mirror of
https://github.com/qodo-ai/pr-agent.git
synced 2025-07-04 21:00:40 +08:00
Compare commits
2 Commits
test_best_
...
hl/jira_se
| Author | SHA1 | Date | |
|---|---|---|---|
| 5cc9dcf72a | |||
| a87dd37f66 |
2
.gitignore
vendored
2
.gitignore
vendored
@ -1,7 +1,6 @@
|
||||
.idea/
|
||||
.lsp/
|
||||
.vscode/
|
||||
.env
|
||||
venv/
|
||||
pr_agent/settings/.secrets.toml
|
||||
__pycache__
|
||||
@ -10,4 +9,3 @@ dist/
|
||||
build/
|
||||
.DS_Store
|
||||
docs/.cache/
|
||||
.qodo
|
||||
|
||||
67
README.md
67
README.md
@ -41,25 +41,6 @@ Qode Merge PR-Agent aims to help efficiently review and handle pull requests, by
|
||||
|
||||
## News and Updates
|
||||
|
||||
### Jan 2, 2025
|
||||
|
||||
New tool [/Implement](https://qodo-merge-docs.qodo.ai/tools/implement/) (💎), which converts human code review discussions and feedback into ready-to-commit code changes.
|
||||
|
||||
<kbd><img src="https://codium.ai/images/pr_agent/implement1.png" width="512"></kbd>
|
||||
|
||||
|
||||
### Jan 1, 2025
|
||||
|
||||
Update logic and [documentation](https://qodo-merge-docs.qodo.ai/usage-guide/changing_a_model/#ollama) for running local models via Ollama.
|
||||
|
||||
### December 30, 2024
|
||||
|
||||
Following [feedback](https://research.kudelskisecurity.com/2024/08/29/careful-where-you-code-multiple-vulnerabilities-in-ai-powered-pr-agent/) from the community, we have addressed two vulnerabilities identified in the open-source PR-Agent project. The fixes are now included in the newly released version (v0.26), available as of today.
|
||||
|
||||
### December 25, 2024
|
||||
|
||||
The `review` tool previously included a legacy feature for providing code suggestions (controlled by '--pr_reviewer.num_code_suggestion'). This functionality has been deprecated. Use instead the [`improve`](https://qodo-merge-docs.qodo.ai/tools/improve/) tool, which offers higher quality and more actionable code suggestions.
|
||||
|
||||
### December 2, 2024
|
||||
|
||||
Open-source repositories can now freely use Qodo Merge Pro, and enjoy easy one-click installation using a marketplace [app](https://github.com/apps/qodo-merge-pro-for-open-source).
|
||||
@ -90,6 +71,12 @@ Focused mode
|
||||
<kbd><img src="https://qodo.ai/images/pr_agent/code_suggestions_focused_mode.png" width="512"></kbd>
|
||||
|
||||
|
||||
### November 4, 2024
|
||||
|
||||
Qodo Merge PR Agent will now leverage context from Jira or GitHub tickets to enhance the PR Feedback. Read more about this feature
|
||||
[here](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/)
|
||||
|
||||
|
||||
## Overview
|
||||
<div style="text-align:left;">
|
||||
|
||||
@ -114,7 +101,6 @@ Supported commands per platform:
|
||||
| | [Similar Code](https://pr-agent-docs.codium.ai/tools/similar_code/) 💎 | ✅ | | | |
|
||||
| | [Custom Prompt](https://pr-agent-docs.codium.ai/tools/custom_prompt/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [Test](https://pr-agent-docs.codium.ai/tools/test/) 💎 | ✅ | ✅ | | |
|
||||
| | [Implement](https://pr-agent-docs.codium.ai/tools/implement/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | | | | | |
|
||||
| USAGE | [CLI](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#local-repo-cli) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [App / webhook](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#github-app) | ✅ | ✅ | ✅ | ✅ |
|
||||
@ -154,8 +140,6 @@ ___
|
||||
\
|
||||
‣ **Analyze 💎 ([`/analyze`](https://pr-agent-docs.codium.ai/tools/analyze/))**: Identify code components that changed in the PR, and enables to interactively generate tests, docs, and code suggestions for each component.
|
||||
\
|
||||
‣ **Test 💎 ([`/test`](https://pr-agent-docs.codium.ai/tools/test/))**: Generate tests for a selected component, based on the PR code changes.
|
||||
\
|
||||
‣ **Custom Prompt 💎 ([`/custom_prompt`](https://pr-agent-docs.codium.ai/tools/custom_prompt/))**: Automatically generates custom suggestions for improving the PR code, based on specific guidelines defined by the user.
|
||||
\
|
||||
‣ **Generate Tests 💎 ([`/test component_name`](https://pr-agent-docs.codium.ai/tools/test/))**: Generates unit tests for a selected component, based on the PR code changes.
|
||||
@ -163,8 +147,6 @@ ___
|
||||
‣ **CI Feedback 💎 ([`/checks ci_job`](https://pr-agent-docs.codium.ai/tools/ci_feedback/))**: Automatically generates feedback and analysis for a failed CI job.
|
||||
\
|
||||
‣ **Similar Code 💎 ([`/find_similar_component`](https://pr-agent-docs.codium.ai/tools/similar_code/))**: Retrieves the most similar code components from inside the organization's codebase, or from open-source code.
|
||||
\
|
||||
‣ **Implement 💎 ([`/implement`](https://qodo-merge-docs.qodo.ai/tools/implement/))**: Generates implementation code from review suggestions.
|
||||
___
|
||||
|
||||
## Example results
|
||||
@ -197,6 +179,43 @@ ___
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
|
||||
[//]: # (<h4><a href="https://github.com/Codium-ai/pr-agent/pull/78#issuecomment-1639739496">/reflect_and_review:</a></h4>)
|
||||
|
||||
[//]: # (<div align="center">)
|
||||
|
||||
[//]: # (<p float="center">)
|
||||
|
||||
[//]: # (<img src="https://www.codium.ai/images/reflect_and_review.gif" width="800">)
|
||||
|
||||
[//]: # (</p>)
|
||||
|
||||
[//]: # (</div>)
|
||||
|
||||
[//]: # (<h4><a href="https://github.com/Codium-ai/pr-agent/pull/229#issuecomment-1695020538">/ask:</a></h4>)
|
||||
|
||||
[//]: # (<div align="center">)
|
||||
|
||||
[//]: # (<p float="center">)
|
||||
|
||||
[//]: # (<img src="https://www.codium.ai/images/ask-2.gif" width="800">)
|
||||
|
||||
[//]: # (</p>)
|
||||
|
||||
[//]: # (</div>)
|
||||
|
||||
[//]: # (<h4><a href="https://github.com/Codium-ai/pr-agent/pull/229#issuecomment-1695024952">/improve:</a></h4>)
|
||||
|
||||
[//]: # (<div align="center">)
|
||||
|
||||
[//]: # (<p float="center">)
|
||||
|
||||
[//]: # (<img src="https://www.codium.ai/images/improve-2.gif" width="800">)
|
||||
|
||||
[//]: # (</p>)
|
||||
|
||||
[//]: # (</div>)
|
||||
<div align="left">
|
||||
|
||||
|
||||
|
||||
@ -1,11 +1,11 @@
|
||||
[Qodo Merge Chrome extension](https://chromewebstore.google.com/detail/pr-agent-chrome-extension/ephlnjeghhogofkifjloamocljapahnl){:target="_blank"} is a collection of tools that integrates seamlessly with your GitHub environment, aiming to enhance your Git usage experience, and providing AI-powered capabilities to your PRs.
|
||||
[Qodo Merge Chrome extension](https://chromewebstore.google.com/detail/pr-agent-chrome-extension/ephlnjeghhogofkifjloamocljapahnl) is a collection of tools that integrates seamlessly with your GitHub environment, aiming to enhance your Git usage experience, and providing AI-powered capabilities to your PRs.
|
||||
|
||||
With a single-click installation you will gain access to a context-aware chat on your pull requests code, a toolbar extension with multiple AI feedbacks, Qodo Merge filters, and additional abilities.
|
||||
|
||||
The extension is powered by top code models like Claude 3.5 Sonnet and GPT4. All the extension's features are free to use on public repositories.
|
||||
|
||||
For private repositories, you will need to install [Qodo Merge Pro](https://github.com/apps/qodo-merge-pro){:target="_blank"} in addition to the extension (Quick GitHub app setup with a 14-day free trial. No credit card needed).
|
||||
For a demonstration of how to install Qodo Merge Pro and use it with the Chrome extension, please refer to the tutorial video at the provided [link](https://codium.ai/images/pr_agent/private_repos.mp4){:target="_blank"}.
|
||||
For private repositories, you will need to install [Qodo Merge Pro](https://github.com/apps/qodo-merge-pro) in addition to the extension (Quick GitHub app setup with a 14-day free trial. No credit card needed).
|
||||
For a demonstration of how to install Qodo Merge Pro and use it with the Chrome extension, please refer to the tutorial video at the provided [link](https://codium.ai/images/pr_agent/private_repos.mp4).
|
||||
|
||||
<img src="https://codium.ai/images/pr_agent/PR-AgentChat.gif" width="768">
|
||||
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
# Fetching Ticket Context for PRs
|
||||
`Supported Git Platforms: GitHub, GitLab, Bitbucket`
|
||||
`Supported Git Platforms : GitHub, GitLab, Bitbucket`
|
||||
|
||||
## Overview
|
||||
Qodo Merge PR Agent streamlines code review workflows by seamlessly connecting with multiple ticket management systems.
|
||||
@ -126,19 +126,18 @@ jira_api_email = "YOUR_EMAIL"
|
||||
|
||||
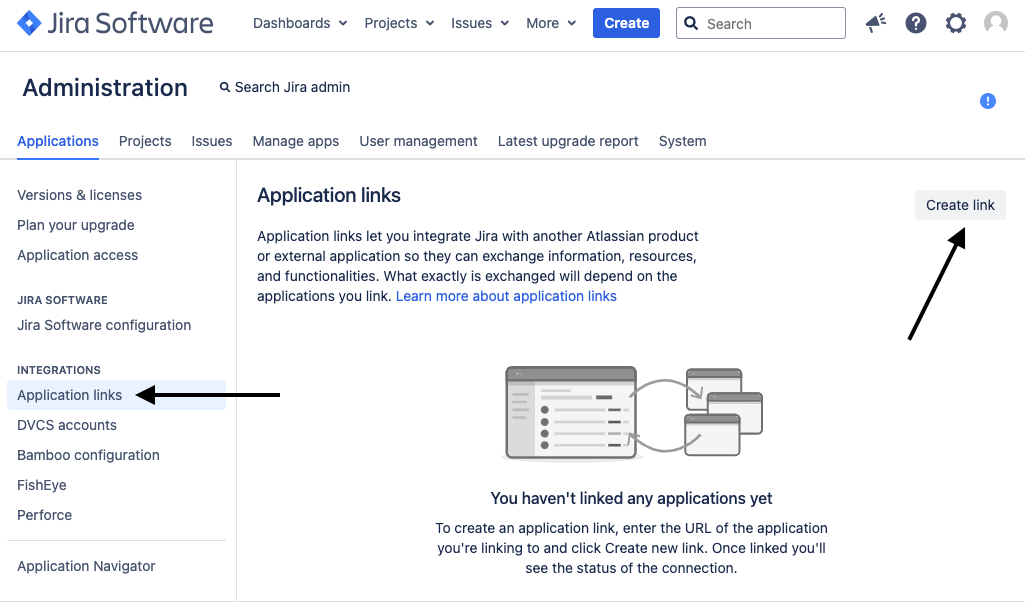
##### 1. Step 1: Set up an application link in Jira Data Center/Server
|
||||
* Go to Jira Administration > Applications > Application Links > Click on `Create link`
|
||||
|
||||
{width=384}
|
||||
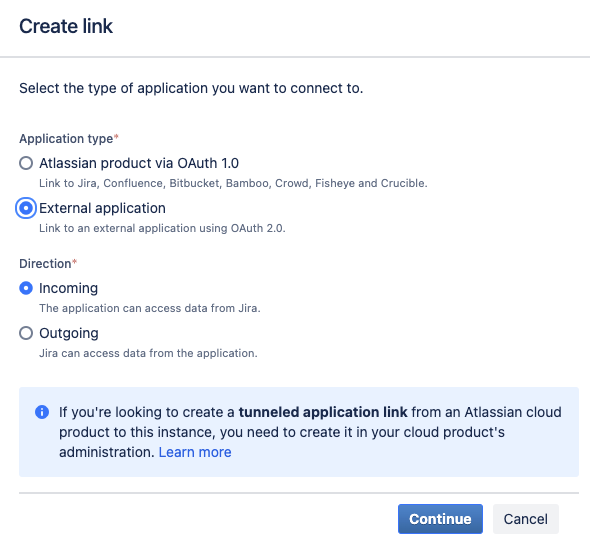
* Choose `External application` and set the direction to `Incoming` and then click `Continue`
|
||||
|
||||
{width=256}
|
||||
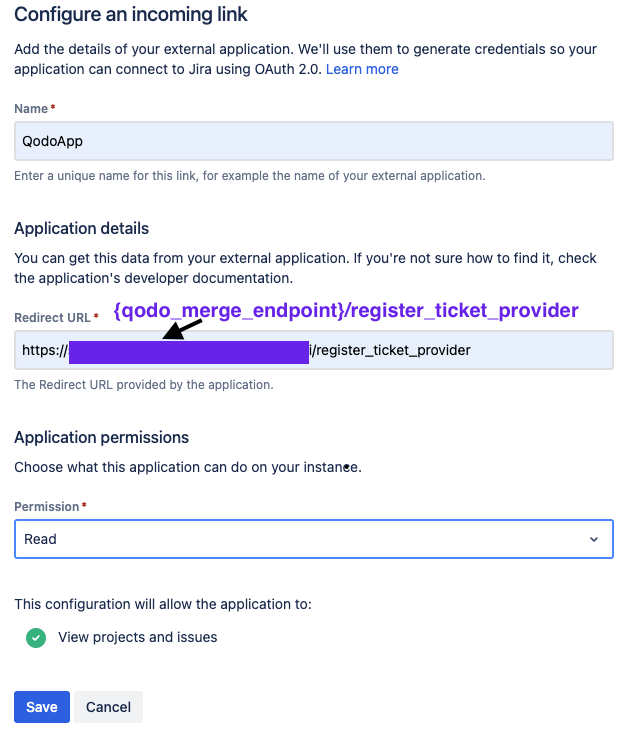
* In the following screen, enter the following details:
|
||||
* Name: `Qodo Merge`
|
||||
* Redirect URL: Enter your Qodo Merge URL followed `https://{QODO_MERGE_ENDPOINT}/register_ticket_provider`
|
||||
* Redirect URL: Enter you Qodo Merge URL followed `https://{QODO_MERGE_ENDPOINT}/register_ticket_provider`
|
||||
* Permission: Select `Read`
|
||||
* Click `Save`
|
||||
|
||||
{width=384}
|
||||
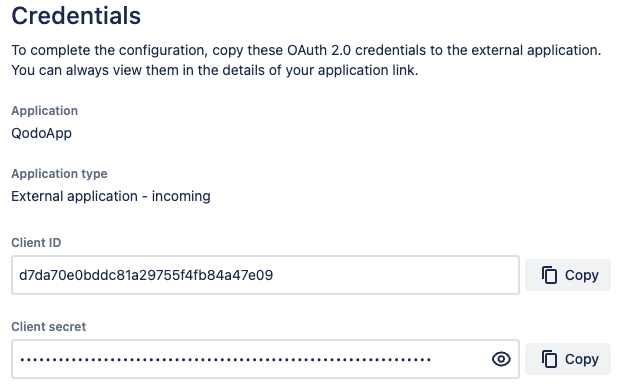
* Copy the `Client ID` and `Client secret` and set them in your `.secrets` file:
|
||||
* Copy the `Client ID` and `Client secret` and set them in you `.secrets` file:
|
||||
|
||||
{width=256}
|
||||
```toml
|
||||
|
||||
@ -32,14 +32,14 @@ For example, when generating code suggestions for different files, Qodo Merge ca
|
||||
|
||||
@@ ... @@ def func1():
|
||||
__new hunk__
|
||||
11 unchanged code line0
|
||||
12 unchanged code line1
|
||||
13 +new code line2 added
|
||||
14 unchanged code line3
|
||||
11 unchanged code line0 in the PR
|
||||
12 unchanged code line1 in the PR
|
||||
13 +new code line2 added in the PR
|
||||
14 unchanged code line3 in the PR
|
||||
__old hunk__
|
||||
unchanged code line0
|
||||
unchanged code line1
|
||||
-old code line2 removed
|
||||
-old code line2 removed in the PR
|
||||
unchanged code line3
|
||||
|
||||
@@ ... @@ def func2():
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
# FAQ
|
||||
|
||||
??? note "Q: Can Qodo Merge serve as a substitute for a human reviewer?"
