Compare commits
1 Commits
v0.27
...
add-pr-tem
| Author | SHA1 | Date | |
|---|---|---|---|
| 058df7b53d |
@ -3,7 +3,7 @@ FROM python:3.12 as base
|
||||
WORKDIR /app
|
||||
ADD pyproject.toml .
|
||||
ADD requirements.txt .
|
||||
RUN pip install --no-cache-dir . && rm pyproject.toml requirements.txt
|
||||
RUN pip install . && rm pyproject.toml requirements.txt
|
||||
ENV PYTHONPATH=/app
|
||||
ADD docs docs
|
||||
ADD pr_agent pr_agent
|
||||
|
||||
48
PULL_REQUEST_TEMPLATE.md
Normal file
@ -0,0 +1,48 @@
|
||||
## 📌 Pull Request Template
|
||||
|
||||
### 1️⃣ Short Description
|
||||
<!-- Provide a concise summary of the changes in this PR. -->
|
||||
|
||||
---
|
||||
|
||||
### 2️⃣ Related Open Issue
|
||||
<!-- Link the related issue(s) this PR is addressing, e.g., Fixes #123 or Closes #456. -->
|
||||
Fixes #
|
||||
|
||||
---
|
||||
|
||||
### 3️⃣ PR Type
|
||||
<!-- Select one of the following by marking `[x]` -->
|
||||
|
||||
- [ ] 🐞 Bug Fix
|
||||
- [ ] ✨ New Feature
|
||||
- [ ] 🔄 Refactoring
|
||||
- [ ] 📖 Documentation Update
|
||||
|
||||
---
|
||||
|
||||
### 4️⃣ Does this PR Introduce a Breaking Change?
|
||||
<!-- Mark the applicable option -->
|
||||
- [ ] ❌ No
|
||||
- [ ] ⚠️ Yes (Explain below)
|
||||
|
||||
If **yes**, describe the impact and necessary migration steps:
|
||||
<!-- Provide a short explanation of what needs to be changed. -->
|
||||
|
||||
---
|
||||
|
||||
### 5️⃣ Current Behavior (Before Changes)
|
||||
<!-- Describe the existing behavior before applying the changes in this PR. -->
|
||||
|
||||
---
|
||||
|
||||
### 6️⃣ New Behavior (After Changes)
|
||||
<!-- Explain how the behavior changes with this PR. -->
|
||||
|
||||
---
|
||||
|
||||
### ✅ Checklist
|
||||
- [ ] Code follows the project's coding guidelines.
|
||||
- [ ] Tests have been added or updated (if applicable).
|
||||
- [ ] Documentation has been updated (if applicable).
|
||||
- [ ] Ready for review and approval.
|
||||
151
README.md
@ -4,18 +4,12 @@
|
||||
|
||||
|
||||
<picture>
|
||||
<source media="(prefers-color-scheme: dark)" srcset="https://www.qodo.ai/wp-content/uploads/2025/02/PR-Agent-Purple-2.png">
|
||||
<source media="(prefers-color-scheme: light)" srcset="https://www.qodo.ai/wp-content/uploads/2025/02/PR-Agent-Purple-2.png">
|
||||
<source media="(prefers-color-scheme: dark)" srcset="https://codium.ai/images/pr_agent/logo-dark.png" width="330">
|
||||
<source media="(prefers-color-scheme: light)" srcset="https://codium.ai/images/pr_agent/logo-light.png" width="330">
|
||||
<img src="https://codium.ai/images/pr_agent/logo-light.png" alt="logo" width="330">
|
||||
|
||||
</picture>
|
||||
<br/>
|
||||
|
||||
[Installation Guide](https://qodo-merge-docs.qodo.ai/installation/) |
|
||||
[Usage Guide](https://qodo-merge-docs.qodo.ai/usage-guide/) |
|
||||
[Tools Guide](https://qodo-merge-docs.qodo.ai/tools/) |
|
||||
[Qodo Merge](https://qodo-merge-docs.qodo.ai/overview/pr_agent_pro/) 💎
|
||||
|
||||
PR-Agent aims to help efficiently review and handle pull requests, by providing AI feedback and suggestions
|
||||
</div>
|
||||
|
||||
@ -28,16 +22,13 @@ PR-Agent aims to help efficiently review and handle pull requests, by providing
|
||||
</a>
|
||||
</div>
|
||||
|
||||
[//]: # (### [Documentation](https://qodo-merge-docs.qodo.ai/))
|
||||
### [Documentation](https://qodo-merge-docs.qodo.ai/)
|
||||
|
||||
[//]: # ()
|
||||
[//]: # (- See the [Installation Guide](https://qodo-merge-docs.qodo.ai/installation/) for instructions on installing PR-Agent on different platforms.)
|
||||
- See the [Installation Guide](https://qodo-merge-docs.qodo.ai/installation/) for instructions on installing PR-Agent on different platforms.
|
||||
|
||||
[//]: # ()
|
||||
[//]: # (- See the [Usage Guide](https://qodo-merge-docs.qodo.ai/usage-guide/) for instructions on running PR-Agent tools via different interfaces, such as CLI, PR Comments, or by automatically triggering them when a new PR is opened.)
|
||||
- See the [Usage Guide](https://qodo-merge-docs.qodo.ai/usage-guide/) for instructions on running PR-Agent tools via different interfaces, such as CLI, PR Comments, or by automatically triggering them when a new PR is opened.
|
||||
|
||||
[//]: # ()
|
||||
[//]: # (- See the [Tools Guide](https://qodo-merge-docs.qodo.ai/tools/) for a detailed description of the different tools, and the available configurations for each tool.)
|
||||
- See the [Tools Guide](https://qodo-merge-docs.qodo.ai/tools/) for a detailed description of the different tools, and the available configurations for each tool.
|
||||
|
||||
|
||||
## Table of Contents
|
||||
@ -46,22 +37,12 @@ PR-Agent aims to help efficiently review and handle pull requests, by providing
|
||||
- [Overview](#overview)
|
||||
- [Example results](#example-results)
|
||||
- [Try it now](#try-it-now)
|
||||
- [Qodo Merge](https://qodo-merge-docs.qodo.ai/overview/pr_agent_pro/)
|
||||
- [Qodo Merge 💎](https://qodo-merge-docs.qodo.ai/overview/pr_agent_pro/)
|
||||
- [How it works](#how-it-works)
|
||||
- [Why use PR-Agent?](#why-use-pr-agent)
|
||||
|
||||
## News and Updates
|
||||
|
||||
### Feb 27, 2025
|
||||
- Updated the default model to `o3-mini` for all tools. You can still use the `gpt-4o` as the default model by setting the `model` parameter in the configuration file.
|
||||
- Important updates and bug fixes for Azure DevOps, see [here](https://github.com/qodo-ai/pr-agent/pull/1583)
|
||||
- Added support for adjusting the [response language](https://qodo-merge-docs.qodo.ai/usage-guide/additional_configurations/#language-settings) of the PR-Agent tools.
|
||||
|
||||
### Feb 6, 2025
|
||||
New design for the `/improve` tool:
|
||||
|
||||
<kbd><img src="https://github.com/user-attachments/assets/26506430-550e-469a-adaa-af0a09b70c6d" width="512"></kbd>
|
||||
|
||||
### Jan 25, 2025
|
||||
|
||||
The open-source GitHub organization was updated:
|
||||
@ -79,7 +60,7 @@ to
|
||||
|
||||
New tool [/Implement](https://qodo-merge-docs.qodo.ai/tools/implement/) (💎), which converts human code review discussions and feedback into ready-to-commit code changes.
|
||||
|
||||
<kbd><img src="https://www.qodo.ai/images/pr_agent/implement1.png?v=2" width="512"></kbd>
|
||||
<kbd><img src="https://www.qodo.ai/images/pr_agent/implement1.png" width="512"></kbd>
|
||||
|
||||
|
||||
### Jan 1, 2025
|
||||
@ -88,7 +69,40 @@ Update logic and [documentation](https://qodo-merge-docs.qodo.ai/usage-guide/cha
|
||||
|
||||
### December 30, 2024
|
||||
|
||||
Following feedback from the community, we have addressed two vulnerabilities identified in the open-source PR-Agent project. The [fixes](https://github.com/qodo-ai/pr-agent/pull/1425) are now included in the newly released version (v0.26), available as of today.
|
||||
Following feedback from the community, we have addressed two vulnerabilities identified in the open-source PR-Agent project. The fixes are now included in the newly released version (v0.26), available as of today.
|
||||
|
||||
### December 25, 2024
|
||||
|
||||
The `review` tool previously included a legacy feature for providing code suggestions (controlled by '--pr_reviewer.num_code_suggestion'). This functionality has been deprecated. Use instead the [`improve`](https://qodo-merge-docs.qodo.ai/tools/improve/) tool, which offers higher quality and more actionable code suggestions.
|
||||
|
||||
### December 2, 2024
|
||||
|
||||
Open-source repositories can now freely use Qodo Merge, and enjoy easy one-click installation using a marketplace [app](https://github.com/apps/qodo-merge-pro-for-open-source).
|
||||
|
||||
<kbd><img src="https://github.com/user-attachments/assets/b0838724-87b9-43b0-ab62-73739a3a855c" width="512"></kbd>
|
||||
|
||||
See [here](https://qodo-merge-docs.qodo.ai/installation/pr_agent_pro/) for more details about installing Qodo Merge for private repositories.
|
||||
|
||||
|
||||
### November 18, 2024
|
||||
|
||||
A new mode was enabled by default for code suggestions - `--pr_code_suggestions.focus_only_on_problems=true`:
|
||||
|
||||
- This option reduces the number of code suggestions received
|
||||
- The suggestions will focus more on identifying and fixing code problems, rather than style considerations like best practices, maintainability, or readability.
|
||||
- The suggestions will be categorized into just two groups: "Possible Issues" and "General".
|
||||
|
||||
Still, if you prefer the previous mode, you can set `--pr_code_suggestions.focus_only_on_problems=false` in the [configuration file](https://qodo-merge-docs.qodo.ai/usage-guide/configuration_options/).
|
||||
|
||||
**Example results:**
|
||||
|
||||
Original mode
|
||||
|
||||
<kbd><img src="https://qodo.ai/images/pr_agent/code_suggestions_original_mode.png" width="512"></kbd>
|
||||
|
||||
Focused mode
|
||||
|
||||
<kbd><img src="https://qodo.ai/images/pr_agent/code_suggestions_focused_mode.png" width="512"></kbd>
|
||||
|
||||
|
||||
## Overview
|
||||
@ -96,43 +110,42 @@ Following feedback from the community, we have addressed two vulnerabilities ide
|
||||
|
||||
Supported commands per platform:
|
||||
|
||||
| | | GitHub | GitLab | Bitbucket | Azure DevOps |
|
||||
|-------|---------------------------------------------------------------------------------------------------------|:--------------------:|:--------------------:|:---------:|:------------:|
|
||||
| TOOLS | [Review](https://qodo-merge-docs.qodo.ai/tools/review/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Describe](https://qodo-merge-docs.qodo.ai/tools/describe/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Improve](https://qodo-merge-docs.qodo.ai/tools/improve/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Ask](https://qodo-merge-docs.qodo.ai/tools/ask/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ [Ask on code lines](https://qodo-merge-docs.qodo.ai/tools/ask/#ask-lines) | ✅ | ✅ | | |
|
||||
| | [Update CHANGELOG](https://qodo-merge-docs.qodo.ai/tools/update_changelog/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Ticket Context](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [Utilizing Best Practices](https://qodo-merge-docs.qodo.ai/tools/improve/#best-practices) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [PR Chat](https://qodo-merge-docs.qodo.ai/chrome-extension/features/#pr-chat) 💎 | ✅ | | | |
|
||||
| | [Suggestion Tracking](https://qodo-merge-docs.qodo.ai/tools/improve/#suggestion-tracking) 💎 | ✅ | ✅ | | |
|
||||
| | [CI Feedback](https://qodo-merge-docs.qodo.ai/tools/ci_feedback/) 💎 | ✅ | | | |
|
||||
| | [PR Documentation](https://qodo-merge-docs.qodo.ai/tools/documentation/) 💎 | ✅ | ✅ | | |
|
||||
| | [Custom Labels](https://qodo-merge-docs.qodo.ai/tools/custom_labels/) 💎 | ✅ | ✅ | | |
|
||||
| | [Analyze](https://qodo-merge-docs.qodo.ai/tools/analyze/) 💎 | ✅ | ✅ | | |
|
||||
| | [Similar Code](https://qodo-merge-docs.qodo.ai/tools/similar_code/) 💎 | ✅ | | | |
|
||||
| | [Custom Prompt](https://qodo-merge-docs.qodo.ai/tools/custom_prompt/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [Test](https://qodo-merge-docs.qodo.ai/tools/test/) 💎 | ✅ | ✅ | | |
|
||||
| | [Implement](https://qodo-merge-docs.qodo.ai/tools/implement/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [Auto-Approve](https://qodo-merge-docs.qodo.ai/tools/improve/?h=auto#auto-approval) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | | | | | |
|
||||
| USAGE | [CLI](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#local-repo-cli) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [App / webhook](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#github-app) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Tagging bot](https://github.com/Codium-ai/pr-agent#try-it-now) | ✅ | | | |
|
||||
| | [Actions](https://qodo-merge-docs.qodo.ai/installation/github/#run-as-a-github-action) | ✅ |✅| ✅ |✅|
|
||||
| | | | | | |
|
||||
| CORE | [PR compression](https://qodo-merge-docs.qodo.ai/core-abilities/compression_strategy/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Adaptive and token-aware file patch fitting | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Multiple models support](https://qodo-merge-docs.qodo.ai/usage-guide/changing_a_model/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Local and global metadata](https://qodo-merge-docs.qodo.ai/core-abilities/metadata/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Dynamic context](https://qodo-merge-docs.qodo.ai/core-abilities/dynamic_context/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Self reflection](https://qodo-merge-docs.qodo.ai/core-abilities/self_reflection/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Static code analysis](https://qodo-merge-docs.qodo.ai/core-abilities/static_code_analysis/) 💎 | ✅ | ✅ | | |
|
||||
| | [Global and wiki configurations](https://qodo-merge-docs.qodo.ai/usage-guide/configuration_options/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [PR interactive actions](https://www.qodo.ai/images/pr_agent/pr-actions.mp4) 💎 | ✅ | ✅ | | |
|
||||
| | [Impact Evaluation](https://qodo-merge-docs.qodo.ai/core-abilities/impact_evaluation/) 💎 | ✅ | ✅ | | |
|
||||
| | | GitHub | GitLab | Bitbucket | Azure DevOps |
|
||||
|-------|---------------------------------------------------------------------------------------------------------|:--------------------:|:--------------------:|:--------------------:|:------------:|
|
||||
| TOOLS | [Review](https://qodo-merge-docs.qodo.ai/tools/review/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Describe](https://qodo-merge-docs.qodo.ai/tools/describe/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Improve](https://qodo-merge-docs.qodo.ai/tools/improve/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Ask](https://qodo-merge-docs.qodo.ai/tools/ask/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ [Ask on code lines](https://qodo-merge-docs.qodo.ai/tools/ask/#ask-lines) | ✅ | ✅ | | |
|
||||
| | [Update CHANGELOG](https://qodo-merge-docs.qodo.ai/tools/update_changelog/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Ticket Context](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [Utilizing Best Practices](https://qodo-merge-docs.qodo.ai/tools/improve/#best-practices) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [PR Chat](https://qodo-merge-docs.qodo.ai/chrome-extension/features/#pr-chat) 💎 | ✅ | | | |
|
||||
| | [Suggestion Tracking](https://qodo-merge-docs.qodo.ai/tools/improve/#suggestion-tracking) 💎 | ✅ | ✅ | | |
|
||||
| | [CI Feedback](https://qodo-merge-docs.qodo.ai/tools/ci_feedback/) 💎 | ✅ | | | |
|
||||
| | [PR Documentation](https://qodo-merge-docs.qodo.ai/tools/documentation/) 💎 | ✅ | ✅ | | |
|
||||
| | [Custom Labels](https://qodo-merge-docs.qodo.ai/tools/custom_labels/) 💎 | ✅ | ✅ | | |
|
||||
| | [Analyze](https://qodo-merge-docs.qodo.ai/tools/analyze/) 💎 | ✅ | ✅ | | |
|
||||
| | [Similar Code](https://qodo-merge-docs.qodo.ai/tools/similar_code/) 💎 | ✅ | | | |
|
||||
| | [Custom Prompt](https://qodo-merge-docs.qodo.ai/tools/custom_prompt/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [Test](https://qodo-merge-docs.qodo.ai/tools/test/) 💎 | ✅ | ✅ | | |
|
||||
| | [Implement](https://qodo-merge-docs.qodo.ai/tools/implement/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | | | | | |
|
||||
| USAGE | [CLI](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#local-repo-cli) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [App / webhook](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#github-app) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Tagging bot](https://github.com/Codium-ai/pr-agent#try-it-now) | ✅ | | | |
|
||||
| | [Actions](https://qodo-merge-docs.qodo.ai/installation/github/#run-as-a-github-action) | ✅ |✅| ✅ |✅|
|
||||
| | | | | | |
|
||||
| CORE | [PR compression](https://qodo-merge-docs.qodo.ai/core-abilities/compression_strategy/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Adaptive and token-aware file patch fitting | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Multiple models support](https://qodo-merge-docs.qodo.ai/usage-guide/changing_a_model/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Local and global metadata](https://qodo-merge-docs.qodo.ai/core-abilities/metadata/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Dynamic context](https://qodo-merge-docs.qodo.ai/core-abilities/dynamic_context/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Self reflection](https://qodo-merge-docs.qodo.ai/core-abilities/self_reflection/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Static code analysis](https://qodo-merge-docs.qodo.ai/core-abilities/static_code_analysis/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [Global and wiki configurations](https://qodo-merge-docs.qodo.ai/usage-guide/configuration_options/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [PR interactive actions](https://www.qodo.ai/images/pr_agent/pr-actions.mp4) 💎 | ✅ | ✅ | | |
|
||||
| | [Impact Evaluation](https://qodo-merge-docs.qodo.ai/core-abilities/impact_evaluation/) 💎 | ✅ | ✅ | | |
|
||||
- 💎 means this feature is available only in [Qodo-Merge](https://www.qodo.ai/pricing/)
|
||||
|
||||
[//]: # (- Support for additional git providers is described in [here](./docs/Full_environments.md))
|
||||
@ -219,6 +232,12 @@ Note that this is a promotional bot, suitable only for initial experimentation.
|
||||
It does not have 'edit' access to your repo, for example, so it cannot update the PR description or add labels (`@CodiumAI-Agent /describe` will publish PR description as a comment). In addition, the bot cannot be used on private repositories, as it does not have access to the files there.
