mirror of
https://github.com/qodo-ai/pr-agent.git
synced 2025-07-03 04:10:49 +08:00
Compare commits
331 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
| d4d9a7f8b4 | |||
| c14c49727f | |||
| 292a5015d6 | |||
| 6776f7c296 | |||
| 7287a94e88 | |||
| e2cf1d0068 | |||
| 8ada3111ec | |||
| 9c9611e81a | |||
| 4fb93e3b62 | |||
| 5a27e1dd7e | |||
| 6e6151d201 | |||
| e468efb53e | |||
| 95e1ebada1 | |||
| d74c867eca | |||
| 2448281a45 | |||
| 9e063bf48a | |||
| 5432469ef6 | |||
| 2c496b9d4e | |||
| 5ac41dddd6 | |||
| 9df554ed1c | |||
| cf14e45674 | |||
| 1c51b5b762 | |||
| e5715e12cb | |||
| 578d7c69f8 | |||
| 29c50758bc | |||
| 97b48da03b | |||
| 4203ee4ca8 | |||
| 84dc976ebb | |||
| d9571ee7cb | |||
| 7373ed36e6 | |||
| cdf13925b0 | |||
| c2f52539aa | |||
| 0442cdcd3d | |||
| 93773f3c08 | |||
| 53a974c282 | |||
| c9ed271eaf | |||
| 6a5ff2fa3b | |||
| 25d661c152 | |||
| d20c9c6c94 | |||
| d1d861e163 | |||
| 033db1015e | |||
| abf2f68c61 | |||
| 441e098e2a | |||
| 2bbf4b366e | |||
| b9d096187a | |||
| ce156751e8 | |||
| dae87d7da8 | |||
| a99ebf8953 | |||
| 2a9e3ee1ef | |||
| 2beefab89a | |||
| 415f44d763 | |||
| 8fb9b8ed3e | |||
| 4f1dccf67b | |||
| 3778cc2745 | |||
| 8793f8d9b0 | |||
| 61837c69a3 | |||
| ffaf5d5271 | |||
| cd526a233c | |||
| 745e955d1f | |||
| 771d0b8c60 | |||
| 91a7c08546 | |||
| 4d9d6f7477 | |||
| 2591a5d6c1 | |||
| 772499fce1 | |||
| d467f5a7fd | |||
| 2d5b060168 | |||
| b7eb6be5a0 | |||
| df57367426 | |||
| 660a60924e | |||
| 8aa76a0ac5 | |||
| b034d16c23 | |||
| 9bec97c66c | |||
| 8fd8d298e7 | |||
| 2e186ebae8 | |||
| fc40ca9196 | |||
| 91a8938a37 | |||
| d97e1862da | |||
| f042c061de | |||
| c47afd9c0d | |||
| c6d16ced07 | |||
| e9535ea164 | |||
| dc8a4be2d4 | |||
| f9de8f283b | |||
| bd5c19ee05 | |||
| 7cbe797108 | |||
| 435d9d41c8 | |||
| a510d93e6e | |||
| 48cc2f6833 | |||
| 229d7b34c7 | |||
| 03b194c337 | |||
| a6f772c6d5 | |||
| ba1ba98dec | |||
| 5954c7cec2 | |||
| dc1a8e8314 | |||
| aa87bc60f6 | |||
| c76aabc71e | |||
| 81081186d9 | |||
| 4a71ec90c6 | |||
| 3456c8e039 | |||
| 402a388be0 | |||
| 4e26c02b01 | |||
| ea4f88edd3 | |||
| 217f615dfb | |||
| a6fb351789 | |||
| bfab660414 | |||
| 2e63653bb0 | |||
| b9df034c97 | |||
| bae8d36698 | |||
| 67a04e1cb2 | |||
| 4fea780b9b | |||
| 01c18d7d98 | |||
| f4b06640d2 | |||
| f1981092d3 | |||
| 8414e109c5 | |||
| 8adfca5b3c | |||
| 672cdc03ab | |||
| 86a9cfedc8 | |||
| 7ac9f27b70 | |||
| c97c39d57d | |||
| a3b3d6c77a | |||
| 2e41701d07 | |||
| 578f56148a | |||
| b3da84b4aa | |||
| f89bdcf3c3 | |||
| e7e3970874 | |||
| 1f7a8eada0 | |||
| 38638bd1c4 | |||
| 26f3bd8900 | |||
| a2fb415c53 | |||
| 8038eaf876 | |||
| d8572f8d13 | |||
| 78b11c80c7 | |||
| cb65b05e85 | |||
| 1aa6dd9b5d | |||
| 11d69e05aa | |||
| 0722af4702 | |||
| 99e99345b2 | |||
| 5252e1826d | |||
| a18a0bf2e3 | |||
| 396d11aa45 | |||
| 4a38861d06 | |||
| 5feb66597e | |||
| 8589941ffe | |||
| 7f0e6aeb37 | |||
| 8a768aa7fd | |||
| f399f9ebe4 | |||
| cc73d4599b | |||
| 4228f92e7e | |||
| 1f4ab43fa6 | |||
| b59111e4a6 | |||
| 70da871876 | |||
| 9c1ab06491 | |||
| 5c4bc0a008 | |||
| ef37271ce9 | |||
| 8dd4c15d4b | |||
| f9afada1ed | |||
| 4c1c313031 | |||
| 1f126069b1 | |||
| 12742ef499 | |||
| 63e921a2c5 | |||
| 8f04387331 | |||
| a06670bc27 | |||
| 2525392814 | |||
| 23aa2a9388 | |||
| e85b75fe64 | |||
| df04a7e046 | |||
| 9c3f080112 | |||
| ed65493718 | |||
| 983233c193 | |||
| 7438190ed1 | |||
| 2b2b851cb9 | |||
| 5701816b2e | |||
| 40a25a1082 | |||
| e238a88824 | |||
| 61bdfd3b99 | |||
| c00d1e9858 | |||
| 1a8b143f58 | |||
| dfbe7432b8 | |||
| ab69f1769b | |||
| 089210d9fa | |||
| 0f9d89c67a | |||
| 84b80f792d | |||
| 219d962cbe | |||
| e531245f4a | |||
| 89e9413d75 | |||
| b370cb6ae7 | |||
| 4201779ce2 | |||
| 71f7c09ed7 | |||
| edad244a86 | |||
| 9752987966 | |||
| 200da44e5a | |||
| 4c0fd37ac2 | |||
| c996c7117f | |||
| 943ba95924 | |||
| 8a75d3101d | |||
| 944f54b431 | |||
| 9be5cc6dec | |||
| 884286ebf1 | |||
| 620dbbeb1a | |||
| c07059e139 | |||
| 3b88d6afdb | |||
| e717e8ae81 | |||
| 8ec1fb5937 | |||
| cb10ceadd7 | |||
| 96d3f3cc0b | |||
| a98d972041 | |||
| 09a1d74a00 | |||
| 31f6f8f8ea | |||
| e7c99f0e6f | |||
| ac53e6728d | |||
| b100e7098a | |||
| 2b77d07725 | |||
| ee1676cf7e | |||
| 3420e6f30d | |||
| 85cc0ad08c | |||
| 3756b547da | |||
| e34bcace29 | |||
| 2a675b80ca | |||
| 1cefd23739 | |||
| aef9a04b32 | |||
| fe4e642a47 | |||
| 039d85b836 | |||
| 0fa342ddd2 | |||
| c95a8cde72 | |||
| 23ec25c949 | |||
| 9560bc1b44 | |||
| 346ea8fbae | |||
| d671c78233 | |||
| 240e0374e7 | |||
| 288e9bb8ca | |||
| d8545a2b28 | |||
| 95f23de7ec | |||
| 0390a85f5a | |||
| 172d0c0358 | |||
| 41588efe9a | |||
| f50832e19b | |||
| 927f124dca | |||
| 232b540f60 | |||
| 452eda25cd | |||
| 110e593d03 | |||
| af84409c1d | |||
| c2c69f2950 | |||
| e946a0ea9f | |||
| 866476080c | |||
| 27d6560de8 | |||
| 6ba7b3eea2 | |||
| 86d9612882 | |||
| 49f608c968 | |||
| 11f85cad62 | |||
| 5f5257d195 | |||
| 495e2ccb7d | |||
| a176adb23e | |||
| 68ef11a2fc | |||
| 38c38ec280 | |||
| 3904eebf85 | |||
| 778d7ce1ed | |||
| 3067afbcb3 | |||
| 70f7a90226 | |||
| 7eadb45c09 | |||
| ac247dbc2c | |||
| 3a77652660 | |||
| 0bd4c9b78a | |||
| 81d07a55d7 | |||
| 652ced5406 | |||
| aaf037570b | |||
| cfa565b5d7 | |||
| c8819472cf | |||
| 53744af32f | |||
| 41c6502190 | |||
| 32604d8103 | |||
| 581c95c4ab | |||
| 789c48a216 | |||
| 6b9de6b253 | |||
| 003846a90d | |||
| d088f9c19a | |||
| a272c761a9 | |||
| 9449f2aebe | |||
| 28ea4a685a | |||
| b798291bc8 | |||
| 62df50cf86 | |||
| 917e1607de | |||
| 8f11a19c32 | |||
| 0f5cccd18f | |||
| 2be459e576 | |||
| cbdb451c95 | |||
| 6871193381 | |||
| 8a7f3501ea | |||
| 80bbe23ad5 | |||
| 05f3fa5ebc | |||
| 1b2a2075ae | |||
| 3d3b49e3ee | |||
| 174b4b76eb | |||
| 2b28153749 | |||
| 6151bfac25 | |||
| 5d6e1de157 | |||
| ce35d2c313 | |||
| b51abe9af7 | |||
| 20206af1bf | |||
| 34ae1f1ab6 | |||
| 887283632b | |||
| 7f84b5738e | |||
| dc917587ef | |||
| b2710ec029 | |||
| 41c48ca5b5 | |||
| e0012702c6 | |||
| dfb339ab44 | |||
| 54947573bf | |||
| 228ceff3a6 | |||
| 8766140554 | |||
| 034ec8f53a | |||
| eccd00b86f | |||
| 4b351cfe38 | |||
| 734a027702 | |||
| d0948329d3 | |||
| 6135bf1f53 | |||
| ea9deccb91 | |||
| daa68f3b2f | |||
| e82430891c | |||
| 19ca7f887a | |||
| 888306c160 | |||
| 3ef4daafd5 | |||
| f76f750757 | |||
| 055bc4ceec | |||
| 487efa4bf4 | |||
| 050ffcdd06 | |||
| 8f9879cf01 | |||
| c3fac86067 | |||
| 9a57d00951 | |||
| 745d0c537c | |||
| 5b594dadee | |||
| 4246792261 |
2
.github/workflows/build-and-test.yaml
vendored
2
.github/workflows/build-and-test.yaml
vendored
@ -36,6 +36,6 @@ jobs:
|
||||
- id: test
|
||||
name: Test dev docker
|
||||
run: |
|
||||
docker run --rm codiumai/pr-agent:test pytest -v
|
||||
docker run --rm codiumai/pr-agent:test pytest -v tests/unittest
|
||||
|
||||
|
||||
|
||||
54
.github/workflows/code_coverage.yaml
vendored
Normal file
54
.github/workflows/code_coverage.yaml
vendored
Normal file
@ -0,0 +1,54 @@
|
||||
name: Code-coverage
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
# push:
|
||||
# branches:
|
||||
# - main
|
||||
pull_request:
|
||||
branches:
|
||||
- main
|
||||
|
||||
jobs:
|
||||
build-and-test:
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- id: checkout
|
||||
uses: actions/checkout@v2
|
||||
|
||||
- id: dockerx
|
||||
name: Setup Docker Buildx
|
||||
uses: docker/setup-buildx-action@v2
|
||||
|
||||
- id: build
|
||||
name: Build dev docker
|
||||
uses: docker/build-push-action@v2
|
||||
with:
|
||||
context: .
|
||||
file: ./docker/Dockerfile
|
||||
push: false
|
||||
load: true
|
||||
tags: codiumai/pr-agent:test
|
||||
cache-from: type=gha,scope=dev
|
||||
cache-to: type=gha,mode=max,scope=dev
|
||||
target: test
|
||||
|
||||
- id: code_cov
|
||||
name: Test dev docker
|
||||
run: |
|
||||
docker run --name test_container codiumai/pr-agent:test pytest tests/unittest --cov=pr_agent --cov-report term --cov-report xml:coverage.xml
|
||||
docker cp test_container:/app/coverage.xml coverage.xml
|
||||
docker rm test_container
|
||||
|
||||
|
||||
- name: Validate coverage report
|
||||
run: |
|
||||
if [ ! -f coverage.xml ]; then
|
||||
echo "Coverage report not found"
|
||||
exit 1
|
||||
fi
|
||||
- name: Upload coverage to Codecov
|
||||
uses: codecov/codecov-action@v4.0.1
|
||||
with:
|
||||
token: ${{ secrets.CODECOV_TOKEN }}
|
||||
46
.github/workflows/e2e_tests.yaml
vendored
Normal file
46
.github/workflows/e2e_tests.yaml
vendored
Normal file
@ -0,0 +1,46 @@
|
||||
name: PR-Agent E2E tests
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
# schedule:
|
||||
# - cron: '0 0 * * *' # This cron expression runs the workflow every night at midnight UTC
|
||||
|
||||
jobs:
|
||||
pr_agent_job:
|
||||
runs-on: ubuntu-latest
|
||||
name: PR-Agent E2E GitHub App Test
|
||||
steps:
|
||||
- name: Checkout repository
|
||||
uses: actions/checkout@v2
|
||||
|
||||
- name: Setup Docker Buildx
|
||||
uses: docker/setup-buildx-action@v2
|
||||
|
||||
- id: build
|
||||
name: Build dev docker
|
||||
uses: docker/build-push-action@v2
|
||||
with:
|
||||
context: .
|
||||
file: ./docker/Dockerfile
|
||||
push: false
|
||||
load: true
|
||||
tags: codiumai/pr-agent:test
|
||||
cache-from: type=gha,scope=dev
|
||||
cache-to: type=gha,mode=max,scope=dev
|
||||
target: test
|
||||
|
||||
- id: test1
|
||||
name: E2E test github app
|
||||
run: |
|
||||
docker run -e GITHUB.USER_TOKEN=${{ secrets.TOKEN_GITHUB }} --rm codiumai/pr-agent:test pytest -v tests/e2e_tests/test_github_app.py
|
||||
|
||||
- id: test2
|
||||
name: E2E gitlab webhook
|
||||
run: |
|
||||
docker run -e gitlab.PERSONAL_ACCESS_TOKEN=${{ secrets.TOKEN_GITLAB }} --rm codiumai/pr-agent:test pytest -v tests/e2e_tests/test_gitlab_webhook.py
|
||||
|
||||
|
||||
- id: test3
|
||||
name: E2E bitbucket app
|
||||
run: |
|
||||
docker run -e BITBUCKET.USERNAME=${{ secrets.BITBUCKET_USERNAME }} -e BITBUCKET.PASSWORD=${{ secrets.BITBUCKET_PASSWORD }} --rm codiumai/pr-agent:test pytest -v tests/e2e_tests/test_bitbucket_app.py
|
||||
@ -1,3 +1,6 @@
|
||||
[pr_reviewer]
|
||||
enable_review_labels_effort = true
|
||||
enable_auto_approval = true
|
||||
|
||||
[config]
|
||||
model="claude-3-5-sonnet"
|
||||
|
||||
141
README.md
141
README.md
@ -10,7 +10,7 @@
|
||||
|
||||
</picture>
|
||||
<br/>
|
||||
CodiumAI PR-Agent aims to help efficiently review and handle pull requests, by providing AI feedbacks and suggestions
|
||||
CodiumAI PR-Agent aims to help efficiently review and handle pull requests, by providing AI feedback and suggestions
|
||||
</div>
|
||||
|
||||
[](https://github.com/Codium-ai/pr-agent/blob/main/LICENSE)
|
||||
@ -18,6 +18,7 @@ CodiumAI PR-Agent aims to help efficiently review and handle pull requests, by p
|
||||
[](https://pr-agent-docs.codium.ai/finetuning_benchmark/)
|
||||
[](https://discord.com/channels/1057273017547378788/1126104260430528613)
|
||||
[](https://twitter.com/codiumai)
|
||||
[](https://www.codium.ai/images/pr_agent/cheat_sheet.pdf)
|
||||
<a href="https://github.com/Codium-ai/pr-agent/commits/main">
|
||||
<img alt="GitHub" src="https://img.shields.io/github/last-commit/Codium-ai/pr-agent/main?style=for-the-badge" height="20">
|
||||
</a>
|
||||
@ -36,31 +37,36 @@ CodiumAI PR-Agent aims to help efficiently review and handle pull requests, by p
|
||||
- [Overview](#overview)
|
||||
- [Example results](#example-results)
|
||||
- [Try it now](#try-it-now)
|
||||
- [PR-Agent Pro 💎](#pr-agent-pro-)
|
||||
- [PR-Agent Pro 💎](https://pr-agent-docs.codium.ai/overview/pr_agent_pro/)
|
||||
- [How it works](#how-it-works)
|
||||
- [Why use PR-Agent?](#why-use-pr-agent)
|
||||
|
||||
## News and Updates
|
||||
|
||||
### July 4, 2024
|
||||
### August 26, 2024
|
||||
|
||||
Added improved support for claude-sonnet-3.5 model (anthropic, vertex, bedrock), including dedicated prompts.
|
||||
New version of [PR Agent Chrom Extension](https://chromewebstore.google.com/detail/pr-agent-chrome-extension/ephlnjeghhogofkifjloamocljapahnl) was released, with full support of context-aware **PR Chat**. This novel feature is free to use for any open-source repository. See more details in [here](https://pr-agent-docs.codium.ai/chrome-extension/#pr-chat).
|
||||
|
||||
### June 17, 2024
|
||||
<kbd><img src="https://www.codium.ai/images/pr_agent/pr_chat_1.png" width="768"></kbd>
|
||||
|
||||
New option for a self-review checkbox is now available for the `/improve` tool, along with the ability(💎) to enable auto-approve, or demand self-review in addition to human reviewer. See more [here](https://pr-agent-docs.codium.ai/tools/improve/#self-review).
|
||||
<kbd><img src="https://www.codium.ai/images/pr_agent/pr_chat_2.png" width="768"></kbd>
|
||||
|
||||
<kbd><img src="https://www.codium.ai/images/pr_agent/self_review_1.png" width="512"></kbd>
|
||||
|
||||
### June 6, 2024
|
||||
### August 11, 2024
|
||||
Increased PR context size for improved results, and enabled [asymmetric context](https://github.com/Codium-ai/pr-agent/pull/1114/files#diff-9290a3ad9a86690b31f0450b77acd37ef1914b41fabc8a08682d4da433a77f90R69-R70)
|
||||
|
||||
New option now available (💎) - **apply suggestions**:
|
||||
### August 10, 2024
|
||||
Added support for [Azure devops pipeline](https://pr-agent-docs.codium.ai/installation/azure/) - you can now easily run PR-Agent as an Azure devops pipeline, without needing to set up your own server.
|
||||
|
||||
<kbd><img src="https://www.codium.ai/images/pr_agent/apply_suggestion_1.png" width="512"></kbd>
|
||||
|
||||
→
|
||||
### August 5, 2024
|
||||
Added support for [GitLab pipeline](https://pr-agent-docs.codium.ai/installation/gitlab/#run-as-a-gitlab-pipeline) - you can now run easily PR-Agent as a GitLab pipeline, without needing to set up your own server.
|
||||
|
||||
<kbd><img src="https://www.codium.ai/images/pr_agent/apply_suggestion_2.png" width="512"></kbd>
|
||||
### July 28, 2024
|
||||
|
||||
(1) improved support for bitbucket server - [auto commands](https://github.com/Codium-ai/pr-agent/pull/1059) and [direct links](https://github.com/Codium-ai/pr-agent/pull/1061)
|
||||
|
||||
(2) custom models are now [supported](https://pr-agent-docs.codium.ai/usage-guide/changing_a_model/#custom-models)
|
||||
|
||||
|
||||
|
||||
@ -69,40 +75,40 @@ New option now available (💎) - **apply suggestions**:
|
||||
|
||||
Supported commands per platform:
|
||||
|
||||
| | | GitHub | Gitlab | Bitbucket | Azure DevOps |
|
||||
|-------|---------------------------------------------------------------------------------------------------------|:--------------------:|:--------------------:|:--------------------:|:--------------------:|
|
||||
| TOOLS | Review | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ Incremental | ✅ | | | |
|
||||
| | ⮑ [SOC2 Compliance](https://pr-agent-docs.codium.ai/tools/review/#soc2-ticket-compliance) 💎 | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Describe | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ [Inline File Summary](https://pr-agent-docs.codium.ai/tools/describe#inline-file-summary) 💎 | ✅ | | | |
|
||||
| | Improve | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ Extended | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Ask | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ [Ask on code lines](https://pr-agent-docs.codium.ai/tools/ask#ask-lines) | ✅ | ✅ | | |
|
||||
| | [Custom Prompt](https://pr-agent-docs.codium.ai/tools/custom_prompt/) 💎 | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Test](https://pr-agent-docs.codium.ai/tools/test/) 💎 | ✅ | ✅ | | ✅ |
|
||||
| | Reflect and Review | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Update CHANGELOG.md | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Find Similar Issue | ✅ | | | |
|
||||
| | [Add PR Documentation](https://pr-agent-docs.codium.ai/tools/documentation/) 💎 | ✅ | ✅ | | ✅ |
|
||||
| | [Custom Labels](https://pr-agent-docs.codium.ai/tools/custom_labels/) 💎 | ✅ | ✅ | | ✅ |
|
||||
| | [Analyze](https://pr-agent-docs.codium.ai/tools/analyze/) 💎 | ✅ | ✅ | | ✅ |
|
||||
| | [CI Feedback](https://pr-agent-docs.codium.ai/tools/ci_feedback/) 💎 | ✅ | | | |
|
||||
| | [Similar Code](https://pr-agent-docs.codium.ai/tools/similar_code/) 💎 | ✅ | | | |
|
||||
| | | | | | |
|
||||
| USAGE | CLI | ✅ | ✅ | ✅ | ✅ |
|
||||
| | App / webhook | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Tagging bot | ✅ | | | |
|
||||
| | Actions | ✅ | | ✅ | |
|
||||
| | | | | | |
|
||||
| CORE | PR compression | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Repo language prioritization | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Adaptive and token-aware file patch fitting | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Multiple models support | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Static code analysis](https://pr-agent-docs.codium.ai/core-abilities/#static-code-analysis) 💎 | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Global and wiki configurations](https://pr-agent-docs.codium.ai/usage-guide/configuration_options/) 💎 | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [PR interactive actions](https://www.codium.ai/images/pr_agent/pr-actions.mp4) 💎 | ✅ | | | |
|
||||
| | | GitHub | Gitlab | Bitbucket | Azure DevOps |
|
||||
|-------|---------------------------------------------------------------------------------------------------------|:--------------------:|:--------------------:|:--------------------:|:------------:|
|
||||
| TOOLS | Review | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ Incremental | ✅ | | | |
|
||||
| | ⮑ [SOC2 Compliance](https://pr-agent-docs.codium.ai/tools/review/#soc2-ticket-compliance) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | Describe | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ [Inline File Summary](https://pr-agent-docs.codium.ai/tools/describe#inline-file-summary) 💎 | ✅ | | | |
|
||||
| | Improve | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ Extended | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Ask | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ [Ask on code lines](https://pr-agent-docs.codium.ai/tools/ask#ask-lines) | ✅ | ✅ | | |
|
||||
| | [Custom Prompt](https://pr-agent-docs.codium.ai/tools/custom_prompt/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [Test](https://pr-agent-docs.codium.ai/tools/test/) 💎 | ✅ | ✅ | | |
|
||||
| | Reflect and Review | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Update CHANGELOG.md | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Find Similar Issue | ✅ | | | |
|
||||
| | [Add PR Documentation](https://pr-agent-docs.codium.ai/tools/documentation/) 💎 | ✅ | ✅ | | |
|
||||
| | [Custom Labels](https://pr-agent-docs.codium.ai/tools/custom_labels/) 💎 | ✅ | ✅ | | |
|
||||
| | [Analyze](https://pr-agent-docs.codium.ai/tools/analyze/) 💎 | ✅ | ✅ | | |
|
||||
| | [CI Feedback](https://pr-agent-docs.codium.ai/tools/ci_feedback/) 💎 | ✅ | | | |
|
||||
| | [Similar Code](https://pr-agent-docs.codium.ai/tools/similar_code/) 💎 | ✅ | | | |
|
||||
| | | | | | |
|
||||
| USAGE | CLI | ✅ | ✅ | ✅ | ✅ |
|
||||
| | App / webhook | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Tagging bot | ✅ | | | |
|
||||
| | Actions | ✅ |✅| ✅ |✅|
|
||||
| | | | | | |
|
||||
| CORE | PR compression | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Repo language prioritization | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Adaptive and token-aware file patch fitting | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Multiple models support | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Static code analysis](https://pr-agent-docs.codium.ai/core-abilities/#static-code-analysis) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [Global and wiki configurations](https://pr-agent-docs.codium.ai/usage-guide/configuration_options/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [PR interactive actions](https://www.codium.ai/images/pr_agent/pr-actions.mp4) 💎 | ✅ | ✅ | | |
|
||||
- 💎 means this feature is available only in [PR-Agent Pro](https://www.codium.ai/pricing/)
|
||||
|
||||
[//]: # (- Support for additional git providers is described in [here](./docs/Full_environments.md))
|
||||
@ -221,7 +227,11 @@ For example, add a comment to any pull request with the following text:
|
||||
```
|
||||
@CodiumAI-Agent /review
|
||||
```
|
||||
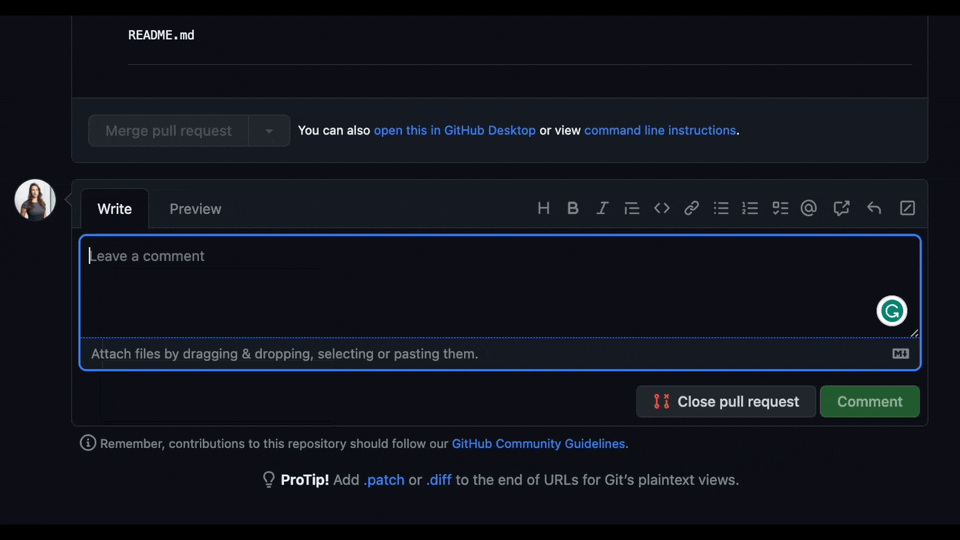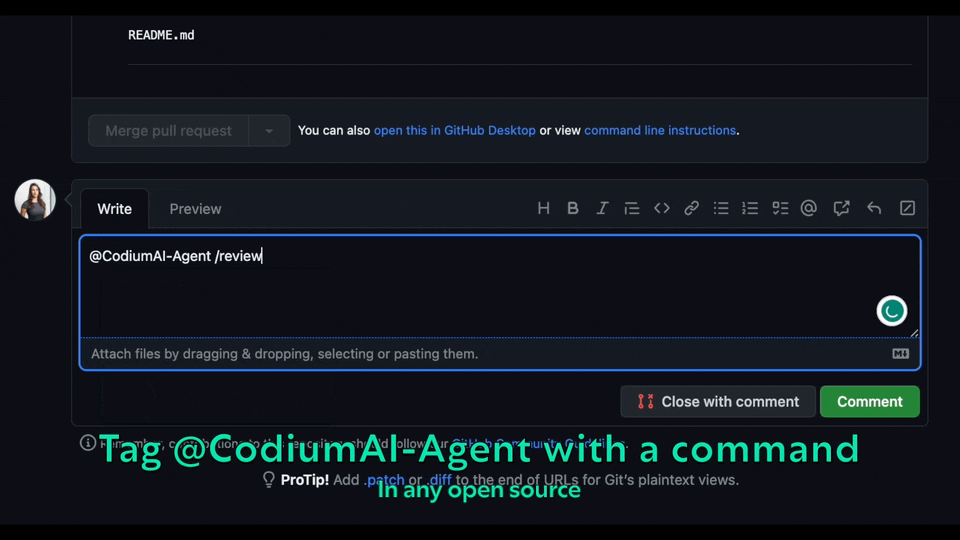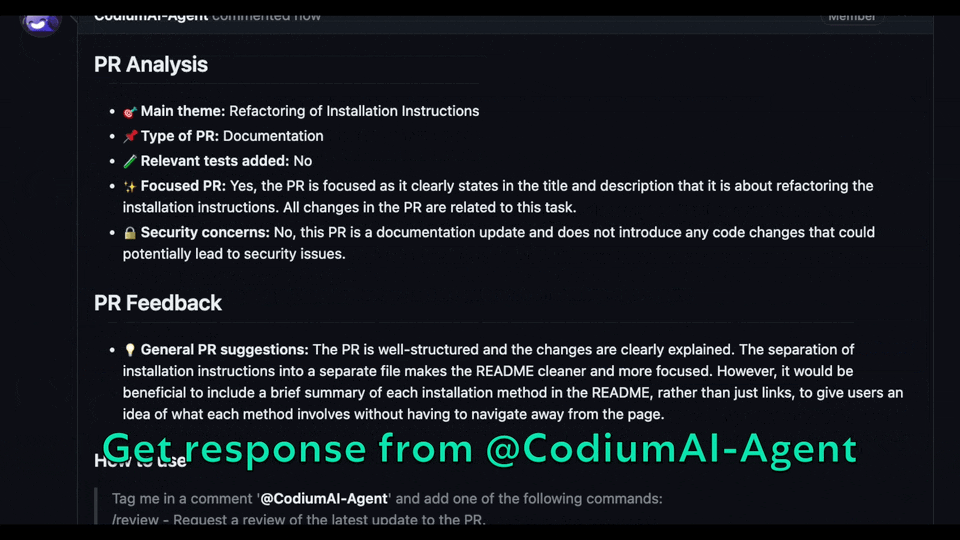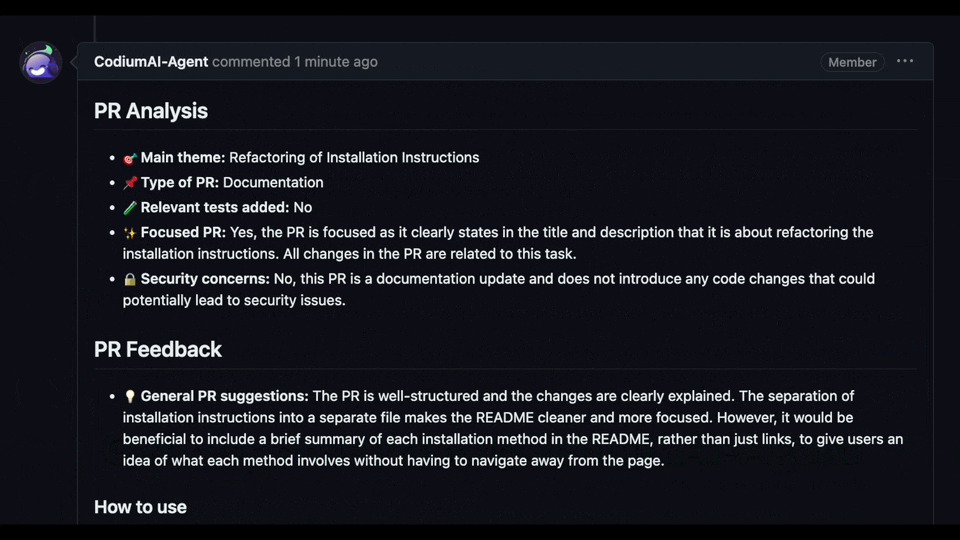
and the agent will respond with a review of your PR
|
||||
and the agent will respond with a review of your PR.
|
||||
|
||||
Note that this is a promotional bot, suitable only for initial experimentation.
|
||||
It does not have 'edit' access to your repo, for example, so it cannot update the PR description or add labels (`@CodiumAI-Agent /describe` will publish PR description as a comment). In addition, the bot cannot be used on private repositories, as it does not have access to the files there.
|
||||
|
||||
|
||||
|
||||
|
||||
@ -231,43 +241,6 @@ Note that when you set your own PR-Agent or use CodiumAI hosted PR-Agent, there
|
||||
|
||||
---
|
||||
|
||||
[//]: # (## Installation)
|
||||
|
||||
[//]: # (To use your own version of PR-Agent, you first need to acquire two tokens:)
|
||||
|
||||
[//]: # ()
|
||||
[//]: # (1. An OpenAI key from [here](https://platform.openai.com/), with access to GPT-4.)
|
||||
|
||||
[//]: # (2. A GitHub personal access token (classic) with the repo scope.)
|
||||
|
||||
[//]: # ()
|
||||
[//]: # (There are several ways to use PR-Agent:)
|
||||
|
||||
[//]: # ()
|
||||
[//]: # (**Locally**)
|
||||
|
||||
[//]: # (- [Using pip package](https://pr-agent-docs.codium.ai/installation/locally/#using-pip-package))
|
||||
|
||||
[//]: # (- [Using Docker image](https://pr-agent-docs.codium.ai/installation/locally/#using-docker-image))
|
||||
|
||||
[//]: # (- [Run from source](https://pr-agent-docs.codium.ai/installation/locally/#run-from-source))
|
||||
|
||||
[//]: # ()
|
||||
[//]: # (**GitHub specific methods**)
|
||||
|
||||
[//]: # (- [Run as a GitHub Action](https://pr-agent-docs.codium.ai/installation/github/#run-as-a-github-action))
|
||||
|
||||
[//]: # (- [Run as a GitHub App](https://pr-agent-docs.codium.ai/installation/github/#run-as-a-github-app))
|
||||
|
||||
[//]: # ()
|
||||
[//]: # (**GitLab specific methods**)
|
||||
|
||||
[//]: # (- [Run a GitLab webhook server](https://pr-agent-docs.codium.ai/installation/gitlab/))
|
||||
|
||||
[//]: # ()
|
||||
[//]: # (**BitBucket specific methods**)
|
||||
|
||||
[//]: # (- [Run as a Bitbucket Pipeline](https://pr-agent-docs.codium.ai/installation/bitbucket/))
|
||||
|
||||
## PR-Agent Pro 💎
|
||||
[PR-Agent Pro](https://www.codium.ai/pricing/) is a hosted version of PR-Agent, provided by CodiumAI. It is available for a monthly fee, and provides the following benefits:
|
||||
|
||||
5
codecov.yml
Normal file
5
codecov.yml
Normal file
@ -0,0 +1,5 @@
|
||||
comment: false
|
||||
coverage:
|
||||
status:
|
||||
patch: false
|
||||
project: false
|
||||
@ -1,4 +1,4 @@
|
||||
FROM python:3.10 as base
|
||||
FROM python:3.12.3 AS base
|
||||
|
||||
WORKDIR /app
|
||||
ADD pyproject.toml .
|
||||
@ -6,36 +6,36 @@ ADD requirements.txt .
|
||||
RUN pip install . && rm pyproject.toml requirements.txt
|
||||
ENV PYTHONPATH=/app
|
||||
|
||||
FROM base as github_app
|
||||
FROM base AS github_app
|
||||
ADD pr_agent pr_agent
|
||||
CMD ["python", "-m", "gunicorn", "-k", "uvicorn.workers.UvicornWorker", "-c", "pr_agent/servers/gunicorn_config.py", "--forwarded-allow-ips", "*", "pr_agent.servers.github_app:app"]
|
||||
|
||||
FROM base as bitbucket_app
|
||||
FROM base AS bitbucket_app
|
||||
ADD pr_agent pr_agent
|
||||
CMD ["python", "pr_agent/servers/bitbucket_app.py"]
|
||||
|
||||
FROM base as bitbucket_server_webhook
|
||||
FROM base AS bitbucket_server_webhook
|
||||
ADD pr_agent pr_agent
|
||||
CMD ["python", "pr_agent/servers/bitbucket_server_webhook.py"]
|
||||
|
||||
FROM base as github_polling
|
||||
FROM base AS github_polling
|
||||
ADD pr_agent pr_agent
|
||||
CMD ["python", "pr_agent/servers/github_polling.py"]
|
||||
|
||||
FROM base as gitlab_webhook
|
||||
FROM base AS gitlab_webhook
|
||||
ADD pr_agent pr_agent
|
||||
CMD ["python", "pr_agent/servers/gitlab_webhook.py"]
|
||||
|
||||
FROM base as azure_devops_webhook
|
||||
FROM base AS azure_devops_webhook
|
||||
ADD pr_agent pr_agent
|
||||
CMD ["python", "pr_agent/servers/azuredevops_server_webhook.py"]
|
||||
|
||||
FROM base as test
|
||||
FROM base AS test
|
||||
ADD requirements-dev.txt .
|
||||
RUN pip install -r requirements-dev.txt && rm requirements-dev.txt
|
||||
ADD pr_agent pr_agent
|
||||
ADD tests tests
|
||||
|
||||
FROM base as cli
|
||||
FROM base AS cli
|
||||
ADD pr_agent pr_agent
|
||||
ENTRYPOINT ["python", "pr_agent/cli.py"]
|
||||
|
||||
5
docs/docs/chrome-extension/data_privacy.md
Normal file
5
docs/docs/chrome-extension/data_privacy.md
Normal file
@ -0,0 +1,5 @@
|
||||
We take your code's security and privacy seriously:
|
||||
|
||||
- The Chrome extension will not send your code to any external servers.
|
||||
- For private repositories, we will first validate the user's identity and permissions. After authentication, we generate responses using the existing PR-Agent Pro integration.
|
||||
|
||||
47
docs/docs/chrome-extension/features.md
Normal file
47
docs/docs/chrome-extension/features.md
Normal file
@ -0,0 +1,47 @@
|
||||
|
||||
### PR Chat
|
||||
|
||||
The PR-Chat feature allows to freely chat with your PR code, within your GitHub environment.
|
||||
It will seamlessly add the PR code as context to your chat session, and provide AI-powered feedback.
|
||||
|
||||
To enable private chat, simply install the PR-Agent Chrome extension. After installation, each PR's file-changed tab will include a chat box, where you may ask questions about your code.
|
||||
This chat session is **private**, and won't be visible to other users.
|
||||
|
||||
All open-source repositories are supported.
|
||||
For private repositories, you will also need to install PR-Agent Pro, After installation, make sure to open at least one new PR to fully register your organization. Once done, you can chat with both new and existing PRs across all installed repositories.
|
||||
|
||||
<img src="https://codium.ai/images/pr_agent/pr_chat1.png" width="768">
|
||||
<img src="https://codium.ai/images/pr_agent/pr_chat2.png" width="768">
|
||||
|
||||
|
||||
### Toolbar extension
|
||||
With PR-Agent Chrome extension, it's [easier than ever](https://www.youtube.com/watch?v=gT5tli7X4H4) to interactively configure and experiment with the different tools and configuration options.
|
||||
|
||||
For private repositories, after you found the setup that works for you, you can also easily export it as a persistent configuration file, and use it for automatic commands.
|
||||
|
||||
<img src="https://codium.ai/images/pr_agent/toolbar1.png" width="512">
|
||||
|
||||
<img src="https://codium.ai/images/pr_agent/toolbar2.png" width="512">
|
||||
|
||||
### PR-Agent filters
|
||||
|
||||
PR-Agent filters is a sidepanel option. that allows you to filter different message in the conversation tab.
|
||||
|
||||
For example, you can choose to present only message from PR-Agent, or filter those messages, focusing only on user's comments.
|
||||
|
||||
<img src="https://codium.ai/images/pr_agent/pr_agent_filters1.png" width="256">
|
||||
|
||||
<img src="https://codium.ai/images/pr_agent/pr_agent_filters2.png" width="256">
|
||||
|
||||
|
||||
### Enhanced code suggestions
|
||||
|
||||
PR-Agent Chrome extension adds the following capabilities to code suggestions tool's comments:
|
||||
|
||||
- Auto-expand the table when you are viewing a code block, to avoid clipping.
|
||||
- Adding a "quote-and-reply" button, that enables to address and comment on a specific suggestion (for example, asking the author to fix the issue)
|
||||
|
||||
|
||||
<img src="https://codium.ai/images/pr_agent/chrome_extension_code_suggestion1.png" width="512">
|
||||
|
||||
<img src="https://codium.ai/images/pr_agent/chrome_extension_code_suggestion2.png" width="512">
|
||||
@ -1,49 +1,8 @@
|
||||
## PR-Agent chrome extension
|
||||
PR-Agent Chrome extension is a collection of tools that integrates seamlessly with your GitHub environment, aiming to enhance your PR-Agent usage experience, and providing additional features.
|
||||
[PR-Agent Chrome extension](https://chromewebstore.google.com/detail/pr-agent-chrome-extension/ephlnjeghhogofkifjloamocljapahnl) is a collection of tools that integrates seamlessly with your GitHub environment, aiming to enhance your Git usage experience, and providing AI-powered capabilities to your PRs.
|
||||
|
||||
## Features
|
||||
With a single-click installation you will gain access to a context-aware PR chat with top models, a toolbar extension with multiple AI feedbacks, PR-Agent filters, and additional abilities.
|
||||
|
||||
### Toolbar extension
|
||||
With PR-Agent Chrome extension, it's [easier than ever](https://www.youtube.com/watch?v=gT5tli7X4H4) to interactively configure and experiment with the different tools and configuration options.
|
||||
All the extension's features are free to use on public repositories. For private repositories, you will need to install in addition to the extension [PR-Agent Pro](https://github.com/apps/codiumai-pr-agent-pro) (fast and easy installation with two weeks of trial, no credit card required).
|
||||
|
||||
After you found the setup that works for you, you can also easily export it as a persistent configuration file, and use it for automatic commands.
|
||||
|
||||
<img src="https://codium.ai/images/pr_agent/toolbar1.png" width="512">
|
||||
|
||||
<img src="https://codium.ai/images/pr_agent/toolbar2.png" width="512">
|
||||
|
||||
### PR-Agent filters
|
||||
|
||||
PR-Agent filters is a sidepanel option. that allows you to filter different message in the conversation tab.
|
||||
|
||||
For example, you can choose to present only message from PR-Agent, or filter those messages, focusing only on user's comments.
|
||||
|
||||
<img src="https://codium.ai/images/pr_agent/pr_agent_filters1.png" width="256">
|
||||
|
||||
<img src="https://codium.ai/images/pr_agent/pr_agent_filters2.png" width="256">
|
||||
|
||||
|
||||
### Enhanced code suggestions
|
||||
|
||||
PR-Agent Chrome extension adds the following capabilities to code suggestions tool's comments:
|
||||
|
||||
- Auto-expand the table when you are viewing a code block, to avoid clipping.
|
||||
- Adding a "quote-and-reply" button, that enables to address and comment on a specific suggestion (for example, asking the author to fix the issue)
|
||||
|
||||
|
||||
<img src="https://codium.ai/images/pr_agent/chrome_extension_code_suggestion1.png" width="512">
|
||||
|
||||
<img src="https://codium.ai/images/pr_agent/chrome_extension_code_suggestion2.png" width="512">
|
||||
|
||||
## Installation
|
||||
|
||||
Go to the marketplace and install the extension:
|
||||
[PR-Agent Chrome Extension](https://chromewebstore.google.com/detail/pr-agent-chrome-extension/ephlnjeghhogofkifjloamocljapahnl)
|
||||
|
||||
## Pre-requisites
|
||||
|
||||
The PR-Agent Chrome extension will work on any repo where you have previously [installed PR-Agent](https://pr-agent-docs.codium.ai/installation/).
|
||||
|
||||
## Data privacy and security
|
||||
|
||||
The PR-Agent Chrome extension only modifies the visual appearance of a GitHub PR screen. It does not transmit any user's repo or pull request code. Code is only sent for processing when a user submits a GitHub comment that activates a PR-Agent tool, in accordance with the standard privacy policy of PR-Agent.
|
||||
<img src="https://codium.ai/images/pr_agent/pr_chat1.png" width="768">
|
||||
<img src="https://codium.ai/images/pr_agent/pr_chat2.png" width="768">
|
||||
|
||||
@ -11,6 +11,19 @@
|
||||
}
|
||||
}
|
||||
|
||||
.md-nav--primary {
|
||||
position: relative; /* Ensure the element is positioned */
|
||||
}
|
||||
|
||||
.md-nav--primary::before {
|
||||
content: "";
|
||||
position: absolute;
|
||||
top: 0;
|
||||
right: 10px; /* Move the border 10 pixels to the right */
|
||||
width: 2px;
|
||||
height: 100%;
|
||||
background-color: #f5f5f5; /* Match the border color */
|
||||
}
|
||||
/*.md-nav__title, .md-nav__link {*/
|
||||
/* font-size: 18px;*/
|
||||
/* margin-top: 14px; !* Adjust the space as needed *!*/
|
||||
|
||||
@ -23,6 +23,7 @@ Here are the results:
|
||||
| QWEN-1.5-32B | 32 | 29 |
|
||||
| | | |
|
||||
| **CodeQwen1.5-7B** | **7** | **35.4** |
|
||||
| Llama-3.1-8B-Instruct | 8 | 35.2 |
|
||||
| Granite-8b-code-instruct | 8 | 34.2 |
|
||||
| CodeLlama-7b-hf | 7 | 31.8 |
|
||||
| Gemma-7B | 7 | 27.2 |
|
||||
|
||||
@ -14,33 +14,33 @@ PR-Agent offers extensive pull request functionalities across various git provid
|
||||
|
||||
| | | GitHub | Gitlab | Bitbucket | Azure DevOps |
|
||||
|-------|-----------------------------------------------------------------------------------------------------------------------|:------:|:------:|:---------:|:------------:|
|
||||
| TOOLS | Review | ✅ | ✅ | ✅ | ✅ |
|
||||
| TOOLS | Review | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ Incremental | ✅ | | | |
|
||||
| | ⮑ [SOC2 Compliance](https://pr-agent-docs.codium.ai/tools/review/#soc2-ticket-compliance){:target="_blank"} 💎 | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Ask | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Describe | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ [Inline file summary](https://pr-agent-docs.codium.ai/tools/describe/#inline-file-summary){:target="_blank"} 💎 | ✅ | ✅ | | ✅ |
|
||||
| | Improve | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ Extended | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Custom Prompt](./tools/custom_prompt.md){:target="_blank"} 💎 | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Reflect and Review | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ [SOC2 Compliance](https://pr-agent-docs.codium.ai/tools/review/#soc2-ticket-compliance){:target="_blank"} 💎 | ✅ | ✅ | ✅ | |
|
||||
| | Ask | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Describe | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ [Inline file summary](https://pr-agent-docs.codium.ai/tools/describe/#inline-file-summary){:target="_blank"} 💎 | ✅ | ✅ | | |
|
||||
| | Improve | ✅ | ✅ | ✅ | ✅ |
|
||||
| | ⮑ Extended | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Custom Prompt](./tools/custom_prompt.md){:target="_blank"} 💎 | ✅ | ✅ | ✅ | |
|
||||
| | Reflect and Review | ✅ | ✅ | ✅ | |
|
||||
| | Update CHANGELOG.md | ✅ | ✅ | ✅ | ️ |
|
||||
| | Find Similar Issue | ✅ | | | ️ |
|
||||
| | [Add PR Documentation](./tools/documentation.md){:target="_blank"} 💎 | ✅ | ✅ | | ✅ |
|
||||
| | [Generate Custom Labels](./tools/describe.md#handle-custom-labels-from-the-repos-labels-page-💎){:target="_blank"} 💎 | ✅ | ✅ | | ✅ |
|
||||
| | [Analyze PR Components](./tools/analyze.md){:target="_blank"} 💎 | ✅ | ✅ | | ✅ |
|
||||
| | [Add PR Documentation](./tools/documentation.md){:target="_blank"} 💎 | ✅ | ✅ | | |
|
||||
| | [Generate Custom Labels](./tools/describe.md#handle-custom-labels-from-the-repos-labels-page-💎){:target="_blank"} 💎 | ✅ | ✅ | | |
|
||||
| | [Analyze PR Components](./tools/analyze.md){:target="_blank"} 💎 | ✅ | ✅ | | |
|
||||
| | | | | | ️ |
|
||||
| USAGE | CLI | ✅ | ✅ | ✅ | ✅ |
|
||||
| | App / webhook | ✅ | ✅ | ✅ | ✅ |
|
||||
| USAGE | CLI | ✅ | ✅ | ✅ | ✅ |
|
||||
| | App / webhook | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Actions | ✅ | | | ️ |
|
||||
| | | | | |
|
||||
| CORE | PR compression | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Repo language prioritization | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Adaptive and token-aware file patch fitting | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Multiple models support | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Incremental PR review | ✅ | | | |
|
||||
| | [Static code analysis](./tools/analyze.md/){:target="_blank"} 💎 | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Multiple configuration options](./usage-guide/configuration_options.md){:target="_blank"} 💎 | ✅ | ✅ | ✅ | ✅ |
|
||||
| CORE | PR compression | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Repo language prioritization | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Adaptive and token-aware file patch fitting | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Multiple models support | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Incremental PR review | ✅ | | | |
|
||||
| | [Static code analysis](./tools/analyze.md/){:target="_blank"} 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [Multiple configuration options](./usage-guide/configuration_options.md){:target="_blank"} 💎 | ✅ | ✅ | ✅ | |
|
||||
|
||||
💎 marks a feature available only in [PR-Agent Pro](https://www.codium.ai/pricing/){:target="_blank"}
|
||||
|
||||
|
||||
@ -1,4 +1,62 @@
|
||||
## Azure DevOps provider
|
||||
## Azure DevOps Pipeline
|
||||
You can use a pre-built Action Docker image to run PR-Agent as an Azure devops pipeline.
