mirror of
https://github.com/qodo-ai/pr-agent.git
synced 2025-07-21 04:50:39 +08:00
Compare commits
111 Commits
v0.24
...
mrT23-patc
| Author | SHA1 | Date | |
|---|---|---|---|
| 621cfe5595 | |||
| b447080777 | |||
| da398ce56f | |||
| 16763d81b4 | |||
| 80fe297bc9 | |||
| 5d68b0c492 | |||
| 8d5f015e5c | |||
| be03f83318 | |||
| cbfd250c0c | |||
| 7ce46e65a1 | |||
| 600f230ba7 | |||
| 4f4f13b8b2 | |||
| 146b8823a9 | |||
| fdb1ff8057 | |||
| ce8e637800 | |||
| 306af02d22 | |||
| a23541912b | |||
| 0851767774 | |||
| 585a7f1c69 | |||
| 8d82cb2e04 | |||
| 7586514abf | |||
| 480a025877 | |||
| 8f943a0d44 | |||
| 2102c51422 | |||
| 29028d43cf | |||
| 95d1b0d0c5 | |||
| cc0e432247 | |||
| 0fb158fd47 | |||
| 867a430a38 | |||
| a94496285f | |||
| 567c144176 | |||
| c08b59a74d | |||
| 0ba81e1ac7 | |||
| 2cb0dd2496 | |||
| a8367d1a22 | |||
| 1a3345c6e6 | |||
| 564845adff | |||
| 3ea691e70a | |||
| 5047d076f8 | |||
| 7de6bb0150 | |||
| a1582b5338 | |||
| dd8d78e7d8 | |||
| 5af6cc7538 | |||
| 6cc562d6a2 | |||
| 19b051b992 | |||
| be68ee89f3 | |||
| db6c75a130 | |||
| 74688846e0 | |||
| 09b0a04a47 | |||
| cc1b65f886 | |||
| 1451d82d6b | |||
| 01ba6fe63d | |||
| 74f9da1135 | |||
| f80c2ae2c8 | |||
| e444da8378 | |||
| 25ad8a09ce | |||
| 897e791b1a | |||
| 7f94dda54e | |||
| 538a592882 | |||
| a3cb7277a7 | |||
| b5cd560402 | |||
| fd38c33fcb | |||
| f767a3dfde | |||
| 9f8b619858 | |||
| 8de16939ba | |||
| 6ed5537065 | |||
| 1a9638cf87 | |||
| 49521aafff | |||
| c8e8ed89d2 | |||
| ebc5cafb2b | |||
| 52e8d7bc6a | |||
| f7344fd787 | |||
| 86103c65e8 | |||
| a4658b9960 | |||
| 5fd831c448 | |||
| 332d3a0c5e | |||
| edef712b6a | |||
| 1831f2cec4 | |||
| 8706f643ef | |||
| 35a75095ea | |||
| 0aa296d03e | |||
| 24f7e8622f | |||
| d01cfe443c | |||
| 6150256040 | |||
| 147a8e0ef3 | |||
| 9199d84796 | |||
| 39913ef12a | |||
| d2a744e70c | |||
| be93c52380 | |||
| 7ccefca35e | |||
| 14b4723734 | |||
| c8f1c03061 | |||
| b02fa22948 | |||
| 85754d2d79 | |||
| f0d780c7ec | |||
| 19048ee705 | |||
| b8d2b263b9 | |||
| 6f17c08f72 | |||
| 65c0bc414f | |||
| 015719134f | |||
| 1ed6b7a54a | |||
| 14067a02db | |||
| be75bb6a16 | |||
| 883d945687 | |||
| 8090115f30 | |||
| 6fa226dee7 | |||
| 13c1cdbf90 | |||
| 2f7f60a469 | |||
| adce35765b | |||
| 23af1afa03 | |||
| fdcbdfce98 |
10
README.md
10
README.md
@ -43,9 +43,17 @@ CodiumAI PR-Agent aims to help efficiently review and handle pull requests, by p
|
||||
|
||||
## News and Updates
|
||||
|
||||
### September 12, 2024
|
||||
[Dynamic context](https://pr-agent-docs.codium.ai/core-abilities/dynamic_context/) is now the default option for context extension.
|
||||
This feature enables PR-Agent to dynamically adjusting the relevant context for each code hunk, while avoiding overflowing the model with too much information.
|
||||
|
||||
### September 3, 2024
|
||||
|
||||
New version of PR-Agent, v0.24 was released. See the [release notes](https://github.com/Codium-ai/pr-agent/releases/tag/v0.24) for more information.
|
||||
|
||||
### August 26, 2024
|
||||
|
||||
New version of [PR Agent Chrom Extension](https://chromewebstore.google.com/detail/pr-agent-chrome-extension/ephlnjeghhogofkifjloamocljapahnl) was released, with full support of context-aware **PR Chat**. This novel feature is free to use for any open-source repository. See more details in [here](https://pr-agent-docs.codium.ai/chrome-extension/#pr-chat).
|
||||
New version of [PR Agent Chrome Extension](https://chromewebstore.google.com/detail/pr-agent-chrome-extension/ephlnjeghhogofkifjloamocljapahnl) was released, with full support of context-aware **PR Chat**. This novel feature is free to use for any open-source repository. See more details in [here](https://pr-agent-docs.codium.ai/chrome-extension/#pr-chat).
|
||||
|
||||
<kbd><img src="https://www.codium.ai/images/pr_agent/pr_chat_1.png" width="768"></kbd>
|
||||
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
|
||||
### PR Chat
|
||||
### PR chat
|
||||
|
||||
The PR-Chat feature allows to freely chat with your PR code, within your GitHub environment.
|
||||
It will seamlessly add the PR code as context to your chat session, and provide AI-powered feedback.
|
||||
It will seamlessly use the PR as context to your chat session, and provide AI-powered feedback.
|
||||
|
||||
To enable private chat, simply install the PR-Agent Chrome extension. After installation, each PR's file-changed tab will include a chat box, where you may ask questions about your code.
|
||||
This chat session is **private**, and won't be visible to other users.
|
||||
@ -10,8 +10,12 @@ This chat session is **private**, and won't be visible to other users.
|
||||
All open-source repositories are supported.
|
||||
For private repositories, you will also need to install PR-Agent Pro, After installation, make sure to open at least one new PR to fully register your organization. Once done, you can chat with both new and existing PRs across all installed repositories.
|
||||
|
||||
<img src="https://codium.ai/images/pr_agent/pr_chat1.png" width="768">
|
||||
<img src="https://codium.ai/images/pr_agent/pr_chat2.png" width="768">
|
||||
#### Context-aware PR chat
|
||||
|
||||
PR-Agent constructs a comprehensive context for each pull request, incorporating the PR description, commit messages, and code changes with extended dynamic context. This contextual information, along with additional PR-related data, forms the foundation for an AI-powered chat session. The agent then leverages this rich context to provide intelligent, tailored responses to user inquiries about the pull request.
|
||||
|
||||
<img src="https://codium.ai/images/pr_agent/pr_chat_1.png" width="768">
|
||||
<img src="https://codium.ai/images/pr_agent/pr_chat_2.png" width="768">
|
||||
|
||||
|
||||
### Toolbar extension
|
||||
|
||||
@ -1,8 +1,14 @@
|
||||
[PR-Agent Chrome extension](https://chromewebstore.google.com/detail/pr-agent-chrome-extension/ephlnjeghhogofkifjloamocljapahnl) is a collection of tools that integrates seamlessly with your GitHub environment, aiming to enhance your Git usage experience, and providing AI-powered capabilities to your PRs.
|
||||
|
||||
With a single-click installation you will gain access to a context-aware PR chat with top models, a toolbar extension with multiple AI feedbacks, PR-Agent filters, and additional abilities.
|
||||
With a single-click installation you will gain access to a context-aware chat on your pull requests code, a toolbar extension with multiple AI feedbacks, PR-Agent filters, and additional abilities.
|
||||
|
||||
All the extension's features are free to use on public repositories. For private repositories, you will need to install in addition to the extension [PR-Agent Pro](https://github.com/apps/codiumai-pr-agent-pro) (fast and easy installation with two weeks of trial, no credit card required).
|
||||
The extension is powered by top code models like Claude 3.5 Sonnet and GPT4. All the extension's features are free to use on public repositories.
|
||||
|
||||
<img src="https://codium.ai/images/pr_agent/pr_chat1.png" width="768">
|
||||
<img src="https://codium.ai/images/pr_agent/pr_chat2.png" width="768">
|
||||
For private repositories, you will need to install [PR-Agent Pro](https://github.com/apps/codiumai-pr-agent-pro) in addition to the extension (Quick GitHub app setup with a 14-day free trial. No credit card needed).
|
||||
For a demonstration of how to install PR-Agent Pro and use it with the Chrome extension, please refer to the tutorial video at the provided [link](https://codium.ai/images/pr_agent/private_repos.mp4).
|
||||
|
||||
<img src="https://codium.ai/images/pr_agent/PR-AgentChat.gif" width="768">
|
||||
|
||||
### Supported browsers
|
||||
|
||||
The extension is supported on all Chromium-based browsers, including Google Chrome, Arc, Opera, Brave, and Microsoft Edge.
|
||||
|
||||
2
docs/docs/core-abilities/code_oriented_yaml.md
Normal file
2
docs/docs/core-abilities/code_oriented_yaml.md
Normal file
@ -0,0 +1,2 @@
|
||||
## Overview
|
||||
TBD
|
||||
47
docs/docs/core-abilities/compression_strategy.md
Normal file
47
docs/docs/core-abilities/compression_strategy.md
Normal file
@ -0,0 +1,47 @@
|
||||
|
||||
## Overview - PR Compression Strategy
|
||||
There are two scenarios:
|
||||
|
||||
1. The PR is small enough to fit in a single prompt (including system and user prompt)
|
||||
2. The PR is too large to fit in a single prompt (including system and user prompt)
|
||||
|
||||
For both scenarios, we first use the following strategy
|
||||
|
||||
#### Repo language prioritization strategy
|
||||
We prioritize the languages of the repo based on the following criteria:
|
||||
|
||||
1. Exclude binary files and non code files (e.g. images, pdfs, etc)
|
||||
2. Given the main languages used in the repo
|
||||
3. We sort the PR files by the most common languages in the repo (in descending order):
|
||||
* ```[[file.py, file2.py],[file3.js, file4.jsx],[readme.md]]```
|
||||
|
||||
|
||||
### Small PR
|
||||
In this case, we can fit the entire PR in a single prompt:
|
||||
1. Exclude binary files and non code files (e.g. images, pdfs, etc)
|
||||
2. We Expand the surrounding context of each patch to 3 lines above and below the patch
|
||||
|
||||
### Large PR
|
||||
|
||||
#### Motivation
|
||||
Pull Requests can be very long and contain a lot of information with varying degree of relevance to the pr-agent.
|
||||
We want to be able to pack as much information as possible in a single LMM prompt, while keeping the information relevant to the pr-agent.
|
||||
|
||||
#### Compression strategy
|
||||
We prioritize additions over deletions:
|
||||
- Combine all deleted files into a single list (`deleted files`)
|
||||
- File patches are a list of hunks, remove all hunks of type deletion-only from the hunks in the file patch
|
||||
|
||||
#### Adaptive and token-aware file patch fitting
|
||||
We use [tiktoken](https://github.com/openai/tiktoken) to tokenize the patches after the modifications described above, and we use the following strategy to fit the patches into the prompt:
|
||||
|
||||
1. Within each language we sort the files by the number of tokens in the file (in descending order):
|
||||
- ```[[file2.py, file.py],[file4.jsx, file3.js],[readme.md]]```
|
||||
2. Iterate through the patches in the order described above
|
||||
3. Add the patches to the prompt until the prompt reaches a certain buffer from the max token length
|
||||
4. If there are still patches left, add the remaining patches as a list called `other modified files` to the prompt until the prompt reaches the max token length (hard stop), skip the rest of the patches.
|
||||
5. If we haven't reached the max token length, add the `deleted files` to the prompt until the prompt reaches the max token length (hard stop), skip the rest of the patches.
|
||||
|
||||
#### Example
|
||||
|
||||
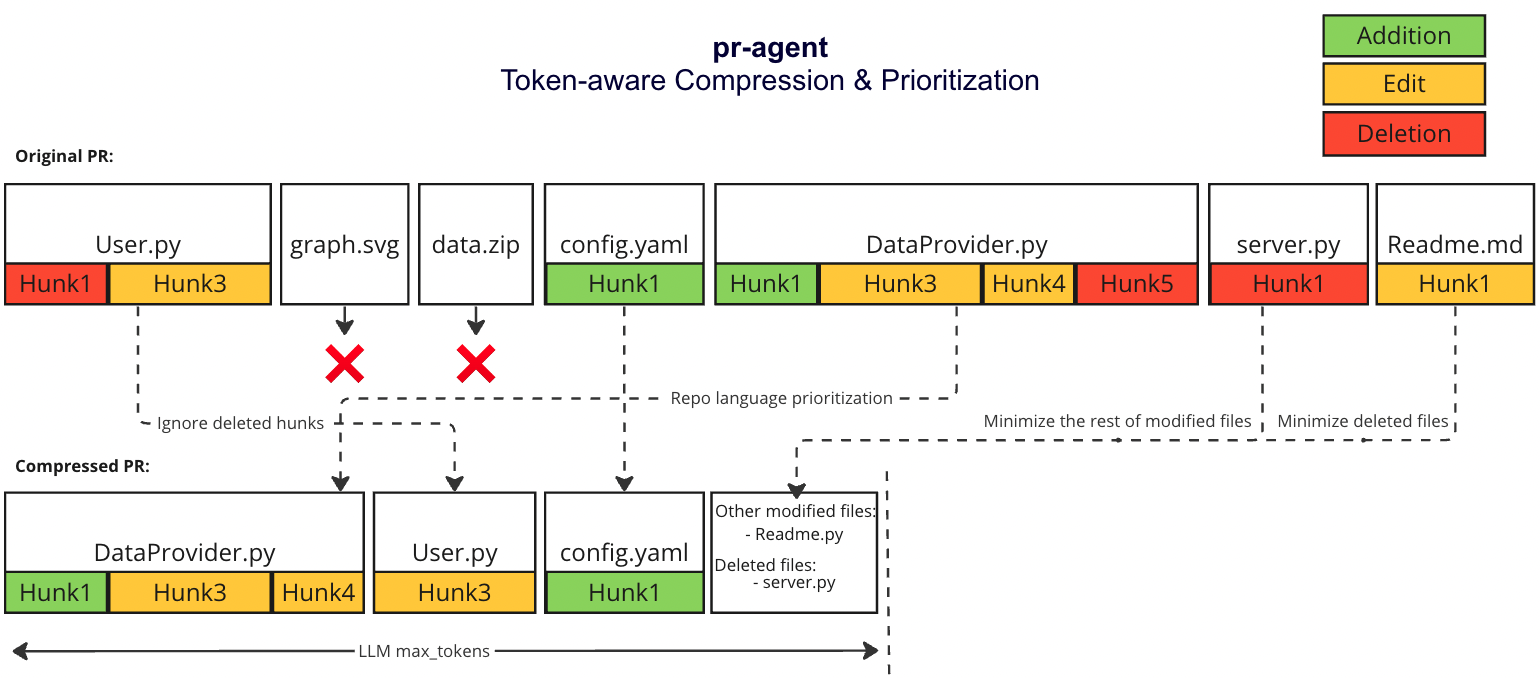{width=768}
|
||||
72
docs/docs/core-abilities/dynamic_context.md
Normal file
72
docs/docs/core-abilities/dynamic_context.md
Normal file
@ -0,0 +1,72 @@
|
||||
## TL;DR
|
||||
|
||||
PR-Agent uses an **asymmetric and dynamic context strategy** to improve AI analysis of code changes in pull requests.
|
||||
It provides more context before changes than after, and dynamically adjusts the context based on code structure (e.g., enclosing functions or classes).
|
||||
This approach balances providing sufficient context for accurate analysis, while avoiding needle-in-the-haystack information overload that could degrade AI performance or exceed token limits.
|
||||
|
||||
## Introduction
|
||||
|
||||
Pull request code changes are retrieved in a unified diff format, showing three lines of context before and after each modified section, with additions marked by '+' and deletions by '-'.
|
||||
```
|
||||
@@ -12,5 +12,5 @@ def func1():
|
||||
code line that already existed in the file...
|
||||
code line that already existed in the file...
|
||||
code line that already existed in the file....
|
||||
-code line that was removed in the PR
|
||||
+new code line added in the PR
|
||||
code line that already existed in the file...
|
||||
code line that already existed in the file...
|
||||
code line that already existed in the file...
|
||||
|
||||
@@ -26,2 +26,4 @@ def func2():
|
||||
...
|
||||
```
|
||||
|
||||
This unified diff format can be challenging for AI models to interpret accurately, as it provides limited context for understanding the full scope of code changes.
|
||||
The presentation of code using '+', '-', and ' ' symbols to indicate additions, deletions, and unchanged lines respectively also differs from the standard code formatting typically used to train AI models.
|
||||
|
||||
|
||||
## Challenges of expanding the context window
|
||||
|
||||
While expanding the context window is technically feasible, it presents a more fundamental trade-off:
|
||||
|
||||
Pros:
|
||||
|
||||
- Enhanced context allows the model to better comprehend and localize the code changes, results (potentially) in more precise analysis and suggestions. Without enough context, the model may struggle to understand the code changes and provide relevant feedback.
|
||||
|
||||
Cons:
|
||||
|
||||
- Excessive context may overwhelm the model with extraneous information, creating a "needle in a haystack" scenario where focusing on the relevant details (the code that actually changed) becomes challenging.
|
||||
LLM quality is known to degrade when the context gets larger.
|
||||
Pull requests often encompass multiple changes across many files, potentially spanning hundreds of lines of modified code. This complexity presents a genuine risk of overwhelming the model with excessive context.
|
||||
|
||||
- Increased context expands the token count, increasing processing time and cost, and may prevent the model from processing the entire pull request in a single pass.
|
||||
|
||||
## Asymmetric and dynamic context
|
||||
To address these challenges, PR-Agent employs an **asymmetric** and **dynamic** context strategy, providing the model with more focused and relevant context information for each code change.
|
||||
|
||||
**Asymmetric:**
|
||||
|
||||
We start by recognizing that the context preceding a code change is typically more crucial for understanding the modification than the context following it.
|
||||
Consequently, PR-Agent implements an asymmetric context policy, decoupling the context window into two distinct segments: one for the code before the change and another for the code after.
|
||||
|
||||
By independently adjusting each context window, PR-Agent can supply the model with a more tailored and pertinent context for individual code changes.
|
||||
|
||||
**Dynamic:**
|
||||
|
||||
We also employ a "dynamic" context strategy.
|
||||
We start by recognizing that the optimal context for a code change often corresponds to its enclosing code component (e.g., function, class), rather than a fixed number of lines.
|
||||
Consequently, we dynamically adjust the context window based on the code's structure, ensuring the model receives the most pertinent information for each modification.
|
||||
|
||||
To prevent overwhelming the model with excessive context, we impose a limit on the number of lines searched when identifying the enclosing component.
|
||||
This balance allows for comprehensive understanding while maintaining efficiency and limiting context token usage.
|
||||
|
||||
## Appendix - relevant configuration options
|
||||
```
|
||||
[config]
|
||||
patch_extension_skip_types =[".md",".txt"] # Skip files with these extensions when trying to extend the context
|
||||
allow_dynamic_context=true # Allow dynamic context extension
|
||||
max_extra_lines_before_dynamic_context = 8 # will try to include up to X extra lines before the hunk in the patch, until we reach an enclosing function or class
|
||||
patch_extra_lines_before = 3 # Number of extra lines (+3 default ones) to include before each hunk in the patch
|
||||
patch_extra_lines_after = 1 # Number of extra lines (+3 default ones) to include after each hunk in the patch
|
||||
```
|
||||
44
docs/docs/core-abilities/impact_evaluation.md
Normal file
44
docs/docs/core-abilities/impact_evaluation.md
Normal file
@ -0,0 +1,44 @@
|
||||
# Overview - Impact Evaluation 💎
|
||||
|
||||
Demonstrating the return on investment (ROI) of AI-powered initiatives is crucial for modern organizations.
|
||||
To address this need, PR-Agent has developed an AI impact measurement tools and metrics, providing advanced analytics to help businesses quantify the tangible benefits of AI adoption in their PR review process.
|
||||
|
||||
|
||||
## Auto Impact Validator - Real-Time Tracking of Implemented PR-Agent Suggestions
|
||||
|
||||
### How It Works
|
||||
When a user pushes a new commit to the pull request, PR-Agent automatically compares the updated code against the previous suggestions, marking them as implemented if the changes address these recommendations, whether directly or indirectly:
|
||||
|
||||
1. **Direct Implementation:** The user directly addresses the suggestion as-is in the PR, either by clicking on the "apply code suggestion" checkbox or by making the changes manually.
|
||||
2. **Indirect Implementation:** PR-Agent recognizes when a suggestion's intent is fulfilled, even if the exact code changes differ from the original recommendation. It marks these suggestions as implemented, acknowledging that users may achieve the same goal through alternative solutions.
