<td style="text-align:left;">GPT-4.1</td>
|
||||
<td style="text-align:center; color: #1E8449;"><b>70.4%</b></td> <td style="text-align:center; color: #D8000C;"><b>29.6%</b></td> </tr>
|
||||
<tr>
|
||||
<td style="text-align:left;">o4-mini</td>
|
||||
<td style="text-align:left;">2025-04-16</td>
|
||||
<td style="text-align:left;">'medium' (<a href="https://ai.google.dev/gemini-api/docs/openai">8000</a>)</td>
|
||||
<td style="text-align:center;"><b>57.7</b></td>
|
||||
</tr>
|
||||
<td style="text-align:left;">Gemini-2.5-pro-preview-05-06</td>
|
||||
<td style="text-align:left;">Sonnet 3.7</td>
|
||||
<td style="text-align:center; color: #1E8449;"><b>78.1%</b></td> <td style="text-align:center; color: #D8000C;"><b>21.9%</b></td> </tr>
|
||||
<tr>
|
||||
<td style="text-align:left;">Gemini-2.5-pro</td>
|
||||
<td style="text-align:left;">2025-06-05</td>
|
||||
<td style="text-align:left;">4096</td>
|
||||
<td style="text-align:center;"><b>56.3</b></td>
|
||||
</tr>
|
||||
<td style="text-align:left;">Gemini-2.5-pro-preview-05-06</td>
|
||||
<td style="text-align:left;">Gemini-2.5-flash-preview-04-17</td>
|
||||
<td style="text-align:center; color: #1E8449;"><b>73.0%</b></td> <td style="text-align:center; color: #D8000C;"><b>27.0%</b></td> </tr>
|
||||
<tr>
|
||||
<td style="text-align:left;">Gemini-2.5-pro</td>
|
||||
<td style="text-align:left;">2025-06-05</td>
|
||||
<td style="text-align:left;">1024</td>
|
||||
<td style="text-align:center;"><b>44.3</b></td>
|
||||
</tr>
|
||||
<td style="text-align:left;">Gemini-2.5-flash-preview-04-17</td>
|
||||
<td style="text-align:left;">GPT-4.1</td>
|
||||
<td style="text-align:center; color: #1E8449;"><b>54.6%</b></td> <td style="text-align:center; color: #D8000C;"><b>45.4%</b></td> </tr>
|
||||
<tr>
|
||||
<td style="text-align:left;">Claude-4-sonnet</td>
|
||||
<td style="text-align:left;">2025-05-14</td>
|
||||
<td style="text-align:left;">4096</td>
|
||||
<td style="text-align:center;"><b>39.7</b></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align:left;">Claude-4-sonnet</td>
|
||||
<td style="text-align:left;">2025-05-14</td>
|
||||
<td style="text-align:left;"></td>
|
||||
<td style="text-align:center;"><b>39.0</b></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align:left;">Gemini-2.5-flash</td>
|
||||
<td style="text-align:left;">2025-04-17</td>
|
||||
<td style="text-align:left;"></td>
|
||||
<td style="text-align:center;"><b>33.5</b></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align:left;">Claude-3.7-sonnet</td>
|
||||
<td style="text-align:left;">2025-02-19</td>
|
||||
<td style="text-align:left;"></td>
|
||||
<td style="text-align:center;"><b>32.4</b></td>
|
||||
</tr>
|
||||
<td style="text-align:left;">Gemini-2.5-flash-preview-04-17</td>
|
||||
<td style="text-align:left;">Sonnet 3.7</td>
|
||||
<td style="text-align:center; color: #1E8449;"><b>60.6%</b></td> <td style="text-align:center; color: #D8000C;"><b>39.4%</b></td> </tr>
|
||||
<tr>
|
||||
<td style="text-align:left;">GPT-4.1</td>
|
||||
<td style="text-align:left;">2025-04-14</td>
|
||||
<td style="text-align:left;"></td>
|
||||
<td style="text-align:center;"><b>26.5</b></td>
|
||||
</tr>
|
||||
<td style="text-align:left;">Sonnet 3.7</td>
|
||||
<td style="text-align:center; color: #1E8449;"><b>61.0%</b></td> <td style="text-align:center; color: #D8000C;"><b>39.0%</b></td> </tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
## Results Analysis
|
||||
|
||||
### O3
|
||||
## Gemini-2.5-pro-preview-05-06 - Model Card
|
||||
|
||||
Final score: **62.5**
|
||||
### Comparison against GPT-4.1
|
||||
|
||||
strengths:
|
||||
{width=768}
|
||||
|
||||
- **High precision & compliance:** Generally respects task rules (limits, “added lines” scope, YAML schema) and avoids false-positive advice, often returning an empty list when appropriate.
|
||||
- **Clear, actionable output:** Suggestions are concise, well-explained and include correct before/after patches, so reviewers can apply them directly.
|
||||
- **Good critical-bug detection rate:** Frequently spots compile-breakers or obvious runtime faults (nil / NPE, overflow, race, wrong selector, etc.), putting it at least on par with many peers.
|
||||
- **Consistent formatting:** Produces syntactically valid YAML with correct labels, making automated consumption easy.
|
||||
#### Analysis Summary
|
||||
|
||||
weaknesses:
|
||||
Model 'Gemini-2.5-pro-preview-05-06' is generally more useful thanks to wider and more accurate bug detection and concrete patches, but it sacrifices compliance discipline and sometimes oversteps the task rules. Model 'GPT-4.1' is safer and highly rule-abiding, yet often too timid—missing many genuine issues and providing limited insight. An ideal reviewer would combine 'GPT-4.1’ restraint with 'Gemini-2.5-pro-preview-05-06' thoroughness.
|
||||
|
||||
- **Narrow coverage:** Tends to stop after 1-2 issues; regularly misses additional critical defects that better answers catch, so it is seldom the top-ranked review.
|
||||
- **Occasional inaccuracies:** A few replies introduce new bugs, give partial/duplicate fixes, or (rarely) violate rules (e.g., import suggestions), hurting trust.
|
||||
- **Conservative bias:** Prefers silence over risk; while this keeps precision high, it lowers recall and overall usefulness on larger diffs.
|
||||
- **Little added insight:** Rarely offers broader context, optimisations or holistic improvements, causing it to rank only mid-tier in many comparisons.
|
||||
#### Detailed Analysis
|
||||
|
||||
### O4 Mini ('medium' thinking tokens)
|
||||
Gemini-2.5-pro-preview-05-06 strengths:
|
||||
|
||||
Final score: **57.7**
|
||||
- better_bug_coverage: Detects and explains more critical issues, winning in ~70 % of comparisons and achieving a higher average score.
|
||||
- actionable_fixes: Supplies clear code snippets, correct language labels, and often multiple coherent suggestions per diff.
|
||||
- deeper_reasoning: Shows stronger grasp of logic, edge cases, and cross-file implications, leading to broader, high-impact reviews.
|
||||
|
||||
strengths:
|
||||
Gemini-2.5-pro-preview-05-06 weaknesses:
|
||||
|
||||
- **Good rule adherence:** Most answers respect the “new-lines only”, 3-suggestion, and YAML-schema limits, and frequently choose the safe empty list when the diff truly adds no critical bug.
|
||||
- **Clear, minimal patches:** When the model does spot a defect it usually supplies terse, valid before/after snippets and short, targeted explanations, making fixes easy to read and apply.
|
||||
- **Language & domain breadth:** Demonstrates competence across many ecosystems (C/C++, Java, TS/JS, Go, Rust, Python, Bash, Markdown, YAML, SQL, CSS, translation files, etc.) and can detect both compile-time and runtime mistakes.
|
||||
- **Often competitive:** In a sizeable minority of cases the model ties for best or near-best answer, occasionally being the only response to catch a subtle crash or build blocker.
|
||||
|
||||
weaknesses:
|
||||
|
||||
- **High miss rate:** A large share of examples show the model returning an empty list or only minor advice while other reviewers catch clear, high-impact bugs—indicative of weak defect-detection recall.
|
||||
- **False or harmful fixes:** Several answers introduce new compilation errors, propose out-of-scope changes, or violate explicit rules (e.g., adding imports, version bumps, touching untouched lines), reducing trustworthiness.
|
||||
- **Shallow coverage:** Even when it identifies one real issue it often stops there, missing additional critical problems found by stronger peers; breadth and depth are inconsistent.
|
||||
|
||||
### Gemini-2.5 Pro (4096 thinking tokens)
|
||||
|
||||
Final score: **56.3**
|
||||
|
||||
strengths:
|
||||
|
||||
- **High formatting compliance:** The model almost always produces valid YAML, respects the three-suggestion limit, and supplies clear before/after code snippets and short rationales.
|
||||
- **Good “first-bug” detection:** It frequently notices the single most obvious regression (crash, compile error, nil/NPE risk, wrong path, etc.) and gives a minimal, correct patch—often judged “on-par” with other solid answers.
|
||||
- **Clear, concise writing:** Explanations are brief yet understandable for reviewers; fixes are scoped to the changed lines and rarely include extraneous context.
|
||||
- **Low rate of harmful fixes:** Truly dangerous or build-breaking advice is rare; most mistakes are omissions rather than wrong code.
|
||||
|
||||
weaknesses:
|
||||
|
||||
- **Limited breadth of review:** The model regularly stops after the first or second issue, missing additional critical problems that stronger answers surface, so it is often out-ranked by more comprehensive peers.
|
||||
- **Occasional guideline violations:** A noticeable minority of answers touch unchanged lines, exceed the 3-item cap, suggest adding imports, or drop the required YAML wrapper, leading to automatic downgrades.
|
||||
- **False positives / speculative fixes:** In several cases it flags non-issues (style, performance, redundant code) or supplies debatable “improvements”, lowering precision and sometimes breaching the “critical bugs only” rule.
|
||||
- **Inconsistent error coverage:** For certain domains (build scripts, schema files, test code) it either returns an empty list when real regressions exist or proposes cosmetic edits, indicating gaps in specialised knowledge.
|
||||
|
||||
### Claude-4 Sonnet (4096 thinking tokens)
|
||||
|
||||
Final score: **39.7**
|
||||
|
||||
strengths:
|
||||
|
||||
- **High guideline & format compliance:** Almost always returns valid YAML, keeps ≤ 3 suggestions, avoids forbidden import/boiler-plate changes and provides clear before/after snippets.
|
||||
- **Good pinpoint accuracy on single issues:** Frequently spots at least one real critical bug and proposes a concise, technically correct fix that compiles/runs.
|
||||
- **Clarity & brevity of patches:** Explanations are short, actionable, and focused on changed lines, making the advice easy for reviewers to apply.
|
||||
|
||||
weaknesses:
|
||||
|
||||
- **Low coverage / recall:** Regularly surfaces only one minor issue (or none) while missing other, often more severe, problems caught by peer models.
|
||||
- **High “empty-list” rate:** In many diffs the model returns no suggestions even when clear critical bugs exist, offering zero reviewer value.
|
||||
- **Occasional incorrect or harmful fixes:** A non-trivial number of suggestions are speculative, contradict code intent, or would break compilation/runtime; sometimes duplicates or contradicts itself.
|
||||
- **Inconsistent severity labelling & duplication:** Repeats the same point in multiple slots, marks cosmetic edits as “critical”, or leaves `improved_code` identical to original.
|
||||
- guideline_violations: More prone to over-eager advice—non-critical tweaks, touching unchanged code, suggesting new imports, or minor format errors.
|
||||
- occasional_overreach: Some fixes are speculative or risky, potentially introducing new bugs.
|
||||
- redundant_or_duplicate: At times repeats the same point or exceeds the required brevity.
|
||||
|
||||
|
||||
### Claude-4 Sonnet
|
||||
### Comparison against Sonnet 3.7
|
||||
|
||||
Final score: **39.0**
|
||||
{width=768}
|
||||
|
||||
strengths:
|
||||
#### Analysis Summary
|
||||
|
||||
- **Consistently well-formatted & rule-compliant output:** Almost every answer follows the required YAML schema, keeps within the 3-suggestion limit, and returns an empty list when no issues are found, showing good instruction following.
|
||||
Model 'Gemini-2.5-pro-preview-05-06' is the stronger reviewer—more frequently identifies genuine, high-impact bugs and provides well-formed, actionable fixes. Model 'Sonnet 3.7' is safer against false positives and tends to be concise but often misses important defects or offers low-value or incorrect suggestions.
|
||||
|
||||
- **Actionable, code-level patches:** When it does spot a defect the model usually supplies clear, minimal diffs or replacement snippets that compile / run, making the fix easy to apply.
|
||||
|
||||
- **Decent hit-rate on “obvious” bugs:** The model reliably catches the most blatant syntax errors, null-checks, enum / cast problems, and other first-order issues, so it often ties or slightly beats weaker baseline replies.
|
||||
|
||||
weaknesses:
|
||||
|
||||
- **Shallow coverage:** It frequently stops after one easy bug and overlooks additional, equally-critical problems that stronger reviewers find, leaving significant risks unaddressed.
