mirror of
https://github.com/qodo-ai/pr-agent.git
synced 2025-07-06 05:40:38 +08:00
Compare commits
1 Commits
v0.26
...
print_test
| Author | SHA1 | Date | |
|---|---|---|---|
| 401dc29dee |
3
.gitignore
vendored
3
.gitignore
vendored
@ -1,7 +1,6 @@
|
||||
.idea/
|
||||
.lsp/
|
||||
.vscode/
|
||||
.env
|
||||
venv/
|
||||
pr_agent/settings/.secrets.toml
|
||||
__pycache__
|
||||
@ -9,4 +8,4 @@ dist/
|
||||
*.egg-info/
|
||||
build/
|
||||
.DS_Store
|
||||
docs/.cache/
|
||||
docs/.cache/
|
||||
|
||||
98
README.md
98
README.md
@ -41,10 +41,6 @@ Qode Merge PR-Agent aims to help efficiently review and handle pull requests, by
|
||||
|
||||
## News and Updates
|
||||
|
||||
### December 25, 2024
|
||||
|
||||
The `review` tool previously included a legacy feature for providing code suggestions (controlled by '--pr_reviewer.num_code_suggestion'). This functionality has been deprecated. Use instead the [`improve`](https://qodo-merge-docs.qodo.ai/tools/improve/) tool, which offers higher quality and more actionable code suggestions.
|
||||
|
||||
### December 2, 2024
|
||||
|
||||
Open-source repositories can now freely use Qodo Merge Pro, and enjoy easy one-click installation using a marketplace [app](https://github.com/apps/qodo-merge-pro-for-open-source).
|
||||
@ -77,7 +73,7 @@ Focused mode
|
||||
|
||||
### November 4, 2024
|
||||
|
||||
Qodo Merge PR Agent will now leverage context from Jira or GitHub tickets to enhance the PR Feedback. Read more about this feature
|
||||
Qodo Merge PR Agent will now leverage context from Jira or GitHub tickets to enhance the PR Feedback. Read more about this feature
|
||||
[here](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/)
|
||||
|
||||
|
||||
@ -86,41 +82,39 @@ Qodo Merge PR Agent will now leverage context from Jira or GitHub tickets to enh
|
||||
|
||||
Supported commands per platform:
|
||||
|
||||
| | | GitHub | GitLab | Bitbucket | Azure DevOps |
|
||||
| | | GitHub | Gitlab | Bitbucket | Azure DevOps |
|
||||
|-------|---------------------------------------------------------------------------------------------------------|:--------------------:|:--------------------:|:--------------------:|:------------:|
|
||||
| TOOLS | [Review](https://qodo-merge-docs.qodo.ai/tools/review/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Describe](https://qodo-merge-docs.qodo.ai/tools/describe/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Improve](https://qodo-merge-docs.qodo.ai/tools/improve/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Ask](https://qodo-merge-docs.qodo.ai/tools/ask/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| TOOLS | Review | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ Incremental | ✅ | | | |
|
||||
| | Describe | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ [Inline File Summary](https://pr-agent-docs.codium.ai/tools/describe#inline-file-summary) 💎 | ✅ | | | |
|
||||
| | Improve | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ Extended | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Ask | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ [Ask on code lines](https://pr-agent-docs.codium.ai/tools/ask#ask-lines) | ✅ | ✅ | | |
|
||||
| | [Update CHANGELOG](https://qodo-merge-docs.qodo.ai/tools/update_changelog/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Ticket Context](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [Utilizing Best Practices](https://qodo-merge-docs.qodo.ai/tools/improve/#best-practices) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [PR Chat](https://qodo-merge-docs.qodo.ai/chrome-extension/features/#pr-chat) 💎 | ✅ | | | |
|
||||
| | [Suggestion Tracking](https://qodo-merge-docs.qodo.ai/tools/improve/#suggestion-tracking) 💎 | ✅ | ✅ | | |
|
||||
| | [CI Feedback](https://pr-agent-docs.codium.ai/tools/ci_feedback/) 💎 | ✅ | | | |
|
||||
| | [PR Documentation](https://pr-agent-docs.codium.ai/tools/documentation/) 💎 | ✅ | ✅ | | |
|
||||
| | [Custom Labels](https://pr-agent-docs.codium.ai/tools/custom_labels/) 💎 | ✅ | ✅ | | |
|
||||
| | [Analyze](https://pr-agent-docs.codium.ai/tools/analyze/) 💎 | ✅ | ✅ | | |
|
||||
| | [Similar Code](https://pr-agent-docs.codium.ai/tools/similar_code/) 💎 | ✅ | | | |
|
||||
| | [Custom Prompt](https://pr-agent-docs.codium.ai/tools/custom_prompt/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [Test](https://pr-agent-docs.codium.ai/tools/test/) 💎 | ✅ | ✅ | | |
|
||||
| | Reflect and Review | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Update CHANGELOG.md | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Find Similar Issue | ✅ | | | |
|
||||
| | [Add PR Documentation](https://pr-agent-docs.codium.ai/tools/documentation/) 💎 | ✅ | ✅ | | |
|
||||
| | [Custom Labels](https://pr-agent-docs.codium.ai/tools/custom_labels/) 💎 | ✅ | ✅ | | |
|
||||
| | [Analyze](https://pr-agent-docs.codium.ai/tools/analyze/) 💎 | ✅ | ✅ | | |
|
||||
| | [CI Feedback](https://pr-agent-docs.codium.ai/tools/ci_feedback/) 💎 | ✅ | | | |
|
||||
| | [Similar Code](https://pr-agent-docs.codium.ai/tools/similar_code/) 💎 | ✅ | | | |
|
||||
| | | | | | |
|
||||
| USAGE | [CLI](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#local-repo-cli) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [App / webhook](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#github-app) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Tagging bot](https://github.com/Codium-ai/pr-agent#try-it-now) | ✅ | | | |
|
||||
| | [Actions](https://qodo-merge-docs.qodo.ai/installation/github/#run-as-a-github-action) | ✅ |✅| ✅ |✅|
|
||||
| USAGE | CLI | ✅ | ✅ | ✅ | ✅ |
|
||||
| | App / webhook | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Tagging bot | ✅ | | | |
|
||||
| | Actions | ✅ |✅| ✅ |✅|
|
||||
| | | | | | |
|
||||
| CORE | [PR compression](https://qodo-merge-docs.qodo.ai/core-abilities/compression_strategy/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| CORE | PR compression | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Repo language prioritization | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Adaptive and token-aware file patch fitting | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Multiple models support](https://qodo-merge-docs.qodo.ai/usage-guide/changing_a_model/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Local and global metadata](https://qodo-merge-docs.qodo.ai/core-abilities/metadata/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Dynamic context](https://qodo-merge-docs.qodo.ai/core-abilities/dynamic_context/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Self reflection](https://qodo-merge-docs.qodo.ai/core-abilities/self_reflection/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Static code analysis](https://qodo-merge-docs.qodo.ai/core-abilities/static_code_analysis/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | Multiple models support | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Static code analysis](https://pr-agent-docs.codium.ai/core-abilities/#static-code-analysis) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [Global and wiki configurations](https://pr-agent-docs.codium.ai/usage-guide/configuration_options/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [PR interactive actions](https://www.codium.ai/images/pr_agent/pr-actions.mp4) 💎 | ✅ | ✅ | | |
|
||||
| | [Impact Evaluation](https://qodo-merge-docs.qodo.ai/core-abilities/impact_evaluation/) 💎 | ✅ | ✅ | | |
|
||||
- 💎 means this feature is available only in [PR-Agent Pro](https://www.codium.ai/pricing/)
|
||||
|
||||
[//]: # (- Support for additional git providers is described in [here](./docs/Full_environments.md))
|
||||
@ -181,8 +175,50 @@ ___
|
||||
</kbd>
|
||||
</p>
|
||||
</div>
|
||||
<hr>
|
||||
|
||||
<h4><a href="https://github.com/Codium-ai/pr-agent/pull/530">/generate_labels</a></h4>
|
||||
<div align="center">
|
||||
<p float="center">
|
||||
<kbd><img src="https://www.codium.ai/images/pr_agent/geneare_custom_labels_main_short.png" width="300"></kbd>
|
||||
</p>
|
||||
</div>
|
||||
|
||||
[//]: # (<h4><a href="https://github.com/Codium-ai/pr-agent/pull/78#issuecomment-1639739496">/reflect_and_review:</a></h4>)
|
||||
|
||||
[//]: # (<div align="center">)
|
||||
|
||||
[//]: # (<p float="center">)
|
||||
|
||||
[//]: # (<img src="https://www.codium.ai/images/reflect_and_review.gif" width="800">)
|
||||
|
||||
[//]: # (</p>)
|
||||
|
||||
[//]: # (</div>)
|
||||
|
||||
[//]: # (<h4><a href="https://github.com/Codium-ai/pr-agent/pull/229#issuecomment-1695020538">/ask:</a></h4>)
|
||||
|
||||
[//]: # (<div align="center">)
|
||||
|
||||
[//]: # (<p float="center">)
|
||||
|
||||
[//]: # (<img src="https://www.codium.ai/images/ask-2.gif" width="800">)
|
||||
|
||||
[//]: # (</p>)
|
||||
|
||||
[//]: # (</div>)
|
||||
|
||||
[//]: # (<h4><a href="https://github.com/Codium-ai/pr-agent/pull/229#issuecomment-1695024952">/improve:</a></h4>)
|
||||
|
||||
[//]: # (<div align="center">)
|
||||
|
||||
[//]: # (<p float="center">)
|
||||
|
||||
[//]: # (<img src="https://www.codium.ai/images/improve-2.gif" width="800">)
|
||||
|
||||
[//]: # (</p>)
|
||||
|
||||
[//]: # (</div>)
|
||||
<div align="left">
|
||||
|
||||
|
||||
|
||||
@ -5,25 +5,20 @@
|
||||
Qodo Merge PR Agent streamlines code review workflows by seamlessly connecting with multiple ticket management systems.
|
||||
This integration enriches the review process by automatically surfacing relevant ticket information and context alongside code changes.
|
||||
|
||||
## Ticket systems supported
|
||||
- GitHub
|
||||
- Jira (💎)
|
||||
## Affected Tools
|
||||
|
||||
Ticket Recognition Requirements:
|
||||
|
||||
1. The PR description should contain a link to the ticket or if the branch name starts with the ticket id / number.
|
||||
2. For Jira tickets, you should follow the instructions in [Jira Integration](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/#jira-integration) in order to authenticate with Jira.
|
||||
|
||||
Ticket data fetched:
|
||||
|
||||
1. Ticket Title
|
||||
2. Ticket Description
|
||||
3. Custom Fields (Acceptance criteria)
|
||||
4. Subtasks (linked tasks)
|
||||
5. Labels
|
||||
6. Attached Images/Screenshots
|
||||
|
||||
## Affected Tools
|
||||
|
||||
Ticket Recognition Requirements:
|
||||
|
||||
- The PR description should contain a link to the ticket or if the branch name starts with the ticket id / number.
|
||||
- For Jira tickets, you should follow the instructions in [Jira Integration](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/#jira-integration) in order to authenticate with Jira.
|
||||
6. Attached Images/Screenshots 💎
|
||||
|
||||
### Describe tool
|
||||
Qodo Merge PR Agent will recognize the ticket and use the ticket content (title, description, labels) to provide additional context for the code changes.
|
||||
|
||||
@ -61,7 +61,7 @@ Or be triggered interactively by using the `analyze` tool.
|
||||
|
||||
### Find Similar Code
|
||||
|
||||
The [`similar code`](https://qodo-merge-docs.qodo.ai/tools/similar_code/) tool retrieves the most similar code components from inside the organization's codebase or from open-source code, including details about the license associated with each repository.
|
||||
The [`similar code`](https://qodo-merge-docs.qodo.ai/tools/similar_code/) tool retrieves the most similar code components from inside the organization's codebase, or from open-source code.
|
||||
|
||||
For example:
|
||||
|
||||
|
||||
@ -25,43 +25,36 @@ To search the documentation site using natural language:
|
||||
|
||||
Qodo Merge offers extensive pull request functionalities across various git providers.
|
||||
|
||||
| | | GitHub | GitLab | Bitbucket | Azure DevOps |
|
||||
|-------|---------------------------------------------------------------------------------------------------------|:--------------------:|:--------------------:|:--------------------:|:------------:|
|
||||
| TOOLS | [Review](https://qodo-merge-docs.qodo.ai/tools/review/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Describe](https://qodo-merge-docs.qodo.ai/tools/describe/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Improve](https://qodo-merge-docs.qodo.ai/tools/improve/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Ask](https://qodo-merge-docs.qodo.ai/tools/ask/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ [Ask on code lines](https://pr-agent-docs.codium.ai/tools/ask#ask-lines) | ✅ | ✅ | | |
|
||||
| | [Update CHANGELOG](https://qodo-merge-docs.qodo.ai/tools/update_changelog/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Ticket Context](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [Utilizing Best Practices](https://qodo-merge-docs.qodo.ai/tools/improve/#best-practices) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [PR Chat](https://qodo-merge-docs.qodo.ai/chrome-extension/features/#pr-chat) 💎 | ✅ | | | |
|
||||
| | [Suggestion Tracking](https://qodo-merge-docs.qodo.ai/tools/improve/#suggestion-tracking) 💎 | ✅ | ✅ | | |
|
||||
| | [CI Feedback](https://pr-agent-docs.codium.ai/tools/ci_feedback/) 💎 | ✅ | | | |
|
||||
| | [PR Documentation](https://pr-agent-docs.codium.ai/tools/documentation/) 💎 | ✅ | ✅ | | |
|
||||
| | [Custom Labels](https://pr-agent-docs.codium.ai/tools/custom_labels/) 💎 | ✅ | ✅ | | |
|
||||
| | [Analyze](https://pr-agent-docs.codium.ai/tools/analyze/) 💎 | ✅ | ✅ | | |
|
||||
| | [Similar Code](https://pr-agent-docs.codium.ai/tools/similar_code/) 💎 | ✅ | | | |
|
||||
| | [Custom Prompt](https://pr-agent-docs.codium.ai/tools/custom_prompt/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [Test](https://pr-agent-docs.codium.ai/tools/test/) 💎 | ✅ | ✅ | | |
|
||||
| | | | | | |
|
||||
| USAGE | [CLI](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#local-repo-cli) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [App / webhook](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#github-app) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Tagging bot](https://github.com/Codium-ai/pr-agent#try-it-now) | ✅ | | | |
|
||||
| | [Actions](https://qodo-merge-docs.qodo.ai/installation/github/#run-as-a-github-action) | ✅ |✅| ✅ |✅|
|
||||
| | | | | | |
|
||||
| CORE | [PR compression](https://qodo-merge-docs.qodo.ai/core-abilities/compression_strategy/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Adaptive and token-aware file patch fitting | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Multiple models support](https://qodo-merge-docs.qodo.ai/usage-guide/changing_a_model/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Local and global metadata](https://qodo-merge-docs.qodo.ai/core-abilities/metadata/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Dynamic context](https://qodo-merge-docs.qodo.ai/core-abilities/dynamic_context/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Self reflection](https://qodo-merge-docs.qodo.ai/core-abilities/self_reflection/) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Static code analysis](https://qodo-merge-docs.qodo.ai/core-abilities/static_code_analysis/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [Global and wiki configurations](https://pr-agent-docs.codium.ai/usage-guide/configuration_options/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [PR interactive actions](https://www.codium.ai/images/pr_agent/pr-actions.mp4) 💎 | ✅ | ✅ | | |
|
||||
| | [Impact Evaluation](https://qodo-merge-docs.qodo.ai/core-abilities/impact_evaluation/) 💎 | ✅ | ✅ | | |
|
||||
| | | GitHub | Gitlab | Bitbucket | Azure DevOps |
|
||||
|-------|-----------------------------------------------------------------------------------------------------------------------|:------:|:------:|:---------:|:------------:|
|
||||
| TOOLS | Review | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ Incremental | ✅ | | | |
|
||||
| | Ask | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Describe | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ [Inline file summary](https://qodo-merge-docs.qodo.ai/tools/describe/#inline-file-summary){:target="_blank"} 💎 | ✅ | ✅ | | |
|
||||
| | Improve | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ Extended | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Custom Prompt](./tools/custom_prompt.md){:target="_blank"} 💎 | ✅ | ✅ | ✅ | |
|
||||
| | Reflect and Review | ✅ | ✅ | ✅ | |
|
||||
| | Update CHANGELOG.md | ✅ | ✅ | ✅ | ️ |
|
||||
| | Find Similar Issue | ✅ | | | ️ |
|
||||
| | [Add PR Documentation](./tools/documentation.md){:target="_blank"} 💎 | ✅ | ✅ | | |
|
||||
| | [Generate Custom Labels](./tools/describe.md#handle-custom-labels-from-the-repos-labels-page-💎){:target="_blank"} 💎 | ✅ | ✅ | | |
|
||||
| | [Analyze PR Components](./tools/analyze.md){:target="_blank"} 💎 | ✅ | ✅ | | |
|
||||
| | | | | | ️ |
|
||||
| USAGE | CLI | ✅ | ✅ | ✅ | ✅ |
|
||||
| | App / webhook | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Actions | ✅ | | | ️ |
|
||||
| | | | | |
|
||||
| CORE | PR compression | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Repo language prioritization | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Adaptive and token-aware file patch fitting | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Multiple models support | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Incremental PR review | ✅ | | | |
|
||||
| | [Static code analysis](./tools/analyze.md/){:target="_blank"} 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [Multiple configuration options](./usage-guide/configuration_options.md){:target="_blank"} 💎 | ✅ | ✅ | ✅ | |
|
||||
|
||||
💎 marks a feature available only in [Qodo Merge Pro](https://www.qodo.ai/pricing/){:target="_blank"}
|
||||
💎 marks a feature available only in [Qodo Merge Pro](https://www.codium.ai/pricing/){:target="_blank"}
|
||||
|
||||
|
||||
## Example Results
|
||||
|
||||
@ -66,30 +66,7 @@ To invoke a tool (for example `review`), you can run directly from the Docker im
|
||||
docker run --rm -it -e CONFIG.GIT_PROVIDER=bitbucket -e OPENAI.KEY=$OPENAI_API_KEY -e BITBUCKET.BEARER_TOKEN=$BITBUCKET_BEARER_TOKEN codiumai/pr-agent:latest --pr_url=<pr_url> review
|
||||
```
|
||||
|
||||
For other git providers, update `CONFIG.GIT_PROVIDER` accordingly and check the `pr_agent/settings/.secrets_template.toml` file for environment variables expected names and values.
|
||||
The `pr_agent` uses [Dynaconf](https://www.dynaconf.com/) to load settings from configuration files.
|
||||
|
||||
It is also possible to provide or override the configuration by setting the corresponding environment variables.
|
||||
You can define the corresponding environment variables by following this convention: `<TABLE>__<KEY>=<VALUE>` or `<TABLE>.<KEY>=<VALUE>`.
|
||||
The `<TABLE>` refers to a table/section in a configuration file and `<KEY>=<VALUE>` refers to the key/value pair of a setting in the configuration file.
|
||||
|
||||
For example, suppose you want to run `pr_agent` that connects to a self-hosted GitLab instance similar to an example above.
|
||||
You can define the environment variables in a plain text file named `.env` with the following content:
|
||||
|
||||
> Warning: Never commit the `.env` file to version control system as it might contains sensitive credentials!
|
||||
|
||||
```
|
||||
CONFIG__GIT_PROVIDER="gitlab"
|
||||
GITLAB__URL="<your url>"
|
||||
GITLAB__PERSONAL_ACCESS_TOKEN="<your token>"
|
||||
OPENAI__KEY="<your key>"
|
||||
```
|
||||
|
||||
Then, you can run `pr_agent` using Docker with the following command:
|
||||
|
||||
```shell
|
||||
docker run --rm -it --env-file .env codiumai/pr-agent:latest <tool> <tool parameter>
|
||||
```
|
||||
For other git providers, update CONFIG.GIT_PROVIDER accordingly, and check the `pr_agent/settings/.secrets_template.toml` file for the environment variables expected names and values.
|
||||
|
||||
---
|
||||
|
||||
|
||||
@ -3,7 +3,7 @@ See [here](https://qodo-merge-docs.qodo.ai/overview/pr_agent_pro/) for more deta
|
||||
|
||||
A complimentary two-week trial is provided to all new users. Following the trial period, user licenses (seats) are required for continued access.
|
||||
To purchase user licenses, please visit our [pricing page](https://www.qodo.ai/pricing/).
|
||||
Once subscribed, users can seamlessly deploy the application across any of their code repositories.
|
||||
Once subscribed, users can seamlessly deploy the application across any of their GitHub repositories.
|
||||
|
||||
## Install Qodo Merge Pro for GitHub
|
||||
|
||||
|
||||
@ -95,112 +95,6 @@ This feature is controlled by a boolean configuration parameter: `pr_code_sugges
|
||||
|
||||
Instead, we leverage a dedicated private page, within your repository wiki, to track suggestions. This approach offers convenient secure suggestion tracking while avoiding pull requests or any noise to the main repository.
|
||||
|
||||
## `Extra instructions` and `best practices`
|
||||
|
||||
The `improve` tool can be further customized by providing additional instructions and best practices to the AI model.
|
||||
|
||||
### Extra instructions
|
||||
|
||||
>`Platforms supported: GitHub, GitLab, Bitbucket, Azure DevOps`
|
||||
|
||||
You can use the `extra_instructions` configuration option to give the AI model additional instructions for the `improve` tool.
|
||||
Be specific, clear, and concise in the instructions. With extra instructions, you are the prompter.
|
||||
|
||||
Examples for possible instructions:
|
||||
```toml
|
||||
[pr_code_suggestions]
|
||||
extra_instructions="""\
|
||||
(1) Answer in japanese
|
||||
(2) Don't suggest to add try-except block
|
||||
(3) Ignore changes in toml files
|
||||
...
|
||||
"""
|
||||
```
|
||||
Use triple quotes to write multi-line instructions. Use bullet points or numbers to make the instructions more readable.
|
||||
|
||||
### Best practices 💎
|
||||
|
||||
>`Platforms supported: GitHub, GitLab, Bitbucket`
|
||||
|
||||
Another option to give additional guidance to the AI model is by creating a dedicated [**wiki page**](https://github.com/Codium-ai/pr-agent/wiki) called `best_practices.md`.
|
||||
This page can contain a list of best practices, coding standards, and guidelines that are specific to your repo/organization.
|
||||
|
||||
The AI model will use this wiki page as a reference, and in case the PR code violates any of the guidelines, it will create additional suggestions, with a dedicated label: `Organization
|
||||
best practice`.
