mirror of
https://github.com/qodo-ai/pr-agent.git
synced 2025-07-15 02:00:39 +08:00
Compare commits
215 Commits
v0.27
...
qodo-merge
| Author | SHA1 | Date | |
|---|---|---|---|
| cd68a92283 | |||
| 44a3e5819c | |||
| 27a7c1a94f | |||
| dc46acb762 | |||
| 0da667d179 | |||
| 73b3e2520c | |||
| 3d2a285091 | |||
| b1bc77c809 | |||
| 14dafc4016 | |||
| 7d00574044 | |||
| 93002acff8 | |||
| f08bed67f1 | |||
| 08bf9593b2 | |||
| 4b58a5488f | |||
| 57808075be | |||
| 2cb226dbcc | |||
| 943af0653b | |||
| 259d67c064 | |||
| 84fdc4ca2b | |||
| c8f519ad70 | |||
| 8bdd11646c | |||
| fc6de449ad | |||
| a649e323d3 | |||
| 7a32faf64f | |||
| 3c8ad9eac8 | |||
| 5f2d4d400e | |||
| 0cbf65dab6 | |||
| c0c307503f | |||
| 60ace1ed09 | |||
| 7f6014e064 | |||
| e4f40da35c | |||
| 0ac7028bc6 | |||
| a919c62606 | |||
| abda701539 | |||
| da59a6dbe8 | |||
| e44b371d34 | |||
| edaab4b6b1 | |||
| 2476dadf53 | |||
| 526d7ff5d2 | |||
| cdc354c33b | |||
| eb9c4fa110 | |||
| ca95e876eb | |||
| 4ee9f784dd | |||
| ef7a8eafb6 | |||
| 83bb3b25d8 | |||
| 665fb90a98 | |||
| 0161769f22 | |||
| 629de489dd | |||
| a4957693ba | |||
| e8171b0289 | |||
| d4cc57c32a | |||
| cb47cd5144 | |||
| 99d88f8d1d | |||
| d938ff05ef | |||
| ae6c4e741a | |||
| 282fb0ed28 | |||
| 9b19fcdc90 | |||
| 76b447a62a | |||
| b7b533ddf6 | |||
| 7987fd1be7 | |||
| db06a8e49e | |||
| 4fa2d82179 | |||
| 1ffddaf719 | |||
| 94aa090552 | |||
| 2683b78e34 | |||
| eac20ba0e2 | |||
| c2e61b7113 | |||
| c74a2efdb7 | |||
| 1710cd49f1 | |||
| 9254225949 | |||
| 14971c4f5f | |||
| ceaca3e621 | |||
| 3b0225544a | |||
| dbfc07ccc1 | |||
| f0e0901b10 | |||
| d749620ebb | |||
| e692735b7b | |||
| ed00ef6ee3 | |||
| c674c5ed02 | |||
| 20cb139161 | |||
| 8513a1a4b9 | |||
| a7ab04ba8d | |||
| afa4adcb23 | |||
| 7bd0fefee4 | |||
| 02d9aed7fe | |||
| 7d47bd5f5e | |||
| 8f0df437dd | |||
| ddf94c14a3 | |||
| 6b2a1ff529 | |||
| 4a5c115d20 | |||
| 069f5eb86f | |||
| 7d57edf959 | |||
| 6950b3ca6b | |||
| e422f50cfe | |||
| 66a667d509 | |||
| 482cd7c680 | |||
| 991a866368 | |||
| fcd9416129 | |||
| 255e1d0fc1 | |||
| 7117e9fe0e | |||
| b42841fcc4 | |||
| 839b6093cb | |||
| 351b9d9115 | |||
| 3e11f07f0b | |||
| 1d57dd7443 | |||
| 7aa3d12876 | |||
| 6f6595c343 | |||
| b300cfa84d | |||
| 9a21069075 | |||
| 85f7b99dea | |||
| d6f79f486a | |||
| b0ed584821 | |||
| 05ea699a92 | |||
| 605eef64e7 | |||
| c94aa58ae4 | |||
| e20e7c138c | |||
| b161672218 | |||
| 5bc253e1d9 | |||
| 8495e4d549 | |||
| fb324d106c | |||
| a4387b5829 | |||
| 477ebf4926 | |||
| fe98779a88 | |||
| e14fc7e02d | |||
| 1bd65934df | |||
| 88a17848eb | |||
| 1aab87516e | |||
| dd80276f3f | |||
| ad17cb4d92 | |||
| 6efb694945 | |||
| dde362bd47 | |||
| a9ce909713 | |||
| e925f31ac0 | |||
| 5e7e353670 | |||
| 52d4312c9a | |||
| 8ec6067b26 | |||
| bc575e5a67 | |||
| b087458e33 | |||
| 6610921bba | |||
| 3fd15042a6 | |||
| 4ab2396be0 | |||
| a75d430751 | |||
| 737cf559d9 | |||
| fa77828db2 | |||
| f506fb1e05 | |||
| 4ea46d5b25 | |||
| ed9fcd0238 | |||
| 9d3bd7289a | |||
| 1724a65ab2 | |||
| 6883ced9e3 | |||
| 29e28056db | |||
| 507cd6e675 | |||
| dd1a0e51bb | |||
| b4e2a32543 | |||
| 677a54c5a0 | |||
| a211175fea | |||
| 64f52288a1 | |||
| 4ee1704862 | |||
| f5e381e1b2 | |||
| 2cacaf56b0 | |||
| 9a574e0caa | |||
| 0f33750035 | |||
| 4713175fcf | |||
| d16012a568 | |||
| 01f1599336 | |||
| f5bd98a3b9 | |||
| 1c86af30b6 | |||
| 0acd5193cb | |||
| ffefcb8a04 | |||
| 35bb2b31e3 | |||
| a18f9d00c9 | |||
| 20d709075c | |||
| 52c99e3f7b | |||
| 692bc449be | |||
| 884b49dd84 | |||
| 338ec5cae0 | |||
| c6e4498653 | |||
| c7c411eb63 | |||
| 222155e4f2 | |||
| f9d5e72058 | |||
| 2619ff3eb3 | |||
| 15e8167115 | |||
| d6ad511511 | |||
| 1943662946 | |||
| c1fb76abcf | |||
| 121d90a9da | |||
| a8935dece3 | |||
| fd12191fcf | |||
| 61b6d1f1a3 | |||
| 874b7c7da4 | |||
| a0d86b532f | |||
| 4f2551e0a6 | |||
| eb5f38b13b | |||
| 1753bc703e | |||
| 31de811820 | |||
| 4c0e371238 | |||
| ca286b8dc0 | |||
| 0c30f084bc | |||
| a33bee5805 | |||
| f32163d57c | |||
| bb24a6f43d | |||
| 5b267332b9 | |||
| 30bf7572b0 | |||
| b5ce49cbc0 | |||
| 440d2368a4 | |||
| 215c10cc8c | |||
| 7623e1a419 | |||
| 5e30e190b8 | |||
| 5447dd2ac6 | |||
| 214200b816 | |||
| fcb7d97640 | |||
| 224920bdb7 | |||
| d3f83f3069 | |||
| 8e6267b0e6 | |||
| 9809e2dbd8 |
102
README.md
102
README.md
@ -22,7 +22,7 @@ PR-Agent aims to help efficiently review and handle pull requests, by providing
|
||||
[](https://chromewebstore.google.com/detail/qodo-merge-ai-powered-cod/ephlnjeghhogofkifjloamocljapahnl)
|
||||
[](https://github.com/apps/qodo-merge-pro/)
|
||||
[](https://github.com/apps/qodo-merge-pro-for-open-source/)
|
||||
[](https://discord.com/channels/1057273017547378788/1126104260430528613)
|
||||
[](https://discord.com/invite/SgSxuQ65GF)
|
||||
<a href="https://github.com/Codium-ai/pr-agent/commits/main">
|
||||
<img alt="GitHub" src="https://img.shields.io/github/last-commit/Codium-ai/pr-agent/main?style=for-the-badge" height="20">
|
||||
</a>
|
||||
@ -52,39 +52,30 @@ PR-Agent aims to help efficiently review and handle pull requests, by providing
|
||||
|
||||
## News and Updates
|
||||
|
||||
## Apr 14, 2025
|
||||
|
||||
GPT-4.1 is out. And its quite good on coding tasks...
|
||||
|
||||
https://openai.com/index/gpt-4-1/
|
||||
|
||||
<img width="635" alt="image" src="https://github.com/user-attachments/assets/a8f4c648-a058-4bdc-9825-2a4bb71a23e5" />
|
||||
|
||||
|
||||
## March 28, 2025
|
||||
A new version, v0.28, was released. See release notes [here](https://github.com/qodo-ai/pr-agent/releases/tag/v0.28).
|
||||
|
||||
This version includes a new tool, [Help Docs](https://qodo-merge-docs.qodo.ai/tools/help_docs/), which can answer free-text questions based on a documentation folder.
|
||||
|
||||
`/help_docs` is now being used to provide immediate automatic feedback to any user who [opens an issue](https://github.com/qodo-ai/pr-agent/issues/1608#issue-2897328825) on PR-Agent's open-source project
|
||||
|
||||
### Feb 28, 2025
|
||||
A new version, v0.27, was released. See release notes [here](https://github.com/qodo-ai/pr-agent/releases/tag/v0.27).
|
||||
|
||||
### Feb 27, 2025
|
||||
- Updated the default model to `o3-mini` for all tools. You can still use the `gpt-4o` as the default model by setting the `model` parameter in the configuration file.
|
||||
- Important updates and bug fixes for Azure DevOps, see [here](https://github.com/qodo-ai/pr-agent/pull/1583)
|
||||
- Added support for adjusting the [response language](https://qodo-merge-docs.qodo.ai/usage-guide/additional_configurations/#language-settings) of the PR-Agent tools.
|
||||
|
||||
### Feb 6, 2025
|
||||
New design for the `/improve` tool:
|
||||
|
||||
<kbd><img src="https://github.com/user-attachments/assets/26506430-550e-469a-adaa-af0a09b70c6d" width="512"></kbd>
|
||||
|
||||
### Jan 25, 2025
|
||||
|
||||
The open-source GitHub organization was updated:
|
||||
`https://github.com/codium-ai/pr-agent` →
|
||||
`https://github.com/qodo-ai/pr-agent`
|
||||
|
||||
The docker should be redirected automatically to the new location.
|
||||
However, if you have any issues, please update the GitHub action docker image from
|
||||
`uses: Codium-ai/pr-agent@main`
|
||||
to
|
||||
`uses: qodo-ai/pr-agent@main`
|
||||
|
||||
|
||||
### Jan 2, 2025
|
||||
|
||||
New tool [/Implement](https://qodo-merge-docs.qodo.ai/tools/implement/) (💎), which converts human code review discussions and feedback into ready-to-commit code changes.
|
||||
|
||||
<kbd><img src="https://www.qodo.ai/images/pr_agent/implement1.png?v=2" width="512"></kbd>
|
||||
|
||||
|
||||
### Jan 1, 2025
|
||||
|
||||
Update logic and [documentation](https://qodo-merge-docs.qodo.ai/usage-guide/changing_a_model/#ollama) for running local models via Ollama.
|
||||
|
||||
### December 30, 2024
|
||||
|
||||
@ -98,18 +89,19 @@ Supported commands per platform:
|
||||
|
||||
| | | GitHub | GitLab | Bitbucket | Azure DevOps |
|
||||
|-------|---------------------------------------------------------------------------------------------------------|:--------------------:|:--------------------:|:---------:|:------------:|
|
||||
| TOOLS | [Review](https://qodo-merge-docs.qodo.ai/tools/review/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Describe](https://qodo-merge-docs.qodo.ai/tools/describe/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Improve](https://qodo-merge-docs.qodo.ai/tools/improve/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Ask](https://qodo-merge-docs.qodo.ai/tools/ask/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ [Ask on code lines](https://qodo-merge-docs.qodo.ai/tools/ask/#ask-lines) | ✅ | ✅ | | |
|
||||
| | [Update CHANGELOG](https://qodo-merge-docs.qodo.ai/tools/update_changelog/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Ticket Context](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [Utilizing Best Practices](https://qodo-merge-docs.qodo.ai/tools/improve/#best-practices) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [PR Chat](https://qodo-merge-docs.qodo.ai/chrome-extension/features/#pr-chat) 💎 | ✅ | | | |
|
||||
| | [Suggestion Tracking](https://qodo-merge-docs.qodo.ai/tools/improve/#suggestion-tracking) 💎 | ✅ | ✅ | | |
|
||||
| TOOLS | [Review](https://qodo-merge-docs.qodo.ai/tools/review/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Describe](https://qodo-merge-docs.qodo.ai/tools/describe/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Improve](https://qodo-merge-docs.qodo.ai/tools/improve/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Ask](https://qodo-merge-docs.qodo.ai/tools/ask/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ [Ask on code lines](https://qodo-merge-docs.qodo.ai/tools/ask/#ask-lines) | ✅ | ✅ | | |
|
||||
| | [Update CHANGELOG](https://qodo-merge-docs.qodo.ai/tools/update_changelog/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Help Docs](https://qodo-merge-docs.qodo.ai/tools/help_docs/?h=auto#auto-approval) | ✅ | ✅ | ✅ | |
|
||||
| | [Ticket Context](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [Utilizing Best Practices](https://qodo-merge-docs.qodo.ai/tools/improve/#best-practices) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [PR Chat](https://qodo-merge-docs.qodo.ai/chrome-extension/features/#pr-chat) 💎 | ✅ | | | |
|
||||
| | [Suggestion Tracking](https://qodo-merge-docs.qodo.ai/tools/improve/#suggestion-tracking) 💎 | ✅ | ✅ | | |
|
||||
| | [CI Feedback](https://qodo-merge-docs.qodo.ai/tools/ci_feedback/) 💎 | ✅ | | | |
|
||||
| | [PR Documentation](https://qodo-merge-docs.qodo.ai/tools/documentation/) 💎 | ✅ | ✅ | | |
|
||||
| | [PR Documentation](https://qodo-merge-docs.qodo.ai/tools/documentation/) 💎 | ✅ | ✅ | | |
|
||||
| | [Custom Labels](https://qodo-merge-docs.qodo.ai/tools/custom_labels/) 💎 | ✅ | ✅ | | |
|
||||
| | [Analyze](https://qodo-merge-docs.qodo.ai/tools/analyze/) 💎 | ✅ | ✅ | | |
|
||||
| | [Similar Code](https://qodo-merge-docs.qodo.ai/tools/similar_code/) 💎 | ✅ | | | |
|
||||
@ -118,21 +110,21 @@ Supported commands per platform:
|
||||
| | [Implement](https://qodo-merge-docs.qodo.ai/tools/implement/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [Auto-Approve](https://qodo-merge-docs.qodo.ai/tools/improve/?h=auto#auto-approval) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | | | | | |
|
||||
| USAGE | [CLI](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#local-repo-cli) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [App / webhook](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#github-app) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Tagging bot](https://github.com/Codium-ai/pr-agent#try-it-now) | ✅ | | | |
|
||||
| | [Actions](https://qodo-merge-docs.qodo.ai/installation/github/#run-as-a-github-action) | ✅ |✅| ✅ |✅|
|
||||
| USAGE | [CLI](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#local-repo-cli) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [App / webhook](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#github-app) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Tagging bot](https://github.com/Codium-ai/pr-agent#try-it-now) | ✅ | | | |
|
||||
| | [Actions](https://qodo-merge-docs.qodo.ai/installation/github/#run-as-a-github-action) | ✅ |✅| ✅ |✅|
|
||||
| | | | | | |
|
||||
| CORE | [PR compression](https://qodo-merge-docs.qodo.ai/core-abilities/compression_strategy/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| CORE | [PR compression](https://qodo-merge-docs.qodo.ai/core-abilities/compression_strategy/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Adaptive and token-aware file patch fitting | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Multiple models support](https://qodo-merge-docs.qodo.ai/usage-guide/changing_a_model/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Local and global metadata](https://qodo-merge-docs.qodo.ai/core-abilities/metadata/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Dynamic context](https://qodo-merge-docs.qodo.ai/core-abilities/dynamic_context/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Self reflection](https://qodo-merge-docs.qodo.ai/core-abilities/self_reflection/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Multiple models support](https://qodo-merge-docs.qodo.ai/usage-guide/changing_a_model/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Local and global metadata](https://qodo-merge-docs.qodo.ai/core-abilities/metadata/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Dynamic context](https://qodo-merge-docs.qodo.ai/core-abilities/dynamic_context/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Self reflection](https://qodo-merge-docs.qodo.ai/core-abilities/self_reflection/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Static code analysis](https://qodo-merge-docs.qodo.ai/core-abilities/static_code_analysis/) 💎 | ✅ | ✅ | | |
|
||||
| | [Global and wiki configurations](https://qodo-merge-docs.qodo.ai/usage-guide/configuration_options/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [PR interactive actions](https://www.qodo.ai/images/pr_agent/pr-actions.mp4) 💎 | ✅ | ✅ | | |
|
||||
| | [Impact Evaluation](https://qodo-merge-docs.qodo.ai/core-abilities/impact_evaluation/) 💎 | ✅ | ✅ | | |
|
||||
| | [PR interactive actions](https://www.qodo.ai/images/pr_agent/pr-actions.mp4) 💎 | ✅ | ✅ | | |
|
||||
| | [Impact Evaluation](https://qodo-merge-docs.qodo.ai/core-abilities/impact_evaluation/) 💎 | ✅ | ✅ | | |
|
||||
- 💎 means this feature is available only in [Qodo-Merge](https://www.qodo.ai/pricing/)
|
||||
|
||||
[//]: # (- Support for additional git providers is described in [here](./docs/Full_environments.md))
|
||||
@ -148,7 +140,7 @@ ___
|
||||
\
|
||||
‣ **Update Changelog ([`/update_changelog`](https://qodo-merge-docs.qodo.ai/tools/update_changelog/))**: Automatically updating the CHANGELOG.md file with the PR changes.
|
||||
\
|
||||
‣ **Find Similar Issue ([`/similar_issue`](https://qodo-merge-docs.qodo.ai/tools/similar_issues/))**: Automatically retrieves and presents similar issues.
|
||||
‣ **Help Docs ([`/help_docs`](https://qodo-merge-docs.qodo.ai/tools/help_docs/))**: Answers a question on any repository by utilizing given documentation.
|
||||
\
|
||||
‣ **Add Documentation 💎 ([`/add_docs`](https://qodo-merge-docs.qodo.ai/tools/documentation/))**: Generates documentation to methods/functions/classes that changed in the PR.
|
||||
\
|
||||
@ -208,7 +200,7 @@ ___
|
||||
|
||||
## Try it now
|
||||
|
||||
Try the GPT-4 powered PR-Agent instantly on _your public GitHub repository_. Just mention `@CodiumAI-Agent` and add the desired command in any PR comment. The agent will generate a response based on your command.
|
||||
Try the Claude Sonnet powered PR-Agent instantly on _your public GitHub repository_. Just mention `@CodiumAI-Agent` and add the desired command in any PR comment. The agent will generate a response based on your command.
|
||||
For example, add a comment to any pull request with the following text:
|
||||
```
|
||||
@CodiumAI-Agent /review
|
||||
@ -246,10 +238,10 @@ A reasonable question that can be asked is: `"Why use PR-Agent? What makes it st
|
||||
|
||||
Here are some advantages of PR-Agent:
|
||||
|
||||
- We emphasize **real-life practical usage**. Each tool (review, improve, ask, ...) has a single GPT-4 call, no more. We feel that this is critical for realistic team usage - obtaining an answer quickly (~30 seconds) and affordably.
|
||||
- We emphasize **real-life practical usage**. Each tool (review, improve, ask, ...) has a single LLM call, no more. We feel that this is critical for realistic team usage - obtaining an answer quickly (~30 seconds) and affordably.
|
||||
- Our [PR Compression strategy](https://qodo-merge-docs.qodo.ai/core-abilities/#pr-compression-strategy) is a core ability that enables to effectively tackle both short and long PRs.
|
||||
- Our JSON prompting strategy enables to have **modular, customizable tools**. For example, the '/review' tool categories can be controlled via the [configuration](pr_agent/settings/configuration.toml) file. Adding additional categories is easy and accessible.
|
||||
- We support **multiple git providers** (GitHub, Gitlab, Bitbucket), **multiple ways** to use the tool (CLI, GitHub Action, GitHub App, Docker, ...), and **multiple models** (GPT-4, GPT-3.5, Anthropic, Cohere, Llama2).
|
||||
- We support **multiple git providers** (GitHub, Gitlab, Bitbucket), **multiple ways** to use the tool (CLI, GitHub Action, GitHub App, Docker, ...), and **multiple models** (GPT, Claude, Deepseek, ...)
|
||||
|
||||
|
||||
## Data privacy
|
||||
|
||||
199
best_practices.md
Normal file
199
best_practices.md
Normal file
@ -0,0 +1,199 @@
|
||||
|
||||
<b>Pattern 1: Wrap critical operations with try-except blocks to handle potential exceptions, especially for file operations, API calls, and data parsing functions.</b>
|
||||
|
||||
Example code before:
|
||||
```
|
||||
def get_git_repo_url(self, issues_or_pr_url: str) -> str:
|
||||
repo_path = self._get_owner_and_repo_path(issues_or_pr_url)
|
||||
if not repo_path or repo_path not in issues_or_pr_url:
|
||||
get_logger().error(f"Unable to retrieve owner/path from url: {issues_or_pr_url}")
|
||||
return ""
|
||||
return f"{issues_or_pr_url.split(repo_path)[0]}{repo_path}.git"
|
||||
```
|
||||
|
||||
Example code after:
|
||||
```
|
||||
def get_git_repo_url(self, issues_or_pr_url: str) -> str:
|
||||
try:
|
||||
repo_path = self._get_owner_and_repo_path(issues_or_pr_url)
|
||||
if not repo_path or repo_path not in issues_or_pr_url:
|
||||
get_logger().error(f"Unable to retrieve owner/path from url: {issues_or_pr_url}")
|
||||
return ""
|
||||
return f"{issues_or_pr_url.split(repo_path)[0]}{repo_path}.git"
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to get git repo url from {issues_or_pr_url}, error: {e}")
|
||||
return ""
|
||||
```
|
||||
|
||||
<details><summary>Examples for relevant past discussions:</summary>
|
||||
|
||||
- https://github.com/qodo-ai/pr-agent/pull/1644#discussion_r2013912636
|
||||
- https://github.com/qodo-ai/pr-agent/pull/1263#discussion_r1782129216
|
||||
- https://github.com/qodo-ai/pr-agent/pull/1391#discussion_r1879870807
|
||||
</details>
|
||||
|
||||
|
||||
___
|
||||
|
||||
<b>Pattern 2: Use proper logging methods instead of print statements, with get_logger().error() for errors, get_logger().warning() for warnings, and get_logger().info() for informational messages.</b>
|
||||
|
||||
Example code before:
|
||||
```
|
||||
if isinstance(response_tuple, tuple) and len(response_tuple) == 3:
|
||||
response_json = json.loads(response_tuple[2])
|
||||
else:
|
||||
print("Unexpected response format:", response_tuple)
|
||||
return sub_issues
|
||||
```
|
||||
|
||||
Example code after:
|
||||
```
|
||||
if isinstance(response_tuple, tuple) and len(response_tuple) == 3:
|
||||
response_json = json.loads(response_tuple[2])
|
||||
else:
|
||||
get_logger().error(f"Unexpected response format", artifact={"response": response_tuple})
|
||||
return sub_issues
|
||||
```
|
||||
|
||||
<details><summary>Examples for relevant past discussions:</summary>
|
||||
|
||||
- https://github.com/qodo-ai/pr-agent/pull/1529#discussion_r1958684550
|
||||
- https://github.com/qodo-ai/pr-agent/pull/1529#discussion_r1958686068
|
||||
- https://github.com/qodo-ai/pr-agent/pull/1529#discussion_r1964110734
|
||||
- https://github.com/qodo-ai/pr-agent/pull/1634#discussion_r2007976915
|
||||
</details>
|
||||
|
||||
|
||||
___
|
||||
|
||||
<b>Pattern 3: Move specific imports to where they are actually used rather than at the top of the file, especially for rarely used or heavy dependencies.</b>
|
||||
|
||||
Example code before:
|
||||
```
|
||||
import os
|
||||
from azure.identity import ClientSecretCredential
|
||||
import litellm
|
||||
import openai
|
||||
import requests
|
||||
```
|
||||
|
||||
Example code after:
|
||||
```
|
||||
import os
|
||||
import litellm
|
||||
import openai
|
||||
import requests
|
||||
|
||||
# Later in the code where Azure AD is actually used:
|
||||
if get_settings().get("AZURE_AD.CLIENT_ID", None):
|
||||
from azure.identity import ClientSecretCredential
|
||||
# Azure AD specific code...
|
||||
```
|
||||
|
||||
<details><summary>Examples for relevant past discussions:</summary>
|
||||
|
||||
- https://github.com/qodo-ai/pr-agent/pull/1698#discussion_r2046221654
|
||||
</details>
|
||||
|
||||
|
||||
___
|
||||
|
||||
<b>Pattern 4: Add defensive checks for potentially None or invalid values before performing operations on them, especially when working with external data or API responses.</b>
|
||||
|
||||
Example code before:
|
||||
```
|
||||
model_is_from_o_series = re.match(r"^o[1-9](-mini|-preview)?$", model)
|
||||
if ('gpt' in get_settings().config.model.lower() or model_is_from_o_series) and get_settings().get('openai.key'):
|
||||
return encoder_estimate
|
||||
```
|
||||
|
||||
Example code after:
|
||||
```
|
||||
if model is None:
|
||||
get_logger().warning("Model is None, cannot determine model type accurately")
|
||||
return encoder_estimate
|
||||
|
||||
if not isinstance(model, str):
|
||||
get_logger().warning(f"Model is not a string type: {type(model)}")
|
||||
return encoder_estimate
|
||||
|
||||
model_is_from_o_series = re.match(r"^o[1-9](-mini|-preview)?$", model)
|
||||
openai_key_exists = get_settings().get('openai.key') is not None
|
||||
|
||||
if (('gpt' in model.lower() or model_is_from_o_series) and openai_key_exists):
|
||||
return encoder_estimate
|
||||
```
|
||||
|
||||
<details><summary>Examples for relevant past discussions:</summary>
|
||||
|
||||
- https://github.com/qodo-ai/pr-agent/pull/1644#discussion_r2032621065
|
||||
- https://github.com/qodo-ai/pr-agent/pull/1529#discussion_r1958694146
|
||||
- https://github.com/qodo-ai/pr-agent/pull/1391#discussion_r1879875496
|
||||
</details>
|
||||
|
||||
|
||||
___
|
||||
|
||||
<b>Pattern 5: Avoid redundant code initialization and reuse existing objects or instances when possible, especially for resource-intensive operations.</b>
|
||||
|
||||
Example code before:
|
||||
```
|
||||
if tickets:
|
||||
provider = GithubProvider()
|
||||
|
||||
for ticket in tickets:
|
||||
# Extract sub-issues
|
||||
sub_issues_content = []
|
||||
try:
|
||||
sub_issues = provider.fetch_sub_issues(ticket)
|
||||
```
|
||||
|
||||
Example code after:
|
||||
```
|
||||
if tickets:
|
||||
for ticket in tickets:
|
||||
# Extract sub-issues
|
||||
sub_issues_content = []
|
||||
try:
|
||||
sub_issues = git_provider.fetch_sub_issues(ticket)
|
||||
```
|
||||
|
||||
<details><summary>Examples for relevant past discussions:</summary>
|
||||
|
||||
- https://github.com/qodo-ai/pr-agent/pull/1529#discussion_r1964085987
|
||||
- https://github.com/qodo-ai/pr-agent/pull/1529#discussion_r1964088304
|
||||
</details>
|
||||
|
||||
|
||||
___
|
||||
|
||||
<b>Pattern 6: Use descriptive variable names and add explanatory comments for complex logic or non-obvious code to improve maintainability and readability.</b>
|
||||
|
||||
Example code before:
|
||||
```
|
||||
issues = value
|
||||
for i, issue in enumerate(issues):
|
||||
try:
|
||||
if not issue or not isinstance(issue, dict):
|
||||
continue
|
||||
```
|
||||
|
||||
Example code after:
|
||||
```
|
||||
focus_areas = value
|
||||
for i, focus_area in enumerate(focus_areas):
|
||||
try:
|
||||
# Skip empty issues or non-dictionary items to ensure valid data structure
|
||||
if not focus_area or not isinstance(focus_area, dict):
|
||||
continue
|
||||
```
|
||||
|
||||
<details><summary>Examples for relevant past discussions:</summary>
|
||||
|
||||
- https://github.com/qodo-ai/pr-agent/pull/1262#discussion_r1782097201
|
||||
- https://github.com/qodo-ai/pr-agent/pull/1262#discussion_r1782097204
|
||||
- https://github.com/qodo-ai/pr-agent/pull/1583#discussion_r1971790979
|
||||
</details>
|
||||
|
||||
|
||||
___
|
||||
@ -1,10 +1,10 @@
|
||||
FROM public.ecr.aws/lambda/python:3.10
|
||||
FROM public.ecr.aws/lambda/python:3.12
|
||||
|
||||
RUN yum update -y && \
|
||||
yum install -y gcc python3-devel git && \
|
||||
yum clean all
|
||||
RUN dnf update -y && \
|
||||
dnf install -y gcc python3-devel git && \
|
||||
dnf clean all
|
||||
|
||||
ADD pyproject.toml requirements.txt .
|
||||
ADD pyproject.toml requirements.txt ./
|
||||
RUN pip install --no-cache-dir . && rm pyproject.toml
|
||||
RUN pip install --no-cache-dir mangum==0.17.0
|
||||
COPY pr_agent/ ${LAMBDA_TASK_ROOT}/pr_agent/
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
|
||||
With a single-click installation you will gain access to a context-aware chat on your pull requests code, a toolbar extension with multiple AI feedbacks, Qodo Merge filters, and additional abilities.
|
||||
|
||||
The extension is powered by top code models like Claude 3.5 Sonnet and GPT4. All the extension's features are free to use on public repositories.
|
||||
The extension is powered by top code models like Claude 3.7 Sonnet and o3-mini. All the extension's features are free to use on public repositories.
|
||||
|
||||
For private repositories, you will need to install [Qodo Merge](https://github.com/apps/qodo-merge-pro){:target="_blank"} in addition to the extension (Quick GitHub app setup with a 14-day free trial. No credit card needed).
|
||||
For a demonstration of how to install Qodo Merge and use it with the Chrome extension, please refer to the tutorial video at the provided [link](https://codium.ai/images/pr_agent/private_repos.mp4){:target="_blank"}.
|
||||
|
||||
41
docs/docs/chrome-extension/options.md
Normal file
41
docs/docs/chrome-extension/options.md
Normal file
@ -0,0 +1,41 @@
|
||||
## Options and Configurations
|
||||
|
||||
### Accessing the Options Page
|
||||
|
||||
To access the options page for the Qodo Merge Chrome extension:
|
||||
|
||||
1. Find the extension icon in your Chrome toolbar (usually in the top-right corner of your browser)
|
||||
2. Right-click on the extension icon
|
||||
3. Select "Options" from the context menu that appears
|
||||
|
||||
Alternatively, you can access the options page directly using this URL:
|
||||
|
||||
[chrome-extension://ephlnjeghhogofkifjloamocljapahnl/options.html](chrome-extension://ephlnjeghhogofkifjloamocljapahnl/options.html)
|
||||
|
||||
<img src="https://codium.ai/images/pr_agent/chrome_ext_options.png" width="256">
|
||||
|
||||
|
||||
### Configuration Options
|
||||
|
||||
<img src="https://codium.ai/images/pr_agent/chrome_ext_settings_page.png" width="512">
|
||||
|
||||
|
||||
#### API Base Host
|
||||
|
||||
For single-tenant customers, you can configure the extension to communicate directly with your company's Qodo Merge server instance.
|
||||
|
||||
To set this up:
|
||||
|
||||
- Enter your organization's Qodo Merge API endpoint in the "API Base Host" field
|
||||
- This endpoint should be provided by your Qodo DevOps Team
|
||||
|
||||
*Note: The extension does not send your code to the server, but only triggers your previously installed Qodo Merge application.*
|
||||
|
||||
#### Interface Options
|
||||
|
||||
You can customize the extension's interface by:
|
||||
|
||||
- Toggling the "Show Qodo Merge Toolbar" option
|
||||
- When disabled, the toolbar will not appear in your Github comment bar
|
||||
|
||||
Remember to click "Save Settings" after making any changes.
|
||||
@ -1,2 +0,0 @@
|
||||
## Overview
|
||||
TBD
|
||||
39
docs/docs/core-abilities/code_validation.md
Normal file
39
docs/docs/core-abilities/code_validation.md
Normal file
@ -0,0 +1,39 @@
|
||||
## Introduction
|
||||
The Git environment usually represents the final stage before code enters production. Hence, Detecting bugs and issues during the review process is critical.
|
||||
|
||||
The [`improve`](https://qodo-merge-docs.qodo.ai/tools/improve/) tool provides actionable code suggestions for your pull requests, aiming to help detect and fix bugs and problems.
|
||||
By default, suggestions appear as a comment in a table format:
|
||||
|
||||
{width=512}
|
||||
|
||||
{width=512}
|
||||
|
||||
## Validation of Code Suggestions
|
||||
|
||||
Each suggestion in the table can be "applied" by clicking on the `Apply this suggestion` checkbox, converting it to a committable Git code change that can be committed directly to the PR.
|
||||
This approach allows to fix issues without returning to your IDE for manual edits — significantly faster and more convenient.
|
||||
|
||||
However, committing a suggestion in a Git environment carries more risk than in a local IDE, as you don't have the opportunity to fully run and test the code before committing.
|
||||
|
||||
To balance convenience with safety, Qodo Merge implements a dual validation system for each generated code suggestion:
|
||||
|
||||
1) **Localization** - Qodo Merge confirms that the suggestion's line numbers and surrounding code, as predicted by the model, actually match the repo code. This means that the model correctly identified the context and location of the code to be changed.
|
||||
|
||||
2) **"Compilation"** - Using static code analysis, Qodo Merge verifies that after applying the suggestion, the modified file will still be valid, meaning tree-sitter syntax processing will not throw an error. This process is relevant for multiple programming languages, see [here](https://pypi.org/project/tree-sitter-languages/) for the full list of supported languages.
|
||||
|
||||
When a suggestion fails to meet these validation criteria, it may still provide valuable feedback, but isn't suitable for direct application to the PR.
|
||||
In such cases, Qodo Merge will omit the 'apply' checkbox and instead display:
|
||||
|
||||
`[To ensure code accuracy, apply this suggestion manually]`
|
||||
|
||||
All suggestions that pass these validations undergo a final stage of **self-reflection**, where the AI model evaluates, scores, and re-ranks its own suggestions, eliminating any that are irrelevant or incorrect.
|
||||
Read more about this process in the [self-reflection](https://qodo-merge-docs.qodo.ai/core-abilities/self_reflection/) page.
|
||||
|
||||
## Conclusion
|
||||
|
||||
The validation methods described above enhance the reliability of code suggestions and help PR authors determine which suggestions are safer to apply in the Git environment.
|
||||
Of course, additional factors should be considered, such as suggestion complexity and potential code impact.
|
||||
|
||||
Human judgment remains essential. After clicking 'apply', Qodo Merge still presents the 'before' and 'after' code snippets for review, allowing you to assess the changes before finalizing the commit.
|
||||
|
||||
{width=512}
|
||||
@ -2,14 +2,15 @@
|
||||
`Supported Git Platforms: GitHub, GitLab, Bitbucket`
|
||||
|
||||
## Overview
|
||||
Qodo Merge PR Agent streamlines code review workflows by seamlessly connecting with multiple ticket management systems.
|
||||
Qodo Merge streamlines code review workflows by seamlessly connecting with multiple ticket management systems.
|
||||
This integration enriches the review process by automatically surfacing relevant ticket information and context alongside code changes.
|
||||
|
||||
## Ticket systems supported
|
||||
**Ticket systems supported**:
|
||||
|
||||
- GitHub
|
||||
- Jira (💎)
|
||||
|
||||
Ticket data fetched:
|
||||
**Ticket data fetched:**
|
||||
|
||||
1. Ticket Title
|
||||
2. Ticket Description
|
||||
@ -26,7 +27,7 @@ Ticket Recognition Requirements:
|
||||
- For Jira tickets, you should follow the instructions in [Jira Integration](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/#jira-integration) in order to authenticate with Jira.
|
||||
|
||||
### Describe tool
|
||||
Qodo Merge PR Agent will recognize the ticket and use the ticket content (title, description, labels) to provide additional context for the code changes.
|
||||
Qodo Merge will recognize the ticket and use the ticket content (title, description, labels) to provide additional context for the code changes.
|
||||
By understanding the reasoning and intent behind modifications, the LLM can offer more insightful and relevant code analysis.
|
||||
|
||||
### Review tool
|
||||
@ -46,41 +47,22 @@ If you want to disable this feedback, add the following line to your configurati
|
||||
require_ticket_analysis_review=false
|
||||
```
|
||||
|
||||
## Providers
|
||||
## GitHub Issues Integration
|
||||
|
||||
### Github Issues Integration
|
||||
|
||||
Qodo Merge PR Agent will automatically recognize Github issues mentioned in the PR description and fetch the issue content.
|
||||
Qodo Merge will automatically recognize GitHub issues mentioned in the PR description and fetch the issue content.
|
||||
Examples of valid GitHub issue references:
|
||||
|
||||
- `https://github.com/<ORG_NAME>/<REPO_NAME>/issues/<ISSUE_NUMBER>`
|
||||
- `#<ISSUE_NUMBER>`
|
||||
- `<ORG_NAME>/<REPO_NAME>#<ISSUE_NUMBER>`
|
||||
|
||||
Since Qodo Merge PR Agent is integrated with GitHub, it doesn't require any additional configuration to fetch GitHub issues.
|
||||
Since Qodo Merge is integrated with GitHub, it doesn't require any additional configuration to fetch GitHub issues.
|
||||
|
||||
### Jira Integration 💎
|
||||
## Jira Integration 💎
|
||||
|
||||
We support both Jira Cloud and Jira Server/Data Center.
|
||||
To integrate with Jira, you can link your PR to a ticket using either of these methods:
|
||||
|
||||
**Method 1: Description Reference:**
|
||||
|
||||
Include a ticket reference in your PR description using either the complete URL format https://<JIRA_ORG>.atlassian.net/browse/ISSUE-123 or the shortened ticket ID ISSUE-123.
|
||||
|
||||
**Method 2: Branch Name Detection:**
|
||||
|
||||
Name your branch with the ticket ID as a prefix (e.g., `ISSUE-123-feature-description` or `ISSUE-123/feature-description`).