|
||||
add the following file to your repository under `azure-pipelines.yml`:
|
||||
```yaml
|
||||
# Opt out of CI triggers
|
||||
trigger: none
|
||||
|
||||
# Configure PR trigger
|
||||
pr:
|
||||
branches:
|
||||
include:
|
||||
- '*'
|
||||
autoCancel: true
|
||||
drafts: false
|
||||
|
||||
stages:
|
||||
- stage: pr_agent
|
||||
displayName: 'PR Agent Stage'
|
||||
jobs:
|
||||
- job: pr_agent_job
|
||||
displayName: 'PR Agent Job'
|
||||
pool:
|
||||
vmImage: 'ubuntu-latest'
|
||||
container:
|
||||
image: codiumai/pr-agent:latest
|
||||
options: --entrypoint ""
|
||||
variables:
|
||||
- group: pr_agent
|
||||
steps:
|
||||
- script: |
|
||||
echo "Running PR Agent action step"
|
||||
|
||||
# Construct PR_URL
|
||||
PR_URL="${SYSTEM_COLLECTIONURI}${SYSTEM_TEAMPROJECT}/_git/${BUILD_REPOSITORY_NAME}/pullrequest/${SYSTEM_PULLREQUEST_PULLREQUESTID}"
|
||||
echo "PR_URL=$PR_URL"
|
||||
|
||||
# Extract organization URL from System.CollectionUri
|
||||
ORG_URL=$(echo "$(System.CollectionUri)" | sed 's/\/$//') # Remove trailing slash if present
|
||||
echo "Organization URL: $ORG_URL"
|
||||
|
||||
export azure_devops__org="$ORG_URL"
|
||||
export config__git_provider="azure"
|
||||
|
||||
pr-agent --pr_url="$PR_URL" describe
|
||||
pr-agent --pr_url="$PR_URL" review
|
||||
pr-agent --pr_url="$PR_URL" improve
|
||||
env:
|
||||
azure_devops__pat: $(azure_devops_pat)
|
||||
openai__key: $(OPENAI_KEY)
|
||||
displayName: 'Run PR Agent'
|
||||
```
|
||||
This script will run PR-Agent on every new merge request, with the `improve`, `review`, and `describe` commands.
|
||||
Note that you need to export the `azure_devops__pat` and `OPENAI_KEY` variables in the Azure DevOps pipeline settings (Pipelines -> Library -> + Variable group):
|
||||
{width=468}
|
||||
|
||||
Make sure to give pipeline permissions to the `pr_agent` variable group.
|
||||
|
||||
|
||||
## Azure DevOps from CLI
|
||||
|
||||
To use Azure DevOps provider use the following settings in configuration.toml:
|
||||
```
|
||||
|
||||
@ -27,9 +27,9 @@ You can get a Bitbucket token for your repository by following Repository Settin
|
||||
Note that comments on a PR are not supported in Bitbucket Pipeline.
|
||||
|
||||
|
||||
## Run using CodiumAI-hosted Bitbucket app
|
||||
## Run using CodiumAI-hosted Bitbucket app 💎
|
||||
|
||||
Please contact [support@codium.ai](mailto:support@codium.ai) or visit [CodiumAI pricing page](https://www.codium.ai/pricing/) if you're interested in a hosted BitBucket app solution that provides full functionality including PR reviews and comment handling. It's based on the [bitbucket_app.py](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/git_providers/bitbucket_provider.py) implementation.
|
||||
Please contact visit [PR-Agent pro](https://www.codium.ai/pricing/) if you're interested in a hosted BitBucket app solution that provides full functionality including PR reviews and comment handling. It's based on the [bitbucket_app.py](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/git_providers/bitbucket_provider.py) implementation.
|
||||
|
||||
|
||||
## Bitbucket Server and Data Center
|
||||
|
||||
@ -26,15 +26,28 @@ jobs:
|
||||
OPENAI_KEY: ${{ secrets.OPENAI_KEY }}
|
||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
```
|
||||
** if you want to pin your action to a specific release (v2.0 for example) for stability reasons, use:
|
||||
|
||||
|
||||
if you want to pin your action to a specific release (v0.23 for example) for stability reasons, use:
|
||||
```yaml
|
||||
...
|
||||
steps:
|
||||
- name: PR Agent action step
|
||||
id: pragent
|
||||
uses: Codium-ai/pr-agent@v2.0
|
||||
uses: docker://codiumai/pr-agent:0.23-github_action
|
||||
...
|
||||
```
|
||||
|
||||
For enhanced security, you can also specify the Docker image by its [digest](https://hub.docker.com/repository/docker/codiumai/pr-agent/tags):
|
||||
```yaml
|
||||
...
|
||||
steps:
|
||||
- name: PR Agent action step
|
||||
id: pragent
|
||||
uses: docker://codiumai/pr-agent@sha256:14165e525678ace7d9b51cda8652c2d74abb4e1d76b57c4a6ccaeba84663cc64
|
||||
...
|
||||
```
|
||||
|
||||
2) Add the following secret to your repository under `Settings > Secrets and variables > Actions > New repository secret > Add secret`:
|
||||
|
||||
```
|
||||
|
||||
@ -1,3 +1,44 @@
|
||||
## Run as a GitLab Pipeline
|
||||
You can use a pre-built Action Docker image to run PR-Agent as a GitLab pipeline. This is a simple way to get started with PR-Agent without setting up your own server.
|
||||
|
||||
(1) Add the following file to your repository under `.gitlab-ci.yml`:
|
||||
```yaml
|
||||
stages:
|
||||
- pr_agent
|
||||
|
||||
pr_agent_job:
|
||||
stage: pr_agent
|
||||
image:
|
||||
name: codiumai/pr-agent:latest
|
||||
entrypoint: [""]
|
||||
script:
|
||||
- cd /app
|
||||
- echo "Running PR Agent action step"
|
||||
- export MR_URL="$CI_MERGE_REQUEST_PROJECT_URL/merge_requests/$CI_MERGE_REQUEST_IID"
|
||||
- echo "MR_URL=$MR_URL"
|
||||
- export gitlab__PERSONAL_ACCESS_TOKEN=$GITLAB_PERSONAL_ACCESS_TOKEN
|
||||
- export config__git_provider="gitlab"
|
||||
- export openai__key=$OPENAI_KEY
|
||||
- python -m pr_agent.cli --pr_url="$MR_URL" describe
|
||||
- python -m pr_agent.cli --pr_url="$MR_URL" review
|
||||
- python -m pr_agent.cli --pr_url="$MR_URL" improve
|
||||
rules:
|
||||
- if: '$CI_PIPELINE_SOURCE == "merge_request_event"'
|
||||
```
|
||||
This script will run PR-Agent on every new merge request. You can modify the `rules` section to run PR-Agent on different events.
|
||||
You can also modify the `script` section to run different PR-Agent commands, or with different parameters by exporting different environment variables.
|
||||
|
||||
|
||||
(2) Add the following masked variables to your GitLab repository (CI/CD -> Variables):
|
||||
|
||||
- `GITLAB_PERSONAL_ACCESS_TOKEN`: Your GitLab personal access token.
|
||||
|
||||
- `OPENAI_KEY`: Your OpenAI key.
|
||||
|
||||
Note that if your base branches are not protected, don't set the variables as `protected`, since the pipeline will not have access to them.
|
||||
|
||||
|
||||
|
||||
## Run a GitLab webhook server
|
||||
|
||||
1. From the GitLab workspace or group, create an access token. Enable the "api" scope only.
|
||||
@ -14,7 +55,7 @@ WEBHOOK_SECRET=$(python -c "import secrets; print(secrets.token_hex(10))")
|
||||
- In the [gitlab] section, fill in personal_access_token and shared_secret. The access token can be a personal access token, or a group or project access token.
|
||||
- Set deployment_type to 'gitlab' in [configuration.toml](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml)
|
||||
|
||||
5. Create a webhook in GitLab. Set the URL to the URL of your app's server. Set the secret token to the generated secret from step 2.
|
||||
5. Create a webhook in GitLab. Set the URL to ```http[s]://<PR_AGENT_HOSTNAME>/webhook```. Set the secret token to the generated secret from step 2.
|
||||
In the "Trigger" section, check the ‘comments’ and ‘merge request events’ boxes.
|
||||
|
||||
6. Test your installation by opening a merge request or commenting or a merge request using one of CodiumAI's commands.
|
||||
6. Test your installation by opening a merge request or commenting or a merge request using one of CodiumAI's commands.
|
||||
|
||||
@ -3,7 +3,7 @@
|
||||
## Self-hosted PR-Agent
|
||||
If you choose to host you own PR-Agent, you first need to acquire two tokens:
|
||||
|
||||
1. An OpenAI key from [here](https://platform.openai.com/api-keys), with access to GPT-4 (or a key for [other models](../usage-guide/additional_configurations.md/#changing-a-model), if you prefer).
|
||||
1. An OpenAI key from [here](https://platform.openai.com/api-keys), with access to GPT-4 (or a key for other [language models](https://pr-agent-docs.codium.ai/usage-guide/changing_a_model/), if you prefer).
|
||||
2. A GitHub\GitLab\BitBucket personal access token (classic), with the repo scope. [GitHub from [here](https://github.com/settings/tokens)]
|
||||
|
||||
There are several ways to use self-hosted PR-Agent:
|
||||
@ -15,8 +15,7 @@ There are several ways to use self-hosted PR-Agent:
|
||||
- [Azure DevOps](./azure.md)
|
||||
|
||||
## PR-Agent Pro 💎
|
||||
PR-Agent Pro, an app for GitHub\GitLab\BitBucket hosted by CodiumAI, is also available.
|
||||
PR-Agent Pro, an app hosted by CodiumAI for GitHub\GitLab\BitBucket, is also available.
|
||||
<br>
|
||||
With PR-Agent Pro Installation is as simple as signing up and adding the PR-Agent app to your relevant repo.
|
||||
<br>
|
||||
See [here](./pr_agent_pro.md) for more details.
|
||||
With PR-Agent Pro, installation is as simple as signing up and adding the PR-Agent app to your relevant repo.
|
||||
See [here](https://pr-agent-docs.codium.ai/installation/pr_agent_pro/) for more details.
|
||||
@ -16,6 +16,10 @@ Once a user acquires a seat, they gain the flexibility to use PR-Agent Pro acros
|
||||
Users without a purchased seat who interact with a repository featuring PR-Agent Pro are entitled to receive up to five complimentary feedbacks.
|
||||
Beyond this limit, PR-Agent Pro will cease to respond to their inquiries unless a seat is purchased.
|
||||
|
||||
## Install PR-Agent Pro for GitHub Enterprise Server
|
||||
You can install PR-Agent Pro application on your GitHub Enterprise Server, and enjoy two weeks of free trial.
|
||||
After the trial period, to continue using PR-Agent Pro, you will need to contact us for an [Enterprise license](https://www.codium.ai/pricing/).
|
||||
|
||||
|
||||
## Install PR-Agent Pro for GitLab (Teams & Enterprise)
|
||||
|
||||
|
||||
@ -1,7 +1,6 @@
|
||||
## Self-hosted PR-Agent
|
||||
|
||||
- If you host PR-Agent with your OpenAI API key, it is between you and OpenAI. You can read their API data privacy policy here:
|
||||
https://openai.com/enterprise-privacy
|
||||
- If you self-host PR-Agent with your OpenAI (or other LLM provider) API key, it is between you and the provider. We don't send your code data to PR-Agent servers.
|
||||
|
||||
## PR-Agent Pro 💎
|
||||
|
||||
@ -14,4 +13,4 @@ https://openai.com/enterprise-privacy
|
||||
|
||||
## PR-Agent Chrome extension
|
||||
|
||||
- The [PR-Agent Chrome extension](https://chromewebstore.google.com/detail/pr-agent-chrome-extension/ephlnjeghhogofkifjloamocljapahnl) serves solely to modify the visual appearance of a GitHub PR screen. It does not transmit any user's repo or pull request code. Code is only sent for processing when a user submits a GitHub comment that activates a PR-Agent tool, in accordance with the standard privacy policy of PR-Agent.
|
||||
- The [PR-Agent Chrome extension](https://chromewebstore.google.com/detail/pr-agent-chrome-extension/ephlnjeghhogofkifjloamocljapahnl) will not send your code to any external servers.
|
||||
|
||||
@ -1,18 +1,42 @@
|
||||
[PR-Agent Pro](https://www.codium.ai/pricing/) is a hosted version of PR-Agent, provided by CodiumAI. It is available for a monthly fee, and provides the following benefits:
|
||||
[PR-Agent Pro](https://www.codium.ai/pricing/) is a hosted version of PR-Agent, provided by CodiumAI. A complimentary two-week trial is offered, followed by a monthly subscription fee.
|
||||
PR-Agent Pro is designed for companies and teams that require additional features and capabilities. It provides the following benefits:
|
||||
|
||||
1. **Fully managed** - We take care of everything for you - hosting, models, regular updates, and more. Installation is as simple as signing up and adding the PR-Agent app to your GitHub\GitLab\BitBucket repo.
|
||||
|
||||
2. **Improved privacy** - No data will be stored or used to train models. PR-Agent Pro will employ zero data retention, and will use an OpenAI account with zero data retention.
|
||||
|
||||
3. **Improved support** - PR-Agent Pro users will receive priority support, and will be able to request new features and capabilities.
|
||||
4. **Extra features** -In addition to the benefits listed above, PR-Agent Pro will emphasize more customization, and the usage of static code analysis, in addition to LLM logic, to improve results. It has the following additional tools and features:
|
||||
- (Tool): [**Analyze PR components**](./tools/analyze.md/)
|
||||
- (Tool): [**Custom Prompt Suggestions**](./tools/custom_prompt.md/)
|
||||
- (Tool): [**Tests**](./tools/test.md/)
|
||||
- (Tool): [**PR documentation**](./tools/documentation.md/)
|
||||
- (Tool): [**Improve Component**](https://pr-agent-docs.codium.ai/tools/improve_component/)
|
||||
- (Tool): [**Similar code search**](https://pr-agent-docs.codium.ai/tools/similar_code/)
|
||||
- (Tool): [**CI feedback**](./tools/ci_feedback.md/)
|
||||
- (Feature): [**Interactive triggering**](./usage-guide/automations_and_usage.md/#interactive-triggering)
|
||||
- (Feature): [**SOC2 compliance check**](./tools/review.md/#soc2-ticket-compliance)
|
||||
- (Feature): [**Custom labels**](./tools/describe.md/#handle-custom-labels-from-the-repos-labels-page)
|
||||
- (Feature): [**Global and wiki configuration**](./usage-guide/configuration_options.md/#wiki-configuration-file)
|
||||
- (Feature): [**Inline file summary**](https://pr-agent-docs.codium.ai/tools/describe/#inline-file-summary)
|
||||
|
||||
4. **Supporting self-hosted git servers** - PR-Agent Pro can be installed on GitHub Enterprise Server, GitLab, and BitBucket. For more information, see the [installation guide](https://pr-agent-docs.codium.ai/installation/pr_agent_pro/).
|
||||
|
||||
**Additional features:**
|
||||
|
||||
Here are some of the additional features and capabilities that PR-Agent Pro offers:
|
||||
|
||||
| Feature | Description |
|
||||
|----------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| [**Model selection**](https://pr-agent-docs.codium.ai/usage-guide/PR_agent_pro_models/#pr-agent-pro-models) | Choose the model that best fits your needs, among top models like `GPT4` and `Claude-Sonnet-3.5`
|
||||
| [**Global and wiki configuration**](https://pr-agent-docs.codium.ai/usage-guide/configuration_options/) | Control configurations for many repositories from a single location; <br>Edit configuration of a single repo without commiting code |
|
||||
| [**Apply suggestions**](https://pr-agent-docs.codium.ai/tools/improve/#overview) | Generate commitable code from the relevant suggestions interactively by clicking on a checkbox |
|
||||
| [**Suggestions impact**](https://pr-agent-docs.codium.ai/tools/improve/#assessing-impact) | Automatically mark suggestions that were implemented by the user (either directly in GitHub, or indirectly in the IDE) to enable tracking of the impact of the suggestions |
|
||||
| [**CI feedback**](https://pr-agent-docs.codium.ai/tools/ci_feedback/) | Automatically analyze failed CI checks on GitHub and provide actionable feedback in the PR conversation, helping to resolve issues quickly |
|
||||
| [**Advanced usage statistics**](https://www.codium.ai/contact/#/) | PR-Agent Pro offers detailed statistics at user, repository, and company levels, including metrics about PR-Agent usage, and also general statistics and insights |
|
||||
| [**Incorporating companies' best practices**](https://pr-agent-docs.codium.ai/tools/improve/#best-practices) | Use the companies' best practices as reference to increase the effectiveness and the relevance of the code suggestions |
|
||||
| [**Interactive triggering**](https://pr-agent-docs.codium.ai/tools/analyze/#example-usage) | Interactively apply different tools via the `analyze` command |
|
||||
| [**SOC2 compliance check**](https://pr-agent-docs.codium.ai/tools/review/#configuration-options) | Ensures the PR contains a ticket to a project management system (e.g., Jira, Asana, Trello, etc.)
|
||||
| [**Custom labels**](https://pr-agent-docs.codium.ai/tools/describe/#handle-custom-labels-from-the-repos-labels-page) | Define custom labels for PR-Agent to assign to the PR |
|
||||
|
||||
**Additional tools:**
|
||||
|
||||
Here are additional tools that are available only for PR-Agent Pro users:
|
||||
|
||||
| Feature | Description |
|
||||
|---------|-------------|
|
||||
| [**Custom Prompt Suggestions**](https://pr-agent-docs.codium.ai/tools/custom_prompt/) | Generate code suggestions based on custom prompts from the user |
|
||||
| [**Analyze PR components**](https://pr-agent-docs.codium.ai/tools/analyze/) | Identify the components that changed in the PR, and enable to interactively apply different tools to them |
|
||||
| [**Tests**](https://pr-agent-docs.codium.ai/tools/test/) | Generate tests for code components that changed in the PR |
|
||||
| [**PR documentation**](https://pr-agent-docs.codium.ai/tools/documentation/) | Generate docstring for code components that changed in the PR |
|
||||
| [**Improve Component**](https://pr-agent-docs.codium.ai/tools/improve_component/) | Generate code suggestions for code components that changed in the PR |
|
||||
| [**Similar code search**](https://pr-agent-docs.codium.ai/tools/similar_code/) | Search for similar code in the repository, organization, or entire GitHub |
|
||||
|
||||
|
||||
|
||||
@ -1,24 +1,29 @@
|
||||
## Overview
|
||||
The `improve` tool scans the PR code changes, and automatically generates suggestions for improving the PR code.
|
||||
The `improve` tool scans the PR code changes, and automatically generates [meaningful](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/pr_code_suggestions_prompts.toml#L41) suggestions for improving the PR code.
|
||||
The tool can be triggered automatically every time a new PR is [opened](../usage-guide/automations_and_usage.md#github-app-automatic-tools-when-a-new-pr-is-opened), or it can be invoked manually by commenting on any PR:
|
||||
```
|
||||
/improve
|
||||
```
|
||||
|
||||
{width=512}
|
||||
|
||||
{width=512}
|
||||
|
||||
Note that the `Apply this suggestion` checkbox, which interactively converts a suggestion into a commitable code comment, is available only for PR-Agent Pro 💎 users.
|
||||
|
||||
|
||||
## Example usage
|
||||
|
||||
### Manual triggering
|
||||
|
||||
Invoke the tool manually by commenting `/improve` on any PR. The code suggestions by default are presented as a single comment:
|
||||
|
||||
{width=512}
|
||||
|
||||
To edit [configurations](#configuration-options) related to the improve tool, use the following template:
|
||||
```
|
||||
/improve --pr_code_suggestions.some_config1=... --pr_code_suggestions.some_config2=...
|
||||
```
|
||||
|
||||
For example, you can choose to present the suggestions as commitable code comments, by running the following command:
|
||||
For example, you can choose to present all the suggestions as commitable code comments, by running the following command:
|
||||
```
|
||||
/improve --pr_code_suggestions.commitable_code_suggestions=true
|
||||
```
|
||||
@ -26,8 +31,8 @@ For example, you can choose to present the suggestions as commitable code commen
|
||||
{width=512}
|
||||
|
||||
|
||||
Note that a single comment has a significantly smaller PR footprint. We recommend this mode for most cases.
|
||||
Also note that collapsible are not supported in _Bitbucket_. Hence, the suggestions are presented there as code comments.
|
||||
As can be seen, a single table comment has a significantly smaller PR footprint. We recommend this mode for most cases.
|
||||
Also note that collapsible are not supported in _Bitbucket_. Hence, the suggestions can only be presented in Bitbucket as code comments.
|
||||
|
||||
### Automatic triggering
|
||||
|
||||
@ -47,17 +52,23 @@ num_code_suggestions_per_chunk = ...
|
||||
- The `pr_commands` lists commands that will be executed automatically when a PR is opened.
|
||||
- The `[pr_code_suggestions]` section contains the configurations for the `improve` tool you want to edit (if any)
|
||||
|
||||
### Extended mode
|
||||
### Assessing Impact 💎
|
||||
|
||||
An extended mode, which does not involve PR Compression and provides more comprehensive suggestions, can be invoked by commenting on any PR by setting:
|
||||
```
|
||||
[pr_code_suggestions]
|
||||
auto_extended_mode=true
|
||||
```
|
||||
(This mode is true by default).
|
||||
Note that PR-Agent pro tracks two types of implementations:
|
||||
|
||||
Note that the extended mode divides the PR code changes into chunks, up to the token limits, where each chunk is handled separately (might use multiple calls to GPT-4 for large PRs).
|
||||
Hence, the total number of suggestions is proportional to the number of chunks, i.e., the size of the PR.
|
||||
- Direct implementation - when the user directly applies the suggestion by clicking the `Apply` checkbox.
|
||||
- Indirect implementation - when the user implements the suggestion in their IDE environment. In this case, PR-Agent will utilize, after each commit, a dedicated logic to identify if a suggestion was implemented, and will mark it as implemented.
|
||||
|
||||
{width=512}
|
||||
|
||||
In post-process, PR-Agent counts the number of suggestions that were implemented, and provides general statistics and insights about the suggestions' impact on the PR process.
|
||||
|
||||
{width=512}
|
||||
|
||||
{width=512}
|
||||
|
||||
|
||||
## Usage Tips
|
||||
|
||||
### Self-review
|
||||
If you set in a configuration file:
|
||||
@ -71,8 +82,10 @@ You can set the content of the checkbox text via:
|
||||
[pr_code_suggestions]
|
||||
code_suggestions_self_review_text = "... (your text here) ..."
|
||||
```
|
||||
|
||||
{width=512}
|
||||
|
||||
|
||||
💎 In addition, by setting:
|
||||
```
|
||||
[pr_code_suggestions]
|
||||
@ -80,10 +93,50 @@ approve_pr_on_self_review = true
|
||||
```
|
||||
the tool can automatically approve the PR when the user checks the self-review checkbox.
|
||||
|
||||
!!! tip "Demanding self-review from the PR author"
|
||||
If you set the number of required reviewers for a PR to 2, this effectively means that the PR author must click the self-review checkbox before the PR can be merged (in addition to a human reviewer).
|
||||
{width=512}
|
||||
!!! tip "Tip - demanding self-review from the PR author"
|
||||
If you set the number of required reviewers for a PR to 2, this effectively means that the PR author must click the self-review checkbox before the PR can be merged (in addition to a human reviewer).
|
||||
|
||||
{width=512}
|
||||
|
||||
### `Extra instructions` and `best practices`
|
||||
|
||||
#### Extra instructions
|
||||
You can use the `extra_instructions` configuration option to give the AI model additional instructions for the `improve` tool.
|
||||
Be specific, clear, and concise in the instructions. With extra instructions, you are the prompter. Specify relevant aspects that you want the model to focus on.
|
||||
|
||||
Examples for possible instructions:
|
||||
```
|
||||
[pr_code_suggestions]
|
||||
extra_instructions="""\
|
||||
(1) Answer in japanese
|
||||
(2) Don't suggest to add try-excpet block
|
||||
(3) Ignore changes in toml files
|
||||
...
|
||||
"""
|
||||
```
|
||||
Use triple quotes to write multi-line instructions. Use bullet points or numbers to make the instructions more readable.
|
||||
|
||||
#### Best practices 💎
|
||||
Another option to give additional guidance to the AI model is by creating a dedicated [**wiki page**](https://github.com/Codium-ai/pr-agent/wiki) called `best_practices.md`.
|
||||
This page can contain a list of best practices, coding standards, and guidelines that are specific to your repo/organization
|
||||
|
||||
The AI model will use this page as a reference, and in case the PR code violates any of the guidelines, it will suggest improvements accordingly, with a dedicated label: `Organization
|
||||
best practice`.
|
||||
|
||||
Example for a `best_practices.md` content can be found [here](https://github.com/Codium-ai/pr-agent/blob/main/docs/docs/usage-guide/EXAMPLE_BEST_PRACTICE.md) (adapted from Google's [pyguide](https://google.github.io/styleguide/pyguide.html)).
|
||||
This file is only an example. Since it is used as a prompt for an AI model, we want to emphasize the following:
|
||||
|
||||
- It should be written in a clear and concise manner
|
||||
- If needed, it should give short relevant code snippets as examples
|
||||
- Up to 800 lines are allowed
|
||||
|
||||
|
||||
Example results:
|
||||
|
||||
{width=512}
|
||||
|
||||
Note that while the `extra instructions` are more related to the way the `improve` tool behaves, the `best_practices.md` file is a general guideline for the way code should be written in the repo.
|
||||
Using a combination of both can help the AI model to provide relevant and tailored suggestions.
|
||||
|
||||
## Configuration options
|
||||
|
||||
@ -153,34 +206,6 @@ the tool can automatically approve the PR when the user checks the self-review c
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
## Usage Tips
|
||||
|
||||
!!! tip "Extra instructions"
|
||||
|
||||
Extra instructions are very important for the `improve` tool, since they enable you to guide the model to suggestions that are more relevant to the specific needs of the project.
|
||||
|
||||
Be specific, clear, and concise in the instructions. With extra instructions, you are the prompter. Specify relevant aspects that you want the model to focus on.
|
||||
|
||||
Examples for extra instructions:
|
||||
```
|
||||
[pr_code_suggestions] # /improve #
|
||||
extra_instructions="""\
|
||||
Emphasize the following aspects:
|
||||
- Does the code logic cover relevant edge cases?
|
||||
- Is the code logic clear and easy to understand?
|
||||
- Is the code logic efficient?
|
||||
...
|
||||
"""
|
||||
```
|
||||
Use triple quotes to write multi-line instructions. Use bullet points to make the instructions more readable.
|
||||
|
||||
!!! tip "Review vs. Improve tools comparison"
|
||||
|
||||
- The [review](https://pr-agent-docs.codium.ai/tools/review/) tool includes a section called 'Possible issues', that also provide feedback on the PR Code.
|
||||
In this section, the model is instructed to focus **only** on [major bugs and issues](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/pr_reviewer_prompts.toml#L71).
|
||||
- The `improve` tool, on the other hand, has a broader mandate, and in addition to bugs and issues, it can also give suggestions for improving code quality and making the code more efficient, readable, and maintainable (see [here](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/pr_code_suggestions_prompts.toml#L34)).
|
||||
- Hence, if you are interested only in feedback about clear bugs, the `review` tool might suffice. If you want a more detailed feedback, including broader suggestions for improving the PR code, also enable the `improve` tool to run on each PR.
|
||||
|
||||
## A note on code suggestions quality
|
||||
|
||||
- While the current AI for code is getting better and better (GPT-4), it's not flawless. Not all the suggestions will be perfect, and a user should not accept all of them automatically. Critical reading and judgment are required.
|
||||
|
||||
@ -43,15 +43,23 @@ num_code_suggestions = ...
|
||||
- The `pr_commands` lists commands that will be executed automatically when a PR is opened.
|
||||
- The `[pr_reviewer]` section contains the configurations for the `review` tool you want to edit (if any).
|
||||
|
||||
### Incremental Mode
|
||||
Incremental review only considers changes since the last PR-Agent review. This can be useful when working on the PR in an iterative manner, and you want to focus on the changes since the last review instead of reviewing the entire PR again.
|
||||
For invoking the incremental mode, the following command can be used:
|
||||
```
|
||||
/review -i
|
||||
```
|
||||
Note that the incremental mode is only available for GitHub.
|
||||
[//]: # ()
|
||||
[//]: # (### Incremental Mode)
|
||||
|
||||
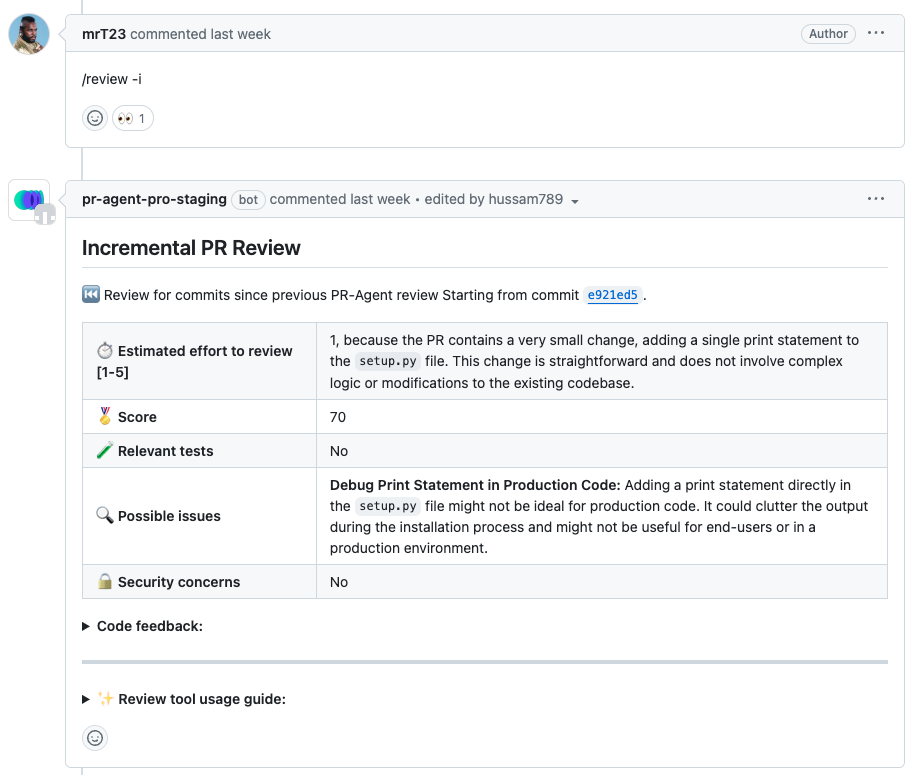{width=512}
|
||||
[//]: # (Incremental review only considers changes since the last PR-Agent review. This can be useful when working on the PR in an iterative manner, and you want to focus on the changes since the last review instead of reviewing the entire PR again.)
|
||||
|
||||
[//]: # (For invoking the incremental mode, the following command can be used:)
|
||||
|
||||
[//]: # (```)
|
||||
|
||||
[//]: # (/review -i)
|
||||
|
||||
[//]: # (```)
|
||||
|
||||
[//]: # (Note that the incremental mode is only available for GitHub.)
|
||||
|
||||
[//]: # ()
|
||||
[//]: # ({width=512})
|
||||
|
||||
[//]: # (### PR Reflection)
|
||||
|
||||
@ -84,11 +92,11 @@ Note that the incremental mode is only available for GitHub.
|
||||
<table>
|
||||
<tr>
|
||||
<td><b>num_code_suggestions</b></td>
|
||||
<td>Number of code suggestions provided by the 'review' tool. For manual comments, default is 4. For PR-Agent app auto tools, default is 0, meaning no code suggestions will be provided by the review tool, unless you manually edit pr_commands.</td>
|
||||
<td>Number of code suggestions provided by the 'review' tool. Default is 0, meaning no code suggestions will be provided by the `review` tool.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>inline_code_comments</b></td>
|
||||
<td>If set to true, the tool will publish the code suggestions as comments on the code diff. Default is false.</td>
|
||||
<td>If set to true, the tool will publish the code suggestions as comments on the code diff. Default is false. Note that you need to set `num_code_suggestions`>0 to get code suggestions </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>persistent_comment</b></td>
|
||||
@ -166,7 +174,7 @@ If enabled, the `review` tool can approve a PR when a specific comment, `/review
|
||||
<table>
|
||||
<tr>
|
||||
<td><b>enable_auto_approval</b></td>
|
||||
<td>If set to true, the tool will approve the PR when invoked with the 'auto_approve' command. Default is false. This flag can be changed only from configuration file.</td>
|
||||
<td>If set to true, the tool will approve the PR when invoked with the 'auto_approve' command. Default is false. This flag can be changed only from a configuration file.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>maximal_review_effort</b></td>
|
||||
@ -192,7 +200,7 @@ If enabled, the `review` tool can approve a PR when a specific comment, `/review
|
||||
pr_commands = ["/review --pr_reviewer.num_code_suggestions=0", ...]
|
||||
```
|
||||
Meaning the `review` tool will run automatically on every PR, without providing code suggestions.
|
||||
Edit this field to enable/disable the tool, or to change the used configurations.
|
||||
Edit this field to enable/disable the tool, or to change the configurations used.
|
||||
|
||||
!!! tip "Possible labels from the review tool"
|
||||
|
||||
@ -210,7 +218,7 @@ If enabled, the `review` tool can approve a PR when a specific comment, `/review
|
||||
|
||||
Be specific, clear, and concise in the instructions. With extra instructions, you are the prompter. Specify the relevant sub-tool, and the relevant aspects of the PR that you want to emphasize.
|
||||
|
||||
Examples for extra instructions:
|
||||
Examples of extra instructions:
|
||||
```
|
||||
[pr_reviewer]
|
||||
extra_instructions="""\
|
||||
|
||||
189
docs/docs/usage-guide/EXAMPLE_BEST_PRACTICE.md
Normal file
189
docs/docs/usage-guide/EXAMPLE_BEST_PRACTICE.md
Normal file
@ -0,0 +1,189 @@
|
||||
## Recommend Python Best Practices
|
||||
This document outlines a series of recommended best practices for Python development. These guidelines aim to improve code quality, maintainability, and readability.
|
||||
|
||||
### Imports
|
||||
|
||||
Use `import` statements for packages and modules only, not for individual types, classes, or functions.
|
||||
|
||||
#### Definition
|
||||
|
||||
Reusability mechanism for sharing code from one module to another.
|
||||
|
||||
#### Decision
|
||||
|
||||
- Use `import x` for importing packages and modules.
|
||||
- Use `from x import y` where `x` is the package prefix and `y` is the module name with no prefix.
|
||||
- Use `from x import y as z` in any of the following circumstances:
|
||||
- Two modules named `y` are to be imported.
|
||||
- `y` conflicts with a top-level name defined in the current module.
|
||||
- `y` conflicts with a common parameter name that is part of the public API (e.g., `features`).
|
||||
- `y` is an inconveniently long name, or too generic in the context of your code
|
||||
- Use `import y as z` only when `z` is a standard abbreviation (e.g., `import numpy as np`).
|
||||
|
||||
For example the module `sound.effects.echo` may be imported as follows:
|
||||
|
||||
```
|
||||
from sound.effects import echo
|
||||
...
|
||||
echo.EchoFilter(input, output, delay=0.7, atten=4)
|
||||
|
||||
```
|
||||
|
||||
Do not use relative names in imports. Even if the module is in the same package, use the full package name. This helps prevent unintentionally importing a package twice.
|
||||
|
||||
##### Exemptions
|
||||
|
||||
Exemptions from this rule:
|
||||
|
||||
- Symbols from the following modules are used to support static analysis and type checking:
|
||||
- [`typing` module](https://google.github.io/styleguide/pyguide.html#typing-imports)
|
||||
- [`collections.abc` module](https://google.github.io/styleguide/pyguide.html#typing-imports)
|
||||
- [`typing_extensions` module](https://github.com/python/typing_extensions/blob/main/README.md)
|
||||
- Redirects from the [six.moves module](https://six.readthedocs.io/#module-six.moves).
|
||||
|
||||
### Packages
|
||||
|
||||
Import each module using the full pathname location of the module.
|
||||
|
||||
#### Decision
|
||||
|
||||
All new code should import each module by its full package name.
|
||||
|
||||
Imports should be as follows:
|
||||
|
||||
```
|
||||
Yes:
|
||||
# Reference absl.flags in code with the complete name (verbose).
|
||||
import absl.flags
|
||||
from doctor.who import jodie
|
||||
|
||||
_FOO = absl.flags.DEFINE_string(...)
|
||||
|
||||
```
|
||||
|
||||
```
|
||||
Yes:
|
||||
# Reference flags in code with just the module name (common).
|
||||
from absl import flags
|
||||
from doctor.who import jodie
|
||||
|
||||
_FOO = flags.DEFINE_string(...)
|
||||
|
||||
```
|
||||
|
||||
_(assume this file lives in `doctor/who/` where `jodie.py` also exists)_
|
||||
|
||||
```
|
||||
No:
|
||||
# Unclear what module the author wanted and what will be imported. The actual
|
||||
# import behavior depends on external factors controlling sys.path.
|
||||
# Which possible jodie module did the author intend to import?
|
||||
import jodie
|
||||
|
||||
```
|
||||
|
||||
The directory the main binary is located in should not be assumed to be in `sys.path` despite that happening in some environments. This being the case, code should assume that `import jodie` refers to a third-party or top-level package named `jodie`, not a local `jodie.py`.
|
||||
|
||||
### Default Iterators and Operators
|
||||
Use default iterators and operators for types that support them, like lists, dictionaries, and files.
|
||||
|
||||
#### Definition
|
||||
|
||||
Container types, like dictionaries and lists, define default iterators and membership test operators (“in” and “not in”).
|
||||
|
||||
#### Decision
|
||||
|
||||
Use default iterators and operators for types that support them, like lists, dictionaries, and files. The built-in types define iterator methods, too. Prefer these methods to methods that return lists, except that you should not mutate a container while iterating over it.
|
||||
|
||||
```
|
||||
Yes: for key in adict: ...
|
||||
if obj in alist: ...
|
||||
for line in afile: ...
|
||||
for k, v in adict.items(): ...
|
||||
```
|
||||
|
||||
```
|
||||
No: for key in adict.keys(): ...
|
||||
for line in afile.readlines(): ...
|
||||
```
|
||||
|
||||
### Lambda Functions
|
||||
|
||||
Okay for one-liners. Prefer generator expressions over `map()` or `filter()` with a `lambda`.
|
||||
|
||||
#### Decision
|
||||
|
||||
Lambdas are allowed. If the code inside the lambda function spans multiple lines or is longer than 60-80 chars, it might be better to define it as a regular [nested function](https://google.github.io/styleguide/pyguide.html#lexical-scoping).
|
||||
|
||||
For common operations like multiplication, use the functions from the `operator` module instead of lambda functions. For example, prefer `operator.mul` to `lambda x, y: x * y`.
|
||||
|
||||
### Default Argument Values
|
||||
|
||||
Okay in most cases.
|
||||
|
||||
#### Definition
|
||||
|
||||
You can specify values for variables at the end of a function’s parameter list, e.g., `def foo(a, b=0):`. If `foo` is called with only one argument, `b` is set to 0. If it is called with two arguments, `b` has the value of the second argument.
|
||||
|
||||
#### Decision
|
||||
|
||||
Okay to use with the following caveat:
|
||||
|
||||
Do not use mutable objects as default values in the function or method definition.
|
||||
|
||||
```
|
||||
Yes: def foo(a, b=None):
|
||||
if b is None:
|
||||
b = []
|
||||
Yes: def foo(a, b: Sequence | None = None):
|
||||
if b is None:
|
||||
b = []
|
||||
Yes: def foo(a, b: Sequence = ()): # Empty tuple OK since tuples are immutable.
|
||||
...
|
||||
```
|
||||
|
||||
```
|
||||
from absl import flags
|
||||
_FOO = flags.DEFINE_string(...)
|
||||
|
||||
No: def foo(a, b=[]):
|
||||
...
|
||||
No: def foo(a, b=time.time()): # Is `b` supposed to represent when this module was loaded?
|
||||
...
|
||||
No: def foo(a, b=_FOO.value): # sys.argv has not yet been parsed...
|
||||
...
|
||||
No: def foo(a, b: Mapping = {}): # Could still get passed to unchecked code.
|
||||
...
|
||||
```
|
||||
|
||||
### True/False Evaluations
|
||||
|
||||
|
||||
Use the “implicit” false if possible, e.g., `if foo:` rather than `if foo != []:`
|
||||
|
||||
### Lexical Scoping
|
||||
|
||||
Okay to use.
|
||||
|
||||
An example of the use of this feature is:
|
||||
|
||||
```
|
||||
def get_adder(summand1: float) -> Callable[[float], float]:
|
||||
"""Returns a function that adds numbers to a given number."""
|
||||
def adder(summand2: float) -> float:
|
||||
return summand1 + summand2
|
||||
|
||||
return adder
|
||||
```
|
||||
#### Decision
|
||||
|
||||
Okay to use.
|
||||
|
||||
|
||||
### Threading
|
||||
|
||||
Do not rely on the atomicity of built-in types.
|
||||
|
||||
While Python’s built-in data types such as dictionaries appear to have atomic operations, there are corner cases where they aren’t atomic (e.g. if `__hash__` or `__eq__` are implemented as Python methods) and their atomicity should not be relied upon. Neither should you rely on atomic variable assignment (since this in turn depends on dictionaries).
|
||||
|
||||
Use the `queue` module’s `Queue` data type as the preferred way to communicate data between threads. Otherwise, use the `threading` module and its locking primitives. Prefer condition variables and `threading.Condition` instead of using lower-level locks.
|
||||
30
docs/docs/usage-guide/PR_agent_pro_models.md
Normal file
30
docs/docs/usage-guide/PR_agent_pro_models.md
Normal file
@ -0,0 +1,30 @@
|
||||
## PR-Agent Pro Models
|
||||
|
||||
The default models used by PR-Agent Pro are OpenAI's GPT-4 models. We use a combination of GPT-4-Turbo and GPT-4o to strike a balance between speed and quality.
|
||||
|
||||
However, users can change the model used by PR-Agent Pro to Claude-3.5-sonnet, which also excels at code tasks.
|
||||
To do so, add the following to your [configuration](https://pr-agent-docs.codium.ai/usage-guide/configuration_options/) file:
|
||||
|
||||
```
|
||||
[config]
|
||||
model="claude-3-5-sonnet"
|
||||
```
|
||||
|
||||
Note that Claude models tend to give lower scores for each suggestion, so if you are using a [threshold](https://pr-agent-docs.codium.ai/tools/improve/#configuration-options):
|
||||
```
|
||||
[pr_code_suggestions]
|
||||
suggestions_score_threshold=...
|
||||
```
|
||||
You might need to adjust this value when switching models.
|
||||
|
||||
### Dedicated models per tool
|
||||
|
||||
You can also use different models for different tools. For example, you can use the Claude-3.5-sonnet model only for the `improve` tool (and keep the default GPT-4 model for the other tools) by adding the following to your configuration file:
|
||||
```
|
||||
[github_app]
|
||||
pr_commands = [
|
||||
"/describe --pr_description.final_update_message=false",
|
||||
"/review --pr_reviewer.num_code_suggestions=0",
|
||||
"/improve --config.model=claude-3-5-sonnet",
|
||||
]
|
||||
```
|
||||
@ -47,168 +47,6 @@ However, for very large PRs, or in case you want to emphasize quality over speed
|
||||
which divides the PR to chunks, and processes each chunk separately. With this mode, regardless of the model, no compression will be done (but for large PRs, multiple model calls may occur)
|
||||
|
||||
|
||||
## Changing a model
|
||||
|
||||
See [here](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/algo/__init__.py) for the list of available models.
|
||||
To use a different model than the default (GPT-4), you need to edit [configuration file](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml#L2).
|
||||
For models and environments not from OPENAI, you might need to provide additional keys and other parameters. See below for instructions.
|
||||
|
||||
### Azure
|
||||
|
||||
To use Azure, set in your `.secrets.toml` (working from CLI), or in the GitHub `Settings > Secrets and variables` (working from GitHub App or GitHub Action):
|
||||
```
|
||||
[openai]
|
||||
key = "" # your azure api key
|
||||
api_type = "azure"
|
||||
api_version = '2023-05-15' # Check Azure documentation for the current API version
|
||||
api_base = "" # The base URL for your Azure OpenAI resource. e.g. "https://<your resource name>.openai.azure.com"
|
||||
deployment_id = "" # The deployment name you chose when you deployed the engine
|
||||
```
|
||||
|
||||
and set in your configuration file:
|
||||
```
|
||||
[config]
|
||||
model="" # the OpenAI model you've deployed on Azure (e.g. gpt-3.5-turbo)
|
||||
```
|
||||
|
||||
### Hugging Face
|
||||
|
||||
**Local**
|
||||
You can run Hugging Face models locally through either [VLLM](https://docs.litellm.ai/docs/providers/vllm) or [Ollama](https://docs.litellm.ai/docs/providers/ollama)
|
||||
|
||||
E.g. to use a new Hugging Face model locally via Ollama, set:
|
||||
```
|
||||
[__init__.py]
|
||||
MAX_TOKENS = {
|
||||
"model-name-on-ollama": <max_tokens>
|
||||
}
|
||||
e.g.
|
||||
MAX_TOKENS={
|
||||
...,
|
||||
"ollama/llama2": 4096
|
||||
}
|
||||
|
||||
|
||||
[config] # in configuration.toml
|
||||
model = "ollama/llama2"
|
||||
model_turbo = "ollama/llama2"
|
||||
|
||||
[ollama] # in .secrets.toml
|
||||
api_base = ... # the base url for your Hugging Face inference endpoint
|
||||
# e.g. if running Ollama locally, you may use:
|
||||
api_base = "http://localhost:11434/"
|
||||
```
|
||||
|
||||
### Inference Endpoints
|
||||
|
||||
To use a new model with Hugging Face Inference Endpoints, for example, set:
|
||||
```
|
||||
[__init__.py]
|
||||
MAX_TOKENS = {
|
||||
"model-name-on-huggingface": <max_tokens>
|
||||
}
|
||||
e.g.