|
||||
|
||||
Example for a python `best_practices.md` content:
|
||||
```markdown
|
||||
## Project best practices
|
||||
- Make sure that I/O operations are encapsulated in a try-except block
|
||||
- Use the `logging` module for logging instead of `print` statements
|
||||
- Use `is` and `is not` to compare with `None`
|
||||
- Use `if __name__ == '__main__':` to run the code only when the script is executed
|
||||
- Use `with` statement to open files
|
||||
...
|
||||
```
|
||||
|
||||
Tips for writing an effective `best_practices.md` file:
|
||||
|
||||
- Write clearly and concisely
|
||||
- Include brief code examples when helpful
|
||||
- Focus on project-specific guidelines, that will result in relevant suggestions you actually want to get
|
||||
- Keep the file relatively short, under 800 lines, since:
|
||||
- AI models may not process effectively very long documents
|
||||
- Long files tend to contain generic guidelines already known to AI
|
||||
|
||||
#### Local and global best practices
|
||||
By default, Qodo Merge will look for a local `best_practices.md` wiki file in the root of the relevant local repo.
|
||||
|
||||
If you want to enable also a global `best_practices.md` wiki file, set first in the global configuration file:
|
||||
|
||||
```toml
|
||||
[best_practices]
|
||||
enable_global_best_practices = true
|
||||
```
|
||||
|
||||
Then, create a `best_practices.md` wiki file in the root of [global](https://qodo-merge-docs.qodo.ai/usage-guide/configuration_options/#global-configuration-file) configuration repository, `pr-agent-settings`.
|
||||
|
||||
#### Best practices for multiple languages
|
||||
For a git organization working with multiple programming languages, you can maintain a centralized global `best_practices.md` file containing language-specific guidelines.
|
||||
When reviewing pull requests, Qodo Merge automatically identifies the programming language and applies the relevant best practices from this file.
|
||||
|
||||
To do this, structure your `best_practices.md` file using the following format:
|
||||
|
||||
```
|
||||
# [Python]
|
||||
...
|
||||
# [Java]
|
||||
...
|
||||
# [JavaScript]
|
||||
...
|
||||
```
|
||||
|
||||
#### Dedicated label for best practices suggestions
|
||||
Best practice suggestions are labeled as `Organization best practice` by default.
|
||||
To customize this label, modify it in your configuration file:
|
||||
|
||||
```toml
|
||||
[best_practices]
|
||||
organization_name = "..."
|
||||
```
|
||||
|
||||
And the label will be: `{organization_name} best practice`.
|
||||
|
||||
|
||||
#### Example results
|
||||
|
||||
{width=512}
|
||||
|
||||
|
||||
### How to combine `extra instructions` and `best practices`
|
||||
|
||||
The `extra instructions` configuration is more related to the `improve` tool prompt. It can be used, for example, to avoid specific suggestions ("Don't suggest to add try-except block", "Ignore changes in toml files", ...) or to emphasize specific aspects or formats ("Answer in Japanese", "Give only short suggestions", ...)
|
||||
|
||||
In contrast, the `best_practices.md` file is a general guideline for the way code should be written in the repo.
|
||||
|
||||
Using a combination of both can help the AI model to provide relevant and tailored suggestions.
|
||||
|
||||
|
||||
## Usage Tips
|
||||
|
||||
### Implementing the proposed code suggestions
|
||||
@ -297,6 +191,99 @@ This approach has two main benefits:
|
||||
Note: Chunking is primarily relevant for large PRs. For most PRs (up to 500 lines of code), Qodo Merge will be able to process the entire code in a single call.
|
||||
|
||||
|
||||
### 'Extra instructions' and 'best practices'
|
||||
|
||||
#### Extra instructions
|
||||
|
||||
>`Platforms supported: GitHub, GitLab, Bitbucket`
|
||||
|
||||
You can use the `extra_instructions` configuration option to give the AI model additional instructions for the `improve` tool.
|
||||
Be specific, clear, and concise in the instructions. With extra instructions, you are the prompter. Specify relevant aspects that you want the model to focus on.
|
||||
|
||||
Examples for possible instructions:
|
||||
```toml
|
||||
[pr_code_suggestions]
|
||||
extra_instructions="""\
|
||||
(1) Answer in japanese
|
||||
(2) Don't suggest to add try-excpet block
|
||||
(3) Ignore changes in toml files
|
||||
...
|
||||
"""
|
||||
```
|
||||
Use triple quotes to write multi-line instructions. Use bullet points or numbers to make the instructions more readable.
|
||||
|
||||
#### Best practices 💎
|
||||
|
||||
>`Platforms supported: GitHub, GitLab`
|
||||
|
||||
Another option to give additional guidance to the AI model is by creating a dedicated [**wiki page**](https://github.com/Codium-ai/pr-agent/wiki) called `best_practices.md`.
|
||||
This page can contain a list of best practices, coding standards, and guidelines that are specific to your repo/organization.
|
||||
|
||||
The AI model will use this wiki page as a reference, and in case the PR code violates any of the guidelines, it will suggest improvements accordingly, with a dedicated label: `Organization
|
||||
best practice`.
|
||||
|
||||
Example for a `best_practices.md` content can be found [here](https://github.com/Codium-ai/pr-agent/blob/main/docs/docs/usage-guide/EXAMPLE_BEST_PRACTICE.md) (adapted from Google's [pyguide](https://google.github.io/styleguide/pyguide.html)).
|
||||
This file is only an example. Since it is used as a prompt for an AI model, we want to emphasize the following:
|
||||
|
||||
- It should be written in a clear and concise manner
|
||||
- If needed, it should give short relevant code snippets as examples
|
||||
- Recommended to limit the text to 800 lines or fewer. Here’s why:
|
||||
|
||||
1) Extremely long best practices documents may not be fully processed by the AI model.
|
||||
|
||||
2) A lengthy file probably represent a more "**generic**" set of guidelines, which the AI model is already familiar with. The objective is to focus on a more targeted set of guidelines tailored to the specific needs of this project.
|
||||
|
||||
##### Local and global best practices
|
||||
By default, Qodo Merge will look for a local `best_practices.md` wiki file in the root of the relevant local repo.
|
||||
|
||||
If you want to enable also a global `best_practices.md` wiki file, set first in the global configuration file:
|
||||
|
||||
```toml
|
||||
[best_practices]
|
||||
enable_global_best_practices = true
|
||||
```
|
||||
|
||||
Then, create a `best_practices.md` wiki file in the root of [global](https://qodo-merge-docs.qodo.ai/usage-guide/configuration_options/#global-configuration-file) configuration repository, `pr-agent-settings`.
|
||||
|
||||
##### Best practices for multiple languages
|
||||
For a git organization working with multiple programming languages, you can maintain a centralized global `best_practices.md` file containing language-specific guidelines.
|
||||
When reviewing pull requests, Qodo Merge automatically identifies the programming language and applies the relevant best practices from this file.
|
||||
Structure your `best_practices.md` file using the following format:
|
||||
|
||||
```
|
||||
# [Python]
|
||||
...
|
||||
# [Java]
|
||||
...
|
||||
# [JavaScript]
|
||||
...
|
||||
```
|
||||
|
||||
##### Dedicated label for best practices suggestions
|
||||
Best practice suggestions are labeled as `Organization best practice` by default.
|
||||
To customize this label, modify it in your configuration file:
|
||||
|
||||
```toml
|
||||
[best_practices]
|
||||
organization_name = ""
|
||||
```
|
||||
|
||||
And the label will be: `{organization_name} best practice`.
|
||||
|
||||
|
||||
##### Example results
|
||||
|
||||
{width=512}
|
||||
|
||||
|
||||
#### How to combine `extra instructions` and `best practices`
|
||||
|
||||
The `extra instructions` configuration is more related to the `improve` tool prompt. It can be used, for example, to avoid specific suggestions ("Don't suggest to add try-except block", "Ignore changes in toml files", ...) or to emphasize specific aspects or formats ("Answer in Japanese", "Give only short suggestions", ...)
|
||||
|
||||
In contrast, the `best_practices.md` file is a general guideline for the way code should be written in the repo.
|
||||
|
||||
Using a combination of both can help the AI model to provide relevant and tailored suggestions.
|
||||
|
||||
## Configuration options
|
||||
|
||||
??? example "General options"
|
||||
@ -342,10 +329,6 @@ Note: Chunking is primarily relevant for large PRs. For most PRs (up to 500 line
|
||||
<td><b>wiki_page_accepted_suggestions</b></td>
|
||||
<td>If set to true, the tool will automatically track accepted suggestions in a dedicated wiki page called `.pr_agent_accepted_suggestions`. Default is true.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>allow_thumbs_up_down</b></td>
|
||||
<td>If set to true, all code suggestions will have thumbs up and thumbs down buttons, to encourage users to provide feedback on the suggestions. Default is false.</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
??? example "Params for number of suggestions and AI calls"
|
||||
@ -363,6 +346,10 @@ Note: Chunking is primarily relevant for large PRs. For most PRs (up to 500 line
|
||||
<td><b>max_number_of_calls</b></td>
|
||||
<td>Maximum number of chunks. Default is 3.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>rank_extended_suggestions</b></td>
|
||||
<td>If set to true, the tool will rank the suggestions, based on importance. Default is true.</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
## A note on code suggestions quality
|
||||
|
||||
@ -39,19 +39,68 @@ pr_commands = [
|
||||
]
|
||||
|
||||
[pr_reviewer]
|
||||
extra_instructions = "..."
|
||||
num_code_suggestions = ...
|
||||
...
|
||||
```
|
||||
|
||||
- The `pr_commands` lists commands that will be executed automatically when a PR is opened.
|
||||
- The `[pr_reviewer]` section contains the configurations for the `review` tool you want to edit (if any).
|
||||
|
||||
[//]: # ()
|
||||
[//]: # (### Incremental Mode)
|
||||
|
||||
[//]: # (Incremental review only considers changes since the last Qodo Merge review. This can be useful when working on the PR in an iterative manner, and you want to focus on the changes since the last review instead of reviewing the entire PR again.)
|
||||
|
||||
[//]: # (For invoking the incremental mode, the following command can be used:)
|
||||
|
||||
[//]: # (```)
|
||||
|
||||
[//]: # (/review -i)
|
||||
|
||||
[//]: # (```)
|
||||
|
||||
[//]: # (Note that the incremental mode is only available for GitHub.)
|
||||
|
||||
[//]: # ()
|
||||
[//]: # (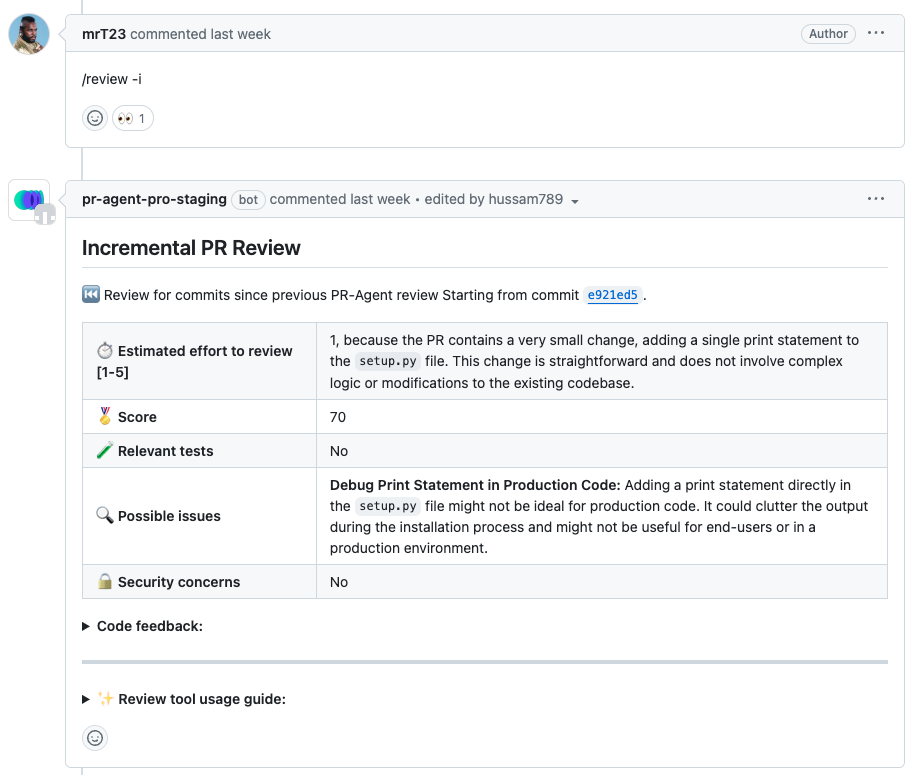{width=512})
|
||||
|
||||
[//]: # (### PR Reflection)
|
||||
|
||||
[//]: # ()
|
||||
[//]: # (By invoking:)
|
||||
|
||||
[//]: # (```)
|
||||
|
||||
[//]: # (/reflect_and_review)
|
||||
|
||||
[//]: # (```)
|
||||
|
||||
[//]: # (The tool will first ask the author questions about the PR, and will guide the review based on their answers.)
|
||||
|
||||
[//]: # ()
|
||||
[//]: # (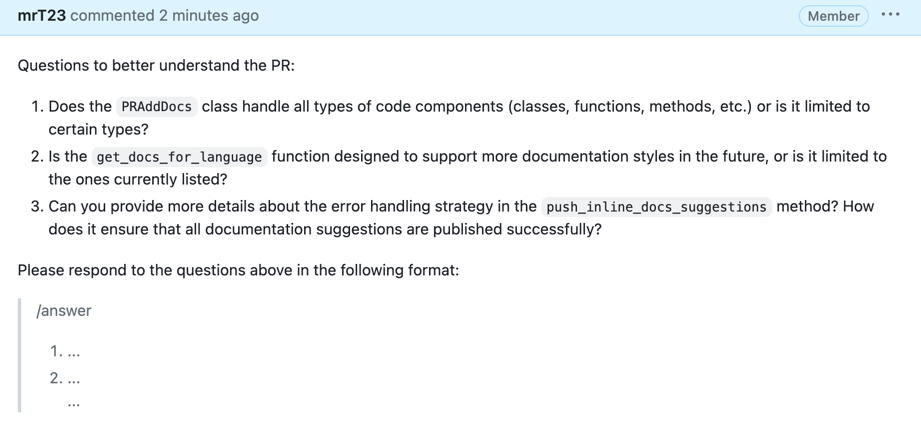{width=512})
|
||||
|
||||
[//]: # ()
|
||||
[//]: # (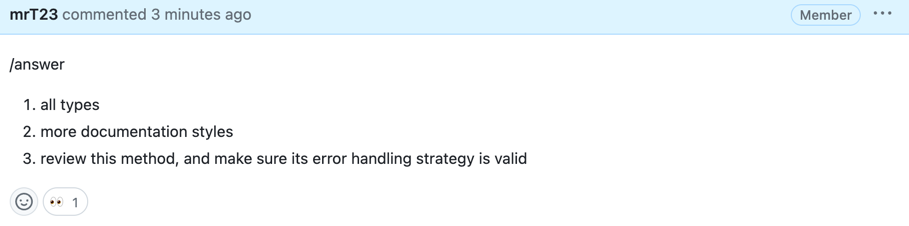{width=512})
|
||||
|
||||
[//]: # ()
|
||||
[//]: # (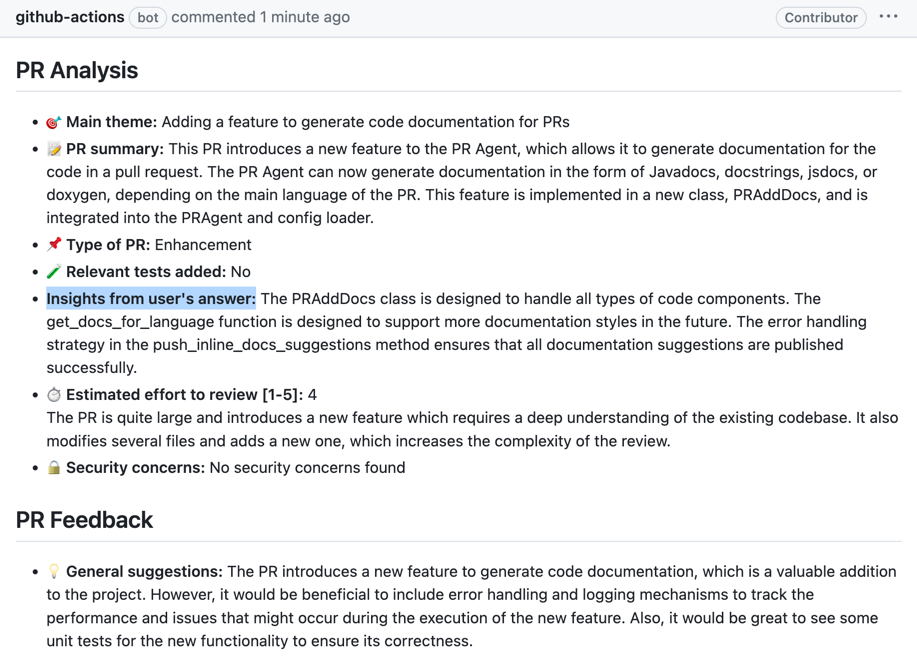{width=512})
|
||||
|
||||
|
||||
|
||||
## Configuration options
|
||||
|
||||
!!! example "General options"
|
||||
|
||||
<table>
|
||||
<tr>
|
||||
<td><b>num_code_suggestions</b></td>
|
||||
<td>Number of code suggestions provided by the 'review' tool. Default is 0, meaning no code suggestions will be provided by the `review` tool.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>inline_code_comments</b></td>
|
||||
<td>If set to true, the tool will publish the code suggestions as comments on the code diff. Default is false. Note that you need to set `num_code_suggestions`>0 to get code suggestions </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>persistent_comment</b></td>
|
||||
<td>If set to true, the review comment will be persistent, meaning that every new review request will edit the previous one. Default is true.</td>
|
||||
@ -140,9 +189,9 @@ If enabled, the `review` tool can approve a PR when a specific comment, `/review
|
||||
!!! tip "Automation"
|
||||
When you first install Qodo Merge app, the [default mode](../usage-guide/automations_and_usage.md#github-app-automatic-tools-when-a-new-pr-is-opened) for the `review` tool is:
|
||||
```
|
||||
pr_commands = ["/review", ...]
|
||||
pr_commands = ["/review --pr_reviewer.num_code_suggestions=0", ...]
|
||||
```
|
||||
Meaning the `review` tool will run automatically on every PR, without any additional configurations.
|
||||
Meaning the `review` tool will run automatically on every PR, without providing code suggestions.
|
||||
Edit this field to enable/disable the tool, or to change the configurations used.
|
||||
|
||||
!!! tip "Possible labels from the review tool"
|
||||
@ -200,8 +249,12 @@ If enabled, the `review` tool can approve a PR when a specific comment, `/review
|
||||
maximal_review_effort = 5
|
||||
```
|
||||
|
||||
!!! tip "Code suggestions"
|
||||
[//]: # (!!! tip "Code suggestions")
|
||||
|
||||
The `review` tool previously included a legacy feature for providing code suggestions (controlled by `--pr_reviewer.num_code_suggestion`). This functionality has been deprecated and replaced by the [`improve`](./improve.md) tool, which offers higher quality and more actionable code suggestions.
|
||||
[//]: # ()
|
||||
[//]: # ( If you set `num_code_suggestions`>0 , the `review` tool will also provide code suggestions.)
|
||||
|
||||
|
||||
[//]: # ( )
|
||||
[//]: # ( Notice If you are interested **only** in the code suggestions, it is recommended to use the [`improve`](./improve.md) feature instead, since it is a dedicated only to code suggestions, and usually gives better results.)
|
||||
|
||||
[//]: # ( Use the `review` tool if you want to get more comprehensive feedback, which includes code suggestions as well.)
|
||||
|
||||
@ -49,10 +49,9 @@ It can be invoked automatically from the analyze table, can be accessed by:
|
||||
/analyze
|
||||
```
|
||||
Choose the components you want to find similar code for, and click on the `similar` checkbox.
|
||||
|
||||
{width=768}
|
||||
|
||||
You can search for similar code either within the organization's codebase or globally, which includes open-source repositories. Each result will include the relevant code components along with their associated license details.
|
||||
If you are looking to search for similar code in the organization's codebase, you can click on the `Organization` checkbox, and it will invoke a new search command just for the organization's codebase.
|
||||
|
||||
{width=768}
|
||||
|
||||
|
||||
@ -17,4 +17,3 @@ Under the section `pr_update_changelog`, the [configuration file](https://github
|
||||
|
||||
- `push_changelog_changes`: whether to push the changes to CHANGELOG.md, or just print them. Default is false (print only).
|
||||
- `extra_instructions`: Optional extra instructions to the tool. For example: "focus on the changes in the file X. Ignore change in ...
|
||||
- `add_pr_link`: whether the model should try to add a link to the PR in the changelog. Default is true.
|
||||
@ -1,5 +1,4 @@
|
||||
## Local repo (CLI)
|
||||
|
||||
When running from your locally cloned Qodo Merge repo (CLI), your local configuration file will be used.
|
||||
Examples of invoking the different tools via the CLI:
|
||||
|
||||
@ -36,29 +35,9 @@ This is useful for debugging or experimenting with different tools.
|
||||
|
||||
Default is "github".
|
||||
|
||||
### CLI Health Check
|
||||
To verify that Qodo Merge has been configured correctly, you can run this health check command from the repository root:
|
||||
|
||||
```bash
|
||||
python -m tests.health_test.main
|
||||
```
|
||||
|
||||
If the health check passes, you will see the following output:
|
||||
|
||||
```
|
||||
========
|
||||
Health test passed successfully
|
||||
========
|
||||
```
|
||||
|
||||
At the end of the run.
|
||||
|
||||
Before running the health check, ensure you have:
|
||||
|
||||
- Configured your [LLM provider](https://qodo-merge-docs.qodo.ai/usage-guide/changing_a_model/)
|
||||
- Added a valid GitHub token to your configuration file
|
||||
|
||||
## Online usage
|
||||
### Online usage
|
||||
|
||||
Online usage means invoking Qodo Merge tools by [comments](https://github.com/Codium-ai/pr-agent/pull/229#issuecomment-1695021901) on a PR.
|
||||
Commands for invoking the different tools via comments:
|
||||
@ -78,11 +57,7 @@ For example, if you want to edit the `review` tool configurations, you can run:
|
||||
```
|
||||
Any configuration value in [configuration file](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml) file can be similarly edited. Comment `/config` to see the list of available configurations.