|
||||
|
||||
!!! note "Jira Base URL"
|
||||
For shortened ticket IDs or branch detection (method 2), you must configure the Jira base URL in your configuration file under the [jira] section:
|
||||
|
||||
```toml
|
||||
[jira]
|
||||
jira_base_url = "https://<JIRA_ORG>.atlassian.net"
|
||||
```
|
||||
|
||||
#### Jira Cloud 💎
|
||||
### Jira Cloud
|
||||
There are two ways to authenticate with Jira Cloud:
|
||||
|
||||
**1) Jira App Authentication**
|
||||
@ -95,7 +77,7 @@ Installation steps:
|
||||
2. After installing the app, you will be redirected to the Qodo Merge registration page. and you will see a success message.<br>
|
||||
{width=384}
|
||||
|
||||
3. Now you can use the Jira integration in Qodo Merge PR Agent.
|
||||
3. Now Qodo Merge will be able to fetch Jira ticket context for your PRs.
|
||||
|
||||
**2) Email/Token Authentication**
|
||||
|
||||
@ -120,45 +102,70 @@ jira_api_email = "YOUR_EMAIL"
|
||||
```
|
||||
|
||||
|
||||
#### Jira Data Center/Server 💎
|
||||
### Jira Data Center/Server
|
||||
|
||||
##### Local App Authentication (For Qodo Merge On-Premise Customers)
|
||||
[//]: # ()
|
||||
[//]: # (##### Local App Authentication (For Qodo Merge On-Premise Customers))
|
||||
|
||||
##### 1. Step 1: Set up an application link in Jira Data Center/Server
|
||||
* Go to Jira Administration > Applications > Application Links > Click on `Create link`
|
||||
[//]: # ()
|
||||
[//]: # (##### 1. Step 1: Set up an application link in Jira Data Center/Server)
|
||||
|
||||
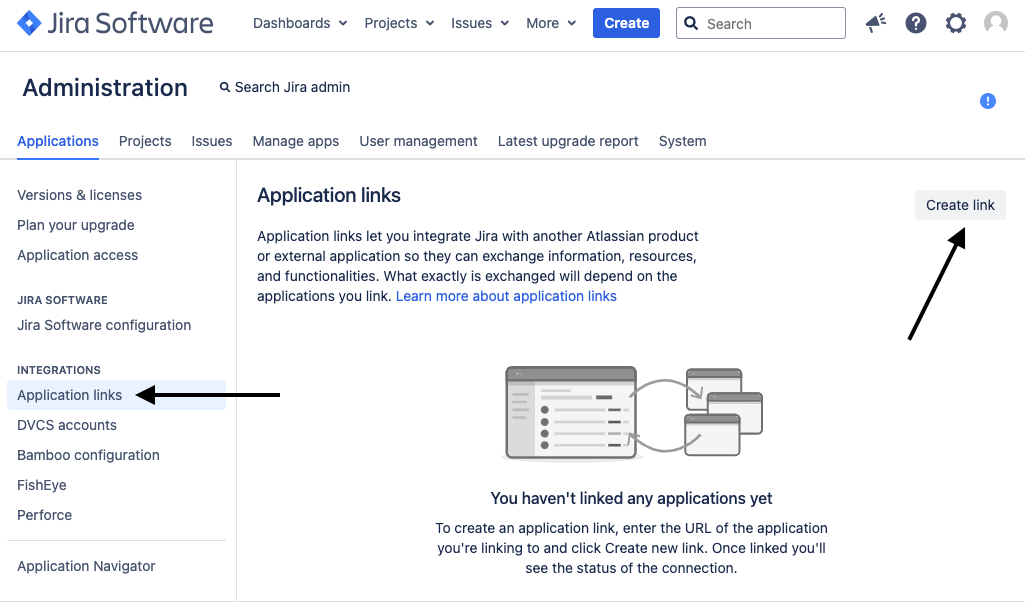{width=384}
|
||||
* Choose `External application` and set the direction to `Incoming` and then click `Continue`
|
||||
[//]: # (* Go to Jira Administration > Applications > Application Links > Click on `Create link`)
|
||||
|
||||
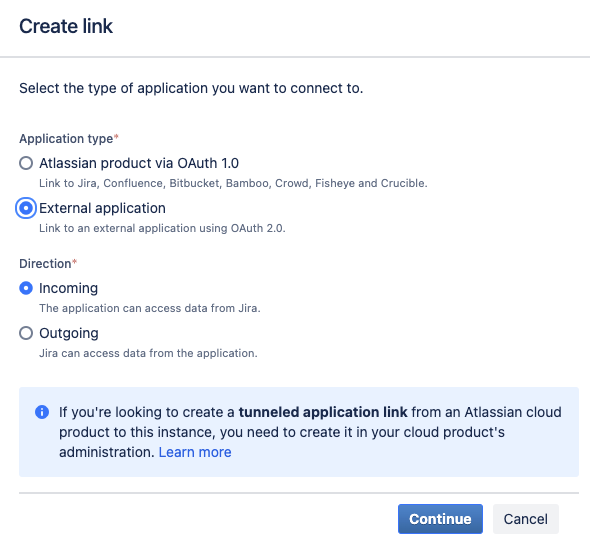{width=256}
|
||||
* In the following screen, enter the following details:
|
||||
* Name: `Qodo Merge`
|
||||
* Redirect URL: Enter your Qodo Merge URL followed `https://{QODO_MERGE_ENDPOINT}/register_ticket_provider`
|
||||
* Permission: Select `Read`
|
||||
* Click `Save`
|
||||
[//]: # ()
|
||||
[//]: # ({width=384})
|
||||
|
||||
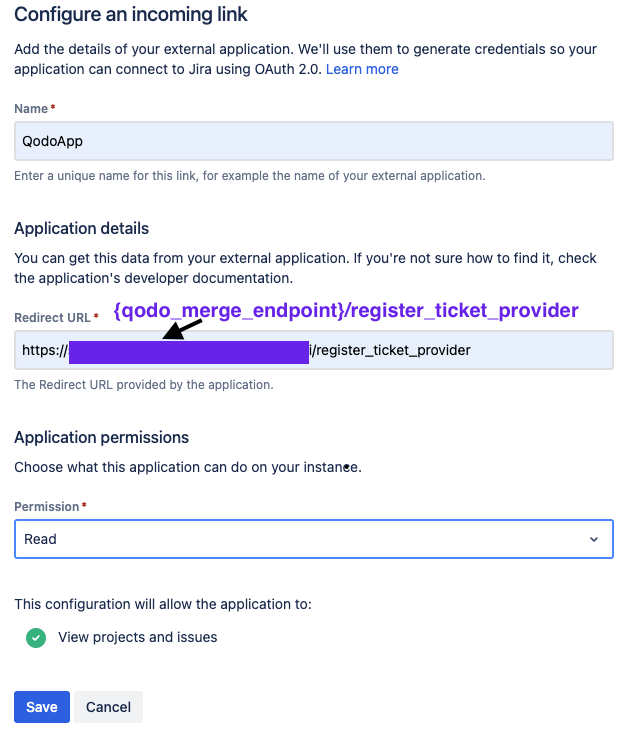{width=384}
|
||||
* Copy the `Client ID` and `Client secret` and set them in your `.secrets` file:
|
||||
[//]: # (* Choose `External application` and set the direction to `Incoming` and then click `Continue`)
|
||||
|
||||
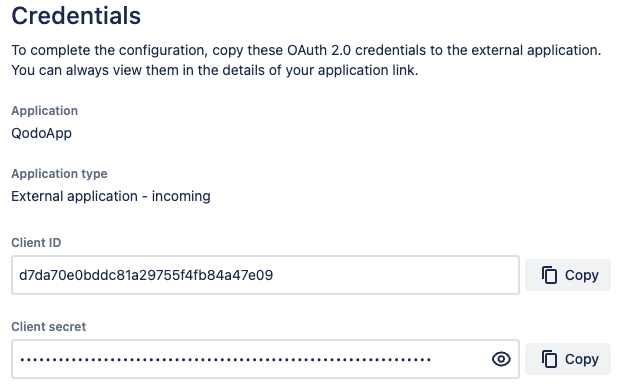{width=256}
|
||||
```toml
|
||||
[jira]
|
||||
jira_app_secret = "..."
|
||||
jira_client_id = "..."
|
||||
```
|
||||
[//]: # ()
|
||||
[//]: # ({width=256})
|
||||
|
||||
##### 2. Step 2: Authenticate with Jira Data Center/Server
|
||||
* Open this URL in your browser: `https://{QODO_MERGE_ENDPOINT}/jira_auth`
|
||||
* Click on link
|
||||
[//]: # (* In the following screen, enter the following details:)
|
||||
|
||||
{width=384}
|
||||
[//]: # ( * Name: `Qodo Merge`)
|
||||
|
||||
* You will be redirected to Jira Data Center/Server, click `Allow`
|
||||
* You will be redirected back to Qodo Merge PR Agent and you will see a success message.
|
||||
[//]: # ( * Redirect URL: Enter your Qodo Merge URL followed `https://{QODO_MERGE_ENDPOINT}/register_ticket_provider`)
|
||||
|
||||
[//]: # ( * Permission: Select `Read`)
|
||||
|
||||
[//]: # ( * Click `Save`)
|
||||
|
||||
[//]: # ()
|
||||
[//]: # ({width=384})
|
||||
|
||||
[//]: # (* Copy the `Client ID` and `Client secret` and set them in your `.secrets` file:)
|
||||
|
||||
[//]: # ()
|
||||
[//]: # ({width=256})
|
||||
|
||||
[//]: # (```toml)
|
||||
|
||||
[//]: # ([jira])
|
||||
|
||||
[//]: # (jira_app_secret = "...")
|
||||
|
||||
[//]: # (jira_client_id = "...")
|
||||
|
||||
[//]: # (```)
|
||||
|
||||
[//]: # ()
|
||||
[//]: # (##### 2. Step 2: Authenticate with Jira Data Center/Server)
|
||||
|
||||
[//]: # (* Open this URL in your browser: `https://{QODO_MERGE_ENDPOINT}/jira_auth`)
|
||||
|
||||
[//]: # (* Click on link)
|
||||
|
||||
[//]: # ()
|
||||
[//]: # ({width=384})
|
||||
|
||||
[//]: # ()
|
||||
[//]: # (* You will be redirected to Jira Data Center/Server, click `Allow`)
|
||||
|
||||
[//]: # (* You will be redirected back to Qodo Merge and you will see a success message.)
|
||||
|
||||
|
||||
##### Personal Access Token (PAT) Authentication
|
||||
We also support Personal Access Token (PAT) Authentication method.
|
||||
[//]: # (Personal Access Token (PAT) Authentication)
|
||||
Currently, JIRA integration for Data Center/Server is available via Personal Access Token (PAT) Authentication method
|
||||
|
||||
1. Create a [Personal Access Token (PAT)](https://confluence.atlassian.com/enterprise/using-personal-access-tokens-1026032365.html) in your Jira account
|
||||
2. In your Configuration file/Environment variables/Secrets file, add the following lines:
|
||||
@ -168,3 +175,67 @@ We also support Personal Access Token (PAT) Authentication method.
|
||||
jira_base_url = "YOUR_JIRA_BASE_URL" # e.g. https://jira.example.com
|
||||
jira_api_token = "YOUR_API_TOKEN"
|
||||
```
|
||||
|
||||
#### Validating PAT token via Python script
|
||||
|
||||
If you are facing issues retrieving tickets in Qodo Merge with PAT token, you can validate the flow using a Python script.
|
||||
This following steps will help you check if the token is working correctly, and if you can access the Jira ticket details:
|
||||
|
||||
1. run `pip install jira==3.8.0`
|
||||
|
||||
2. run the following Python script (after replacing the placeholders with your actual values):
|
||||
|
||||
??? example "Script to validate PAT token"
|
||||
|
||||
```python
|
||||
from jira import JIRA
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
try:
|
||||
# Jira server URL
|
||||
server = "https://..."
|
||||
# Jira PAT token
|
||||
token_auth = "..."
|
||||
# Jira ticket code (e.g. "PROJ-123")
|
||||
ticket_id = "..."
|
||||
|
||||
print("Initializing JiraServerTicketProvider with JIRA server")
|
||||
# Initialize JIRA client
|
||||
jira = JIRA(
|
||||
server=server,
|
||||
token_auth=token_auth,
|
||||
timeout=30
|
||||
)
|
||||
if jira:
|
||||
print(f"JIRA client initialized successfully")
|
||||
else:
|
||||
print("Error initializing JIRA client")
|
||||
|
||||
# Fetch ticket details
|
||||
ticket = jira.issue(ticket_id)
|
||||
print(f"Ticket title: {ticket.fields.summary}")
|
||||
|
||||
except Exception as e:
|
||||
print(f"Error fetching JIRA ticket details: {e}")
|
||||
```
|
||||
|
||||
### How to link a PR to a Jira ticket
|
||||
|
||||
To integrate with Jira, you can link your PR to a ticket using either of these methods:
|
||||
|
||||
**Method 1: Description Reference:**
|
||||
|
||||
Include a ticket reference in your PR description using either the complete URL format https://<JIRA_ORG>.atlassian.net/browse/ISSUE-123 or the shortened ticket ID ISSUE-123.
|
||||
|
||||
**Method 2: Branch Name Detection:**
|
||||
|
||||
Name your branch with the ticket ID as a prefix (e.g., `ISSUE-123-feature-description` or `ISSUE-123/feature-description`).
|
||||
|
||||
!!! note "Jira Base URL"
|
||||
For shortened ticket IDs or branch detection (method 2 for JIRA cloud), you must configure the Jira base URL in your configuration file under the [jira] section:
|
||||
|
||||
```toml
|
||||
[jira]
|
||||
jira_base_url = "https://<JIRA_ORG>.atlassian.net"
|
||||
```
|
||||
|
||||
@ -1,17 +1,18 @@
|
||||
# Core Abilities
|
||||
Qodo Merge utilizes a variety of core abilities to provide a comprehensive and efficient code review experience. These abilities include:
|
||||
|
||||
- [Fetching ticket context](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/)
|
||||
- [Auto best practices](https://qodo-merge-docs.qodo.ai/core-abilities/auto_best_practices/)
|
||||
- [Local and global metadata](https://qodo-merge-docs.qodo.ai/core-abilities/metadata/)
|
||||
- [Pull request benchmark](https://qodo-merge-docs.qodo.ai/finetuning_benchmark/)
|
||||
- [Code validation](https://qodo-merge-docs.qodo.ai/core-abilities/code_validation/)
|
||||
- [Compression strategy](https://qodo-merge-docs.qodo.ai/core-abilities/compression_strategy/)
|
||||
- [Dynamic context](https://qodo-merge-docs.qodo.ai/core-abilities/dynamic_context/)
|
||||
- [Self-reflection](https://qodo-merge-docs.qodo.ai/core-abilities/self_reflection/)
|
||||
- [Fetching ticket context](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/)
|
||||
- [Impact evaluation](https://qodo-merge-docs.qodo.ai/core-abilities/impact_evaluation/)
|
||||
- [Interactivity](https://qodo-merge-docs.qodo.ai/core-abilities/interactivity/)
|
||||
- [Compression strategy](https://qodo-merge-docs.qodo.ai/core-abilities/compression_strategy/)
|
||||
- [Code-oriented YAML](https://qodo-merge-docs.qodo.ai/core-abilities/code_oriented_yaml/)
|
||||
- [Local and global metadata](https://qodo-merge-docs.qodo.ai/core-abilities/metadata/)
|
||||
- [RAG context enrichment](https://qodo-merge-docs.qodo.ai/core-abilities/rag_context_enrichment/)
|
||||
- [Self-reflection](https://qodo-merge-docs.qodo.ai/core-abilities/self_reflection/)
|
||||
- [Static code analysis](https://qodo-merge-docs.qodo.ai/core-abilities/static_code_analysis/)
|
||||
- [Code fine-tuning benchmark](https://qodo-merge-docs.qodo.ai/finetuning_benchmark/)
|
||||
|
||||
## Blogs
|
||||
|
||||
|
||||
@ -1,2 +1,43 @@
|
||||
## Interactive invocation 💎
|
||||
TBD
|
||||
# Interactivity
|
||||
|
||||
`Supported Git Platforms: GitHub, GitLab`
|
||||
|
||||
## Overview
|
||||
|
||||
Qodo Merge transforms static code reviews into interactive experiences by enabling direct actions from pull request (PR) comments.
|
||||
Developers can immediately trigger actions and apply changes with simple checkbox clicks.
|
||||
|
||||
This focused workflow maintains context while dramatically reducing the time between PR creation and final merge.
|
||||
The approach eliminates manual steps, provides clear visual indicators, and creates immediate feedback loops all within the same interface.
|
||||
|
||||
## Key Interactive Features
|
||||
|
||||
### 1\. Interactive `/improve` Tool
|
||||
|
||||
The [`/improve`](https://qodo-merge-docs.qodo.ai/tools/improve/) command delivers a comprehensive interactive experience:
|
||||
|
||||
- _**Apply this suggestion**_: Clicking this checkbox instantly converts a suggestion into a committable code change. When committed to the PR, changes made to code that was flagged for improvement will be marked with a check mark, allowing developers to easily track and review implemented recommendations.
|
||||
|
||||
- _**More**_: Triggers additional suggestions generation while keeping each suggestion focused and relevant as the original set
|
||||
|
||||
- _**Update**_: Triggers a re-analysis of the code, providing updated suggestions based on the latest changes
|
||||
|
||||
- _**Author self-review**_: Interactive acknowledgment that developers have opened and reviewed collapsed suggestions
|
||||
|
||||
|
||||
### 2\. Interactive `/analyze` Tool
|
||||
|
||||
The [`/analyze`](https://qodo-merge-docs.qodo.ai/tools/analyze/) command provides component-level analysis with interactive options for each identified code component:
|
||||
|
||||
- Interactive checkboxes to generate tests, documentation, and code suggestions for specific components
|
||||
|
||||
- On-demand similar code search that activates when a checkbox is clicked
|
||||
|
||||
- Component-specific actions that trigger only for the selected elements, providing focused assistance
|
||||
|
||||
|
||||
### 3\. Interactive `/help` Tool
|
||||
|
||||
The [`/help`](https://qodo-merge-docs.qodo.ai/tools/help/) command not only lists available tools and their descriptions but also enables immediate tool invocation through interactive checkboxes.
|
||||
When a user checks a tool's checkbox, Qodo Merge instantly triggers that tool without requiring additional commands.
|
||||
This transforms the standard help menu into an interactive launch pad for all Qodo Merge capabilities, eliminating context switching by keeping developers within their PR workflow.
|
||||
|
||||
78
docs/docs/core-abilities/rag_context_enrichment.md
Normal file
78
docs/docs/core-abilities/rag_context_enrichment.md
Normal file
@ -0,0 +1,78 @@
|
||||
# RAG Context Enrichment 💎
|
||||
|
||||
`Supported Git Platforms: GitHub`
|
||||
|
||||
!!! info "Prerequisites"
|
||||
- RAG is available only for Qodo enterprise plan users, with single tenant or on-premises setup.
|
||||
- Database setup and codebase indexing must be completed before proceeding. [Contact support](https://www.qodo.ai/contact/) for more information.
|
||||
|
||||
|
||||
## Overview
|
||||
|
||||
### What is RAG Context Enrichment?
|
||||
|
||||
A feature that enhances AI analysis by retrieving and referencing relevant code patterns from your project, enabling context-aware insights during code reviews.
|
||||
|
||||
### How does RAG Context Enrichment work?
|
||||
|
||||
Using Retrieval-Augmented Generation (RAG), it searches your configured repositories for contextually relevant code segments, enriching pull request (PR) insights and accelerating review accuracy.
|
||||
|
||||
|
||||
## Getting started
|
||||
|
||||
### Configuration options
|
||||
|
||||
In order to enable the RAG feature, add the following lines to your configuration file:
|
||||
``` toml
|
||||
[rag_arguments]
|
||||
enable_rag=true
|
||||
```
|
||||
|
||||
!!! example "RAG Arguments Options"
|
||||
|
||||
<table>
|
||||
<tr>
|
||||
<td><b>enable_rag</b></td>
|
||||
<td>If set to true, repository enrichment using RAG will be enabled. Default is false.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>rag_repo_list</b></td>
|
||||
<td>A list of repositories that will be used by the semantic search for RAG. Use `['all']` to consider the entire codebase or a select list of repositories, for example: ['my-org/my-repo', ...]. Default: the repository from which the PR was opened.</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
### Applications
|
||||
|
||||
#### 1\. The `/review` Tool
|
||||
|
||||
The [`/review`](https://qodo-merge-docs.qodo.ai/tools/review/) tool offers the _Focus area from RAG data_ which contains feedback based on the RAG references analysis.
|
||||
The complete list of references found relevant to the PR will be shown in the _References_ section, helping developers understand the broader context by exploring the provided references.
|
||||
|
||||
{width=640}
|
||||
|
||||
#### 2\. The `/implement` Tool
|
||||
|
||||
The [`/implement`](https://qodo-merge-docs.qodo.ai/tools/implement/) tool utilizes the RAG feature to provide comprehensive context of the repository codebase, allowing it to generate more refined code output.
|
||||
The _References_ section contains links to the content used to support the code generation.
|
||||
|
||||
{width=640}
|
||||
|
||||
#### 3\. The `/ask` Tool
|
||||
|
||||
The [`/ask`](https://qodo-merge-docs.qodo.ai/tools/ask/) tool can access broader repository context through the RAG feature when answering questions that go beyond the PR scope alone.
|
||||
The _References_ section displays the additional repository content consulted to formulate the answer.
|
||||
|
||||
{width=640}
|
||||
|
||||
|
||||
## Limitations
|
||||
|
||||
### Querying the codebase presents significant challenges
|
||||
- **Search Method**: RAG uses natural language queries to find semantically relevant code sections
|
||||
- **Result Quality**: No guarantee that RAG results will be useful for all queries
|
||||
- **Scope Recommendation**: To reduce noise, focus on the PR repository rather than searching across multiple repositories
|
||||
|
||||
### This feature has several requirements and restrictions
|
||||
- **Codebase**: Must be properly indexed for search functionality
|
||||
- **Security**: Requires secure and private indexed codebase implementation
|
||||
- **Deployment**: Only available for Qodo Merge Enterprise plan using single tenant or on-premises setup
|
||||
@ -26,7 +26,7 @@ ___
|
||||
|
||||
#### Answer:<span style="display:none;">2</span>
|
||||
|
||||
- Modern AI models, like Claude 3.5 Sonnet and GPT-4, are improving rapidly but remain imperfect. Users should critically evaluate all suggestions rather than accepting them automatically.
|
||||
- Modern AI models, like Claude Sonnet and GPT-4, are improving rapidly but remain imperfect. Users should critically evaluate all suggestions rather than accepting them automatically.
|
||||
- AI errors are rare, but possible. A main value from reviewing the code suggestions lies in their high probability of catching **mistakes or bugs made by the PR author**. We believe it's worth spending 30-60 seconds reviewing suggestions, even if some aren't relevant, as this practice can enhance code quality and prevent bugs in production.
|
||||
|
||||
|
||||
|
||||
@ -1,10 +1,10 @@
|
||||
# Qodo Merge Code Fine-tuning Benchmark
|
||||
# Qodo Merge Pull Request Benchmark
|
||||
|
||||
On coding tasks, the gap between open-source models and top closed-source models such as GPT4 is significant.
|
||||
On coding tasks, the gap between open-source models and top closed-source models such as Claude and GPT is significant.
|
||||
<br>
|
||||
In practice, open-source models are unsuitable for most real-world code tasks, and require further fine-tuning to produce acceptable results.
|
||||
|
||||
_Qodo Merge fine-tuning benchmark_ aims to benchmark open-source models on their ability to be fine-tuned for a coding task.
|
||||
_Qodo Merge pull request benchmark_ aims to benchmark models on their ability to be fine-tuned for a coding task.
|
||||
Specifically, we chose to fine-tune open-source models on the task of analyzing a pull request, and providing useful feedback and code suggestions.
|
||||
|
||||
Here are the results:
|
||||
@ -49,7 +49,7 @@ Here are the results:
|
||||
- **The best small model** - For small 7B code-dedicated models, the gaps when fine-tuning are much larger. **CodeQWEN 1.5-7B** is by far the best model for fine-tuning.
|
||||
- **Base vs. instruct** - For the top model (deepseek), we saw small advantage when starting from the instruct version. However, we recommend testing both versions on each specific task, as the base model is generally considered more suitable for fine-tuning.
|
||||
|
||||
## The dataset
|
||||
## Dataset
|
||||
|
||||
### Training dataset
|
||||
|
||||
@ -68,7 +68,7 @@ Here are the prompts, and example outputs, used as input-output pairs to fine-tu
|
||||
|
||||
### Evaluation dataset
|
||||
|
||||
- For each tool, we aggregated 100 additional examples to be used for evaluation. These examples were not used in the training dataset, and were manually selected to represent diverse real-world use-cases.
|
||||
- For each tool, we aggregated 200 additional examples to be used for evaluation. These examples were not used in the training dataset, and were manually selected to represent diverse real-world use-cases.
|
||||
- For each test example, we generated two responses: one from the fine-tuned model, and one from the best code model in the world, `gpt-4-turbo-2024-04-09`.
|
||||
|
||||
- We used a third LLM to judge which response better answers the prompt, and will likely be perceived by a human as better response.
|
||||
@ -91,3 +91,11 @@ why: |
|
||||
actionable suggestions, such as changing variable names and adding comments, which are less
|
||||
critical for immediate code improvement."
|
||||
```
|
||||
|
||||
## Comparing Top Closed-Source Models
|
||||
|
||||
Another application of the Pull Request Benchmark is comparing leading closed-source models to determine which performs better at analyzing pull request code.
|
||||
|
||||
The evaluation methodology resembles the approach used for evaluating fine-tuned models:
|
||||
- We ran each model across 200 diverse pull requests, asking them to generate code suggestions using Qodo Merge's `improve` tool
|
||||
- A third top model served as judge to determine which response better fulfilled the prompt and would likely be perceived as superior by human users
|
||||
@ -9,6 +9,7 @@ Qodo Merge is a hosted version of PR-Agent, designed for companies and teams tha
|
||||
|
||||
- See the [Tools Guide](./tools/index.md) for a detailed description of the different tools.
|
||||
|
||||
- See the [Video Tutorials](https://www.youtube.com/playlist?list=PLRTpyDOSgbwFMA_VBeKMnPLaaZKwjGBFT) for practical demonstrations on how to use the tools.
|
||||
|
||||
## Docs Smart Search
|
||||
|
||||
@ -22,42 +23,51 @@ To search the documentation site using natural language:
|
||||
2) The bot will respond with an [answer](https://github.com/Codium-ai/pr-agent/pull/1241#issuecomment-2365259334) that includes relevant documentation links.
|
||||
|
||||
|
||||
## Qodo Merge Features
|
||||
## Features
|
||||
|
||||
Qodo Merge offers extensive pull request functionalities across various git providers:
|
||||
PR-Agent and Qodo Merge offers extensive pull request functionalities across various git providers:
|
||||
|
||||
| | | GitHub | Gitlab | Bitbucket | Azure DevOps |
|
||||
|-------|-----------------------------------------------------------------------------------------------------------------------|:------:|:------:|:---------:|:------------:|
|
||||
| TOOLS | Review | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ Incremental | ✅ | | | |
|
||||
| | Ask | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Describe | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ [Inline file summary](https://qodo-merge-docs.qodo.ai/tools/describe/#inline-file-summary){:target="_blank"} 💎 | ✅ | ✅ | | ✅ |
|
||||
| | Improve | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ Extended | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Auto-Approve](https://qodo-merge-docs.qodo.ai/tools/improve/#auto-approval) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [Custom Prompt](./tools/custom_prompt.md){:target="_blank"} 💎 | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Reflect and Review | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Update CHANGELOG.md | ✅ | ✅ | ✅ | ️ |
|
||||
| | Find Similar Issue | ✅ | | | ️ |
|
||||
| | [Add PR Documentation](./tools/documentation.md){:target="_blank"} 💎 | ✅ | ✅ | | ✅ |
|
||||
| | [Generate Custom Labels](./tools/describe.md#handle-custom-labels-from-the-repos-labels-page-💎){:target="_blank"} 💎 | ✅ | ✅ | | ✅ |
|
||||
| | [Analyze PR Components](./tools/analyze.md){:target="_blank"} 💎 | ✅ | ✅ | | ✅ |
|
||||
| | [Test](https://pr-agent-docs.codium.ai/tools/test/) 💎 | ✅ | ✅ | | |
|
||||
| | [Implement](https://pr-agent-docs.codium.ai/tools/implement/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | | | | | ️ |
|
||||
| USAGE | CLI | ✅ | ✅ | ✅ | ✅ |
|
||||
| | App / webhook | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Actions | ✅ | | | ️ |
|
||||
| | | | | |
|
||||
| CORE | PR compression | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Repo language prioritization | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Adaptive and token-aware file patch fitting | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Multiple models support | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Static code analysis](./core-abilities/static_code_analysis/){:target="_blank"} 💎 | ✅ | ✅ | | |
|
||||
| | [Multiple configuration options](./usage-guide/configuration_options.md){:target="_blank"} 💎 | ✅ | ✅ | ✅ | ✅ |
|
||||
| | | GitHub | GitLab | Bitbucket | Azure DevOps |
|
||||
|-------|---------------------------------------------------------------------------------------------------------|:--------------------:|:--------------------:|:---------:|:------------:|
|
||||
| TOOLS | [Review](https://qodo-merge-docs.qodo.ai/tools/review/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Describe](https://qodo-merge-docs.qodo.ai/tools/describe/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Improve](https://qodo-merge-docs.qodo.ai/tools/improve/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Ask](https://qodo-merge-docs.qodo.ai/tools/ask/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ [Ask on code lines](https://qodo-merge-docs.qodo.ai/tools/ask/#ask-lines) | ✅ | ✅ | | |
|
||||
| | [Update CHANGELOG](https://qodo-merge-docs.qodo.ai/tools/update_changelog/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Help Docs](https://qodo-merge-docs.qodo.ai/tools/help_docs/?h=auto#auto-approval) | ✅ | ✅ | ✅ | |
|
||||
| | [Ticket Context](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [Utilizing Best Practices](https://qodo-merge-docs.qodo.ai/tools/improve/#best-practices) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [PR Chat](https://qodo-merge-docs.qodo.ai/chrome-extension/features/#pr-chat) 💎 | ✅ | | | |
|
||||
| | [Suggestion Tracking](https://qodo-merge-docs.qodo.ai/tools/improve/#suggestion-tracking) 💎 | ✅ | ✅ | | |
|
||||
| | [CI Feedback](https://qodo-merge-docs.qodo.ai/tools/ci_feedback/) 💎 | ✅ | | | |
|
||||
| | [PR Documentation](https://qodo-merge-docs.qodo.ai/tools/documentation/) 💎 | ✅ | ✅ | | |
|
||||
| | [Custom Labels](https://qodo-merge-docs.qodo.ai/tools/custom_labels/) 💎 | ✅ | ✅ | | |
|
||||
| | [Analyze](https://qodo-merge-docs.qodo.ai/tools/analyze/) 💎 | ✅ | ✅ | | |
|
||||
| | [Similar Code](https://qodo-merge-docs.qodo.ai/tools/similar_code/) 💎 | ✅ | | | |
|
||||
| | [Custom Prompt](https://qodo-merge-docs.qodo.ai/tools/custom_prompt/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [Test](https://qodo-merge-docs.qodo.ai/tools/test/) 💎 | ✅ | ✅ | | |
|
||||
| | [Implement](https://qodo-merge-docs.qodo.ai/tools/implement/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [Auto-Approve](https://qodo-merge-docs.qodo.ai/tools/improve/?h=auto#auto-approval) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | | | | | |
|
||||
| USAGE | [CLI](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#local-repo-cli) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [App / webhook](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#github-app) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Tagging bot](https://github.com/Codium-ai/pr-agent#try-it-now) | ✅ | | | |
|
||||
| | [Actions](https://qodo-merge-docs.qodo.ai/installation/github/#run-as-a-github-action) | ✅ |✅| ✅ |✅|
|
||||
| | | | | | |
|
||||
| CORE | [PR compression](https://qodo-merge-docs.qodo.ai/core-abilities/compression_strategy/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Adaptive and token-aware file patch fitting | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Multiple models support](https://qodo-merge-docs.qodo.ai/usage-guide/changing_a_model/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Local and global metadata](https://qodo-merge-docs.qodo.ai/core-abilities/metadata/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Dynamic context](https://qodo-merge-docs.qodo.ai/core-abilities/dynamic_context/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Self reflection](https://qodo-merge-docs.qodo.ai/core-abilities/self_reflection/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Static code analysis](https://qodo-merge-docs.qodo.ai/core-abilities/static_code_analysis/) 💎 | ✅ | ✅ | | |
|
||||
| | [Global and wiki configurations](https://qodo-merge-docs.qodo.ai/usage-guide/configuration_options/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [PR interactive actions](https://www.qodo.ai/images/pr_agent/pr-actions.mp4) 💎 | ✅ | ✅ | | |
|
||||
| | [Impact Evaluation](https://qodo-merge-docs.qodo.ai/core-abilities/impact_evaluation/) 💎 | ✅ | ✅ | | |
|
||||
|
||||
💎 marks a feature available only in [Qodo Merge](https://www.codium.ai/pricing/){:target="_blank"}, and not in the open-source version.
|
||||
!!! note "💎 means Qodo Merge only"
|
||||
All along the documentation, 💎 marks a feature available only in [Qodo Merge](https://www.codium.ai/pricing/){:target="_blank"}, and not in the open-source version.
|
||||
|
||||
|
||||
## Example Results
|
||||
|
||||
@ -1,33 +1,33 @@
|
||||
## Run as a Bitbucket Pipeline
|
||||
|
||||
|
||||
You can use the Bitbucket Pipeline system to run Qodo Merge on every pull request open or update.
|
||||
You can use the Bitbucket Pipeline system to run PR-Agent on every pull request open or update.
|
||||
|
||||
1. Add the following file in your repository bitbucket-pipelines.yml
|
||||
|
||||
```yaml
|
||||
pipelines:
|
||||
pull-requests:
|
||||
'**':
|
||||
- step:
|
||||
name: PR Agent Review
|
||||
image: python:3.10
|
||||
services:
|
||||
- docker
|
||||
script:
|
||||
- docker run -e CONFIG.GIT_PROVIDER=bitbucket -e OPENAI.KEY=$OPENAI_API_KEY -e BITBUCKET.BEARER_TOKEN=$BITBUCKET_BEARER_TOKEN codiumai/pr-agent:latest --pr_url=https://bitbucket.org/$BITBUCKET_WORKSPACE/$BITBUCKET_REPO_SLUG/pull-requests/$BITBUCKET_PR_ID review
|
||||
pull-requests:
|
||||
"**":
|
||||
- step:
|
||||
name: PR Agent Review
|
||||
image: python:3.12
|
||||
services:
|
||||
- docker
|
||||
script:
|
||||
- docker run -e CONFIG.GIT_PROVIDER=bitbucket -e OPENAI.KEY=$OPENAI_API_KEY -e BITBUCKET.BEARER_TOKEN=$BITBUCKET_BEARER_TOKEN codiumai/pr-agent:latest --pr_url=https://bitbucket.org/$BITBUCKET_WORKSPACE/$BITBUCKET_REPO_SLUG/pull-requests/$BITBUCKET_PR_ID review
|
||||
```
|
||||
|
||||
2. Add the following secure variables to your repository under Repository settings > Pipelines > Repository variables.
|
||||
OPENAI_API_KEY: `<your key>`
|
||||
BITBUCKET_BEARER_TOKEN: `<your token>`
|
||||
OPENAI_API_KEY: `<your key>`
|
||||
BITBUCKET.AUTH_TYPE: `basic` or `bearer` (default is `bearer`)
|
||||
BITBUCKET.BEARER_TOKEN: `<your token>` (required when auth_type is bearer)
|
||||
BITBUCKET.BASIC_TOKEN: `<your token>` (required when auth_type is basic)
|
||||
|
||||
You can get a Bitbucket token for your repository by following Repository Settings -> Security -> Access Tokens.
|
||||
For basic auth, you can generate a base64 encoded token from your username:password combination.
|
||||
|
||||
Note that comments on a PR are not supported in Bitbucket Pipeline.
|
||||
|
||||
|
||||
|
||||
## Bitbucket Server and Data Center
|
||||
|
||||
Login into your on-prem instance of Bitbucket with your service account username and password.
|
||||
@ -48,13 +48,15 @@ git_provider="bitbucket_server"
|
||||
```
|
||||
|
||||
and pass the Pull request URL:
|
||||
|
||||
```shell
|
||||
python cli.py --pr_url https://git.onpreminstanceofbitbucket.com/projects/PROJECT/repos/REPO/pull-requests/1 review
|
||||
```
|
||||
|
||||
### Run it as service
|
||||
|
||||
To run Qodo Merge as webhook, build the docker image:
|
||||
To run PR-Agent as webhook, build the docker image:
|
||||
|
||||
```
|
||||
docker build . -t codiumai/pr-agent:bitbucket_server_webhook --target bitbucket_server_webhook -f docker/Dockerfile
|
||||
docker push codiumai/pr-agent:bitbucket_server_webhook # Push to your Docker repository
|
||||
|
||||
@ -43,36 +43,47 @@ Note that if your base branches are not protected, don't set the variables as `p
|
||||
|
||||
## Run a GitLab webhook server
|
||||
|
||||
1. From the GitLab workspace or group, create an access token with "Reporter" role ("Developer" if using Pro version of the agent) and "api" scope.
|
||||
1. In GitLab create a new user and give it "Reporter" role ("Developer" if using Pro version of the agent) for the intended group or project.
|
||||
|
||||
2. Generate a random secret for your app, and save it for later. For example, you can use:
|
||||
2. For the user from step 1. generate a `personal_access_token` with `api` access.
|
||||
|
||||
3. Generate a random secret for your app, and save it for later (`shared_secret`). For example, you can use:
|
||||
|
||||
```
|
||||
WEBHOOK_SECRET=$(python -c "import secrets; print(secrets.token_hex(10))")
|
||||
SHARED_SECRET=$(python -c "import secrets; print(secrets.token_hex(10))")
|
||||
```
|
||||
|
||||
3. Clone this repository:
|
||||
4. Clone this repository:
|
||||
|
||||
```
|
||||
git clone https://github.com/Codium-ai/pr-agent.git
|
||||
git clone https://github.com/qodo-ai/pr-agent.git
|
||||
```
|
||||
|
||||
4. Prepare variables and secrets. Skip this step if you plan on settings these as environment variables when running the agent:
|
||||
5. Prepare variables and secrets. Skip this step if you plan on setting these as environment variables when running the agent:
|
||||
1. In the configuration file/variables:
|
||||
- Set `deployment_type` to "gitlab"
|
||||
- Set `config.git_provider` to "gitlab"
|
||||
|
||||
2. In the secrets file/variables:
|
||||
- Set your AI model key in the respective section
|
||||
- In the [gitlab] section, set `personal_access_token` (with token from step 1) and `shared_secret` (with secret from step 2)
|
||||
- In the [gitlab] section, set `personal_access_token` (with token from step 2) and `shared_secret` (with secret from step 3)
|
||||
|
||||
|
||||
5. Build a Docker image for the app and optionally push it to a Docker repository. We'll use Dockerhub as an example:
|
||||
6. Build a Docker image for the app and optionally push it to a Docker repository. We'll use Dockerhub as an example:
|
||||
```
|
||||
docker build . -t gitlab_pr_agent --target gitlab_webhook -f docker/Dockerfile
|
||||
docker push codiumai/pr-agent:gitlab_webhook # Push to your Docker repository
|
||||
```
|
||||
|
||||
6. Create a webhook in GitLab. Set the URL to ```http[s]://<PR_AGENT_HOSTNAME>/webhook```, the secret token to the generated secret from step 2, and enable the triggers `push`, `comments` and `merge request events`.