|
||||
??? note "Question: Can Qodo Merge serve as a substitute for a human reviewer?"
|
||||
#### Answer:<span style="display:none;">1</span>
|
||||
|
||||
Qodo Merge is designed to assist, not replace, human reviewers.
|
||||
@ -12,7 +12,7 @@
|
||||
|
||||
1. Preserves user's original PR header
|
||||
2. Places user's description above the AI-generated PR description
|
||||
3. Won't approve PRs; approval remains reviewer's responsibility
|
||||
3. Cannot approve PRs; approval remains reviewer's responsibility
|
||||
4. The code suggestions are optional, and aim to:
|
||||
- Encourage self-review and self-reflection
|
||||
- Highlight potential bugs or oversights
|
||||
@ -22,15 +22,15 @@
|
||||
|
||||
___
|
||||
|
||||
??? note "Q: I received an incorrect or irrelevant suggestion. Why?"
|
||||
??? note "Question: I received an incorrect or irrelevant suggestion. Why?"
|
||||
|
||||
#### Answer:<span style="display:none;">2</span>
|
||||
|
||||
- Modern AI models, like Claude 3.5 Sonnet and GPT-4, are improving rapidly but remain imperfect. Users should critically evaluate all suggestions rather than accepting them automatically.
|
||||
- AI errors are rare, but possible. A main value from reviewing the code suggestions lies in their high probability of catching **mistakes or bugs made by the PR author**. We believe it's worth spending 30-60 seconds reviewing suggestions, even if some aren't relevant, as this practice can enhance code quality and prevent bugs in production.
|
||||
- AI errors are rare, but possible. A main value from reviewing the code suggestions lies in their high probability of catching **mistakes or bugs made by the PR author**. We believe it's worth spending 30-60 seconds reviewing suggestions, even if some aren't relevant, as this practice can enhances code quality and prevent bugs in production.
|
||||
|
||||
|
||||
- The hierarchical structure of the suggestions is designed to help the user _quickly_ understand them, and to decide which ones are relevant and which are not:
|
||||
- The hierarchical structure of the suggestions is designed to help the user to _quickly_ understand them, and to decide which ones are relevant and which are not:
|
||||
|
||||
- Only if the `Category` header is relevant, the user should move to the summarized suggestion description.
|
||||
- Only if the summarized suggestion description is relevant, the user should click on the collapsible, to read the full suggestion description with a code preview example.
|
||||
@ -40,14 +40,14 @@ ___
|
||||
|
||||
___
|
||||
|
||||
??? note "Q: How can I get more tailored suggestions?"
|
||||
??? note "Question: How can I get more tailored suggestions?"
|
||||
#### Answer:<span style="display:none;">3</span>
|
||||
|
||||
See [here](https://qodo-merge-docs.qodo.ai/tools/improve/#extra-instructions-and-best-practices) for more information on how to use the `extra_instructions` and `best_practices` configuration options, to guide the model to more tailored suggestions.
|
||||
|
||||
___
|
||||
|
||||
??? note "Q: Will you store my code? Are you using my code to train models?"
|
||||
??? note "Question: Will you store my code ? Are you using my code to train models?"
|
||||
#### Answer:<span style="display:none;">4</span>
|
||||
|
||||
No. Qodo Merge strict privacy policy ensures that your code is not stored or used for training purposes.
|
||||
@ -56,35 +56,12 @@ ___
|
||||
|
||||
___
|
||||
|
||||
??? note "Q: Can I use my own LLM keys with Qodo Merge?"
|
||||
??? note "Question: Can I use my own LLM keys with Qodo Merge?"
|
||||
#### Answer:<span style="display:none;">5</span>
|
||||
|
||||
When you self-host the [open-source](https://github.com/Codium-ai/pr-agent) version, you use your own keys.
|
||||
When you self-host, you use your own keys.
|
||||
|
||||
Qodo Merge Pro with SaaS deployment is a hosted version of Qodo Merge, where Qodo manages the infrastructure and the keys.
|
||||
For enterprise customers, on-prem deployment is also available. [Contact us](https://www.codium.ai/contact/#pricing) for more information.
|
||||
___
|
||||
|
||||
??? note "Q: Can Qodo Merge review draft/offline PRs?"
|
||||
#### Answer:<span style="display:none;">5</span>
|
||||
|
||||
Yes. While Qodo Merge won't automatically review draft PRs, you can still get feedback by manually requesting it through [online commenting](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#online-usage).
|
||||
|
||||
For active PRs, you can customize the automatic feedback settings [here](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#qodo-merge-automatic-feedback) to match your team's workflow.
|
||||
___
|
||||
|
||||
??? note "Q: Can the 'Review effort' feedback be calibrated or customized?"
|
||||
#### Answer:<span style="display:none;">5</span>
|
||||
|
||||
Yes, you can customize review effort estimates using the `extra_instructions` configuration option (see [documentation](https://qodo-merge-docs.qodo.ai/tools/review/#configuration-options)).
|
||||
|
||||
Example mapping:
|
||||
|
||||
- Effort 1: < 30 minutes review time
|
||||
- Effort 2: 30-60 minutes review time
|
||||
- Effort 3: 60-90 minutes review time
|
||||
- ...
|
||||
|
||||
Note: The effort levels (1-5) are primarily meant for _comparative_ purposes, helping teams prioritize reviewing smaller PRs first. The actual review duration may vary, as the focus is on providing consistent relative effort estimates.
|
||||
|
||||
___
|
||||
|
||||
@ -44,7 +44,6 @@ Qodo Merge offers extensive pull request functionalities across various git prov
|
||||
| | [Similar Code](https://pr-agent-docs.codium.ai/tools/similar_code/) 💎 | ✅ | | | |
|
||||
| | [Custom Prompt](https://pr-agent-docs.codium.ai/tools/custom_prompt/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | [Test](https://pr-agent-docs.codium.ai/tools/test/) 💎 | ✅ | ✅ | | |
|
||||
| | [Implement](https://pr-agent-docs.codium.ai/tools/implement/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | | | | | |
|
||||
| USAGE | [CLI](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#local-repo-cli) | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [App / webhook](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#github-app) | ✅ | ✅ | ✅ | ✅ |
|
||||
|
||||
@ -3,8 +3,8 @@
|
||||
## Self-hosted Qodo Merge
|
||||
If you choose to host your own Qodo Merge, you first need to acquire two tokens:
|
||||
|
||||
1. An OpenAI key from [here](https://platform.openai.com/api-keys){:target="_blank"}, with access to GPT-4 (or a key for other [language models](https://qodo-merge-docs.qodo.ai/usage-guide/changing_a_model/), if you prefer).
|
||||
2. A GitHub\GitLab\BitBucket personal access token (classic), with the repo scope. [GitHub from [here](https://github.com/settings/tokens){:target="_blank"}]
|
||||
1. An OpenAI key from [here](https://platform.openai.com/api-keys), with access to GPT-4 (or a key for other [language models](https://qodo-merge-docs.qodo.ai/usage-guide/changing_a_model/), if you prefer).
|
||||
2. A GitHub\GitLab\BitBucket personal access token (classic), with the repo scope. [GitHub from [here](https://github.com/settings/tokens)]
|
||||
|
||||
There are several ways to use self-hosted Qodo Merge:
|
||||
|
||||
|
||||
@ -66,30 +66,7 @@ To invoke a tool (for example `review`), you can run directly from the Docker im
|
||||
docker run --rm -it -e CONFIG.GIT_PROVIDER=bitbucket -e OPENAI.KEY=$OPENAI_API_KEY -e BITBUCKET.BEARER_TOKEN=$BITBUCKET_BEARER_TOKEN codiumai/pr-agent:latest --pr_url=<pr_url> review
|
||||
```
|
||||
|
||||
For other git providers, update `CONFIG.GIT_PROVIDER` accordingly and check the `pr_agent/settings/.secrets_template.toml` file for environment variables expected names and values.
|
||||
The `pr_agent` uses [Dynaconf](https://www.dynaconf.com/) to load settings from configuration files.
|
||||
|
||||
It is also possible to provide or override the configuration by setting the corresponding environment variables.
|
||||
You can define the corresponding environment variables by following this convention: `<TABLE>__<KEY>=<VALUE>` or `<TABLE>.<KEY>=<VALUE>`.
|
||||
The `<TABLE>` refers to a table/section in a configuration file and `<KEY>=<VALUE>` refers to the key/value pair of a setting in the configuration file.
|
||||
|
||||
For example, suppose you want to run `pr_agent` that connects to a self-hosted GitLab instance similar to an example above.
|
||||
You can define the environment variables in a plain text file named `.env` with the following content:
|
||||
|
||||
> Warning: Never commit the `.env` file to version control system as it might contains sensitive credentials!
|
||||
|
||||
```
|
||||
CONFIG__GIT_PROVIDER="gitlab"
|
||||
GITLAB__URL="<your url>"
|
||||
GITLAB__PERSONAL_ACCESS_TOKEN="<your token>"
|
||||
OPENAI__KEY="<your key>"
|
||||
```
|
||||
|
||||
Then, you can run `pr_agent` using Docker with the following command:
|
||||
|
||||
```shell
|
||||
docker run --rm -it --env-file .env codiumai/pr-agent:latest <tool> <tool parameter>
|
||||
```
|
||||
For other git providers, update CONFIG.GIT_PROVIDER accordingly, and check the `pr_agent/settings/.secrets_template.toml` file for the environment variables expected names and values.
|
||||
|
||||
---
|
||||
|
||||
|
||||
@ -41,8 +41,6 @@ Qodo Merge offers extensive pull request functionalities across various git prov
|
||||
| | [Add PR Documentation](./tools/documentation.md){:target="_blank"} 💎 | ✅ | ✅ | | ✅ |
|
||||
| | [Generate Custom Labels](./tools/describe.md#handle-custom-labels-from-the-repos-labels-page-💎){:target="_blank"} 💎 | ✅ | ✅ | | ✅ |
|
||||
| | [Analyze PR Components](./tools/analyze.md){:target="_blank"} 💎 | ✅ | ✅ | | ✅ |
|
||||
| | [Test](https://pr-agent-docs.codium.ai/tools/test/) 💎 | ✅ | ✅ | | |
|
||||
| | [Implement](https://pr-agent-docs.codium.ai/tools/implement/) 💎 | ✅ | ✅ | ✅ | |
|
||||
| | | | | | ️ |
|
||||
| USAGE | CLI | ✅ | ✅ | ✅ | ✅ |
|
||||
| | App / webhook | ✅ | ✅ | ✅ | ✅ |
|
||||
@ -53,8 +51,8 @@ Qodo Merge offers extensive pull request functionalities across various git prov
|
||||
| | Adaptive and token-aware file patch fitting | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Multiple models support | ✅ | ✅ | ✅ | ✅ |
|
||||
| | Incremental PR review | ✅ | | | |
|
||||
| | [Static code analysis](./tools/analyze.md/){:target="_blank"} 💎 | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Multiple configuration options](./usage-guide/configuration_options.md){:target="_blank"} 💎 | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Static code analysis](./tools/analyze.md/){:target="_blank"} 💎 | ✅ | ✅ | ✅ | ✅ |
|
||||
| | [Multiple configuration options](./usage-guide/configuration_options.md){:target="_blank"} 💎 | ✅ | ✅ | ✅ | ✅ |
|
||||
|
||||
💎 marks a feature available only in [Qodo Merge Pro](https://www.codium.ai/pricing/){:target="_blank"}
|
||||
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
### Overview
|
||||
|
||||
[Qodo Merge Pro](https://www.codium.ai/pricing/){:target="_blank"} is a hosted version of open-source [Qodo Merge (PR-Agent)](https://github.com/Codium-ai/pr-agent){:target="_blank"}. A complimentary two-week trial is offered, followed by a monthly subscription fee.
|
||||
[Qodo Merge Pro](https://www.codium.ai/pricing/) is a hosted version of open-source [Qodo Merge (PR-Agent)](https://github.com/Codium-ai/pr-agent). A complimentary two-week trial is offered, followed by a monthly subscription fee.
|
||||
Qodo Merge Pro is designed for companies and teams that require additional features and capabilities. It provides the following benefits:
|
||||
|
||||
1. **Fully managed** - We take care of everything for you - hosting, models, regular updates, and more. Installation is as simple as signing up and adding the Qodo Merge app to your GitHub\GitLab\BitBucket repo.
|
||||
@ -33,15 +33,14 @@ Here are some of the additional features and capabilities that Qodo Merge Pro of
|
||||
|
||||
Here are additional tools that are available only for Qodo Merge Pro users:
|
||||
|
||||
| Feature | Description |
|
||||
|---------------------------------------------------------------------------------------|-------------|
|
||||
| Feature | Description |
|
||||
|---------|-------------|
|
||||
| [**Custom Prompt Suggestions**](https://qodo-merge-docs.qodo.ai/tools/custom_prompt/) | Generate code suggestions based on custom prompts from the user |
|
||||
| [**Analyze PR components**](https://qodo-merge-docs.qodo.ai/tools/analyze/) | Identify the components that changed in the PR, and enable to interactively apply different tools to them |
|
||||
| [**Tests**](https://qodo-merge-docs.qodo.ai/tools/test/) | Generate tests for code components that changed in the PR |
|
||||
| [**PR documentation**](https://qodo-merge-docs.qodo.ai/tools/documentation/) | Generate docstring for code components that changed in the PR |
|
||||
| [**Improve Component**](https://qodo-merge-docs.qodo.ai/tools/improve_component/) | Generate code suggestions for code components that changed in the PR |
|
||||
| [**Similar code search**](https://qodo-merge-docs.qodo.ai/tools/similar_code/) | Search for similar code in the repository, organization, or entire GitHub |
|
||||
| [**Code implementation**](https://qodo-merge-docs.qodo.ai/tools/implement/) | Generates implementation code from review suggestions |
|
||||
| [**Analyze PR components**](https://qodo-merge-docs.qodo.ai/tools/analyze/) | Identify the components that changed in the PR, and enable to interactively apply different tools to them |
|
||||
| [**Tests**](https://qodo-merge-docs.qodo.ai/tools/test/) | Generate tests for code components that changed in the PR |
|
||||
| [**PR documentation**](https://qodo-merge-docs.qodo.ai/tools/documentation/) | Generate docstring for code components that changed in the PR |
|
||||
| [**Improve Component**](https://qodo-merge-docs.qodo.ai/tools/improve_component/) | Generate code suggestions for code components that changed in the PR |
|
||||
| [**Similar code search**](https://qodo-merge-docs.qodo.ai/tools/similar_code/) | Search for similar code in the repository, organization, or entire GitHub |
|
||||
|
||||
|
||||
### Supported languages
|
||||
|
||||
@ -1,50 +0,0 @@
|
||||
## Overview
|
||||
|
||||
The `implement` tool converts human code review discussions and feedback into ready-to-commit code changes.