|
||||
|
||||
- **False positives & harmful fixes:** In a noticeable minority of cases it misdiagnoses code, suggests changes that break compilation or behaviour, or flags non-issues, sometimes making its output worse than doing nothing.
|
||||
|
||||
- **Drifts into non-critical or out-of-scope advice:** The model regularly proposes style tweaks, documentation edits, or changes to unchanged lines, violating the “critical new-code only” requirement.
|
||||
See raw results [here](https://github.com/Codium-ai/pr-agent-settings/blob/main/benchmark/sonnet_37_vs_gemini-2.5-pro-preview-05-06.md)
|
||||
|
||||
|
||||
### Gemini-2.5 Flash
|
||||
#### Detailed Analysis
|
||||
|
||||
strengths:
|
||||
Gemini-2.5-pro-preview-05-06 strengths:
|
||||
|
||||
- **High precision / low false-positive rate:** The model often stays silent or gives a single, well-justified fix, so when it does speak the suggestion is usually correct and seldom touches unchanged lines, keeping guideline compliance high.
|
||||
- **Good guideline awareness:** YAML structure is consistently valid; suggestions rarely exceed the 3-item limit and generally restrict themselves to newly-added lines.
|
||||
- **Clear, concise patches:** When a defect is found, the model produces short rationales and tidy “improved_code” blocks that reviewers can apply directly.
|
||||
- **Risk-averse behaviour pays off in “no-bug” PRs:** In examples where the diff truly contained no critical issue, the model’s empty output ranked above peers that offered speculative or stylistic advice.
|
||||
- higher_accuracy_and_coverage: finds real critical bugs and supplies actionable patches in most examples (better in 78 % of cases).
|
||||
- guideline_awareness: usually respects new-lines-only scope, ≤3 suggestions, proper YAML, and stays silent when no issues exist.
|
||||
- detailed_reasoning_and_patches: explanations tie directly to the diff and fixes are concrete, often catching multiple related defects that 'Sonnet 3.7' overlooks.
|
||||
|
||||
weaknesses:
|
||||
Gemini-2.5-pro-preview-05-06 weaknesses:
|
||||
|
||||
- **Very low recall / shallow coverage:** In a large majority of cases it gives 0-1 suggestions and misses other evident, critical bugs highlighted by peer models, leading to inferior rankings.
|
||||
- **Occasional incorrect or harmful fixes:** A noticeable subset of answers propose changes that break functionality or misunderstand the code (e.g. bad constant, wrong header logic, speculative rollbacks).
|
||||
- **Non-actionable placeholders:** Some “improved_code” sections contain comments or “…” rather than real patches, reducing practical value.
|
||||
-
|
||||
### GPT-4.1
|
||||
- occasional_rule_violations: sometimes proposes new imports, package-version changes, or edits outside the added lines.
|
||||
- overzealous_suggestions: may add speculative or stylistic fixes that exceed the “critical” scope, or mis-label severity.
|
||||
- sporadic_technical_slips: a few patches contain minor coding errors, oversized snippets, or duplicate/contradicting advice.
|
||||
|
||||
Final score: **26.5**
|
||||
## GPT-4.1 - Model Card
|
||||
|
||||
strengths:
|
||||
### Comparison against Sonnet 3.7
|
||||
|
||||
- **Consistent format & guideline obedience:** Output is almost always valid YAML, within the 3-suggestion limit, and rarely touches lines not prefixed with “+”.
|
||||
- **Low false-positive rate:** When no real defect exists, the model correctly returns an empty list instead of inventing speculative fixes, avoiding the “noise” many baseline answers add.
|
||||
- **Clear, concise patches when it does act:** In the minority of cases where it detects a bug (e.g., ex-13, 46, 212), the fix is usually correct, minimal, and easy to apply.
|
||||
{width=768}
|
||||
|
||||
weaknesses:
|
||||
#### Analysis Summary
|
||||
|
||||
- **Very low recall / coverage:** In a large majority of examples it outputs an empty list or only 1 trivial suggestion while obvious critical issues remain unfixed; it systematically misses circular bugs, null-checks, schema errors, etc.
|
||||
- **Shallow analysis:** Even when it finds one problem it seldom looks deeper, so more severe or additional bugs in the same diff are left unaddressed.
|
||||
- **Occasional technical inaccuracies:** A noticeable subset of suggestions are wrong (mis-ordered assertions, harmful Bash `set` change, false dangling-reference claims) or carry metadata errors (mis-labeling files as “python”).
|
||||
- **Repetitive / derivative fixes:** Many outputs duplicate earlier simplistic ideas (e.g., single null-check) without new insight, showing limited reasoning breadth.
|
||||
Model 'GPT-4.1' is safer and more compliant, preferring silence over speculation, which yields fewer rule breaches and false positives but misses some real bugs.
|
||||
Model 'Sonnet 3.7' is more adventurous and often uncovers important issues that 'GPT-4.1' ignores, yet its aggressive style leads to frequent guideline violations and a higher proportion of incorrect or non-critical advice.
|
||||
|
||||
See raw results [here](https://github.com/Codium-ai/pr-agent-settings/blob/main/benchmark/gpt-4.1_vs_sonnet_3.7_judge_o3.md)
|
||||
|
||||
|
||||
## Appendix - models used for generating the benchmark baseline
|
||||
#### Detailed Analysis
|
||||
|
||||
- anthropic_sonnet_3.7_v1:0
|
||||
- claude-4-opus-20250514
|
||||
- claude-4-sonnet-20250514
|
||||
- claude-4-sonnet-20250514_thinking_2048
|
||||
- gemini-2.5-flash-preview-04-17
|
||||
- gemini-2.5-pro-preview-05-06
|
||||
- gemini-2.5-pro-preview-06-05_1024
|
||||
- gemini-2.5-pro-preview-06-05_4096
|
||||
- gpt-4.1
|
||||
- o3
|
||||
- o4-mini_medium
|
||||
GPT-4.1 strengths:
|
||||
- Strong guideline adherence: usually stays strictly on `+` lines, avoids non-critical or stylistic advice, and rarely suggests forbidden imports; often outputs an empty list when no real bug exists.
|
||||
- Lower false-positive rate: suggestions are more accurate and seldom introduce new bugs; fixes compile more reliably.
|
||||
- Good schema discipline: YAML is almost always well-formed and fields are populated correctly.
|
||||
|
||||
GPT-4.1 weaknesses:
|
||||
- Misses bugs: often returns an empty list even when a clear critical issue is present, so coverage is narrower.
|
||||
- Sparse feedback: when it does comment, it tends to give fewer suggestions and sometimes lacks depth or completeness.
|
||||
- Occasional metadata/slip-ups (wrong language tags, overly broad code spans), though less harmful than Sonnet 3.7 errors.
|
||||
|
||||
### Comparison against Gemini-2.5-pro-preview-05-06
|
||||
|
||||
{width=768}
|
||||
|
||||
#### Analysis Summary
|
||||
|
||||
Model 'Gemini-2.5-pro-preview-05-06' is generally more useful thanks to wider and more accurate bug detection and concrete patches, but it sacrifices compliance discipline and sometimes oversteps the task rules. Model 'GPT-4.1' is safer and highly rule-abiding, yet often too timid—missing many genuine issues and providing limited insight. An ideal reviewer would combine 'GPT-4.1’ restraint with 'Gemini-2.5-pro-preview-05-06' thoroughness.
|
||||
|
||||
#### Detailed Analysis
|
||||
|
||||
GPT-4.1 strengths:
|
||||
- strict_compliance: Usually sticks to the “critical bugs only / new ‘+’ lines only” rule, so outputs rarely violate task constraints.
|
||||
- low_risk: Conservative behaviour avoids harmful or speculative fixes; safer when no obvious issue exists.
|
||||
- concise_formatting: Tends to produce minimal, correctly-structured YAML without extra noise.
|
||||
|
||||
GPT-4.1 weaknesses:
|
||||
- under_detection: Frequently returns an empty list even when real bugs are present, missing ~70 % of the time.
|
||||
- shallow_analysis: When it does suggest fixes, coverage is narrow and technical depth is limited, sometimes with wrong language tags or minor format slips.
|
||||
- occasional_inaccuracy: A few suggestions are unfounded or duplicate, and rare guideline breaches (e.g., import advice) still occur.
|
||||
|
||||
|
||||
## Sonnet 3.7 - Model Card
|
||||
|
||||
### Comparison against GPT-4.1
|
||||
|
||||
{width=768}
|
||||
|
||||
#### Analysis Summary
|
||||
|
||||
Model 'GPT-4.1' is safer and more compliant, preferring silence over speculation, which yields fewer rule breaches and false positives but misses some real bugs.
|
||||
Model 'Sonnet 3.7' is more adventurous and often uncovers important issues that 'GPT-4.1' ignores, yet its aggressive style leads to frequent guideline violations and a higher proportion of incorrect or non-critical advice.
|
||||
|
||||
See raw results [here](https://github.com/Codium-ai/pr-agent-settings/blob/main/benchmark/gpt-4.1_vs_sonnet_3.7_judge_o3.md)
|
||||
|
||||
#### Detailed Analysis
|
||||
|
||||
'Sonnet 3.7' strengths:
|
||||
- Better bug discovery breadth: more willing to dive into logic and spot critical problems that 'GPT-4.1' overlooks; often supplies multiple, detailed fixes.
|
||||
- Richer explanations & patches: gives fuller context and, when correct, proposes more functional or user-friendly solutions.
|
||||
- Generally correct language/context tagging and targeted code snippets.
|
||||
|
||||
'Sonnet 3.7' weaknesses:
|
||||
- Guideline violations: frequently flags non-critical issues, edits untouched code, or recommends adding imports, breaching task rules.
|
||||
- Higher error rate: suggestions are more speculative and sometimes introduce new defects or duplicate work already done.
|
||||
- Occasional schema or formatting mistakes (missing list value, duplicated suggestions), reducing reliability.
|
||||
|
||||
|
||||
### Comparison against Gemini-2.5-pro-preview-05-06
|
||||
|
||||
{width=768}
|
||||
|
||||
#### Analysis Summary
|
||||
|
||||
Model 'Gemini-2.5-pro-preview-05-06' is the stronger reviewer—more frequently identifies genuine, high-impact bugs and provides well-formed, actionable fixes. Model 'Sonnet 3.7' is safer against false positives and tends to be concise but often misses important defects or offers low-value or incorrect suggestions.
|
||||
|
||||
See raw results [here](https://github.com/Codium-ai/pr-agent-settings/blob/main/benchmark/sonnet_37_vs_gemini-2.5-pro-preview-05-06.md)
|
||||
|
||||
@ -17,4 +17,4 @@ An example result:
|
||||
{width=750}
|
||||
|
||||
!!! note "Language that are currently supported:"
|
||||
Python, Java, C++, JavaScript, TypeScript, C#, Go.
|
||||
Python, Java, C++, JavaScript, TypeScript, C#.
|
||||
|
||||
@ -483,6 +483,86 @@ code_suggestions_self_review_text = "... (your text here) ..."
|
||||
|
||||
To prevent unauthorized approvals, this configuration defaults to false, and cannot be altered through online comments; enabling requires a direct update to the configuration file and a commit to the repository. This ensures that utilizing the feature demands a deliberate documented decision by the repository owner.
|
||||
|
||||
### Auto-approval
|
||||
|
||||
> `💎 feature. Platforms supported: GitHub, GitLab, Bitbucket`
|
||||
|
||||
Under specific conditions, Qodo Merge can auto-approve a PR when a specific comment is invoked, or when the PR meets certain criteria.
|
||||
|
||||
**To ensure safety, the auto-approval feature is disabled by default.**
|
||||
To enable auto-approval features, you need to actively set one or both of the following options in a pre-defined _configuration file_:
|
||||
|
||||
```toml
|
||||
[config]
|
||||
enable_comment_approval = true # For approval via comments
|
||||
enable_auto_approval = true # For criteria-based auto-approval
|
||||
```
|
||||
|
||||
!!! note "Notes"
|
||||
- Note that this specific flag cannot be set with a command line argument, only in the configuration file, committed to the repository.
|
||||
- Enabling auto-approval must be a deliberate decision by the repository owner.
|
||||
|
||||
1\. **Auto-approval by commenting**
|
||||
|
||||
To enable auto-approval by commenting, set in the configuration file:
|
||||
|
||||
```toml
|
||||
[config]
|
||||
enable_comment_approval = true
|
||||
```
|
||||
|
||||
After enabling, by commenting on a PR:
|
||||
|
||||
```
|
||||
/review auto_approve
|
||||
```
|
||||
|
||||
Qodo Merge will automatically approve the PR, and add a comment with the approval.