|
||||
7. Set the environmental variables, the method depends on your docker runtime. Skip this step if you included your secrets/configuration directly in the Docker image.
|
||||
|
||||
```
|
||||
"CONFIG.GIT_PROVIDER": "gitlab"
|
||||
"GITLAB.PERSONAL_ACCESS_TOKEN": "<personal_access_token>"
|
||||
"GITLAB.SHARED_SECRET": "<shared_secret>"
|
||||
"GITLAB.URL": "https://gitlab.com"
|
||||
"OPENAI.KEY": "<your_openai_api_key>"
|
||||
```
|
||||
|
||||
8. Create a webhook in your GitLab project. Set the URL to ```http[s]://<PR_AGENT_HOSTNAME>/webhook```, the secret token to the generated secret from step 3, and enable the triggers `push`, `comments` and `merge request events`.
|
||||
|
||||
9. Test your installation by opening a merge request or commenting on a merge request using one of PR Agent's commands.
|
||||
|
||||
7. Test your installation by opening a merge request or commenting on a merge request using one of CodiumAI's commands.
|
||||
boxes
|
||||
|
||||
@ -1,12 +1,12 @@
|
||||
To run PR-Agent locally, you first need to acquire two keys:
|
||||
|
||||
1. An OpenAI key from [here](https://platform.openai.com/api-keys){:target="_blank"}, with access to GPT-4 (or a key for other [language models](https://qodo-merge-docs.qodo.ai/usage-guide/changing_a_model/), if you prefer).
|
||||
1. An OpenAI key from [here](https://platform.openai.com/api-keys){:target="_blank"}, with access to GPT-4 and o3-mini (or a key for other [language models](https://qodo-merge-docs.qodo.ai/usage-guide/changing_a_model/), if you prefer).
|
||||
2. A personal access token from your Git platform (GitHub, GitLab, BitBucket) with repo scope. GitHub token, for example, can be issued from [here](https://github.com/settings/tokens){:target="_blank"}
|
||||
|
||||
|
||||
## Using Docker image
|
||||
|
||||
A list of the relevant tools can be found in the [tools guide](../tools/ask.md).
|
||||
A list of the relevant tools can be found in the [tools guide](../tools/).
|
||||
|
||||
To invoke a tool (for example `review`), you can run PR-Agent directly from the Docker image. Here's how:
|
||||
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
Qodo Merge is a versatile application compatible with GitHub, GitLab, and BitBucket, hosted by QodoAI.
|
||||
See [here](https://qodo-merge-docs.qodo.ai/overview/pr_agent_pro/) for more details about the benefits of using Qodo Merge.
|
||||
|
||||
A complimentary two-week trial is provided to all new users. Following the trial period, user licenses (seats) are required for continued access.
|
||||
A complimentary two-week trial is provided to all new users (with three additional grace usages). Following the trial period, user licenses (seats) are required for continued access.
|
||||
To purchase user licenses, please visit our [pricing page](https://www.qodo.ai/pricing/).
|
||||
Once subscribed, users can seamlessly deploy the application across any of their code repositories.
|
||||
|
||||
|
||||
@ -19,7 +19,7 @@ Here are some of the additional features and capabilities that Qodo Merge offers
|
||||
|
||||
| Feature | Description |
|
||||
|----------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| [**Model selection**](https://qodo-merge-docs.qodo.ai/usage-guide/PR_agent_pro_models/) | Choose the model that best fits your needs, among top models like `GPT4` and `Claude-Sonnet-3.5`
|
||||
| [**Model selection**](https://qodo-merge-docs.qodo.ai/usage-guide/PR_agent_pro_models/) | Choose the model that best fits your needs, among top models like `Claude Sonnet` and `o3-mini`
|
||||
| [**Global and wiki configuration**](https://qodo-merge-docs.qodo.ai/usage-guide/configuration_options/) | Control configurations for many repositories from a single location; <br>Edit configuration of a single repo without committing code |
|
||||
| [**Apply suggestions**](https://qodo-merge-docs.qodo.ai/tools/improve/#overview) | Generate committable code from the relevant suggestions interactively by clicking on a checkbox |
|
||||
| [**Suggestions impact**](https://qodo-merge-docs.qodo.ai/tools/improve/#assessing-impact) | Automatically mark suggestions that were implemented by the user (either directly in GitHub, or indirectly in the IDE) to enable tracking of the impact of the suggestions |
|
||||
@ -46,7 +46,7 @@ Here are additional tools that are available only for Qodo Merge users:
|
||||
|
||||
### Supported languages
|
||||
|
||||
Qodo Merge leverages the world's leading code models - Claude 3.5 Sonnet and GPT-4.
|
||||
Qodo Merge leverages the world's leading code models, such as Claude 3.7 Sonnet and o3-mini.
|
||||
As a result, its primary tools such as `describe`, `review`, and `improve`, as well as the PR-chat feature, support virtually all programming languages.
|
||||
|
||||
For specialized commands that require static code analysis, Qodo Merge offers support for specific languages. For more details about features that require static code analysis, please refer to the [documentation](https://qodo-merge-docs.qodo.ai/tools/analyze/#overview).
|
||||
|
||||
@ -53,6 +53,6 @@ Results obtained with the prompt above:
|
||||
|
||||
- `prompt`: the prompt for the tool. It should be a multi-line string.
|
||||
|
||||
- `num_code_suggestions_per_chunk`: number of code suggestions provided by the 'custom_prompt' tool, per chunk. Default is 4.
|
||||
- `num_code_suggestions_per_chunk`: number of code suggestions provided by the 'custom_prompt' tool, per chunk. Default is 3.
|
||||
|
||||
- `enable_help_text`: if set to true, the tool will display a help text in the comment. Default is true.
|
||||
|
||||
@ -46,56 +46,56 @@ publish_labels = true
|
||||
|
||||
!!! example "Possible configurations"
|
||||
|
||||
<table>
|
||||
<tr>
|
||||
<td><b>publish_labels</b></td>
|
||||
<td>If set to true, the tool will publish labels to the PR. Default is false.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>publish_description_as_comment</b></td>
|
||||
<td>If set to true, the tool will publish the description as a comment to the PR. If false, it will overwrite the original description. Default is false.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>publish_description_as_comment_persistent</b></td>
|
||||
<td>If set to true and `publish_description_as_comment` is true, the tool will publish the description as a persistent comment to the PR. Default is true.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>add_original_user_description</b></td>
|
||||
<td>If set to true, the tool will add the original user description to the generated description. Default is true.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>generate_ai_title</b></td>
|
||||
<td>If set to true, the tool will also generate an AI title for the PR. Default is false.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>extra_instructions</b></td>
|
||||
<td>Optional extra instructions to the tool. For example: "focus on the changes in the file X. Ignore change in ..."</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>enable_pr_type</b></td>
|
||||
<td>If set to false, it will not show the `PR type` as a text value in the description content. Default is true.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>final_update_message</b></td>
|
||||
<td>If set to true, it will add a comment message [`PR Description updated to latest commit...`](https://github.com/Codium-ai/pr-agent/pull/499#issuecomment-1837412176) after finishing calling `/describe`. Default is false.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>enable_semantic_files_types</b></td>
|
||||
<td>If set to true, "Changes walkthrough" section will be generated. Default is true.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>collapsible_file_list</b></td>
|
||||
<td>If set to true, the file list in the "Changes walkthrough" section will be collapsible. If set to "adaptive", the file list will be collapsible only if there are more than 8 files. Default is "adaptive".</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>enable_large_pr_handling</b></td>
|
||||
<td>Pro feature. If set to true, in case of a large PR the tool will make several calls to the AI and combine them to be able to cover more files. Default is true.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>enable_help_text</b></td>
|
||||
<td>If set to true, the tool will display a help text in the comment. Default is false.</td>
|
||||
</tr>
|
||||
</table>
|
||||
<table>
|
||||
<tr>
|
||||
<td><b>publish_labels</b></td>
|
||||
<td>If set to true, the tool will publish labels to the PR. Default is false.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>publish_description_as_comment</b></td>
|
||||
<td>If set to true, the tool will publish the description as a comment to the PR. If false, it will overwrite the original description. Default is false.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>publish_description_as_comment_persistent</b></td>
|
||||
<td>If set to true and `publish_description_as_comment` is true, the tool will publish the description as a persistent comment to the PR. Default is true.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>add_original_user_description</b></td>
|
||||
<td>If set to true, the tool will add the original user description to the generated description. Default is true.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>generate_ai_title</b></td>
|
||||
<td>If set to true, the tool will also generate an AI title for the PR. Default is false.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>extra_instructions</b></td>
|
||||
<td>Optional extra instructions to the tool. For example: "focus on the changes in the file X. Ignore change in ..."</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>enable_pr_type</b></td>
|
||||
<td>If set to false, it will not show the `PR type` as a text value in the description content. Default is true.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>final_update_message</b></td>
|
||||
<td>If set to true, it will add a comment message [`PR Description updated to latest commit...`](https://github.com/Codium-ai/pr-agent/pull/499#issuecomment-1837412176) after finishing calling `/describe`. Default is false.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>enable_semantic_files_types</b></td>
|
||||
<td>If set to true, "Changes walkthrough" section will be generated. Default is true.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>collapsible_file_list</b></td>
|
||||
<td>If set to true, the file list in the "Changes walkthrough" section will be collapsible. If set to "adaptive", the file list will be collapsible only if there are more than 8 files. Default is "adaptive".</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>enable_large_pr_handling</b></td>
|
||||
<td>Pro feature. If set to true, in case of a large PR the tool will make several calls to the AI and combine them to be able to cover more files. Default is true.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>enable_help_text</b></td>
|
||||
<td>If set to true, the tool will display a help text in the comment. Default is false.</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
|
||||
## Inline file summary 💎
|
||||
|
||||
108
docs/docs/tools/help_docs.md
Normal file
108
docs/docs/tools/help_docs.md
Normal file
@ -0,0 +1,108 @@
|
||||
## Overview
|
||||
|
||||
The `help_docs` tool can answer a free-text question based on a git documentation folder.
|
||||
|
||||
It can be invoked manually by commenting on any PR or Issue:
|
||||
```
|
||||
/help_docs "..."
|
||||
```
|
||||
Or configured to be triggered automatically when a [new issue is opened](#run-as-a-github-action).
|
||||
|
||||
The tool assumes by default that the documentation is located in the root of the repository, at `/docs` folder.
|
||||
However, this can be customized by setting the `docs_path` configuration option:
|
||||
|
||||
```toml
|
||||
[pr_help_docs]
|
||||
repo_url = "" # The repository to use as context
|
||||
docs_path = "docs" # The documentation folder
|
||||
repo_default_branch = "main" # The branch to use in case repo_url overwritten
|
||||
|
||||
```
|
||||
|
||||
See more configuration options in the [Configuration options](#configuration-options) section.
|
||||
|
||||
## Example usage
|
||||
|
||||
[//]: # (#### Asking a question about this repository:)
|
||||
|
||||
[//]: # ({width=512})
|
||||
|
||||
**Asking a question about another repository**
|
||||
|
||||
{width=512}
|
||||
|
||||
**Response**:
|
||||
|
||||
{width=512}
|
||||
|
||||
## Run automatically when a new issue is opened
|
||||
|
||||
You can configure PR-Agent to run `help_docs` automatically on any newly created issue.
|
||||
This can be useful, for example, for providing immediate feedback to users who open issues with questions on open-source projects with extensive documentation.
|
||||
|
||||
Here's how:
|
||||
|
||||
1) Follow the steps depicted under [Run as a Github Action](https://qodo-merge-docs.qodo.ai/installation/github/#run-as-a-github-action) to create a new workflow, such as:`.github/workflows/help_docs.yml`:
|
||||
|
||||
2) Edit your yaml file to the following:
|
||||
|
||||
```yaml
|
||||
name: Run pr agent on every opened issue, respond to user comments on an issue
|
||||
|
||||
#When the action is triggered
|
||||
on:
|
||||
issues:
|
||||
types: [opened] #New issue
|
||||
|
||||
# Read env. variables
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
GITHUB_API_URL: ${{ github.api_url }}
|
||||
GIT_REPO_URL: ${{ github.event.repository.clone_url }}
|
||||
ISSUE_URL: ${{ github.event.issue.html_url || github.event.comment.html_url }}
|
||||
ISSUE_BODY: ${{ github.event.issue.body || github.event.comment.body }}
|
||||
OPENAI_KEY: ${{ secrets.OPENAI_KEY }}
|
||||
|
||||
# The actual set of actions
|
||||
jobs:
|
||||
issue_agent:
|
||||
runs-on: ubuntu-latest
|
||||
if: ${{ github.event.sender.type != 'Bot' }} #Do not respond to bots
|
||||
|
||||
# Set required permissions
|
||||
permissions:
|
||||
contents: read # For reading repository contents
|
||||
issues: write # For commenting on issues
|
||||
|
||||
steps:
|
||||
- name: Run PR Agent on Issues
|
||||
if: ${{ env.ISSUE_URL != '' }}
|
||||
uses: docker://codiumai/pr-agent:latest
|
||||
with:
|
||||
entrypoint: /bin/bash #Replace invoking cli.py directly with a shell
|
||||
args: |
|
||||
-c "cd /app && \
|
||||
echo 'Running Issue Agent action step on ISSUE_URL=$ISSUE_URL' && \
|
||||
export config__git_provider='github' && \
|
||||
export github__user_token=$GITHUB_TOKEN && \
|
||||
export github__base_url=$GITHUB_API_URL && \
|
||||
export openai__key=$OPENAI_KEY && \
|
||||
python -m pr_agent.cli --issue_url=$ISSUE_URL --pr_help_docs.repo_url="..." --pr_help_docs.docs_path="..." --pr_help_docs.openai_key=$OPENAI_KEY && \help_docs \"$ISSUE_BODY\""
|
||||
```
|
||||
|
||||
3) Following completion of the remaining steps (such as adding secrets and relevant configurations, such as `repo_url` and `docs_path`) merge this change to your main branch.
|
||||
When a new issue is opened, you should see a comment from `github-actions` bot with an auto response, assuming the question is related to the documentation of the repository.
|
||||
---
|
||||
|
||||
|
||||
## Configuration options
|
||||
|
||||
Under the section `pr_help_docs`, the [configuration file](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml#L50) contains options to customize the 'help docs' tool:
|
||||
|
||||
- `repo_url`: If not overwritten, will use the repo from where the context came from (issue or PR), otherwise - use the given repo as context.
|
||||
- `repo_default_branch`: The branch to use in case repo_url overwritten, otherwise - has no effect.
|
||||
- `docs_path`: Relative path from root of repository (either the one this PR has been issued for, or above repo url).
|
||||
- `exclude_root_readme`: Whether or not to exclude the root README file for querying the model.
|
||||
- `supported_doc_exts` : Which file extensions should be included for the purpose of querying the model.
|
||||
|
||||
---
|
||||
@ -122,10 +122,10 @@ Use triple quotes to write multi-line instructions. Use bullet points or numbers
|
||||
|
||||
> `💎 feature. Platforms supported: GitHub, GitLab, Bitbucket`
|
||||
|
||||
Another option to give additional guidance to the AI model is by creating a `best_practices.md` file, either in your repository's root directory or as a [**wiki page**](https://github.com/Codium-ai/pr-agent/wiki) (we recommend the wiki page, as editing and maintaining it over time is easier).
|
||||
Another option to give additional guidance to the AI model is by creating a `best_practices.md` file in your repository's root directory.
|
||||
This page can contain a list of best practices, coding standards, and guidelines that are specific to your repo/organization.
|
||||
|
||||
The AI model will use this wiki page as a reference, and in case the PR code violates any of the guidelines, it will create additional suggestions, with a dedicated label: `Organization
|
||||
The AI model will use this `best_practices.md` file as a reference, and in case the PR code violates any of the guidelines, it will create additional suggestions, with a dedicated label: `Organization
|
||||
best practice`.
|
||||
|
||||
Example for a python `best_practices.md` content:
|
||||
@ -149,16 +149,16 @@ Tips for writing an effective `best_practices.md` file:
|
||||
- Long files tend to contain generic guidelines already known to AI
|
||||
|
||||
#### Local and global best practices
|
||||
By default, Qodo Merge will look for a local `best_practices.md` wiki file in the root of the relevant local repo.
|
||||
By default, Qodo Merge will look for a local `best_practices.md` in the root of the relevant local repo.
|
||||
|
||||
If you want to enable also a global `best_practices.md` wiki file, set first in the global configuration file:
|
||||
If you want to enable also a global `best_practices.md` file, set first in the global configuration file:
|
||||
|
||||
```toml
|
||||
[best_practices]
|
||||
enable_global_best_practices = true
|
||||
```
|
||||
|
||||
Then, create a `best_practices.md` wiki file in the root of [global](https://qodo-merge-docs.qodo.ai/usage-guide/configuration_options/#global-configuration-file) configuration repository, `pr-agent-settings`.
|
||||
Then, create a `best_practices.md` file in the root of [global](https://qodo-merge-docs.qodo.ai/usage-guide/configuration_options/#global-configuration-file) configuration repository, `pr-agent-settings`.
|
||||
|
||||
#### Best practices for multiple languages
|
||||
For a git organization working with multiple programming languages, you can maintain a centralized global `best_practices.md` file containing language-specific guidelines.
|
||||
@ -268,7 +268,7 @@ dual_publishing_score_threshold = x
|
||||
Where x represents the minimum score threshold (>=) for suggestions to be presented as commitable PR comments in addition to the table. Default is -1 (disabled).
|
||||
|
||||
### Self-review
|
||||
> `💎 feature`
|
||||
> `💎 feature` Platforms supported: GitHub, GitLab
|
||||
|
||||
If you set in a configuration file:
|
||||
```toml
|
||||
@ -318,15 +318,25 @@ code_suggestions_self_review_text = "... (your text here) ..."
|
||||
|
||||
Under specific conditions, Qodo Merge can auto-approve a PR when a specific comment is invoked, or when the PR meets certain criteria.
|
||||
|
||||
To ensure safety, the auto-approval feature is disabled by default. To enable auto-approval, you need to actively set, in a pre-defined _configuration file_, the following:
|
||||
**To ensure safety, the auto-approval feature is disabled by default.**
|
||||
To enable auto-approval features, you need to actively set one or both of the following options in a pre-defined _configuration file_:
|
||||
```toml
|
||||
[config]
|
||||
enable_auto_approval = true
|
||||
enable_comment_approval = true # For approval via comments
|
||||
enable_auto_approval = true # For criteria-based auto-approval
|
||||
```
|
||||
Note that this specific flag cannot be set with a command line argument, only in the configuration file, committed to the repository.
|
||||
This ensures that enabling auto-approval is a deliberate decision by the repository owner.
|
||||
|
||||
**(1) Auto-approval by commenting**
|
||||
!!! note "Notes"
|
||||
- Note that this specific flag cannot be set with a command line argument, only in the configuration file, committed to the repository.
|
||||
- Enabling auto-approval must be a deliberate decision by the repository owner.
|
||||
|
||||
1\. **Auto-approval by commenting**
|
||||
|
||||
To enable auto-approval by commenting, set in the configuration file:
|
||||
```toml
|
||||
[config]
|
||||
enable_comment_approval = true
|
||||
```
|
||||
|
||||
After enabling, by commenting on a PR:
|
||||
```
|
||||
@ -334,13 +344,20 @@ After enabling, by commenting on a PR:
|
||||
```
|
||||
Qodo Merge will automatically approve the PR, and add a comment with the approval.
|
||||
|
||||
**(2) Auto-approval when the PR meets certain criteria**
|
||||
2\. **Auto-approval when the PR meets certain criteria**
|
||||
|
||||
To enable auto-approval based on specific criteria, first, you need to enable the top-level flag:
|
||||
```toml
|
||||
[config]
|
||||
enable_auto_approval = true
|
||||
```
|
||||
|
||||
There are two criteria that can be set for auto-approval:
|
||||
|
||||
- **Review effort score**
|
||||
```toml
|
||||
[config]
|
||||
enable_auto_approval = true
|
||||
auto_approve_for_low_review_effort = X # X is a number between 1 to 5
|
||||
```
|
||||
When the [review effort score](https://www.qodo.ai/images/pr_agent/review3.png) is lower or equal to X, the PR will be auto-approved.
|
||||
@ -349,6 +366,7 @@ ___
|
||||
- **No code suggestions**
|
||||
```toml
|
||||
[config]
|
||||
enable_auto_approval = true
|
||||
auto_approve_for_no_suggestions = true
|
||||
```
|
||||
When no [code suggestion](https://www.qodo.ai/images/pr_agent/code_suggestions_as_comment_closed.png) were found for the PR, the PR will be auto-approved.
|
||||
@ -361,7 +379,7 @@ Qodo Merge uses a dynamic strategy to generate code suggestions based on the siz
|
||||
- Each chunk contains up to `pr_code_suggestions.max_context_tokens` tokens (default: 14,000).
|
||||
|
||||
#### 2. Generating suggestions
|
||||
- For each chunk, Qodo Merge generates up to `pr_code_suggestions.num_code_suggestions_per_chunk` suggestions (default: 4).
|
||||
- For each chunk, Qodo Merge generates up to `pr_code_suggestions.num_code_suggestions_per_chunk` suggestions (default: 3).
|
||||
|
||||
This approach has two main benefits:
|
||||
|
||||
@ -394,7 +412,7 @@ Note: Chunking is primarily relevant for large PRs. For most PRs (up to 500 line
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>persistent_comment</b></td>
|
||||
<td>If set to true, the improve comment will be persistent, meaning that every new improve request will edit the previous one. Default is false.</td>
|
||||
<td>If set to true, the improve comment will be persistent, meaning that every new improve request will edit the previous one. Default is true.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>suggestions_score_threshold</b></td>
|
||||
@ -416,13 +434,16 @@ Note: Chunking is primarily relevant for large PRs. For most PRs (up to 500 line
|
||||
<td><b>enable_chat_text</b></td>
|
||||
<td>If set to true, the tool will display a reference to the PR chat in the comment. Default is true.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>publish_output_no_suggestions</b></td>
|
||||
<td>If set to true, the tool will publish a comment even if no suggestions were found. Default is true.</td>
|
||||
<tr>
|
||||
<td><b>wiki_page_accepted_suggestions</b></td>
|
||||
<td>If set to true, the tool will automatically track accepted suggestions in a dedicated wiki page called `.pr_agent_accepted_suggestions`. Default is true.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>allow_thumbs_up_down</b></td>
|
||||
<td>If set to true, all code suggestions will have thumbs up and thumbs down buttons, to encourage users to provide feedback on the suggestions. Default is false.</td>
|
||||
<td>If set to true, all code suggestions will have thumbs up and thumbs down buttons, to encourage users to provide feedback on the suggestions. Default is false. Note that this feature is for statistics tracking. It will not affect future feedback from the AI model.</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
@ -435,7 +456,7 @@ Note: Chunking is primarily relevant for large PRs. For most PRs (up to 500 line
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>num_code_suggestions_per_chunk</b></td>
|
||||
<td>Number of code suggestions provided by the 'improve' tool, per chunk. Default is 4.</td>
|
||||
<td>Number of code suggestions provided by the 'improve' tool, per chunk. Default is 3.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>max_number_of_calls</b></td>
|
||||
@ -443,14 +464,12 @@ Note: Chunking is primarily relevant for large PRs. For most PRs (up to 500 line
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
## A note on code suggestions quality
|
||||
## Understanding AI Code Suggestions
|
||||
|
||||
- AI models for code are getting better and better (Sonnet-3.5 and GPT-4), but they are not flawless. Not all the suggestions will be perfect, and a user should not accept all of them automatically. Critical reading and judgment are required.
|
||||
- While mistakes of the AI are rare but can happen, a real benefit from the suggestions of the `improve` (and [`review`](https://qodo-merge-docs.qodo.ai/tools/review/)) tool is to catch, with high probability, **mistakes or bugs done by the PR author**, when they happen. So, it's a good practice to spend the needed ~30-60 seconds to review the suggestions, even if not all of them are always relevant.
|
||||
- The hierarchical structure of the suggestions is designed to help the user to _quickly_ understand them, and to decide which ones are relevant and which are not:
|
||||
|
||||
- Only if the `Category` header is relevant, the user should move to the summarized suggestion description
|
||||
- Only if the summarized suggestion description is relevant, the user should click on the collapsible, to read the full suggestion description with a code preview example.
|
||||
|
||||
- In addition, we recommend to use the [`extra_instructions`](https://qodo-merge-docs.qodo.ai/tools/improve/#extra-instructions-and-best-practices) field to guide the model to suggestions that are more relevant to the specific needs of the project.
|
||||
- The interactive [PR chat](https://qodo-merge-docs.qodo.ai/chrome-extension/) also provides an easy way to get more tailored suggestions and feedback from the AI model.
|
||||
- **AI Limitations:** AI models for code are getting better and better, but they are not flawless. Not all the suggestions will be perfect, and a user should not accept all of them automatically. Critical reading and judgment are required. Mistakes of the AI are rare but can happen, and it is usually quite easy for a human to spot them.
|
||||
- **Purpose of Suggestions:**
|
||||
- **Self-reflection:** The suggestions aim to enable developers to _self-reflect_ and improve their pull requests. This process can help to identify blind spots, uncover missed edge cases, and enhance code readability and coherency. Even when a specific code suggestion isn't suitable, the underlying issue it highlights often reveals something important that might deserve attention.
|
||||
- **Bug detection:** The suggestions also alert on any _critical bugs_ that may have been identified during the analysis. This provides an additional safety net to catch potential issues before they make it into production. It's perfectly acceptable to implement only the suggestions you find valuable for your specific context.
|
||||
- **Hierarchy:** Presenting the suggestions in a structured hierarchical table enables the user to _quickly_ understand them, and to decide which ones are relevant and which are not.
|
||||
- **Customization:** To guide the model to suggestions that are more relevant to the specific needs of your project, we recommend to use the [`extra_instructions`](https://qodo-merge-docs.qodo.ai/tools/improve/#extra-instructions-and-best-practices) and [`best practices`](https://qodo-merge-docs.qodo.ai/tools/improve/#best-practices) fields.
|
||||
- **Interactive usage:** The interactive [PR chat](https://qodo-merge-docs.qodo.ai/chrome-extension/) also provides an easy way to get more tailored suggestions and feedback from the AI model.
|
||||
|
||||
@ -9,7 +9,6 @@ Here is a list of Qodo Merge tools, each with a dedicated page that explains how
|
||||
| **[Code Suggestions (`/improve`](./improve.md))** | Code suggestions for improving the PR |
|
||||
| **[Question Answering (`/ask ...`](./ask.md))** | Answering free-text questions about the PR, or on specific code lines |
|
||||
| **[Update Changelog (`/update_changelog`](./update_changelog.md))** | Automatically updating the CHANGELOG.md file with the PR changes |
|
||||
| **[Find Similar Issue (`/similar_issue`](./similar_issues.md))** | Automatically retrieves and presents similar issues |
|
||||
| **[Help (`/help`](./help.md))** | Provides a list of all the available tools. Also enables to trigger them interactively (💎) |
|
||||
| **💎 [Add Documentation (`/add_docs`](./documentation.md))** | Generates documentation to methods/functions/classes that changed in the PR |
|
||||
| **💎 [Generate Custom Labels (`/generate_labels`](./custom_labels.md))** | Generates custom labels for the PR, based on specific guidelines defined by the user |
|
||||
|
||||
@ -51,68 +51,68 @@ extra_instructions = "..."
|
||||
|
||||
!!! example "General options"
|
||||
|
||||
<table>
|
||||
<tr>
|
||||
<td><b>persistent_comment</b></td>
|
||||
<td>If set to true, the review comment will be persistent, meaning that every new review request will edit the previous one. Default is true.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>final_update_message</b></td>
|
||||
<td>When set to true, updating a persistent review comment during online commenting will automatically add a short comment with a link to the updated review in the pull request .Default is true.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>extra_instructions</b></td>
|
||||
<td>Optional extra instructions to the tool. For example: "focus on the changes in the file X. Ignore change in ...".</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>enable_help_text</b></td>
|
||||
<td>If set to true, the tool will display a help text in the comment. Default is true.</td>
|
||||
</tr>
|
||||
</table>
|
||||
<table>
|
||||
<tr>
|
||||
<td><b>persistent_comment</b></td>
|
||||
<td>If set to true, the review comment will be persistent, meaning that every new review request will edit the previous one. Default is true.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>final_update_message</b></td>
|
||||
<td>When set to true, updating a persistent review comment during online commenting will automatically add a short comment with a link to the updated review in the pull request .Default is true.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>extra_instructions</b></td>
|
||||
<td>Optional extra instructions to the tool. For example: "focus on the changes in the file X. Ignore change in ...".</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>enable_help_text</b></td>
|
||||
<td>If set to true, the tool will display a help text in the comment. Default is true.</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
!!! example "Enable\\disable specific sub-sections"
|
||||
|
||||
<table>
|
||||
<tr>
|
||||
<td><b>require_score_review</b></td>
|
||||
<td>If set to true, the tool will add a section that scores the PR. Default is false.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>require_tests_review</b></td>
|
||||
<td>If set to true, the tool will add a section that checks if the PR contains tests. Default is true.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>require_estimate_effort_to_review</b></td>
|
||||
<td>If set to true, the tool will add a section that estimates the effort needed to review the PR. Default is true.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>require_can_be_split_review</b></td>
|
||||
<td>If set to true, the tool will add a section that checks if the PR contains several themes, and can be split into smaller PRs. Default is false.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>require_security_review</b></td>
|
||||
<td>If set to true, the tool will add a section that checks if the PR contains a possible security or vulnerability issue. Default is true.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>require_ticket_analysis_review</b></td>
|
||||
<td>If set to true, and the PR contains a GitHub or Jira ticket link, the tool will add a section that checks if the PR in fact fulfilled the ticket requirements. Default is true.</td>
|
||||
</tr>
|
||||
</table>
|
||||
<table>
|
||||
<tr>
|
||||
<td><b>require_score_review</b></td>
|
||||
<td>If set to true, the tool will add a section that scores the PR. Default is false.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>require_tests_review</b></td>
|
||||
<td>If set to true, the tool will add a section that checks if the PR contains tests. Default is true.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>require_estimate_effort_to_review</b></td>
|
||||
<td>If set to true, the tool will add a section that estimates the effort needed to review the PR. Default is true.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>require_can_be_split_review</b></td>
|
||||
<td>If set to true, the tool will add a section that checks if the PR contains several themes, and can be split into smaller PRs. Default is false.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>require_security_review</b></td>
|
||||
<td>If set to true, the tool will add a section that checks if the PR contains a possible security or vulnerability issue. Default is true.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>require_ticket_analysis_review</b></td>
|
||||
<td>If set to true, and the PR contains a GitHub or Jira ticket link, the tool will add a section that checks if the PR in fact fulfilled the ticket requirements. Default is true.</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
!!! example "Adding PR labels"
|
||||
|
||||
You can enable\disable the `review` tool to add specific labels to the PR:
|
||||
You can enable\disable the `review` tool to add specific labels to the PR:
|
||||
|
||||
<table>
|
||||
<tr>
|
||||
<td><b>enable_review_labels_security</b></td>
|
||||
<td>If set to true, the tool will publish a 'possible security issue' label if it detects a security issue. Default is true.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>enable_review_labels_effort</b></td>
|
||||
<td>If set to true, the tool will publish a 'Review effort [1-5]: x' label. Default is true.</td>
|
||||
</tr>
|
||||
</table>
|
||||
<table>
|
||||
<tr>
|
||||
<td><b>enable_review_labels_security</b></td>
|
||||
<td>If set to true, the tool will publish a 'possible security issue' label if it detects a security issue. Default is true.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>enable_review_labels_effort</b></td>
|
||||
<td>If set to true, the tool will publish a 'Review effort [1-5]: x' label. Default is true.</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
|
||||
## Usage Tips
|
||||
|
||||
@ -15,6 +15,7 @@ It can be invoked manually by commenting on any PR:
|
||||
|
||||
Under the section `pr_update_changelog`, the [configuration file](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml#L50) contains options to customize the 'update changelog' tool:
|
||||
|
||||
- `push_changelog_changes`: whether to push the changes to CHANGELOG.md, or just print them. Default is false (print only).
|
||||
- `extra_instructions`: Optional extra instructions to the tool. For example: "focus on the changes in the file X. Ignore change in ...
|
||||
- `add_pr_link`: whether the model should try to add a link to the PR in the changelog. Default is true.
|
||||
- `push_changelog_changes`: whether to push the changes to CHANGELOG.md, or just publish them as a comment. Default is false (publish as comment).
|
||||
- `extra_instructions`: Optional extra instructions to the tool. For example: "Use the following structure: ..."
|
||||
- `add_pr_link`: whether the model should try to add a link to the PR in the changelog. Default is true.
|
||||
- `skip_ci_on_push`: whether the commit message (when `push_changelog_changes` is true) will include the term "[skip ci]", preventing CI tests to be triggered on the changelog commit. Default is true.
|
||||
@ -74,16 +74,23 @@ This will set the response language globally for all the commands to Italian.
|
||||
|
||||
> **Important:** Note that only dynamic text generated by the AI model is translated to the configured language. Static text such as labels and table headers that are not part of the AI models response will remain in US English. In addition, the model you are using must have good support for the specified language.
|
||||
|
||||
## Working with large PRs
|
||||
[//]: # (## Working with large PRs)
|
||||
|
||||
The default mode of CodiumAI is to have a single call per tool, using GPT-4, which has a token limit of 8000 tokens.
|
||||
This mode provides a very good speed-quality-cost tradeoff, and can handle most PRs successfully.
|
||||
When the PR is above the token limit, it employs a [PR Compression strategy](../core-abilities/index.md).
|
||||
[//]: # ()
|
||||
[//]: # (The default mode of CodiumAI is to have a single call per tool, using GPT-4, which has a token limit of 8000 tokens.)
|
||||
|
||||
However, for very large PRs, or in case you want to emphasize quality over speed and cost, there are two possible solutions:
|
||||
1) [Use a model](https://qodo-merge-docs.qodo.ai/usage-guide/changing_a_model/) with larger context, like GPT-32K, or claude-100K. This solution will be applicable for all the tools.
|
||||
2) For the `/improve` tool, there is an ['extended' mode](https://qodo-merge-docs.qodo.ai/tools/improve/) (`/improve --extended`),
|
||||
which divides the PR into chunks, and processes each chunk separately. With this mode, regardless of the model, no compression will be done (but for large PRs, multiple model calls may occur)
|
||||
[//]: # (This mode provides a very good speed-quality-cost tradeoff, and can handle most PRs successfully.)
|
||||
|
||||
[//]: # (When the PR is above the token limit, it employs a [PR Compression strategy](../core-abilities/index.md).)
|
||||
|
||||
[//]: # ()
|
||||
[//]: # (However, for very large PRs, or in case you want to emphasize quality over speed and cost, there are two possible solutions:)
|
||||
|
||||
[//]: # (1) [Use a model](https://qodo-merge-docs.qodo.ai/usage-guide/changing_a_model/) with larger context, like GPT-32K, or claude-100K. This solution will be applicable for all the tools.)
|
||||
|
||||
[//]: # (2) For the `/improve` tool, there is an ['extended' mode](https://qodo-merge-docs.qodo.ai/tools/improve/) (`/improve --extended`),)
|
||||
|
||||
[//]: # (which divides the PR into chunks, and processes each chunk separately. With this mode, regardless of the model, no compression will be done (but for large PRs, multiple model calls may occur))
|
||||
|
||||
|
||||
|
||||
@ -113,24 +120,16 @@ Increasing this number provides more context to the model, but will also increas
|
||||
|
||||
If the PR is too large (see [PR Compression strategy](https://github.com/Codium-ai/pr-agent/blob/main/PR_COMPRESSION.md)), Qodo Merge may automatically set this number to 0, and will use the original git patch.
|
||||
|
||||
## Log Level
|
||||
|
||||
## Editing the prompts
|
||||
Qodo Merge allows you to control the verbosity of logging by using the `log_level` configuration parameter. This is particularly useful for troubleshooting and debugging issues with your PR workflows.
|
||||
|
||||
The prompts for the various Qodo Merge tools are defined in the `pr_agent/settings` folder.
|
||||
In practice, the prompts are loaded and stored as a standard setting object.
|
||||
Hence, editing them is similar to editing any other configuration value - just place the relevant key in `.pr_agent.toml`file, and override the default value.
|
||||
|
||||
For example, if you want to edit the prompts of the [describe](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/pr_description_prompts.toml) tool, you can add the following to your `.pr_agent.toml` file:
|
||||
```
|
||||
[pr_description_prompt]
|
||||
system="""
|
||||
...
|
||||
"""
|
||||
user="""
|
||||
...
|
||||
"""
|
||||
[config]
|
||||
log_level = "DEBUG" # Options: "DEBUG", "INFO", "WARNING", "ERROR", "CRITICAL"
|
||||
```
|
||||
Note that the new prompt will need to generate an output compatible with the relevant [post-process function](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/tools/pr_description.py#L137).
|
||||
|
||||
The default log level is "DEBUG", which provides detailed output of all operations. If you prefer less verbose logs, you can set higher log levels like "INFO" or "WARNING".
|
||||
|
||||
## Integrating with Logging Observability Platforms
|
||||
|
||||
@ -200,7 +199,7 @@ For the configuration above, automatic feedback will only be triggered when the
|
||||
|
||||
### Ignoring PRs containing specific labels
|
||||
|
||||
To ignore PRs containg specific labels, you can add the following to your `configuration.toml` file:
|
||||
To ignore PRs containing specific labels, you can add the following to your `configuration.toml` file:
|
||||
|
||||
```
|
||||
[config]
|
||||
|
||||
@ -7,7 +7,6 @@ Examples of invoking the different tools via the CLI:
|
||||
- **Describe**: `python -m pr_agent.cli --pr_url=<pr_url> describe`
|
||||
- **Improve**: `python -m pr_agent.cli --pr_url=<pr_url> improve`
|
||||
- **Ask**: `python -m pr_agent.cli --pr_url=<pr_url> ask "Write me a poem about this PR"`
|
||||
- **Reflect**: `python -m pr_agent.cli --pr_url=<pr_url> reflect`
|
||||
- **Update Changelog**: `python -m pr_agent.cli --pr_url=<pr_url> update_changelog`
|
||||
|
||||
`<pr_url>` is the url of the relevant PR (for example: [#50](https://github.com/Codium-ai/pr-agent/pull/50)).
|
||||
@ -62,7 +61,6 @@ Commands for invoking the different tools via comments:
|
||||
- **Describe**: `/describe`
|
||||
- **Improve**: `/improve` (or `/improve_code` for bitbucket, since `/improve` is sometimes reserved)
|
||||
- **Ask**: `/ask "..."`
|
||||
- **Reflect**: `/reflect`
|
||||
- **Update Changelog**: `/update_changelog`
|
||||
|
||||
|
||||
@ -168,7 +166,7 @@ If not set, the default configuration is `["opened", "reopened", "ready_for_revi
|
||||
|
||||
`github_action_config.enable_output` are used to enable/disable github actions [output parameter](https://docs.github.com/en/actions/creating-actions/metadata-syntax-for-github-actions#outputs-for-docker-container-and-javascript-actions) (default is `true`).
|
||||
Review result is output as JSON to `steps.{step-id}.outputs.review` property.