|
||||
MAX_TOKENS={
|
||||
...,
|
||||
"meta-llama/Llama-2-7b-chat-hf": 4096
|
||||
}
|
||||
[config] # in configuration.toml
|
||||
model = "huggingface/meta-llama/Llama-2-7b-chat-hf"
|
||||
model_turbo = "huggingface/meta-llama/Llama-2-7b-chat-hf"
|
||||
|
||||
[huggingface] # in .secrets.toml
|
||||
key = ... # your Hugging Face api key
|
||||
api_base = ... # the base url for your Hugging Face inference endpoint
|
||||
```
|
||||
(you can obtain a Llama2 key from [here](https://replicate.com/replicate/llama-2-70b-chat/api))
|
||||
|
||||
### Replicate
|
||||
|
||||
To use Llama2 model with Replicate, for example, set:
|
||||
```
|
||||
[config] # in configuration.toml
|
||||
model = "replicate/llama-2-70b-chat:2c1608e18606fad2812020dc541930f2d0495ce32eee50074220b87300bc16e1"
|
||||
model_turbo = "replicate/llama-2-70b-chat:2c1608e18606fad2812020dc541930f2d0495ce32eee50074220b87300bc16e1"
|
||||
[replicate] # in .secrets.toml
|
||||
key = ...
|
||||
```
|
||||
(you can obtain a Llama2 key from [here](https://replicate.com/replicate/llama-2-70b-chat/api))
|
||||
|
||||
|
||||
Also, review the [AiHandler](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/algo/ai_handler.py) file for instructions on how to set keys for other models.
|
||||
|
||||
### Groq
|
||||
|
||||
To use Llama3 model with Groq, for example, set:
|
||||
```
|
||||
[config] # in configuration.toml
|
||||
model = "llama3-70b-8192"
|
||||
model_turbo = "llama3-70b-8192"
|
||||
fallback_models = ["groq/llama3-70b-8192"]
|
||||
[groq] # in .secrets.toml
|
||||
key = ... # your Groq api key
|
||||
```
|
||||
(you can obtain a Groq key from [here](https://console.groq.com/keys))
|
||||
|
||||
### Vertex AI
|
||||
|
||||
To use Google's Vertex AI platform and its associated models (chat-bison/codechat-bison) set:
|
||||
|
||||
```
|
||||
[config] # in configuration.toml
|
||||
model = "vertex_ai/codechat-bison"
|
||||
model_turbo = "vertex_ai/codechat-bison"
|
||||
fallback_models="vertex_ai/codechat-bison"
|
||||
|
||||
[vertexai] # in .secrets.toml
|
||||
vertex_project = "my-google-cloud-project"
|
||||
vertex_location = ""
|
||||
```
|
||||
|
||||
Your [application default credentials](https://cloud.google.com/docs/authentication/application-default-credentials) will be used for authentication so there is no need to set explicit credentials in most environments.
|
||||
|
||||
If you do want to set explicit credentials then you can use the `GOOGLE_APPLICATION_CREDENTIALS` environment variable set to a path to a json credentials file.
|
||||
|
||||
### Anthropic
|
||||
|
||||
To use Anthropic models, set the relevant models in the configuration section of the configuration file:
|
||||
```
|
||||
[config]
|
||||
model="anthropic/claude-3-opus-20240229"
|
||||
model_turbo="anthropic/claude-3-opus-20240229"
|
||||
fallback_models=["anthropic/claude-3-opus-20240229"]
|
||||
```
|
||||
|
||||
And also set the api key in the .secrets.toml file:
|
||||
```
|
||||
[anthropic]
|
||||
KEY = "..."
|
||||
```
|
||||
|
||||
### Amazon Bedrock
|
||||
|
||||
To use Amazon Bedrock and its foundational models, add the below configuration:
|
||||
|
||||
```
|
||||
[config] # in configuration.toml
|
||||
model="bedrock/anthropic.claude-3-sonnet-20240229-v1:0"
|
||||
model_turbo="bedrock/anthropic.claude-3-sonnet-20240229-v1:0"
|
||||
fallback_models=["bedrock/anthropic.claude-v2:1"]
|
||||
|
||||
[aws] # in .secrets.toml
|
||||
bedrock_region = "us-east-1"
|
||||
```
|
||||
|
||||
Note that you have to add access to foundational models before using them. Please refer to [this document](https://docs.aws.amazon.com/bedrock/latest/userguide/setting-up.html) for more details.
|
||||
|
||||
If you are using the claude-3 model, please configure the following settings as there are parameters incompatible with claude-3.
|
||||
```
|
||||
[litellm]
|
||||
drop_params = true
|
||||
```
|
||||
|
||||
AWS session is automatically authenticated from your environment, but you can also explicitly set `AWS_ACCESS_KEY_ID` and `AWS_SECRET_ACCESS_KEY` environment variables.
|
||||
|
||||
|
||||
## Patch Extra Lines
|
||||
|
||||
@ -228,7 +66,8 @@ By default, around any change in your PR, git patch provides three lines of cont
|
||||
For the `review`, `describe`, `ask` and `add_docs` tools, if the token budget allows, PR-Agent tries to increase the number of lines of context, via the parameter:
|
||||
```
|
||||
[config]
|
||||
patch_extra_lines=3
|
||||
patch_extra_lines_before=4
|
||||
patch_extra_lines_after=2
|
||||
```
|
||||
|
||||
Increasing this number provides more context to the model, but will also increase the token budget.
|
||||
@ -252,3 +91,24 @@ user="""
|
||||
"""
|
||||
```
|
||||
Note that the new prompt will need to generate an output compatible with the relevant [post-process function](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/tools/pr_description.py#L137).
|
||||
|
||||
## Integrating with Logging Observability Platforms
|
||||
|
||||
Various logging observability tools can be used out-of-the box when using the default LiteLLM AI Handler. Simply configure the LiteLLM callback settings in `configuration.toml` and set environment variables according to the LiteLLM [documentation](https://docs.litellm.ai/docs/).
|
||||
|
||||
For example, to use [LangSmith](https://www.langchain.com/langsmith) you can add the following to your `configuration.toml` file:
|
||||
```
|
||||
[litellm]
|
||||
enable_callbacks = true
|
||||
success_callback = ["langsmith"]
|
||||
failure_callback = ["langsmith"]
|
||||
service_callback = []
|
||||
```
|
||||
|
||||
Then set the following environment variables:
|
||||
|
||||
```
|
||||
LANGSMITH_API_KEY=<api_key>
|
||||
LANGSMITH_PROJECT=<project>
|
||||
LANGSMITH_BASE_URL=<url>
|
||||
```
|
||||
|
||||
@ -26,6 +26,16 @@ verbosity_level=2
|
||||
```
|
||||
This is useful for debugging or experimenting with different tools.
|
||||
|
||||
(3)
|
||||
|
||||
**git provider**: The [git_provider](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml#L5) field in a configuration file determines the GIT provider that will be used by PR-Agent. Currently, the following providers are supported:
|
||||
`
|
||||
"github", "gitlab", "bitbucket", "azure", "codecommit", "local", "gerrit"
|
||||
`
|
||||
|
||||
Default is "github".
|
||||
|
||||
|
||||
|
||||
### Online usage
|
||||
|
||||
@ -34,7 +44,7 @@ Commands for invoking the different tools via comments:
|
||||
|
||||
- **Review**: `/review`
|
||||
- **Describe**: `/describe`
|
||||
- **Improve**: `/improve`
|
||||
- **Improve**: `/improve` (or `/improve_code` for bitbucket, since `/improve` is sometimes reserved)
|
||||
- **Ask**: `/ask "..."`
|
||||
- **Reflect**: `/reflect`
|
||||
- **Update Changelog**: `/update_changelog`
|
||||
|
||||
189
docs/docs/usage-guide/changing_a_model.md
Normal file
189
docs/docs/usage-guide/changing_a_model.md
Normal file
@ -0,0 +1,189 @@
|
||||
## Changing a model
|
||||
|
||||
See [here](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/algo/__init__.py) for a list of available models.
|
||||
To use a different model than the default (GPT-4), you need to edit in the [configuration file](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml#L2) the fields:
|
||||
```
|
||||
[config]
|
||||
model = "..."
|
||||
model_turbo = "..."
|
||||
fallback_models = ["..."]
|
||||
```
|
||||
|
||||
For models and environments not from OpenAI, you might need to provide additional keys and other parameters.
|
||||
You can give parameters via a configuration file (see below for instructions), or from environment variables. See [litellm documentation](https://litellm.vercel.app/docs/proxy/quick_start#supported-llms) for the environment variables relevant per model.
|
||||
|
||||
### Azure
|
||||
|
||||
To use Azure, set in your `.secrets.toml` (working from CLI), or in the GitHub `Settings > Secrets and variables` (working from GitHub App or GitHub Action):
|
||||
```
|
||||
[openai]
|
||||
key = "" # your azure api key
|
||||
api_type = "azure"
|
||||
api_version = '2023-05-15' # Check Azure documentation for the current API version
|
||||
api_base = "" # The base URL for your Azure OpenAI resource. e.g. "https://<your resource name>.openai.azure.com"
|
||||
deployment_id = "" # The deployment name you chose when you deployed the engine
|
||||
```
|
||||
|
||||
and set in your configuration file:
|
||||
```
|
||||
[config]
|
||||
model="" # the OpenAI model you've deployed on Azure (e.g. gpt-3.5-turbo)
|
||||
model_turbo="" # the OpenAI model you've deployed on Azure (e.g. gpt-3.5-turbo)
|
||||
fallback_models=["..."] # the OpenAI model you've deployed on Azure (e.g. gpt-3.5-turbo)
|
||||
```
|
||||
|
||||
### Hugging Face
|
||||
|
||||
**Local**
|
||||
You can run Hugging Face models locally through either [VLLM](https://docs.litellm.ai/docs/providers/vllm) or [Ollama](https://docs.litellm.ai/docs/providers/ollama)
|
||||
|
||||
E.g. to use a new Hugging Face model locally via Ollama, set:
|
||||
```
|
||||
[__init__.py]
|
||||
MAX_TOKENS = {
|
||||
"model-name-on-ollama": <max_tokens>
|
||||
}
|
||||
e.g.
|
||||
MAX_TOKENS={
|
||||
...,
|
||||
"ollama/llama2": 4096
|
||||
}
|
||||
|
||||
|
||||
[config] # in configuration.toml
|
||||
model = "ollama/llama2"
|
||||
model_turbo = "ollama/llama2"
|
||||
fallback_models=["ollama/llama2"]
|
||||
|
||||
[ollama] # in .secrets.toml
|
||||
api_base = ... # the base url for your Hugging Face inference endpoint
|
||||
# e.g. if running Ollama locally, you may use:
|
||||
api_base = "http://localhost:11434/"
|
||||
```
|
||||
|
||||
### Inference Endpoints
|
||||
|
||||
To use a new model with Hugging Face Inference Endpoints, for example, set:
|
||||
```
|
||||
[__init__.py]
|
||||
MAX_TOKENS = {
|
||||
"model-name-on-huggingface": <max_tokens>
|
||||
}
|
||||
e.g.
|
||||
MAX_TOKENS={
|
||||
...,
|
||||
"meta-llama/Llama-2-7b-chat-hf": 4096
|
||||
}
|
||||
[config] # in configuration.toml
|
||||
model = "huggingface/meta-llama/Llama-2-7b-chat-hf"
|
||||
model_turbo = "huggingface/meta-llama/Llama-2-7b-chat-hf"
|
||||
fallback_models=["huggingface/meta-llama/Llama-2-7b-chat-hf"]
|
||||
|
||||
[huggingface] # in .secrets.toml
|
||||
key = ... # your Hugging Face api key
|
||||
api_base = ... # the base url for your Hugging Face inference endpoint
|
||||
```
|
||||
(you can obtain a Llama2 key from [here](https://replicate.com/replicate/llama-2-70b-chat/api))
|
||||
|
||||
### Replicate
|
||||
|
||||
To use Llama2 model with Replicate, for example, set:
|
||||
```
|
||||
[config] # in configuration.toml
|
||||
model = "replicate/llama-2-70b-chat:2c1608e18606fad2812020dc541930f2d0495ce32eee50074220b87300bc16e1"
|
||||
model_turbo = "replicate/llama-2-70b-chat:2c1608e18606fad2812020dc541930f2d0495ce32eee50074220b87300bc16e1"
|
||||
fallback_models=["replicate/llama-2-70b-chat:2c1608e18606fad2812020dc541930f2d0495ce32eee50074220b87300bc16e1"]
|
||||
[replicate] # in .secrets.toml
|
||||
key = ...
|
||||
```
|
||||
(you can obtain a Llama2 key from [here](https://replicate.com/replicate/llama-2-70b-chat/api))
|
||||
|
||||
|
||||
Also, review the [AiHandler](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/algo/ai_handler.py) file for instructions on how to set keys for other models.
|
||||
|
||||
### Groq
|
||||
|
||||
To use Llama3 model with Groq, for example, set:
|
||||
```
|
||||
[config] # in configuration.toml
|
||||
model = "llama3-70b-8192"
|
||||
model_turbo = "llama3-70b-8192"
|
||||
fallback_models = ["groq/llama3-70b-8192"]
|
||||
[groq] # in .secrets.toml
|
||||
key = ... # your Groq api key
|
||||
```
|
||||
(you can obtain a Groq key from [here](https://console.groq.com/keys))
|
||||
|
||||
### Vertex AI
|
||||
|
||||
To use Google's Vertex AI platform and its associated models (chat-bison/codechat-bison) set:
|
||||
|
||||
```
|
||||
[config] # in configuration.toml
|
||||
model = "vertex_ai/codechat-bison"
|
||||
model_turbo = "vertex_ai/codechat-bison"
|
||||
fallback_models="vertex_ai/codechat-bison"
|
||||
|
||||
[vertexai] # in .secrets.toml
|
||||
vertex_project = "my-google-cloud-project"
|
||||
vertex_location = ""
|
||||
```
|
||||
|
||||
Your [application default credentials](https://cloud.google.com/docs/authentication/application-default-credentials) will be used for authentication so there is no need to set explicit credentials in most environments.
|
||||
|
||||
If you do want to set explicit credentials, then you can use the `GOOGLE_APPLICATION_CREDENTIALS` environment variable set to a path to a json credentials file.
|
||||
|
||||
### Anthropic
|
||||
|
||||
To use Anthropic models, set the relevant models in the configuration section of the configuration file:
|
||||
```
|
||||
[config]
|
||||
model="anthropic/claude-3-opus-20240229"
|
||||
model_turbo="anthropic/claude-3-opus-20240229"
|
||||
fallback_models=["anthropic/claude-3-opus-20240229"]
|
||||
```
|
||||
|
||||
And also set the api key in the .secrets.toml file:
|
||||
```
|
||||
[anthropic]
|
||||
KEY = "..."
|
||||
```
|
||||
|
||||
### Amazon Bedrock
|
||||
|
||||
To use Amazon Bedrock and its foundational models, add the below configuration:
|
||||
|
||||
```
|
||||
[config] # in configuration.toml
|
||||
model="bedrock/anthropic.claude-3-sonnet-20240229-v1:0"
|
||||
model_turbo="bedrock/anthropic.claude-3-sonnet-20240229-v1:0"
|
||||
fallback_models=["bedrock/anthropic.claude-v2:1"]
|
||||
```
|
||||
|
||||
Note that you have to add access to foundational models before using them. Please refer to [this document](https://docs.aws.amazon.com/bedrock/latest/userguide/setting-up.html) for more details.
|
||||
|
||||
If you are using the claude-3 model, please configure the following settings as there are parameters incompatible with claude-3.
|
||||
```
|
||||
[litellm]
|
||||
drop_params = true
|
||||
```
|
||||
|
||||
AWS session is automatically authenticated from your environment, but you can also explicitly set `AWS_ACCESS_KEY_ID`, `AWS_SECRET_ACCESS_KEY` and `AWS_REGION_NAME` environment variables. Please refer to [this document](https://litellm.vercel.app/docs/providers/bedrock) for more details.
|
||||
|
||||
### Custom models
|
||||
|
||||
If the relevant model doesn't appear [here](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/algo/__init__.py), you can still use it as a custom model:
|
||||
|
||||
(1) Set the model name in the configuration file:
|
||||
```
|
||||
[config]
|
||||
model="custom_model_name"
|
||||
model_turbo="custom_model_name"
|
||||
fallback_models=["custom_model_name"]
|
||||
```
|
||||
(2) Set the maximal tokens for the model:
|
||||
```
|
||||
[config]
|
||||
custom_model_max_tokens= ...
|
||||
```
|
||||
(3) Go to [litellm documentation](https://litellm.vercel.app/docs/proxy/quick_start#supported-llms), find the model you want to use, and set the relevant environment variables.
|
||||
@ -18,23 +18,29 @@ In terms of precedence, wiki configurations will override local configurations,
|
||||
|
||||
## Wiki configuration file 💎
|
||||
|
||||
For GitHub and GitLab, with PR-Agent-Pro you can set configurations by creating a page called `.pr_agent.toml` in the [wiki](https://github.com/Codium-ai/pr-agent/wiki/pr_agent.toml) of the repo.
|
||||
`Platforms supported: GitHub, GitLab`
|
||||
|
||||
With PR-Agent-Pro, you can set configurations by creating a page called `.pr_agent.toml` in the [wiki](https://github.com/Codium-ai/pr-agent/wiki/pr_agent.toml) of the repo.
|
||||
The advantage of this method is that it allows to set configurations without needing to commit new content to the repo - just edit the wiki page and **save**.
|
||||
|
||||
|
||||
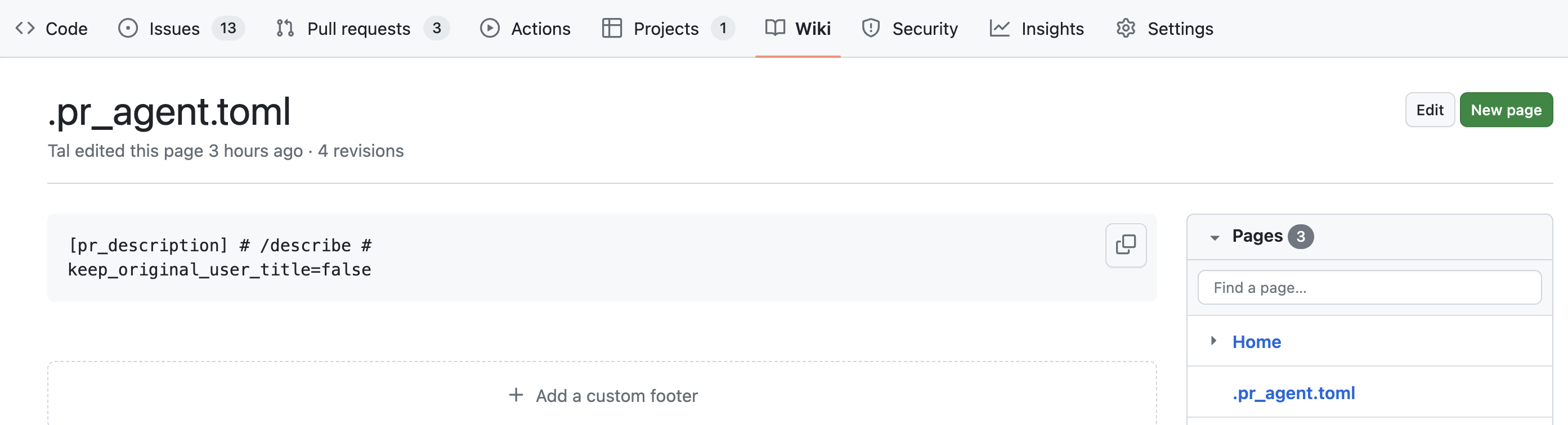{width=512}
|
||||
|
||||
Click [here](https://codium.ai/images/pr_agent/wiki_configuration_pr_agent.mp4) to see a short instructional video. We recommend surrounding the configuration content with triple-quotes, to allow better presentation when displayed in the wiki as markdown.
|
||||
Click [here](https://codium.ai/images/pr_agent/wiki_configuration_pr_agent.mp4) to see a short instructional video. We recommend surrounding the configuration content with triple-quotes (or \`\`\`toml), to allow better presentation when displayed in the wiki as markdown.
|
||||
An example content:
|
||||
|
||||
```
|
||||
```toml
|
||||
[pr_description]
|
||||
generate_ai_title=true
|
||||
```
|
||||
|
||||
PR-Agent will know to remove the triple-quotes when reading the configuration content.
|
||||
PR-Agent will know to remove the surrounding quotes when reading the configuration content.
|
||||
|
||||
## Local configuration file
|
||||
|
||||
`Platforms supported: GitHub, GitLab, Bitbucket, Azure DevOps`
|
||||
|
||||
|
||||
By uploading a local `.pr_agent.toml` file to the root of the repo's main branch, you can edit and customize any configuration parameter. Note that you need to upload `.pr_agent.toml` prior to creating a PR, in order for the configuration to take effect.
|
||||
|
||||
For example, if you set in `.pr_agent.toml`:
|
||||
@ -53,9 +59,13 @@ Then you can give a list of extra instructions to the `review` tool.
|
||||
|
||||
## Global configuration file 💎
|
||||
|
||||
`Platforms supported: GitHub, GitLab, Bitbucket`
|
||||
|
||||
If you create a repo called `pr-agent-settings` in your **organization**, it's configuration file `.pr_agent.toml` will be used as a global configuration file for any other repo that belongs to the same organization.
|
||||
Parameters from a local `.pr_agent.toml` file, in a specific repo, will override the global configuration parameters.
|
||||
|
||||
For example, in the GitHub organization `Codium-ai`:
|
||||
- The repo [`https://github.com/Codium-ai/pr-agent-settings`](https://github.com/Codium-ai/pr-agent-settings/blob/main/.pr_agent.toml) contains a `.pr_agent.toml` file that serves as a global configuration file for all the repos in the GitHub organization `Codium-ai`.
|
||||
|
||||
- The file [`https://github.com/Codium-ai/pr-agent-settings/.pr_agent.toml`](https://github.com/Codium-ai/pr-agent-settings/blob/main/.pr_agent.toml) serves as a global configuration file for all the repos in the GitHub organization `Codium-ai`.
|
||||
|
||||
- The repo [`https://github.com/Codium-ai/pr-agent`](https://github.com/Codium-ai/pr-agent/blob/main/.pr_agent.toml) inherits the global configuration file from `pr-agent-settings`.
|
||||
|
||||
@ -1,10 +1,11 @@
|
||||
# Usage guide
|
||||
|
||||
This page provides a detailed guide on how to use PR-Agent. It includes information on how to adjust PR-Agent configurations, define which tools will run automatically, manage mail notifications, and other advanced configurations.
|
||||
This page provides a detailed guide on how to use PR-Agent.
|
||||
It includes information on how to adjust PR-Agent configurations, define which tools will run automatically, and other advanced configurations.
|
||||
|
||||
|
||||
- [Introduction](./introduction.md)
|
||||
- [Configuration Options](./configuration_options.md)
|
||||
- [Configuration File](./configuration_options.md)
|
||||
- [Usage and Automation](./automations_and_usage.md)
|
||||
- [Local Repo (CLI)](./automations_and_usage.md#local-repo-cli)
|
||||
- [Online Usage](./automations_and_usage.md#online-usage)
|
||||
@ -14,10 +15,12 @@ This page provides a detailed guide on how to use PR-Agent. It includes informat
|
||||
- [BitBucket App](./automations_and_usage.md#bitbucket-app)
|
||||
- [Azure DevOps Provider](./automations_and_usage.md#azure-devops-provider)
|
||||
- [Managing Mail Notifications](./mail_notifications.md)
|
||||
- [Changing a Model](./changing_a_model.md)
|
||||
- [Additional Configurations Walkthrough](./additional_configurations.md)
|
||||
- [Ignoring files from analysis](./additional_configurations.md#ignoring-files-from-analysis)
|
||||
- [Extra instructions](./additional_configurations.md#extra-instructions)
|
||||
- [Working with large PRs](./additional_configurations.md#working-with-large-prs)
|
||||
- [Changing a model](./additional_configurations.md#changing-a-model)
|
||||
- [Patch Extra Lines](./additional_configurations.md#patch-extra-lines)
|
||||
- [Editing the prompts](./additional_configurations.md#editing-the-prompts)
|
||||
- [Editing the prompts](./additional_configurations.md#editing-the-prompts)
|
||||
- [PR-Agent Pro Models](./PR_agent_pro_models.md)
|
||||
@ -7,12 +7,7 @@ After [installation](https://pr-agent-docs.codium.ai/installation/), there are t
|
||||
|
||||
|
||||
Specifically, CLI commands can be issued by invoking a pre-built [docker image](https://pr-agent-docs.codium.ai/installation/locally/#using-docker-image), or by invoking a [locally cloned repo](https://pr-agent-docs.codium.ai/installation/locally/#run-from-source).
|
||||
For online usage, you will need to setup either a [GitHub App](https://pr-agent-docs.codium.ai/installation/github/#run-as-a-github-app), or a [GitHub Action](https://pr-agent-docs.codium.ai/installation/github/#run-as-a-github-action).
|
||||
GitHub App and GitHub Action also enable to run PR-Agent specific tool automatically when a new PR is opened.
|
||||
|
||||
|
||||
**git provider**: The [git_provider](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml#L5) field in the configuration file determines the GIT provider that will be used by PR-Agent. Currently, the following providers are supported:
|
||||
`
|
||||
"github", "gitlab", "bitbucket", "azure", "codecommit", "local", "gerrit"
|
||||
`
|
||||
For online usage, you will need to setup either a [GitHub App](https://pr-agent-docs.codium.ai/installation/github/#run-as-a-github-app) or a [GitHub Action](https://pr-agent-docs.codium.ai/installation/github/#run-as-a-github-action) (GitHub), a [GitLab webhook](https://pr-agent-docs.codium.ai/installation/gitlab/#run-a-gitlab-webhook-server) (GitLab), or a [BitBucket App](https://pr-agent-docs.codium.ai/installation/bitbucket/#run-using-codiumai-hosted-bitbucket-app) (BitBucket).
|
||||
These platforms also enable to run PR-Agent specific tools automatically when a new PR is opened, or on each push to a branch.
|
||||
|
||||
|
||||
@ -18,10 +18,12 @@ nav:
|
||||
- Usage Guide:
|
||||
- 'usage-guide/index.md'
|
||||
- Introduction: 'usage-guide/introduction.md'
|
||||
- Configuration Options: 'usage-guide/configuration_options.md'
|
||||
- Managing Mail Notifications: 'usage-guide/mail_notifications.md'
|
||||
- Configuration File: 'usage-guide/configuration_options.md'
|
||||
- Usage and Automation: 'usage-guide/automations_and_usage.md'
|
||||
- Managing Mail Notifications: 'usage-guide/mail_notifications.md'
|
||||
- Changing a Model: 'usage-guide/changing_a_model.md'
|
||||
- Additional Configurations: 'usage-guide/additional_configurations.md'
|
||||
- 💎 PR-Agent Pro Models: 'usage-guide/PR_agent_pro_models'
|
||||
- Tools:
|
||||
- 'tools/index.md'
|
||||
- Describe: 'tools/describe.md'
|
||||
@ -40,7 +42,10 @@ nav:
|
||||
- 💎 CI Feedback: 'tools/ci_feedback.md'
|
||||
- 💎 Similar Code: 'tools/similar_code.md'
|
||||
- Core Abilities: 'core-abilities/index.md'
|
||||
- Chrome Extension: 'chrome-extension/index.md'
|
||||
- Chrome Extension:
|
||||
- PR-Agent Chrome Extension: 'chrome-extension/index.md'
|
||||
- Features: 'chrome-extension/features.md'
|
||||
- Data Privacy: 'chrome-extension/data_privacy.md'
|
||||
- Code Fine-tuning Benchmark: 'finetuning_benchmark/index.md'
|
||||
|
||||
theme:
|
||||
@ -131,7 +136,7 @@ markdown_extensions:
|
||||
emoji_generator: !!python/name:material.extensions.emoji.to_svg
|
||||
- toc:
|
||||
title: On this page
|
||||
toc_depth: 2
|
||||
toc_depth: 3
|
||||
permalink: true
|
||||
|
||||
|
||||
|
||||
@ -79,7 +79,7 @@ class PRAgent:
|
||||
if action not in command2class:
|
||||
get_logger().debug(f"Unknown command: {action}")
|
||||
return False
|
||||
with get_logger().contextualize(command=action):
|
||||
with get_logger().contextualize(command=action, pr_url=pr_url):
|
||||
get_logger().info("PR-Agent request handler started", analytics=True)
|
||||
if action == "reflect_and_review":
|
||||
get_settings().pr_reviewer.ask_and_reflect = True
|
||||
|
||||
@ -16,6 +16,9 @@ MAX_TOKENS = {
|
||||
'gpt-4-turbo-preview': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
'gpt-4-turbo-2024-04-09': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
'gpt-4-turbo': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
'gpt-4o-mini': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
'gpt-4o-mini-2024-07-18': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
'gpt-4o-2024-08-06': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
'claude-instant-1': 100000,
|
||||
'claude-2': 100000,
|
||||
'command-nightly': 4096,
|
||||
@ -28,6 +31,8 @@ MAX_TOKENS = {
|
||||
'vertex_ai/claude-3-opus@20240229': 100000,
|
||||
'vertex_ai/claude-3-5-sonnet@20240620': 100000,
|
||||
'vertex_ai/gemini-1.5-pro': 1048576,
|
||||
'vertex_ai/gemini-1.5-flash': 1048576,
|
||||
'vertex_ai/gemma2': 8200,
|
||||
'codechat-bison': 6144,
|
||||
'codechat-bison-32k': 32000,
|
||||
'anthropic.claude-instant-v1': 100000,
|
||||
@ -41,7 +46,18 @@ MAX_TOKENS = {
|
||||
'bedrock/anthropic.claude-3-sonnet-20240229-v1:0': 100000,
|
||||
'bedrock/anthropic.claude-3-haiku-20240307-v1:0': 100000,
|
||||
'bedrock/anthropic.claude-3-5-sonnet-20240620-v1:0': 100000,
|
||||
'claude-3-5-sonnet': 100000,
|
||||
'groq/llama3-8b-8192': 8192,
|
||||
'groq/llama3-70b-8192': 8192,
|
||||
'groq/mixtral-8x7b-32768': 32768,
|
||||
'groq/llama-3.1-8b-instant': 131072,
|
||||
'groq/llama-3.1-70b-versatile': 131072,
|
||||
'groq/llama-3.1-405b-reasoning': 131072,
|
||||
'ollama/llama3': 4096,
|
||||
'watsonx/meta-llama/llama-3-8b-instruct': 4096,
|
||||
"watsonx/meta-llama/llama-3-70b-instruct": 4096,
|
||||
"watsonx/meta-llama/llama-3-405b-instruct": 16384,
|
||||
"watsonx/ibm/granite-13b-chat-v2": 8191,
|
||||
"watsonx/ibm/granite-34b-code-instruct": 8191,
|
||||
"watsonx/mistralai/mistral-large": 32768,
|
||||
}
|
||||
|
||||
@ -20,35 +20,13 @@ class LangChainOpenAIHandler(BaseAiHandler):
|
||||
# Initialize OpenAIHandler specific attributes here
|
||||
super().__init__()
|
||||
self.azure = get_settings().get("OPENAI.API_TYPE", "").lower() == "azure"
|
||||
try:
|
||||
if self.azure:
|
||||
# using a partial function so we can set the deployment_id later to support fallback_deployments
|
||||
# but still need to access the other settings now so we can raise a proper exception if they're missing
|
||||
self._chat = functools.partial(
|
||||
lambda **kwargs: AzureChatOpenAI(**kwargs),
|
||||
openai_api_key=get_settings().openai.key,
|
||||
openai_api_base=get_settings().openai.api_base,
|
||||
openai_api_version=get_settings().openai.api_version,
|
||||
)
|
||||
else:
|
||||
# for llms that compatible with openai, should use custom api base
|
||||
openai_api_base = get_settings().get("OPENAI.API_BASE", None)
|
||||
if openai_api_base is None or len(openai_api_base) == 0:
|
||||
self._chat = ChatOpenAI(openai_api_key=get_settings().openai.key)
|
||||
else:
|
||||
self._chat = ChatOpenAI(openai_api_key=get_settings().openai.key, openai_api_base=openai_api_base)
|
||||
except AttributeError as e:
|
||||
if getattr(e, "name"):
|
||||
raise ValueError(f"OpenAI {e.name} is required") from e
|
||||
else:
|
||||
raise e
|
||||
|
||||
# Create a default unused chat object to trigger early validation
|
||||
self._create_chat(self.deployment_id)
|
||||
|
||||
def chat(self, messages: list, model: str, temperature: float):
|
||||
if self.azure:
|
||||
# we must set the deployment_id only here (instead of the __init__ method) to support fallback_deployments
|
||||
return self._chat.invoke(input = messages, model=model, temperature=temperature, deployment_name=self.deployment_id)
|
||||
else:
|
||||
return self._chat.invoke(input = messages, model=model, temperature=temperature)
|
||||
chat = self._create_chat(self.deployment_id)
|
||||
return chat.invoke(input=messages, model=model, temperature=temperature)
|
||||
|
||||
@property
|
||||
def deployment_id(self):
|
||||
@ -71,3 +49,28 @@ class LangChainOpenAIHandler(BaseAiHandler):
|
||||
except (Exception) as e:
|
||||
get_logger().error("Unknown error during OpenAI inference: ", e)
|
||||
raise e
|
||||
|
||||
def _create_chat(self, deployment_id=None):
|
||||
try:
|
||||
if self.azure:
|
||||
# using a partial function so we can set the deployment_id later to support fallback_deployments
|
||||
# but still need to access the other settings now so we can raise a proper exception if they're missing
|
||||
return AzureChatOpenAI(
|
||||
openai_api_key=get_settings().openai.key,
|
||||
openai_api_version=get_settings().openai.api_version,
|
||||
azure_deployment=deployment_id,
|
||||
azure_endpoint=get_settings().openai.api_base,
|
||||
)
|
||||
else:
|
||||
# for llms that compatible with openai, should use custom api base
|
||||
openai_api_base = get_settings().get("OPENAI.API_BASE", None)
|
||||
if openai_api_base is None or len(openai_api_base) == 0:
|
||||
return ChatOpenAI(openai_api_key=get_settings().openai.key)
|
||||
else:
|
||||
return ChatOpenAI(openai_api_key=get_settings().openai.key, openai_api_base=openai_api_base)
|
||||
except AttributeError as e:
|
||||
if getattr(e, "name"):
|
||||
raise ValueError(f"OpenAI {e.name} is required") from e
|
||||
else:
|
||||
raise e
|
||||
|
||||
|
||||
@ -1,10 +1,10 @@
|
||||
import os
|
||||
import requests
|
||||
import boto3
|
||||
import litellm
|
||||
import openai
|
||||
from litellm import acompletion
|
||||
from tenacity import retry, retry_if_exception_type, stop_after_attempt
|
||||
|
||||
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.log import get_logger
|
||||
@ -44,6 +44,12 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||
litellm.use_client = True
|
||||
if get_settings().get("LITELLM.DROP_PARAMS", None):
|
||||
litellm.drop_params = get_settings().litellm.drop_params
|
||||
if get_settings().get("LITELLM.SUCCESS_CALLBACK", None):
|
||||
litellm.success_callback = get_settings().litellm.success_callback
|
||||
if get_settings().get("LITELLM.FAILURE_CALLBACK", None):
|
||||
litellm.failure_callback = get_settings().litellm.failure_callback
|
||||
if get_settings().get("LITELLM.SERVICE_CALLBACK", None):
|
||||
litellm.service_callback = get_settings().litellm.service_callback
|
||||
if get_settings().get("OPENAI.ORG", None):
|
||||
litellm.organization = get_settings().openai.org
|
||||
if get_settings().get("OPENAI.API_TYPE", None):
|
||||
@ -89,6 +95,60 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||
response_log['main_pr_language'] = 'unknown'
|
||||
return response_log
|
||||
|
||||
def add_litellm_callbacks(selfs, kwargs) -> dict:
|
||||
captured_extra = []
|
||||
|
||||
def capture_logs(message):
|
||||
# Parsing the log message and context
|
||||
record = message.record
|
||||
log_entry = {}
|
||||
if record.get('extra', None).get('command', None) is not None:
|
||||
log_entry.update({"command": record['extra']["command"]})
|
||||
if record.get('extra', {}).get('pr_url', None) is not None:
|
||||
log_entry.update({"pr_url": record['extra']["pr_url"]})
|
||||
|
||||
# Append the log entry to the captured_logs list
|
||||
captured_extra.append(log_entry)
|
||||
|
||||
# Adding the custom sink to Loguru
|
||||
handler_id = get_logger().add(capture_logs)
|
||||
get_logger().debug("Capturing logs for litellm callbacks")
|
||||
get_logger().remove(handler_id)
|
||||
|
||||
context = captured_extra[0] if len(captured_extra) > 0 else None
|
||||
|
||||
command = context.get("command", "unknown")
|
||||
pr_url = context.get("pr_url", "unknown")
|
||||
git_provider = get_settings().config.git_provider
|
||||
|
||||
metadata = dict()
|
||||
callbacks = litellm.success_callback + litellm.failure_callback + litellm.service_callback
|
||||
if "langfuse" in callbacks:
|
||||
metadata.update({
|
||||
"trace_name": command,
|
||||
"tags": [git_provider, command],
|
||||
"trace_metadata": {
|
||||
"command": command,
|
||||
"pr_url": pr_url,
|
||||
},
|
||||
})
|
||||
if "langsmith" in callbacks:
|
||||
metadata.update({
|
||||
"run_name": command,
|
||||
"tags": [git_provider, command],
|
||||
"extra": {
|
||||
"metadata": {
|
||||
"command": command,
|
||||
"pr_url": pr_url,
|
||||
}
|
||||
},
|
||||
})
|
||||
|
||||
# Adding the captured logs to the kwargs
|
||||
kwargs["metadata"] = metadata
|
||||
|
||||
return kwargs
|
||||
|
||||
@property
|
||||
def deployment_id(self):
|
||||
"""
|
||||
@ -106,6 +166,10 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||
deployment_id = self.deployment_id
|
||||
if self.azure:
|
||||
model = 'azure/' + model
|
||||
if 'claude' in model and not system:
|
||||
system = "\n"
|
||||
get_logger().warning(
|
||||
"Empty system prompt for claude model. Adding a newline character to prevent OpenAI API error.")
|
||||
messages = [{"role": "system", "content": system}, {"role": "user", "content": user}]
|
||||
if img_path:
|
||||
try:
|
||||
@ -126,9 +190,20 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||
"deployment_id": deployment_id,
|
||||
"messages": messages,
|
||||
"temperature": temperature,
|
||||
"force_timeout": get_settings().config.ai_timeout,
|
||||
"timeout": get_settings().config.ai_timeout,
|
||||
"api_base": self.api_base,
|
||||
}
|
||||
|
||||
if get_settings().litellm.get("enable_callbacks", False):
|
||||
kwargs = self.add_litellm_callbacks(kwargs)
|
||||
|
||||
seed = get_settings().config.get("seed", -1)
|
||||
if temperature > 0 and seed >= 0:
|
||||
raise ValueError(f"Seed ({seed}) is not supported with temperature ({temperature}) > 0")
|
||||
elif seed >= 0:
|
||||
get_logger().info(f"Using fixed seed of {seed}")
|
||||
kwargs["seed"] = seed
|
||||
|
||||
if self.repetition_penalty:
|
||||
kwargs["repetition_penalty"] = self.repetition_penalty
|
||||
|
||||
@ -140,13 +215,13 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||
|
||||
response = await acompletion(**kwargs)
|
||||
except (openai.APIError, openai.APITimeoutError) as e:
|
||||
get_logger().error("Error during OpenAI inference: ", e)
|
||||
get_logger().warning("Error during OpenAI inference: ", e)
|
||||
raise
|
||||
except (openai.RateLimitError) as e:
|
||||
get_logger().error("Rate limit error during OpenAI inference: ", e)
|
||||
raise
|
||||
except (Exception) as e:
|
||||
get_logger().error("Unknown error during OpenAI inference: ", e)
|
||||
get_logger().warning("Unknown error during OpenAI inference: ", e)
|
||||
raise openai.APIError from e
|
||||
if response is None or len(response["choices"]) == 0:
|
||||
raise openai.APIError
|
||||
|
||||
@ -33,9 +33,29 @@ def filter_ignored(files, platform = 'github'):
|
||||
if platform == 'github':
|
||||
files = [f for f in files if (f.filename and not r.match(f.filename))]
|
||||
elif platform == 'bitbucket':
|
||||
files = [f for f in files if (f.new.path and not r.match(f.new.path))]
|
||||
# files = [f for f in files if (f.new.path and not r.match(f.new.path))]
|
||||
files_o = []
|
||||
for f in files:
|
||||
if hasattr(f, 'new'):
|
||||
if f.new and f.new.path and not r.match(f.new.path):
|
||||
files_o.append(f)
|
||||
continue
|
||||
if hasattr(f, 'old'):
|
||||
if f.old and f.old.path and not r.match(f.old.path):
|
||||
files_o.append(f)
|
||||
continue
|
||||
files = files_o
|
||||
elif platform == 'gitlab':
|
||||
files = [f for f in files if (f['new_path'] and not r.match(f['new_path']))]
|
||||
# files = [f for f in files if (f['new_path'] and not r.match(f['new_path']))]
|
||||
files_o = []
|
||||
for f in files:
|
||||
if 'new_path' in f and f['new_path'] and not r.match(f['new_path']):
|
||||
files_o.append(f)
|
||||
continue
|
||||
if 'old_path' in f and f['old_path'] and not r.match(f['old_path']):
|
||||
files_o.append(f)
|
||||
continue
|
||||
files = files_o
|
||||
elif platform == 'azure':
|
||||
files = [f for f in files if not r.match(f)]
|
||||
|
||||
|
||||
@ -7,19 +7,9 @@ from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
|
||||
from pr_agent.log import get_logger
|
||||
|
||||
|
||||
def extend_patch(original_file_str, patch_str, num_lines) -> str:
|
||||
"""
|
||||
Extends the given patch to include a specified number of surrounding lines.
|
||||
|
||||
Args:
|
||||
original_file_str (str): The original file to which the patch will be applied.
|
||||
patch_str (str): The patch to be applied to the original file.
|
||||
num_lines (int): The number of surrounding lines to include in the extended patch.
|
||||
|
||||
Returns:
|
||||
str: The extended patch string.
|
||||
"""
|
||||
if not patch_str or num_lines == 0:
|
||||
def extend_patch(original_file_str, patch_str, patch_extra_lines_before=0,
|
||||
patch_extra_lines_after=0, filename: str = "") -> str:
|
||||
if not patch_str or (patch_extra_lines_before == 0 and patch_extra_lines_after == 0) or not original_file_str:
|
||||
return patch_str
|
||||
|
||||
if type(original_file_str) == bytes:
|
||||
@ -28,7 +18,24 @@ def extend_patch(original_file_str, patch_str, num_lines) -> str:
|
||||
except UnicodeDecodeError:
|
||||
return ""
|
||||
|
||||
# skip patches
|
||||
patch_extension_skip_types = get_settings().config.patch_extension_skip_types #[".md",".txt"]
|
||||
if patch_extension_skip_types and filename:
|
||||
if any([filename.endswith(skip_type) for skip_type in patch_extension_skip_types]):
|
||||
return patch_str
|
||||
|
||||
# dynamic context settings
|
||||
allow_dynamic_context = get_settings().config.allow_dynamic_context
|
||||
max_extra_lines_before_dynamic_context = get_settings().config.max_extra_lines_before_dynamic_context
|
||||
patch_extra_lines_before_dynamic = patch_extra_lines_before
|
||||
if allow_dynamic_context:
|
||||
if max_extra_lines_before_dynamic_context > patch_extra_lines_before:
|
||||
patch_extra_lines_before_dynamic = max_extra_lines_before_dynamic_context
|
||||
else:
|
||||
get_logger().warning(f"'max_extra_lines_before_dynamic_context' should be greater than 'patch_extra_lines_before'")
|
||||
|
||||
original_lines = original_file_str.splitlines()
|
||||
len_original_lines = len(original_lines)
|
||||
patch_lines = patch_str.splitlines()
|
||||
extended_patch_lines = []
|
||||
|
||||
@ -40,10 +47,11 @@ def extend_patch(original_file_str, patch_str, num_lines) -> str:
|
||||
if line.startswith('@@'):
|
||||
match = RE_HUNK_HEADER.match(line)
|
||||
if match:
|
||||
# finish previous hunk
|
||||
if start1 != -1:
|
||||
extended_patch_lines.extend(
|
||||
original_lines[start1 + size1 - 1:start1 + size1 - 1 + num_lines])
|
||||
# finish last hunk
|
||||
if start1 != -1 and patch_extra_lines_after > 0:
|
||||
delta_lines = original_lines[start1 + size1 - 1:start1 + size1 - 1 + patch_extra_lines_after]
|
||||
delta_lines = [f' {line}' for line in delta_lines]
|
||||
extended_patch_lines.extend(delta_lines)
|
||||
|
||||
res = list(match.groups())
|
||||
for i in range(len(res)):
|
||||
@ -55,15 +63,60 @@ def extend_patch(original_file_str, patch_str, num_lines) -> str:
|
||||
start1, size1, size2 = map(int, res[:3])
|
||||
start2 = 0
|
||||
section_header = res[4]
|
||||
extended_start1 = max(1, start1 - num_lines)
|
||||
extended_size1 = size1 + (start1 - extended_start1) + num_lines
|
||||
extended_start2 = max(1, start2 - num_lines)
|
||||
extended_size2 = size2 + (start2 - extended_start2) + num_lines
|
||||
|
||||
if patch_extra_lines_before > 0 or patch_extra_lines_after > 0:
|
||||
def _calc_context_limits(patch_lines_before):
|
||||
extended_start1 = max(1, start1 - patch_lines_before)
|
||||
extended_size1 = size1 + (start1 - extended_start1) + patch_extra_lines_after
|
||||
extended_start2 = max(1, start2 - patch_lines_before)
|
||||
extended_size2 = size2 + (start2 - extended_start2) + patch_extra_lines_after
|
||||
if extended_start1 - 1 + extended_size1 > len_original_lines:
|
||||
# we cannot extend beyond the original file
|
||||
delta_cap = extended_start1 - 1 + extended_size1 - len_original_lines
|
||||
extended_size1 = max(extended_size1 - delta_cap, size1)
|
||||
extended_size2 = max(extended_size2 - delta_cap, size2)
|
||||
return extended_start1, extended_size1, extended_start2, extended_size2
|
||||
|
||||
if allow_dynamic_context:
|
||||
extended_start1, extended_size1, extended_start2, extended_size2 = \
|
||||
_calc_context_limits(patch_extra_lines_before_dynamic)
|
||||
lines_before = original_lines[extended_start1 - 1:start1 - 1]
|
||||
found_header = False
|
||||
for i,line, in enumerate(lines_before):
|
||||
if section_header in line:
|
||||
found_header = True
|
||||
# Update start and size in one line each
|
||||
extended_start1, extended_start2 = extended_start1 + i, extended_start2 + i
|
||||
extended_size1, extended_size2 = extended_size1 - i, extended_size2 - i
|
||||
get_logger().debug(f"Found section header in line {i} before the hunk")
|
||||
section_header = ''
|
||||
break
|
||||
if not found_header:
|
||||
get_logger().debug(f"Section header not found in the extra lines before the hunk")
|
||||
extended_start1, extended_size1, extended_start2, extended_size2 = \
|
||||
_calc_context_limits(patch_extra_lines_before)
|
||||
else:
|
||||
extended_start1, extended_size1, extended_start2, extended_size2 = \
|
||||
_calc_context_limits(patch_extra_lines_before)
|
||||
|
||||
delta_lines = original_lines[extended_start1 - 1:start1 - 1]
|
||||
delta_lines = [f' {line}' for line in delta_lines]
|
||||
if section_header and not allow_dynamic_context:
|
||||
for line in delta_lines:
|
||||
if section_header in line:
|
||||
section_header = '' # remove section header if it is in the extra delta lines
|
||||
break
|
||||
else:
|
||||
extended_start1 = start1
|
||||
extended_size1 = size1
|
||||
extended_start2 = start2
|
||||
extended_size2 = size2
|
||||
delta_lines = []
|
||||
extended_patch_lines.append('')
|
||||
extended_patch_lines.append(
|
||||
f'@@ -{extended_start1},{extended_size1} '
|
||||
f'+{extended_start2},{extended_size2} @@ {section_header}')
|
||||
extended_patch_lines.extend(
|
||||
original_lines[extended_start1 - 1:start1 - 1]) # one to zero based
|
||||
extended_patch_lines.extend(delta_lines) # one to zero based
|
||||
continue
|
||||
extended_patch_lines.append(line)
|
||||
except Exception as e:
|
||||
@ -71,10 +124,12 @@ def extend_patch(original_file_str, patch_str, num_lines) -> str:
|
||||
get_logger().error(f"Failed to extend patch: {e}")
|
||||
return patch_str
|
||||
|
||||
# finish previous hunk
|
||||
if start1 != -1:
|
||||
extended_patch_lines.extend(
|
||||
original_lines[start1 + size1 - 1:start1 + size1 - 1 + num_lines])
|
||||
# finish last hunk
|
||||
if start1 != -1 and patch_extra_lines_after > 0:
|
||||
delta_lines = original_lines[start1 + size1 - 1:start1 + size1 - 1 + patch_extra_lines_after]
|
||||
# add space at the beginning of each extra line
|
||||
delta_lines = [f' {line}' for line in delta_lines]
|
||||
extended_patch_lines.extend(delta_lines)
|
||||
|
||||
extended_patch_str = '\n'.join(extended_patch_lines)
|
||||
return extended_patch_str
|
||||
@ -109,9 +164,10 @@ def omit_deletion_hunks(patch_lines) -> str:
|
||||
inside_hunk = True
|
||||
else:
|
||||
temp_hunk.append(line)
|
||||
edit_type = line[0]
|
||||
if edit_type == '+':
|
||||
add_hunk = True
|
||||
if line:
|
||||
edit_type = line[0]
|
||||
if edit_type == '+':
|
||||
add_hunk = True
|
||||
if inside_hunk and add_hunk:
|
||||
added_patched.extend(temp_hunk)
|
||||
|
||||
@ -183,7 +239,10 @@ __old hunk__
|
||||
line6
|
||||
...