|
||||
|
||||
### Real-Time Visual Feedback
|
||||
Upon confirming that a suggestion was implemented, PR-Agent automatically adds a ✅ (check mark) to the relevant suggestion, enabling transparent tracking of PR-Agent's impact analysis.
|
||||
PR-Agent will also add, inside the relevant suggestions, an explanation of how the new code was impacted by each suggestion.
|
||||
|
||||
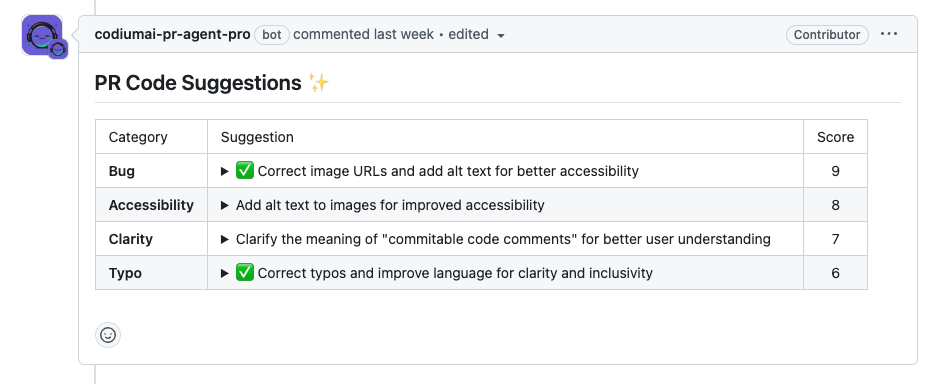{width=512}
|
||||
|
||||
### Dashboard Metrics
|
||||
The dashboard provides macro-level insights into the overall impact of PR-Agent on the pull-request process with key productivity metrics.
|
||||
|
||||
By offering clear, data-driven evidence of PR-Agent's impact, it empowers leadership teams to make informed decisions about the tool's effectiveness and ROI.
|
||||
|
||||
Here are key metrics that the dashboard tracks:
|
||||
|
||||
#### PR-Agent Impacts per 1K Lines
|
||||
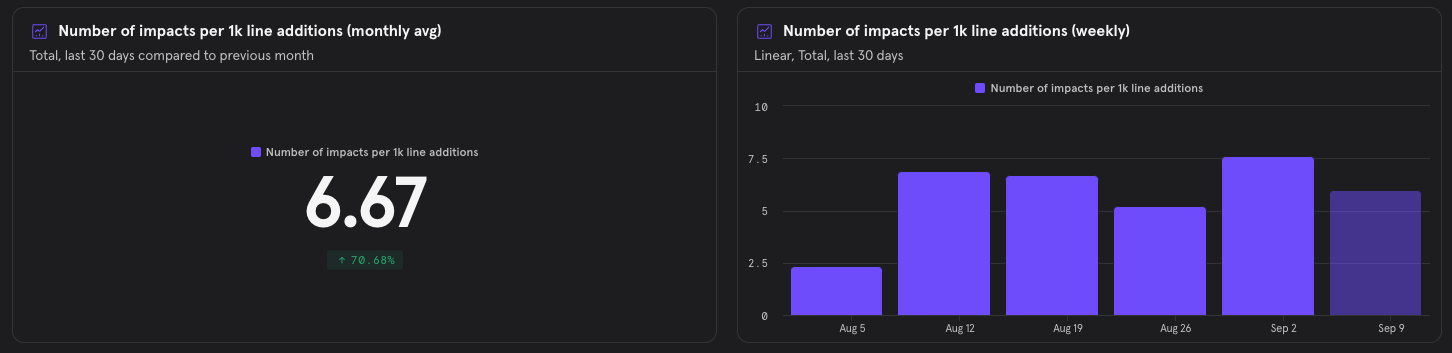{width=512}
|
||||
> Explanation: for every 1K lines of code (additions/edits), PR-Agent had on average ~X suggestions implemented.
|
||||
|
||||
**Why This Metric Matters:**
|
||||
|
||||
1. **Standardized and Comparable Measurement:** By measuring impacts per 1K lines of code additions, you create a standardized metric that can be compared across different projects, teams, customers, and time periods. This standardization is crucial for meaningful analysis, benchmarking, and identifying where PR-Agent is most effective.
|
||||
2. **Accounts for PR Variability and Incentivizes Quality:** This metric addresses the fact that "Not all PRs are created equal." By normalizing against lines of code rather than PR count, you account for the variability in PR sizes and focus on the quality and impact of suggestions rather than just the number of PRs affected.
|
||||
3. **Quantifies Value and ROI:** The metric directly correlates with the value PR-Agent is providing, showing how frequently it offers improvements relative to the amount of new code being written. This provides a clear, quantifiable way to demonstrate PR-Agent's return on investment to stakeholders.
|
||||
|
||||
#### Suggestion Effectiveness Across Categories
|
||||
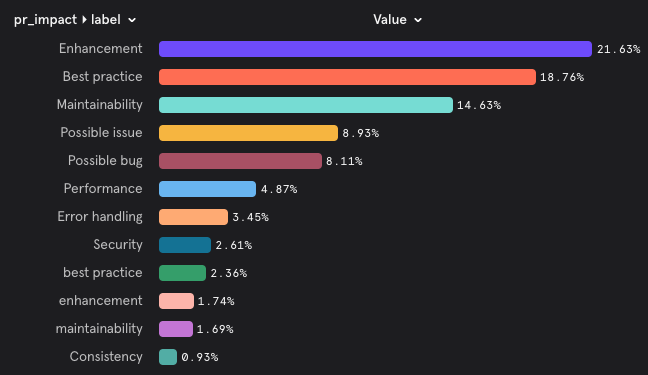{width=512}
|
||||
> Explanation: This chart illustrates the distribution of implemented suggestions across different categories, enabling teams to better understand PR-Agent's impact on various aspects of code quality and development practices.
|
||||
|
||||
#### Suggestion Score Distribution
|
||||
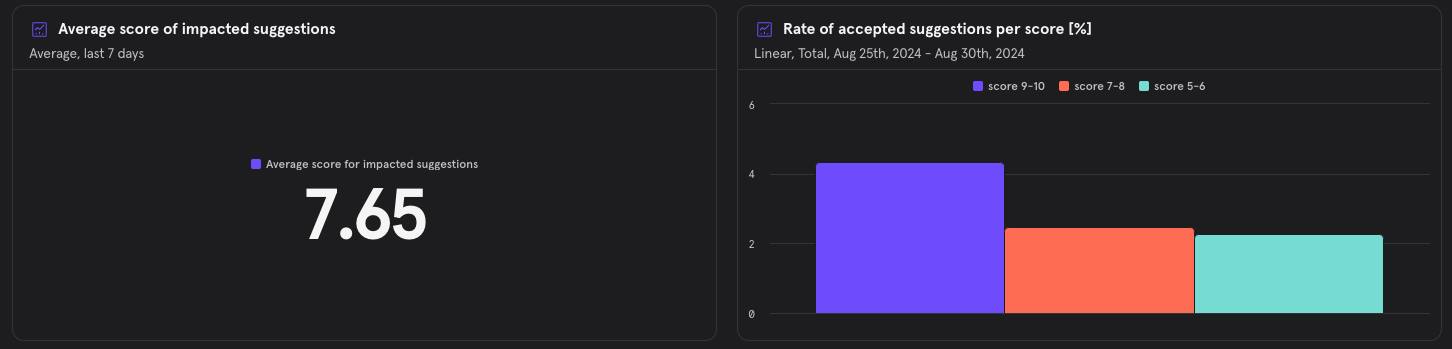{width=512}
|
||||
> Explanation: The distribution of the suggestion score for the implemented suggestions, ensuring that higher-scored suggestions truly represent more significant improvements.
|
||||
@ -1,52 +1,12 @@
|
||||
## PR Compression Strategy
|
||||
There are two scenarios:
|
||||
# Core Abilities
|
||||
PR-Agent utilizes a variety of core abilities to provide a comprehensive and efficient code review experience. These abilities include:
|
||||
|
||||
1. The PR is small enough to fit in a single prompt (including system and user prompt)
|
||||
2. The PR is too large to fit in a single prompt (including system and user prompt)
|
||||
|
||||
For both scenarios, we first use the following strategy
|
||||
|
||||
#### Repo language prioritization strategy
|
||||
We prioritize the languages of the repo based on the following criteria:
|
||||
|
||||
1. Exclude binary files and non code files (e.g. images, pdfs, etc)
|
||||
2. Given the main languages used in the repo
|
||||
3. We sort the PR files by the most common languages in the repo (in descending order):
|
||||
* ```[[file.py, file2.py],[file3.js, file4.jsx],[readme.md]]```
|
||||
|
||||
|
||||
### Small PR
|
||||
In this case, we can fit the entire PR in a single prompt:
|
||||
1. Exclude binary files and non code files (e.g. images, pdfs, etc)
|
||||
2. We Expand the surrounding context of each patch to 3 lines above and below the patch
|
||||
|
||||
### Large PR
|
||||
|
||||
#### Motivation
|
||||
Pull Requests can be very long and contain a lot of information with varying degree of relevance to the pr-agent.
|
||||
We want to be able to pack as much information as possible in a single LMM prompt, while keeping the information relevant to the pr-agent.
|
||||
|
||||
#### Compression strategy
|
||||
We prioritize additions over deletions:
|
||||
- Combine all deleted files into a single list (`deleted files`)
|
||||
- File patches are a list of hunks, remove all hunks of type deletion-only from the hunks in the file patch
|
||||
|
||||
#### Adaptive and token-aware file patch fitting
|
||||
We use [tiktoken](https://github.com/openai/tiktoken) to tokenize the patches after the modifications described above, and we use the following strategy to fit the patches into the prompt:
|
||||
|
||||
1. Within each language we sort the files by the number of tokens in the file (in descending order):
|
||||
- ```[[file2.py, file.py],[file4.jsx, file3.js],[readme.md]]```
|
||||
2. Iterate through the patches in the order described above
|
||||
3. Add the patches to the prompt until the prompt reaches a certain buffer from the max token length
|
||||
4. If there are still patches left, add the remaining patches as a list called `other modified files` to the prompt until the prompt reaches the max token length (hard stop), skip the rest of the patches.
|
||||
5. If we haven't reached the max token length, add the `deleted files` to the prompt until the prompt reaches the max token length (hard stop), skip the rest of the patches.
|
||||
|
||||
#### Example
|
||||
|
||||
{width=768}
|
||||
|
||||
## YAML Prompting
|
||||
TBD
|
||||
|
||||
## Static Code Analysis 💎
|
||||
TBD
|
||||
- [Local and global metadata](https://pr-agent-docs.codium.ai/core-abilities/metadata/)
|
||||
- [Dynamic context](https://pr-agent-docs.codium.ai/core-abilities/dynamic_context/)
|
||||
- [Self-reflection](https://pr-agent-docs.codium.ai/core-abilities/self_reflection/)
|
||||
- [Impact evaluation](https://pr-agent-docs.codium.ai/core-abilities/impact_evaluation/)
|
||||
- [Interactivity](https://pr-agent-docs.codium.ai/core-abilities/interactivity/)
|
||||
- [Compression strategy](https://pr-agent-docs.codium.ai/core-abilities/compression_strategy/)
|
||||
- [Code-oriented YAML](https://pr-agent-docs.codium.ai/core-abilities/code_oriented_yaml/)
|
||||
- [Static code analysis](https://pr-agent-docs.codium.ai/core-abilities/static_code_analysis/)
|
||||
- [Code fine-tuning benchmark](https://pr-agent-docs.codium.ai/finetuning_benchmark/)
|
||||
2
docs/docs/core-abilities/interactivity.md
Normal file
2
docs/docs/core-abilities/interactivity.md
Normal file
@ -0,0 +1,2 @@
|
||||
## Interactive invocation 💎
|
||||
TBD
|
||||
56
docs/docs/core-abilities/metadata.md
Normal file
56
docs/docs/core-abilities/metadata.md
Normal file
@ -0,0 +1,56 @@
|
||||
## Local and global metadata injection with multi-stage analysis
|
||||
(1)
|
||||
PR-Agent initially retrieves for each PR the following data:
|
||||
|
||||
- PR title and branch name
|
||||
- PR original description
|
||||
- Commit messages history
|
||||
- PR diff patches, in [hunk diff](https://loicpefferkorn.net/2014/02/diff-files-what-are-hunks-and-how-to-extract-them/) format
|
||||
- The entire content of the files that were modified in the PR
|
||||
|
||||
!!! tip "Tip: Organization-level metadata"
|
||||
In addition to the inputs above, PR-Agent can incorporate supplementary preferences provided by the user, like [`extra_instructions` and `organization best practices`](https://pr-agent-docs.codium.ai/tools/improve/#extra-instructions-and-best-practices). This information can be used to enhance the PR analysis.
|
||||
|
||||
(2)
|
||||
By default, the first command that PR-Agent executes is [`describe`](https://pr-agent-docs.codium.ai/tools/describe/), which generates three types of outputs:
|
||||
|
||||
- PR Type (e.g. bug fix, feature, refactor, etc)
|
||||
- PR Description - a bullet point summary of the PR
|
||||
- Changes walkthrough - for each modified file, provide a one-line summary followed by a detailed bullet point list of the changes.
|
||||
|
||||
These AI-generated outputs are now considered as part of the PR metadata, and can be used in subsequent commands like `review` and `improve`.
|
||||
This effectively enables multi-stage chain-of-thought analysis, without doing any additional API calls which will cost time and money.
|
||||
|
||||
For example, when generating code suggestions for different files, PR-Agent can inject the AI-generated ["Changes walkthrough"](https://github.com/Codium-ai/pr-agent/pull/1202#issue-2511546839) file summary in the prompt:
|
||||
|
||||
```
|
||||
## File: 'src/file1.py'
|
||||
### AI-generated file summary:
|
||||
- edited function `func1` that does X
|
||||
- Removed function `func2` that was not used
|
||||
- ....
|
||||
|
||||
@@ ... @@ def func1():
|
||||
__new hunk__
|
||||
11 unchanged code line0 in the PR
|
||||
12 unchanged code line1 in the PR
|
||||
13 +new code line2 added in the PR
|
||||
14 unchanged code line3 in the PR
|
||||
__old hunk__
|
||||
unchanged code line0
|
||||
unchanged code line1
|
||||
-old code line2 removed in the PR
|
||||
unchanged code line3
|
||||
|
||||
@@ ... @@ def func2():
|
||||
__new hunk__
|
||||
...
|
||||
__old hunk__
|
||||
...
|
||||
```
|
||||
|
||||
(3) The entire PR files that were retrieved are also used to expand and enhance the PR context (see [Dynamic Context](https://pr-agent-docs.codium.ai/core-abilities/dynamic-context/)).
|
||||
|
||||
|
||||
(4) All the metadata described above represents several level of cumulative analysis - ranging from hunk level, to file level, to PR level, to organization level.
|
||||
This comprehensive approach enables PR-Agent AI models to generate more precise and contextually relevant suggestions and feedback.
|
||||
51
docs/docs/core-abilities/self_reflection.md
Normal file
51
docs/docs/core-abilities/self_reflection.md
Normal file
@ -0,0 +1,51 @@
|
||||
## TL;DR
|
||||
|
||||
PR-Agent implements a **self-reflection** process where the AI model reflects, scores, and re-ranks its own suggestions, eliminating irrelevant or incorrect ones.
|
||||
This approach improves the quality and relevance of suggestions, saving users time and enhancing their experience.
|
||||
Configuration options allow users to set a score threshold for further filtering out suggestions.
|
||||
|
||||
## Introduction - Efficient Review with Hierarchical Presentation
|
||||
|
||||
|
||||
Given that not all generated code suggestions will be relevant, it is crucial to enable users to review them in a fast and efficient way, allowing quick identification and filtering of non-applicable ones.
|
||||
|
||||
To achieve this goal, PR-Agent offers a dedicated hierarchical structure when presenting suggestions to users:
|
||||
|
||||
- A "category" section groups suggestions by their category, allowing users to quickly dismiss irrelevant suggestions.
|
||||
- Each suggestion is first described by a one-line summary, which can be expanded to a full description by clicking on a collapsible.
|
||||
- Upon expanding a suggestion, the user receives a more comprehensive description, and a code snippet demonstrating the recommendation.
|
||||
|
||||
!!! note "Fast Review"
|
||||
This hierarchical structure is designed to facilitate rapid review of each suggestion, with users spending an average of ~5-10 seconds per item.
|
||||
|
||||
## Self-reflection and Re-ranking
|
||||
|
||||
The AI model is initially tasked with generating suggestions, and outputting them in order of importance.
|
||||
However, in practice we observe that models often struggle to simultaneously generate high-quality code suggestions and rank them well in a single pass.
|
||||
Furthermore, the initial set of generated suggestions sometimes contains easily identifiable errors.
|
||||
|
||||
To address these issues, we implemented a "self-reflection" process that refines suggestion ranking and eliminates irrelevant or incorrect proposals.
|
||||
This process consists of the following steps:
|
||||
|
||||
1. Presenting the generated suggestions to the model in a follow-up call.
|
||||
2. Instructing the model to score each suggestion on a scale of 0-10 and provide a rationale for the assigned score.
|
||||
3. Utilizing these scores to re-rank the suggestions and filter out incorrect ones (with a score of 0).
|
||||
4. Optionally, filtering out all suggestions below a user-defined score threshold.
|
||||
|
||||
Note that presenting all generated suggestions simultaneously provides the model with a comprehensive context, enabling it to make more informed decisions compared to evaluating each suggestion individually.
|
||||
|
||||
To conclude, the self-reflection process enables PR-Agent to prioritize suggestions based on their importance, eliminate inaccurate or irrelevant proposals, and optionally exclude suggestions that fall below a specified threshold of significance.
|
||||
This results in a more refined and valuable set of suggestions for the user, saving time and improving the overall experience.
|
||||
|
||||
## Example Results
|
||||
|
||||
{width=768}
|
||||
{width=768}
|
||||
|
||||
|
||||
## Appendix - Relevant Configuration Options
|
||||
```
|
||||
[pr_code_suggestions]
|
||||
self_reflect_on_suggestions = true # Enable self-reflection on code suggestions
|
||||
suggestions_score_threshold = 0 # Filter out suggestions with a score below this threshold (0-10)
|
||||
```
|
||||
70
docs/docs/core-abilities/static_code_analysis.md
Normal file
70
docs/docs/core-abilities/static_code_analysis.md
Normal file
@ -0,0 +1,70 @@
|
||||
## Overview - Static Code Analysis 💎
|
||||
|
||||
By combining static code analysis with LLM capabilities, PR-Agent can provide a comprehensive analysis of the PR code changes on a component level.
|
||||
|
||||
It scans the PR code changes, finds all the code components (methods, functions, classes) that changed, and enables to interactively generate tests, docs, code suggestions and similar code search for each component.
|
||||
|
||||
!!! note "Language that are currently supported:"
|
||||
Python, Java, C++, JavaScript, TypeScript, C#.
|
||||
|
||||
|
||||
## Capabilities
|
||||
|
||||
### Analyze PR
|
||||
|
||||
|
||||
The [`analyze`](https://pr-agent-docs.codium.ai/tools/analyze/) tool enables to interactively generate tests, docs, code suggestions and similar code search for each component that changed in the PR.
|
||||
It can be invoked manually by commenting on any PR:
|
||||
```
|
||||
/analyze
|
||||
```
|
||||
|
||||
An example result:
|
||||
|
||||
{width=768}
|
||||
|
||||
Clicking on each checkbox will trigger the relevant tool for the selected component.
|
||||
|
||||
### Generate Tests
|
||||
|
||||
The [`test`](https://pr-agent-docs.codium.ai/tools/test/) tool generate tests for a selected component, based on the PR code changes.
|
||||
It can be invoked manually by commenting on any PR:
|
||||
```
|
||||
/test component_name
|
||||
```
|
||||
where 'component_name' is the name of a specific component in the PR, Or be triggered interactively by using the `analyze` tool.
|
||||
|
||||
{width=768}
|
||||
|
||||
### Generate Docs for a Component
|
||||
|
||||
The [`add_docs`](https://pr-agent-docs.codium.ai/tools/documentation/) tool scans the PR code changes, and automatically generate docstrings for any code components that changed in the PR.
|
||||
It can be invoked manually by commenting on any PR:
|
||||
```
|
||||
/add_docs component_name
|
||||
```
|
||||
|
||||
Or be triggered interactively by using the `analyze` tool.
|
||||
|
||||
{width=768}
|
||||
|
||||
### Generate Code Suggestions for a Component
|
||||
The [`improve_component`](https://pr-agent-docs.codium.ai/tools/improve_component/) tool generates code suggestions for a specific code component that changed in the PR.
|
||||
It can be invoked manually by commenting on any PR:
|
||||
```
|
||||
/improve_component component_name
|
||||
```
|
||||
|
||||
Or be triggered interactively by using the `analyze` tool.