|
||||
The JSON structure is equivalent to the yaml data structure defined in [pr_reviewer_prompts.toml](https://github.com/idubnori/pr-agent/blob/main/pr_agent/settings/pr_reviewer_prompts.toml).
|
||||
The JSON structure is equivalent to the yaml data structure defined in [pr_reviewer_prompts.toml](https://github.com/qodo-ai/pr-agent/blob/main/pr_agent/settings/pr_reviewer_prompts.toml).
|
||||
|
||||
Note that you can give additional config parameters by adding environment variables to `.github/workflows/pr_agent.yml`, or by using a `.pr_agent.toml` [configuration file](https://qodo-merge-docs.qodo.ai/usage-guide/configuration_options/#global-configuration-file) in the root of your repo
|
||||
|
||||
@ -208,9 +206,9 @@ push_commands = [
|
||||
Note that to use the 'handle_push_trigger' feature, you need to give the gitlab webhook also the "Push events" scope.
|
||||
|
||||
### BitBucket App
|
||||
Similar to GitHub app, when running Qodo Merge from BitBucket App, the default [configuration file](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml) from a pre-built docker will be initially loaded.
|
||||
Similar to GitHub app, when running Qodo Merge from BitBucket App, the default [configuration file](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml) will be initially loaded.
|
||||
|
||||
By uploading a local `.pr_agent.toml` file to the root of the repo's main branch, you can edit and customize any configuration parameter. Note that you need to upload `.pr_agent.toml` prior to creating a PR, in order for the configuration to take effect.
|
||||
By uploading a local `.pr_agent.toml` file to the root of the repo's default branch, you can edit and customize any configuration parameter. Note that you need to upload `.pr_agent.toml` prior to creating a PR, in order for the configuration to take effect.
|
||||
|
||||
For example, if your local `.pr_agent.toml` file contains:
|
||||
```toml
|
||||
|
||||
@ -1,20 +1,26 @@
|
||||
## Changing a model in PR-Agent
|
||||
|
||||
See [here](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/algo/__init__.py) for a list of available models.
|
||||
To use a different model than the default (GPT-4), you need to edit in the [configuration file](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml#L2) the fields:
|
||||
```
|
||||
To use a different model than the default (o3-mini), you need to edit in the [configuration file](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml#L2) the fields:
|
||||
|
||||
```toml
|
||||
[config]
|
||||
model = "..."
|
||||
fallback_models = ["..."]
|
||||
```
|
||||
|
||||
For models and environments not from OpenAI, you might need to provide additional keys and other parameters.
|
||||
You can give parameters via a configuration file (see below for instructions), or from environment variables. See [litellm documentation](https://litellm.vercel.app/docs/proxy/quick_start#supported-llms) for the environment variables relevant per model.
|
||||
You can give parameters via a configuration file, or from environment variables.
|
||||
|
||||
!!! note "Model-specific environment variables"
|
||||
See [litellm documentation](https://litellm.vercel.app/docs/proxy/quick_start#supported-llms) for the environment variables needed per model, as they may vary and change over time. Our documentation per-model may not always be up-to-date with the latest changes.
|
||||
Failing to set the needed keys of a specific model will usually result in litellm not identifying the model type, and failing to utilize it.
|
||||
|
||||
### Azure
|
||||
|
||||
To use Azure, set in your `.secrets.toml` (working from CLI), or in the GitHub `Settings > Secrets and variables` (working from GitHub App or GitHub Action):
|
||||
```
|
||||
|
||||
```toml
|
||||
[openai]
|
||||
key = "" # your azure api key
|
||||
api_type = "azure"
|
||||
@ -24,26 +30,40 @@ deployment_id = "" # The deployment name you chose when you deployed the engine
|
||||
```
|
||||
|
||||
and set in your configuration file:
|
||||
```
|
||||
|
||||
```toml
|
||||
[config]
|
||||
model="" # the OpenAI model you've deployed on Azure (e.g. gpt-4o)
|
||||
fallback_models=["..."]
|
||||
```
|
||||
|
||||
Passing custom headers to the underlying LLM Model API can be done by setting extra_headers parameter to litellm.
|
||||
To use Azure AD (Entra id) based authentication set in your `.secrets.toml` (working from CLI), or in the GitHub `Settings > Secrets and variables` (working from GitHub App or GitHub Action):
|
||||
|
||||
```toml
|
||||
[azure_ad]
|
||||
client_id = "" # Your Azure AD application client ID
|
||||
client_secret = "" # Your Azure AD application client secret
|
||||
tenant_id = "" # Your Azure AD tenant ID
|
||||
api_base = "" # Your Azure OpenAI service base URL (e.g., https://openai.xyz.com/)
|
||||
```
|
||||
|
||||
|
||||
Passing custom headers to the underlying LLM Model API can be done by setting extra_headers parameter to litellm.
|
||||
|
||||
```toml
|
||||
[litellm]
|
||||
extra_headers='{"projectId": "<authorized projectId >", ...}') #The value of this setting should be a JSON string representing the desired headers, a ValueError is thrown otherwise.
|
||||
```
|
||||
This enables users to pass authorization tokens or API keys, when routing requests through an API management gateway.
|
||||
|
||||
This enables users to pass authorization tokens or API keys, when routing requests through an API management gateway.
|
||||
|
||||
### Ollama
|
||||
|
||||
You can run models locally through either [VLLM](https://docs.litellm.ai/docs/providers/vllm) or [Ollama](https://docs.litellm.ai/docs/providers/ollama)
|
||||
|
||||
E.g. to use a new model locally via Ollama, set in `.secrets.toml` or in a configuration file:
|
||||
```
|
||||
|
||||
```toml
|
||||
[config]
|
||||
model = "ollama/qwen2.5-coder:32b"
|
||||
fallback_models=["ollama/qwen2.5-coder:32b"]
|
||||
@ -54,9 +74,13 @@ duplicate_examples=true # will duplicate the examples in the prompt, to help the
|
||||
api_base = "http://localhost:11434" # or whatever port you're running Ollama on
|
||||
```
|
||||
|
||||
By default, Ollama uses a context window size of 2048 tokens. In most cases this is not enough to cover pr-agent promt and pull-request diff. Context window size can be overridden with the `OLLAMA_CONTEXT_LENGTH` environment variable. For example, to set the default context length to 8K, use: `OLLAMA_CONTEXT_LENGTH=8192 ollama serve`. More information you can find on the [official ollama faq](https://github.com/ollama/ollama/blob/main/docs/faq.md#how-can-i-specify-the-context-window-size).
|
||||
|
||||
Please note that the `custom_model_max_tokens` setting should be configured in accordance with the `OLLAMA_CONTEXT_LENGTH`. Failure to do so may result in unexpected model output.
|
||||
|
||||
!!! note "Local models vs commercial models"
|
||||
Qodo Merge is compatible with almost any AI model, but analyzing complex code repositories and pull requests requires a model specifically optimized for code analysis.
|
||||
|
||||
|
||||
Commercial models such as GPT-4, Claude Sonnet, and Gemini have demonstrated robust capabilities in generating structured output for code analysis tasks with large input. In contrast, most open-source models currently available (as of January 2025) face challenges with these complex tasks.
|
||||
|
||||
Based on our testing, local open-source models are suitable for experimentation and learning purposes (mainly for the `ask` command), but they are not suitable for production-level code analysis tasks.
|
||||
@ -66,7 +90,8 @@ api_base = "http://localhost:11434" # or whatever port you're running Ollama on
|
||||
### Hugging Face
|
||||
|
||||
To use a new model with Hugging Face Inference Endpoints, for example, set:
|
||||
```
|
||||
|
||||
```toml
|
||||
[config] # in configuration.toml
|
||||
model = "huggingface/meta-llama/Llama-2-7b-chat-hf"
|
||||
fallback_models=["huggingface/meta-llama/Llama-2-7b-chat-hf"]
|
||||
@ -76,40 +101,59 @@ custom_model_max_tokens=... # set the maximal input tokens for the model
|
||||
key = ... # your Hugging Face api key
|
||||
api_base = ... # the base url for your Hugging Face inference endpoint
|
||||
```
|
||||
|
||||
(you can obtain a Llama2 key from [here](https://replicate.com/replicate/llama-2-70b-chat/api))
|
||||
|
||||
### Replicate
|
||||
|
||||
To use Llama2 model with Replicate, for example, set:
|
||||
```
|
||||
|
||||
```toml
|
||||
[config] # in configuration.toml
|
||||
model = "replicate/llama-2-70b-chat:2c1608e18606fad2812020dc541930f2d0495ce32eee50074220b87300bc16e1"
|
||||
fallback_models=["replicate/llama-2-70b-chat:2c1608e18606fad2812020dc541930f2d0495ce32eee50074220b87300bc16e1"]
|
||||
[replicate] # in .secrets.toml
|
||||
key = ...
|
||||
```
|
||||
(you can obtain a Llama2 key from [here](https://replicate.com/replicate/llama-2-70b-chat/api))
|
||||
|
||||
(you can obtain a Llama2 key from [here](https://replicate.com/replicate/llama-2-70b-chat/api))
|
||||
|
||||
Also, review the [AiHandler](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/algo/ai_handler.py) file for instructions on how to set keys for other models.
|
||||
|
||||
### Groq
|
||||
|
||||
To use Llama3 model with Groq, for example, set:
|
||||
```
|
||||
|
||||
```toml
|
||||
[config] # in configuration.toml
|
||||
model = "llama3-70b-8192"
|
||||
fallback_models = ["groq/llama3-70b-8192"]
|
||||
[groq] # in .secrets.toml
|
||||
key = ... # your Groq api key
|
||||
```
|
||||
|
||||
(you can obtain a Groq key from [here](https://console.groq.com/keys))
|
||||
|
||||
### xAI
|
||||
|
||||
To use xAI's models with PR-Agent, set:
|
||||
|
||||
```toml
|
||||
[config] # in configuration.toml
|
||||
model = "xai/grok-2-latest"
|
||||
fallback_models = ["xai/grok-2-latest"] # or any other model as fallback
|
||||
|
||||
[xai] # in .secrets.toml
|
||||
key = "..." # your xAI API key
|
||||
```
|
||||
|
||||
You can obtain an xAI API key from [xAI's console](https://console.x.ai/) by creating an account and navigating to the developer settings page.
|
||||
|
||||
### Vertex AI
|
||||
|
||||
To use Google's Vertex AI platform and its associated models (chat-bison/codechat-bison) set:
|
||||
|
||||
```
|
||||
```toml
|
||||
[config] # in configuration.toml
|
||||
model = "vertex_ai/codechat-bison"
|
||||
fallback_models="vertex_ai/codechat-bison"
|
||||
@ -142,37 +186,37 @@ If you don't want to set the API key in the .secrets.toml file, you can set the
|
||||
|
||||
To use Anthropic models, set the relevant models in the configuration section of the configuration file:
|
||||
|
||||
```
|
||||
```toml
|
||||
[config]
|
||||
model="anthropic/claude-3-opus-20240229"
|
||||
fallback_models=["anthropic/claude-3-opus-20240229"]
|
||||
```
|
||||
|
||||
And also set the api key in the .secrets.toml file:
|
||||
```
|
||||
|
||||
```toml
|
||||
[anthropic]
|
||||
KEY = "..."
|
||||
```
|
||||
|
||||
See [litellm](https://docs.litellm.ai/docs/providers/anthropic#usage) documentation for more information about the environment variables required for Anthropic.
|
||||
|
||||
### Amazon Bedrock
|
||||
|
||||
To use Amazon Bedrock and its foundational models, add the below configuration:
|
||||
|
||||
```
|
||||
```toml
|
||||
[config] # in configuration.toml
|
||||
model="bedrock/anthropic.claude-3-sonnet-20240229-v1:0"
|
||||
fallback_models=["bedrock/anthropic.claude-v2:1"]
|
||||
model="bedrock/anthropic.claude-3-5-sonnet-20240620-v1:0"
|
||||
fallback_models=["bedrock/anthropic.claude-3-5-sonnet-20240620-v1:0"]
|
||||
|
||||
[aws]
|
||||
AWS_ACCESS_KEY_ID="..."
|
||||
AWS_SECRET_ACCESS_KEY="..."
|
||||
AWS_REGION_NAME="..."
|
||||
```
|
||||
|
||||
Note that you have to add access to foundational models before using them. Please refer to [this document](https://docs.aws.amazon.com/bedrock/latest/userguide/setting-up.html) for more details.
|
||||
|
||||
If you are using the claude-3 model, please configure the following settings as there are parameters incompatible with claude-3.
|
||||
```
|
||||
[litellm]
|
||||
drop_params = true
|
||||
```
|
||||
|
||||
AWS session is automatically authenticated from your environment, but you can also explicitly set `AWS_ACCESS_KEY_ID`, `AWS_SECRET_ACCESS_KEY` and `AWS_REGION_NAME` environment variables. Please refer to [this document](https://litellm.vercel.app/docs/providers/bedrock) for more details.
|
||||
See [litellm](https://docs.litellm.ai/docs/providers/bedrock#usage) documentation for more information about the environment variables required for Amazon Bedrock.
|
||||
|
||||
### DeepSeek
|
||||
|
||||
@ -193,31 +237,60 @@ key = ...
|
||||
|
||||
(you can obtain a deepseek-chat key from [here](https://platform.deepseek.com))
|
||||
|
||||
### DeepInfra
|
||||
|
||||
To use DeepSeek model with DeepInfra, for example, set:
|
||||
|
||||
```toml
|
||||
[config] # in configuration.toml
|
||||
model = "deepinfra/deepseek-ai/DeepSeek-R1-Distill-Llama-70B"
|
||||
fallback_models = ["deepinfra/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B"]
|
||||
[deepinfra] # in .secrets.toml
|
||||
key = ... # your DeepInfra api key
|
||||
```
|
||||
|
||||
(you can obtain a DeepInfra key from [here](https://deepinfra.com/dash/api_keys))
|
||||
|
||||
### Custom models
|
||||
|
||||
If the relevant model doesn't appear [here](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/algo/__init__.py), you can still use it as a custom model:
|
||||
|
||||
1. Set the model name in the configuration file:
|
||||
```
|
||||
|
||||
```toml
|
||||
[config]
|
||||
model="custom_model_name"
|
||||
fallback_models=["custom_model_name"]
|
||||
```
|
||||
|
||||
2. Set the maximal tokens for the model:
|
||||
```
|
||||
|
||||
```toml
|
||||
[config]
|
||||
custom_model_max_tokens= ...
|
||||
```
|
||||
|
||||
3. Go to [litellm documentation](https://litellm.vercel.app/docs/proxy/quick_start#supported-llms), find the model you want to use, and set the relevant environment variables.
|
||||
|
||||
4. Most reasoning models do not support chat-style inputs (`system` and `user` messages) or temperature settings.
|
||||
4. Most reasoning models do not support chat-style inputs (`system` and `user` messages) or temperature settings.
|
||||
To bypass chat templates and temperature controls, set `config.custom_reasoning_model = true` in your configuration file.
|
||||
|
||||
## Dedicated parameters
|
||||
|
||||
### OpenAI models
|
||||
|
||||
```toml
|
||||
[config]
|
||||
reasoning_efffort= = "medium" # "low", "medium", "high"
|
||||
```
|
||||
|
||||
With the OpenAI models that support reasoning effort (eg: o3-mini), you can specify its reasoning effort via `config` section. The default value is `medium`. You can change it to `high` or `low` based on your usage.
|
||||
|
||||
### Anthropic models
|
||||
|
||||
```toml
|
||||
[config]
|
||||
enable_claude_extended_thinking = false # Set to true to enable extended thinking feature
|
||||
extended_thinking_budget_tokens = 2048
|
||||
extended_thinking_max_output_tokens = 4096
|
||||
```
|
||||
|
||||
@ -41,7 +41,7 @@ Qodo Merge will know to remove the surrounding quotes when reading the configura
|
||||
`Platforms supported: GitHub, GitLab, Bitbucket, Azure DevOps`
|
||||
|
||||
|
||||
By uploading a local `.pr_agent.toml` file to the root of the repo's main branch, you can edit and customize any configuration parameter. Note that you need to upload `.pr_agent.toml` prior to creating a PR, in order for the configuration to take effect.
|
||||
By uploading a local `.pr_agent.toml` file to the root of the repo's default branch, you can edit and customize any configuration parameter. Note that you need to upload `.pr_agent.toml` prior to creating a PR, in order for the configuration to take effect.
|
||||
|
||||
For example, if you set in `.pr_agent.toml`:
|
||||
|
||||
@ -61,7 +61,7 @@ Then you can give a list of extra instructions to the `review` tool.
|
||||
|
||||
`Platforms supported: GitHub, GitLab, Bitbucket`
|
||||
|
||||
If you create a repo called `pr-agent-settings` in your **organization**, it's configuration file `.pr_agent.toml` will be used as a global configuration file for any other repo that belongs to the same organization.
|
||||
If you create a repo called `pr-agent-settings` in your **organization**, its configuration file `.pr_agent.toml` will be used as a global configuration file for any other repo that belongs to the same organization.
|
||||
Parameters from a local `.pr_agent.toml` file, in a specific repo, will override the global configuration parameters.
|
||||
|
||||
For example, in the GitHub organization `Codium-ai`:
|
||||
@ -69,3 +69,29 @@ For example, in the GitHub organization `Codium-ai`:
|
||||
- The file [`https://github.com/Codium-ai/pr-agent-settings/.pr_agent.toml`](https://github.com/Codium-ai/pr-agent-settings/blob/main/.pr_agent.toml) serves as a global configuration file for all the repos in the GitHub organization `Codium-ai`.
|
||||
|
||||
- The repo [`https://github.com/Codium-ai/pr-agent`](https://github.com/Codium-ai/pr-agent/blob/main/.pr_agent.toml) inherits the global configuration file from `pr-agent-settings`.
|
||||
|
||||
### Bitbucket Organization level configuration file 💎
|
||||
`Relevant platforms: Bitbucket Data Center`
|
||||
|
||||
In Bitbucket Data Center, there are two levels where you can define a global configuration file:
|
||||
|
||||
* Project-level global configuration:
|
||||
|
||||
Create a repository named `pr-agent-settings` within a specific project. The configuration file in this repository will apply to all repositories under the same project.
|
||||
|
||||
* Organization-level global configuration:
|
||||
|
||||
Create a dedicated project to hold a global configuration file that affects all repositories across all projects in your organization.
|
||||
|
||||
**Setting up organization-level global configuration:**
|
||||
|
||||
1. Create a new project with both the name and key: PR_AGENT_SETTINGS.
|
||||
2. Inside the PR_AGENT_SETTINGS project, create a repository named pr-agent-settings.
|
||||
3. In this repository, add a `.pr_agent.toml` configuration file—structured similarly to the global configuration file described above.
|
||||
4. Optionally, you can add organizational-level [global best practices file](https://qodo-merge-docs.qodo.ai/usage-guide/configuration_options/#global-configuration-file).
|
||||
|
||||
Repositories across your entire Bitbucket organization will inherit the configuration from this file.
|
||||
|
||||
!!! note "Note"
|
||||
If both organization-level and project-level global settings are defined, the project-level settings will take precedence over the organization-level configuration. Additionally, parameters from a repository’s local .pr_agent.toml file will always override both global settings.
|
||||
|
||||
|
||||
@ -6,7 +6,6 @@ For optimal functionality of Qodo Merge, we recommend enabling a wiki for each r
|
||||
**Key Wiki Features: 💎**
|
||||
|
||||
- Storing a [configuration file](https://qodo-merge-docs.qodo.ai/usage-guide/configuration_options/#wiki-configuration-file)
|
||||
- Defining a [`best_practices.md`](https://qodo-merge-docs.qodo.ai/tools/improve/#best-practices) file
|
||||
- Track [accepted suggestions](https://qodo-merge-docs.qodo.ai/tools/improve/#suggestion-tracking)
|
||||
- Facilitates learning over time by creating an [auto_best_practices.md](https://qodo-merge-docs.qodo.ai/core-abilities/auto_best_practices) file
|
||||
|
||||
@ -26,7 +25,7 @@ To enable a wiki for your repository:
|
||||
### Why Wiki?
|
||||
|
||||
- Your code (and its derivatives, including accepted code suggestions) is yours. Qodo Merge will never store it on external servers.
|
||||
- Repository changes typically require pull requests, which create overhead and are time-consuming. This process is too cumbersome for auto data aggregation, and is not very convenient even for managing frequently updated content like configuration files and best practices.
|
||||
- Repository changes typically require pull requests, which create overhead and are time-consuming. This process is too cumbersome for auto data aggregation, and is not very convenient even for managing frequently updated content like configuration files.
|
||||
- A repository wiki page provides an ideal balance:
|
||||
- It lives within your repository, making it suitable for code-related documentation
|
||||
- It enables quick updates without the overhead of pull requests
|
||||
|
||||
@ -23,5 +23,4 @@ It includes information on how to adjust Qodo Merge configurations, define which
|
||||
- [Working with large PRs](./additional_configurations.md#working-with-large-prs)
|
||||
- [Changing a model](./additional_configurations.md#changing-a-model)
|
||||
- [Patch Extra Lines](./additional_configurations.md#patch-extra-lines)
|
||||
- [Editing the prompts](./additional_configurations.md#editing-the-prompts)
|
||||
- [Qodo Merge Models](./qodo_merge_models)
|
||||
|
||||
@ -1,36 +1,32 @@
|
||||
|
||||
The default models used by Qodo Merge are a combination of Claude-3.5-sonnet and OpenAI's GPT-4 models.
|
||||
The default model used by Qodo Merge (March 2025) is Claude Sonnet 3.7.
|
||||
|
||||
### Selecting a Specific Model
|
||||
|
||||
Users can configure Qodo Merge to use a specific model by editing the [configuration](https://qodo-merge-docs.qodo.ai/usage-guide/configuration_options/) file.
|
||||
The models supported by Qodo Merge are:
|
||||
|
||||
- `claude-3-5-sonnet`
|
||||
- `gpt-4o`
|
||||
- `claude-3-7-sonnet` (default)
|
||||
- `o3-mini`
|
||||
|
||||
To restrict Qodo Merge to using only `Claude-3.5-sonnet`, add this setting:
|
||||
|
||||
```
|
||||
[config]
|
||||
model="claude-3-5-sonnet"
|
||||
```
|
||||
|
||||
To restrict Qodo Merge to using only `GPT-4o`, add this setting:
|
||||
```
|
||||
[config]
|
||||
model="gpt-4o"
|
||||
```
|
||||
|
||||
[//]: # (To restrict Qodo Merge to using only `deepseek-r1` us-hosted, add this setting:)
|
||||
[//]: # (```)
|
||||
[//]: # ([config])
|
||||
[//]: # (model="deepseek/r1")
|
||||
[//]: # (```)
|
||||
- `gpt-4.1`
|
||||
- `deepseek/r1`
|
||||
|
||||
To restrict Qodo Merge to using only `o3-mini`, add this setting:
|
||||
```
|
||||
[config]
|
||||
model="o3-mini"
|
||||
```
|
||||
|
||||
To restrict Qodo Merge to using only `GPT-4.1`, add this setting:
|
||||
```
|
||||
[config]
|
||||
model="gpt-4.1"
|
||||
```
|
||||
|
||||
To restrict Qodo Merge to using only `deepseek-r1` us-hosted, add this setting:
|
||||
```
|
||||
[config]
|
||||
model="deepseek/r1"
|
||||
```
|
||||
|
||||
|
||||
|
||||
@ -28,7 +28,7 @@ nav:
|
||||
- Improve: 'tools/improve.md'
|
||||
- Ask: 'tools/ask.md'
|
||||
- Update Changelog: 'tools/update_changelog.md'
|
||||
- Similar Issues: 'tools/similar_issues.md'
|
||||
- Help Docs: 'tools/help_docs.md'
|
||||
- Help: 'tools/help.md'
|
||||
- 💎 Analyze: 'tools/analyze.md'
|
||||
- 💎 Test: 'tools/test.md'
|
||||
@ -41,21 +41,23 @@ nav:
|
||||
- 💎 Implement: 'tools/implement.md'
|
||||
- Core Abilities:
|
||||
- 'core-abilities/index.md'
|
||||
- Fetching ticket context: 'core-abilities/fetching_ticket_context.md'
|
||||
- Auto best practices: 'core-abilities/auto_best_practices.md'
|
||||
- Local and global metadata: 'core-abilities/metadata.md'
|
||||
- Pull request benchmark: 'finetuning_benchmark/index.md'
|
||||
- Code validation: 'core-abilities/code_validation.md'
|
||||
- Compression strategy: 'core-abilities/compression_strategy.md'
|
||||
- Dynamic context: 'core-abilities/dynamic_context.md'
|
||||
- Self-reflection: 'core-abilities/self_reflection.md'
|
||||
- Fetching ticket context: 'core-abilities/fetching_ticket_context.md'
|
||||
- Impact evaluation: 'core-abilities/impact_evaluation.md'
|
||||
- Interactivity: 'core-abilities/interactivity.md'
|
||||
- Compression strategy: 'core-abilities/compression_strategy.md'
|
||||
- Code-oriented YAML: 'core-abilities/code_oriented_yaml.md'
|
||||
- Local and global metadata: 'core-abilities/metadata.md'
|
||||
- RAG context enrichment: 'core-abilities/rag_context_enrichment.md'
|
||||
- Self-reflection: 'core-abilities/self_reflection.md'
|
||||
- Static code analysis: 'core-abilities/static_code_analysis.md'
|
||||
- Code Fine-tuning Benchmark: 'finetuning_benchmark/index.md'
|
||||
- Chrome Extension:
|
||||
- Qodo Merge Chrome Extension: 'chrome-extension/index.md'
|
||||
- Features: 'chrome-extension/features.md'
|
||||
- Data Privacy: 'chrome-extension/data_privacy.md'
|
||||
- Options: 'chrome-extension/options.md'
|
||||
- FAQ:
|
||||
- FAQ: 'faq/index.md'
|
||||
- AI Docs Search: 'ai_search/index.md'
|
||||
|
||||
@ -13,6 +13,7 @@ from pr_agent.tools.pr_code_suggestions import PRCodeSuggestions
|
||||
from pr_agent.tools.pr_config import PRConfig
|
||||
from pr_agent.tools.pr_description import PRDescription
|
||||
from pr_agent.tools.pr_generate_labels import PRGenerateLabels
|
||||
from pr_agent.tools.pr_help_docs import PRHelpDocs
|
||||
from pr_agent.tools.pr_help_message import PRHelpMessage
|
||||
from pr_agent.tools.pr_line_questions import PR_LineQuestions
|
||||
from pr_agent.tools.pr_questions import PRQuestions
|
||||
@ -39,6 +40,7 @@ command2class = {
|
||||
"similar_issue": PRSimilarIssue,
|
||||
"add_docs": PRAddDocs,
|
||||
"generate_labels": PRGenerateLabels,
|
||||
"help_docs": PRHelpDocs,
|
||||
}
|
||||
|
||||
commands = list(command2class.keys())
|
||||
@ -89,7 +91,7 @@ class PRAgent:
|
||||
|
||||
action = action.lstrip("/").lower()
|
||||
if action not in command2class:
|
||||
get_logger().error(f"Unknown command: {action}")
|
||||
get_logger().warning(f"Unknown command: {action}")
|
||||
return False
|
||||
with get_logger().contextualize(command=action, pr_url=pr_url):
|
||||
get_logger().info("PR-Agent request handler started", analytics=True)
|
||||
|
||||
@ -20,6 +20,14 @@ MAX_TOKENS = {
|
||||
'gpt-4o-mini-2024-07-18': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
'gpt-4o-2024-08-06': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
'gpt-4o-2024-11-20': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
'gpt-4.5-preview': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
'gpt-4.5-preview-2025-02-27': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
'gpt-4.1': 1047576,
|
||||
'gpt-4.1-2025-04-14': 1047576,
|
||||
'gpt-4.1-mini': 1047576,
|
||||
'gpt-4.1-mini-2025-04-14': 1047576,
|
||||
'gpt-4.1-nano': 1047576,
|
||||
'gpt-4.1-nano-2025-04-14': 1047576,
|
||||
'o1-mini': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
'o1-mini-2024-09-12': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
'o1-preview': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
@ -51,6 +59,7 @@ MAX_TOKENS = {
|
||||
'gemini/gemini-1.5-pro': 1048576,
|
||||
'gemini/gemini-1.5-flash': 1048576,
|
||||
'gemini/gemini-2.0-flash': 1048576,
|
||||
'gemini/gemini-2.5-pro-preview-03-25': 1048576,
|
||||
'codechat-bison': 6144,
|
||||
'codechat-bison-32k': 32000,
|
||||
'anthropic.claude-instant-v1': 100000,
|
||||
@ -60,6 +69,7 @@ MAX_TOKENS = {
|
||||
'anthropic/claude-3-5-sonnet-20240620': 100000,
|
||||
'anthropic/claude-3-5-sonnet-20241022': 100000,
|
||||
'anthropic/claude-3-7-sonnet-20250219': 200000,
|
||||
'claude-3-7-sonnet-20250219': 200000,
|
||||
'anthropic/claude-3-5-haiku-20241022': 100000,
|
||||
'bedrock/anthropic.claude-instant-v1': 100000,
|
||||
'bedrock/anthropic.claude-v2': 100000,
|
||||
@ -71,13 +81,23 @@ MAX_TOKENS = {
|
||||
'bedrock/anthropic.claude-3-5-sonnet-20241022-v2:0': 100000,
|
||||
'bedrock/anthropic.claude-3-7-sonnet-20250219-v1:0': 200000,
|
||||
"bedrock/us.anthropic.claude-3-5-sonnet-20241022-v2:0": 100000,
|
||||
"bedrock/us.anthropic.claude-3-7-sonnet-20250219-v1:0": 200000,
|
||||
'claude-3-5-sonnet': 100000,
|
||||
'groq/meta-llama/llama-4-scout-17b-16e-instruct': 131072,
|
||||
'groq/meta-llama/llama-4-maverick-17b-128e-instruct': 131072,
|
||||
'groq/llama3-8b-8192': 8192,
|
||||
'groq/llama3-70b-8192': 8192,
|
||||
'groq/llama-3.1-8b-instant': 8192,
|
||||
'groq/llama-3.3-70b-versatile': 128000,
|
||||
'groq/mixtral-8x7b-32768': 32768,
|
||||
'groq/gemma2-9b-it': 8192,
|
||||
'xai/grok-2': 131072,
|
||||
'xai/grok-2-1212': 131072,
|
||||
'xai/grok-2-latest': 131072,
|
||||
'xai/grok-3-beta': 131072,
|
||||
'xai/grok-3-fast-beta': 131072,
|
||||
'xai/grok-3-mini-beta': 131072,
|
||||
'xai/grok-3-mini-fast-beta': 131072,
|
||||
'ollama/llama3': 4096,
|
||||
'watsonx/meta-llama/llama-3-8b-instruct': 4096,
|
||||
"watsonx/meta-llama/llama-3-70b-instruct": 4096,
|
||||
@ -85,6 +105,9 @@ MAX_TOKENS = {
|
||||
"watsonx/ibm/granite-13b-chat-v2": 8191,
|
||||
"watsonx/ibm/granite-34b-code-instruct": 8191,
|
||||
"watsonx/mistralai/mistral-large": 32768,
|
||||
"deepinfra/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B": 128000,
|
||||
"deepinfra/deepseek-ai/DeepSeek-R1-Distill-Llama-70B": 128000,
|
||||
"deepinfra/deepseek-ai/DeepSeek-R1": 128000,
|
||||
}
|
||||
|
||||
USER_MESSAGE_ONLY_MODELS = [
|
||||
@ -109,3 +132,8 @@ SUPPORT_REASONING_EFFORT_MODELS = [
|
||||
"o3-mini",
|
||||
"o3-mini-2025-01-31"
|
||||
]
|
||||
|
||||
CLAUDE_EXTENDED_THINKING_MODELS = [
|
||||
"anthropic/claude-3-7-sonnet-20250219",
|
||||
"claude-3-7-sonnet-20250219"
|
||||
]
|
||||
|
||||
@ -1,12 +1,11 @@
|
||||
import os
|
||||
|
||||
import litellm
|
||||
import openai
|
||||
import requests
|
||||
from litellm import acompletion
|
||||
from tenacity import retry, retry_if_exception_type, stop_after_attempt
|
||||
|
||||
from pr_agent.algo import NO_SUPPORT_TEMPERATURE_MODELS, SUPPORT_REASONING_EFFORT_MODELS, USER_MESSAGE_ONLY_MODELS
|
||||
from pr_agent.algo import CLAUDE_EXTENDED_THINKING_MODELS, NO_SUPPORT_TEMPERATURE_MODELS, SUPPORT_REASONING_EFFORT_MODELS, USER_MESSAGE_ONLY_MODELS
|
||||
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||
from pr_agent.algo.utils import ReasoningEffort, get_version
|
||||
from pr_agent.config_loader import get_settings
|
||||
@ -31,6 +30,7 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||
self.azure = False
|
||||
self.api_base = None
|
||||
self.repetition_penalty = None
|
||||
|
||||
if get_settings().get("OPENAI.KEY", None):
|
||||
openai.api_key = get_settings().openai.key
|
||||
litellm.openai_key = get_settings().openai.key
|
||||
@ -41,11 +41,6 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||
os.environ["AWS_ACCESS_KEY_ID"] = get_settings().aws.AWS_ACCESS_KEY_ID
|
||||
os.environ["AWS_SECRET_ACCESS_KEY"] = get_settings().aws.AWS_SECRET_ACCESS_KEY
|
||||
os.environ["AWS_REGION_NAME"] = get_settings().aws.AWS_REGION_NAME
|
||||
if get_settings().get("litellm.use_client"):
|
||||
litellm_token = get_settings().get("litellm.LITELLM_TOKEN")
|
||||
assert litellm_token, "LITELLM_TOKEN is required"
|
||||
os.environ["LITELLM_TOKEN"] = litellm_token
|
||||
litellm.use_client = True
|
||||
if get_settings().get("LITELLM.DROP_PARAMS", None):
|
||||
litellm.drop_params = get_settings().litellm.drop_params
|
||||
if get_settings().get("LITELLM.SUCCESS_CALLBACK", None):
|
||||
@ -72,6 +67,8 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||
litellm.api_key = get_settings().groq.key
|
||||
if get_settings().get("REPLICATE.KEY", None):
|
||||
litellm.replicate_key = get_settings().replicate.key
|
||||
if get_settings().get("XAI.KEY", None):
|
||||
litellm.api_key = get_settings().xai.key
|
||||
if get_settings().get("HUGGINGFACE.KEY", None):
|
||||
litellm.huggingface_key = get_settings().huggingface.key
|
||||
if get_settings().get("HUGGINGFACE.API_BASE", None) and 'huggingface' in get_settings().config.model:
|
||||
@ -96,6 +93,23 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||
if get_settings().get("DEEPSEEK.KEY", None):
|
||||
os.environ['DEEPSEEK_API_KEY'] = get_settings().get("DEEPSEEK.KEY")
|
||||
|
||||
# Support deepinfra models
|
||||
if get_settings().get("DEEPINFRA.KEY", None):
|
||||
os.environ['DEEPINFRA_API_KEY'] = get_settings().get("DEEPINFRA.KEY")
|
||||
|
||||
# Check for Azure AD configuration
|
||||
if get_settings().get("AZURE_AD.CLIENT_ID", None):
|
||||
self.azure = True
|
||||
# Generate access token using Azure AD credentials from settings
|
||||
access_token = self._get_azure_ad_token()
|
||||
litellm.api_key = access_token
|
||||
openai.api_key = access_token
|
||||
|
||||
# Set API base from settings
|
||||
self.api_base = get_settings().azure_ad.api_base
|
||||
litellm.api_base = self.api_base
|
||||
openai.api_base = self.api_base
|
||||
|
||||
# Models that only use user meessage
|
||||
self.user_message_only_models = USER_MESSAGE_ONLY_MODELS
|
||||
|
||||
@ -105,6 +119,29 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||
# Models that support reasoning effort
|
||||
self.support_reasoning_models = SUPPORT_REASONING_EFFORT_MODELS
|
||||
|
||||
# Models that support extended thinking
|
||||
self.claude_extended_thinking_models = CLAUDE_EXTENDED_THINKING_MODELS
|
||||
|
||||
def _get_azure_ad_token(self):
|
||||
"""
|
||||
Generates an access token using Azure AD credentials from settings.
|
||||
Returns:
|
||||
str: The access token
|
||||
"""
|
||||
from azure.identity import ClientSecretCredential
|
||||
try:
|
||||
credential = ClientSecretCredential(
|
||||
tenant_id=get_settings().azure_ad.tenant_id,
|
||||
client_id=get_settings().azure_ad.client_id,
|
||||
client_secret=get_settings().azure_ad.client_secret
|
||||
)
|
||||
# Get token for Azure OpenAI service
|
||||
token = credential.get_token("https://cognitiveservices.azure.com/.default")
|
||||
return token.token
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to get Azure AD token: {e}")
|
||||
raise
|
||||
|
||||
def prepare_logs(self, response, system, user, resp, finish_reason):
|
||||
response_log = response.dict().copy()
|
||||
response_log['system'] = system
|
||||
@ -117,6 +154,43 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||
response_log['main_pr_language'] = 'unknown'
|
||||
return response_log
|
||||
|
||||
def _configure_claude_extended_thinking(self, model: str, kwargs: dict) -> dict:
|
||||
"""
|
||||
Configure Claude extended thinking parameters if applicable.
|
||||
|
||||
Args:
|
||||
model (str): The AI model being used
|
||||
kwargs (dict): The keyword arguments for the model call
|
||||
|
||||
Returns:
|
||||
dict: Updated kwargs with extended thinking configuration
|
||||
"""
|
||||
extended_thinking_budget_tokens = get_settings().config.get("extended_thinking_budget_tokens", 2048)
|
||||
extended_thinking_max_output_tokens = get_settings().config.get("extended_thinking_max_output_tokens", 4096)
|
||||
|
||||
# Validate extended thinking parameters
|
||||
if not isinstance(extended_thinking_budget_tokens, int) or extended_thinking_budget_tokens <= 0:
|
||||
raise ValueError(f"extended_thinking_budget_tokens must be a positive integer, got {extended_thinking_budget_tokens}")
|
||||
if not isinstance(extended_thinking_max_output_tokens, int) or extended_thinking_max_output_tokens <= 0:
|
||||
raise ValueError(f"extended_thinking_max_output_tokens must be a positive integer, got {extended_thinking_max_output_tokens}")
|
||||
if extended_thinking_max_output_tokens < extended_thinking_budget_tokens:
|
||||
raise ValueError(f"extended_thinking_max_output_tokens ({extended_thinking_max_output_tokens}) must be greater than or equal to extended_thinking_budget_tokens ({extended_thinking_budget_tokens})")
|
||||
|
||||
kwargs["thinking"] = {
|
||||
"type": "enabled",
|
||||
"budget_tokens": extended_thinking_budget_tokens
|
||||
}
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().info(f"Adding max output tokens {extended_thinking_max_output_tokens} to model {model}, extended thinking budget tokens: {extended_thinking_budget_tokens}")
|
||||
kwargs["max_tokens"] = extended_thinking_max_output_tokens
|
||||
|
||||
# temperature may only be set to 1 when thinking is enabled
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().info("Temperature may only be set to 1 when thinking is enabled with claude models.")