|
||||
|
||||
|
||||
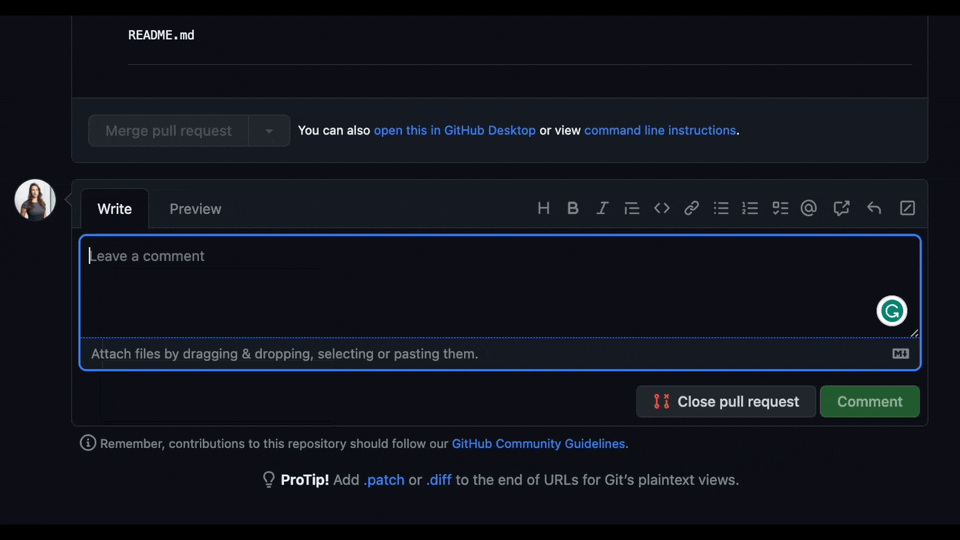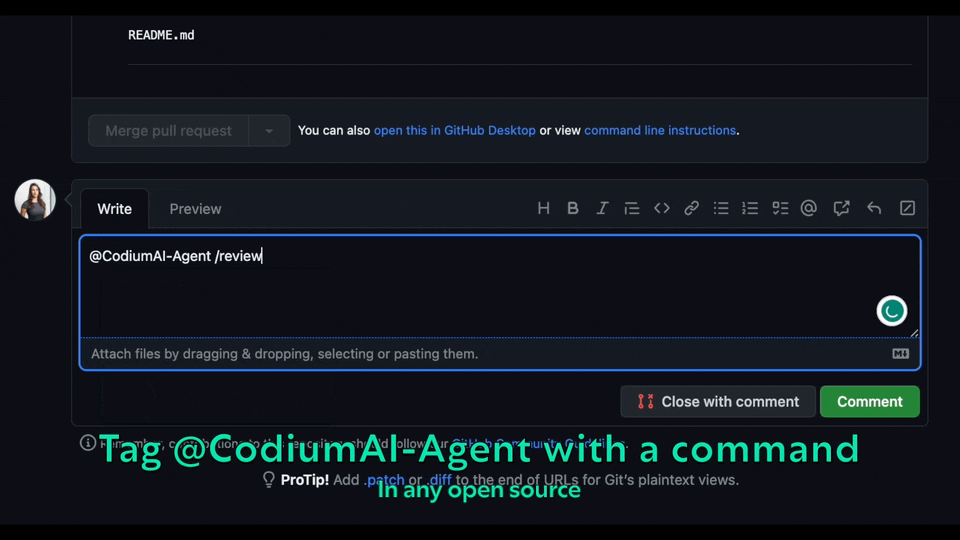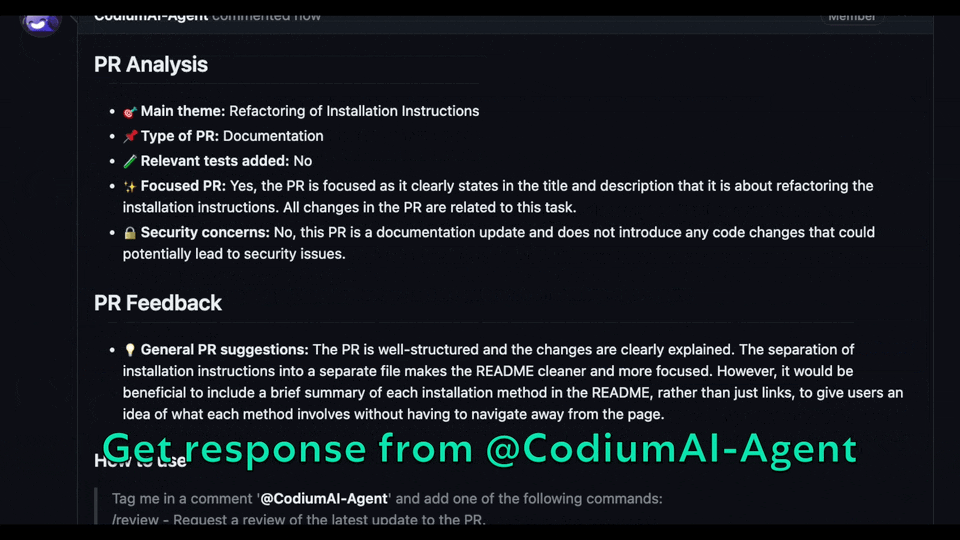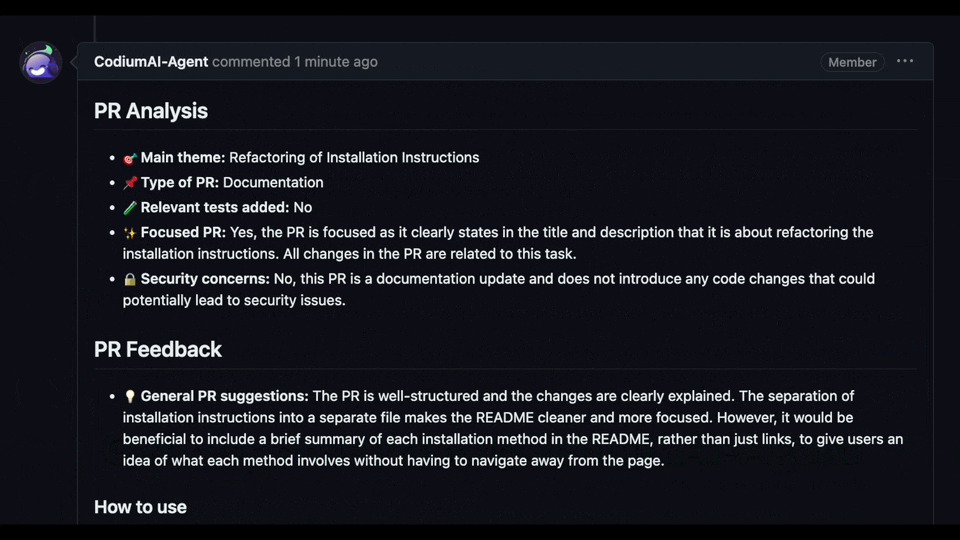
|
||||
|
||||
|
||||
To set up your own PR-Agent, see the [Installation](https://qodo-merge-docs.qodo.ai/installation/) section below.
|
||||
Note that when you set your own PR-Agent or use Qodo hosted PR-Agent, there is no need to mention `@CodiumAI-Agent ...`. Instead, directly start with the command, e.g., `/ask ...`.
|
||||
|
||||
---
|
||||
|
||||
|
||||
@ -273,6 +292,8 @@ https://openai.com/enterprise-privacy
|
||||
|
||||
## Links
|
||||
|
||||
[](https://discord.gg/kG35uSHDBc)
|
||||
|
||||
- Discord community: https://discord.gg/kG35uSHDBc
|
||||
- Qodo site: https://www.qodo.ai/
|
||||
- Blog: https://www.qodo.ai/blog/
|
||||
|
||||
@ -1,315 +0,0 @@
|
||||
<div class="search-section">
|
||||
<h1>AI Docs Search</h1>
|
||||
<p class="search-description">
|
||||
Search through our documentation using AI-powered natural language queries.
|
||||
</p>
|
||||
<div class="search-container">
|
||||
<input
|
||||
type="text"
|
||||
id="searchInput"
|
||||
class="search-input"
|
||||
placeholder="Enter your search term..."
|
||||
>
|
||||
<button id="searchButton" class="search-button">Search</button>
|
||||
</div>
|
||||
<div id="spinner" class="spinner-container" style="display: none;">
|
||||
<div class="spinner"></div>
|
||||
</div>
|
||||
<div id="results" class="results-container"></div>
|
||||
</div>
|
||||
|
||||
<style>
|
||||
Untitled
|
||||
.search-section {
|
||||
max-width: 800px;
|
||||
margin: 0 auto;
|
||||
padding: 0 1rem 2rem;
|
||||
}
|
||||
|
||||
h1 {
|
||||
color: #666;
|
||||
font-size: 2.125rem;
|
||||
font-weight: normal;
|
||||
margin-bottom: 1rem;
|
||||
}
|
||||
|
||||
.search-description {
|
||||
color: #666;
|
||||
font-size: 1rem;
|
||||
line-height: 1.5;
|
||||
margin-bottom: 2rem;
|
||||
max-width: 800px;
|
||||
}
|
||||
|
||||
.search-container {
|
||||
display: flex;
|
||||
gap: 1rem;
|
||||
max-width: 800px;
|
||||
margin: 0; /* Changed from auto to 0 to align left */
|
||||
}
|
||||
|
||||
.search-input {
|
||||
flex: 1;
|
||||
padding: 0 0.875rem;
|
||||
border: 1px solid #ddd;
|
||||
border-radius: 4px;
|
||||
font-size: 0.9375rem;
|
||||
outline: none;
|
||||
height: 40px; /* Explicit height */
|
||||
}
|
||||
|
||||
.search-input:focus {
|
||||
border-color: #6c63ff;
|
||||
}
|
||||
|
||||
.search-button {
|
||||
padding: 0 1.25rem;
|
||||
background-color: #2196F3;
|
||||
color: white;
|
||||
border: none;
|
||||
border-radius: 4px;
|
||||
cursor: pointer;
|
||||
font-size: 0.875rem;
|
||||
transition: background-color 0.2s;
|
||||
height: 40px; /* Match the height of search input */
|
||||
display: flex;
|
||||
align-items: center;
|
||||
justify-content: center;
|
||||
}
|
||||
|
||||
.search-button:hover {
|
||||
background-color: #1976D2;
|
||||
}
|
||||
|
||||
.spinner-container {
|
||||
display: flex;
|
||||
justify-content: center;
|
||||
margin-top: 2rem;
|
||||
}
|
||||
|
||||
.spinner {
|
||||
width: 40px;
|
||||
height: 40px;
|
||||
border: 4px solid #f3f3f3;
|
||||
border-top: 4px solid #2196F3;
|
||||
border-radius: 50%;
|
||||
animation: spin 1s linear infinite;
|
||||
}
|
||||
|
||||
@keyframes spin {
|
||||
0% { transform: rotate(0deg); }
|
||||
100% { transform: rotate(360deg); }
|
||||
}
|
||||
|
||||
.results-container {
|
||||
margin-top: 2rem;
|
||||
max-width: 800px;
|
||||
}
|
||||
|
||||
.result-item {
|
||||
padding: 1rem;
|
||||
border: 1px solid #ddd;
|
||||
border-radius: 4px;
|
||||
margin-bottom: 1rem;
|
||||
}
|
||||
|
||||
.result-title {
|
||||
font-size: 1.2rem;
|
||||
color: #2196F3;
|
||||
margin-bottom: 0.5rem;
|
||||
}
|
||||
|
||||
.result-description {
|
||||
color: #666;
|
||||
}
|
||||
|
||||
.error-message {
|
||||
color: #dc3545;
|
||||
padding: 1rem;
|
||||
border: 1px solid #dc3545;
|
||||
border-radius: 4px;
|
||||
margin-top: 1rem;
|
||||
}
|
||||
|
||||
.markdown-content {
|
||||
line-height: 1.6;
|
||||
color: var(--md-typeset-color);
|
||||
background: var(--md-default-bg-color);
|
||||
border: 1px solid var(--md-default-fg-color--lightest);
|
||||
border-radius: 12px;
|
||||
padding: 1.5rem;
|
||||
box-shadow: 0 2px 4px rgba(0,0,0,0.05);
|
||||
position: relative;
|
||||
margin-top: 2rem;
|
||||
}
|
||||
|
||||
.markdown-content::before {
|
||||
content: '';
|
||||
position: absolute;
|
||||
top: -8px;
|
||||
left: 24px;
|
||||
width: 16px;
|
||||
height: 16px;
|
||||
background: var(--md-default-bg-color);
|
||||
border-left: 1px solid var(--md-default-fg-color--lightest);
|
||||
border-top: 1px solid var(--md-default-fg-color--lightest);
|
||||
transform: rotate(45deg);
|
||||
}
|
||||
|
||||
.markdown-content > *:first-child {
|
||||
margin-top: 0;
|
||||
padding-top: 0;
|
||||
}
|
||||
|
||||
.markdown-content p {
|
||||
margin-bottom: 1rem;
|
||||
}
|
||||
|
||||
.markdown-content p:last-child {
|
||||
margin-bottom: 0;
|
||||
}
|
||||
|
||||
.markdown-content code {
|
||||
background: var(--md-code-bg-color);
|
||||
color: var(--md-code-fg-color);
|
||||
padding: 0.2em 0.4em;
|
||||
border-radius: 3px;
|
||||
font-size: 0.9em;
|
||||
font-family: ui-monospace, SFMono-Regular, SF Mono, Menlo, Consolas, Liberation Mono, monospace;
|
||||
}
|
||||
|
||||
.markdown-content pre {
|
||||
background: var(--md-code-bg-color);
|
||||
padding: 1rem;
|
||||
border-radius: 6px;
|
||||
overflow-x: auto;
|
||||
margin: 1rem 0;
|
||||
}
|
||||
|
||||
.markdown-content pre code {
|
||||
background: none;
|
||||
padding: 0;
|
||||
font-size: 0.9em;
|
||||
}
|
||||
|
||||
[data-md-color-scheme="slate"] .markdown-content {
|
||||
box-shadow: 0 2px 4px rgba(0,0,0,0.1);
|
||||
}
|
||||
|
||||
</style>
|
||||
|
||||
<script src="https://cdnjs.cloudflare.com/ajax/libs/marked/9.1.6/marked.min.js"></script>
|
||||
|
||||
<script>
|
||||
window.addEventListener('load', function() {
|
||||
function displayResults(responseText) {
|
||||
const resultsContainer = document.getElementById('results');
|
||||
const spinner = document.getElementById('spinner');
|
||||
const searchContainer = document.querySelector('.search-container');
|
||||
|
||||
// Hide spinner
|
||||
spinner.style.display = 'none';
|
||||
|
||||
// Scroll to search bar
|
||||
searchContainer.scrollIntoView({ behavior: 'smooth', block: 'start' });
|
||||
|
||||
try {
|
||||
const results = JSON.parse(responseText);
|
||||
|
||||
marked.setOptions({
|
||||
breaks: true,
|
||||
gfm: true,
|
||||
headerIds: false,
|
||||
sanitize: false
|
||||
});
|
||||
|
||||
const htmlContent = marked.parse(results.message);
|
||||
|
||||
resultsContainer.className = 'markdown-content';
|
||||
resultsContainer.innerHTML = htmlContent;
|
||||
|
||||
// Scroll after content is rendered
|
||||
setTimeout(() => {
|
||||
const searchContainer = document.querySelector('.search-container');
|
||||
const offset = 55; // Offset from top in pixels
|
||||
const elementPosition = searchContainer.getBoundingClientRect().top;
|
||||
const offsetPosition = elementPosition + window.pageYOffset - offset;
|
||||
|
||||
window.scrollTo({
|
||||
top: offsetPosition,
|
||||
behavior: 'smooth'
|
||||
});
|
||||
}, 100);
|
||||
} catch (error) {
|
||||
console.error('Error parsing results:', error);
|
||||
resultsContainer.innerHTML = '<div class="error-message">Error processing results</div>';
|
||||
}
|
||||
}
|
||||
|
||||
async function performSearch() {
|
||||
const searchInput = document.getElementById('searchInput');
|
||||
const resultsContainer = document.getElementById('results');
|
||||
const spinner = document.getElementById('spinner');
|
||||
const searchTerm = searchInput.value.trim();
|
||||
|
||||
if (!searchTerm) {
|
||||
resultsContainer.innerHTML = '<div class="error-message">Please enter a search term</div>';
|
||||
return;
|
||||
}
|
||||
|
||||
// Show spinner, clear results
|
||||
spinner.style.display = 'flex';
|
||||
resultsContainer.innerHTML = '';
|
||||
|
||||
try {
|
||||
const data = {
|
||||
"query": searchTerm
|
||||
};
|
||||
|
||||
const options = {
|
||||
method: 'POST',
|
||||
headers: {
|
||||
'accept': 'text/plain',
|
||||
'content-type': 'application/json',
|
||||
},
|
||||
body: JSON.stringify(data)
|
||||
};
|
||||
|
||||
// const API_ENDPOINT = 'http://0.0.0.0:3000/api/v1/docs_help';
|
||||
const API_ENDPOINT = 'https://help.merge.qodo.ai/api/v1/docs_help';
|
||||
|
||||
const response = await fetch(API_ENDPOINT, options);
|
||||
|
||||
if (!response.ok) {
|
||||
throw new Error(`HTTP error! status: ${response.status}`);
|
||||
}
|
||||
|
||||
const responseText = await response.text();
|
||||
displayResults(responseText);
|
||||
} catch (error) {
|
||||
spinner.style.display = 'none';
|
||||
resultsContainer.innerHTML = `
|
||||
<div class="error-message">
|
||||
An error occurred while searching. Please try again later.
|
||||
</div>
|
||||
`;
|
||||
}
|
||||
}
|
||||
|
||||
// Add event listeners
|
||||
const searchButton = document.getElementById('searchButton');
|
||||
const searchInput = document.getElementById('searchInput');
|
||||
|
||||
if (searchButton) {
|
||||
searchButton.addEventListener('click', performSearch);
|
||||
}
|
||||
|
||||
if (searchInput) {
|
||||
searchInput.addEventListener('keypress', function(e) {
|
||||
if (e.key === 'Enter') {
|
||||
performSearch();
|
||||
}
|
||||
});
|
||||
}
|
||||
});
|
||||
</script>
|
||||
|
Before Width: | Height: | Size: 15 KiB After Width: | Height: | Size: 4.2 KiB |
{kind=link}
|
Before Width: | Height: | Size: 57 KiB After Width: | Height: | Size: 263 KiB |
{kind=link}
|
Before Width: | Height: | Size: 24 KiB After Width: | Height: | Size: 1.2 KiB |
{kind=link}
|
Before Width: | Height: | Size: 17 KiB After Width: | Height: | Size: 8.7 KiB |
@ -1,5 +1,5 @@
|
||||
## Local and global metadata injection with multi-stage analysis
|
||||
1\.
|
||||
(1)
|
||||
Qodo Merge initially retrieves for each PR the following data:
|
||||
|
||||
- PR title and branch name
|
||||
@ -11,7 +11,7 @@ Qodo Merge initially retrieves for each PR the following data:
|
||||
!!! tip "Tip: Organization-level metadata"
|
||||
In addition to the inputs above, Qodo Merge can incorporate supplementary preferences provided by the user, like [`extra_instructions` and `organization best practices`](https://qodo-merge-docs.qodo.ai/tools/improve/#extra-instructions-and-best-practices). This information can be used to enhance the PR analysis.
|
||||
|
||||
2\.
|
||||
(2)
|
||||
By default, the first command that Qodo Merge executes is [`describe`](https://qodo-merge-docs.qodo.ai/tools/describe/), which generates three types of outputs:
|
||||
|
||||
- PR Type (e.g. bug fix, feature, refactor, etc)
|
||||
@ -49,8 +49,8 @@ __old hunk__
|
||||
...
|
||||
```
|
||||
|
||||
3\. The entire PR files that were retrieved are also used to expand and enhance the PR context (see [Dynamic Context](https://qodo-merge-docs.qodo.ai/core-abilities/dynamic_context/)).
|
||||
(3) The entire PR files that were retrieved are also used to expand and enhance the PR context (see [Dynamic Context](https://qodo-merge-docs.qodo.ai/core-abilities/dynamic_context/)).
|
||||
|
||||
|
||||
4\. All the metadata described above represents several level of cumulative analysis - ranging from hunk level, to file level, to PR level, to organization level.
|
||||
(4) All the metadata described above represents several level of cumulative analysis - ranging from hunk level, to file level, to PR level, to organization level.
|
||||
This comprehensive approach enables Qodo Merge AI models to generate more precise and contextually relevant suggestions and feedback.