|
||||
|
||||
|
||||
## Qodo Merge Automatic Feedback
|
||||
|
||||
|
||||
### Disabling all automatic feedback
|
||||
## Disabling automatic feedback
|
||||
|
||||
To easily disable all automatic feedback from Qodo Merge (GitHub App, GitLab Webhook, BitBucket App, Azure DevOps Webhook), set in a configuration file:
|
||||
|
||||
@ -91,52 +66,46 @@ To easily disable all automatic feedback from Qodo Merge (GitHub App, GitLab Web
|
||||
disable_auto_feedback = true
|
||||
```
|
||||
|
||||
When this parameter is set to `true`, Qodo Merge will not run any automatic tools (like `describe`, `review`, `improve`) when a new PR is opened, or when new code is pushed to an open PR.
|
||||
|
||||
### GitHub App
|
||||
## GitHub App
|
||||
|
||||
!!! note "Configurations for Qodo Merge Pro"
|
||||
Qodo Merge Pro for GitHub is an App, hosted by CodiumAI. So all the instructions below are relevant also for Qodo Merge Pro users.
|
||||
Same goes for [GitLab webhook](#gitlab-webhook) and [BitBucket App](#bitbucket-app) sections.
|
||||
|
||||
#### GitHub app automatic tools when a new PR is opened
|
||||
### GitHub app automatic tools when a new PR is opened
|
||||
|
||||
The [github_app](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml#L220) section defines GitHub app specific configurations.
|
||||
The [github_app](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml#L108) section defines GitHub app specific configurations.
|
||||
|
||||
The configuration parameter `pr_commands` defines the list of tools that will be **run automatically** when a new PR is opened:
|
||||
The configuration parameter `pr_commands` defines the list of tools that will be **run automatically** when a new PR is opened.
|
||||
```toml
|
||||
[github_app]
|
||||
pr_commands = [
|
||||
"/describe",
|
||||
"/review",
|
||||
"/improve",
|
||||
"/improve --pr_code_suggestions.suggestions_score_threshold=5",
|
||||
]
|
||||
```
|
||||
|
||||
This means that when a new PR is opened/reopened or marked as ready for review, Qodo Merge will run the `describe`, `review` and `improve` tools.
|
||||
For the `improve` tool, for example, the `suggestions_score_threshold` parameter will be set to 5 (suggestions below a score of 5 won't be presented)
|
||||
|
||||
You can override the default tool parameters by using one the three options for a [configuration file](https://qodo-merge-docs.qodo.ai/usage-guide/configuration_options/): **wiki**, **local**, or **global**.
|
||||
For example, if your configuration file contains:
|
||||
|
||||
For example, if your local `.pr_agent.toml` file contains:
|
||||
```toml
|
||||
[pr_description]
|
||||
generate_ai_title = true
|
||||
```
|
||||
Every time you run the `describe` tool, including automatic runs, the PR title will be generated by the AI.
|
||||
|
||||
Every time you run the `describe` tool (including automatic runs) the PR title will be generated by the AI.
|
||||
|
||||
You can customize configurations specifically for automated runs by using the `--config_path=<value>` parameter.
|
||||
For instance, to modify the `review` tool settings only for newly opened PRs, use:
|
||||
To change which tools will run automatically when a new PR is opened, you can set the `pr_commands` parameter in the configuration file.
|
||||
```toml
|
||||
[github_app]
|
||||
pr_commands = [
|
||||
"/describe",
|
||||
"/review --pr_reviewer.extra_instructions='focus on the file: ...'",
|
||||
"/improve",
|
||||
]
|
||||
pr_commands = ["describe", "review"]
|
||||
```
|
||||
|
||||
#### GitHub app automatic tools for push actions (commits to an open PR)
|
||||
In this case, only the `describe` and `review` tools will run automatically when a new PR is opened.
|
||||
|
||||
### GitHub app automatic tools for push actions (commits to an open PR)
|
||||
|
||||
In addition to running automatic tools when a PR is opened, the GitHub app can also respond to new code that is pushed to an open PR.
|
||||
|
||||
@ -152,7 +121,7 @@ push_commands = [
|
||||
```
|
||||
This means that when new code is pushed to the PR, the Qodo Merge will run the `describe` and `review` tools, with the specified parameters.
|
||||
|
||||
### GitHub Action
|
||||
## GitHub Action
|
||||
`GitHub Action` is a different way to trigger Qodo Merge tools, and uses a different configuration mechanism than `GitHub App`.<br>
|
||||
You can configure settings for `GitHub Action` by adding environment variables under the env section in `.github/workflows/pr_agent.yml` file.
|
||||
Specifically, start by setting the following environment variables:
|
||||
@ -163,7 +132,7 @@ Specifically, start by setting the following environment variables:
|
||||
github_action_config.auto_review: "true" # enable\disable auto review
|
||||
github_action_config.auto_describe: "true" # enable\disable auto describe
|
||||
github_action_config.auto_improve: "true" # enable\disable auto improve
|
||||
github_action_config.pr_actions: '["opened", "reopened", "ready_for_review", "review_requested"]'
|
||||
github_action_config.pr_actions: ["opened", "reopened", "ready_for_review", "review_requested"]
|
||||
```
|
||||
`github_action_config.auto_review`, `github_action_config.auto_describe` and `github_action_config.auto_improve` are used to enable/disable automatic tools that run when a new PR is opened.
|
||||
If not set, the default configuration is for all three tools to run automatically when a new PR is opened.
|
||||
@ -186,7 +155,7 @@ publish_labels = false
|
||||
|
||||
to prevent Qodo Merge from publishing labels when running the `describe` tool.
|
||||
|
||||
### GitLab Webhook
|
||||
## GitLab Webhook
|
||||
After setting up a GitLab webhook, to control which commands will run automatically when a new MR is opened, you can set the `pr_commands` parameter in the configuration file, similar to the GitHub App:
|
||||
|
||||
```toml
|
||||
@ -212,7 +181,7 @@ push_commands = [
|
||||
|
||||
Note that to use the 'handle_push_trigger' feature, you need to give the gitlab webhook also the "Push events" scope.
|
||||
|
||||
### BitBucket App
|
||||
## BitBucket App
|
||||
Similar to GitHub app, when running Qodo Merge from BitBucket App, the default [configuration file](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml) from a pre-built docker will be initially loaded.
|
||||
|
||||
By uploading a local `.pr_agent.toml` file to the root of the repo's main branch, you can edit and customize any configuration parameter. Note that you need to upload `.pr_agent.toml` prior to creating a PR, in order for the configuration to take effect.
|
||||
@ -231,7 +200,7 @@ If you experience a lack of responses from Qodo Merge, you might want to set: `b
|
||||
This will prevent Qodo Merge from acquiring the full file content, and will only use the diff content. This will reduce the number of requests made to BitBucket, at the cost of small decrease in accuracy, as dynamic context will not be applicable.
|
||||
|
||||
|
||||
#### BitBucket Self-Hosted App automatic tools
|
||||
### BitBucket Self-Hosted App automatic tools
|
||||
|
||||
To control which commands will run automatically when a new PR is opened, you can set the `pr_commands` parameter in the configuration file:
|
||||
Specifically, set the following values:
|
||||
@ -256,7 +225,7 @@ push_commands = [
|
||||
]
|
||||
```
|
||||
|
||||
### Azure DevOps provider
|
||||
## Azure DevOps provider
|
||||
|
||||
To use Azure DevOps provider use the following settings in configuration.toml:
|
||||
```toml
|
||||
@ -278,14 +247,14 @@ org = "https://dev.azure.com/YOUR_ORGANIZATION/"
|
||||
# pat = "YOUR_PAT_TOKEN" needed only if using PAT for authentication
|
||||
```
|
||||
|
||||
#### Azure DevOps Webhook
|
||||
### Azure DevOps Webhook
|
||||
|
||||
To control which commands will run automatically when a new PR is opened, you can set the `pr_commands` parameter in the configuration file, similar to the GitHub App:
|
||||
```toml
|
||||
[azure_devops_server]
|
||||
pr_commands = [
|
||||
"/describe",
|
||||
"/review",
|
||||
"/review --pr_reviewer.num_code_suggestions=0",
|
||||
"/improve",
|
||||
]
|
||||
```
|
||||
|
||||
@ -5,6 +5,7 @@ To use a different model than the default (GPT-4), you need to edit in the [conf
|
||||
```
|
||||
[config]
|
||||
model = "..."
|
||||
model_turbo = "..."
|
||||
fallback_models = ["..."]
|
||||
```
|
||||
|
||||
@ -26,8 +27,9 @@ deployment_id = "" # The deployment name you chose when you deployed the engine
|
||||
and set in your configuration file:
|
||||
```
|
||||
[config]
|
||||
model="" # the OpenAI model you've deployed on Azure (e.g. gpt-4o)
|
||||
fallback_models=["..."]
|
||||
model="" # the OpenAI model you've deployed on Azure (e.g. gpt-3.5-turbo)
|
||||
model_turbo="" # the OpenAI model you've deployed on Azure (e.g. gpt-3.5-turbo)
|
||||
fallback_models=["..."] # the OpenAI model you've deployed on Azure (e.g. gpt-3.5-turbo)
|
||||
```
|
||||
|
||||
### Hugging Face
|
||||
@ -50,6 +52,7 @@ MAX_TOKENS={
|
||||
|
||||
[config] # in configuration.toml
|
||||
model = "ollama/llama2"
|
||||
model_turbo = "ollama/llama2"
|
||||
fallback_models=["ollama/llama2"]
|
||||
|
||||
[ollama] # in .secrets.toml
|
||||
@ -73,6 +76,7 @@ MAX_TOKENS={
|
||||
}
|
||||
[config] # in configuration.toml
|
||||
model = "huggingface/meta-llama/Llama-2-7b-chat-hf"
|
||||
model_turbo = "huggingface/meta-llama/Llama-2-7b-chat-hf"
|
||||
fallback_models=["huggingface/meta-llama/Llama-2-7b-chat-hf"]
|
||||
|
||||
[huggingface] # in .secrets.toml
|
||||
@ -87,6 +91,7 @@ To use Llama2 model with Replicate, for example, set:
|
||||
```
|
||||
[config] # in configuration.toml
|
||||
model = "replicate/llama-2-70b-chat:2c1608e18606fad2812020dc541930f2d0495ce32eee50074220b87300bc16e1"
|
||||
model_turbo = "replicate/llama-2-70b-chat:2c1608e18606fad2812020dc541930f2d0495ce32eee50074220b87300bc16e1"
|
||||
fallback_models=["replicate/llama-2-70b-chat:2c1608e18606fad2812020dc541930f2d0495ce32eee50074220b87300bc16e1"]
|
||||
[replicate] # in .secrets.toml
|
||||
key = ...
|
||||
@ -102,6 +107,7 @@ To use Llama3 model with Groq, for example, set:
|
||||
```
|
||||
[config] # in configuration.toml
|
||||
model = "llama3-70b-8192"
|
||||
model_turbo = "llama3-70b-8192"
|
||||
fallback_models = ["groq/llama3-70b-8192"]
|
||||
[groq] # in .secrets.toml
|
||||
key = ... # your Groq api key
|
||||
@ -115,6 +121,7 @@ To use Google's Vertex AI platform and its associated models (chat-bison/codecha
|
||||
```
|
||||
[config] # in configuration.toml
|
||||
model = "vertex_ai/codechat-bison"
|
||||
model_turbo = "vertex_ai/codechat-bison"
|
||||
fallback_models="vertex_ai/codechat-bison"
|
||||
|
||||
[vertexai] # in .secrets.toml
|
||||
@ -133,6 +140,7 @@ To use [Google AI Studio](https://aistudio.google.com/) models, set the relevant
|
||||
```toml
|
||||
[config] # in configuration.toml
|
||||
model="google_ai_studio/gemini-1.5-flash"
|
||||
model_turbo="google_ai_studio/gemini-1.5-flash"
|
||||
fallback_models=["google_ai_studio/gemini-1.5-flash"]
|
||||
|
||||
[google_ai_studio] # in .secrets.toml
|
||||
@ -148,6 +156,7 @@ To use Anthropic models, set the relevant models in the configuration section of
|
||||
```
|
||||
[config]
|
||||
model="anthropic/claude-3-opus-20240229"
|
||||
model_turbo="anthropic/claude-3-opus-20240229"
|
||||
fallback_models=["anthropic/claude-3-opus-20240229"]
|
||||
```
|
||||
|
||||
@ -164,6 +173,7 @@ To use Amazon Bedrock and its foundational models, add the below configuration:
|
||||
```
|
||||
[config] # in configuration.toml
|
||||
model="bedrock/anthropic.claude-3-sonnet-20240229-v1:0"
|
||||
model_turbo="bedrock/anthropic.claude-3-sonnet-20240229-v1:0"
|
||||
fallback_models=["bedrock/anthropic.claude-v2:1"]
|
||||
```
|
||||
|
||||
@ -185,6 +195,7 @@ If the relevant model doesn't appear [here](https://github.com/Codium-ai/pr-agen
|
||||
```
|
||||
[config]
|
||||
model="custom_model_name"
|
||||
model_turbo="custom_model_name"
|
||||
fallback_models=["custom_model_name"]
|
||||
```
|
||||
(2) Set the maximal tokens for the model:
|
||||
|
||||
@ -13,6 +13,7 @@ from pr_agent.tools.pr_config import PRConfig
|
||||
from pr_agent.tools.pr_description import PRDescription
|
||||
from pr_agent.tools.pr_generate_labels import PRGenerateLabels
|
||||
from pr_agent.tools.pr_help_message import PRHelpMessage
|
||||
from pr_agent.tools.pr_information_from_user import PRInformationFromUser
|
||||
from pr_agent.tools.pr_line_questions import PR_LineQuestions
|
||||
from pr_agent.tools.pr_questions import PRQuestions
|
||||
from pr_agent.tools.pr_reviewer import PRReviewer
|
||||
@ -24,6 +25,8 @@ command2class = {
|
||||
"answer": PRReviewer,
|
||||
"review": PRReviewer,
|
||||
"review_pr": PRReviewer,
|
||||
"reflect": PRInformationFromUser,
|
||||
"reflect_and_review": PRInformationFromUser,
|
||||
"describe": PRDescription,
|
||||
"describe_pr": PRDescription,
|
||||
"improve": PRCodeSuggestions,
|
||||
@ -46,6 +49,7 @@ commands = list(command2class.keys())
|
||||
class PRAgent:
|
||||
def __init__(self, ai_handler: partial[BaseAiHandler,] = LiteLLMAIHandler):
|
||||
self.ai_handler = ai_handler # will be initialized in run_action
|
||||
self.forbidden_cli_args = ['enable_auto_approval']
|
||||
|
||||
async def handle_request(self, pr_url, request, notify=None) -> bool:
|
||||
# First, apply repo specific settings if exists
|
||||
@ -60,13 +64,10 @@ class PRAgent:
|
||||
else:
|
||||
action, *args = request
|
||||
|
||||
forbidden_cli_args = ['enable_auto_approval', 'base_url', 'url', 'app_name', 'secret_provider',
|
||||
'git_provider', 'skip_keys', 'key', 'ANALYTICS_FOLDER', 'uri', 'app_id', 'webhook_secret',
|
||||
'bearer_token', 'PERSONAL_ACCESS_TOKEN', 'override_deployment_type', 'private_key', 'api_base', 'api_type', 'api_version']
|
||||
if args:
|
||||
for forbidden_arg in forbidden_cli_args:
|
||||
for forbidden_arg in self.forbidden_cli_args:
|
||||
for arg in args:
|
||||
if forbidden_arg.lower() in arg.lower():
|
||||
if forbidden_arg in arg:
|
||||
get_logger().error(
|
||||
f"CLI argument for param '{forbidden_arg}' is forbidden. Use instead a configuration file."
|
||||
)
|
||||
@ -75,10 +76,12 @@ class PRAgent:
|
||||
|
||||
action = action.lstrip("/").lower()
|
||||
if action not in command2class:
|
||||
get_logger().error(f"Unknown command: {action}")
|
||||
get_logger().debug(f"Unknown command: {action}")
|
||||
return False
|
||||
with get_logger().contextualize(command=action, pr_url=pr_url):
|
||||
get_logger().info("PR-Agent request handler started", analytics=True)
|
||||
if action == "reflect_and_review":
|
||||
get_settings().pr_reviewer.ask_and_reflect = True
|
||||
if action == "answer":
|
||||
if notify:
|
||||
notify()
|
||||
|
||||
@ -24,8 +24,6 @@ MAX_TOKENS = {
|
||||
'o1-mini-2024-09-12': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
'o1-preview': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
'o1-preview-2024-09-12': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
'o1-2024-12-17': 204800, # 200K, but may be limited by config.max_model_tokens
|
||||
'o1': 204800, # 200K, but may be limited by config.max_model_tokens
|
||||
'claude-instant-1': 100000,
|
||||
'claude-2': 100000,
|
||||
'command-nightly': 4096,
|
||||
@ -44,7 +42,6 @@ MAX_TOKENS = {
|
||||
'vertex_ai/gemma2': 8200,
|
||||
'gemini/gemini-1.5-pro': 1048576,
|
||||
'gemini/gemini-1.5-flash': 1048576,
|
||||
'gemini/gemini-2.0-flash-exp': 1048576,
|
||||
'codechat-bison': 6144,
|
||||
'codechat-bison-32k': 32000,
|
||||
'anthropic.claude-instant-v1': 100000,
|
||||
@ -62,14 +59,13 @@ MAX_TOKENS = {
|
||||
'bedrock/anthropic.claude-3-5-haiku-20241022-v1:0': 100000,
|
||||
'bedrock/anthropic.claude-3-5-sonnet-20240620-v1:0': 100000,
|
||||
'bedrock/anthropic.claude-3-5-sonnet-20241022-v2:0': 100000,
|
||||
"bedrock/us.anthropic.claude-3-5-sonnet-20241022-v2:0": 100000,
|
||||
'claude-3-5-sonnet': 100000,
|
||||
'groq/llama3-8b-8192': 8192,
|
||||
'groq/llama3-70b-8192': 8192,
|
||||
'groq/llama-3.1-8b-instant': 8192,
|
||||
'groq/llama-3.3-70b-versatile': 128000,
|
||||
'groq/mixtral-8x7b-32768': 32768,
|
||||
'groq/gemma2-9b-it': 8192,
|
||||
'groq/llama-3.1-8b-instant': 131072,
|
||||
'groq/llama-3.1-70b-versatile': 131072,
|
||||
'groq/llama-3.1-405b-reasoning': 131072,
|
||||
'ollama/llama3': 4096,
|
||||
'watsonx/meta-llama/llama-3-8b-instruct': 4096,
|
||||
"watsonx/meta-llama/llama-3-70b-instruct": 4096,
|
||||
|
||||
@ -7,7 +7,6 @@ from litellm import acompletion
|
||||
from tenacity import retry, retry_if_exception_type, stop_after_attempt
|
||||
|
||||
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||
from pr_agent.algo.utils import get_version
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.log import get_logger
|
||||
|
||||
@ -133,7 +132,7 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||
if "langfuse" in callbacks:
|
||||
metadata.update({
|
||||
"trace_name": command,
|
||||
"tags": [git_provider, command, f'version:{get_version()}'],
|
||||
"tags": [git_provider, command],
|
||||
"trace_metadata": {
|
||||
"command": command,
|
||||
"pr_url": pr_url,
|
||||
@ -142,7 +141,7 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||
if "langsmith" in callbacks:
|
||||
metadata.update({
|
||||
"run_name": command,
|
||||
"tags": [git_provider, command, f'version:{get_version()}'],
|
||||
"tags": [git_provider, command],
|
||||
"extra": {
|
||||
"metadata": {
|
||||
"command": command,
|
||||
@ -193,8 +192,8 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||
messages[1]["content"] = [{"type": "text", "text": messages[1]["content"]},
|
||||
{"type": "image_url", "image_url": {"url": img_path}}]
|
||||
|
||||
# Currently, model OpenAI o1 series does not support a separate system and user prompts
|
||||
O1_MODEL_PREFIX = 'o1'
|
||||
# Currently O1 does not support separate system and user prompts
|
||||
O1_MODEL_PREFIX = 'o1-'
|
||||
model_type = model.split('/')[-1] if '/' in model else model
|
||||
if model_type.startswith(O1_MODEL_PREFIX):
|
||||
user = f"{system}\n\n\n{user}"
|
||||
|
||||
@ -364,51 +364,48 @@ __old hunk__
|
||||
|
||||
|
||||
def extract_hunk_lines_from_patch(patch: str, file_name, line_start, line_end, side) -> tuple[str, str]:
|
||||
try:
|
||||
patch_with_lines_str = f"\n\n## File: '{file_name.strip()}'\n\n"
|
||||
selected_lines = ""
|
||||
patch_lines = patch.splitlines()
|
||||
RE_HUNK_HEADER = re.compile(
|
||||
r"^@@ -(\d+)(?:,(\d+))? \+(\d+)(?:,(\d+))? @@[ ]?(.*)")
|
||||
match = None
|
||||
start1, size1, start2, size2 = -1, -1, -1, -1
|
||||
skip_hunk = False
|
||||
selected_lines_num = 0
|
||||
for line in patch_lines:
|
||||
if 'no newline at end of file' in line.lower():
|
||||
continue
|
||||
|
||||
if line.startswith('@@'):
|
||||
skip_hunk = False
|
||||
selected_lines_num = 0
|
||||
header_line = line
|
||||
patch_with_lines_str = f"\n\n## File: '{file_name.strip()}'\n\n"
|
||||
selected_lines = ""
|
||||
patch_lines = patch.splitlines()
|
||||
RE_HUNK_HEADER = re.compile(
|
||||
r"^@@ -(\d+)(?:,(\d+))? \+(\d+)(?:,(\d+))? @@[ ]?(.*)")
|
||||
match = None
|
||||
start1, size1, start2, size2 = -1, -1, -1, -1
|
||||
skip_hunk = False
|
||||
selected_lines_num = 0
|
||||
for line in patch_lines:
|
||||
if 'no newline at end of file' in line.lower():
|
||||
continue
|
||||
|
||||
match = RE_HUNK_HEADER.match(line)
|
||||
if line.startswith('@@'):
|
||||
skip_hunk = False
|
||||
selected_lines_num = 0
|
||||
header_line = line
|
||||
|
||||
section_header, size1, size2, start1, start2 = extract_hunk_headers(match)
|
||||
match = RE_HUNK_HEADER.match(line)
|
||||
|
||||
section_header, size1, size2, start1, start2 = extract_hunk_headers(match)
|
||||
|
||||
# check if line range is in this hunk
|
||||
if side.lower() == 'left':
|
||||
# check if line range is in this hunk
|
||||
if side.lower() == 'left':
|
||||
# check if line range is in this hunk
|
||||
if not (start1 <= line_start <= start1 + size1):
|
||||
skip_hunk = True
|
||||
continue
|
||||
elif side.lower() == 'right':
|
||||
if not (start2 <= line_start <= start2 + size2):
|
||||
skip_hunk = True
|
||||
continue
|
||||
patch_with_lines_str += f'\n{header_line}\n'
|
||||
if not (start1 <= line_start <= start1 + size1):
|
||||
skip_hunk = True
|
||||
continue
|
||||
elif side.lower() == 'right':
|
||||
if not (start2 <= line_start <= start2 + size2):
|
||||
skip_hunk = True
|
||||
continue
|
||||
patch_with_lines_str += f'\n{header_line}\n'
|
||||
|
||||
elif not skip_hunk:
|
||||
if side.lower() == 'right' and line_start <= start2 + selected_lines_num <= line_end:
|
||||
selected_lines += line + '\n'
|
||||
if side.lower() == 'left' and start1 <= selected_lines_num + start1 <= line_end:
|
||||
selected_lines += line + '\n'
|
||||
patch_with_lines_str += line + '\n'
|
||||
if not line.startswith('-'): # currently we don't support /ask line for deleted lines
|
||||
selected_lines_num += 1
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to extract hunk lines from patch: {e}", artifact={"traceback": traceback.format_exc()})
|
||||
return "", ""
|
||||
elif not skip_hunk:
|
||||
if side.lower() == 'right' and line_start <= start2 + selected_lines_num <= line_end:
|
||||
selected_lines += line + '\n'
|
||||
if side.lower() == 'left' and start1 <= selected_lines_num + start1 <= line_end:
|
||||
selected_lines += line + '\n'
|
||||
patch_with_lines_str += line + '\n'
|
||||
if not line.startswith('-'): # currently we don't support /ask line for deleted lines
|
||||
selected_lines_num += 1
|
||||
|
||||
return patch_with_lines_str.rstrip(), selected_lines.rstrip()
|
||||
|
||||
@ -11,7 +11,7 @@ from pr_agent.algo.git_patch_processing import (
|
||||
from pr_agent.algo.language_handler import sort_files_by_main_languages
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
|
||||
from pr_agent.algo.utils import ModelType, clip_tokens, get_max_tokens, get_weak_model
|
||||
from pr_agent.algo.utils import ModelType, clip_tokens, get_max_tokens
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers.git_provider import GitProvider
|
||||
from pr_agent.log import get_logger
|
||||
@ -316,13 +316,13 @@ def generate_full_patch(convert_hunks_to_line_numbers, file_dict, max_tokens_mod
|
||||
# TODO: Option for alternative logic to remove hunks from the patch to reduce the number of tokens
|
||||
# until we meet the requirements
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().warning(f"Patch too large, skipping it: '{filename}'")
|
||||
get_logger().warning(f"Patch too large, skipping it, {filename}")
|
||||
remaining_files_list_new.append(filename)
|
||||
continue
|
||||
|
||||
if patch:
|
||||
if not convert_hunks_to_line_numbers:
|
||||
patch_final = f"\n\n## File: '{filename.strip()}'\n\n{patch.strip()}\n"
|
||||
patch_final = f"\n\n## File: '{filename.strip()}\n\n{patch.strip()}\n'"
|
||||
else:
|
||||
patch_final = "\n\n" + patch.strip()
|
||||
patches.append(patch_final)
|
||||
@ -354,8 +354,8 @@ async def retry_with_fallback_models(f: Callable, model_type: ModelType = ModelT
|
||||
|
||||
|
||||
def _get_all_models(model_type: ModelType = ModelType.REGULAR) -> List[str]:
|
||||
if model_type == ModelType.WEAK:
|
||||
model = get_weak_model()
|
||||
if model_type == ModelType.TURBO:
|
||||
model = get_settings().config.model_turbo
|
||||
else:
|
||||
model = get_settings().config.model
|
||||
fallback_models = get_settings().config.fallback_models
|
||||
|
||||
@ -1,6 +1,5 @@
|
||||
from dataclasses import dataclass
|
||||
from enum import Enum
|
||||
from typing import Optional
|
||||
|
||||
|
||||
class EDIT_TYPE(Enum):
|
||||
@ -22,5 +21,4 @@ class FilePatchInfo:
|
||||
old_filename: str = None
|
||||
num_plus_lines: int = -1
|
||||
num_minus_lines: int = -1
|
||||
language: Optional[str] = None
|
||||
ai_file_summary: str = None
|
||||
|
||||
@ -7,13 +7,11 @@ import html
|
||||
import json
|
||||
import os
|
||||
import re
|
||||
import sys
|
||||
import textwrap
|
||||
import time
|
||||
import traceback
|
||||
from datetime import datetime
|
||||
from enum import Enum
|
||||
from importlib.metadata import PackageNotFoundError, version
|
||||
from typing import Any, List, Tuple
|
||||
|
||||
import html2text
|
||||
@ -23,19 +21,12 @@ from pydantic import BaseModel
|
||||
from starlette_context import context
|
||||
|
||||
from pr_agent.algo import MAX_TOKENS
|
||||
from pr_agent.algo.git_patch_processing import extract_hunk_lines_from_patch
|
||||
from pr_agent.algo.token_handler import TokenEncoder
|
||||
from pr_agent.algo.types import FilePatchInfo
|
||||
from pr_agent.config_loader import get_settings, global_settings
|
||||
from pr_agent.log import get_logger
|
||||
|
||||
|
||||
def get_weak_model() -> str:
|
||||
if get_settings().get("config.model_weak"):
|
||||
return get_settings().config.model_weak
|
||||
return get_settings().config.model
|
||||
|
||||
|
||||
class Range(BaseModel):
|
||||
line_start: int # should be 0-indexed
|
||||
line_end: int
|
||||
@ -44,7 +35,8 @@ class Range(BaseModel):
|
||||
|
||||
class ModelType(str, Enum):
|
||||
REGULAR = "regular"
|
||||
WEAK = "weak"
|
||||
TURBO = "turbo"
|
||||
|
||||
|
||||
class PRReviewHeader(str, Enum):
|
||||
REGULAR = "## PR Reviewer Guide"
|
||||
@ -105,8 +97,7 @@ def unique_strings(input_list: List[str]) -> List[str]:
|
||||
def convert_to_markdown_v2(output_data: dict,
|
||||
gfm_supported: bool = True,
|
||||
incremental_review=None,
|
||||
git_provider=None,
|
||||
files=None) -> str:
|
||||
git_provider=None) -> str:
|
||||
"""
|
||||
Convert a dictionary of data into markdown format.