|
||||
kwargs["temperature"] = 1
|
||||
|
||||
return kwargs
|
||||
|
||||
def add_litellm_callbacks(selfs, kwargs) -> dict:
|
||||
captured_extra = []
|
||||
|
||||
@ -242,6 +316,10 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||
get_logger().info(f"Adding reasoning_effort with value {reasoning_effort} to model {model}.")
|
||||
kwargs["reasoning_effort"] = reasoning_effort
|
||||
|
||||
# https://docs.anthropic.com/en/docs/build-with-claude/extended-thinking
|
||||
if (model in self.claude_extended_thinking_models) and get_settings().config.get("enable_claude_extended_thinking", False):
|
||||
kwargs = self._configure_claude_extended_thinking(model, kwargs)
|
||||
|
||||
if get_settings().litellm.get("enable_callbacks", False):
|
||||
kwargs = self.add_litellm_callbacks(kwargs)
|
||||
|
||||
@ -264,13 +342,13 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||
except json.JSONDecodeError as e:
|
||||
raise ValueError(f"LITELLM.EXTRA_HEADERS contains invalid JSON: {str(e)}")
|
||||
kwargs["extra_headers"] = litellm_extra_headers
|
||||
|
||||
|
||||
get_logger().debug("Prompts", artifact={"system": system, "user": user})
|
||||
|
||||
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().info(f"\nSystem prompt:\n{system}")
|
||||
get_logger().info(f"\nUser prompt:\n{user}")
|
||||
|
||||
|
||||
response = await acompletion(**kwargs)
|
||||
except (openai.APIError, openai.APITimeoutError) as e:
|
||||
get_logger().warning(f"Error during LLM inference: {e}")
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
from base64 import b64decode
|
||||
from base64 import b64decode, encode, b64encode
|
||||
import hashlib
|
||||
|
||||
class CliArgs:
|
||||
@ -9,7 +9,9 @@ class CliArgs:
|
||||
return True, ""
|
||||
|
||||
# decode forbidden args
|
||||
_encoded_args = 'ZW5hYmxlX2F1dG9fYXBwcm92YWw=:YXBwcm92ZV9wcl9vbl9zZWxmX3Jldmlldw==:YmFzZV91cmw=:dXJs:YXBwX25hbWU=:c2VjcmV0X3Byb3ZpZGVy:Z2l0X3Byb3ZpZGVy:c2tpcF9rZXlz:b3BlbmFpLmtleQ==:QU5BTFlUSUNTX0ZPTERFUg==:dXJp:YXBwX2lk:d2ViaG9va19zZWNyZXQ=:YmVhcmVyX3Rva2Vu:UEVSU09OQUxfQUNDRVNTX1RPS0VO:b3ZlcnJpZGVfZGVwbG95bWVudF90eXBl:cHJpdmF0ZV9rZXk=:bG9jYWxfY2FjaGVfcGF0aA==:ZW5hYmxlX2xvY2FsX2NhY2hl:amlyYV9iYXNlX3VybA==:YXBpX2Jhc2U=:YXBpX3R5cGU=:YXBpX3ZlcnNpb24=:c2tpcF9rZXlz'
|
||||
# b64encode('word'.encode()).decode()
|
||||
_encoded_args = 'c2hhcmVkX3NlY3JldA==:dXNlcg==:c3lzdGVt:ZW5hYmxlX2NvbW1lbnRfYXBwcm92YWw=:ZW5hYmxlX21hbnVhbF9hcHByb3ZhbA==:ZW5hYmxlX2F1dG9fYXBwcm92YWw=:YXBwcm92ZV9wcl9vbl9zZWxmX3Jldmlldw==:YmFzZV91cmw=:dXJs:YXBwX25hbWU=:c2VjcmV0X3Byb3ZpZGVy:Z2l0X3Byb3ZpZGVy:c2tpcF9rZXlz:b3BlbmFpLmtleQ==:QU5BTFlUSUNTX0ZPTERFUg==:dXJp:YXBwX2lk:d2ViaG9va19zZWNyZXQ=:YmVhcmVyX3Rva2Vu:UEVSU09OQUxfQUNDRVNTX1RPS0VO:b3ZlcnJpZGVfZGVwbG95bWVudF90eXBl:cHJpdmF0ZV9rZXk=:bG9jYWxfY2FjaGVfcGF0aA==:ZW5hYmxlX2xvY2FsX2NhY2hl:amlyYV9iYXNlX3VybA==:YXBpX2Jhc2U=:YXBpX3R5cGU=:YXBpX3ZlcnNpb24=:c2tpcF9rZXlz'
|
||||
|
||||
forbidden_cli_args = []
|
||||
for e in _encoded_args.split(':'):
|
||||
forbidden_cli_args.append(b64decode(e).decode())
|
||||
|
||||
@ -285,7 +285,7 @@ def handle_patch_deletions(patch: str, original_file_content_str: str,
|
||||
return patch
|
||||
|
||||
|
||||
def convert_to_hunks_with_lines_numbers(patch: str, file) -> str:
|
||||
def decouple_and_convert_to_hunks_with_lines_numbers(patch: str, file) -> str:
|
||||
"""
|
||||
Convert a given patch string into a string with line numbers for each hunk, indicating the new and old content of
|
||||
the file.
|
||||
@ -317,11 +317,17 @@ __old hunk__
|
||||
line6
|
||||
...
|
||||
"""
|
||||
# if the file was deleted, return a message indicating that the file was deleted
|
||||
if hasattr(file, 'edit_type') and file.edit_type == EDIT_TYPE.DELETED:
|
||||
return f"\n\n## File '{file.filename.strip()}' was deleted\n"
|
||||
|
||||
patch_with_lines_str = f"\n\n## File: '{file.filename.strip()}'\n"
|
||||
# Add a header for the file
|
||||
if file:
|
||||
# if the file was deleted, return a message indicating that the file was deleted
|
||||
if hasattr(file, 'edit_type') and file.edit_type == EDIT_TYPE.DELETED:
|
||||
return f"\n\n## File '{file.filename.strip()}' was deleted\n"
|
||||
|
||||
patch_with_lines_str = f"\n\n## File: '{file.filename.strip()}'\n"
|
||||
else:
|
||||
patch_with_lines_str = ""
|
||||
|
||||
patch_lines = patch.splitlines()
|
||||
RE_HUNK_HEADER = re.compile(
|
||||
r"^@@ -(\d+)(?:,(\d+))? \+(\d+)(?:,(\d+))? @@[ ]?(.*)")
|
||||
|
||||
@ -19,6 +19,12 @@ def is_valid_file(filename:str, bad_extensions=None) -> bool:
|
||||
bad_extensions = get_settings().bad_extensions.default
|
||||
if get_settings().config.use_extra_bad_extensions:
|
||||
bad_extensions += get_settings().bad_extensions.extra
|
||||
|
||||
auto_generated_files = ['package-lock.json', 'yarn.lock', 'composer.lock', 'Gemfile.lock', 'poetry.lock']
|
||||
for forbidden_file in auto_generated_files:
|
||||
if filename.endswith(forbidden_file):
|
||||
return False
|
||||
|
||||
return filename.split('.')[-1] not in bad_extensions
|
||||
|
||||
|
||||
@ -41,6 +47,7 @@ def sort_files_by_main_languages(languages: Dict, files: list):
|
||||
|
||||
# filter out files bad extensions
|
||||
files_filtered = filter_bad_extensions(files)
|
||||
|
||||
# sort files by their extension, put the files that are in the main extension first
|
||||
# and the rest files after, map languages_sorted to their respective files
|
||||
files_sorted = []
|
||||
|
||||
@ -7,7 +7,8 @@ from github import RateLimitExceededException
|
||||
|
||||
from pr_agent.algo.file_filter import filter_ignored
|
||||
from pr_agent.algo.git_patch_processing import (
|
||||
convert_to_hunks_with_lines_numbers, extend_patch, handle_patch_deletions)
|
||||
extend_patch, handle_patch_deletions,
|
||||
decouple_and_convert_to_hunks_with_lines_numbers)
|
||||
from pr_agent.algo.language_handler import sort_files_by_main_languages
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
|
||||
@ -50,22 +51,11 @@ def get_pr_diff(git_provider: GitProvider, token_handler: TokenHandler,
|
||||
PATCH_EXTRA_LINES_AFTER = cap_and_log_extra_lines(PATCH_EXTRA_LINES_AFTER, "after")
|
||||
|
||||
try:
|
||||
diff_files_original = git_provider.get_diff_files()
|
||||
diff_files = git_provider.get_diff_files()
|
||||
except RateLimitExceededException as e:
|
||||
get_logger().error(f"Rate limit exceeded for git provider API. original message {e}")
|
||||
raise
|
||||
|
||||
diff_files = filter_ignored(diff_files_original)
|
||||
if diff_files != diff_files_original:
|
||||
try:
|
||||
get_logger().info(f"Filtered out {len(diff_files_original) - len(diff_files)} files")
|
||||
new_names = set([a.filename for a in diff_files])
|
||||
orig_names = set([a.filename for a in diff_files_original])
|
||||
get_logger().info(f"Filtered out files: {orig_names - new_names}")
|
||||
except Exception as e:
|
||||
pass
|
||||
|
||||
|
||||
# get pr languages
|
||||
pr_languages = sort_files_by_main_languages(git_provider.get_languages(), diff_files)
|
||||
if pr_languages:
|
||||
@ -155,21 +145,11 @@ def get_pr_diff(git_provider: GitProvider, token_handler: TokenHandler,
|
||||
def get_pr_diff_multiple_patchs(git_provider: GitProvider, token_handler: TokenHandler, model: str,
|
||||
add_line_numbers_to_hunks: bool = False, disable_extra_lines: bool = False):
|
||||
try:
|
||||
diff_files_original = git_provider.get_diff_files()
|
||||
diff_files = git_provider.get_diff_files()
|
||||
except RateLimitExceededException as e:
|
||||
get_logger().error(f"Rate limit exceeded for git provider API. original message {e}")
|
||||
raise
|
||||
|
||||
diff_files = filter_ignored(diff_files_original)
|
||||
if diff_files != diff_files_original:
|
||||
try:
|
||||
get_logger().info(f"Filtered out {len(diff_files_original) - len(diff_files)} files")
|
||||
new_names = set([a.filename for a in diff_files])
|
||||
orig_names = set([a.filename for a in diff_files_original])
|
||||
get_logger().info(f"Filtered out files: {orig_names - new_names}")
|
||||
except Exception as e:
|
||||
pass
|
||||
|
||||
# get pr languages
|
||||
pr_languages = sort_files_by_main_languages(git_provider.get_languages(), diff_files)
|
||||
if pr_languages:
|
||||
@ -209,9 +189,10 @@ def pr_generate_extended_diff(pr_languages: list,
|
||||
continue
|
||||
|
||||
if add_line_numbers_to_hunks:
|
||||
full_extended_patch = convert_to_hunks_with_lines_numbers(extended_patch, file)
|
||||
full_extended_patch = decouple_and_convert_to_hunks_with_lines_numbers(extended_patch, file)
|
||||
else:
|
||||
full_extended_patch = f"\n\n## File: '{file.filename.strip()}'\n{extended_patch.rstrip()}\n"
|
||||
extended_patch = extended_patch.replace('\n@@ ', '\n\n@@ ') # add extra line before each hunk
|
||||
full_extended_patch = f"\n\n## File: '{file.filename.strip()}'\n\n{extended_patch.strip()}\n"
|
||||
|
||||
# add AI-summary metadata to the patch
|
||||
if file.ai_file_summary and get_settings().get("config.enable_ai_metadata", False):
|
||||
@ -254,7 +235,7 @@ def pr_generate_compressed_diff(top_langs: list, token_handler: TokenHandler, mo
|
||||
continue
|
||||
|
||||
if convert_hunks_to_line_numbers:
|
||||
patch = convert_to_hunks_with_lines_numbers(patch, file)
|
||||
patch = decouple_and_convert_to_hunks_with_lines_numbers(patch, file)
|
||||
|
||||
## add AI-summary metadata to the patch (disabled, since we are in the compressed diff)
|
||||
# if file.ai_file_summary and get_settings().config.get('config.is_auto_command', False):
|
||||
@ -410,8 +391,6 @@ def get_pr_multi_diffs(git_provider: GitProvider,
|
||||
get_logger().error(f"Rate limit exceeded for git provider API. original message {e}")
|
||||
raise
|
||||
|
||||
diff_files = filter_ignored(diff_files)
|
||||
|
||||
# Sort files by main language
|
||||
pr_languages = sort_files_by_main_languages(git_provider.get_languages(), diff_files)
|
||||
|
||||
@ -460,7 +439,7 @@ def get_pr_multi_diffs(git_provider: GitProvider,
|
||||
|
||||
# Add line numbers and metadata to the patch
|
||||
if add_line_numbers:
|
||||
patch = convert_to_hunks_with_lines_numbers(patch, file)
|
||||
patch = decouple_and_convert_to_hunks_with_lines_numbers(patch, file)
|
||||
else:
|
||||
patch = f"\n\n## File: '{file.filename.strip()}'\n\n{patch.strip()}\n"
|
||||
|
||||
@ -511,7 +490,7 @@ def get_pr_multi_diffs(git_provider: GitProvider,
|
||||
# Add the last chunk
|
||||
if patches:
|
||||
final_diff = "\n".join(patches)
|
||||
final_diff_list.append(final_diff)
|
||||
final_diff_list.append(final_diff.strip())
|
||||
|
||||
return final_diff_list
|
||||
|
||||
|
||||
@ -19,8 +19,11 @@ class TokenEncoder:
|
||||
with cls._lock: # Lock acquisition to ensure thread safety
|
||||
if cls._encoder_instance is None or model != cls._model:
|
||||
cls._model = model
|
||||
cls._encoder_instance = encoding_for_model(cls._model) if "gpt" in cls._model else get_encoding(
|
||||
"cl100k_base")
|
||||
try:
|
||||
cls._encoder_instance = encoding_for_model(cls._model) if "gpt" in cls._model else get_encoding(
|
||||
"o200k_base")
|
||||
except:
|
||||
cls._encoder_instance = get_encoding("o200k_base")
|
||||
return cls._encoder_instance
|
||||
|
||||
|
||||
@ -76,7 +79,48 @@ class TokenHandler:
|
||||
get_logger().error(f"Error in _get_system_user_tokens: {e}")
|
||||
return 0
|
||||
|
||||
def count_tokens(self, patch: str) -> int:
|
||||
def calc_claude_tokens(self, patch):
|
||||
try:
|
||||
import anthropic
|
||||
from pr_agent.algo import MAX_TOKENS
|
||||
client = anthropic.Anthropic(api_key=get_settings(use_context=False).get('anthropic.key'))
|
||||
MaxTokens = MAX_TOKENS[get_settings().config.model]
|
||||
|
||||
# Check if the content size is too large (9MB limit)
|
||||
if len(patch.encode('utf-8')) > 9_000_000:
|
||||
get_logger().warning(
|
||||
"Content too large for Anthropic token counting API, falling back to local tokenizer"
|
||||
)
|
||||
return MaxTokens
|
||||
|
||||
response = client.messages.count_tokens(
|
||||
model="claude-3-7-sonnet-20250219",
|
||||
system="system",
|
||||
messages=[{
|
||||
"role": "user",
|
||||
"content": patch
|
||||
}],
|
||||
)
|
||||
return response.input_tokens
|
||||
|
||||
except Exception as e:
|
||||
get_logger().error( f"Error in Anthropic token counting: {e}")
|
||||
return MaxTokens
|
||||
|
||||
def estimate_token_count_for_non_anth_claude_models(self, model, default_encoder_estimate):
|
||||
from math import ceil
|
||||
import re
|
||||
|
||||
model_is_from_o_series = re.match(r"^o[1-9](-mini|-preview)?$", model)
|
||||
if ('gpt' in get_settings().config.model.lower() or model_is_from_o_series) and get_settings(use_context=False).get('openai.key'):
|
||||
return default_encoder_estimate
|
||||
#else: Model is not an OpenAI one - therefore, cannot provide an accurate token count and instead, return a higher number as best effort.
|
||||
|
||||
elbow_factor = 1 + get_settings().get('config.model_token_count_estimate_factor', 0)
|
||||
get_logger().warning(f"{model}'s expected token count cannot be accurately estimated. Using {elbow_factor} of encoder output as best effort estimate")
|
||||
return ceil(elbow_factor * default_encoder_estimate)
|
||||
|
||||
def count_tokens(self, patch: str, force_accurate=False) -> int:
|
||||
"""
|
||||
Counts the number of tokens in a given patch string.
|
||||
|
||||
@ -86,4 +130,16 @@ class TokenHandler:
|
||||
Returns:
|
||||
The number of tokens in the patch string.
|
||||
"""
|
||||
return len(self.encoder.encode(patch, disallowed_special=()))
|
||||
encoder_estimate = len(self.encoder.encode(patch, disallowed_special=()))
|
||||
|
||||
#If an estimate is enough (for example, in cases where the maximal allowed tokens is way below the known limits), return it.
|
||||
if not force_accurate:
|
||||
return encoder_estimate
|
||||
|
||||
#else, force_accurate==True: User requested providing an accurate estimation:
|
||||
model = get_settings().config.model.lower()
|
||||
if 'claude' in model and get_settings(use_context=False).get('anthropic.key'):
|
||||
return self.calc_claude_tokens(patch) # API call to Anthropic for accurate token counting for Claude models
|
||||
|
||||
#else: Non Anthropic provided model:
|
||||
return self.estimate_token_count_for_non_anth_claude_models(model, encoder_estimate)
|
||||
|
||||
@ -704,12 +704,14 @@ def _fix_key_value(key: str, value: str):
|
||||
|
||||
|
||||
def load_yaml(response_text: str, keys_fix_yaml: List[str] = [], first_key="", last_key="") -> dict:
|
||||
response_text_original = copy.deepcopy(response_text)
|
||||
response_text = response_text.strip('\n').removeprefix('```yaml').rstrip().removesuffix('```')
|
||||
try:
|
||||
data = yaml.safe_load(response_text)
|
||||
except Exception as e:
|
||||
get_logger().warning(f"Initial failure to parse AI prediction: {e}")
|
||||
data = try_fix_yaml(response_text, keys_fix_yaml=keys_fix_yaml, first_key=first_key, last_key=last_key)
|
||||
data = try_fix_yaml(response_text, keys_fix_yaml=keys_fix_yaml, first_key=first_key, last_key=last_key,
|
||||
response_text_original=response_text_original)
|
||||
if not data:
|
||||
get_logger().error(f"Failed to parse AI prediction after fallbacks",
|
||||
artifact={'response_text': response_text})
|
||||
@ -723,7 +725,8 @@ def load_yaml(response_text: str, keys_fix_yaml: List[str] = [], first_key="", l
|
||||
def try_fix_yaml(response_text: str,
|
||||
keys_fix_yaml: List[str] = [],
|
||||
first_key="",
|
||||
last_key="",) -> dict:
|
||||
last_key="",
|
||||
response_text_original="") -> dict:
|
||||
response_text_lines = response_text.split('\n')
|
||||
|
||||
keys_yaml = ['relevant line:', 'suggestion content:', 'relevant file:', 'existing code:', 'improved code:']
|
||||
@ -745,6 +748,8 @@ def try_fix_yaml(response_text: str,
|
||||
# second fallback - try to extract only range from first ```yaml to ````
|
||||
snippet_pattern = r'```(yaml)?[\s\S]*?```'
|
||||
snippet = re.search(snippet_pattern, '\n'.join(response_text_lines_copy))
|
||||
if not snippet:
|
||||
snippet = re.search(snippet_pattern, response_text_original) # before we removed the "```"
|
||||
if snippet:
|
||||
snippet_text = snippet.group()
|
||||
try:
|
||||
|
||||
@ -22,6 +22,7 @@ def set_parser():
|
||||
- cli.py --pr_url=... ask "write me a poem about this PR"
|
||||
- cli.py --pr_url=... reflect
|
||||
- cli.py --issue_url=... similar_issue
|
||||
- cli.py --pr_url/--issue_url= help_docs [<asked question>]
|
||||
|
||||
Supported commands:
|
||||
- review / review_pr - Add a review that includes a summary of the PR and specific suggestions for improvement.
|
||||
@ -40,6 +41,8 @@ def set_parser():
|
||||
- add_docs
|
||||
|
||||
- generate_labels
|
||||
|
||||
- help_docs - Ask a question, from either an issue or PR context, on a given repo (current context or a different one)
|
||||
|
||||
|
||||
Configuration:
|
||||
|
||||
@ -19,15 +19,17 @@ global_settings = Dynaconf(
|
||||
"settings/pr_questions_prompts.toml",
|
||||
"settings/pr_line_questions_prompts.toml",
|
||||
"settings/pr_description_prompts.toml",
|
||||
"settings/pr_code_suggestions_prompts.toml",
|
||||
"settings/pr_code_suggestions_reflect_prompts.toml",
|
||||
"settings/pr_sort_code_suggestions_prompts.toml",
|
||||
"settings/code_suggestions/pr_code_suggestions_prompts.toml",
|
||||
"settings/code_suggestions/pr_code_suggestions_prompts_not_decoupled.toml",
|
||||
"settings/code_suggestions/pr_code_suggestions_reflect_prompts.toml",
|
||||
"settings/pr_information_from_user_prompts.toml",
|
||||
"settings/pr_update_changelog_prompts.toml",
|
||||
"settings/pr_custom_labels.toml",
|
||||
"settings/pr_add_docs.toml",
|
||||
"settings/custom_labels.toml",
|
||||
"settings/pr_help_prompts.toml",
|
||||
"settings/pr_help_docs_prompts.toml",
|
||||
"settings/pr_help_docs_headings_prompts.toml",
|
||||
"settings/.secrets.toml",
|
||||
"settings_prod/.secrets.toml",
|
||||
]]
|
||||
|
||||
@ -383,7 +383,7 @@ class AzureDevopsProvider(GitProvider):
|
||||
get_logger().debug(f"Skipping publish_comment for temporary comment: {pr_comment}")
|
||||
return None
|
||||
comment = Comment(content=pr_comment)
|
||||
thread = CommentThread(comments=[comment], thread_context=thread_context, status=5)
|
||||
thread = CommentThread(comments=[comment], thread_context=thread_context, status=1)
|
||||
thread_response = self.azure_devops_client.create_thread(
|
||||
comment_thread=thread,
|
||||
project=self.workspace_slug,
|
||||
|
||||
@ -29,14 +29,36 @@ class BitbucketProvider(GitProvider):
|
||||
self, pr_url: Optional[str] = None, incremental: Optional[bool] = False
|
||||
):
|
||||
s = requests.Session()
|
||||
try:
|
||||
bearer = context.get("bitbucket_bearer_token", None)
|
||||
s.headers["Authorization"] = f"Bearer {bearer}"
|
||||
except Exception:
|
||||
s.headers[
|
||||
"Authorization"
|
||||
] = f'Bearer {get_settings().get("BITBUCKET.BEARER_TOKEN", None)}'
|
||||
s.headers["Content-Type"] = "application/json"
|
||||
|
||||
self.auth_type = get_settings().get("BITBUCKET.AUTH_TYPE", "bearer")
|
||||
|
||||
try:
|
||||
def get_token(token_name, auth_type_name):
|
||||
token = get_settings().get(f"BITBUCKET.{token_name.upper()}", None)
|
||||
if not token:
|
||||
raise ValueError(f"{auth_type_name} auth requires a token")
|
||||
return token
|
||||
|
||||
if self.auth_type == "basic":
|
||||
self.basic_token = get_token("basic_token", "Basic")
|
||||
s.headers["Authorization"] = f"Basic {self.basic_token}"
|
||||
elif self.auth_type == "bearer":
|
||||
try:
|
||||
self.bearer_token = context.get("bitbucket_bearer_token", None)
|
||||
except:
|
||||
self.bearer_token = None
|
||||
|
||||
if not self.bearer_token:
|
||||
self.bearer_token = get_token("bearer_token", "Bearer")
|
||||
s.headers["Authorization"] = f"Bearer {self.bearer_token}"
|
||||
else:
|
||||
raise ValueError(f"Unsupported auth_type: {self.auth_type}")
|
||||
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Failed to initialize Bitbucket authentication: {e}")
|
||||
raise
|
||||
|
||||
self.headers = s.headers
|
||||
self.bitbucket_client = Cloud(session=s)
|
||||
self.max_comment_length = 31000
|
||||
@ -67,6 +89,37 @@ class BitbucketProvider(GitProvider):
|
||||
except Exception:
|
||||
return ""
|
||||
|
||||
def get_git_repo_url(self, pr_url: str=None) -> str: #bitbucket does not support issue url, so ignore param
|
||||
try:
|
||||
parsed_url = urlparse(self.pr_url)
|
||||
return f"{parsed_url.scheme}://{parsed_url.netloc}/{self.workspace_slug}/{self.repo_slug}.git"
|
||||
except Exception as e:
|
||||
get_logger().exception(f"url is not a valid merge requests url: {self.pr_url}")
|
||||
return ""
|
||||
|
||||
# Given a git repo url, return prefix and suffix of the provider in order to view a given file belonging to that repo.
|
||||
# Example: git clone git clone https://bitbucket.org/codiumai/pr-agent.git and branch: main -> prefix: "https://bitbucket.org/codiumai/pr-agent/src/main", suffix: ""
|
||||
# In case git url is not provided, provider will use PR context (which includes branch) to determine the prefix and suffix.
|
||||
def get_canonical_url_parts(self, repo_git_url:str=None, desired_branch:str=None) -> Tuple[str, str]:
|
||||
scheme_and_netloc = None
|
||||
if repo_git_url:
|
||||
parsed_git_url = urlparse(repo_git_url)
|
||||
scheme_and_netloc = parsed_git_url.scheme + "://" + parsed_git_url.netloc
|
||||
repo_path = parsed_git_url.path.split('.git')[0][1:] #/<workspace>/<repo>.git -> <workspace>/<repo>
|
||||
if repo_path.count('/') != 1:
|
||||
get_logger().error(f"repo_git_url is not a valid git repo url: {repo_git_url}")
|
||||
return ("", "")
|
||||
workspace_name, project_name = repo_path.split('/')
|
||||
else:
|
||||
desired_branch = self.get_repo_default_branch()
|
||||
parsed_pr_url = urlparse(self.pr_url)
|
||||
scheme_and_netloc = parsed_pr_url.scheme + "://" + parsed_pr_url.netloc
|
||||
workspace_name, project_name = (self.workspace_slug, self.repo_slug)
|
||||
prefix = f"{scheme_and_netloc}/{workspace_name}/{project_name}/src/{desired_branch}"
|
||||
suffix = "" #None
|
||||
return (prefix, suffix)
|
||||
|
||||
|
||||
def publish_code_suggestions(self, code_suggestions: list) -> bool:
|
||||
"""
|
||||
Publishes code suggestions as comments on the PR.
|
||||
@ -436,6 +489,16 @@ class BitbucketProvider(GitProvider):
|
||||
def get_pr_branch(self):
|
||||
return self.pr.source_branch
|
||||
|
||||
# This function attempts to get the default branch of the repository. As a fallback, uses the PR destination branch.
|
||||
# Note: Must be running from a PR context.
|
||||
def get_repo_default_branch(self):
|
||||
try:
|
||||
url_repo = f"https://api.bitbucket.org/2.0/repositories/{self.workspace_slug}/{self.repo_slug}/"
|
||||
response_repo = requests.request("GET", url_repo, headers=self.headers).json()
|
||||
return response_repo['mainbranch']['name']
|
||||
except:
|
||||
return self.pr.destination_branch
|
||||
|
||||
def get_pr_owner_id(self) -> str | None:
|
||||
return self.workspace_slug
|
||||
|
||||
@ -457,7 +520,7 @@ class BitbucketProvider(GitProvider):
|
||||
return True
|
||||
|
||||
@staticmethod
|
||||
def _parse_pr_url(pr_url: str) -> Tuple[str, int]:
|
||||
def _parse_pr_url(pr_url: str) -> Tuple[str, int, int]:
|
||||
parsed_url = urlparse(pr_url)
|
||||
|
||||
if "bitbucket.org" not in parsed_url.netloc:
|
||||
@ -559,3 +622,26 @@ class BitbucketProvider(GitProvider):
|
||||
# bitbucket does not support labels
|
||||
def get_pr_labels(self, update=False):
|
||||
pass
|
||||
#Clone related
|
||||
def _prepare_clone_url_with_token(self, repo_url_to_clone: str) -> str | None:
|
||||
if "bitbucket.org" not in repo_url_to_clone:
|
||||
get_logger().error("Repo URL is not a valid bitbucket URL.")
|
||||
return None
|
||||
|
||||
(scheme, base_url) = repo_url_to_clone.split("bitbucket.org")
|
||||
if not all([scheme, base_url]):
|
||||
get_logger().error(f"repo_url_to_clone: {repo_url_to_clone} is not a valid bitbucket URL.")
|
||||
return None
|
||||
|
||||
if self.auth_type == "basic":
|
||||
# Basic auth with token
|
||||
clone_url = f"{scheme}x-token-auth:{self.basic_token}@bitbucket.org{base_url}"
|
||||
elif self.auth_type == "bearer":
|
||||
# Bearer token
|
||||
clone_url = f"{scheme}x-token-auth:{self.bearer_token}@bitbucket.org{base_url}"
|
||||
else:
|
||||
# This case should ideally not be reached if __init__ validates auth_type
|
||||
get_logger().error(f"Unsupported or uninitialized auth_type: {getattr(self, 'auth_type', 'N/A')}. Returning None")
|
||||
return None
|
||||
|
||||
return clone_url
|
||||
|
||||
@ -7,6 +7,8 @@ from urllib.parse import quote_plus, urlparse
|
||||
|
||||
from atlassian.bitbucket import Bitbucket
|
||||
from requests.exceptions import HTTPError
|
||||
import shlex
|
||||
import subprocess
|
||||
|
||||
from ..algo.git_patch_processing import decode_if_bytes
|
||||
from ..algo.language_handler import is_valid_file
|
||||
@ -34,7 +36,7 @@ class BitbucketServerProvider(GitProvider):
|
||||
self.incremental = incremental
|
||||
self.diff_files = None
|
||||
self.bitbucket_pull_request_api_url = pr_url
|
||||
|
||||
self.bearer_token = get_settings().get("BITBUCKET_SERVER.BEARER_TOKEN", None)
|
||||
self.bitbucket_server_url = self._parse_bitbucket_server(url=pr_url)
|
||||
self.bitbucket_client = bitbucket_client or Bitbucket(url=self.bitbucket_server_url,
|
||||
token=get_settings().get("BITBUCKET_SERVER.BEARER_TOKEN",
|
||||
@ -47,6 +49,41 @@ class BitbucketServerProvider(GitProvider):
|
||||
if pr_url:
|
||||
self.set_pr(pr_url)
|
||||
|
||||
def get_git_repo_url(self, pr_url: str=None) -> str: #bitbucket server does not support issue url, so ignore param
|
||||
try:
|
||||
parsed_url = urlparse(self.pr_url)
|
||||
return f"{parsed_url.scheme}://{parsed_url.netloc}/scm/{self.workspace_slug.lower()}/{self.repo_slug.lower()}.git"
|
||||
except Exception as e:
|
||||
get_logger().exception(f"url is not a valid merge requests url: {self.pr_url}")
|
||||
return ""
|
||||
|
||||
# Given a git repo url, return prefix and suffix of the provider in order to view a given file belonging to that repo.
|
||||
# Example: https://bitbucket.dev.my_inc.com/scm/my_work/my_repo.git and branch: my_branch -> prefix: "https://bitbucket.dev.my_inc.com/projects/MY_WORK/repos/my_repo/browse/src", suffix: "?at=refs%2Fheads%2Fmy_branch"
|
||||
# In case git url is not provided, provider will use PR context (which includes branch) to determine the prefix and suffix.
|
||||
def get_canonical_url_parts(self, repo_git_url:str=None, desired_branch:str=None) -> Tuple[str, str]:
|
||||
workspace_name = None
|
||||
project_name = None
|
||||
if not repo_git_url:
|
||||
workspace_name = self.workspace_slug
|
||||
project_name = self.repo_slug
|
||||
default_branch_dict = self.bitbucket_client.get_default_branch(workspace_name, project_name)
|
||||
if 'displayId' in default_branch_dict:
|
||||
desired_branch = default_branch_dict['displayId']
|
||||
else:
|
||||
get_logger().error(f"Cannot obtain default branch for workspace_name={workspace_name}, "
|
||||
f"project_name={project_name}, default_branch_dict={default_branch_dict}")
|
||||
return ("", "")
|
||||
elif '.git' in repo_git_url and 'scm/' in repo_git_url:
|
||||
repo_path = repo_git_url.split('.git')[0].split('scm/')[-1]
|
||||
if repo_path.count('/') == 1: # Has to have the form <workspace>/<repo>
|
||||
workspace_name, project_name = repo_path.split('/')
|
||||
if not workspace_name or not project_name:
|
||||
get_logger().error(f"workspace_name or project_name not found in context, either git url: {repo_git_url} or uninitialized workspace/project.")
|
||||
return ("", "")
|
||||
prefix = f"{self.bitbucket_server_url}/projects/{workspace_name}/repos/{project_name}/browse"
|
||||
suffix = f"?at=refs%2Fheads%2F{desired_branch}"
|
||||
return (prefix, suffix)
|
||||
|
||||
def get_repo_settings(self):
|
||||
try:
|
||||
content = self.bitbucket_client.get_content_of_file(self.workspace_slug, self.repo_slug, ".pr_agent.toml", self.get_pr_branch())
|
||||
@ -481,3 +518,28 @@ class BitbucketServerProvider(GitProvider):
|
||||
|
||||
def _get_merge_base(self):
|
||||
return f"rest/api/latest/projects/{self.workspace_slug}/repos/{self.repo_slug}/pull-requests/{self.pr_num}/merge-base"
|
||||
# Clone related
|
||||
def _prepare_clone_url_with_token(self, repo_url_to_clone: str) -> str | None:
|
||||
if 'bitbucket.' not in repo_url_to_clone:
|
||||
get_logger().error("Repo URL is not a valid bitbucket URL.")
|
||||
return None
|
||||
bearer_token = self.bearer_token
|
||||
if not bearer_token:
|
||||
get_logger().error("No bearer token provided. Returning None")
|
||||
return None
|
||||
# Return unmodified URL as the token is passed via HTTP headers in _clone_inner, as seen below.
|
||||
return repo_url_to_clone
|
||||
|
||||
#Overriding the shell command, since for some reason usage of x-token-auth doesn't work, as mentioned here:
|
||||
# https://stackoverflow.com/questions/56760396/cloning-bitbucket-server-repo-with-access-tokens
|
||||
def _clone_inner(self, repo_url: str, dest_folder: str, operation_timeout_in_seconds: int=None):
|
||||
bearer_token = self.bearer_token
|
||||
if not bearer_token:
|
||||
#Shouldn't happen since this is checked in _prepare_clone, therefore - throwing an exception.
|
||||
raise RuntimeError(f"Bearer token is required!")
|
||||
|
||||
cli_args = shlex.split(f"git clone -c http.extraHeader='Authorization: Bearer {bearer_token}' "
|
||||
f"--filter=blob:none --depth 1 {repo_url} {dest_folder}")
|
||||
|
||||
subprocess.run(cli_args, check=True, # check=True will raise an exception if the command fails
|
||||
stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL, timeout=operation_timeout_in_seconds)
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
from abc import ABC, abstractmethod
|
||||
# enum EDIT_TYPE (ADDED, DELETED, MODIFIED, RENAMED)
|
||||
from typing import Optional
|
||||
import os
|
||||
import shutil
|
||||
import subprocess
|
||||
from typing import Optional, Tuple
|
||||
|
||||
from pr_agent.algo.types import FilePatchInfo
|
||||
from pr_agent.algo.utils import Range, process_description
|
||||
@ -14,6 +17,75 @@ class GitProvider(ABC):
|
||||
def is_supported(self, capability: str) -> bool:
|
||||
pass
|
||||
|
||||
#Given a url (issues or PR/MR) - get the .git repo url to which they belong. Needs to be implemented by the provider.
|
||||
def get_git_repo_url(self, issues_or_pr_url: str) -> str:
|
||||
get_logger().warning("Not implemented! Returning empty url")
|
||||
return ""
|
||||
|
||||
# Given a git repo url, return prefix and suffix of the provider in order to view a given file belonging to that repo. Needs to be implemented by the provider.
|
||||
# For example: For a git: https://git_provider.com/MY_PROJECT/MY_REPO.git and desired branch: <MY_BRANCH> then it should return ('https://git_provider.com/projects/MY_PROJECT/repos/MY_REPO/.../<MY_BRANCH>', '?=<SOME HEADER>')
|
||||
# so that to properly view the file: docs/readme.md -> <PREFIX>/docs/readme.md<SUFFIX> -> https://git_provider.com/projects/MY_PROJECT/repos/MY_REPO/<MY_BRANCH>/docs/readme.md?=<SOME HEADER>)
|
||||
def get_canonical_url_parts(self, repo_git_url:str, desired_branch:str) -> Tuple[str, str]:
|
||||
get_logger().warning("Not implemented! Returning empty prefix and suffix")
|
||||
return ("", "")
|
||||
|
||||
|
||||
#Clone related API
|
||||
#An object which ensures deletion of a cloned repo, once it becomes out of scope.
|
||||
# Example usage:
|
||||
# with TemporaryDirectory() as tmp_dir:
|
||||
# returned_obj: GitProvider.ScopedClonedRepo = self.git_provider.clone(self.repo_url, tmp_dir, remove_dest_folder=False)
|
||||
# print(returned_obj.path) #Use returned_obj.path.
|
||||
# #From this point, returned_obj.path may be deleted at any point and therefore must not be used.
|
||||
class ScopedClonedRepo(object):
|
||||
def __init__(self, dest_folder):
|
||||
self.path = dest_folder
|
||||
|
||||
def __del__(self):
|
||||
if self.path and os.path.exists(self.path):
|
||||
shutil.rmtree(self.path, ignore_errors=True)
|
||||
|
||||
#Method to allow implementors to manipulate the repo url to clone (such as embedding tokens in the url string). Needs to be implemented by the provider.
|
||||
def _prepare_clone_url_with_token(self, repo_url_to_clone: str) -> str | None:
|
||||
get_logger().warning("Not implemented! Returning None")
|
||||
return None
|
||||
|
||||
# Does a shallow clone, using a forked process to support a timeout guard.
|
||||
# In case operation has failed, it is expected to throw an exception as this method does not return a value.
|
||||
def _clone_inner(self, repo_url: str, dest_folder: str, operation_timeout_in_seconds: int=None) -> None:
|
||||
#The following ought to be equivalent to:
|
||||
# #Repo.clone_from(repo_url, dest_folder)
|
||||
# , but with throwing an exception upon timeout.
|
||||
# Note: This can only be used in context that supports using pipes.
|
||||
subprocess.run([
|
||||
"git", "clone",
|
||||
"--filter=blob:none",
|
||||
"--depth", "1",
|
||||
repo_url, dest_folder
|
||||
], check=True, # check=True will raise an exception if the command fails
|
||||
stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL, timeout=operation_timeout_in_seconds)
|
||||
|
||||
CLONE_TIMEOUT_SEC = 20
|
||||
# Clone a given url to a destination folder. If successful, returns an object that wraps the destination folder,
|
||||
# deleting it once it is garbage collected. See: GitProvider.ScopedClonedRepo for more details.
|
||||
def clone(self, repo_url_to_clone: str, dest_folder: str, remove_dest_folder: bool = True,
|
||||
operation_timeout_in_seconds: int=CLONE_TIMEOUT_SEC) -> ScopedClonedRepo|None:
|
||||
returned_obj = None
|
||||
clone_url = self._prepare_clone_url_with_token(repo_url_to_clone)
|
||||
if not clone_url:
|
||||
get_logger().error("Clone failed: Unable to obtain url to clone.")