|
||||
It leverages LLM technology to transform PR comments and review suggestions into concrete implementation code, helping developers quickly turn feedback into working solutions.
|
||||
|
||||
## Usage Scenarios
|
||||
|
||||
|
||||
### For Reviewers
|
||||
|
||||
Reviewers can request code changes by: <br>
|
||||
1. Selecting the code block to be modified. <br>
|
||||
2. Adding a comment with the syntax:
|
||||
```
|
||||
/implement <code-change-description>
|
||||
```
|
||||
|
||||
{width=640}
|
||||
|
||||
|
||||
### For PR Authors
|
||||
|
||||
PR authors can implement suggested changes by replying to a review comment using either: <br>
|
||||
1. Add specific implementation details as described above
|
||||
```
|
||||
/implement <code-change-description>
|
||||
```
|
||||
2. Use the original review comment as instructions
|
||||
```
|
||||
/implement
|
||||
```
|
||||
|
||||
{width=640}
|
||||
|
||||
### For Referencing Comments
|
||||
|
||||
You can reference and implement changes from any comment by:
|
||||
```
|
||||
/implement <link-to-review-comment>
|
||||
```
|
||||
|
||||
{width=640}
|
||||
|
||||
Note that the implementation will occur within the review discussion thread.
|
||||
|
||||
|
||||
**Configuration options** <br>
|
||||
- Use `/implement` to implement code change within and based on the review discussion. <br>
|
||||
- Use `/implement <code-change-description>` inside a review discussion to implement specific instructions. <br>
|
||||
- Use `/implement <link-to-review-comment>` to indirectly call the tool from any comment. <br>
|
||||
@ -122,7 +122,7 @@ Use triple quotes to write multi-line instructions. Use bullet points or numbers
|
||||
|
||||
>`Platforms supported: GitHub, GitLab, Bitbucket`
|
||||
|
||||
Another option to give additional guidance to the AI model is by creating a `best_practices.md` file, either in your repository's root directory or as a [**wiki page**](https://github.com/Codium-ai/pr-agent/wiki) (we recommend the wiki page, as editing and maintaining it over time is easier).
|
||||
Another option to give additional guidance to the AI model is by creating a dedicated [**wiki page**](https://github.com/Codium-ai/pr-agent/wiki) called `best_practices.md`.
|
||||
This page can contain a list of best practices, coding standards, and guidelines that are specific to your repo/organization.
|
||||
|
||||
The AI model will use this wiki page as a reference, and in case the PR code violates any of the guidelines, it will create additional suggestions, with a dedicated label: `Organization
|
||||
|
||||
@ -2,22 +2,21 @@
|
||||
|
||||
Here is a list of Qodo Merge tools, each with a dedicated page that explains how to use it:
|
||||
|
||||
| Tool | Description |
|
||||
|------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| **[PR Description (`/describe`](./describe.md))** | Automatically generating PR description - title, type, summary, code walkthrough and labels |
|
||||
| **[PR Review (`/review`](./review.md))** | Adjustable feedback about the PR, possible issues, security concerns, review effort and more |
|
||||
| **[Code Suggestions (`/improve`](./improve.md))** | Code suggestions for improving the PR |
|
||||
| **[Question Answering (`/ask ...`](./ask.md))** | Answering free-text questions about the PR, or on specific code lines |
|
||||
| **[Update Changelog (`/update_changelog`](./update_changelog.md))** | Automatically updating the CHANGELOG.md file with the PR changes |
|
||||
| **[Find Similar Issue (`/similar_issue`](./similar_issues.md))** | Automatically retrieves and presents similar issues |
|
||||
| **[Help (`/help`](./help.md))** | Provides a list of all the available tools. Also enables to trigger them interactively (💎) |
|
||||
| **💎 [Add Documentation (`/add_docs`](./documentation.md))** | Generates documentation to methods/functions/classes that changed in the PR |
|
||||
| **💎 [Generate Custom Labels (`/generate_labels`](./custom_labels.md))** | Generates custom labels for the PR, based on specific guidelines defined by the user |
|
||||
| **💎 [Analyze (`/analyze`](./analyze.md))** | Identify code components that changed in the PR, and enables to interactively generate tests, docs, and code suggestions for each component|
|
||||
| **💎 [Test (`/test`](./test.md))** | generate tests for a selected component, based on the PR code changes |
|
||||
| **💎 [Custom Prompt (`/custom_prompt`](./custom_prompt.md))** | Automatically generates custom suggestions for improving the PR code, based on specific guidelines defined by the user |
|
||||
| **💎 [Generate Tests (`/test component_name`](./test.md))** | Automatically generates unit tests for a selected component, based on the PR code changes |
|
||||
| **💎 [Improve Component (`/improve_component component_name`](./improve_component.md))** | Generates code suggestions for a specific code component that changed in the PR |
|
||||
| **💎 [CI Feedback (`/checks ci_job`](./ci_feedback.md))** | Automatically generates feedback and analysis for a failed CI job |
|
||||
| **💎 [Implement (`/implement`](./implement.md))** | Generates implementation code from review suggestions |
|
||||
| Tool | Description |
|
||||
|------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| **[PR Description (`/describe`](./describe.md))** | Automatically generating PR description - title, type, summary, code walkthrough and labels |
|
||||
| **[PR Review (`/review`](./review.md))** | Adjustable feedback about the PR, possible issues, security concerns, review effort and more |
|
||||
| **[Code Suggestions (`/improve`](./improve.md))** | Code suggestions for improving the PR |
|
||||
| **[Question Answering (`/ask ...`](./ask.md))** | Answering free-text questions about the PR, or on specific code lines |
|
||||
| **[Update Changelog (`/update_changelog`](./update_changelog.md))** | Automatically updating the CHANGELOG.md file with the PR changes |
|
||||
| **[Find Similar Issue (`/similar_issue`](./similar_issues.md))** | Automatically retrieves and presents similar issues |
|
||||
| **[Help (`/help`](./help.md))** | Provides a list of all the available tools. Also enables to trigger them interactively (💎) |
|
||||
| **💎 [Add Documentation (`/add_docs`](./documentation.md))** | Generates documentation to methods/functions/classes that changed in the PR |
|
||||
| **💎 [Generate Custom Labels (`/generate_labels`](./custom_labels.md))** | Generates custom labels for the PR, based on specific guidelines defined by the user |
|
||||
| **💎 [Analyze (`/analyze`](./analyze.md))** | Identify code components that changed in the PR, and enables to interactively generate tests, docs, and code suggestions for each component |
|
||||
| **💎 [Custom Prompt (`/custom_prompt`](./custom_prompt.md))** | Automatically generates custom suggestions for improving the PR code, based on specific guidelines defined by the user |
|
||||
| **💎 [Generate Tests (`/test component_name`](./test.md))** | Automatically generates unit tests for a selected component, based on the PR code changes |
|
||||
| **💎 [Improve Component (`/improve_component component_name`](./improve_component.md))** | Generates code suggestions for a specific code component that changed in the PR |
|
||||
| **💎 [CI Feedback (`/checks ci_job`](./ci_feedback.md))** | Automatically generates feedback and analysis for a failed CI job |
|
||||
|
||||
Note that the tools marked with 💎 are available only for Qodo Merge Pro users.
|
||||
|
||||
@ -46,6 +46,47 @@ extra_instructions = "..."
|
||||
- The `pr_commands` lists commands that will be executed automatically when a PR is opened.
|
||||
- The `[pr_reviewer]` section contains the configurations for the `review` tool you want to edit (if any).
|
||||
|
||||
[//]: # ()
|
||||
[//]: # (### Incremental Mode)
|
||||
|
||||
[//]: # (Incremental review only considers changes since the last Qodo Merge review. This can be useful when working on the PR in an iterative manner, and you want to focus on the changes since the last review instead of reviewing the entire PR again.)
|
||||
|
||||
[//]: # (For invoking the incremental mode, the following command can be used:)
|
||||
|
||||
[//]: # (```)
|
||||
|
||||
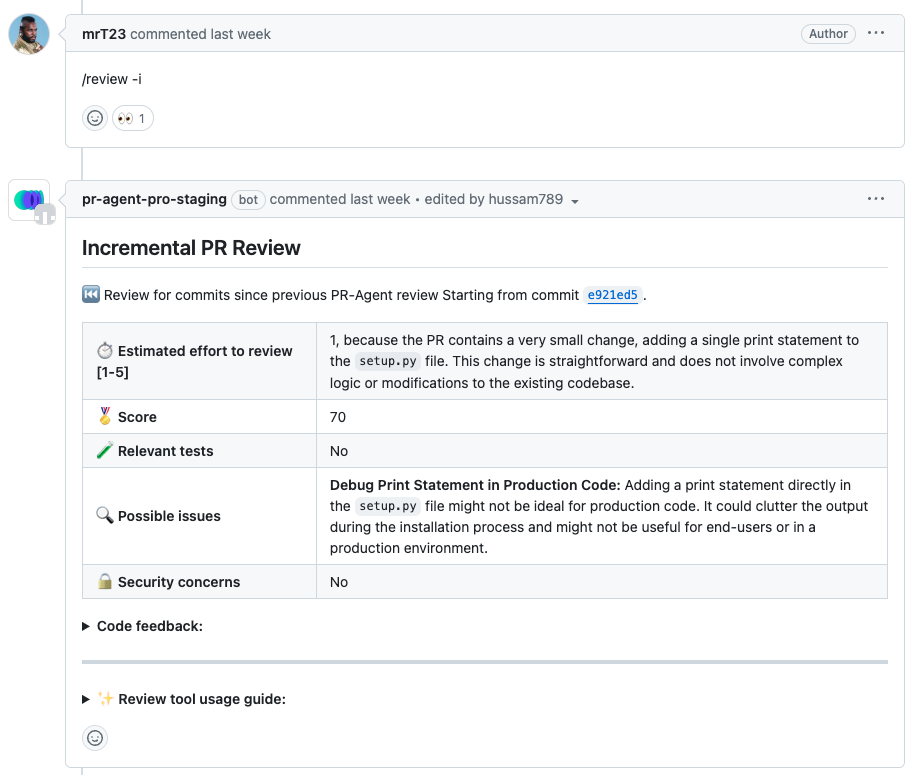
[//]: # (/review -i)
|
||||
|
||||
[//]: # (```)
|
||||
|
||||
[//]: # (Note that the incremental mode is only available for GitHub.)
|
||||
|
||||
[//]: # ()
|
||||
[//]: # ({width=512})
|
||||
|
||||
[//]: # (### PR Reflection)
|
||||
|
||||
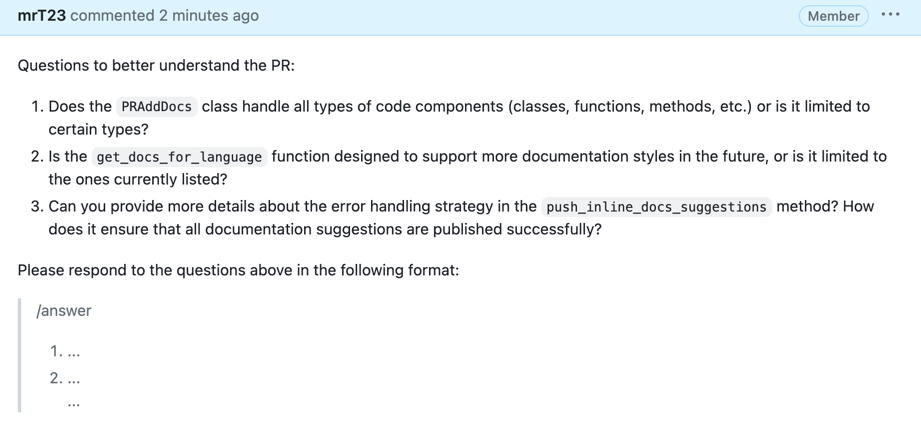
[//]: # ()
|
||||
[//]: # (By invoking:)
|
||||
|
||||
[//]: # (```)
|
||||
|
||||
[//]: # (/reflect_and_review)
|
||||
|
||||
[//]: # (```)
|
||||
|
||||
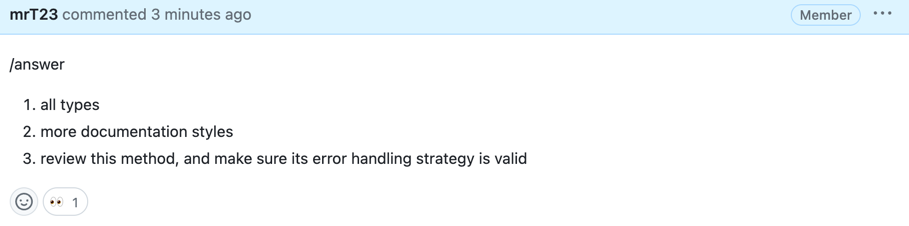
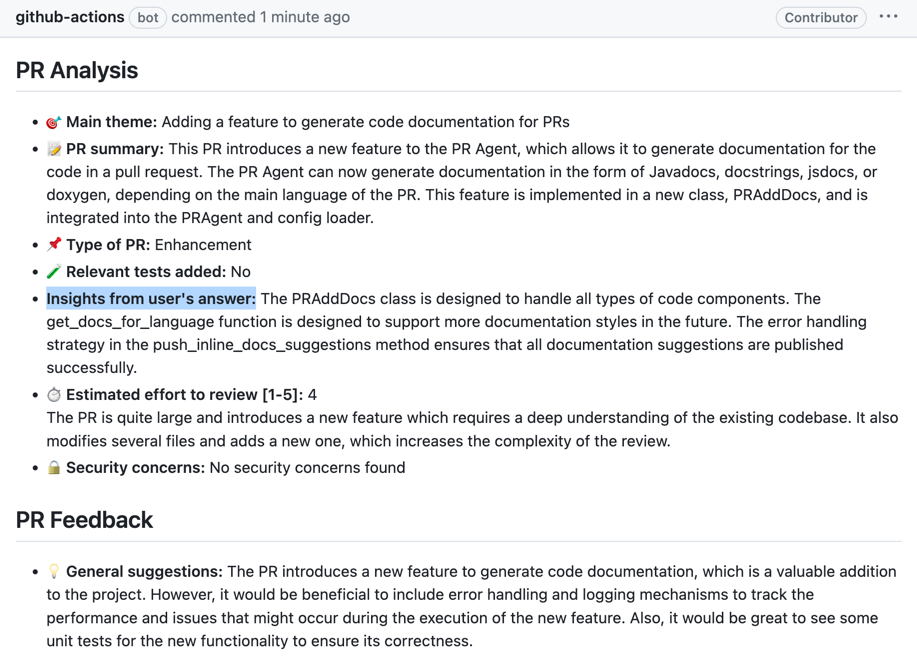
[//]: # (The tool will first ask the author questions about the PR, and will guide the review based on their answers.)
|
||||
|
||||
[//]: # ()
|
||||
[//]: # ({width=512})
|
||||
|
||||
[//]: # ()
|
||||
[//]: # ({width=512})
|
||||
|
||||
[//]: # ()
|
||||
[//]: # ({width=512})
|
||||
|
||||
|
||||
|
||||
## Configuration options
|
||||
|
||||
@ -53,12 +94,16 @@ extra_instructions = "..."