|
||||
Args:
|
||||
@ -230,13 +221,9 @@ def convert_to_markdown_v2(output_data: dict,
|
||||
continue
|
||||
relevant_file = issue.get('relevant_file', '').strip()
|
||||
issue_header = issue.get('issue_header', '').strip()
|
||||
if issue_header.lower() == 'possible bug':
|
||||
issue_header = 'Possible Issue' # Make the header less frightening
|
||||
issue_content = issue.get('issue_content', '').strip()
|
||||
start_line = int(str(issue.get('start_line', 0)).strip())
|
||||
end_line = int(str(issue.get('end_line', 0)).strip())
|
||||
|
||||
relevant_lines_str = extract_relevant_lines_str(end_line, files, relevant_file, start_line, dedent=True)
|
||||
if git_provider:
|
||||
reference_link = git_provider.get_line_link(relevant_file, start_line, end_line)
|
||||
else:
|
||||
@ -244,10 +231,7 @@ def convert_to_markdown_v2(output_data: dict,
|
||||
|
||||
if gfm_supported:
|
||||
if reference_link is not None and len(reference_link) > 0:
|
||||
if relevant_lines_str:
|
||||
issue_str = f"<details><summary><a href='{reference_link}'><strong>{issue_header}</strong></a>\n\n{issue_content}</summary>\n\n{relevant_lines_str}\n\n</details>"
|
||||
else:
|
||||
issue_str = f"<a href='{reference_link}'><strong>{issue_header}</strong></a><br>{issue_content}"
|
||||
issue_str = f"<a href='{reference_link}'><strong>{issue_header}</strong></a><br>{issue_content}"
|
||||
else:
|
||||
issue_str = f"<strong>{issue_header}</strong><br>{issue_content}"
|
||||
else:
|
||||
@ -271,49 +255,25 @@ def convert_to_markdown_v2(output_data: dict,
|
||||
if gfm_supported:
|
||||
markdown_text += "</table>\n"
|
||||
|
||||
if 'code_feedback' in output_data:
|
||||
if gfm_supported:
|
||||
markdown_text += f"\n\n"
|
||||
markdown_text += f"<details><summary> <strong>Code feedback:</strong></summary>\n\n"
|
||||
markdown_text += "<hr>"
|
||||
else:
|
||||
markdown_text += f"\n\n### Code feedback:\n\n"
|
||||
for i, value in enumerate(output_data['code_feedback']):
|
||||
if value is None or value == '' or value == {} or value == []:
|
||||
continue
|
||||
markdown_text += parse_code_suggestion(value, i, gfm_supported)+"\n\n"
|
||||
if markdown_text.endswith('<hr>'):
|
||||
markdown_text= markdown_text[:-4]
|
||||
if gfm_supported:
|
||||
markdown_text += f"</details>"
|
||||
|
||||
return markdown_text
|
||||
|
||||
|
||||
def extract_relevant_lines_str(end_line, files, relevant_file, start_line, dedent=False) -> str:
|
||||
"""
|
||||
Finds 'relevant_file' in 'files', and extracts the lines from 'start_line' to 'end_line' string from the file content.
|
||||
"""
|
||||
try:
|
||||
relevant_lines_str = ""
|
||||
if files:
|
||||
files = set_file_languages(files)
|
||||
for file in files:
|
||||
if file.filename.strip() == relevant_file:
|
||||
if not file.head_file:
|
||||
# as a fallback, extract relevant lines directly from patch
|
||||
patch = file.patch
|
||||
get_logger().info(f"No content found in file: '{file.filename}' for 'extract_relevant_lines_str'. Using patch instead")
|
||||
_, selected_lines = extract_hunk_lines_from_patch(patch, file.filename, start_line, end_line,side='right')
|
||||
if not selected_lines:
|
||||
get_logger().error(f"Failed to extract relevant lines from patch: {file.filename}")
|
||||
return ""
|
||||
# filter out '-' lines
|
||||
relevant_lines_str = ""
|
||||
for line in selected_lines.splitlines():
|
||||
if line.startswith('-'):
|
||||
continue
|
||||
relevant_lines_str += line[1:] + '\n'
|
||||
else:
|
||||
relevant_file_lines = file.head_file.splitlines()
|
||||
relevant_lines_str = "\n".join(relevant_file_lines[start_line - 1:end_line])
|
||||
|
||||
if dedent and relevant_lines_str:
|
||||
# Remove the longest leading string of spaces and tabs common to all lines.
|
||||
relevant_lines_str = textwrap.dedent(relevant_lines_str)
|
||||
relevant_lines_str = f"```{file.language}\n{relevant_lines_str}\n```"
|
||||
break
|
||||
|
||||
return relevant_lines_str
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Failed to extract relevant lines: {e}")
|
||||
return ""
|
||||
|
||||
|
||||
def ticket_markdown_logic(emoji, markdown_text, value, gfm_supported) -> str:
|
||||
ticket_compliance_str = ""
|
||||
final_compliance_level = -1
|
||||
@ -583,20 +543,27 @@ def load_large_diff(filename, new_file_content_str: str, original_file_content_s
|
||||
"""
|
||||
Generate a patch for a modified file by comparing the original content of the file with the new content provided as
|
||||
input.
|
||||
"""
|
||||
if not original_file_content_str and not new_file_content_str:
|
||||
return ""
|
||||
|
||||
Args:
|
||||
new_file_content_str: The new content of the file as a string.
|
||||
original_file_content_str: The original content of the file as a string.
|
||||
|
||||
Returns:
|
||||
The generated or provided patch string.
|
||||
|
||||
Raises:
|
||||
None.
|
||||
"""
|
||||
patch = ""
|
||||
try:
|
||||
diff = difflib.unified_diff(original_file_content_str.splitlines(keepends=True),
|
||||
new_file_content_str.splitlines(keepends=True))
|
||||
if get_settings().config.verbosity_level >= 2 and show_warning:
|
||||
get_logger().info(f"File was modified, but no patch was found. Manually creating patch: {filename}.")
|
||||
get_logger().warning(f"File was modified, but no patch was found. Manually creating patch: {filename}.")
|
||||
patch = ''.join(diff)
|
||||
return patch
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Failed to generate patch for file: {filename}")
|
||||
return ""
|
||||
except Exception:
|
||||
pass
|
||||
return patch
|
||||
|
||||
|
||||
def update_settings_from_args(args: List[str]) -> List[str]:
|
||||
@ -1139,48 +1106,3 @@ def process_description(description_full: str) -> Tuple[str, List]:
|
||||
get_logger().exception(f"Failed to process description: {e}")
|
||||
|
||||
return base_description_str, files
|
||||
|
||||
def get_version() -> str:
|
||||
# First check pyproject.toml if running directly out of repository
|
||||
if os.path.exists("pyproject.toml"):
|
||||
if sys.version_info >= (3, 11):
|
||||
import tomllib
|
||||
with open("pyproject.toml", "rb") as f:
|
||||
data = tomllib.load(f)
|
||||
if "project" in data and "version" in data["project"]:
|
||||
return data["project"]["version"]
|
||||
else:
|
||||
get_logger().warning("Version not found in pyproject.toml")
|
||||
else:
|
||||
get_logger().warning("Unable to determine local version from pyproject.toml")
|
||||
|
||||
# Otherwise get the installed pip package version
|
||||
try:
|
||||
return version('pr-agent')
|
||||
except PackageNotFoundError:
|
||||
get_logger().warning("Unable to find package named 'pr-agent'")
|
||||
return "unknown"
|
||||
|
||||
|
||||
def set_file_languages(diff_files) -> List[FilePatchInfo]:
|
||||
try:
|
||||
# if the language is already set, do not change it
|
||||
if hasattr(diff_files[0], 'language') and diff_files[0].language:
|
||||
return diff_files
|
||||
|
||||
# map file extensions to programming languages
|
||||
language_extension_map_org = get_settings().language_extension_map_org
|
||||
extension_to_language = {}
|
||||
for language, extensions in language_extension_map_org.items():
|
||||
for ext in extensions:
|
||||
extension_to_language[ext] = language
|
||||
for file in diff_files:
|
||||
extension_s = '.' + file.filename.rsplit('.')[-1]
|
||||
language_name = "txt"
|
||||
if extension_s and (extension_s in extension_to_language):
|
||||
language_name = extension_to_language[extension_s]
|
||||
file.language = language_name.lower()
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Failed to set file languages: {e}")
|
||||
|
||||
return diff_files
|
||||
|
||||
@ -3,7 +3,6 @@ import asyncio
|
||||
import os
|
||||
|
||||
from pr_agent.agent.pr_agent import PRAgent, commands
|
||||
from pr_agent.algo.utils import get_version
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.log import get_logger, setup_logger
|
||||
|
||||
@ -46,7 +45,6 @@ def set_parser():
|
||||
To edit any configuration parameter from 'configuration.toml', just add -config_path=<value>.
|
||||
For example: 'python cli.py --pr_url=... review --pr_reviewer.extra_instructions="focus on the file: ..."'
|
||||
""")
|
||||
parser.add_argument('--version', action='version', version=f'pr-agent {get_version()}')
|
||||
parser.add_argument('--pr_url', type=str, help='The URL of the PR to review', default=None)
|
||||
parser.add_argument('--issue_url', type=str, help='The URL of the Issue to review', default=None)
|
||||
parser.add_argument('command', type=str, help='The', choices=commands, default='review')
|
||||
|
||||
@ -19,7 +19,7 @@ from ..algo.language_handler import is_valid_file
|
||||
from ..algo.types import EDIT_TYPE
|
||||
from ..algo.utils import (PRReviewHeader, Range, clip_tokens,
|
||||
find_line_number_of_relevant_line_in_file,
|
||||
load_large_diff, set_file_languages)
|
||||
load_large_diff)
|
||||
from ..config_loader import get_settings
|
||||
from ..log import get_logger
|
||||
from ..servers.utils import RateLimitExceeded
|
||||
@ -174,24 +174,6 @@ class GithubProvider(GitProvider):
|
||||
|
||||
diff_files = []
|
||||
invalid_files_names = []
|
||||
is_close_to_rate_limit = False
|
||||
|
||||
# The base.sha will point to the current state of the base branch (including parallel merges), not the original base commit when the PR was created
|
||||
# We can fix this by finding the merge base commit between the PR head and base branches
|
||||
# Note that The pr.head.sha is actually correct as is - it points to the latest commit in your PR branch.
|
||||
# This SHA isn't affected by parallel merges to the base branch since it's specific to your PR's branch.
|
||||
repo = self.repo_obj
|
||||
pr = self.pr
|
||||
try:
|
||||
compare = repo.compare(pr.base.sha, pr.head.sha) # communication with GitHub
|
||||
merge_base_commit = compare.merge_base_commit
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to get merge base commit: {e}")
|
||||
merge_base_commit = pr.base
|
||||
if merge_base_commit.sha != pr.base.sha:
|
||||
get_logger().info(
|
||||
f"Using merge base commit {merge_base_commit.sha} instead of base commit ")
|
||||
|
||||
counter_valid = 0
|
||||
for file in files:
|
||||
if not is_valid_file(file.filename):
|
||||
@ -199,36 +181,48 @@ class GithubProvider(GitProvider):
|
||||
continue
|
||||
|
||||
patch = file.patch
|
||||
if is_close_to_rate_limit:
|
||||
|
||||
# allow only a limited number of files to be fully loaded. We can manage the rest with diffs only
|
||||
counter_valid += 1
|
||||
avoid_load = False
|
||||
if counter_valid >= MAX_FILES_ALLOWED_FULL and patch and not self.incremental.is_incremental:
|
||||
avoid_load = True
|
||||
if counter_valid == MAX_FILES_ALLOWED_FULL:
|
||||
get_logger().info(f"Too many files in PR, will avoid loading full content for rest of files")
|
||||
|
||||
if avoid_load:
|
||||
new_file_content_str = ""
|
||||
original_file_content_str = ""
|
||||
else:
|
||||
# allow only a limited number of files to be fully loaded. We can manage the rest with diffs only
|
||||
counter_valid += 1
|
||||
avoid_load = False
|
||||
if counter_valid >= MAX_FILES_ALLOWED_FULL and patch and not self.incremental.is_incremental:
|
||||
avoid_load = True
|
||||
if counter_valid == MAX_FILES_ALLOWED_FULL:
|
||||
get_logger().info(f"Too many files in PR, will avoid loading full content for rest of files")
|
||||
new_file_content_str = self._get_pr_file_content(file, self.pr.head.sha) # communication with GitHub
|
||||
|
||||
if self.incremental.is_incremental and self.unreviewed_files_set:
|
||||
original_file_content_str = self._get_pr_file_content(file, self.incremental.last_seen_commit_sha)
|
||||
patch = load_large_diff(file.filename, new_file_content_str, original_file_content_str)
|
||||
self.unreviewed_files_set[file.filename] = patch
|
||||
else:
|
||||
if avoid_load:
|
||||
new_file_content_str = ""
|
||||
original_file_content_str = ""
|
||||
else:
|
||||
new_file_content_str = self._get_pr_file_content(file, self.pr.head.sha) # communication with GitHub
|
||||
# The base.sha will point to the current state of the base branch (including parallel merges), not the original base commit when the PR was created