|
||||
|
||||
{width=768}
|
||||
|
||||
### Find Similar Code
|
||||
|
||||
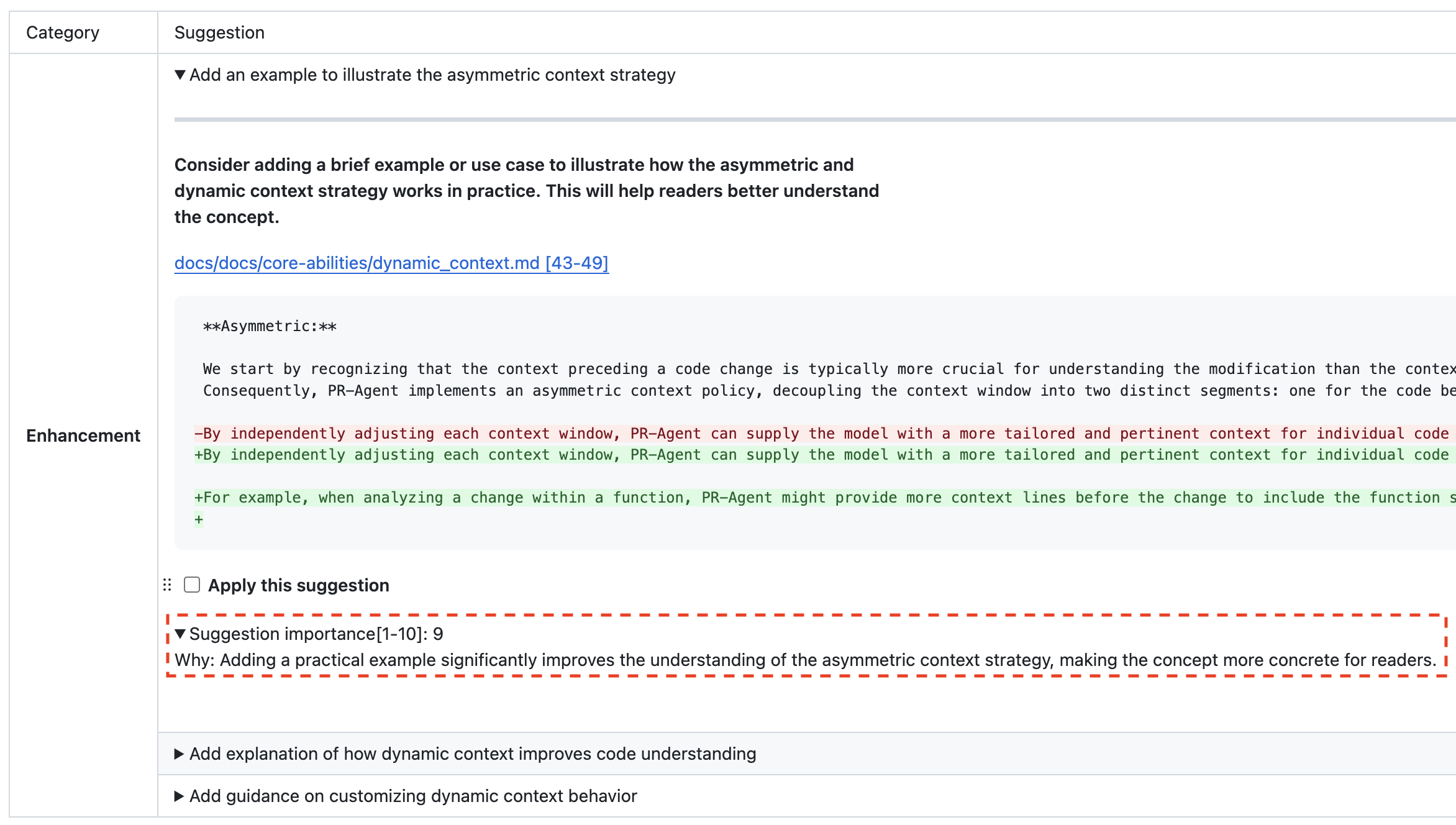
The [`similar code`](https://pr-agent-docs.codium.ai/tools/similar_code/) tool retrieves the most similar code components from inside the organization's codebase, or from open-source code.
|
||||
|
||||
For example:
|
||||
|
||||
`Global Search` for a method called `chat_completion`:
|
||||
|
||||
{width=768}
|
||||
67
docs/docs/faq/index.md
Normal file
67
docs/docs/faq/index.md
Normal file
@ -0,0 +1,67 @@
|
||||
# FAQ
|
||||
|
||||
??? note "Question: Can PR-Agent serve as a substitute for a human reviewer?"
|
||||
#### Answer:<span style="display:none;">1</span>
|
||||
|
||||
PR-Agent is designed to assist, not replace, human reviewers.
|
||||
|
||||
Reviewing PRs is a tedious and time-consuming task often seen as a "chore". In addition, the longer the PR – the shorter the relative feedback, since long PRs can overwhelm reviewers, both in terms of technical difficulty, and the actual review time.
|
||||
PR-Agent aims to address these pain points, and to assist and empower both the PR author and reviewer.
|
||||
|
||||
However, PR-Agent has built-in safeguards to ensure the developer remains in the driver's seat. For example:
|
||||
|
||||
1. Preserves user's original PR header
|
||||
2. Places user's description above the AI-generated PR description
|
||||
3. Cannot approve PRs; approval remains reviewer's responsibility
|
||||
4. The code suggestions are optional, and aim to:
|
||||
- Encourage self-review and self-reflection
|
||||
- Highlight potential bugs or oversights
|
||||
- Enhance code quality and promote best practices
|
||||
|
||||
Read more about this issue in our [blog](https://www.codium.ai/blog/understanding-the-challenges-and-pain-points-of-the-pull-request-cycle/)
|
||||
|
||||
___
|
||||
|
||||
??? note "Question: I received an incorrect or irrelevant suggestion. Why?"
|
||||
|
||||
#### Answer:<span style="display:none;">2</span>
|
||||
|
||||
- Modern AI models, like Claude 3.5 Sonnet and GPT-4, are improving rapidly but remain imperfect. Users should critically evaluate all suggestions rather than accepting them automatically.
|
||||
- AI errors are rare, but possible. A main value from reviewing the code suggestions lies in their high probability of catching **mistakes or bugs made by the PR author**. We believe it's worth spending 30-60 seconds reviewing suggestions, even if some aren't relevant, as this practice can enhances code quality and prevent bugs in production.
|
||||
|
||||
|
||||
- The hierarchical structure of the suggestions is designed to help the user to _quickly_ understand them, and to decide which ones are relevant and which are not:
|
||||
|
||||
- Only if the `Category` header is relevant, the user should move to the summarized suggestion description.
|
||||
- Only if the summarized suggestion description is relevant, the user should click on the collapsible, to read the full suggestion description with a code preview example.
|
||||
|
||||
- In addition, we recommend to use the [`extra_instructions`](https://pr-agent-docs.codium.ai/tools/improve/#extra-instructions-and-best-practices) field to guide the model to suggestions that are more relevant to the specific needs of the project.
|
||||
- The interactive [PR chat](https://pr-agent-docs.codium.ai/chrome-extension/) also provides an easy way to get more tailored suggestions and feedback from the AI model.
|
||||
|
||||
___
|
||||
|
||||
??? note "Question: How can I get more tailored suggestions?"
|
||||
#### Answer:<span style="display:none;">3</span>
|
||||
|
||||
See [here](https://pr-agent-docs.codium.ai/tools/improve/#extra-instructions-and-best-practices) for more information on how to use the `extra_instructions` and `best_practices` configuration options, to guide the model to more tailored suggestions.
|
||||
|
||||
___
|
||||
|
||||
??? note "Question: Will you store my code ? Are you using my code to train models?"
|
||||
#### Answer:<span style="display:none;">4</span>
|
||||
|
||||
No. PR-Agent strict privacy policy ensures that your code is not stored or used for training purposes.
|
||||
|
||||
For a detailed overview of our data privacy policy, please refer to [this link](https://pr-agent-docs.codium.ai/overview/data_privacy/)
|
||||
|
||||
___
|
||||
|
||||
??? note "Question: Can I use my own LLM keys with PR-Agent?"
|
||||
#### Answer:<span style="display:none;">5</span>
|
||||
|
||||
When you self-host, you use your own keys.
|
||||
|
||||
PR-Agent Pro with SaaS deployment is a hosted version of PR-Agent, where Codium AI manages the infrastructure and the keys.
|
||||
For enterprise customers, on-prem deployment is also available. [Contact us](https://www.codium.ai/contact/#pricing) for more information.
|
||||
|
||||
___
|
||||
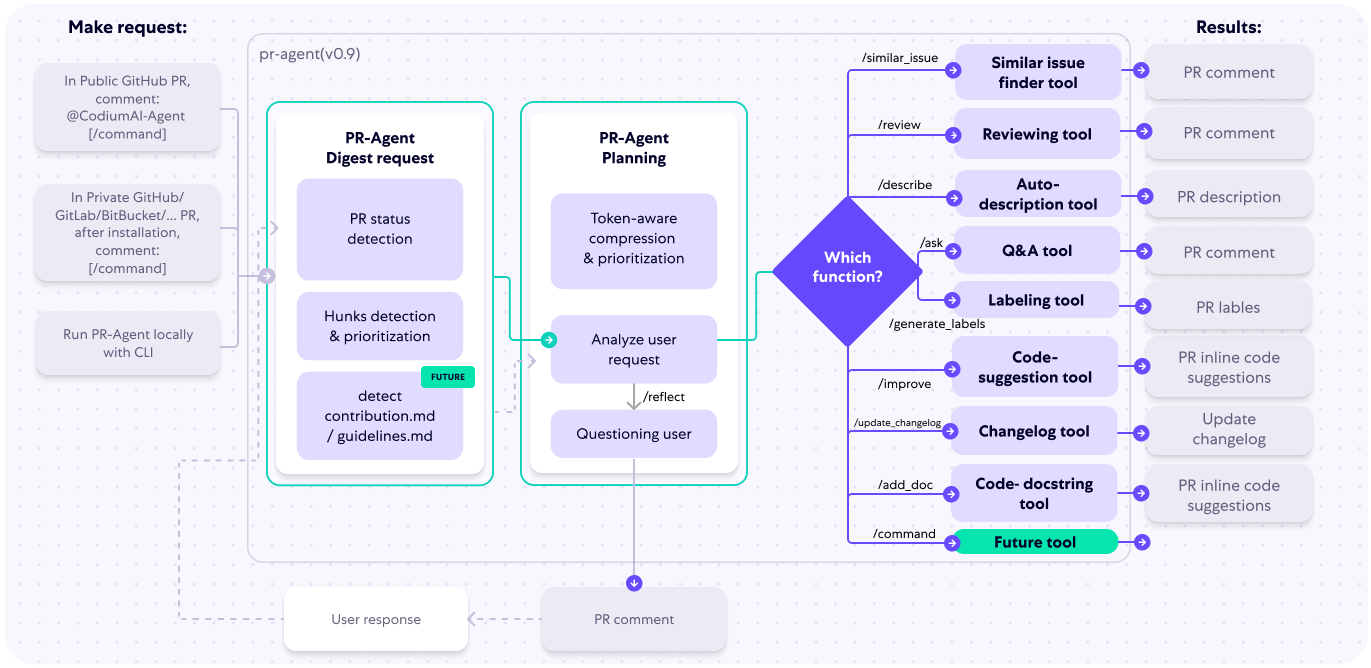
@ -78,4 +78,4 @@ The following diagram illustrates PR-Agent tools and their flow:
|
||||
|
||||
|
||||
|
||||
Check out the [PR Compression strategy](core-abilities/index.md) page for more details on how we convert a code diff to a manageable LLM prompt
|
||||
Check out the [core abilities](core-abilities/index.md) page for a comprehensive overview of the variety of core abilities used by PR-Agent.
|
||||
|
||||
@ -1,15 +1,19 @@
|
||||
### Overview
|
||||
|
||||
[PR-Agent Pro](https://www.codium.ai/pricing/) is a hosted version of PR-Agent, provided by CodiumAI. A complimentary two-week trial is offered, followed by a monthly subscription fee.
|
||||
PR-Agent Pro is designed for companies and teams that require additional features and capabilities. It provides the following benefits:
|
||||
|
||||
1. **Fully managed** - We take care of everything for you - hosting, models, regular updates, and more. Installation is as simple as signing up and adding the PR-Agent app to your GitHub\GitLab\BitBucket repo.
|
||||
|
||||
2. **Improved privacy** - No data will be stored or used to train models. PR-Agent Pro will employ zero data retention, and will use an OpenAI account with zero data retention.
|
||||
2. **Improved privacy** - No data will be stored or used to train models. PR-Agent Pro will employ zero data retention, and will use an OpenAI and Claude accounts with zero data retention.
|
||||
|
||||
3. **Improved support** - PR-Agent Pro users will receive priority support, and will be able to request new features and capabilities.
|
||||
|
||||
4. **Supporting self-hosted git servers** - PR-Agent Pro can be installed on GitHub Enterprise Server, GitLab, and BitBucket. For more information, see the [installation guide](https://pr-agent-docs.codium.ai/installation/pr_agent_pro/).
|
||||
|
||||
**Additional features:**
|
||||
5. **PR Chat** - PR-Agent Pro allows you to engage in [private chat](https://pr-agent-docs.codium.ai/chrome-extension/features/#pr-chat) about your pull requests on private repositories.
|
||||
|
||||
### Additional features
|
||||
|
||||
Here are some of the additional features and capabilities that PR-Agent Pro offers:
|
||||
|
||||
@ -26,7 +30,7 @@ Here are some of the additional features and capabilities that PR-Agent Pro offe
|
||||
| [**SOC2 compliance check**](https://pr-agent-docs.codium.ai/tools/review/#configuration-options) | Ensures the PR contains a ticket to a project management system (e.g., Jira, Asana, Trello, etc.)
|
||||
| [**Custom labels**](https://pr-agent-docs.codium.ai/tools/describe/#handle-custom-labels-from-the-repos-labels-page) | Define custom labels for PR-Agent to assign to the PR |
|
||||
|
||||
**Additional tools:**
|
||||
### Additional tools
|
||||
|
||||
Here are additional tools that are available only for PR-Agent Pro users:
|
||||
|
||||
@ -40,3 +44,9 @@ Here are additional tools that are available only for PR-Agent Pro users:
|
||||
| [**Similar code search**](https://pr-agent-docs.codium.ai/tools/similar_code/) | Search for similar code in the repository, organization, or entire GitHub |
|
||||
|
||||
|
||||
### Supported languages
|
||||
|
||||
PR-Agent Pro leverages the world's leading code models - Claude 3.5 Sonnet and GPT-4.
|
||||
As a result, its primary tools such as `describe`, `review`, and `improve`, as well as the PR-chat feature, support virtually all programming languages.
|
||||
|
||||
For specialized commands that require static code analysis, PR-Agent Pro offers support for specific languages. For more details about features that require static code analysis, please refer to the [documentation](https://pr-agent-docs.codium.ai/tools/analyze/#overview).
|
||||
@ -1,7 +1,7 @@
|
||||
## Overview
|
||||
The `analyze` tool combines advanced static code analysis with LLM capabilities to provide a comprehensive analysis of the PR code changes.
|
||||
|
||||
The tool scans the PR code changes, find the code components (methods, functions, classes) that changed, and enables to interactively generate tests, docs, code suggestions and similar code search for each component.
|
||||
The tool scans the PR code changes, finds the code components (methods, functions, classes) that changed, and enables to interactively generate tests, docs, code suggestions and similar code search for each component.
|
||||
|
||||
It can be invoked manually by commenting on any PR:
|
||||
```
|
||||
|
||||
@ -98,9 +98,12 @@ the tool can automatically approve the PR when the user checks the self-review c
|
||||
|
||||
{width=512}
|
||||
|
||||
### `Extra instructions` and `best practices`
|
||||
### 'Extra instructions' and 'best practices'
|
||||
|
||||
#### Extra instructions
|
||||
|
||||
>`Platforms supported: GitHub, GitLab, Bitbucket`
|
||||
|
||||
You can use the `extra_instructions` configuration option to give the AI model additional instructions for the `improve` tool.
|
||||
Be specific, clear, and concise in the instructions. With extra instructions, you are the prompter. Specify relevant aspects that you want the model to focus on.
|
||||
|
||||
@ -117,10 +120,13 @@ extra_instructions="""\
|
||||
Use triple quotes to write multi-line instructions. Use bullet points or numbers to make the instructions more readable.
|
||||
|
||||
#### Best practices 💎
|
||||
Another option to give additional guidance to the AI model is by creating a dedicated [**wiki page**](https://github.com/Codium-ai/pr-agent/wiki) called `best_practices.md`.
|
||||
This page can contain a list of best practices, coding standards, and guidelines that are specific to your repo/organization
|
||||
|
||||
The AI model will use this page as a reference, and in case the PR code violates any of the guidelines, it will suggest improvements accordingly, with a dedicated label: `Organization
|
||||
>`Platforms supported: GitHub, GitLab`
|
||||
|
||||
Another option to give additional guidance to the AI model is by creating a dedicated [**wiki page**](https://github.com/Codium-ai/pr-agent/wiki) called `best_practices.md`.
|
||||
This page can contain a list of best practices, coding standards, and guidelines that are specific to your repo/organization.
|
||||
|
||||
The AI model will use this wiki page as a reference, and in case the PR code violates any of the guidelines, it will suggest improvements accordingly, with a dedicated label: `Organization
|
||||
best practice`.
|
||||
|
||||
Example for a `best_practices.md` content can be found [here](https://github.com/Codium-ai/pr-agent/blob/main/docs/docs/usage-guide/EXAMPLE_BEST_PRACTICE.md) (adapted from Google's [pyguide](https://google.github.io/styleguide/pyguide.html)).
|
||||
@ -128,21 +134,42 @@ This file is only an example. Since it is used as a prompt for an AI model, we w
|
||||
|
||||
- It should be written in a clear and concise manner
|
||||
- If needed, it should give short relevant code snippets as examples
|
||||
- Up to 800 lines are allowed
|
||||
- Recommended to limit the text to 800 lines or fewer. Here’s why:
|
||||
|
||||
1) Extremely long best practices documents may not be fully processed by the AI model.
|
||||
|
||||
Example results:
|
||||
2) A lengthy file probably represent a more "**generic**" set of guidelines, which the AI model is already familiar with. The objective is to focus on a more targeted set of guidelines tailored to the specific needs of this project.
|
||||
|
||||
##### Local and global best practices
|
||||
By default, PR-Agent will look for a local `best_practices.md` wiki file in the root of the relevant local repo.
|
||||
|
||||
If you want to enable also a global `best_practices.md` wiki file, set first in the global configuration file:
|
||||
|
||||
```
|
||||
[best_practices]
|
||||
enable_global_best_practices = true
|
||||
```
|
||||
|
||||
Then, create a `best_practices.md` wiki file in the root of [global](https://pr-agent-docs.codium.ai/usage-guide/configuration_options/#global-configuration-file) configuration repository, `pr-agent-settings`.
|
||||
|
||||
##### Example results
|
||||
|
||||
{width=512}
|
||||
|
||||
Note that while the `extra instructions` are more related to the way the `improve` tool behaves, the `best_practices.md` file is a general guideline for the way code should be written in the repo.
|
||||
|
||||
#### How to combine `extra instructions` and `best practices`
|
||||
|
||||
The `extra instructions` configuration is more related to the `improve` tool prompt. It can be used, for example, to avoid specific suggestions ("Don't suggest to add try-except block", "Ignore changes in toml files", ...) or to emphasize specific aspects or formats ("Answer in Japanese", "Give only short suggestions", ...)
|
||||
|
||||
In contrast, the `best_practices.md` file is a general guideline for the way code should be written in the repo.
|
||||
|
||||
Using a combination of both can help the AI model to provide relevant and tailored suggestions.
|
||||
|
||||
## Configuration options
|
||||
|
||||
!!! example "General options"
|
||||
??? example "General options"
|
||||
|
||||
<table>
|
||||
<table>
|
||||
<tr>
|
||||
<td><b>num_code_suggestions</b></td>
|
||||
<td>Number of code suggestions provided by the 'improve' tool. Default is 4 for CLI, 0 for auto tools.</td>
|
||||
@ -179,11 +206,15 @@ Using a combination of both can help the AI model to provide relevant and tailor
|
||||
<td><b>enable_help_text</b></td>
|
||||
<td>If set to true, the tool will display a help text in the comment. Default is true.</td>
|
||||
</tr>
|
||||
</table>
|
||||
<tr>
|
||||
<td><b>enable_chat_text</b></td>
|
||||
<td>If set to true, the tool will display a reference to the PR chat in the comment. Default is true.</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
!!! example "params for 'extended' mode"
|
||||
??? example "params for 'extended' mode"
|
||||
|
||||
<table>
|
||||
<table>
|
||||
<tr>
|
||||
<td><b>auto_extended_mode</b></td>
|
||||
<td>Enable extended mode automatically (no need for the --extended option). Default is true.</td>
|
||||
@ -204,17 +235,16 @@ Using a combination of both can help the AI model to provide relevant and tailor
|
||||
<td><b>final_clip_factor</b></td>
|
||||
<td>Factor to remove suggestions with low confidence. Default is 0.9.</td>
|
||||
</tr>
|
||||
</table>
|
||||
</table>
|
||||
|
||||
## A note on code suggestions quality
|
||||
|
||||
- While the current AI for code is getting better and better (GPT-4), it's not flawless. Not all the suggestions will be perfect, and a user should not accept all of them automatically. Critical reading and judgment are required.