|
||||
|
||||
2\. **Auto-approval when the PR meets certain criteria**
|
||||
|
||||
To enable auto-approval based on specific criteria, first, you need to enable the top-level flag:
|
||||
|
||||
```toml
|
||||
[config]
|
||||
enable_auto_approval = true
|
||||
```
|
||||
|
||||
There are several criteria that can be set for auto-approval:
|
||||
|
||||
- **Review effort score**
|
||||
|
||||
```toml
|
||||
[config]
|
||||
enable_auto_approval = true
|
||||
auto_approve_for_low_review_effort = X # X is a number between 1 to 5
|
||||
```
|
||||
|
||||
When the [review effort score](https://www.qodo.ai/images/pr_agent/review3.png) is lower or equal to X, the PR will be auto-approved.
|
||||
|
||||
___
|
||||
|
||||
- **No code suggestions**
|
||||
|
||||
```toml
|
||||
[config]
|
||||
enable_auto_approval = true
|
||||
auto_approve_for_no_suggestions = true
|
||||
```
|
||||
|
||||
When no [code suggestions](https://www.qodo.ai/images/pr_agent/code_suggestions_as_comment_closed.png) were found for the PR, the PR will be auto-approved.
|
||||
|
||||
___
|
||||
|
||||
- **Ticket Compliance**
|
||||
|
||||
```toml
|
||||
[config]
|
||||
enable_auto_approval = true
|
||||
ensure_ticket_compliance = true # Default is false
|
||||
```
|
||||
|
||||
If `ensure_ticket_compliance` is set to `true`, auto-approval will be disabled if a ticket is linked to the PR and the ticket is not compliant (e.g., the `review` tool did not mark the PR as fully compliant with the ticket). This ensures that PRs are only auto-approved if their associated tickets are properly resolved.
|
||||
|
||||
### How many code suggestions are generated?
|
||||
|
||||
|
||||
@ -98,11 +98,6 @@ extra_instructions = "..."
|
||||
<tr>
|
||||
<td><b>require_security_review</b></td>
|
||||
<td>If set to true, the tool will add a section that checks if the PR contains a possible security or vulnerability issue. Default is true.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>require_todo_scan</b></td>
|
||||
<td>If set to true, the tool will add a section that lists TODO comments found in the PR code changes. Default is false.
|
||||
</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>require_ticket_analysis_review</b></td>
|
||||
@ -160,7 +155,7 @@ extra_instructions = "..."
|
||||
- **`ticket compliance`**: Adds a label indicating code compliance level ("Fully compliant" | "PR Code Verified" | "Partially compliant" | "Not compliant") to any GitHub/Jira/Linea ticket linked in the PR. Controlled by the 'require_ticket_labels' flag (default: false). If 'require_no_ticket_labels' is also enabled, PRs without ticket links will receive a "No ticket found" label.
|
||||
|
||||
|
||||
### Auto-blocking PRs from being merged based on the generated labels
|
||||
### Blocking PRs from merging based on the generated labels
|
||||
|
||||
!!! tip ""
|
||||
|
||||
|
||||
@ -90,7 +90,7 @@ duplicate_examples=true # will duplicate the examples in the prompt, to help the
|
||||
api_base = "http://localhost:11434" # or whatever port you're running Ollama on
|
||||
```
|
||||
|
||||
By default, Ollama uses a context window size of 2048 tokens. In most cases this is not enough to cover pr-agent prompt and pull-request diff. Context window size can be overridden with the `OLLAMA_CONTEXT_LENGTH` environment variable. For example, to set the default context length to 8K, use: `OLLAMA_CONTEXT_LENGTH=8192 ollama serve`. More information you can find on the [official ollama faq](https://github.com/ollama/ollama/blob/main/docs/faq.md#how-can-i-specify-the-context-window-size).
|
||||
By default, Ollama uses a context window size of 2048 tokens. In most cases this is not enough to cover pr-agent promt and pull-request diff. Context window size can be overridden with the `OLLAMA_CONTEXT_LENGTH` environment variable. For example, to set the default context length to 8K, use: `OLLAMA_CONTEXT_LENGTH=8192 ollama serve`. More information you can find on the [official ollama faq](https://github.com/ollama/ollama/blob/main/docs/faq.md#how-can-i-specify-the-context-window-size).
|
||||
|
||||
Please note that the `custom_model_max_tokens` setting should be configured in accordance with the `OLLAMA_CONTEXT_LENGTH`. Failure to do so may result in unexpected model output.
|
||||
|
||||
|
||||
@ -25,3 +25,4 @@ It includes information on how to adjust Qodo Merge configurations, define which
|
||||
- [Patch Extra Lines](./additional_configurations.md#patch-extra-lines)
|
||||
- [FAQ](https://qodo-merge-docs.qodo.ai/faq/)
|
||||
- [Qodo Merge Models](./qodo_merge_models)
|
||||
- [Qodo Merge Endpoints](./qm_endpoints)
|
||||
|
||||
369
docs/docs/usage-guide/qm_endpoints.md
Normal file
369
docs/docs/usage-guide/qm_endpoints.md
Normal file
@ -0,0 +1,369 @@
|
||||
|
||||
# Overview
|
||||
|
||||
By default, Qodo Merge processes webhooks that respond to events or comments (for example, PR is opened), posting its responses directly on the PR page.
|
||||
|
||||
Qodo Merge now features two CLI endpoints that let you invoke its tools and receive responses directly (both as formatted markdown as well as a raw JSON), rather than having them posted to the PR page:
|
||||
|
||||
- **Pull Request Endpoint** - Accepts GitHub PR URL, along with the desired tool to invoke (**note**: only available on-premises, or single tenant).
|
||||
- **Diff Endpoint** - Git agnostic option that accepts a comparison of two states, either as a list of “before” and “after” files’ contents, or as a unified diff file, along with the desired tool to invoke.
|
||||
|
||||
# Setup
|
||||
|
||||
## Enabling desired endpoints (for on-prem deployment)
|
||||
|
||||
:bulb: Add the following to your helm chart\secrets file:
|
||||
|
||||
Pull Request Endpoint:
|
||||
|
||||
```toml
|
||||
[qm_pull_request_endpoint]
|
||||
enabled = true
|
||||
```
|
||||
|
||||
Diff Endpoint:
|
||||
|
||||
```toml
|
||||
[qm_diff_endpoint]
|
||||
enabled = true
|
||||
```
|
||||
|
||||
**Important:** This endpoint can only be enabled through the pod's main secret file, **not** through standard configuration files.
|
||||
|
||||
## Access Key
|
||||
|
||||
The endpoints require the user to provide an access key in each invocation. Choose one of the following options to retrieve such key.
|
||||
|
||||
### Option 1: Endpoint Key (On Premise / Single Tenant only)
|
||||
|
||||
Define an endpoint key in the helm chart of your pod configuration:
|
||||
|
||||
```toml
|
||||
[qm_pull_request_endpoint]
|
||||
enabled = true
|
||||
endpoint_key = "your-secure-key-here"
|
||||
|
||||
```
|
||||
|
||||
```toml
|
||||
[qm_diff_endpoint]
|
||||
enabled = true
|
||||
endpoint_key = "your-secure-key-here"
|
||||
```
|
||||
|
||||
### Option 2: API Key for Cloud users (Diff Endpoint only)
|
||||
|
||||
Generate a long-lived API key by authenticating the user. We offer two different methods to achieve this:
|
||||
|
||||
### - Shell script
|
||||
|
||||
Download and run the following script: [gen_api_key.sh](https://github.com/qodo-ai/pr-agent/blob/5dfd696c2b1f43e1d620fe17b9dc10c25c2304f9/pr_agent/scripts/qm_endpoint_auth/gen_api_key.sh)
|
||||
|
||||
### - npx
|
||||
|
||||
1. Install node
|
||||
2. Run: `npx @qodo/gen login`
|
||||
|
||||
Regardless of which method used, follow the instructions in the opened browser page. Once logged in successfully via the website, the script will return the generated API key:
|
||||
|
||||
```toml
|
||||
✅ Authentication successful! API key saved.
|
||||
📋 Your API key: ...
|
||||
```
|
||||
|
||||
**Note:** Each login generates a new API key, making any previous ones **obsolete**.
|
||||
|
||||
# Available Tools
|
||||
Both endpoints support the following Qodo Merge tools:
|
||||
|
||||
[**Improve**](https://qodo-merge-docs.qodo.ai/tools/improve/) | [**Review**](https://qodo-merge-docs.qodo.ai/tools/review/) | [**Describe**](https://qodo-merge-docs.qodo.ai/tools/describe/) | [**Ask**](https://qodo-merge-docs.qodo.ai/tools/ask/) | [**Add Docs**](https://qodo-merge-docs.qodo.ai/tools/documentation/) | [**Analyze**](https://qodo-merge-docs.qodo.ai/tools/analyze/) | [**Config**](https://qodo-merge-docs.qodo.ai/tools/config/) | [**Generate Labels**](https://qodo-merge-docs.qodo.ai/tools/custom_labels/) | [**Improve Component**](https://qodo-merge-docs.qodo.ai/tools/improve_component/) | [**Test**](https://qodo-merge-docs.qodo.ai/tools/test/) | [**Custom Prompt**](https://qodo-merge-docs.qodo.ai/tools/custom_prompt/)
|
||||
|
||||
# How to Run
|
||||
For all endpoints, there is a need to specify the access key in the header as the value next to the field: “X-API-Key”.
|
||||
|
||||
## Pull Request Endpoint
|
||||
|
||||
**URL:** `/api/v1/qm_pull_request`
|
||||
|
||||
### Request Format
|
||||
|
||||
```json
|
||||
{
|
||||
"pr_url": "<https://github.com/owner/repo/pull/123>",
|
||||
"command": "<COMMAND> ARG_1 ARG_2 ..."
|
||||
}
|
||||
```
|
||||
|
||||
### Usage Examples
|
||||
|
||||
### cURL
|
||||
|
||||
```bash
|
||||
curl -X POST "<your-server>/api/v1/qm_pull_request" \\
|
||||
-H "Content-Type: application/json" \\
|
||||
-H "X-API-Key: <your-key>"
|
||||
-d '{
|
||||
"pr_url": "<https://github.com/owner/repo/pull/123>",
|
||||
"command": "improve"
|
||||
}'
|
||||
```
|
||||
|
||||
### Python
|
||||
|
||||
```python
|
||||
import requests
|
||||
import json
|
||||
|
||||
def call_qm_pull_request(pr_url: str, command: str, endpoint_key: str):
|
||||
url = "<your-server>/api/v1/qm_pull_request"
|
||||
|
||||
payload = {
|
||||
"pr_url": pr_url,
|
||||
"command": command
|
||||
}
|
||||
|
||||
response = requests.post(
|
||||
url=url,
|
||||
headers={"Content-Type": "application/json", "X-API-Key": endpoint_key},
|
||||
data=json.dumps(payload)
|
||||
)
|
||||
|
||||
if response.status_code == 200:
|
||||
result = response.json()
|
||||
response_str = result.get("response_str") # Formatted response
|
||||
raw_data = result.get("raw_data") # Metadata and suggestions
|
||||
return response_str, raw_data
|
||||
else:
|
||||
print(f"Error: {response.status_code} - {response.text}")
|
||||
return None, None
|
||||
```
|
||||
|
||||
## Diff Endpoint
|
||||
|
||||
**URL:** `/api/v1/qm_diff`
|
||||
|
||||
### Request Format
|
||||
|
||||
With before and after files’ contents:
|
||||
|
||||
```json
|
||||
{
|
||||
"command": "<COMMAND> ARG_1 ARG_2 ...",
|
||||
"diff_files": {
|
||||
"<FILE_PATH>": ["<BEFORE_CONTENT>", "<AFTER_CONTENT>"],
|
||||
"...": ["...", "..."]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Alternatively, with unified diff:
|
||||
|
||||
```toml
|
||||
{
|
||||
"command": "<COMMAND> ARG_1 ARG_2 ...",
|
||||
"diff": "<UNIFIED_DIFF_CONTENT>"
|
||||
}
|
||||
```
|
||||
|
||||
### Example Payloads
|
||||
|
||||
**Using before and after per file (recommended):**
|
||||
|
||||
```json
|
||||
{
|
||||
"command": "improve_component hello",
|
||||
"diff_files": {
|
||||
"src/main.py": [
|
||||
"def hello():\\n print('Hello')",
|
||||
"def hello():\\n print('Hello World')\\n return 'success'"
|
||||
]
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
**Using unified diff:**
|
||||
|
||||
```json
|
||||
{
|
||||
"command": "improve",
|
||||
"diff": "diff --git a/src/main.py b/src/main.py\\nindex 123..456 100644\\n--- a/src/main.py\\n+++ b/src/main.py\\n@@ -1,2 +1,3 @@\\n def hello():\\n- print('Hello')\\n+ print('Hello World')\\n+ return 'success'"
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
### Usage Examples
|
||||
|
||||
### cURL
|
||||
|
||||
```bash
|
||||
curl -X POST "<your-server>/api/v1/qm_diff" \\
|
||||
-H "X-API-Key: <YOUR_KEY>" \\
|
||||
-H "Content-Type: application/json" \\
|
||||
-d @your_request.json
|
||||
```
|
||||
|
||||
### Python
|
||||
|
||||
```python
|
||||
import requests
|
||||
import json
|
||||
|
||||
def call_qm_diff(api_key: str, payload: dict):
|
||||
url = "<your-server>/api/v1/qm_diff"
|
||||
|
||||
response = requests.post(
|
||||
url=url,
|
||||
headers={"Content-Type": "application/json", "X-API-Key": api_key},
|
||||
data=json.dumps(payload)
|
||||
)
|
||||
|
||||
if response.status_code == 200:
|
||||
result = response.json()
|
||||
markdown_result = result.get("response_str") # Formatted markdown
|
||||
raw_data = result.get("raw_data") # Metadata and suggestions
|
||||
return markdown_result, raw_data
|
||||
else:
|
||||
print(f"Error: {response.status_code} - {response.text}")
|
||||
return None, None
|
||||
```
|
||||
|
||||
# Response Format
|
||||
Both endpoints return identical JSON structure:
|
||||
|
||||
```json
|
||||
{
|
||||
"response_str": "## PR Code Suggestions ✨\n\n<table>...",
|
||||
"raw_data": {
|
||||
<FIELD>: <VALUE>
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
- **`response_str`** - Formatted markdown for display
|
||||
- **`raw_data`** - Structured data with detailed suggestions and metadata, if applicable
|
||||
|
||||
# Complete Workflows Examples
|
||||
### Pull Request Endpoint
|
||||
|
||||
Given the following “/improve” request:
|
||||
|
||||
```toml
|
||||
{
|
||||
"command": "improve",
|
||||
"pr_url": "https://github.com/qodo-ai/pr-agent/pull/1831"
|
||||
}
|
||||
```
|
||||
|
||||
Received the following response:
|
||||
|
||||
```toml
|
||||
{"response_str":"## PR Code Suggestions ✨\n\n<table><thead><tr><td><strong>Category
|
||||
</strong></td><td align=left><strong>Suggestion
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
</strong></td><td align=center>
|
||||
<strong>Impact</strong></td></tr><tbody><tr><td rowspan=1>Learned<br>best practice</td>
|
||||
\n<td>\n\n\n\n<details><summary>Improve documentation clarity</summary>\n\n___\n
|
||||
\n\n**The documentation parameter description contains a grammatical issue.