|
||||
|
||||
@ -28,34 +28,34 @@ Qodo Merge offers extensive pull request functionalities across various git prov
|
||||
|
||||
| | | GitHub | Gitlab | Bitbucket | Azure DevOps |
|
||||
|-------|-----------------------------------------------------------------------------------------------------------------------|:------:|:------:|:---------:|:------------:|
|
||||
| TOOLS | Review | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ Incremental | ✅ | | | |
|
||||
| | Ask | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Describe | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ [Inline file summary](https://qodo-merge-docs.qodo.ai/tools/describe/#inline-file-summary){:target="_blank"} 💎 | ✅ | ✅ | | ✅ |
|
||||
| | Improve | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ Extended | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Auto-Approve](https://qodo-merge-docs.qodo.ai/tools/improve/#auto-approval) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [Custom Prompt](./tools/custom_prompt.md){:target="_blank"} 💎 | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Reflect and Review | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Update CHANGELOG.md | ✅ | ✅ | ✅ | ️ |
|
||||
| | Find Similar Issue | ✅ | | | ️ |
|
||||
| | [Add PR Documentation](./tools/documentation.md){:target="_blank"} 💎 | ✅ | ✅ | | ✅ |
|
||||
| | [Generate Custom Labels](./tools/describe.md#handle-custom-labels-from-the-repos-labels-page-💎){:target="_blank"} 💎 | ✅ | ✅ | | ✅ |
|
||||
| | [Analyze PR Components](./tools/analyze.md){:target="_blank"} 💎 | ✅ | ✅ | | ✅ |
|
||||
| | [Test](https://pr-agent-docs.codium.ai/tools/test/) 💎 | ✅ | ✅ | | |
|
||||
| | [Implement](https://pr-agent-docs.codium.ai/tools/implement/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | | | | | ️ |
|
||||
| USAGE | CLI | ✅ | ✅ | ✅ | ✅ |
|
||||
| | App / webhook | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Actions | ✅ | | | ️ |
|
||||
| | | | | |
|
||||
| CORE | PR compression | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Repo language prioritization | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Adaptive and token-aware file patch fitting | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Multiple models support | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Static code analysis](./core-abilities/static_code_analysis/){:target="_blank"} 💎 | ✅ | ✅ | | |
|
||||
| | [Multiple configuration options](./usage-guide/configuration_options.md){:target="_blank"} 💎 | ✅ | ✅ | ✅ | ✅ |
|
||||
| TOOLS | Review | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ Incremental | ✅ | | | |
|
||||
| | Ask | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Describe | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ [Inline file summary](https://qodo-merge-docs.qodo.ai/tools/describe/#inline-file-summary){:target="_blank"} 💎 | ✅ | ✅ | | ✅ |
|
||||
| | Improve | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ Extended | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Custom Prompt](./tools/custom_prompt.md){:target="_blank"} 💎 | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Reflect and Review | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Update CHANGELOG.md | ✅ | ✅ | ✅ | ️ |
|
||||
| | Find Similar Issue | ✅ | | | ️ |
|
||||
| | [Add PR Documentation](./tools/documentation.md){:target="_blank"} 💎 | ✅ | ✅ | | ✅ |
|
||||
| | [Generate Custom Labels](./tools/describe.md#handle-custom-labels-from-the-repos-labels-page-💎){:target="_blank"} 💎 | ✅ | ✅ | | ✅ |
|
||||
| | [Analyze PR Components](./tools/analyze.md){:target="_blank"} 💎 | ✅ | ✅ | | ✅ |
|
||||
| | [Test](https://pr-agent-docs.codium.ai/tools/test/) 💎 | ✅ | ✅ | | |
|
||||
| | [Implement](https://pr-agent-docs.codium.ai/tools/implement/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | | | | | ️ |
|
||||
| USAGE | CLI | ✅ | ✅ | ✅ | ✅ |
|
||||
| | App / webhook | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Actions | ✅ | | | ️ |
|
||||
| | | | | |
|
||||
| CORE | PR compression | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Repo language prioritization | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Adaptive and token-aware file patch fitting | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Multiple models support | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Incremental PR review | ✅ | | | |
|
||||
| | [Static code analysis](./tools/analyze.md/){:target="_blank"} 💎 | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Multiple configuration options](./usage-guide/configuration_options.md){:target="_blank"} 💎 | ✅ | ✅ | ✅ | ✅ |
|
||||
|
||||
💎 marks a feature available only in [Qodo Merge](https://www.codium.ai/pricing/){:target="_blank"}, and not in the open-source version.
|
||||
|
||||
|
||||
@ -15,7 +15,7 @@ Qodo Merge for GitHub cloud is available for installation through the [GitHub Ma
|
||||
|
||||
### GitHub Enterprise Server
|
||||
|
||||
To use Qodo Merge application on your private GitHub Enterprise Server, you will need to [contact](https://www.qodo.ai/contact/#pricing) Qodo for starting an Enterprise trial.
|
||||
To use Qodo Merge application on your private GitHub Enterprise Server, you will need to contact us for starting an [Enterprise](https://www.codium.ai/pricing/) trial.
|
||||
|
||||
### GitHub Open Source Projects
|
||||
|
||||
@ -34,9 +34,7 @@ Qodo Merge for Bitbucket Cloud is available for installation through the followi
|
||||
To use Qodo Merge application on your private Bitbucket Server, you will need to contact us for starting an [Enterprise](https://www.qodo.ai/pricing/) trial.
|
||||
|
||||
|
||||
## Install Qodo Merge for GitLab
|
||||
|
||||
### GitLab Cloud
|
||||
## Install Qodo Merge for GitLab (Teams & Enterprise)
|
||||
|
||||
Since GitLab platform does not support apps, installing Qodo Merge for GitLab is a bit more involved, and requires the following steps:
|
||||
|
||||
@ -81,7 +79,3 @@ Enable SSL verification: Check the box.
|
||||
You’re all set!
|
||||
|
||||
Open a new merge request or add a MR comment with one of Qodo Merge’s commands such as /review, /describe or /improve.
|
||||
|
||||
### GitLab Server
|
||||
|
||||
For a trial period of two weeks on your private GitLab Server, the same [installation steps](#gitlab-cloud) as for GitLab Cloud apply. After the trial period, you will need to [contact](https://www.qodo.ai/contact/#pricing) Qodo for moving to an Enterprise account.
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
### Overview
|
||||
|
||||
[Qodo Merge](https://www.codium.ai/pricing/){:target="_blank"} is a paid, hosted version of open-source [PR-Agent](https://github.com/Codium-ai/pr-agent){:target="_blank"}. A complimentary two-week trial is offered, followed by a monthly subscription fee.
|
||||
[Qodo Merge](https://www.codium.ai/pricing/){:target="_blank"} is a hosted version of open-source [PR-Agent](https://github.com/Codium-ai/pr-agent){:target="_blank"}. A complimentary two-week trial is offered, followed by a monthly subscription fee.
|
||||
Qodo Merge is designed for companies and teams that require additional features and capabilities. It provides the following benefits:
|
||||
|
||||
1. **Fully managed** - We take care of everything for you - hosting, models, regular updates, and more. Installation is as simple as signing up and adding the Qodo Merge app to your GitHub\GitLab\BitBucket repo.
|
||||
|
||||
@ -14,5 +14,6 @@ An example result:
|
||||
|
||||
{width=750}
|
||||
|
||||
!!! note "Language that are currently supported:"
|
||||
Python, Java, C++, JavaScript, TypeScript, C#.
|
||||
**Notes**
|
||||
|
||||
- Language that are currently supported: Python, Java, C++, JavaScript, TypeScript, C#.
|
||||
|
||||
@ -38,20 +38,20 @@ where `https://real_link_to_image` is the direct link to the image.
|
||||
Note that GitHub has a built-in mechanism of pasting images in comments. However, pasted image does not provide a direct link.
|
||||
To get a direct link to an image, we recommend using the following scheme:
|
||||
|
||||
1\. First, post a comment that contains **only** the image:
|
||||
1) First, post a comment that contains **only** the image:
|
||||
|
||||
{width=512}
|
||||
|
||||
2\. Quote reply to that comment:
|
||||
2) Quote reply to that comment:
|
||||
|
||||
{width=512}
|
||||
|
||||
3\. In the screen opened, type the question below the image:
|
||||
3) In the screen opened, type the question below the image:
|
||||
|
||||
{width=512}
|
||||
{width=512}
|
||||
|
||||
4\. Post the comment, and receive the answer:
|
||||
4) Post the comment, and receive the answer:
|
||||
|
||||
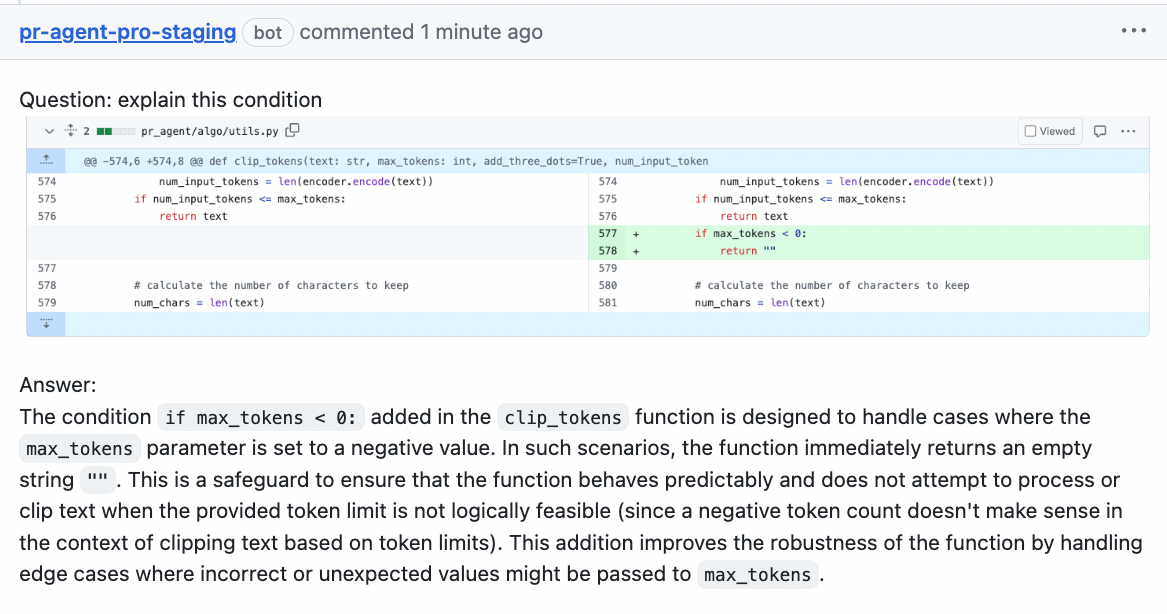{width=512}
|
||||
|
||||
|
||||
@ -51,8 +51,8 @@ Results obtained with the prompt above:
|
||||
|
||||
## Configuration options
|
||||
|
||||
- `prompt`: the prompt for the tool. It should be a multi-line string.
|
||||
`prompt`: the prompt for the tool. It should be a multi-line string.
|
||||
|
||||
- `num_code_suggestions_per_chunk`: number of code suggestions provided by the 'custom_prompt' tool, per chunk. Default is 4.
|
||||
`num_code_suggestions`: number of code suggestions provided by the 'custom_prompt' tool. Default is 4.
|
||||
|
||||
- `enable_help_text`: if set to true, the tool will display a help text in the comment. Default is true.
|
||||
`enable_help_text`: if set to true, the tool will display a help text in the comment. Default is true.
|
||||
|
||||
@ -143,7 +143,7 @@ The marker `pr_agent:type` will be replaced with the PR type, `pr_agent:summary`
|
||||
|
||||
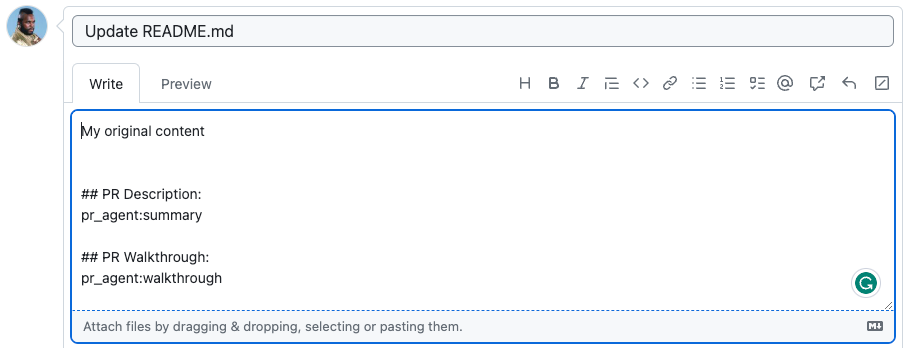{width=512}
|
||||
|
||||
becomes
|
||||
→
|
||||
|
||||
{width=512}
|
||||
|
||||
|
||||
@ -27,6 +27,7 @@ You can state a name of a specific component in the PR to get documentation only
|
||||
- `docs_style`: The exact style of the documentation (for python docstring). you can choose between: `google`, `numpy`, `sphinx`, `restructuredtext`, `plain`. Default is `sphinx`.
|
||||
- `extra_instructions`: Optional extra instructions to the tool. For example: "focus on the changes in the file X. Ignore change in ...".
|
||||
|
||||
!!! note "Notes"
|
||||
- The following languages are currently supported: Python, Java, C++, JavaScript, TypeScript, C#.
|
||||
- This tool can also be triggered interactively by using the [`analyze`](./analyze.md) tool.
|
||||
**Notes**
|
||||
|
||||
- Language that are currently fully supported: Python, Java, C++, JavaScript, TypeScript, C#.
|
||||
- This tool can also be triggered interactively by using the [`analyze`](./analyze.md) tool.
|
||||
|
||||
@ -10,9 +10,8 @@ It leverages LLM technology to transform PR comments and review suggestions into
|
||||
|
||||
### For Reviewers
|
||||
|
||||
Reviewers can request code changes by:
|
||||
|
||||
1. Selecting the code block to be modified.
|
||||
Reviewers can request code changes by: <br>
|
||||
1. Selecting the code block to be modified. <br>
|
||||
2. Adding a comment with the syntax:
|
||||
```
|
||||
/implement <code-change-description>
|
||||
@ -47,8 +46,7 @@ You can reference and implement changes from any comment by:
|
||||
Note that the implementation will occur within the review discussion thread.
|
||||
|
||||
|
||||
**Configuration options**
|
||||
|
||||
- Use `/implement` to implement code change within and based on the review discussion.
|
||||
- Use `/implement <code-change-description>` inside a review discussion to implement specific instructions.
|
||||
- Use `/implement <link-to-review-comment>` to indirectly call the tool from any comment.
|
||||
**Configuration options** <br>
|
||||
- Use `/implement` to implement code change within and based on the review discussion. <br>
|
||||
- Use `/implement <code-change-description>` inside a review discussion to implement specific instructions. <br>
|
||||
- Use `/implement <link-to-review-comment>` to indirectly call the tool from any comment. <br>
|
||||
|
||||
@ -9,9 +9,8 @@ The tool can be triggered automatically every time a new PR is [opened](../usage
|
||||
|
||||
{width=512}
|
||||
|
||||
!!! note "The following features are available only for Qodo Merge 💎 users:"
|
||||
- The `Apply this suggestion` checkbox, which interactively converts a suggestion into a committable code comment
|
||||
- The `More` checkbox to generate additional suggestions
|
||||
Note that the `Apply this suggestion` checkbox, which interactively converts a suggestion into a commitable code comment, is available only for Qodo Merge💎 users.
|
||||
|
||||
|
||||
## Example usage
|
||||
|
||||
@ -53,10 +52,9 @@ num_code_suggestions_per_chunk = ...
|
||||
- The `pr_commands` lists commands that will be executed automatically when a PR is opened.
|
||||
- The `[pr_code_suggestions]` section contains the configurations for the `improve` tool you want to edit (if any)
|
||||
|
||||
### Assessing Impact
|
||||
>`💎 feature`
|
||||
### Assessing Impact 💎
|
||||
|
||||
Qodo Merge tracks two types of implementations for tracking implemented suggestions:
|
||||
Note that Qodo Merge tracks two types of implementations:
|
||||
|
||||
- Direct implementation - when the user directly applies the suggestion by clicking the `Apply` checkbox.
|
||||
- Indirect implementation - when the user implements the suggestion in their IDE environment. In this case, Qodo Merge will utilize, after each commit, a dedicated logic to identify if a suggestion was implemented, and will mark it as implemented.
|
||||
@ -69,8 +67,8 @@ In post-process, Qodo Merge counts the number of suggestions that were implement
|
||||
|
||||
{width=512}
|
||||
|
||||
## Suggestion tracking
|
||||
>`💎 feature. Platforms supported: GitHub, GitLab`
|
||||
## Suggestion tracking 💎
|
||||
`Platforms supported: GitHub, GitLab`
|
||||
|
||||
Qodo Merge employs a novel detection system to automatically [identify](https://qodo-merge-docs.qodo.ai/core-abilities/impact_evaluation/) AI code suggestions that PR authors have accepted and implemented.
|
||||
|
||||
@ -103,6 +101,8 @@ The `improve` tool can be further customized by providing additional instruction
|
||||
|
||||
### Extra instructions
|
||||
|
||||
>`Platforms supported: GitHub, GitLab, Bitbucket, Azure DevOps`
|
||||
|
||||
You can use the `extra_instructions` configuration option to give the AI model additional instructions for the `improve` tool.
|
||||
Be specific, clear, and concise in the instructions. With extra instructions, you are the prompter.
|
||||
|
||||
@ -118,9 +118,9 @@ extra_instructions="""\
|
||||
```
|
||||
Use triple quotes to write multi-line instructions. Use bullet points or numbers to make the instructions more readable.
|
||||
|
||||
### Best practices
|
||||
### Best practices 💎
|
||||
|
||||
> `💎 feature. Platforms supported: GitHub, GitLab, Bitbucket`
|
||||
>`Platforms supported: GitHub, GitLab, Bitbucket`
|
||||
|
||||
Another option to give additional guidance to the AI model is by creating a `best_practices.md` file, either in your repository's root directory or as a [**wiki page**](https://github.com/Codium-ai/pr-agent/wiki) (we recommend the wiki page, as editing and maintaining it over time is easier).
|
||||
This page can contain a list of best practices, coding standards, and guidelines that are specific to your repo/organization.
|
||||
@ -191,11 +191,11 @@ And the label will be: `{organization_name} best practice`.
|
||||
|
||||
{width=512}
|
||||
|
||||
### Auto best practices
|
||||
### Auto best practices 💎
|
||||
|
||||
>`💎 feature. Platforms supported: GitHub.`
|
||||
>`Platforms supported: GitHub`
|
||||
|
||||
`Auto best practices` is a novel Qodo Merge capability that:
|
||||
'Auto best practices' is a novel Qodo Merge capability that:
|
||||
|
||||
1. Identifies recurring patterns from accepted suggestions
|
||||
2. **Automatically** generates [best practices page](https://github.com/qodo-ai/pr-agent/wiki/.pr_agent_auto_best_practices) based on what your team consistently values
|
||||
@ -228,8 +228,7 @@ max_patterns = 5
|
||||
```
|
||||
|
||||
|
||||
### Combining 'extra instructions' and 'best practices'
|
||||
> `💎 feature`
|
||||
### Combining `extra instructions` and `best practices` 💎
|
||||
|
||||
The `extra instructions` configuration is more related to the `improve` tool prompt. It can be used, for example, to avoid specific suggestions ("Don't suggest to add try-except block", "Ignore changes in toml files", ...) or to emphasize specific aspects or formats ("Answer in Japanese", "Give only short suggestions", ...)
|
||||
|
||||
@ -268,8 +267,6 @@ dual_publishing_score_threshold = x
|
||||
Where x represents the minimum score threshold (>=) for suggestions to be presented as commitable PR comments in addition to the table. Default is -1 (disabled).
|
||||
|
||||
### Self-review
|
||||
> `💎 feature`
|
||||
|
||||
If you set in a configuration file:
|
||||
```toml
|
||||
[pr_code_suggestions]
|
||||
@ -313,56 +310,21 @@ code_suggestions_self_review_text = "... (your text here) ..."
|
||||
|
||||
To prevent unauthorized approvals, this configuration defaults to false, and cannot be altered through online comments; enabling requires a direct update to the configuration file and a commit to the repository. This ensures that utilizing the feature demands a deliberate documented decision by the repository owner.
|
||||
|
||||
### Auto-approval
|
||||
> `💎 feature. Platforms supported: GitHub, GitLab, Bitbucket`
|
||||
|
||||
Under specific conditions, Qodo Merge can auto-approve a PR when a specific comment is invoked, or when the PR meets certain criteria.
|
||||
|
||||
To ensure safety, the auto-approval feature is disabled by default. To enable auto-approval, you need to actively set, in a pre-defined _configuration file_, the following:
|
||||
```toml
|
||||
[config]
|
||||
enable_auto_approval = true
|
||||
```
|
||||
Note that this specific flag cannot be set with a command line argument, only in the configuration file, committed to the repository.
|
||||
This ensures that enabling auto-approval is a deliberate decision by the repository owner.
|
||||
|
||||
**(1) Auto-approval by commenting**
|
||||
|
||||
After enabling, by commenting on a PR:
|
||||
```
|
||||
/review auto_approve
|
||||
```
|
||||
Qodo Merge will automatically approve the PR, and add a comment with the approval.
|
||||
|
||||
**(2) Auto-approval when the PR meets certain criteria**
|
||||
|
||||
There are two criteria that can be set for auto-approval:
|
||||
|
||||
- **Review effort score**
|
||||
```toml
|
||||
[config]
|
||||
auto_approve_for_low_review_effort = X # X is a number between 1 to 5
|
||||
```
|
||||
When the [review effort score](https://www.qodo.ai/images/pr_agent/review3.png) is lower or equal to X, the PR will be auto-approved.
|
||||
|
||||
___
|
||||
- **No code suggestions**
|
||||
```toml
|
||||
[config]
|
||||
auto_approve_for_no_suggestions = true
|
||||
```
|
||||
When no [code suggestion](https://www.qodo.ai/images/pr_agent/code_suggestions_as_comment_closed.png) were found for the PR, the PR will be auto-approved.