|
||||
# We can fix this by finding the merge base commit between the PR head and base branches
|
||||
# Note that The pr.head.sha is actually correct as is - it points to the latest commit in your PR branch.
|
||||
# This SHA isn't affected by parallel merges to the base branch since it's specific to your PR's branch.
|
||||
repo = self.repo_obj
|
||||
pr = self.pr
|
||||
try:
|
||||
compare = repo.compare(pr.base.sha, pr.head.sha)
|
||||
merge_base_commit = compare.merge_base_commit
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to get merge base commit: {e}")
|
||||
merge_base_commit = pr.base
|
||||
if merge_base_commit.sha != pr.base.sha:
|
||||
get_logger().info(
|
||||
f"Using merge base commit {merge_base_commit.sha} instead of base commit "
|
||||
f"{pr.base.sha} for {file.filename}")
|
||||
original_file_content_str = self._get_pr_file_content(file, merge_base_commit.sha)
|
||||
|
||||
if self.incremental.is_incremental and self.unreviewed_files_set:
|
||||
original_file_content_str = self._get_pr_file_content(file, self.incremental.last_seen_commit_sha)
|
||||
if not patch:
|
||||
patch = load_large_diff(file.filename, new_file_content_str, original_file_content_str)
|
||||
self.unreviewed_files_set[file.filename] = patch
|
||||
else:
|
||||
if avoid_load:
|
||||
original_file_content_str = ""
|
||||
else:
|
||||
original_file_content_str = self._get_pr_file_content(file, merge_base_commit.sha)
|
||||
# original_file_content_str = self._get_pr_file_content(file, self.pr.base.sha)
|
||||
if not patch:
|
||||
patch = load_large_diff(file.filename, new_file_content_str, original_file_content_str)
|
||||
|
||||
|
||||
if file.status == 'added':
|
||||
edit_type = EDIT_TYPE.ADDED
|
||||
@ -243,14 +237,9 @@ class GithubProvider(GitProvider):
|
||||
edit_type = EDIT_TYPE.UNKNOWN
|
||||
|
||||
# count number of lines added and removed
|
||||
if hasattr(file, 'additions') and hasattr(file, 'deletions'):
|
||||
num_plus_lines = file.additions
|
||||
num_minus_lines = file.deletions
|
||||
else:
|
||||
patch_lines = patch.splitlines(keepends=True)
|
||||
num_plus_lines = len([line for line in patch_lines if line.startswith('+')])
|
||||
num_minus_lines = len([line for line in patch_lines if line.startswith('-')])
|
||||
|
||||
patch_lines = patch.splitlines(keepends=True)
|
||||
num_plus_lines = len([line for line in patch_lines if line.startswith('+')])
|
||||
num_minus_lines = len([line for line in patch_lines if line.startswith('-')])
|
||||
file_patch_canonical_structure = FilePatchInfo(original_file_content_str, new_file_content_str, patch,
|
||||
file.filename, edit_type=edit_type,
|
||||
num_plus_lines=num_plus_lines,
|
||||
@ -900,7 +889,18 @@ class GithubProvider(GitProvider):
|
||||
RE_HUNK_HEADER = re.compile(
|
||||
r"^@@ -(\d+)(?:,(\d+))? \+(\d+)(?:,(\d+))? @@[ ]?(.*)")
|
||||
|
||||
diff_files = set_file_languages(diff_files)
|
||||
# map file extensions to programming languages
|
||||
language_extension_map_org = get_settings().language_extension_map_org
|
||||
extension_to_language = {}
|
||||
for language, extensions in language_extension_map_org.items():
|
||||
for ext in extensions:
|
||||
extension_to_language[ext] = language
|
||||
for file in diff_files:
|
||||
extension_s = '.' + file.filename.rsplit('.')[-1]
|
||||
language_name = "txt"
|
||||
if extension_s and (extension_s in extension_to_language):
|
||||
language_name = extension_to_language[extension_s]
|
||||
file.language = language_name.lower()
|
||||
|
||||
for suggestion in code_suggestions_copy:
|
||||
try:
|
||||
|
||||
@ -99,5 +99,5 @@ def set_claude_model():
|
||||
"""
|
||||
model_claude = "bedrock/anthropic.claude-3-5-sonnet-20240620-v1:0"
|
||||
get_settings().set('config.model', model_claude)
|
||||
get_settings().set('config.model_weak', model_claude)
|
||||
get_settings().set('config.model_turbo', model_claude)
|
||||
get_settings().set('config.fallback_models', [model_claude])
|
||||
|
||||
@ -84,7 +84,6 @@ async def is_valid_notification(notification, headers, handled_ids, session, use
|
||||
return False, handled_ids
|
||||
async with session.get(latest_comment, headers=headers) as comment_response:
|
||||
check_prev_comments = False
|
||||
user_tag = "@" + user_id
|
||||
if comment_response.status == 200:
|
||||
comment = await comment_response.json()
|
||||
if 'id' in comment:
|
||||
@ -102,6 +101,7 @@ async def is_valid_notification(notification, headers, handled_ids, session, use
|
||||
get_logger().debug(f"no comment_body")
|
||||
check_prev_comments = True
|
||||
else:
|
||||
user_tag = "@" + user_id
|
||||
if user_tag not in comment_body:
|
||||
get_logger().debug(f"user_tag not in comment_body")
|
||||
check_prev_comments = True
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
[config]
|
||||
# models
|
||||
model="gpt-4o-2024-11-20"
|
||||
model="gpt-4-turbo-2024-04-09"
|
||||
model_turbo="gpt-4o-2024-11-20"
|
||||
fallback_models=["gpt-4o-2024-08-06"]
|
||||
#model_weak="gpt-4o-mini-2024-07-18" # optional, a weaker model to use for some easier tasks
|
||||
# CLI
|
||||
git_provider="github"
|
||||
publish_output=true
|
||||
@ -55,6 +55,10 @@ require_can_be_split_review=false
|
||||
require_security_review=true
|
||||
require_ticket_analysis_review=true
|
||||
# general options
|
||||
num_code_suggestions=0
|
||||
inline_code_comments = false
|
||||
ask_and_reflect=false
|
||||
#automatic_review=true
|
||||
persistent_comment=true
|
||||
extra_instructions = ""
|
||||
final_update_message = true
|
||||
@ -88,7 +92,6 @@ publish_description_as_comment_persistent=true
|
||||
## changes walkthrough section
|
||||
enable_semantic_files_types=true
|
||||
collapsible_file_list='adaptive' # true, false, 'adaptive'
|
||||
collapsible_file_list_threshold=8
|
||||
inline_file_summary=false # false, true, 'table'
|
||||
# markers
|
||||
use_description_markers=false
|
||||
@ -97,6 +100,7 @@ include_generated_by_header=true
|
||||
enable_large_pr_handling=true
|
||||
max_ai_calls=4
|
||||
async_ai_calls=true
|
||||
mention_extra_files=true
|
||||
#custom_labels = ['Bug fix', 'Tests', 'Bug fix with tests', 'Enhancement', 'Documentation', 'Other']
|
||||
|
||||
[pr_questions] # /ask #
|
||||
@ -111,6 +115,7 @@ dual_publishing_score_threshold=-1 # -1 to disable, [0-10] to set the threshold
|
||||
focus_only_on_problems=true
|
||||
#
|
||||
extra_instructions = ""
|
||||
rank_suggestions = false
|
||||
enable_help_text=false
|
||||
enable_chat_text=false
|
||||
enable_intro_text=true
|
||||
@ -125,7 +130,7 @@ auto_extended_mode=true
|
||||
num_code_suggestions_per_chunk=4
|
||||
max_number_of_calls = 3
|
||||
parallel_calls = true
|
||||
|
||||
rank_extended_suggestions = false
|
||||
final_clip_factor = 0.8
|
||||
# self-review checkbox
|
||||
demand_code_suggestions_self_review=false # add a checkbox for the author to self-review the code suggestions
|
||||
@ -135,7 +140,6 @@ fold_suggestions_on_self_review=true # Pro feature. if true, the code suggestion
|
||||
# Suggestion impact 💎
|
||||
publish_post_process_suggestion_impact=true
|
||||
wiki_page_accepted_suggestions=true
|
||||
allow_thumbs_up_down=false
|
||||
|
||||
[pr_custom_prompt] # /custom_prompt #
|
||||
prompt = """\
|
||||
@ -159,7 +163,6 @@ class_name = "" # in case there are several methods with the same name in
|
||||
[pr_update_changelog] # /update_changelog #
|
||||
push_changelog_changes=false
|
||||
extra_instructions = ""
|
||||
add_pr_link=true
|
||||
|
||||
[pr_analyze] # /analyze #
|
||||
enable_help_text=true
|
||||
@ -216,7 +219,7 @@ override_deployment_type = true
|
||||
handle_pr_actions = ['opened', 'reopened', 'ready_for_review']
|
||||
pr_commands = [
|
||||
"/describe --pr_description.final_update_message=false",
|
||||
"/review",
|
||||
"/review --pr_reviewer.num_code_suggestions=0",
|
||||
"/improve",
|
||||
]
|
||||
# settings for "pull_request" event with "synchronize" action - used to detect and handle push triggers for new commits
|
||||
@ -228,27 +231,27 @@ push_trigger_pending_tasks_backlog = true
|
||||
push_trigger_pending_tasks_ttl = 300
|
||||
push_commands = [
|
||||
"/describe",
|
||||
"/review",
|
||||
"/review --pr_reviewer.num_code_suggestions=0",
|
||||
]
|
||||
|
||||
[gitlab]
|
||||
url = "https://gitlab.com"
|
||||
pr_commands = [
|
||||
"/describe --pr_description.final_update_message=false",
|
||||
"/review",
|
||||
"/review --pr_reviewer.num_code_suggestions=0",
|
||||
"/improve",
|
||||
]
|
||||
handle_push_trigger = false
|
||||
push_commands = [
|
||||
"/describe",
|
||||
"/review",
|
||||
"/review --pr_reviewer.num_code_suggestions=0",
|
||||
]
|
||||
|
||||
[bitbucket_app]
|
||||
pr_commands = [
|
||||
"/describe --pr_description.final_update_message=false",
|
||||
"/review",
|
||||
"/improve --pr_code_suggestions.commitable_code_suggestions=true",
|
||||
"/review --pr_reviewer.num_code_suggestions=0",
|
||||
"/improve --pr_code_suggestions.commitable_code_suggestions=true --pr_code_suggestions.suggestions_score_threshold=7",
|
||||
]
|
||||
avoid_full_files = false
|
||||
|
||||
@ -273,8 +276,8 @@ avoid_full_files = false
|
||||
url = ""
|
||||
pr_commands = [
|
||||
"/describe --pr_description.final_update_message=false",
|
||||
"/review",
|
||||
"/improve --pr_code_suggestions.commitable_code_suggestions=true",
|
||||
"/review --pr_reviewer.num_code_suggestions=0",
|
||||
"/improve --pr_code_suggestions.commitable_code_suggestions=true --pr_code_suggestions.suggestions_score_threshold=7",
|
||||
]
|
||||
|
||||
[litellm]
|
||||
|
||||
@ -9,7 +9,7 @@ Your task is to provide a full description for the PR content - files walkthroug
|
||||
- Keep in mind that the 'Previous title', 'Previous description' and 'Commit messages' sections may be partial, simplistic, non-informative or out of date. Hence, compare them to the PR diff code, and use them only as a reference.
|
||||
- The generated title and description should prioritize the most significant changes.
|
||||
- If needed, each YAML output should be in block scalar indicator ('|-')
|
||||
- When quoting variables, names or file paths from the code, use backticks (`) instead of single quote (').
|
||||
- When quoting variables or names from the code, use backticks (`) instead of single quote (').
|
||||
|
||||
{%- if extra_instructions %}
|
||||
|
||||
@ -38,22 +38,23 @@ class PRType(str, Enum):
|
||||
{%- if enable_semantic_files_types %}
|
||||
|
||||
class FileDescription(BaseModel):
|
||||
filename: str = Field(description="The full file path of the relevant file")
|
||||
language: str = Field(description="The programming language of the relevant file")
|
||||
{%- if include_file_summary_changes %}
|
||||
filename: str = Field(description="The full file path of the relevant file.")
|
||||
language: str = Field(description="The programming language of the relevant file.")
|
||||
changes_summary: str = Field(description="concise summary of the changes in the relevant file, in bullet points (1-4 bullet points).")
|
||||
{%- endif %}
|
||||
changes_title: str = Field(description="one-line summary (5-10 words) capturing the main theme of changes in the file")
|
||||
changes_title: str = Field(description="an informative title for the changes in the files, describing its main theme (5-10 words).")
|
||||
label: str = Field(description="a single semantic label that represents a type of code changes that occurred in the File. Possible values (partial list): 'bug fix', 'tests', 'enhancement', 'documentation', 'error handling', 'configuration changes', 'dependencies', 'formatting', 'miscellaneous', ...")
|
||||
{%- endif %}
|
||||
|
||||
class PRDescription(BaseModel):
|
||||
type: List[PRType] = Field(description="one or more types that describe the PR content. Return the label member value (e.g. 'Bug fix', not 'bug_fix')")
|
||||
{%- if enable_semantic_files_types %}
|
||||
pr_files: List[FileDescription] = Field(max_items=20, description="a list of all the files that were changed in the PR, and summary of their changes. Each file must be analyzed regardless of change size.")
|
||||
pr_files: List[FileDescription] = Field(max_items=15, description="a list of the files in the PR, and summary of their changes")
|
||||
{%- endif %}
|
||||
description: str = Field(description="an informative and concise description of the PR. Use bullet points. Display first the most significant changes.")
|
||||
title: str = Field(description="an informative title for the PR, describing its main theme")
|
||||
{%- if enable_custom_labels %}
|
||||
labels: List[Label] = Field(min_items=0, description="choose the relevant custom labels that describe the PR content, and return their keys. Use the value field of the Label object to better understand the label meaning.")
|
||||
{%- endif %}
|
||||
=====
|
||||
|
||||
|
||||
@ -69,20 +70,25 @@ pr_files:
|
||||
...
|
||||
language: |
|
||||
...
|
||||
{%- if include_file_summary_changes %}
|
||||
changes_summary: |
|
||||
...
|
||||
{%- endif %}
|
||||
changes_title: |
|
||||
...
|
||||
label: |
|
||||
label_key_1
|
||||
...
|
||||
...
|
||||
{%- endif %}
|
||||
description: |
|
||||
...
|
||||
title: |
|
||||
...
|
||||
{%- if enable_custom_labels %}
|
||||
labels:
|
||||
- |
|
||||
...
|
||||
- |
|
||||
...
|
||||
{%- endif %}
|
||||
```
|
||||
|
||||
Answer should be a valid YAML, and nothing else. Each YAML output MUST be after a newline, with proper indent, and block scalar indicator ('|')
|
||||
|
||||
@ -1,6 +1,10 @@
|
||||
[pr_review_prompt]
|
||||
system="""You are PR-Reviewer, a language model designed to review a Git Pull Request (PR).
|
||||
{%- if num_code_suggestions > 0 %}
|
||||
Your task is to provide constructive and concise feedback for the PR, and also provide meaningful code suggestions.
|
||||
{%- else %}
|
||||
Your task is to provide constructive and concise feedback for the PR.
|
||||
{%- endif %}
|
||||
The review should focus on new code added in the PR code diff (lines starting with '+')
|
||||
|
||||
|
||||
@ -45,6 +49,16 @@ __new hunk__
|
||||
{%- endif %}
|
||||
- When quoting variables or names from the code, use backticks (`) instead of single quote (').
|
||||
|
||||
{%- if num_code_suggestions > 0 %}
|
||||
|
||||
|
||||
Code suggestions guidelines:
|
||||
- Provide up to {{ num_code_suggestions }} code suggestions. Try to provide diverse and insightful suggestions.
|
||||
- Focus on important suggestions like fixing code problems, issues and bugs. As a second priority, provide suggestions for meaningful code improvements, like performance, vulnerability, modularity, and best practices.
|
||||
- Avoid making suggestions that have already been implemented in the PR code. For example, if you want to add logs, or change a variable to const, or anything else, make sure it isn't already in the PR code.
|
||||
- Don't suggest to add docstring, type hints, or comments.
|
||||
- Suggestions should address the new code added in the PR diff (lines starting with '+')
|
||||
{%- endif %}
|
||||
|
||||
{%- if extra_instructions %}
|
||||
|
||||
@ -66,8 +80,8 @@ class SubPR(BaseModel):
|
||||
|
||||
class KeyIssuesComponentLink(BaseModel):
|
||||
relevant_file: str = Field(description="The full file path of the relevant file")
|
||||
issue_header: str = Field(description="One or two word title for the the issue. For example: 'Possible Bug', etc.")
|
||||
issue_content: str = Field(description="A short and concise summary of what should be further inspected and validated during the PR review process for this issue. Do not reference line numbers in this field.")
|
||||
issue_header: str = Field(description="One or two word title for the the issue. For example: 'Possible Bug', 'Performance Issue', 'Code Smell', etc.")
|
||||
issue_content: str = Field(description="A short and concise summary of what should be further inspected and validated during the PR review process for this issue. Don't state line numbers here")
|
||||
start_line: int = Field(description="The start line that corresponds to this issue in the relevant file")
|
||||
end_line: int = Field(description="The end line that corresponds to this issue in the relevant file")
|
||||
|
||||
@ -97,16 +111,32 @@ class Review(BaseModel):
|
||||
{%- if question_str %}
|
||||
insights_from_user_answers: str = Field(description="shortly summarize the insights you gained from the user's answers to the questions")
|
||||
{%- endif %}
|
||||
key_issues_to_review: List[KeyIssuesComponentLink] = Field("A short and diverse list (0-3 issues) of high-priority bugs, problems or performance concerns introduced in the PR code, which the PR reviewer should further focus on and validate during the review process.")
|
||||
key_issues_to_review: List[KeyIssuesComponentLink] = Field("A diverse list of bugs, issue or major performance concerns introduced in this PR, which the PR reviewer should further investigate")
|
||||
{%- if require_security_review %}
|
||||
security_concerns: str = Field(description="Does this PR code introduce possible vulnerabilities such as exposure of sensitive information (e.g., API keys, secrets, passwords), or security concerns like SQL injection, XSS, CSRF, and others ? Answer 'No' (without explaining why) if there are no possible issues. If there are security concerns or issues, start your answer with a short header, such as: 'Sensitive information exposure: ...', 'SQL injection: ...' etc. Explain your answer. Be specific and give examples if possible")
|
||||
{%- endif %}
|
||||
{%- if require_can_be_split_review %}
|
||||
can_be_split: List[SubPR] = Field(min_items=0, max_items=3, description="Can this PR, which contains {{ num_pr_files }} changed files in total, be divided into smaller sub-PRs with distinct tasks that can be reviewed and merged independently, regardless of the order ? Make sure that the sub-PRs are indeed independent, with no code dependencies between them, and that each sub-PR represent a meaningful independent task. Output an empty list if the PR code does not need to be split.")
|
||||
{%- endif %}
|
||||
{%- if num_code_suggestions > 0 %}
|
||||
|
||||
class CodeSuggestion(BaseModel):
|
||||
relevant_file: str = Field(description="The full file path of the relevant file")
|
||||
language: str = Field(description="The programming language of the relevant file")
|
||||
suggestion: str = Field(description="a concrete suggestion for meaningfully improving the new PR code. Also describe how, specifically, the suggestion can be applied to new PR code. Add tags with importance measure that matches each suggestion ('important' or 'medium'). Do not make suggestions for updating or adding docstrings, renaming PR title and description, or linter like.")
|
||||
relevant_line: str = Field(description="a single code line taken from the relevant file, to which the suggestion applies. The code line should start with a '+'. Make sure to output the line exactly as it appears in the relevant file")
|
||||
{%- endif %}
|
||||
{%- if num_code_suggestions > 0 %}
|
||||
|
||||
class PRReview(BaseModel):
|
||||
review: Review
|
||||
code_feedback: List[CodeSuggestion]
|
||||
{%- else %}
|
||||
|
||||
|
||||
class PRReview(BaseModel):
|
||||
review: Review
|
||||
{%- endif %}
|
||||
=====
|
||||
|
||||
|
||||
@ -155,6 +185,18 @@ review:
|
||||
title: ...
|
||||
- ...
|
||||
{%- endif %}
|
||||
|
||||
{%- if num_code_suggestions > 0 %}
|
||||
code_feedback:
|
||||
- relevant_file: |
|
||||
directory/xxx.py
|
||||
language: |
|
||||
python
|
||||
suggestion: |
|
||||
xxx [important]
|
||||
relevant_line: |
|
||||
xxx
|
||||
{%- endif %}
|
||||
```
|
||||
|
||||
Answer should be a valid YAML, and nothing else. Each YAML output MUST be after a newline, with proper indent, and block scalar indicator ('|')
|
||||
|
||||
@ -1,14 +1,9 @@
|
||||
[pr_update_changelog_prompt]
|
||||
system="""You are a language model called PR-Changelog-Updater.
|
||||
Your task is to add a brief summary of this PR's changes to CHANGELOG.md file of the project:
|
||||
- Follow the file's existing format and style conventions like dates, section titles, etc.
|
||||
- Only add new changes (don't repeat existing entries)
|
||||
- Be general, and avoid specific details, files, etc. The output should be minimal, no more than 3-4 short lines.
|
||||
- Write only the new content to be added to CHANGELOG.md, without any introduction or summary. The content should appear as if it's a natural part of the existing file.
|
||||
{%- if pr_link %}
|
||||
- If relevant, convert the changelog main header into a clickable link using the PR URL '{{ pr_link }}'. Format: header [*][pr_link]
|
||||
{%- endif %}
|
||||
|
||||
Your task is to update the CHANGELOG.md file of the project, to shortly summarize important changes introduced in this PR (the '+' lines).
|
||||
- The output should match the existing CHANGELOG.md format, style and conventions, so it will look like a natural part of the file. For example, if previous changes were summarized in a single line, you should do the same.
|
||||
- Don't repeat previous changes. Generate only new content, that is not already in the CHANGELOG.md file.
|
||||
- Be general, and avoid specific details, files, etc. The output should be minimal, no more than 3-4 short lines. Ignore non-relevant subsections.
|
||||
|
||||
{%- if extra_instructions %}
|
||||
|
||||
@ -52,19 +47,16 @@ The PR Git Diff:
|
||||
{{ diff|trim }}
|
||||
======
|
||||
|
||||
|
||||
Current date:
|
||||
```
|
||||
{{today}}
|
||||
```
|
||||
|
||||
|
||||
The current 'CHANGELOG.md' file
|
||||
The current CHANGELOG.md:
|
||||
======
|
||||
{{ changelog_file_str }}
|
||||
======
|
||||
|
||||
|
||||
Response:
|
||||
```markdown
|
||||
"""
|
||||
|
||||
@ -21,7 +21,7 @@ from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers import (AzureDevopsProvider, GithubProvider,
|
||||
GitLabProvider, get_git_provider,
|
||||
get_git_provider_with_context)
|
||||
from pr_agent.git_providers.git_provider import get_main_pr_language, GitProvider
|
||||
from pr_agent.git_providers.git_provider import get_main_pr_language
|
||||
from pr_agent.log import get_logger
|
||||
from pr_agent.servers.help import HelpMessage
|
||||
from pr_agent.tools.pr_description import insert_br_after_x_chars
|
||||
@ -103,8 +103,6 @@ class PRCodeSuggestions:
|
||||
relevant_configs = {'pr_code_suggestions': dict(get_settings().pr_code_suggestions),
|
||||
'config': dict(get_settings().config)}
|
||||
get_logger().debug("Relevant configs", artifacts=relevant_configs)
|
||||
|
||||
# publish "Preparing suggestions..." comments
|
||||
if (get_settings().config.publish_output and get_settings().config.publish_output_progress and
|
||||
not get_settings().config.get('is_auto_command', False)):
|
||||
if self.git_provider.is_supported("gfm_markdown"):
|
||||
@ -112,26 +110,33 @@ class PRCodeSuggestions:
|
||||
else:
|
||||
self.git_provider.publish_comment("Preparing suggestions...", is_temporary=True)
|
||||
|
||||
# call the model to get the suggestions, and self-reflect on them
|
||||
if not self.is_extended:
|
||||
data = await retry_with_fallback_models(self._prepare_prediction, model_type=ModelType.REGULAR)
|
||||
data = await retry_with_fallback_models(self._prepare_prediction)
|
||||
else:
|
||||
data = await retry_with_fallback_models(self._prepare_prediction_extended, model_type=ModelType.REGULAR)
|
||||
data = await retry_with_fallback_models(self._prepare_prediction_extended)
|
||||
if not data:
|
||||
data = {"code_suggestions": []}
|
||||
self.data = data
|
||||
|
||||
# Handle the case where the PR has no suggestions
|
||||
if (data is None or 'code_suggestions' not in data or not data['code_suggestions']):
|
||||
await self.publish_no_suggestions()
|
||||
pr_body = "## PR Code Suggestions ✨\n\nNo code suggestions found for the PR."
|
||||
get_logger().warning('No code suggestions found for the PR.')