|
||||
The <br>sentence \"This field remains empty if not applicable\" is unclear in context
|
||||
and <br>should be clarified to better explain what happens when the feature is not
|
||||
<br>applicable.**\n\n[docs/docs/tools/describe.md [128-129]]
|
||||
(https://github.com/qodo-ai/pr-agent/pull/1831/files#diff-960aad71fec9617804a02c904da37db217b6ba8a48fec3ac8bda286511d534ebR128-R129)
|
||||
\n\n```diff\n <td><b>enable_pr_diagram</b></td>\n-<td>If set to true, the tool
|
||||
will generate a horizontal Mermaid flowchart summarizing the main pull request
|
||||
changes. This field remains empty if not applicable. Default is false.</td>\n
|
||||
+<td>If set to true, the tool will generate a horizontal Mermaid flowchart
|
||||
summarizing the main pull request changes. No diagram will be generated if
|
||||
changes cannot be effectively visualized. Default is false.</td>\n```\n\n
|
||||
- [ ] **Apply / Chat** <!-- /improve --apply_suggestion=0 -->\n\n<details>
|
||||
<summary>Suggestion importance[1-10]: 6</summary>\n\n__\n\nWhy: \nRelevant
|
||||
best practice - Fix grammatical errors and typos in user-facing documentation
|
||||
to maintain professionalism and clarity.\n\n</details></details></td><td
|
||||
align=center>Low\n\n</td></tr>\n<tr><td align=\"center\" colspan=\"2\">\n\n
|
||||
- [ ] More <!-- /improve --more_suggestions=true -->\n\n</td><td></td></tr>
|
||||
</tbody></table>","raw_data":{"code_suggestions":[{"relevant_file":
|
||||
"docs/docs/tools/describe.md\n","language":"markdown\n","relevant_best_practice":
|
||||
"Fix grammatical errors and typos in user-facing documentation to maintain
|
||||
professionalism and clarity.\n","existing_code":"<td><b>enable_pr_diagram</b>
|
||||
</td>\n<td>If set to true, the tool will generate a horizontal Mermaid flowchart
|
||||
summarizing the main pull request changes. This field remains empty if not applicable.
|
||||
Default is false.</td>\n","suggestion_content":"The documentation parameter description
|
||||
contains a grammatical issue. The sentence \"This field remains empty if not applicable\"
|
||||
is unclear in context and should be clarified to better explain what happens when the
|
||||
feature is not applicable.\n","improved_code":"<td><b>enable_pr_diagram</b></td>
|
||||
\n<td>If set to true, the tool will generate a horizontal Mermaid flowchart summarizing
|
||||
the main pull request changes. No diagram will be generated if changes cannot be effectively
|
||||
visualized. Default is false.</td>\n","one_sentence_summary":"Improve documentation clarity\n",
|
||||
"score":6,"score_why":"\nRelevant best practice - Fix grammatical errors and typos in
|
||||
user-facing documentation to maintain professionalism and clarity.","label":"Learned best practice",
|
||||
"relevant_lines_start":128,"relevant_lines_end":129,"enable_apply":true}]}}
|
||||
```
|
||||
|
||||
In case user has failed authentication, due to not enabling the endpoint in the helm chart:
|
||||
|
||||
```toml
|
||||
HTTP/1.1 400 Bad Request
|
||||
date: Tue, 03 Jun 2025 09:40:21 GMT
|
||||
server: uvicorn
|
||||
content-length: 3486
|
||||
content-type: application/json
|
||||
|
||||
{"detail":{"error":"QM Pull Request endpoint is not enabled"}}
|
||||
```
|
||||
|
||||
### Diff Endpoint
|
||||
|
||||
Given the following “/improve” request’s payload:
|
||||
|
||||
[improve_example_short.json](https://codium.ai/images/pr_agent/improve_example_short.json)
|
||||
|
||||
Received the following response:
|
||||
|
||||
```toml
|
||||
{"response_str":"## PR Code Suggestions ✨\n\n<table><thead><tr><td><strong>Category</strong></td><td align=left><strong>Suggestion
|
||||
</strong></td><td align=center><strong>Impact</strong></td></tr><tbody><tr><td rowspan=1>Possible issue</td>\n<td>\n\n\n\n<details>
|
||||
<summary>Fix invalid repository URL</summary>\n\n___\n\n\n**The <code>base_branch</code> is set to <code>None</code> but then used
|
||||
in the <code>repo_url</code> string <br>interpolation, which will cause a runtime error. Also, the repository URL format <br>is incorrect
|
||||
as it includes the branch in the middle of the organization/repo <br>path.**\n\n[tests/e2e_tests/test_github_app.py [1]]
|
||||
(file://tests/e2e_tests/test_github_app.py#L1-1)\n\ndiff\\n-base_branch = None\\n+base_branch = \\"main\\" # or any base branch you want\\n
|
||||
new_branch = f\\"github_app_e2e_test-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}-where-am-I\\"\\n-repo_url =
|
||||
f'Codium-ai/{base_branch}/pr-agent-tests'\\n+repo_url = 'Codium-ai/pr-agent-tests'\\n\n<details><summary>Suggestion importance[1-10]: 9</summary>
|
||||
\n\n__\n\nWhy: The suggestion correctly identifies a critical runtime bug where base_branch = None is used in string interpolation,
|
||||
which would produce an invalid repository URL Codium-ai/None/pr-agent-tests. This would cause the test to fail at runtime.\n\n\n</details></details>
|
||||
</td><td align=center>High\n\n</td></tr></tbody></table>",
|
||||
|
||||
"raw_data":{"code_suggestions":[{"relevant_file":"tests/e2e_tests/test_github_app.py\n",
|
||||
"language":"python\n","existing_code":"base_branch = None\nnew_branch = f\"github_app_e2e_test-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}
|
||||
-where-am-I\"\nrepo_url = f'Codium-ai/{base_branch}/pr-agent-tests'\n","suggestion_content":"The base_branch is set to None but then used in the
|
||||
repo_url string interpolation, which will cause a runtime error. Also, the repository URL format is incorrect as it includes the branch in the middle
|
||||
of the organization/repo path.\n","improved_code":"base_branch = \"main\" # or any base branch you want\nnew_branch = f\"github_app_e2e_test-
|
||||
{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}-where-am-I\"\nrepo_url = 'Codium-ai/pr-agent-tests'\n","one_sentence_summary":"Fix invalid repository
|
||||
URL\n","label":"possible issue","score":9,"score_why":"The suggestion correctly identifies a critical runtime bug where base_branch = None is used in
|
||||
string interpolation, which would produce an invalid repository URL Codium-ai/None/pr-agent-tests. This would cause the test to fail at runtime.\n",
|
||||
"relevant_lines_start":1,"relevant_lines_end":1,"enable_apply":false}]}}
|
||||
```
|
||||
|
||||
In case user has failed authentication:
|
||||
|
||||
```toml
|
||||
HTTP/1.1 400 Bad Request
|
||||
date: Tue, 03 Jun 2025 08:45:36 GMT
|
||||
server: uvicorn
|
||||
content-length: 43
|
||||
content-type: application/json
|
||||
|
||||
{"detail":{"error":"Invalid API key"}}
|
||||
```
|
||||
|
||||
# Appendix: Endpoints Comparison Table
|
||||
|
||||
| **Feature** | **Pull Request Endpoint** | **Diff Endpoint** |
|
||||
| --- | --- | --- |
|
||||
| **Input** | GitHub PR URL | File diffs / Unified diff |
|
||||
| **Git Provider** | GitHub only | N/A |
|
||||
| **Deployment** | On-premise/Single Tenant | All deployments |
|
||||
| **Authentication** | Endpoint key only | Endpoint key or API key |
|
||||
@ -1,12 +1,12 @@
|
||||
|
||||
The default models used by Qodo Merge (June 2025) are a combination of Claude Sonnet 4 and Gemini 2.5 Pro.
|
||||
The default models used by Qodo Merge (April 2025) are a combination of Claude Sonnet 3.7 and Gemini 2.5 Pro.
|
||||
|
||||
### Selecting a Specific Model
|
||||
|
||||
Users can configure Qodo Merge to use only a specific model by editing the [configuration](https://qodo-merge-docs.qodo.ai/usage-guide/configuration_options/) file.