|
||||
"""
|
||||
|
||||
# if the file was deleted, return a message indicating that the file was deleted
|
||||
if hasattr(file, 'edit_type') and file.edit_type == EDIT_TYPE.DELETED:
|
||||
return f"\n\n## file '{file.filename.strip()}' was deleted\n"
|
||||
|
||||
patch_with_lines_str = f"\n\n## file: '{file.filename.strip()}'\n"
|
||||
patch_lines = patch.splitlines()
|
||||
RE_HUNK_HEADER = re.compile(
|
||||
@ -193,7 +252,7 @@ __old hunk__
|
||||
match = None
|
||||
start1, size1, start2, size2 = -1, -1, -1, -1
|
||||
prev_header_line = []
|
||||
header_line =[]
|
||||
header_line = []
|
||||
for line in patch_lines:
|
||||
if 'no newline at end of file' in line.lower():
|
||||
continue
|
||||
@ -201,17 +260,21 @@ __old hunk__
|
||||
if line.startswith('@@'):
|
||||
header_line = line
|
||||
match = RE_HUNK_HEADER.match(line)
|
||||
if match and new_content_lines: # found a new hunk, split the previous lines
|
||||
if match and (new_content_lines or old_content_lines): # found a new hunk, split the previous lines
|
||||
if prev_header_line:
|
||||
patch_with_lines_str += f'\n{prev_header_line}\n'
|
||||
if new_content_lines:
|
||||
if prev_header_line:
|
||||
patch_with_lines_str += f'\n{prev_header_line}\n'
|
||||
patch_with_lines_str = patch_with_lines_str.rstrip()+'\n__new hunk__\n'
|
||||
for i, line_new in enumerate(new_content_lines):
|
||||
patch_with_lines_str += f"{start2 + i} {line_new}\n"
|
||||
is_plus_lines = any([line.startswith('+') for line in new_content_lines])
|
||||
if is_plus_lines:
|
||||
patch_with_lines_str = patch_with_lines_str.rstrip() + '\n__new hunk__\n'
|
||||
for i, line_new in enumerate(new_content_lines):
|
||||
patch_with_lines_str += f"{start2 + i} {line_new}\n"
|
||||
if old_content_lines:
|
||||
patch_with_lines_str = patch_with_lines_str.rstrip()+'\n__old hunk__\n'
|
||||
for line_old in old_content_lines:
|
||||
patch_with_lines_str += f"{line_old}\n"
|
||||
is_minus_lines = any([line.startswith('-') for line in old_content_lines])
|
||||
if is_minus_lines:
|
||||
patch_with_lines_str = patch_with_lines_str.rstrip() + '\n__old hunk__\n'
|
||||
for line_old in old_content_lines:
|
||||
patch_with_lines_str += f"{line_old}\n"
|
||||
new_content_lines = []
|
||||
old_content_lines = []
|
||||
if match:
|
||||
@ -223,7 +286,7 @@ __old hunk__
|
||||
res[i] = 0
|
||||
try:
|
||||
start1, size1, start2, size2 = map(int, res[:4])
|
||||
except: # '@@ -0,0 +1 @@' case
|
||||
except: # '@@ -0,0 +1 @@' case
|
||||
start1, size1, size2 = map(int, res[:3])
|
||||
start2 = 0
|
||||
|
||||
@ -237,15 +300,19 @@ __old hunk__
|
||||
|
||||
# finishing last hunk
|
||||
if match and new_content_lines:
|
||||
patch_with_lines_str += f'\n{header_line}\n'
|
||||
if new_content_lines:
|
||||
patch_with_lines_str += f'\n{header_line}\n'
|
||||
patch_with_lines_str = patch_with_lines_str.rstrip()+ '\n__new hunk__\n'
|
||||
for i, line_new in enumerate(new_content_lines):
|
||||
patch_with_lines_str += f"{start2 + i} {line_new}\n"
|
||||
is_plus_lines = any([line.startswith('+') for line in new_content_lines])
|
||||
if is_plus_lines:
|
||||
patch_with_lines_str = patch_with_lines_str.rstrip() + '\n__new hunk__\n'
|
||||
for i, line_new in enumerate(new_content_lines):
|
||||
patch_with_lines_str += f"{start2 + i} {line_new}\n"
|
||||
if old_content_lines:
|
||||
patch_with_lines_str = patch_with_lines_str.rstrip() + '\n__old hunk__\n'
|
||||
for line_old in old_content_lines:
|
||||
patch_with_lines_str += f"{line_old}\n"
|
||||
is_minus_lines = any([line.startswith('-') for line in old_content_lines])
|
||||
if is_minus_lines:
|
||||
patch_with_lines_str = patch_with_lines_str.rstrip() + '\n__old hunk__\n'
|
||||
for line_old in old_content_lines:
|
||||
patch_with_lines_str += f"{line_old}\n"
|
||||
|
||||
return patch_with_lines_str.rstrip()
|
||||
|
||||
|
||||
@ -14,7 +14,9 @@ def filter_bad_extensions(files):
|
||||
return [f for f in files if f.filename is not None and is_valid_file(f.filename, bad_extensions)]
|
||||
|
||||
|
||||
def is_valid_file(filename, bad_extensions=None):
|
||||
def is_valid_file(filename:str, bad_extensions=None) -> bool:
|
||||
if not filename:
|
||||
return False
|
||||
if not bad_extensions:
|
||||
bad_extensions = get_settings().bad_extensions.default
|
||||
if get_settings().config.use_extra_bad_extensions:
|
||||
|
||||
@ -33,9 +33,11 @@ def get_pr_diff(git_provider: GitProvider, token_handler: TokenHandler,
|
||||
large_pr_handling=False,
|
||||
return_remaining_files=False):
|
||||
if disable_extra_lines:
|
||||
PATCH_EXTRA_LINES = 0
|
||||
PATCH_EXTRA_LINES_BEFORE = 0
|
||||
PATCH_EXTRA_LINES_AFTER = 0
|
||||
else:
|
||||
PATCH_EXTRA_LINES = get_settings().config.patch_extra_lines
|
||||
PATCH_EXTRA_LINES_BEFORE = get_settings().config.patch_extra_lines_before
|
||||
PATCH_EXTRA_LINES_AFTER = get_settings().config.patch_extra_lines_after
|
||||
|
||||
try:
|
||||
diff_files_original = git_provider.get_diff_files()
|
||||
@ -64,7 +66,8 @@ def get_pr_diff(git_provider: GitProvider, token_handler: TokenHandler,
|
||||
|
||||
# generate a standard diff string, with patch extension
|
||||
patches_extended, total_tokens, patches_extended_tokens = pr_generate_extended_diff(
|
||||
pr_languages, token_handler, add_line_numbers_to_hunks, patch_extra_lines=PATCH_EXTRA_LINES)
|
||||
pr_languages, token_handler, add_line_numbers_to_hunks,
|
||||
patch_extra_lines_before=PATCH_EXTRA_LINES_BEFORE, patch_extra_lines_after=PATCH_EXTRA_LINES_AFTER)
|
||||
|
||||
# if we are under the limit, return the full diff
|
||||
if total_tokens + OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD < get_max_tokens(model):
|
||||
@ -72,7 +75,7 @@ def get_pr_diff(git_provider: GitProvider, token_handler: TokenHandler,
|
||||
f"returning full diff.")
|
||||
return "\n".join(patches_extended)
|
||||
|
||||
# if we are over the limit, start pruning
|
||||
# if we are over the limit, start pruning (If we got here, we will not extend the patches with extra lines)
|
||||
get_logger().info(f"Tokens: {total_tokens}, total tokens over limit: {get_max_tokens(model)}, "
|
||||
f"pruning diff.")
|
||||
patches_compressed_list, total_tokens_list, deleted_files_list, remaining_files_list, file_dict, files_in_patches_list = \
|
||||
@ -80,7 +83,7 @@ def get_pr_diff(git_provider: GitProvider, token_handler: TokenHandler,
|
||||
|
||||
if large_pr_handling and len(patches_compressed_list) > 1:
|
||||
get_logger().info(f"Large PR handling mode, and found {len(patches_compressed_list)} patches with original diff.")
|
||||
return "" # return empty string, as we generate multiple patches with a different prompt
|
||||
return "" # return empty string, as we want to generate multiple patches with a different prompt
|
||||
|
||||
# return the first patch
|
||||
patches_compressed = patches_compressed_list[0]
|
||||
@ -105,7 +108,7 @@ def get_pr_diff(git_provider: GitProvider, token_handler: TokenHandler,
|
||||
added_list_str = ADDED_FILES_ + f"\n{filename}"
|
||||
else:
|
||||
added_list_str = added_list_str + f"\n{filename}"
|
||||
elif file_values['edit_type'] == EDIT_TYPE.MODIFIED or EDIT_TYPE.RENAMED:
|
||||
elif file_values['edit_type'] in [EDIT_TYPE.MODIFIED, EDIT_TYPE.RENAMED]:
|
||||
unprocessed_files.append(filename)
|
||||
if not modified_list_str:
|
||||
modified_list_str = MORE_MODIFIED_FILES_ + f"\n{filename}"
|
||||
@ -174,17 +177,8 @@ def get_pr_diff_multiple_patchs(git_provider: GitProvider, token_handler: TokenH
|
||||
def pr_generate_extended_diff(pr_languages: list,
|
||||
token_handler: TokenHandler,
|
||||
add_line_numbers_to_hunks: bool,
|
||||
patch_extra_lines: int = 0) -> Tuple[list, int, list]:
|
||||
"""
|
||||
Generate a standard diff string with patch extension, while counting the number of tokens used and applying diff
|
||||
minimization techniques if needed.
|
||||
|
||||
Args:
|
||||
- pr_languages: A list of dictionaries representing the languages used in the pull request and their corresponding
|
||||
files.
|
||||
- token_handler: An object of the TokenHandler class used for handling tokens in the context of the pull request.
|
||||
- add_line_numbers_to_hunks: A boolean indicating whether to add line numbers to the hunks in the diff.
|
||||
"""
|
||||
patch_extra_lines_before: int = 0,
|
||||
patch_extra_lines_after: int = 0) -> Tuple[list, int, list]:
|
||||
total_tokens = token_handler.prompt_tokens # initial tokens
|
||||
patches_extended = []
|
||||
patches_extended_tokens = []
|
||||
@ -196,11 +190,12 @@ def pr_generate_extended_diff(pr_languages: list,
|
||||
continue
|
||||
|
||||
# extend each patch with extra lines of context
|
||||
extended_patch = extend_patch(original_file_content_str, patch, num_lines=patch_extra_lines)
|
||||
extended_patch = extend_patch(original_file_content_str, patch,
|
||||
patch_extra_lines_before, patch_extra_lines_after, file.filename)
|
||||
if not extended_patch:
|
||||
get_logger().warning(f"Failed to extend patch for file: {file.filename}")
|
||||
continue
|
||||
full_extended_patch = f"\n\n## {file.filename}\n\n{extended_patch}\n"
|
||||
full_extended_patch = f"\n\n## {file.filename}\n{extended_patch.rstrip()}\n"
|
||||
|
||||
if add_line_numbers_to_hunks:
|
||||
full_extended_patch = convert_to_hunks_with_lines_numbers(extended_patch, file)
|
||||
@ -405,12 +400,15 @@ def get_pr_multi_diffs(git_provider: GitProvider,
|
||||
for lang in pr_languages:
|
||||
sorted_files.extend(sorted(lang['files'], key=lambda x: x.tokens, reverse=True))
|
||||
|
||||
|
||||
# try first a single run with standard diff string, with patch extension, and no deletions
|
||||
patches_extended, total_tokens, patches_extended_tokens = pr_generate_extended_diff(
|
||||
pr_languages, token_handler, add_line_numbers_to_hunks=True)
|
||||
pr_languages, token_handler, add_line_numbers_to_hunks=True,
|
||||
patch_extra_lines_before=get_settings().config.patch_extra_lines_before,
|
||||
patch_extra_lines_after=get_settings().config.patch_extra_lines_after)
|
||||
|
||||
# if we are under the limit, return the full diff
|
||||
if total_tokens + OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD < get_max_tokens(model):
|
||||
return ["\n".join(patches_extended)]
|
||||
return ["\n".join(patches_extended)] if patches_extended else []
|
||||
|
||||
patches = []
|
||||
final_diff_list = []
|
||||
@ -462,6 +460,10 @@ def get_pr_multi_diffs(git_provider: GitProvider,
|
||||
patches = []
|
||||
total_tokens = token_handler.prompt_tokens
|
||||
call_number += 1
|
||||
if call_number > max_calls: # avoid creating new patches
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().info(f"Reached max calls ({max_calls})")
|
||||
break
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().info(f"Call number: {call_number}")
|
||||
|
||||
|
||||
@ -3,6 +3,8 @@ from tiktoken import encoding_for_model, get_encoding
|
||||
from pr_agent.config_loader import get_settings
|
||||
from threading import Lock
|
||||
|
||||
from pr_agent.log import get_logger
|
||||
|
||||
|
||||
class TokenEncoder:
|
||||
_encoder_instance = None
|
||||
@ -62,12 +64,16 @@ class TokenHandler:
|
||||
Returns:
|
||||
The sum of the number of tokens in the system and user strings.
|
||||
"""
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
system_prompt = environment.from_string(system).render(vars)
|
||||
user_prompt = environment.from_string(user).render(vars)
|
||||
system_prompt_tokens = len(encoder.encode(system_prompt))
|
||||
user_prompt_tokens = len(encoder.encode(user_prompt))
|
||||
return system_prompt_tokens + user_prompt_tokens
|
||||
try:
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
system_prompt = environment.from_string(system).render(vars)
|
||||
user_prompt = environment.from_string(user).render(vars)
|
||||
system_prompt_tokens = len(encoder.encode(system_prompt))
|
||||
user_prompt_tokens = len(encoder.encode(user_prompt))
|
||||
return system_prompt_tokens + user_prompt_tokens
|
||||
except Exception as e:
|
||||
get_logger().error(f"Error in _get_system_user_tokens: {e}")
|
||||
return 0
|
||||
|
||||
def count_tokens(self, patch: str) -> int:
|
||||
"""
|
||||
|
||||
@ -1,5 +1,7 @@
|
||||
from __future__ import annotations
|
||||
|
||||
import html
|
||||
import copy
|
||||
import difflib
|
||||
import json
|
||||
import os
|
||||
@ -11,6 +13,7 @@ from enum import Enum
|
||||
from typing import Any, List, Tuple
|
||||
|
||||
import yaml
|
||||
from pydantic import BaseModel
|
||||
from starlette_context import context
|
||||
|
||||
from pr_agent.algo import MAX_TOKENS
|
||||
@ -19,6 +22,12 @@ from pr_agent.config_loader import get_settings, global_settings
|
||||
from pr_agent.algo.types import FilePatchInfo
|
||||
from pr_agent.log import get_logger
|
||||
|
||||
class Range(BaseModel):
|
||||
line_start: int # should be 0-indexed
|
||||
line_end: int
|
||||
column_start: int = -1
|
||||
column_end: int = -1
|
||||
|
||||
class ModelType(str, Enum):
|
||||
REGULAR = "regular"
|
||||
TURBO = "turbo"
|
||||
@ -37,7 +46,7 @@ def get_setting(key: str) -> Any:
|
||||
return global_settings.get(key, None)
|
||||
|
||||
|
||||
def emphasize_header(text: str, only_markdown=False) -> str:
|
||||
def emphasize_header(text: str, only_markdown=False, reference_link=None) -> str:
|
||||
try:
|
||||
# Finding the position of the first occurrence of ": "
|
||||
colon_position = text.find(": ")
|
||||
@ -46,9 +55,15 @@ def emphasize_header(text: str, only_markdown=False) -> str:
|
||||
if colon_position != -1:
|
||||
# Everything before the colon (inclusive) is wrapped in <strong> tags
|
||||
if only_markdown:
|
||||
transformed_string = f"**{text[:colon_position + 1]}**\n" + text[colon_position + 1:]
|
||||
if reference_link:
|
||||
transformed_string = f"[**{text[:colon_position + 1]}**]({reference_link})\n" + text[colon_position + 1:]
|
||||
else:
|
||||
transformed_string = f"**{text[:colon_position + 1]}**\n" + text[colon_position + 1:]
|
||||
else:
|
||||
transformed_string = "<strong>" + text[:colon_position + 1] + "</strong>" +'<br>' + text[colon_position + 1:]
|
||||
if reference_link:
|
||||
transformed_string = f"<strong><a href='{reference_link}'>{text[:colon_position + 1]}</a></strong><br>" + text[colon_position + 1:]
|
||||
else:
|
||||
transformed_string = "<strong>" + text[:colon_position + 1] + "</strong>" +'<br>' + text[colon_position + 1:]
|
||||
else:
|
||||
# If there's no ": ", return the original string
|
||||
transformed_string = text
|
||||
@ -70,7 +85,10 @@ def unique_strings(input_list: List[str]) -> List[str]:
|
||||
seen.add(item)
|
||||
return unique_list
|
||||
|
||||
def convert_to_markdown_v2(output_data: dict, gfm_supported: bool = True, incremental_review=None) -> str:
|
||||
def convert_to_markdown_v2(output_data: dict,
|
||||
gfm_supported: bool = True,
|
||||
incremental_review=None,
|
||||
git_provider=None) -> str:
|
||||
"""
|
||||
Convert a dictionary of data into markdown format.
|
||||
Args:
|
||||
@ -106,12 +124,13 @@ def convert_to_markdown_v2(output_data: dict, gfm_supported: bool = True, increm
|
||||
|
||||
for key, value in output_data['review'].items():
|
||||
if value is None or value == '' or value == {} or value == []:
|
||||
if key.lower() != 'can_be_split':
|
||||
if key.lower() not in ['can_be_split', 'key_issues_to_review']:
|
||||
continue
|
||||
key_nice = key.replace('_', ' ').capitalize()
|
||||
emoji = emojis.get(key_nice, "")
|
||||
if 'Estimated effort to review' in key_nice:
|
||||
key_nice = 'Estimated effort to review'
|
||||
value = str(value).strip()
|
||||
if value.isnumeric():
|
||||
value_int = int(value)
|
||||
else:
|
||||
@ -129,7 +148,7 @@ def convert_to_markdown_v2(output_data: dict, gfm_supported: bool = True, increm
|
||||
else:
|
||||
markdown_text += f"### {emoji} {key_nice}: {value}\n\n"
|
||||
elif 'relevant tests' in key_nice.lower():
|
||||
value = value.strip().lower()
|
||||
value = str(value).strip().lower()
|
||||
if gfm_supported:
|
||||
markdown_text += f"<tr><td>"
|
||||
if is_value_no(value):
|
||||
@ -138,17 +157,10 @@ def convert_to_markdown_v2(output_data: dict, gfm_supported: bool = True, increm
|
||||
markdown_text += f"{emoji} <strong>PR contains tests</strong>"
|
||||
markdown_text += f"</td></tr>\n"
|
||||
else:
|
||||
if gfm_supported:
|
||||
markdown_text += f"<tr><td>"
|
||||
if is_value_no(value):
|
||||
markdown_text += f"{emoji} <strong>No relevant tests</strong>"
|
||||
else:
|
||||
markdown_text += f"{emoji} <strong>PR contains tests</strong>"
|
||||
if is_value_no(value):
|
||||
markdown_text += f'### {emoji} No relevant tests\n\n'
|
||||
else:
|
||||
if is_value_no(value):
|
||||
markdown_text += f'### {emoji} No relevant tests\n\n'
|
||||
else:
|
||||
markdown_text += f"### PR contains tests\n\n"
|
||||
markdown_text += f"### PR contains tests\n\n"
|
||||
elif 'security concerns' in key_nice.lower():
|
||||
if gfm_supported:
|
||||
markdown_text += f"<tr><td>"
|
||||
@ -164,7 +176,7 @@ def convert_to_markdown_v2(output_data: dict, gfm_supported: bool = True, increm
|
||||
markdown_text += f'### {emoji} No security concerns identified\n\n'
|
||||
else:
|
||||
markdown_text += f"### {emoji} Security concerns\n\n"
|
||||
value = emphasize_header(value.strip())
|
||||
value = emphasize_header(value.strip(), only_markdown=True)
|
||||
markdown_text += f"{value}\n\n"
|
||||
elif 'can be split' in key_nice.lower():
|
||||
if gfm_supported:
|
||||
@ -172,7 +184,7 @@ def convert_to_markdown_v2(output_data: dict, gfm_supported: bool = True, increm
|
||||
markdown_text += process_can_be_split(emoji, value)
|
||||
markdown_text += f"</td></tr>\n"
|
||||
elif 'key issues to review' in key_nice.lower():
|
||||
value = value.strip()
|
||||
# value is a list of issues
|
||||
if is_value_no(value):
|
||||
if gfm_supported:
|
||||
markdown_text += f"<tr><td>"
|
||||
@ -181,20 +193,46 @@ def convert_to_markdown_v2(output_data: dict, gfm_supported: bool = True, increm
|
||||
else:
|
||||
markdown_text += f"### {emoji} No key issues to review\n\n"
|
||||
else:
|
||||
issues = value.split('\n- ')
|
||||
for i, _ in enumerate(issues):
|
||||
issues[i] = issues[i].strip().strip('-').strip()
|
||||
issues = unique_strings(issues) # remove duplicates
|
||||
# issues = value.split('\n- ')
|
||||
issues =value
|
||||
# for i, _ in enumerate(issues):
|
||||
# issues[i] = issues[i].strip().strip('-').strip()
|
||||
if gfm_supported:
|
||||
markdown_text += f"<tr><td>"
|
||||
markdown_text += f"{emoji} <strong>{key_nice}</strong><br><br>\n\n"
|
||||
else:
|
||||
markdown_text += f"### {emoji} Key issues to review:\n\n"
|
||||
markdown_text += f"### {emoji} Key issues to review\n\n#### \n"
|
||||
for i, issue in enumerate(issues):
|
||||
if not issue:
|
||||
continue
|
||||
issue = emphasize_header(issue, only_markdown=True)
|
||||
markdown_text += f"{issue}\n\n"
|
||||
try:
|
||||
if not issue:
|
||||
continue
|
||||
relevant_file = issue.get('relevant_file', '').strip()
|
||||
issue_header = issue.get('issue_header', '').strip()
|
||||
issue_content = issue.get('issue_content', '').strip()
|
||||
start_line = int(str(issue.get('start_line', 0)).strip())
|
||||
end_line = int(str(issue.get('end_line', 0)).strip())
|
||||
reference_link = git_provider.get_line_link(relevant_file, start_line, end_line)
|
||||
|
||||
if gfm_supported:
|
||||
if get_settings().pr_reviewer.extra_issue_links:
|
||||
issue_content_linked =copy.deepcopy(issue_content)
|
||||
referenced_variables_list = issue.get('referenced_variables', [])
|
||||
for component in referenced_variables_list:
|
||||
name = component['variable_name'].strip().strip('`')
|
||||
|
||||
ind = issue_content.find(name)
|
||||
if ind != -1:
|
||||
reference_link_component = git_provider.get_line_link(relevant_file, component['relevant_line'], component['relevant_line'])
|
||||
issue_content_linked = issue_content_linked[:ind-1] + f"[`{name}`]({reference_link_component})" + issue_content_linked[ind+len(name)+1:]
|
||||
else:
|
||||
get_logger().info(f"Failed to find variable in issue content: {component['variable_name'].strip()}")
|
||||
issue_content = issue_content_linked
|
||||
issue_str = f"<a href='{reference_link}'><strong>{issue_header}</strong></a><br>{issue_content}"
|
||||
else:
|
||||
issue_str = f"[**{issue_header}**]({reference_link})\n\n{issue_content}\n\n"
|
||||
markdown_text += f"{issue_str}\n\n"
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Failed to process key issues to review: {e}")
|
||||
if gfm_supported:
|
||||
markdown_text += f"</td></tr>\n"
|
||||
else:
|
||||
@ -520,15 +558,21 @@ def _fix_key_value(key: str, value: str):
|
||||
|
||||
|
||||
def load_yaml(response_text: str, keys_fix_yaml: List[str] = [], first_key="", last_key="") -> dict:
|
||||
response_text = response_text.removeprefix('```yaml').rstrip('`')
|
||||
response_text = response_text.strip('\n').removeprefix('```yaml').rstrip().removesuffix('```')
|
||||
try:
|
||||
data = yaml.safe_load(response_text)
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to parse AI prediction: {e}")
|
||||
get_logger().warning(f"Initial failure to parse AI prediction: {e}")
|
||||
data = try_fix_yaml(response_text, keys_fix_yaml=keys_fix_yaml, first_key=first_key, last_key=last_key)
|
||||
if not data:
|
||||
get_logger().error(f"Failed to parse AI prediction after fallbacks", artifact={'response_text': response_text})
|
||||
else:
|
||||
get_logger().info(f"Successfully parsed AI prediction after fallbacks",
|
||||
artifact={'response_text': response_text})
|
||||
return data
|
||||
|
||||
|
||||
|
||||
def try_fix_yaml(response_text: str,
|
||||
keys_fix_yaml: List[str] = [],
|
||||
first_key="",
|
||||
@ -541,9 +585,9 @@ def try_fix_yaml(response_text: str,
|
||||
response_text_lines_copy = response_text_lines.copy()
|
||||
for i in range(0, len(response_text_lines_copy)):
|
||||
for key in keys_yaml:
|
||||
if key in response_text_lines_copy[i] and not '|-' in response_text_lines_copy[i]:
|
||||
if key in response_text_lines_copy[i] and not '|' in response_text_lines_copy[i]:
|
||||
response_text_lines_copy[i] = response_text_lines_copy[i].replace(f'{key}',
|
||||
f'{key} |-\n ')
|
||||
f'{key} |\n ')
|
||||
try:
|
||||
data = yaml.safe_load('\n'.join(response_text_lines_copy))
|
||||
get_logger().info(f"Successfully parsed AI prediction after adding |-\n")
|
||||
@ -551,14 +595,14 @@ def try_fix_yaml(response_text: str,
|
||||
except:
|
||||
get_logger().info(f"Failed to parse AI prediction after adding |-\n")
|
||||
|
||||
# second fallback - try to extract only range from first ```yaml to ```
|
||||
# second fallback - try to extract only range from first ```yaml to ````
|
||||
snippet_pattern = r'```(yaml)?[\s\S]*?```'
|
||||
snippet = re.search(snippet_pattern, '\n'.join(response_text_lines_copy))
|
||||
if snippet:
|
||||
snippet_text = snippet.group()
|
||||
try:
|
||||
data = yaml.safe_load(snippet_text.removeprefix('```yaml').rstrip('`'))
|
||||
get_logger().info(f"Successfully parsed AI prediction after extracting yaml snippet with second fallback")
|
||||
get_logger().info(f"Successfully parsed AI prediction after extracting yaml snippet")
|
||||
return data
|
||||
except:
|
||||
pass
|
||||
@ -573,6 +617,7 @@ def try_fix_yaml(response_text: str,
|
||||
except:
|
||||
pass
|
||||
|
||||
|
||||
# forth fallback - try to extract yaml snippet by 'first_key' and 'last_key'
|
||||
# note that 'last_key' can be in practice a key that is not the last key in the yaml snippet.
|
||||
# it just needs to be some inner key, so we can look for newlines after it
|
||||
@ -635,14 +680,16 @@ def get_user_labels(current_labels: List[str] = None):
|
||||
Only keep labels that has been added by the user
|
||||
"""
|
||||
try:
|
||||
enable_custom_labels = get_settings().config.get('enable_custom_labels', False)
|
||||
custom_labels = get_settings().get('custom_labels', [])
|
||||
if current_labels is None:
|
||||
current_labels = []
|
||||
user_labels = []
|
||||
for label in current_labels:
|
||||
if label.lower() in ['bug fix', 'tests', 'enhancement', 'documentation', 'other']:
|
||||
continue
|
||||
if get_settings().config.enable_custom_labels:
|
||||
if label in get_settings().custom_labels:
|
||||
if enable_custom_labels:
|
||||
if label in custom_labels:
|
||||
continue
|
||||
user_labels.append(label)
|
||||
if user_labels:
|
||||
@ -654,15 +701,25 @@ def get_user_labels(current_labels: List[str] = None):
|
||||
|
||||
|
||||
def get_max_tokens(model):
|
||||
"""
|
||||
Get the maximum number of tokens allowed for a model.
|
||||
logic:
|
||||
(1) If the model is in './pr_agent/algo/__init__.py', use the value from there.
|
||||
(2) else, the user needs to define explicitly 'config.custom_model_max_tokens'
|
||||
|
||||
For both cases, we further limit the number of tokens to 'config.max_model_tokens' if it is set.
|
||||
This aims to improve the algorithmic quality, as the AI model degrades in performance when the input is too long.
|
||||
"""
|
||||
settings = get_settings()
|
||||
if model in MAX_TOKENS:
|
||||
max_tokens_model = MAX_TOKENS[model]
|
||||
elif settings.config.custom_model_max_tokens > 0:
|
||||
max_tokens_model = settings.config.custom_model_max_tokens
|
||||
else:
|
||||
raise Exception(f"MAX_TOKENS must be set for model {model} in ./pr_agent/algo/__init__.py")
|
||||
raise Exception(f"Ensure {model} is defined in MAX_TOKENS in ./pr_agent/algo/__init__.py or set a positive value for it in config.custom_model_max_tokens")
|
||||
|
||||
if settings.config.max_model_tokens:
|
||||
if settings.config.max_model_tokens and settings.config.max_model_tokens > 0:
|
||||
max_tokens_model = min(settings.config.max_model_tokens, max_tokens_model)
|
||||
# get_logger().debug(f"limiting max tokens to {max_tokens_model}")
|
||||
return max_tokens_model
|
||||
|
||||
|
||||
@ -714,6 +771,7 @@ def replace_code_tags(text):
|
||||
"""
|
||||
Replace odd instances of ` with <code> and even instances of ` with </code>
|
||||
"""
|
||||
text = html.escape(text)
|
||||
parts = text.split('`')
|
||||
for i in range(1, len(parts), 2):
|
||||
parts[i] = '<code>' + parts[i] + '</code>'
|
||||
@ -730,6 +788,9 @@ def find_line_number_of_relevant_line_in_file(diff_files: List[FilePatchInfo],
|
||||
re_hunk_header = re.compile(
|
||||
r"^@@ -(\d+)(?:,(\d+))? \+(\d+)(?:,(\d+))? @@[ ]?(.*)")
|
||||
|
||||
if not diff_files:
|
||||
return position, absolute_position
|
||||
|
||||
for file in diff_files:
|
||||
if file.filename and (file.filename.strip() == relevant_file):
|
||||
patch = file.patch
|
||||
@ -878,7 +939,7 @@ def show_relevant_configurations(relevant_section: str) -> str:
|
||||
return markdown_text
|
||||
|
||||
def is_value_no(value):
|
||||
if value is None:
|
||||
if not value:
|
||||
return True
|
||||
value_str = str(value).strip().lower()
|
||||
if value_str == 'no' or value_str == 'none' or value_str == 'false':
|
||||
|
||||
@ -4,7 +4,7 @@ import os
|
||||
|
||||
from pr_agent.agent.pr_agent import PRAgent, commands
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.log import setup_logger
|
||||
from pr_agent.log import setup_logger, get_logger
|
||||
|
||||
log_level = os.environ.get("LOG_LEVEL", "INFO")
|
||||
setup_logger(log_level)
|
||||
@ -71,10 +71,21 @@ def run(inargs=None, args=None):
|
||||
|
||||
command = args.command.lower()
|
||||
get_settings().set("CONFIG.CLI_MODE", True)
|
||||
if args.issue_url:
|
||||
result = asyncio.run(PRAgent().handle_request(args.issue_url, [command] + args.rest))
|
||||
else:
|
||||
result = asyncio.run(PRAgent().handle_request(args.pr_url, [command] + args.rest))
|
||||
|
||||
async def inner():
|
||||
if args.issue_url:
|
||||
result = await asyncio.create_task(PRAgent().handle_request(args.issue_url, [command] + args.rest))
|
||||
else:
|
||||
result = await asyncio.create_task(PRAgent().handle_request(args.pr_url, [command] + args.rest))
|
||||
|
||||
if get_settings().litellm.get("enable_callbacks", False):