|
||||
if get_settings().config.publish_output and get_settings().config.publish_output_no_suggestions:
|
||||
get_logger().debug(f"PR output", artifact=pr_body)
|
||||
if self.progress_response:
|
||||
self.git_provider.edit_comment(self.progress_response, body=pr_body)
|
||||
else:
|
||||
self.git_provider.publish_comment(pr_body)
|
||||
else:
|
||||
get_settings().data = {"artifact": ""}
|
||||
return
|
||||
|
||||
# publish the suggestions
|
||||
if get_settings().config.publish_output:
|
||||
# If a temporary comment was published, remove it
|
||||
self.git_provider.remove_initial_comment()
|
||||
if (not self.is_extended and get_settings().pr_code_suggestions.rank_suggestions) or \
|
||||
(self.is_extended and get_settings().pr_code_suggestions.rank_extended_suggestions):
|
||||
get_logger().info('Ranking Suggestions...')
|
||||
data['code_suggestions'] = await self.rank_suggestions(data['code_suggestions'])
|
||||
|
||||
# Publish table summarized suggestions
|
||||
if get_settings().config.publish_output:
|
||||
self.git_provider.remove_initial_comment()
|
||||
if ((not get_settings().pr_code_suggestions.commitable_code_suggestions) and
|
||||
self.git_provider.is_supported("gfm_markdown")):
|
||||
|
||||
@ -141,7 +146,10 @@ class PRCodeSuggestions:
|
||||
|
||||
# require self-review
|
||||
if get_settings().pr_code_suggestions.demand_code_suggestions_self_review:
|
||||
pr_body = await self.add_self_review_text(pr_body)
|
||||
text = get_settings().pr_code_suggestions.code_suggestions_self_review_text
|
||||
pr_body += f"\n\n- [ ] {text}"
|
||||
if get_settings().pr_code_suggestions.approve_pr_on_self_review:
|
||||
pr_body += ' <!-- approve pr self-review -->'
|
||||
|
||||
# add usage guide
|
||||
if (get_settings().pr_code_suggestions.enable_chat_text and get_settings().config.is_auto_command
|
||||
@ -157,13 +165,13 @@ class PRCodeSuggestions:
|
||||
pr_body += show_relevant_configurations(relevant_section='pr_code_suggestions')
|
||||
|
||||
# publish the PR comment
|
||||
if get_settings().pr_code_suggestions.persistent_comment: # true by default
|
||||
self.publish_persistent_comment_with_history(self.git_provider,
|
||||
pr_body,
|
||||
if get_settings().pr_code_suggestions.persistent_comment:
|
||||
final_update_message = False
|
||||
self.publish_persistent_comment_with_history(pr_body,
|
||||
initial_header="## PR Code Suggestions ✨",
|
||||
update_header=True,
|
||||
name="suggestions",
|
||||
final_update_message=False,
|
||||
final_update_message=final_update_message,
|
||||
max_previous_comments=get_settings().pr_code_suggestions.max_history_len,
|
||||
progress_response=self.progress_response)
|
||||
else:
|
||||
@ -174,15 +182,29 @@ class PRCodeSuggestions:
|
||||
|
||||
# dual publishing mode
|
||||
if int(get_settings().pr_code_suggestions.dual_publishing_score_threshold) > 0:
|
||||
await self.dual_publishing(data)
|
||||
data_above_threshold = {'code_suggestions': []}
|
||||
try:
|
||||
for suggestion in data['code_suggestions']:
|
||||
if int(suggestion.get('score', 0)) >= int(get_settings().pr_code_suggestions.dual_publishing_score_threshold) \
|
||||
and suggestion.get('improved_code'):
|
||||
data_above_threshold['code_suggestions'].append(suggestion)
|
||||
if not data_above_threshold['code_suggestions'][-1]['existing_code']:
|
||||
get_logger().info(f'Identical existing and improved code for dual publishing found')
|
||||
data_above_threshold['code_suggestions'][-1]['existing_code'] = suggestion[
|
||||
'improved_code']
|
||||
if data_above_threshold['code_suggestions']:
|
||||
get_logger().info(
|
||||
f"Publishing {len(data_above_threshold['code_suggestions'])} suggestions in dual publishing mode")
|
||||
self.push_inline_code_suggestions(data_above_threshold)
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to publish dual publishing suggestions, error: {e}")
|
||||
else:
|
||||
await self.push_inline_code_suggestions(data)
|
||||
self.push_inline_code_suggestions(data)
|
||||
if self.progress_response:
|
||||
self.git_provider.remove_comment(self.progress_response)
|
||||
else:
|
||||
get_logger().info('Code suggestions generated for PR, but not published since publish_output is False.')
|
||||
pr_body = self.generate_summarized_suggestions(data)
|
||||
get_settings().data = {"artifact": pr_body}
|
||||
get_settings().data = {"artifact": data}
|
||||
return
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to generate code suggestions for PR, error: {e}",
|
||||
@ -195,108 +217,47 @@ class PRCodeSuggestions:
|
||||
self.git_provider.remove_initial_comment()
|
||||
self.git_provider.publish_comment(f"Failed to generate code suggestions for PR")
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Failed to update persistent review, error: {e}")
|
||||
pass
|
||||
|
||||
async def add_self_review_text(self, pr_body):
|
||||
text = get_settings().pr_code_suggestions.code_suggestions_self_review_text
|
||||
pr_body += f"\n\n- [ ] {text}"
|
||||
approve_pr_on_self_review = get_settings().pr_code_suggestions.approve_pr_on_self_review
|
||||
fold_suggestions_on_self_review = get_settings().pr_code_suggestions.fold_suggestions_on_self_review
|
||||
if approve_pr_on_self_review and not fold_suggestions_on_self_review:
|
||||
pr_body += ' <!-- approve pr self-review -->'
|
||||
elif fold_suggestions_on_self_review and not approve_pr_on_self_review:
|
||||
pr_body += ' <!-- fold suggestions self-review -->'
|
||||
else:
|
||||
pr_body += ' <!-- approve and fold suggestions self-review -->'
|
||||
return pr_body
|
||||
|
||||
async def publish_no_suggestions(self):
|
||||
pr_body = "## PR Code Suggestions ✨\n\nNo code suggestions found for the PR."
|
||||
if get_settings().config.publish_output and get_settings().config.publish_output_no_suggestions:
|
||||
get_logger().warning('No code suggestions found for the PR.')
|
||||
get_logger().debug(f"PR output", artifact=pr_body)
|
||||
if self.progress_response:
|
||||
self.git_provider.edit_comment(self.progress_response, body=pr_body)
|
||||
else:
|
||||
self.git_provider.publish_comment(pr_body)
|
||||
else:
|
||||
get_settings().data = {"artifact": ""}
|
||||
|
||||
async def dual_publishing(self, data):
|
||||
data_above_threshold = {'code_suggestions': []}
|
||||
try:
|
||||
for suggestion in data['code_suggestions']:
|
||||
if int(suggestion.get('score', 0)) >= int(
|
||||
get_settings().pr_code_suggestions.dual_publishing_score_threshold) \
|
||||
and suggestion.get('improved_code'):
|
||||
data_above_threshold['code_suggestions'].append(suggestion)
|
||||
if not data_above_threshold['code_suggestions'][-1]['existing_code']:
|
||||
get_logger().info(f'Identical existing and improved code for dual publishing found')
|
||||
data_above_threshold['code_suggestions'][-1]['existing_code'] = suggestion[
|
||||
'improved_code']
|
||||
if data_above_threshold['code_suggestions']:
|
||||
get_logger().info(
|
||||
f"Publishing {len(data_above_threshold['code_suggestions'])} suggestions in dual publishing mode")
|
||||
await self.push_inline_code_suggestions(data_above_threshold)
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to publish dual publishing suggestions, error: {e}")
|
||||
|
||||
@staticmethod
|
||||
def publish_persistent_comment_with_history(git_provider: GitProvider,
|
||||
pr_comment: str,
|
||||
def publish_persistent_comment_with_history(self, pr_comment: str,
|
||||
initial_header: str,
|
||||
update_header: bool = True,
|
||||
name='review',
|
||||
final_update_message=True,
|
||||
max_previous_comments=4,
|
||||
progress_response=None,
|
||||
only_fold=False):
|
||||
progress_response=None):
|
||||
|
||||
def _extract_link(comment_text: str):
|
||||
r = re.compile(r"<!--.*?-->")
|
||||
match = r.search(comment_text)
|
||||
|
||||
up_to_commit_txt = ""
|
||||
if match:
|
||||
up_to_commit_txt = f" up to commit {match.group(0)[4:-3].strip()}"
|
||||
return up_to_commit_txt
|
||||
|
||||
if isinstance(git_provider, AzureDevopsProvider): # get_latest_commit_url is not supported yet
|
||||
if isinstance(self.git_provider, AzureDevopsProvider): # get_latest_commit_url is not supported yet
|
||||
if progress_response:
|
||||
git_provider.edit_comment(progress_response, pr_comment)
|
||||
new_comment = progress_response
|
||||
self.git_provider.edit_comment(progress_response, pr_comment)
|
||||
else:
|
||||
new_comment = git_provider.publish_comment(pr_comment)
|
||||
return new_comment
|
||||
self.git_provider.publish_comment(pr_comment)
|
||||
return
|
||||
|
||||
history_header = f"#### Previous suggestions\n"
|
||||
last_commit_num = git_provider.get_latest_commit_url().split('/')[-1][:7]
|
||||
if only_fold: # A user clicked on the 'self-review' checkbox
|
||||
text = get_settings().pr_code_suggestions.code_suggestions_self_review_text
|
||||
latest_suggestion_header = f"\n\n- [x] {text}"
|
||||
else:
|
||||
latest_suggestion_header = f"Latest suggestions up to {last_commit_num}"
|
||||
last_commit_num = self.git_provider.get_latest_commit_url().split('/')[-1][:7]
|
||||
latest_suggestion_header = f"Latest suggestions up to {last_commit_num}"
|
||||
latest_commit_html_comment = f"<!-- {last_commit_num} -->"
|
||||
found_comment = None
|
||||
|
||||
if max_previous_comments > 0:
|
||||
try:
|
||||
prev_comments = list(git_provider.get_issue_comments())
|
||||
prev_comments = list(self.git_provider.get_issue_comments())
|
||||
for comment in prev_comments:
|
||||
if comment.body.startswith(initial_header):
|
||||
prev_suggestions = comment.body
|
||||
found_comment = comment
|
||||
comment_url = git_provider.get_comment_url(comment)
|
||||
comment_url = self.git_provider.get_comment_url(comment)
|
||||
|
||||
if history_header.strip() not in comment.body:
|
||||
# no history section
|
||||
# extract everything between <table> and </table> in comment.body including <table> and </table>
|
||||
table_index = comment.body.find("<table>")
|
||||
if table_index == -1:
|
||||
git_provider.edit_comment(comment, pr_comment)
|
||||
self.git_provider.edit_comment(comment, pr_comment)
|
||||
continue
|
||||
# find http link from comment.body[:table_index]
|
||||
up_to_commit_txt = _extract_link(comment.body[:table_index])
|
||||
up_to_commit_txt = self.extract_link(comment.body[:table_index])
|
||||
prev_suggestion_table = comment.body[
|
||||
table_index:comment.body.rfind("</table>") + len("</table>")]
|
||||
|
||||
@ -317,7 +278,7 @@ class PRCodeSuggestions:
|
||||
|
||||
# get text after the latest_suggestion_header in comment.body
|
||||
table_ind = latest_table.find("<table>")
|
||||
up_to_commit_txt = _extract_link(latest_table[:table_ind])
|
||||
up_to_commit_txt = self.extract_link(latest_table[:table_ind])
|
||||
|
||||
latest_table = latest_table[table_ind:latest_table.rfind("</table>") + len("</table>")]
|
||||
# enforce max_previous_comments
|
||||
@ -344,12 +305,11 @@ class PRCodeSuggestions:
|
||||
|
||||
get_logger().info(f"Persistent mode - updating comment {comment_url} to latest {name} message")
|
||||
if progress_response: # publish to 'progress_response' comment, because it refreshes immediately
|
||||
git_provider.edit_comment(progress_response, pr_comment_updated)
|
||||
git_provider.remove_comment(comment)
|
||||
comment = progress_response
|
||||
self.git_provider.edit_comment(progress_response, pr_comment_updated)
|
||||
self.git_provider.remove_comment(comment)
|
||||
else:
|
||||
git_provider.edit_comment(comment, pr_comment_updated)
|
||||
return comment
|
||||
self.git_provider.edit_comment(comment, pr_comment_updated)
|
||||
return
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Failed to update persistent review, error: {e}")
|
||||
pass
|
||||
@ -358,12 +318,9 @@ class PRCodeSuggestions:
|
||||
body = pr_comment.replace(initial_header, "").strip()
|
||||
pr_comment = f"{initial_header}\n\n{latest_commit_html_comment}\n\n{body}\n\n"
|
||||
if progress_response:
|
||||
git_provider.edit_comment(progress_response, pr_comment)
|
||||
new_comment = progress_response
|
||||
self.git_provider.edit_comment(progress_response, pr_comment)
|
||||
else:
|
||||
new_comment = git_provider.publish_comment(pr_comment)
|
||||
return new_comment
|
||||
|
||||
self.git_provider.publish_comment(pr_comment)
|
||||
|
||||
def extract_link(self, s):
|
||||
r = re.compile(r"<!--.*?-->")
|
||||
@ -414,7 +371,50 @@ class PRCodeSuggestions:
|
||||
response_reflect = await self.self_reflect_on_suggestions(data["code_suggestions"],
|
||||
patches_diff, model=model_reflection)
|
||||
if response_reflect:
|
||||
await self.analyze_self_reflection_response(data, response_reflect)
|
||||
response_reflect_yaml = load_yaml(response_reflect)
|
||||
code_suggestions_feedback = response_reflect_yaml["code_suggestions"]
|
||||
if len(code_suggestions_feedback) == len(data["code_suggestions"]):
|
||||
for i, suggestion in enumerate(data["code_suggestions"]):
|
||||
try:
|
||||
suggestion["score"] = code_suggestions_feedback[i]["suggestion_score"]
|
||||
suggestion["score_why"] = code_suggestions_feedback[i]["why"]
|
||||
|
||||
if 'relevant_lines_start' not in suggestion:
|
||||
relevant_lines_start = code_suggestions_feedback[i].get('relevant_lines_start', -1)
|
||||
relevant_lines_end = code_suggestions_feedback[i].get('relevant_lines_end', -1)
|
||||
suggestion['relevant_lines_start'] = relevant_lines_start
|
||||
suggestion['relevant_lines_end'] = relevant_lines_end
|
||||
if relevant_lines_start < 0 or relevant_lines_end < 0:
|
||||
suggestion["score"] = 0
|
||||
|
||||
try:
|
||||
if get_settings().config.publish_output:
|
||||
suggestion_statistics_dict = {'score': int(suggestion["score"]),
|
||||
'label': suggestion["label"].lower().strip()}
|
||||
get_logger().info(f"PR-Agent suggestions statistics",
|
||||
statistics=suggestion_statistics_dict, analytics=True)
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to log suggestion statistics, error: {e}")
|
||||
pass
|
||||
|
||||
except Exception as e: #
|
||||
get_logger().error(f"Error processing suggestion score {i}",
|
||||
artifact={"suggestion": suggestion,
|
||||
"code_suggestions_feedback": code_suggestions_feedback[i]})
|
||||
suggestion["score"] = 7
|
||||
suggestion["score_why"] = ""
|
||||
|
||||
# if the before and after code is the same, clear one of them
|
||||
try:
|
||||
if suggestion['existing_code'] == suggestion['improved_code']:
|
||||
get_logger().debug(
|
||||
f"edited improved suggestion {i + 1}, because equal to existing code: {suggestion['existing_code']}")
|
||||
if get_settings().pr_code_suggestions.commitable_code_suggestions:
|
||||
suggestion['improved_code'] = "" # we need 'existing_code' to locate the code in the PR
|
||||
else:
|
||||
suggestion['existing_code'] = ""
|
||||
except Exception as e:
|
||||
get_logger().error(f"Error processing suggestion {i + 1}, error: {e}")
|
||||
else:
|
||||
# get_logger().error(f"Could not self-reflect on suggestions. using default score 7")
|
||||
for i, suggestion in enumerate(data["code_suggestions"]):
|
||||
@ -423,58 +423,6 @@ class PRCodeSuggestions:
|
||||
|
||||
return data
|
||||
|
||||
async def analyze_self_reflection_response(self, data, response_reflect):
|
||||
response_reflect_yaml = load_yaml(response_reflect)
|
||||
code_suggestions_feedback = response_reflect_yaml.get("code_suggestions", [])
|
||||
if code_suggestions_feedback and len(code_suggestions_feedback) == len(data["code_suggestions"]):
|
||||
for i, suggestion in enumerate(data["code_suggestions"]):
|
||||
try:
|
||||
suggestion["score"] = code_suggestions_feedback[i]["suggestion_score"]
|
||||
suggestion["score_why"] = code_suggestions_feedback[i]["why"]
|
||||
|
||||
if 'relevant_lines_start' not in suggestion:
|
||||
relevant_lines_start = code_suggestions_feedback[i].get('relevant_lines_start', -1)
|
||||
relevant_lines_end = code_suggestions_feedback[i].get('relevant_lines_end', -1)
|
||||
suggestion['relevant_lines_start'] = relevant_lines_start
|
||||
suggestion['relevant_lines_end'] = relevant_lines_end
|
||||
if relevant_lines_start < 0 or relevant_lines_end < 0:
|
||||
suggestion["score"] = 0
|
||||
|
||||
try:
|
||||
if get_settings().config.publish_output:
|
||||
if not suggestion["score"]:
|
||||
score = -1
|
||||
else:
|
||||
score = int(suggestion["score"])
|
||||
label = suggestion["label"].lower().strip()
|
||||
label = label.replace('<br>', ' ')
|
||||
suggestion_statistics_dict = {'score': score,
|
||||
'label': label}
|
||||
get_logger().info(f"PR-Agent suggestions statistics",
|
||||
statistics=suggestion_statistics_dict, analytics=True)
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to log suggestion statistics, error: {e}")
|
||||
pass
|
||||
|
||||
except Exception as e: #
|
||||
get_logger().error(f"Error processing suggestion score {i}",
|
||||
artifact={"suggestion": suggestion,
|
||||
"code_suggestions_feedback": code_suggestions_feedback[i]})
|
||||
suggestion["score"] = 7
|
||||
suggestion["score_why"] = ""
|
||||
|
||||
# if the before and after code is the same, clear one of them
|
||||
try:
|
||||
if suggestion['existing_code'] == suggestion['improved_code']:
|
||||
get_logger().debug(
|
||||
f"edited improved suggestion {i + 1}, because equal to existing code: {suggestion['existing_code']}")
|
||||
if get_settings().pr_code_suggestions.commitable_code_suggestions:
|
||||
suggestion['improved_code'] = "" # we need 'existing_code' to locate the code in the PR
|
||||
else:
|
||||
suggestion['existing_code'] = ""
|
||||
except Exception as e:
|
||||
get_logger().error(f"Error processing suggestion {i + 1}, error: {e}")
|
||||
|
||||
@staticmethod
|
||||
def _truncate_if_needed(suggestion):
|
||||
max_code_suggestion_length = get_settings().get("PR_CODE_SUGGESTIONS.MAX_CODE_SUGGESTION_LENGTH", 0)
|
||||
@ -538,7 +486,7 @@ class PRCodeSuggestions:
|
||||
|
||||
return data
|
||||
|
||||
async def push_inline_code_suggestions(self, data):
|
||||
def push_inline_code_suggestions(self, data):
|
||||
code_suggestions = []
|
||||
|
||||
if not data['code_suggestions']:
|
||||
@ -636,9 +584,7 @@ class PRCodeSuggestions:
|
||||
patches_diff_lines = patches_diff.splitlines()
|
||||
for i, line in enumerate(patches_diff_lines):
|
||||
if line.strip():
|
||||
if line.isnumeric():
|
||||
patches_diff_lines[i] = ''
|
||||
elif line[0].isdigit():
|
||||
if line[0].isdigit():
|
||||
# find the first letter in the line that starts with a valid letter
|
||||
for j, char in enumerate(line):
|
||||
if not char.isdigit():
|
||||
@ -696,6 +642,62 @@ class PRCodeSuggestions:
|
||||
self.data = data = None
|
||||
return data
|
||||
|
||||
async def rank_suggestions(self, data: List) -> List:
|
||||
"""
|
||||
Call a model to rank (sort) code suggestions based on their importance order.
|
||||
|
||||
Args:
|
||||
data (List): A list of code suggestions to be ranked.
|
||||
|
||||
Returns:
|
||||
List: The ranked list of code suggestions.