|
||||
|
||||
### How many code suggestions are generated?
|
||||
Qodo Merge uses a dynamic strategy to generate code suggestions based on the size of the pull request (PR). Here's how it works:
|
||||
|
||||
#### 1. Chunking large PRs
|
||||
1) Chunking large PRs:
|
||||
|
||||
- Qodo Merge divides large PRs into 'chunks'.
|
||||
- Each chunk contains up to `pr_code_suggestions.max_context_tokens` tokens (default: 14,000).
|
||||
|
||||
#### 2. Generating suggestions
|
||||
|
||||
2) Generating suggestions:
|
||||
|
||||
- For each chunk, Qodo Merge generates up to `pr_code_suggestions.num_code_suggestions_per_chunk` suggestions (default: 4).
|
||||
|
||||
|
||||
This approach has two main benefits:
|
||||
|
||||
- Scalability: The number of suggestions scales with the PR size, rather than being fixed.
|
||||
@ -404,10 +366,6 @@ Note: Chunking is primarily relevant for large PRs. For most PRs (up to 500 line
|
||||
<td><b>apply_suggestions_checkbox</b></td>
|
||||
<td> Enable the checkbox to create a committable suggestion. Default is true.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>enable_more_suggestions_checkbox</b></td>
|
||||
<td> Enable the checkbox to generate more suggestions. Default is true.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>enable_help_text</b></td>
|
||||
<td>If set to true, the tool will display a help text in the comment. Default is true.</td>
|
||||
|
||||
@ -18,9 +18,9 @@ The tool will generate code suggestions for the selected component (if no compon
|
||||
|
||||
{width=768}
|
||||
|
||||
!!! note "Notes"
|
||||
- Language that are currently supported by the tool: Python, Java, C++, JavaScript, TypeScript, C#.
|
||||
- This tool can also be triggered interactively by using the [`analyze`](./analyze.md) tool.
|
||||
**Notes**
|
||||
- Language that are currently supported by the tool: Python, Java, C++, JavaScript, TypeScript, C#.
|
||||
- This tool can also be triggered interactively by using the [`analyze`](./analyze.md) tool.
|
||||
|
||||
## Configuration options
|
||||
- `num_code_suggestions`: number of code suggestions to provide. Default is 4
|
||||
|
||||
@ -114,6 +114,16 @@ You can enable\disable the `review` tool to add specific labels to the PR:
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
!!! example "Auto-approval"
|
||||
|
||||
If enabled, the `review` tool can approve a PR when a specific comment, `/review auto_approve`, is invoked.
|
||||
|
||||
<table>
|
||||
<tr>
|
||||
<td><b>enable_auto_approval</b></td>
|
||||
<td>If set to true, the tool will approve the PR when invoked with the 'auto_approve' command. Default is false. This flag can be changed only from a configuration file.</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
## Usage Tips
|
||||
|
||||
@ -165,6 +175,23 @@ You can enable\disable the `review` tool to add specific labels to the PR:
|
||||
Use triple quotes to write multi-line instructions. Use bullet points to make the instructions more readable.
|
||||
|
||||
|
||||
!!! tip "Auto-approval"
|
||||
|
||||
Qodo Merge can approve a PR when a specific comment is invoked.
|
||||
|
||||
To ensure safety, the auto-approval feature is disabled by default. To enable auto-approval, you need to actively set in a pre-defined configuration file the following:
|
||||
```
|
||||
[pr_reviewer]
|
||||
enable_auto_approval = true
|
||||
```
|
||||
(this specific flag cannot be set with a command line argument, only in the configuration file, committed to the repository)
|
||||
|
||||
|
||||
After enabling, by commenting on a PR:
|
||||
```
|
||||
/review auto_approve
|
||||
```
|
||||
Qodo Merge will automatically approve the PR, and add a comment with the approval.
|
||||
|
||||
|
||||
!!! tip "Code suggestions"
|
||||
|
||||
@ -16,17 +16,14 @@ It can be invoked manually by commenting on any PR:
|
||||
|
||||
Note that to perform retrieval, the `similar_issue` tool indexes all the repo previous issues (once).
|
||||
|
||||
### Selecting a Vector Database
|
||||
Configure your preferred database by changing the `pr_similar_issue` parameter in `configuration.toml` file.
|
||||
|
||||
#### Available Options
|
||||
Choose from the following Vector Databases:
|
||||
**Select VectorDBs** by changing `pr_similar_issue` parameter in `configuration.toml` file
|
||||
|
||||
2 VectorDBs are available to switch in
|
||||
1. LanceDB
|
||||
2. Pinecone
|
||||
|
||||
#### Pinecone Configuration
|
||||
To use Pinecone with the `similar issue` tool, add these credentials to `.secrets.toml` (or set as environment variables):
|
||||
To enable usage of the '**similar issue**' tool for Pinecone, you need to set the following keys in `.secrets.toml` (or in the relevant environment variables):
|
||||
|
||||
```
|
||||
[pinecone]
|
||||
|
||||
@ -17,9 +17,9 @@ The tool will generate tests for the selected component (if no component is stat
|
||||
|
||||
(Example taken from [here](https://github.com/Codium-ai/pr-agent/pull/598#issuecomment-1913679429)):
|
||||
|
||||
!!! note "Notes"
|
||||
- The following languages are currently supported: Python, Java, C++, JavaScript, TypeScript, C#.
|
||||
- This tool can also be triggered interactively by using the [`analyze`](./analyze.md) tool.
|
||||
**Notes** <br>
|
||||
- The following languages are currently supported: Python, Java, C++, JavaScript, TypeScript, C#. <br>
|
||||
- This tool can also be triggered interactively by using the [`analyze`](./analyze.md) tool.
|
||||
|
||||
|
||||
## Configuration options
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
## Qodo Merge Models
|
||||
|
||||
The default models used by Qodo Merge are a combination of Claude-3.5-sonnet and OpenAI's GPT-4 models.
|
||||
|
||||
@ -8,6 +9,7 @@ The models supported by Qodo Merge are:
|
||||
|
||||
- `claude-3-5-sonnet`
|
||||
- `gpt-4o`
|
||||
- `deepseek-r1`
|
||||
- `o3-mini`
|
||||
|
||||
To restrict Qodo Merge to using only `Claude-3.5-sonnet`, add this setting:
|
||||
@ -23,11 +25,11 @@ To restrict Qodo Merge to using only `GPT-4o`, add this setting:
|
||||
model="gpt-4o"
|
||||
```
|
||||
|
||||
[//]: # (To restrict Qodo Merge to using only `deepseek-r1` us-hosted, add this setting:)
|
||||
[//]: # (```)
|
||||
[//]: # ([config])
|
||||
[//]: # (model="deepseek/r1")
|
||||
[//]: # (```)
|
||||
To restrict Qodo Merge to using only `deepseek-r1`, add this setting:
|
||||
```
|
||||
[config]
|
||||
model="deepseek/r1"
|
||||
```
|
||||
|
||||
To restrict Qodo Merge to using only `o3-mini`, add this setting:
|
||||
```
|
||||
@ -57,23 +57,6 @@ All Qodo Merge tools have a parameter called `extra_instructions`, that enables
|
||||
/update_changelog --pr_update_changelog.extra_instructions="Make sure to update also the version ..."
|
||||
```
|
||||
|
||||
## Language Settings
|
||||
|
||||
The default response language for Qodo Merge is **U.S. English**. However, some development teams may prefer to display information in a different language. For example, your team's workflow might improve if PR descriptions and code suggestions are set to your country's native language.
|
||||
|
||||
To configure this, set the `response_language` parameter in the configuration file. This will prompt the model to respond in the specified language. Use a **standard locale code** based on [ISO 3166](https://en.wikipedia.org/wiki/ISO_3166) (country codes) and [ISO 639](https://en.wikipedia.org/wiki/ISO_639) (language codes) to define a language-country pair. See this [comprehensive list of locale codes](https://simplelocalize.io/data/locales/).
|
||||
|
||||
Example:
|
||||
|
||||
```toml
|
||||
[config]
|
||||
response_language: "it-IT"
|
||||
```
|
||||
|
||||
This will set the response language globally for all the commands to Italian.
|
||||
|
||||
> **Important:** Note that only dynamic text generated by the AI model is translated to the configured language. Static text such as labels and table headers that are not part of the AI models response will remain in US English. In addition, the model you are using must have good support for the specified language.
|
||||
|
||||
## Working with large PRs
|
||||
|
||||
The default mode of CodiumAI is to have a single call per tool, using GPT-4, which has a token limit of 8000 tokens.
|
||||
@ -159,11 +142,13 @@ Qodo Merge allows you to automatically ignore certain PRs based on various crite
|
||||
|
||||
- PRs with specific titles (using regex matching)
|
||||
- PRs between specific branches (using regex matching)
|
||||
- PRs not from specific folders
|
||||
- PRs that don't include changes from specific folders (using regex matching)
|
||||
- PRs containing specific labels
|
||||
- PRs opened by specific users
|
||||
|
||||
### Ignoring PRs with specific titles
|
||||
### Example usage
|
||||
|
||||
#### Ignoring PRs with specific titles
|
||||
|
||||
To ignore PRs with a specific title such as "[Bump]: ...", you can add the following to your `configuration.toml` file:
|
||||
|
||||
@ -174,7 +159,7 @@ ignore_pr_title = ["\\[Bump\\]"]
|
||||
|
||||
Where the `ignore_pr_title` is a list of regex patterns to match the PR title you want to ignore. Default is `ignore_pr_title = ["^\\[Auto\\]", "^Auto"]`.
|
||||
|
||||
### Ignoring PRs between specific branches
|
||||
#### Ignoring PRs between specific branches
|
||||
|
||||
To ignore PRs from specific source or target branches, you can add the following to your `configuration.toml` file:
|
||||
|
||||
@ -187,7 +172,7 @@ ignore_pr_target_branches = ["qa"]
|
||||
Where the `ignore_pr_source_branches` and `ignore_pr_target_branches` are lists of regex patterns to match the source and target branches you want to ignore.
|
||||
They are not mutually exclusive, you can use them together or separately.
|
||||
|
||||
### Ignoring PRs not from specific folders
|
||||
#### Ignoring PRs that don't include changes from specific folders
|
||||
|
||||
To allow only specific folders (often needed in large monorepos), set:
|
||||
|
||||
@ -196,9 +181,9 @@ To allow only specific folders (often needed in large monorepos), set:
|
||||
allow_only_specific_folders=['folder1','folder2']
|
||||
```
|
||||
|
||||
For the configuration above, automatic feedback will only be triggered when the PR changes include files where 'folder1' or 'folder2' is in the file path
|
||||
For the configuration above, automatic feedback will only be triggered when the PR changes include files from 'folder1' or 'folder2'
|
||||
|
||||
### Ignoring PRs containing specific labels
|
||||
#### Ignoring PRs containg specific labels
|
||||
|
||||
To ignore PRs containg specific labels, you can add the following to your `configuration.toml` file:
|
||||
|
||||
@ -209,7 +194,7 @@ ignore_pr_labels = ["do-not-merge"]
|
||||
|
||||
Where the `ignore_pr_labels` is a list of labels that when present in the PR, the PR will be ignored.
|
||||
|
||||
### Ignoring PRs from specific users
|
||||
#### Ignoring PRs from specific users
|
||||
|
||||
Qodo Merge automatically identifies and ignores pull requests created by bots using:
|
||||
|
||||
|
||||
@ -14,12 +14,12 @@ Examples of invoking the different tools via the CLI:
|
||||
|
||||
**Notes:**
|
||||
|
||||
1. in addition to editing your local configuration file, you can also change any configuration value by adding it to the command line:
|
||||
(1) in addition to editing your local configuration file, you can also change any configuration value by adding it to the command line:
|
||||
```
|
||||
python -m pr_agent.cli --pr_url=<pr_url> /review --pr_reviewer.extra_instructions="focus on the file: ..."
|
||||
```
|
||||
|
||||
2. You can print results locally, without publishing them, by setting in `configuration.toml`:
|
||||
(2) You can print results locally, without publishing them, by setting in `configuration.toml`:
|
||||
```
|
||||
[config]
|
||||
publish_output=false
|
||||
@ -27,9 +27,14 @@ verbosity_level=2
|
||||
```
|
||||
This is useful for debugging or experimenting with different tools.
|
||||
|
||||
3. **git provider**: The [git_provider](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml#L5) field in a configuration file determines the GIT provider that will be used by Qodo Merge. Currently, the following providers are supported:
|
||||
`github` **(default)**, `gitlab`, `bitbucket`, `azure`, `codecommit`, `local`, and `gerrit`.
|
||||
(3)
|
||||
|
||||
**git provider**: The [git_provider](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml#L5) field in a configuration file determines the GIT provider that will be used by Qodo Merge. Currently, the following providers are supported:
|
||||
`
|
||||
"github", "gitlab", "bitbucket", "azure", "codecommit", "local", "gerrit"
|
||||
`
|
||||
|
||||
Default is "github".
|
||||
|
||||
### CLI Health Check
|
||||
To verify that Qodo Merge has been configured correctly, you can run this health check command from the repository root:
|
||||
|
||||
@ -30,14 +30,6 @@ model="" # the OpenAI model you've deployed on Azure (e.g. gpt-4o)
|
||||
fallback_models=["..."]
|
||||
```
|
||||
|
||||
Passing custom headers to the underlying LLM Model API can be done by setting extra_headers parameter to litellm.
|
||||
```
|
||||
[litellm]
|
||||
extra_headers='{"projectId": "<authorized projectId >", ...}') #The value of this setting should be a JSON string representing the desired headers, a ValueError is thrown otherwise.
|
||||
```
|
||||
This enables users to pass authorization tokens or API keys, when routing requests through an API management gateway.
|
||||
|
||||
|
||||
### Ollama
|
||||
|
||||
You can run models locally through either [VLLM](https://docs.litellm.ai/docs/providers/vllm) or [Ollama](https://docs.litellm.ai/docs/providers/ollama)
|
||||
@ -59,7 +51,7 @@ api_base = "http://localhost:11434" # or whatever port you're running Ollama on
|
||||
|
||||
Commercial models such as GPT-4, Claude Sonnet, and Gemini have demonstrated robust capabilities in generating structured output for code analysis tasks with large input. In contrast, most open-source models currently available (as of January 2025) face challenges with these complex tasks.
|
||||
|
||||
Based on our testing, local open-source models are suitable for experimentation and learning purposes (mainly for the `ask` command), but they are not suitable for production-level code analysis tasks.
|
||||
Based on our testing, local open-source models are suitable for experimentation and learning purposes, but they are not suitable for production-level code analysis tasks.
|
||||
|
||||
Hence, for production workflows and real-world usage, we recommend using commercial models.
|
||||
|
||||
@ -197,27 +189,15 @@ key = ...
|
||||
|
||||
If the relevant model doesn't appear [here](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/algo/__init__.py), you can still use it as a custom model:
|
||||
|
||||
1. Set the model name in the configuration file:
|
||||
(1) Set the model name in the configuration file:
|
||||
```
|
||||
[config]
|
||||
model="custom_model_name"
|
||||
fallback_models=["custom_model_name"]
|
||||
```
|
||||
2. Set the maximal tokens for the model:
|
||||
(2) Set the maximal tokens for the model:
|
||||
```
|
||||
[config]
|
||||
custom_model_max_tokens= ...
|
||||
```
|
||||
3. Go to [litellm documentation](https://litellm.vercel.app/docs/proxy/quick_start#supported-llms), find the model you want to use, and set the relevant environment variables.
|
||||
|
||||
4. Most reasoning models do not support chat-style inputs (`system` and `user` messages) or temperature settings.
|
||||
To bypass chat templates and temperature controls, set `config.custom_reasoning_model = true` in your configuration file.
|
||||
|
||||
## Dedicated parameters
|
||||
|
||||
### OpenAI models
|
||||
|
||||
[config]
|
||||
reasoning_efffort= = "medium" # "low", "medium", "high"
|
||||
|
||||
With the OpenAI models that support reasoning effort (eg: o3-mini), you can specify its reasoning effort via `config` section. The default value is `medium`. You can change it to `high` or `low` based on your usage.
|
||||
(3) Go to [litellm documentation](https://litellm.vercel.app/docs/proxy/quick_start#supported-llms), find the model you want to use, and set the relevant environment variables.
|
||||
|
||||
@ -24,4 +24,4 @@ It includes information on how to adjust Qodo Merge configurations, define which
|
||||
- [Changing a model](./additional_configurations.md#changing-a-model)
|
||||
- [Patch Extra Lines](./additional_configurations.md#patch-extra-lines)
|
||||
- [Editing the prompts](./additional_configurations.md#editing-the-prompts)
|
||||
- [Qodo Merge Models](./qodo_merge_models)
|
||||
- [Qodo Merge Models](./PR_agent_pro_models.md)
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
site_name: Qodo Merge (and open-source PR-Agent)
|
||||
repo_url: https://github.com/qodo-ai/pr-agent
|
||||
repo_name: Qodo-ai/pr-agent
|
||||
repo_url: https://github.com/Codium-ai/pr-agent
|
||||
repo_name: Codium-ai/pr-agent
|
||||
|
||||
nav:
|
||||
- Overview:
|
||||
@ -20,7 +20,7 @@ nav:
|
||||
- Managing Mail Notifications: 'usage-guide/mail_notifications.md'
|
||||
- Changing a Model: 'usage-guide/changing_a_model.md'
|
||||
- Additional Configurations: 'usage-guide/additional_configurations.md'
|
||||
- 💎 Qodo Merge Models: 'usage-guide/qodo_merge_models.md'
|
||||
- 💎 Qodo Merge Models: 'usage-guide/PR_agent_pro_models'
|
||||
- Tools:
|
||||
- 'tools/index.md'
|
||||
- Describe: 'tools/describe.md'
|
||||
@ -58,7 +58,6 @@ nav:
|
||||
- Data Privacy: 'chrome-extension/data_privacy.md'
|
||||
- FAQ:
|
||||
- FAQ: 'faq/index.md'
|
||||
- AI Docs Search: 'ai_search/index.md'
|
||||
# - Code Fine-tuning Benchmark: 'finetuning_benchmark/index.md'
|
||||
|
||||
theme:
|
||||
@ -154,4 +153,4 @@ markdown_extensions:
|
||||
|
||||
|
||||
copyright: |
|
||||
© 2025 <a href="https://www.codium.ai/" target="_blank" rel="noopener">QodoAI</a>
|
||||
© 2024 <a href="https://www.codium.ai/" target="_blank" rel="noopener">CodiumAI</a>
|
||||
|
||||
@ -82,7 +82,7 @@
|
||||
|
||||
<footer class="wrapper">
|
||||
<div class="container">
|
||||
<p class="footer-text">© 2025 <a href="https://www.qodo.ai/" target="_blank" rel="noopener">Qodo</a></p>
|
||||
<p class="footer-text">© 2024 <a href="https://www.qodo.ai/" target="_blank" rel="noopener">Qodo</a></p>
|
||||
<div class="footer-links">
|
||||
<a href="https://qodo-gen-docs.qodo.ai/">Qodo Gen</a>
|
||||
<p>|</p>
|
||||
|
||||
@ -3,7 +3,6 @@ from functools import partial
|
||||
|
||||
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||
from pr_agent.algo.ai_handlers.litellm_ai_handler import LiteLLMAIHandler
|
||||
from pr_agent.algo.cli_args import CliArgs
|
||||
from pr_agent.algo.utils import update_settings_from_args
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers.utils import apply_repo_settings
|
||||
@ -44,7 +43,6 @@ command2class = {
|
||||
commands = list(command2class.keys())
|
||||
|
||||
|
||||
|
||||
class PRAgent:
|
||||
def __init__(self, ai_handler: partial[BaseAiHandler,] = LiteLLMAIHandler):
|
||||
self.ai_handler = ai_handler # will be initialized in run_action
|
||||
@ -62,31 +60,27 @@ class PRAgent:
|
||||
else:
|
||||
action, *args = request
|
||||
|
||||
# validate args
|
||||
is_valid, arg = CliArgs.validate_user_args(args)
|
||||
if not is_valid:
|
||||
get_logger().error(
|
||||
f"CLI argument for param '{arg}' is forbidden. Use instead a configuration file."