|
||||
- AI models for code are getting better and better (Sonnet-3.5 and GPT-4), but they are not flawless. Not all the suggestions will be perfect, and a user should not accept all of them automatically. Critical reading and judgment are required.
|
||||
- While mistakes of the AI are rare but can happen, a real benefit from the suggestions of the `improve` (and [`review`](https://pr-agent-docs.codium.ai/tools/review/)) tool is to catch, with high probability, **mistakes or bugs done by the PR author**, when they happen. So, it's a good practice to spend the needed ~30-60 seconds to review the suggestions, even if not all of them are always relevant.
|
||||
- The hierarchical structure of the suggestions is designed to help the user to _quickly_ understand them, and to decide which ones are relevant and which are not:
|
||||
|
||||
- Only if the `Category` header is relevant, the user should move to the summarized suggestion description
|
||||
- Only if the summarized suggestion description is relevant, the user should click on the collapsible, to read the full suggestion description with a code preview example.
|
||||
|
||||
In addition, we recommend to use the `extra_instructions` field to guide the model to suggestions that are more relevant to the specific needs of the project.
|
||||
<br>
|
||||
Consider also trying the [Custom Prompt Tool](./custom_prompt.md) 💎, that will **only** propose code suggestions that follow specific guidelines defined by user.
|
||||
- In addition, we recommend to use the [`extra_instructions`](https://pr-agent-docs.codium.ai/tools/improve/#extra-instructions-and-best-practices) field to guide the model to suggestions that are more relevant to the specific needs of the project.
|
||||
- The interactive [PR chat](https://pr-agent-docs.codium.ai/chrome-extension/) also provides an easy way to get more tailored suggestions and feedback from the AI model.
|
||||
|
||||
@ -8,6 +8,9 @@ The tool can be triggered automatically every time a new PR is [opened](../usage
|
||||
|
||||
Note that the main purpose of the `review` tool is to provide the **PR reviewer** with useful feedbacks and insights. The PR author, in contrast, may prefer to save time and focus on the output of the [improve](./improve.md) tool, which provides actionable code suggestions.
|
||||
|
||||
(Read more about the different personas in the PR process and how PR-Agent aims to assist them in our [blog](https://www.codium.ai/blog/understanding-the-challenges-and-pain-points-of-the-pull-request-cycle/))
|
||||
|
||||
|
||||
## Example usage
|
||||
|
||||
### Manual triggering
|
||||
|
||||
@ -10,14 +10,10 @@ To get a list of the components that changed in the PR and choose the relevant c
|
||||
## Example usage
|
||||
|
||||
Invoke the tool manually by commenting `/test` on any PR:
|
||||
|
||||
{width=704}
|
||||
|
||||
The tool will generate tests for the selected component (if no component is stated, it will generate tests for largest component):
|
||||
|
||||
{width=768}
|
||||
{width=768}
|
||||
|
||||
{width=768}
|
||||
|
||||
(Example taken from [here](https://github.com/Codium-ai/pr-agent/pull/598#issuecomment-1913679429)):
|
||||
|
||||
|
||||
@ -1,6 +1,28 @@
|
||||
## Show possible configurations
|
||||
The possible configurations of pr-agent are stored in [here](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml).
|
||||
In the [tools](https://pr-agent-docs.codium.ai/tools/) page you can find explanations on how to use these configurations for each tool.
|
||||
|
||||
To print all the available configurations as a comment on your PR, you can use the following command:
|
||||
```
|
||||
/config
|
||||
```
|
||||
|
||||
{width=512}
|
||||
|
||||
|
||||
To view the **actual** configurations used for a specific tool, after all the user settings are applied, you can add for each tool a `--config.output_relevant_configurations=true` suffix.
|
||||
For example:
|
||||
```
|
||||
/improve --config.output_relevant_configurations=true
|
||||
```
|
||||
Will output an additional field showing the actual configurations used for the `improve` tool.
|
||||
|
||||
{width=512}
|
||||
|
||||
|
||||
## Ignoring files from analysis
|
||||
|
||||
In some cases, you may want to exclude specific files or directories from the analysis performed by CodiumAI PR-Agent. This can be useful, for example, when you have files that are generated automatically or files that shouldn't be reviewed, like vendored code.
|
||||
In some cases, you may want to exclude specific files or directories from the analysis performed by CodiumAI PR-Agent. This can be useful, for example, when you have files that are generated automatically or files that shouldn't be reviewed, like vendor code.
|
||||
|
||||
You can ignore files or folders using the following methods:
|
||||
- `IGNORE.GLOB`
|
||||
@ -44,7 +66,7 @@ When the PR is above the token limit, it employs a [PR Compression strategy](../
|
||||
However, for very large PRs, or in case you want to emphasize quality over speed and cost, there are two possible solutions:
|
||||
1) [Use a model](https://codium-ai.github.io/Docs-PR-Agent/usage-guide/#changing-a-model) with larger context, like GPT-32K, or claude-100K. This solution will be applicable for all the tools.
|
||||
2) For the `/improve` tool, there is an ['extended' mode](https://codium-ai.github.io/Docs-PR-Agent/tools/#improve) (`/improve --extended`),
|
||||
which divides the PR to chunks, and processes each chunk separately. With this mode, regardless of the model, no compression will be done (but for large PRs, multiple model calls may occur)
|
||||
which divides the PR into chunks, and processes each chunk separately. With this mode, regardless of the model, no compression will be done (but for large PRs, multiple model calls may occur)
|
||||
|
||||
|
||||
|
||||
@ -63,15 +85,16 @@ By default, around any change in your PR, git patch provides three lines of cont
|
||||
code line that already existed in the file...
|
||||
```
|
||||
|
||||
For the `review`, `describe`, `ask` and `add_docs` tools, if the token budget allows, PR-Agent tries to increase the number of lines of context, via the parameter:
|
||||
PR-Agent will try to increase the number of lines of context, via the parameter:
|
||||
```
|
||||
[config]
|
||||
patch_extra_lines_before=4
|
||||
patch_extra_lines_after=2
|
||||
patch_extra_lines_before=3
|
||||
patch_extra_lines_after=1
|
||||
```
|
||||
|
||||
Increasing this number provides more context to the model, but will also increase the token budget.
|
||||
If the PR is too large (see [PR Compression strategy](https://github.com/Codium-ai/pr-agent/blob/main/PR_COMPRESSION.md)), PR-Agent automatically sets this number to 0, using the original git patch.
|
||||
Increasing this number provides more context to the model, but will also increase the token budget, and may overwhelm the model with too much information, unrelated to the actual PR code changes.
|
||||
|
||||
If the PR is too large (see [PR Compression strategy](https://github.com/Codium-ai/pr-agent/blob/main/PR_COMPRESSION.md)), PR-Agent may automatically set this number to 0, and will use the original git patch.
|
||||
|
||||
|
||||
## Editing the prompts
|
||||
@ -112,3 +135,28 @@ LANGSMITH_API_KEY=<api_key>
|
||||
LANGSMITH_PROJECT=<project>
|
||||
LANGSMITH_BASE_URL=<url>
|
||||
```
|
||||
|
||||
## Ignoring automatic commands in PRs
|
||||
|
||||
In some cases, you may want to automatically ignore specific PRs . PR-Agent enables you to ignore PR with a specific title, or from/to specific branches (regex matching).
|
||||
|
||||
To ignore PRs with a specific title such as "[Bump]: ...", you can add the following to your `configuration.toml` file:
|
||||
|
||||
```
|
||||
[config]
|
||||
ignore_pr_title = ["\\[Bump\\]"]
|
||||
```
|
||||
|
||||
Where the `ignore_pr_title` is a list of regex patterns to match the PR title you want to ignore. Default is `ignore_pr_title = ["^\\[Auto\\]", "^Auto"]`.
|
||||
|
||||
|
||||
To ignore PRs from specific source or target branches, you can add the following to your `configuration.toml` file:
|
||||
|
||||
```
|
||||
[config]
|
||||
ignore_pr_source_branches = ['develop', 'main', 'master', 'stage']
|
||||
ignore_pr_target_branches = ["qa"]
|
||||
```
|
||||
|
||||
Where the `ignore_pr_source_branches` and `ignore_pr_target_branches` are lists of regex patterns to match the source and target branches you want to ignore.
|
||||
They are not mutually exclusive, you can use them together or separately.
|
||||
|
||||
@ -94,13 +94,6 @@ To cancel the automatic run of all the tools, set:
|
||||
pr_commands = []
|
||||
```
|
||||
|
||||
You can also disable automatic runs for PRs with specific titles, by setting the `ignore_pr_titles` parameter with the relevant regex. For example:
|
||||
```
|
||||
[github_app]
|
||||
ignore_pr_title = ["^[Auto]", ".*ignore.*"]
|
||||
```
|
||||
will ignore PRs with titles that start with "Auto" or contain the word "ignore".
|
||||
|
||||
### GitHub app automatic tools for push actions (commits to an open PR)
|
||||
|
||||
In addition to running automatic tools when a PR is opened, the GitHub app can also respond to new code that is pushed to an open PR.
|
||||
@ -128,10 +121,14 @@ Specifically, start by setting the following environment variables:
|
||||
github_action_config.auto_review: "true" # enable\disable auto review
|
||||
github_action_config.auto_describe: "true" # enable\disable auto describe
|
||||
github_action_config.auto_improve: "true" # enable\disable auto improve
|
||||
github_action_config.pr_actions: ["opened", "reopened", "ready_for_review", "review_requested"]
|
||||
```
|
||||
`github_action_config.auto_review`, `github_action_config.auto_describe` and `github_action_config.auto_improve` are used to enable/disable automatic tools that run when a new PR is opened.
|
||||
If not set, the default configuration is for all three tools to run automatically when a new PR is opened.
|
||||
|
||||
`github_action_config.pr_actions` is used to configure which `pull_requests` events will trigger the enabled auto flags
|
||||
If not set, the default configuration is `["opened", "reopened", "ready_for_review", "review_requested"]`
|
||||
|
||||
`github_action_config.enable_output` are used to enable/disable github actions [output parameter](https://docs.github.com/en/actions/creating-actions/metadata-syntax-for-github-actions#outputs-for-docker-container-and-javascript-actions) (default is `true`).
|
||||
Review result is output as JSON to `steps.{step-id}.outputs.review` property.
|
||||
The JSON structure is equivalent to the yaml data structure defined in [pr_reviewer_prompts.toml](https://github.com/idubnori/pr-agent/blob/main/pr_agent/settings/pr_reviewer_prompts.toml).
|
||||
@ -183,6 +180,12 @@ inline_code_comments = true
|
||||
|
||||
Each time you invoke a `/review` tool, it will use inline code comments.
|
||||
|
||||
|
||||
Note that among other limitations, BitBucket provides relatively low rate-limits for applications (up to 1000 requests per hour), and does not provide an API to track the actual rate-limit usage.
|
||||
If you experience lack of responses from PR-Agent, you might want to set: `bitbucket_app.avoid_full_files=true` in your configuration file.
|
||||
This will prevent PR-Agent from acquiring the full file content, and will only use the diff content. This will reduce the number of requests made to BitBucket, at the cost of small decrease in accuracy, as dynamic context will not be applicable.
|
||||
|
||||
|
||||
### BitBucket Self-Hosted App automatic tools
|
||||
|
||||
To control which commands will run automatically when a new PR is opened, you can set the `pr_commands` parameter in the configuration file:
|
||||
|
||||
@ -41,12 +41,24 @@ nav:
|
||||
- 💎 Custom Prompt: 'tools/custom_prompt.md'
|
||||
- 💎 CI Feedback: 'tools/ci_feedback.md'
|
||||
- 💎 Similar Code: 'tools/similar_code.md'
|
||||
- Core Abilities: 'core-abilities/index.md'
|
||||
- Core Abilities:
|
||||
- 'core-abilities/index.md'
|
||||
- Local and global metadata: 'core-abilities/metadata.md'
|
||||
- Dynamic context: 'core-abilities/dynamic_context.md'
|
||||
- Self-reflection: 'core-abilities/self_reflection.md'
|
||||
- Impact evaluation: 'core-abilities/impact_evaluation.md'
|
||||
- Interactivity: 'core-abilities/interactivity.md'
|
||||
- Compression strategy: 'core-abilities/compression_strategy.md'
|
||||
- Code-oriented YAML: 'core-abilities/code_oriented_yaml.md'
|
||||
- Static code analysis: 'core-abilities/static_code_analysis.md'
|
||||
- Code Fine-tuning Benchmark: 'finetuning_benchmark/index.md'
|
||||
- Chrome Extension:
|
||||
- PR-Agent Chrome Extension: 'chrome-extension/index.md'
|
||||
- Features: 'chrome-extension/features.md'
|
||||
- Data Privacy: 'chrome-extension/data_privacy.md'
|
||||
- Code Fine-tuning Benchmark: 'finetuning_benchmark/index.md'
|
||||
- FAQ:
|
||||
- FAQ: 'faq/index.md'
|
||||
# - Code Fine-tuning Benchmark: 'finetuning_benchmark/index.md'
|
||||
|
||||
theme:
|
||||
logo: assets/logo.svg
|
||||
|
||||
@ -19,6 +19,10 @@ MAX_TOKENS = {
|
||||
'gpt-4o-mini': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
'gpt-4o-mini-2024-07-18': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
'gpt-4o-2024-08-06': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
'o1-mini': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
'o1-mini-2024-09-12': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
'o1-preview': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
'o1-preview-2024-09-12': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
'claude-instant-1': 100000,
|
||||
'claude-2': 100000,
|
||||
'command-nightly': 4096,
|
||||
|
||||
@ -167,7 +167,7 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||
if self.azure:
|
||||
model = 'azure/' + model
|
||||
if 'claude' in model and not system:
|
||||
system = "\n"
|
||||
system = "No system prompt provided"
|
||||
get_logger().warning(
|
||||
"Empty system prompt for claude model. Adding a newline character to prevent OpenAI API error.")
|
||||
messages = [{"role": "system", "content": system}, {"role": "user", "content": user}]
|
||||
@ -215,13 +215,13 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||
|
||||
response = await acompletion(**kwargs)
|
||||
except (openai.APIError, openai.APITimeoutError) as e:
|
||||
get_logger().warning("Error during OpenAI inference: ", e)
|
||||
get_logger().warning(f"Error during LLM inference: {e}")
|
||||
raise
|
||||
except (openai.RateLimitError) as e:
|
||||
get_logger().error("Rate limit error during OpenAI inference: ", e)
|
||||
get_logger().error(f"Rate limit error during LLM inference: {e}")
|
||||
raise
|
||||
except (Exception) as e:
|
||||
get_logger().warning("Unknown error during OpenAI inference: ", e)
|
||||
get_logger().warning(f"Unknown error during LLM inference: {e}")
|
||||
raise openai.APIError from e
|
||||
if response is None or len(response["choices"]) == 0:
|
||||
raise openai.APIError
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
from __future__ import annotations
|
||||
|
||||
import re
|
||||
import traceback
|
||||
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
|
||||
@ -12,27 +13,48 @@ def extend_patch(original_file_str, patch_str, patch_extra_lines_before=0,
|
||||
if not patch_str or (patch_extra_lines_before == 0 and patch_extra_lines_after == 0) or not original_file_str:
|
||||
return patch_str
|
||||
|
||||
if type(original_file_str) == bytes:
|
||||
try:
|
||||
original_file_str = original_file_str.decode('utf-8')
|
||||
except UnicodeDecodeError:
|
||||
return ""
|
||||
|
||||
# skip patches
|
||||
patch_extension_skip_types = get_settings().config.patch_extension_skip_types #[".md",".txt"]
|
||||
if patch_extension_skip_types and filename:
|
||||
if any([filename.endswith(skip_type) for skip_type in patch_extension_skip_types]):
|
||||
original_file_str = decode_if_bytes(original_file_str)
|
||||
if not original_file_str:
|
||||
return patch_str
|
||||
|
||||
# dynamic context settings
|
||||
if should_skip_patch(filename):
|
||||
return patch_str
|
||||
|
||||
try:
|
||||
extended_patch_str = process_patch_lines(patch_str, original_file_str,
|
||||
patch_extra_lines_before, patch_extra_lines_after)
|
||||
except Exception as e:
|
||||
get_logger().warning(f"Failed to extend patch: {e}", artifact={"traceback": traceback.format_exc()})
|
||||
return patch_str
|
||||
|
||||
return extended_patch_str
|
||||
|
||||
|
||||
def decode_if_bytes(original_file_str):
|
||||
if isinstance(original_file_str, bytes):
|
||||
try:
|
||||
return original_file_str.decode('utf-8')
|
||||
except UnicodeDecodeError:
|
||||
encodings_to_try = ['iso-8859-1', 'latin-1', 'ascii', 'utf-16']
|
||||
for encoding in encodings_to_try:
|
||||
try:
|
||||
return original_file_str.decode(encoding)
|
||||
except UnicodeDecodeError:
|
||||
continue
|
||||
return ""
|
||||
return original_file_str
|
||||
|
||||
|
||||
def should_skip_patch(filename):
|
||||
patch_extension_skip_types = get_settings().config.patch_extension_skip_types
|
||||
if patch_extension_skip_types and filename:
|
||||
return any(filename.endswith(skip_type) for skip_type in patch_extension_skip_types)
|
||||
return False
|
||||
|
||||
|
||||
def process_patch_lines(patch_str, original_file_str, patch_extra_lines_before, patch_extra_lines_after):
|
||||
allow_dynamic_context = get_settings().config.allow_dynamic_context
|
||||
max_extra_lines_before_dynamic_context = get_settings().config.max_extra_lines_before_dynamic_context
|
||||
patch_extra_lines_before_dynamic = patch_extra_lines_before
|
||||
if allow_dynamic_context:
|
||||
if max_extra_lines_before_dynamic_context > patch_extra_lines_before:
|
||||
patch_extra_lines_before_dynamic = max_extra_lines_before_dynamic_context
|
||||
else:
|
||||
get_logger().warning(f"'max_extra_lines_before_dynamic_context' should be greater than 'patch_extra_lines_before'")
|
||||
patch_extra_lines_before_dynamic = get_settings().config.max_extra_lines_before_dynamic_context
|
||||
|
||||
original_lines = original_file_str.splitlines()
|
||||
len_original_lines = len(original_lines)
|
||||
@ -46,23 +68,14 @@ def extend_patch(original_file_str, patch_str, patch_extra_lines_before=0,
|
||||
for line in patch_lines:
|
||||
if line.startswith('@@'):
|
||||
match = RE_HUNK_HEADER.match(line)
|
||||
# identify hunk header
|
||||
if match:
|
||||
# finish last hunk
|
||||
# finish processing previous hunk
|
||||
if start1 != -1 and patch_extra_lines_after > 0:
|
||||
delta_lines = original_lines[start1 + size1 - 1:start1 + size1 - 1 + patch_extra_lines_after]
|
||||
delta_lines = [f' {line}' for line in delta_lines]
|
||||
delta_lines = [f' {line}' for line in original_lines[start1 + size1 - 1:start1 + size1 - 1 + patch_extra_lines_after]]
|
||||
extended_patch_lines.extend(delta_lines)
|
||||
|
||||
res = list(match.groups())
|
||||
for i in range(len(res)):
|
||||
if res[i] is None:
|
||||
res[i] = 0
|
||||
try:
|
||||
start1, size1, start2, size2 = map(int, res[:4])
|
||||
except: # '@@ -0,0 +1 @@' case
|
||||
start1, size1, size2 = map(int, res[:3])
|
||||
start2 = 0
|
||||
section_header = res[4]
|
||||
section_header, size1, size2, start1, start2 = extract_hunk_headers(match)
|
||||
|
||||
if patch_extra_lines_before > 0 or patch_extra_lines_after > 0:
|
||||
def _calc_context_limits(patch_lines_before):
|
||||
@ -82,7 +95,7 @@ def extend_patch(original_file_str, patch_str, patch_extra_lines_before=0,
|
||||
_calc_context_limits(patch_extra_lines_before_dynamic)
|
||||
lines_before = original_lines[extended_start1 - 1:start1 - 1]
|
||||
found_header = False
|
||||
for i,line, in enumerate(lines_before):
|
||||
for i, line, in enumerate(lines_before):
|
||||
if section_header in line:
|
||||
found_header = True
|
||||
# Update start and size in one line each
|
||||
@ -99,8 +112,9 @@ def extend_patch(original_file_str, patch_str, patch_extra_lines_before=0,
|
||||
extended_start1, extended_size1, extended_start2, extended_size2 = \
|
||||
_calc_context_limits(patch_extra_lines_before)
|
||||
|
||||
delta_lines = original_lines[extended_start1 - 1:start1 - 1]
|
||||
delta_lines = [f' {line}' for line in delta_lines]
|
||||
delta_lines = [f' {line}' for line in original_lines[extended_start1 - 1:start1 - 1]]
|
||||
|
||||
# logic to remove section header if its in the extra delta lines (in dynamic context, this is also done)
|
||||
if section_header and not allow_dynamic_context:
|
||||
for line in delta_lines:
|
||||
if section_header in line:
|
||||
@ -120,11 +134,10 @@ def extend_patch(original_file_str, patch_str, patch_extra_lines_before=0,
|
||||
continue
|
||||
extended_patch_lines.append(line)
|
||||
except Exception as e:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().error(f"Failed to extend patch: {e}")
|
||||
get_logger().warning(f"Failed to extend patch: {e}", artifact={"traceback": traceback.format_exc()})
|
||||
return patch_str
|
||||
|
||||
# finish last hunk
|
||||
# finish processing last hunk
|
||||
if start1 != -1 and patch_extra_lines_after > 0:
|
||||
delta_lines = original_lines[start1 + size1 - 1:start1 + size1 - 1 + patch_extra_lines_after]
|
||||
# add space at the beginning of each extra line
|
||||
@ -135,6 +148,20 @@ def extend_patch(original_file_str, patch_str, patch_extra_lines_before=0,
|
||||
return extended_patch_str
|
||||
|
||||
|
||||
def extract_hunk_headers(match):
|
||||
res = list(match.groups())
|
||||
for i in range(len(res)):
|
||||
if res[i] is None:
|
||||
res[i] = 0
|
||||
try:
|
||||
start1, size1, start2, size2 = map(int, res[:4])
|
||||
except: # '@@ -0,0 +1 @@' case
|
||||
start1, size1, size2 = map(int, res[:3])
|
||||
start2 = 0
|
||||
section_header = res[4]
|
||||
return section_header, size1, size2, start1, start2
|
||||
|
||||
|
||||
def omit_deletion_hunks(patch_lines) -> str:
|
||||
"""
|
||||
Omit deletion hunks from the patch and return the modified patch.