|
||||
|
||||
<table>
|
||||
<tr>
|
||||
<td><b>persistent_comment</b></td>
|
||||
<td>If set to true, the review comment will be persistent, meaning that every new review request will edit the previous one. Default is true.</td>
|
||||
<td><b>num_code_suggestions</b></td>
|
||||
<td>Number of code suggestions provided by the 'review' tool. Default is 0, meaning no code suggestions will be provided by the `review` tool. Note that this is a legacy feature, that will be removed in future releases. Use the `improve` tool instead for code suggestions</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>final_update_message</b></td>
|
||||
<td>When set to true, updating a persistent review comment during online commenting will automatically add a short comment with a link to the updated review in the pull request .Default is true.</td>
|
||||
<td><b>inline_code_comments</b></td>
|
||||
<td>If set to true, the tool will publish the code suggestions as comments on the code diff. Default is false. Note that you need to set `num_code_suggestions`>0 to get code suggestions </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>persistent_comment</b></td>
|
||||
<td>If set to true, the review comment will be persistent, meaning that every new review request will edit the previous one. Default is true.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>extra_instructions</b></td>
|
||||
@ -144,9 +189,9 @@ If enabled, the `review` tool can approve a PR when a specific comment, `/review
|
||||
!!! tip "Automation"
|
||||
When you first install Qodo Merge app, the [default mode](../usage-guide/automations_and_usage.md#github-app-automatic-tools-when-a-new-pr-is-opened) for the `review` tool is:
|
||||
```
|
||||
pr_commands = ["/review", ...]
|
||||
pr_commands = ["/review --pr_reviewer.num_code_suggestions=0", ...]
|
||||
```
|
||||
Meaning the `review` tool will run automatically on every PR, without any additional configurations.
|
||||
Meaning the `review` tool will run automatically on every PR, without providing code suggestions.
|
||||
Edit this field to enable/disable the tool, or to change the configurations used.
|
||||
|
||||
!!! tip "Possible labels from the review tool"
|
||||
@ -204,8 +249,12 @@ If enabled, the `review` tool can approve a PR when a specific comment, `/review
|
||||
maximal_review_effort = 5
|
||||
```
|
||||
|
||||
!!! tip "Code suggestions"
|
||||
[//]: # (!!! tip "Code suggestions")
|
||||
|
||||
The `review` tool previously included a legacy feature for providing code suggestions (controlled by `--pr_reviewer.num_code_suggestion`). This functionality has been deprecated and replaced by the [`improve`](./improve.md) tool, which offers higher quality and more actionable code suggestions.
|
||||
[//]: # ()
|
||||
[//]: # ( If you set `num_code_suggestions`>0 , the `review` tool will also provide code suggestions.)
|
||||
|
||||
[//]: # ( )
|
||||
[//]: # ( Notice If you are interested **only** in the code suggestions, it is recommended to use the [`improve`](./improve.md) feature instead, since it is a dedicated only to code suggestions, and usually gives better results.)
|
||||
|
||||
[//]: # ( Use the `review` tool if you want to get more comprehensive feedback, which includes code suggestions as well.)
|
||||
|
||||
@ -17,8 +17,8 @@ The tool will generate tests for the selected component (if no component is stat
|
||||
|
||||
(Example taken from [here](https://github.com/Codium-ai/pr-agent/pull/598#issuecomment-1913679429)):
|
||||
|
||||
**Notes** <br>
|
||||
- The following languages are currently supported: Python, Java, C++, JavaScript, TypeScript, C#. <br>
|
||||
**Notes**
|
||||
- Language that are currently supported by the tool: Python, Java, C++, JavaScript, TypeScript, C#.
|
||||
- This tool can also be triggered interactively by using the [`analyze`](./analyze.md) tool.
|
||||
|
||||
|
||||
|
||||
@ -17,4 +17,3 @@ Under the section `pr_update_changelog`, the [configuration file](https://github
|
||||
|
||||
- `push_changelog_changes`: whether to push the changes to CHANGELOG.md, or just print them. Default is false (print only).
|
||||
- `extra_instructions`: Optional extra instructions to the tool. For example: "focus on the changes in the file X. Ignore change in ...
|
||||
- `add_pr_link`: whether the model should try to add a link to the PR in the changelog. Default is true.
|
||||
@ -1,5 +1,5 @@
|
||||
## Show possible configurations
|
||||
The possible configurations of Qodo Merge are stored in [here](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml){:target="_blank"}.
|
||||
The possible configurations of Qodo Merge are stored in [here](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml).
|
||||
In the [tools](https://qodo-merge-docs.qodo.ai/tools/) page you can find explanations on how to use these configurations for each tool.
|
||||
|
||||
To print all the available configurations as a comment on your PR, you can use the following command:
|
||||
@ -138,17 +138,7 @@ LANGSMITH_BASE_URL=<url>
|
||||
|
||||
## Ignoring automatic commands in PRs
|
||||
|
||||
Qodo Merge allows you to automatically ignore certain PRs based on various criteria:
|
||||
|
||||
- PRs with specific titles (using regex matching)
|
||||
- PRs between specific branches (using regex matching)
|
||||
- PRs that don't include changes from specific folders (using regex matching)
|
||||
- PRs containing specific labels
|
||||
- PRs opened by specific users
|
||||
|
||||
### Example usage
|
||||
|
||||
#### Ignoring PRs with specific titles
|
||||
In some cases, you may want to automatically ignore specific PRs . Qodo Merge enables you to ignore PR with a specific title, or from/to specific branches (regex matching).
|
||||
|
||||
To ignore PRs with a specific title such as "[Bump]: ...", you can add the following to your `configuration.toml` file:
|
||||
|
||||
@ -159,7 +149,6 @@ ignore_pr_title = ["\\[Bump\\]"]
|
||||
|
||||
Where the `ignore_pr_title` is a list of regex patterns to match the PR title you want to ignore. Default is `ignore_pr_title = ["^\\[Auto\\]", "^Auto"]`.
|
||||
|
||||
#### Ignoring PRs between specific branches
|
||||
|
||||
To ignore PRs from specific source or target branches, you can add the following to your `configuration.toml` file:
|
||||
|
||||
@ -172,7 +161,6 @@ ignore_pr_target_branches = ["qa"]
|
||||
Where the `ignore_pr_source_branches` and `ignore_pr_target_branches` are lists of regex patterns to match the source and target branches you want to ignore.
|
||||
They are not mutually exclusive, you can use them together or separately.
|
||||
|
||||
#### Ignoring PRs that don't include changes from specific folders
|
||||
|
||||
To allow only specific folders (often needed in large monorepos), set:
|
||||
|
||||
@ -182,35 +170,3 @@ allow_only_specific_folders=['folder1','folder2']
|
||||
```
|
||||
|
||||
For the configuration above, automatic feedback will only be triggered when the PR changes include files from 'folder1' or 'folder2'
|
||||
|
||||
#### Ignoring PRs containg specific labels
|
||||
|
||||
To ignore PRs containg specific labels, you can add the following to your `configuration.toml` file:
|
||||
|
||||
```
|
||||
[config]
|
||||
ignore_pr_labels = ["do-not-merge"]
|
||||
```
|
||||
|
||||
Where the `ignore_pr_labels` is a list of labels that when present in the PR, the PR will be ignored.
|
||||
|
||||
#### Ignoring PRs from specific users
|
||||
|
||||
Qodo Merge automatically identifies and ignores pull requests created by bots using:
|
||||
|
||||
- GitHub's native bot detection system
|
||||
- Name-based pattern matching
|
||||
|
||||
While this detection is robust, it may not catch all cases, particularly when:
|
||||
|
||||
- Bots are registered as regular user accounts
|
||||
- Bot names don't match common patterns
|
||||
|
||||
To supplement the automatic bot detection, you can manually specify users to ignore. Add the following to your `configuration.toml` file to ignore PRs from specific users:
|
||||
```
|
||||
[config]
|
||||
ignore_pr_authors = ["my-special-bot-user", ...]
|
||||
```
|
||||
|
||||
Where the `ignore_pr_authors` is a list of usernames that you want to ignore.
|
||||
|
||||
|
||||
@ -285,7 +285,7 @@ To control which commands will run automatically when a new PR is opened, you ca
|
||||
[azure_devops_server]
|
||||
pr_commands = [
|
||||
"/describe",
|
||||
"/review",
|
||||
"/review --pr_reviewer.num_code_suggestions=0",
|
||||
"/improve",
|
||||
]
|
||||
```
|
||||
|
||||
@ -30,39 +30,50 @@ model="" # the OpenAI model you've deployed on Azure (e.g. gpt-4o)
|
||||
fallback_models=["..."]
|
||||
```
|
||||
|
||||
### Ollama
|
||||
|
||||
You can run models locally through either [VLLM](https://docs.litellm.ai/docs/providers/vllm) or [Ollama](https://docs.litellm.ai/docs/providers/ollama)
|
||||
|
||||
E.g. to use a new model locally via Ollama, set in `.secrets.toml` or in a configuration file:
|
||||
```
|
||||
[config]
|
||||
model = "ollama/qwen2.5-coder:32b"
|
||||
fallback_models=["ollama/qwen2.5-coder:32b"]
|
||||
custom_model_max_tokens=128000 # set the maximal input tokens for the model
|
||||
duplicate_examples=true # will duplicate the examples in the prompt, to help the model to generate structured output
|
||||
|
||||
[ollama]
|
||||
api_base = "http://localhost:11434" # or whatever port you're running Ollama on
|
||||
```
|
||||
|
||||
!!! note "Local models vs commercial models"
|
||||
Qodo Merge is compatible with almost any AI model, but analyzing complex code repositories and pull requests requires a model specifically optimized for code analysis.
|
||||
|
||||
Commercial models such as GPT-4, Claude Sonnet, and Gemini have demonstrated robust capabilities in generating structured output for code analysis tasks with large input. In contrast, most open-source models currently available (as of January 2025) face challenges with these complex tasks.
|
||||
|
||||
Based on our testing, local open-source models are suitable for experimentation and learning purposes, but they are not suitable for production-level code analysis tasks.
|
||||
|
||||
Hence, for production workflows and real-world usage, we recommend using commercial models.
|
||||
|
||||
### Hugging Face
|
||||
|
||||
**Local**
|
||||
You can run Hugging Face models locally through either [VLLM](https://docs.litellm.ai/docs/providers/vllm) or [Ollama](https://docs.litellm.ai/docs/providers/ollama)
|
||||
|
||||
E.g. to use a new Hugging Face model locally via Ollama, set:
|
||||
```
|
||||
[__init__.py]
|
||||
MAX_TOKENS = {
|
||||
"model-name-on-ollama": <max_tokens>
|
||||
}
|
||||
e.g.
|
||||
MAX_TOKENS={
|
||||
...,
|
||||
"ollama/llama2": 4096
|
||||
}
|
||||
|
||||
|
||||
[config] # in configuration.toml
|
||||
model = "ollama/llama2"
|
||||
fallback_models=["ollama/llama2"]
|
||||
|
||||
[ollama] # in .secrets.toml
|
||||
api_base = ... # the base url for your Hugging Face inference endpoint
|
||||
# e.g. if running Ollama locally, you may use:
|
||||
api_base = "http://localhost:11434/"
|
||||
```
|
||||
|
||||
### Inference Endpoints
|
||||
|
||||
To use a new model with Hugging Face Inference Endpoints, for example, set:
|
||||
```
|
||||
[__init__.py]
|
||||
MAX_TOKENS = {
|
||||
"model-name-on-huggingface": <max_tokens>
|
||||
}
|
||||
e.g.
|
||||
MAX_TOKENS={
|
||||
...,
|
||||
"meta-llama/Llama-2-7b-chat-hf": 4096
|
||||
}
|
||||
[config] # in configuration.toml
|
||||
model = "huggingface/meta-llama/Llama-2-7b-chat-hf"
|
||||
fallback_models=["huggingface/meta-llama/Llama-2-7b-chat-hf"]
|
||||
custom_model_max_tokens=... # set the maximal input tokens for the model
|
||||
|
||||
[huggingface] # in .secrets.toml
|
||||
key = ... # your Hugging Face api key
|
||||
@ -166,25 +177,6 @@ drop_params = true
|
||||
|
||||
AWS session is automatically authenticated from your environment, but you can also explicitly set `AWS_ACCESS_KEY_ID`, `AWS_SECRET_ACCESS_KEY` and `AWS_REGION_NAME` environment variables. Please refer to [this document](https://litellm.vercel.app/docs/providers/bedrock) for more details.
|
||||
|
||||
### DeepSeek
|
||||
|
||||
To use deepseek-chat model with DeepSeek, for example, set:
|
||||
|
||||
```toml
|
||||
[config] # in configuration.toml
|
||||
model = "deepseek/deepseek-chat"
|
||||
fallback_models=["deepseek/deepseek-chat"]
|
||||
```
|
||||
|
||||
and fill up your key
|
||||
|
||||
```toml
|
||||
[deepseek] # in .secrets.toml
|
||||
key = ...