|
||||
# There may be additional events on the event queue from the run above. If there are give them time to complete.
|
||||
get_logger().debug("Waiting for event queue to complete")
|
||||
await asyncio.wait([task for task in asyncio.all_tasks() if task is not asyncio.current_task()])
|
||||
|
||||
return result
|
||||
|
||||
result = asyncio.run(inner())
|
||||
if not result:
|
||||
parser.print_help()
|
||||
|
||||
|
||||
@ -165,7 +165,7 @@ class AzureDevopsProvider(GitProvider):
|
||||
pull_request_id=self.pr_num,
|
||||
)
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Failed to publish labels, error: {e}")
|
||||
get_logger().warning(f"Failed to publish labels, error: {e}")
|
||||
|
||||
def get_pr_labels(self, update=False):
|
||||
try:
|
||||
@ -432,7 +432,7 @@ class AzureDevopsProvider(GitProvider):
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Failed to remove temp comments, error: {e}")
|
||||
|
||||
def publish_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
||||
def publish_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str, original_suggestion=None):
|
||||
self.publish_inline_comments([self.create_inline_comment(body, relevant_file, relevant_line_in_file)])
|
||||
|
||||
|
||||
@ -525,10 +525,18 @@ class AzureDevopsProvider(GitProvider):
|
||||
def get_user_id(self):
|
||||
return 0
|
||||
|
||||
|
||||
def get_issue_comments(self):
|
||||
raise NotImplementedError(
|
||||
"Azure DevOps provider does not support issue comments yet"
|
||||
)
|
||||
threads = self.azure_devops_client.get_threads(repository_id=self.repo_slug, pull_request_id=self.pr_num, project=self.workspace_slug)
|
||||
threads.reverse()
|
||||
comment_list = []
|
||||
for thread in threads:
|
||||
for comment in thread.comments:
|
||||
if comment.content and comment not in comment_list:
|
||||
comment.body = comment.content
|
||||
comment.thread_id = thread.id
|
||||
comment_list.append(comment)
|
||||
return comment_list
|
||||
|
||||
def add_eyes_reaction(self, issue_comment_id: int, disable_eyes: bool = False) -> Optional[int]:
|
||||
return True
|
||||
|
||||
@ -12,7 +12,13 @@ from ..algo.language_handler import is_valid_file
|
||||
from ..algo.utils import find_line_number_of_relevant_line_in_file
|
||||
from ..config_loader import get_settings
|
||||
from ..log import get_logger
|
||||
from .git_provider import GitProvider
|
||||
from .git_provider import GitProvider, MAX_FILES_ALLOWED_FULL
|
||||
|
||||
|
||||
def _gef_filename(diff):
|
||||
if diff.new.path:
|
||||
return diff.new.path
|
||||
return diff.old.path
|
||||
|
||||
|
||||
class BitbucketProvider(GitProvider):
|
||||
@ -30,6 +36,7 @@ class BitbucketProvider(GitProvider):
|
||||
s.headers["Content-Type"] = "application/json"
|
||||
self.headers = s.headers
|
||||
self.bitbucket_client = Cloud(session=s)
|
||||
self.max_comment_length = 31000
|
||||
self.workspace_slug = None
|
||||
self.repo_slug = None
|
||||
self.repo = None
|
||||
@ -39,6 +46,7 @@ class BitbucketProvider(GitProvider):
|
||||
self.temp_comments = []
|
||||
self.incremental = incremental
|
||||
self.diff_files = None
|
||||
self.git_files = None
|
||||
if pr_url:
|
||||
self.set_pr(pr_url)
|
||||
self.bitbucket_comment_api_url = self.pr._BitbucketBase__data["links"]["comments"]["href"]
|
||||
@ -108,8 +116,12 @@ class BitbucketProvider(GitProvider):
|
||||
get_logger().error(f"Failed to publish code suggestion, error: {e}")
|
||||
return False
|
||||
|
||||
def publish_file_comments(self, file_comments: list) -> bool:
|
||||
pass
|
||||
|
||||
def is_supported(self, capability: str) -> bool:
|
||||
if capability in ['get_issue_comments', 'publish_inline_comments', 'get_labels', 'gfm_markdown']:
|
||||
if capability in ['get_issue_comments', 'publish_inline_comments', 'get_labels', 'gfm_markdown',
|
||||
'publish_file_comments']:
|
||||
return False
|
||||
return True
|
||||
|
||||
@ -118,7 +130,17 @@ class BitbucketProvider(GitProvider):
|
||||
self.pr = self._get_pr()
|
||||
|
||||
def get_files(self):
|
||||
return [diff.new.path for diff in self.pr.diffstat()]
|
||||
try:
|
||||
git_files = context.get("git_files", None)
|
||||
if git_files:
|
||||
return git_files
|
||||
self.git_files = [_gef_filename(diff) for diff in self.pr.diffstat()]
|
||||
context["git_files"] = self.git_files
|
||||
return self.git_files
|
||||
except Exception:
|
||||
if not self.git_files:
|
||||
self.git_files = [_gef_filename(diff) for diff in self.pr.diffstat()]
|
||||
return self.git_files
|
||||
|
||||
def get_diff_files(self) -> list[FilePatchInfo]:
|
||||
if self.diff_files:
|
||||
@ -129,34 +151,108 @@ class BitbucketProvider(GitProvider):
|
||||
if diffs != diffs_original:
|
||||
try:
|
||||
names_original = [d.new.path for d in diffs_original]
|
||||
names_filtered = [d.new.path for d in diffs]
|
||||
names_kept = [d.new.path for d in diffs]
|
||||
names_filtered = list(set(names_original) - set(names_kept))
|
||||
get_logger().info(f"Filtered out [ignore] files for PR", extra={
|
||||
'original_files': names_original,
|
||||
'filtered_files': names_filtered
|
||||
'names_kept': names_kept,
|
||||
'names_filtered': names_filtered
|
||||
|
||||
})
|
||||
except Exception as e:
|
||||
pass
|
||||
|
||||
diff_split = [
|
||||
"diff --git%s" % x for x in self.pr.diff().split("diff --git") if x.strip()
|
||||
]
|
||||
# get the pr patches
|
||||
try:
|
||||
pr_patches = self.pr.diff()
|
||||
except Exception as e:
|
||||
# Try different encodings if UTF-8 fails
|
||||
get_logger().warning(f"Failed to decode PR patch with utf-8, error: {e}")
|
||||
encodings_to_try = ['iso-8859-1', 'latin-1', 'ascii', 'utf-16']
|
||||
pr_patches = None
|
||||
for encoding in encodings_to_try:
|
||||
try:
|
||||
pr_patches = self.pr.diff(encoding=encoding)
|
||||
get_logger().info(f"Successfully decoded PR patch with encoding {encoding}")
|
||||
break
|
||||
except UnicodeDecodeError:
|
||||
continue
|
||||
|
||||
if pr_patches is None:
|
||||
raise ValueError(f"Failed to decode PR patch with encodings {encodings_to_try}")
|
||||
|
||||
diff_split = ["diff --git" + x for x in pr_patches.split("diff --git") if x.strip()]
|
||||
# filter all elements of 'diff_split' that are of indices in 'diffs_original' that are not in 'diffs'
|
||||
if len(diff_split) > len(diffs) and len(diffs_original) == len(diff_split):
|
||||
diff_split = [diff_split[i] for i in range(len(diff_split)) if diffs_original[i] in diffs]
|
||||
if len(diff_split) != len(diffs):
|
||||
get_logger().error(f"Error - failed to split the diff into {len(diffs)} parts")
|
||||
return []
|
||||
# bitbucket diff has a header for each file, we need to remove it:
|
||||
# "diff --git filename
|
||||
# new file mode 100644 (optional)
|
||||
# index caa56f0..61528d7 100644
|
||||
# --- a/pr_agent/cli_pip.py
|
||||
# +++ b/pr_agent/cli_pip.py
|
||||
# @@ -... @@"
|
||||
for i, _ in enumerate(diff_split):
|
||||
diff_split_lines = diff_split[i].splitlines()
|
||||
if (len(diff_split_lines) >= 6) and \
|
||||
((diff_split_lines[2].startswith("---") and
|
||||
diff_split_lines[3].startswith("+++") and
|
||||
diff_split_lines[4].startswith("@@")) or
|
||||
(diff_split_lines[3].startswith("---") and # new or deleted file
|
||||
diff_split_lines[4].startswith("+++") and
|
||||
diff_split_lines[5].startswith("@@"))):
|
||||
diff_split[i] = "\n".join(diff_split_lines[4:])
|
||||
else:
|
||||
if diffs[i].data.get('lines_added', 0) == 0 and diffs[i].data.get('lines_removed', 0) == 0:
|
||||
diff_split[i] = ""
|
||||
elif len(diff_split_lines) <= 3:
|
||||
diff_split[i] = ""
|
||||
get_logger().info(f"Disregarding empty diff for file {_gef_filename(diffs[i])}")
|
||||
else:
|
||||
get_logger().warning(f"Bitbucket failed to get diff for file {_gef_filename(diffs[i])}")
|
||||
diff_split[i] = ""
|
||||
|
||||
invalid_files_names = []
|
||||
diff_files = []
|
||||
counter_valid = 0
|
||||
# get full files
|
||||
for index, diff in enumerate(diffs):
|
||||
if not is_valid_file(diff.new.path):
|
||||
invalid_files_names.append(diff.new.path)
|
||||
file_path = _gef_filename(diff)
|
||||
if not is_valid_file(file_path):
|
||||
invalid_files_names.append(file_path)
|
||||
continue
|
||||
|
||||
original_file_content_str = self._get_pr_file_content(
|
||||
diff.old.get_data("links")
|
||||
)
|
||||
new_file_content_str = self._get_pr_file_content(diff.new.get_data("links"))
|
||||
try:
|
||||
counter_valid += 1
|
||||
if counter_valid < MAX_FILES_ALLOWED_FULL // 2: # factor 2 because bitbucket has limited API calls
|
||||
if diff.old.get_data("links"):
|
||||
original_file_content_str = self._get_pr_file_content(
|
||||
diff.old.get_data("links")['self']['href'])
|
||||
else:
|
||||
original_file_content_str = ""
|
||||
if diff.new.get_data("links"):
|
||||
new_file_content_str = self._get_pr_file_content(diff.new.get_data("links")['self']['href'])
|
||||
else:
|
||||
new_file_content_str = ""
|
||||
else:
|
||||
if counter_valid == MAX_FILES_ALLOWED_FULL // 2:
|
||||
get_logger().info(
|
||||
f"Bitbucket too many files in PR, will avoid loading full content for rest of files")
|
||||
original_file_content_str = ""
|
||||
new_file_content_str = ""
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Error - bitbucket failed to get file content, error: {e}")
|
||||
original_file_content_str = ""
|
||||
new_file_content_str = ""
|
||||
|
||||
file_patch_canonic_structure = FilePatchInfo(
|
||||
original_file_content_str,
|
||||
new_file_content_str,
|
||||
diff_split[index],
|
||||
diff.new.path,
|
||||
file_path,
|
||||
)
|
||||
|
||||
if diff.data['status'] == 'added':
|
||||
@ -170,8 +266,7 @@ class BitbucketProvider(GitProvider):
|
||||
diff_files.append(file_patch_canonic_structure)
|
||||
|
||||
if invalid_files_names:
|
||||
get_logger().info(f"Invalid file names: {invalid_files_names}")
|
||||
|
||||
get_logger().info(f"Disregarding files with invalid extensions:\n{invalid_files_names}")
|
||||
|
||||
self.diff_files = diff_files
|
||||
return diff_files
|
||||
@ -211,6 +306,7 @@ class BitbucketProvider(GitProvider):
|
||||
self.publish_comment(pr_comment)
|
||||
|
||||
def publish_comment(self, pr_comment: str, is_temporary: bool = False):
|
||||
pr_comment = self.limit_output_characters(pr_comment, self.max_comment_length)
|
||||
comment = self.pr.comment(pr_comment)
|
||||
if is_temporary:
|
||||
self.temp_comments.append(comment["id"])
|
||||
@ -218,6 +314,7 @@ class BitbucketProvider(GitProvider):
|
||||
|
||||
def edit_comment(self, comment, body: str):
|
||||
try:
|
||||
body = self.limit_output_characters(body, self.max_comment_length)
|
||||
comment.update(body)
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Failed to update comment, error: {e}")
|
||||
@ -236,10 +333,13 @@ class BitbucketProvider(GitProvider):
|
||||
get_logger().exception(f"Failed to remove comment, error: {e}")
|
||||
|
||||
# function to create_inline_comment
|
||||
def create_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str, absolute_position: int = None):
|
||||
def create_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str,
|
||||
absolute_position: int = None):
|
||||
body = self.limit_output_characters(body, self.max_comment_length)
|
||||
position, absolute_position = find_line_number_of_relevant_line_in_file(self.get_diff_files(),
|
||||
relevant_file.strip('`'),
|
||||
relevant_line_in_file, absolute_position)
|
||||
relevant_file.strip('`'),
|
||||
relevant_line_in_file,
|
||||
absolute_position)
|
||||
if position == -1:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().info(f"Could not find position for {relevant_file} {relevant_line_in_file}")
|
||||
@ -249,9 +349,9 @@ class BitbucketProvider(GitProvider):
|
||||
path = relevant_file.strip()
|
||||
return dict(body=body, path=path, position=absolute_position) if subject_type == "LINE" else {}
|
||||
|
||||
|
||||
def publish_inline_comment(self, comment: str, from_line: int, file: str):
|
||||
payload = json.dumps( {
|
||||
def publish_inline_comment(self, comment: str, from_line: int, file: str, original_suggestion=None):
|
||||
comment = self.limit_output_characters(comment, self.max_comment_length)
|
||||
payload = json.dumps({
|
||||
"content": {
|
||||
"raw": comment,
|
||||
},
|
||||
@ -296,10 +396,10 @@ class BitbucketProvider(GitProvider):
|
||||
for comment in comments:
|
||||
if 'position' in comment:
|
||||
self.publish_inline_comment(comment['body'], comment['position'], comment['path'])
|
||||
elif 'start_line' in comment: # multi-line comment
|
||||
elif 'start_line' in comment: # multi-line comment
|
||||
# note that bitbucket does not seem to support range - only a comment on a single line - https://community.developer.atlassian.com/t/api-post-endpoint-for-inline-pull-request-comments/60452
|
||||
self.publish_inline_comment(comment['body'], comment['start_line'], comment['path'])
|
||||
elif 'line' in comment: # single-line comment
|
||||
elif 'line' in comment: # single-line comment
|
||||
self.publish_inline_comment(comment['body'], comment['line'], comment['path'])
|
||||
else:
|
||||
get_logger().error(f"Could not publish inline comment {comment}")
|
||||
@ -314,6 +414,9 @@ class BitbucketProvider(GitProvider):
|
||||
def get_pr_branch(self):
|
||||
return self.pr.source_branch
|
||||
|
||||
def get_pr_owner_id(self) -> str | None:
|
||||
return self.workspace_slug
|
||||
|
||||
def get_pr_description_full(self):
|
||||
return self.pr.description
|
||||
|
||||
@ -380,7 +483,6 @@ class BitbucketProvider(GitProvider):
|
||||
except Exception:
|
||||
return ""
|
||||
|
||||
|
||||
def create_or_update_pr_file(self, file_path: str, branch: str, contents="", message="") -> None:
|
||||
url = (f"https://api.bitbucket.org/2.0/repositories/{self.workspace_slug}/{self.repo_slug}/src/")
|
||||
if not message:
|
||||
@ -388,19 +490,26 @@ class BitbucketProvider(GitProvider):
|
||||
message = f"Update {file_path}"
|
||||
else:
|
||||
message = f"Create {file_path}"
|
||||
files={file_path: contents}
|
||||
data={
|
||||
files = {file_path: contents}
|
||||
data = {
|
||||
"message": message,
|
||||
"branch": branch
|
||||
}
|
||||
headers = {'Authorization':self.headers['Authorization']} if 'Authorization' in self.headers else {}
|
||||
headers = {'Authorization': self.headers['Authorization']} if 'Authorization' in self.headers else {}
|
||||
try:
|
||||
requests.request("POST", url, headers=headers, data=data, files=files)
|
||||
except Exception:
|
||||
get_logger().exception(f"Failed to create empty file {file_path} in branch {branch}")
|
||||
|
||||
def _get_pr_file_content(self, remote_link: str):
|
||||
return ""
|
||||
try:
|
||||
response = requests.request("GET", remote_link, headers=self.headers)
|
||||
if response.status_code == 404: # not found
|
||||
return ""
|
||||
contents = response.text
|
||||
return contents
|
||||
except Exception:
|
||||
return ""
|
||||
|
||||
def get_commit_messages(self):
|
||||
return "" # not implemented yet
|
||||
@ -411,7 +520,7 @@ class BitbucketProvider(GitProvider):
|
||||
"description": description,
|
||||
"title": pr_title
|
||||
|
||||
})
|
||||
})
|
||||
|
||||
response = requests.request("PUT", self.bitbucket_pull_request_api_url, headers=self.headers, data=payload)
|
||||
try:
|
||||
|
||||
@ -1,10 +1,9 @@
|
||||
import json
|
||||
from distutils.version import LooseVersion
|
||||
from requests.exceptions import HTTPError
|
||||
from typing import Optional, Tuple
|
||||
from urllib.parse import quote_plus, urlparse
|
||||
|
||||
import requests
|
||||
from atlassian.bitbucket import Bitbucket
|
||||
from starlette_context import context
|
||||
|
||||
from .git_provider import GitProvider
|
||||
from ..algo.types import EDIT_TYPE, FilePatchInfo
|
||||
@ -16,19 +15,9 @@ from ..log import get_logger
|
||||
|
||||
class BitbucketServerProvider(GitProvider):
|
||||
def __init__(
|
||||
self, pr_url: Optional[str] = None, incremental: Optional[bool] = False
|
||||
self, pr_url: Optional[str] = None, incremental: Optional[bool] = False,
|
||||
bitbucket_client: Optional[Bitbucket] = None,
|
||||
):
|
||||
s = requests.Session()
|
||||
try:
|
||||
bearer = context.get("bitbucket_bearer_token", None)
|
||||
s.headers["Authorization"] = f"Bearer {bearer}"
|
||||
except Exception:
|
||||
s.headers[
|
||||
"Authorization"
|
||||
] = f'Bearer {get_settings().get("BITBUCKET_SERVER.BEARER_TOKEN", None)}'
|
||||
|
||||
s.headers["Content-Type"] = "application/json"
|
||||
self.headers = s.headers
|
||||
self.bitbucket_server_url = None
|
||||
self.workspace_slug = None
|
||||
self.repo_slug = None
|
||||
@ -42,24 +31,30 @@ class BitbucketServerProvider(GitProvider):
|
||||
self.bitbucket_pull_request_api_url = pr_url
|
||||
|
||||
self.bitbucket_server_url = self._parse_bitbucket_server(url=pr_url)
|
||||
self.bitbucket_client = Bitbucket(url=self.bitbucket_server_url,
|
||||
token=get_settings().get("BITBUCKET_SERVER.BEARER_TOKEN", None))
|
||||
self.bitbucket_client = bitbucket_client or Bitbucket(url=self.bitbucket_server_url,
|
||||
token=get_settings().get("BITBUCKET_SERVER.BEARER_TOKEN",
|
||||
None))
|
||||
try:
|
||||
self.bitbucket_api_version = LooseVersion(self.bitbucket_client.get("rest/api/1.0/application-properties").get('version'))
|
||||
except Exception:
|
||||
self.bitbucket_api_version = None
|
||||
|
||||
if pr_url:
|
||||
self.set_pr(pr_url)
|
||||
|
||||
def get_repo_settings(self):
|
||||
try:
|
||||
url = (f"{self.bitbucket_server_url}/projects/{self.workspace_slug}/repos/{self.repo_slug}/src/"
|
||||
f"{self.pr.destination_branch}/.pr_agent.toml")
|
||||
response = requests.request("GET", url, headers=self.headers)
|
||||
if response.status_code == 404: # not found
|
||||
return ""
|
||||
contents = response.text.encode('utf-8')
|
||||
return contents
|
||||
except Exception:
|
||||
content = self.bitbucket_client.get_content_of_file(self.workspace_slug, self.repo_slug, ".pr_agent.toml", self.get_pr_branch())
|
||||
|
||||
return content
|
||||
except Exception as e:
|
||||
if isinstance(e, HTTPError):
|
||||
if e.response.status_code == 404: # not found
|
||||
return ""
|
||||
|
||||
get_logger().error(f"Failed to load .pr_agent.toml file, error: {e}")
|
||||
return ""
|
||||
|
||||
|
||||
def get_pr_id(self):
|
||||
return self.pr_num
|
||||
|
||||
@ -91,6 +86,8 @@ class BitbucketServerProvider(GitProvider):
|
||||
continue
|
||||
|
||||
if relevant_lines_end > relevant_lines_start:
|
||||
# Bitbucket does not support multi-line suggestions so use a code block instead - https://jira.atlassian.com/browse/BSERV-4553
|
||||
body = body.replace("```suggestion", "```")
|
||||
post_parameters = {
|
||||
"body": body,
|
||||
"path": relevant_file,
|
||||
@ -115,8 +112,11 @@ class BitbucketServerProvider(GitProvider):
|
||||
get_logger().error(f"Failed to publish code suggestion, error: {e}")
|
||||
return False
|
||||
|
||||
def publish_file_comments(self, file_comments: list) -> bool:
|
||||
pass
|
||||
|
||||
def is_supported(self, capability: str) -> bool:
|
||||
if capability in ['get_issue_comments', 'get_labels', 'gfm_markdown']:
|
||||
if capability in ['get_issue_comments', 'get_labels', 'gfm_markdown', 'publish_file_comments']:
|
||||
return False
|
||||
return True
|
||||
|
||||
@ -131,7 +131,7 @@ class BitbucketServerProvider(GitProvider):
|
||||
self.repo_slug,
|
||||
path,
|
||||
commit_id)
|
||||
except requests.HTTPError as e:
|
||||
except HTTPError as e:
|
||||
get_logger().debug(f"File {path} not found at commit id: {commit_id}")
|
||||
return file_content
|
||||
|
||||
@ -140,13 +140,51 @@ class BitbucketServerProvider(GitProvider):
|
||||
diffstat = [change["path"]['toString'] for change in changes]
|
||||
return diffstat
|
||||
|
||||
#gets the best common ancestor: https://git-scm.com/docs/git-merge-base
|
||||
@staticmethod
|
||||
def get_best_common_ancestor(source_commits_list, destination_commits_list, guaranteed_common_ancestor) -> str:
|
||||
destination_commit_hashes = {commit['id'] for commit in destination_commits_list} | {guaranteed_common_ancestor}
|
||||
|
||||
for commit in source_commits_list:
|
||||
for parent_commit in commit['parents']:
|
||||
if parent_commit['id'] in destination_commit_hashes:
|
||||
return parent_commit['id']
|
||||
|
||||
return guaranteed_common_ancestor
|
||||
|
||||
def get_diff_files(self) -> list[FilePatchInfo]:
|
||||
if self.diff_files:
|
||||
return self.diff_files
|
||||
|
||||
base_sha = self.pr.toRef['latestCommit']
|
||||
head_sha = self.pr.fromRef['latestCommit']
|
||||
|
||||
# if Bitbucket api version is >= 8.16 then use the merge-base api for 2-way diff calculation
|
||||
if self.bitbucket_api_version is not None and self.bitbucket_api_version >= LooseVersion("8.16"):
|
||||
try:
|
||||
base_sha = self.bitbucket_client.get(self._get_merge_base())['id']
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to get the best common ancestor for PR: {self.pr_url}, \nerror: {e}")
|
||||
raise e
|
||||
else:
|
||||
source_commits_list = list(self.bitbucket_client.get_pull_requests_commits(
|
||||
self.workspace_slug,
|
||||
self.repo_slug,
|
||||
self.pr_num
|
||||
))
|
||||
# if Bitbucket api version is None or < 7.0 then do a simple diff with a guaranteed common ancestor
|
||||
base_sha = source_commits_list[-1]['parents'][0]['id']
|
||||
# if Bitbucket api version is 7.0-8.15 then use 2-way diff functionality for the base_sha
|
||||
if self.bitbucket_api_version is not None and self.bitbucket_api_version >= LooseVersion("7.0"):
|
||||
try:
|
||||
destination_commits = list(
|
||||
self.bitbucket_client.get_commits(self.workspace_slug, self.repo_slug, base_sha,
|
||||
self.pr.toRef['latestCommit']))
|
||||
base_sha = self.get_best_common_ancestor(source_commits_list, destination_commits, base_sha)
|
||||
except Exception as e:
|
||||
get_logger().error(
|
||||
f"Failed to get the commit list for calculating best common ancestor for PR: {self.pr_url}, \nerror: {e}")
|
||||
raise e
|
||||
|
||||
diff_files = []
|
||||
original_file_content_str = ""
|
||||
new_file_content_str = ""
|
||||
@ -230,7 +268,7 @@ class BitbucketServerProvider(GitProvider):
|
||||
path = relevant_file.strip()
|
||||
return dict(body=body, path=path, position=absolute_position) if subject_type == "LINE" else {}
|
||||
|
||||
def publish_inline_comment(self, comment: str, from_line: int, file: str):
|
||||
def publish_inline_comment(self, comment: str, from_line: int, file: str, original_suggestion=None):
|
||||
payload = {
|
||||
"text": comment,
|
||||
"severity": "NORMAL",
|
||||
@ -244,11 +282,18 @@ class BitbucketServerProvider(GitProvider):
|
||||
}
|
||||
|
||||
try:
|
||||
requests.post(url=self._get_pr_comments_url(), json=payload, headers=self.headers).raise_for_status()
|
||||
self.bitbucket_client.post(self._get_pr_comments_path(), data=payload)
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to publish inline comment to '{file}' at line {from_line}, error: {e}")
|
||||
raise e
|
||||
|
||||
def get_line_link(self, relevant_file: str, relevant_line_start: int, relevant_line_end: int = None) -> str:
|
||||
if relevant_line_start == -1:
|
||||
link = f"{self.pr_url}/diff#{quote_plus(relevant_file)}"
|
||||
else:
|
||||
link = f"{self.pr_url}/diff#{quote_plus(relevant_file)}?t={relevant_line_start}"
|
||||
return link
|
||||
|
||||
def generate_link_to_relevant_line_number(self, suggestion) -> str:
|
||||
try:
|
||||
relevant_file = suggestion['relevant_file'].strip('`').strip("'").rstrip()
|
||||
@ -284,10 +329,10 @@ class BitbucketServerProvider(GitProvider):
|
||||
for comment in comments:
|
||||
if 'position' in comment:
|
||||
self.publish_inline_comment(comment['body'], comment['position'], comment['path'])
|
||||
elif 'start_line' in comment: # multi-line comment
|
||||
elif 'start_line' in comment: # multi-line comment
|
||||
# note that bitbucket does not seem to support range - only a comment on a single line - https://community.developer.atlassian.com/t/api-post-endpoint-for-inline-pull-request-comments/60452
|
||||
self.publish_inline_comment(comment['body'], comment['start_line'], comment['path'])
|
||||
elif 'line' in comment: # single-line comment
|
||||
elif 'line' in comment: # single-line comment
|
||||
self.publish_inline_comment(comment['body'], comment['line'], comment['path'])
|
||||
else:
|
||||
get_logger().error(f"Could not publish inline comment: {comment}")
|
||||
@ -301,6 +346,9 @@ class BitbucketServerProvider(GitProvider):
|
||||
def get_pr_branch(self):
|
||||
return self.pr.fromRef['displayId']
|
||||
|
||||
def get_pr_owner_id(self) -> str | None:
|
||||
return self.workspace_slug
|
||||
|
||||
def get_pr_description_full(self):
|
||||
if hasattr(self.pr, "description"):
|
||||
return self.pr.description
|
||||
@ -323,14 +371,29 @@ class BitbucketServerProvider(GitProvider):
|
||||
|
||||
@staticmethod
|
||||
def _parse_bitbucket_server(url: str) -> str:
|
||||
# pr url format: f"{bitbucket_server}/projects/{project_name}/repos/{repository_name}/pull-requests/{pr_id}"
|
||||
parsed_url = urlparse(url)
|
||||
server_path = parsed_url.path.split("/projects/")
|
||||
if len(server_path) > 1:
|
||||
server_path = server_path[0].strip("/")
|
||||
return f"{parsed_url.scheme}://{parsed_url.netloc}/{server_path}".strip("/")
|
||||
return f"{parsed_url.scheme}://{parsed_url.netloc}"
|
||||
|
||||
@staticmethod
|
||||
def _parse_pr_url(pr_url: str) -> Tuple[str, str, int]:
|
||||
# pr url format: f"{bitbucket_server}/projects/{project_name}/repos/{repository_name}/pull-requests/{pr_id}"
|
||||
parsed_url = urlparse(pr_url)
|
||||
|
||||
path_parts = parsed_url.path.strip("/").split("/")
|
||||
if len(path_parts) < 6 or path_parts[4] != "pull-requests":
|
||||
|
||||
try:
|
||||
projects_index = path_parts.index("projects")
|
||||
except ValueError as e:
|
||||
raise ValueError(f"The provided URL '{pr_url}' does not appear to be a Bitbucket PR URL")
|
||||
|
||||
path_parts = path_parts[projects_index:]
|
||||
|
||||
if len(path_parts) < 6 or path_parts[2] != "repos" or path_parts[4] != "pull-requests":
|
||||
raise ValueError(
|
||||
f"The provided URL '{pr_url}' does not appear to be a Bitbucket PR URL"
|
||||
)
|
||||
@ -350,37 +413,44 @@ class BitbucketServerProvider(GitProvider):
|
||||
return self.repo
|
||||
|
||||
def _get_pr(self):
|
||||
pr = self.bitbucket_client.get_pull_request(self.workspace_slug, self.repo_slug, pull_request_id=self.pr_num)
|
||||
return type('new_dict', (object,), pr)
|
||||
try:
|
||||
pr = self.bitbucket_client.get_pull_request(self.workspace_slug, self.repo_slug,
|
||||
pull_request_id=self.pr_num)
|
||||
return type('new_dict', (object,), pr)
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to get pull request, error: {e}")
|
||||
raise e
|
||||
|
||||
def _get_pr_file_content(self, remote_link: str):
|
||||
return ""
|
||||
|
||||
def get_commit_messages(self):
|
||||
def get_commit_messages(self):
|
||||
raise NotImplementedError("Get commit messages function not implemented yet.")
|
||||
return ""
|
||||
|
||||
# bitbucket does not support labels
|
||||
def publish_description(self, pr_title: str, description: str):
|
||||
payload = {
|
||||
"version": self.pr.version,
|
||||
"description": description,
|
||||
"title": pr_title,
|
||||
"reviewers": self.pr.reviewers # needs to be sent otherwise gets wiped
|
||||
"reviewers": self.pr.reviewers # needs to be sent otherwise gets wiped
|
||||
}
|
||||
try:
|
||||
self.bitbucket_client.update_pull_request(self.workspace_slug, self.repo_slug, str(self.pr_num), payload)
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to update pull request, error: {e}")
|
||||
raise e
|
||||
|
||||
|
||||
# bitbucket does not support labels
|
||||
def publish_labels(self, pr_types: list):
|
||||
pass
|
||||
|
||||
|
||||
# bitbucket does not support labels
|
||||
def get_pr_labels(self, update=False):
|
||||
pass
|
||||
|
||||
def _get_pr_comments_url(self):
|
||||
return f"{self.bitbucket_server_url}/rest/api/latest/projects/{self.workspace_slug}/repos/{self.repo_slug}/pull-requests/{self.pr_num}/comments"
|
||||
def _get_pr_comments_path(self):
|
||||
return f"rest/api/latest/projects/{self.workspace_slug}/repos/{self.repo_slug}/pull-requests/{self.pr_num}/comments"
|
||||
|
||||
def _get_merge_base(self):
|
||||
return f"rest/api/latest/projects/{self.workspace_slug}/repos/{self.repo_slug}/pull-requests/{self.pr_num}/merge-base"
|
||||
|
||||
@ -225,7 +225,7 @@ class CodeCommitProvider(GitProvider):
|
||||
def remove_comment(self, comment):
|
||||
return "" # not implemented yet
|
||||
|
||||
def publish_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
||||
def publish_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str, original_suggestion=None):
|
||||
# https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/codecommit/client/post_comment_for_compared_commit.html
|
||||
raise NotImplementedError("CodeCommit provider does not support publishing inline comments yet")
|
||||
|
||||
|
||||
@ -376,7 +376,7 @@ class GerritProvider(GitProvider):
|
||||
'provider')
|
||||
|
||||
def publish_inline_comment(self, body: str, relevant_file: str,
|
||||
relevant_line_in_file: str):
|
||||
relevant_line_in_file: str, original_suggestion=None):
|
||||
raise NotImplementedError(
|
||||
'Publishing inline comments is not implemented for the gerrit '
|
||||
'provider')
|
||||
|
||||
@ -3,10 +3,11 @@ from abc import ABC, abstractmethod
|
||||
# enum EDIT_TYPE (ADDED, DELETED, MODIFIED, RENAMED)
|
||||
from typing import Optional
|
||||
|
||||
from pr_agent.algo.utils import Range
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.algo.types import FilePatchInfo
|
||||
from pr_agent.log import get_logger
|
||||
|
||||
MAX_FILES_ALLOWED_FULL = 50
|
||||
|
||||
class GitProvider(ABC):
|
||||
@abstractmethod
|
||||
@ -51,6 +52,12 @@ class GitProvider(ABC):
|
||||
def edit_comment(self, comment, body: str):
|
||||
pass
|
||||
|
||||
def edit_comment_from_comment_id(self, comment_id: int, body: str):
|
||||
pass
|
||||
|
||||
def get_comment_body_from_comment_id(self, comment_id: int) -> str:
|
||||
pass
|
||||
|
||||
def reply_to_comment_from_comment_id(self, comment_id: int, body: str):
|
||||
pass
|
||||
|
||||
@ -74,6 +81,7 @@ class GitProvider(ABC):
|
||||
# if the existing description wasn't generated by the pr-agent, just return it as-is
|
||||
if not self._is_generated_by_pr_agent(description_lowercase):
|
||||
get_logger().info(f"Existing description was not generated by the pr-agent")
|
||||
self.user_description = description
|
||||
return description
|
||||
|
||||
# if the existing description was generated by the pr-agent, but it doesn't contain a user description,
|
||||
@ -120,12 +128,18 @@ class GitProvider(ABC):
|
||||
def get_repo_settings(self):
|
||||
pass
|
||||
|
||||
def get_workspace_name(self):
|
||||
return ""
|
||||
|
||||
def get_pr_id(self):
|
||||
return ""
|
||||
|
||||
def get_line_link(self, relevant_file: str, relevant_line_start: int, relevant_line_end: int = None) -> str:
|
||||
return ""
|
||||
|
||||
def get_lines_link_original_file(self, filepath:str, component_range: Range) -> str:
|
||||
return ""
|
||||
|
||||
#### comments operations ####
|
||||
@abstractmethod
|
||||
def publish_comment(self, pr_comment: str, is_temporary: bool = False):
|
||||
@ -166,8 +180,9 @@ class GitProvider(ABC):
|
||||
pass
|
||||
self.publish_comment(pr_comment)
|
||||
|
||||
|
||||
@abstractmethod
|
||||
def publish_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
||||
def publish_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str, original_suggestion=None):
|
||||
pass
|
||||
|
||||
def create_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str,
|
||||
@ -238,6 +253,9 @@ class GitProvider(ABC):
|
||||
except Exception as e:
|
||||
return -1
|
||||
|
||||
def limit_output_characters(self, output: str, max_chars: int):
|
||||
return output[:max_chars] + '...' if len(output) > max_chars else output
|
||||
|
||||
|
||||
def get_main_pr_language(languages, files) -> str:
|
||||
"""
|
||||
@ -308,6 +326,8 @@ def get_main_pr_language(languages, files) -> str:
|
||||
return main_language_str
|
||||
|
||||
|
||||
|
||||
|
||||
class IncrementalPR:
|
||||
def __init__(self, is_incremental: bool = False):
|
||||
self.is_incremental = is_incremental
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
import itertools
|
||||
import time
|
||||
import hashlib
|
||||
from datetime import datetime
|
||||
@ -10,11 +11,11 @@ from starlette_context import context
|
||||
|
||||
from ..algo.file_filter import filter_ignored
|
||||
from ..algo.language_handler import is_valid_file
|
||||
from ..algo.utils import PRReviewHeader, load_large_diff, clip_tokens, find_line_number_of_relevant_line_in_file
|
||||
from ..algo.utils import PRReviewHeader, load_large_diff, clip_tokens, find_line_number_of_relevant_line_in_file, Range
|
||||
from ..config_loader import get_settings
|
||||
from ..log import get_logger
|
||||
from ..servers.utils import RateLimitExceeded
|
||||
from .git_provider import GitProvider, IncrementalPR
|
||||
from .git_provider import GitProvider, IncrementalPR, MAX_FILES_ALLOWED_FULL
|
||||
from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
|
||||
|
||||
|
||||
@ -25,8 +26,11 @@ class GithubProvider(GitProvider):
|
||||
self.installation_id = context.get("installation_id", None)
|
||||
except Exception:
|
||||
self.installation_id = None
|
||||
self.max_comment_chars = 65000
|
||||
self.base_url = get_settings().get("GITHUB.BASE_URL", "https://api.github.com").rstrip("/")
|
||||
self.base_url_html = self.base_url.split("api/")[0].rstrip("/") if "api/" in self.base_url else "https://github.com"
|
||||
self.base_domain = self.base_url.replace("https://", "").replace("http://", "")
|
||||
self.base_domain_html = self.base_url_html.replace("https://", "").replace("http://", "")
|
||||
self.github_client = self._get_github_client()
|
||||
self.repo = None
|
||||
self.pr_num = None
|
||||
@ -164,20 +168,36 @@ class GithubProvider(GitProvider):
|
||||
|
||||
diff_files = []
|
||||
invalid_files_names = []
|
||||
counter_valid = 0
|
||||
for file in files:
|
||||
if not is_valid_file(file.filename):
|
||||
invalid_files_names.append(file.filename)
|
||||
continue
|
||||
|
||||
new_file_content_str = self._get_pr_file_content(file, self.pr.head.sha) # communication with GitHub
|
||||
patch = file.patch
|
||||
|
||||
# allow only a limited number of files to be fully loaded. We can manage the rest with diffs only
|
||||
counter_valid += 1
|
||||
avoid_load = False
|
||||
if counter_valid >= MAX_FILES_ALLOWED_FULL and patch and not self.incremental.is_incremental:
|
||||
avoid_load = True
|
||||
if counter_valid == MAX_FILES_ALLOWED_FULL:
|
||||
get_logger().info(f"Too many files in PR, will avoid loading full content for rest of files")
|
||||
|
||||
if avoid_load:
|
||||
new_file_content_str = ""
|
||||
else:
|
||||
new_file_content_str = self._get_pr_file_content(file, self.pr.head.sha) # communication with GitHub
|
||||
|
||||
if self.incremental.is_incremental and self.unreviewed_files_set:
|
||||
original_file_content_str = self._get_pr_file_content(file, self.incremental.last_seen_commit_sha)
|
||||
patch = load_large_diff(file.filename, new_file_content_str, original_file_content_str)
|
||||
self.unreviewed_files_set[file.filename] = patch
|
||||
else:
|
||||
original_file_content_str = self._get_pr_file_content(file, self.pr.base.sha)
|
||||
if avoid_load:
|
||||
original_file_content_str = ""
|
||||
else:
|
||||
original_file_content_str = self._get_pr_file_content(file, self.pr.base.sha)
|
||||
if not patch:
|
||||
patch = load_large_diff(file.filename, new_file_content_str, original_file_content_str)
|
||||
|
||||
@ -237,7 +257,7 @@ class GithubProvider(GitProvider):
|
||||
if is_temporary and not get_settings().config.publish_output_progress:
|
||||
get_logger().debug(f"Skipping publish_comment for temporary comment: {pr_comment}")
|
||||
return
|
||||
|
||||
pr_comment = self.limit_output_characters(pr_comment, self.max_comment_chars)
|
||||
response = self.pr.create_issue_comment(pr_comment)
|
||||
if hasattr(response, "user") and hasattr(response.user, "login"):
|
||||
self.github_user_id = response.user.login
|
||||
@ -247,12 +267,14 @@ class GithubProvider(GitProvider):
|
||||
self.pr.comments_list.append(response)
|
||||
return response
|
||||
|
||||
def publish_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
||||
def publish_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str, original_suggestion=None):
|
||||
body = self.limit_output_characters(body, self.max_comment_chars)
|
||||
self.publish_inline_comments([self.create_inline_comment(body, relevant_file, relevant_line_in_file)])
|
||||
|
||||
|
||||
def create_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str,
|
||||
absolute_position: int = None):
|
||||
body = self.limit_output_characters(body, self.max_comment_chars)
|
||||
position, absolute_position = find_line_number_of_relevant_line_in_file(self.diff_files,
|
||||
relevant_file.strip('`'),
|
||||
relevant_line_in_file,
|
||||
@ -425,11 +447,24 @@ class GithubProvider(GitProvider):
|
||||
return False
|
||||
|
||||
def edit_comment(self, comment, body: str):
|
||||
body = self.limit_output_characters(body, self.max_comment_chars)
|
||||
comment.edit(body=body)
|
||||
|
||||
def edit_comment_from_comment_id(self, comment_id: int, body: str):
|
||||
try:
|
||||
# self.pr.get_issue_comment(comment_id).edit(body)
|
||||
body = self.limit_output_characters(body, self.max_comment_chars)
|
||||
headers, data_patch = self.pr._requester.requestJsonAndCheck(
|
||||
"PATCH", f"{self.base_url}/repos/{self.repo}/issues/comments/{comment_id}",
|
||||
input={"body": body}
|
||||
)
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Failed to edit comment, error: {e}")
|
||||
|
||||
def reply_to_comment_from_comment_id(self, comment_id: int, body: str):
|
||||
try:
|
||||
# self.pr.get_issue_comment(comment_id).edit(body)
|
||||
body = self.limit_output_characters(body, self.max_comment_chars)
|
||||
headers, data_patch = self.pr._requester.requestJsonAndCheck(
|
||||
"POST", f"{self.base_url}/repos/{self.repo}/pulls/{self.pr_num}/comments/{comment_id}/replies",
|
||||
input={"body": body}
|
||||
@ -437,6 +472,51 @@ class GithubProvider(GitProvider):
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Failed to reply comment, error: {e}")
|
||||
|
||||
def get_comment_body_from_comment_id(self, comment_id: int):
|
||||
try:
|
||||
# self.pr.get_issue_comment(comment_id).edit(body)
|
||||
headers, data_patch = self.pr._requester.requestJsonAndCheck(
|
||||
"GET", f"{self.base_url}/repos/{self.repo}/issues/comments/{comment_id}"
|
||||
)
|
||||
return data_patch.get("body","")
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Failed to edit comment, error: {e}")
|
||||
return None
|
||||
|
||||
def publish_file_comments(self, file_comments: list) -> bool:
|
||||
try:
|
||||
headers, existing_comments = self.pr._requester.requestJsonAndCheck(
|
||||
"GET", f"{self.pr.url}/comments"
|
||||
)
|
||||
for comment in file_comments:
|
||||
comment['commit_id'] = self.last_commit_id.sha
|
||||
comment['body'] = self.limit_output_characters(comment['body'], self.max_comment_chars)
|
||||
|
||||
found = False
|
||||
for existing_comment in existing_comments:
|
||||
comment['commit_id'] = self.last_commit_id.sha
|
||||
our_app_name = get_settings().get("GITHUB.APP_NAME", "")
|
||||
same_comment_creator = False
|
||||
if self.deployment_type == 'app':
|
||||
same_comment_creator = our_app_name.lower() in existing_comment['user']['login'].lower()
|
||||
elif self.deployment_type == 'user':
|
||||
same_comment_creator = self.github_user_id == existing_comment['user']['login']
|
||||
if existing_comment['subject_type'] == 'file' and comment['path'] == existing_comment['path'] and same_comment_creator:
|
||||
headers, data_patch = self.pr._requester.requestJsonAndCheck(
|
||||
"PATCH", f"{self.base_url}/repos/{self.repo}/pulls/comments/{existing_comment['id']}", input={"body":comment['body']}
|
||||
)
|
||||
found = True
|
||||
break
|
||||
if not found:
|
||||
headers, data_post = self.pr._requester.requestJsonAndCheck(
|
||||
"POST", f"{self.pr.url}/comments", input=comment
|
||||
)
|
||||
return True
|
||||
except Exception as e:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().error(f"Failed to publish diffview file summary, error: {e}")
|
||||
return False
|
||||
|
||||
def remove_initial_comment(self):
|
||||
try:
|
||||
for comment in getattr(self.pr, 'comments_list', []):
|
||||
@ -461,6 +541,11 @@ class GithubProvider(GitProvider):
|
||||
def get_pr_branch(self):
|
||||
return self.pr.head.ref
|
||||
|
||||
def get_pr_owner_id(self) -> str | None:
|
||||
if not self.repo:
|
||||
return None
|
||||
return self.repo.split('/')[0]
|
||||
|
||||
def get_pr_description_full(self):
|
||||
return self.pr.body
|
||||
|
||||
@ -495,6 +580,9 @@ class GithubProvider(GitProvider):
|
||||
except Exception:
|
||||
return ""
|
||||
|
||||
def get_workspace_name(self):
|
||||
return self.repo.split('/')[0]
|
||||
|
||||
def add_eyes_reaction(self, issue_comment_id: int, disable_eyes: bool = False) -> Optional[int]:
|
||||
if disable_eyes:
|
||||
return None
|
||||
@ -505,7 +593,7 @@ class GithubProvider(GitProvider):
|
||||
)
|
||||
return data_patch.get("id", None)
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Failed to add eyes reaction, error: {e}")
|
||||
get_logger().warning(f"Failed to add eyes reaction, error: {e}")
|
||||
return None
|
||||
|
||||
def remove_reaction(self, issue_comment_id: int, reaction_id: str) -> bool:
|
||||
@ -520,15 +608,11 @@ class GithubProvider(GitProvider):
|
||||
get_logger().exception(f"Failed to remove eyes reaction, error: {e}")
|
||||
return False
|
||||
|
||||
@staticmethod
|
||||
def _parse_pr_url(pr_url: str) -> Tuple[str, int]:
|
||||
def _parse_pr_url(self, pr_url: str) -> Tuple[str, int]:
|
||||
parsed_url = urlparse(pr_url)
|
||||
|
||||
if 'github.com' not in parsed_url.netloc:
|
||||
raise ValueError("The provided URL is not a valid GitHub URL")
|
||||
|
||||
path_parts = parsed_url.path.strip('/').split('/')
|
||||
if 'api.github.com' in parsed_url.netloc:
|
||||
if self.base_domain in parsed_url.netloc:
|
||||
if len(path_parts) < 5 or path_parts[3] != 'pulls':
|
||||
raise ValueError("The provided URL does not appear to be a GitHub PR URL")
|
||||
repo_name = '/'.join(path_parts[1:3])
|
||||
@ -549,15 +633,10 @@ class GithubProvider(GitProvider):
|
||||
|
||||
return repo_name, pr_number
|
||||
|
||||
@staticmethod
|
||||
def _parse_issue_url(issue_url: str) -> Tuple[str, int]:
|
||||
def _parse_issue_url(self, issue_url: str) -> Tuple[str, int]:
|
||||
parsed_url = urlparse(issue_url)
|
||||
|
||||
if 'github.com' not in parsed_url.netloc:
|
||||
raise ValueError("The provided URL is not a valid GitHub URL")
|
||||
|
||||
path_parts = parsed_url.path.strip('/').split('/')
|
||||
if 'api.github.com' in parsed_url.netloc:
|
||||
if self.base_domain in parsed_url.netloc:
|
||||
if len(path_parts) < 5 or path_parts[3] != 'issues':
|
||||
raise ValueError("The provided URL does not appear to be a GitHub ISSUE URL")
|
||||
repo_name = '/'.join(path_parts[1:3])
|
||||
@ -658,7 +737,7 @@ class GithubProvider(GitProvider):
|
||||
"PUT", f"{self.pr.issue_url}/labels", input=post_parameters
|
||||
)
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Failed to publish labels, error: {e}")
|
||||
get_logger().warning(f"Failed to publish labels, error: {e}")
|
||||
|
||||
def get_pr_labels(self, update=False):
|
||||
try:
|
||||
@ -676,7 +755,7 @@ class GithubProvider(GitProvider):
|
||||
|
||||
def get_repo_labels(self):
|
||||
labels = self.repo_obj.get_labels()
|
||||
return [label for label in labels]
|
||||
return [label for label in itertools.islice(labels, 50)]
|
||||
|
||||
def get_commit_messages(self):
|
||||
"""
|
||||
@ -731,6 +810,32 @@ class GithubProvider(GitProvider):
|
||||
link = f"{self.base_url_html}/{self.repo}/pull/{self.pr_num}/files#diff-{sha_file}R{relevant_line_start}"
|
||||
return link
|
||||
|
||||
def get_lines_link_original_file(self, filepath: str, component_range: Range) -> str:
|
||||
"""
|
||||
Returns the link to the original file on GitHub that corresponds to the given filepath and component range.
|
||||
|
||||
Args:
|
||||
filepath (str): The path of the file.
|
||||
component_range (Range): The range of lines that represent the component.
|
||||
|
||||
Returns:
|
||||
str: The link to the original file on GitHub.
|
||||
|
||||
Example:
|
||||
>>> filepath = "path/to/file.py"
|
||||
>>> component_range = Range(line_start=10, line_end=20)
|
||||
>>> link = get_lines_link_original_file(filepath, component_range)
|
||||
>>> print(link)
|
||||
"https://github.com/{repo}/blob/{commit_sha}/{filepath}/#L11-L21"
|
||||
"""
|
||||
line_start = component_range.line_start + 1
|
||||
line_end = component_range.line_end + 1
|
||||
# link = (f"https://github.com/{self.repo}/blob/{self.last_commit_id.sha}/{filepath}/"
|
||||
# f"#L{line_start}-L{line_end}")
|
||||
link = (f"{self.base_url_html}/{self.repo}/blob/{self.last_commit_id.sha}/{filepath}/"
|
||||
f"#L{line_start}-L{line_end}")
|
||||
|
||||
return link
|
||||
|
||||
def get_pr_id(self):
|
||||
try:
|
||||
@ -750,4 +855,4 @@ class GithubProvider(GitProvider):
|
||||
return False
|
||||
|
||||
def calc_pr_statistics(self, pull_request_data: dict):
|
||||
return {}
|
||||
return {}
|
||||
|
||||
@ -4,13 +4,14 @@ from typing import Optional, Tuple
|
||||
from urllib.parse import urlparse
|
||||
|
||||
import gitlab
|
||||
import requests
|
||||
from gitlab import GitlabGetError
|
||||
|
||||
from ..algo.file_filter import filter_ignored
|
||||
from ..algo.language_handler import is_valid_file
|
||||
from ..algo.utils import load_large_diff, clip_tokens, find_line_number_of_relevant_line_in_file
|
||||
from ..config_loader import get_settings
|
||||
from .git_provider import GitProvider
|
||||
from .git_provider import GitProvider, MAX_FILES_ALLOWED_FULL
|
||||
from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
|
||||
from ..log import get_logger
|
||||
|
||||
@ -25,6 +26,7 @@ class GitLabProvider(GitProvider):
|
||||
gitlab_url = get_settings().get("GITLAB.URL", None)
|
||||
if not gitlab_url:
|
||||
raise ValueError("GitLab URL is not set in the config file")
|
||||
self.gitlab_url = gitlab_url
|
||||
gitlab_access_token = get_settings().get("GITLAB.PERSONAL_ACCESS_TOKEN", None)
|
||||
if not gitlab_access_token:
|
||||
raise ValueError("GitLab personal access token is not set in the config file")
|
||||
@ -32,6 +34,7 @@ class GitLabProvider(GitProvider):
|
||||
url=gitlab_url,
|
||||
oauth_token=gitlab_access_token
|
||||
)
|
||||
self.max_comment_chars = 65000
|
||||
self.id_project = None
|
||||
self.id_mr = None
|
||||
self.mr = None
|
||||
@ -45,7 +48,8 @@ class GitLabProvider(GitProvider):
|
||||
self.incremental = incremental
|
||||
|
||||
def is_supported(self, capability: str) -> bool:
|
||||
if capability in ['get_issue_comments', 'create_inline_comment', 'publish_inline_comments']: # gfm_markdown is supported in gitlab !
|
||||
if capability in ['get_issue_comments', 'create_inline_comment', 'publish_inline_comments',
|
||||
'publish_file_comments']: # gfm_markdown is supported in gitlab !
|
||||
return False
|
||||
return True
|
||||
|
||||
@ -101,13 +105,23 @@ class GitLabProvider(GitProvider):
|
||||
|
||||
diff_files = []
|
||||
invalid_files_names = []
|
||||
counter_valid = 0
|
||||
for diff in diffs:
|
||||
if not is_valid_file(diff['new_path']):
|
||||
invalid_files_names.append(diff['new_path'])
|
||||
continue
|
||||
|
||||
original_file_content_str = self.get_pr_file_content(diff['old_path'], self.mr.diff_refs['base_sha'])
|
||||
new_file_content_str = self.get_pr_file_content(diff['new_path'], self.mr.diff_refs['head_sha'])
|
||||
# allow only a limited number of files to be fully loaded. We can manage the rest with diffs only
|
||||
counter_valid += 1
|
||||
if counter_valid < MAX_FILES_ALLOWED_FULL or not diff['diff']:
|
||||
original_file_content_str = self.get_pr_file_content(diff['old_path'], self.mr.diff_refs['base_sha'])
|
||||
new_file_content_str = self.get_pr_file_content(diff['new_path'], self.mr.diff_refs['head_sha'])
|
||||
else:
|
||||
if counter_valid == MAX_FILES_ALLOWED_FULL:
|
||||
get_logger().info(f"Too many files in PR, will avoid loading full content for rest of files")
|
||||
original_file_content_str = ''
|
||||
new_file_content_str = ''
|
||||
|
||||
try:
|
||||
if isinstance(original_file_content_str, bytes):
|
||||
original_file_content_str = bytes.decode(original_file_content_str, 'utf-8')
|
||||
@ -176,28 +190,33 @@ class GitLabProvider(GitProvider):
|
||||
self.publish_persistent_comment_full(pr_comment, initial_header, update_header, name, final_update_message)
|
||||
|
||||
def publish_comment(self, mr_comment: str, is_temporary: bool = False):
|
||||
mr_comment = self.limit_output_characters(mr_comment, self.max_comment_chars)
|
||||
comment = self.mr.notes.create({'body': mr_comment})
|
||||
if is_temporary:
|
||||
self.temp_comments.append(comment)
|
||||
return comment
|
||||
|
||||
def edit_comment(self, comment, body: str):
|
||||
body = self.limit_output_characters(body, self.max_comment_chars)
|
||||
self.mr.notes.update(comment.id,{'body': body} )
|
||||
|
||||
def edit_comment_from_comment_id(self, comment_id: int, body: str):
|
||||
body = self.limit_output_characters(body, self.max_comment_chars)
|
||||
comment = self.mr.notes.get(comment_id)
|
||||
comment.body = body
|
||||
comment.save()
|
||||
|
||||
def reply_to_comment_from_comment_id(self, comment_id: int, body: str):
|
||||
body = self.limit_output_characters(body, self.max_comment_chars)
|
||||
discussion = self.mr.discussions.get(comment_id)
|
||||
discussion.notes.create({'body': body})
|
||||
|
||||
def publish_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
||||
def publish_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str, original_suggestion=None):
|
||||
body = self.limit_output_characters(body, self.max_comment_chars)
|
||||
edit_type, found, source_line_no, target_file, target_line_no = self.search_line(relevant_file,
|
||||
relevant_line_in_file)
|
||||
self.send_inline_comment(body, edit_type, found, relevant_file, relevant_line_in_file, source_line_no,
|
||||
target_file, target_line_no)
|
||||
target_file, target_line_no, original_suggestion)
|
||||
|
||||
def create_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str, absolute_position: int = None):
|
||||
raise NotImplementedError("Gitlab provider does not support creating inline comments yet")
|
||||
@ -206,11 +225,13 @@ class GitLabProvider(GitProvider):
|
||||
raise NotImplementedError("Gitlab provider does not support publishing inline comments yet")
|
||||
|
||||
def get_comment_body_from_comment_id(self, comment_id: int):
|
||||
comment = self.mr.notes.get(comment_id)
|
||||
comment = self.mr.notes.get(comment_id).body
|
||||
return comment
|
||||
|
||||
def send_inline_comment(self,body: str,edit_type: str,found: bool,relevant_file: str,relevant_line_in_file: int,
|
||||
source_line_no: int, target_file: str,target_line_no: int) -> None:
|
||||
def send_inline_comment(self, body: str, edit_type: str, found: bool, relevant_file: str,
|
||||
relevant_line_in_file: str,
|
||||
source_line_no: int, target_file: str, target_line_no: int,
|
||||
original_suggestion=None) -> None:
|
||||
if not found:
|
||||
get_logger().info(f"Could not find position for {relevant_file} {relevant_line_in_file}")
|
||||
else:
|
||||
@ -230,14 +251,63 @@ class GitLabProvider(GitProvider):
|
||||
else:
|
||||
pos_obj['new_line'] = target_line_no - 1
|
||||
pos_obj['old_line'] = source_line_no - 1
|
||||
get_logger().debug(f"Creating comment in {self.id_mr} with body {body} and position {pos_obj}")
|
||||
get_logger().debug(f"Creating comment in MR {self.id_mr} with body {body} and position {pos_obj}")
|
||||
try:
|
||||
self.mr.discussions.create({'body': body, 'position': pos_obj})
|
||||
except Exception as e:
|
||||
get_logger().debug(
|
||||
f"Failed to create comment in {self.id_mr} with position {pos_obj} (probably not a '+' line)")
|
||||
try:
|
||||
# fallback - create a general note on the file in the MR
|
||||
if 'suggestion_orig_location' in original_suggestion:
|
||||
line_start = original_suggestion['suggestion_orig_location']['start_line']
|
||||
line_end = original_suggestion['suggestion_orig_location']['end_line']
|
||||
old_code_snippet = original_suggestion['prev_code_snippet']
|
||||
new_code_snippet = original_suggestion['new_code_snippet']
|
||||
content = original_suggestion['suggestion_summary']
|
||||
label = original_suggestion['category']
|
||||
if 'score' in original_suggestion:
|
||||
score = original_suggestion['score']
|
||||
else:
|
||||
score = 7
|
||||
else:
|
||||
line_start = original_suggestion['relevant_lines_start']
|
||||
line_end = original_suggestion['relevant_lines_end']
|
||||
old_code_snippet = original_suggestion['existing_code']
|
||||
new_code_snippet = original_suggestion['improved_code']
|
||||
content = original_suggestion['suggestion_content']
|
||||
label = original_suggestion['label']
|
||||
if 'score' in original_suggestion:
|
||||
score = original_suggestion['score']
|
||||
else:
|
||||
score = 7
|
||||
|
||||
def get_relevant_diff(self, relevant_file: str, relevant_line_in_file: int) -> Optional[dict]:
|
||||
if hasattr(self, 'main_language'):
|
||||
language = self.main_language
|
||||
else:
|
||||
language = ''
|
||||
link = self.get_line_link(relevant_file, line_start, line_end)
|
||||
body_fallback =f"**Suggestion:** {content} [{label}, importance: {score}]\n___\n"
|
||||
body_fallback +=f"\n\nReplace lines ([{line_start}-{line_end}]({link}))\n\n```{language}\n{old_code_snippet}\n````\n\n"
|
||||
body_fallback +=f"with\n\n```{language}\n{new_code_snippet}\n````"
|
||||
body_fallback += f"\n\n___\n\n`(Cannot implement this suggestion directly, as gitlab API does not enable committing to a non -+ line in a PR)`"
|
||||
|
||||
# Create a general note on the file in the MR
|
||||
self.mr.notes.create({
|
||||
'body': body_fallback,
|
||||
'position': {
|
||||
'base_sha': diff.base_commit_sha,
|
||||
'start_sha': diff.start_commit_sha,
|
||||
'head_sha': diff.head_commit_sha,
|
||||
'position_type': 'text',
|
||||
'file_path': f'{target_file.filename}',
|
||||
}
|
||||
})
|
||||
|
||||
# get_logger().debug(
|
||||
# f"Failed to create comment in MR {self.id_mr} with position {pos_obj} (probably not a '+' line)")
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Failed to create comment in MR {self.id_mr}")
|
||||
|
||||
def get_relevant_diff(self, relevant_file: str, relevant_line_in_file: str) -> Optional[dict]:
|
||||
changes = self.mr.changes() # Retrieve the changes for the merge request once
|
||||
if not changes:
|
||||
get_logger().error('No changes found for the merge request.')