|
||||
@ -243,7 +270,7 @@ __old hunk__
|
||||
if hasattr(file, 'edit_type') and file.edit_type == EDIT_TYPE.DELETED:
|
||||
return f"\n\n## file '{file.filename.strip()}' was deleted\n"
|
||||
|
||||
patch_with_lines_str = f"\n\n## file: '{file.filename.strip()}'\n"
|
||||
patch_with_lines_str = f"\n\n## File: '{file.filename.strip()}'\n"
|
||||
patch_lines = patch.splitlines()
|
||||
RE_HUNK_HEADER = re.compile(
|
||||
r"^@@ -(\d+)(?:,(\d+))? \+(\d+)(?:,(\d+))? @@[ ]?(.*)")
|
||||
@ -253,8 +280,8 @@ __old hunk__
|
||||
start1, size1, start2, size2 = -1, -1, -1, -1
|
||||
prev_header_line = []
|
||||
header_line = []
|
||||
for line in patch_lines:
|
||||
if 'no newline at end of file' in line.lower():
|
||||
for line_i, line in enumerate(patch_lines):
|
||||
if 'no newline at end of file' in line.lower().strip().strip('//'):
|
||||
continue
|
||||
|
||||
if line.startswith('@@'):
|
||||
@ -280,21 +307,18 @@ __old hunk__
|
||||
if match:
|
||||
prev_header_line = header_line
|
||||
|
||||
res = list(match.groups())
|
||||
for i in range(len(res)):
|
||||
if res[i] is None:
|
||||
res[i] = 0
|
||||
try:
|
||||
start1, size1, start2, size2 = map(int, res[:4])
|
||||
except: # '@@ -0,0 +1 @@' case
|
||||
start1, size1, size2 = map(int, res[:3])
|
||||
start2 = 0
|
||||
section_header, size1, size2, start1, start2 = extract_hunk_headers(match)
|
||||
|
||||
elif line.startswith('+'):
|
||||
new_content_lines.append(line)
|
||||
elif line.startswith('-'):
|
||||
old_content_lines.append(line)
|
||||
else:
|
||||
if not line and line_i: # if this line is empty and the next line is a hunk header, skip it
|
||||
if line_i + 1 < len(patch_lines) and patch_lines[line_i + 1].startswith('@@'):
|
||||
continue
|
||||
elif line_i + 1 == len(patch_lines):
|
||||
continue
|
||||
new_content_lines.append(line)
|
||||
old_content_lines.append(line)
|
||||
|
||||
@ -319,7 +343,7 @@ __old hunk__
|
||||
|
||||
def extract_hunk_lines_from_patch(patch: str, file_name, line_start, line_end, side) -> tuple[str, str]:
|
||||
|
||||
patch_with_lines_str = f"\n\n## file: '{file_name.strip()}'\n\n"
|
||||
patch_with_lines_str = f"\n\n## File: '{file_name.strip()}'\n\n"
|
||||
selected_lines = ""
|
||||
patch_lines = patch.splitlines()
|
||||
RE_HUNK_HEADER = re.compile(
|
||||
@ -339,15 +363,7 @@ def extract_hunk_lines_from_patch(patch: str, file_name, line_start, line_end, s
|
||||
|
||||
match = RE_HUNK_HEADER.match(line)
|
||||
|
||||
res = list(match.groups())
|
||||
for i in range(len(res)):
|
||||
if res[i] is None:
|
||||
res[i] = 0
|
||||
try:
|
||||
start1, size1, start2, size2 = map(int, res[:4])
|
||||
except: # '@@ -0,0 +1 @@' case
|
||||
start1, size1, size2 = map(int, res[:3])
|
||||
start2 = 0
|
||||
section_header, size1, size2, start1, start2 = extract_hunk_headers(match)
|
||||
|
||||
# check if line range is in this hunk
|
||||
if side.lower() == 'left':
|
||||
|
||||
@ -23,8 +23,15 @@ ADDED_FILES_ = "Additional added files (insufficient token budget to process):\n
|
||||
|
||||
OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD = 1500
|
||||
OUTPUT_BUFFER_TOKENS_HARD_THRESHOLD = 1000
|
||||
MAX_EXTRA_LINES = 10
|
||||
|
||||
|
||||
def cap_and_log_extra_lines(value, direction) -> int:
|
||||
if value > MAX_EXTRA_LINES:
|
||||
get_logger().warning(f"patch_extra_lines_{direction} was {value}, capping to {MAX_EXTRA_LINES}")
|
||||
return MAX_EXTRA_LINES
|
||||
return value
|
||||
|
||||
|
||||
def get_pr_diff(git_provider: GitProvider, token_handler: TokenHandler,
|
||||
model: str,
|
||||
@ -38,6 +45,8 @@ def get_pr_diff(git_provider: GitProvider, token_handler: TokenHandler,
|
||||
else:
|
||||
PATCH_EXTRA_LINES_BEFORE = get_settings().config.patch_extra_lines_before
|
||||
PATCH_EXTRA_LINES_AFTER = get_settings().config.patch_extra_lines_after
|
||||
PATCH_EXTRA_LINES_BEFORE = cap_and_log_extra_lines(PATCH_EXTRA_LINES_BEFORE, "before")
|
||||
PATCH_EXTRA_LINES_AFTER = cap_and_log_extra_lines(PATCH_EXTRA_LINES_AFTER, "after")
|
||||
|
||||
try:
|
||||
diff_files_original = git_provider.get_diff_files()
|
||||
@ -200,6 +209,10 @@ def pr_generate_extended_diff(pr_languages: list,
|
||||
if add_line_numbers_to_hunks:
|
||||
full_extended_patch = convert_to_hunks_with_lines_numbers(extended_patch, file)
|
||||
|
||||
# add AI-summary metadata to the patch
|
||||
if file.ai_file_summary and get_settings().get("config.enable_ai_metadata", False):
|
||||
full_extended_patch = add_ai_summary_top_patch(file, full_extended_patch)
|
||||
|
||||
patch_tokens = token_handler.count_tokens(full_extended_patch)
|
||||
file.tokens = patch_tokens
|
||||
total_tokens += patch_tokens
|
||||
@ -239,6 +252,10 @@ def pr_generate_compressed_diff(top_langs: list, token_handler: TokenHandler, mo
|
||||
if convert_hunks_to_line_numbers:
|
||||
patch = convert_to_hunks_with_lines_numbers(patch, file)
|
||||
|
||||
## add AI-summary metadata to the patch (disabled, since we are in the compressed diff)
|
||||
# if file.ai_file_summary and get_settings().config.get('config.is_auto_command', False):
|
||||
# patch = add_ai_summary_top_patch(file, patch)
|
||||
|
||||
new_patch_tokens = token_handler.count_tokens(patch)
|
||||
file_dict[file.filename] = {'patch': patch, 'tokens': new_patch_tokens, 'edit_type': file.edit_type}
|
||||
|
||||
@ -304,7 +321,7 @@ def generate_full_patch(convert_hunks_to_line_numbers, file_dict, max_tokens_mod
|
||||
|
||||
if patch:
|
||||
if not convert_hunks_to_line_numbers:
|
||||
patch_final = f"\n\n## file: '{filename.strip()}\n\n{patch.strip()}\n'"
|
||||
patch_final = f"\n\n## File: '{filename.strip()}\n\n{patch.strip()}\n'"
|
||||
else:
|
||||
patch_final = "\n\n" + patch.strip()
|
||||
patches.append(patch_final)
|
||||
@ -330,11 +347,9 @@ async def retry_with_fallback_models(f: Callable, model_type: ModelType = ModelT
|
||||
except:
|
||||
get_logger().warning(
|
||||
f"Failed to generate prediction with {model}"
|
||||
f"{(' from deployment ' + deployment_id) if deployment_id else ''}: "
|
||||
f"{traceback.format_exc()}"
|
||||
)
|
||||
if i == len(all_models) - 1: # If it's the last iteration
|
||||
raise # Re-raise the last exception
|
||||
raise Exception(f"Failed to generate prediction with any model of {all_models}")
|
||||
|
||||
|
||||
def _get_all_models(model_type: ModelType = ModelType.REGULAR) -> List[str]:
|
||||
@ -400,11 +415,17 @@ def get_pr_multi_diffs(git_provider: GitProvider,
|
||||
for lang in pr_languages:
|
||||
sorted_files.extend(sorted(lang['files'], key=lambda x: x.tokens, reverse=True))
|
||||
|
||||
# Get the maximum number of extra lines before and after the patch
|
||||
PATCH_EXTRA_LINES_BEFORE = get_settings().config.patch_extra_lines_before
|
||||
PATCH_EXTRA_LINES_AFTER = get_settings().config.patch_extra_lines_after
|
||||
PATCH_EXTRA_LINES_BEFORE = cap_and_log_extra_lines(PATCH_EXTRA_LINES_BEFORE, "before")
|
||||
PATCH_EXTRA_LINES_AFTER = cap_and_log_extra_lines(PATCH_EXTRA_LINES_AFTER, "after")
|
||||
|
||||
# try first a single run with standard diff string, with patch extension, and no deletions
|
||||
patches_extended, total_tokens, patches_extended_tokens = pr_generate_extended_diff(
|
||||
pr_languages, token_handler, add_line_numbers_to_hunks=True,
|
||||
patch_extra_lines_before=get_settings().config.patch_extra_lines_before,
|
||||
patch_extra_lines_after=get_settings().config.patch_extra_lines_after)
|
||||
patch_extra_lines_before=PATCH_EXTRA_LINES_BEFORE,
|
||||
patch_extra_lines_after=PATCH_EXTRA_LINES_AFTER)
|
||||
|
||||
# if we are under the limit, return the full diff
|
||||
if total_tokens + OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD < get_max_tokens(model):
|
||||
@ -432,6 +453,9 @@ def get_pr_multi_diffs(git_provider: GitProvider,
|
||||
continue
|
||||
|
||||
patch = convert_to_hunks_with_lines_numbers(patch, file)
|
||||
# add AI-summary metadata to the patch
|
||||
if file.ai_file_summary and get_settings().get("config.enable_ai_metadata", False):
|
||||
patch = add_ai_summary_top_patch(file, patch)
|
||||
new_patch_tokens = token_handler.count_tokens(patch)
|
||||
|
||||
if patch and (token_handler.prompt_tokens + new_patch_tokens) > get_max_tokens(
|
||||
@ -479,3 +503,46 @@ def get_pr_multi_diffs(git_provider: GitProvider,
|
||||
final_diff_list.append(final_diff)
|
||||
|
||||
return final_diff_list
|
||||
|
||||
|
||||
def add_ai_metadata_to_diff_files(git_provider, pr_description_files):
|
||||
"""
|
||||
Adds AI metadata to the diff files based on the PR description files (FilePatchInfo.ai_file_summary).
|
||||
"""
|
||||
try:
|
||||
if not pr_description_files:
|
||||
get_logger().warning(f"PR description files are empty.")
|
||||
return
|
||||
available_files = {pr_file['full_file_name'].strip(): pr_file for pr_file in pr_description_files}
|
||||
diff_files = git_provider.get_diff_files()
|
||||
found_any_match = False
|
||||
for file in diff_files:
|
||||
filename = file.filename.strip()
|
||||
if filename in available_files:
|
||||
file.ai_file_summary = available_files[filename]
|
||||
found_any_match = True
|
||||
if not found_any_match:
|
||||
get_logger().error(f"Failed to find any matching files between PR description and diff files.",
|
||||
artifact={"pr_description_files": pr_description_files})
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to add AI metadata to diff files: {e}",
|
||||
artifact={"traceback": traceback.format_exc()})
|
||||
|
||||
|
||||
def add_ai_summary_top_patch(file, full_extended_patch):
|
||||
try:
|
||||
# below every instance of '## File: ...' in the patch, add the ai-summary metadata
|
||||
full_extended_patch_lines = full_extended_patch.split("\n")
|
||||
for i, line in enumerate(full_extended_patch_lines):
|
||||
if line.startswith("## File:") or line.startswith("## file:"):
|
||||
full_extended_patch_lines.insert(i + 1,
|
||||
f"### AI-generated changes summary:\n{file.ai_file_summary['long_summary']}")
|
||||
full_extended_patch = "\n".join(full_extended_patch_lines)
|
||||
return full_extended_patch
|
||||
|
||||
# if no '## File: ...' was found
|
||||
return full_extended_patch
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to add AI summary to the top of the patch: {e}",
|
||||
artifact={"traceback": traceback.format_exc()})
|
||||
return full_extended_patch
|
||||
|
||||
@ -21,3 +21,4 @@ class FilePatchInfo:
|
||||
old_filename: str = None
|
||||
num_plus_lines: int = -1
|
||||
num_minus_lines: int = -1
|
||||
ai_file_summary: str = None
|
||||
|
||||
@ -1,4 +1,5 @@
|
||||
from __future__ import annotations
|
||||
import html2text
|
||||
|
||||
import html
|
||||
import copy
|
||||
@ -214,19 +215,6 @@ def convert_to_markdown_v2(output_data: dict,
|
||||
reference_link = git_provider.get_line_link(relevant_file, start_line, end_line)
|
||||
|
||||
if gfm_supported:
|
||||
if get_settings().pr_reviewer.extra_issue_links:
|
||||
issue_content_linked =copy.deepcopy(issue_content)
|
||||
referenced_variables_list = issue.get('referenced_variables', [])
|
||||
for component in referenced_variables_list:
|
||||
name = component['variable_name'].strip().strip('`')
|
||||
|
||||
ind = issue_content.find(name)
|
||||
if ind != -1:
|
||||
reference_link_component = git_provider.get_line_link(relevant_file, component['relevant_line'], component['relevant_line'])
|
||||
issue_content_linked = issue_content_linked[:ind-1] + f"[`{name}`]({reference_link_component})" + issue_content_linked[ind+len(name)+1:]
|
||||
else:
|
||||
get_logger().info(f"Failed to find variable in issue content: {component['variable_name'].strip()}")
|
||||
issue_content = issue_content_linked
|
||||
issue_str = f"<a href='{reference_link}'><strong>{issue_header}</strong></a><br>{issue_content}"
|
||||
else:
|
||||
issue_str = f"[**{issue_header}**]({reference_link})\n\n{issue_content}\n\n"
|
||||
@ -917,21 +905,24 @@ def github_action_output(output_data: dict, key_name: str):
|
||||
|
||||
|
||||
def show_relevant_configurations(relevant_section: str) -> str:
|
||||
forbidden_keys = ['ai_disclaimer', 'ai_disclaimer_title', 'ANALYTICS_FOLDER', 'secret_provider',
|
||||
skip_keys = ['ai_disclaimer', 'ai_disclaimer_title', 'ANALYTICS_FOLDER', 'secret_provider', "skip_keys",
|
||||
'trial_prefix_message', 'no_eligible_message', 'identity_provider', 'ALLOWED_REPOS','APP_NAME']
|
||||
extra_skip_keys = get_settings().config.get('config.skip_keys', [])
|
||||
if extra_skip_keys:
|
||||
skip_keys.extend(extra_skip_keys)
|
||||
|
||||
markdown_text = ""
|
||||
markdown_text += "\n<hr>\n<details> <summary><strong>🛠️ Relevant configurations:</strong></summary> \n\n"
|
||||
markdown_text +="<br>These are the relevant [configurations](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml) for this tool:\n\n"
|
||||
markdown_text += f"**[config**]\n```yaml\n\n"
|
||||
for key, value in get_settings().config.items():
|
||||
if key in forbidden_keys:
|
||||
if key in skip_keys:
|
||||
continue
|
||||
markdown_text += f"{key}: {value}\n"
|
||||
markdown_text += "\n```\n"
|
||||
markdown_text += f"\n**[{relevant_section}]**\n```yaml\n\n"
|
||||
for key, value in get_settings().get(relevant_section, {}).items():
|
||||
if key in forbidden_keys:
|
||||
if key in skip_keys:
|
||||
continue
|
||||
markdown_text += f"{key}: {value}\n"
|
||||
markdown_text += "\n```"
|
||||
@ -945,3 +936,73 @@ def is_value_no(value):
|
||||
if value_str == 'no' or value_str == 'none' or value_str == 'false':
|
||||
return True
|
||||
return False
|
||||
|
||||
|
||||
def process_description(description_full: str) -> Tuple[str, List]:
|
||||
if not description_full:
|
||||
return "", []
|
||||
|
||||
split_str = "### **Changes walkthrough** 📝"
|
||||
description_split = description_full.split(split_str)
|
||||
base_description_str = description_split[0]
|
||||
changes_walkthrough_str = ""
|
||||
files = []
|
||||
if len(description_split) > 1:
|
||||
changes_walkthrough_str = description_split[1]
|
||||
else:
|
||||
get_logger().debug("No changes walkthrough found")
|
||||
|
||||
try:
|
||||
if changes_walkthrough_str:
|
||||
# get the end of the table
|
||||
if '</table>\n\n___' in changes_walkthrough_str:
|
||||
end = changes_walkthrough_str.index("</table>\n\n___")
|
||||
elif '\n___' in changes_walkthrough_str:
|
||||
end = changes_walkthrough_str.index("\n___")
|
||||
else:
|
||||
end = len(changes_walkthrough_str)
|
||||
changes_walkthrough_str = changes_walkthrough_str[:end]
|
||||
|
||||
h = html2text.HTML2Text()
|
||||
h.body_width = 0 # Disable line wrapping
|
||||
|
||||
# find all the files
|
||||
pattern = r'<tr>\s*<td>\s*(<details>\s*<summary>(.*?)</summary>(.*?)</details>)\s*</td>'
|
||||
files_found = re.findall(pattern, changes_walkthrough_str, re.DOTALL)
|
||||
for file_data in files_found:
|
||||
try:
|
||||
if isinstance(file_data, tuple):
|
||||
file_data = file_data[0]
|
||||
pattern = r'<details>\s*<summary><strong>(.*?)</strong>\s*<dd><code>(.*?)</code>.*?</summary>\s*<hr>\s*(.*?)\s*<li>(.*?)</details>'
|
||||
res = re.search(pattern, file_data, re.DOTALL)
|
||||
if not res or res.lastindex != 4:
|
||||
pattern_back = r'<details>\s*<summary><strong>(.*?)</strong><dd><code>(.*?)</code>.*?</summary>\s*<hr>\s*(.*?)\n\n\s*(.*?)</details>'
|
||||
res = re.search(pattern_back, file_data, re.DOTALL)
|
||||
if res and res.lastindex == 4:
|
||||
short_filename = res.group(1).strip()
|
||||
short_summary = res.group(2).strip()
|
||||
long_filename = res.group(3).strip()
|
||||
long_summary = res.group(4).strip()
|
||||
long_summary = long_summary.replace('<br> *', '\n*').replace('<br>','').replace('\n','<br>')
|
||||
long_summary = h.handle(long_summary).strip()
|
||||
if long_summary.startswith('\\-'):
|
||||
long_summary = "* " + long_summary[2:]
|
||||
elif not long_summary.startswith('*'):
|
||||
long_summary = f"* {long_summary}"
|
||||
|
||||
files.append({
|
||||
'short_file_name': short_filename,
|
||||
'full_file_name': long_filename,
|
||||
'short_summary': short_summary,
|
||||
'long_summary': long_summary
|
||||
})
|
||||
else:
|
||||
get_logger().error(f"Failed to parse description", artifact={'description': file_data})
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Failed to process description: {e}", artifact={'description': file_data})
|
||||
|
||||
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Failed to process description: {e}")
|
||||
|
||||
return base_description_str, files
|
||||
|
||||
@ -316,7 +316,7 @@ class AzureDevopsProvider(GitProvider):
|
||||
|
||||
new_file_content_str = new_file_content_str.content
|
||||
except Exception as error:
|
||||
get_logger().error(f"Failed to retrieve new file content of {file} at version {version}. Error: {str(error)}")
|
||||
get_logger().error(f"Failed to retrieve new file content of {file} at version {version}", error=error)
|
||||
# get_logger().error(
|
||||
# "Failed to retrieve new file content of %s at version %s. Error: %s",
|
||||
# file,
|
||||
@ -347,7 +347,7 @@ class AzureDevopsProvider(GitProvider):
|
||||
)
|
||||
original_file_content_str = original_file_content_str.content
|
||||
except Exception as error:
|
||||
get_logger().error(f"Failed to retrieve original file content of {file} at version {version}. Error: {str(error)}")
|
||||
get_logger().error(f"Failed to retrieve original file content of {file} at version {version}", error=error)
|
||||
original_file_content_str = ""
|
||||
|
||||
patch = load_large_diff(
|
||||
@ -375,12 +375,12 @@ class AzureDevopsProvider(GitProvider):
|
||||
self.diff_files = diff_files
|
||||
return diff_files
|
||||
except Exception as e:
|
||||
print(f"Error: {str(e)}")
|
||||
get_logger().exception(f"Failed to get diff files, error: {e}")
|
||||
return []
|
||||
|
||||
def publish_comment(self, pr_comment: str, is_temporary: bool = False, thread_context=None):
|
||||
comment = Comment(content=pr_comment)
|
||||
thread = CommentThread(comments=[comment], thread_context=thread_context, status=1)
|
||||
thread = CommentThread(comments=[comment], thread_context=thread_context, status=5)
|
||||
thread_response = self.azure_devops_client.create_thread(
|
||||
comment_thread=thread,
|
||||
project=self.workspace_slug,
|
||||
@ -516,16 +516,9 @@ class AzureDevopsProvider(GitProvider):
|
||||
source_branch = pr_info.source_ref_name.split("/")[-1]