|
||||
The models supported by Qodo Merge are:
|
||||
|
||||
- `claude-4-sonnet`
|
||||
- `claude-3-7-sonnet`
|
||||
- `o4-mini`
|
||||
- `gpt-4.1`
|
||||
- `gemini-2.5-pro`
|
||||
|
||||
@ -22,6 +22,7 @@ nav:
|
||||
- Additional Configurations: 'usage-guide/additional_configurations.md'
|
||||
- Frequently Asked Questions: 'faq/index.md'
|
||||
- 💎 Qodo Merge Models: 'usage-guide/qodo_merge_models.md'
|
||||
- 💎 Qodo Merge Endpoints: 'usage-guide/qm_endpoints.md'
|
||||
- Tools:
|
||||
- 'tools/index.md'
|
||||
- Describe: 'tools/describe.md'
|
||||
@ -43,11 +44,10 @@ nav:
|
||||
- 💎 Similar Code: 'tools/similar_code.md'
|
||||
- Core Abilities:
|
||||
- 'core-abilities/index.md'
|
||||
- Auto approval: 'core-abilities/auto_approval.md'
|
||||
- Auto best practices: 'core-abilities/auto_best_practices.md'
|
||||
- Chat on code suggestions: 'core-abilities/chat_on_code_suggestions.md'
|
||||
- Code validation: 'core-abilities/code_validation.md'
|
||||
# - Compression strategy: 'core-abilities/compression_strategy.md'
|
||||
- Compression strategy: 'core-abilities/compression_strategy.md'
|
||||
- Dynamic context: 'core-abilities/dynamic_context.md'
|
||||
- Fetching ticket context: 'core-abilities/fetching_ticket_context.md'
|
||||
- Impact evaluation: 'core-abilities/impact_evaluation.md'
|
||||
|
||||
@ -131,7 +131,7 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||
self.api_base = openrouter_api_base
|
||||
litellm.api_base = openrouter_api_base
|
||||
|
||||
# Models that only use user message
|
||||
# Models that only use user meessage
|
||||
self.user_message_only_models = USER_MESSAGE_ONLY_MODELS
|
||||
|
||||
# Model that doesn't support temperature argument
|
||||
@ -212,7 +212,7 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||
|
||||
return kwargs
|
||||
|
||||
def add_litellm_callbacks(self, kwargs) -> dict:
|
||||
def add_litellm_callbacks(selfs, kwargs) -> dict:
|
||||
captured_extra = []
|
||||
|
||||
def capture_logs(message):
|
||||
|
||||
@ -1,6 +1,5 @@
|
||||
from __future__ import annotations
|
||||
|
||||
import ast
|
||||
import copy
|
||||
import difflib
|
||||
import hashlib
|
||||
@ -15,7 +14,7 @@ import traceback
|
||||
from datetime import datetime
|
||||
from enum import Enum
|
||||
from importlib.metadata import PackageNotFoundError, version
|
||||
from typing import Any, List, Tuple, TypedDict
|
||||
from typing import Any, List, Tuple
|
||||
|
||||
import html2text
|
||||
import requests
|
||||
@ -38,31 +37,21 @@ def get_model(model_type: str = "model_weak") -> str:
|
||||
return get_settings().config.model_reasoning
|
||||
return get_settings().config.model
|
||||
|
||||
|
||||
class Range(BaseModel):
|
||||
line_start: int # should be 0-indexed
|
||||
line_end: int
|
||||
column_start: int = -1
|
||||
column_end: int = -1
|
||||
|
||||
|
||||
class ModelType(str, Enum):
|
||||
REGULAR = "regular"
|
||||
WEAK = "weak"
|
||||
REASONING = "reasoning"
|
||||
|
||||
|
||||
class TodoItem(TypedDict):
|
||||
relevant_file: str
|
||||
line_range: Tuple[int, int]
|
||||
content: str
|
||||
|
||||
|
||||
class PRReviewHeader(str, Enum):
|
||||
REGULAR = "## PR Reviewer Guide"
|
||||
INCREMENTAL = "## Incremental PR Reviewer Guide"
|
||||
|
||||
|
||||
class ReasoningEffort(str, Enum):
|
||||
HIGH = "high"
|
||||
MEDIUM = "medium"
|
||||
@ -120,7 +109,6 @@ def unique_strings(input_list: List[str]) -> List[str]:
|
||||
seen.add(item)
|
||||
return unique_list
|
||||
|
||||
|
||||
def convert_to_markdown_v2(output_data: dict,
|
||||
gfm_supported: bool = True,
|
||||
incremental_review=None,
|
||||
@ -143,7 +131,6 @@ def convert_to_markdown_v2(output_data: dict,
|
||||
"Focused PR": "✨",
|
||||
"Relevant ticket": "🎫",
|
||||
"Security concerns": "🔒",
|
||||
"Todo sections": "📝",
|
||||
"Insights from user's answers": "📝",
|
||||
"Code feedback": "🤖",
|
||||
"Estimated effort to review [1-5]": "⏱️",
|
||||
@ -164,7 +151,6 @@ def convert_to_markdown_v2(output_data: dict,
|
||||
if gfm_supported:
|
||||
markdown_text += "<table>\n"
|
||||
|
||||
todo_summary = output_data['review'].pop('todo_summary', '')
|
||||
for key, value in output_data['review'].items():
|
||||
if value is None or value == '' or value == {} or value == []:
|
||||
if key.lower() not in ['can_be_split', 'key_issues_to_review']:
|
||||
@ -223,23 +209,6 @@ def convert_to_markdown_v2(output_data: dict,
|
||||
markdown_text += f"### {emoji} Security concerns\n\n"
|
||||
value = emphasize_header(value.strip(), only_markdown=True)
|
||||
markdown_text += f"{value}\n\n"
|
||||
elif 'todo sections' in key_nice.lower():
|
||||
if gfm_supported:
|
||||
markdown_text += "<tr><td>"
|
||||
if is_value_no(value):
|
||||
markdown_text += f"✅ <strong>No TODO sections</strong>"
|
||||
else:
|
||||
markdown_todo_items = format_todo_items(value, git_provider, gfm_supported)
|
||||
markdown_text += f"{emoji} <strong>TODO sections</strong>\n<br><br>\n"
|
||||
markdown_text += markdown_todo_items
|
||||
markdown_text += "</td></tr>\n"
|
||||
else:
|
||||
if is_value_no(value):
|
||||
markdown_text += f"### ✅ No TODO sections\n\n"
|
||||
else:
|
||||
markdown_todo_items = format_todo_items(value, git_provider, gfm_supported)
|
||||
markdown_text += f"### {emoji} TODO sections\n\n"
|
||||
markdown_text += markdown_todo_items
|
||||
elif 'can be split' in key_nice.lower():
|
||||
if gfm_supported:
|
||||
markdown_text += f"<tr><td>"
|
||||
@ -1320,7 +1289,7 @@ def process_description(description_full: str) -> Tuple[str, List]:
|
||||
pattern_back = r'<details>\s*<summary><strong>(.*?)</strong><dd><code>(.*?)</code>.*?</summary>\s*<hr>\s*(.*?)\n\n\s*(.*?)</details>'
|
||||
res = re.search(pattern_back, file_data, re.DOTALL)
|
||||
if not res or res.lastindex != 4:
|
||||
pattern_back = r'<details>\s*<summary><strong>(.*?)</strong>\s*<dd><code>(.*?)</code>.*?</summary>\s*<hr>\s*(.*?)\s*-\s*(.*?)\s*</details>' # looking for hyphen ('- ')
|
||||
pattern_back = r'<details>\s*<summary><strong>(.*?)</strong>\s*<dd><code>(.*?)</code>.*?</summary>\s*<hr>\s*(.*?)\s*-\s*(.*?)\s*</details>' # looking for hypen ('- ')
|
||||
res = re.search(pattern_back, file_data, re.DOTALL)
|
||||
if res and res.lastindex == 4:
|
||||
short_filename = res.group(1).strip()
|
||||
@ -1398,47 +1367,3 @@ def set_file_languages(diff_files) -> List[FilePatchInfo]:
|
||||
get_logger().exception(f"Failed to set file languages: {e}")
|
||||
|
||||
return diff_files
|
||||
|
||||
def format_todo_item(todo_item: TodoItem, git_provider, gfm_supported) -> str:
|
||||
relevant_file = todo_item.get('relevant_file', '').strip()
|
||||
line_number = todo_item.get('line_number', '')
|
||||
content = todo_item.get('content', '')
|
||||
reference_link = git_provider.get_line_link(relevant_file, line_number, line_number)
|
||||
file_ref = f"{relevant_file} [{line_number}]"
|
||||
if reference_link:
|
||||
if gfm_supported:
|
||||
file_ref = f"<a href='{reference_link}'>{file_ref}</a>"
|
||||
else:
|
||||
file_ref = f"[{file_ref}]({reference_link})"
|
||||
|
||||
if content:
|
||||
return f"{file_ref}: {content.strip()}"
|
||||
else:
|
||||
# if content is empty, return only the file reference
|
||||
return file_ref
|
||||
|
||||
|
||||
def format_todo_items(value: list[TodoItem] | TodoItem, git_provider, gfm_supported) -> str:
|
||||
markdown_text = ""
|
||||
MAX_ITEMS = 5 # limit the number of items to display
|
||||
if gfm_supported:
|
||||
if isinstance(value, list):
|
||||
markdown_text += "<ul>\n"
|
||||
if len(value) > MAX_ITEMS:
|
||||
get_logger().debug(f"Truncating todo items to {MAX_ITEMS} items")
|
||||
value = value[:MAX_ITEMS]
|
||||
for todo_item in value:
|
||||
markdown_text += f"<li>{format_todo_item(todo_item, git_provider, gfm_supported)}</li>\n"
|
||||
markdown_text += "</ul>\n"
|
||||
else:
|
||||
markdown_text += f"<p>{format_todo_item(value, git_provider, gfm_supported)}</p>\n"
|
||||
else:
|
||||
if isinstance(value, list):
|
||||
if len(value) > MAX_ITEMS:
|
||||
get_logger().debug(f"Truncating todo items to {MAX_ITEMS} items")
|
||||
value = value[:MAX_ITEMS]
|
||||
for todo_item in value:
|
||||
markdown_text += f"- {format_todo_item(todo_item, git_provider, gfm_supported)}\n"
|
||||
else:
|
||||
markdown_text += f"- {format_todo_item(value, git_provider, gfm_supported)}\n"
|
||||
return markdown_text
|
||||
@ -86,7 +86,7 @@ class BitbucketServerProvider(GitProvider):
|
||||
|
||||
def get_repo_settings(self):
|
||||
try:
|
||||
content = self.bitbucket_client.get_content_of_file(self.workspace_slug, self.repo_slug, ".pr_agent.toml")
|
||||
content = self.bitbucket_client.get_content_of_file(self.workspace_slug, self.repo_slug, ".pr_agent.toml", self.get_pr_branch())
|
||||
|
||||
return content
|
||||
except Exception as e:
|
||||
|
||||
@ -41,12 +41,6 @@ class GiteaProvider(GitProvider):
|
||||
configuration.host = "{}/api/v1".format(self.base_url)
|
||||
configuration.api_key['Authorization'] = f'token {gitea_access_token}'
|
||||
|
||||
if get_settings().get("GITEA.SKIP_SSL_VERIFICATION", False):
|
||||
configuration.verify_ssl = False
|
||||
|
||||
# Use custom cert (self-signed)
|
||||
configuration.ssl_ca_cert = get_settings().get("GITEA.SSL_CA_CERT", None)
|
||||
|
||||
client = giteapy.ApiClient(configuration)
|
||||
self.repo_api = RepoApi(client)
|
||||
self.owner = None
|
||||
|
||||
@ -1,17 +1,16 @@
|
||||
import difflib
|
||||
import hashlib
|
||||
import re
|
||||
from typing import Optional, Tuple, Any, Union
|
||||
from urllib.parse import urlparse, parse_qs
|
||||
from typing import Optional, Tuple
|
||||
from urllib.parse import urlparse
|
||||
|
||||
import gitlab
|
||||
import requests
|
||||
from gitlab import GitlabGetError, GitlabAuthenticationError, GitlabCreateError, GitlabUpdateError
|
||||
from gitlab import GitlabGetError
|
||||
|
||||
from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
|
||||
|
||||
from ..algo.file_filter import filter_ignored
|
||||
from ..algo.git_patch_processing import decode_if_bytes
|
||||
from ..algo.language_handler import is_valid_file
|
||||
from ..algo.utils import (clip_tokens,
|
||||
find_line_number_of_relevant_line_in_file,
|
||||
@ -113,50 +112,14 @@ class GitLabProvider(GitProvider):
|
||||
get_logger().error(f"Could not get diff for merge request {self.id_mr}")
|
||||
raise DiffNotFoundError(f"Could not get diff for merge request {self.id_mr}") from e
|
||||
|
||||
|
||||
def get_pr_file_content(self, file_path: str, branch: str) -> str:
|
||||
try:
|
||||
file_obj = self.gl.projects.get(self.id_project).files.get(file_path, branch)
|
||||
content = file_obj.decode()
|
||||
return decode_if_bytes(content)
|
||||
return self.gl.projects.get(self.id_project).files.get(file_path, branch).decode()
|
||||
except GitlabGetError:
|
||||
# In case of file creation the method returns GitlabGetError (404 file not found).
|
||||
# In this case we return an empty string for the diff.
|
||||
return ''
|
||||
except Exception as e:
|
||||
get_logger().warning(f"Error retrieving file {file_path} from branch {branch}: {e}")
|
||||
return ''
|
||||
|
||||
def create_or_update_pr_file(self, file_path: str, branch: str, contents="", message="") -> None:
|
||||
"""Create or update a file in the GitLab repository."""
|
||||
try:
|
||||
project = self.gl.projects.get(self.id_project)
|
||||
|
||||
if not message:
|
||||
action = "Update" if contents else "Create"
|
||||
message = f"{action} {file_path}"
|
||||
|
||||
try:
|
||||
existing_file = project.files.get(file_path, branch)
|
||||
existing_file.content = contents
|
||||
existing_file.save(branch=branch, commit_message=message)
|
||||
get_logger().debug(f"Updated file {file_path} in branch {branch}")
|
||||
except GitlabGetError:
|
||||
project.files.create({
|
||||
'file_path': file_path,
|
||||
'branch': branch,
|
||||
'content': contents,
|
||||
'commit_message': message
|
||||
})
|
||||
get_logger().debug(f"Created file {file_path} in branch {branch}")
|
||||
except GitlabAuthenticationError as e:
|
||||
get_logger().error(f"Authentication failed while creating/updating file {file_path} in branch {branch}: {e}")
|
||||
raise
|
||||
except (GitlabCreateError, GitlabUpdateError) as e:
|
||||
get_logger().error(f"Permission denied or validation error for file {file_path} in branch {branch}: {e}")
|
||||
raise
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Unexpected error creating/updating file {file_path} in branch {branch}: {e}")
|
||||
raise
|
||||
|
||||
def get_diff_files(self) -> list[FilePatchInfo]:
|
||||
"""
|
||||
@ -204,9 +167,14 @@ class GitLabProvider(GitProvider):
|
||||
original_file_content_str = ''
|
||||
new_file_content_str = ''
|
||||
|
||||
# Ensure content is properly decoded
|
||||
original_file_content_str = decode_if_bytes(original_file_content_str)
|
||||
new_file_content_str = decode_if_bytes(new_file_content_str)
|
||||
try:
|
||||
if isinstance(original_file_content_str, bytes):
|
||||
original_file_content_str = bytes.decode(original_file_content_str, 'utf-8')
|
||||
if isinstance(new_file_content_str, bytes):
|
||||
new_file_content_str = bytes.decode(new_file_content_str, 'utf-8')
|
||||
except UnicodeDecodeError:
|
||||
get_logger().warning(
|
||||
f"Cannot decode file {diff['old_path']} or {diff['new_path']} in merge request {self.id_mr}")
|
||||
|
||||
edit_type = EDIT_TYPE.MODIFIED
|
||||
if diff['new_file']:
|
||||
|
||||
@ -80,30 +80,6 @@ async def run_action():
|
||||
except Exception as e:
|
||||
get_logger().info(f"github action: failed to apply repo settings: {e}")
|
||||
|
||||
# Append the response language in the extra instructions
|
||||
try:
|
||||
response_language = get_settings().config.get('response_language', 'en-us')
|
||||
if response_language.lower() != 'en-us':
|
||||
get_logger().info(f'User has set the response language to: {response_language}')
|
||||
|
||||
lang_instruction_text = f"Your response MUST be written in the language corresponding to locale code: '{response_language}'. This is crucial."