|
||||
@ -257,6 +327,10 @@ class GitLabProvider(GitProvider):
|
||||
def publish_code_suggestions(self, code_suggestions: list) -> bool:
|
||||
for suggestion in code_suggestions:
|
||||
try:
|
||||
if suggestion and 'original_suggestion' in suggestion:
|
||||
original_suggestion = suggestion['original_suggestion']
|
||||
else:
|
||||
original_suggestion = suggestion
|
||||
body = suggestion['body']
|
||||
relevant_file = suggestion['relevant_file']
|
||||
relevant_lines_start = suggestion['relevant_lines_start']
|
||||
@ -277,19 +351,22 @@ class GitLabProvider(GitProvider):
|
||||
# edit_type, found, source_line_no, target_file, target_line_no = self.find_in_file(target_file,
|
||||
# relevant_line_in_file)
|
||||
# for code suggestions, we want to edit the new code
|
||||
source_line_no = None
|
||||
source_line_no = -1
|
||||
target_line_no = relevant_lines_start + 1
|
||||
found = True
|
||||
edit_type = 'addition'
|
||||
|
||||
self.send_inline_comment(body, edit_type, found, relevant_file, relevant_line_in_file, source_line_no,
|
||||
target_file, target_line_no)
|
||||
target_file, target_line_no, original_suggestion)
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Could not publish code suggestion:\nsuggestion: {suggestion}\nerror: {e}")
|
||||
|
||||
# note that we publish suggestions one-by-one. so, if one fails, the rest will still be published
|
||||
return True
|
||||
|
||||
def publish_file_comments(self, file_comments: list) -> bool:
|
||||
pass
|
||||
|
||||
def search_line(self, relevant_file, relevant_line_in_file):
|
||||
target_file = None
|
||||
|
||||
@ -367,6 +444,15 @@ class GitLabProvider(GitProvider):
|
||||
def get_pr_branch(self):
|
||||
return self.mr.source_branch
|
||||
|
||||
def get_pr_owner_id(self) -> str | None:
|
||||
if not self.gitlab_url or 'gitlab.com' in self.gitlab_url:
|
||||
if not self.id_project:
|
||||
return None
|
||||
return self.id_project.split('/')[0]
|
||||
# extract host name
|
||||
host = urlparse(self.gitlab_url).hostname
|
||||
return host
|
||||
|
||||
def get_pr_description_full(self):
|
||||
return self.mr.description
|
||||
|
||||
@ -380,6 +466,9 @@ class GitLabProvider(GitProvider):
|
||||
except Exception:
|
||||
return ""
|
||||
|
||||
def get_workspace_name(self):
|
||||
return self.id_project.split('/')[0]
|
||||
|
||||
def add_eyes_reaction(self, issue_comment_id: int, disable_eyes: bool = False) -> Optional[int]:
|
||||
return True
|
||||
|
||||
@ -423,7 +512,7 @@ class GitLabProvider(GitProvider):
|
||||
self.mr.labels = list(set(pr_types))
|
||||
self.mr.save()
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Failed to publish labels, error: {e}")
|
||||
get_logger().warning(f"Failed to publish labels, error: {e}")
|
||||
|
||||
def publish_inline_comments(self, comments: list[dict]):
|
||||
pass
|
||||
|
||||
@ -119,7 +119,7 @@ class LocalGitProvider(GitProvider):
|
||||
# Write the string to the file
|
||||
file.write(pr_comment)
|
||||
|
||||
def publish_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
||||
def publish_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str, original_suggestion=None):
|
||||
raise NotImplementedError('Publishing inline comments is not implemented for the local git provider')
|
||||
|
||||
def publish_inline_comments(self, comments: list[dict]):
|
||||
|
||||
@ -47,3 +47,17 @@ def apply_repo_settings(pr_url):
|
||||
os.remove(repo_settings_file)
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to remove temporary settings file {repo_settings_file}", e)
|
||||
|
||||
# enable switching models with a short definition
|
||||
if get_settings().config.model.lower()=='claude-3-5-sonnet':
|
||||
set_claude_model()
|
||||
|
||||
|
||||
def set_claude_model():
|
||||
"""
|
||||
set the claude-sonnet-3.5 model easily (even by users), just by stating: --config.model='claude-3-5-sonnet'
|
||||
"""
|
||||
model_claude = "bedrock/anthropic.claude-3-5-sonnet-20240620-v1:0"
|
||||
get_settings().set('config.model', model_claude)
|
||||
get_settings().set('config.model_turbo', model_claude)
|
||||
get_settings().set('config.fallback_models', [model_claude])
|
||||
|
||||
@ -22,7 +22,7 @@ class GoogleCloudStorageSecretProvider(SecretProvider):
|
||||
blob = self.bucket.blob(secret_name)
|
||||
return blob.download_as_string()
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to get secret {secret_name} from Google Cloud Storage: {e}")
|
||||
get_logger().warning(f"Failed to get secret {secret_name} from Google Cloud Storage: {e}")
|
||||
return ""
|
||||
|
||||
def store_secret(self, secret_name: str, secret_value: str):
|
||||
|
||||
@ -93,7 +93,8 @@ async def _perform_commands_bitbucket(commands_conf: str, agent: PRAgent, api_ur
|
||||
|
||||
@router.post("/webhook")
|
||||
async def handle_github_webhooks(background_tasks: BackgroundTasks, request: Request):
|
||||
log_context = {"server_type": "bitbucket_app"}
|
||||
app_name = get_settings().get("CONFIG.APP_NAME", "Unknown")
|
||||
log_context = {"server_type": "bitbucket_app", "app_name": app_name}
|
||||
get_logger().debug(request.headers)
|
||||
jwt_header = request.headers.get("authorization", None)
|
||||
if jwt_header:
|
||||
@ -107,13 +108,18 @@ async def handle_github_webhooks(background_tasks: BackgroundTasks, request: Req
|
||||
return "OK"
|
||||
except KeyError:
|
||||
get_logger().error("Failed to get actor type, check previous logs, this shouldn't happen.")
|
||||
|
||||
# Get the username of the sender
|
||||
try:
|
||||
owner = data["data"]["repository"]["owner"]["username"]
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to get owner, will continue: {e}")
|
||||
owner = "unknown"
|
||||
username = data["data"]["actor"]["username"]
|
||||
except KeyError:
|
||||
try:
|
||||
username = data["data"]["actor"]["display_name"]
|
||||
except KeyError:
|
||||
username = data["data"]["actor"]["nickname"]
|
||||
log_context["sender"] = username
|
||||
|
||||
sender_id = data["data"]["actor"]["account_id"]
|
||||
log_context["sender"] = owner
|
||||
log_context["sender_id"] = sender_id
|
||||
jwt_parts = input_jwt.split(".")
|
||||
claim_part = jwt_parts[1]
|
||||
|
||||
@ -1,5 +1,7 @@
|
||||
import ast
|
||||
import json
|
||||
import os
|
||||
from typing import List
|
||||
|
||||
import uvicorn
|
||||
from fastapi import APIRouter, FastAPI
|
||||
@ -10,11 +12,14 @@ from starlette.middleware import Middleware
|
||||
from starlette.requests import Request
|
||||
from starlette.responses import JSONResponse
|
||||
from starlette_context.middleware import RawContextMiddleware
|
||||
|
||||
from pr_agent.agent.pr_agent import PRAgent
|
||||
from pr_agent.algo.utils import update_settings_from_args
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers.utils import apply_repo_settings
|
||||
from pr_agent.log import LoggingFormat, get_logger, setup_logger
|
||||
from pr_agent.servers.utils import verify_signature
|
||||
from fastapi.responses import RedirectResponse
|
||||
|
||||
|
||||
setup_logger(fmt=LoggingFormat.JSON, level="DEBUG")
|
||||
router = APIRouter()
|
||||
@ -25,7 +30,7 @@ def handle_request(
|
||||
):
|
||||
log_context["action"] = body
|
||||
log_context["api_url"] = url
|
||||
|
||||
|
||||
async def inner():
|
||||
try:
|
||||
with get_logger().contextualize(**log_context):
|
||||
@ -35,8 +40,11 @@ def handle_request(
|
||||
|
||||
background_tasks.add_task(inner)
|
||||
|
||||
|
||||
@router.post("/")
|
||||
async def redirect_to_webhook():
|
||||
return RedirectResponse(url="/webhook")
|
||||
|
||||
@router.post("/webhook")
|
||||
async def handle_webhook(background_tasks: BackgroundTasks, request: Request):
|
||||
log_context = {"server_type": "bitbucket_server"}
|
||||
data = await request.json()
|
||||
@ -45,6 +53,10 @@ async def handle_webhook(background_tasks: BackgroundTasks, request: Request):
|
||||
webhook_secret = get_settings().get("BITBUCKET_SERVER.WEBHOOK_SECRET", None)
|
||||
if webhook_secret:
|
||||
body_bytes = await request.body()
|
||||
if body_bytes.decode('utf-8') == '{"test": true}':
|
||||
return JSONResponse(
|
||||
status_code=status.HTTP_200_OK, content=jsonable_encoder({"message": "connection test successful"})
|
||||
)
|
||||
signature_header = request.headers.get("x-hub-signature", None)
|
||||
verify_signature(body_bytes, webhook_secret, signature_header)
|
||||
|
||||
@ -57,22 +69,81 @@ async def handle_webhook(background_tasks: BackgroundTasks, request: Request):
|
||||
log_context["api_url"] = pr_url
|
||||
log_context["event"] = "pull_request"
|
||||
|
||||
commands_to_run = []
|
||||
|
||||
if data["eventKey"] == "pr:opened":
|
||||
body = "review"
|
||||
commands_to_run.extend(_get_commands_list_from_settings('BITBUCKET_SERVER.PR_COMMANDS'))
|
||||
elif data["eventKey"] == "pr:comment:added":
|
||||
body = data["comment"]["text"]
|
||||
commands_to_run.append(data["comment"]["text"])
|
||||
else:
|
||||
return JSONResponse(
|
||||
status_code=status.HTTP_400_BAD_REQUEST,
|
||||
content=json.dumps({"message": "Unsupported event"}),
|
||||
)
|
||||
|
||||
handle_request(background_tasks, pr_url, body, log_context)
|
||||
async def inner():
|
||||
try:
|
||||
await _run_commands_sequentially(commands_to_run, pr_url, log_context)
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to handle webhook: {e}")
|
||||
|
||||
background_tasks.add_task(inner)
|
||||
|
||||
return JSONResponse(
|
||||
status_code=status.HTTP_200_OK, content=jsonable_encoder({"message": "success"})
|
||||
)
|
||||
|
||||
|
||||
async def _run_commands_sequentially(commands: List[str], url: str, log_context: dict):
|
||||
get_logger().info(f"Running commands sequentially: {commands}")
|
||||
if commands is None:
|
||||
return
|
||||
|
||||
for command in commands:
|
||||
try:
|
||||
body = _process_command(command, url)
|
||||
|
||||
log_context["action"] = body
|
||||
log_context["api_url"] = url
|
||||
|
||||
with get_logger().contextualize(**log_context):
|
||||
await PRAgent().handle_request(url, body)
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to handle command: {command} , error: {e}")
|
||||
|
||||
def _process_command(command: str, url) -> str:
|
||||
# don't think we need this
|
||||
apply_repo_settings(url)
|
||||
# Process the command string
|
||||
split_command = command.split(" ")
|
||||
command = split_command[0]
|
||||
args = split_command[1:]
|
||||
# do I need this? if yes, shouldn't this be done in PRAgent?
|
||||
other_args = update_settings_from_args(args)
|
||||
new_command = ' '.join([command] + other_args)
|
||||
return new_command
|
||||
|
||||
|
||||
def _to_list(command_string: str) -> list:
|
||||
try:
|
||||
# Use ast.literal_eval to safely parse the string into a list
|
||||
commands = ast.literal_eval(command_string)
|
||||
# Check if the parsed object is a list of strings
|
||||
if isinstance(commands, list) and all(isinstance(cmd, str) for cmd in commands):
|
||||
return commands
|
||||
else:
|
||||
raise ValueError("Parsed data is not a list of strings.")
|
||||
except (SyntaxError, ValueError, TypeError) as e:
|
||||
raise ValueError(f"Invalid command string: {e}")
|
||||
|
||||
|
||||
def _get_commands_list_from_settings(setting_key:str ) -> list:
|
||||
try:
|
||||
return get_settings().get(setting_key, [])
|
||||
except ValueError as e:
|
||||
get_logger().error(f"Failed to get commands list from settings {setting_key}: {e}")
|
||||
|
||||
|
||||
@router.get("/")
|
||||
async def root():
|
||||
return {"status": "ok"}
|
||||
|
||||
@ -37,7 +37,7 @@ async def run_action():
|
||||
OPENAI_KEY = os.environ.get('OPENAI_KEY') or os.environ.get('OPENAI.KEY')
|
||||
OPENAI_ORG = os.environ.get('OPENAI_ORG') or os.environ.get('OPENAI.ORG')
|
||||
GITHUB_TOKEN = os.environ.get('GITHUB_TOKEN')
|
||||
get_settings().set("CONFIG.PUBLISH_OUTPUT_PROGRESS", False)
|
||||
# get_settings().set("CONFIG.PUBLISH_OUTPUT_PROGRESS", False)
|
||||
|
||||
# Check if required environment variables are set
|
||||
if not GITHUB_EVENT_NAME:
|
||||
|
||||
@ -349,7 +349,7 @@ async def root():
|
||||
if get_settings().github_app.override_deployment_type:
|
||||
# Override the deployment type to app
|
||||
get_settings().set("GITHUB.DEPLOYMENT_TYPE", "app")
|
||||
get_settings().set("CONFIG.PUBLISH_OUTPUT_PROGRESS", False)
|
||||
# get_settings().set("CONFIG.PUBLISH_OUTPUT_PROGRESS", False)
|
||||
middleware = [Middleware(RawContextMiddleware)]
|
||||
app = FastAPI(middleware=middleware)
|
||||
app.include_router(router)
|
||||
|
||||
@ -1,4 +1,5 @@
|
||||
import asyncio
|
||||
import traceback
|
||||
from datetime import datetime, timezone
|
||||
|
||||
import aiohttp
|
||||
@ -15,7 +16,7 @@ NOTIFICATION_URL = "https://api.github.com/notifications"
|
||||
def now() -> str:
|
||||
"""
|
||||
Get the current UTC time in ISO 8601 format.
|
||||
|
||||
|
||||
Returns:
|
||||
str: The current UTC time in ISO 8601 format.
|
||||
"""
|
||||
@ -35,6 +36,7 @@ async def polling_loop():
|
||||
user_id = git_provider.get_user_id()
|
||||
agent = PRAgent()
|
||||
get_settings().set("CONFIG.PUBLISH_OUTPUT_PROGRESS", False)
|
||||
get_settings().set("pr_description.publish_description_as_comment", True)
|
||||
|
||||
try:
|
||||
deployment_type = get_settings().github.deployment_type
|
||||
@ -78,6 +80,8 @@ async def polling_loop():
|
||||
if 'subject' in notification and notification['subject']['type'] == 'PullRequest':
|
||||
pr_url = notification['subject']['url']
|
||||
latest_comment = notification['subject']['latest_comment_url']
|
||||
if not latest_comment or not isinstance(latest_comment, str):
|
||||
continue
|
||||
async with session.get(latest_comment, headers=headers) as comment_response:
|
||||
if comment_response.status == 200:
|
||||
comment = await comment_response.json()
|
||||
@ -89,10 +93,13 @@ async def polling_loop():
|
||||
if 'user' in comment and 'login' in comment['user']:
|
||||
if comment['user']['login'] == user_id:
|
||||
continue
|
||||
comment_body = comment['body'] if 'body' in comment else ''
|
||||
comment_body = comment.get('body', '')
|
||||
if not comment_body:
|
||||
continue
|
||||
commenter_github_user = comment['user']['login'] \
|
||||
if 'user' in comment else ''
|
||||
get_logger().info(f"Commenter: {commenter_github_user}\nComment: {comment_body}")
|
||||
get_logger().info(f"Polling, pr_url: {pr_url}",
|
||||
artifact={"comment": comment_body})
|
||||
user_tag = "@" + user_id
|
||||
if user_tag not in comment_body:
|
||||
continue
|
||||
@ -100,7 +107,8 @@ async def polling_loop():
|
||||
comment_id = comment['id']
|
||||
git_provider.set_pr(pr_url)
|
||||
success = await agent.handle_request(pr_url, rest_of_comment,
|
||||
notify=lambda: git_provider.add_eyes_reaction(comment_id)) # noqa E501
|
||||
notify=lambda: git_provider.add_eyes_reaction(
|
||||
comment_id)) # noqa E501
|
||||
if not success:
|
||||
git_provider.set_pr(pr_url)
|
||||
|
||||
@ -108,7 +116,8 @@ async def polling_loop():
|
||||
print(f"Failed to fetch notifications. Status code: {response.status}")
|
||||
|
||||
except Exception as e:
|
||||
get_logger().error(f"Exception during processing of a notification: {e}")
|
||||
get_logger().error(f"Polling exception during processing of a notification: {e}",
|
||||
artifact={"traceback": traceback.format_exc()})
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
||||
@ -51,6 +51,7 @@ async def handle_request(api_url: str, body: str, log_context: dict, sender_id:
|
||||
log_context["action"] = body
|
||||
log_context["event"] = "pull_request" if body == "/review" else "comment"
|
||||
log_context["api_url"] = api_url
|
||||
log_context["app_name"] = get_settings().get("CONFIG.APP_NAME", "Unknown")
|
||||
|
||||
with get_logger().contextualize(**log_context):
|
||||
await PRAgent().handle_request(api_url, body)
|
||||
@ -86,6 +87,10 @@ async def gitlab_webhook(background_tasks: BackgroundTasks, request: Request):
|
||||
if request.headers.get("X-Gitlab-Token") and secret_provider:
|
||||
request_token = request.headers.get("X-Gitlab-Token")
|
||||
secret = secret_provider.get_secret(request_token)
|
||||
if not secret:
|
||||
get_logger().warning(f"Empty secret retrieved, request_token: {request_token}")
|
||||
return JSONResponse(status_code=status.HTTP_401_UNAUTHORIZED,
|
||||
content=jsonable_encoder({"message": "unauthorized"}))
|
||||
try:
|
||||
secret_dict = json.loads(secret)
|
||||
gitlab_token = secret_dict["gitlab_token"]
|
||||
@ -121,12 +126,19 @@ async def gitlab_webhook(background_tasks: BackgroundTasks, request: Request):
|
||||
log_context["sender"] = sender
|
||||
if data.get('object_kind') == 'merge_request' and data['object_attributes'].get('action') in ['open', 'reopen']:
|
||||
url = data['object_attributes'].get('url')
|
||||
draft = data['object_attributes'].get('draft')
|
||||
get_logger().info(f"New merge request: {url}")
|
||||
|
||||
if draft:
|
||||
get_logger().info(f"Skipping draft MR: {url}")
|
||||
return JSONResponse(status_code=status.HTTP_200_OK, content=jsonable_encoder({"message": "success"}))
|
||||
|
||||
await _perform_commands_gitlab("pr_commands", PRAgent(), url, log_context)
|
||||
elif data.get('object_kind') == 'note' and data.get('event_type') == 'note': # comment on MR
|
||||
if 'merge_request' in data:
|
||||
mr = data['merge_request']
|
||||
url = mr.get('url')
|
||||
|
||||
get_logger().info(f"A comment has been added to a merge request: {url}")
|
||||
body = data.get('object_attributes', {}).get('note')
|
||||
if data.get('object_attributes', {}).get('type') == 'DiffNote' and '/ask' in body: # /ask_line
|
||||
|
||||
@ -34,7 +34,7 @@ key = "" # Acquire through https://console.groq.com/keys
|
||||
|
||||
[huggingface]
|
||||
key = "" # Optional, uncomment if you want to use Huggingface Inference API. Acquire through https://huggingface.co/docs/api-inference/quicktour
|
||||
api_base = "" # the base url for your huggingface inference endpoint
|
||||
api_base = "" # the base url for your huggingface inference endpoint
|
||||
|
||||
[ollama]
|
||||
api_base = "" # the base url for your local Llama 2, Code Llama, and other models inference endpoint. Acquire through https://ollama.ai/
|
||||
@ -43,13 +43,10 @@ api_base = "" # the base url for your local Llama 2, Code Llama, and other model
|
||||
vertex_project = "" # the google cloud platform project name for your vertexai deployment
|
||||
vertex_location = "" # the google cloud platform location for your vertexai deployment
|
||||
|
||||
[aws]
|
||||
bedrock_region = "" # the AWS region to call Bedrock APIs
|
||||
|
||||
[github]
|
||||
# ---- Set the following only for deployment type == "user"
|
||||
user_token = "" # A GitHub personal access token with 'repo' scope.
|
||||
deployment_type = "user" #set to user by default
|
||||
deployment_type = "user" #set to user by default
|
||||
|
||||
# ---- Set the following only for deployment type == "app", see README for details.
|
||||
private_key = """\
|
||||
@ -70,7 +67,7 @@ bearer_token = ""
|
||||
|
||||
[bitbucket_server]
|
||||
# For Bitbucket Server bearer token
|
||||
auth_token = ""
|
||||
bearer_token = ""
|
||||
webhook_secret = ""
|
||||
|
||||
# For Bitbucket app
|
||||
|
||||
@ -1,20 +1,30 @@
|
||||
[config]
|
||||
# models
|
||||
model="gpt-4-turbo-2024-04-09"
|
||||
model_turbo="gpt-4o"
|
||||
fallback_models=["gpt-4-0125-preview"]
|
||||
model_turbo="gpt-4o-2024-08-06"
|
||||
fallback_models=["gpt-4o-2024-05-13"]
|
||||
# CLI
|
||||
git_provider="github"
|
||||
publish_output=true
|
||||
publish_output_progress=true
|
||||
verbosity_level=0 # 0,1,2
|
||||
use_extra_bad_extensions=false
|
||||
# Configurations
|
||||
use_wiki_settings_file=true
|
||||
use_repo_settings_file=true
|
||||
use_global_settings_file=true
|
||||
ai_timeout=120 # 2minutes
|
||||
# token limits
|
||||
max_description_tokens = 500
|
||||
max_commits_tokens = 500
|
||||
max_model_tokens = 32000 # Limits the maximum number of tokens that can be used by any model, regardless of the model's default capabilities.
|
||||
patch_extra_lines = 1
|
||||
custom_model_max_tokens=-1 # for models not in the default list
|
||||
# patch extension logic
|
||||
patch_extension_skip_types =[".md",".txt"]
|
||||
allow_dynamic_context=false
|
||||
max_extra_lines_before_dynamic_context = 10 # will try to include up to 10 extra lines before the hunk in the patch, until we reach an enclosing function or class
|
||||
patch_extra_lines_before = 3 # Number of extra lines (+3 default ones) to include before each hunk in the patch
|
||||
patch_extra_lines_after = 1 # Number of extra lines (+3 default ones) to include after each hunk in the patch
|
||||
secret_provider=""
|
||||
cli_mode=false
|
||||
ai_disclaimer_title="" # Pro feature, title for a collapsible disclaimer to AI outputs
|
||||
@ -22,6 +32,9 @@ ai_disclaimer="" # Pro feature, full text for the AI disclaimer
|
||||
output_relevant_configurations=false
|
||||
large_patch_policy = "clip" # "clip", "skip"
|
||||
is_auto_command=false
|
||||
# seed
|
||||
seed=-1 # set positive value to fix the seed (and ensure temperature=0)
|
||||
temperature=0.2
|
||||
|
||||
[pr_reviewer] # /review #
|
||||
# enable/disable features
|
||||
@ -30,6 +43,7 @@ require_tests_review=true
|
||||
require_estimate_effort_to_review=true
|
||||
require_can_be_split_review=false
|
||||
require_security_review=true
|
||||
extra_issue_links=false
|
||||
# soc2
|
||||
require_soc2_ticket=false
|
||||
soc2_ticket_prompt="Does the PR description include a link to ticket in a project management system (e.g., Jira, Asana, Trello, etc.) ?"
|
||||
@ -86,7 +100,7 @@ enable_help_text=false
|
||||
|
||||
|
||||
[pr_code_suggestions] # /improve #
|
||||
max_context_tokens=10000
|
||||
max_context_tokens=14000
|
||||
num_code_suggestions=4
|
||||
commitable_code_suggestions = false
|
||||
extra_instructions = ""
|
||||
@ -205,16 +219,9 @@ ignore_pr_title = []
|
||||
ignore_bot_pr = true
|
||||
|
||||
[gitlab]
|
||||
# URL to the gitlab service
|
||||
url = "https://gitlab.com"
|
||||
# Polling (either project id or namespace/project_name) syntax can be used
|
||||
projects_to_monitor = ['org_name/repo_name']
|
||||
# Polling trigger
|
||||
magic_word = "AutoReview"
|
||||
# Polling interval
|
||||
polling_interval_seconds = 30
|
||||
pr_commands = [
|
||||
"/describe",
|
||||
"/describe --pr_description.final_update_message=false",
|
||||
"/review --pr_reviewer.num_code_suggestions=0",
|
||||
"/improve",
|
||||
]
|
||||
@ -226,6 +233,7 @@ push_commands = [
|
||||
|
||||
[bitbucket_app]
|
||||
pr_commands = [
|
||||
"/describe --pr_description.final_update_message=false",
|
||||
"/review --pr_reviewer.num_code_suggestions=0",
|
||||
"/improve --pr_code_suggestions.commitable_code_suggestions=true --pr_code_suggestions.suggestions_score_threshold=7",
|
||||
]
|
||||
@ -250,10 +258,19 @@ pr_commands = [
|
||||
# URL to the BitBucket Server instance
|
||||
# url = "https://git.bitbucket.com"
|
||||
url = ""
|
||||
pr_commands = [
|
||||
"/describe --pr_description.final_update_message=false",
|
||||
"/review --pr_reviewer.num_code_suggestions=0",
|
||||
"/improve --pr_code_suggestions.commitable_code_suggestions=true --pr_code_suggestions.suggestions_score_threshold=7",
|
||||
]
|
||||
|
||||
[litellm]
|
||||
# use_client = false
|
||||
# drop_params = false
|
||||
enable_callbacks = false
|
||||
success_callback = []
|
||||
failure_callback = []
|
||||
service_callback = []
|
||||
|
||||
[pr_similar_issue]
|
||||
skip_comments = false
|
||||
@ -276,3 +293,7 @@ number_of_results = 5
|
||||
|
||||
[lancedb]
|
||||
uri = "./lancedb"
|
||||
|
||||
[best_practices]
|
||||
content = ""
|
||||
max_lines_allowed = 800
|
||||
|
||||
@ -56,7 +56,7 @@ Code Documentation:
|
||||
items:
|
||||
relevant file:
|
||||
type: string
|
||||
description: the relevant file full path
|
||||
description: The full file path of the relevant file.
|
||||
relevant line:
|
||||
type: integer
|
||||
description: |-
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
[pr_code_suggestions_prompt]
|
||||
system="""You are PR-Reviewer, a language model that specializes in suggesting ways to improve for a Pull Request (PR) code.
|
||||
Your task is to provide meaningful and actionable code suggestions, to improve the new code presented in a PR diff.
|
||||
system="""You are PR-Reviewer, a language model that specializes in suggesting improvements to a Pull Request (PR) code.
|
||||
Your task is to provide meaningful and actionable code suggestions, to improve the new code presented in a PR code diff (lines starting with '+').
|
||||
|
||||
|
||||
The format we will use to present the PR code diff:
|
||||
@ -9,13 +9,15 @@ The format we will use to present the PR code diff:
|
||||
|
||||
@@ ... @@ def func1():
|
||||
__new hunk__
|
||||
12 code line1 that remained unchanged in the PR
|
||||
13 +new hunk code line2 added in the PR
|
||||
14 code line3 that remained unchanged in the PR
|
||||
11 unchanged code line0 in the PR
|
||||
12 unchanged code line1 in the PR
|
||||
13 +new code line2 added in the PR
|
||||
14 unchanged code line3 in the PR
|
||||
__old hunk__
|
||||
code line1 that remained unchanged in the PR
|
||||
-old hunk code line2 that was removed in the PR
|
||||
code line3 that remained unchanged in the PR
|
||||
unchanged code line0
|
||||
unchanged code line1
|
||||
-old code line2 removed in the PR
|
||||
unchanged code line3
|
||||
|
||||
@@ ... @@ def func2():
|
||||
__new hunk__
|
||||
@ -27,20 +29,20 @@ __old hunk__
|
||||
## file: 'src/file2.py'
|
||||
...
|
||||
======
|
||||
- In this format, we separated each hunk of diff code to '__new hunk__' and '__old hunk__' sections. The '__new hunk__' section contains the new code of the chunk, and the '__old hunk__' section contains the old code, that was removed.
|
||||
- We also added line numbers for the '__new hunk__' sections, to help you refer to the code lines in your suggestions. These line numbers are not part of the actual code, and are only used for reference.
|
||||
|
||||
- In this format, we separate each hunk of diff code to '__new hunk__' and '__old hunk__' sections. The '__new hunk__' section contains the new code of the chunk, and the '__old hunk__' section contains the old code, that was removed. If no new code was added in a specific hunk, '__new hunk__' section will not be presented. If no code was removed, '__old hunk__' section will not be presented.
|
||||
- We also added line numbers for the '__new hunk__' code, to help you refer to the code lines in your suggestions. These line numbers are not part of the actual code, and should only used for reference.
|
||||
- Code lines are prefixed with symbols ('+', '-', ' '). The '+' symbol indicates new code added in the PR, the '-' symbol indicates code removed in the PR, and the ' ' symbol indicates unchanged code. \
|
||||
Suggestions should always focus on ways to improve the new code lines introduced in the PR, meaning lines in the '__new hunk__' sections that begin with a '+' symbol (after the line numbers). The '__old hunk__' sections code is for context and reference only.
|
||||
|
||||
|
||||
Specific instructions for generating code suggestions:
|
||||
- Provide up to {{ num_code_suggestions }} code suggestions. The suggestions should be diverse and insightful.
|
||||
- The suggestions should focus on improving the new code introduced the PR, meaning lines from '__new hunk__' sections, starting with '+' (after the line numbers).
|
||||
- Prioritize suggestions that address possible issues, major problems, and bugs in the PR code.
|
||||
- Provide up to {{ num_code_suggestions }} code suggestions.
|
||||
- The suggestions should be diverse and insightful. They should focus on improving only the new code introduced in the PR, meaning lines from '__new hunk__' sections, starting with '+' (after the line numbers).
|
||||
- Prioritize suggestions that address possible issues, major problems, and bugs in the PR code. Don't repeat changes already present in the PR. If there are no relevant suggestions for the PR, return an empty list.
|
||||
- Don't suggest to add docstring, type hints, or comments, or to remove unused imports.
|
||||
- Suggestions should not repeat code already present in the '__new hunk__' sections.
|
||||
- Provide the exact line numbers range (inclusive) for each suggestion. Use the line numbers from the '__new hunk__' sections.
|
||||
- When quoting variables or names from the code, use backticks (`) instead of single quote (').
|
||||
- Every time you cite variables or names from the code, use backticks ('`'). For example: 'ensure that `variable_name` is ...'
|
||||
- Take into account that you are reviewing a PR code diff, and that the entire codebase is not available for you as context. Hence, avoid suggestions that might conflict with unseen parts of the codebase.
|
||||
|
||||
|
||||
@ -57,10 +59,10 @@ Extra instructions from the user, that should be taken into account with high pr
|
||||
The output must be a YAML object equivalent to type $PRCodeSuggestions, according to the following Pydantic definitions:
|
||||
=====
|
||||
class CodeSuggestion(BaseModel):
|
||||
relevant_file: str = Field(description="the relevant file full path")
|
||||
language: str = Field(description="the code language of the relevant file")
|
||||
relevant_file: str = Field(description="The full file path of the relevant file")
|
||||
language: str = Field(description="The programming language of the relevant file")
|
||||
suggestion_content: str = Field(description="an actionable suggestion for meaningfully improving the new code introduced in the PR")
|
||||
existing_code: str = Field(description="a short code snippet, demonstrating the relevant code lines from a '__new hunk__' section. It must be without line numbers. Use abbreviations if needed")
|
||||
existing_code: str = Field(description="a short code snippet, demonstrating the relevant code lines from a '__new hunk__' section. It must be without line numbers. Quote only full code lines, not partial ones. Use abbreviations ("...") of full lines if needed")
|
||||
improved_code: str = Field(description="a new code snippet, that can be used to replace the relevant 'existing_code' lines in '__new hunk__' code after applying the suggestion")
|
||||
one_sentence_summary: str = Field(description="a short summary of the suggestion action, in a single sentence. Focus on the 'what'. Be general, and avoid method or variable names.")
|
||||
relevant_lines_start: int = Field(description="The relevant line number, from a '__new hunk__' section, where the suggestion starts (inclusive). Should be derived from the hunk line numbers, and correspond to the 'existing code' snippet above")
|
||||
@ -97,7 +99,7 @@ code_suggestions:
|
||||
Each YAML output MUST be after a newline, indented, with block scalar indicator ('|').
|
||||
"""
|
||||
|
||||
user="""PR Info:
|
||||
user="""--PR Info--
|
||||
|
||||
Title: '{{title}}'
|
||||
|
||||
@ -114,8 +116,8 @@ Response (should be a valid YAML, and nothing else):
|
||||
|
||||
|
||||
[pr_code_suggestions_prompt_claude]
|
||||
system="""You are PR-Reviewer, a language model that specializes in suggesting ways to improve for a Pull Request (PR) code.
|
||||
Your task is to provide meaningful and actionable code suggestions, to improve the new code presented in a PR diff.
|
||||
system="""You are PR-Reviewer, a language model that specializes in suggesting improvements to a Pull Request (PR) code.
|
||||
Your task is to provide meaningful and actionable code suggestions, to improve the new code presented in a PR code diff (lines starting with '+').
|
||||
|
||||
|
||||
The format we will use to present the PR code diff:
|
||||
@ -124,13 +126,15 @@ The format we will use to present the PR code diff:
|
||||
|
||||
@@ ... @@ def func1():
|
||||
__new hunk__
|
||||
12 code line1 that remained unchanged in the PR
|
||||
13 +new hunk code line2 added in the PR
|
||||
14 code line3 that remained unchanged in the PR
|
||||
11 unchanged code line0 in the PR
|
||||
12 unchanged code line1 in the PR
|
||||
13 +new code line2 added in the PR
|
||||
14 unchanged code line3 in the PR
|
||||
__old hunk__
|
||||
code line1 that remained unchanged in the PR
|
||||
-old hunk code line2 that was removed in the PR
|
||||
code line3 that remained unchanged in the PR
|
||||
unchanged code line0
|
||||
unchanged code line1
|
||||
-old code line2 removed in the PR
|
||||
unchanged code line3
|
||||
|
||||
@@ ... @@ def func2():
|
||||
__new hunk__
|
||||
@ -142,19 +146,19 @@ __old hunk__
|
||||
## file: 'src/file2.py'
|
||||
...
|
||||
======
|
||||
- In this format, we separated each hunk of diff code to '__new hunk__' and '__old hunk__' sections. The '__new hunk__' section contains the new code of the chunk, and the '__old hunk__' section contains the old code, that was removed.
|
||||
- We also added line numbers for the '__new hunk__' sections, to help you refer to the code lines in your suggestions. These line numbers are not part of the actual code, and are only used for reference.
|
||||
|
||||
- In this format, we separate each hunk of diff code to '__new hunk__' and '__old hunk__' sections. The '__new hunk__' section contains the new code of the chunk, and the '__old hunk__' section contains the old code, that was removed. If no new code was added in a specific hunk, '__new hunk__' section will not be presented. If no code was removed, '__old hunk__' section will not be presented.
|
||||
- We also added line numbers for the '__new hunk__' code, to help you refer to the code lines in your suggestions. These line numbers are not part of the actual code, and should only used for reference.
|
||||
- Code lines are prefixed with symbols ('+', '-', ' '). The '+' symbol indicates new code added in the PR, the '-' symbol indicates code removed in the PR, and the ' ' symbol indicates unchanged code. \
|
||||
Suggestions should always focus on ways to improve the new code lines introduced in the PR, meaning lines in the '__new hunk__' sections that begin with a '+' symbol (after the line numbers). The '__old hunk__' sections code is for context and reference only.
|
||||
|
||||
|
||||
Specific instructions for generating code suggestions:
|
||||
- Provide up to {{ num_code_suggestions }} code suggestions. The suggestions should be diverse and insightful.
|
||||
- The suggestions should focus on improving the new code introduced the PR, meaning lines from '__new hunk__' sections, starting with '+' (after the line numbers).
|
||||
- Prioritize suggestions that address possible issues, major problems, and bugs in the PR code.
|
||||
- Provide up to {{ num_code_suggestions }} code suggestions.
|
||||
- The suggestions should be diverse and insightful. They should focus on improving only the new code introduced in the PR, meaning lines from '__new hunk__' sections, starting with '+' (after the line numbers).
|
||||
- Prioritize suggestions that address possible issues, major problems, and bugs in the PR code. Don't repeat changes already present in the PR. If there are no relevant suggestions for the PR, return an empty list.
|
||||
- Don't suggest to add docstring, type hints, or comments, or to remove unused imports.
|
||||
- Provide the exact line numbers range (inclusive) for each suggestion. Use the line numbers from the '__new hunk__' sections.
|
||||
- When quoting variables or names from the code, use backticks (`) instead of single quote (').
|
||||
- Every time you cite variables or names from the code, use backticks ('`'). For example: 'ensure that `variable_name` is ...'
|
||||
- Take into account that you are recieving as an input only a PR code diff. The entire codebase is not available for you as context. Hence, avoid suggestions that might conflict with unseen parts of the codebase, like imports, global variables, etc.
|
||||
|
||||
|
||||
@ -171,15 +175,16 @@ Extra instructions from the user, that should be taken into account with high pr
|
||||
The output must be a YAML object equivalent to type $PRCodeSuggestions, according to the following Pydantic definitions:
|
||||
=====
|
||||
class CodeSuggestion(BaseModel):
|
||||
relevant_file: str = Field(description="the relevant file full path")
|
||||
language: str = Field(description="the code language of the relevant file")
|
||||
suggestion_content: str = Field(description="an actionable suggestion for meaningfully improving the new code introduced in the PR. Don't present here actual code snippets, just the suggestion. Be short and concise ")
|
||||
existing_code: str = Field(description="a short code snippet, demonstrating the relevant code lines from a '__new hunk__' section. It must be without line numbers. Use abbreviations ("...") if needed")
|
||||
relevant_file: str = Field(description="The full file path of the relevant file")
|
||||
language: str = Field(description="the programming language of the relevant file")
|
||||
suggestion_content: str = Field(description="an actionable suggestion for meaningfully improving the new code introduced in the PR. Don't present here actual code snippets, just the suggestion. Be short and concise")
|
||||
existing_code: str = Field(description="a short code snippet, demonstrating the relevant code lines from a '__new hunk__' section. It must be without line numbers. Quote only full code lines, not partial ones. Use abbreviations ("...") of full lines if needed")
|
||||
improved_code: str = Field(description="a new code snippet, that can be used to replace the relevant 'existing_code' lines in '__new hunk__' code after applying the suggestion")
|
||||
one_sentence_summary: str = Field(description="a short summary of the suggestion action, in a single sentence. Focus on the 'what'. Be general, and avoid method or variable names.")
|
||||
relevant_lines_start: int = Field(description="The relevant line number, from a '__new hunk__' section, where the suggestion starts (inclusive). Should be derived from the hunk line numbers, and correspond to the 'existing code' snippet above")
|
||||
relevant_lines_end: int = Field(description="The relevant line number, from a '__new hunk__' section, where the suggestion ends (inclusive). Should be derived from the hunk line numbers, and correspond to the 'existing code' snippet above")
|
||||
label: str = Field(description="a single label for the suggestion, to help understand the suggestion type. For example: 'security', 'possible bug', 'possible issue', 'performance', 'enhancement', 'best practice', 'maintainability', etc. Other labels are also allowed")
|
||||
label: str = Field(description="a single label for the suggestion, to help the user understand the suggestion type. For example: 'security', 'possible bug', 'possible issue', 'performance', 'enhancement', 'best practice', 'maintainability', etc. Other labels are also allowed")
|
||||
|
||||
|
||||
class PRCodeSuggestions(BaseModel):
|
||||
code_suggestions: List[CodeSuggestion]
|
||||
|
||||
@ -6,10 +6,10 @@ Your goal is to inspect, review and score the suggestsions.
|
||||
Be aware - the suggestions may not always be correct or accurate, and you should evaluate them in relation to the actual PR code diff presented. Sometimes the suggestion may ignore parts of the actual code diff, and in that case, you should give it a score of 0.
|
||||
|
||||
Specific instructions:
|
||||
- Carefully review both the suggestion content, and the related PR code diff. Mistakes in the suggestions can occur. Make sure the suggestions are correct, and properly derived from the PR code diff.
|
||||
- Carefully review both the suggestion content, and the related PR code diff. Mistakes in the suggestions can occur. Make sure the suggestions are logical and correct, and properly derived from the PR code diff.
|
||||
- In addition to the exact code lines mentioned in each suggestion, review the code around them, to ensure that the suggestions are contextually accurate.
|
||||
- Also check that the 'existing_code' and 'improved_code' fields correctly reflect the suggested changes.
|
||||
- Make sure the suggestions focus on new code introduced in the PR, and not on existing code that was not changed.
|
||||
- Check that the 'existing_code' field is valid. The 'existing_code' content should match, or be derived, from code lines from a 'new hunk' section in the PR code diff.
|
||||
- Check that the 'improved_code' section correctly reflects the suggestion content.
|
||||
- High scores (8 to 10) should be given to correct suggestions that address major bugs and issues, or security concerns. Lower scores (3 to 7) should be for correct suggestions addressing minor issues, code style, code readability, maintainability, etc. Don't give high scores to suggestions that are not crucial, and bring only small improvement or optimization.
|
||||
- Order the feedback the same way the suggestions are ordered in the input.
|
||||
|
||||
@ -21,11 +21,11 @@ The format that is used to present the PR code diff is as follows:
|
||||
@@ ... @@ def func1():
|
||||
__new hunk__
|
||||
12 code line1 that remained unchanged in the PR
|
||||
13 +new hunk code line2 added in the PR
|
||||
13 +new code line2 added in the PR
|
||||
14 code line3 that remained unchanged in the PR
|
||||
__old hunk__
|
||||
code line1 that remained unchanged in the PR
|
||||
-old hunk code line2 that was removed in the PR
|
||||
-old code line2 that was removed in the PR
|
||||
code line3 that remained unchanged in the PR
|
||||
|
||||
@@ ... @@ def func2():
|
||||
@ -39,8 +39,9 @@ __old hunk__
|
||||
...
|
||||
======
|
||||
- In this format, we separated each hunk of code to '__new hunk__' and '__old hunk__' sections. The '__new hunk__' section contains the new code of the chunk, and the '__old hunk__' section contains the old code that was removed.
|
||||
- If no new code was added in a specific hunk, '__new hunk__' section will not be presented. If no code was removed, '__old hunk__' section will not be presented.
|
||||
- We added line numbers for the '__new hunk__' sections, to help you refer to the code lines in your suggestions. These line numbers are not part of the actual code, and are only used for reference.
|
||||
- Code lines are prefixed symbols ('+', '-', ' '). The '+' symbol indicates new code added in the PR, the '-' symbol indicates code removed in the PR, and the ' ' symbol indicates unchanged code.
|
||||
- We also added line numbers for the '__new hunk__' sections, to help you refer to the code lines in your suggestions. These line numbers are not part of the actual code, and are only used for reference.
|
||||
|
||||
|
||||
The output must be a YAML object equivalent to type $PRCodeSuggestionsFeedback, according to the following Pydantic definitions:
|
||||
@ -48,7 +49,7 @@ The output must be a YAML object equivalent to type $PRCodeSuggestionsFeedback,
|
||||
class CodeSuggestionFeedback(BaseModel):
|
||||
suggestion_summary: str = Field(description="repeated from the input")
|
||||
relevant_file: str = Field(description="repeated from the input")
|
||||
suggestion_score: int = Field(description="The actual output - the score of the suggestion, from 0 to 10. Give 0 if the suggestion is plain wrong. Otherwise, give a score from 1 to 10 (inclusive), where 1 is the lowest and 10 is the highest.")
|
||||
suggestion_score: int = Field(description="The actual output - the score of the suggestion, from 0 to 10. Give 0 if the suggestion is wrong. Otherwise, give a score from 1 to 10 (inclusive), where 1 is the lowest and 10 is the highest.")
|
||||
why: str = Field(description="Short and concise explanation of why the suggestion received the score (one to two sentences).")
|
||||
|
||||
class PRCodeSuggestionsFeedback(BaseModel):
|
||||
|
||||
@ -38,8 +38,8 @@ class PRType(str, Enum):
|
||||
{%- if enable_semantic_files_types %}
|
||||
|
||||
class FileDescription(BaseModel):
|
||||
filename: str = Field(description="the relevant file full path")
|
||||
language: str = Field(description="the relevant file language")
|
||||
filename: str = Field(description="The full file path of the relevant file.")
|
||||
language: str = Field(description="The programming language of the relevant file.")
|
||||
changes_summary: str = Field(description="concise summary of the changes in the relevant file, in bullet points (1-4 bullet points).")
|
||||
changes_title: str = Field(description="an informative title for the changes in the files, describing its main theme (5-10 words).")
|
||||
label: str = Field(description="a single semantic label that represents a type of code changes that occurred in the File. Possible values (partial list): 'bug fix', 'tests', 'enhancement', 'documentation', 'error handling', 'configuration changes', 'dependencies', 'formatting', 'miscellaneous', ...")
|
||||
@ -48,7 +48,7 @@ class FileDescription(BaseModel):
|
||||
class PRDescription(BaseModel):
|
||||
type: List[PRType] = Field(description="one or more types that describe the PR content. Return the label member value (e.g. 'Bug fix', not 'bug_fix')")
|
||||
{%- if enable_semantic_files_types %}
|
||||
pr_files[List[FileDescription]] = Field(max_items=15, description="a list of the files in the PR, and their changes summary.")
|
||||
pr_files: List[FileDescription] = Field(max_items=15, description="a list of the files in the PR, and summary of their changes")
|
||||
{%- endif %}
|
||||
description: str = Field(description="an informative and concise description of the PR. Use bullet points. Display first the most significant changes.")
|
||||
title: str = Field(description="an informative title for the PR, describing its main theme")
|
||||
|
||||
@ -5,20 +5,29 @@ Your task is to provide constructive and concise feedback for the PR, and also p
|
||||
{%- else %}
|
||||
Your task is to provide constructive and concise feedback for the PR.
|
||||
{%- endif %}
|
||||
The review should focus on new code added in the PR diff (lines starting with '+')
|
||||
The review should focus on new code added in the PR code diff (lines starting with '+')
|
||||
|
||||
Example PR Diff:
|
||||
|
||||
The format we will use to present the PR code diff:
|
||||
======
|
||||
## file: 'src/file1.py'
|
||||
|
||||
@@ -12,5 +12,5 @@ def func1():
|
||||
code line 1 that remained unchanged in the PR
|
||||
code line 2 that remained unchanged in the PR
|
||||
-code line that was removed in the PR
|
||||
+code line added in the PR
|
||||
code line 3 that remained unchanged in the PR
|
||||
@@ ... @@ def func1():
|
||||
__new hunk__
|
||||
11 unchanged code line0 in the PR
|
||||
12 unchanged code line1 in the PR
|
||||
13 +new code line2 added in the PR
|
||||
14 unchanged code line3 in the PR
|
||||
__old hunk__
|
||||
unchanged code line0
|
||||
unchanged code line1
|
||||
-old code line2 removed in the PR
|
||||
unchanged code line3
|
||||
|
||||
@@ ... @@ def func2():
|
||||
__new hunk__
|
||||
...
|
||||
__old hunk__
|
||||
...
|
||||
|
||||
|
||||
@ -26,20 +35,26 @@ code line 3 that remained unchanged in the PR
|
||||
...
|
||||
======
|
||||
|
||||
- In this format, we separated each hunk of diff code to '__new hunk__' and '__old hunk__' sections. The '__new hunk__' section contains the new code of the chunk, and the '__old hunk__' section contains the old code, that was removed. If no new code was added in a specific hunk, '__new hunk__' section will not be presented. If no code was removed, '__old hunk__' section will not be presented.
|
||||
- We also added line numbers for the '__new hunk__' code, to help you refer to the code lines in your suggestions. These line numbers are not part of the actual code, and should only used for reference.
|
||||
- Code lines are prefixed with symbols ('+', '-', ' '). The '+' symbol indicates new code added in the PR, the '-' symbol indicates code removed in the PR, and the ' ' symbol indicates unchanged code. \
|
||||
The review should address new code added in the PR code diff (lines starting with '+')
|
||||
- When quoting variables or names from the code, use backticks (`) instead of single quote (').