|
||||
return source_branch
|
||||
|
||||
def get_pr_description(self, *, full: bool = True) -> str:
|
||||
max_tokens = get_settings().get("CONFIG.MAX_DESCRIPTION_TOKENS", None)
|
||||
if max_tokens:
|
||||
return clip_tokens(self.pr.description, max_tokens)
|
||||
return self.pr.description
|
||||
|
||||
def get_user_id(self):
|
||||
return 0
|
||||
|
||||
|
||||
def get_issue_comments(self):
|
||||
threads = self.azure_devops_client.get_threads(repository_id=self.repo_slug, pull_request_id=self.pr_num, project=self.workspace_slug)
|
||||
threads.reverse()
|
||||
@ -549,18 +542,20 @@ class AzureDevopsProvider(GitProvider):
|
||||
parsed_url = urlparse(pr_url)
|
||||
|
||||
path_parts = parsed_url.path.strip("/").split("/")
|
||||
|
||||
if len(path_parts) < 6 or path_parts[4] != "pullrequest":
|
||||
if "pullrequest" not in path_parts:
|
||||
raise ValueError(
|
||||
"The provided URL does not appear to be a Azure DevOps PR URL"
|
||||
)
|
||||
|
||||
if len(path_parts) == 6: # "https://dev.azure.com/organization/project/_git/repo/pullrequest/1"
|
||||
workspace_slug = path_parts[1]
|
||||
repo_slug = path_parts[3]
|
||||
try:
|
||||
pr_number = int(path_parts[5])
|
||||
except ValueError as e:
|
||||
raise ValueError("Unable to convert PR number to integer") from e
|
||||
elif len(path_parts) == 5: # 'https://organization.visualstudio.com/project/_git/repo/pullrequest/1'
|
||||
workspace_slug = path_parts[0]
|
||||
repo_slug = path_parts[2]
|
||||
pr_number = int(path_parts[4])
|
||||
else:
|
||||
raise ValueError("The provided URL does not appear to be a Azure DevOps PR URL")
|
||||
|
||||
return workspace_slug, repo_slug, pr_number
|
||||
|
||||
@ -620,3 +615,6 @@ class AzureDevopsProvider(GitProvider):
|
||||
get_logger().error(f"Failed to get pr id, error: {e}")
|
||||
return ""
|
||||
|
||||
def publish_file_comments(self, file_comments: list) -> bool:
|
||||
pass
|
||||
|
||||
|
||||
@ -227,7 +227,10 @@ class BitbucketProvider(GitProvider):
|
||||
|
||||
try:
|
||||
counter_valid += 1
|
||||
if counter_valid < MAX_FILES_ALLOWED_FULL // 2: # factor 2 because bitbucket has limited API calls
|
||||
if get_settings().get("bitbucket_app.avoid_full_files", False):
|
||||
original_file_content_str = ""
|
||||
new_file_content_str = ""
|
||||
elif counter_valid < MAX_FILES_ALLOWED_FULL // 2: # factor 2 because bitbucket has limited API calls
|
||||
if diff.old.get_data("links"):
|
||||
original_file_content_str = self._get_pr_file_content(
|
||||
diff.old.get_data("links")['self']['href'])
|
||||
|
||||
@ -3,7 +3,7 @@ from abc import ABC, abstractmethod
|
||||
# enum EDIT_TYPE (ADDED, DELETED, MODIFIED, RENAMED)
|
||||
from typing import Optional
|
||||
|
||||
from pr_agent.algo.utils import Range
|
||||
from pr_agent.algo.utils import Range, process_description
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.algo.types import FilePatchInfo
|
||||
from pr_agent.log import get_logger
|
||||
@ -61,13 +61,19 @@ class GitProvider(ABC):
|
||||
def reply_to_comment_from_comment_id(self, comment_id: int, body: str):
|
||||
pass
|
||||
|
||||
def get_pr_description(self, *, full: bool = True) -> str:
|
||||
def get_pr_description(self, full: bool = True, split_changes_walkthrough=False) -> str or tuple:
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.algo.utils import clip_tokens
|
||||
max_tokens_description = get_settings().get("CONFIG.MAX_DESCRIPTION_TOKENS", None)
|
||||
description = self.get_pr_description_full() if full else self.get_user_description()
|
||||
if split_changes_walkthrough:
|
||||
description, files = process_description(description)
|
||||
if max_tokens_description:
|
||||
return clip_tokens(description, max_tokens_description)
|
||||
description = clip_tokens(description, max_tokens_description)
|
||||
return description, files
|
||||
else:
|
||||
if max_tokens_description:
|
||||
description = clip_tokens(description, max_tokens_description)
|
||||
return description
|
||||
|
||||
def get_user_description(self) -> str:
|
||||
|
||||
@ -551,7 +551,7 @@ class GitLabProvider(GitProvider):
|
||||
if relevant_line_start == -1:
|
||||
link = f"{self.gl.url}/{self.id_project}/-/blob/{self.mr.source_branch}/{relevant_file}?ref_type=heads"
|
||||
elif relevant_line_end:
|
||||
link = f"{self.gl.url}/{self.id_project}/-/blob/{self.mr.source_branch}/{relevant_file}?ref_type=heads#L{relevant_line_start}-L{relevant_line_end}"
|
||||
link = f"{self.gl.url}/{self.id_project}/-/blob/{self.mr.source_branch}/{relevant_file}?ref_type=heads#L{relevant_line_start}-{relevant_line_end}"
|
||||
else:
|
||||
link = f"{self.gl.url}/{self.id_project}/-/blob/{self.mr.source_branch}/{relevant_file}?ref_type=heads#L{relevant_line_start}"
|
||||
return link
|
||||
|
||||
@ -68,6 +68,7 @@ def authorize(credentials: HTTPBasicCredentials = Depends(security)):
|
||||
async def _perform_commands_azure(commands_conf: str, agent: PRAgent, api_url: str, log_context: dict):
|
||||
apply_repo_settings(api_url)
|
||||
commands = get_settings().get(f"azure_devops_server.{commands_conf}")
|
||||
get_settings().set("config.is_auto_command", True)
|
||||
for command in commands:
|
||||
try:
|
||||
split_command = command.split(" ")
|
||||
|
||||
@ -3,6 +3,7 @@ import copy
|
||||
import hashlib
|
||||
import json
|
||||
import os
|
||||
import re
|
||||
import time
|
||||
|
||||
import jwt
|
||||
@ -77,6 +78,7 @@ async def handle_manifest(request: Request, response: Response):
|
||||
async def _perform_commands_bitbucket(commands_conf: str, agent: PRAgent, api_url: str, log_context: dict):
|
||||
apply_repo_settings(api_url)
|
||||
commands = get_settings().get(f"bitbucket_app.{commands_conf}", {})
|
||||
get_settings().set("config.is_auto_command", True)
|
||||
for command in commands:
|
||||
try:
|
||||
split_command = command.split(" ")
|
||||
@ -91,6 +93,48 @@ async def _perform_commands_bitbucket(commands_conf: str, agent: PRAgent, api_ur
|
||||
get_logger().error(f"Failed to perform command {command}: {e}")
|
||||
|
||||
|
||||
def is_bot_user(data) -> bool:
|
||||
try:
|
||||
if data["data"]["actor"]["type"] != "user":
|
||||
get_logger().info(f"BitBucket actor type is not 'user': {data['data']['actor']['type']}")
|
||||
return True
|
||||
except Exception as e:
|
||||
get_logger().error("Failed 'is_bot_user' logic: {e}")
|
||||
return False
|
||||
|
||||
|
||||
def should_process_pr_logic(data) -> bool:
|
||||
try:
|
||||
pr_data = data.get("data", {}).get("pullrequest", {})
|
||||
title = pr_data.get("title", "")
|
||||
source_branch = pr_data.get("source", {}).get("branch", {}).get("name", "")
|
||||
target_branch = pr_data.get("destination", {}).get("branch", {}).get("name", "")
|
||||
|
||||
# logic to ignore PRs with specific titles
|
||||
if title:
|
||||
ignore_pr_title_re = get_settings().get("CONFIG.IGNORE_PR_TITLE", [])
|
||||
if not isinstance(ignore_pr_title_re, list):
|
||||
ignore_pr_title_re = [ignore_pr_title_re]
|
||||
if ignore_pr_title_re and any(re.search(regex, title) for regex in ignore_pr_title_re):
|
||||
get_logger().info(f"Ignoring PR with title '{title}' due to config.ignore_pr_title setting")
|
||||
return False
|
||||
|
||||
ignore_pr_source_branches = get_settings().get("CONFIG.IGNORE_PR_SOURCE_BRANCHES", [])
|
||||
ignore_pr_target_branches = get_settings().get("CONFIG.IGNORE_PR_TARGET_BRANCHES", [])
|
||||
if (ignore_pr_source_branches or ignore_pr_target_branches):
|
||||
if any(re.search(regex, source_branch) for regex in ignore_pr_source_branches):
|
||||
get_logger().info(
|
||||
f"Ignoring PR with source branch '{source_branch}' due to config.ignore_pr_source_branches settings")
|
||||
return False
|
||||
if any(re.search(regex, target_branch) for regex in ignore_pr_target_branches):
|
||||
get_logger().info(
|
||||
f"Ignoring PR with target branch '{target_branch}' due to config.ignore_pr_target_branches settings")
|
||||
return False
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed 'should_process_pr_logic': {e}")
|
||||
return True
|
||||
|
||||
|
||||
@router.post("/webhook")
|
||||
async def handle_github_webhooks(background_tasks: BackgroundTasks, request: Request):
|
||||
app_name = get_settings().get("CONFIG.APP_NAME", "Unknown")
|
||||
@ -101,13 +145,17 @@ async def handle_github_webhooks(background_tasks: BackgroundTasks, request: Req
|
||||
input_jwt = jwt_header.split(" ")[1]
|
||||
data = await request.json()
|
||||
get_logger().debug(data)
|
||||
|
||||
async def inner():
|
||||
try:
|
||||
try:
|
||||
if data["data"]["actor"]["type"] != "user":
|
||||
# ignore bot users
|
||||
if is_bot_user(data):
|
||||
return "OK"
|
||||
|
||||
# Check if the PR should be processed
|
||||
if data.get("event", "") == "pullrequest:created":
|
||||
if not should_process_pr_logic(data):
|
||||
return "OK"
|
||||
except KeyError:
|
||||
get_logger().error("Failed to get actor type, check previous logs, this shouldn't happen.")
|
||||
|
||||
# Get the username of the sender
|
||||
try:
|
||||
@ -146,16 +194,6 @@ async def handle_github_webhooks(background_tasks: BackgroundTasks, request: Req
|
||||
sender_id, pr_url) is not Eligibility.NOT_ELIGIBLE:
|
||||
if get_settings().get("bitbucket_app.pr_commands"):
|
||||
await _perform_commands_bitbucket("pr_commands", PRAgent(), pr_url, log_context)
|
||||
else: # backwards compatibility
|
||||
auto_review = get_setting_or_env("BITBUCKET_APP.AUTO_REVIEW", None)
|
||||
if is_true(auto_review): # by default, auto review is disabled
|
||||
await PRReviewer(pr_url).run()
|
||||
auto_improve = get_setting_or_env("BITBUCKET_APP.AUTO_IMPROVE", None)
|
||||
if is_true(auto_improve): # by default, auto improve is disabled
|
||||
await PRCodeSuggestions(pr_url).run()
|
||||
auto_describe = get_setting_or_env("BITBUCKET_APP.AUTO_DESCRIBE", None)
|
||||
if is_true(auto_describe): # by default, auto describe is disabled
|
||||
await PRDescription(pr_url).run()
|
||||
elif event == "pullrequest:comment_created":
|
||||
pr_url = data["data"]["pullrequest"]["links"]["html"]["href"]
|
||||
log_context["api_url"] = pr_url
|
||||
|
||||
@ -83,7 +83,11 @@ async def run_action():
|
||||
# Handle pull request event
|
||||
if GITHUB_EVENT_NAME == "pull_request":
|
||||
action = event_payload.get("action")
|
||||
if action in ["opened", "reopened", "ready_for_review", "review_requested"]:
|
||||
|
||||
# Retrieve the list of actions from the configuration
|
||||
pr_actions = get_settings().get("GITHUB_ACTION_CONFIG.PR_ACTIONS", ["opened", "reopened", "ready_for_review", "review_requested"])
|
||||
|
||||
if action in pr_actions:
|
||||
pr_url = event_payload.get("pull_request", {}).get("url")
|
||||
if pr_url:
|
||||
# legacy - supporting both GITHUB_ACTION and GITHUB_ACTION_CONFIG
|
||||
|
||||
@ -128,8 +128,6 @@ async def handle_new_pr_opened(body: Dict[str, Any],
|
||||
log_context: Dict[str, Any],
|
||||
agent: PRAgent):
|
||||
title = body.get("pull_request", {}).get("title", "")
|
||||
get_settings().config.is_auto_command = True
|
||||
|
||||
|
||||
pull_request, api_url = _check_pull_request_event(action, body, log_context)
|
||||
if not (pull_request and api_url):
|
||||
@ -138,13 +136,6 @@ async def handle_new_pr_opened(body: Dict[str, Any],
|
||||
if action in get_settings().github_app.handle_pr_actions: # ['opened', 'reopened', 'ready_for_review']
|
||||
# logic to ignore PRs with specific titles (e.g. "[Auto] ...")
|
||||
apply_repo_settings(api_url)
|
||||
ignore_pr_title_re = get_settings().get("GITHUB_APP.IGNORE_PR_TITLE", [])
|
||||
if not isinstance(ignore_pr_title_re, list):
|
||||
ignore_pr_title_re = [ignore_pr_title_re]
|
||||
if ignore_pr_title_re and any(re.search(regex, title) for regex in ignore_pr_title_re):
|
||||
get_logger().info(f"Ignoring PR with title '{title}' due to github_app.ignore_pr_title setting")
|
||||
return {}
|
||||
|
||||
if get_identity_provider().verify_eligibility("github", sender_id, api_url) is not Eligibility.NOT_ELIGIBLE:
|
||||
await _perform_auto_commands_github("pr_commands", agent, body, api_url, log_context)
|
||||
else:
|
||||
@ -246,6 +237,60 @@ def get_log_context(body, event, action, build_number):
|
||||
return log_context, sender, sender_id, sender_type
|
||||
|
||||
|
||||
def is_bot_user(sender, sender_type):
|
||||
try:
|
||||
# logic to ignore PRs opened by bot
|
||||
if get_settings().get("GITHUB_APP.IGNORE_BOT_PR", False) and sender_type == "Bot":
|
||||
if 'pr-agent' not in sender:
|
||||
get_logger().info(f"Ignoring PR from '{sender=}' because it is a bot")
|
||||
return True
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed 'is_bot_user' logic: {e}")
|
||||
return False
|
||||
|
||||
|
||||
def should_process_pr_logic(sender_type, sender, body) -> bool:
|
||||
try:
|
||||
pull_request = body.get("pull_request", {})
|
||||
title = pull_request.get("title", "")
|
||||
pr_labels = pull_request.get("labels", [])
|
||||
source_branch = pull_request.get("head", {}).get("ref", "")
|
||||
target_branch = pull_request.get("base", {}).get("ref", "")
|
||||
|
||||
# logic to ignore PRs with specific titles
|
||||
if title:
|
||||
ignore_pr_title_re = get_settings().get("CONFIG.IGNORE_PR_TITLE", [])
|
||||
if not isinstance(ignore_pr_title_re, list):
|
||||
ignore_pr_title_re = [ignore_pr_title_re]
|
||||
if ignore_pr_title_re and any(re.search(regex, title) for regex in ignore_pr_title_re):
|
||||
get_logger().info(f"Ignoring PR with title '{title}' due to config.ignore_pr_title setting")
|
||||
return False
|
||||
|
||||
# logic to ignore PRs with specific labels or source branches or target branches.
|
||||
ignore_pr_labels = get_settings().get("CONFIG.IGNORE_PR_LABELS", [])
|
||||
if pr_labels and ignore_pr_labels:
|
||||
labels = [label['name'] for label in pr_labels]
|
||||
if any(label in ignore_pr_labels for label in labels):
|
||||
labels_str = ", ".join(labels)
|
||||
get_logger().info(f"Ignoring PR with labels '{labels_str}' due to config.ignore_pr_labels settings")
|
||||
return False
|
||||
|
||||
ignore_pr_source_branches = get_settings().get("CONFIG.IGNORE_PR_SOURCE_BRANCHES", [])
|
||||
ignore_pr_target_branches = get_settings().get("CONFIG.IGNORE_PR_TARGET_BRANCHES", [])
|
||||
if pull_request and (ignore_pr_source_branches or ignore_pr_target_branches):
|
||||
if any(re.search(regex, source_branch) for regex in ignore_pr_source_branches):
|
||||
get_logger().info(
|
||||
f"Ignoring PR with source branch '{source_branch}' due to config.ignore_pr_source_branches settings")
|
||||
return False
|
||||
if any(re.search(regex, target_branch) for regex in ignore_pr_target_branches):
|
||||
get_logger().info(
|
||||
f"Ignoring PR with target branch '{target_branch}' due to config.ignore_pr_target_branches settings")
|
||||
return False
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed 'should_process_pr_logic': {e}")
|
||||
return True
|
||||
|
||||
|
||||
async def handle_request(body: Dict[str, Any], event: str):
|
||||
"""
|
||||
Handle incoming GitHub webhook requests.
|
||||
@ -260,10 +305,11 @@ async def handle_request(body: Dict[str, Any], event: str):
|
||||
agent = PRAgent()
|
||||
log_context, sender, sender_id, sender_type = get_log_context(body, event, action, build_number)
|
||||
|
||||
# logic to ignore PRs opened by bot
|
||||
if get_settings().get("GITHUB_APP.IGNORE_BOT_PR", False) and sender_type == "Bot":
|
||||
if 'pr-agent' not in sender:
|
||||
get_logger().info(f"Ignoring PR from '{sender=}' because it is a bot")
|
||||
# logic to ignore PRs opened by bot, PRs with specific titles, labels, source branches, or target branches
|
||||
if is_bot_user(sender, sender_type):
|
||||
return {}
|
||||
if action != 'created' and 'check_run' not in body:
|
||||
if not should_process_pr_logic(sender_type, sender, body):
|
||||
return {}
|
||||
|
||||
if 'check_run' in body: # handle failed checks
|
||||
@ -281,7 +327,6 @@ async def handle_request(body: Dict[str, Any], event: str):
|
||||
pass # handle_checkbox_clicked
|
||||
# handle pull_request event with synchronize action - "push trigger" for new commits
|
||||
elif event == 'pull_request' and action == 'synchronize':
|
||||
# get_logger().debug(f'Request body', artifact=body, event=event) # added inside handle_push_trigger_for_new_commits
|
||||
await handle_push_trigger_for_new_commits(body, event, sender,sender_id, action, log_context, agent)
|
||||
elif event == 'pull_request' and action == 'closed':
|
||||
if get_settings().get("CONFIG.ANALYTICS_FOLDER", ""):
|
||||
@ -325,12 +370,14 @@ def _check_pull_request_event(action: str, body: dict, log_context: dict) -> Tup
|
||||
return pull_request, api_url
|
||||
|
||||
|
||||
async def _perform_auto_commands_github(commands_conf: str, agent: PRAgent, body: dict, api_url: str, log_context: dict):
|
||||
async def _perform_auto_commands_github(commands_conf: str, agent: PRAgent, body: dict, api_url: str,
|
||||
log_context: dict):
|
||||
apply_repo_settings(api_url)
|
||||
commands = get_settings().get(f"github_app.{commands_conf}")
|
||||
if not commands:
|
||||
get_logger().info(f"New PR, but no auto commands configured")
|
||||
return
|
||||
get_settings().set("config.is_auto_command", True)
|
||||
for command in commands:
|
||||
split_command = command.split(" ")
|
||||
command = split_command[0]
|
||||
|
||||
@ -1,7 +1,10 @@
|
||||
import asyncio
|
||||
import multiprocessing
|
||||
from collections import deque
|
||||
import traceback
|
||||
from datetime import datetime, timezone
|
||||
|
||||
import time
|
||||
import requests
|
||||
import aiohttp
|
||||
|
||||
from pr_agent.agent.pr_agent import PRAgent
|
||||
@ -13,6 +16,15 @@ setup_logger(fmt=LoggingFormat.JSON, level="DEBUG")
|
||||
NOTIFICATION_URL = "https://api.github.com/notifications"
|
||||
|
||||
|
||||
async def mark_notification_as_read(headers, notification, session):
|
||||
async with session.patch(
|
||||
f"https://api.github.com/notifications/threads/{notification['id']}",
|
||||
headers=headers) as mark_read_response:
|
||||
if mark_read_response.status != 205:
|
||||
get_logger().error(
|
||||
f"Failed to mark notification as read. Status code: {mark_read_response.status}")
|
||||
|
||||
|
||||
def now() -> str:
|
||||
"""
|
||||
Get the current UTC time in ISO 8601 format.