|
||||
separator_text = "\n======\n\nIn addition, "
|
||||
|
||||
for key in get_settings():
|
||||
setting = get_settings().get(key)
|
||||
if str(type(setting)) == "<class 'dynaconf.utils.boxing.DynaBox'>":
|
||||
if key.lower() in ['pr_description', 'pr_code_suggestions', 'pr_reviewer']:
|
||||
if hasattr(setting, 'extra_instructions'):
|
||||
extra_instructions = setting.extra_instructions
|
||||
|
||||
if lang_instruction_text not in str(extra_instructions):
|
||||
updated_instructions = (
|
||||
str(extra_instructions) + separator_text + lang_instruction_text
|
||||
if extra_instructions else lang_instruction_text
|
||||
)
|
||||
setting.extra_instructions = updated_instructions
|
||||
except Exception as e:
|
||||
get_logger().info(f"github action: failed to apply language-specific instructions: {e}")
|
||||
# Handle pull request opened event
|
||||
if GITHUB_EVENT_NAME == "pull_request" or GITHUB_EVENT_NAME == "pull_request_target":
|
||||
action = event_payload.get("action")
|
||||
@ -126,7 +102,7 @@ async def run_action():
|
||||
auto_improve = get_setting_or_env("GITHUB_ACTION_CONFIG.AUTO_IMPROVE", None)
|
||||
|
||||
# Set the configuration for auto actions
|
||||
get_settings().config.is_auto_command = True # Set the flag to indicate that the command is auto
|
||||
get_settings().config.is_auto_command = True # Set the flag to indicate that the command is auto
|
||||
get_settings().pr_description.final_update_message = False # No final update message when auto_describe is enabled
|
||||
get_logger().info(f"Running auto actions: auto_describe={auto_describe}, auto_review={auto_review}, auto_improve={auto_improve}")
|
||||
|
||||
|
||||
@ -1,27 +0,0 @@
|
||||
from fastapi import FastAPI
|
||||
from mangum import Mangum
|
||||
from starlette.middleware import Middleware
|
||||
from starlette_context.middleware import RawContextMiddleware
|
||||
|
||||
from pr_agent.servers.gitlab_webhook import router
|
||||
|
||||
try:
|
||||
from pr_agent.config_loader import apply_secrets_manager_config
|
||||
apply_secrets_manager_config()
|
||||
except Exception as e:
|
||||
try:
|
||||
from pr_agent.log import get_logger
|
||||
get_logger().debug(f"AWS Secrets Manager initialization failed, falling back to environment variables: {e}")
|
||||
except:
|
||||
# Fail completely silently if log module is not available
|
||||
pass
|
||||
|
||||
middleware = [Middleware(RawContextMiddleware)]
|
||||
app = FastAPI(middleware=middleware)
|
||||
app.include_router(router)
|
||||
|
||||
handler = Mangum(app, lifespan="off")
|
||||
|
||||
|
||||
def lambda_handler(event, context):
|
||||
return handler(event, context)
|
||||
@ -23,5 +23,5 @@ app.include_router(router)
|
||||
handler = Mangum(app, lifespan="off")
|
||||
|
||||
|
||||
def lambda_handler(event, context):
|
||||
return handler(event, context)
|
||||
def serverless(event, context):
|
||||
return handler(event, context)
|
||||
@ -78,10 +78,8 @@ require_tests_review=true
|
||||
require_estimate_effort_to_review=true
|
||||
require_can_be_split_review=false
|
||||
require_security_review=true
|
||||
require_todo_scan=false
|
||||
require_ticket_analysis_review=true
|
||||
# general options
|
||||
publish_output_no_suggestions=true # Set to "false" if you only need the reviewer's remarks (not labels, not "security audit", etc.) and want to avoid noisy "No major issues detected" comments.
|
||||
persistent_comment=true
|
||||
extra_instructions = ""
|
||||
num_max_findings = 3
|
||||
|
||||
@ -1,12 +1,11 @@
|
||||
[pr_description_prompt]
|
||||
system="""You are PR-Reviewer, a language model designed to review a Git Pull Request (PR).
|
||||
Your task is to provide a full description for the PR content: type, description, title, and files walkthrough.
|
||||
Your task is to provide a full description for the PR content - type, description, title and files walkthrough.
|
||||
- Focus on the new PR code (lines starting with '+' in the 'PR Git Diff' section).
|
||||
- Keep in mind that the 'Previous title', 'Previous description' and 'Commit messages' sections may be partial, simplistic, non-informative or out of date. Hence, compare them to the PR diff code, and use them only as a reference.
|
||||
- The generated title and description should prioritize the most significant changes.
|
||||
- If needed, each YAML output should be in block scalar indicator ('|')
|
||||
- When quoting variables, names or file paths from the code, use backticks (`) instead of single quote (').
|
||||
- When needed, use '- ' as bullets
|
||||
|
||||
{%- if extra_instructions %}
|
||||
|
||||
@ -182,4 +181,4 @@ pr_files:
|
||||
|
||||
Response (should be a valid YAML, and nothing else):
|
||||
```yaml
|
||||
"""
|
||||
"""
|
||||
@ -1,12 +1,12 @@
|
||||
[pr_help_prompts]
|
||||
system="""You are Doc-helper, a language models designed to answer questions about a documentation website for an open-soure project called "PR-Agent" (recently renamed to "Qodo Merge").
|
||||
You will receive a question, and the full documentation website content.
|
||||
You will recieve a question, and the full documentation website content.
|
||||
Your goal is to provide the best answer to the question using the documentation provided.
|
||||
|
||||
Additional instructions:
|
||||
- Try to be short and concise in your answers. Try to give examples if needed.
|
||||
- The main tools of PR-Agent are 'describe', 'review', 'improve'. If there is ambiguity to which tool the user is referring to, prioritize snippets of these tools over others.
|
||||
- If the question has ambiguity and can relate to different tools or platforms, provide the best answer possible based on what is available, but also state in your answer what additional information would be needed to give a more accurate answer.
|
||||
- If the question has ambiguity and can relate to different tools or platfroms, provide the best answer possible based on what is available, but also state in your answer what additional information would be needed to give a more accurate answer.
|
||||
|
||||
|
||||
The output must be a YAML object equivalent to type $DocHelper, according to the following Pydantic definitions:
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
system="""You are PR-Reviewer, a language model designed to review a Git Pull Request (PR).
|
||||
Given the PR Info and the PR Git Diff, generate 3 short questions about the PR code for the PR author.
|
||||
The goal of the questions is to help the language model understand the PR better, so the questions should be insightful, informative, non-trivial, and relevant to the PR.
|
||||
You should prefer asking yes/no questions, or multiple choice questions. Also add at least one open-ended question, but make sure they are not too difficult, and can be answered in a sentence or two.
|
||||
You should prefer asking yes\\no questions, or multiple choice questions. Also add at least one open-ended question, but make sure they are not too difficult, and can be answered in a sentence or two.
|
||||
|
||||
|
||||
Example output:
|
||||
|
||||
@ -37,9 +37,9 @@ __new hunk__
|
||||
======
|
||||
|
||||
- In the format above, the diff is organized into separate '__new hunk__' and '__old hunk__' sections for each code chunk. '__new hunk__' contains the updated code, while '__old hunk__' shows the removed code. If no code was removed in a specific chunk, the __old hunk__ section will be omitted.
|
||||
- We also added line numbers for the '__new hunk__' code, to help you refer to the code lines in your suggestions. These line numbers are not part of the actual code, and should only be used for reference.
|
||||
- We also added line numbers for the '__new hunk__' code, to help you refer to the code lines in your suggestions. These line numbers are not part of the actual code, and should only used for reference.
|
||||
- Code lines are prefixed with symbols ('+', '-', ' '). The '+' symbol indicates new code added in the PR, the '-' symbol indicates code removed in the PR, and the ' ' symbol indicates unchanged code. \
|
||||
The review should address new code added in the PR code diff (lines starting with '+').
|
||||
The review should address new code added in the PR code diff (lines starting with '+')
|
||||
{%- if is_ai_metadata %}
|
||||
- If available, an AI-generated summary will appear and provide a high-level overview of the file changes. Note that this summary may not be fully accurate or complete.
|
||||
{%- endif %}
|
||||
@ -72,13 +72,6 @@ class KeyIssuesComponentLink(BaseModel):
|
||||
start_line: int = Field(description="The start line that corresponds to this issue in the relevant file")
|
||||
end_line: int = Field(description="The end line that corresponds to this issue in the relevant file")
|
||||
|
||||
{%- if require_todo_scan %}
|
||||
class TodoSection(BaseModel):
|
||||
relevant_file: str = Field(description="The full path of the file containing the TODO comment")
|
||||
line_number: int = Field(description="The line number where the TODO comment starts")
|
||||
content: str = Field(description="The content of the TODO comment. Only include actual TODO comments within code comments (e.g., comments starting with '#', '//', '/*', '<!--', ...). Remove leading 'TODO' prefixes. If more than 10 words, summarize the TODO comment to a single short sentence up to 10 words.")
|
||||
{%- endif %}
|
||||
|
||||
{%- if related_tickets %}
|
||||
|
||||
class TicketCompliance(BaseModel):
|
||||
@ -100,17 +93,14 @@ class Review(BaseModel):
|
||||
score: str = Field(description="Rate this PR on a scale of 0-100 (inclusive), where 0 means the worst possible PR code, and 100 means PR code of the highest quality, without any bugs or performance issues, that is ready to be merged immediately and run in production at scale.")
|
||||
{%- endif %}
|
||||
{%- if require_tests %}
|
||||
relevant_tests: str = Field(description="yes/no question: does this PR have relevant tests added or updated ?")
|
||||
relevant_tests: str = Field(description="yes\\no question: does this PR have relevant tests added or updated ?")
|
||||
{%- endif %}
|
||||
{%- if question_str %}
|
||||
insights_from_user_answers: str = Field(description="shortly summarize the insights you gained from the user's answers to the questions")
|
||||
{%- endif %}
|
||||
key_issues_to_review: List[KeyIssuesComponentLink] = Field("A short and diverse list (0-{{ num_max_findings }} issues) of high-priority bugs, problems or performance concerns introduced in the PR code, which the PR reviewer should further focus on and validate during the review process.")
|
||||
{%- if require_security_review %}
|
||||
security_concerns: str = Field(description="Does this PR code introduce vulnerabilities such as exposure of sensitive information (e.g., API keys, secrets, passwords), or security concerns like SQL injection, XSS, CSRF, and others ? Answer 'No' (without explaining why) if there are no possible issues. If there are security concerns or issues, start your answer with a short header, such as: 'Sensitive information exposure: ...', 'SQL injection: ...', etc. Explain your answer. Be specific and give examples if possible")
|
||||
{%- endif %}
|
||||
{%- if require_todo_scan %}
|
||||
todo_sections: Union[List[TodoSection], str] = Field(description="A list of TODO comments found in the PR code. Return 'No' (as a string) if there are no TODO comments in the PR")
|
||||
security_concerns: str = Field(description="Does this PR code introduce possible vulnerabilities such as exposure of sensitive information (e.g., API keys, secrets, passwords), or security concerns like SQL injection, XSS, CSRF, and others ? Answer 'No' (without explaining why) if there are no possible issues. If there are security concerns or issues, start your answer with a short header, such as: 'Sensitive information exposure: ...', 'SQL injection: ...' etc. Explain your answer. Be specific and give examples if possible")
|
||||
{%- endif %}
|
||||
{%- if require_can_be_split_review %}
|
||||
can_be_split: List[SubPR] = Field(min_items=0, max_items=3, description="Can this PR, which contains {{ num_pr_files }} changed files in total, be divided into smaller sub-PRs with distinct tasks that can be reviewed and merged independently, regardless of the order ? Make sure that the sub-PRs are indeed independent, with no code dependencies between them, and that each sub-PR represent a meaningful independent task. Output an empty list if the PR code does not need to be split.")