|
||||
)
|
||||
return False
|
||||
|
||||
# Update settings from args
|
||||
forbidden_cli_args = ['enable_auto_approval', 'approve_pr_on_self_review', 'base_url', 'url', 'app_name', 'secret_provider',
|
||||
'git_provider', 'skip_keys', 'openai.key', 'ANALYTICS_FOLDER', 'uri', 'app_id', 'webhook_secret',
|
||||
'bearer_token', 'PERSONAL_ACCESS_TOKEN', 'override_deployment_type', 'private_key',
|
||||
'local_cache_path', 'enable_local_cache', 'jira_base_url', 'api_base', 'api_type', 'api_version',
|
||||
'skip_keys']
|
||||
if args:
|
||||
for arg in args:
|
||||
if arg.startswith('--'):
|
||||
arg_word = arg.lower()
|
||||
arg_word = arg_word.replace('__', '.') # replace double underscore with dot, e.g. --openai__key -> --openai.key
|
||||
for forbidden_arg in forbidden_cli_args:
|
||||
forbidden_arg_word = forbidden_arg.lower()
|
||||
if '.' not in forbidden_arg_word:
|
||||
forbidden_arg_word = '.' + forbidden_arg_word
|
||||
if forbidden_arg_word in arg_word:
|
||||
get_logger().error(
|
||||
f"CLI argument for param '{forbidden_arg}' is forbidden. Use instead a configuration file."
|
||||
)
|
||||
return False
|
||||
args = update_settings_from_args(args)
|
||||
|
||||
# Append the response language in the extra instructions
|
||||
response_language = get_settings().config.get('response_language', 'en-us')
|
||||
if response_language.lower() != 'en-us':
|
||||
get_logger().info(f'User has set the response language to: {response_language}')
|
||||
for key in get_settings():
|
||||
setting = get_settings().get(key)
|
||||
if str(type(setting)) == "<class 'dynaconf.utils.boxing.DynaBox'>":
|
||||
if hasattr(setting, 'extra_instructions'):
|
||||
current_extra_instructions = setting.extra_instructions
|
||||
if current_extra_instructions:
|
||||
setting.extra_instructions = current_extra_instructions+ f"\n======\n\nIn addition, Your response MUST be written in the language corresponding to local code: {response_language}. This is crucial."
|
||||
else:
|
||||
setting.extra_instructions = f"Your response MUST be written in the language corresponding to locale code: '{response_language}'. This is crucial."
|
||||
|
||||
action = action.lstrip("/").lower()
|
||||
if action not in command2class:
|
||||
get_logger().error(f"Unknown command: {action}")
|
||||
|
||||
@ -43,14 +43,13 @@ MAX_TOKENS = {
|
||||
'vertex_ai/claude-3-opus@20240229': 100000,
|
||||
'vertex_ai/claude-3-5-sonnet@20240620': 100000,
|
||||
'vertex_ai/claude-3-5-sonnet-v2@20241022': 100000,
|
||||
'vertex_ai/claude-3-7-sonnet@20250219': 200000,
|
||||
'vertex_ai/gemini-1.5-pro': 1048576,
|
||||
'vertex_ai/gemini-1.5-flash': 1048576,
|
||||
'vertex_ai/gemini-2.0-flash': 1048576,
|
||||
'vertex_ai/gemini-2.0-flash-exp': 1048576,
|
||||
'vertex_ai/gemma2': 8200,
|
||||
'gemini/gemini-1.5-pro': 1048576,
|
||||
'gemini/gemini-1.5-flash': 1048576,
|
||||
'gemini/gemini-2.0-flash': 1048576,
|
||||
'gemini/gemini-2.0-flash-exp': 1048576,
|
||||
'codechat-bison': 6144,
|
||||
'codechat-bison-32k': 32000,
|
||||
'anthropic.claude-instant-v1': 100000,
|
||||
@ -59,7 +58,6 @@ MAX_TOKENS = {
|
||||
'anthropic/claude-3-opus-20240229': 100000,
|
||||
'anthropic/claude-3-5-sonnet-20240620': 100000,
|
||||
'anthropic/claude-3-5-sonnet-20241022': 100000,
|
||||
'anthropic/claude-3-7-sonnet-20250219': 200000,
|
||||
'anthropic/claude-3-5-haiku-20241022': 100000,
|
||||
'bedrock/anthropic.claude-instant-v1': 100000,
|
||||
'bedrock/anthropic.claude-v2': 100000,
|
||||
@ -69,7 +67,6 @@ MAX_TOKENS = {
|
||||
'bedrock/anthropic.claude-3-5-haiku-20241022-v1:0': 100000,
|
||||
'bedrock/anthropic.claude-3-5-sonnet-20240620-v1:0': 100000,
|
||||
'bedrock/anthropic.claude-3-5-sonnet-20241022-v2:0': 100000,
|
||||
'bedrock/anthropic.claude-3-7-sonnet-20250219-v1:0': 200000,
|
||||
"bedrock/us.anthropic.claude-3-5-sonnet-20241022-v2:0": 100000,
|
||||
'claude-3-5-sonnet': 100000,
|
||||
'groq/llama3-8b-8192': 8192,
|
||||
@ -88,24 +85,11 @@ MAX_TOKENS = {
|
||||
}
|
||||
|
||||
USER_MESSAGE_ONLY_MODELS = [
|
||||
"deepseek/deepseek-reasoner",
|
||||
"o1-mini",
|
||||
"o1-mini-2024-09-12",
|
||||
"o1-preview"
|
||||
]
|
||||
|
||||
NO_SUPPORT_TEMPERATURE_MODELS = [
|
||||
"deepseek/deepseek-reasoner",
|
||||
"o1-mini",
|
||||
"o1-mini-2024-09-12",
|
||||
"o1",
|
||||
"o1-2024-12-17",
|
||||
"o3-mini",
|
||||
"o3-mini-2025-01-31",
|
||||
"o1-preview"
|
||||
]
|
||||
|
||||
SUPPORT_REASONING_EFFORT_MODELS = [
|
||||
"o3-mini",
|
||||
"o3-mini-2025-01-31"
|
||||
]
|
||||
|
||||
@ -6,12 +6,11 @@ import requests
|
||||
from litellm import acompletion
|
||||
from tenacity import retry, retry_if_exception_type, stop_after_attempt
|
||||
|
||||
from pr_agent.algo import NO_SUPPORT_TEMPERATURE_MODELS, SUPPORT_REASONING_EFFORT_MODELS, USER_MESSAGE_ONLY_MODELS
|
||||
from pr_agent.algo import USER_MESSAGE_ONLY_MODELS
|
||||
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||
from pr_agent.algo.utils import ReasoningEffort, get_version
|
||||
from pr_agent.algo.utils import get_version
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.log import get_logger
|
||||
import json
|
||||
|
||||
OPENAI_RETRIES = 5
|
||||
|
||||
@ -99,12 +98,6 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||
# Models that only use user meessage
|
||||
self.user_message_only_models = USER_MESSAGE_ONLY_MODELS
|
||||
|
||||
# Model that doesn't support temperature argument
|
||||
self.no_support_temperature_models = NO_SUPPORT_TEMPERATURE_MODELS
|
||||
|
||||
# Models that support reasoning effort
|
||||
self.support_reasoning_models = SUPPORT_REASONING_EFFORT_MODELS
|
||||
|
||||
def prepare_logs(self, response, system, user, resp, finish_reason):
|
||||
response_log = response.dict().copy()
|
||||
response_log['system'] = system
|
||||
@ -209,7 +202,7 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||
{"type": "image_url", "image_url": {"url": img_path}}]
|
||||
|
||||
# Currently, some models do not support a separate system and user prompts
|
||||
if model in self.user_message_only_models or get_settings().config.custom_reasoning_model:
|
||||
if self.user_message_only_models and any(entry.lower() in model.lower() for entry in self.user_message_only_models):
|
||||
user = f"{system}\n\n\n{user}"
|
||||
system = ""
|
||||
get_logger().info(f"Using model {model}, combining system and user prompts")
|
||||
@ -226,22 +219,11 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||
"model": model,
|
||||
"deployment_id": deployment_id,
|
||||
"messages": messages,
|
||||
"temperature": temperature,
|
||||
"timeout": get_settings().config.ai_timeout,
|
||||
"api_base": self.api_base,
|
||||
}
|
||||
|
||||
# Add temperature only if model supports it
|
||||
if model not in self.no_support_temperature_models and not get_settings().config.custom_reasoning_model:
|
||||
# get_logger().info(f"Adding temperature with value {temperature} to model {model}.")
|
||||
kwargs["temperature"] = temperature
|
||||
|
||||
# Add reasoning_effort if model supports it
|
||||
if (model in self.support_reasoning_models):
|
||||
supported_reasoning_efforts = [ReasoningEffort.HIGH.value, ReasoningEffort.MEDIUM.value, ReasoningEffort.LOW.value]
|
||||
reasoning_effort = get_settings().config.reasoning_effort if (get_settings().config.reasoning_effort in supported_reasoning_efforts) else ReasoningEffort.MEDIUM.value
|
||||
get_logger().info(f"Adding reasoning_effort with value {reasoning_effort} to model {model}.")
|
||||
kwargs["reasoning_effort"] = reasoning_effort
|
||||
|
||||
if get_settings().litellm.get("enable_callbacks", False):
|
||||
kwargs = self.add_litellm_callbacks(kwargs)
|
||||
|
||||
@ -255,22 +237,12 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||
if self.repetition_penalty:
|
||||
kwargs["repetition_penalty"] = self.repetition_penalty
|
||||
|
||||
#Added support for extra_headers while using litellm to call underlying model, via a api management gateway, would allow for passing custom headers for security and authorization
|
||||
if get_settings().get("LITELLM.EXTRA_HEADERS", None):
|
||||
try:
|
||||
litellm_extra_headers = json.loads(get_settings().litellm.extra_headers)
|
||||
if not isinstance(litellm_extra_headers, dict):
|
||||
raise ValueError("LITELLM.EXTRA_HEADERS must be a JSON object")
|
||||
except json.JSONDecodeError as e:
|
||||
raise ValueError(f"LITELLM.EXTRA_HEADERS contains invalid JSON: {str(e)}")
|
||||
kwargs["extra_headers"] = litellm_extra_headers
|
||||
|
||||
get_logger().debug("Prompts", artifact={"system": system, "user": user})
|
||||
|
||||
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().info(f"\nSystem prompt:\n{system}")
|
||||
get_logger().info(f"\nUser prompt:\n{user}")
|
||||
|
||||
|
||||
response = await acompletion(**kwargs)
|
||||
except (openai.APIError, openai.APITimeoutError) as e:
|
||||
get_logger().warning(f"Error during LLM inference: {e}")
|
||||
|
||||
@ -1,34 +0,0 @@
|
||||
from base64 import b64decode
|
||||
import hashlib
|
||||
|
||||
class CliArgs:
|
||||
@staticmethod
|
||||
def validate_user_args(args: list) -> (bool, str):
|
||||
try:
|
||||
if not args:
|
||||
return True, ""
|
||||
|
||||
# decode forbidden args
|
||||
_encoded_args = 'ZW5hYmxlX2F1dG9fYXBwcm92YWw=:YXBwcm92ZV9wcl9vbl9zZWxmX3Jldmlldw==:YmFzZV91cmw=:dXJs:YXBwX25hbWU=:c2VjcmV0X3Byb3ZpZGVy:Z2l0X3Byb3ZpZGVy:c2tpcF9rZXlz:b3BlbmFpLmtleQ==:QU5BTFlUSUNTX0ZPTERFUg==:dXJp:YXBwX2lk:d2ViaG9va19zZWNyZXQ=:YmVhcmVyX3Rva2Vu:UEVSU09OQUxfQUNDRVNTX1RPS0VO:b3ZlcnJpZGVfZGVwbG95bWVudF90eXBl:cHJpdmF0ZV9rZXk=:bG9jYWxfY2FjaGVfcGF0aA==:ZW5hYmxlX2xvY2FsX2NhY2hl:amlyYV9iYXNlX3VybA==:YXBpX2Jhc2U=:YXBpX3R5cGU=:YXBpX3ZlcnNpb24=:c2tpcF9rZXlz'
|
||||
forbidden_cli_args = []
|
||||
for e in _encoded_args.split(':'):
|
||||
forbidden_cli_args.append(b64decode(e).decode())
|
||||
|
||||
# lowercase all forbidden args
|
||||
for i, _ in enumerate(forbidden_cli_args):
|
||||
forbidden_cli_args[i] = forbidden_cli_args[i].lower()
|
||||
if '.' not in forbidden_cli_args[i]:
|
||||
forbidden_cli_args[i] = '.' + forbidden_cli_args[i]
|
||||
|
||||
for arg in args:
|
||||
if arg.startswith('--'):
|
||||
arg_word = arg.lower()
|
||||
arg_word = arg_word.replace('__', '.') # replace double underscore with dot, e.g. --openai__key -> --openai.key
|
||||
for forbidden_arg_word in forbidden_cli_args:
|
||||
if forbidden_arg_word in arg_word:
|
||||
return False, forbidden_arg_word
|
||||
return True, ""
|
||||
except Exception as e:
|
||||
return False, str(e)
|
||||
|
||||
|
||||
@ -9,12 +9,11 @@ from pr_agent.log import get_logger
|
||||
|
||||
|
||||
def extend_patch(original_file_str, patch_str, patch_extra_lines_before=0,
|
||||
patch_extra_lines_after=0, filename: str = "", new_file_str="") -> str:
|
||||
patch_extra_lines_after=0, filename: str = "") -> str:
|
||||
if not patch_str or (patch_extra_lines_before == 0 and patch_extra_lines_after == 0) or not original_file_str:
|
||||
return patch_str
|
||||
|
||||
original_file_str = decode_if_bytes(original_file_str)
|
||||
new_file_str = decode_if_bytes(new_file_str)
|
||||
if not original_file_str:
|
||||
return patch_str
|
||||
|
||||
@ -23,7 +22,7 @@ def extend_patch(original_file_str, patch_str, patch_extra_lines_before=0,
|
||||
|
||||
try:
|
||||
extended_patch_str = process_patch_lines(patch_str, original_file_str,
|
||||
patch_extra_lines_before, patch_extra_lines_after, new_file_str)
|
||||
patch_extra_lines_before, patch_extra_lines_after)
|
||||
except Exception as e:
|
||||
get_logger().warning(f"Failed to extend patch: {e}", artifact={"traceback": traceback.format_exc()})
|
||||
return patch_str
|
||||
@ -53,13 +52,12 @@ def should_skip_patch(filename):
|
||||
return False
|
||||
|
||||
|
||||
def process_patch_lines(patch_str, original_file_str, patch_extra_lines_before, patch_extra_lines_after, new_file_str=""):
|
||||
def process_patch_lines(patch_str, original_file_str, patch_extra_lines_before, patch_extra_lines_after):
|
||||
allow_dynamic_context = get_settings().config.allow_dynamic_context
|
||||
patch_extra_lines_before_dynamic = get_settings().config.max_extra_lines_before_dynamic_context
|
||||
|
||||
file_original_lines = original_file_str.splitlines()
|
||||
file_new_lines = new_file_str.splitlines() if new_file_str else []
|
||||
len_original_lines = len(file_original_lines)
|
||||
original_lines = original_file_str.splitlines()
|
||||
len_original_lines = len(original_lines)
|
||||
patch_lines = patch_str.splitlines()
|
||||
extended_patch_lines = []
|
||||
|
||||
@ -75,12 +73,12 @@ def process_patch_lines(patch_str, original_file_str, patch_extra_lines_before,
|
||||
if match:
|
||||
# finish processing previous hunk
|
||||
if is_valid_hunk and (start1 != -1 and patch_extra_lines_after > 0):
|
||||
delta_lines_original = [f' {line}' for line in file_original_lines[start1 + size1 - 1:start1 + size1 - 1 + patch_extra_lines_after]]
|
||||
extended_patch_lines.extend(delta_lines_original)
|
||||
delta_lines = [f' {line}' for line in original_lines[start1 + size1 - 1:start1 + size1 - 1 + patch_extra_lines_after]]
|
||||
extended_patch_lines.extend(delta_lines)
|
||||
|
||||
section_header, size1, size2, start1, start2 = extract_hunk_headers(match)
|
||||
|
||||
is_valid_hunk = check_if_hunk_lines_matches_to_file(i, file_original_lines, patch_lines, start1)
|
||||
is_valid_hunk = check_if_hunk_lines_matches_to_file(i, original_lines, patch_lines, start1)
|
||||
|
||||
if is_valid_hunk and (patch_extra_lines_before > 0 or patch_extra_lines_after > 0):
|
||||
def _calc_context_limits(patch_lines_before):
|
||||
@ -95,28 +93,20 @@ def process_patch_lines(patch_str, original_file_str, patch_extra_lines_before,
|
||||
extended_size2 = max(extended_size2 - delta_cap, size2)
|
||||
return extended_start1, extended_size1, extended_start2, extended_size2
|
||||
|
||||
if allow_dynamic_context and file_new_lines:
|
||||
if allow_dynamic_context:
|
||||
extended_start1, extended_size1, extended_start2, extended_size2 = \
|
||||
_calc_context_limits(patch_extra_lines_before_dynamic)
|
||||
|
||||
lines_before_original = file_original_lines[extended_start1 - 1:start1 - 1]
|
||||
lines_before_new = file_new_lines[extended_start2 - 1:start2 - 1]
|
||||
lines_before = original_lines[extended_start1 - 1:start1 - 1]
|
||||
found_header = False
|
||||
if lines_before_original == lines_before_new: # Making sure no changes from a previous hunk
|
||||
for i, line, in enumerate(lines_before_original):
|
||||
if section_header in line:
|
||||
found_header = True
|
||||
# Update start and size in one line each
|
||||
extended_start1, extended_start2 = extended_start1 + i, extended_start2 + i
|
||||
extended_size1, extended_size2 = extended_size1 - i, extended_size2 - i
|
||||
# get_logger().debug(f"Found section header in line {i} before the hunk")
|
||||
section_header = ''
|
||||
break
|
||||
else:
|
||||
get_logger().debug(f"Extra lines before hunk are different in original and new file - dynamic context",
|
||||
artifact={"lines_before_original": lines_before_original,
|
||||
"lines_before_new": lines_before_new})
|
||||
|
||||
for i, line, in enumerate(lines_before):
|
||||
if section_header in line:
|
||||
found_header = True
|
||||
# Update start and size in one line each
|
||||
extended_start1, extended_start2 = extended_start1 + i, extended_start2 + i
|
||||
extended_size1, extended_size2 = extended_size1 - i, extended_size2 - i
|
||||
# get_logger().debug(f"Found section header in line {i} before the hunk")
|
||||
section_header = ''
|
||||
break
|
||||
if not found_header:
|
||||
# get_logger().debug(f"Section header not found in the extra lines before the hunk")
|
||||
extended_start1, extended_size1, extended_start2, extended_size2 = \
|
||||
@ -125,23 +115,11 @@ def process_patch_lines(patch_str, original_file_str, patch_extra_lines_before,
|
||||
extended_start1, extended_size1, extended_start2, extended_size2 = \
|
||||
_calc_context_limits(patch_extra_lines_before)
|
||||
|
||||
# check if extra lines before hunk are different in original and new file
|
||||
delta_lines_original = [f' {line}' for line in file_original_lines[extended_start1 - 1:start1 - 1]]
|
||||
if file_new_lines:
|
||||
delta_lines_new = [f' {line}' for line in file_new_lines[extended_start2 - 1:start2 - 1]]
|
||||
if delta_lines_original != delta_lines_new:
|
||||
get_logger().debug(f"Extra lines before hunk are different in original and new file",
|
||||
artifact={"delta_lines_original": delta_lines_original,
|
||||
"delta_lines_new": delta_lines_new})
|
||||
extended_start1 = start1
|
||||
extended_size1 = size1
|
||||
extended_start2 = start2
|
||||
extended_size2 = size2
|
||||
delta_lines_original = []
|
||||
delta_lines = [f' {line}' for line in original_lines[extended_start1 - 1:start1 - 1]]
|
||||
|
||||
# logic to remove section header if its in the extra delta lines (in dynamic context, this is also done)
|
||||
if section_header and not allow_dynamic_context:
|
||||
for line in delta_lines_original:
|
||||
for line in delta_lines:
|
||||
if section_header in line:
|
||||
section_header = '' # remove section header if it is in the extra delta lines
|
||||
break
|
||||
@ -150,12 +128,12 @@ def process_patch_lines(patch_str, original_file_str, patch_extra_lines_before,
|
||||
extended_size1 = size1
|
||||
extended_start2 = start2
|
||||
extended_size2 = size2
|
||||
delta_lines_original = []
|
||||
delta_lines = []
|
||||
extended_patch_lines.append('')
|
||||
extended_patch_lines.append(
|
||||
f'@@ -{extended_start1},{extended_size1} '
|
||||
f'+{extended_start2},{extended_size2} @@ {section_header}')
|
||||
extended_patch_lines.extend(delta_lines_original) # one to zero based
|
||||
extended_patch_lines.extend(delta_lines) # one to zero based
|
||||
continue
|
||||
extended_patch_lines.append(line)
|
||||
except Exception as e:
|
||||
@ -164,14 +142,15 @@ def process_patch_lines(patch_str, original_file_str, patch_extra_lines_before,
|
||||
|
||||
# finish processing last hunk
|
||||
if start1 != -1 and patch_extra_lines_after > 0 and is_valid_hunk:
|
||||
delta_lines_original = file_original_lines[start1 + size1 - 1:start1 + size1 - 1 + patch_extra_lines_after]
|
||||
delta_lines = original_lines[start1 + size1 - 1:start1 + size1 - 1 + patch_extra_lines_after]
|
||||
# add space at the beginning of each extra line
|
||||
delta_lines_original = [f' {line}' for line in delta_lines_original]
|
||||
extended_patch_lines.extend(delta_lines_original)