|
||||
@ -24,6 +36,108 @@ def now() -> str:
|
||||
now_utc = now_utc.replace("+00:00", "Z")
|
||||
return now_utc
|
||||
|
||||
async def async_handle_request(pr_url, rest_of_comment, comment_id, git_provider):
|
||||
agent = PRAgent()
|
||||
success = await agent.handle_request(
|
||||
pr_url,
|
||||
rest_of_comment,
|
||||
notify=lambda: git_provider.add_eyes_reaction(comment_id)
|
||||
)
|
||||
return success
|
||||
|
||||
def run_handle_request(pr_url, rest_of_comment, comment_id, git_provider):
|
||||
return asyncio.run(async_handle_request(pr_url, rest_of_comment, comment_id, git_provider))
|
||||
|
||||
|
||||
def process_comment_sync(pr_url, rest_of_comment, comment_id):
|
||||
try:
|
||||
# Run the async handle_request in a separate function
|
||||
git_provider = get_git_provider()(pr_url=pr_url)
|
||||
success = run_handle_request(pr_url, rest_of_comment, comment_id, git_provider)
|
||||
except Exception as e:
|
||||
get_logger().error(f"Error processing comment: {e}", artifact={"traceback": traceback.format_exc()})
|
||||
|
||||
|
||||
async def process_comment(pr_url, rest_of_comment, comment_id):
|
||||
try:
|
||||
git_provider = get_git_provider()(pr_url=pr_url)
|
||||
git_provider.set_pr(pr_url)
|
||||
agent = PRAgent()
|
||||
success = await agent.handle_request(
|
||||
pr_url,
|
||||
rest_of_comment,
|
||||
notify=lambda: git_provider.add_eyes_reaction(comment_id)
|
||||
)
|
||||
get_logger().info(f"Finished processing comment for PR: {pr_url}")
|
||||
except Exception as e:
|
||||
get_logger().error(f"Error processing comment: {e}", artifact={"traceback": traceback.format_exc()})
|
||||
|
||||
async def is_valid_notification(notification, headers, handled_ids, session, user_id):
|
||||
try:
|
||||
if 'reason' in notification and notification['reason'] == 'mention':
|
||||
if 'subject' in notification and notification['subject']['type'] == 'PullRequest':
|
||||
pr_url = notification['subject']['url']
|
||||
latest_comment = notification['subject']['latest_comment_url']
|
||||
if not latest_comment or not isinstance(latest_comment, str):
|
||||
get_logger().debug(f"no latest_comment")
|
||||
return False, handled_ids
|
||||
async with session.get(latest_comment, headers=headers) as comment_response:
|
||||
check_prev_comments = False
|
||||
if comment_response.status == 200:
|
||||
comment = await comment_response.json()
|
||||
if 'id' in comment:
|
||||
if comment['id'] in handled_ids:
|
||||
get_logger().debug(f"comment['id'] in handled_ids")
|
||||
return False, handled_ids
|
||||
else:
|
||||
handled_ids.add(comment['id'])
|
||||
if 'user' in comment and 'login' in comment['user']:
|
||||
if comment['user']['login'] == user_id:
|
||||
get_logger().debug(f"comment['user']['login'] == user_id")
|
||||
check_prev_comments = True
|
||||
comment_body = comment.get('body', '')
|
||||
if not comment_body:
|
||||
get_logger().debug(f"no comment_body")
|
||||
check_prev_comments = True
|
||||
else:
|
||||
user_tag = "@" + user_id
|
||||
if user_tag not in comment_body:
|
||||
get_logger().debug(f"user_tag not in comment_body")
|
||||
check_prev_comments = True
|
||||
else:
|
||||
get_logger().info(f"Polling, pr_url: {pr_url}",
|
||||
artifact={"comment": comment_body})
|
||||
|
||||
if not check_prev_comments:
|
||||
return True, handled_ids, comment, comment_body, pr_url, user_tag
|
||||
else: # we could not find the user tag in the latest comment. Check previous comments
|
||||
# get all comments in the PR
|
||||
requests_url = f"{pr_url}/comments".replace("pulls", "issues")
|
||||
comments_response = requests.get(requests_url, headers=headers)
|
||||
comments = comments_response.json()[::-1]
|
||||
max_comment_to_scan = 4
|
||||
for comment in comments[:max_comment_to_scan]:
|
||||
if 'user' in comment and 'login' in comment['user']:
|
||||
if comment['user']['login'] == user_id:
|
||||
continue
|
||||
comment_body = comment.get('body', '')
|
||||
if not comment_body:
|
||||
continue
|
||||
if user_tag in comment_body:
|
||||
get_logger().info("found user tag in previous comments")
|
||||
get_logger().info(f"Polling, pr_url: {pr_url}",
|
||||
artifact={"comment": comment_body})
|
||||
return True, handled_ids, comment, comment_body, pr_url, user_tag
|
||||
|
||||
get_logger().error(f"Failed to fetch comments for PR: {pr_url}")
|
||||
return False, handled_ids
|
||||
|
||||
return False, handled_ids
|
||||
except Exception as e:
|
||||
get_logger().error(f"Error processing notification: {e}", artifact={"traceback": traceback.format_exc()})
|
||||
return False, handled_ids
|
||||
|
||||
|
||||
|
||||
async def polling_loop():
|
||||
"""
|
||||
@ -34,7 +148,6 @@ async def polling_loop():
|
||||
last_modified = [None]
|
||||
git_provider = get_git_provider()()
|
||||
user_id = git_provider.get_user_id()
|
||||
agent = PRAgent()
|
||||
get_settings().set("CONFIG.PUBLISH_OUTPUT_PROGRESS", False)
|
||||
get_settings().set("pr_description.publish_description_as_comment", True)
|
||||
|
||||
@ -74,43 +187,45 @@ async def polling_loop():
|
||||
notifications = await response.json()
|
||||
if not notifications:
|
||||
continue
|
||||
get_logger().info(f"Received {len(notifications)} notifications")
|
||||
task_queue = deque()
|
||||
for notification in notifications:
|
||||
if not notification:
|
||||
continue
|
||||
# mark notification as read
|
||||
await mark_notification_as_read(headers, notification, session)
|
||||
|
||||
handled_ids.add(notification['id'])
|
||||
if 'reason' in notification and notification['reason'] == 'mention':
|
||||
if 'subject' in notification and notification['subject']['type'] == 'PullRequest':
|
||||
pr_url = notification['subject']['url']
|
||||
latest_comment = notification['subject']['latest_comment_url']
|
||||
if not latest_comment or not isinstance(latest_comment, str):
|
||||
continue
|
||||
async with session.get(latest_comment, headers=headers) as comment_response:
|
||||
if comment_response.status == 200:
|
||||
comment = await comment_response.json()
|
||||
if 'id' in comment:
|
||||
if comment['id'] in handled_ids:
|
||||
continue
|
||||
else:
|
||||
handled_ids.add(comment['id'])
|
||||
if 'user' in comment and 'login' in comment['user']:
|
||||
if comment['user']['login'] == user_id:
|
||||
continue
|
||||
comment_body = comment.get('body', '')
|
||||
if not comment_body:
|
||||
continue
|
||||
commenter_github_user = comment['user']['login'] \
|
||||
if 'user' in comment else ''
|
||||
get_logger().info(f"Polling, pr_url: {pr_url}",
|
||||
artifact={"comment": comment_body})
|
||||
user_tag = "@" + user_id
|
||||
if user_tag not in comment_body:
|
||||
continue
|
||||
output = await is_valid_notification(notification, headers, handled_ids, session, user_id)
|
||||
if output[0]:
|
||||
_, handled_ids, comment, comment_body, pr_url, user_tag = output
|
||||
rest_of_comment = comment_body.split(user_tag)[1].strip()
|
||||
comment_id = comment['id']
|
||||
git_provider.set_pr(pr_url)
|
||||
success = await agent.handle_request(pr_url, rest_of_comment,
|
||||
notify=lambda: git_provider.add_eyes_reaction(
|
||||
comment_id)) # noqa E501
|
||||
if not success:
|
||||
git_provider.set_pr(pr_url)
|
||||
|
||||
# Add to the task queue
|
||||
get_logger().info(
|
||||
f"Adding comment processing to task queue for PR, {pr_url}, comment_body: {comment_body}")
|
||||
task_queue.append((process_comment_sync, (pr_url, rest_of_comment, comment_id)))
|
||||
get_logger().info(f"Queued comment processing for PR: {pr_url}")
|
||||
else:
|
||||
get_logger().debug(f"Skipping comment processing for PR")
|
||||
|
||||
max_allowed_parallel_tasks = 10
|
||||
if task_queue:
|
||||
processes = []
|
||||
for i, (func, args) in enumerate(task_queue): # Create parallel tasks
|
||||
p = multiprocessing.Process(target=func, args=args)
|
||||
processes.append(p)
|
||||
p.start()
|
||||
if i > max_allowed_parallel_tasks:
|
||||
get_logger().error(
|
||||
f"Dropping {len(task_queue) - max_allowed_parallel_tasks} tasks from polling session")
|
||||
break
|
||||
task_queue.clear()
|
||||
|
||||
# Dont wait for all processes to complete. Move on to the next iteration
|
||||
# for p in processes:
|
||||
# p.join()
|
||||
|
||||
elif response.status != 304:
|
||||
print(f"Failed to fetch notifications. Status code: {response.status}")
|
||||
|
||||
@ -1,4 +1,5 @@
|
||||
import copy
|
||||
import re
|
||||
import json
|
||||
from datetime import datetime
|
||||
|
||||
@ -61,6 +62,7 @@ async def _perform_commands_gitlab(commands_conf: str, agent: PRAgent, api_url:
|
||||
log_context: dict):
|
||||
apply_repo_settings(api_url)
|
||||
commands = get_settings().get(f"gitlab.{commands_conf}", {})
|
||||
get_settings().set("config.is_auto_command", True)
|
||||
for command in commands:
|
||||
try:
|
||||
split_command = command.split(" ")
|
||||
@ -75,6 +77,57 @@ async def _perform_commands_gitlab(commands_conf: str, agent: PRAgent, api_url:
|
||||
get_logger().error(f"Failed to perform command {command}: {e}")
|
||||
|
||||
|
||||
def is_bot_user(data) -> bool:
|
||||
try:
|
||||
# logic to ignore bot users (unlike Github, no direct flag for bot users in gitlab)
|
||||
sender_name = data.get("user", {}).get("name", "unknown").lower()
|
||||
bot_indicators = ['codium', 'bot_', 'bot-', '_bot', '-bot']
|
||||
if any(indicator in sender_name for indicator in bot_indicators):
|
||||
get_logger().info(f"Skipping GitLab bot user: {sender_name}")
|
||||
return True
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed 'is_bot_user' logic: {e}")
|
||||
return False
|
||||
|
||||
|
||||
def should_process_pr_logic(data, title) -> bool:
|
||||
try:
|
||||
# logic to ignore MRs for titles, labels and source, target branches.
|
||||
ignore_mr_title = get_settings().get("CONFIG.IGNORE_PR_TITLE", [])
|
||||
ignore_mr_labels = get_settings().get("CONFIG.IGNORE_PR_LABELS", [])
|
||||
ignore_mr_source_branches = get_settings().get("CONFIG.IGNORE_PR_SOURCE_BRANCHES", [])
|
||||
ignore_mr_target_branches = get_settings().get("CONFIG.IGNORE_PR_TARGET_BRANCHES", [])
|
||||
|
||||
#
|
||||
if ignore_mr_source_branches:
|
||||
source_branch = data['object_attributes'].get('source_branch')
|
||||
if any(re.search(regex, source_branch) for regex in ignore_mr_source_branches):
|
||||
get_logger().info(
|
||||
f"Ignoring MR with source branch '{source_branch}' due to gitlab.ignore_mr_source_branches settings")
|
||||
return False
|
||||
|
||||
if ignore_mr_target_branches:
|
||||
target_branch = data['object_attributes'].get('target_branch')
|
||||
if any(re.search(regex, target_branch) for regex in ignore_mr_target_branches):
|
||||
get_logger().info(
|
||||
f"Ignoring MR with target branch '{target_branch}' due to gitlab.ignore_mr_target_branches settings")
|
||||
return False
|
||||
|
||||
if ignore_mr_labels:
|
||||
labels = [label['title'] for label in data['object_attributes'].get('labels', [])]
|
||||
if any(label in ignore_mr_labels for label in labels):
|
||||
labels_str = ", ".join(labels)
|
||||
get_logger().info(f"Ignoring MR with labels '{labels_str}' due to gitlab.ignore_mr_labels settings")
|
||||
return False
|
||||
|
||||
if ignore_mr_title:
|
||||
if any(re.search(regex, title) for regex in ignore_mr_title):
|
||||
get_logger().info(f"Ignoring MR with title '{title}' due to gitlab.ignore_mr_title settings")
|
||||
return False
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed 'should_process_pr_logic': {e}")
|
||||
return True
|
||||
|
||||
|
||||
@router.post("/webhook")
|
||||
async def gitlab_webhook(background_tasks: BackgroundTasks, request: Request):
|
||||
@ -117,18 +170,20 @@ async def gitlab_webhook(background_tasks: BackgroundTasks, request: Request):
|
||||
sender = data.get("user", {}).get("username", "unknown")
|
||||
sender_id = data.get("user", {}).get("id", "unknown")
|
||||
|
||||
# logic to ignore bot users (unlike Github, no direct flag for bot users in gitlab)
|
||||
sender_name = data.get("user", {}).get("name", "unknown").lower()
|
||||
if 'codium' in sender_name or 'bot_' in sender_name or 'bot-' in sender_name or '_bot' in sender_name or '-bot' in sender_name:
|
||||
get_logger().info(f"Skipping bot user: {sender_name}")
|
||||
# ignore bot users
|
||||
if is_bot_user(data):
|
||||
return JSONResponse(status_code=status.HTTP_200_OK, content=jsonable_encoder({"message": "success"}))
|
||||
if data.get('event_type') != 'note' and data.get('object_attributes', {}): # not a comment
|
||||
# ignore MRs based on title, labels, source and target branches
|
||||
if not should_process_pr_logic(data, data['object_attributes'].get('title')):
|
||||
return JSONResponse(status_code=status.HTTP_200_OK, content=jsonable_encoder({"message": "success"}))
|
||||
|
||||
log_context["sender"] = sender
|
||||
if data.get('object_kind') == 'merge_request' and data['object_attributes'].get('action') in ['open', 'reopen']:
|
||||
title = data['object_attributes'].get('title')
|
||||
url = data['object_attributes'].get('url')
|
||||
draft = data['object_attributes'].get('draft')
|
||||
get_logger().info(f"New merge request: {url}")
|
||||
|
||||
if draft:
|
||||
get_logger().info(f"Skipping draft MR: {url}")
|
||||
return JSONResponse(status_code=status.HTTP_200_OK, content=jsonable_encoder({"message": "success"}))
|
||||
|
||||
@ -14,6 +14,7 @@ use_wiki_settings_file=true
|
||||
use_repo_settings_file=true
|
||||
use_global_settings_file=true
|
||||
ai_timeout=120 # 2minutes
|
||||
skip_keys = []
|
||||
# token limits
|
||||
max_description_tokens = 500
|
||||
max_commits_tokens = 500
|
||||
@ -21,8 +22,8 @@ max_model_tokens = 32000 # Limits the maximum number of tokens that can be used
|
||||
custom_model_max_tokens=-1 # for models not in the default list
|
||||
# patch extension logic
|
||||
patch_extension_skip_types =[".md",".txt"]
|
||||
allow_dynamic_context=false
|
||||
max_extra_lines_before_dynamic_context = 10 # will try to include up to 10 extra lines before the hunk in the patch, until we reach an enclosing function or class
|
||||
allow_dynamic_context=true
|
||||
max_extra_lines_before_dynamic_context = 8 # will try to include up to 10 extra lines before the hunk in the patch, until we reach an enclosing function or class
|
||||
patch_extra_lines_before = 3 # Number of extra lines (+3 default ones) to include before each hunk in the patch
|
||||
patch_extra_lines_after = 1 # Number of extra lines (+3 default ones) to include after each hunk in the patch
|
||||
secret_provider=""
|
||||
@ -31,10 +32,17 @@ ai_disclaimer_title="" # Pro feature, title for a collapsible disclaimer to AI
|
||||
ai_disclaimer="" # Pro feature, full text for the AI disclaimer
|
||||
output_relevant_configurations=false
|
||||
large_patch_policy = "clip" # "clip", "skip"
|
||||
is_auto_command=false
|
||||
# seed
|
||||
seed=-1 # set positive value to fix the seed (and ensure temperature=0)
|
||||
temperature=0.2
|
||||
# ignore logic
|
||||
ignore_pr_title = ["^\\[Auto\\]", "^Auto"] # a list of regular expressions to match against the PR title to ignore the PR agent
|
||||
ignore_pr_target_branches = [] # a list of regular expressions of target branches to ignore from PR agent when an PR is created
|
||||
ignore_pr_source_branches = [] # a list of regular expressions of source branches to ignore from PR agent when an PR is created
|
||||
ignore_pr_labels = [] # labels to ignore from PR agent when an PR is created
|
||||
#
|
||||
is_auto_command = false # will be auto-set to true if the command is triggered by an automation
|
||||
enable_ai_metadata = false # will enable adding ai metadata
|
||||
|
||||
[pr_reviewer] # /review #
|
||||
# enable/disable features
|
||||
@ -43,7 +51,6 @@ require_tests_review=true
|
||||
require_estimate_effort_to_review=true
|
||||
require_can_be_split_review=false
|
||||
require_security_review=true
|
||||
extra_issue_links=false
|
||||
# soc2
|
||||
require_soc2_ticket=false
|
||||
soc2_ticket_prompt="Does the PR description include a link to ticket in a project management system (e.g., Jira, Asana, Trello, etc.) ?"
|
||||
@ -187,11 +194,13 @@ base_url = "https://api.github.com"
|
||||
publish_inline_comments_fallback_with_verification = true
|
||||
try_fix_invalid_inline_comments = true
|
||||
app_name = "pr-agent"
|
||||
ignore_bot_pr = true
|
||||
|
||||
[github_action_config]
|
||||
# auto_review = true # set as env var in .github/workflows/pr-agent.yaml
|
||||
# auto_describe = true # set as env var in .github/workflows/pr-agent.yaml
|
||||
# auto_improve = true # set as env var in .github/workflows/pr-agent.yaml
|
||||
# pr_actions = ['opened', 'reopened', 'ready_for_review', 'review_requested']
|
||||
|
||||
[github_app]
|
||||
# these toggles allows running the github app from custom deployments
|
||||
@ -215,8 +224,6 @@ push_commands = [
|
||||
"/describe",
|
||||
"/review --pr_reviewer.num_code_suggestions=0",
|
||||
]
|
||||
ignore_pr_title = []
|
||||
ignore_bot_pr = true
|
||||
|
||||
[gitlab]
|
||||
url = "https://gitlab.com"
|
||||
@ -237,7 +244,7 @@ pr_commands = [
|
||||
"/review --pr_reviewer.num_code_suggestions=0",
|
||||
"/improve --pr_code_suggestions.commitable_code_suggestions=true --pr_code_suggestions.suggestions_score_threshold=7",
|
||||
]
|
||||
|
||||
avoid_full_files = false
|
||||
|
||||
[local]
|
||||
# LocalGitProvider settings - uncomment to use paths other than default
|
||||
@ -293,7 +300,7 @@ number_of_results = 5
|
||||
|
||||
[lancedb]
|
||||
uri = "./lancedb"
|
||||
|
||||
[best_practices]
|
||||
content = ""
|
||||
max_lines_allowed = 800
|
||||
enable_global_best_practices = false
|
||||
@ -63,6 +63,7 @@ extra = [
|
||||
]
|
||||
|
||||
[language_extension_map_org]
|
||||
"1C Enterprise" = ["*.bsl", ]
|
||||
ABAP = [".abap", ]
|
||||
"AGS Script" = [".ash", ]
|
||||
AMPL = [".ampl", ]
|
||||
|
||||
@ -5,7 +5,7 @@ Your task is to generate {{ docs_for_language }} for code components in the PR D
|
||||
|
||||
Example for the PR Diff format:
|
||||
======
|
||||
## file: 'src/file1.py'
|
||||
## File: 'src/file1.py'
|
||||
|
||||
@@ -12,3 +12,4 @@ def func1():
|
||||
__new hunk__
|
||||
@ -25,7 +25,7 @@ __old hunk__
|
||||
...