|
||||
@ -158,10 +148,6 @@ review:
|
||||
- ...
|
||||
security_concerns: |
|
||||
No
|
||||
{%- if require_todo_scan %}
|
||||
todo_sections: |
|
||||
No
|
||||
{%- endif %}
|
||||
{%- if require_can_be_split_review %}
|
||||
can_be_split:
|
||||
- relevant_files:
|
||||
@ -280,10 +266,6 @@ review:
|
||||
- ...
|
||||
security_concerns: |
|
||||
No
|
||||
{%- if require_todo_scan %}
|
||||
todo_sections: |
|
||||
No
|
||||
{%- endif %}
|
||||
{%- if require_can_be_split_review %}
|
||||
can_be_split:
|
||||
- relevant_files:
|
||||
|
||||
@ -21,7 +21,7 @@ from pr_agent.servers.help import HelpMessage
|
||||
|
||||
#Common code that can be called from similar tools:
|
||||
def modify_answer_section(ai_response: str) -> str | None:
|
||||
# Gets the model's answer and relevant sources section, replacing the heading of the answer section with:
|
||||
# Gets the model's answer and relevant sources section, repacing the heading of the answer section with:
|
||||
# :bulb: Auto-generated documentation-based answer:
|
||||
"""
|
||||
For example: The following input:
|
||||
|
||||
@ -87,7 +87,6 @@ class PRReviewer:
|
||||
"require_estimate_effort_to_review": get_settings().pr_reviewer.require_estimate_effort_to_review,
|
||||
'require_can_be_split_review': get_settings().pr_reviewer.require_can_be_split_review,
|
||||
'require_security_review': get_settings().pr_reviewer.require_security_review,
|
||||
'require_todo_scan': get_settings().pr_reviewer.get("require_todo_scan", False),
|
||||
'question_str': question_str,
|
||||
'answer_str': answer_str,
|
||||
"extra_instructions": get_settings().pr_reviewer.extra_instructions,
|
||||
@ -159,32 +158,25 @@ class PRReviewer:
|
||||
pr_review = self._prepare_pr_review()
|
||||
get_logger().debug(f"PR output", artifact=pr_review)
|
||||
|
||||
should_publish = get_settings().config.publish_output and self._should_publish_review_no_suggestions(pr_review)
|
||||
if not should_publish:
|
||||
reason = "Review output is not published"
|
||||
if get_settings().config.publish_output:
|
||||
reason += ": no major issues detected."
|
||||
get_logger().info(reason)
|
||||
if get_settings().config.publish_output:
|
||||
# publish the review
|
||||
if get_settings().pr_reviewer.persistent_comment and not self.incremental.is_incremental:
|
||||
final_update_message = get_settings().pr_reviewer.final_update_message
|
||||
self.git_provider.publish_persistent_comment(pr_review,
|
||||
initial_header=f"{PRReviewHeader.REGULAR.value} 🔍",
|
||||
update_header=True,
|
||||
final_update_message=final_update_message, )
|
||||
else:
|
||||
self.git_provider.publish_comment(pr_review)
|
||||
|
||||
self.git_provider.remove_initial_comment()
|
||||
else:
|
||||
get_logger().info("Review output is not published")
|
||||
get_settings().data = {"artifact": pr_review}
|
||||
return
|
||||
|
||||
# publish the review
|
||||
if get_settings().pr_reviewer.persistent_comment and not self.incremental.is_incremental:
|
||||
final_update_message = get_settings().pr_reviewer.final_update_message
|
||||
self.git_provider.publish_persistent_comment(pr_review,
|
||||
initial_header=f"{PRReviewHeader.REGULAR.value} 🔍",
|
||||
update_header=True,
|
||||
final_update_message=final_update_message, )
|
||||
else:
|
||||
self.git_provider.publish_comment(pr_review)
|
||||
|
||||
self.git_provider.remove_initial_comment()
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to review PR: {e}")
|
||||
|
||||
def _should_publish_review_no_suggestions(self, pr_review: str) -> bool:
|
||||
return get_settings().pr_reviewer.get('publish_output_no_suggestions', True) or "No major issues detected" not in pr_review
|
||||
|
||||
async def _prepare_prediction(self, model: str) -> None:
|
||||
self.patches_diff = get_pr_diff(self.git_provider,
|
||||
self.token_handler,
|
||||
|
||||
@ -58,7 +58,7 @@ class PRUpdateChangelog:
|
||||
'config': dict(get_settings().config)}
|
||||
get_logger().debug("Relevant configs", artifacts=relevant_configs)
|
||||
|
||||
# check if the git provider supports pushing changelog changes
|
||||
# currently only GitHub is supported for pushing changelog changes
|
||||
if get_settings().pr_update_changelog.push_changelog_changes and not hasattr(
|
||||
self.git_provider, "create_or_update_pr_file"
|
||||
):
|
||||
@ -128,7 +128,6 @@ class PRUpdateChangelog:
|
||||
existing_content = self.changelog_file
|
||||
else:
|
||||
existing_content = ""
|
||||
|
||||
if existing_content:
|
||||
new_file_content = answer + "\n\n" + self.changelog_file
|
||||
else:
|
||||
@ -187,18 +186,12 @@ Example:
|
||||
self.changelog_file = self.git_provider.get_pr_file_content(
|
||||
"CHANGELOG.md", self.git_provider.get_pr_branch()
|
||||
)
|
||||
|
||||
if isinstance(self.changelog_file, bytes):
|
||||
self.changelog_file = self.changelog_file.decode('utf-8')
|
||||
|
||||
changelog_file_lines = self.changelog_file.splitlines()
|
||||
changelog_file_lines = changelog_file_lines[:CHANGELOG_LINES]
|
||||
self.changelog_file_str = "\n".join(changelog_file_lines)
|
||||
except Exception as e:
|
||||
get_logger().warning(f"Error getting changelog file: {e}")
|
||||
except Exception:
|
||||
self.changelog_file_str = ""
|
||||
self.changelog_file = ""
|
||||
return
|
||||
|
||||
if not self.changelog_file_str:
|
||||
self.changelog_file_str = self._get_default_changelog()
|
||||
|
||||
@ -1,147 +0,0 @@
|
||||
import pytest
|
||||
from unittest.mock import MagicMock, patch
|
||||
|
||||
from pr_agent.git_providers.gitlab_provider import GitLabProvider
|
||||
from gitlab import Gitlab
|
||||
from gitlab.v4.objects import Project, ProjectFile
|
||||
from gitlab.exceptions import GitlabGetError
|
||||
|
||||
|
||||
class TestGitLabProvider:
|
||||
"""Test suite for GitLab provider functionality."""
|
||||
|
||||
@pytest.fixture
|
||||
def mock_gitlab_client(self):
|
||||
client = MagicMock()
|
||||
return client
|
||||
|
||||
@pytest.fixture
|
||||
def mock_project(self):
|
||||
project = MagicMock()
|
||||
return project
|
||||
|
||||
@pytest.fixture
|
||||
def gitlab_provider(self, mock_gitlab_client, mock_project):
|
||||
with patch('pr_agent.git_providers.gitlab_provider.gitlab.Gitlab', return_value=mock_gitlab_client), \
|
||||
patch('pr_agent.git_providers.gitlab_provider.get_settings') as mock_settings:
|
||||
|
||||
mock_settings.return_value.get.side_effect = lambda key, default=None: {
|
||||
"GITLAB.URL": "https://gitlab.com",
|
||||
"GITLAB.PERSONAL_ACCESS_TOKEN": "fake_token"
|
||||
}.get(key, default)
|
||||
|
||||
mock_gitlab_client.projects.get.return_value = mock_project
|
||||
provider = GitLabProvider("https://gitlab.com/test/repo/-/merge_requests/1")
|
||||
provider.gl = mock_gitlab_client
|
||||
provider.id_project = "test/repo"
|
||||
return provider
|
||||
|
||||
def test_get_pr_file_content_success(self, gitlab_provider, mock_project):
|
||||
mock_file = MagicMock(ProjectFile)
|
||||
mock_file.decode.return_value = "# Changelog\n\n## v1.0.0\n- Initial release"
|
||||
mock_project.files.get.return_value = mock_file
|
||||
|
||||
content = gitlab_provider.get_pr_file_content("CHANGELOG.md", "main")
|
||||
|
||||
assert content == "# Changelog\n\n## v1.0.0\n- Initial release"
|
||||
mock_project.files.get.assert_called_once_with("CHANGELOG.md", "main")
|
||||
mock_file.decode.assert_called_once()
|
||||
|
||||
def test_get_pr_file_content_with_bytes(self, gitlab_provider, mock_project):
|
||||
mock_file = MagicMock(ProjectFile)
|
||||
mock_file.decode.return_value = b"# Changelog\n\n## v1.0.0\n- Initial release"
|
||||
mock_project.files.get.return_value = mock_file
|
||||
|
||||
content = gitlab_provider.get_pr_file_content("CHANGELOG.md", "main")
|
||||
|
||||
assert content == "# Changelog\n\n## v1.0.0\n- Initial release"
|
||||
mock_project.files.get.assert_called_once_with("CHANGELOG.md", "main")
|
||||
|
||||
def test_get_pr_file_content_file_not_found(self, gitlab_provider, mock_project):
|
||||
mock_project.files.get.side_effect = GitlabGetError("404 Not Found")
|
||||
|
||||
content = gitlab_provider.get_pr_file_content("CHANGELOG.md", "main")
|
||||
|
||||
assert content == ""
|
||||
mock_project.files.get.assert_called_once_with("CHANGELOG.md", "main")
|
||||
|
||||
def test_get_pr_file_content_other_exception(self, gitlab_provider, mock_project):
|
||||
mock_project.files.get.side_effect = Exception("Network error")
|
||||
|
||||
content = gitlab_provider.get_pr_file_content("CHANGELOG.md", "main")
|
||||
|
||||
assert content == ""
|
||||
|
||||
def test_create_or_update_pr_file_create_new(self, gitlab_provider, mock_project):
|
||||
mock_project.files.get.side_effect = GitlabGetError("404 Not Found")
|
||||
mock_file = MagicMock()
|
||||
mock_project.files.create.return_value = mock_file
|
||||
|
||||
new_content = "# Changelog\n\n## v1.1.0\n- New feature"
|
||||
commit_message = "Add CHANGELOG.md"
|
||||
|
||||
gitlab_provider.create_or_update_pr_file(
|
||||
"CHANGELOG.md", "feature-branch", new_content, commit_message
|
||||
)
|
||||
|
||||
mock_project.files.get.assert_called_once_with("CHANGELOG.md", "feature-branch")
|
||||
mock_project.files.create.assert_called_once_with({
|
||||
'file_path': 'CHANGELOG.md',
|
||||
'branch': 'feature-branch',
|
||||
'content': new_content,
|
||||
'commit_message': commit_message,
|
||||
})
|
||||
|
||||
def test_create_or_update_pr_file_update_existing(self, gitlab_provider, mock_project):
|
||||
mock_file = MagicMock(ProjectFile)
|
||||
mock_file.decode.return_value = "# Old changelog content"
|
||||
mock_project.files.get.return_value = mock_file
|
||||
|
||||
new_content = "# New changelog content"
|
||||
commit_message = "Update CHANGELOG.md"
|
||||
|
||||
gitlab_provider.create_or_update_pr_file(
|
||||
"CHANGELOG.md", "feature-branch", new_content, commit_message
|
||||
)
|
||||
|
||||
mock_project.files.get.assert_called_once_with("CHANGELOG.md", "feature-branch")
|
||||
mock_file.content = new_content
|
||||
mock_file.save.assert_called_once_with(branch="feature-branch", commit_message=commit_message)
|
||||
|
||||
def test_create_or_update_pr_file_update_exception(self, gitlab_provider, mock_project):
|
||||
mock_project.files.get.side_effect = Exception("Network error")
|
||||
|
||||
with pytest.raises(Exception):
|
||||
gitlab_provider.create_or_update_pr_file(
|
||||
"CHANGELOG.md", "feature-branch", "content", "message"
|
||||
)
|
||||
|
||||
def test_has_create_or_update_pr_file_method(self, gitlab_provider):
|
||||
assert hasattr(gitlab_provider, "create_or_update_pr_file")
|
||||
assert callable(getattr(gitlab_provider, "create_or_update_pr_file"))
|
||||
|
||||
def test_method_signature_compatibility(self, gitlab_provider):
|
||||
import inspect
|
||||
|
||||
sig = inspect.signature(gitlab_provider.create_or_update_pr_file)
|
||||
params = list(sig.parameters.keys())
|
||||
|
||||
expected_params = ['file_path', 'branch', 'contents', 'message']
|
||||
assert params == expected_params
|
||||
|
||||
@pytest.mark.parametrize("content,expected", [
|
||||
("simple text", "simple text"),
|
||||
(b"bytes content", "bytes content"),
|
||||
("", ""),
|
||||
(b"", ""),
|
||||
("unicode: café", "unicode: café"),
|
||||
(b"unicode: caf\xc3\xa9", "unicode: café"),
|
||||
])
|
||||
def test_content_encoding_handling(self, gitlab_provider, mock_project, content, expected):
|
||||
mock_file = MagicMock(ProjectFile)
|
||||
mock_file.decode.return_value = content
|
||||
mock_project.files.get.return_value = mock_file
|
||||
|
||||
result = gitlab_provider.get_pr_file_content("test.md", "main")
|
||||
|
||||
assert result == expected
|
||||
@ -1,247 +0,0 @@
|
||||
import pytest
|
||||
from unittest.mock import MagicMock, patch, AsyncMock
|
||||
from pr_agent.tools.pr_update_changelog import PRUpdateChangelog
|
||||
|
||||
|
||||
class TestPRUpdateChangelog:
|
||||
"""Test suite for the PR Update Changelog functionality."""