|
||||
```
|
||||
|
||||
(you can obtain a deepseek-chat key from [here](https://platform.deepseek.com))
|
||||
|
||||
### Custom models
|
||||
|
||||
If the relevant model doesn't appear [here](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/algo/__init__.py), you can still use it as a custom model:
|
||||
|
||||
@ -1,24 +0,0 @@
|
||||
`Supported Git Platforms: GitHub, GitLab, Bitbucket`
|
||||
|
||||
|
||||
For optimal functionality of Qodo Merge, we recommend enabling a wiki for each repository where Qodo Merge is installed. The wiki serves several important purposes:
|
||||
|
||||
**Key Wiki Features:**
|
||||
|
||||
- Storing a [configuration file](https://qodo-merge-docs.qodo.ai/usage-guide/configuration_options/#wiki-configuration-file)
|
||||
- Defining a [`best_practices.md`](https://qodo-merge-docs.qodo.ai/tools/improve/#best-practices) file
|
||||
- Track [accepted suggestions](https://qodo-merge-docs.qodo.ai/tools/improve/#suggestion-tracking)
|
||||
- Facilitates learning over time by creating an [auto_best_practices.md]() file
|
||||
|
||||
|
||||
**Setup Instructions (GitHub):**
|
||||
|
||||
To enable a wiki for your repository:
|
||||
|
||||
1. Navigate to your repository's main page on GitHub
|
||||
2. Select "Settings" from the top navigation bar
|
||||
3. Locate the "Features" section
|
||||
4. Enable the "Wikis" option by checking the corresponding box
|
||||
5. Return to your repository's main page
|
||||
6. Look for the newly added "Wiki" tab in the top navigation
|
||||
7. Initialize your wiki by clicking "Create the first page" (this step is important - without creating an initial page, the wiki will not be fully functional)
|
||||
@ -5,7 +5,6 @@ It includes information on how to adjust Qodo Merge configurations, define which
|
||||
|
||||
|
||||
- [Introduction](./introduction.md)
|
||||
- [Enabling a Wiki](./enabling_a_wiki)
|
||||
- [Configuration File](./configuration_options.md)
|
||||
- [Usage and Automation](./automations_and_usage.md)
|
||||
- [Local Repo (CLI)](./automations_and_usage.md#local-repo-cli)
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
After [installation](https://qodo-merge-docs.qodo.ai/installation/), there are three basic ways to invoke Qodo Merge:
|
||||
|
||||
1. Locally running a CLI command
|
||||
2. Online usage - by [commenting](https://github.com/Codium-ai/pr-agent/pull/229#issuecomment-1695021901){:target="_blank"} on a PR
|
||||
2. Online usage - by [commenting](https://github.com/Codium-ai/pr-agent/pull/229#issuecomment-1695021901) on a PR
|
||||
3. Enabling Qodo Merge tools to run automatically when a new PR is opened
|
||||
|
||||
|
||||
|
||||
@ -18,7 +18,6 @@ nav:
|
||||
- Usage Guide:
|
||||
- 'usage-guide/index.md'
|
||||
- Introduction: 'usage-guide/introduction.md'
|
||||
- Enabling a Wiki: 'usage-guide/enabling_a_wiki.md'
|
||||
- Configuration File: 'usage-guide/configuration_options.md'
|
||||
- Usage and Automation: 'usage-guide/automations_and_usage.md'
|
||||
- Managing Mail Notifications: 'usage-guide/mail_notifications.md'
|
||||
@ -42,7 +41,6 @@ nav:
|
||||
- 💎 Custom Prompt: 'tools/custom_prompt.md'
|
||||
- 💎 CI Feedback: 'tools/ci_feedback.md'
|
||||
- 💎 Similar Code: 'tools/similar_code.md'
|
||||
- 💎 Implement: 'tools/implement.md'
|
||||
- Core Abilities:
|
||||
- 'core-abilities/index.md'
|
||||
- Fetching ticket context: 'core-abilities/fetching_ticket_context.md'
|
||||
|
||||
@ -13,6 +13,7 @@ from pr_agent.tools.pr_config import PRConfig
|
||||
from pr_agent.tools.pr_description import PRDescription
|
||||
from pr_agent.tools.pr_generate_labels import PRGenerateLabels
|
||||
from pr_agent.tools.pr_help_message import PRHelpMessage
|
||||
from pr_agent.tools.pr_information_from_user import PRInformationFromUser
|
||||
from pr_agent.tools.pr_line_questions import PR_LineQuestions
|
||||
from pr_agent.tools.pr_questions import PRQuestions
|
||||
from pr_agent.tools.pr_reviewer import PRReviewer
|
||||
@ -24,6 +25,8 @@ command2class = {
|
||||
"answer": PRReviewer,
|
||||
"review": PRReviewer,
|
||||
"review_pr": PRReviewer,
|
||||
"reflect": PRInformationFromUser,
|
||||
"reflect_and_review": PRInformationFromUser,
|
||||
"describe": PRDescription,
|
||||
"describe_pr": PRDescription,
|
||||
"improve": PRCodeSuggestions,
|
||||
@ -46,6 +49,7 @@ commands = list(command2class.keys())
|
||||
class PRAgent:
|
||||
def __init__(self, ai_handler: partial[BaseAiHandler,] = LiteLLMAIHandler):
|
||||
self.ai_handler = ai_handler # will be initialized in run_action
|
||||
self.forbidden_cli_args = ['enable_auto_approval']
|
||||
|
||||
async def handle_request(self, pr_url, request, notify=None) -> bool:
|
||||
# First, apply repo specific settings if exists
|
||||
@ -60,33 +64,24 @@ class PRAgent:
|
||||
else:
|
||||
action, *args = request
|
||||
|
||||
forbidden_cli_args = ['enable_auto_approval', 'approve_pr_on_self_review', 'base_url', 'url', 'app_name', 'secret_provider',
|
||||
'git_provider', 'skip_keys', 'openai.key', 'ANALYTICS_FOLDER', 'uri', 'app_id', 'webhook_secret',
|
||||
'bearer_token', 'PERSONAL_ACCESS_TOKEN', 'override_deployment_type', 'private_key',
|
||||
'local_cache_path', 'enable_local_cache', 'jira_base_url', 'api_base', 'api_type', 'api_version',
|
||||
'skip_keys']
|
||||
if args:
|
||||
for arg in args:
|
||||
if arg.startswith('--'):
|
||||
arg_word = arg.lower()
|
||||
arg_word = arg_word.replace('__', '.') # replace double underscore with dot, e.g. --openai__key -> --openai.key
|
||||
for forbidden_arg in forbidden_cli_args:
|
||||
forbidden_arg_word = forbidden_arg.lower()
|
||||
if '.' not in forbidden_arg_word:
|
||||
forbidden_arg_word = '.' + forbidden_arg_word
|
||||
if forbidden_arg_word in arg_word:
|
||||
get_logger().error(
|
||||
f"CLI argument for param '{forbidden_arg}' is forbidden. Use instead a configuration file."
|
||||
)
|
||||
return False
|
||||
for forbidden_arg in self.forbidden_cli_args:
|
||||
for arg in args:
|
||||
if forbidden_arg in arg:
|
||||
get_logger().error(
|
||||
f"CLI argument for param '{forbidden_arg}' is forbidden. Use instead a configuration file."
|
||||
)
|
||||
return False
|
||||
args = update_settings_from_args(args)
|
||||
|
||||
action = action.lstrip("/").lower()
|
||||
if action not in command2class:
|
||||
get_logger().error(f"Unknown command: {action}")
|
||||
get_logger().debug(f"Unknown command: {action}")
|
||||
return False
|
||||
with get_logger().contextualize(command=action, pr_url=pr_url):
|
||||
get_logger().info("PR-Agent request handler started", analytics=True)
|
||||
if action == "reflect_and_review":
|
||||
get_settings().pr_reviewer.ask_and_reflect = True
|
||||
if action == "answer":
|
||||
if notify:
|
||||
notify()
|
||||
|
||||
@ -29,7 +29,6 @@ MAX_TOKENS = {
|
||||
'claude-instant-1': 100000,
|
||||
'claude-2': 100000,
|
||||
'command-nightly': 4096,
|
||||
'deepseek/deepseek-chat': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
'replicate/llama-2-70b-chat:2c1608e18606fad2812020dc541930f2d0495ce32eee50074220b87300bc16e1': 4096,
|
||||
'meta-llama/Llama-2-7b-chat-hf': 4096,
|
||||
'vertex_ai/codechat-bison': 6144,
|
||||
@ -42,7 +41,6 @@ MAX_TOKENS = {
|
||||
'vertex_ai/claude-3-5-sonnet-v2@20241022': 100000,
|
||||
'vertex_ai/gemini-1.5-pro': 1048576,
|
||||
'vertex_ai/gemini-1.5-flash': 1048576,
|
||||
'vertex_ai/gemini-2.0-flash-exp': 1048576,
|
||||
'vertex_ai/gemma2': 8200,
|
||||
'gemini/gemini-1.5-pro': 1048576,
|
||||
'gemini/gemini-1.5-flash': 1048576,
|
||||
@ -64,14 +62,13 @@ MAX_TOKENS = {
|
||||
'bedrock/anthropic.claude-3-5-haiku-20241022-v1:0': 100000,
|
||||
'bedrock/anthropic.claude-3-5-sonnet-20240620-v1:0': 100000,
|
||||
'bedrock/anthropic.claude-3-5-sonnet-20241022-v2:0': 100000,
|
||||
"bedrock/us.anthropic.claude-3-5-sonnet-20241022-v2:0": 100000,
|
||||
'claude-3-5-sonnet': 100000,
|
||||
'groq/llama3-8b-8192': 8192,
|
||||
'groq/llama3-70b-8192': 8192,
|
||||
'groq/llama-3.1-8b-instant': 8192,
|
||||
'groq/llama-3.3-70b-versatile': 128000,
|
||||
'groq/mixtral-8x7b-32768': 32768,
|
||||
'groq/gemma2-9b-it': 8192,
|
||||
'groq/llama-3.1-8b-instant': 131072,
|
||||
'groq/llama-3.1-70b-versatile': 131072,
|
||||
'groq/llama-3.1-405b-reasoning': 131072,
|
||||
'ollama/llama3': 4096,
|
||||
'watsonx/meta-llama/llama-3-8b-instruct': 4096,
|
||||
"watsonx/meta-llama/llama-3-70b-instruct": 4096,
|
||||
|
||||
@ -90,10 +90,6 @@ class LiteLLMAIHandler(BaseAiHandler):
|
||||
if get_settings().get("GOOGLE_AI_STUDIO.GEMINI_API_KEY", None):
|
||||
os.environ["GEMINI_API_KEY"] = get_settings().google_ai_studio.gemini_api_key
|
||||
|
||||
# Support deepseek models
|
||||
if get_settings().get("DEEPSEEK.KEY", None):
|
||||
os.environ['DEEPSEEK_API_KEY'] = get_settings().get("DEEPSEEK.KEY")
|
||||
|
||||
def prepare_logs(self, response, system, user, resp, finish_reason):
|
||||
response_log = response.dict().copy()
|
||||
response_log['system'] = system
|
||||
|
||||
@ -364,51 +364,48 @@ __old hunk__
|
||||
|
||||
|
||||
def extract_hunk_lines_from_patch(patch: str, file_name, line_start, line_end, side) -> tuple[str, str]:
|
||||
try:
|
||||
patch_with_lines_str = f"\n\n## File: '{file_name.strip()}'\n\n"
|
||||
selected_lines = ""
|
||||
patch_lines = patch.splitlines()
|
||||
RE_HUNK_HEADER = re.compile(
|
||||
r"^@@ -(\d+)(?:,(\d+))? \+(\d+)(?:,(\d+))? @@[ ]?(.*)")
|
||||
match = None
|
||||
start1, size1, start2, size2 = -1, -1, -1, -1
|
||||
skip_hunk = False
|
||||
selected_lines_num = 0
|
||||
for line in patch_lines:
|
||||
if 'no newline at end of file' in line.lower():
|
||||
continue
|
||||
|
||||
if line.startswith('@@'):
|
||||
skip_hunk = False
|
||||
selected_lines_num = 0
|
||||
header_line = line
|
||||
patch_with_lines_str = f"\n\n## File: '{file_name.strip()}'\n\n"
|
||||
selected_lines = ""
|
||||
patch_lines = patch.splitlines()
|
||||
RE_HUNK_HEADER = re.compile(
|
||||
r"^@@ -(\d+)(?:,(\d+))? \+(\d+)(?:,(\d+))? @@[ ]?(.*)")
|
||||
match = None
|
||||
start1, size1, start2, size2 = -1, -1, -1, -1
|
||||
skip_hunk = False
|
||||
selected_lines_num = 0
|
||||
for line in patch_lines:
|
||||
if 'no newline at end of file' in line.lower():
|
||||
continue
|
||||
|
||||
match = RE_HUNK_HEADER.match(line)
|
||||
if line.startswith('@@'):
|
||||
skip_hunk = False
|
||||
selected_lines_num = 0
|
||||
header_line = line
|
||||
|
||||
section_header, size1, size2, start1, start2 = extract_hunk_headers(match)
|
||||
match = RE_HUNK_HEADER.match(line)
|
||||
|
||||
section_header, size1, size2, start1, start2 = extract_hunk_headers(match)
|
||||
|
||||
# check if line range is in this hunk
|
||||
if side.lower() == 'left':
|
||||
# check if line range is in this hunk
|
||||
if side.lower() == 'left':
|
||||
# check if line range is in this hunk
|
||||
if not (start1 <= line_start <= start1 + size1):
|
||||
skip_hunk = True
|
||||
continue
|
||||
elif side.lower() == 'right':
|
||||
if not (start2 <= line_start <= start2 + size2):
|
||||
skip_hunk = True
|
||||
continue
|
||||
patch_with_lines_str += f'\n{header_line}\n'
|
||||
if not (start1 <= line_start <= start1 + size1):
|
||||
skip_hunk = True
|
||||
continue
|
||||
elif side.lower() == 'right':
|
||||
if not (start2 <= line_start <= start2 + size2):
|
||||
skip_hunk = True
|
||||
continue
|
||||
patch_with_lines_str += f'\n{header_line}\n'
|
||||
|
||||
elif not skip_hunk:
|
||||
if side.lower() == 'right' and line_start <= start2 + selected_lines_num <= line_end:
|
||||
selected_lines += line + '\n'
|
||||
if side.lower() == 'left' and start1 <= selected_lines_num + start1 <= line_end:
|
||||
selected_lines += line + '\n'
|
||||
patch_with_lines_str += line + '\n'
|
||||
if not line.startswith('-'): # currently we don't support /ask line for deleted lines
|
||||
selected_lines_num += 1
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to extract hunk lines from patch: {e}", artifact={"traceback": traceback.format_exc()})
|
||||
return "", ""
|
||||
elif not skip_hunk:
|
||||
if side.lower() == 'right' and line_start <= start2 + selected_lines_num <= line_end:
|
||||
selected_lines += line + '\n'
|
||||
if side.lower() == 'left' and start1 <= selected_lines_num + start1 <= line_end:
|
||||
selected_lines += line + '\n'
|
||||
patch_with_lines_str += line + '\n'
|
||||
if not line.startswith('-'): # currently we don't support /ask line for deleted lines
|
||||
selected_lines_num += 1
|
||||
|
||||
return patch_with_lines_str.rstrip(), selected_lines.rstrip()
|
||||
|
||||
@ -205,11 +205,10 @@ def pr_generate_extended_diff(pr_languages: list,
|
||||
if not extended_patch:
|
||||
get_logger().warning(f"Failed to extend patch for file: {file.filename}")
|
||||
continue
|
||||
full_extended_patch = f"\n\n## {file.filename}\n{extended_patch.rstrip()}\n"
|
||||
|
||||
if add_line_numbers_to_hunks:
|
||||
full_extended_patch = convert_to_hunks_with_lines_numbers(extended_patch, file)
|
||||
else:
|
||||
full_extended_patch = f"\n\n## File: '{file.filename.strip()}'\n{extended_patch.rstrip()}\n"
|
||||
|
||||
# add AI-summary metadata to the patch
|
||||
if file.ai_file_summary and get_settings().get("config.enable_ai_metadata", False):
|
||||
@ -317,13 +316,13 @@ def generate_full_patch(convert_hunks_to_line_numbers, file_dict, max_tokens_mod
|
||||
# TODO: Option for alternative logic to remove hunks from the patch to reduce the number of tokens
|
||||
# until we meet the requirements
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().warning(f"Patch too large, skipping it: '{filename}'")
|
||||
get_logger().warning(f"Patch too large, skipping it, {filename}")
|
||||
remaining_files_list_new.append(filename)
|
||||
continue
|
||||
|
||||
if patch:
|
||||
if not convert_hunks_to_line_numbers:
|
||||
patch_final = f"\n\n## File: '{filename.strip()}'\n\n{patch.strip()}\n"
|
||||
patch_final = f"\n\n## File: '{filename.strip()}\n\n{patch.strip()}\n'"
|
||||
else:
|
||||
patch_final = "\n\n" + patch.strip()
|
||||
patches.append(patch_final)
|
||||
|
||||
@ -1,6 +1,5 @@
|
||||
from dataclasses import dataclass
|
||||
from enum import Enum
|
||||
from typing import Optional
|
||||
|
||||
|
||||
class EDIT_TYPE(Enum):
|
||||
@ -22,5 +21,4 @@ class FilePatchInfo:
|
||||
old_filename: str = None
|
||||
num_plus_lines: int = -1
|
||||
num_minus_lines: int = -1
|
||||
language: Optional[str] = None
|
||||
ai_file_summary: str = None
|
||||
|
||||
@ -23,7 +23,6 @@ from pydantic import BaseModel
|
||||
from starlette_context import context
|
||||
|
||||
from pr_agent.algo import MAX_TOKENS
|
||||
from pr_agent.algo.git_patch_processing import extract_hunk_lines_from_patch
|
||||
from pr_agent.algo.token_handler import TokenEncoder
|
||||
from pr_agent.algo.types import FilePatchInfo
|
||||
from pr_agent.config_loader import get_settings, global_settings
|
||||
@ -236,7 +235,7 @@ def convert_to_markdown_v2(output_data: dict,
|
||||
start_line = int(str(issue.get('start_line', 0)).strip())
|
||||
end_line = int(str(issue.get('end_line', 0)).strip())
|
||||
|
||||
relevant_lines_str = extract_relevant_lines_str(end_line, files, relevant_file, start_line, dedent=True)
|
||||
relevant_lines_str = extract_relevant_lines_str(end_line, files, relevant_file, start_line)
|
||||
if git_provider:
|
||||
reference_link = git_provider.get_line_link(relevant_file, start_line, end_line)
|
||||
else:
|
||||
@ -271,13 +270,25 @@ def convert_to_markdown_v2(output_data: dict,
|
||||
if gfm_supported:
|
||||
markdown_text += "</table>\n"
|
||||
|
||||
if 'code_feedback' in output_data:
|
||||
if gfm_supported:
|
||||
markdown_text += f"\n\n"
|
||||
markdown_text += f"<details><summary> <strong>Code feedback:</strong></summary>\n\n"
|
||||
markdown_text += "<hr>"
|
||||
else:
|
||||
markdown_text += f"\n\n### Code feedback:\n\n"
|
||||
for i, value in enumerate(output_data['code_feedback']):
|
||||
if value is None or value == '' or value == {} or value == []:
|
||||
continue
|
||||
markdown_text += parse_code_suggestion(value, i, gfm_supported)+"\n\n"
|
||||
if markdown_text.endswith('<hr>'):
|
||||
markdown_text= markdown_text[:-4]
|
||||
if gfm_supported:
|
||||
markdown_text += f"</details>"
|
||||
|
||||
return markdown_text
|
||||
|
||||
|
||||
def extract_relevant_lines_str(end_line, files, relevant_file, start_line, dedent=False) -> str:
|
||||
"""
|
||||
Finds 'relevant_file' in 'files', and extracts the lines from 'start_line' to 'end_line' string from the file content.