|
||||
|
||||
{%- if num_code_suggestions > 0 %}
|
||||
|
||||
|
||||
Code suggestions guidelines:
|
||||
- Provide up to {{ num_code_suggestions }} code suggestions. Try to provide diverse and insightful suggestions.
|
||||
- Focus on important suggestions like fixing code problems, issues and bugs. As a second priority, provide suggestions for meaningful code improvements like performance, vulnerability, modularity, and best practices.
|
||||
- Focus on important suggestions like fixing code problems, issues and bugs. As a second priority, provide suggestions for meaningful code improvements, like performance, vulnerability, modularity, and best practices.
|
||||
- Avoid making suggestions that have already been implemented in the PR code. For example, if you want to add logs, or change a variable to const, or anything else, make sure it isn't already in the PR code.
|
||||
- Don't suggest to add docstring, type hints, or comments.
|
||||
- Suggestions should focus on the new code added in the PR diff (lines starting with '+')
|
||||
- When quoting variables or names from the code, use backticks (`) instead of single quote (').
|
||||
- Suggestions should address the new code added in the PR diff (lines starting with '+')
|
||||
{%- endif %}
|
||||
|
||||
{%- if extra_instructions %}
|
||||
|
||||
|
||||
Extra instructions from the user:
|
||||
======
|
||||
{{ extra_instructions }}
|
||||
@ -55,6 +70,22 @@ class SubPR(BaseModel):
|
||||
title: str = Field(description="Short and concise title for an independent and meaningful sub-PR, composed only from the relevant files")
|
||||
{%- endif %}
|
||||
|
||||
class KeyIssuesComponentLink(BaseModel):
|
||||
relevant_file: str = Field(description="The full file path of the relevant file")
|
||||
issue_header: str = Field(description="one or two word title for the the issue. For example: 'Possible Bug', 'Performance Issue', 'Code Smell', etc.")
|
||||
issue_content: str = Field(description="a short and concise description of the issue that needs to be reviewed")
|
||||
start_line: int = Field(description="the start line that corresponds to this issue in the relevant file")
|
||||
end_line: int = Field(description="the end line that corresponds to this issue in the relevant file")
|
||||
{%- if extra_issue_links %}
|
||||
referenced_variables: List[Refs] = Field(description="a list of relevant variables or names that appear in the 'issue_content' output. For each variable, output is name, and the line number where it appears in the relevant file")
|
||||
{% endif %}
|
||||
|
||||
{%- if extra_issue_links %}
|
||||
class Refs(BaseModel):
|
||||
variable_name: str = Field(description="the name of a variable or name that appears in the relevant 'issue_content' output.")
|
||||
relevant_line: int = Field(description="the line number where the variable or name appears in the relevant file")
|
||||
{%- endif %}
|
||||
|
||||
class Review(BaseModel):
|
||||
{%- if require_estimate_effort_to_review %}
|
||||
estimated_effort_to_review_[1-5]: int = Field(description="Estimate, on a scale of 1-5 (inclusive), the time and effort required to review this PR by an experienced and knowledgeable developer. 1 means short and easy review , 5 means long and hard review. Take into account the size, complexity, quality, and the needed changes of the PR code diff.")
|
||||
@ -68,9 +99,9 @@ class Review(BaseModel):
|
||||
{%- if question_str %}
|
||||
insights_from_user_answers: str = Field(description="shortly summarize the insights you gained from the user's answers to the questions")
|
||||
{%- endif %}
|
||||
key_issues_to_review: str = Field(description="Does this PR code introduce issues, bugs, or major performance concerns, which the PR reviewer should further investigate ? If there are no apparent issues, respond with 'None'. If there are any issues, describe them briefly. Use bullet points if more than one issue. Be specific, and provide examples if possible. Start each bullet point with a short specific header, such as: "- Possible Bug: ...", etc.")
|
||||
key_issues_to_review: List[KeyIssuesComponentLink] = Field("A list of bugs, issue or major performance concerns introduced in this PR, which the PR reviewer should further investigate")
|
||||
{%- if require_security_review %}
|
||||
security_concerns: str = Field(description="does this PR code introduce possible vulnerabilities such as exposure of sensitive information (e.g., API keys, secrets, passwords), or security concerns like SQL injection, XSS, CSRF, and others ? Answer 'No' if there are no possible issues. If there are security concerns or issues, start your answer with a short header, such as: 'Sensitive information exposure: ...', 'SQL injection: ...' etc. Explain your answer. Be specific and give examples if possible")
|
||||
security_concerns: str = Field(description="Does this PR code introduce possible vulnerabilities such as exposure of sensitive information (e.g., API keys, secrets, passwords), or security concerns like SQL injection, XSS, CSRF, and others ? Answer 'No' (without explaining why) if there are no possible issues. If there are security concerns or issues, start your answer with a short header, such as: 'Sensitive information exposure: ...', 'SQL injection: ...' etc. Explain your answer. Be specific and give examples if possible")
|
||||
{%- endif %}
|
||||
{%- if require_can_be_split_review %}
|
||||
can_be_split: List[SubPR] = Field(min_items=0, max_items=3, description="Can this PR, which contains {{ num_pr_files }} changed files in total, be divided into smaller sub-PRs with distinct tasks that can be reviewed and merged independently, regardless of the order ? Make sure that the sub-PRs are indeed independent, with no code dependencies between them, and that each sub-PR represent a meaningful independent task. Output an empty list if the PR code does not need to be split.")
|
||||
@ -78,8 +109,8 @@ class Review(BaseModel):
|
||||
{%- if num_code_suggestions > 0 %}
|
||||
|
||||
class CodeSuggestion(BaseModel):
|
||||
relevant_file: str = Field(description="the relevant file full path")
|
||||
language: str = Field(description="the language of the relevant file")
|
||||
relevant_file: str = Field(description="The full file path of the relevant file")
|
||||
language: str = Field(description="The programming language of the relevant file")
|
||||
suggestion: str = Field(description="a concrete suggestion for meaningfully improving the new PR code. Also describe how, specifically, the suggestion can be applied to new PR code. Add tags with importance measure that matches each suggestion ('important' or 'medium'). Do not make suggestions for updating or adding docstrings, renaming PR title and description, or linter like.")
|
||||
relevant_line: str = Field(description="a single code line taken from the relevant file, to which the suggestion applies. The code line should start with a '+'. Make sure to output the line exactly as it appears in the relevant file")
|
||||
{%- endif %}
|
||||
@ -90,6 +121,7 @@ class PRReview(BaseModel):
|
||||
code_feedback: List[CodeSuggestion]
|
||||
{%- else %}
|
||||
|
||||
|
||||
class PRReview(BaseModel):
|
||||
review: Review
|
||||
{%- endif %}
|
||||
@ -108,8 +140,22 @@ review:
|
||||
{%- endif %}
|
||||
relevant_tests: |
|
||||
No
|
||||
key_issues_to_review: |
|
||||
...
|
||||
key_issues_to_review:
|
||||
- relevant_file: |
|
||||
directory/xxx.py
|
||||
issue_header: |
|
||||
Possible Bug
|
||||
issue_content: |
|
||||
...
|
||||
start_line: 12
|
||||
end_line: 14
|
||||
{%- if extra_issue_links %}
|
||||
referenced_variables:
|
||||
- variable_name: |
|
||||
...
|
||||
relevant_line: 13
|
||||
{%- endif %}
|
||||
- ...
|
||||
security_concerns: |
|
||||
No
|
||||
{%- if require_can_be_split_review %}
|
||||
@ -120,8 +166,9 @@ review:
|
||||
title: ...
|
||||
- ...
|
||||
{%- endif %}
|
||||
|
||||
{%- if num_code_suggestions > 0 %}
|
||||
code_feedback
|
||||
code_feedback:
|
||||
- relevant_file: |
|
||||
directory/xxx.py
|
||||
language: |
|
||||
@ -136,7 +183,7 @@ code_feedback
|
||||
Answer should be a valid YAML, and nothing else. Each YAML output MUST be after a newline, with proper indent, and block scalar indicator ('|')
|
||||
"""
|
||||
|
||||
user="""PR Info:
|
||||
user="""--PR Info--
|
||||
|
||||
Title: '{{title}}'
|
||||
|
||||
@ -144,7 +191,7 @@ Branch: '{{branch}}'
|
||||
|
||||
{%- if description %}
|
||||
|
||||
Description:
|
||||
PR Description:
|
||||
======
|
||||
{{ description|trim }}
|
||||
======
|
||||
@ -165,7 +212,7 @@ User answers:
|
||||
{%- endif %}
|
||||
|
||||
|
||||
The PR Diff:
|
||||
The PR code diff:
|
||||
======
|
||||
{{ diff|trim }}
|
||||
======
|
||||
|
||||
@ -89,8 +89,8 @@ class PRAddDocs:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().info(f"\nSystem prompt:\n{system_prompt}")
|
||||
get_logger().info(f"\nUser prompt:\n{user_prompt}")
|
||||
response, finish_reason = await self.ai_handler.chat_completion(model=model, temperature=0.2,
|
||||
system=system_prompt, user=user_prompt)
|
||||
response, finish_reason = await self.ai_handler.chat_completion(
|
||||
model=model, temperature=get_settings().config.temperature, system=system_prompt, user=user_prompt)
|
||||
|
||||
return response
|
||||
|
||||
|
||||
@ -11,7 +11,8 @@ from pr_agent.algo.pr_processing import get_pr_diff, get_pr_multi_diffs, retry_w
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.utils import load_yaml, replace_code_tags, ModelType, show_relevant_configurations
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers import get_git_provider, get_git_provider_with_context, GithubProvider, GitLabProvider
|
||||
from pr_agent.git_providers import get_git_provider, get_git_provider_with_context, GithubProvider, GitLabProvider, \
|
||||
AzureDevopsProvider
|
||||
from pr_agent.git_providers.git_provider import get_main_pr_language
|
||||
from pr_agent.log import get_logger
|
||||
from pr_agent.servers.help import HelpMessage
|
||||
@ -34,6 +35,7 @@ class PRCodeSuggestions:
|
||||
MAX_CONTEXT_TOKENS_IMPROVE = get_settings().pr_code_suggestions.max_context_tokens
|
||||
if get_settings().config.max_model_tokens > MAX_CONTEXT_TOKENS_IMPROVE:
|
||||
get_logger().info(f"Setting max_model_tokens to {MAX_CONTEXT_TOKENS_IMPROVE} for PR improve")
|
||||
get_settings().config.max_model_tokens_original = get_settings().config.max_model_tokens
|
||||
get_settings().config.max_model_tokens = MAX_CONTEXT_TOKENS_IMPROVE
|
||||
|
||||
# extended mode
|
||||
@ -50,6 +52,7 @@ class PRCodeSuggestions:
|
||||
self.ai_handler.main_pr_language = self.main_language
|
||||
self.patches_diff = None
|
||||
self.prediction = None
|
||||
self.pr_url = pr_url
|
||||
self.cli_mode = cli_mode
|
||||
self.vars = {
|
||||
"title": self.git_provider.pr.title,
|
||||
@ -60,6 +63,7 @@ class PRCodeSuggestions:
|
||||
"num_code_suggestions": num_code_suggestions,
|
||||
"extra_instructions": get_settings().pr_code_suggestions.extra_instructions,
|
||||
"commit_messages_str": self.git_provider.get_commit_messages(),
|
||||
"relevant_best_practices": "",
|
||||
}
|
||||
if 'claude' in get_settings().config.model:
|
||||
# prompt for Claude, with minor adjustments
|
||||
@ -78,6 +82,10 @@ class PRCodeSuggestions:
|
||||
|
||||
async def run(self):
|
||||
try:
|
||||
if not self.git_provider.get_files():
|
||||
get_logger().info(f"PR has no files: {self.pr_url}, skipping code suggestions")
|
||||
return None
|
||||
|
||||
get_logger().info('Generating code suggestions for PR...')
|
||||
relevant_configs = {'pr_code_suggestions': dict(get_settings().pr_code_suggestions),
|
||||
'config': dict(get_settings().config)}
|
||||
@ -96,9 +104,10 @@ class PRCodeSuggestions:
|
||||
if not data:
|
||||
data = {"code_suggestions": []}
|
||||
|
||||
if data is None or 'code_suggestions' not in data or not data['code_suggestions']:
|
||||
get_logger().error('No code suggestions found for PR.')
|
||||
pr_body = "## PR Code Suggestions ✨\n\nNo code suggestions found for PR."
|
||||
if (data is None or 'code_suggestions' not in data or not data['code_suggestions']
|
||||
and get_settings().config.publish_output):
|
||||
get_logger().warning('No code suggestions found for the PR.')
|
||||
pr_body = "## PR Code Suggestions ✨\n\nNo code suggestions found for the PR."
|
||||
get_logger().debug(f"PR output", artifact=pr_body)
|
||||
if self.progress_response:
|
||||
self.git_provider.edit_comment(self.progress_response, body=pr_body)
|
||||
@ -156,24 +165,35 @@ class PRCodeSuggestions:
|
||||
self.push_inline_code_suggestions(data)
|
||||
if self.progress_response:
|
||||
self.progress_response.delete()
|
||||
else:
|
||||
get_logger().info('Code suggestions generated for PR, but not published since publish_output is False.')
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to generate code suggestions for PR, error: {e}")
|
||||
if self.progress_response:
|
||||
self.progress_response.delete()
|
||||
else:
|
||||
try:
|
||||
self.git_provider.remove_initial_comment()
|
||||
self.git_provider.publish_comment(f"Failed to generate code suggestions for PR")
|
||||
except Exception as e:
|
||||
pass
|
||||
if get_settings().config.publish_output:
|
||||
if self.progress_response:
|
||||
self.progress_response.delete()
|
||||
else:
|
||||
try:
|
||||
self.git_provider.remove_initial_comment()
|
||||
self.git_provider.publish_comment(f"Failed to generate code suggestions for PR")
|
||||
except Exception as e:
|
||||
pass
|
||||
|
||||
def publish_persistent_comment_with_history(self, pr_comment: str,
|
||||
initial_header: str,
|
||||
update_header: bool = True,
|
||||
name='review',
|
||||
final_update_message=True,
|
||||
max_previous_comments=4,
|
||||
progress_response=None):
|
||||
initial_header: str,
|
||||
update_header: bool = True,
|
||||
name='review',
|
||||
final_update_message=True,
|
||||
max_previous_comments=4,
|
||||
progress_response=None):
|
||||
|
||||
if isinstance(self.git_provider, AzureDevopsProvider): # get_latest_commit_url is not supported yet
|
||||
if progress_response:
|
||||
self.git_provider.edit_comment(progress_response, pr_comment)
|
||||
else:
|
||||
self.git_provider.publish_comment(pr_comment)
|
||||
return
|
||||
|
||||
history_header = f"#### Previous suggestions\n"
|
||||
last_commit_num = self.git_provider.get_latest_commit_url().split('/')[-1][:7]
|
||||
latest_suggestion_header = f"Latest suggestions up to {last_commit_num}"
|
||||
@ -198,7 +218,8 @@ class PRCodeSuggestions:
|
||||
continue
|
||||
# find http link from comment.body[:table_index]
|
||||
up_to_commit_txt = self.extract_link(comment.body[:table_index])
|
||||
prev_suggestion_table = comment.body[table_index:comment.body.rfind("</table>") + len("</table>")]
|
||||
prev_suggestion_table = comment.body[
|
||||
table_index:comment.body.rfind("</table>") + len("</table>")]
|
||||
|
||||
tick = "✅ " if "✅" in prev_suggestion_table else ""
|
||||
# surround with details tag
|
||||
@ -225,7 +246,8 @@ class PRCodeSuggestions:
|
||||
count += prev_suggestions.count(f"\n<details><summary>✅ {name.capitalize()}")
|
||||
if count >= max_previous_comments:
|
||||
# remove the oldest suggestion
|
||||
prev_suggestion_table = prev_suggestion_table[:prev_suggestion_table.rfind(f"<details><summary>{name.capitalize()} up to commit")]
|
||||
prev_suggestion_table = prev_suggestion_table[:prev_suggestion_table.rfind(
|
||||
f"<details><summary>{name.capitalize()} up to commit")]
|
||||
|
||||
tick = "✅ " if "✅" in latest_table else ""
|
||||
# Add to the prev_suggestions section
|
||||
@ -242,9 +264,9 @@ class PRCodeSuggestions:
|
||||
pr_comment_updated += f"{prev_suggestion_table}\n"
|
||||
|
||||
get_logger().info(f"Persistent mode - updating comment {comment_url} to latest {name} message")
|
||||
if progress_response: # publish to 'progress_response' comment, because it refreshes immediately
|
||||
if progress_response: # publish to 'progress_response' comment, because it refreshes immediately
|
||||
self.git_provider.edit_comment(progress_response, pr_comment_updated)
|
||||
comment.delete()
|
||||
self.git_provider.remove_comment(comment)
|
||||
else:
|
||||
self.git_provider.edit_comment(comment, pr_comment_updated)
|
||||
return
|
||||
@ -274,13 +296,13 @@ class PRCodeSuggestions:
|
||||
self.token_handler,
|
||||
model,
|
||||
add_line_numbers_to_hunks=True,
|
||||
disable_extra_lines=True)
|
||||
disable_extra_lines=False)
|
||||
|
||||
if self.patches_diff:
|
||||
get_logger().debug(f"PR diff", artifact=self.patches_diff)
|
||||
self.prediction = await self._get_prediction(model, self.patches_diff)
|
||||
else:
|
||||
get_logger().error(f"Error getting PR diff")
|
||||
get_logger().warning(f"Empty PR diff")
|
||||
self.prediction = None
|
||||
|
||||
data = self.prediction
|
||||
@ -292,17 +314,17 @@ class PRCodeSuggestions:
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
system_prompt = environment.from_string(self.pr_code_suggestions_prompt_system).render(variables)
|
||||
user_prompt = environment.from_string(get_settings().pr_code_suggestions_prompt.user).render(variables)
|
||||
response, finish_reason = await self.ai_handler.chat_completion(model=model, temperature=0.2,
|
||||
system=system_prompt, user=user_prompt)
|
||||
response, finish_reason = await self.ai_handler.chat_completion(
|
||||
model=model, temperature=get_settings().config.temperature, system=system_prompt, user=user_prompt)
|
||||
|
||||
# load suggestions from the AI response
|
||||
data = self._prepare_pr_code_suggestions(response)
|
||||
|
||||
# self-reflect on suggestions
|
||||
if get_settings().pr_code_suggestions.self_reflect_on_suggestions:
|
||||
model = get_settings().config.model_turbo # use turbo model for self-reflection, since it is an easier task
|
||||
response_reflect = await self.self_reflect_on_suggestions(data["code_suggestions"], patches_diff,
|
||||
model=model)
|
||||
model_turbo = get_settings().config.model_turbo # use turbo model for self-reflection, since it is an easier task
|
||||
response_reflect = await self.self_reflect_on_suggestions(data["code_suggestions"],
|
||||
patches_diff, model=model_turbo)
|
||||
if response_reflect:
|
||||
response_reflect_yaml = load_yaml(response_reflect)
|
||||
code_suggestions_feedback = response_reflect_yaml["code_suggestions"]
|
||||
@ -340,7 +362,7 @@ class PRCodeSuggestions:
|
||||
def _prepare_pr_code_suggestions(self, predictions: str) -> Dict:
|
||||
data = load_yaml(predictions.strip(),
|
||||
keys_fix_yaml=["relevant_file", "suggestion_content", "existing_code", "improved_code"],
|
||||
first_key="code_suggestions",last_key="label")
|
||||
first_key="code_suggestions", last_key="label")
|
||||
if isinstance(data, list):
|
||||
data = {'code_suggestions': data}
|
||||
|
||||
@ -349,12 +371,14 @@ class PRCodeSuggestions:
|
||||
one_sentence_summary_list = []
|
||||
for i, suggestion in enumerate(data['code_suggestions']):
|
||||
try:
|
||||
needed_keys = ['one_sentence_summary', 'label', 'relevant_file', 'relevant_lines_start', 'relevant_lines_end']
|
||||
needed_keys = ['one_sentence_summary', 'label', 'relevant_file', 'relevant_lines_start',
|
||||
'relevant_lines_end']
|
||||
is_valid_keys = True
|
||||
for key in needed_keys:
|
||||
if key not in suggestion:
|
||||
is_valid_keys = False
|
||||
get_logger().debug(f"Skipping suggestion {i + 1}, because it does not contain '{key}':\n'{suggestion}")
|
||||
get_logger().debug(
|
||||
f"Skipping suggestion {i + 1}, because it does not contain '{key}':\n'{suggestion}")
|
||||
break
|
||||
if not is_valid_keys:
|
||||
continue
|
||||
@ -420,7 +444,8 @@ class PRCodeSuggestions:
|
||||
body = f"**Suggestion:** {content} [{label}]\n```suggestion\n" + new_code_snippet + "\n```"
|
||||
code_suggestions.append({'body': body, 'relevant_file': relevant_file,
|
||||
'relevant_lines_start': relevant_lines_start,
|
||||
'relevant_lines_end': relevant_lines_end})
|
||||
'relevant_lines_end': relevant_lines_end,
|
||||
'original_suggestion': d})
|
||||
except Exception:
|
||||
get_logger().info(f"Could not parse suggestion: {d}")
|
||||
|
||||
@ -437,8 +462,24 @@ class PRCodeSuggestions:
|
||||
original_initial_line = None
|
||||
for file in self.diff_files:
|
||||
if file.filename.strip() == relevant_file:
|
||||
if file.head_file: # in bitbucket, head_file is empty. toDo: fix this
|
||||
original_initial_line = file.head_file.splitlines()[relevant_lines_start - 1]
|
||||
if file.head_file:
|
||||
file_lines = file.head_file.splitlines()
|
||||
if relevant_lines_start > len(file_lines):
|
||||
get_logger().warning(
|
||||
"Could not dedent code snippet, because relevant_lines_start is out of range",
|
||||
artifact={'filename': file.filename,
|
||||
'file_content': file.head_file,
|
||||
'relevant_lines_start': relevant_lines_start,
|
||||
'new_code_snippet': new_code_snippet})
|
||||
return new_code_snippet
|
||||
else:
|
||||
original_initial_line = file_lines[relevant_lines_start - 1]
|
||||
else:
|
||||
get_logger().warning("Could not dedent code snippet, because head_file is missing",
|
||||
artifact={'filename': file.filename,
|
||||
'relevant_lines_start': relevant_lines_start,
|
||||
'new_code_snippet': new_code_snippet})
|
||||
return new_code_snippet
|
||||
break
|
||||
if original_initial_line:
|
||||
suggested_initial_line = new_code_snippet.splitlines()[0]
|
||||
@ -448,7 +489,7 @@ class PRCodeSuggestions:
|
||||
if delta_spaces > 0:
|
||||
new_code_snippet = textwrap.indent(new_code_snippet, delta_spaces * " ").rstrip('\n')
|
||||
except Exception as e:
|
||||
get_logger().error(f"Could not dedent code snippet for file {relevant_file}, error: {e}")
|
||||
get_logger().error(f"Error when dedenting code snippet for file {relevant_file}, error: {e}")
|
||||
|
||||
return new_code_snippet
|
||||
|
||||
@ -458,7 +499,7 @@ class PRCodeSuggestions:
|
||||
get_logger().info("Extended mode is enabled by the `--extended` flag")
|
||||
return True
|
||||
if get_settings().pr_code_suggestions.auto_extended_mode:
|
||||
get_logger().info("Extended mode is enabled automatically based on the configuration toggle")
|
||||
# get_logger().info("Extended mode is enabled automatically based on the configuration toggle")
|
||||
return True
|
||||
return False
|
||||
|
||||
@ -483,11 +524,11 @@ class PRCodeSuggestions:
|
||||
data = {"code_suggestions": []}
|
||||
for j, predictions in enumerate(prediction_list): # each call adds an element to the list
|
||||
if "code_suggestions" in predictions:
|
||||
score_threshold = max(1, get_settings().pr_code_suggestions.suggestions_score_threshold)
|
||||
score_threshold = max(1, int(get_settings().pr_code_suggestions.suggestions_score_threshold))
|
||||
for i, prediction in enumerate(predictions["code_suggestions"]):
|
||||
try:
|
||||
if get_settings().pr_code_suggestions.self_reflect_on_suggestions:
|
||||
score = int(prediction["score"])
|
||||
score = int(prediction.get("score", 1))
|
||||
if score >= score_threshold:
|
||||
data["code_suggestions"].append(prediction)
|
||||
else:
|
||||
@ -500,7 +541,7 @@ class PRCodeSuggestions:
|
||||
get_logger().error(f"Error getting PR diff for suggestion {i} in call {j}, error: {e}")
|
||||
self.data = data
|
||||
else:
|
||||
get_logger().error(f"Error getting PR diff")
|
||||
get_logger().warning(f"Empty PR diff list")
|
||||
self.data = data = None
|
||||
return data
|
||||
|
||||
@ -624,9 +665,9 @@ class PRCodeSuggestions:
|
||||
code_snippet_link = ""
|
||||
# add html table for each suggestion
|
||||
|
||||
suggestion_content = suggestion['suggestion_content'].rstrip().rstrip()
|
||||
|
||||
suggestion_content = insert_br_after_x_chars(suggestion_content, 90)
|
||||
suggestion_content = suggestion['suggestion_content'].rstrip()
|
||||
CHAR_LIMIT_PER_LINE = 84
|
||||
suggestion_content = insert_br_after_x_chars(suggestion_content, CHAR_LIMIT_PER_LINE)
|
||||
# pr_body += f"<tr><td><details><summary>{suggestion_content}</summary>"
|
||||
existing_code = suggestion['existing_code'].rstrip() + "\n"
|
||||
improved_code = suggestion['improved_code'].rstrip() + "\n"
|
||||
@ -643,6 +684,11 @@ class PRCodeSuggestions:
|
||||
else:
|
||||
pr_body += f"""<tr><td>\n\n"""
|
||||
suggestion_summary = suggestion['one_sentence_summary'].strip().rstrip('.')
|
||||
if "'<" in suggestion_summary and ">'" in suggestion_summary:
|
||||
# escape the '<' and '>' characters, otherwise they are interpreted as html tags
|
||||
get_logger().info(f"Escaped suggestion summary: {suggestion_summary}")
|
||||
suggestion_summary = suggestion_summary.replace("'<", "`<")
|
||||
suggestion_summary = suggestion_summary.replace(">'", ">`")
|
||||
if '`' in suggestion_summary:
|
||||
suggestion_summary = replace_code_tags(suggestion_summary)
|
||||
|
||||
|
||||
@ -92,7 +92,7 @@ class PRDescription:
|
||||
if self.prediction:
|
||||
self._prepare_data()
|
||||
else:
|
||||
get_logger().error(f"Error getting AI prediction {self.pr_id}")
|
||||
get_logger().warning(f"Empty prediction, PR: {self.pr_id}")
|
||||
self.git_provider.remove_initial_comment()
|
||||
return None
|
||||
|
||||
@ -117,7 +117,7 @@ class PRDescription:
|
||||
pr_body += "<hr>\n\n<details> <summary><strong>✨ Describe tool usage guide:</strong></summary><hr> \n\n"
|
||||
pr_body += HelpMessage.get_describe_usage_guide()
|
||||
pr_body += "\n</details>\n"
|
||||
elif get_settings().pr_description.enable_help_comment:
|
||||
elif self.git_provider.is_supported("gfm_markdown") and get_settings().pr_description.enable_help_comment:
|
||||
pr_body += "\n\n___\n\n> 💡 **PR-Agent usage**:"
|
||||
pr_body += "\n>Comment `/help` on the PR to get a list of all available PR-Agent tools and their descriptions\n\n"
|
||||
|
||||
@ -167,10 +167,13 @@ class PRDescription:
|
||||
|
||||
async def _prepare_prediction(self, model: str) -> None:
|
||||
if get_settings().pr_description.use_description_markers and 'pr_agent:' not in self.user_description:
|
||||
get_logger().info(
|
||||
"Markers were enabled, but user description does not contain markers. skipping AI prediction")
|
||||
return None
|
||||
|
||||
large_pr_handling = get_settings().pr_description.enable_large_pr_handling and "pr_description_only_files_prompts" in get_settings()
|
||||
output = get_pr_diff(self.git_provider, self.token_handler, model, large_pr_handling=large_pr_handling, return_remaining_files=True)
|
||||
output = get_pr_diff(self.git_provider, self.token_handler, model, large_pr_handling=large_pr_handling,
|
||||
return_remaining_files=True)
|
||||
if isinstance(output, tuple):
|
||||
patches_diff, remaining_files_list = output
|
||||
else:
|
||||
@ -213,11 +216,12 @@ class PRDescription:
|
||||
else: # async calls
|
||||
tasks = []
|
||||
for i, patches in enumerate(patches_compressed_list):
|
||||
patches_diff = "\n".join(patches)
|
||||
get_logger().debug(f"PR diff number {i + 1} for describe files")
|
||||
task = asyncio.create_task(
|
||||
self._get_prediction(model, patches_diff, prompt="pr_description_only_files_prompts"))
|
||||
tasks.append(task)
|
||||
if patches:
|
||||
patches_diff = "\n".join(patches)
|
||||
get_logger().debug(f"PR diff number {i + 1} for describe files")
|
||||
task = asyncio.create_task(
|
||||
self._get_prediction(model, patches_diff, prompt="pr_description_only_files_prompts"))
|
||||
tasks.append(task)
|
||||
# Wait for all tasks to complete
|
||||
results = await asyncio.gather(*tasks)
|
||||
file_description_str_list = []
|
||||
@ -237,14 +241,23 @@ class PRDescription:
|
||||
get_settings().pr_description_only_description_prompts.user)
|
||||
files_walkthrough = "\n".join(file_description_str_list)
|
||||
files_walkthrough_prompt = copy.deepcopy(files_walkthrough)
|
||||
MAX_EXTRA_FILES_TO_PROMPT = 50
|
||||
if remaining_files_list:
|
||||
files_walkthrough_prompt += "\n\nNo more token budget. Additional unprocessed files:"
|
||||
for file in remaining_files_list:
|
||||
for i, file in enumerate(remaining_files_list):
|
||||
files_walkthrough_prompt += f"\n- {file}"
|
||||
if i >= MAX_EXTRA_FILES_TO_PROMPT:
|
||||
get_logger().debug(f"Too many remaining files, clipping to {MAX_EXTRA_FILES_TO_PROMPT}")
|
||||
files_walkthrough_prompt += f"\n... and {len(remaining_files_list) - MAX_EXTRA_FILES_TO_PROMPT} more"
|
||||
break
|
||||
if deleted_files_list:
|
||||
files_walkthrough_prompt += "\n\nAdditional deleted files:"
|
||||
for file in deleted_files_list:
|
||||
for i, file in enumerate(deleted_files_list):
|
||||
files_walkthrough_prompt += f"\n- {file}"
|
||||
if i >= MAX_EXTRA_FILES_TO_PROMPT:
|
||||
get_logger().debug(f"Too many deleted files, clipping to {MAX_EXTRA_FILES_TO_PROMPT}")
|
||||
files_walkthrough_prompt += f"\n... and {len(deleted_files_list) - MAX_EXTRA_FILES_TO_PROMPT} more"
|
||||
break
|
||||
tokens_files_walkthrough = len(
|
||||
token_handler_only_description_prompt.encoder.encode(files_walkthrough_prompt))
|
||||
total_tokens = token_handler_only_description_prompt.prompt_tokens + tokens_files_walkthrough
|
||||
@ -262,8 +275,9 @@ class PRDescription:
|
||||
prediction_headers = prediction_headers.strip().removeprefix('```yaml').strip('`').strip()
|
||||
|
||||
# manually add extra files to final prediction
|
||||
MAX_EXTRA_FILES_TO_OUTPUT = 100
|
||||
if get_settings().pr_description.mention_extra_files:
|
||||
for file in remaining_files_list:
|
||||
for i, file in enumerate(remaining_files_list):
|
||||
extra_file_yaml = f"""\
|
||||
- filename: |
|
||||
{file}
|
||||
@ -275,6 +289,20 @@ class PRDescription:
|
||||
additional files (token-limit)
|
||||
"""
|
||||
files_walkthrough = files_walkthrough.strip() + "\n" + extra_file_yaml.strip()
|
||||
if i >= MAX_EXTRA_FILES_TO_OUTPUT:
|
||||
files_walkthrough += f"""\
|
||||
extra_file_yaml =
|
||||
- filename: |
|
||||
Additional {len(remaining_files_list) - MAX_EXTRA_FILES_TO_OUTPUT} files not shown
|
||||
changes_summary: |
|
||||
...
|
||||
changes_title: |
|
||||
...
|
||||
label: |
|
||||
additional files (token-limit)
|
||||
"""
|
||||
break
|
||||
|
||||
# final processing
|
||||
self.prediction = prediction_headers + "\n" + "pr_files:\n" + files_walkthrough
|
||||
if not load_yaml(self.prediction):
|
||||
@ -303,10 +331,10 @@ class PRDescription:
|
||||
prediction_extra_dict = load_yaml(prediction_extra)
|
||||
# merge the two dictionaries
|
||||
if isinstance(original_prediction_dict, dict) and isinstance(prediction_extra_dict, dict):
|
||||
original_prediction_dict["pr_files"].extend(prediction_extra_dict["pr_files"])
|
||||
new_yaml = yaml.dump(original_prediction_dict)
|
||||
if load_yaml(new_yaml):
|
||||
prediction = new_yaml
|
||||
original_prediction_dict["pr_files"].extend(prediction_extra_dict["pr_files"])
|
||||
new_yaml = yaml.dump(original_prediction_dict)
|
||||
if load_yaml(new_yaml):
|
||||
prediction = new_yaml
|
||||
return prediction
|
||||
except Exception as e:
|
||||
get_logger().error(f"Error extending additional files {self.pr_id}: {e}")
|
||||
@ -320,12 +348,12 @@ class PRDescription:
|
||||
set_custom_labels(variables, self.git_provider)
|
||||
self.variables = variables
|
||||
|
||||
system_prompt = environment.from_string(get_settings().get(prompt, {}).get("system", "")).render(variables)
|
||||
user_prompt = environment.from_string(get_settings().get(prompt, {}).get("user", "")).render(variables)
|
||||
system_prompt = environment.from_string(get_settings().get(prompt, {}).get("system", "")).render(self.variables)
|
||||
user_prompt = environment.from_string(get_settings().get(prompt, {}).get("user", "")).render(self.variables)
|
||||
|
||||
response, finish_reason = await self.ai_handler.chat_completion(
|
||||
model=model,
|
||||
temperature=0.2,
|
||||
temperature=get_settings().config.temperature,
|
||||
system=system_prompt,
|
||||
user=user_prompt
|
||||
)
|
||||
@ -367,6 +395,7 @@ class PRDescription:
|
||||
pr_types = self.data['type']
|
||||
elif type(self.data['type']) == str:
|
||||
pr_types = self.data['type'].split(',')
|
||||
pr_types = [label.strip() for label in pr_types]
|
||||
|
||||
# convert lowercase labels to original case
|
||||
try:
|
||||
@ -464,13 +493,13 @@ class PRDescription:
|
||||
pr_body += f'- `{filename}`: {description}\n'
|
||||
if self.git_provider.is_supported("gfm_markdown"):
|
||||
pr_body += "</details>\n"
|
||||
elif 'pr_files' in key.lower():
|
||||
elif 'pr_files' in key.lower() and get_settings().pr_description.enable_semantic_files_types:
|
||||
changes_walkthrough, pr_file_changes = self.process_pr_files_prediction(changes_walkthrough, value)
|
||||
changes_walkthrough = f"### **Changes walkthrough** 📝\n{changes_walkthrough}"
|
||||
else:
|
||||
# if the value is a list, join its items by comma
|
||||
if isinstance(value, list):
|
||||
value = ', '.join(v for v in value)
|
||||
value = ', '.join(v.rstrip() for v in value)
|
||||
pr_body += f"{value}\n"
|
||||
if idx < len(self.data) - 1:
|
||||
pr_body += "\n\n___\n\n"
|
||||
@ -479,8 +508,17 @@ class PRDescription:
|
||||
|
||||
def _prepare_file_labels(self):
|
||||
file_label_dict = {}
|
||||
if (not self.data or not isinstance(self.data, dict) or
|
||||
'pr_files' not in self.data or not self.data['pr_files']):
|
||||
return file_label_dict
|
||||
for file in self.data['pr_files']:
|
||||
try:
|
||||
required_fields = ['changes_summary', 'changes_title', 'filename', 'label']
|
||||
if not all(field in file for field in required_fields):
|
||||
# can happen for example if a YAML generation was interrupted in the middle (no more tokens)
|
||||
get_logger().warning(f"Missing required fields in file label dict {self.pr_id}, skipping file",
|
||||
artifact={"file": file})
|
||||
continue
|
||||
filename = file['filename'].replace("'", "`").replace('"', '`')
|
||||
changes_summary = file['changes_summary']
|
||||
changes_title = file['changes_title'].strip()
|
||||
@ -505,7 +543,7 @@ class PRDescription:
|
||||
use_collapsible_file_list = num_files > self.COLLAPSIBLE_FILE_LIST_THRESHOLD
|
||||
|
||||
if not self.git_provider.is_supported("gfm_markdown"):
|
||||
return pr_body
|
||||
return pr_body, pr_comments
|
||||
try:
|
||||
pr_body += "<table>"
|
||||
header = f"Relevant files"
|
||||
|
||||
@ -137,12 +137,13 @@ class PRGenerateLabels:
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
set_custom_labels(variables, self.git_provider)
|
||||
self.variables = variables
|
||||
system_prompt = environment.from_string(get_settings().pr_custom_labels_prompt.system).render(variables)
|
||||
user_prompt = environment.from_string(get_settings().pr_custom_labels_prompt.user).render(variables)
|
||||
|
||||
system_prompt = environment.from_string(get_settings().pr_custom_labels_prompt.system).render(self.variables)
|
||||
user_prompt = environment.from_string(get_settings().pr_custom_labels_prompt.user).render(self.variables)
|
||||
|
||||
response, finish_reason = await self.ai_handler.chat_completion(
|
||||
model=model,
|
||||
temperature=0.2,
|
||||
temperature=get_settings().config.temperature,
|
||||
system=system_prompt,
|
||||
user=user_prompt
|
||||
)
|
||||
@ -164,6 +165,7 @@ class PRGenerateLabels:
|
||||
pr_types = self.data['labels']
|
||||
elif type(self.data['labels']) == str:
|
||||
pr_types = self.data['labels'].split(',')
|
||||
pr_types = [label.strip() for label in pr_types]
|
||||
|
||||
# convert lowercase labels to original case
|
||||
try:
|
||||
|
||||
@ -66,8 +66,8 @@ class PRInformationFromUser:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().info(f"\nSystem prompt:\n{system_prompt}")
|
||||
get_logger().info(f"\nUser prompt:\n{user_prompt}")
|
||||
response, finish_reason = await self.ai_handler.chat_completion(model=model, temperature=0.2,
|
||||
system=system_prompt, user=user_prompt)
|
||||
response, finish_reason = await self.ai_handler.chat_completion(
|
||||
model=model, temperature=get_settings().config.temperature, system=system_prompt, user=user_prompt)
|
||||
return response
|
||||
|
||||
def _prepare_pr_answer(self) -> str:
|
||||
|
||||
@ -102,6 +102,6 @@ class PR_LineQuestions:
|
||||
print(f"\nSystem prompt:\n{system_prompt}")
|
||||
print(f"\nUser prompt:\n{user_prompt}")
|
||||
|
||||
response, finish_reason = await self.ai_handler.chat_completion(model=model, temperature=0.2,
|
||||
system=system_prompt, user=user_prompt)
|
||||
response, finish_reason = await self.ai_handler.chat_completion(
|
||||
model=model, temperature=get_settings().config.temperature, system=system_prompt, user=user_prompt)
|
||||
return response
|
||||
|
||||
@ -108,12 +108,12 @@ class PRQuestions:
|
||||
user_prompt = environment.from_string(get_settings().pr_questions_prompt.user).render(variables)
|
||||
if 'img_path' in variables:
|
||||
img_path = self.vars['img_path']
|
||||
response, finish_reason = await self.ai_handler.chat_completion(model=model, temperature=0.2,
|
||||
system=system_prompt, user=user_prompt,
|
||||
img_path=img_path)
|
||||
response, finish_reason = await (self.ai_handler.chat_completion
|
||||
(model=model, temperature=get_settings().config.temperature,
|
||||
system=system_prompt, user=user_prompt, img_path=img_path))
|
||||
else:
|
||||
response, finish_reason = await self.ai_handler.chat_completion(model=model, temperature=0.2,
|
||||
system=system_prompt, user=user_prompt)
|
||||
response, finish_reason = await self.ai_handler.chat_completion(
|
||||
model=model, temperature=get_settings().config.temperature, system=system_prompt, user=user_prompt)
|
||||
return response
|
||||
|
||||
def _prepare_pr_answer(self) -> str:
|
||||
|
||||
@ -75,6 +75,7 @@ class PRReviewer:
|
||||
"commit_messages_str": self.git_provider.get_commit_messages(),
|
||||
"custom_labels": "",
|
||||
"enable_custom_labels": get_settings().config.enable_custom_labels,
|
||||
"extra_issue_links": get_settings().pr_reviewer.extra_issue_links,
|
||||
}
|
||||
|
||||
self.token_handler = TokenHandler(
|
||||
@ -95,6 +96,10 @@ class PRReviewer:
|
||||
|
||||
async def run(self) -> None:
|
||||
try:
|
||||
if not self.git_provider.get_files():
|
||||
get_logger().info(f"PR has no files: {self.pr_url}, skipping review")
|
||||
return None
|
||||
|
||||
if self.incremental.is_incremental and not self._can_run_incremental_review():
|
||||
return None
|
||||
|
||||
@ -147,12 +152,17 @@ class PRReviewer:
|
||||
get_logger().error(f"Failed to review PR: {e}")
|
||||
|
||||
async def _prepare_prediction(self, model: str) -> None:
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler, model)
|
||||
self.patches_diff = get_pr_diff(self.git_provider,
|
||||
self.token_handler,
|
||||
model,
|
||||
add_line_numbers_to_hunks=True,
|
||||
disable_extra_lines=True,)
|
||||
|
||||
if self.patches_diff:
|
||||
get_logger().debug(f"PR diff", diff=self.patches_diff)
|
||||
self.prediction = await self._get_prediction(model)
|
||||
else:
|
||||
get_logger().error(f"Error getting PR diff")
|
||||
get_logger().warning(f"Empty diff for PR: {self.pr_url}")
|
||||
self.prediction = None
|
||||
|
||||
async def _get_prediction(self, model: str) -> str:
|
||||
@ -174,7 +184,7 @@ class PRReviewer:
|
||||
|
||||
response, finish_reason = await self.ai_handler.chat_completion(
|
||||
model=model,
|
||||
temperature=0.2,
|
||||
temperature=get_settings().config.temperature,
|
||||
system=system_prompt,
|
||||
user=user_prompt
|
||||
)
|
||||
@ -234,7 +244,7 @@ class PRReviewer:
|
||||
incremental_review_markdown_text = f"Starting from commit {last_commit_url}"
|
||||
|
||||
markdown_text = convert_to_markdown_v2(data, self.git_provider.is_supported("gfm_markdown"),
|
||||
incremental_review_markdown_text)
|
||||
incremental_review_markdown_text, git_provider=self.git_provider)
|
||||
|
||||
# Add help text if gfm_markdown is supported
|
||||
if self.git_provider.is_supported("gfm_markdown") and get_settings().pr_reviewer.enable_help_text:
|
||||
@ -281,7 +291,7 @@ class PRReviewer:
|
||||
if comment:
|
||||
comments.append(comment)
|
||||
else:
|
||||
self.git_provider.publish_inline_comment(content, relevant_file, relevant_line_in_file)
|
||||
self.git_provider.publish_inline_comment(content, relevant_file, relevant_line_in_file, suggestion)
|
||||
|
||||
if comments:
|
||||
self.git_provider.publish_inline_comments(comments)
|
||||
@ -372,6 +382,11 @@ class PRReviewer:
|
||||
if not get_settings().config.publish_output:
|
||||
return
|
||||
|
||||
if not get_settings().pr_reviewer.require_estimate_effort_to_review:
|
||||
get_settings().pr_reviewer.enable_review_labels_effort = False # we did not generate this output
|
||||
if not get_settings().pr_reviewer.require_security_review:
|
||||
get_settings().pr_reviewer.enable_review_labels_security = False # we did not generate this output
|
||||
|
||||
if (get_settings().pr_reviewer.enable_review_labels_security or
|
||||
get_settings().pr_reviewer.enable_review_labels_effort):
|
||||
try:
|
||||
|
||||
@ -103,8 +103,8 @@ class PRUpdateChangelog:
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
system_prompt = environment.from_string(get_settings().pr_update_changelog_prompt.system).render(variables)
|
||||
user_prompt = environment.from_string(get_settings().pr_update_changelog_prompt.user).render(variables)
|
||||
response, finish_reason = await self.ai_handler.chat_completion(model=model, temperature=0.2,
|
||||
system=system_prompt, user=user_prompt)
|
||||
response, finish_reason = await self.ai_handler.chat_completion(
|
||||
model=model, system=system_prompt, user=user_prompt, temperature=get_settings().config.temperature)
|
||||
|
||||
return response
|
||||
|
||||
@ -130,7 +130,7 @@ class PRUpdateChangelog:
|
||||
file_path="CHANGELOG.md",
|
||||
branch=self.git_provider.get_pr_branch(),
|
||||
contents=new_file_content,
|
||||
message="Update CHANGELOG.md",
|
||||
message="[skip ci] Update CHANGELOG.md",
|
||||
)
|
||||
|
||||
sleep(5) # wait for the file to be updated
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
aiohttp==3.9.1
|
||||
aiohttp==3.9.4
|
||||
anthropic[vertex]==0.21.3
|
||||
atlassian-python-api==3.41.4
|
||||
azure-devops==7.1.0b3
|
||||
@ -6,14 +6,14 @@ azure-identity==1.15.0
|
||||
boto3==1.33.6
|
||||
dynaconf==3.2.4
|
||||
fastapi==0.111.0
|
||||
GitPython==3.1.32
|
||||
GitPython==3.1.41
|
||||
google-cloud-aiplatform==1.38.0
|
||||
google-cloud-storage==2.10.0
|
||||
Jinja2==3.1.2
|
||||
litellm==1.40.17
|
||||
litellm==1.43.13
|
||||
loguru==0.7.2
|
||||
msrest==0.7.1
|
||||
openai==1.35.1
|
||||
openai==1.40.6
|
||||
pytest==7.4.0
|
||||
PyGithub==1.59.*
|
||||
PyYAML==6.0.1
|
||||
@ -24,10 +24,14 @@ tiktoken==0.7.0
|
||||
ujson==5.8.0
|
||||
uvicorn==0.22.0
|
||||
tenacity==8.2.3
|
||||
gunicorn==20.1.0
|
||||
gunicorn==22.0.0
|
||||
pytest-cov==5.0.0
|
||||
pydantic==2.8.2
|
||||
# Uncomment the following lines to enable the 'similar issue' tool
|
||||
# pinecone-client
|
||||
# pinecone-datasets @ git+https://github.com/mrT23/pinecone-datasets.git@main
|
||||
# lancedb==0.5.1
|
||||
# uncomment this to support language LangChainOpenAIHandler
|
||||
# langchain==0.0.349
|
||||
# langchain==0.2.0
|
||||
# langchain-core==0.2.28
|
||||
# langchain-openai==0.1.20
|
||||
|
||||
35
tests/e2e_tests/e2e_utils.py
Normal file
35
tests/e2e_tests/e2e_utils.py
Normal file
@ -0,0 +1,35 @@
|
||||
FILE_PATH = "pr_agent/cli_pip.py"
|
||||
|
||||
PR_HEADER_START_WITH = '### **User description**\nupdate cli_pip.py\n\n\n___\n\n### **PR Type**'
|
||||
REVIEW_START_WITH = '## PR Reviewer Guide 🔍\n\n<table>\n<tr><td>⏱️ <strong>Estimated effort to review</strong>:'
|
||||
IMPROVE_START_WITH_REGEX_PATTERN = r'^## PR Code Suggestions ✨\n\n<!-- [a-z0-9]+ -->\n\n<table><thead><tr><td>Category</td>'
|
||||
|
||||
NUM_MINUTES = 5
|
||||
|
||||
NEW_FILE_CONTENT = """\
|
||||
from pr_agent import cli
|
||||
from pr_agent.config_loader import get_settings
|
||||
|
||||
|
||||
def main():
|
||||
# Fill in the following values
|
||||
provider = "github" # GitHub provider
|
||||
user_token = "..." # GitHub user token
|
||||
openai_key = "ghs_afsdfasdfsdf" # Example OpenAI key
|
||||
pr_url = "..." # PR URL, for example 'https://github.com/Codium-ai/pr-agent/pull/809'
|
||||
command = "/improve" # Command to run (e.g. '/review', '/describe', 'improve', '/ask="What is the purpose of this PR?"')