|
||||
|
||||
@pytest.fixture
|
||||
def mock_git_provider(self):
|
||||
"""Create a mock git provider."""
|
||||
provider = MagicMock()
|
||||
provider.get_pr_branch.return_value = "feature-branch"
|
||||
provider.get_pr_file_content.return_value = ""
|
||||
provider.pr.title = "Test PR"
|
||||
provider.get_pr_description.return_value = "Test description"
|
||||
provider.get_commit_messages.return_value = "fix: test commit"
|
||||
provider.get_languages.return_value = {"Python": 80, "JavaScript": 20}
|
||||
provider.get_files.return_value = ["test.py", "test.js"]
|
||||
return provider
|
||||
|
||||
@pytest.fixture
|
||||
def mock_ai_handler(self):
|
||||
"""Create a mock AI handler."""
|
||||
handler = MagicMock()
|
||||
handler.chat_completion = AsyncMock(return_value=("Test changelog entry", "stop"))
|
||||
return handler
|
||||
|
||||
@pytest.fixture
|
||||
def changelog_tool(self, mock_git_provider, mock_ai_handler):
|
||||
"""Create a PRUpdateChangelog instance with mocked dependencies."""
|
||||
with patch('pr_agent.tools.pr_update_changelog.get_git_provider', return_value=lambda url: mock_git_provider), \
|
||||
patch('pr_agent.tools.pr_update_changelog.get_main_pr_language', return_value="Python"), \
|
||||
patch('pr_agent.tools.pr_update_changelog.get_settings') as mock_settings:
|
||||
|
||||
# Configure mock settings
|
||||
mock_settings.return_value.pr_update_changelog.push_changelog_changes = False
|
||||
mock_settings.return_value.pr_update_changelog.extra_instructions = ""
|
||||
mock_settings.return_value.pr_update_changelog_prompt.system = "System prompt"
|
||||
mock_settings.return_value.pr_update_changelog_prompt.user = "User prompt"
|
||||
mock_settings.return_value.config.temperature = 0.2
|
||||
|
||||
tool = PRUpdateChangelog("https://gitlab.com/test/repo/-/merge_requests/1", ai_handler=lambda: mock_ai_handler)
|
||||
return tool
|
||||
|
||||
def test_get_changelog_file_with_existing_content(self, changelog_tool, mock_git_provider):
|
||||
"""Test retrieving existing changelog content."""
|
||||
# Arrange
|
||||
existing_content = "# Changelog\n\n## v1.0.0\n- Initial release\n- Bug fixes"
|
||||
mock_git_provider.get_pr_file_content.return_value = existing_content
|
||||
|
||||
# Act
|
||||
changelog_tool._get_changelog_file()
|
||||
|
||||
# Assert
|
||||
assert changelog_tool.changelog_file == existing_content
|
||||
assert "# Changelog" in changelog_tool.changelog_file_str
|
||||
|
||||
def test_get_changelog_file_with_no_existing_content(self, changelog_tool, mock_git_provider):
|
||||
"""Test handling when no changelog file exists."""
|
||||
# Arrange
|
||||
mock_git_provider.get_pr_file_content.return_value = ""
|
||||
|
||||
# Act
|
||||
changelog_tool._get_changelog_file()
|
||||
|
||||
# Assert
|
||||
assert changelog_tool.changelog_file == ""
|
||||
assert "Example:" in changelog_tool.changelog_file_str # Default template
|
||||
|
||||
def test_get_changelog_file_with_bytes_content(self, changelog_tool, mock_git_provider):
|
||||
"""Test handling when git provider returns bytes instead of string."""
|
||||
# Arrange
|
||||
content_bytes = b"# Changelog\n\n## v1.0.0\n- Initial release"
|
||||
mock_git_provider.get_pr_file_content.return_value = content_bytes
|
||||
|
||||
# Act
|
||||
changelog_tool._get_changelog_file()
|
||||
|
||||
# Assert
|
||||
assert isinstance(changelog_tool.changelog_file, str)
|
||||
assert changelog_tool.changelog_file == "# Changelog\n\n## v1.0.0\n- Initial release"
|
||||
|
||||
def test_get_changelog_file_with_exception(self, changelog_tool, mock_git_provider):
|
||||
"""Test handling exceptions during file retrieval."""
|
||||
# Arrange
|
||||
mock_git_provider.get_pr_file_content.side_effect = Exception("Network error")
|
||||
|
||||
# Act
|
||||
changelog_tool._get_changelog_file()
|
||||
|
||||
# Assert
|
||||
assert changelog_tool.changelog_file == ""
|
||||
assert changelog_tool.changelog_file_str == "" # Exception should result in empty string, no default template
|
||||
|
||||
def test_prepare_changelog_update_with_existing_content(self, changelog_tool):
|
||||
"""Test preparing changelog update when existing content exists."""
|
||||
# Arrange
|
||||
changelog_tool.prediction = "## v1.1.0\n- New feature\n- Bug fix"
|
||||
changelog_tool.changelog_file = "# Changelog\n\n## v1.0.0\n- Initial release"
|
||||
changelog_tool.commit_changelog = True
|
||||
|
||||
# Act
|
||||
new_content, answer = changelog_tool._prepare_changelog_update()
|
||||
|
||||
# Assert
|
||||
assert new_content.startswith("## v1.1.0\n- New feature\n- Bug fix\n\n")
|
||||
assert "# Changelog\n\n## v1.0.0\n- Initial release" in new_content
|
||||
assert answer == "## v1.1.0\n- New feature\n- Bug fix"
|
||||
|
||||
def test_prepare_changelog_update_without_existing_content(self, changelog_tool):
|
||||
"""Test preparing changelog update when no existing content."""
|
||||
# Arrange
|
||||
changelog_tool.prediction = "## v1.0.0\n- Initial release"
|
||||
changelog_tool.changelog_file = ""
|
||||
changelog_tool.commit_changelog = True
|
||||
|
||||
# Act
|
||||
new_content, answer = changelog_tool._prepare_changelog_update()
|
||||
|
||||
# Assert
|
||||
assert new_content == "## v1.0.0\n- Initial release"
|
||||
assert answer == "## v1.0.0\n- Initial release"
|
||||
|
||||
def test_prepare_changelog_update_no_commit(self, changelog_tool):
|
||||
"""Test preparing changelog update when not committing."""
|
||||
# Arrange
|
||||
changelog_tool.prediction = "## v1.1.0\n- New feature"
|
||||
changelog_tool.changelog_file = ""
|
||||
changelog_tool.commit_changelog = False
|
||||
|
||||
# Act
|
||||
new_content, answer = changelog_tool._prepare_changelog_update()
|
||||
|
||||
# Assert
|
||||
assert new_content == "## v1.1.0\n- New feature"
|
||||
assert "to commit the new content" in answer
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_run_without_push_support(self, changelog_tool, mock_git_provider):
|
||||
"""Test running changelog update when git provider doesn't support pushing."""
|
||||
# Arrange
|
||||
delattr(mock_git_provider, 'create_or_update_pr_file') # Remove the method
|
||||
changelog_tool.commit_changelog = True
|
||||
|
||||
with patch('pr_agent.tools.pr_update_changelog.get_settings') as mock_settings:
|
||||
mock_settings.return_value.pr_update_changelog.push_changelog_changes = True
|
||||
mock_settings.return_value.config.publish_output = True
|
||||
|
||||
# Act
|
||||
await changelog_tool.run()
|
||||
|
||||
# Assert
|
||||
mock_git_provider.publish_comment.assert_called_once()
|
||||
assert "not currently supported" in str(mock_git_provider.publish_comment.call_args)
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_run_with_push_support(self, changelog_tool, mock_git_provider):
|
||||
"""Test running changelog update when git provider supports pushing."""
|
||||
# Arrange
|
||||
mock_git_provider.create_or_update_pr_file = MagicMock()
|
||||
changelog_tool.commit_changelog = True
|
||||
changelog_tool.prediction = "## v1.1.0\n- New feature"
|
||||
|
||||
with patch('pr_agent.tools.pr_update_changelog.get_settings') as mock_settings, \
|
||||
patch('pr_agent.tools.pr_update_changelog.retry_with_fallback_models') as mock_retry, \
|
||||
patch('pr_agent.tools.pr_update_changelog.sleep'):
|
||||
|
||||
mock_settings.return_value.pr_update_changelog.push_changelog_changes = True
|
||||
mock_settings.return_value.pr_update_changelog.get.return_value = True
|
||||
mock_settings.return_value.config.publish_output = True
|
||||
mock_settings.return_value.config.git_provider = "gitlab"
|
||||
mock_retry.return_value = None
|
||||
|
||||
# Act
|
||||
await changelog_tool.run()
|
||||
|
||||
# Assert
|
||||
mock_git_provider.create_or_update_pr_file.assert_called_once()
|
||||
call_args = mock_git_provider.create_or_update_pr_file.call_args
|
||||
assert call_args[1]['file_path'] == 'CHANGELOG.md'
|
||||
assert call_args[1]['branch'] == 'feature-branch'
|
||||
|
||||
def test_push_changelog_update(self, changelog_tool, mock_git_provider):
|
||||
"""Test the push changelog update functionality."""
|
||||
# Arrange
|
||||
mock_git_provider.create_or_update_pr_file = MagicMock()
|
||||
mock_git_provider.get_pr_branch.return_value = "feature-branch"
|
||||
new_content = "# Updated changelog content"
|
||||
answer = "Changes made"
|
||||
|
||||
with patch('pr_agent.tools.pr_update_changelog.get_settings') as mock_settings, \
|
||||
patch('pr_agent.tools.pr_update_changelog.sleep'):
|
||||
|
||||
mock_settings.return_value.pr_update_changelog.get.return_value = True
|
||||
|
||||
# Act
|
||||
changelog_tool._push_changelog_update(new_content, answer)
|
||||
|
||||
# Assert
|
||||
mock_git_provider.create_or_update_pr_file.assert_called_once_with(
|
||||
file_path="CHANGELOG.md",
|
||||
branch="feature-branch",
|
||||
contents=new_content,
|
||||
message="[skip ci] Update CHANGELOG.md"
|
||||
)
|
||||
|
||||
def test_gitlab_provider_method_detection(self, changelog_tool, mock_git_provider):
|
||||
"""Test that the tool correctly detects GitLab provider method availability."""
|
||||
# Arrange
|
||||
mock_git_provider.create_or_update_pr_file = MagicMock()
|
||||
|
||||
# Act & Assert
|
||||
assert hasattr(mock_git_provider, "create_or_update_pr_file")
|
||||
|
||||
@pytest.mark.parametrize("existing_content,new_entry,expected_order", [
|
||||
(
|
||||
"# Changelog\n\n## v1.0.0\n- Old feature",
|
||||
"## v1.1.0\n- New feature",
|
||||
["v1.1.0", "v1.0.0"]
|
||||
),
|
||||
(
|
||||
"",
|
||||
"## v1.0.0\n- Initial release",
|
||||
["v1.0.0"]
|
||||
),
|
||||
(
|
||||
"Some existing content",
|
||||
"## v1.0.0\n- New entry",
|
||||
["v1.0.0", "Some existing content"]
|
||||
),
|
||||
])
|
||||
def test_changelog_order_preservation(self, changelog_tool, existing_content, new_entry, expected_order):
|
||||
"""Test that changelog entries are properly ordered (newest first)."""
|
||||
# Arrange
|
||||
changelog_tool.prediction = new_entry
|
||||
changelog_tool.changelog_file = existing_content
|
||||
changelog_tool.commit_changelog = True
|
||||
|
||||
# Act
|
||||
new_content, _ = changelog_tool._prepare_changelog_update()
|
||||
|
||||
# Assert
|
||||
for i, expected in enumerate(expected_order[:-1]):
|
||||
current_pos = new_content.find(expected)
|
||||
next_pos = new_content.find(expected_order[i + 1])
|
||||
assert current_pos < next_pos, f"Expected {expected} to come before {expected_order[i + 1]}"
|
||||
Reference in New Issue
Block a user