|
||||
return returned_obj
|
||||
try:
|
||||
if remove_dest_folder and os.path.exists(dest_folder) and os.path.isdir(dest_folder):
|
||||
shutil.rmtree(dest_folder)
|
||||
self._clone_inner(clone_url, dest_folder, operation_timeout_in_seconds)
|
||||
returned_obj = GitProvider.ScopedClonedRepo(dest_folder)
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Clone failed: Could not clone url.",
|
||||
artifact={"error": str(e), "url": clone_url, "dest_folder": dest_folder})
|
||||
finally:
|
||||
return returned_obj
|
||||
|
||||
@abstractmethod
|
||||
def get_files(self) -> list:
|
||||
pass
|
||||
|
||||
@ -10,6 +10,7 @@ from datetime import datetime
|
||||
from typing import Optional, Tuple
|
||||
from urllib.parse import urlparse
|
||||
|
||||
from github.Issue import Issue
|
||||
from github import AppAuthentication, Auth, Github, GithubException
|
||||
from retry import retry
|
||||
from starlette_context import context
|
||||
@ -42,6 +43,7 @@ class GithubProvider(GitProvider):
|
||||
self.repo = None
|
||||
self.pr_num = None
|
||||
self.pr = None
|
||||
self.issue_main = None
|
||||
self.github_user_id = None
|
||||
self.diff_files = None
|
||||
self.git_files = None
|
||||
@ -51,9 +53,29 @@ class GithubProvider(GitProvider):
|
||||
self.pr_commits = list(self.pr.get_commits())
|
||||
self.last_commit_id = self.pr_commits[-1]
|
||||
self.pr_url = self.get_pr_url() # pr_url for github actions can be as api.github.com, so we need to get the url from the pr object
|
||||
else:
|
||||
elif pr_url and 'issue' in pr_url: #url is an issue
|
||||
self.issue_main = self._get_issue_handle(pr_url)
|
||||
else: #Instantiated the provider without a PR / Issue
|
||||
self.pr_commits = None
|
||||
|
||||
def _get_issue_handle(self, issue_url) -> Optional[Issue]:
|
||||
repo_name, issue_number = self._parse_issue_url(issue_url)
|
||||
if not repo_name or not issue_number:
|
||||
get_logger().error(f"Given url: {issue_url} is not a valid issue.")
|
||||
return None
|
||||
# else: Check if can get a valid Repo handle:
|
||||
try:
|
||||
repo_obj = self.github_client.get_repo(repo_name)
|
||||
if not repo_obj:
|
||||
get_logger().error(f"Given url: {issue_url}, belonging to owner/repo: {repo_name} does "
|
||||
f"not have a valid repository: {self.get_git_repo_url(issue_url)}")
|
||||
return None
|
||||
# else: Valid repo handle:
|
||||
return repo_obj.get_issue(issue_number)
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Failed to get an issue object for issue: {issue_url}, belonging to owner/repo: {repo_name}")
|
||||
return None
|
||||
|
||||
def get_incremental_commits(self, incremental=IncrementalPR(False)):
|
||||
self.incremental = incremental
|
||||
if self.incremental.is_incremental:
|
||||
@ -63,6 +85,63 @@ class GithubProvider(GitProvider):
|
||||
def is_supported(self, capability: str) -> bool:
|
||||
return True
|
||||
|
||||
def _get_owner_and_repo_path(self, given_url: str) -> str:
|
||||
try:
|
||||
repo_path = None
|
||||
if 'issues' in given_url:
|
||||
repo_path, _ = self._parse_issue_url(given_url)
|
||||
elif 'pull' in given_url:
|
||||
repo_path, _ = self._parse_pr_url(given_url)
|
||||
elif given_url.endswith('.git'):
|
||||
parsed_url = urlparse(given_url)
|
||||
repo_path = (parsed_url.path.split('.git')[0])[1:] # /<owner>/<repo>.git -> <owner>/<repo>
|
||||
if not repo_path:
|
||||
get_logger().error(f"url is neither an issues url nor a pr url nor a valid git url: {given_url}. Returning empty result.")
|
||||
return ""
|
||||
return repo_path
|
||||
except Exception as e:
|
||||
get_logger().exception(f"unable to parse url: {given_url}. Returning empty result.")
|
||||
return ""
|
||||
|
||||
def get_git_repo_url(self, issues_or_pr_url: str) -> str:
|
||||
repo_path = self._get_owner_and_repo_path(issues_or_pr_url) #Return: <OWNER>/<REPO>
|
||||
if not repo_path or repo_path not in issues_or_pr_url:
|
||||
get_logger().error(f"Unable to retrieve owner/path from url: {issues_or_pr_url}")
|
||||
return ""
|
||||
return f"{self.base_url_html}/{repo_path}.git" #https://github.com / <OWNER>/<REPO>.git
|
||||
|
||||
# Given a git repo url, return prefix and suffix of the provider in order to view a given file belonging to that repo.
|
||||
# Example: https://github.com/qodo-ai/pr-agent.git and branch: v0.8 -> prefix: "https://github.com/qodo-ai/pr-agent/blob/v0.8", suffix: ""
|
||||
# In case git url is not provided, provider will use PR context (which includes branch) to determine the prefix and suffix.
|
||||
def get_canonical_url_parts(self, repo_git_url:str, desired_branch:str) -> Tuple[str, str]:
|
||||
owner = None
|
||||
repo = None
|
||||
scheme_and_netloc = None
|
||||
|
||||
if repo_git_url or self.issue_main: #Either user provided an external git url, which may be different than what this provider was initialized with, or an issue:
|
||||
desired_branch = desired_branch if repo_git_url else self.issue_main.repository.default_branch
|
||||
html_url = repo_git_url if repo_git_url else self.issue_main.html_url
|
||||
parsed_git_url = urlparse(html_url)
|
||||
scheme_and_netloc = parsed_git_url.scheme + "://" + parsed_git_url.netloc
|
||||
repo_path = self._get_owner_and_repo_path(html_url)
|
||||
if repo_path.count('/') == 1: #Has to have the form <owner>/<repo>
|
||||
owner, repo = repo_path.split('/')
|
||||
else:
|
||||
get_logger().error(f"Invalid repo_path: {repo_path} from url: {html_url}")
|
||||
return ("", "")
|
||||
|
||||
if (not owner or not repo) and self.repo: #"else" - User did not provide an external git url, or not an issue, use self.repo object
|
||||
owner, repo = self.repo.split('/')
|
||||
scheme_and_netloc = self.base_url_html
|
||||
desired_branch = self.repo_obj.default_branch
|
||||
if not all([scheme_and_netloc, owner, repo]): #"else": Not invoked from a PR context,but no provided git url for context
|
||||
get_logger().error(f"Unable to get canonical url parts since missing context (PR or explicit git url)")
|
||||
return ("", "")
|
||||
|
||||
prefix = f"{scheme_and_netloc}/{owner}/{repo}/blob/{desired_branch}"
|
||||
suffix = "" # github does not add a suffix
|
||||
return (prefix, suffix)
|
||||
|
||||
def get_pr_url(self) -> str:
|
||||
return self.pr.html_url
|
||||
|
||||
@ -290,10 +369,19 @@ class GithubProvider(GitProvider):
|
||||
self.publish_persistent_comment_full(pr_comment, initial_header, update_header, name, final_update_message)
|
||||
|
||||
def publish_comment(self, pr_comment: str, is_temporary: bool = False):
|
||||
if not self.pr and not self.issue_main:
|
||||
get_logger().error("Cannot publish a comment if missing PR/Issue context")
|
||||
return None
|
||||
|
||||
if is_temporary and not get_settings().config.publish_output_progress:
|
||||
get_logger().debug(f"Skipping publish_comment for temporary comment: {pr_comment}")
|
||||
return None
|
||||
pr_comment = self.limit_output_characters(pr_comment, self.max_comment_chars)
|
||||
|
||||
# In case this is an issue, can publish the comment on the issue.
|
||||
if self.issue_main:
|
||||
return self.issue_main.create_comment(pr_comment)
|
||||
|
||||
response = self.pr.create_issue_comment(pr_comment)
|
||||
if hasattr(response, "user") and hasattr(response.user, "login"):
|
||||
self.github_user_id = response.user.login
|
||||
@ -677,11 +765,11 @@ class GithubProvider(GitProvider):
|
||||
def _parse_issue_url(self, issue_url: str) -> Tuple[str, int]:
|
||||
parsed_url = urlparse(issue_url)
|
||||
|
||||
if 'github.com' not in parsed_url.netloc:
|
||||
raise ValueError("The provided URL is not a valid GitHub URL")
|
||||
if parsed_url.path.startswith('/api/v3'): #Check if came from github app
|
||||
parsed_url = urlparse(issue_url.replace("/api/v3", ""))
|
||||
|
||||
path_parts = parsed_url.path.strip('/').split('/')
|
||||
if 'api.github.com' in parsed_url.netloc:
|
||||
if 'api.github.com' in parsed_url.netloc or '/api/v3' in issue_url: #Check if came from github app
|
||||
if len(path_parts) < 5 or path_parts[3] != 'issues':
|
||||
raise ValueError("The provided URL does not appear to be a GitHub ISSUE URL")
|
||||
repo_name = '/'.join(path_parts[1:3])
|
||||
@ -703,9 +791,9 @@ class GithubProvider(GitProvider):
|
||||
return repo_name, issue_number
|
||||
|
||||
def _get_github_client(self):
|
||||
deployment_type = get_settings().get("GITHUB.DEPLOYMENT_TYPE", "user")
|
||||
|
||||
if deployment_type == 'app':
|
||||
self.deployment_type = get_settings().get("GITHUB.DEPLOYMENT_TYPE", "user")
|
||||
self.auth = None
|
||||
if self.deployment_type == 'app':
|
||||
try:
|
||||
private_key = get_settings().github.private_key
|
||||
app_id = get_settings().github.app_id
|
||||
@ -715,16 +803,19 @@ class GithubProvider(GitProvider):
|
||||
raise ValueError("GitHub app installation ID is required when using GitHub app deployment")
|
||||
auth = AppAuthentication(app_id=app_id, private_key=private_key,
|
||||
installation_id=self.installation_id)
|
||||
return Github(app_auth=auth, base_url=self.base_url)
|
||||
|
||||
if deployment_type == 'user':
|
||||
self.auth = auth
|
||||
elif self.deployment_type == 'user':
|
||||
try:
|
||||
token = get_settings().github.user_token
|
||||
except AttributeError as e:
|
||||
raise ValueError(
|
||||
"GitHub token is required when using user deployment. See: "
|
||||
"https://github.com/Codium-ai/pr-agent#method-2-run-from-source") from e
|
||||
return Github(auth=Auth.Token(token), base_url=self.base_url)
|
||||
self.auth = Auth.Token(token)
|
||||
if self.auth:
|
||||
return Github(auth=self.auth, base_url=self.base_url)
|
||||
else:
|
||||
raise ValueError("Could not authenticate to GitHub")
|
||||
|
||||
def _get_repo(self):
|
||||
if hasattr(self, 'repo_obj') and \
|
||||
@ -1064,3 +1155,37 @@ class GithubProvider(GitProvider):
|
||||
get_logger().error(f"Failed to process patch for committable comment, error: {e}")
|
||||
return code_suggestions_copy
|
||||
|
||||
#Clone related
|
||||
def _prepare_clone_url_with_token(self, repo_url_to_clone: str) -> str | None:
|
||||
scheme = "https://"
|
||||
|
||||
#For example, to clone:
|
||||
#https://github.com/Codium-ai/pr-agent-pro.git
|
||||
#Need to embed inside the github token:
|
||||
#https://<token>@github.com/Codium-ai/pr-agent-pro.git
|
||||
|
||||
github_token = self.auth.token
|
||||
github_base_url = self.base_url_html
|
||||
if not all([github_token, github_base_url]):
|
||||
get_logger().error("Either missing auth token or missing base url")
|
||||
return None
|
||||
if scheme not in github_base_url:
|
||||
get_logger().error(f"Base url: {github_base_url} is missing prefix: {scheme}")
|
||||
return None
|
||||
github_com = github_base_url.split(scheme)[1] # e.g. 'github.com' or github.<org>.com
|
||||
if not github_com:
|
||||
get_logger().error(f"Base url: {github_base_url} has an empty base url")
|
||||
return None
|
||||
if github_com not in repo_url_to_clone:
|
||||
get_logger().error(f"url to clone: {repo_url_to_clone} does not contain {github_com}")
|
||||
return None
|
||||
repo_full_name = repo_url_to_clone.split(github_com)[-1]
|
||||
if not repo_full_name:
|
||||
get_logger().error(f"url to clone: {repo_url_to_clone} is malformed")
|
||||
return None
|
||||
|
||||
clone_url = scheme
|
||||
if self.deployment_type == 'app':
|
||||
clone_url += "git:"
|
||||
clone_url += f"{github_token}@{github_com}{repo_full_name}"
|
||||
return clone_url
|
||||
|
||||
@ -57,6 +57,47 @@ class GitLabProvider(GitProvider):
|
||||
return False
|
||||
return True
|
||||
|
||||
def _get_project_path_from_pr_or_issue_url(self, pr_or_issue_url: str) -> str:
|
||||
repo_project_path = None
|
||||
if 'issues' in pr_or_issue_url:
|
||||
#replace 'issues' with 'merge_requests', since gitlab provider does not support issue urls, just to get the git repo url:
|
||||
pr_or_issue_url = pr_or_issue_url.replace('issues', 'merge_requests')
|
||||
if 'merge_requests' in pr_or_issue_url:
|
||||
repo_project_path, _ = self._parse_merge_request_url(pr_or_issue_url)
|
||||
if not repo_project_path:
|
||||
get_logger().error(f"url is not a valid merge requests url: {pr_or_issue_url}")
|
||||
return ""
|
||||
return repo_project_path
|
||||
|
||||
def get_git_repo_url(self, issues_or_pr_url: str) -> str:
|
||||
provider_url = issues_or_pr_url
|
||||
repo_path = self._get_project_path_from_pr_or_issue_url(provider_url)
|
||||
if not repo_path or repo_path not in issues_or_pr_url:
|
||||
get_logger().error(f"Unable to retrieve project path from url: {issues_or_pr_url}")
|
||||
return ""
|
||||
return f"{issues_or_pr_url.split(repo_path)[0]}{repo_path}.git"
|
||||
|
||||
# Given a git repo url, return prefix and suffix of the provider in order to view a given file belonging to that repo.
|
||||
# Example: https://gitlab.com/codiumai/pr-agent.git and branch: t1 -> prefix: "https://gitlab.com/codiumai/pr-agent/-/blob/t1", suffix: "?ref_type=heads"
|
||||
# In case git url is not provided, provider will use PR context (which includes branch) to determine the prefix and suffix.
|
||||
def get_canonical_url_parts(self, repo_git_url:str=None, desired_branch:str=None) -> Tuple[str, str]:
|
||||
repo_path = ""
|
||||
if not repo_git_url and not self.pr_url:
|
||||
get_logger().error("Cannot get canonical URL parts: missing either context PR URL or a repo GIT URL")
|
||||
return ("", "")
|
||||
if not repo_git_url: #Use PR url as context
|
||||
repo_path = self._get_project_path_from_pr_or_issue_url(self.pr_url)
|
||||
try:
|
||||
desired_branch = self.gl.projects.get(self.id_project).default_branch
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Cannot get PR: {self.pr_url} default branch. Tried project ID: {self.id_project}")
|
||||
return ("", "")
|
||||
else: #Use repo git url
|
||||
repo_path = repo_git_url.split('.git')[0].split('.com/')[-1]
|
||||
prefix = f"{self.gitlab_url}/{repo_path}/-/blob/{desired_branch}"
|
||||
suffix = "?ref_type=heads" # gitlab cloud adds this suffix. gitlab server does not, but it is harmless.
|
||||
return (prefix, suffix)
|
||||
|
||||
@property
|
||||
def pr(self):
|
||||
'''The GitLab terminology is merge request (MR) instead of pull request (PR)'''
|
||||
@ -478,7 +519,8 @@ class GitLabProvider(GitProvider):
|
||||
|
||||
def get_repo_settings(self):
|
||||
try:
|
||||
contents = self.gl.projects.get(self.id_project).files.get(file_path='.pr_agent.toml', ref=self.mr.target_branch).decode()
|
||||
main_branch = self.gl.projects.get(self.id_project).default_branch
|
||||
contents = self.gl.projects.get(self.id_project).files.get(file_path='.pr_agent.toml', ref=main_branch).decode()
|
||||
return contents
|
||||
except Exception:
|
||||
return ""
|
||||
@ -597,3 +639,24 @@ class GitLabProvider(GitProvider):
|
||||
get_logger().info(f"Failed adding line link, error: {e}")
|
||||
|
||||
return ""
|
||||
#Clone related
|
||||
def _prepare_clone_url_with_token(self, repo_url_to_clone: str) -> str | None:
|
||||
if "gitlab." not in repo_url_to_clone:
|
||||
get_logger().error(f"Repo URL: {repo_url_to_clone} is not a valid gitlab URL.")
|
||||
return None
|
||||
(scheme, base_url) = repo_url_to_clone.split("gitlab.")
|
||||
access_token = self.gl.oauth_token
|
||||
if not all([scheme, access_token, base_url]):
|
||||
get_logger().error(f"Either no access token found, or repo URL: {repo_url_to_clone} "
|
||||
f"is missing prefix: {scheme} and/or base URL: {base_url}.")
|
||||
return None
|
||||
|
||||
#Note that the ""official"" method found here:
|
||||
# https://docs.gitlab.com/user/profile/personal_access_tokens/#clone-repository-using-personal-access-token
|
||||
# requires a username, which may not be applicable.
|
||||
# The following solution is taken from: https://stackoverflow.com/questions/25409700/using-gitlab-token-to-clone-without-authentication/35003812#35003812
|
||||
# For example: For repo url: https://gitlab.codium-inc.com/qodo/autoscraper.git
|
||||
# Then to clone one will issue: 'git clone https://oauth2:<access token>@gitlab.codium-inc.com/qodo/autoscraper.git'
|
||||
|
||||
clone_url = f"{scheme}oauth2:{access_token}@gitlab.{base_url}"
|
||||
return clone_url
|
||||
|
||||
@ -12,6 +12,7 @@ from pr_agent.log import get_logger
|
||||
|
||||
|
||||
def apply_repo_settings(pr_url):
|
||||
os.environ["AUTO_CAST_FOR_DYNACONF"] = "false"
|
||||
git_provider = get_git_provider_with_context(pr_url)
|
||||
if get_settings().config.use_repo_settings_file:
|
||||
repo_settings_file = None
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
import os
|
||||
os.environ["AUTO_CAST_FOR_DYNACONF"] = "false"
|
||||
import json
|
||||
import logging
|
||||
import os
|
||||
import sys
|
||||
from enum import Enum
|
||||
|
||||
|
||||
@ -25,7 +25,7 @@ from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers.utils import apply_repo_settings
|
||||
from pr_agent.log import LoggingFormat, get_logger, setup_logger
|
||||
|
||||
setup_logger(fmt=LoggingFormat.JSON, level="DEBUG")
|
||||
setup_logger(fmt=LoggingFormat.JSON, level=get_settings().get("CONFIG.LOG_LEVEL", "DEBUG"))
|
||||
security = HTTPBasic()
|
||||
router = APIRouter()
|
||||
available_commands_rgx = re.compile(r"^\/(" + "|".join(command2class.keys()) + r")\s*")
|
||||
|
||||
@ -25,7 +25,7 @@ from pr_agent.identity_providers.identity_provider import Eligibility
|
||||
from pr_agent.log import LoggingFormat, get_logger, setup_logger
|
||||
from pr_agent.secret_providers import get_secret_provider
|
||||
|
||||
setup_logger(fmt=LoggingFormat.JSON, level="DEBUG")
|
||||
setup_logger(fmt=LoggingFormat.JSON, level=get_settings().get("CONFIG.LOG_LEVEL", "DEBUG"))
|
||||
router = APIRouter()
|
||||
secret_provider = get_secret_provider() if get_settings().get("CONFIG.SECRET_PROVIDER") else None
|
||||
|
||||
|
||||
@ -21,7 +21,7 @@ from pr_agent.git_providers.utils import apply_repo_settings
|
||||
from pr_agent.log import LoggingFormat, get_logger, setup_logger
|
||||
from pr_agent.servers.utils import verify_signature
|
||||
|
||||
setup_logger(fmt=LoggingFormat.JSON, level="DEBUG")
|
||||
setup_logger(fmt=LoggingFormat.JSON, level=get_settings().get("CONFIG.LOG_LEVEL", "DEBUG"))
|
||||
router = APIRouter()
|
||||
|
||||
|
||||
|
||||
@ -24,7 +24,7 @@ from pr_agent.identity_providers.identity_provider import Eligibility
|
||||
from pr_agent.log import LoggingFormat, get_logger, setup_logger
|
||||
from pr_agent.servers.utils import DefaultDictWithTimeout, verify_signature
|
||||
|
||||
setup_logger(fmt=LoggingFormat.JSON, level="DEBUG")
|
||||
setup_logger(fmt=LoggingFormat.JSON, level=get_settings().get("CONFIG.LOG_LEVEL", "DEBUG"))
|
||||
base_path = os.path.dirname(os.path.dirname(os.path.realpath(__file__)))
|
||||
build_number_path = os.path.join(base_path, "build_number.txt")
|
||||
if os.path.exists(build_number_path):
|
||||
@ -64,7 +64,7 @@ async def get_body(request):
|
||||
try:
|
||||
body = await request.json()
|
||||
except Exception as e:
|
||||
get_logger().error("Error parsing request body", e)
|
||||
get_logger().error("Error parsing request body", artifact={'error': e})
|
||||
raise HTTPException(status_code=400, detail="Error parsing request body") from e
|
||||
webhook_secret = getattr(get_settings().github, 'webhook_secret', None)
|
||||
if webhook_secret:
|
||||
@ -107,7 +107,7 @@ async def handle_comments_on_pr(body: Dict[str, Any],
|
||||
comment_body = handle_line_comments(body, comment_body)
|
||||
disable_eyes = True
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to handle line comments: {e}")
|
||||
get_logger().error("Failed to get log context", artifact={'error': e})
|
||||
else:
|
||||
return {}
|
||||
log_context["api_url"] = api_url
|
||||
@ -138,7 +138,7 @@ async def handle_new_pr_opened(body: Dict[str, Any],
|
||||
# logic to ignore PRs with specific titles (e.g. "[Auto] ...")
|
||||
apply_repo_settings(api_url)
|
||||
if get_identity_provider().verify_eligibility("github", sender_id, api_url) is not Eligibility.NOT_ELIGIBLE:
|
||||
await _perform_auto_commands_github("pr_commands", agent, body, api_url, log_context)
|
||||
await _perform_auto_commands_github("pr_commands", agent, body, api_url, log_context)
|
||||
else:
|
||||
get_logger().info(f"User {sender=} is not eligible to process PR {api_url=}")
|
||||
|
||||
@ -196,8 +196,8 @@ async def handle_push_trigger_for_new_commits(body: Dict[str, Any],
|
||||
|
||||
try:
|
||||
if get_identity_provider().verify_eligibility("github", sender_id, api_url) is not Eligibility.NOT_ELIGIBLE:
|
||||
get_logger().info(f"Performing incremental review for {api_url=} because of {event=} and {action=}")
|
||||
await _perform_auto_commands_github("push_commands", agent, body, api_url, log_context)
|
||||
get_logger().info(f"Performing incremental review for {api_url=} because of {event=} and {action=}")
|
||||
await _perform_auto_commands_github("push_commands", agent, body, api_url, log_context)
|
||||
|
||||
finally:
|
||||
# release the waiting task block
|
||||
@ -233,7 +233,7 @@ def get_log_context(body, event, action, build_number):
|
||||
"request_id": uuid.uuid4().hex, "build_number": build_number, "app_name": app_name,
|
||||
"repo": repo, "git_org": git_org, "installation_id": installation_id}
|
||||
except Exception as e:
|
||||
get_logger().error("Failed to get log context", e)
|
||||
get_logger().error(f"Failed to get log context", artifact={'error': e})
|
||||
log_context = {}
|
||||
return log_context, sender, sender_id, sender_type
|
||||
|
||||
@ -310,16 +310,20 @@ async def handle_request(body: Dict[str, Any], event: str):
|
||||
event: The GitHub event type (e.g. "pull_request", "issue_comment", etc.).
|
||||
"""
|
||||
action = body.get("action") # "created", "opened", "reopened", "ready_for_review", "review_requested", "synchronize"
|
||||
get_logger().debug(f"Handling request with event: {event}, action: {action}")
|
||||
if not action:
|
||||
get_logger().debug(f"No action found in request body, exiting handle_request")
|
||||
return {}
|
||||
agent = PRAgent()
|
||||
log_context, sender, sender_id, sender_type = get_log_context(body, event, action, build_number)
|
||||
|
||||
# logic to ignore PRs opened by bot, PRs with specific titles, labels, source branches, or target branches
|
||||
if is_bot_user(sender, sender_type) and 'check_run' not in body:
|
||||
get_logger().debug(f"Request ignored: bot user detected")
|
||||
return {}
|
||||
if action != 'created' and 'check_run' not in body:
|
||||
if not should_process_pr_logic(body):
|
||||
get_logger().debug(f"Request ignored: PR logic filtering")
|
||||
return {}
|
||||
|
||||
if 'check_run' in body: # handle failed checks
|
||||
|
||||
@ -13,7 +13,7 @@ from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers import get_git_provider
|
||||
from pr_agent.log import LoggingFormat, get_logger, setup_logger
|
||||
|
||||
setup_logger(fmt=LoggingFormat.JSON, level="DEBUG")
|
||||
setup_logger(fmt=LoggingFormat.JSON, level=get_settings().get("CONFIG.LOG_LEVEL", "DEBUG"))
|
||||
NOTIFICATION_URL = "https://api.github.com/notifications"
|
||||
|
||||
|
||||
|
||||
@ -19,7 +19,7 @@ from pr_agent.git_providers.utils import apply_repo_settings
|
||||
from pr_agent.log import LoggingFormat, get_logger, setup_logger
|
||||
from pr_agent.secret_providers import get_secret_provider
|
||||
|
||||
setup_logger(fmt=LoggingFormat.JSON, level="DEBUG")
|
||||
setup_logger(fmt=LoggingFormat.JSON, level=get_settings().get("CONFIG.LOG_LEVEL", "DEBUG"))
|
||||
router = APIRouter()
|
||||
|
||||
secret_provider = get_secret_provider() if get_settings().get("CONFIG.SECRET_PROVIDER") else None
|
||||
|
||||
@ -6,6 +6,7 @@ class HelpMessage:
|
||||
"> - **/improve [--extended]**: Suggest code improvements. Extended mode provides a higher quality feedback. \n" \
|
||||
"> - **/ask \\<QUESTION\\>**: Ask a question about the PR. \n" \
|
||||
"> - **/update_changelog**: Update the changelog based on the PR's contents. \n" \
|
||||
"> - **/help_docs \\<QUESTION\\>**: Given a path to documentation (either for this repository or for a given one), ask a question. \n" \
|
||||
"> - **/add_docs** 💎: Generate docstring for new components introduced in the PR. \n" \
|
||||
"> - **/generate_labels** 💎: Generate labels for the PR based on the PR's contents. \n" \
|
||||
"> - **/analyze** 💎: Automatically analyzes the PR, and presents changes walkthrough for each component. \n\n" \
|
||||
@ -201,3 +202,17 @@ some_config2=...
|
||||
output += f"\n\nSee the improve [usage page](https://pr-agent-docs.codium.ai/tools/improve/) for a comprehensive guide on using this tool.\n\n"
|
||||
|
||||
return output
|
||||
|
||||
|
||||
@staticmethod
|
||||
def get_help_docs_usage_guide():
|
||||
output = "**Overview:**\n"
|
||||
output += """\
|
||||
The help docs tool, named `help_docs`, answers a question based on a given relative path of documentation, either from the repository of this merge request or from a given one."
|
||||
It can be invoked manually by commenting on any PR:
|
||||
```
|
||||
/help_docs "..."
|
||||
```
|
||||
"""
|
||||
output += f"\n\nSee the [help_docs usage](https://pr-agent-docs.codium.ai/tools/help_docs/) page for a comprehensive guide on using this tool.\n\n"
|
||||
return output
|
||||
|
||||
@ -32,6 +32,9 @@ key = "" # Optional, uncomment if you want to use Replicate. Acquire through htt
|
||||
[groq]
|
||||
key = "" # Acquire through https://console.groq.com/keys
|
||||
|
||||
[xai]
|
||||
key = "" # Optional, uncomment if you want to use xAI. Acquire through https://console.x.ai/
|
||||
|
||||
[huggingface]
|
||||
key = "" # Optional, uncomment if you want to use Huggingface Inference API. Acquire through https://huggingface.co/docs/api-inference/quicktour
|
||||
api_base = "" # the base url for your huggingface inference endpoint
|
||||
@ -66,8 +69,12 @@ personal_access_token = ""
|
||||
shared_secret = "" # webhook secret
|
||||
|
||||
[bitbucket]
|
||||
# For Bitbucket personal/repository bearer token
|
||||
# For Bitbucket authentication
|
||||
auth_type = "bearer" # "bearer" or "basic"
|
||||
# For bearer token authentication
|
||||
bearer_token = ""
|
||||
# For basic authentication (uses token only)
|
||||
basic_token = ""
|
||||
|
||||
[bitbucket_server]
|
||||
# For Bitbucket Server bearer token
|
||||
@ -78,9 +85,6 @@ webhook_secret = ""
|
||||
app_key = ""
|
||||
base_url = ""
|
||||
|
||||
[litellm]
|
||||
LITELLM_TOKEN = "" # see https://docs.litellm.ai/docs/debugging/hosted_debugging for details and instructions on how to get a token
|
||||
|
||||
[azure_devops]
|
||||
# For Azure devops personal access token
|
||||
org = ""
|
||||
@ -94,3 +98,13 @@ pat = ""
|
||||
|
||||
[deepseek]
|
||||
key = ""
|
||||
|
||||
[deepinfra]
|
||||
key = ""
|
||||
|
||||
[azure_ad]
|
||||
# Azure AD authentication for OpenAI services
|
||||
client_id = "" # Your Azure AD application client ID
|
||||
client_secret = "" # Your Azure AD application client secret
|
||||
tenant_id = "" # Your Azure AD tenant ID
|
||||
api_base = "" # Your Azure OpenAI service base URL (e.g., https://openai.xyz.com/)
|
||||
@ -83,8 +83,8 @@ The output must be a YAML object equivalent to type $PRCodeSuggestions, accordin
|
||||
class CodeSuggestion(BaseModel):
|
||||
relevant_file: str = Field(description="Full path of the relevant file")
|
||||
language: str = Field(description="Programming language used by the relevant file")
|
||||
suggestion_content: str = Field(description="An actionable suggestion to enhance, improve or fix the new code introduced in the PR. Don't present here actual code snippets, just the suggestion. Be short and concise")
|
||||
existing_code: str = Field(description="A short code snippet, from a '__new hunk__' section after the PR changes, that the suggestion aims to enhance or fix. Include only complete code lines. Use ellipsis (...) for brevity if needed. This snippet should represent the specific PR code targeted for improvement.")
|
||||
suggestion_content: str = Field(description="An actionable suggestion to enhance, improve or fix the new code introduced in the PR. Don't present here actual code snippets, just the suggestion. Be short and concise")
|
||||
improved_code: str = Field(description="A refined code snippet that replaces the 'existing_code' snippet after implementing the suggestion.")
|
||||
one_sentence_summary: str = Field(description="A concise, single-sentence overview (up to 6 words) of the suggested improvement. Focus on the 'what'. Be general, and avoid method or variable names.")
|
||||
{%- if not focus_only_on_problems %}
|
||||
@ -106,10 +106,10 @@ code_suggestions:
|
||||
src/file1.py
|
||||
language: |
|
||||
python
|
||||
suggestion_content: |
|
||||
...
|
||||
existing_code: |
|
||||
...
|
||||
suggestion_content: |
|
||||
...
|
||||
improved_code: |
|
||||
...
|
||||
one_sentence_summary: |
|
||||
@ -145,10 +145,10 @@ code_suggestions:
|
||||
src/file1.py
|
||||
language: |
|
||||
python
|
||||
suggestion_content: |
|
||||
...
|
||||
existing_code: |
|
||||
...
|
||||
suggestion_content: |
|
||||
...
|
||||
improved_code: |
|
||||
...
|
||||
one_sentence_summary: |
|
||||
@ -0,0 +1,159 @@
|
||||
[pr_code_suggestions_prompt_not_decoupled]
|
||||
system="""You are PR-Reviewer, an AI specializing in Pull Request (PR) code analysis and suggestions.
|
||||
{%- if not focus_only_on_problems %}
|
||||
Your task is to examine the provided code diff, focusing on new code (lines prefixed with '+'), and offer concise, actionable suggestions to fix possible bugs and problems, and enhance code quality and performance.
|
||||
{%- else %}
|
||||
Your task is to examine the provided code diff, focusing on new code (lines prefixed with '+'), and offer concise, actionable suggestions to fix critical bugs and problems.
|
||||
{%- endif %}
|
||||
|
||||
|
||||
The PR code diff will be in the following structured format:
|
||||
======
|
||||
## File: 'src/file1.py'
|
||||
{%- if is_ai_metadata %}
|
||||
### AI-generated changes summary:
|
||||
* ...
|
||||
* ...
|
||||
{%- endif %}
|
||||
|
||||
@@ ... @@ def func1():
|
||||
unchanged code line0
|
||||
unchanged code line1
|
||||
+new code line2
|
||||
-removed code line2
|
||||
unchanged code line3
|
||||
|
||||
@@ ... @@ def func2():
|
||||
...
|
||||
|
||||
|
||||
## File: 'src/file2.py'
|
||||
...
|
||||
======
|
||||
The diff structure above uses line prefixes to show changes:
|
||||
'+' → new line code added
|
||||
'-' → line code removed
|
||||
' ' → unchanged context lines
|
||||
{%- if is_ai_metadata %}
|
||||
|
||||
When available, an AI-generated summary will precede each file's diff, with a high-level overview of the changes. Note that this summary may not be fully accurate or complete.
|
||||
{%- endif %}
|
||||
|
||||
|
||||
Specific guidelines for generating code suggestions:
|
||||
{%- if not focus_only_on_problems %}
|
||||
- Provide up to {{ num_code_suggestions }} distinct and insightful code suggestions.
|
||||
{%- else %}
|
||||
- Provide up to {{ num_code_suggestions }} distinct and insightful code suggestions. Return less suggestions if no pertinent ones are applicable.
|
||||
{%- endif %}
|
||||
- Focus your suggestions ONLY on improving the new code introduced in the PR (lines starting with '+' in the diff). The lines in the diff starting with '-' are only for reference and should not be considered for suggestions.
|
||||
{%- if not focus_only_on_problems %}
|
||||
- Prioritize suggestions that address potential issues, critical problems, and bugs in the PR code. Avoid repeating changes already implemented in the PR. If no pertinent suggestions are applicable, return an empty list.
|
||||
- Don't suggest to add docstring, type hints, or comments, to remove unused imports, or to use more specific exception types.
|
||||
{%- else %}
|
||||
- Only give suggestions that address critical problems and bugs in the PR code. If no relevant suggestions are applicable, return an empty list.
|
||||
- DO NOT suggest the following:
|
||||
- change packages version
|
||||
- add missing import statement
|
||||
- declare undefined variable
|
||||
- use more specific exception types
|
||||
{%- endif %}
|
||||
- When mentioning code elements (variables, names, or files) in your response, surround them with backticks (`). For example: "verify that `user_id` is..."
|
||||
- Note that you will only see partial code segments that were changed (diff hunks in a PR), and not the entire codebase. Avoid suggestions that might duplicate existing functionality or question the existence of code elements like variables, functions, classes, and import statements, that may be defined elsewhere in the codebase.
|
||||
- Also note that if the code ends at an opening brace or statement that begins a new scope (like 'if', 'for', 'try'), don't treat it as incomplete. Instead, acknowledge the visible scope boundary and analyze only the code shown.
|
||||
|
||||
{%- if extra_instructions %}
|
||||
|
||||
|
||||
Extra user-provided instructions (should be addressed with high priority):
|
||||
======
|
||||
{{ extra_instructions }}
|
||||
======
|
||||
{%- endif %}
|
||||
|
||||
|
||||
The output must be a YAML object equivalent to type $PRCodeSuggestions, according to the following Pydantic definitions:
|
||||
=====
|
||||
class CodeSuggestion(BaseModel):
|
||||
relevant_file: str = Field(description="Full path of the relevant file")
|
||||
language: str = Field(description="Programming language used by the relevant file")
|
||||
existing_code: str = Field(description="A short code snippet from the final state of the PR diff that the suggestion will address. Select only the span of code that will be modified - without surrounding unchanged code. Preserve all indentation, newlines, and original formatting. Use ellipsis (...) for brevity if needed.")
|
||||
suggestion_content: str = Field(description="An actionable suggestion to enhance, improve or fix the new code introduced in the PR. Don't present here actual code snippets, just the suggestion. Be short and concise")
|
||||
improved_code: str = Field(description="A refined code snippet that replaces the 'existing_code' snippet after implementing the suggestion.")
|
||||
one_sentence_summary: str = Field(description="A concise, single-sentence overview (up to 6 words) of the suggested improvement. Focus on the 'what'. Be general, and avoid method or variable names.")
|
||||
{%- if not focus_only_on_problems %}
|
||||
label: str = Field(description="A single, descriptive label that best characterizes the suggestion type. Possible labels include 'security', 'possible bug', 'possible issue', 'performance', 'enhancement', 'best practice', 'maintainability', 'typo'. Other relevant labels are also acceptable.")
|
||||
{%- else %}
|
||||
label: str = Field(description="A single, descriptive label that best characterizes the suggestion type. Possible labels include 'security', 'critical bug', 'general'. The 'general' section should be used for suggestions that address a major issue, but are not necessarily on a critical level.")
|
||||
{%- endif %}
|
||||
|
||||
|
||||
class PRCodeSuggestions(BaseModel):
|
||||
code_suggestions: List[CodeSuggestion]
|
||||
=====
|
||||
|
||||
|
||||
Example output:
|
||||
```yaml
|
||||
code_suggestions:
|
||||
- relevant_file: |
|
||||
src/file1.py
|
||||
language: |
|
||||
python
|
||||
existing_code: |
|
||||
...
|
||||
suggestion_content: |
|
||||
...
|
||||
improved_code: |
|
||||
...
|
||||
one_sentence_summary: |
|
||||
...
|
||||
label: |
|
||||
...
|
||||
```
|
||||
|
||||
Each YAML output MUST be after a newline, indented, with block scalar indicator ('|').