|
||||
|
||||
|
||||
## file: 'src/file2.py'
|
||||
## File: 'src/file2.py'
|
||||
...
|
||||
======
|
||||
|
||||
|
||||
@ -5,7 +5,12 @@ Your task is to provide meaningful and actionable code suggestions, to improve t
|
||||
|
||||
The format we will use to present the PR code diff:
|
||||
======
|
||||
## file: 'src/file1.py'
|
||||
## File: 'src/file1.py'
|
||||
{%- if is_ai_metadata %}
|
||||
### AI-generated changes summary:
|
||||
* ...
|
||||
* ...
|
||||
{%- endif %}
|
||||
|
||||
@@ ... @@ def func1():
|
||||
__new hunk__
|
||||
@ -26,14 +31,16 @@ __old hunk__
|
||||
...
|
||||
|
||||
|
||||
## file: 'src/file2.py'
|
||||
## File: 'src/file2.py'
|
||||
...
|
||||
======
|
||||
|
||||
- In this format, we separate each hunk of diff code to '__new hunk__' and '__old hunk__' sections. The '__new hunk__' section contains the new code of the chunk, and the '__old hunk__' section contains the old code, that was removed. If no new code was added in a specific hunk, '__new hunk__' section will not be presented. If no code was removed, '__old hunk__' section will not be presented.
|
||||
- We also added line numbers for the '__new hunk__' code, to help you refer to the code lines in your suggestions. These line numbers are not part of the actual code, and should only used for reference.
|
||||
- Code lines are prefixed with symbols ('+', '-', ' '). The '+' symbol indicates new code added in the PR, the '-' symbol indicates code removed in the PR, and the ' ' symbol indicates unchanged code. \
|
||||
|
||||
{%- if is_ai_metadata %}
|
||||
- If available, an AI-generated summary will appear and provide a high-level overview of the file changes. Note that this summary may not be fully accurate or complete.
|
||||
{%- endif %}
|
||||
|
||||
Specific instructions for generating code suggestions:
|
||||
- Provide up to {{ num_code_suggestions }} code suggestions.
|
||||
@ -122,7 +129,12 @@ Your task is to provide meaningful and actionable code suggestions, to improve t
|
||||
|
||||
The format we will use to present the PR code diff:
|
||||
======
|
||||
## file: 'src/file1.py'
|
||||
## File: 'src/file1.py'
|
||||
{%- if is_ai_metadata %}
|
||||
### AI-generated changes summary:
|
||||
* ...
|
||||
* ...
|
||||
{%- endif %}
|
||||
|
||||
@@ ... @@ def func1():
|
||||
__new hunk__
|
||||
@ -143,14 +155,16 @@ __old hunk__
|
||||
...
|
||||
|
||||
|
||||
## file: 'src/file2.py'
|
||||
## File: 'src/file2.py'
|
||||
...
|
||||
======
|
||||
|
||||
- In this format, we separate each hunk of diff code to '__new hunk__' and '__old hunk__' sections. The '__new hunk__' section contains the new code of the chunk, and the '__old hunk__' section contains the old code, that was removed. If no new code was added in a specific hunk, '__new hunk__' section will not be presented. If no code was removed, '__old hunk__' section will not be presented.
|
||||
- We also added line numbers for the '__new hunk__' code, to help you refer to the code lines in your suggestions. These line numbers are not part of the actual code, and should only used for reference.
|
||||
- Code lines are prefixed with symbols ('+', '-', ' '). The '+' symbol indicates new code added in the PR, the '-' symbol indicates code removed in the PR, and the ' ' symbol indicates unchanged code. \
|
||||
|
||||
{%- if is_ai_metadata %}
|
||||
- If available, an AI-generated summary will appear and provide a high-level overview of the file changes. Note that this summary may not be fully accurate or complete.
|
||||
{%- endif %}
|
||||
|
||||
Specific instructions for generating code suggestions:
|
||||
- Provide up to {{ num_code_suggestions }} code suggestions.
|
||||
|
||||
@ -16,7 +16,7 @@ Specific instructions:
|
||||
|
||||
The format that is used to present the PR code diff is as follows:
|
||||
======
|
||||
## file: 'src/file1.py'
|
||||
## File: 'src/file1.py'
|
||||
|
||||
@@ ... @@ def func1():
|
||||
__new hunk__
|
||||
@ -35,7 +35,7 @@ __old hunk__
|
||||
...
|
||||
|
||||
|
||||
## file: 'src/file2.py'
|
||||
## File: 'src/file2.py'
|
||||
...
|
||||
======
|
||||
- In this format, we separated each hunk of code to '__new hunk__' and '__old hunk__' sections. The '__new hunk__' section contains the new code of the chunk, and the '__old hunk__' section contains the old code that was removed.
|
||||
|
||||
@ -12,7 +12,7 @@ Additional guidelines:
|
||||
|
||||
Example Hunk Structure:
|
||||
======
|
||||
## file: 'src/file1.py'
|
||||
## File: 'src/file1.py'
|
||||
|
||||
@@ -12,5 +12,5 @@ def func1():
|
||||
code line 1 that remained unchanged in the PR
|
||||
|
||||
@ -10,7 +10,13 @@ The review should focus on new code added in the PR code diff (lines starting wi
|
||||
|
||||
The format we will use to present the PR code diff:
|
||||
======
|
||||
## file: 'src/file1.py'
|
||||
## File: 'src/file1.py'
|
||||
{%- if is_ai_metadata %}
|
||||
### AI-generated changes summary:
|
||||
* ...
|
||||
* ...
|
||||
{%- endif %}
|
||||
|
||||
|
||||
@@ ... @@ def func1():
|
||||
__new hunk__
|
||||
@ -31,7 +37,7 @@ __old hunk__
|
||||
...
|
||||
|
||||
|
||||
## file: 'src/file2.py'
|
||||
## File: 'src/file2.py'
|
||||
...
|
||||
======
|
||||
|
||||
@ -39,6 +45,9 @@ __old hunk__
|
||||
- We also added line numbers for the '__new hunk__' code, to help you refer to the code lines in your suggestions. These line numbers are not part of the actual code, and should only used for reference.
|
||||
- Code lines are prefixed with symbols ('+', '-', ' '). The '+' symbol indicates new code added in the PR, the '-' symbol indicates code removed in the PR, and the ' ' symbol indicates unchanged code. \
|
||||
The review should address new code added in the PR code diff (lines starting with '+')
|
||||
{%- if is_ai_metadata %}
|
||||
- If available, an AI-generated summary will appear and provide a high-level overview of the file changes. Note that this summary may not be fully accurate or complete.
|
||||
{%- endif %}
|
||||
- When quoting variables or names from the code, use backticks (`) instead of single quote (').
|
||||
|
||||
{%- if num_code_suggestions > 0 %}
|
||||
@ -76,15 +85,6 @@ class KeyIssuesComponentLink(BaseModel):
|
||||
issue_content: str = Field(description="a short and concise description of the issue that needs to be reviewed")
|
||||
start_line: int = Field(description="the start line that corresponds to this issue in the relevant file")
|
||||
end_line: int = Field(description="the end line that corresponds to this issue in the relevant file")
|
||||
{%- if extra_issue_links %}
|
||||
referenced_variables: List[Refs] = Field(description="a list of relevant variables or names that appear in the 'issue_content' output. For each variable, output is name, and the line number where it appears in the relevant file")
|
||||
{% endif %}
|
||||
|
||||
{%- if extra_issue_links %}
|
||||
class Refs(BaseModel):
|
||||
variable_name: str = Field(description="the name of a variable or name that appears in the relevant 'issue_content' output.")
|
||||
relevant_line: int = Field(description="the line number where the variable or name appears in the relevant file")
|
||||
{%- endif %}
|
||||
|
||||
class Review(BaseModel):
|
||||
{%- if require_estimate_effort_to_review %}
|
||||
@ -149,12 +149,6 @@ review:
|
||||
...
|
||||
start_line: 12
|
||||
end_line: 14
|
||||
{%- if extra_issue_links %}
|
||||
referenced_variables:
|
||||
- variable_name: |
|
||||
...
|
||||
relevant_line: 13
|
||||
{%- endif %}
|
||||
- ...
|
||||
security_concerns: |
|
||||
No
|
||||
|
||||
@ -7,7 +7,8 @@ from jinja2 import Environment, StrictUndefined
|
||||
|
||||
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||
from pr_agent.algo.ai_handlers.litellm_ai_handler import LiteLLMAIHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, get_pr_multi_diffs, retry_with_fallback_models
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, get_pr_multi_diffs, retry_with_fallback_models, \
|
||||
add_ai_metadata_to_diff_files
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.utils import load_yaml, replace_code_tags, ModelType, show_relevant_configurations
|
||||
from pr_agent.config_loader import get_settings
|
||||
@ -54,16 +55,27 @@ class PRCodeSuggestions:
|
||||
self.prediction = None
|
||||
self.pr_url = pr_url
|
||||
self.cli_mode = cli_mode
|
||||
self.pr_description, self.pr_description_files = (
|
||||
self.git_provider.get_pr_description(split_changes_walkthrough=True))
|
||||
if (self.pr_description_files and get_settings().get("config.is_auto_command", False) and
|
||||
get_settings().get("config.enable_ai_metadata", False)):
|
||||
add_ai_metadata_to_diff_files(self.git_provider, self.pr_description_files)
|
||||
get_logger().debug(f"AI metadata added to the this command")
|
||||
else:
|
||||
get_settings().set("config.enable_ai_metadata", False)
|
||||
get_logger().debug(f"AI metadata is disabled for this command")
|
||||
|
||||
self.vars = {
|
||||
"title": self.git_provider.pr.title,
|
||||
"branch": self.git_provider.get_pr_branch(),
|
||||
"description": self.git_provider.get_pr_description(),
|
||||
"description": self.pr_description,
|
||||
"language": self.main_language,
|
||||
"diff": "", # empty diff for initial calculation
|
||||
"num_code_suggestions": num_code_suggestions,
|
||||
"extra_instructions": get_settings().pr_code_suggestions.extra_instructions,
|
||||
"commit_messages_str": self.git_provider.get_commit_messages(),
|
||||
"relevant_best_practices": "",
|
||||
"is_ai_metadata": get_settings().get("config.enable_ai_metadata", False),
|
||||
}
|
||||
if 'claude' in get_settings().config.model:
|
||||
# prompt for Claude, with minor adjustments
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
from dynaconf import Dynaconf
|
||||
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers import get_git_provider
|
||||
from pr_agent.log import get_logger
|
||||
@ -28,20 +30,33 @@ class PRConfig:
|
||||
return ""
|
||||
|
||||
def _prepare_pr_configs(self) -> str:
|
||||
import tomli
|
||||
with open(get_settings().find_file("configuration.toml"), "rb") as conf_file:
|
||||
configuration_headers = [header.lower() for header in tomli.load(conf_file).keys()]
|
||||
conf_file = get_settings().find_file("configuration.toml")
|
||||
conf_settings = Dynaconf(settings_files=[conf_file])
|
||||
configuration_headers = [header.lower() for header in conf_settings.keys()]
|
||||
relevant_configs = {
|
||||
header: configs for header, configs in get_settings().to_dict().items()
|
||||
if header.lower().startswith("pr_") and header.lower() in configuration_headers
|
||||
if (header.lower().startswith("pr_") or header.lower().startswith("config")) and header.lower() in configuration_headers
|
||||
}
|
||||
comment_str = "Possible Configurations:"
|
||||
|
||||
skip_keys = ['ai_disclaimer', 'ai_disclaimer_title', 'ANALYTICS_FOLDER', 'secret_provider', "skip_keys",
|
||||
'trial_prefix_message', 'no_eligible_message', 'identity_provider', 'ALLOWED_REPOS',
|
||||
'APP_NAME']
|
||||
extra_skip_keys = get_settings().config.get('config.skip_keys', [])
|
||||
if extra_skip_keys:
|
||||
skip_keys.extend(extra_skip_keys)
|
||||
|
||||
markdown_text = "<details> <summary><strong>🛠️ PR-Agent Configurations:</strong></summary> \n\n"
|
||||
markdown_text += f"\n\n```yaml\n\n"
|
||||
for header, configs in relevant_configs.items():
|
||||
if configs:
|
||||
comment_str += "\n"
|
||||
markdown_text += "\n\n"
|
||||
markdown_text += f"==================== {header} ===================="
|
||||
for key, value in configs.items():
|
||||
comment_str += f"\n{header.lower()}.{key.lower()} = {repr(value) if isinstance(value, str) else value}"
|
||||
comment_str += " "
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().info(f"comment_str:\n{comment_str}")
|
||||
return comment_str
|
||||
if key in skip_keys:
|
||||
continue
|
||||
markdown_text += f"\n{header.lower()}.{key.lower()} = {repr(value) if isinstance(value, str) else value}"
|
||||
markdown_text += " "
|
||||
markdown_text += "\n```"
|
||||
markdown_text += "\n</details>\n"
|
||||
get_logger().info(f"Possible Configurations outputted to PR comment", artifact=markdown_text)
|
||||
return markdown_text
|
||||
|
||||
@ -638,9 +638,10 @@ def insert_br_after_x_chars(text, x=70):
|
||||
text = replace_code_tags(text)
|
||||
|
||||
# convert list items to <li>
|
||||
if text.startswith("- "):
|
||||
if text.startswith("- ") or text.startswith("* "):
|
||||
text = "<li>" + text[2:]
|
||||
text = text.replace("\n- ", '<br><li> ').replace("\n - ", '<br><li> ')
|
||||
text = text.replace("\n* ", '<br><li> ').replace("\n * ", '<br><li> ')
|
||||
|
||||
# convert new lines to <br>
|
||||
text = text.replace("\n", '<br>')
|
||||
|
||||
@ -6,7 +6,7 @@ from typing import List, Tuple
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||
from pr_agent.algo.ai_handlers.litellm_ai_handler import LiteLLMAIHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models, add_ai_metadata_to_diff_files
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.utils import github_action_output, load_yaml, ModelType, \
|
||||
show_relevant_configurations, convert_to_markdown_v2, PRReviewHeader
|
||||
@ -51,15 +51,23 @@ class PRReviewer:
|
||||
raise Exception(f"Answer mode is not supported for {get_settings().config.git_provider} for now")
|
||||
self.ai_handler = ai_handler()
|
||||
self.ai_handler.main_pr_language = self.main_language
|
||||
|
||||
self.patches_diff = None
|
||||
self.prediction = None
|
||||
|
||||
answer_str, question_str = self._get_user_answers()
|
||||
self.pr_description, self.pr_description_files = (
|
||||
self.git_provider.get_pr_description(split_changes_walkthrough=True))
|
||||
if (self.pr_description_files and get_settings().get("config.is_auto_command", False) and
|
||||
get_settings().get("config.enable_ai_metadata", False)):
|
||||
add_ai_metadata_to_diff_files(self.git_provider, self.pr_description_files)
|
||||
get_logger().debug(f"AI metadata added to the this command")
|
||||
else:
|
||||
get_settings().set("config.enable_ai_metadata", False)
|
||||
get_logger().debug(f"AI metadata is disabled for this command")
|
||||
|
||||
self.vars = {
|
||||
"title": self.git_provider.pr.title,
|
||||
"branch": self.git_provider.get_pr_branch(),
|
||||
"description": self.git_provider.get_pr_description(),
|
||||
"description": self.pr_description,
|
||||
"language": self.main_language,
|
||||
"diff": "", # empty diff for initial calculation
|
||||
"num_pr_files": self.git_provider.get_num_of_files(),
|
||||
@ -75,7 +83,7 @@ class PRReviewer:
|
||||
"commit_messages_str": self.git_provider.get_commit_messages(),
|
||||
"custom_labels": "",
|
||||
"enable_custom_labels": get_settings().config.enable_custom_labels,
|
||||
"extra_issue_links": get_settings().pr_reviewer.extra_issue_links,
|
||||
"is_ai_metadata": get_settings().get("config.enable_ai_metadata", False),
|
||||
}
|
||||
|
||||
self.token_handler = TokenHandler(
|
||||
@ -156,7 +164,7 @@ class PRReviewer:
|
||||
self.token_handler,
|
||||
model,
|
||||
add_line_numbers_to_hunks=True,
|
||||
disable_extra_lines=True,)
|
||||
disable_extra_lines=False,)
|
||||
|
||||
if self.patches_diff:
|
||||
get_logger().debug(f"PR diff", diff=self.patches_diff)
|
||||
|
||||
@ -4,7 +4,7 @@ build-backend = "setuptools.build_meta"
|
||||
|
||||
[project]
|
||||
name = "pr-agent"
|
||||
version = "0.2.2"
|
||||
version = "0.2.4"
|
||||
|
||||
authors = [{name= "CodiumAI", email = "tal.r@codium.ai"}]
|
||||
|
||||
|
||||
@ -27,6 +27,7 @@ tenacity==8.2.3
|
||||
gunicorn==22.0.0
|
||||
pytest-cov==5.0.0
|
||||
pydantic==2.8.2
|
||||
html2text==2024.2.26
|
||||
# Uncomment the following lines to enable the 'similar issue' tool
|
||||
# pinecone-client
|
||||
# pinecone-datasets @ git+https://github.com/mrT23/pinecone-datasets.git@main
|
||||
|
||||
15
tests/unittest/test_azure_devops_parsing.py
Normal file
15
tests/unittest/test_azure_devops_parsing.py
Normal file
@ -0,0 +1,15 @@
|
||||
from pr_agent.git_providers import AzureDevopsProvider
|
||||
|
||||
|
||||
class TestAzureDevOpsParsing():
|
||||
def test_regular_address(self):
|
||||
pr_url = "https://dev.azure.com/organization/project/_git/repo/pullrequest/1"
|
||||
|
||||
# workspace_slug, repo_slug, pr_number
|
||||
assert AzureDevopsProvider._parse_pr_url(pr_url) == ("project", "repo", 1)
|
||||
|
||||
def test_visualstudio_address(self):
|
||||
pr_url = "https://organization.visualstudio.com/project/_git/repo/pullrequest/1"
|
||||
|
||||
# workspace_slug, repo_slug, pr_number
|
||||
assert AzureDevopsProvider._parse_pr_url(pr_url) == ("project", "repo", 1)
|
||||
@ -60,11 +60,22 @@ class TestExtendPatch:
|
||||
original_file_str = 'line1\nline2\nline3\nline4\nline5\nline6'
|
||||
patch_str = '@@ -2,3 +2,3 @@ init()\n-line2\n+new_line2\n line3\n line4\n@@ -4,1 +4,1 @@ init2()\n-line4\n+new_line4' # noqa: E501
|
||||
num_lines = 1
|
||||
original_allow_dynamic_context = get_settings().config.allow_dynamic_context
|
||||
|
||||
get_settings().config.allow_dynamic_context = False
|
||||
expected_output = '\n@@ -1,5 +1,5 @@ init()\n line1\n-line2\n+new_line2\n line3\n line4\n line5\n\n@@ -3,3 +3,3 @@ init2()\n line3\n-line4\n+new_line4\n line5' # noqa: E501
|
||||
actual_output = extend_patch(original_file_str, patch_str,
|
||||
patch_extra_lines_before=num_lines, patch_extra_lines_after=num_lines)
|
||||
assert actual_output == expected_output
|
||||
|
||||
get_settings().config.allow_dynamic_context = True
|
||||
expected_output = '\n@@ -1,5 +1,5 @@ init()\n line1\n-line2\n+new_line2\n line3\n line4\n line5\n\n@@ -3,3 +3,3 @@ init2()\n line3\n-line4\n+new_line4\n line5' # noqa: E501
|
||||
actual_output = extend_patch(original_file_str, patch_str,
|
||||
patch_extra_lines_before=num_lines, patch_extra_lines_after=num_lines)
|
||||
assert actual_output == expected_output
|
||||
get_settings().config.allow_dynamic_context = original_allow_dynamic_context
|
||||
|
||||
|
||||
def test_dynamic_context(self):
|
||||
get_settings().config.max_extra_lines_before_dynamic_context = 10
|
||||
original_file_str = "def foo():"
|
||||
@ -94,10 +105,11 @@ class TestExtendedPatchMoreLines:
|
||||
get_settings().config.allow_dynamic_context = False
|
||||
|
||||
class File:
|
||||
def __init__(self, base_file, patch, filename):
|
||||
def __init__(self, base_file, patch, filename, ai_file_summary=None):
|
||||
self.base_file = base_file
|
||||
self.patch = patch
|
||||
self.filename = filename
|
||||
self.ai_file_summary = ai_file_summary
|
||||
|
||||
@pytest.fixture
|
||||
def token_handler(self):
|
||||
|
||||
Reference in New Issue
Block a user