|
||||
"""
|
||||
def extract_relevant_lines_str(end_line, files, relevant_file, start_line):
|
||||
try:
|
||||
relevant_lines_str = ""
|
||||
if files:
|
||||
@ -285,29 +296,12 @@ def extract_relevant_lines_str(end_line, files, relevant_file, start_line, deden
|
||||
for file in files:
|
||||
if file.filename.strip() == relevant_file:
|
||||
if not file.head_file:
|
||||
# as a fallback, extract relevant lines directly from patch
|
||||
patch = file.patch
|
||||
get_logger().info(f"No content found in file: '{file.filename}' for 'extract_relevant_lines_str'. Using patch instead")
|
||||
_, selected_lines = extract_hunk_lines_from_patch(patch, file.filename, start_line, end_line,side='right')
|
||||
if not selected_lines:
|
||||
get_logger().error(f"Failed to extract relevant lines from patch: {file.filename}")
|
||||
return ""
|
||||
# filter out '-' lines
|
||||
relevant_lines_str = ""
|
||||
for line in selected_lines.splitlines():
|
||||
if line.startswith('-'):
|
||||
continue
|
||||
relevant_lines_str += line[1:] + '\n'
|
||||
else:
|
||||
relevant_file_lines = file.head_file.splitlines()
|
||||
relevant_lines_str = "\n".join(relevant_file_lines[start_line - 1:end_line])
|
||||
|
||||
if dedent and relevant_lines_str:
|
||||
# Remove the longest leading string of spaces and tabs common to all lines.
|
||||
relevant_lines_str = textwrap.dedent(relevant_lines_str)
|
||||
get_logger().warning(f"No content found in file: {file.filename}")
|
||||
return ""
|
||||
relevant_file_lines = file.head_file.splitlines()
|
||||
relevant_lines_str = "\n".join(relevant_file_lines[start_line - 1:end_line])
|
||||
relevant_lines_str = f"```{file.language}\n{relevant_lines_str}\n```"
|
||||
break
|
||||
|
||||
return relevant_lines_str
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Failed to extract relevant lines: {e}")
|
||||
@ -583,22 +577,27 @@ def load_large_diff(filename, new_file_content_str: str, original_file_content_s
|
||||
"""
|
||||
Generate a patch for a modified file by comparing the original content of the file with the new content provided as
|
||||
input.
|
||||
"""
|
||||
if not original_file_content_str and not new_file_content_str:
|
||||
return ""
|
||||
|
||||
Args:
|
||||
new_file_content_str: The new content of the file as a string.
|
||||
original_file_content_str: The original content of the file as a string.
|
||||
|
||||
Returns:
|
||||
The generated or provided patch string.
|
||||
|
||||
Raises:
|
||||
None.
|
||||
"""
|
||||
patch = ""
|
||||
try:
|
||||
original_file_content_str = (original_file_content_str or "").rstrip() + "\n"
|
||||
new_file_content_str = (new_file_content_str or "").rstrip() + "\n"
|
||||
diff = difflib.unified_diff(original_file_content_str.splitlines(keepends=True),
|
||||
new_file_content_str.splitlines(keepends=True))
|
||||
if get_settings().config.verbosity_level >= 2 and show_warning:
|
||||
get_logger().info(f"File was modified, but no patch was found. Manually creating patch: {filename}.")
|
||||
get_logger().warning(f"File was modified, but no patch was found. Manually creating patch: {filename}.")
|
||||
patch = ''.join(diff)
|
||||
return patch
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Failed to generate patch for file: {filename}")
|
||||
return ""
|
||||
except Exception:
|
||||
pass
|
||||
return patch
|
||||
|
||||
|
||||
def update_settings_from_args(args: List[str]) -> List[str]:
|
||||
|
||||
@ -77,8 +77,6 @@ def run(inargs=None, args=None):
|
||||
async def inner():
|
||||
if args.issue_url:
|
||||
result = await asyncio.create_task(PRAgent().handle_request(args.issue_url, [command] + args.rest))
|
||||
elif args.repo_url:
|
||||
result = await asyncio.create_task(PRAgent().handle_request(args.repo_url, [command] + args.rest))
|
||||
else:
|
||||
result = await asyncio.create_task(PRAgent().handle_request(args.pr_url, [command] + args.rest))
|
||||
|
||||
|
||||
@ -12,6 +12,7 @@ global_settings = Dynaconf(
|
||||
envvar_prefix=False,
|
||||
merge_enabled=True,
|
||||
settings_files=[join(current_dir, f) for f in [
|
||||
"settings/.secrets.toml",
|
||||
"settings/configuration.toml",
|
||||
"settings/ignore.toml",
|
||||
"settings/language_extensions.toml",
|
||||
@ -28,7 +29,6 @@ global_settings = Dynaconf(
|
||||
"settings/pr_add_docs.toml",
|
||||
"settings/custom_labels.toml",
|
||||
"settings/pr_help_prompts.toml",
|
||||
"settings/.secrets.toml",
|
||||
"settings_prod/.secrets.toml",
|
||||
]]
|
||||
)
|
||||
|
||||
@ -326,13 +326,13 @@ class AzureDevopsProvider(GitProvider):
|
||||
edit_type = EDIT_TYPE.ADDED
|
||||
elif diff_types[file] == "delete":
|
||||
edit_type = EDIT_TYPE.DELETED
|
||||
elif "rename" in diff_types[file]: # diff_type can be `rename` | `edit, rename`
|
||||
elif diff_types[file] == "rename":
|
||||
edit_type = EDIT_TYPE.RENAMED
|
||||
|
||||
version = GitVersionDescriptor(
|
||||
version=base_sha.commit_id, version_type="commit"
|
||||
)
|
||||
if edit_type == EDIT_TYPE.ADDED or edit_type == EDIT_TYPE.RENAMED:
|
||||
if edit_type == EDIT_TYPE.ADDED:
|
||||
original_file_content_str = ""
|
||||
else:
|
||||
try:
|
||||
|
||||
@ -402,21 +402,10 @@ class BitbucketServerProvider(GitProvider):
|
||||
|
||||
try:
|
||||
projects_index = path_parts.index("projects")
|
||||
except ValueError:
|
||||
projects_index = -1
|
||||
|
||||
try:
|
||||
users_index = path_parts.index("users")
|
||||
except ValueError:
|
||||
users_index = -1
|
||||
|
||||
if projects_index == -1 and users_index == -1:
|
||||
except ValueError as e:
|
||||
raise ValueError(f"The provided URL '{pr_url}' does not appear to be a Bitbucket PR URL")
|
||||
|
||||
if projects_index != -1:
|
||||
path_parts = path_parts[projects_index:]
|
||||
else:
|
||||
path_parts = path_parts[users_index:]
|
||||
path_parts = path_parts[projects_index:]
|
||||
|
||||
if len(path_parts) < 6 or path_parts[2] != "repos" or path_parts[4] != "pull-requests":
|
||||
raise ValueError(
|
||||
@ -424,8 +413,6 @@ class BitbucketServerProvider(GitProvider):
|
||||
)
|
||||
|
||||
workspace_slug = path_parts[1]
|
||||
if users_index != -1:
|
||||
workspace_slug = f"~{workspace_slug}"
|
||||
repo_slug = path_parts[3]
|
||||
try:
|
||||
pr_number = int(path_parts[5])
|
||||
|
||||
@ -174,24 +174,6 @@ class GithubProvider(GitProvider):
|
||||
|
||||
diff_files = []
|
||||
invalid_files_names = []
|
||||
is_close_to_rate_limit = False
|
||||
|
||||
# The base.sha will point to the current state of the base branch (including parallel merges), not the original base commit when the PR was created
|
||||
# We can fix this by finding the merge base commit between the PR head and base branches
|
||||
# Note that The pr.head.sha is actually correct as is - it points to the latest commit in your PR branch.
|
||||
# This SHA isn't affected by parallel merges to the base branch since it's specific to your PR's branch.
|
||||
repo = self.repo_obj
|
||||
pr = self.pr
|
||||
try:
|
||||
compare = repo.compare(pr.base.sha, pr.head.sha) # communication with GitHub
|
||||
merge_base_commit = compare.merge_base_commit
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to get merge base commit: {e}")
|
||||
merge_base_commit = pr.base
|
||||
if merge_base_commit.sha != pr.base.sha:
|
||||
get_logger().info(
|
||||
f"Using merge base commit {merge_base_commit.sha} instead of base commit ")
|
||||
|
||||
counter_valid = 0
|
||||
for file in files:
|
||||
if not is_valid_file(file.filename):
|
||||
@ -199,36 +181,48 @@ class GithubProvider(GitProvider):
|
||||
continue
|
||||
|
||||
patch = file.patch
|
||||
if is_close_to_rate_limit:
|
||||
|
||||
# allow only a limited number of files to be fully loaded. We can manage the rest with diffs only
|
||||
counter_valid += 1
|
||||
avoid_load = False
|
||||
if counter_valid >= MAX_FILES_ALLOWED_FULL and patch and not self.incremental.is_incremental:
|
||||
avoid_load = True
|
||||
if counter_valid == MAX_FILES_ALLOWED_FULL:
|
||||
get_logger().info(f"Too many files in PR, will avoid loading full content for rest of files")
|
||||
|
||||
if avoid_load:
|
||||
new_file_content_str = ""
|
||||
original_file_content_str = ""
|
||||
else:
|
||||
# allow only a limited number of files to be fully loaded. We can manage the rest with diffs only
|
||||
counter_valid += 1
|
||||
avoid_load = False
|
||||
if counter_valid >= MAX_FILES_ALLOWED_FULL and patch and not self.incremental.is_incremental:
|
||||
avoid_load = True
|
||||
if counter_valid == MAX_FILES_ALLOWED_FULL:
|
||||
get_logger().info(f"Too many files in PR, will avoid loading full content for rest of files")
|
||||
new_file_content_str = self._get_pr_file_content(file, self.pr.head.sha) # communication with GitHub
|
||||
|
||||
if self.incremental.is_incremental and self.unreviewed_files_set:
|
||||
original_file_content_str = self._get_pr_file_content(file, self.incremental.last_seen_commit_sha)
|
||||
patch = load_large_diff(file.filename, new_file_content_str, original_file_content_str)
|
||||
self.unreviewed_files_set[file.filename] = patch
|
||||
else:
|
||||
if avoid_load:
|
||||
new_file_content_str = ""
|
||||
original_file_content_str = ""
|
||||
else:
|
||||
new_file_content_str = self._get_pr_file_content(file, self.pr.head.sha) # communication with GitHub
|
||||
# The base.sha will point to the current state of the base branch (including parallel merges), not the original base commit when the PR was created
|
||||
# We can fix this by finding the merge base commit between the PR head and base branches
|
||||
# Note that The pr.head.sha is actually correct as is - it points to the latest commit in your PR branch.
|
||||
# This SHA isn't affected by parallel merges to the base branch since it's specific to your PR's branch.
|
||||
repo = self.repo_obj
|
||||
pr = self.pr
|
||||
try:
|
||||
compare = repo.compare(pr.base.sha, pr.head.sha)
|
||||
merge_base_commit = compare.merge_base_commit
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to get merge base commit: {e}")
|
||||
merge_base_commit = pr.base
|
||||
if merge_base_commit.sha != pr.base.sha:
|
||||
get_logger().info(
|
||||
f"Using merge base commit {merge_base_commit.sha} instead of base commit "
|
||||
f"{pr.base.sha} for {file.filename}")
|
||||
original_file_content_str = self._get_pr_file_content(file, merge_base_commit.sha)
|
||||
|
||||
if self.incremental.is_incremental and self.unreviewed_files_set:
|
||||
original_file_content_str = self._get_pr_file_content(file, self.incremental.last_seen_commit_sha)
|
||||
if not patch:
|
||||
patch = load_large_diff(file.filename, new_file_content_str, original_file_content_str)
|
||||
self.unreviewed_files_set[file.filename] = patch
|
||||
else:
|
||||
if avoid_load:
|
||||
original_file_content_str = ""
|
||||
else:
|
||||
original_file_content_str = self._get_pr_file_content(file, merge_base_commit.sha)
|
||||
# original_file_content_str = self._get_pr_file_content(file, self.pr.base.sha)
|
||||
if not patch:
|
||||
patch = load_large_diff(file.filename, new_file_content_str, original_file_content_str)
|
||||
|
||||
|
||||
if file.status == 'added':
|
||||
edit_type = EDIT_TYPE.ADDED
|
||||
@ -243,14 +237,9 @@ class GithubProvider(GitProvider):
|
||||
edit_type = EDIT_TYPE.UNKNOWN
|
||||
|
||||
# count number of lines added and removed
|
||||
if hasattr(file, 'additions') and hasattr(file, 'deletions'):
|
||||
num_plus_lines = file.additions
|
||||
num_minus_lines = file.deletions
|
||||
else:
|
||||
patch_lines = patch.splitlines(keepends=True)
|
||||
num_plus_lines = len([line for line in patch_lines if line.startswith('+')])
|
||||
num_minus_lines = len([line for line in patch_lines if line.startswith('-')])
|
||||
|
||||
patch_lines = patch.splitlines(keepends=True)
|
||||
num_plus_lines = len([line for line in patch_lines if line.startswith('+')])
|
||||
num_minus_lines = len([line for line in patch_lines if line.startswith('-')])
|
||||
file_patch_canonical_structure = FilePatchInfo(original_file_content_str, new_file_content_str, patch,
|
||||
file.filename, edit_type=edit_type,
|
||||
num_plus_lines=num_plus_lines,
|
||||
|
||||
@ -141,18 +141,6 @@ class LocalGitProvider(GitProvider):
|
||||
def remove_comment(self, comment):
|
||||
pass # Not applicable to the local git provider, but required by the interface
|
||||
|
||||
def add_eyes_reaction(self, comment):
|
||||
pass # Not applicable to the local git provider, but required by the interface
|
||||
|
||||
def get_commit_messages(self):
|
||||
pass # Not applicable to the local git provider, but required by the interface
|
||||
|
||||
def get_repo_settings(self):
|
||||
pass # Not applicable to the local git provider, but required by the interface
|
||||
|
||||
def remove_reaction(self, comment):
|
||||
pass # Not applicable to the local git provider, but required by the interface
|
||||
|
||||
def get_languages(self):
|
||||
"""
|
||||
Calculate percentage of languages in repository. Used for hunk prioritisation.