|
||||
"""
|
||||
|
||||
user="""--PR Info--
|
||||
|
||||
Title: '{{title}}'
|
||||
|
||||
{%- if date %}
|
||||
|
||||
Today's Date: {{date}}
|
||||
{%- endif %}
|
||||
|
||||
The PR Diff:
|
||||
======
|
||||
{{ diff_no_line_numbers|trim }}
|
||||
======
|
||||
|
||||
{%- if duplicate_prompt_examples %}
|
||||
|
||||
|
||||
Example output:
|
||||
```yaml
|
||||
code_suggestions:
|
||||
- relevant_file: |
|
||||
src/file1.py
|
||||
language: |
|
||||
python
|
||||
existing_code: |
|
||||
...
|
||||
suggestion_content: |
|
||||
...
|
||||
improved_code: |
|
||||
...
|
||||
one_sentence_summary: |
|
||||
...
|
||||
label: |
|
||||
...
|
||||
```
|
||||
(replace '...' with actual content)
|
||||
{%- endif %}
|
||||
|
||||
|
||||
Response (should be a valid YAML, and nothing else):
|
||||
```yaml
|
||||
"""
|
||||
@ -2,7 +2,7 @@
|
||||
system="""You are an AI language model specialized in reviewing and evaluating code suggestions for a Pull Request (PR).
|
||||
Your task is to analyze a PR code diff and evaluate a set of AI-generated code suggestions. These suggestions aim to address potential bugs and problems, and enhance the new code introduced in the PR.
|
||||
|
||||
Examine each suggestion meticulously, assessing its quality, relevance, and accuracy within the context of PR. Keep in mind that the suggestions may vary in their correctness and accuracy. Your evaluation should be based on a thorough comparison between each suggestion and the actual PR code diff.
|
||||
Examine each suggestion meticulously, assessing its quality, relevance, and accuracy within the context of PR. Keep in mind that the suggestions may vary in their correctness, accuracy and impact.
|
||||
Consider the following components of each suggestion:
|
||||
1. 'one_sentence_summary' - A brief summary of the suggestion's purpose
|
||||
2. 'suggestion_content' - The detailed suggestion content, explaining the proposed modification
|
||||
@ -31,9 +31,11 @@ Key guidelines for evaluation:
|
||||
|
||||
Additional scoring considerations:
|
||||
- If the suggestion is not actionable, and only asks the user to verify or ensure a change, reduce its score by 1-2 points.
|
||||
- Error handling or type checking suggestions should not receive a score above 8 (and may be lower).
|
||||
- Assign a score of 0 to suggestions aiming at:
|
||||
- Adding docstring, type hints, or comments
|
||||
- Remove unused imports or variables
|
||||
- Add missing import statements
|
||||
- Using more specific exception types.
|
||||
|
||||
|
||||
@ -82,8 +84,8 @@ The output must be a YAML object equivalent to type $PRCodeSuggestionsFeedback,
|
||||
class CodeSuggestionFeedback(BaseModel):
|
||||
suggestion_summary: str = Field(description="Repeated from the input")
|
||||
relevant_file: str = Field(description="Repeated from the input")
|
||||
relevant_lines_start: int = Field(description="The relevant line number, from a '__new hunk__' section, where the suggestion starts (inclusive). Should be derived from the hunk line numbers, and correspond to the beginning of the relevant 'existing code' snippet")
|
||||
relevant_lines_end: int = Field(description="The relevant line number, from a '__new hunk__' section, where the suggestion ends (inclusive). Should be derived from the hunk line numbers, and correspond to the end of the relevant 'existing code' snippet")
|
||||
relevant_lines_start: int = Field(description="The relevant line number, from a '__new hunk__' section, where the suggestion starts (inclusive). Should be derived from the added '__new hunk__' line numbers, and correspond to the first line of the relevant 'existing code' snippet.")
|
||||
relevant_lines_end: int = Field(description="The relevant line number, from a '__new hunk__' section, where the suggestion ends (inclusive). Should be derived from the added '__new hunk__' line numbers, and correspond to the end of the relevant 'existing code' snippet")
|
||||
suggestion_score: int = Field(description="Evaluate the suggestion and assign a score from 0 to 10. Give 0 if the suggestion is wrong. For valid suggestions, score from 1 (lowest impact/importance) to 10 (highest impact/importance).")
|
||||
why: str = Field(description="Briefly explain the score given in 1-2 sentences, focusing on the suggestion's impact, relevance, and accuracy.")
|
||||
|
||||
@ -1,20 +1,22 @@
|
||||
# Important: This file contains all available configuration options.
|
||||
# Do not copy this entire file to your repository configuration.
|
||||
# Your repository configuration should only include options you wish to override from the defaults.
|
||||
#
|
||||
# Use this page: 'https://qodo-merge-docs.qodo.ai/ai_search/' to ask questions about the configuration options.
|
||||
|
||||
[config]
|
||||
# models
|
||||
model="o3-mini"
|
||||
fallback_models=["gpt-4o-2024-11-20"]
|
||||
#model_weak="gpt-4o-mini-2024-07-18" # optional, a weaker model to use for some easier tasks
|
||||
response_language="en-US" # Language locales code for PR responses in ISO 3166 and ISO 639 format (e.g., "en-US", "it-IT", "zh-CN", ...)
|
||||
# CLI
|
||||
git_provider="github"
|
||||
publish_output=true
|
||||
publish_output_progress=true
|
||||
publish_output_no_suggestions=true
|
||||
verbosity_level=0 # 0,1,2
|
||||
use_extra_bad_extensions=false
|
||||
# Log
|
||||
log_level="DEBUG"
|
||||
# Configurations
|
||||
use_wiki_settings_file=true
|
||||
use_repo_settings_file=true
|
||||
@ -23,11 +25,13 @@ disable_auto_feedback = false
|
||||
ai_timeout=120 # 2minutes
|
||||
skip_keys = []
|
||||
custom_reasoning_model = false # when true, disables system messages and temperature controls for models that don't support chat-style inputs
|
||||
response_language="en-US" # Language locales code for PR responses in ISO 3166 and ISO 639 format (e.g., "en-US", "it-IT", "zh-CN", ...)
|
||||
# token limits
|
||||
max_description_tokens = 500
|
||||
max_commits_tokens = 500
|
||||
max_model_tokens = 32000 # Limits the maximum number of tokens that can be used by any model, regardless of the model's default capabilities.
|
||||
custom_model_max_tokens=-1 # for models not in the default list
|
||||
model_token_count_estimate_factor=0.3 # factor to increase the token count estimate, in order to reduce likelihood of model failure due to too many tokens - applicable only when requesting an accurate estimate.
|
||||
# patch extension logic
|
||||
patch_extension_skip_types =[".md",".txt"]
|
||||
allow_dynamic_context=true
|
||||
@ -58,6 +62,10 @@ reasoning_effort = "medium" # "low", "medium", "high"
|
||||
enable_auto_approval=false # Set to true to enable auto-approval of PRs under certain conditions
|
||||
auto_approve_for_low_review_effort=-1 # -1 to disable, [1-5] to set the threshold for auto-approval
|
||||
auto_approve_for_no_suggestions=false # If true, the PR will be auto-approved if there are no suggestions
|
||||
# extended thinking for Claude reasoning models
|
||||
enable_claude_extended_thinking = false # Set to true to enable extended thinking feature
|
||||
extended_thinking_budget_tokens = 2048
|
||||
extended_thinking_max_output_tokens = 4096
|
||||
|
||||
|
||||
[pr_reviewer] # /review #
|
||||
@ -98,7 +106,7 @@ publish_description_as_comment_persistent=true
|
||||
## changes walkthrough section
|
||||
enable_semantic_files_types=true
|
||||
collapsible_file_list='adaptive' # true, false, 'adaptive'
|
||||
collapsible_file_list_threshold=8
|
||||
collapsible_file_list_threshold=6
|
||||
inline_file_summary=false # false, true, 'table'
|
||||
# markers
|
||||
use_description_markers=false
|
||||
@ -123,9 +131,9 @@ focus_only_on_problems=true
|
||||
extra_instructions = ""
|
||||
enable_help_text=false
|
||||
enable_chat_text=false
|
||||
enable_intro_text=true
|
||||
persistent_comment=true
|
||||
max_history_len=4
|
||||
publish_output_no_suggestions=true
|
||||
# enable to apply suggestion 💎
|
||||
apply_suggestions_checkbox=true
|
||||
# suggestions scoring
|
||||
@ -135,11 +143,12 @@ new_score_mechanism_th_high=9
|
||||
new_score_mechanism_th_medium=7
|
||||
# params for '/improve --extended' mode
|
||||
auto_extended_mode=true
|
||||
num_code_suggestions_per_chunk=4
|
||||
num_code_suggestions_per_chunk=3
|
||||
max_number_of_calls = 3
|
||||
parallel_calls = true
|
||||
|
||||
final_clip_factor = 0.8
|
||||
decouple_hunks = false
|
||||
# self-review checkbox
|
||||
demand_code_suggestions_self_review=false # add a checkbox for the author to self-review the code suggestions
|
||||
code_suggestions_self_review_text= "**Author self-review**: I have reviewed the PR code suggestions, and addressed the relevant ones."
|
||||
@ -158,7 +167,7 @@ The code suggestions should focus only on the following:
|
||||
...
|
||||
"""
|
||||
suggestions_score_threshold=0
|
||||
num_code_suggestions_per_chunk=4
|
||||
num_code_suggestions_per_chunk=3
|
||||
self_reflect_on_custom_suggestions=true
|
||||
enable_help_text=false
|
||||
|
||||
@ -173,6 +182,7 @@ class_name = "" # in case there are several methods with the same name in
|
||||
push_changelog_changes=false
|
||||
extra_instructions = ""
|
||||
add_pr_link=true
|
||||
skip_ci_on_push=true
|
||||
|
||||
[pr_analyze] # /analyze #
|
||||
enable_help_text=true
|
||||
@ -205,6 +215,14 @@ num_retrieved_snippets=5
|
||||
|
||||
[pr_config] # /config #
|
||||
|
||||
[pr_help_docs]
|
||||
repo_url = "" #If not overwritten, will use the repo from where the context came from (issue or PR)
|
||||
repo_default_branch = "main"
|
||||
docs_path = "docs"
|
||||
exclude_root_readme = false
|
||||
supported_doc_exts = [".md", ".mdx", ".rst"]
|
||||
enable_help_text=false
|
||||
|
||||
[github]
|
||||
# The type of deployment to create. Valid values are 'app' or 'user'.
|
||||
deployment_type = "user"
|
||||
@ -339,4 +357,4 @@ pr_commands = [
|
||||
"/describe",
|
||||
"/review",
|
||||
"/improve",
|
||||
]
|
||||
]
|
||||
|
||||
101
pr_agent/settings/pr_help_docs_headings_prompts.toml
Normal file
101
pr_agent/settings/pr_help_docs_headings_prompts.toml
Normal file
@ -0,0 +1,101 @@
|
||||
|
||||
[pr_help_docs_headings_prompts]
|
||||
system="""You are Doc-helper, a language model that ranks documentation files based on their relevance to user questions.
|
||||
You will receive a question, a repository url and file names along with optional groups of headings extracted from such files from that repository (either as markdown or as restructred text).
|
||||
Your task is to rank file paths based on how likely they contain the answer to a user's question, using only the headings from each such file and the file name.
|
||||
|
||||
======
|
||||
==file name==
|
||||
|
||||
'src/file1.py'
|
||||
|
||||
==index==
|
||||
|
||||
0 based integer
|
||||
|
||||
==file headings==
|
||||
heading #1
|
||||
heading #2
|
||||
...
|
||||
|
||||
==file name==
|
||||
|
||||
'src/file2.py'
|
||||
|
||||
==index==
|
||||
|
||||
0 based integer
|
||||
|
||||
==file headings==
|
||||
heading #1
|
||||
heading #2
|
||||
...
|
||||
|
||||
...
|
||||
======
|
||||
|
||||
Additional instructions:
|
||||
- Consider only the file names and section headings within each document
|
||||
- Present the most relevant files first, based strictly on how well their headings and file names align with user question
|
||||
|
||||
The output must be a YAML object equivalent to type $DocHeadingsHelper, according to the following Pydantic definitions:
|
||||
=====
|
||||
class file_idx_and_path(BaseModel):
|
||||
idx: int = Field(description="The zero based index of file_name, as it appeared in the original list of headings. Cannot be negative.")
|
||||
file_name: str = Field(description="The file_name exactly as it appeared in the question")
|
||||
|
||||
class DocHeadingsHelper(BaseModel):
|
||||
user_question: str = Field(description="The user's question")
|
||||
relevant_files_ranking: List[file_idx_and_path] = Field(description="Files sorted in descending order by relevance to question")
|
||||
=====
|
||||
|
||||
|
||||
Example output:
|
||||
```yaml
|
||||
user_question: |
|
||||
...
|
||||
relevant_files_ranking:
|
||||
- idx: 101
|
||||
file_name: "src/file1.py"
|
||||
- ...
|
||||
"""
|
||||
|
||||
user="""\
|
||||
Documentation url: '{{ docs_url|trim }}'
|
||||
-----
|
||||
|
||||
|
||||
User's Question:
|
||||
=====
|
||||
{{ question|trim }}
|
||||
=====
|
||||
|
||||
|
||||
Filenames with optional headings from documentation website content:
|
||||
=====
|
||||
{{ snippets|trim }}
|
||||
=====
|
||||
|
||||
|
||||
Reminder: The output must be a YAML object equivalent to type $DocHeadingsHelper, similar to the following example output:
|
||||
=====
|
||||
|
||||
|
||||
Example output:
|
||||
```yaml
|
||||
user_question: |
|
||||
...
|
||||
relevant_files_ranking:
|
||||
- idx: 101
|
||||
file_name: "src/file1.py"
|
||||
- ...
|
||||
=====
|
||||
|
||||
Important Notes:
|
||||
1. Output most relevant file names first, by descending order of relevancy.
|
||||
2. Only include files with non-negative indices
|
||||
|
||||
|
||||
Response (should be a valid YAML, and nothing else).
|
||||
```yaml
|
||||
"""
|
||||
77
pr_agent/settings/pr_help_docs_prompts.toml
Normal file
77
pr_agent/settings/pr_help_docs_prompts.toml
Normal file
@ -0,0 +1,77 @@
|
||||
[pr_help_docs_prompts]
|
||||
system="""You are Doc-helper, a language model designed to answer questions about a documentation website for a given repository.
|
||||
You will receive a question, a repository url and the full documentation content for that repository (either as markdown or as restructred text).
|
||||
Your goal is to provide the best answer to the question using the documentation provided.
|
||||
|
||||
Additional instructions:
|
||||
- Be short and concise in your answers. Give examples if needed.
|
||||
- Answer only questions that are related to the documentation website content. If the question is completely unrelated to the documentation, return an empty response.
|
||||
|
||||
|
||||
The output must be a YAML object equivalent to type $DocHelper, according to the following Pydantic definitions:
|
||||
=====
|
||||
class relevant_section(BaseModel):
|
||||
file_name: str = Field(description="The name of the relevant file")
|
||||
relevant_section_header_string: str = Field(description="The exact text of the relevant markdown/restructured text section heading from the relevant file (starting with '#', '##', etc.). Return empty string if the entire file is the relevant section, or if the relevant section has no heading")
|
||||
|
||||
class DocHelper(BaseModel):
|
||||
user_question: str = Field(description="The user's question")
|
||||
response: str = Field(description="The response to the user's question")
|
||||
relevant_sections: List[relevant_section] = Field(description="A list of the relevant markdown/restructured text sections in the documentation that answer the user's question, ordered by importance (most relevant first)")
|
||||
question_is_relevant: int = Field(description="Return 1 if the question is somewhat relevant to documentation. 0 - otherwise")
|
||||
=====
|
||||
|
||||
|
||||
Example output:
|
||||
```yaml
|
||||
user_question: |
|
||||
...
|
||||
response: |
|
||||
...
|
||||
relevant_sections:
|
||||
- file_name: "src/file1.py"
|
||||
relevant_section_header_string: |
|
||||
...
|
||||
- ...
|
||||
question_is_relevant: |
|
||||
1
|
||||
"""
|
||||
|
||||
user="""\
|
||||
Documentation url: '{{ docs_url| trim }}'
|
||||
-----
|
||||
|
||||
|
||||
User's Question:
|
||||
=====
|
||||
{{ question|trim }}
|
||||
=====
|
||||
|
||||
|
||||
Documentation website content:
|
||||
=====
|
||||
{{ snippets|trim }}
|
||||
=====
|
||||
|
||||
|
||||
Reminder: The output must be a YAML object equivalent to type $DocHelper, similar to the following example output:
|
||||
=====
|
||||
Example output:
|
||||
```yaml
|
||||
user_question: |
|
||||
...
|
||||
response: |
|
||||
...
|
||||
relevant_sections:
|
||||
- file_name: "src/file1.py"
|
||||
relevant_section_header_string: |
|
||||
...
|
||||
- ...
|
||||
question_is_relevant: |
|
||||
1
|
||||
=====
|
||||
|
||||
|
||||
Response (should be a valid YAML, and nothing else).
|
||||
```yaml
|
||||
"""
|
||||
@ -29,7 +29,7 @@ __old hunk__
|
||||
@@ ... @@ def func2():
|
||||
__new hunk__
|
||||
unchanged code line4
|
||||
+new code line5 removed
|
||||
+new code line5 added
|
||||
unchanged code line6
|
||||
|
||||
## File: 'src/file2.py'
|
||||
@ -44,7 +44,8 @@ __new hunk__
|
||||
- If available, an AI-generated summary will appear and provide a high-level overview of the file changes. Note that this summary may not be fully accurate or complete.
|
||||
{%- endif %}
|
||||
- When quoting variables, names or file paths from the code, use backticks (`) instead of single quote (').
|
||||
|
||||
- Note that you only see changed code segments (diff hunks in a PR), not the entire codebase. Avoid suggestions that might duplicate existing functionality or questioning code elements (like variables declarations or import statements) that may be defined elsewhere in the codebase.
|
||||
- Also note that if the code ends at an opening brace or statement that begins a new scope (like 'if', 'for', 'try'), don't treat it as incomplete. Instead, acknowledge the visible scope boundary and analyze only the code shown.
|
||||
|
||||
{%- if extra_instructions %}
|
||||
|
||||
@ -66,8 +67,8 @@ class SubPR(BaseModel):
|
||||
|
||||
class KeyIssuesComponentLink(BaseModel):
|
||||
relevant_file: str = Field(description="The full file path of the relevant file")
|
||||
issue_header: str = Field(description="One or two word title for the the issue. For example: 'Possible Bug', etc.")
|
||||
issue_content: str = Field(description="A short and concise summary of what should be further inspected and validated during the PR review process for this issue. Do not reference line numbers in this field.")
|
||||
issue_header: str = Field(description="One or two word title for the issue. For example: 'Possible Bug', etc.")
|
||||
issue_content: str = Field(description="A short and concise summary of what should be further inspected and validated during the PR review process for this issue. Do not mention line numbers in this field.")
|
||||
start_line: int = Field(description="The start line that corresponds to this issue in the relevant file")
|
||||
end_line: int = Field(description="The end line that corresponds to this issue in the relevant file")
|
||||
|
||||
|
||||
@ -1,46 +0,0 @@
|
||||
[pr_sort_code_suggestions_prompt]
|
||||
system="""
|
||||
"""
|
||||
|
||||
user="""You are given a list of code suggestions to improve a Git Pull Request (PR):
|
||||
======
|
||||
{{ suggestion_str|trim }}
|
||||
======
|
||||
|
||||
Your task is to sort the code suggestions by their order of importance, and return a list with sorting order.
|
||||
The sorting order is a list of pairs, where each pair contains the index of the suggestion in the original list.
|
||||
Rank the suggestions based on their importance to improving the PR, with critical issues first and minor issues last.
|
||||
|
||||
You must use the following YAML schema to format your answer:
|
||||
```yaml
|
||||
Sort Order:
|
||||
type: array
|
||||
maxItems: {{ suggestion_list|length }}
|
||||
uniqueItems: true
|
||||
items:
|
||||
suggestion number:
|
||||
type: integer
|
||||
minimum: 1
|
||||
maximum: {{ suggestion_list|length }}
|
||||
importance order:
|
||||
type: integer
|
||||
minimum: 1
|
||||
maximum: {{ suggestion_list|length }}
|
||||
```
|
||||
|
||||
Example output:
|
||||
```yaml
|
||||
Sort Order:
|
||||
- suggestion number: 1
|
||||
importance order: 2
|
||||
- suggestion number: 2
|
||||
importance order: 3
|
||||
- suggestion number: 3
|
||||
importance order: 1
|
||||
```
|
||||
|
||||
Make sure to output a valid YAML. Use multi-line block scalar ('|') if needed.
|
||||
Don't repeat the prompt in the answer, and avoid outputting the 'type' and 'description' fields.
|
||||
Response (should be a valid YAML, and nothing else):
|
||||
```yaml
|
||||
"""
|
||||
@ -10,14 +10,16 @@ from typing import Dict, List
|
||||
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
|
||||
from pr_agent.algo import MAX_TOKENS
|
||||
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||
from pr_agent.algo.ai_handlers.litellm_ai_handler import LiteLLMAIHandler
|
||||
from pr_agent.algo.git_patch_processing import decouple_and_convert_to_hunks_with_lines_numbers
|
||||
from pr_agent.algo.pr_processing import (add_ai_metadata_to_diff_files,
|
||||
get_pr_diff, get_pr_multi_diffs,
|
||||
retry_with_fallback_models)
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.utils import (ModelType, load_yaml, replace_code_tags,
|
||||
show_relevant_configurations)
|
||||
show_relevant_configurations, get_max_tokens, clip_tokens)
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers import (AzureDevopsProvider, GithubProvider,
|
||||
GitLabProvider, get_git_provider,
|
||||
@ -45,14 +47,8 @@ class PRCodeSuggestions:
|
||||
get_settings().config.max_model_tokens_original = get_settings().config.max_model_tokens
|
||||
get_settings().config.max_model_tokens = MAX_CONTEXT_TOKENS_IMPROVE
|
||||
|
||||
# extended mode
|
||||
try:
|
||||
self.is_extended = self._get_is_extended(args or [])
|
||||
except:
|
||||
self.is_extended = False
|
||||
num_code_suggestions = int(get_settings().pr_code_suggestions.num_code_suggestions_per_chunk)
|
||||
|
||||
|
||||
self.ai_handler = ai_handler()
|
||||
self.ai_handler.main_pr_language = self.main_language
|
||||
self.patches_diff = None
|
||||
@ -85,12 +81,18 @@ class PRCodeSuggestions:
|
||||
"date": datetime.now().strftime('%Y-%m-%d'),
|
||||
'duplicate_prompt_examples': get_settings().config.get('duplicate_prompt_examples', False),
|
||||
}
|
||||
self.pr_code_suggestions_prompt_system = get_settings().pr_code_suggestions_prompt.system
|
||||
|
||||
if get_settings().pr_code_suggestions.get("decouple_hunks", True):
|
||||
self.pr_code_suggestions_prompt_system = get_settings().pr_code_suggestions_prompt.system
|
||||
self.pr_code_suggestions_prompt_user = get_settings().pr_code_suggestions_prompt.user
|
||||
else:
|
||||
self.pr_code_suggestions_prompt_system = get_settings().pr_code_suggestions_prompt_not_decoupled.system
|
||||
self.pr_code_suggestions_prompt_user = get_settings().pr_code_suggestions_prompt_not_decoupled.user
|
||||
|
||||
self.token_handler = TokenHandler(self.git_provider.pr,
|
||||
self.vars,
|
||||
self.pr_code_suggestions_prompt_system,
|
||||
get_settings().pr_code_suggestions_prompt.user)
|
||||
self.pr_code_suggestions_prompt_user)
|
||||
|
||||
self.progress = f"## Generating PR code suggestions\n\n"
|
||||
self.progress += f"""\nWork in progress ...<br>\n<img src="https://codium.ai/images/pr_agent/dual_ball_loading-crop.gif" width=48>"""
|
||||
@ -115,11 +117,11 @@ class PRCodeSuggestions:
|
||||
else:
|
||||
self.git_provider.publish_comment("Preparing suggestions...", is_temporary=True)
|
||||
|
||||
# call the model to get the suggestions, and self-reflect on them
|
||||
if not self.is_extended:
|
||||
data = await retry_with_fallback_models(self._prepare_prediction, model_type=ModelType.REGULAR)
|
||||
else:
|
||||
data = await retry_with_fallback_models(self._prepare_prediction_extended, model_type=ModelType.REGULAR)
|
||||
# # call the model to get the suggestions, and self-reflect on them
|
||||
# if not self.is_extended:
|
||||
# data = await retry_with_fallback_models(self._prepare_prediction, model_type=ModelType.REGULAR)
|
||||
# else:
|
||||
data = await retry_with_fallback_models(self._prepare_prediction_extended, model_type=ModelType.REGULAR)
|
||||
if not data:
|
||||
data = {"code_suggestions": []}
|
||||
self.data = data
|
||||
@ -215,7 +217,8 @@ class PRCodeSuggestions:
|
||||
|
||||
async def publish_no_suggestions(self):
|
||||
pr_body = "## PR Code Suggestions ✨\n\nNo code suggestions found for the PR."
|
||||
if get_settings().config.publish_output and get_settings().config.publish_output_no_suggestions:
|
||||
if (get_settings().config.publish_output and
|
||||
get_settings().pr_code_suggestions.get('publish_output_no_suggestions', True)):
|
||||
get_logger().warning('No code suggestions found for the PR.')
|
||||
get_logger().debug(f"PR output", artifact=pr_body)
|
||||
if self.progress_response:
|
||||
@ -466,6 +469,8 @@ class PRCodeSuggestions:
|
||||
suggestion["score"] = 7
|
||||
suggestion["score_why"] = ""
|
||||
|
||||
suggestion = self.validate_one_liner_suggestion_not_repeating_code(suggestion)
|
||||
|
||||
# if the before and after code is the same, clear one of them
|
||||
try:
|
||||
if suggestion['existing_code'] == suggestion['improved_code']:
|
||||
@ -621,15 +626,32 @@ class PRCodeSuggestions:
|
||||
|
||||
return new_code_snippet
|
||||
|
||||
def _get_is_extended(self, args: list[str]) -> bool:
|
||||
"""Check if extended mode should be enabled by the `--extended` flag or automatically according to the configuration"""
|
||||
if any(["extended" in arg for arg in args]):
|
||||
get_logger().info("Extended mode is enabled by the `--extended` flag")
|
||||
return True
|
||||
if get_settings().pr_code_suggestions.auto_extended_mode:
|
||||
# get_logger().info("Extended mode is enabled automatically based on the configuration toggle")
|
||||
return True
|
||||
return False
|
||||
def validate_one_liner_suggestion_not_repeating_code(self, suggestion):
|
||||
try:
|
||||
existing_code = suggestion.get('existing_code', '').strip()
|
||||
if '...' in existing_code:
|
||||
return suggestion
|
||||
new_code = suggestion.get('improved_code', '').strip()
|
||||
|
||||
relevant_file = suggestion.get('relevant_file', '').strip()
|
||||
diff_files = self.git_provider.get_diff_files()
|
||||
for file in diff_files:
|
||||
if file.filename.strip() == relevant_file:
|
||||
# protections
|
||||
if not file.head_file:
|
||||
get_logger().info(f"head_file is empty")
|
||||
return suggestion
|
||||
head_file = file.head_file
|
||||
base_file = file.base_file
|
||||
if existing_code in base_file and existing_code not in head_file and new_code in head_file:
|
||||
suggestion["score"] = 0
|
||||
get_logger().warning(
|
||||
f"existing_code is in the base file but not in the head file, setting score to 0",
|
||||
artifact={"suggestion": suggestion})
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Error validating one-liner suggestion", artifact={"error": e})
|
||||
|
||||
return suggestion
|
||||
|
||||
def remove_line_numbers(self, patches_diff_list: List[str]) -> List[str]:
|
||||
# create a copy of the patches_diff_list, without line numbers for '__new hunk__' sections
|
||||
@ -654,11 +676,31 @@ class PRCodeSuggestions:
|
||||
return patches_diff_list
|
||||
|
||||
async def _prepare_prediction_extended(self, model: str) -> dict:
|
||||
self.patches_diff_list = get_pr_multi_diffs(self.git_provider, self.token_handler, model,
|
||||
max_calls=get_settings().pr_code_suggestions.max_number_of_calls)
|
||||
# get PR diff
|
||||
if get_settings().pr_code_suggestions.decouple_hunks:
|
||||
self.patches_diff_list = get_pr_multi_diffs(self.git_provider,
|
||||
self.token_handler,
|
||||
model,
|
||||
max_calls=get_settings().pr_code_suggestions.max_number_of_calls,
|
||||
add_line_numbers=True) # decouple hunk with line numbers
|
||||
self.patches_diff_list_no_line_numbers = self.remove_line_numbers(self.patches_diff_list) # decouple hunk
|
||||
|
||||
# create a copy of the patches_diff_list, without line numbers for '__new hunk__' sections
|
||||
self.patches_diff_list_no_line_numbers = self.remove_line_numbers(self.patches_diff_list)
|
||||
else:
|
||||
# non-decoupled hunks
|
||||
self.patches_diff_list_no_line_numbers = get_pr_multi_diffs(self.git_provider,
|
||||
self.token_handler,
|
||||
model,
|
||||
max_calls=get_settings().pr_code_suggestions.max_number_of_calls,
|
||||
add_line_numbers=False)
|
||||
self.patches_diff_list = await self.convert_to_decoupled_with_line_numbers(
|
||||
self.patches_diff_list_no_line_numbers, model)
|
||||
if not self.patches_diff_list:
|
||||
# fallback to decoupled hunks
|
||||
self.patches_diff_list = get_pr_multi_diffs(self.git_provider,
|
||||
self.token_handler,
|
||||
model,
|
||||
max_calls=get_settings().pr_code_suggestions.max_number_of_calls,
|
||||
add_line_numbers=True) # decouple hunk with line numbers
|
||||
|
||||
if self.patches_diff_list:
|
||||
get_logger().info(f"Number of PR chunk calls: {len(self.patches_diff_list)}")
|
||||
@ -699,6 +741,42 @@ class PRCodeSuggestions:
|
||||
self.data = data = None
|
||||
return data
|
||||
|
||||
async def convert_to_decoupled_with_line_numbers(self, patches_diff_list_no_line_numbers, model) -> List[str]:
|
||||
with get_logger().contextualize(sub_feature='convert_to_decoupled_with_line_numbers'):
|
||||
try:
|
||||
patches_diff_list = []
|
||||
for patch_prompt in patches_diff_list_no_line_numbers:
|
||||
file_prefix = "## File: "
|
||||
patches = patch_prompt.strip().split(f"\n{file_prefix}")
|
||||
patches_new = copy.deepcopy(patches)
|
||||
for i in range(len(patches_new)):
|
||||
if i == 0:
|
||||
prefix = patches_new[i].split("\n@@")[0].strip()
|
||||
else:
|
||||
prefix = file_prefix + patches_new[i].split("\n@@")[0][1:]
|
||||
prefix = prefix.strip()
|
||||
patches_new[i] = prefix + '\n\n' + decouple_and_convert_to_hunks_with_lines_numbers(patches_new[i],
|
||||
file=None).strip()
|
||||
patches_new[i] = patches_new[i].strip()
|
||||
patch_final = "\n\n\n".join(patches_new)
|
||||
if model in MAX_TOKENS:
|
||||
max_tokens_full = MAX_TOKENS[
|
||||
model] # note - here we take the actual max tokens, without any reductions. we do aim to get the full documentation website in the prompt
|
||||
else:
|
||||
max_tokens_full = get_max_tokens(model)
|
||||
delta_output = 2000
|
||||
token_count = self.token_handler.count_tokens(patch_final)
|
||||
if token_count > max_tokens_full - delta_output:
|
||||
get_logger().warning(
|
||||
f"Token count {token_count} exceeds the limit {max_tokens_full - delta_output}. clipping the tokens")
|
||||
patch_final = clip_tokens(patch_final, max_tokens_full - delta_output)
|
||||
patches_diff_list.append(patch_final)
|
||||
return patches_diff_list
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Error converting to decoupled with line numbers",
|
||||
artifact={'patches_diff_list_no_line_numbers': patches_diff_list_no_line_numbers})
|
||||
return []
|
||||
|
||||
def generate_summarized_suggestions(self, data: Dict) -> str:
|
||||
try:
|
||||
pr_body = "## PR Code Suggestions ✨\n\n"
|
||||
@ -707,7 +785,7 @@ class PRCodeSuggestions:
|
||||
pr_body += "No suggestions found to improve this PR."
|
||||
return pr_body
|
||||
|
||||
if get_settings().pr_code_suggestions.enable_intro_text and get_settings().config.is_auto_command:
|
||||
if get_settings().config.is_auto_command:
|
||||
pr_body += "Explore these optional code suggestions:\n\n"
|
||||
|
||||
language_extension_map_org = get_settings().language_extension_map_org
|
||||
|
||||
@ -41,7 +41,8 @@ class PRConfig:
|
||||
skip_keys = ['ai_disclaimer', 'ai_disclaimer_title', 'ANALYTICS_FOLDER', 'secret_provider', "skip_keys", "app_id", "redirect",
|
||||
'trial_prefix_message', 'no_eligible_message', 'identity_provider', 'ALLOWED_REPOS',
|
||||
'APP_NAME', 'PERSONAL_ACCESS_TOKEN', 'shared_secret', 'key', 'AWS_ACCESS_KEY_ID', 'AWS_SECRET_ACCESS_KEY', 'user_token',
|
||||
'private_key', 'private_key_id', 'client_id', 'client_secret', 'token', 'bearer_token']
|
||||
'private_key', 'private_key_id', 'client_id', 'client_secret', 'token', 'bearer_token', 'jira_api_token','webhook_secret']
|
||||
partial_skip_keys = ['key', 'secret', 'token', 'private']
|
||||
extra_skip_keys = get_settings().config.get('config.skip_keys', [])
|
||||
if extra_skip_keys:
|
||||
skip_keys.extend(extra_skip_keys)
|
||||
@ -57,6 +58,8 @@ class PRConfig:
|
||||
for key, value in configs.items():
|
||||
if key.lower() in skip_keys_lower:
|
||||
continue
|
||||
if any(skip_key in key.lower() for skip_key in partial_skip_keys):
|
||||
continue
|
||||
markdown_text += f"\n{header.lower()}.{key.lower()} = {repr(value) if isinstance(value, str) else value}"
|
||||
markdown_text += " "
|
||||
markdown_text += "\n```"
|
||||
|
||||
560
pr_agent/tools/pr_help_docs.py
Normal file
560
pr_agent/tools/pr_help_docs.py
Normal file
@ -0,0 +1,560 @@
|
||||
import copy
|
||||
from functools import partial
|
||||
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
import math
|
||||
import os
|
||||
import re
|
||||
from tempfile import TemporaryDirectory
|
||||
|
||||
from pr_agent.algo import MAX_TOKENS
|
||||
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||
from pr_agent.algo.ai_handlers.litellm_ai_handler import LiteLLMAIHandler
|
||||
from pr_agent.algo.pr_processing import retry_with_fallback_models
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.utils import clip_tokens, get_max_tokens, load_yaml, ModelType
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers import get_git_provider_with_context
|
||||
from pr_agent.log import get_logger
|
||||
from pr_agent.servers.help import HelpMessage
|
||||
|
||||
|
||||
#Common code that can be called from similar tools:
|
||||
def modify_answer_section(ai_response: str) -> str | None:
|
||||
# Gets the model's answer and relevant sources section, repacing the heading of the answer section with:
|
||||
# :bulb: Auto-generated documentation-based answer:
|
||||
"""
|
||||
For example: The following input:
|
||||
|
||||
### Question: \nThe following general issue was asked by a user: Title: How does one request to re-review a PR? More Info: I cannot seem to find to do this.
|
||||
### Answer:\nAccording to the documentation, one needs to invoke the command: /review
|
||||
#### Relevant Sources...
|
||||
|
||||
Should become:
|
||||
|
||||
### :bulb: Auto-generated documentation-based answer:\n
|
||||
According to the documentation, one needs to invoke the command: /review
|
||||
#### Relevant Sources...
|
||||
"""
|
||||
model_answer_and_relevant_sections_in_response \
|
||||
= extract_model_answer_and_relevant_sources(ai_response)
|
||||
if model_answer_and_relevant_sections_in_response is not None:
|
||||
cleaned_question_with_answer = "### :bulb: Auto-generated documentation-based answer:\n"
|
||||
cleaned_question_with_answer += model_answer_and_relevant_sections_in_response
|
||||
return cleaned_question_with_answer
|
||||
get_logger().warning(f"Either no answer section found, or that section is malformed: {ai_response}")
|
||||
return None
|
||||
|
||||
def extract_model_answer_and_relevant_sources(ai_response: str) -> str | None:
|
||||
# It is assumed that the input contains several sections with leading "### ",
|
||||
# where the answer is the last one of them having the format: "### Answer:\n"), since the model returns the answer
|
||||
# AFTER the user question. By splitting using the string: "### Answer:\n" and grabbing the last part,
|
||||
# the model answer is guaranteed to be in that last part, provided it is followed by a "#### Relevant Sources:\n\n".
|
||||
# (for more details, see here: https://github.com/Codium-ai/pr-agent-pro/blob/main/pr_agent/tools/pr_help_message.py#L173)
|
||||
"""
|
||||
For example:
|
||||
### Question: \nHow does one request to re-review a PR?\n\n
|
||||
### Answer:\nAccording to the documentation, one needs to invoke the command: /review\n\n
|
||||
#### Relevant Sources:\n\n...
|
||||
|
||||
The answer part is: "According to the documentation, one needs to invoke the command: /review\n\n"
|
||||
followed by "Relevant Sources:\n\n".
|
||||
"""
|
||||
if "### Answer:\n" in ai_response:
|
||||
model_answer_and_relevant_sources_sections_in_response = ai_response.split("### Answer:\n")[-1]
|
||||
# Split such part by "Relevant Sources" section to contain only the model answer:
|
||||
if "#### Relevant Sources:\n\n" in model_answer_and_relevant_sources_sections_in_response:
|
||||
model_answer_section_in_response \
|
||||
= model_answer_and_relevant_sources_sections_in_response.split("#### Relevant Sources:\n\n")[0]
|
||||
get_logger().info(f"Found model answer: {model_answer_section_in_response}")
|
||||
return model_answer_and_relevant_sources_sections_in_response \
|
||||
if len(model_answer_section_in_response) > 0 else None
|
||||
get_logger().warning(f"Either no answer section found, or that section is malformed: {ai_response}")
|
||||
return None
|
||||
|
||||
def get_maximal_text_input_length_for_token_count_estimation():
|
||||
model = get_settings().config.model
|
||||
if 'claude-3-7-sonnet' in model.lower():
|
||||
return 900000 #Claude API for token estimation allows maximal text input of 900K chars
|
||||
return math.inf #Otherwise, no known limitation on input text just for token estimation
|
||||
|
||||
def return_document_headings(text: str, ext: str) -> str:
|
||||
try:
|
||||
lines = text.split('\n')
|
||||
headings = set()
|
||||
|
||||
if not text or not re.search(r'[a-zA-Z]', text):
|
||||
get_logger().error(f"Empty or non text content found in text: {text}.")