|
||||
delta_lines = [f' {line}' for line in delta_lines]
|
||||
extended_patch_lines.extend(delta_lines)
|
||||
|
||||
extended_patch_str = '\n'.join(extended_patch_lines)
|
||||
return extended_patch_str
|
||||
|
||||
|
||||
def check_if_hunk_lines_matches_to_file(i, original_lines, patch_lines, start1):
|
||||
"""
|
||||
Check if the hunk lines match the original file content. We saw cases where the hunk header line doesn't match the original file content, and then
|
||||
@ -181,18 +160,8 @@ def check_if_hunk_lines_matches_to_file(i, original_lines, patch_lines, start1):
|
||||
try:
|
||||
if i + 1 < len(patch_lines) and patch_lines[i + 1][0] == ' ': # an existing line in the file
|
||||
if patch_lines[i + 1].strip() != original_lines[start1 - 1].strip():
|
||||
# check if different encoding is needed
|
||||
original_line = original_lines[start1 - 1].strip()
|
||||
for encoding in ['iso-8859-1', 'latin-1', 'ascii', 'utf-16']:
|
||||
try:
|
||||
if original_line.encode(encoding).decode().strip() == patch_lines[i + 1].strip():
|
||||
get_logger().info(f"Detected different encoding in hunk header line {start1}, needed encoding: {encoding}")
|
||||
return False # we still want to avoid extending the hunk. But we don't want to log an error
|
||||
except:
|
||||
pass
|
||||
|
||||
is_valid_hunk = False
|
||||
get_logger().info(
|
||||
get_logger().error(
|
||||
f"Invalid hunk in PR, line {start1} in hunk header doesn't match the original file content")
|
||||
except:
|
||||
pass
|
||||
@ -319,7 +288,7 @@ __old hunk__
|
||||
"""
|
||||
# if the file was deleted, return a message indicating that the file was deleted
|
||||
if hasattr(file, 'edit_type') and file.edit_type == EDIT_TYPE.DELETED:
|
||||
return f"\n\n## File '{file.filename.strip()}' was deleted\n"
|
||||
return f"\n\n## file '{file.filename.strip()}' was deleted\n"
|
||||
|
||||
patch_with_lines_str = f"\n\n## File: '{file.filename.strip()}'\n"
|
||||
patch_lines = patch.splitlines()
|
||||
@ -394,7 +363,7 @@ __old hunk__
|
||||
return patch_with_lines_str.rstrip()
|
||||
|
||||
|
||||
def extract_hunk_lines_from_patch(patch: str, file_name, line_start, line_end, side, remove_trailing_chars: bool = True) -> tuple[str, str]:
|
||||
def extract_hunk_lines_from_patch(patch: str, file_name, line_start, line_end, side) -> tuple[str, str]:
|
||||
try:
|
||||
patch_with_lines_str = f"\n\n## File: '{file_name.strip()}'\n\n"
|
||||
selected_lines = ""
|
||||
@ -442,8 +411,4 @@ def extract_hunk_lines_from_patch(patch: str, file_name, line_start, line_end, s
|
||||
get_logger().error(f"Failed to extract hunk lines from patch: {e}", artifact={"traceback": traceback.format_exc()})
|
||||
return "", ""
|
||||
|
||||
if remove_trailing_chars:
|
||||
patch_with_lines_str = patch_with_lines_str.rstrip()
|
||||
selected_lines = selected_lines.rstrip()
|
||||
|
||||
return patch_with_lines_str, selected_lines
|
||||
return patch_with_lines_str.rstrip(), selected_lines.rstrip()
|
||||
|
||||
@ -195,15 +195,13 @@ def pr_generate_extended_diff(pr_languages: list,
|
||||
for lang in pr_languages:
|
||||
for file in lang['files']:
|
||||
original_file_content_str = file.base_file
|
||||
new_file_content_str = file.head_file
|
||||
patch = file.patch
|
||||
if not patch:
|
||||
continue
|
||||
|
||||
# extend each patch with extra lines of context
|
||||
extended_patch = extend_patch(original_file_content_str, patch,
|
||||
patch_extra_lines_before, patch_extra_lines_after, file.filename,
|
||||
new_file_str=new_file_content_str)
|
||||
patch_extra_lines_before, patch_extra_lines_after, file.filename)
|
||||
if not extended_patch:
|
||||
get_logger().warning(f"Failed to extend patch for file: {file.filename}")
|
||||
continue
|
||||
@ -214,7 +212,7 @@ def pr_generate_extended_diff(pr_languages: list,
|
||||
full_extended_patch = f"\n\n## File: '{file.filename.strip()}'\n{extended_patch.rstrip()}\n"
|
||||
|
||||
# add AI-summary metadata to the patch
|
||||
if file.ai_file_summary and get_settings().get("config.enable_ai_metadata", False):
|
||||
if file.ai_file_summary and get_settings().get("config.enable_ai_metadata", False):
|
||||
full_extended_patch = add_ai_summary_top_patch(file, full_extended_patch)
|
||||
|
||||
patch_tokens = token_handler.count_tokens(full_extended_patch)
|
||||
@ -386,8 +384,7 @@ def _get_all_deployments(all_models: List[str]) -> List[str]:
|
||||
def get_pr_multi_diffs(git_provider: GitProvider,
|
||||
token_handler: TokenHandler,
|
||||
model: str,
|
||||
max_calls: int = 5,
|
||||
add_line_numbers: bool = True) -> List[str]:
|
||||
max_calls: int = 5) -> List[str]:
|
||||
"""
|
||||
Retrieves the diff files from a Git provider, sorts them by main language, and generates patches for each file.
|
||||
The patches are split into multiple groups based on the maximum number of tokens allowed for the given model.
|
||||
@ -428,8 +425,7 @@ def get_pr_multi_diffs(git_provider: GitProvider,
|
||||
|
||||
# try first a single run with standard diff string, with patch extension, and no deletions
|
||||
patches_extended, total_tokens, patches_extended_tokens = pr_generate_extended_diff(
|
||||
pr_languages, token_handler,
|
||||
add_line_numbers_to_hunks=add_line_numbers,
|
||||
pr_languages, token_handler, add_line_numbers_to_hunks=True,
|
||||
patch_extra_lines_before=PATCH_EXTRA_LINES_BEFORE,
|
||||
patch_extra_lines_after=PATCH_EXTRA_LINES_AFTER)
|
||||
|
||||
@ -458,12 +454,7 @@ def get_pr_multi_diffs(git_provider: GitProvider,
|
||||
if patch is None:
|
||||
continue
|
||||
|
||||
# Add line numbers and metadata to the patch
|
||||
if add_line_numbers:
|
||||
patch = convert_to_hunks_with_lines_numbers(patch, file)
|
||||
else:
|
||||
patch = f"\n\n## File: '{file.filename.strip()}'\n\n{patch.strip()}\n"
|
||||
|
||||
patch = convert_to_hunks_with_lines_numbers(patch, file)
|
||||
# add AI-summary metadata to the patch
|
||||
if file.ai_file_summary and get_settings().get("config.enable_ai_metadata", False):
|
||||
patch = add_ai_summary_top_patch(file, patch)
|
||||
|
||||
@ -50,11 +50,6 @@ class PRReviewHeader(str, Enum):
|
||||
REGULAR = "## PR Reviewer Guide"
|
||||
INCREMENTAL = "## Incremental PR Reviewer Guide"
|
||||
|
||||
class ReasoningEffort(str, Enum):
|
||||
HIGH = "high"
|
||||
MEDIUM = "medium"
|
||||
LOW = "low"
|
||||
|
||||
|
||||
class PRDescriptionHeader(str, Enum):
|
||||
CHANGES_WALKTHROUGH = "### **Changes walkthrough** 📝"
|
||||
@ -250,7 +245,7 @@ def convert_to_markdown_v2(output_data: dict,
|
||||
if gfm_supported:
|
||||
if reference_link is not None and len(reference_link) > 0:
|
||||
if relevant_lines_str:
|
||||
issue_str = f"<details><summary><a href='{reference_link}'><strong>{issue_header}</strong></a>\n\n{issue_content}\n</summary>\n\n{relevant_lines_str}\n\n</details>"
|
||||
issue_str = f"<details><summary><a href='{reference_link}'><strong>{issue_header}</strong></a>\n\n{issue_content}</summary>\n\n{relevant_lines_str}\n\n</details>"
|
||||
else:
|
||||
issue_str = f"<a href='{reference_link}'><strong>{issue_header}</strong></a><br>{issue_content}"
|
||||
else:
|
||||
@ -787,8 +782,7 @@ def try_fix_yaml(response_text: str,
|
||||
# fifth fallback - try to remove leading '+' (sometimes added by AI for 'existing code' and 'improved code')
|
||||
response_text_lines_copy = response_text_lines.copy()
|
||||
for i in range(0, len(response_text_lines_copy)):
|
||||
if response_text_lines_copy[i].startswith('+'):
|
||||
response_text_lines_copy[i] = ' ' + response_text_lines_copy[i][1:]
|
||||
response_text_lines_copy[i] = ' ' + response_text_lines_copy[i][1:]
|
||||
try:
|
||||
data = yaml.safe_load('\n'.join(response_text_lines_copy))
|
||||
get_logger().info(f"Successfully parsed AI prediction after removing leading '+'")
|
||||
|
||||
@ -34,7 +34,7 @@ global_settings = Dynaconf(
|
||||
)
|
||||
|
||||
|
||||
def get_settings(use_context=False):
|
||||
def get_settings():
|
||||
"""
|
||||
Retrieves the current settings.
|
||||
|
||||
|
||||
@ -183,7 +183,6 @@ class AzureDevopsProvider(GitProvider):
|
||||
return True
|
||||
|
||||
def set_pr(self, pr_url: str):
|
||||
self.pr_url = pr_url
|
||||
self.workspace_slug, self.repo_slug, self.pr_num = self._parse_pr_url(pr_url)
|
||||
self.pr = self._get_pr()
|
||||
|
||||
@ -615,11 +614,8 @@ class AzureDevopsProvider(GitProvider):
|
||||
return pr_id
|
||||
except Exception as e:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().info(f"Failed to get pr id, error: {e}")
|
||||
get_logger().error(f"Failed to get pr id, error: {e}")
|
||||
return ""
|
||||
|
||||
def publish_file_comments(self, file_comments: list) -> bool:
|
||||
pass
|
||||
|
||||
def get_line_link(self, relevant_file: str, relevant_line_start: int, relevant_line_end: int = None) -> str:
|
||||
return self.pr_url+f"?_a=files&path={relevant_file}"
|
||||
|
||||
@ -5,7 +5,6 @@ import itertools
|
||||
import re
|
||||
import time
|
||||
import traceback
|
||||
import json
|
||||
from datetime import datetime
|
||||
from typing import Optional, Tuple
|
||||
from urllib.parse import urlparse
|
||||
@ -888,84 +887,6 @@ class GithubProvider(GitProvider):
|
||||
except:
|
||||
return ""
|
||||
|
||||
def fetch_sub_issues(self, issue_url):
|
||||
"""
|
||||
Fetch sub-issues linked to the given GitHub issue URL using GraphQL via PyGitHub.
|
||||
"""
|
||||
sub_issues = set()
|
||||
|
||||
# Extract owner, repo, and issue number from URL
|
||||
parts = issue_url.rstrip("/").split("/")
|
||||
owner, repo, issue_number = parts[-4], parts[-3], parts[-1]
|
||||
|
||||
try:
|
||||
# Gets Issue ID from Issue Number
|
||||
query = f"""
|
||||
query {{
|
||||
repository(owner: "{owner}", name: "{repo}") {{
|
||||
issue(number: {issue_number}) {{
|
||||
id
|
||||
}}
|
||||
}}
|
||||
}}
|
||||
"""
|
||||
response_tuple = self.github_client._Github__requester.requestJson("POST", "/graphql",
|
||||
input={"query": query})
|
||||
|
||||
# Extract the JSON response from the tuple and parses it
|
||||
if isinstance(response_tuple, tuple) and len(response_tuple) == 3:
|
||||
response_json = json.loads(response_tuple[2])
|
||||
else:
|
||||
get_logger().error(f"Unexpected response format: {response_tuple}")
|
||||
return sub_issues
|
||||
|
||||
|
||||
issue_id = response_json.get("data", {}).get("repository", {}).get("issue", {}).get("id")
|
||||
|
||||
if not issue_id:
|
||||
get_logger().warning(f"Issue ID not found for {issue_url}")
|
||||
return sub_issues
|
||||
|
||||
# Fetch Sub-Issues
|
||||
sub_issues_query = f"""
|
||||
query {{
|
||||
node(id: "{issue_id}") {{
|
||||
... on Issue {{
|
||||
subIssues(first: 10) {{
|
||||
nodes {{
|
||||
url
|
||||
}}
|
||||
}}
|
||||
}}
|
||||
}}
|
||||
}}
|
||||
"""
|
||||
sub_issues_response_tuple = self.github_client._Github__requester.requestJson("POST", "/graphql", input={
|
||||
"query": sub_issues_query})
|
||||
|
||||
# Extract the JSON response from the tuple and parses it
|
||||
if isinstance(sub_issues_response_tuple, tuple) and len(sub_issues_response_tuple) == 3:
|
||||
sub_issues_response_json = json.loads(sub_issues_response_tuple[2])
|
||||
else:
|
||||
get_logger().error("Unexpected sub-issues response format", artifact={"response": sub_issues_response_tuple})
|
||||
return sub_issues
|
||||
|
||||
if not sub_issues_response_json.get("data", {}).get("node", {}).get("subIssues"):
|
||||
get_logger().error("Invalid sub-issues response structure")
|
||||
return sub_issues
|
||||
|
||||
nodes = sub_issues_response_json.get("data", {}).get("node", {}).get("subIssues", {}).get("nodes", [])
|
||||
get_logger().info(f"Github Sub-issues fetched: {len(nodes)}", artifact={"nodes": nodes})
|
||||
|
||||
for sub_issue in nodes:
|
||||
if "url" in sub_issue:
|
||||
sub_issues.add(sub_issue["url"])
|
||||
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Failed to fetch sub-issues. Error: {e}")
|
||||
|
||||
return sub_issues
|
||||
|
||||
def auto_approve(self) -> bool:
|
||||
try:
|
||||
res = self.pr.create_review(event="APPROVE")
|
||||
|
||||
@ -181,13 +181,7 @@ class GitLabProvider(GitProvider):
|
||||
get_logger().exception(f"Could not update merge request {self.id_mr} description: {e}")
|
||||
|
||||
def get_latest_commit_url(self):
|
||||
try:
|
||||
return self.mr.commits().next().web_url
|
||||
except StopIteration: # no commits
|
||||
return ""
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Could not get latest commit URL: {e}")
|
||||
return ""
|
||||
return self.mr.commits().next().web_url
|
||||
|
||||
def get_comment_url(self, comment):
|
||||
return f"{self.mr.web_url}#note_{comment.id}"
|
||||
|
||||
@ -33,16 +33,20 @@ azure_devops_server = get_settings().get("azure_devops_server")
|
||||
WEBHOOK_USERNAME = azure_devops_server.get("webhook_username")
|
||||
WEBHOOK_PASSWORD = azure_devops_server.get("webhook_password")
|
||||
|
||||
async def handle_request_comment( url: str, body: str, log_context: dict
|
||||
def handle_request(
|
||||
background_tasks: BackgroundTasks, url: str, body: str, log_context: dict
|
||||
):
|
||||
log_context["action"] = body
|
||||
log_context["api_url"] = url
|
||||
|
||||
try:
|
||||
with get_logger().contextualize(**log_context):
|
||||
await PRAgent().handle_request(url, body)
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Failed to handle webhook", artifact={"url": url, "body": body}, error=str(e))
|
||||
async def inner():
|
||||
try:
|
||||
with get_logger().contextualize(**log_context):
|
||||
await PRAgent().handle_request(url, body)
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to handle webhook: {e}")
|
||||
|
||||
background_tasks.add_task(inner)
|
||||
|
||||
|
||||
# currently only basic auth is supported with azure webhooks
|
||||
@ -64,9 +68,6 @@ async def _perform_commands_azure(commands_conf: str, agent: PRAgent, api_url: s
|
||||
get_logger().info(f"Auto feedback is disabled, skipping auto commands for PR {api_url=}", **log_context)
|
||||
return
|
||||
commands = get_settings().get(f"azure_devops_server.{commands_conf}")
|
||||
if not commands:
|
||||
return
|
||||
|
||||
get_settings().set("config.is_auto_command", True)
|
||||
for command in commands:
|
||||
try:
|
||||
@ -82,7 +83,12 @@ async def _perform_commands_azure(commands_conf: str, agent: PRAgent, api_url: s
|
||||
get_logger().error(f"Failed to perform command {command}: {e}")
|
||||
|
||||
|
||||
async def handle_request_azure(data, log_context):
|
||||
@router.post("/", dependencies=[Depends(authorize)])
|
||||
async def handle_webhook(background_tasks: BackgroundTasks, request: Request):
|
||||
log_context = {"server_type": "azure_devops_server"}
|
||||
data = await request.json()
|
||||
get_logger().info(json.dumps(data))
|
||||
|
||||
actions = []
|
||||
if data["eventType"] == "git.pullrequest.created":
|
||||
# API V1 (latest)
|
||||
@ -90,10 +96,7 @@ async def handle_request_azure(data, log_context):
|
||||
log_context["event"] = data["eventType"]
|
||||
log_context["api_url"] = pr_url
|
||||
await _perform_commands_azure("pr_commands", PRAgent(), pr_url, log_context)
|
||||
return JSONResponse(
|
||||
status_code=status.HTTP_202_ACCEPTED,
|
||||
content=jsonable_encoder({"message": "webhook triggered successfully"})
|
||||
)
|
||||
return
|
||||
elif data["eventType"] == "ms.vss-code.git-pullrequest-comment-event" and "content" in data["resource"]["comment"]:
|
||||
if available_commands_rgx.match(data["resource"]["comment"]["content"]):
|
||||
if(data["resourceVersion"] == "2.0"):
|
||||
@ -121,7 +124,7 @@ async def handle_request_azure(data, log_context):
|
||||
|
||||
for action in actions:
|
||||
try:
|
||||
await handle_request_comment(pr_url, action, log_context)
|
||||
handle_request(background_tasks, pr_url, action, log_context)
|
||||
except Exception as e:
|
||||
get_logger().error("Azure DevOps Trigger failed. Error:" + str(e))
|
||||
return JSONResponse(
|
||||
@ -132,18 +135,6 @@ async def handle_request_azure(data, log_context):
|
||||
status_code=status.HTTP_202_ACCEPTED, content=jsonable_encoder({"message": "webhook triggered successfully"})
|
||||
)
|
||||
|
||||
@router.post("/", dependencies=[Depends(authorize)])
|
||||
async def handle_webhook(background_tasks: BackgroundTasks, request: Request):
|
||||
log_context = {"server_type": "azure_devops_server"}
|
||||
data = await request.json()
|
||||
# get_logger().info(json.dumps(data))
|
||||
|
||||
background_tasks.add_task(handle_request_azure, data, log_context)
|
||||
|
||||
return JSONResponse(
|
||||
status_code=status.HTTP_202_ACCEPTED, content=jsonable_encoder({"message": "webhook triggered successfully"})
|
||||
)
|
||||
|
||||
@router.get("/")
|
||||
async def root():
|
||||
return {"status": "ok"}
|
||||
|
||||
@ -81,7 +81,7 @@ async def run_action():
|
||||
get_logger().info(f"github action: failed to apply repo settings: {e}")
|
||||
|
||||
# Handle pull request opened event
|
||||
if GITHUB_EVENT_NAME == "pull_request" or GITHUB_EVENT_NAME == "pull_request_target":
|
||||
if GITHUB_EVENT_NAME == "pull_request":
|
||||
action = event_payload.get("action")
|
||||
|
||||
# Retrieve the list of actions from the configuration
|
||||
|
||||
@ -25,6 +25,29 @@ router = APIRouter()
|
||||
secret_provider = get_secret_provider() if get_settings().get("CONFIG.SECRET_PROVIDER") else None
|
||||
|
||||
|
||||
async def get_mr_url_from_commit_sha(commit_sha, gitlab_token, project_id):
|
||||
try:
|
||||
import requests
|
||||
headers = {
|
||||
'Private-Token': f'{gitlab_token}'
|
||||
}
|
||||
# API endpoint to find MRs containing the commit
|
||||
gitlab_url = get_settings().get("GITLAB.URL", 'https://gitlab.com')
|
||||
response = requests.get(
|
||||
f'{gitlab_url}/api/v4/projects/{project_id}/repository/commits/{commit_sha}/merge_requests',
|
||||
headers=headers
|
||||
)
|
||||
merge_requests = response.json()
|
||||
if merge_requests and response.status_code == 200:
|
||||
pr_url = merge_requests[0]['web_url']
|
||||
return pr_url
|
||||
else:
|
||||
get_logger().info(f"No merge requests found for commit: {commit_sha}")
|
||||
return None
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to get MR url from commit sha: {e}")
|
||||
return None
|
||||
|
||||
async def handle_request(api_url: str, body: str, log_context: dict, sender_id: str):
|
||||
log_context["action"] = body
|
||||
log_context["event"] = "pull_request" if body == "/review" else "comment"
|
||||
@ -71,31 +94,6 @@ def is_bot_user(data) -> bool:
|
||||
get_logger().error(f"Failed 'is_bot_user' logic: {e}")
|
||||
return False
|
||||
|
||||
def is_draft(data) -> bool:
|
||||
try:
|
||||
if 'draft' in data.get('object_attributes', {}):
|
||||
return data['object_attributes']['draft']
|
||||
|
||||
# for gitlab server version before 16
|
||||
elif 'Draft:' in data.get('object_attributes', {}).get('title'):
|
||||
return True
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed 'is_draft' logic: {e}")
|
||||
return False
|
||||
|
||||
def is_draft_ready(data) -> bool:
|
||||
try:
|
||||
if 'draft' in data.get('changes', {}):
|
||||
if data['changes']['draft']['previous'] == 'true' and data['changes']['draft']['current'] == 'false':
|
||||
return True
|
||||
|
||||
# for gitlab server version before 16
|
||||
elif 'title' in data.get('changes', {}):
|
||||
if 'Draft:' in data['changes']['title']['previous'] and 'Draft:' not in data['changes']['title']['current']:
|
||||
return True
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed 'is_draft_ready' logic: {e}")
|
||||
return False
|
||||
|
||||
def should_process_pr_logic(data) -> bool:
|
||||
try:
|
||||
@ -192,48 +190,22 @@ async def gitlab_webhook(background_tasks: BackgroundTasks, request: Request):
|
||||
# ignore bot users
|
||||
if is_bot_user(data):
|
||||
return JSONResponse(status_code=status.HTTP_200_OK, content=jsonable_encoder({"message": "success"}))
|
||||
|
||||
log_context["sender"] = sender
|
||||
if data.get('object_kind') == 'merge_request':
|
||||
if data.get('event_type') != 'note': # not a comment
|
||||
# ignore MRs based on title, labels, source and target branches
|
||||
if not should_process_pr_logic(data):
|
||||
return JSONResponse(status_code=status.HTTP_200_OK, content=jsonable_encoder({"message": "success"}))
|
||||
object_attributes = data.get('object_attributes', {})
|
||||
if object_attributes.get('action') in ['open', 'reopen']:
|
||||
url = object_attributes.get('url')
|
||||
get_logger().info(f"New merge request: {url}")
|
||||
if is_draft(data):
|
||||
get_logger().info(f"Skipping draft MR: {url}")
|
||||
return JSONResponse(status_code=status.HTTP_200_OK, content=jsonable_encoder({"message": "success"}))
|
||||
|
||||
await _perform_commands_gitlab("pr_commands", PRAgent(), url, log_context, data)
|
||||
|
||||
# for push event triggered merge requests
|
||||
elif object_attributes.get('action') == 'update' and object_attributes.get('oldrev'):
|
||||
url = object_attributes.get('url')
|
||||
get_logger().info(f"New merge request: {url}")
|
||||
if is_draft(data):
|
||||
get_logger().info(f"Skipping draft MR: {url}")
|
||||
return JSONResponse(status_code=status.HTTP_200_OK, content=jsonable_encoder({"message": "success"}))
|
||||
|
||||
commands_on_push = get_settings().get(f"gitlab.push_commands", {})
|
||||
handle_push_trigger = get_settings().get(f"gitlab.handle_push_trigger", False)
|
||||
if not commands_on_push or not handle_push_trigger:
|
||||
get_logger().info("Push event, but no push commands found or push trigger is disabled")
|
||||
return JSONResponse(status_code=status.HTTP_200_OK,
|
||||
content=jsonable_encoder({"message": "success"}))
|
||||
|
||||
get_logger().debug(f'A push event has been received: {url}')
|
||||
await _perform_commands_gitlab("push_commands", PRAgent(), url, log_context, data)
|
||||
|
||||
# for draft to ready triggered merge requests
|
||||
elif object_attributes.get('action') == 'update' and is_draft_ready(data):
|
||||
url = object_attributes.get('url')
|
||||
get_logger().info(f"Draft MR is ready: {url}")
|
||||
|
||||
# same as open MR
|
||||
await _perform_commands_gitlab("pr_commands", PRAgent(), url, log_context, data)
|
||||
log_context["sender"] = sender
|
||||
if data.get('object_kind') == 'merge_request' and data['object_attributes'].get('action') in ['open', 'reopen']:
|
||||
title = data['object_attributes'].get('title')
|
||||
url = data['object_attributes'].get('url')
|
||||
draft = data['object_attributes'].get('draft')
|
||||
get_logger().info(f"New merge request: {url}")
|
||||
if draft:
|
||||
get_logger().info(f"Skipping draft MR: {url}")
|
||||
return JSONResponse(status_code=status.HTTP_200_OK, content=jsonable_encoder({"message": "success"}))
|
||||
|
||||
await _perform_commands_gitlab("pr_commands", PRAgent(), url, log_context, data)
|
||||
elif data.get('object_kind') == 'note' and data.get('event_type') == 'note': # comment on MR
|
||||
if 'merge_request' in data:
|
||||
mr = data['merge_request']
|
||||
@ -245,6 +217,29 @@ async def gitlab_webhook(background_tasks: BackgroundTasks, request: Request):
|
||||
body = handle_ask_line(body, data)
|
||||
|
||||
await handle_request(url, body, log_context, sender_id)
|
||||
elif data.get('object_kind') == 'push' and data.get('event_name') == 'push':
|
||||
try:
|
||||
project_id = data['project_id']
|
||||
commit_sha = data['checkout_sha']
|
||||
url = await get_mr_url_from_commit_sha(commit_sha, gitlab_token, project_id)
|
||||
if not url:
|
||||
get_logger().info(f"No MR found for commit: {commit_sha}")
|
||||
return JSONResponse(status_code=status.HTTP_200_OK,
|
||||
content=jsonable_encoder({"message": "success"}))
|
||||
|
||||
# we need first to apply_repo_settings
|
||||
apply_repo_settings(url)
|
||||
commands_on_push = get_settings().get(f"gitlab.push_commands", {})
|
||||
handle_push_trigger = get_settings().get(f"gitlab.handle_push_trigger", False)
|
||||
if not commands_on_push or not handle_push_trigger:
|
||||
get_logger().info("Push event, but no push commands found or push trigger is disabled")
|
||||
return JSONResponse(status_code=status.HTTP_200_OK,
|
||||
content=jsonable_encoder({"message": "success"}))
|
||||
|
||||
get_logger().debug(f'A push event has been received: {url}')
|
||||
await _perform_commands_gitlab("push_commands", PRAgent(), url, log_context, data)
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to handle push event: {e}")
|
||||
|
||||
background_tasks.add_task(inner, request_json)
|
||||
end_time = datetime.now()
|
||||
|
||||
@ -1,13 +1,8 @@
|
||||
# Important: This file contains all available configuration options.
|
||||
# Do not copy this entire file to your repository configuration.
|
||||
# Your repository configuration should only include options you wish to override from the defaults.
|
||||
|
||||
[config]
|
||||
# models
|
||||
model="o3-mini"
|
||||
fallback_models=["gpt-4o-2024-11-20"]
|
||||
model="gpt-4o-2024-11-20"
|
||||
fallback_models=["gpt-4o-2024-08-06"]
|
||||
#model_weak="gpt-4o-mini-2024-07-18" # optional, a weaker model to use for some easier tasks
|
||||
response_language="en-US" # Language locales code for PR responses in ISO 3166 and ISO 639 format (e.g., "en-US", "it-IT", "zh-CN", ...)
|
||||
# CLI
|
||||
git_provider="github"
|
||||
publish_output=true
|
||||
@ -22,7 +17,6 @@ use_global_settings_file=true
|
||||
disable_auto_feedback = false
|
||||
ai_timeout=120 # 2minutes
|
||||
skip_keys = []
|
||||
custom_reasoning_model = false # when true, disables system messages and temperature controls for models that don't support chat-style inputs
|
||||
# token limits
|
||||
max_description_tokens = 500
|
||||
max_commits_tokens = 500
|
||||
@ -53,12 +47,6 @@ ignore_pr_authors = [] # authors to ignore from PR agent when an PR is created
|
||||
#
|
||||
is_auto_command = false # will be auto-set to true if the command is triggered by an automation
|
||||
enable_ai_metadata = false # will enable adding ai metadata
|
||||
reasoning_effort = "medium" # "low", "medium", "high"
|
||||
# auto approval 💎
|
||||
enable_auto_approval=false # Set to true to enable auto-approval of PRs under certain conditions
|
||||
auto_approve_for_low_review_effort=-1 # -1 to disable, [1-5] to set the threshold for auto-approval
|
||||
auto_approve_for_no_suggestions=false # If true, the PR will be auto-approved if there are no suggestions
|
||||
|
||||
|
||||
[pr_reviewer] # /review #
|
||||
# enable/disable features
|
||||
@ -81,6 +69,9 @@ minimal_commits_for_incremental_review=0
|
||||
minimal_minutes_for_incremental_review=0
|
||||
enable_intro_text=true
|
||||
enable_help_text=false # Determines whether to include help text in the PR review. Enabled by default.
|
||||
# auto approval
|
||||
enable_auto_approval=false
|
||||
|
||||
|
||||
[pr_description] # /describe #
|
||||
publish_labels=false
|
||||
@ -332,11 +323,3 @@ utilize_auto_best_practices = true # public - disable usage of auto best practic
|
||||
extra_instructions = "" # public - extra instructions to the auto best practices generation prompt
|
||||
content = ""
|
||||
max_patterns = 5 # max number of patterns to be detected
|
||||
|
||||
|
||||
[azure_devops_server]
|
||||
pr_commands = [
|
||||
"/describe",
|
||||
"/review",
|
||||
"/improve",
|
||||
]
|
||||
@ -13,7 +13,7 @@ The output must be a YAML object equivalent to type $DocHelper, according to the
|
||||
=====
|
||||
class relevant_section(BaseModel):
|
||||
file_name: str = Field(description="The name of the relevant file")
|
||||
relevant_section_header_string: str = Field(description="The exact text of the relevant markdown section heading from the relevant file (starting with '#', '##', etc.). Return empty string if the entire file is the relevant section, or if the relevant section has no heading")
|
||||
relevant_section_header_string: str = Field(description="From the relevant file, exact text of the relevant section heading. If no markdown heading is relevant, return empty string")
|
||||
|
||||
class DocHelper(BaseModel):
|
||||
user_question: str = Field(description="The user's question")
|
||||
|
||||
@ -187,10 +187,6 @@ Ticket Description:
|
||||
|
||||
|
||||
--PR Info--
|
||||
{%- if date %}
|
||||
|
||||
Today's Date: {{date}}
|
||||
{%- endif %}
|
||||
|
||||
Title: '{{title}}'
|
||||
|
||||
|
||||
@ -328,10 +328,7 @@ class PRDescription:
|
||||
original_prediction_dict = {"pr_files": original_prediction_loaded}
|
||||
else:
|
||||
original_prediction_dict = original_prediction_loaded
|
||||
if original_prediction_dict:
|
||||
filenames_predicted = [file.get('filename', '').strip() for file in original_prediction_dict.get('pr_files', [])]
|
||||
else:
|
||||
filenames_predicted = []
|
||||
filenames_predicted = [file['filename'].strip() for file in original_prediction_dict.get('pr_files', [])]
|
||||
|
||||
# extend the prediction with additional files not included in the original prediction
|
||||
pr_files = self.git_provider.get_diff_files()
|
||||
@ -371,12 +368,8 @@ class PRDescription:
|
||||
if counter_extra_files > 0:
|
||||
get_logger().info(f"Adding {counter_extra_files} unprocessed extra files to table prediction")
|
||||
prediction_extra_dict = load_yaml(prediction_extra, keys_fix_yaml=self.keys_fix)
|
||||
if original_prediction_dict and isinstance(original_prediction_dict, dict) and \
|
||||
isinstance(prediction_extra_dict, dict) and "pr_files" in prediction_extra_dict:
|
||||
if "pr_files" in original_prediction_dict:
|
||||
original_prediction_dict["pr_files"].extend(prediction_extra_dict["pr_files"])
|
||||
else:
|
||||
original_prediction_dict["pr_files"] = prediction_extra_dict["pr_files"]
|
||||
if isinstance(original_prediction_dict, dict) and isinstance(prediction_extra_dict, dict):
|
||||
original_prediction_dict["pr_files"].extend(prediction_extra_dict["pr_files"])
|
||||
new_yaml = yaml.dump(original_prediction_dict)
|
||||
if load_yaml(new_yaml, keys_fix_yaml=self.keys_fix):
|
||||
prediction = new_yaml
|
||||
@ -385,7 +378,7 @@ class PRDescription:
|
||||
|
||||
return prediction
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Error extending uncovered files {self.pr_id}", artifact={"error": e})
|
||||
get_logger().error(f"Error extending uncovered files {self.pr_id}: {e}")
|
||||
return original_prediction
|
||||
|
||||
|
||||
@ -690,9 +683,8 @@ class PRDescription:
|
||||
filename = filename.strip()
|
||||
link = self.git_provider.get_line_link(filename, relevant_line_start=-1)
|
||||
if (not link or not diff_plus_minus) and ('additional files' not in filename.lower()):
|
||||
# get_logger().warning(f"Error getting line link for '{filename}'")
|
||||
link = ""
|
||||
# continue
|
||||
get_logger().warning(f"Error getting line link for '{filename}'")
|
||||
continue
|
||||
|
||||
# Add file data to the PR body
|
||||
file_change_description_br = insert_br_after_x_chars(file_change_description, x=(delta - 5))
|
||||
|
||||
@ -1,5 +1,4 @@
|
||||
import copy
|
||||
import re
|
||||
from functools import partial
|
||||
from pathlib import Path
|
||||
|
||||
@ -10,9 +9,10 @@ from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||
from pr_agent.algo.ai_handlers.litellm_ai_handler import LiteLLMAIHandler
|
||||
from pr_agent.algo.pr_processing import retry_with_fallback_models
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.utils import ModelType, clip_tokens, load_yaml, get_max_tokens
|
||||
from pr_agent.algo.utils import ModelType, clip_tokens, load_yaml
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers import BitbucketServerProvider, GithubProvider, get_git_provider_with_context
|
||||
from pr_agent.git_providers import (BitbucketServerProvider, GithubProvider,
|
||||
get_git_provider_with_context)
|
||||
from pr_agent.log import get_logger
|
||||
|
||||
|
||||
@ -30,11 +30,10 @@ def extract_header(snippet):
|
||||
return res
|
||||
|
||||
class PRHelpMessage:
|
||||
def __init__(self, pr_url: str, args=None, ai_handler: partial[BaseAiHandler,] = LiteLLMAIHandler, return_as_string=False):
|
||||
def __init__(self, pr_url: str, args=None, ai_handler: partial[BaseAiHandler,] = LiteLLMAIHandler):
|
||||
self.git_provider = get_git_provider_with_context(pr_url)
|
||||
self.ai_handler = ai_handler()
|
||||
self.question_str = self.parse_args(args)
|
||||
self.return_as_string = return_as_string
|
||||
self.num_retrieved_snippets = get_settings().get('pr_help.num_retrieved_snippets', 5)
|
||||
if self.question_str:
|
||||
self.vars = {
|
||||
@ -66,34 +65,6 @@ class PRHelpMessage:
|
||||
question_str = ""
|
||||
return question_str
|
||||
|
||||
def format_markdown_header(self, header: str) -> str:
|
||||
try:
|
||||
# First, strip common characters from both ends
|
||||
cleaned = header.strip('# 💎\n')
|
||||
|
||||
# Define all characters to be removed/replaced in a single pass
|
||||
replacements = {
|
||||
"'": '',
|
||||
"`": '',
|
||||
'(': '',
|
||||
')': '',
|
||||
',': '',
|
||||
'.': '',
|
||||
'?': '',
|
||||
'!': '',
|
||||
' ': '-'
|
||||
}
|
||||
|
||||
# Compile regex pattern for characters to remove
|
||||
pattern = re.compile('|'.join(map(re.escape, replacements.keys())))
|
||||
|
||||
# Perform replacements in a single pass and convert to lowercase
|
||||
return pattern.sub(lambda m: replacements[m.group()], cleaned).lower()
|
||||
except Exception:
|
||||
get_logger().exception(f"Error while formatting markdown header", artifacts={'header': header})
|
||||
return ""
|
||||
|
||||
|
||||
async def run(self):
|
||||
try:
|
||||
if self.question_str:
|
||||
@ -135,10 +106,7 @@ class PRHelpMessage:
|
||||
get_logger().debug(f"Token count of full documentation website: {token_count}")
|
||||
|
||||
model = get_settings().config.model
|
||||
if model in MAX_TOKENS:
|
||||
max_tokens_full = MAX_TOKENS[model] # note - here we take the actual max tokens, without any reductions. we do aim to get the full documentation website in the prompt
|
||||
else:
|
||||
max_tokens_full = get_max_tokens(model)
|
||||
max_tokens_full = MAX_TOKENS[model] # note - here we take the actual max tokens, without any reductions. we do aim to get the full documentation website in the prompt
|
||||
delta_output = 2000
|
||||
if token_count > max_tokens_full - delta_output:
|
||||
get_logger().info(f"Token count {token_count} exceeds the limit {max_tokens_full - delta_output}. Skipping the PR Help message.")
|
||||
@ -146,16 +114,8 @@ class PRHelpMessage:
|
||||
self.vars['snippets'] = docs_prompt.strip()
|
||||
|
||||
# run the AI model
|
||||
response = await retry_with_fallback_models(self._prepare_prediction, model_type=ModelType.REGULAR)
|
||||
response = await retry_with_fallback_models(self._prepare_prediction, model_type=ModelType.WEAK)
|
||||
response_yaml = load_yaml(response)
|
||||
if isinstance(response_yaml, str):
|
||||
get_logger().warning(f"failing to parse response: {response_yaml}, publishing the response as is")
|
||||
if get_settings().config.publish_output:
|
||||
answer_str = f"### Question: \n{self.question_str}\n\n"
|
||||
answer_str += f"### Answer:\n\n"
|
||||
answer_str += response_yaml
|
||||
self.git_provider.publish_comment(answer_str)
|
||||
return ""
|
||||
response_str = response_yaml.get('response')
|
||||
relevant_sections = response_yaml.get('relevant_sections')
|
||||
|
||||
@ -178,7 +138,7 @@ class PRHelpMessage:
|
||||
for section in relevant_sections:
|
||||
file = section.get('file_name').strip().removesuffix('.md')
|
||||
if str(section['relevant_section_header_string']).strip():
|
||||
markdown_header = self.format_markdown_header(section['relevant_section_header_string'])
|
||||
markdown_header = section['relevant_section_header_string'].strip().strip('#').strip().lower().replace(' ', '-').replace("'", '').replace('(', '').replace(')', '').replace(',', '').replace('.', '').replace('?', '').replace('!', '')
|
||||
answer_str += f"> - {base_path}{file}#{markdown_header}\n"
|
||||
else:
|
||||
answer_str += f"> - {base_path}{file}\n"
|
||||
|
||||
@ -95,7 +95,6 @@ class PRReviewer:
|
||||
"is_ai_metadata": get_settings().get("config.enable_ai_metadata", False),
|
||||
"related_tickets": get_settings().get('related_tickets', []),
|
||||
'duplicate_prompt_examples': get_settings().config.get('duplicate_prompt_examples', False),
|
||||
"date": datetime.datetime.now().strftime('%Y-%m-%d'),
|
||||
}
|
||||
|
||||
self.token_handler = TokenHandler(
|
||||
@ -123,10 +122,10 @@ class PRReviewer:
|
||||
if self.incremental.is_incremental and not self._can_run_incremental_review():
|
||||
return None
|
||||
|
||||
# if isinstance(self.args, list) and self.args and self.args[0] == 'auto_approve':
|
||||
# get_logger().info(f'Auto approve flow PR: {self.pr_url} ...')
|
||||
# self.auto_approve_logic()
|
||||
# return None
|
||||
if isinstance(self.args, list) and self.args and self.args[0] == 'auto_approve':
|
||||
get_logger().info(f'Auto approve flow PR: {self.pr_url} ...')