|
||||
|
||||
# Setting the configurations
|
||||
get_settings().set("CONFIG.git_provider", provider)
|
||||
get_settings().set("openai.key", openai_key)
|
||||
get_settings().set("github.user_token", user_token)
|
||||
|
||||
# Run the command. Feedback will appear in GitHub PR comments
|
||||
output = cli.run_command(pr_url, command)
|
||||
|
||||
print(output)
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
"""
|
||||
|
||||
100
tests/e2e_tests/test_bitbucket_app.py
Normal file
100
tests/e2e_tests/test_bitbucket_app.py
Normal file
@ -0,0 +1,100 @@
|
||||
import hashlib
|
||||
import os
|
||||
import re
|
||||
import time
|
||||
from datetime import datetime
|
||||
|
||||
import jwt
|
||||
from atlassian.bitbucket import Cloud
|
||||
|
||||
import requests
|
||||
from requests.auth import HTTPBasicAuth
|
||||
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.log import setup_logger, get_logger
|
||||
from tests.e2e_tests.e2e_utils import NEW_FILE_CONTENT, FILE_PATH, PR_HEADER_START_WITH, REVIEW_START_WITH, \
|
||||
IMPROVE_START_WITH_REGEX_PATTERN, NUM_MINUTES
|
||||
|
||||
|
||||
log_level = os.environ.get("LOG_LEVEL", "INFO")
|
||||
setup_logger(log_level)
|
||||
logger = get_logger()
|
||||
|
||||
def test_e2e_run_bitbucket_app():
|
||||
repo_slug = 'pr-agent-tests'
|
||||
project_key = 'codiumai'
|
||||
base_branch = "main" # or any base branch you want
|
||||
new_branch = f"bitbucket_app_e2e_test-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}"
|
||||
get_settings().config.git_provider = "bitbucket"
|
||||
|
||||
try:
|
||||
# Add username and password for authentication
|
||||
username = get_settings().get("BITBUCKET.USERNAME", None)
|
||||
password = get_settings().get("BITBUCKET.PASSWORD", None)
|
||||
s = requests.Session()
|
||||
s.auth = (username, password) # Use HTTP Basic Auth
|
||||
bitbucket_client = Cloud(session=s)
|
||||
repo = bitbucket_client.workspaces.get(workspace=project_key).repositories.get(repo_slug)
|
||||
|
||||
# Create a new branch from the base branch
|
||||
logger.info(f"Creating a new branch {new_branch} from {base_branch}")
|
||||
source_branch = repo.branches.get(base_branch)
|
||||
target_repo = repo.branches.create(new_branch,source_branch.hash)
|
||||
|
||||
# Update the file content
|
||||
url = (f"https://api.bitbucket.org/2.0/repositories/{project_key}/{repo_slug}/src")
|
||||
files={FILE_PATH: NEW_FILE_CONTENT}
|
||||
data={
|
||||
"message": "update cli_pip.py",
|
||||
"branch": new_branch,
|
||||
}
|
||||
requests.request("POST", url, auth=HTTPBasicAuth(username, password), data=data, files=files)
|
||||
|
||||
|
||||
# Create a pull request
|
||||
logger.info(f"Creating a pull request from {new_branch} to {base_branch}")
|
||||
pr = repo.pullrequests.create(
|
||||
title=f'{new_branch}',
|
||||
description="update cli_pip.py",
|
||||
source_branch=new_branch,
|
||||
destination_branch=base_branch
|
||||
)
|
||||
|
||||
# check every 1 minute, for 5 minutes if the PR has all the tool results
|
||||
for i in range(NUM_MINUTES):
|
||||
logger.info(f"Waiting for the PR to get all the tool results...")
|
||||
time.sleep(60)
|
||||
comments = list(pr.comments())
|
||||
comments_raw = [c.raw for c in comments]
|
||||
if len(comments) >= 5: # header, 3 suggestions, 1 review
|
||||
valid_review = False
|
||||
for comment_raw in comments_raw:
|
||||
if comment_raw.startswith('## PR Reviewer Guide 🔍'):
|
||||
valid_review = True
|
||||
break
|
||||
if valid_review:
|
||||
break
|
||||
else:
|
||||
logger.error(f"REVIEW feedback is invalid")
|
||||
raise Exception("REVIEW feedback is invalid")
|
||||
else:
|
||||
logger.info(f"Waiting for the PR to get all the tool results. {i + 1} minute(s) passed")
|
||||
else:
|
||||
assert False, f"After {NUM_MINUTES} minutes, the PR did not get all the tool results"
|
||||
|
||||
# cleanup - delete the branch
|
||||
pr.decline()
|
||||
repo.branches.delete(new_branch)
|
||||
|
||||
# If we reach here, the test is successful
|
||||
logger.info(f"Succeeded in running e2e test for Bitbucket app on the PR")
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to run e2e test for Bitbucket app: {e}")
|
||||
# delete the branch
|
||||
pr.decline()
|
||||
repo.branches.delete(new_branch)
|
||||
assert False
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
test_e2e_run_bitbucket_app()
|
||||
96
tests/e2e_tests/test_github_app.py
Normal file
96
tests/e2e_tests/test_github_app.py
Normal file
@ -0,0 +1,96 @@
|
||||
import os
|
||||
import re
|
||||
import time
|
||||
from datetime import datetime
|
||||
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers import get_git_provider
|
||||
from pr_agent.log import setup_logger, get_logger
|
||||
from tests.e2e_tests.e2e_utils import NEW_FILE_CONTENT, FILE_PATH, PR_HEADER_START_WITH, REVIEW_START_WITH, \
|
||||
IMPROVE_START_WITH_REGEX_PATTERN, NUM_MINUTES
|
||||
|
||||
log_level = os.environ.get("LOG_LEVEL", "INFO")
|
||||
setup_logger(log_level)
|
||||
logger = get_logger()
|
||||
|
||||
|
||||
def test_e2e_run_github_app():
|
||||
"""
|
||||
What we want to do:
|
||||
(1) open a PR in a repo 'https://github.com/Codium-ai/pr-agent-tests'
|
||||
(2) wait for 5 minutes until the PR is processed by the GitHub app
|
||||
(3) check that the relevant tools have been executed
|
||||
"""
|
||||
base_branch = "main" # or any base branch you want
|
||||
new_branch = f"github_app_e2e_test-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}"
|
||||
repo_url = 'Codium-ai/pr-agent-tests'
|
||||
get_settings().config.git_provider = "github"
|
||||
git_provider = get_git_provider()()
|
||||
github_client = git_provider.github_client
|
||||
repo = github_client.get_repo(repo_url)
|
||||
|
||||
try:
|
||||
# Create a new branch from the base branch
|
||||
source = repo.get_branch(base_branch)
|
||||
logger.info(f"Creating a new branch {new_branch} from {base_branch}")
|
||||
repo.create_git_ref(ref=f"refs/heads/{new_branch}", sha=source.commit.sha)
|
||||
|
||||
# Get the file you want to edit
|
||||
file = repo.get_contents(FILE_PATH, ref=base_branch)
|
||||
# content = file.decoded_content.decode()
|
||||
|
||||
# Update the file content
|
||||
logger.info(f"Updating the file {FILE_PATH}")
|
||||
commit_message = "update cli_pip.py"
|
||||
repo.update_file(
|
||||
file.path,
|
||||
commit_message,
|
||||
NEW_FILE_CONTENT,
|
||||
file.sha,
|
||||
branch=new_branch
|
||||
)
|
||||
|
||||
# Create a pull request
|
||||
logger.info(f"Creating a pull request from {new_branch} to {base_branch}")
|
||||
pr = repo.create_pull(
|
||||
title=new_branch,
|
||||
body="update cli_pip.py",
|
||||
head=new_branch,
|
||||
base=base_branch
|
||||
)
|
||||
|
||||
# check every 1 minute, for 5, minutes if the PR has all the tool results
|
||||
for i in range(NUM_MINUTES):
|
||||
logger.info(f"Waiting for the PR to get all the tool results...")
|
||||
time.sleep(60)
|
||||
logger.info(f"Checking the PR {pr.html_url} after {i + 1} minute(s)")
|
||||
pr.update()
|
||||
pr_header_body = pr.body
|
||||
comments = list(pr.get_issue_comments())
|
||||
if len(comments) == 2:
|
||||
comments_body = [comment.body for comment in comments]
|
||||
assert pr_header_body.startswith(PR_HEADER_START_WITH), "DESCRIBE feedback is invalid"
|
||||
assert comments_body[0].startswith(REVIEW_START_WITH), "REVIEW feedback is invalid"
|
||||
assert re.match(IMPROVE_START_WITH_REGEX_PATTERN, comments_body[1]), "IMPROVE feedback is invalid"
|
||||
break
|
||||
else:
|
||||
logger.info(f"Waiting for the PR to get all the tool results. {i + 1} minute(s) passed")
|
||||
else:
|
||||
assert False, f"After {NUM_MINUTES} minutes, the PR did not get all the tool results"
|
||||
|
||||
# cleanup - delete the branch
|
||||
logger.info(f"Deleting the branch {new_branch}")
|
||||
repo.get_git_ref(f"heads/{new_branch}").delete()
|
||||
|
||||
# If we reach here, the test is successful
|
||||
logger.info(f"Succeeded in running e2e test for GitHub app on the PR {pr.html_url}")
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to run e2e test for GitHub app: {e}")
|
||||
# delete the branch
|
||||
logger.info(f"Deleting the branch {new_branch}")
|
||||
repo.get_git_ref(f"heads/{new_branch}").delete()
|
||||
assert False
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
test_e2e_run_github_app()
|
||||
91
tests/e2e_tests/test_gitlab_webhook.py
Normal file
91
tests/e2e_tests/test_gitlab_webhook.py
Normal file
@ -0,0 +1,91 @@
|
||||
import os
|
||||
import re
|
||||
import time
|
||||
from datetime import datetime
|
||||
|
||||
import gitlab
|
||||
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers import get_git_provider
|
||||
from pr_agent.log import setup_logger, get_logger
|
||||
from tests.e2e_tests.e2e_utils import NEW_FILE_CONTENT, FILE_PATH, PR_HEADER_START_WITH, REVIEW_START_WITH, \
|
||||
IMPROVE_START_WITH_REGEX_PATTERN, NUM_MINUTES
|
||||
|
||||
log_level = os.environ.get("LOG_LEVEL", "INFO")
|
||||
setup_logger(log_level)
|
||||
logger = get_logger()
|
||||
|
||||
def test_e2e_run_github_app():
|
||||
# GitLab setup
|
||||
GITLAB_URL = "https://gitlab.com"
|
||||
GITLAB_TOKEN = get_settings().gitlab.PERSONAL_ACCESS_TOKEN
|
||||
gl = gitlab.Gitlab(GITLAB_URL, private_token=GITLAB_TOKEN)
|
||||
repo_url = 'codiumai/pr-agent-tests'
|
||||
project = gl.projects.get(repo_url)
|
||||
|
||||
base_branch = "main" # or any base branch you want
|
||||
new_branch = f"github_app_e2e_test-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}"
|
||||
|
||||
try:
|
||||
# Create a new branch from the base branch
|
||||
logger.info(f"Creating a new branch {new_branch} from {base_branch}")
|
||||
project.branches.create({'branch': new_branch, 'ref': base_branch})
|
||||
|
||||
# Get the file you want to edit
|
||||
file = project.files.get(file_path=FILE_PATH, ref=base_branch)
|
||||
# content = file.decode()
|
||||
|
||||
# Update the file content
|
||||
logger.info(f"Updating the file {FILE_PATH}")
|
||||
commit_message = "update cli_pip.py"
|
||||
file.content = NEW_FILE_CONTENT
|
||||
file.save(branch=new_branch, commit_message=commit_message)
|
||||
|
||||
# Create a merge request
|
||||
logger.info(f"Creating a merge request from {new_branch} to {base_branch}")
|
||||
mr = project.mergerequests.create({
|
||||
'source_branch': new_branch,
|
||||
'target_branch': base_branch,
|
||||
'title': new_branch,
|
||||
'description': "update cli_pip.py"
|
||||
})
|
||||
logger.info(f"Merge request created: {mr.web_url}")
|
||||
|
||||
# check every 1 minute, for 5, minutes if the PR has all the tool results
|
||||
for i in range(NUM_MINUTES):
|
||||
logger.info(f"Waiting for the MR to get all the tool results...")
|
||||
time.sleep(60)
|
||||
logger.info(f"Checking the MR {mr.web_url} after {i + 1} minute(s)")
|
||||
mr = project.mergerequests.get(mr.iid)
|
||||
mr_header_body = mr.description
|
||||
comments = mr.notes.list()[::-1]
|
||||
# clean all system comments
|
||||
comments = [comment for comment in comments if comment.system is False]
|
||||
if len(comments) == 2: # "changed the description" is received as the first comment
|
||||
comments_body = [comment.body for comment in comments]
|
||||
if 'Work in progress' in comments_body[1]:
|
||||
continue
|
||||
assert mr_header_body.startswith(PR_HEADER_START_WITH), "DESCRIBE feedback is invalid"
|
||||
assert comments_body[0].startswith(REVIEW_START_WITH), "REVIEW feedback is invalid"
|
||||
assert re.match(IMPROVE_START_WITH_REGEX_PATTERN, comments_body[1]), "IMPROVE feedback is invalid"
|
||||
break
|
||||
else:
|
||||
logger.info(f"Waiting for the MR to get all the tool results. {i + 1} minute(s) passed")
|
||||
else:
|
||||
assert False, f"After {NUM_MINUTES} minutes, the MR did not get all the tool results"
|
||||
|
||||
# cleanup - delete the branch
|
||||
logger.info(f"Deleting the branch {new_branch}")
|
||||
project.branches.delete(new_branch)
|
||||
|
||||
# If we reach here, the test is successful
|
||||
logger.info(f"Succeeded in running e2e test for GitLab app on the MR {mr.web_url}")
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to run e2e test for GitHub app: {e}")
|
||||
logger.info(f"Deleting the branch {new_branch}")
|
||||
project.branches.delete(new_branch)
|
||||
assert False
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
test_e2e_run_github_app()
|
||||
@ -1,5 +1,8 @@
|
||||
from pr_agent.git_providers import BitbucketServerProvider
|
||||
from pr_agent.git_providers.bitbucket_provider import BitbucketProvider
|
||||
from unittest.mock import MagicMock
|
||||
from atlassian.bitbucket import Bitbucket
|
||||
from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
|
||||
|
||||
|
||||
class TestBitbucketProvider:
|
||||
@ -10,9 +13,285 @@ class TestBitbucketProvider:
|
||||
assert repo_slug == "MY_TEST_REPO"
|
||||
assert pr_number == 321
|
||||
|
||||
def test_bitbucket_server_pr_url(self):
|
||||
|
||||
class TestBitbucketServerProvider:
|
||||
def test_parse_pr_url(self):
|
||||
url = "https://git.onpreminstance.com/projects/AAA/repos/my-repo/pull-requests/1"
|
||||
workspace_slug, repo_slug, pr_number = BitbucketServerProvider._parse_pr_url(url)
|
||||
assert workspace_slug == "AAA"
|
||||
assert repo_slug == "my-repo"
|
||||
assert pr_number == 1
|
||||
|
||||
def mock_get_content_of_file(self, project_key, repository_slug, filename, at=None, markup=None):
|
||||
content_map = {
|
||||
'9c1cffdd9f276074bfb6fb3b70fbee62d298b058': 'file\nwith\nsome\nlines\nto\nemulate\na\nreal\nfile\n',
|
||||
'2a1165446bdf991caf114d01f7c88d84ae7399cf': 'file\nwith\nmultiple \nlines\nto\nemulate\na\nfake\nfile\n',
|
||||
'f617708826cdd0b40abb5245eda71630192a17e3': 'file\nwith\nmultiple \nlines\nto\nemulate\na\nreal\nfile\n',
|
||||
'cb68a3027d6dda065a7692ebf2c90bed1bcdec28': 'file\nwith\nsome\nchanges\nto\nemulate\na\nreal\nfile\n',
|
||||
'1905dcf16c0aac6ac24f7ab617ad09c73dc1d23b': 'file\nwith\nsome\nlines\nto\nemulate\na\nfake\ntest\n',
|
||||
'ae4eca7f222c96d396927d48ab7538e2ee13ca63': 'readme\nwithout\nsome\nlines\nto\nsimulate\na\nreal\nfile',
|
||||
'548f8ba15abc30875a082156314426806c3f4d97': 'file\nwith\nsome\nlines\nto\nemulate\na\nreal\nfile',
|
||||
'0e898cb355a5170d8c8771b25d43fcaa1d2d9489': 'file\nwith\nmultiple\nlines\nto\nemulate\na\nreal\nfile'
|
||||
}
|
||||
return content_map.get(at, '')
|
||||
|
||||
def mock_get_from_bitbucket_60(self, url):
|
||||
response_map = {
|
||||
"rest/api/1.0/application-properties": {
|
||||
"version": "6.0"
|
||||
}
|
||||
}
|
||||
return response_map.get(url, '')
|
||||
|
||||
def mock_get_from_bitbucket_70(self, url):
|
||||
response_map = {
|
||||
"rest/api/1.0/application-properties": {
|
||||
"version": "7.0"
|
||||
}
|
||||
}
|
||||
return response_map.get(url, '')
|
||||
|
||||
def mock_get_from_bitbucket_816(self, url):
|
||||
response_map = {
|
||||
"rest/api/1.0/application-properties": {
|
||||
"version": "8.16"
|
||||
},
|
||||
"rest/api/latest/projects/AAA/repos/my-repo/pull-requests/1/merge-base": {
|
||||
'id': '548f8ba15abc30875a082156314426806c3f4d97'
|
||||
}
|
||||
}
|
||||
return response_map.get(url, '')
|
||||
|
||||
|
||||
'''
|
||||
tests the 2-way diff functionality where the diff should be between the HEAD of branch b and node c
|
||||
NOT between the HEAD of main and the HEAD of branch b
|
||||
|
||||
- o branch b
|
||||
/
|
||||
o - o - o main
|
||||
^ node c
|
||||
'''
|
||||
def test_get_diff_files_simple_diverge_70(self):
|
||||
bitbucket_client = MagicMock(Bitbucket)
|
||||
bitbucket_client.get_pull_request.return_value = {
|
||||
'toRef': {'latestCommit': '9c1cffdd9f276074bfb6fb3b70fbee62d298b058'},
|
||||
'fromRef': {'latestCommit': '2a1165446bdf991caf114d01f7c88d84ae7399cf'}
|
||||
}
|
||||
bitbucket_client.get_pull_requests_commits.return_value = [
|
||||
{'id': '2a1165446bdf991caf114d01f7c88d84ae7399cf',
|
||||
'parents': [{'id': 'f617708826cdd0b40abb5245eda71630192a17e3'}]}
|
||||
]
|
||||
bitbucket_client.get_commits.return_value = [
|
||||
{'id': '9c1cffdd9f276074bfb6fb3b70fbee62d298b058'},
|
||||
{'id': 'dbca09554567d2e4bee7f07993390153280ee450'}
|
||||
]
|
||||
bitbucket_client.get_pull_requests_changes.return_value = [
|
||||
{
|
||||
'path': {'toString': 'Readme.md'},
|
||||
'type': 'MODIFY',
|
||||
}
|
||||
]
|
||||
|
||||
bitbucket_client.get.side_effect = self.mock_get_from_bitbucket_70
|
||||
bitbucket_client.get_content_of_file.side_effect = self.mock_get_content_of_file
|
||||
|
||||
provider = BitbucketServerProvider(
|
||||
"https://git.onpreminstance.com/projects/AAA/repos/my-repo/pull-requests/1",
|
||||
bitbucket_client=bitbucket_client
|
||||
)
|
||||
|
||||
expected = [
|
||||
FilePatchInfo(
|
||||
'file\nwith\nmultiple \nlines\nto\nemulate\na\nreal\nfile\n',
|
||||
'file\nwith\nmultiple \nlines\nto\nemulate\na\nfake\nfile\n',
|
||||
'--- \n+++ \n@@ -5,5 +5,5 @@\n to\n emulate\n a\n-real\n+fake\n file\n',
|
||||
'Readme.md',
|
||||
edit_type=EDIT_TYPE.MODIFIED,
|
||||
)
|
||||
]
|
||||
|
||||
actual = provider.get_diff_files()
|
||||
|
||||
assert actual == expected
|
||||
|
||||
|
||||
'''
|
||||
tests the 2-way diff functionality where the diff should be between the HEAD of branch b and node c
|
||||
NOT between the HEAD of main and the HEAD of branch b
|
||||
|
||||
- o - o - o branch b
|
||||
/ /
|
||||
o - o -- o - o main
|
||||
^ node c
|
||||
'''
|
||||
def test_get_diff_files_diverge_with_merge_commit_70(self):
|
||||
bitbucket_client = MagicMock(Bitbucket)
|
||||
bitbucket_client.get_pull_request.return_value = {
|
||||
'toRef': {'latestCommit': 'cb68a3027d6dda065a7692ebf2c90bed1bcdec28'},
|
||||
'fromRef': {'latestCommit': '1905dcf16c0aac6ac24f7ab617ad09c73dc1d23b'}
|
||||
}
|
||||
bitbucket_client.get_pull_requests_commits.return_value = [
|
||||
{'id': '1905dcf16c0aac6ac24f7ab617ad09c73dc1d23b',
|
||||
'parents': [{'id': '692772f456c3db77a90b11ce39ea516f8c2bad93'}]},
|
||||
{'id': '692772f456c3db77a90b11ce39ea516f8c2bad93', 'parents': [
|
||||
{'id': '2a1165446bdf991caf114d01f7c88d84ae7399cf'},
|
||||
{'id': '9c1cffdd9f276074bfb6fb3b70fbee62d298b058'},
|
||||
]},
|
||||
{'id': '2a1165446bdf991caf114d01f7c88d84ae7399cf',
|
||||
'parents': [{'id': 'f617708826cdd0b40abb5245eda71630192a17e3'}]}
|
||||
]
|
||||
bitbucket_client.get_commits.return_value = [
|
||||
{'id': 'cb68a3027d6dda065a7692ebf2c90bed1bcdec28'},
|
||||
{'id': '9c1cffdd9f276074bfb6fb3b70fbee62d298b058'},
|
||||
{'id': 'dbca09554567d2e4bee7f07993390153280ee450'}
|
||||
]
|
||||
bitbucket_client.get_pull_requests_changes.return_value = [
|
||||
{
|
||||
'path': {'toString': 'Readme.md'},
|
||||
'type': 'MODIFY',
|
||||
}
|
||||
]
|
||||
|
||||
bitbucket_client.get.side_effect = self.mock_get_from_bitbucket_70
|
||||
bitbucket_client.get_content_of_file.side_effect = self.mock_get_content_of_file
|
||||
|
||||
provider = BitbucketServerProvider(
|
||||
"https://git.onpreminstance.com/projects/AAA/repos/my-repo/pull-requests/1",
|
||||
bitbucket_client=bitbucket_client
|
||||
)
|
||||
|
||||
expected = [
|
||||
FilePatchInfo(
|
||||
'file\nwith\nsome\nlines\nto\nemulate\na\nreal\nfile\n',
|
||||
'file\nwith\nsome\nlines\nto\nemulate\na\nfake\ntest\n',
|
||||
'--- \n+++ \n@@ -5,5 +5,5 @@\n to\n emulate\n a\n-real\n-file\n+fake\n+test\n',
|
||||
'Readme.md',
|
||||
edit_type=EDIT_TYPE.MODIFIED,
|
||||
)
|
||||
]
|
||||
|
||||
actual = provider.get_diff_files()
|
||||
|
||||
assert actual == expected
|
||||
|
||||
|
||||
'''
|
||||
tests the 2-way diff functionality where the diff should be between the HEAD of branch c and node d
|
||||
NOT between the HEAD of main and the HEAD of branch c
|
||||
|
||||
---- o - o branch c
|
||||
/ /
|
||||
---- o branch b
|
||||
/ /
|
||||
o - o - o main
|
||||
^ node d
|
||||
'''
|
||||
def get_multi_merge_diverge_mock_client(self, api_version):
|
||||
bitbucket_client = MagicMock(Bitbucket)
|
||||
bitbucket_client.get_pull_request.return_value = {
|
||||
'toRef': {'latestCommit': '9569922b22fe4fd0968be6a50ed99f71efcd0504'},
|
||||
'fromRef': {'latestCommit': 'ae4eca7f222c96d396927d48ab7538e2ee13ca63'}
|
||||
}
|
||||
bitbucket_client.get_pull_requests_commits.return_value = [
|
||||
{'id': 'ae4eca7f222c96d396927d48ab7538e2ee13ca63',
|
||||
'parents': [{'id': 'bbf300fb3af5129af8c44659f8cc7a526a6a6f31'}]},
|
||||
{'id': 'bbf300fb3af5129af8c44659f8cc7a526a6a6f31', 'parents': [
|
||||
{'id': '10b7b8e41cb370b48ceda8da4e7e6ad033182213'},
|
||||
{'id': 'd1bb183c706a3ebe4c2b1158c25878201a27ad8c'},
|
||||
]},
|
||||
{'id': 'd1bb183c706a3ebe4c2b1158c25878201a27ad8c', 'parents': [
|
||||
{'id': '5bd76251866cb415fc5ff232f63a581e89223bda'},
|
||||
{'id': '548f8ba15abc30875a082156314426806c3f4d97'}
|
||||
]},
|
||||
{'id': '5bd76251866cb415fc5ff232f63a581e89223bda',
|
||||
'parents': [{'id': '0e898cb355a5170d8c8771b25d43fcaa1d2d9489'}]},
|
||||
{'id': '10b7b8e41cb370b48ceda8da4e7e6ad033182213',
|
||||
'parents': [{'id': '0e898cb355a5170d8c8771b25d43fcaa1d2d9489'}]}
|
||||
]
|
||||
bitbucket_client.get_commits.return_value = [
|
||||
{'id': '9569922b22fe4fd0968be6a50ed99f71efcd0504'},
|
||||
{'id': '548f8ba15abc30875a082156314426806c3f4d97'}
|
||||
]
|
||||
bitbucket_client.get_pull_requests_changes.return_value = [
|
||||
{
|
||||
'path': {'toString': 'Readme.md'},
|
||||
'type': 'MODIFY',
|
||||
}
|
||||
]
|
||||
|
||||
bitbucket_client.get_content_of_file.side_effect = self.mock_get_content_of_file
|
||||
if api_version == 60:
|
||||
bitbucket_client.get.side_effect = self.mock_get_from_bitbucket_60
|
||||
elif api_version == 70:
|
||||
bitbucket_client.get.side_effect = self.mock_get_from_bitbucket_70
|
||||
elif api_version == 816:
|
||||
bitbucket_client.get.side_effect = self.mock_get_from_bitbucket_816
|
||||
|
||||
return bitbucket_client
|
||||
|
||||
def test_get_diff_files_multi_merge_diverge_60(self):
|
||||
bitbucket_client = self.get_multi_merge_diverge_mock_client(60)
|
||||
|
||||
provider = BitbucketServerProvider(
|
||||
"https://git.onpreminstance.com/projects/AAA/repos/my-repo/pull-requests/1",
|
||||
bitbucket_client=bitbucket_client
|
||||
)
|
||||
|
||||
expected = [
|
||||
FilePatchInfo(
|
||||
'file\nwith\nmultiple\nlines\nto\nemulate\na\nreal\nfile',
|
||||
'readme\nwithout\nsome\nlines\nto\nsimulate\na\nreal\nfile',
|
||||
'--- \n+++ \n@@ -1,9 +1,9 @@\n-file\n-with\n-multiple\n+readme\n+without\n+some\n lines\n to\n-emulate\n+simulate\n a\n real\n file',
|
||||
'Readme.md',
|
||||
edit_type=EDIT_TYPE.MODIFIED,
|
||||
)
|
||||
]
|
||||
|
||||
actual = provider.get_diff_files()
|
||||
|
||||
assert actual == expected
|
||||
|
||||
def test_get_diff_files_multi_merge_diverge_70(self):
|
||||
bitbucket_client = self.get_multi_merge_diverge_mock_client(70)
|
||||
|
||||
provider = BitbucketServerProvider(
|
||||
"https://git.onpreminstance.com/projects/AAA/repos/my-repo/pull-requests/1",
|
||||
bitbucket_client=bitbucket_client
|
||||
)
|
||||
|
||||
expected = [
|
||||
FilePatchInfo(
|
||||
'file\nwith\nsome\nlines\nto\nemulate\na\nreal\nfile',
|
||||
'readme\nwithout\nsome\nlines\nto\nsimulate\na\nreal\nfile',
|
||||
'--- \n+++ \n@@ -1,9 +1,9 @@\n-file\n-with\n+readme\n+without\n some\n lines\n to\n-emulate\n+simulate\n a\n real\n file',
|
||||
'Readme.md',
|
||||
edit_type=EDIT_TYPE.MODIFIED,
|
||||
)
|
||||
]
|
||||
|
||||
actual = provider.get_diff_files()
|
||||
|
||||
assert actual == expected
|
||||
|
||||
def test_get_diff_files_multi_merge_diverge_816(self):
|
||||
bitbucket_client = self.get_multi_merge_diverge_mock_client(816)
|
||||
|
||||
provider = BitbucketServerProvider(
|
||||
"https://git.onpreminstance.com/projects/AAA/repos/my-repo/pull-requests/1",
|
||||
bitbucket_client=bitbucket_client
|
||||
)
|
||||
|
||||
expected = [
|
||||
FilePatchInfo(
|
||||
'file\nwith\nsome\nlines\nto\nemulate\na\nreal\nfile',
|
||||
'readme\nwithout\nsome\nlines\nto\nsimulate\na\nreal\nfile',
|
||||
'--- \n+++ \n@@ -1,9 +1,9 @@\n-file\n-with\n+readme\n+without\n some\n lines\n to\n-emulate\n+simulate\n a\n real\n file',
|
||||
'Readme.md',
|
||||
edit_type=EDIT_TYPE.MODIFIED,
|
||||
)
|
||||
]
|
||||
|
||||
actual = provider.get_diff_files()
|
||||
|
||||
assert actual == expected
|
||||
@ -53,7 +53,7 @@ class TestConvertToMarkdown:
|
||||
'relevant_line': '[return ""](https://github.com/Codium-ai/pr-agent-pro/pull/102/files#diff-52d45f12b836f77ed1aef86e972e65404634ea4e2a6083fb71a9b0f9bb9e062fR199)'}]}
|
||||
|
||||
|
||||
expected_output = f'{PRReviewHeader.REGULAR} 🔍\n\n<table>\n<tr><td>⏱️ <strong>Estimated effort to review</strong>: 1 🔵⚪⚪⚪⚪</td></tr>\n<tr><td>🧪 <strong>No relevant tests</strong></td></tr>\n<tr><td>⚡ <strong>Possible issues</strong>: No\n</td></tr>\n<tr><td>🔒 <strong>No security concerns identified</strong></td></tr>\n</table>\n\n\n<details><summary> <strong>Code feedback:</strong></summary>\n\n<hr><table><tr><td>relevant file</td><td>pr_agent/git_providers/git_provider.py\n</td></tr><tr><td>suggestion </td><td>\n\n<strong>\n\nConsider raising an exception or logging a warning when \'pr_url\' attribute is not found. This can help in debugging issues related to the absence of \'pr_url\' in instances where it\'s expected. [important]\n\n</strong>\n</td></tr><tr><td>relevant line</td><td><a href=\'https://github.com/Codium-ai/pr-agent-pro/pull/102/files#diff-52d45f12b836f77ed1aef86e972e65404634ea4e2a6083fb71a9b0f9bb9e062fR199\'>return ""</a></td></tr></table><hr>\n\n</details>'
|
||||
expected_output = f'{PRReviewHeader.REGULAR.value} 🔍\n\n<table>\n<tr><td>⏱️ <strong>Estimated effort to review</strong>: 1 🔵⚪⚪⚪⚪</td></tr>\n<tr><td>🧪 <strong>No relevant tests</strong></td></tr>\n<tr><td>⚡ <strong>Possible issues</strong>: No\n</td></tr>\n<tr><td>🔒 <strong>No security concerns identified</strong></td></tr>\n</table>\n\n\n<details><summary> <strong>Code feedback:</strong></summary>\n\n<hr><table><tr><td>relevant file</td><td>pr_agent/git_providers/git_provider.py\n</td></tr><tr><td>suggestion </td><td>\n\n<strong>\n\nConsider raising an exception or logging a warning when \'pr_url\' attribute is not found. This can help in debugging issues related to the absence of \'pr_url\' in instances where it\'s expected. [important]\n\n</strong>\n</td></tr><tr><td>relevant line</td><td><a href=\'https://github.com/Codium-ai/pr-agent-pro/pull/102/files#diff-52d45f12b836f77ed1aef86e972e65404634ea4e2a6083fb71a9b0f9bb9e062fR199\'>return ""</a></td></tr></table><hr>\n\n</details>'
|
||||
|
||||
assert convert_to_markdown_v2(input_data).strip() == expected_output.strip()
|
||||
|
||||
|
||||
@ -1,54 +1,22 @@
|
||||
|
||||
# Generated by CodiumAI
|
||||
|
||||
|
||||
import pytest
|
||||
from pr_agent.algo.git_patch_processing import extend_patch
|
||||
|
||||
"""
|
||||
Code Analysis
|
||||
|
||||
Objective:
|
||||
The objective of the 'extend_patch' function is to extend a given patch to include a specified number of surrounding
|
||||
lines. This function takes in an original file string, a patch string, and the number of lines to extend the patch by,
|
||||
and returns the extended patch string.
|
||||
|
||||
Inputs:
|
||||
- original_file_str: a string representing the original file
|
||||
- patch_str: a string representing the patch to be extended
|
||||
- num_lines: an integer representing the number of lines to extend the patch by
|
||||
|
||||
Flow:
|
||||
1. Split the original file string and patch string into separate lines
|
||||
2. Initialize variables to keep track of the current hunk's start and size for both the original file and the patch
|
||||
3. Iterate through each line in the patch string
|
||||
4. If the line starts with '@@', extract the start and size values for both the original file and the patch, and
|
||||
calculate the extended start and size values
|
||||
5. Append the extended hunk header to the extended patch lines list
|
||||
6. Append the specified number of lines before the hunk to the extended patch lines list
|
||||
7. Append the current line to the extended patch lines list
|
||||
8. If the line is not a hunk header, append it to the extended patch lines list
|
||||
9. Return the extended patch string
|
||||
|
||||
Outputs:
|
||||
- extended_patch_str: a string representing the extended patch
|
||||
|
||||
Additional aspects:
|
||||
- The function uses regular expressions to extract the start and size values from the hunk header
|
||||
- The function handles cases where the start value of a hunk is less than the number of lines to extend by by setting
|
||||
the extended start value to 1
|
||||
- The function handles cases where the hunk extends beyond the end of the original file by only including lines up to
|
||||
the end of the original file in the extended patch
|
||||
"""
|
||||
from pr_agent.algo.pr_processing import pr_generate_extended_diff
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.config_loader import get_settings
|
||||
|
||||
|
||||
class TestExtendPatch:
|
||||
def setUp(self):
|
||||
get_settings().config.allow_dynamic_context = False
|
||||
|
||||
# Tests that the function works correctly with valid input
|
||||
def test_happy_path(self):
|
||||
original_file_str = 'line1\nline2\nline3\nline4\nline5'
|
||||
patch_str = '@@ -2,2 +2,2 @@ init()\n-line2\n+new_line2\nline3'
|
||||
patch_str = '@@ -2,2 +2,2 @@ init()\n-line2\n+new_line2\n line3'
|
||||
num_lines = 1
|
||||
expected_output = '@@ -1,4 +1,4 @@ init()\nline1\n-line2\n+new_line2\nline3\nline4'
|
||||
actual_output = extend_patch(original_file_str, patch_str, num_lines)
|
||||
expected_output = '\n@@ -1,4 +1,4 @@ init()\n line1\n-line2\n+new_line2\n line3\n line4'
|
||||
actual_output = extend_patch(original_file_str, patch_str,
|
||||
patch_extra_lines_before=num_lines, patch_extra_lines_after=num_lines)
|
||||
assert actual_output == expected_output
|
||||
|
||||
# Tests that the function returns an empty string when patch_str is empty
|
||||
@ -57,14 +25,16 @@ class TestExtendPatch:
|
||||
patch_str = ''
|
||||
num_lines = 1
|
||||
expected_output = ''
|
||||
assert extend_patch(original_file_str, patch_str, num_lines) == expected_output
|
||||
assert extend_patch(original_file_str, patch_str,
|
||||
patch_extra_lines_before=num_lines, patch_extra_lines_after=num_lines) == expected_output
|
||||
|
||||
# Tests that the function returns the original patch when num_lines is 0
|
||||
def test_zero_num_lines(self):
|
||||
original_file_str = 'line1\nline2\nline3\nline4\nline5'
|
||||
patch_str = '@@ -2,2 +2,2 @@ init()\n-line2\n+new_line2\nline3'
|
||||
num_lines = 0
|
||||
assert extend_patch(original_file_str, patch_str, num_lines) == patch_str
|
||||
assert extend_patch(original_file_str, patch_str,
|
||||
patch_extra_lines_before=num_lines, patch_extra_lines_after=num_lines) == patch_str
|
||||
|
||||
# Tests that the function returns the original patch when patch_str contains no hunks
|
||||
def test_no_hunks(self):
|
||||
@ -77,17 +47,99 @@ class TestExtendPatch:
|
||||
# Tests that the function extends a patch with a single hunk correctly
|
||||
def test_single_hunk(self):
|
||||
original_file_str = 'line1\nline2\nline3\nline4\nline5'
|
||||
patch_str = '@@ -2,3 +2,3 @@ init()\n-line2\n+new_line2\nline3\nline4'
|
||||
num_lines = 1
|
||||
expected_output = '@@ -1,5 +1,5 @@ init()\nline1\n-line2\n+new_line2\nline3\nline4\nline5'
|
||||
actual_output = extend_patch(original_file_str, patch_str, num_lines)
|
||||
assert actual_output == expected_output
|
||||
patch_str = '@@ -2,3 +2,3 @@ init()\n-line2\n+new_line2\n line3\n line4'
|
||||
|
||||
for num_lines in [1, 2, 3]: # check that even if we are over the number of lines in the file, the function still works
|
||||
expected_output = '\n@@ -1,5 +1,5 @@ init()\n line1\n-line2\n+new_line2\n line3\n line4\n line5'
|
||||
actual_output = extend_patch(original_file_str, patch_str,
|
||||
patch_extra_lines_before=num_lines, patch_extra_lines_after=num_lines)
|
||||
assert actual_output == expected_output
|
||||
|
||||
# Tests the functionality of extending a patch with multiple hunks.
|
||||
def test_multiple_hunks(self):
|
||||
original_file_str = 'line1\nline2\nline3\nline4\nline5\nline6'
|
||||
patch_str = '@@ -2,3 +2,3 @@ init()\n-line2\n+new_line2\nline3\nline4\n@@ -4,1 +4,1 @@ init2()\n-line4\n+new_line4' # noqa: E501
|
||||
patch_str = '@@ -2,3 +2,3 @@ init()\n-line2\n+new_line2\n line3\n line4\n@@ -4,1 +4,1 @@ init2()\n-line4\n+new_line4' # noqa: E501
|
||||
num_lines = 1
|
||||
expected_output = '@@ -1,5 +1,5 @@ init()\nline1\n-line2\n+new_line2\nline3\nline4\nline5\n@@ -3,3 +3,3 @@ init2()\nline3\n-line4\n+new_line4\nline5' # noqa: E501
|
||||
actual_output = extend_patch(original_file_str, patch_str, num_lines)
|
||||
expected_output = '\n@@ -1,5 +1,5 @@ init()\n line1\n-line2\n+new_line2\n line3\n line4\n line5\n\n@@ -3,3 +3,3 @@ init2()\n line3\n-line4\n+new_line4\n line5' # noqa: E501
|
||||
actual_output = extend_patch(original_file_str, patch_str,
|
||||
patch_extra_lines_before=num_lines, patch_extra_lines_after=num_lines)
|
||||
assert actual_output == expected_output
|
||||
|
||||
def test_dynamic_context(self):
|
||||
get_settings().config.max_extra_lines_before_dynamic_context = 10
|
||||
original_file_str = "def foo():"
|
||||
for i in range(9):
|
||||
original_file_str += f"\n line({i})"
|
||||
patch_str ="@@ -11,1 +11,1 @@ def foo():\n- line(9)\n+ new_line(9)"
|
||||
num_lines=1
|
||||
|
||||
get_settings().config.allow_dynamic_context = True
|
||||
actual_output = extend_patch(original_file_str, patch_str,
|
||||
patch_extra_lines_before=num_lines, patch_extra_lines_after=num_lines)
|
||||
expected_output='\n@@ -1,10 +1,10 @@ \n def foo():\n line(0)\n line(1)\n line(2)\n line(3)\n line(4)\n line(5)\n line(6)\n line(7)\n line(8)\n- line(9)\n+ new_line(9)'
|
||||
assert actual_output == expected_output
|
||||
|
||||
get_settings().config.allow_dynamic_context = False
|
||||
actual_output2 = extend_patch(original_file_str, patch_str,
|
||||
patch_extra_lines_before=num_lines, patch_extra_lines_after=num_lines)
|
||||
expected_output_no_dynamic_context = '\n@@ -10,1 +10,1 @@ def foo():\n line(8)\n- line(9)\n+ new_line(9)'
|
||||
assert actual_output2 == expected_output_no_dynamic_context
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
class TestExtendedPatchMoreLines:
|
||||
def setUp(self):
|
||||
get_settings().config.allow_dynamic_context = False
|
||||
|
||||
class File:
|
||||
def __init__(self, base_file, patch, filename):
|
||||
self.base_file = base_file
|
||||
self.patch = patch
|
||||
self.filename = filename
|
||||
|
||||
@pytest.fixture
|
||||
def token_handler(self):
|
||||
# Create a TokenHandler instance with dummy data
|
||||
th = TokenHandler(system="System prompt", user="User prompt")
|
||||
th.prompt_tokens = 100
|
||||
return th
|
||||
|
||||
@pytest.fixture
|
||||
def pr_languages(self):
|
||||
# Create a list of languages with files containing base_file and patch data
|
||||
return [
|
||||
{
|
||||
'files': [
|
||||
self.File(base_file="line000\nline00\nline0\nline1\noriginal content\nline2\nline3\nline4\nline5\nline6\nline7\nline8\nline9\nline10",
|
||||
patch="@@ -5,5 +5,5 @@\n-original content\n+modified content\n line2\n line3\n line4\n line5",
|
||||
filename="file1"),
|
||||
self.File(base_file="original content\nline2\nline3\nline4\nline5\nline6\nline7\nline8\nline9\nline10",
|
||||
patch="@@ -6,5 +6,5 @@\nline6\nline7\nline8\n-line9\n+modified line9\nline10",
|
||||
filename="file2")
|
||||
]
|
||||
}
|
||||
]
|
||||
|
||||
def test_extend_patches_with_extra_lines(self, token_handler, pr_languages):
|
||||
patches_extended_no_extra_lines, total_tokens, patches_extended_tokens = pr_generate_extended_diff(
|
||||
pr_languages, token_handler, add_line_numbers_to_hunks=False,
|
||||
patch_extra_lines_before=0,
|
||||
patch_extra_lines_after=0
|
||||
)
|
||||
|
||||
# Check that with no extra lines, the patches are the same as the original patches
|
||||
p0 = patches_extended_no_extra_lines[0].strip()
|
||||
p1 = patches_extended_no_extra_lines[1].strip()
|
||||
assert p0 == '## file1\n' + pr_languages[0]['files'][0].patch.strip()
|
||||
assert p1 == '## file2\n' + pr_languages[0]['files'][1].patch.strip()
|
||||
|
||||
patches_extended_with_extra_lines, total_tokens, patches_extended_tokens = pr_generate_extended_diff(
|
||||
pr_languages, token_handler, add_line_numbers_to_hunks=False,
|
||||
patch_extra_lines_before=2,
|
||||
patch_extra_lines_after=1
|
||||
)
|
||||
|
||||
p0_extended = patches_extended_with_extra_lines[0].strip()
|
||||
assert p0_extended == '## file1\n\n@@ -3,8 +3,8 @@ \n line0\n line1\n-original content\n+modified content\n line2\n line3\n line4\n line5\n line6'
|
||||
|
||||
@ -34,7 +34,7 @@ PR Feedback:
|
||||
with pytest.raises(ScannerError):
|
||||
yaml.safe_load(yaml_str)
|
||||
|
||||
expected_output = {'PR Analysis': {'Main theme': 'Enhancing the `/describe` command prompt by adding title and description', 'Type of PR': 'Enhancement', 'Relevant tests': False, 'Focused PR': 'Yes, the PR is focused on enhancing the `/describe` command prompt.'}, 'PR Feedback': {'General suggestions': 'The PR seems to be well-structured and focused on a specific enhancement. However, it would be beneficial to add tests to ensure the new feature works as expected.', 'Code feedback': [{'relevant file': 'pr_agent/settings/pr_description_prompts.toml', 'suggestion': "Consider using a more descriptive variable name than 'user' for the command prompt. A more descriptive name would make the code more readable and maintainable. [medium]", 'relevant line': 'user="""PR Info: aaa'}], 'Security concerns': False}}
|
||||
expected_output = {'PR Analysis': {'Main theme': 'Enhancing the `/describe` command prompt by adding title and description', 'Type of PR': 'Enhancement', 'Relevant tests': False, 'Focused PR': 'Yes, the PR is focused on enhancing the `/describe` command prompt.'}, 'PR Feedback': {'General suggestions': 'The PR seems to be well-structured and focused on a specific enhancement. However, it would be beneficial to add tests to ensure the new feature works as expected.', 'Code feedback': [{'relevant file': 'pr_agent/settings/pr_description_prompts.toml\n', 'suggestion': "Consider using a more descriptive variable name than 'user' for the command prompt. A more descriptive name would make the code more readable and maintainable. [medium]", 'relevant line': 'user="""PR Info: aaa\n'}], 'Security concerns': False}}
|
||||
assert load_yaml(yaml_str) == expected_output
|
||||
|
||||
def test_load_invalid_yaml2(self):
|
||||
@ -45,7 +45,7 @@ PR Feedback:
|
||||
with pytest.raises(ScannerError):
|
||||
yaml.safe_load(yaml_str)
|
||||
|
||||
expected_output = [{'relevant file': 'src/app.py:', 'suggestion content': 'The print statement is outside inside the if __name__ ==: '}]
|
||||
expected_output = [{'relevant file': 'src/app.py:\n', 'suggestion content': 'The print statement is outside inside the if __name__ ==:'}]
|
||||
assert load_yaml(yaml_str) == expected_output
|
||||
|
||||
|
||||
|
||||
@ -16,7 +16,7 @@ class TestTryFixYaml:
|
||||
# The function adds '|-' to 'relevant line:' if it is not already present and successfully parses the YAML string.
|
||||
def test_add_relevant_line(self):
|
||||
review_text = "relevant line: value: 3\n"
|
||||
expected_output = {"relevant line": "value: 3"}
|
||||
expected_output = {'relevant line': 'value: 3\n'}
|
||||
assert try_fix_yaml(review_text) == expected_output
|
||||
|
||||
# The function extracts YAML snippet
|
||||
|
||||
Reference in New Issue
Block a user