|
||||
return ""
|
||||
|
||||
if ext in ['.md', '.mdx']:
|
||||
# Extract Markdown headings (lines starting with #)
|
||||
headings = {line.strip() for line in lines if line.strip().startswith('#')}
|
||||
elif ext == '.rst':
|
||||
# Find indices of lines that have all same character:
|
||||
#Allowed characters according to list from: https://docutils.sourceforge.io/docs/ref/rst/restructuredtext.html#sections
|
||||
section_chars = set('!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~')
|
||||
|
||||
# Find potential section marker lines (underlines/overlines): They have to be the same character
|
||||
marker_lines = []
|
||||
for i, line in enumerate(lines):
|
||||
line = line.rstrip()
|
||||
if line and all(c == line[0] for c in line) and line[0] in section_chars:
|
||||
marker_lines.append((i, len(line)))
|
||||
|
||||
# Check for headings adjacent to marker lines (below + text must be in length equal or less)
|
||||
for idx, length in marker_lines:
|
||||
# Check if it's an underline (heading is above it)
|
||||
if idx > 0 and lines[idx - 1].rstrip() and len(lines[idx - 1].rstrip()) <= length:
|
||||
headings.add(lines[idx - 1].rstrip())
|
||||
else:
|
||||
get_logger().error(f"Unsupported file extension: {ext}")
|
||||
return ""
|
||||
|
||||
return '\n'.join(headings)
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Unexpected exception thrown. Returning empty result.")
|
||||
return ""
|
||||
|
||||
# Load documentation files to memory: full file path (as will be given as prompt) -> doc contents
|
||||
def map_documentation_files_to_contents(base_path: str, doc_files: list[str], max_allowed_file_len=5000) -> dict[str, str]:
|
||||
try:
|
||||
returned_dict = {}
|
||||
for file in doc_files:
|
||||
try:
|
||||
with open(file, 'r', encoding='utf-8') as f:
|
||||
content = f.read()
|
||||
# Skip files with no text content
|
||||
if not re.search(r'[a-zA-Z]', content):
|
||||
continue
|
||||
if len(content) > max_allowed_file_len:
|
||||
get_logger().warning(f"File {file} length: {len(content)} exceeds limit: {max_allowed_file_len}, so it will be trimmed.")
|
||||
content = content[:max_allowed_file_len]
|
||||
file_path = str(file).replace(str(base_path), '')
|
||||
returned_dict[file_path] = content.strip()
|
||||
except Exception as e:
|
||||
get_logger().warning(f"Error while reading the file {file}: {e}")
|
||||
continue
|
||||
if not returned_dict:
|
||||
get_logger().error("Couldn't find any usable documentation files. Returning empty dict.")
|
||||
return returned_dict
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Unexpected exception thrown. Returning empty dict.")
|
||||
return {}
|
||||
|
||||
# Goes over files' contents, generating payload for prompt while decorating them with a header to mark where each file begins,
|
||||
# as to help the LLM to give a better answer.
|
||||
def aggregate_documentation_files_for_prompt_contents(file_path_to_contents: dict[str, str], return_just_headings=False) -> str:
|
||||
try:
|
||||
docs_prompt = ""
|
||||
for idx, file_path in enumerate(file_path_to_contents):
|
||||
file_contents = file_path_to_contents[file_path].strip()
|
||||
if not file_contents:
|
||||
get_logger().error(f"Got empty file contents for: {file_path}. Skipping this file.")
|
||||
continue
|
||||
if return_just_headings:
|
||||
file_headings = return_document_headings(file_contents, os.path.splitext(file_path)[-1]).strip()
|
||||
if file_headings:
|
||||
docs_prompt += f"\n==file name==\n\n{file_path}\n\n==index==\n\n{idx}\n\n==file headings==\n\n{file_headings}\n=========\n\n"
|
||||
else:
|
||||
get_logger().warning(f"No headers for: {file_path}. Will only use filename")
|
||||
docs_prompt += f"\n==file name==\n\n{file_path}\n\n==index==\n\n{idx}\n\n"
|
||||
else:
|
||||
docs_prompt += f"\n==file name==\n\n{file_path}\n\n==file content==\n\n{file_contents}\n=========\n\n"
|
||||
return docs_prompt
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Unexpected exception thrown. Returning empty result.")
|
||||
return ""
|
||||
|
||||
def format_markdown_q_and_a_response(question_str: str, response_str: str, relevant_sections: list[dict[str, str]],
|
||||
supported_suffixes: list[str], base_url_prefix: str, base_url_suffix: str="") -> str:
|
||||
try:
|
||||
base_url_prefix = base_url_prefix.strip('/') #Sanitize base_url_prefix
|
||||
answer_str = ""
|
||||
answer_str += f"### Question: \n{question_str}\n\n"
|
||||
answer_str += f"### Answer:\n{response_str.strip()}\n\n"
|
||||
answer_str += f"#### Relevant Sources:\n\n"
|
||||
for section in relevant_sections:
|
||||
file = section.get('file_name').lstrip('/').strip() #Remove any '/' in the beginning, since some models do it anyway
|
||||
ext = [suffix for suffix in supported_suffixes if file.endswith(suffix)]
|
||||
if not ext:
|
||||
get_logger().warning(f"Unsupported file extension: {file}")
|
||||
continue
|
||||
if str(section['relevant_section_header_string']).strip():
|
||||
markdown_header = format_markdown_header(section['relevant_section_header_string'])
|
||||
if base_url_prefix:
|
||||
answer_str += f"> - {base_url_prefix}/{file}{base_url_suffix}#{markdown_header}\n"
|
||||
else:
|
||||
answer_str += f"> - {base_url_prefix}/{file}{base_url_suffix}\n"
|
||||
return answer_str
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Unexpected exception thrown. Returning empty result.")
|
||||
return ""
|
||||
|
||||
def format_markdown_header(header: str) -> str:
|
||||
try:
|
||||
# First, strip common characters from both ends
|
||||
cleaned = header.strip('# 💎\n')
|
||||
|
||||
# Define all characters to be removed/replaced in a single pass
|
||||
replacements = {
|
||||
"'": '',
|
||||
"`": '',
|
||||
'(': '',
|
||||
')': '',
|
||||
',': '',
|
||||
'.': '',
|
||||
'?': '',
|
||||
'!': '',
|
||||
' ': '-'
|
||||
}
|
||||
|
||||
# Compile regex pattern for characters to remove
|
||||
pattern = re.compile('|'.join(map(re.escape, replacements.keys())))
|
||||
|
||||
# Perform replacements in a single pass and convert to lowercase
|
||||
return pattern.sub(lambda m: replacements[m.group()], cleaned).lower()
|
||||
except Exception:
|
||||
get_logger().exception(f"Error while formatting markdown header", artifacts={'header': header})
|
||||
return ""
|
||||
|
||||
def clean_markdown_content(content: str) -> str:
|
||||
"""
|
||||
Remove hidden comments and unnecessary elements from markdown content to reduce size.
|
||||
|
||||
Args:
|
||||
content: The original markdown content
|
||||
|
||||
Returns:
|
||||
Cleaned markdown content
|
||||
"""
|
||||
try:
|
||||
# Remove HTML comments
|
||||
content = re.sub(r'<!--.*?-->', '', content, flags=re.DOTALL)
|
||||
|
||||
# Remove frontmatter (YAML between --- or +++ delimiters)
|
||||
content = re.sub(r'^---\s*\n.*?\n---\s*\n', '', content, flags=re.DOTALL)
|
||||
content = re.sub(r'^\+\+\+\s*\n.*?\n\+\+\+\s*\n', '', content, flags=re.DOTALL)
|
||||
|
||||
# Remove excessive blank lines (more than 2 consecutive)
|
||||
content = re.sub(r'\n{3,}', '\n\n', content)
|
||||
|
||||
# Remove HTML tags that are often used for styling only
|
||||
content = re.sub(r'<div.*?>|</div>|<span.*?>|</span>', '', content, flags=re.DOTALL)
|
||||
|
||||
# Remove image alt text which can be verbose
|
||||
content = re.sub(r'!\[(.*?)\]', '![]', content)
|
||||
|
||||
# Remove images completely
|
||||
content = re.sub(r'!\[.*?\]\(.*?\)', '', content)
|
||||
|
||||
# Remove simple HTML tags but preserve content between them
|
||||
content = re.sub(r'<(?!table|tr|td|th|thead|tbody)([a-zA-Z][a-zA-Z0-9]*)[^>]*>(.*?)</\1>',
|
||||
r'\2', content, flags=re.DOTALL)
|
||||
return content.strip()
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Unexpected exception thrown. Returning empty result.")
|
||||
return ""
|
||||
|
||||
class PredictionPreparator:
|
||||
def __init__(self, ai_handler, vars, system_prompt, user_prompt):
|
||||
try:
|
||||
self.ai_handler = ai_handler
|
||||
variables = copy.deepcopy(vars)
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
self.system_prompt = environment.from_string(system_prompt).render(variables)
|
||||
self.user_prompt = environment.from_string(user_prompt).render(variables)
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Caught exception during init. Setting ai_handler to None to prevent __call__.")
|
||||
self.ai_handler = None
|
||||
|
||||
#Called by retry_with_fallback_models and therefore, on any failure must throw an exception:
|
||||
async def __call__(self, model: str) -> str:
|
||||
if not self.ai_handler:
|
||||
get_logger().error("ai handler not set. Cannot invoke model!")
|
||||
raise ValueError("PredictionPreparator not initialized")
|
||||
try:
|
||||
response, finish_reason = await self.ai_handler.chat_completion(
|
||||
model=model, temperature=get_settings().config.temperature, system=self.system_prompt, user=self.user_prompt)
|
||||
return response
|
||||
except Exception as e:
|
||||
get_logger().exception("Caught exception during prediction.", artifacts={'system': self.system_prompt, 'user': self.user_prompt})
|
||||
raise e
|
||||
|
||||
|
||||
class PRHelpDocs(object):
|
||||
def __init__(self, ctx_url, ai_handler:partial[BaseAiHandler,] = LiteLLMAIHandler, args: tuple[str]=None, return_as_string: bool=False):
|
||||
try:
|
||||
self.ctx_url = ctx_url
|
||||
self.question = args[0] if args else None
|
||||
self.return_as_string = return_as_string
|
||||
self.repo_url_given_explicitly = True
|
||||
self.repo_url = get_settings().get('PR_HELP_DOCS.REPO_URL', '')
|
||||
self.repo_desired_branch = get_settings().get('PR_HELP_DOCS.REPO_DEFAULT_BRANCH', 'main') #Ignored if self.repo_url is empty
|
||||
self.include_root_readme_file = not(get_settings()['PR_HELP_DOCS.EXCLUDE_ROOT_README'])
|
||||
self.supported_doc_exts = get_settings()['PR_HELP_DOCS.SUPPORTED_DOC_EXTS']
|
||||
self.docs_path = get_settings()['PR_HELP_DOCS.DOCS_PATH']
|
||||
|
||||
retrieved_settings = [self.include_root_readme_file, self.supported_doc_exts, self.docs_path]
|
||||
if any([setting is None for setting in retrieved_settings]):
|
||||
raise Exception(f"One of the settings is invalid: {retrieved_settings}")
|
||||
|
||||
self.git_provider = get_git_provider_with_context(ctx_url)
|
||||
if not self.git_provider:
|
||||
raise Exception(f"No git provider found at {ctx_url}")
|
||||
if not self.repo_url:
|
||||
self.repo_url_given_explicitly = False
|
||||
get_logger().debug(f"No explicit repo url provided, deducing it from type: {self.git_provider.__class__.__name__} "
|
||||
f"context url: {self.ctx_url}")
|
||||
self.repo_url = self.git_provider.get_git_repo_url(self.ctx_url)
|
||||
if not self.repo_url:
|
||||
raise Exception(f"Unable to deduce repo url from type: {self.git_provider.__class__.__name__} url: {self.ctx_url}")
|
||||
get_logger().debug(f"deduced repo url: {self.repo_url}")
|
||||
self.repo_desired_branch = None #Inferred from the repo provider.
|
||||
|
||||
self.ai_handler = ai_handler()
|
||||
self.vars = {
|
||||
"docs_url": self.repo_url,
|
||||
"question": self.question,
|
||||
"snippets": "",
|
||||
}
|
||||
self.token_handler = TokenHandler(None,
|
||||
self.vars,
|
||||
get_settings().pr_help_docs_prompts.system,
|
||||
get_settings().pr_help_docs_prompts.user)
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Caught exception during init. Setting self.question to None to prevent run() to do anything.")
|
||||
self.question = None
|
||||
|
||||
async def run(self):
|
||||
if not self.question:
|
||||
get_logger().warning('No question provided. Will do nothing.')
|
||||
return None
|
||||
|
||||
try:
|
||||
# Clone the repository and gather relevant documentation files.
|
||||
docs_filepath_to_contents = self._gen_filenames_to_contents_map_from_repo()
|
||||
|
||||
#Generate prompt for the AI model. This will be the full text of all the documentation files combined.
|
||||
docs_prompt = aggregate_documentation_files_for_prompt_contents(docs_filepath_to_contents)
|
||||
if not docs_filepath_to_contents or not docs_prompt:
|
||||
get_logger().warning(f"Could not find any usable documentation. Returning with no result...")
|
||||
return None
|
||||
docs_prompt_to_send_to_model = docs_prompt
|
||||
|
||||
# Estimate how many tokens will be needed.
|
||||
# In case the expected number of tokens exceeds LLM limits, retry with just headings, asking the LLM to rank according to relevance to the question.
|
||||
# Based on returned ranking, rerun but sort the documents accordingly, this time, trim in case of exceeding limit.
|
||||
|
||||
#First, check if the text is not too long to even query the LLM provider:
|
||||
max_allowed_txt_input = get_maximal_text_input_length_for_token_count_estimation()
|
||||
invoke_llm_just_with_headings = self._trim_docs_input(docs_prompt_to_send_to_model, max_allowed_txt_input,
|
||||
only_return_if_trim_needed=True)
|
||||
if invoke_llm_just_with_headings:
|
||||
#Entire docs is too long. Rank and return according to relevance.
|
||||
docs_prompt_to_send_to_model = await self._rank_docs_and_return_them_as_prompt(docs_filepath_to_contents,
|
||||
max_allowed_txt_input)
|
||||
|
||||
if not docs_prompt_to_send_to_model:
|
||||
get_logger().error("Failed to generate docs prompt for model. Returning with no result...")
|
||||
return
|
||||
# At this point, either all original documents be used (if their total length doesn't exceed limits), or only those selected.
|
||||
self.vars['snippets'] = docs_prompt_to_send_to_model.strip()
|
||||
# Run the AI model and extract sections from its response
|
||||
response = await retry_with_fallback_models(PredictionPreparator(self.ai_handler, self.vars,
|
||||
get_settings().pr_help_docs_prompts.system,
|
||||
get_settings().pr_help_docs_prompts.user),
|
||||
model_type=ModelType.REGULAR)
|
||||
response_yaml = load_yaml(response)
|
||||
if not response_yaml:
|
||||
get_logger().error("Failed to parse the AI response.", artifacts={'response': response})
|
||||
return
|
||||
response_str = response_yaml.get('response')
|
||||
relevant_sections = response_yaml.get('relevant_sections')
|
||||
if not response_str or not relevant_sections:
|
||||
get_logger().error("Failed to extract response/relevant sections.",
|
||||
artifacts={'raw_response': response, 'response_str': response_str, 'relevant_sections': relevant_sections})
|
||||
return
|
||||
if int(response_yaml.get('question_is_relevant', '1')) == 0:
|
||||
get_logger().warning(f"Question is not relevant. Returning without an answer...",
|
||||
artifacts={'raw_response': response})
|
||||
return
|
||||
|
||||
# Format the response as markdown
|
||||
answer_str = self._format_model_answer(response_str, relevant_sections)
|
||||
if self.return_as_string: #Skip publishing
|
||||
return answer_str
|
||||
#Otherwise, publish the answer if answer is non empty and publish is not turned off:
|
||||
if answer_str and get_settings().config.publish_output:
|
||||
self.git_provider.publish_comment(answer_str)
|
||||
else:
|
||||
get_logger().info("Answer:", artifacts={'answer_str': answer_str})
|
||||
return answer_str
|
||||
except Exception as e:
|
||||
get_logger().exception('failed to provide answer to given user question as a result of a thrown exception (see above)')
|
||||
|
||||
def _find_all_document_files_matching_exts(self, abs_docs_path: str, ignore_readme=False, max_allowed_files=5000) -> list[str]:
|
||||
try:
|
||||
matching_files = []
|
||||
|
||||
# Ensure extensions don't have leading dots and are lowercase
|
||||
dotless_extensions = [ext.lower().lstrip('.') for ext in self.supported_doc_exts]
|
||||
|
||||
# Walk through directory and subdirectories
|
||||
file_cntr = 0
|
||||
for root, _, files in os.walk(abs_docs_path):
|
||||
for file in files:
|
||||
if ignore_readme and root == abs_docs_path and file.lower() in [f"readme.{ext}" for ext in dotless_extensions]:
|
||||
continue
|
||||
# Check if file has one of the specified extensions
|
||||
if any(file.lower().endswith(f'.{ext}') for ext in dotless_extensions):
|
||||
file_cntr+=1
|
||||
matching_files.append(os.path.join(root, file))
|
||||
if file_cntr >= max_allowed_files:
|
||||
get_logger().warning(f"Found at least {max_allowed_files} files in {abs_docs_path}, skipping the rest.")
|
||||
return matching_files
|
||||
return matching_files
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Unexpected exception thrown. Returning empty list.")
|
||||
return []
|
||||
|
||||
def _gen_filenames_to_contents_map_from_repo(self) -> dict[str, str]:
|
||||
try:
|
||||
with TemporaryDirectory() as tmp_dir:
|
||||
get_logger().debug(f"About to clone repository: {self.repo_url} to temporary directory: {tmp_dir}...")
|
||||
returned_cloned_repo_root = self.git_provider.clone(self.repo_url, tmp_dir, remove_dest_folder=False)
|
||||
if not returned_cloned_repo_root:
|
||||
raise Exception(f"Failed to clone {self.repo_url} to {tmp_dir}")
|
||||
|
||||
get_logger().debug(f"About to gather relevant documentation files...")
|
||||
doc_files = []
|
||||
if self.include_root_readme_file:
|
||||
for root, _, files in os.walk(returned_cloned_repo_root.path):
|
||||
# Only look at files in the root directory, not subdirectories
|
||||
if root == returned_cloned_repo_root.path:
|
||||
for file in files:
|
||||
if file.lower().startswith("readme."):
|
||||
doc_files.append(os.path.join(root, file))
|
||||
abs_docs_path = os.path.join(returned_cloned_repo_root.path, self.docs_path)
|
||||
if os.path.exists(abs_docs_path):
|
||||
doc_files.extend(self._find_all_document_files_matching_exts(abs_docs_path,
|
||||
ignore_readme=(self.docs_path=='.')))
|
||||
if not doc_files:
|
||||
get_logger().warning(f"No documentation files found matching file extensions: "
|
||||
f"{self.supported_doc_exts} under repo: {self.repo_url} "
|
||||
f"path: {self.docs_path}. Returning empty dict.")
|
||||
return {}
|
||||
|
||||
get_logger().info(f'For context {self.ctx_url} and repo: {self.repo_url}'
|
||||
f' will be using the following documentation files: ',
|
||||
artifacts={'doc_files': doc_files})
|
||||
|
||||
return map_documentation_files_to_contents(returned_cloned_repo_root.path, doc_files)
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Unexpected exception thrown. Returning empty dict.")
|
||||
return {}
|
||||
|
||||
def _trim_docs_input(self, docs_input: str, max_allowed_txt_input: int, only_return_if_trim_needed=False) -> bool|str:
|
||||
try:
|
||||
if len(docs_input) >= max_allowed_txt_input:
|
||||
get_logger().warning(
|
||||
f"Text length: {len(docs_input)} exceeds the current returned limit of {max_allowed_txt_input} just for token count estimation. Trimming the text...")
|
||||
if only_return_if_trim_needed:
|
||||
return True
|
||||
docs_input = docs_input[:max_allowed_txt_input]
|
||||
# Then, count the tokens in the prompt. If the count exceeds the limit, trim the text.
|
||||
token_count = self.token_handler.count_tokens(docs_input, force_accurate=True)
|
||||
get_logger().debug(f"Estimated token count of documentation to send to model: {token_count}")
|
||||
model = get_settings().config.model
|
||||
if model in MAX_TOKENS:
|
||||
max_tokens_full = MAX_TOKENS[
|
||||
model] # note - here we take the actual max tokens, without any reductions. we do aim to get the full documentation website in the prompt
|
||||
else:
|
||||
max_tokens_full = get_max_tokens(model)
|
||||
delta_output = 5000 # Elbow room to reduce chance of exceeding token limit or model paying less attention to prompt guidelines.
|
||||
if token_count > max_tokens_full - delta_output:
|
||||
if only_return_if_trim_needed:
|
||||
return True
|
||||
docs_input = clean_markdown_content(
|
||||
docs_input) # Reduce unnecessary text/images/etc.
|
||||
get_logger().info(
|
||||
f"Token count {token_count} exceeds the limit {max_tokens_full - delta_output}. Attempting to clip text to fit within the limit...")
|
||||
docs_input = clip_tokens(docs_input, max_tokens_full - delta_output,
|
||||
num_input_tokens=token_count)
|
||||
if only_return_if_trim_needed:
|
||||
return False
|
||||
return docs_input
|
||||
except Exception as e:
|
||||
# Unexpected exception. Rethrowing it since:
|
||||
# 1. This is an internal function.
|
||||
# 2. An empty str/False result is a valid one - would require now checking also for None.
|
||||
get_logger().exception(f"Unexpected exception thrown. Rethrowing it...")
|
||||
raise e
|
||||
|
||||
async def _rank_docs_and_return_them_as_prompt(self, docs_filepath_to_contents: dict[str, str], max_allowed_txt_input: int) -> str:
|
||||
try:
|
||||
#Return just file name and their headings (if exist):
|
||||
docs_prompt_to_send_to_model = (
|
||||
aggregate_documentation_files_for_prompt_contents(docs_filepath_to_contents,
|
||||
return_just_headings=True))
|
||||
# Verify list of headings does not exceed limits - trim it if it does.
|
||||
docs_prompt_to_send_to_model = self._trim_docs_input(docs_prompt_to_send_to_model, max_allowed_txt_input,
|
||||
only_return_if_trim_needed=False)
|
||||
if not docs_prompt_to_send_to_model:
|
||||
get_logger().error("_trim_docs_input returned an empty result.")
|
||||
return ""
|
||||
|
||||
self.vars['snippets'] = docs_prompt_to_send_to_model.strip()
|
||||
# Run the AI model and extract sections from its response
|
||||
response = await retry_with_fallback_models(PredictionPreparator(self.ai_handler, self.vars,
|
||||
get_settings().pr_help_docs_headings_prompts.system,
|
||||
get_settings().pr_help_docs_headings_prompts.user),
|
||||
model_type=ModelType.REGULAR)
|
||||
response_yaml = load_yaml(response)
|
||||
if not response_yaml:
|
||||
get_logger().error("Failed to parse the AI response.", artifacts={'response': response})
|
||||
return ""
|
||||
# else: Sanitize the output so that the file names match 1:1 dictionary keys. Do this via the file index and not its name, which may be altered by the model.
|
||||
valid_indices = [int(entry['idx']) for entry in response_yaml.get('relevant_files_ranking')
|
||||
if int(entry['idx']) >= 0 and int(entry['idx']) < len(docs_filepath_to_contents)]
|
||||
valid_file_paths = [list(docs_filepath_to_contents.keys())[idx] for idx in valid_indices]
|
||||
selected_docs_dict = {file_path: docs_filepath_to_contents[file_path] for file_path in valid_file_paths}
|
||||
docs_prompt = aggregate_documentation_files_for_prompt_contents(selected_docs_dict)
|
||||
docs_prompt_to_send_to_model = docs_prompt
|
||||
|
||||
# Check if the updated list of documents does not exceed limits and trim if it does:
|
||||
docs_prompt_to_send_to_model = self._trim_docs_input(docs_prompt_to_send_to_model, max_allowed_txt_input,
|
||||
only_return_if_trim_needed=False)
|
||||
if not docs_prompt_to_send_to_model:
|
||||
get_logger().error("_trim_docs_input returned an empty result.")
|
||||
return ""
|
||||
return docs_prompt_to_send_to_model
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Unexpected exception thrown. Returning empty result.")
|
||||
return ""
|
||||
|
||||
def _format_model_answer(self, response_str: str, relevant_sections: list[dict[str, str]]) -> str:
|
||||
try:
|
||||
canonical_url_prefix, canonical_url_suffix = (
|
||||
self.git_provider.get_canonical_url_parts(repo_git_url=self.repo_url if self.repo_url_given_explicitly else None,
|
||||
desired_branch=self.repo_desired_branch))
|
||||
answer_str = format_markdown_q_and_a_response(self.question, response_str, relevant_sections,
|
||||
self.supported_doc_exts, canonical_url_prefix, canonical_url_suffix)
|
||||
if answer_str:
|
||||
#Remove the question phrase and replace with light bulb and a heading mentioning this is an automated answer:
|
||||
answer_str = modify_answer_section(answer_str)
|
||||
#In case the response should not be published and returned as string, stop here:
|
||||
if answer_str and self.return_as_string:
|
||||
get_logger().info(f"Chat help docs answer", artifacts={'answer_str': answer_str})
|
||||
return answer_str
|
||||
if not answer_str:
|
||||
get_logger().info(f"No answer found")
|
||||
return ""
|
||||
if self.git_provider.is_supported("gfm_markdown") and get_settings().pr_help_docs.enable_help_text:
|
||||
answer_str += "<hr>\n\n<details> <summary><strong>💡 Tool usage guide:</strong></summary><hr> \n\n"
|
||||
answer_str += HelpMessage.get_help_docs_usage_guide()
|
||||
answer_str += "\n</details>\n"
|
||||
return answer_str
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Unexpected exception thrown. Returning empty result.")
|
||||
return ""
|
||||
@ -35,7 +35,6 @@ class PRHelpMessage:
|
||||
self.ai_handler = ai_handler()
|
||||
self.question_str = self.parse_args(args)
|
||||
self.return_as_string = return_as_string
|
||||
self.num_retrieved_snippets = get_settings().get('pr_help.num_retrieved_snippets', 5)
|
||||
if self.question_str:
|
||||
self.vars = {
|
||||
"question": self.question_str,
|
||||
@ -209,12 +208,12 @@ class PRHelpMessage:
|
||||
tool_names.append(f"[REVIEW]({base_path}/review/)")
|
||||
tool_names.append(f"[IMPROVE]({base_path}/improve/)")
|
||||
tool_names.append(f"[UPDATE CHANGELOG]({base_path}/update_changelog/)")
|
||||
tool_names.append(f"[HELP DOCS]({base_path}/help_docs/)")
|
||||
tool_names.append(f"[ADD DOCS]({base_path}/documentation/) 💎")
|
||||
tool_names.append(f"[TEST]({base_path}/test/) 💎")
|
||||
tool_names.append(f"[IMPROVE COMPONENT]({base_path}/improve_component/) 💎")
|
||||
tool_names.append(f"[ANALYZE]({base_path}/analyze/) 💎")
|
||||
tool_names.append(f"[ASK]({base_path}/ask/)")
|
||||
tool_names.append(f"[SIMILAR ISSUE]({base_path}/similar_issues/)")
|
||||
tool_names.append(f"[GENERATE CUSTOM LABELS]({base_path}/custom_labels/) 💎")
|
||||
tool_names.append(f"[CI FEEDBACK]({base_path}/ci_feedback/) 💎")
|
||||
tool_names.append(f"[CUSTOM PROMPT]({base_path}/custom_prompt/) 💎")
|
||||
@ -225,6 +224,7 @@ class PRHelpMessage:
|
||||
descriptions.append("Adjustable feedback about the PR, possible issues, security concerns, review effort and more")
|
||||
descriptions.append("Code suggestions for improving the PR")
|
||||
descriptions.append("Automatically updates the changelog")
|
||||
descriptions.append("Answers a question regarding this repository, or a given one, based on given documentation path")
|
||||
descriptions.append("Generates documentation to methods/functions/classes that changed in the PR")
|
||||
descriptions.append("Generates unit tests for a specific component, based on the PR code change")
|
||||
descriptions.append("Code suggestions for a specific component that changed in the PR")
|
||||
@ -241,12 +241,12 @@ class PRHelpMessage:
|
||||
commands.append("`/review`")
|
||||
commands.append("`/improve`")
|
||||
commands.append("`/update_changelog`")
|
||||
commands.append("`/help_docs`")
|
||||
commands.append("`/add_docs`")
|
||||
commands.append("`/test`")
|
||||
commands.append("`/improve_component`")
|
||||
commands.append("`/analyze`")
|
||||
commands.append("`/ask`")
|
||||
commands.append("`/similar_issue`")
|
||||
commands.append("`/generate_labels`")
|
||||
commands.append("`/checks`")
|
||||
commands.append("`/custom_prompt`")
|
||||
@ -257,6 +257,7 @@ class PRHelpMessage:
|
||||
checkbox_list.append(" - [ ] Run <!-- /review -->")
|
||||
checkbox_list.append(" - [ ] Run <!-- /improve -->")
|
||||
checkbox_list.append(" - [ ] Run <!-- /update_changelog -->")
|
||||
checkbox_list.append(" - [ ] Run <!-- /help_docs -->")
|
||||
checkbox_list.append(" - [ ] Run <!-- /add_docs -->")
|
||||
checkbox_list.append(" - [ ] Run <!-- /test -->")
|
||||
checkbox_list.append(" - [ ] Run <!-- /improve_component -->")
|
||||
|
||||
@ -7,7 +7,7 @@ from jinja2 import Environment, StrictUndefined
|
||||
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||
from pr_agent.algo.ai_handlers.litellm_ai_handler import LiteLLMAIHandler
|
||||
from pr_agent.algo.git_patch_processing import (
|
||||
convert_to_hunks_with_lines_numbers, extract_hunk_lines_from_patch)
|
||||
decouple_and_convert_to_hunks_with_lines_numbers, extract_hunk_lines_from_patch)
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.utils import ModelType
|
||||
|
||||
@ -9,7 +9,7 @@ from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.utils import ModelType
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers import get_git_provider
|
||||
from pr_agent.git_providers import get_git_provider, GitLabProvider
|
||||
from pr_agent.git_providers.git_provider import get_main_pr_language
|
||||
from pr_agent.log import get_logger
|
||||
from pr_agent.servers.help import HelpMessage
|
||||
@ -116,10 +116,22 @@ class PRQuestions:
|
||||
model=model, temperature=get_settings().config.temperature, system=system_prompt, user=user_prompt)
|
||||
return response
|
||||
|
||||
def gitlab_protections(self, model_answer: str) -> str:
|
||||
github_quick_actions_MR = ["/approve", "/close", "/merge", "/reopen", "/unapprove", "/title", "/assign",
|
||||
"/copy_metadata", "/target_branch"]
|
||||
if any(action in model_answer for action in github_quick_actions_MR):
|
||||
str_err = "Model answer contains GitHub quick actions, which are not supported in GitLab"
|
||||
get_logger().error(str_err)
|
||||
return str_err
|
||||
return model_answer
|
||||
|
||||
def _prepare_pr_answer(self) -> str:
|
||||
model_answer = self.prediction.strip()
|
||||
# sanitize the answer so that no line will start with "/"
|
||||
model_answer_sanitized = model_answer.replace("\n/", "\n /")
|
||||
model_answer_sanitized = model_answer_sanitized.replace("\r/", "\r /")
|
||||
if isinstance(self.git_provider, GitLabProvider):
|
||||
model_answer_sanitized = self.gitlab_protections(model_answer_sanitized)
|
||||
if model_answer_sanitized.startswith("/"):
|
||||
model_answer_sanitized = " " + model_answer_sanitized
|
||||
if model_answer_sanitized != model_answer:
|
||||
|
||||
@ -229,6 +229,10 @@ class PRReviewer:
|
||||
first_key=first_key, last_key=last_key)
|
||||
github_action_output(data, 'review')
|
||||
|
||||
if 'review' not in data:
|
||||
get_logger().exception("Failed to parse review data", artifact={"data": data})
|
||||
return ""
|
||||
|
||||
# move data['review'] 'key_issues_to_review' key to the end of the dictionary
|
||||
if 'key_issues_to_review' in data['review']:
|
||||
key_issues_to_review = data['review'].pop('key_issues_to_review')
|
||||
|
||||
@ -140,11 +140,15 @@ class PRUpdateChangelog:
|
||||
return new_file_content, answer
|
||||
|
||||
def _push_changelog_update(self, new_file_content, answer):
|
||||
if get_settings().pr_update_changelog.get("skip_ci_on_push", True):
|
||||
commit_message = "[skip ci] Update CHANGELOG.md"
|
||||
else:
|
||||
commit_message = "Update CHANGELOG.md"
|
||||
self.git_provider.create_or_update_pr_file(
|
||||
file_path="CHANGELOG.md",
|
||||
branch=self.git_provider.get_pr_branch(),
|
||||
contents=new_file_content,
|
||||
message="[skip ci] Update CHANGELOG.md",
|
||||
message=commit_message,
|
||||
)
|
||||
|
||||
sleep(5) # wait for the file to be updated
|
||||
|
||||
@ -4,19 +4,17 @@ build-backend = "setuptools.build_meta"
|
||||
|
||||
[project]
|
||||
name = "pr-agent"
|
||||
version = "0.2.5"
|
||||
version = "0.2.7"
|
||||
|
||||
authors = [{ name = "CodiumAI", email = "tal.r@codium.ai" }]
|
||||
authors = [{ name = "QodoAI", email = "tal.r@qodo.ai" }]
|
||||
|
||||
maintainers = [
|
||||
{ name = "Tal Ridnik", email = "tal.r@codium.ai" },
|
||||
{ name = "Ori Kotek", email = "ori.k@codium.ai" },
|
||||
{ name = "Hussam Lawen", email = "hussam.l@codium.ai" },
|
||||
{ name = "Tal Ridnik", email = "tal.r@qodo.ai" },
|
||||
]
|
||||
|
||||
description = "CodiumAI PR-Agent aims to help efficiently review and handle pull requests, by providing AI feedbacks and suggestions."
|
||||
description = "QodoAI PR-Agent aims to help efficiently review and handle pull requests, by providing AI feedbacks and suggestions."
|
||||
readme = "README.md"
|
||||
requires-python = ">=3.10"
|
||||
requires-python = ">=3.12"
|
||||
keywords = ["AI", "Agents", "Pull Request", "Automation", "Code Review"]
|
||||
license = { name = "Apache 2.0", file = "LICENSE" }
|
||||
|
||||
@ -32,7 +30,7 @@ dependencies = { file = ["requirements.txt"] }
|
||||
|
||||
[project.urls]
|
||||
"Homepage" = "https://github.com/qodo-ai/pr-agent"
|
||||
"Documentation" = "https://pr-agent-docs.codium.ai/"
|
||||
"Documentation" = "https://qodo-merge-docs.qodo.ai/"
|
||||
|
||||
[tool.setuptools]
|
||||
include-package-data = true
|
||||
|
||||
@ -1,5 +1,6 @@
|
||||
aiohttp==3.9.5
|
||||
anthropic[vertex]==0.47.1
|
||||
anthropic>=0.48
|
||||
#anthropic[vertex]==0.47.1
|
||||
atlassian-python-api==3.41.4
|
||||
azure-devops==7.1.0b3
|
||||
azure-identity==1.15.0
|
||||
@ -12,10 +13,10 @@ google-cloud-aiplatform==1.38.0
|
||||
google-generativeai==0.8.3
|
||||
google-cloud-storage==2.10.0
|
||||
Jinja2==3.1.2
|
||||
litellm==1.52.12
|
||||
litellm==1.66.1
|
||||
loguru==0.7.2
|
||||
msrest==0.7.1
|
||||
openai==1.55.3
|
||||
openai>=1.55.3
|
||||
pytest==7.4.0
|
||||
PyGithub==1.59.*
|
||||
PyYAML==6.0.1
|
||||
|
||||
@ -5,8 +5,8 @@ from pr_agent.algo.pr_processing import pr_generate_extended_diff
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.utils import load_large_diff
|
||||
from pr_agent.config_loader import get_settings
|
||||
get_settings().set("CONFIG.CLI_MODE", True)
|
||||
get_settings().config.allow_dynamic_context = False
|
||||
get_settings(use_context=False).set("CONFIG.CLI_MODE", True)
|
||||
get_settings(use_context=False).config.allow_dynamic_context = False
|
||||
|
||||
|
||||
class TestExtendPatch:
|
||||
@ -61,15 +61,15 @@ class TestExtendPatch:
|
||||
original_file_str = 'line1\nline2\nline3\nline4\nline5\nline6'
|
||||
patch_str = '@@ -2,3 +2,3 @@ init()\n-line2\n+new_line2\n line3\n line4\n@@ -4,1 +4,1 @@ init2()\n-line4\n+new_line4' # noqa: E501
|
||||
num_lines = 1
|
||||
original_allow_dynamic_context = get_settings().config.allow_dynamic_context
|
||||
original_allow_dynamic_context = get_settings(use_context=False).config.allow_dynamic_context
|
||||
|
||||
get_settings().config.allow_dynamic_context = False
|
||||
get_settings(use_context=False).config.allow_dynamic_context = False
|
||||
expected_output = '\n@@ -1,5 +1,5 @@ init()\n line1\n-line2\n+new_line2\n line3\n line4\n line5\n\n@@ -3,3 +3,3 @@ init2()\n line3\n-line4\n+new_line4\n line5' # noqa: E501
|
||||
actual_output = extend_patch(original_file_str, patch_str,
|
||||
patch_extra_lines_before=num_lines, patch_extra_lines_after=num_lines)
|
||||
assert actual_output == expected_output
|
||||
|
||||
get_settings().config.allow_dynamic_context = True
|
||||
get_settings(use_context=False).config.allow_dynamic_context = True
|
||||
expected_output = '\n@@ -1,5 +1,5 @@ init()\n line1\n-line2\n+new_line2\n line3\n line4\n line5\n\n@@ -3,3 +3,3 @@ init2()\n line3\n-line4\n+new_line4\n line5' # noqa: E501
|
||||
actual_output = extend_patch(original_file_str, patch_str,
|
||||
patch_extra_lines_before=num_lines, patch_extra_lines_after=num_lines)
|
||||
@ -152,8 +152,8 @@ class TestExtendedPatchMoreLines:
|
||||
# Check that with no extra lines, the patches are the same as the original patches
|
||||
p0 = patches_extended_no_extra_lines[0].strip()
|
||||
p1 = patches_extended_no_extra_lines[1].strip()
|
||||
assert p0 == "## File: 'file1'\n" + pr_languages[0]['files'][0].patch.strip()
|
||||
assert p1 == "## File: 'file2'\n" + pr_languages[0]['files'][1].patch.strip()
|
||||
assert p0 == "## File: 'file1'\n\n" + pr_languages[0]['files'][0].patch.strip()
|
||||
assert p1 == "## File: 'file2'\n\n" + pr_languages[0]['files'][1].patch.strip()
|
||||
|
||||
patches_extended_with_extra_lines, total_tokens, patches_extended_tokens = pr_generate_extended_diff(
|
||||
pr_languages, token_handler, add_line_numbers_to_hunks=False,
|
||||
|
||||
Reference in New Issue
Block a user