|
||||
self.auto_approve_logic()
|
||||
return None
|
||||
|
||||
get_logger().info(f'Reviewing PR: {self.pr_url} ...')
|
||||
relevant_configs = {'pr_reviewer': dict(get_settings().pr_reviewer),
|
||||
@ -372,7 +371,7 @@ class PRReviewer:
|
||||
else:
|
||||
get_logger().warning(f"Unexpected type for estimated_effort: {type(estimated_effort)}")
|
||||
if 1 <= estimated_effort_number <= 5: # 1, because ...
|
||||
review_labels.append(f'Review effort {estimated_effort_number}/5')
|
||||
review_labels.append(f'Review effort [1-5]: {estimated_effort_number}')
|
||||
if get_settings().pr_reviewer.enable_review_labels_security and get_settings().pr_reviewer.require_security_review:
|
||||
security_concerns = data['review']['security_concerns'] # yes, because ...
|
||||
security_concerns_bool = 'yes' in security_concerns.lower() or 'true' in security_concerns.lower()
|
||||
@ -402,7 +401,7 @@ class PRReviewer:
|
||||
"""
|
||||
Auto-approve a pull request if it meets the conditions for auto-approval.
|
||||
"""
|
||||
if get_settings().config.enable_auto_approval:
|
||||
if get_settings().pr_reviewer.enable_auto_approval:
|
||||
is_auto_approved = self.git_provider.auto_approve()
|
||||
if is_auto_approved:
|
||||
get_logger().info("Auto-approved PR")
|
||||
|
||||
@ -70,65 +70,41 @@ async def extract_tickets(git_provider):
|
||||
user_description = git_provider.get_user_description()
|
||||
tickets = extract_ticket_links_from_pr_description(user_description, git_provider.repo, git_provider.base_url_html)
|
||||
tickets_content = []
|
||||
|
||||
if tickets:
|
||||
|
||||
for ticket in tickets:
|
||||
# extract ticket number and repo name
|
||||
repo_name, original_issue_number = git_provider._parse_issue_url(ticket)
|
||||
|
||||
# get the ticket object
|
||||
try:
|
||||
issue_main = git_provider.repo_obj.get_issue(original_issue_number)
|
||||
except Exception as e:
|
||||
get_logger().error(f"Error getting main issue: {e}",
|
||||
get_logger().error(f"Error getting issue_main error= {e}",
|
||||
artifact={"traceback": traceback.format_exc()})
|
||||
continue
|
||||
|
||||
issue_body_str = issue_main.body or ""
|
||||
# clip issue_main.body max length
|
||||
issue_body_str = issue_main.body
|
||||
if not issue_body_str:
|
||||
issue_body_str = ""
|
||||
if len(issue_body_str) > MAX_TICKET_CHARACTERS:
|
||||
issue_body_str = issue_body_str[:MAX_TICKET_CHARACTERS] + "..."
|
||||
|
||||
# Extract sub-issues
|
||||
sub_issues_content = []
|
||||
try:
|
||||
sub_issues = git_provider.fetch_sub_issues(ticket)
|
||||
for sub_issue_url in sub_issues:
|
||||
try:
|
||||
sub_repo, sub_issue_number = git_provider._parse_issue_url(sub_issue_url)
|
||||
sub_issue = git_provider.repo_obj.get_issue(sub_issue_number)
|
||||
|
||||
sub_body = sub_issue.body or ""
|
||||
if len(sub_body) > MAX_TICKET_CHARACTERS:
|
||||
sub_body = sub_body[:MAX_TICKET_CHARACTERS] + "..."
|
||||
|
||||
sub_issues_content.append({
|
||||
'ticket_url': sub_issue_url,
|
||||
'title': sub_issue.title,
|
||||
'body': sub_body
|
||||
})
|
||||
except Exception as e:
|
||||
get_logger().warning(f"Failed to fetch sub-issue content for {sub_issue_url}: {e}")
|
||||
|
||||
except Exception as e:
|
||||
get_logger().warning(f"Failed to fetch sub-issues for {ticket}: {e}")
|
||||
|
||||
# Extract labels
|
||||
# extract labels
|
||||
labels = []
|
||||
try:
|
||||
for label in issue_main.labels:
|
||||
labels.append(label.name if hasattr(label, 'name') else label)
|
||||
if isinstance(label, str):
|
||||
labels.append(label)
|
||||
else:
|
||||
labels.append(label.name)
|
||||
except Exception as e:
|
||||
get_logger().error(f"Error extracting labels error= {e}",
|
||||
artifact={"traceback": traceback.format_exc()})
|
||||
|
||||
tickets_content.append({
|
||||
'ticket_id': issue_main.number,
|
||||
'ticket_url': ticket,
|
||||
'title': issue_main.title,
|
||||
'body': issue_body_str,
|
||||
'labels': ", ".join(labels),
|
||||
'sub_issues': sub_issues_content # Store sub-issues content
|
||||
})
|
||||
|
||||
tickets_content.append(
|
||||
{'ticket_id': issue_main.number,
|
||||
'ticket_url': ticket, 'title': issue_main.title, 'body': issue_body_str,
|
||||
'labels': ", ".join(labels)})
|
||||
return tickets_content
|
||||
|
||||
except Exception as e:
|
||||
@ -139,27 +115,14 @@ async def extract_tickets(git_provider):
|
||||
async def extract_and_cache_pr_tickets(git_provider, vars):
|
||||
if not get_settings().get('pr_reviewer.require_ticket_analysis_review', False):
|
||||
return
|
||||
|
||||
related_tickets = get_settings().get('related_tickets', [])
|
||||
|
||||
if not related_tickets:
|
||||
tickets_content = await extract_tickets(git_provider)
|
||||
|
||||
if tickets_content:
|
||||
# Store sub-issues along with main issues
|
||||
for ticket in tickets_content:
|
||||
if "sub_issues" in ticket and ticket["sub_issues"]:
|
||||
for sub_issue in ticket["sub_issues"]:
|
||||
related_tickets.append(sub_issue) # Add sub-issues content
|
||||
|
||||
related_tickets.append(ticket)
|
||||
|
||||
get_logger().info("Extracted tickets and sub-issues from PR description",
|
||||
artifact={"tickets": related_tickets})
|
||||
|
||||
vars['related_tickets'] = related_tickets
|
||||
get_settings().set('related_tickets', related_tickets)
|
||||
else:
|
||||
get_logger().info("Extracted tickets from PR description", artifact={"tickets": tickets_content})
|
||||
vars['related_tickets'] = tickets_content
|
||||
get_settings().set('related_tickets', tickets_content)
|
||||
else: # if tickets are already cached
|
||||
get_logger().info("Using cached tickets", artifact={"tickets": related_tickets})
|
||||
vars['related_tickets'] = related_tickets
|
||||
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
aiohttp==3.9.5
|
||||
anthropic[vertex]==0.47.1
|
||||
anthropic[vertex]==0.39.0
|
||||
atlassian-python-api==3.41.4
|
||||
azure-devops==7.1.0b3
|
||||
azure-identity==1.15.0
|
||||
|
||||
@ -5,11 +5,12 @@ from pr_agent.algo.pr_processing import pr_generate_extended_diff
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.utils import load_large_diff
|
||||
from pr_agent.config_loader import get_settings
|
||||
get_settings().set("CONFIG.CLI_MODE", True)
|
||||
get_settings().config.allow_dynamic_context = False
|
||||
|
||||
|
||||
class TestExtendPatch:
|
||||
def setUp(self):
|
||||
get_settings().config.allow_dynamic_context = False
|
||||
|
||||
# Tests that the function works correctly with valid input
|
||||
def test_happy_path(self):
|
||||
original_file_str = 'line1\nline2\nline3\nline4\nline5'
|
||||
@ -74,46 +75,41 @@ class TestExtendPatch:
|
||||
actual_output = extend_patch(original_file_str, patch_str,
|
||||
patch_extra_lines_before=num_lines, patch_extra_lines_after=num_lines)
|
||||
assert actual_output == expected_output
|
||||
get_settings(use_context=False).config.allow_dynamic_context = original_allow_dynamic_context
|
||||
get_settings().config.allow_dynamic_context = original_allow_dynamic_context
|
||||
|
||||
|
||||
def test_dynamic_context(self):
|
||||
get_settings(use_context=False).config.max_extra_lines_before_dynamic_context = 10
|
||||
get_settings().config.max_extra_lines_before_dynamic_context = 10
|
||||
original_file_str = "def foo():"
|
||||
for i in range(9):
|
||||
original_file_str += f"\n line({i})"
|
||||
patch_str ="@@ -10,1 +10,1 @@ def foo():\n- line(8)\n+ new_line(8)"
|
||||
new_file_str = "\n".join(original_file_str.splitlines()[:-1] + [" new_line(8)"])
|
||||
patch_str ="@@ -11,1 +11,1 @@ def foo():\n- line(9)\n+ new_line(9)"
|
||||
num_lines=1
|
||||
|
||||
get_settings(use_context=False).config.allow_dynamic_context = True
|
||||
get_settings().config.allow_dynamic_context = True
|
||||
actual_output = extend_patch(original_file_str, patch_str,
|
||||
patch_extra_lines_before=num_lines, patch_extra_lines_after=num_lines, new_file_str=new_file_str)
|
||||
expected_output='\n@@ -1,10 +1,10 @@ \n def foo():\n line(0)\n line(1)\n line(2)\n line(3)\n line(4)\n line(5)\n line(6)\n line(7)\n- line(8)\n+ new_line(8)'
|
||||
patch_extra_lines_before=num_lines, patch_extra_lines_after=num_lines)
|
||||
expected_output='\n@@ -1,10 +1,10 @@ \n def foo():\n line(0)\n line(1)\n line(2)\n line(3)\n line(4)\n line(5)\n line(6)\n line(7)\n line(8)\n- line(9)\n+ new_line(9)'
|
||||
assert actual_output == expected_output
|
||||
|
||||
get_settings(use_context=False).config.allow_dynamic_context = False
|
||||
get_settings().config.allow_dynamic_context = False
|
||||
actual_output2 = extend_patch(original_file_str, patch_str,
|
||||
patch_extra_lines_before=1, patch_extra_lines_after=1)
|
||||
expected_output_no_dynamic_context = '\n@@ -9,2 +9,2 @@ def foo():\n line(7)\n- line(8)\n+ new_line(8)'
|
||||
patch_extra_lines_before=num_lines, patch_extra_lines_after=num_lines)
|
||||
expected_output_no_dynamic_context = '\n@@ -10,1 +10,1 @@ def foo():\n line(8)\n- line(9)\n+ new_line(9)'
|
||||
assert actual_output2 == expected_output_no_dynamic_context
|
||||
|
||||
get_settings(use_context=False).config.allow_dynamic_context = False
|
||||
actual_output3 = extend_patch(original_file_str, patch_str,
|
||||
patch_extra_lines_before=3, patch_extra_lines_after=3)
|
||||
expected_output_no_dynamic_context = '\n@@ -7,4 +7,4 @@ def foo():\n line(5)\n line(6)\n line(7)\n- line(8)\n+ new_line(8)'
|
||||
assert actual_output3 == expected_output_no_dynamic_context
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
class TestExtendedPatchMoreLines:
|
||||
def setUp(self):
|
||||
get_settings().config.allow_dynamic_context = False
|
||||
|
||||
class File:
|
||||
def __init__(self, base_file, patch, head_file, filename, ai_file_summary=None):
|
||||
def __init__(self, base_file, patch, filename, ai_file_summary=None):
|
||||
self.base_file = base_file
|
||||
self.patch = patch
|
||||
self.head_file = head_file
|
||||
self.filename = filename
|
||||
self.ai_file_summary = ai_file_summary
|
||||
|
||||
@ -132,11 +128,9 @@ class TestExtendedPatchMoreLines:
|
||||
'files': [
|
||||
self.File(base_file="line000\nline00\nline0\nline1\noriginal content\nline2\nline3\nline4\nline5\nline6\nline7\nline8\nline9\nline10",
|
||||
patch="@@ -5,5 +5,5 @@\n-original content\n+modified content\n line2\n line3\n line4\n line5",
|
||||
head_file="line000\nline00\nline0\nline1\nmodified content\nline2\nline3\nline4\nline5\nline6\nline7\nline8\nline9\nline10",
|
||||
filename="file1"),
|
||||
self.File(base_file="original content\nline2\nline3\nline4\nline5\nline6\nline7\nline8\nline9\nline10",
|
||||
patch="@@ -6,5 +6,5 @@\nline6\nline7\nline8\n-line9\n+modified line9\nline10",
|
||||
head_file="original content\nline2\nline3\nline4\nline5\nline6\nline7\nline8\nmodified line9\nline10",
|
||||
filename="file2")
|
||||
]
|
||||
}
|
||||
@ -161,9 +155,11 @@ class TestExtendedPatchMoreLines:
|
||||
patch_extra_lines_after=1
|
||||
)
|
||||
|
||||
|
||||
p0_extended = patches_extended_with_extra_lines[0].strip()
|
||||
assert p0_extended == "## File: 'file1'\n\n@@ -3,8 +3,8 @@ \n line0\n line1\n-original content\n+modified content\n line2\n line3\n line4\n line5\n line6"
|
||||
|
||||
|
||||
class TestLoadLargeDiff:
|
||||
def test_no_newline(self):
|
||||
patch = load_large_diff("test.py",
|
||||
|
||||
@ -1,121 +0,0 @@
|
||||
# Currently doing API calls - wrong !
|
||||
|
||||
|
||||
# import unittest
|
||||
# import asyncio
|
||||
# from unittest.mock import AsyncMock, patch
|
||||
# from pr_agent.tools.ticket_pr_compliance_check import extract_tickets, extract_and_cache_pr_tickets
|
||||
# from pr_agent.git_providers.github_provider import GithubProvider
|
||||
#
|
||||
#
|
||||
# class TestTicketCompliance(unittest.TestCase):
|
||||
#
|
||||
# @patch.object(GithubProvider, 'get_user_description', return_value="Fixes #1 and relates to #2")
|
||||
# @patch.object(GithubProvider, '_parse_issue_url', side_effect=lambda url: ("WonOfAKind/KimchiBot", int(url.split('#')[-1])))
|
||||
# @patch.object(GithubProvider, 'repo_obj')
|
||||
# async def test_extract_tickets(self, mock_repo, mock_parse_issue_url, mock_user_desc):
|
||||
# """
|
||||
# Test extract_tickets() to ensure it extracts tickets correctly
|
||||
# and fetches their content.
|
||||
# """
|
||||
# github_provider = GithubProvider()
|
||||
# github_provider.repo = "WonOfAKind/KimchiBot"
|
||||
# github_provider.base_url_html = "https://github.com"
|
||||
#
|
||||
# # Mock issue retrieval
|
||||
# mock_issue = AsyncMock()
|
||||
# mock_issue.number = 1
|
||||
# mock_issue.title = "Sample Issue"
|
||||
# mock_issue.body = "This is a test issue body."
|
||||
# mock_issue.labels = ["bug", "high priority"]
|
||||
#
|
||||
# # Mock repo object
|
||||
# mock_repo.get_issue.return_value = mock_issue
|
||||
#
|
||||
# tickets = await extract_tickets(github_provider)
|
||||
#
|
||||
# # Verify tickets were extracted correctly
|
||||
# self.assertIsInstance(tickets, list)
|
||||
# self.assertGreater(len(tickets), 0, "Expected at least one ticket!")
|
||||
#
|
||||
# # Verify ticket structure
|
||||
# first_ticket = tickets[0]
|
||||
# self.assertIn("ticket_id", first_ticket)
|
||||
# self.assertIn("ticket_url", first_ticket)
|
||||
# self.assertIn("title", first_ticket)
|
||||
# self.assertIn("body", first_ticket)
|
||||
# self.assertIn("labels", first_ticket)
|
||||
#
|
||||
# print("\n Test Passed: extract_tickets() successfully retrieved ticket info!")
|
||||
#
|
||||
# @patch.object(GithubProvider, 'get_user_description', return_value="Fixes #1 and relates to #2")
|
||||
# @patch.object(GithubProvider, '_parse_issue_url', side_effect=lambda url: ("WonOfAKind/KimchiBot", int(url.split('#')[-1])))
|
||||
# @patch.object(GithubProvider, 'repo_obj')
|
||||
# async def test_extract_and_cache_pr_tickets(self, mock_repo, mock_parse_issue_url, mock_user_desc):
|
||||
# """
|
||||
# Test extract_and_cache_pr_tickets() to ensure tickets are extracted and cached correctly.
|
||||
# """
|
||||
# github_provider = GithubProvider()
|
||||
# github_provider.repo = "WonOfAKind/KimchiBot"
|
||||
# github_provider.base_url_html = "https://github.com"
|
||||
#
|
||||
# vars = {} # Simulate the dictionary to store results
|
||||
#
|
||||
# # Mock issue retrieval
|
||||
# mock_issue = AsyncMock()
|
||||
# mock_issue.number = 1
|
||||
# mock_issue.title = "Sample Issue"
|
||||
# mock_issue.body = "This is a test issue body."
|
||||
# mock_issue.labels = ["bug", "high priority"]
|
||||
#
|
||||
# # Mock repo object
|
||||
# mock_repo.get_issue.return_value = mock_issue
|
||||
#
|
||||
# # Run function
|
||||
# await extract_and_cache_pr_tickets(github_provider, vars)
|
||||
#
|
||||
# # Ensure tickets are cached
|
||||
# self.assertIn("related_tickets", vars)
|
||||
# self.assertIsInstance(vars["related_tickets"], list)
|
||||
# self.assertGreater(len(vars["related_tickets"]), 0, "Expected at least one cached ticket!")
|
||||
#
|
||||
# print("\n Test Passed: extract_and_cache_pr_tickets() successfully cached ticket data!")
|
||||
#
|
||||
# def test_fetch_sub_issues(self):
|
||||
# """
|
||||
# Test fetch_sub_issues() to ensure sub-issues are correctly retrieved.
|
||||
# """
|
||||
# github_provider = GithubProvider()
|
||||
# issue_url = "https://github.com/WonOfAKind/KimchiBot/issues/1" # Known issue with sub-issues
|
||||
# result = github_provider.fetch_sub_issues(issue_url)
|
||||
#
|
||||
# print("Fetched sub-issues:", result)
|
||||
#
|
||||
# self.assertIsInstance(result, set) # Ensure result is a set
|
||||
# self.assertGreater(len(result), 0, "Expected at least one sub-issue but found none!")
|
||||
#
|
||||
# print("\n Test Passed: fetch_sub_issues() retrieved sub-issues correctly!")
|
||||
#
|
||||
# def test_fetch_sub_issues_with_no_results(self):
|
||||
# """
|
||||
# Test fetch_sub_issues() to ensure an empty set is returned for an issue with no sub-issues.
|
||||
# """
|
||||
# github_provider = GithubProvider()
|
||||
# issue_url = "https://github.com/qodo-ai/pr-agent/issues/1499" # Likely non-existent issue
|
||||
# result = github_provider.fetch_sub_issues(issue_url)
|
||||
#
|
||||
# print("Fetched sub-issues for non-existent issue:", result)
|
||||
#
|
||||
# self.assertIsInstance(result, set) # Ensure result is a set
|
||||
# self.assertEqual(len(result), 0, "Expected no sub-issues but some were found!")
|
||||
#
|
||||
# print("\n Test Passed: fetch_sub_issues_with_no_results() correctly returned an empty set!")
|
||||
#
|
||||
#
|
||||
# if __name__ == "__main__":
|
||||
# asyncio.run(unittest.main())
|
||||
#
|
||||
#
|
||||
#
|
||||
#
|
||||
#
|
||||