|
||||
"""
|
||||
|
||||
suggestion_list = []
|
||||
if not data:
|
||||
return suggestion_list
|
||||
for suggestion in data:
|
||||
suggestion_list.append(suggestion)
|
||||
data_sorted = [[]] * len(suggestion_list)
|
||||
|
||||
if len(suggestion_list) == 1:
|
||||
return suggestion_list
|
||||
|
||||
try:
|
||||
suggestion_str = ""
|
||||
for i, suggestion in enumerate(suggestion_list):
|
||||
suggestion_str += f"suggestion {i + 1}: " + str(suggestion) + '\n\n'
|
||||
|
||||
variables = {'suggestion_list': suggestion_list, 'suggestion_str': suggestion_str}
|
||||
model = get_settings().config.model
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
system_prompt = environment.from_string(get_settings().pr_sort_code_suggestions_prompt.system).render(
|
||||
variables)
|
||||
user_prompt = environment.from_string(get_settings().pr_sort_code_suggestions_prompt.user).render(variables)
|
||||
response, finish_reason = await self.ai_handler.chat_completion(model=model, system=system_prompt,
|
||||
user=user_prompt)
|
||||
|
||||
sort_order = load_yaml(response)
|
||||
for s in sort_order['Sort Order']:
|
||||
suggestion_number = s['suggestion number']
|
||||
importance_order = s['importance order']
|
||||
data_sorted[importance_order - 1] = suggestion_list[suggestion_number - 1]
|
||||
|
||||
if get_settings().pr_code_suggestions.final_clip_factor != 1:
|
||||
max_len = max(
|
||||
len(data_sorted),
|
||||
int(get_settings().pr_code_suggestions.num_code_suggestions_per_chunk),
|
||||
)
|
||||
new_len = int(0.5 + max_len * get_settings().pr_code_suggestions.final_clip_factor)
|
||||
if new_len < len(data_sorted):
|
||||
data_sorted = data_sorted[:new_len]
|
||||
except Exception as e:
|
||||
if get_settings().config.verbosity_level >= 1:
|
||||
get_logger().info(f"Could not sort suggestions, error: {e}")
|
||||
data_sorted = suggestion_list
|
||||
|
||||
return data_sorted
|
||||
|
||||
def generate_summarized_suggestions(self, data: Dict) -> str:
|
||||
try:
|
||||
pr_body = "## PR Code Suggestions ✨\n\n"
|
||||
@ -811,12 +813,7 @@ class PRCodeSuggestions:
|
||||
get_logger().info(f"Failed to publish summarized code suggestions, error: {e}")
|
||||
return ""
|
||||
|
||||
async def self_reflect_on_suggestions(self,
|
||||
suggestion_list: List,
|
||||
patches_diff: str,
|
||||
model: str,
|
||||
prev_suggestions_str: str = "",
|
||||
dedicated_prompt: str = "") -> str:
|
||||
async def self_reflect_on_suggestions(self, suggestion_list: List, patches_diff: str, model: str) -> str:
|
||||
if not suggestion_list:
|
||||
return ""
|
||||
|
||||
@ -829,21 +826,13 @@ class PRCodeSuggestions:
|
||||
'suggestion_str': suggestion_str,
|
||||
"diff": patches_diff,
|
||||
'num_code_suggestions': len(suggestion_list),
|
||||
'prev_suggestions_str': prev_suggestions_str,
|
||||
"is_ai_metadata": get_settings().get("config.enable_ai_metadata", False)}
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
|
||||
if dedicated_prompt:
|
||||
system_prompt_reflect = environment.from_string(
|
||||
get_settings().get(dedicated_prompt).system).render(variables)
|
||||
user_prompt_reflect = environment.from_string(
|
||||
get_settings().get(dedicated_prompt).user).render(variables)
|
||||
else:
|
||||
system_prompt_reflect = environment.from_string(
|
||||
get_settings().pr_code_suggestions_reflect_prompt.system).render(variables)
|
||||
user_prompt_reflect = environment.from_string(
|
||||
get_settings().pr_code_suggestions_reflect_prompt.user).render(variables)
|
||||
|
||||
system_prompt_reflect = environment.from_string(
|
||||
get_settings().pr_code_suggestions_reflect_prompt.system).render(
|
||||
variables)
|
||||
user_prompt_reflect = environment.from_string(
|
||||
get_settings().pr_code_suggestions_reflect_prompt.user).render(variables)
|
||||
with get_logger().contextualize(command="self_reflect_on_suggestions"):
|
||||
response_reflect, finish_reason_reflect = await self.ai_handler.chat_completion(model=model,
|
||||
system=system_prompt_reflect,
|
||||
@ -851,4 +840,4 @@ class PRCodeSuggestions:
|
||||
except Exception as e:
|
||||
get_logger().info(f"Could not reflect on suggestions, error: {e}")
|
||||
return ""
|
||||
return response_reflect
|
||||
return response_reflect
|
||||
|
||||
@ -1,7 +1,6 @@
|
||||
import asyncio
|
||||
import copy
|
||||
import re
|
||||
import traceback
|
||||
from functools import partial
|
||||
from typing import List, Tuple
|
||||
|
||||
@ -58,7 +57,6 @@ class PRDescription:
|
||||
self.ai_handler.main_pr_language = self.main_pr_language
|
||||
|
||||
# Initialize the variables dictionary
|
||||
self.COLLAPSIBLE_FILE_LIST_THRESHOLD = get_settings().pr_description.get("collapsible_file_list_threshold", 8)
|
||||
self.vars = {
|
||||
"title": self.git_provider.pr.title,
|
||||
"branch": self.git_provider.get_pr_branch(),
|
||||
@ -71,7 +69,6 @@ class PRDescription:
|
||||
"custom_labels_class": "", # will be filled if necessary in 'set_custom_labels' function
|
||||
"enable_semantic_files_types": get_settings().pr_description.enable_semantic_files_types,
|
||||
"related_tickets": "",
|
||||
"include_file_summary_changes": len(self.git_provider.get_diff_files()) <= self.COLLAPSIBLE_FILE_LIST_THRESHOLD
|
||||
}
|
||||
|
||||
self.user_description = self.git_provider.get_user_description()
|
||||
@ -88,6 +85,7 @@ class PRDescription:
|
||||
self.patches_diff = None
|
||||
self.prediction = None
|
||||
self.file_label_dict = None
|
||||
self.COLLAPSIBLE_FILE_LIST_THRESHOLD = 8
|
||||
|
||||
async def run(self):
|
||||
try:
|
||||
@ -101,7 +99,7 @@ class PRDescription:
|
||||
# ticket extraction if exists
|
||||
await extract_and_cache_pr_tickets(self.git_provider, self.vars)
|
||||
|
||||
await retry_with_fallback_models(self._prepare_prediction, ModelType.WEAK)
|
||||
await retry_with_fallback_models(self._prepare_prediction, ModelType.TURBO)
|
||||
|
||||
if self.prediction:
|
||||
self._prepare_data()
|
||||
@ -116,8 +114,6 @@ class PRDescription:
|
||||
pr_labels, pr_file_changes = [], []
|
||||
if get_settings().pr_description.publish_labels:
|
||||
pr_labels = self._prepare_labels()
|
||||
else:
|
||||
get_logger().debug(f"Publishing labels disabled")
|
||||
|
||||
if get_settings().pr_description.use_description_markers:
|
||||
pr_title, pr_body, changes_walkthrough, pr_file_changes = self._prepare_pr_answer_with_markers()
|
||||
@ -141,7 +137,6 @@ class PRDescription:
|
||||
pr_body += show_relevant_configurations(relevant_section='pr_description')
|
||||
|
||||
if get_settings().config.publish_output:
|
||||
|
||||
# publish labels
|
||||
if get_settings().pr_description.publish_labels and pr_labels and self.git_provider.is_supported("get_labels"):
|
||||
original_labels = self.git_provider.get_pr_labels(update=True)
|
||||
@ -169,49 +164,43 @@ class PRDescription:
|
||||
self.git_provider.publish_description(pr_title, pr_body)
|
||||
|
||||
# publish final update message
|
||||
if (get_settings().pr_description.final_update_message and not get_settings().config.get('is_auto_command', False)):
|
||||
if (get_settings().pr_description.final_update_message):
|
||||
latest_commit_url = self.git_provider.get_latest_commit_url()
|
||||
if latest_commit_url:
|
||||
pr_url = self.git_provider.get_pr_url()
|
||||
update_comment = f"**[PR Description]({pr_url})** updated to latest commit ({latest_commit_url})"
|
||||
self.git_provider.publish_comment(update_comment)
|
||||
self.git_provider.remove_initial_comment()
|
||||
else:
|
||||
get_logger().info('PR description, but not published since publish_output is False.')
|
||||
get_settings().data = {"artifact": pr_body}
|
||||
return
|
||||
except Exception as e:
|
||||
get_logger().error(f"Error generating PR description {self.pr_id}: {e}",
|
||||
artifact={"traceback": traceback.format_exc()})
|
||||
get_logger().error(f"Error generating PR description {self.pr_id}: {e}")
|
||||
|
||||
return ""
|
||||
|
||||
async def _prepare_prediction(self, model: str) -> None:
|
||||
if get_settings().pr_description.use_description_markers and 'pr_agent:' not in self.user_description:
|
||||
get_logger().info("Markers were enabled, but user description does not contain markers. skipping AI prediction")
|
||||
get_logger().info(
|
||||
"Markers were enabled, but user description does not contain markers. skipping AI prediction")
|
||||
return None
|
||||
|
||||
large_pr_handling = get_settings().pr_description.enable_large_pr_handling and "pr_description_only_files_prompts" in get_settings()
|
||||
output = get_pr_diff(self.git_provider, self.token_handler, model, large_pr_handling=large_pr_handling, return_remaining_files=True)
|
||||
output = get_pr_diff(self.git_provider, self.token_handler, model, large_pr_handling=large_pr_handling,
|
||||
return_remaining_files=True)
|
||||
if isinstance(output, tuple):
|
||||
patches_diff, remaining_files_list = output
|
||||
else:
|
||||
patches_diff = output
|
||||
remaining_files_list = []
|
||||
|
||||
if not large_pr_handling or patches_diff:
|
||||
self.patches_diff = patches_diff
|
||||
if patches_diff:
|
||||
# generate the prediction
|
||||
get_logger().debug(f"PR diff", artifact=self.patches_diff)
|
||||
self.prediction = await self._get_prediction(model, patches_diff, prompt="pr_description_prompt")
|
||||
|
||||
# extend the prediction with additional files not shown
|
||||
if get_settings().pr_description.enable_semantic_files_types:
|
||||
self.prediction = await self.extend_uncovered_files(self.prediction)
|
||||
if (remaining_files_list and 'pr_files' in self.prediction and 'label:' in self.prediction and
|
||||
get_settings().pr_description.mention_extra_files):
|
||||
get_logger().debug(f"Extending additional files, {len(remaining_files_list)} files")
|
||||
self.prediction = await self.extend_additional_files(remaining_files_list)
|
||||
else:
|
||||
get_logger().error(f"Error getting PR diff {self.pr_id}",
|
||||
artifact={"traceback": traceback.format_exc()})
|
||||
get_logger().error(f"Error getting PR diff {self.pr_id}")
|
||||
self.prediction = None
|
||||
else:
|
||||
# get the diff in multiple patches, with the token handler only for the files prompt
|
||||
@ -296,81 +285,43 @@ class PRDescription:
|
||||
prompt="pr_description_only_description_prompts")
|
||||
prediction_headers = prediction_headers.strip().removeprefix('```yaml').strip('`').strip()
|
||||
|
||||
# extend the tables with the files not shown
|
||||
files_walkthrough_extended = await self.extend_uncovered_files(files_walkthrough)
|
||||
# manually add extra files to final prediction
|
||||
MAX_EXTRA_FILES_TO_OUTPUT = 100
|
||||
if get_settings().pr_description.mention_extra_files:
|
||||
for i, file in enumerate(remaining_files_list):
|
||||
extra_file_yaml = f"""\
|
||||
- filename: |
|
||||
{file}
|
||||
changes_summary: |
|
||||
...
|
||||
changes_title: |
|
||||
...
|
||||
label: |
|
||||
additional files (token-limit)
|
||||
"""
|
||||
files_walkthrough = files_walkthrough.strip() + "\n" + extra_file_yaml.strip()
|
||||
if i >= MAX_EXTRA_FILES_TO_OUTPUT:
|
||||
files_walkthrough += f"""\
|
||||
extra_file_yaml =
|
||||
- filename: |
|
||||
Additional {len(remaining_files_list) - MAX_EXTRA_FILES_TO_OUTPUT} files not shown
|
||||
changes_summary: |
|
||||
...
|
||||
changes_title: |
|
||||
...
|
||||
label: |
|
||||
additional files (token-limit)
|
||||
"""
|
||||
break
|
||||
|
||||
# final processing
|
||||
self.prediction = prediction_headers + "\n" + "pr_files:\n" + files_walkthrough_extended
|
||||
self.prediction = prediction_headers + "\n" + "pr_files:\n" + files_walkthrough
|
||||
if not load_yaml(self.prediction, keys_fix_yaml=self.keys_fix):
|
||||
get_logger().error(f"Error getting valid YAML in large PR handling for describe {self.pr_id}")
|
||||
if load_yaml(prediction_headers, keys_fix_yaml=self.keys_fix):
|
||||
get_logger().debug(f"Using only headers for describe {self.pr_id}")
|
||||
self.prediction = prediction_headers
|
||||
|
||||
async def extend_uncovered_files(self, original_prediction: str) -> str:
|
||||
try:
|
||||
prediction = original_prediction
|
||||
|
||||
# get the original prediction filenames
|
||||
original_prediction_loaded = load_yaml(original_prediction, keys_fix_yaml=self.keys_fix)
|
||||
if isinstance(original_prediction_loaded, list):
|
||||
original_prediction_dict = {"pr_files": original_prediction_loaded}
|
||||
else:
|
||||
original_prediction_dict = original_prediction_loaded
|
||||
filenames_predicted = [file['filename'].strip() for file in original_prediction_dict.get('pr_files', [])]
|
||||
|
||||
# extend the prediction with additional files not included in the original prediction
|
||||
pr_files = self.git_provider.get_diff_files()
|
||||
prediction_extra = "pr_files:"
|
||||
MAX_EXTRA_FILES_TO_OUTPUT = 100
|
||||
counter_extra_files = 0
|
||||
for file in pr_files:
|
||||
if file.filename in filenames_predicted:
|
||||
continue
|
||||
|
||||
# add up to MAX_EXTRA_FILES_TO_OUTPUT files
|
||||
counter_extra_files += 1
|
||||
if counter_extra_files > MAX_EXTRA_FILES_TO_OUTPUT:
|
||||
extra_file_yaml = f"""\
|
||||
- filename: |
|
||||
Additional files not shown
|
||||
changes_title: |
|
||||
...
|
||||
label: |
|
||||
additional files
|
||||
"""
|
||||
prediction_extra = prediction_extra + "\n" + extra_file_yaml.strip()
|
||||
get_logger().debug(f"Too many remaining files, clipping to {MAX_EXTRA_FILES_TO_OUTPUT}")
|
||||
break
|
||||
|
||||
extra_file_yaml = f"""\
|
||||
- filename: |
|
||||
{file.filename}
|
||||
changes_title: |
|
||||
...
|
||||
label: |
|
||||
additional files
|
||||
"""
|
||||
prediction_extra = prediction_extra + "\n" + extra_file_yaml.strip()
|
||||
|
||||
# merge the two dictionaries
|
||||
if counter_extra_files > 0:
|
||||
get_logger().info(f"Adding {counter_extra_files} unprocessed extra files to table prediction")
|
||||
prediction_extra_dict = load_yaml(prediction_extra, keys_fix_yaml=self.keys_fix)
|
||||
if isinstance(original_prediction_dict, dict) and isinstance(prediction_extra_dict, dict):
|
||||
original_prediction_dict["pr_files"].extend(prediction_extra_dict["pr_files"])
|
||||
new_yaml = yaml.dump(original_prediction_dict)
|
||||
if load_yaml(new_yaml, keys_fix_yaml=self.keys_fix):
|
||||
prediction = new_yaml
|
||||
if isinstance(original_prediction, list):
|
||||
prediction = yaml.dump(original_prediction_dict["pr_files"])
|
||||
|
||||
return prediction
|
||||
except Exception as e:
|
||||
get_logger().error(f"Error extending uncovered files {self.pr_id}: {e}")
|
||||
return original_prediction
|
||||
|
||||
|
||||
async def extend_additional_files(self, remaining_files_list) -> str:
|
||||
prediction = self.prediction
|
||||
try:
|
||||
@ -442,31 +393,31 @@ class PRDescription:
|
||||
self.data['pr_files'] = self.data.pop('pr_files')
|
||||
|
||||
def _prepare_labels(self) -> List[str]:
|
||||
pr_labels = []
|
||||
pr_types = []
|
||||
|
||||
# If the 'PR Type' key is present in the dictionary, split its value by comma and assign it to 'pr_types'
|
||||
if 'labels' in self.data and self.data['labels']:
|
||||
if 'labels' in self.data:
|
||||
if type(self.data['labels']) == list:
|
||||
pr_labels = self.data['labels']
|
||||
pr_types = self.data['labels']
|
||||
elif type(self.data['labels']) == str:
|
||||
pr_labels = self.data['labels'].split(',')
|
||||
elif 'type' in self.data and self.data['type'] and get_settings().pr_description.publish_labels:
|
||||
pr_types = self.data['labels'].split(',')
|
||||
elif 'type' in self.data:
|
||||
if type(self.data['type']) == list:
|
||||
pr_labels = self.data['type']
|
||||
pr_types = self.data['type']
|
||||
elif type(self.data['type']) == str:
|
||||
pr_labels = self.data['type'].split(',')
|
||||
pr_labels = [label.strip() for label in pr_labels]
|
||||
pr_types = self.data['type'].split(',')
|
||||
pr_types = [label.strip() for label in pr_types]
|
||||
|
||||
# convert lowercase labels to original case
|
||||
try:
|
||||
if "labels_minimal_to_labels_dict" in self.variables:
|
||||
d: dict = self.variables["labels_minimal_to_labels_dict"]
|
||||
for i, label_i in enumerate(pr_labels):
|
||||
for i, label_i in enumerate(pr_types):
|
||||
if label_i in d:
|
||||
pr_labels[i] = d[label_i]
|
||||
pr_types[i] = d[label_i]
|
||||
except Exception as e:
|
||||
get_logger().error(f"Error converting labels to original case {self.pr_id}: {e}")
|
||||
return pr_labels
|
||||
return pr_types
|
||||
|
||||
def _prepare_pr_answer_with_markers(self) -> Tuple[str, str, str, List[dict]]:
|
||||
get_logger().info(f"Using description marker replacements {self.pr_id}")
|
||||
@ -573,18 +524,14 @@ class PRDescription:
|
||||
return file_label_dict
|
||||
for file in self.data['pr_files']:
|
||||
try:
|
||||
required_fields = ['changes_title', 'filename', 'label']
|
||||
required_fields = ['changes_summary', 'changes_title', 'filename', 'label']
|
||||
if not all(field in file for field in required_fields):
|
||||
# can happen for example if a YAML generation was interrupted in the middle (no more tokens)
|
||||
get_logger().warning(f"Missing required fields in file label dict {self.pr_id}, skipping file",
|
||||
artifact={"file": file})
|
||||
continue
|
||||
if not file.get('changes_title'):
|
||||
get_logger().warning(f"Empty changes title or summary in file label dict {self.pr_id}, skipping file",
|
||||
artifact={"file": file})
|
||||
continue
|
||||
filename = file['filename'].replace("'", "`").replace('"', '`')
|
||||
changes_summary = file.get('changes_summary', "").strip()
|
||||
changes_summary = file['changes_summary']
|
||||
changes_title = file['changes_title'].strip()
|
||||
label = file.get('label').strip().lower()
|
||||
if label not in file_label_dict:
|
||||
@ -627,14 +574,12 @@ class PRDescription:
|
||||
for filename, file_changes_title, file_change_description in list_tuples:
|
||||
filename = filename.replace("'", "`").rstrip()
|
||||
filename_publish = filename.split("/")[-1]
|
||||
if file_changes_title and file_changes_title.strip() != "...":
|
||||
file_changes_title_code = f"<code>{file_changes_title}</code>"
|
||||
file_changes_title_code_br = insert_br_after_x_chars(file_changes_title_code, x=(delta - 5)).strip()
|
||||
if len(file_changes_title_code_br) < (delta - 5):
|
||||
file_changes_title_code_br += " " * ((delta - 5) - len(file_changes_title_code_br))
|
||||
filename_publish = f"<strong>{filename_publish}</strong><dd>{file_changes_title_code_br}</dd>"
|
||||
else:
|
||||
filename_publish = f"<strong>{filename_publish}</strong>"
|
||||
|
||||
file_changes_title_code = f"<code>{file_changes_title}</code>"
|
||||
file_changes_title_code_br = insert_br_after_x_chars(file_changes_title_code, x=(delta - 5)).strip()
|
||||
if len(file_changes_title_code_br) < (delta - 5):
|
||||
file_changes_title_code_br += " " * ((delta - 5) - len(file_changes_title_code_br))
|
||||
filename_publish = f"<strong>{filename_publish}</strong><dd>{file_changes_title_code_br}</dd>"
|
||||
diff_plus_minus = ""
|
||||
delta_nbsp = ""
|
||||
diff_files = self.git_provider.get_diff_files()
|
||||
@ -643,8 +588,6 @@ class PRDescription:
|
||||
num_plus_lines = f.num_plus_lines
|
||||
num_minus_lines = f.num_minus_lines
|
||||
diff_plus_minus += f"+{num_plus_lines}/-{num_minus_lines}"
|
||||
if len(diff_plus_minus) > 12 or diff_plus_minus == "+0/-0":
|
||||
diff_plus_minus = "[link]"
|
||||
delta_nbsp = " " * max(0, (8 - len(diff_plus_minus)))
|
||||
break
|
||||
|
||||
@ -653,40 +596,9 @@ class PRDescription:
|
||||
if hasattr(self.git_provider, 'get_line_link'):
|
||||
filename = filename.strip()
|
||||
link = self.git_provider.get_line_link(filename, relevant_line_start=-1)
|
||||
if (not link or not diff_plus_minus) and ('additional files' not in filename.lower()):
|
||||
get_logger().warning(f"Error getting line link for '{filename}'")
|
||||
continue
|
||||
|
||||
# Add file data to the PR body
|
||||
file_change_description_br = insert_br_after_x_chars(file_change_description, x=(delta - 5))
|
||||
pr_body = self.add_file_data(delta_nbsp, diff_plus_minus, file_change_description_br, filename,
|
||||
filename_publish, link, pr_body)
|
||||
|
||||
# Close the collapsible file list
|
||||
if use_collapsible_file_list:
|
||||
pr_body += """</table></details></td></tr>"""
|
||||
else:
|
||||
pr_body += """</table></td></tr>"""
|
||||
pr_body += """</tr></tbody></table>"""
|
||||
|
||||
except Exception as e:
|
||||
get_logger().error(f"Error processing pr files to markdown {self.pr_id}: {str(e)}")
|
||||
pass
|
||||
return pr_body, pr_comments
|
||||
|
||||
def add_file_data(self, delta_nbsp, diff_plus_minus, file_change_description_br, filename, filename_publish, link,
|
||||
pr_body) -> str:
|
||||
|
||||
if not file_change_description_br:
|
||||
pr_body += f"""
|
||||
<tr>
|
||||
<td>{filename_publish}</td>
|
||||
<td><a href="{link}">{diff_plus_minus}</a>{delta_nbsp}</td>
|
||||
|
||||
</tr>
|
||||
"""
|
||||
else:
|
||||
pr_body += f"""
|
||||
pr_body += f"""
|
||||
<tr>
|
||||
<td>
|
||||
<details>
|
||||
@ -706,7 +618,17 @@ class PRDescription:
|
||||
|
||||
</tr>
|
||||
"""
|
||||
return pr_body
|
||||
if use_collapsible_file_list:
|
||||
pr_body += """</table></details></td></tr>"""
|
||||
else:
|
||||
pr_body += """</table></td></tr>"""
|
||||
pr_body += """</tr></tbody></table>"""
|
||||
|
||||
except Exception as e:
|
||||
get_logger().error(f"Error processing pr files to markdown {self.pr_id}: {e}")
|
||||
pass
|
||||
return pr_body, pr_comments
|
||||
|
||||
|
||||
def count_chars_without_html(string):
|
||||
if '<' not in string:
|
||||
@ -715,14 +637,11 @@ def count_chars_without_html(string):
|
||||
return len(no_html_string)
|
||||
|
||||
|
||||
def insert_br_after_x_chars(text: str, x=70):
|
||||
def insert_br_after_x_chars(text, x=70):
|
||||
"""
|
||||
Insert <br> into a string after a word that increases its length above x characters.