|
||||
|
||||
@ -101,3 +101,22 @@ def set_claude_model():
|
||||
get_settings().set('config.model', model_claude)
|
||||
get_settings().set('config.model_weak', model_claude)
|
||||
get_settings().set('config.fallback_models', [model_claude])
|
||||
|
||||
|
||||
def is_user_name_a_bot(name: str) -> bool:
|
||||
if not name:
|
||||
return False
|
||||
bot_indicators = ['codium', 'bot_', 'bot-', '_bot', '-bot', 'qodo', "service", "github", "jenkins", "auto",
|
||||
"cicd", "validator", "ci-", "assistant", "srv-"]
|
||||
return any(indicator in name.lower() for indicator in bot_indicators)
|
||||
|
||||
|
||||
def is_pr_description_indicating_bot(description: str) -> bool:
|
||||
if not description:
|
||||
return False
|
||||
bot_descriptions = ["Snyk has created this PR", "This PR was created automatically by",
|
||||
"This PR was created by a bot",
|
||||
"This pull request was automatically generated by"]
|
||||
# Check is it's a Snyk bot
|
||||
if any(bot_description in description for bot_description in bot_descriptions):
|
||||
return True
|
||||
@ -19,11 +19,15 @@ from starlette_context.middleware import RawContextMiddleware
|
||||
from pr_agent.agent.pr_agent import PRAgent
|
||||
from pr_agent.algo.utils import update_settings_from_args
|
||||
from pr_agent.config_loader import get_settings, global_settings
|
||||
from pr_agent.git_providers.utils import apply_repo_settings
|
||||
from pr_agent.git_providers.utils import apply_repo_settings, is_user_name_a_bot, is_pr_description_indicating_bot
|
||||
from pr_agent.identity_providers import get_identity_provider
|
||||
from pr_agent.identity_providers.identity_provider import Eligibility
|
||||
from pr_agent.log import LoggingFormat, get_logger, setup_logger
|
||||
from pr_agent.secret_providers import get_secret_provider
|
||||
from pr_agent.servers.github_action_runner import get_setting_or_env, is_true
|
||||
from pr_agent.tools.pr_code_suggestions import PRCodeSuggestions
|
||||
from pr_agent.tools.pr_description import PRDescription
|
||||
from pr_agent.tools.pr_reviewer import PRReviewer
|
||||
|
||||
setup_logger(fmt=LoggingFormat.JSON, level="DEBUG")
|
||||
router = APIRouter()
|
||||
@ -71,18 +75,6 @@ async def handle_manifest(request: Request, response: Response):
|
||||
return JSONResponse(manifest_obj)
|
||||
|
||||
|
||||
def _get_username(data):
|
||||
actor = data.get("data", {}).get("actor", {})
|
||||
if actor:
|
||||
if "username" in actor:
|
||||
return actor["username"]
|
||||
elif "display_name" in actor:
|
||||
return actor["display_name"]
|
||||
elif "nickname" in actor:
|
||||
return actor["nickname"]
|
||||
return ""
|
||||
|
||||
|
||||
async def _perform_commands_bitbucket(commands_conf: str, agent: PRAgent, api_url: str, log_context: dict, data: dict):
|
||||
apply_repo_settings(api_url)
|
||||
if commands_conf == "pr_commands" and get_settings().config.disable_auto_feedback: # auto commands for PR, and auto feedback is disabled
|
||||
@ -110,11 +102,22 @@ async def _perform_commands_bitbucket(commands_conf: str, agent: PRAgent, api_ur
|
||||
def is_bot_user(data) -> bool:
|
||||
try:
|
||||
actor = data.get("data", {}).get("actor", {})
|
||||
description = data.get("data", {}).get("pullrequest", {}).get("description", "")
|
||||
# allow actor type: user . if it's "AppUser" or "team" then it is a bot user
|
||||
allowed_actor_types = {"user"}
|
||||
if actor and actor["type"].lower() not in allowed_actor_types:
|
||||
get_logger().info(f"BitBucket actor type is not 'user', skipping: {actor}")
|
||||
return True
|
||||
|
||||
username = actor.get("username", "")
|
||||
if username and is_user_name_a_bot(username):
|
||||
get_logger().info(f"BitBucket actor is a bot user, skipping: {username}")
|
||||
return True
|
||||
|
||||
if description and is_pr_description_indicating_bot(description):
|
||||
get_logger().info(f"Description indicates a bot user: {actor}",
|
||||
artifact={"description": description})
|
||||
return True
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed 'is_bot_user' logic: {e}")
|
||||
return False
|
||||
@ -126,14 +129,6 @@ def should_process_pr_logic(data) -> bool:
|
||||
title = pr_data.get("title", "")
|
||||
source_branch = pr_data.get("source", {}).get("branch", {}).get("name", "")
|
||||
target_branch = pr_data.get("destination", {}).get("branch", {}).get("name", "")
|
||||
sender = _get_username(data)
|
||||
|
||||
# logic to ignore PRs from specific users
|
||||
ignore_pr_users = get_settings().get("CONFIG.IGNORE_PR_AUTHORS", [])
|
||||
if ignore_pr_users and sender:
|
||||
if sender in ignore_pr_users:
|
||||
get_logger().info(f"Ignoring PR from user '{sender}' due to 'config.ignore_pr_authors' setting")
|
||||
return False
|
||||
|
||||
# logic to ignore PRs with specific titles
|
||||
if title:
|
||||
@ -183,7 +178,16 @@ async def handle_github_webhooks(background_tasks: BackgroundTasks, request: Req
|
||||
return "OK"
|
||||
|
||||
# Get the username of the sender
|
||||
log_context["sender"] = _get_username(data)
|
||||
actor = data.get("data", {}).get("actor", {})
|
||||
if actor:
|
||||
try:
|
||||
username = actor["username"]
|
||||
except KeyError:
|
||||
try:
|
||||
username = actor["display_name"]
|
||||
except KeyError:
|
||||
username = actor["nickname"]
|
||||
log_context["sender"] = username
|
||||
|
||||
sender_id = data.get("data", {}).get("actor", {}).get("account_id", "")
|
||||
log_context["sender_id"] = sender_id
|
||||
|
||||
@ -18,7 +18,7 @@ from pr_agent.config_loader import get_settings, global_settings
|
||||
from pr_agent.git_providers import (get_git_provider,
|
||||
get_git_provider_with_context)
|
||||
from pr_agent.git_providers.git_provider import IncrementalPR
|
||||
from pr_agent.git_providers.utils import apply_repo_settings
|
||||
from pr_agent.git_providers.utils import apply_repo_settings, is_user_name_a_bot, is_pr_description_indicating_bot
|
||||
from pr_agent.identity_providers import get_identity_provider
|
||||
from pr_agent.identity_providers.identity_provider import Eligibility
|
||||
from pr_agent.log import LoggingFormat, get_logger, setup_logger
|
||||
@ -238,13 +238,22 @@ def get_log_context(body, event, action, build_number):
|
||||
return log_context, sender, sender_id, sender_type
|
||||
|
||||
|
||||
def is_bot_user(sender, sender_type):
|
||||
def is_bot_user(sender, sender_type, user_description):
|
||||
try:
|
||||
# logic to ignore PRs opened by bot
|
||||
if get_settings().get("GITHUB_APP.IGNORE_BOT_PR", False) and sender_type == "Bot":
|
||||
if 'pr-agent' not in sender:
|
||||
if get_settings().get("GITHUB_APP.IGNORE_BOT_PR", False):
|
||||
if sender_type.lower() == "bot":
|
||||
if 'pr-agent' not in sender:
|
||||
get_logger().info(f"Ignoring PR from '{sender=}' because it is a bot")
|
||||
return True
|
||||
if is_user_name_a_bot(sender):
|
||||
get_logger().info(f"Ignoring PR from '{sender=}' because it is a bot")
|
||||
return True
|
||||
return True
|
||||
# Ignore PRs opened by bot users based on their description
|
||||
if isinstance(user_description, str) and is_pr_description_indicating_bot(user_description):
|
||||
get_logger().info(f"Description indicates a bot user: {sender}",
|
||||
artifact={"description": user_description})
|
||||
return True
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed 'is_bot_user' logic: {e}")
|
||||
return False
|
||||
@ -257,14 +266,6 @@ def should_process_pr_logic(body) -> bool:
|
||||
pr_labels = pull_request.get("labels", [])
|
||||
source_branch = pull_request.get("head", {}).get("ref", "")
|
||||
target_branch = pull_request.get("base", {}).get("ref", "")
|
||||
sender = body.get("sender", {}).get("login")
|
||||
|
||||
# logic to ignore PRs from specific users
|
||||
ignore_pr_users = get_settings().get("CONFIG.IGNORE_PR_AUTHORS", [])
|
||||
if ignore_pr_users and sender:
|
||||
if sender in ignore_pr_users:
|
||||
get_logger().info(f"Ignoring PR from user '{sender}' due to 'config.ignore_pr_authors' setting")
|
||||
return False
|
||||
|
||||
# logic to ignore PRs with specific titles
|
||||
if title:
|
||||
@ -284,7 +285,6 @@ def should_process_pr_logic(body) -> bool:
|
||||
get_logger().info(f"Ignoring PR with labels '{labels_str}' due to config.ignore_pr_labels settings")
|
||||
return False
|
||||
|
||||
# logic to ignore PRs with specific source or target branches
|
||||
ignore_pr_source_branches = get_settings().get("CONFIG.IGNORE_PR_SOURCE_BRANCHES", [])
|
||||
ignore_pr_target_branches = get_settings().get("CONFIG.IGNORE_PR_TARGET_BRANCHES", [])
|
||||
if pull_request and (ignore_pr_source_branches or ignore_pr_target_branches):
|
||||
@ -316,7 +316,8 @@ async def handle_request(body: Dict[str, Any], event: str):
|
||||
log_context, sender, sender_id, sender_type = get_log_context(body, event, action, build_number)
|
||||
|
||||
# logic to ignore PRs opened by bot, PRs with specific titles, labels, source branches, or target branches
|
||||
if is_bot_user(sender, sender_type) and 'check_run' not in body:
|
||||
pr_description = body.get("pull_request", {}).get("body", "")
|
||||
if is_bot_user(sender, sender_type, pr_description) and 'check_run' not in body:
|
||||
return {}
|
||||
if action != 'created' and 'check_run' not in body:
|
||||
if not should_process_pr_logic(body):
|
||||
|
||||
@ -15,7 +15,7 @@ from starlette_context.middleware import RawContextMiddleware
|
||||
from pr_agent.agent.pr_agent import PRAgent
|
||||
from pr_agent.algo.utils import update_settings_from_args
|
||||
from pr_agent.config_loader import get_settings, global_settings
|
||||
from pr_agent.git_providers.utils import apply_repo_settings
|
||||
from pr_agent.git_providers.utils import apply_repo_settings, is_user_name_a_bot, is_pr_description_indicating_bot
|
||||
from pr_agent.log import LoggingFormat, get_logger, setup_logger
|
||||
from pr_agent.secret_providers import get_secret_provider
|
||||
|
||||
@ -86,10 +86,14 @@ def is_bot_user(data) -> bool:
|
||||
try:
|
||||
# logic to ignore bot users (unlike Github, no direct flag for bot users in gitlab)
|
||||
sender_name = data.get("user", {}).get("name", "unknown").lower()
|
||||
bot_indicators = ['codium', 'bot_', 'bot-', '_bot', '-bot']
|
||||
if any(indicator in sender_name for indicator in bot_indicators):
|
||||
if is_user_name_a_bot(sender_name):
|
||||
get_logger().info(f"Skipping GitLab bot user: {sender_name}")
|
||||
return True
|
||||
pr_description = data.get('object_attributes', {}).get('description', '')
|
||||
if pr_description and is_pr_description_indicating_bot(pr_description):
|
||||
get_logger().info(f"Description indicates a bot user: {sender_name}",
|
||||
artifact={"description": pr_description})
|
||||
return True
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed 'is_bot_user' logic: {e}")
|
||||
return False
|
||||
@ -100,14 +104,6 @@ def should_process_pr_logic(data) -> bool:
|
||||
if not data.get('object_attributes', {}):
|
||||
return False
|
||||
title = data['object_attributes'].get('title')
|
||||
sender = data.get("user", {}).get("username", "")
|
||||
|
||||
# logic to ignore PRs from specific users
|
||||
ignore_pr_users = get_settings().get("CONFIG.IGNORE_PR_AUTHORS", [])
|
||||
if ignore_pr_users and sender:
|
||||
if sender in ignore_pr_users:
|
||||
get_logger().info(f"Ignoring PR from user '{sender}' due to 'config.ignore_pr_authors' settings")
|
||||
return False
|
||||
|
||||
# logic to ignore MRs for titles, labels and source, target branches.
|
||||
ignore_mr_title = get_settings().get("CONFIG.IGNORE_PR_TITLE", [])
|
||||
|
||||
@ -91,6 +91,3 @@ pat = ""
|
||||
# Optional, uncomment if you want to use Azure devops webhooks. Value assinged when you create the webhook
|
||||
# webhook_username = "<basic auth user>"
|
||||
# webhook_password = "<basic auth password>"
|
||||
|
||||
[deepseek]
|
||||
key = ""
|
||||
|
||||
@ -34,7 +34,6 @@ ai_disclaimer_title="" # Pro feature, title for a collapsible disclaimer to AI
|
||||
ai_disclaimer="" # Pro feature, full text for the AI disclaimer
|
||||
output_relevant_configurations=false
|
||||
large_patch_policy = "clip" # "clip", "skip"
|
||||
duplicate_prompt_examples = false
|
||||
# seed
|
||||
seed=-1 # set positive value to fix the seed (and ensure temperature=0)
|
||||
temperature=0.2
|
||||
@ -43,7 +42,6 @@ ignore_pr_title = ["^\\[Auto\\]", "^Auto"] # a list of regular expressions to ma
|
||||
ignore_pr_target_branches = [] # a list of regular expressions of target branches to ignore from PR agent when an PR is created
|
||||
ignore_pr_source_branches = [] # a list of regular expressions of source branches to ignore from PR agent when an PR is created
|
||||
ignore_pr_labels = [] # labels to ignore from PR agent when an PR is created
|
||||
ignore_pr_authors = [] # authors to ignore from PR agent when an PR is created
|
||||
#
|
||||
is_auto_command = false # will be auto-set to true if the command is triggered by an automation
|
||||
enable_ai_metadata = false # will enable adding ai metadata
|
||||
@ -57,6 +55,9 @@ require_can_be_split_review=false
|
||||
require_security_review=true
|
||||
require_ticket_analysis_review=true
|
||||
# general options
|
||||
num_code_suggestions=0 # legacy mode. use the `improve` command instead
|
||||
inline_code_comments = false
|
||||
ask_and_reflect=false
|
||||
persistent_comment=true
|
||||
extra_instructions = ""
|
||||
final_update_message = true
|
||||
@ -90,7 +91,6 @@ publish_description_as_comment_persistent=true
|
||||
## changes walkthrough section
|
||||
enable_semantic_files_types=true
|
||||
collapsible_file_list='adaptive' # true, false, 'adaptive'
|
||||
collapsible_file_list_threshold=8
|
||||
inline_file_summary=false # false, true, 'table'
|
||||
# markers
|
||||
use_description_markers=false
|
||||
@ -99,6 +99,7 @@ include_generated_by_header=true
|
||||
enable_large_pr_handling=true
|
||||
max_ai_calls=4
|
||||
async_ai_calls=true
|
||||
mention_extra_files=true
|
||||
#custom_labels = ['Bug fix', 'Tests', 'Bug fix with tests', 'Enhancement', 'Documentation', 'Other']
|
||||
|
||||
[pr_questions] # /ask #
|
||||
@ -161,7 +162,6 @@ class_name = "" # in case there are several methods with the same name in
|
||||
[pr_update_changelog] # /update_changelog #
|
||||
push_changelog_changes=false
|
||||
extra_instructions = ""
|
||||
add_pr_link=true
|
||||
|
||||
[pr_analyze] # /analyze #
|
||||
enable_help_text=true
|
||||
|
||||
@ -17,36 +17,30 @@ The PR code diff will be in the following structured format:
|
||||
|
||||
@@ ... @@ def func1():
|
||||
__new hunk__
|
||||
unchanged code line0
|
||||
unchanged code line1
|
||||
+new code line2 added
|
||||
unchanged code line3
|
||||
unchanged code line0 in the PR
|
||||
unchanged code line1 in the PR
|
||||
+new code line2 added in the PR
|
||||
unchanged code line3 in the PR
|
||||
__old hunk__
|
||||
unchanged code line0
|
||||
unchanged code line1
|
||||
-old code line2 removed
|
||||
-old code line2 removed in the PR
|
||||
unchanged code line3
|
||||
|
||||
@@ ... @@ def func2():
|
||||
__new hunk__
|
||||
unchanged code line4
|
||||
+new code line5 removed
|
||||
+new code line5 removed in the PR
|
||||
unchanged code line6
|
||||
|
||||
## File: 'src/file2.py'
|
||||
...