|
||||
Use proper HTML tags for code and new lines.
|
||||
"""
|
||||
|
||||
if not text:
|
||||
return ""
|
||||
if count_chars_without_html(text) < x:
|
||||
return text
|
||||
|
||||
|
||||
@ -114,7 +114,7 @@ class PRHelpMessage:
|
||||
self.vars['snippets'] = docs_prompt.strip()
|
||||
|
||||
# run the AI model
|
||||
response = await retry_with_fallback_models(self._prepare_prediction, model_type=ModelType.WEAK)
|
||||
response = await retry_with_fallback_models(self._prepare_prediction, model_type=ModelType.REGULAR)
|
||||
response_yaml = load_yaml(response)
|
||||
response_str = response_yaml.get('response')
|
||||
relevant_sections = response_yaml.get('relevant_sections')
|
||||
|
||||
79
pr_agent/tools/pr_information_from_user.py
Normal file
79
pr_agent/tools/pr_information_from_user.py
Normal file
@ -0,0 +1,79 @@
|
||||
import copy
|
||||
from functools import partial
|
||||
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
|
||||
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||
from pr_agent.algo.ai_handlers.litellm_ai_handler import LiteLLMAIHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers import get_git_provider
|
||||
from pr_agent.git_providers.git_provider import get_main_pr_language
|
||||
from pr_agent.log import get_logger
|
||||
|
||||
|
||||
class PRInformationFromUser:
|
||||
def __init__(self, pr_url: str, args: list = None,
|
||||
ai_handler: partial[BaseAiHandler,] = LiteLLMAIHandler):
|
||||
self.git_provider = get_git_provider()(pr_url)
|
||||
self.main_pr_language = get_main_pr_language(
|
||||
self.git_provider.get_languages(), self.git_provider.get_files()
|
||||
)
|
||||
self.ai_handler = ai_handler()
|
||||
self.ai_handler.main_pr_language = self.main_pr_language
|
||||
|
||||
self.vars = {
|
||||
"title": self.git_provider.pr.title,
|
||||
"branch": self.git_provider.get_pr_branch(),
|
||||
"description": self.git_provider.get_pr_description(),
|
||||
"language": self.main_pr_language,
|
||||
"diff": "", # empty diff for initial calculation
|
||||
"commit_messages_str": self.git_provider.get_commit_messages(),
|
||||
}
|
||||
self.token_handler = TokenHandler(self.git_provider.pr,
|
||||
self.vars,
|
||||
get_settings().pr_information_from_user_prompt.system,
|
||||
get_settings().pr_information_from_user_prompt.user)
|
||||
self.patches_diff = None
|
||||
self.prediction = None
|
||||
|
||||
async def run(self):
|
||||
get_logger().info('Generating question to the user...')
|
||||
if get_settings().config.publish_output:
|
||||
self.git_provider.publish_comment("Preparing questions...", is_temporary=True)
|
||||
await retry_with_fallback_models(self._prepare_prediction)
|
||||
get_logger().info('Preparing questions...')
|
||||
pr_comment = self._prepare_pr_answer()
|
||||
if get_settings().config.publish_output:
|
||||
get_logger().info('Pushing questions...')
|
||||
self.git_provider.publish_comment(pr_comment)
|
||||
self.git_provider.remove_initial_comment()
|
||||
return ""
|
||||
|
||||
async def _prepare_prediction(self, model):
|
||||
get_logger().info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler, model)
|
||||
get_logger().info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction(model)
|
||||
|
||||
async def _get_prediction(self, model: str):
|
||||
variables = copy.deepcopy(self.vars)
|
||||
variables["diff"] = self.patches_diff # update diff
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
system_prompt = environment.from_string(get_settings().pr_information_from_user_prompt.system).render(variables)
|
||||
user_prompt = environment.from_string(get_settings().pr_information_from_user_prompt.user).render(variables)
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().info(f"\nSystem prompt:\n{system_prompt}")
|
||||
get_logger().info(f"\nUser prompt:\n{user_prompt}")
|
||||
response, finish_reason = await self.ai_handler.chat_completion(
|
||||
model=model, temperature=get_settings().config.temperature, system=system_prompt, user=user_prompt)
|
||||
return response
|
||||
|
||||
def _prepare_pr_answer(self) -> str:
|
||||
model_output = self.prediction.strip()
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().info(f"answer_str:\n{model_output}")
|
||||
answer_str = f"{model_output}\n\n Please respond to the questions above in the following format:\n\n" +\
|
||||
"\n>/answer\n>1) ...\n>2) ...\n>...\n"
|
||||
return answer_str
|
||||
@ -79,17 +79,13 @@ class PR_LineQuestions:
|
||||
line_end=line_end,
|
||||
side=side)
|
||||
if self.patch_with_lines:
|
||||
model_answer = await retry_with_fallback_models(self._get_prediction, model_type=ModelType.WEAK)
|
||||
# sanitize the answer so that no line will start with "/"
|
||||
model_answer_sanitized = model_answer.strip().replace("\n/", "\n /")
|
||||
if model_answer_sanitized.startswith("/"):
|
||||
model_answer_sanitized = " " + model_answer_sanitized
|
||||
response = await retry_with_fallback_models(self._get_prediction, model_type=ModelType.TURBO)
|
||||
|
||||
get_logger().info('Preparing answer...')
|
||||
if comment_id:
|
||||
self.git_provider.reply_to_comment_from_comment_id(comment_id, model_answer_sanitized)
|
||||
self.git_provider.reply_to_comment_from_comment_id(comment_id, response)
|
||||
else:
|
||||
self.git_provider.publish_comment(model_answer_sanitized)
|
||||
self.git_provider.publish_comment(response)
|
||||
|
||||
return ""
|
||||
|
||||
|
||||
@ -63,7 +63,7 @@ class PRQuestions:
|
||||
if img_path:
|
||||
get_logger().debug(f"Image path identified", artifact=img_path)
|
||||
|
||||
await retry_with_fallback_models(self._prepare_prediction, model_type=ModelType.WEAK)
|
||||
await retry_with_fallback_models(self._prepare_prediction, model_type=ModelType.TURBO)
|
||||
|
||||
pr_comment = self._prepare_pr_answer()
|
||||
get_logger().debug(f"PR output", artifact=pr_comment)
|
||||
@ -117,16 +117,6 @@ class PRQuestions:
|
||||
return response
|
||||
|
||||
def _prepare_pr_answer(self) -> str:
|
||||
model_answer = self.prediction.strip()
|
||||
# sanitize the answer so that no line will start with "/"
|
||||
model_answer_sanitized = model_answer.replace("\n/", "\n /")
|
||||
if model_answer_sanitized.startswith("/"):
|
||||
model_answer_sanitized = " " + model_answer_sanitized
|
||||
if model_answer_sanitized != model_answer:
|
||||
get_logger().debug(f"Sanitized model answer",
|
||||
artifact={"model_answer": model_answer, "sanitized_answer": model_answer_sanitized})
|
||||
|
||||
|
||||
answer_str = f"### **Ask**❓\n{self.question_str}\n\n"
|
||||
answer_str += f"### **Answer:**\n{model_answer_sanitized}\n\n"
|
||||
answer_str += f"### **Answer:**\n{self.prediction.strip()}\n\n"
|
||||
return answer_str
|
||||
|
||||
@ -86,6 +86,7 @@ class PRReviewer:
|
||||
"require_estimate_effort_to_review": get_settings().pr_reviewer.require_estimate_effort_to_review,
|
||||
'require_can_be_split_review': get_settings().pr_reviewer.require_can_be_split_review,
|
||||
'require_security_review': get_settings().pr_reviewer.require_security_review,
|
||||
'num_code_suggestions': get_settings().pr_reviewer.num_code_suggestions,
|
||||
'question_str': question_str,
|
||||
'answer_str': answer_str,
|
||||
"extra_instructions": get_settings().pr_reviewer.extra_instructions,
|
||||
@ -147,7 +148,7 @@ class PRReviewer:
|
||||
if get_settings().config.publish_output and not get_settings().config.get('is_auto_command', False):
|
||||
self.git_provider.publish_comment("Preparing review...", is_temporary=True)
|
||||
|
||||
await retry_with_fallback_models(self._prepare_prediction, model_type=ModelType.REGULAR)
|
||||
await retry_with_fallback_models(self._prepare_prediction)
|
||||
if not self.prediction:
|
||||
self.git_provider.remove_initial_comment()
|
||||
return None
|
||||
@ -167,10 +168,8 @@ class PRReviewer:
|
||||
self.git_provider.publish_comment(pr_review)
|
||||
|
||||
self.git_provider.remove_initial_comment()
|
||||
else:
|
||||
get_logger().info("Review output is not published")
|
||||
get_settings().data = {"artifact": pr_review}
|
||||
return
|
||||
if get_settings().pr_reviewer.inline_code_comments:
|
||||
self._publish_inline_code_comments()
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to review PR: {e}")
|
||||
|
||||
@ -232,6 +231,33 @@ class PRReviewer:
|
||||
key_issues_to_review = data['review'].pop('key_issues_to_review')
|
||||
data['review']['key_issues_to_review'] = key_issues_to_review
|
||||
|
||||
if 'code_feedback' in data:
|
||||
code_feedback = data['code_feedback']
|
||||
|
||||
# Filter out code suggestions that can be submitted as inline comments
|
||||
if get_settings().pr_reviewer.inline_code_comments:
|
||||
del data['code_feedback']
|
||||
else:
|
||||
for suggestion in code_feedback:
|
||||
if ('relevant_file' in suggestion) and (not suggestion['relevant_file'].startswith('``')):
|
||||
suggestion['relevant_file'] = f"``{suggestion['relevant_file']}``"
|
||||
|
||||
if 'relevant_line' not in suggestion:
|
||||
suggestion['relevant_line'] = ''
|
||||
|
||||
relevant_line_str = suggestion['relevant_line'].split('\n')[0]
|
||||
|
||||
# removing '+'
|
||||
suggestion['relevant_line'] = relevant_line_str.lstrip('+').strip()
|
||||
|
||||
# try to add line numbers link to code suggestions
|
||||
if hasattr(self.git_provider, 'generate_link_to_relevant_line_number'):
|
||||
link = self.git_provider.generate_link_to_relevant_line_number(suggestion)
|
||||
if link:
|
||||
suggestion['relevant_line'] = f"[{suggestion['relevant_line']}]({link})"
|
||||
else:
|
||||
pass
|
||||
|
||||
incremental_review_markdown_text = None
|
||||
# Add incremental review section
|
||||
if self.incremental.is_incremental:
|
||||
@ -240,9 +266,7 @@ class PRReviewer:
|
||||
incremental_review_markdown_text = f"Starting from commit {last_commit_url}"
|
||||
|
||||
markdown_text = convert_to_markdown_v2(data, self.git_provider.is_supported("gfm_markdown"),
|
||||
incremental_review_markdown_text,
|
||||
git_provider=self.git_provider,
|
||||
files=self.git_provider.get_diff_files())
|
||||
incremental_review_markdown_text, git_provider=self.git_provider)
|
||||
|
||||
# Add help text if gfm_markdown is supported
|
||||
if self.git_provider.is_supported("gfm_markdown") and get_settings().pr_reviewer.enable_help_text:
|
||||
@ -262,6 +286,38 @@ class PRReviewer:
|
||||
|
||||
return markdown_text
|
||||
|
||||
def _publish_inline_code_comments(self) -> None:
|
||||
"""
|
||||
Publishes inline comments on a pull request with code suggestions generated by the AI model.
|
||||
"""
|
||||
if get_settings().pr_reviewer.num_code_suggestions == 0:
|
||||
return
|
||||
|
||||
first_key = 'review'
|
||||
last_key = 'security_concerns'
|
||||
data = load_yaml(self.prediction.strip(),
|
||||
keys_fix_yaml=["ticket_compliance_check", "estimated_effort_to_review_[1-5]:", "security_concerns:", "key_issues_to_review:",
|
||||
"relevant_file:", "relevant_line:", "suggestion:"],
|
||||
first_key=first_key, last_key=last_key)
|
||||
comments: List[str] = []
|
||||
for suggestion in data.get('code_feedback', []):
|
||||
relevant_file = suggestion.get('relevant_file', '').strip()
|
||||
relevant_line_in_file = suggestion.get('relevant_line', '').strip()
|
||||
content = suggestion.get('suggestion', '')
|
||||
if not relevant_file or not relevant_line_in_file or not content:
|
||||
get_logger().info("Skipping inline comment with missing file/line/content")
|
||||
continue
|
||||
|
||||
if self.git_provider.is_supported("create_inline_comment"):
|
||||
comment = self.git_provider.create_inline_comment(content, relevant_file, relevant_line_in_file)
|
||||
if comment:
|
||||
comments.append(comment)
|
||||
else:
|
||||
self.git_provider.publish_inline_comment(content, relevant_file, relevant_line_in_file, suggestion)
|
||||
|
||||
if comments:
|
||||
self.git_provider.publish_inline_comments(comments)
|
||||
|
||||
def _get_user_answers(self) -> Tuple[str, str]:
|
||||
"""
|
||||
Retrieves the question and answer strings from the discussion messages related to a pull request.
|
||||
|
||||
@ -41,7 +41,6 @@ class PRUpdateChangelog:
|
||||
"description": self.git_provider.get_pr_description(),
|
||||
"language": self.main_language,
|
||||
"diff": "", # empty diff for initial calculation
|
||||
"pr_link": "",
|
||||
"changelog_file_str": self.changelog_file_str,
|
||||
"today": date.today(),
|
||||
"extra_instructions": get_settings().pr_update_changelog.extra_instructions,
|
||||
@ -74,7 +73,7 @@ class PRUpdateChangelog:
|
||||
if get_settings().config.publish_output:
|
||||
self.git_provider.publish_comment("Preparing changelog updates...", is_temporary=True)
|
||||
|
||||
await retry_with_fallback_models(self._prepare_prediction, model_type=ModelType.WEAK)
|
||||
await retry_with_fallback_models(self._prepare_prediction, model_type=ModelType.TURBO)
|
||||
|
||||
new_file_content, answer = self._prepare_changelog_update()
|
||||
|
||||
@ -103,23 +102,12 @@ class PRUpdateChangelog:
|
||||
async def _get_prediction(self, model: str):
|
||||
variables = copy.deepcopy(self.vars)
|
||||
variables["diff"] = self.patches_diff # update diff
|
||||
if get_settings().pr_update_changelog.add_pr_link:
|
||||
variables["pr_link"] = self.git_provider.get_pr_url()
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
system_prompt = environment.from_string(get_settings().pr_update_changelog_prompt.system).render(variables)
|
||||
user_prompt = environment.from_string(get_settings().pr_update_changelog_prompt.user).render(variables)
|
||||
response, finish_reason = await self.ai_handler.chat_completion(
|
||||
model=model, system=system_prompt, user=user_prompt, temperature=get_settings().config.temperature)
|
||||
|
||||
# post-process the response
|
||||
response = response.strip()
|
||||
if not response:
|
||||
return ""
|
||||
if response.startswith("```"):
|
||||
response_lines = response.splitlines()
|
||||
response_lines = response_lines[1:]
|
||||
response = "\n".join(response_lines)
|
||||
response = response.strip("`")
|
||||
return response
|
||||
|
||||
def _prepare_changelog_update(self) -> Tuple[str, str]:
|
||||
|
||||
@ -4,7 +4,7 @@ build-backend = "setuptools.build_meta"
|
||||
|
||||
[project]
|
||||
name = "pr-agent"
|
||||
version = "0.2.5"
|
||||
version = "0.2.4"
|
||||
|
||||
authors = [{ name = "CodiumAI", email = "tal.r@codium.ai" }]
|
||||
|
||||
|
||||
@ -1,70 +0,0 @@
|
||||
import argparse
|
||||
import asyncio
|
||||
import copy
|
||||
import os
|
||||
from pathlib import Path
|
||||
|
||||
from starlette_context import request_cycle_context, context
|
||||
|
||||
from pr_agent.cli import run_command
|
||||
from pr_agent.config_loader import get_settings, global_settings
|
||||
|
||||
from pr_agent.agent.pr_agent import PRAgent, commands
|
||||
from pr_agent.log import get_logger, setup_logger
|
||||
from tests.e2e_tests import e2e_utils
|
||||
|
||||
log_level = os.environ.get("LOG_LEVEL", "INFO")
|
||||
setup_logger(log_level)
|
||||
|
||||
|
||||
async def run_async():
|
||||
pr_url = os.getenv('TEST_PR_URL', 'https://github.com/Codium-ai/pr-agent/pull/1385')
|
||||
|
||||
get_settings().set("config.git_provider", "github")
|
||||
get_settings().set("config.publish_output", False)
|
||||
get_settings().set("config.fallback_models", [])
|
||||
|
||||
agent = PRAgent()
|
||||
try:
|
||||
# Run the 'describe' command
|
||||
get_logger().info(f"\nSanity check for the 'describe' command...")
|
||||
original_settings = copy.deepcopy(get_settings())
|
||||
await agent.handle_request(pr_url, ['describe'])
|
||||
pr_header_body = dict(get_settings().data)['artifact']
|
||||
assert pr_header_body.startswith('###') and 'PR Type' in pr_header_body and 'Description' in pr_header_body
|
||||
context['settings'] = copy.deepcopy(original_settings) # Restore settings state after each test to prevent test interference
|
||||
get_logger().info("PR description generated successfully\n")
|
||||
|
||||
# Run the 'review' command
|
||||
get_logger().info(f"\nSanity check for the 'review' command...")
|
||||
original_settings = copy.deepcopy(get_settings())
|
||||
await agent.handle_request(pr_url, ['review'])
|
||||
pr_review_body = dict(get_settings().data)['artifact']
|
||||
assert pr_review_body.startswith('##') and 'PR Reviewer Guide' in pr_review_body
|
||||
context['settings'] = copy.deepcopy(original_settings) # Restore settings state after each test to prevent test interference
|
||||
get_logger().info("PR review generated successfully\n")
|
||||
|
||||
# Run the 'improve' command
|
||||
get_logger().info(f"\nSanity check for the 'improve' command...")
|
||||
original_settings = copy.deepcopy(get_settings())
|
||||
await agent.handle_request(pr_url, ['improve'])
|
||||
pr_improve_body = dict(get_settings().data)['artifact']
|
||||
assert pr_improve_body.startswith('##') and 'PR Code Suggestions' in pr_improve_body
|
||||
context['settings'] = copy.deepcopy(original_settings) # Restore settings state after each test to prevent test interference
|
||||
get_logger().info("PR improvements generated successfully\n")
|
||||
|
||||
get_logger().info(f"\n\n========\nHealth test passed successfully\n========")
|
||||
|
||||
except Exception as e:
|
||||
get_logger().exception(f"\n\n========\nHealth test failed\n========")
|
||||
raise e
|
||||
|
||||
|
||||
def run():
|
||||
with request_cycle_context({}):
|
||||
context['settings'] = copy.deepcopy(global_settings)
|
||||
asyncio.run(run_async())
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
run()
|
||||
@ -47,10 +47,13 @@ class TestConvertToMarkdown:
|
||||
def test_simple_dictionary_input(self):
|
||||
input_data = {'review': {
|
||||
'estimated_effort_to_review_[1-5]': '1, because the changes are minimal and straightforward, focusing on a single functionality addition.\n',
|
||||
'relevant_tests': 'No\n', 'possible_issues': 'No\n', 'security_concerns': 'No\n'}}
|
||||
'relevant_tests': 'No\n', 'possible_issues': 'No\n', 'security_concerns': 'No\n'}, 'code_feedback': [
|
||||
{'relevant_file': '``pr_agent/git_providers/git_provider.py\n``', 'language': 'python\n',
|
||||
'suggestion': "Consider raising an exception or logging a warning when 'pr_url' attribute is not found. This can help in debugging issues related to the absence of 'pr_url' in instances where it's expected. [important]\n",
|
||||
'relevant_line': '[return ""](https://github.com/Codium-ai/pr-agent-pro/pull/102/files#diff-52d45f12b836f77ed1aef86e972e65404634ea4e2a6083fb71a9b0f9bb9e062fR199)'}]}
|
||||
|
||||
|
||||
expected_output = f'{PRReviewHeader.REGULAR.value} 🔍\n\nHere are some key observations to aid the review process:\n\n<table>\n<tr><td>⏱️ <strong>Estimated effort to review</strong>: 1 🔵⚪⚪⚪⚪</td></tr>\n<tr><td>🧪 <strong>No relevant tests</strong></td></tr>\n<tr><td> <strong>Possible issues</strong>: No\n</td></tr>\n<tr><td>🔒 <strong>No security concerns identified</strong></td></tr>\n</table>'
|
||||
expected_output = f'{PRReviewHeader.REGULAR.value} 🔍\n\nHere are some key observations to aid the review process:\n\n<table>\n<tr><td>⏱️ <strong>Estimated effort to review</strong>: 1 🔵⚪⚪⚪⚪</td></tr>\n<tr><td>🧪 <strong>No relevant tests</strong></td></tr>\n<tr><td> <strong>Possible issues</strong>: No\n</td></tr>\n<tr><td>🔒 <strong>No security concerns identified</strong></td></tr>\n</table>\n\n\n<details><summary> <strong>Code feedback:</strong></summary>\n\n<hr><table><tr><td>relevant file</td><td>pr_agent/git_providers/git_provider.py\n</td></tr><tr><td>suggestion </td><td>\n\n<strong>\n\nConsider raising an exception or logging a warning when \'pr_url\' attribute is not found. This can help in debugging issues related to the absence of \'pr_url\' in instances where it\'s expected. [important]\n\n</strong>\n</td></tr><tr><td>relevant line</td><td><a href=\'https://github.com/Codium-ai/pr-agent-pro/pull/102/files#diff-52d45f12b836f77ed1aef86e972e65404634ea4e2a6083fb71a9b0f9bb9e062fR199\'>return ""</a></td></tr></table><hr>\n\n</details>'
|
||||
|
||||
assert convert_to_markdown_v2(input_data).strip() == expected_output.strip()
|
||||
|
||||
@ -64,7 +67,7 @@ class TestConvertToMarkdown:
|
||||
assert convert_to_markdown_v2(input_data).strip() == expected_output.strip()
|
||||
|
||||
def test_dictionary_with_empty_dictionaries(self):
|
||||
input_data = {'review': {}}
|
||||
input_data = {'review': {}, 'code_feedback': [{}]}
|
||||
|
||||
expected_output = ''
|
||||
|
||||
|
||||
Reference in New Issue
Block a user