|
||||
======
|
||||
|
||||
Important notes about the structured diff format above:
|
||||
1. Each PR code chunk is decoupled into separate '__new hunk__' and '__old hunk__' sections:
|
||||
- The '__new hunk__' section shows the code chunk AFTER the PR changes.
|
||||
- The '__old hunk__' section shows the code chunk BEFORE the PR changes. If no code was removed from the chunk, the '__old hunk__' section will be omitted.
|
||||
2. The diff uses line prefixes to show changes:
|
||||
'+' → new line code added (will appear only in '__new hunk__')
|
||||
'-' → line code removed (will appear only in '__old hunk__')
|
||||
' ' → unchanged context lines (will appear in both sections)
|
||||
- In the format above, the diff is organized into separate '__new hunk__' and '__old hunk__' sections for each code chunk. '__new hunk__' contains the updated code, while '__old hunk__' shows the removed code. If no code was removed in a specific chunk, the __old hunk__ section will be omitted.
|
||||
- Code lines are prefixed with symbols: '+' for new code added in the PR, '-' for code removed, and ' ' for unchanged code.
|
||||
{%- if is_ai_metadata %}
|
||||
3. When available, an AI-generated summary will precede each file's diff, with a high-level overview of the changes. Note that this summary may not be fully accurate or complete.
|
||||
- When available, an AI-generated summary will precede each file's diff, with a high-level overview of the changes. Note that this summary may not be fully accurate or complete.
|
||||
{%- endif %}
|
||||
|
||||
|
||||
@ -56,17 +50,16 @@ Specific guidelines for generating code suggestions:
|
||||
{%- else %}
|
||||
- Provide up to {{ num_code_suggestions }} distinct and insightful code suggestions. Return less suggestions if no pertinent ones are applicable.
|
||||
{%- endif %}
|
||||
- DO NOT suggest implementing changes that are already present in the '+' lines compared to the '-' lines.
|
||||
- Focus your suggestions ONLY on new code introduced in the PR ('+' lines in '__new hunk__' sections).
|
||||
- Focus solely on enhancing new code introduced in the PR, identified by '+' prefixes in '__new hunk__' sections.
|
||||
{%- if not focus_only_on_problems %}
|
||||
- Prioritize suggestions that address potential issues, critical problems, and bugs in the PR code. Avoid repeating changes already implemented in the PR. If no pertinent suggestions are applicable, return an empty list.
|
||||
- Don't suggest to add docstring, type hints, or comments, to remove unused imports, or to use more specific exception types.
|
||||
{%- else %}
|
||||
- Only give suggestions that address critical problems and bugs in the PR code. If no relevant suggestions are applicable, return an empty list.
|
||||
- Do not suggest to change packages version, add missing import statement, or declare undefined variable.
|
||||
{%- endif %}
|
||||
- When mentioning code elements (variables, names, or files) in your response, surround them with backticks (`). For example: "verify that `user_id` is..."
|
||||
- Note that you only see changed code segments (diff hunks in a PR), not the entire codebase. Avoid suggestions that might duplicate existing functionality or questioning code elements (like variables declerations or import statements) that may be defined elsewhere in the codebase.
|
||||
- Don't suggest to add docstring, type hints, or comments, to remove unused imports, or to use more specific exception types.
|
||||
- When referencing variables or names from the code, enclose them in backticks (`). Example: "ensure that `variable_name` is..."
|
||||
- Be mindful you are viewing a partial PR code diff, not the full codebase. Avoid suggestions that might conflict with unseen code or alerting variables not declared in the visible scope, as the context is incomplete.
|
||||
|
||||
|
||||
{%- if extra_instructions %}
|
||||
|
||||
@ -86,7 +79,7 @@ class CodeSuggestion(BaseModel):
|
||||
suggestion_content: str = Field(description="An actionable suggestion to enhance, improve or fix the new code introduced in the PR. Don't present here actual code snippets, just the suggestion. Be short and concise")
|
||||
existing_code: str = Field(description="A short code snippet from a '__new hunk__' section that the suggestion aims to enhance or fix. Include only complete code lines. Use ellipsis (...) for brevity if needed. This snippet should represent the specific PR code targeted for improvement.")
|
||||
improved_code: str = Field(description="A refined code snippet that replaces the 'existing_code' snippet after implementing the suggestion.")
|
||||
one_sentence_summary: str = Field(description="A concise, single-sentence overview (up to 6 words) of the suggested improvement. Focus on the 'what'. Be general, and avoid method or variable names.")
|
||||
one_sentence_summary: str = Field(description="A concise, single-sentence overview of the suggested improvement. Focus on the 'what'. Be general, and avoid method or variable names.")
|
||||
{%- if not focus_only_on_problems %}
|
||||
label: str = Field(description="A single, descriptive label that best characterizes the suggestion type. Possible labels include 'security', 'possible bug', 'possible issue', 'performance', 'enhancement', 'best practice', 'maintainability', 'typo'. Other relevant labels are also acceptable.")
|
||||
{%- else %}
|
||||
@ -118,6 +111,7 @@ code_suggestions:
|
||||
...
|
||||
```
|
||||
|
||||
|
||||
Each YAML output MUST be after a newline, indented, with block scalar indicator ('|').
|
||||
"""
|
||||
|
||||
@ -125,40 +119,12 @@ user="""--PR Info--
|
||||
|
||||
Title: '{{title}}'
|
||||
|
||||
{%- if date %}
|
||||
|
||||
Today's Date: {{date}}
|
||||
{%- endif %}
|
||||
|
||||
The PR Diff:
|
||||
======
|
||||
{{ diff_no_line_numbers|trim }}
|
||||
======
|
||||
|
||||
{%- if duplicate_prompt_examples %}
|
||||
|
||||
|
||||
Example output:
|
||||
```yaml
|
||||
code_suggestions:
|
||||
- relevant_file: |
|
||||
src/file1.py
|
||||
language: |
|
||||
python
|
||||
suggestion_content: |
|
||||
...
|
||||
existing_code: |
|
||||
...
|
||||
improved_code: |
|
||||
...
|
||||
one_sentence_summary: |
|
||||
...
|
||||
label: |
|
||||
...
|
||||
```
|
||||
(replace '...' with actual content)
|
||||
{%- endif %}
|
||||
|
||||
|
||||
Response (should be a valid YAML, and nothing else):
|
||||
```yaml
|
||||
|
||||
@ -49,14 +49,14 @@ The PR code diff will be presented in the following structured format:
|
||||
|
||||
@@ ... @@ def func1():
|
||||
__new hunk__
|
||||
11 unchanged code line0
|
||||
12 unchanged code line1
|
||||
13 +new code line2 added
|
||||
14 unchanged code line3
|
||||
11 unchanged code line0 in the PR
|
||||
12 unchanged code line1 in the PR
|
||||
13 +new code line2 added in the PR
|
||||
14 unchanged code line3 in the PR
|
||||
__old hunk__
|
||||
unchanged code line0
|
||||
unchanged code line1
|
||||
-old code line2 removed
|
||||
-old code line2 removed in the PR
|
||||
unchanged code line3
|
||||
|
||||
@@ ... @@ def func2():
|
||||
@ -122,25 +122,6 @@ Below are {{ num_code_suggestions }} AI-generated code suggestions for enhancing
|
||||
======
|
||||
|
||||
|
||||
{%- if duplicate_prompt_examples %}
|
||||
|
||||
|
||||
Example output:
|
||||
```yaml
|
||||
code_suggestions:
|
||||
- suggestion_summary: |
|
||||
...
|
||||
relevant_file: "..."
|
||||
relevant_lines_start: ...
|
||||
relevant_lines_end: ...
|
||||
suggestion_score: ...
|
||||
why: |
|
||||
...
|
||||
- ...
|
||||
```
|
||||
(replace '...' with actual content)
|
||||
{%- endif %}
|
||||
|
||||
Response (should be a valid YAML, and nothing else):
|
||||
```yaml
|
||||
"""
|
||||
|
||||
@ -1,11 +1,15 @@
|
||||
[pr_description_prompt]
|
||||
system="""You are PR-Reviewer, a language model designed to review a Git Pull Request (PR).
|
||||
Your task is to provide a full description for the PR content - type, description, title and files walkthrough.
|
||||
- Focus on the new PR code (lines starting with '+' in the 'PR Git Diff' section).
|
||||
{%- if enable_custom_labels %}
|
||||
Your task is to provide a full description for the PR content - files walkthrough, title, type, description and labels.
|
||||
{%- else %}
|
||||
Your task is to provide a full description for the PR content - files walkthrough, title, type, and description.
|
||||
{%- endif %}
|
||||
- Focus on the new PR code (lines starting with '+').
|
||||
- Keep in mind that the 'Previous title', 'Previous description' and 'Commit messages' sections may be partial, simplistic, non-informative or out of date. Hence, compare them to the PR diff code, and use them only as a reference.
|
||||
- The generated title and description should prioritize the most significant changes.
|
||||
- If needed, each YAML output should be in block scalar indicator ('|')
|
||||
- When quoting variables, names or file paths from the code, use backticks (`) instead of single quote (').
|
||||
- If needed, each YAML output should be in block scalar indicator ('|-')
|
||||
- When quoting variables or names from the code, use backticks (`) instead of single quote (').
|
||||
|
||||
{%- if extra_instructions %}
|
||||
|
||||
@ -34,20 +38,22 @@ class PRType(str, Enum):
|
||||
{%- if enable_semantic_files_types %}
|
||||
|
||||
class FileDescription(BaseModel):
|
||||
filename: str = Field(description="The full file path of the relevant file")
|
||||
{%- if include_file_summary_changes %}
|
||||
filename: str = Field(description="The full file path of the relevant file.")
|
||||
language: str = Field(description="The programming language of the relevant file.")
|
||||
changes_summary: str = Field(description="concise summary of the changes in the relevant file, in bullet points (1-4 bullet points).")
|
||||
{%- endif %}
|
||||
changes_title: str = Field(description="one-line summary (5-10 words) capturing the main theme of changes in the file")
|
||||
changes_title: str = Field(description="an informative title for the changes in the files, describing its main theme (5-10 words).")
|
||||
label: str = Field(description="a single semantic label that represents a type of code changes that occurred in the File. Possible values (partial list): 'bug fix', 'tests', 'enhancement', 'documentation', 'error handling', 'configuration changes', 'dependencies', 'formatting', 'miscellaneous', ...")
|
||||
{%- endif %}
|
||||
|
||||
class PRDescription(BaseModel):
|
||||
type: List[PRType] = Field(description="one or more types that describe the PR content. Return the label member value (e.g. 'Bug fix', not 'bug_fix')")
|
||||
description: str = Field(description="summarize the PR changes in up to four bullet points, each up to 8 words. For large PRs, add sub-bullets if needed. Order bullets by importance, with each bullet highlighting a key change group.")
|
||||
title: str = Field(description="a concise and descriptive title that captures the PR's main theme")
|
||||
{%- if enable_semantic_files_types %}
|
||||
pr_files: List[FileDescription] = Field(max_items=20, description="a list of all the files that were changed in the PR, and summary of their changes. Each file must be analyzed regardless of change size.")
|
||||
pr_files: List[FileDescription] = Field(max_items=15, description="a list of the files in the PR, and summary of their changes")
|
||||
{%- endif %}
|
||||
description: str = Field(description="an informative and concise description of the PR. Use bullet points. Display first the most significant changes.")
|
||||
title: str = Field(description="an informative title for the PR, describing its main theme")
|
||||
{%- if enable_custom_labels %}
|
||||
labels: List[Label] = Field(min_items=0, description="choose the relevant custom labels that describe the PR content, and return their keys. Use the value field of the Label object to better understand the label meaning.")
|
||||
{%- endif %}
|
||||
=====
|
||||
|
||||
@ -58,24 +64,31 @@ Example output:
|
||||
type:
|
||||
- ...
|
||||
- ...
|
||||
description: |
|
||||
...
|
||||
title: |
|
||||
...
|
||||
{%- if enable_semantic_files_types %}
|
||||
pr_files:
|
||||
- filename: |
|
||||
...
|
||||
{%- if include_file_summary_changes %}
|
||||
language: |
|
||||
...
|
||||
changes_summary: |
|
||||
...
|
||||
{%- endif %}
|
||||
changes_title: |
|
||||
...
|
||||
label: |
|
||||
label_key_1
|
||||
...
|
||||
...
|
||||
{%- endif %}
|
||||
description: |
|
||||
...
|
||||
title: |
|
||||
...
|
||||
{%- if enable_custom_labels %}
|
||||
labels:
|
||||
- |
|
||||
...
|
||||
- |
|
||||
...
|
||||
{%- endif %}
|
||||
```
|
||||
|
||||
Answer should be a valid YAML, and nothing else. Each YAML output MUST be after a newline, with proper indent, and block scalar indicator ('|')
|
||||
@ -123,44 +136,13 @@ Commit messages:
|
||||
{%- endif %}
|
||||
|
||||
|
||||
The PR Git Diff:
|
||||
The PR Diff:
|
||||
=====
|
||||
{{ diff|trim }}
|
||||
=====
|
||||
|
||||
Note that lines in the diff body are prefixed with a symbol that represents the type of change: '-' for deletions, '+' for additions, and ' ' (a space) for unchanged lines.
|
||||
|
||||
{%- if duplicate_prompt_examples %}
|
||||
|
||||
|
||||
Example output:
|
||||
```yaml
|
||||
type:
|
||||
- Bug fix
|
||||
- Refactoring
|
||||
- ...
|
||||
description: |
|
||||
...
|
||||
title: |
|
||||
...
|
||||
{%- if enable_semantic_files_types %}
|
||||
pr_files:
|
||||
- filename: |
|
||||
...
|
||||
{%- if include_file_summary_changes %}
|
||||
changes_summary: |
|
||||
...
|
||||
{%- endif %}
|
||||
changes_title: |
|
||||
...
|
||||
label: |
|
||||
label_key_1
|
||||
...
|
||||
{%- endif %}
|
||||
```
|
||||
(replace '...' with the actual values)
|
||||
{%- endif %}
|
||||
|
||||
|
||||
Response (should be a valid YAML, and nothing else):
|
||||
```yaml
|
||||
|
||||
@ -1,6 +1,10 @@
|
||||
[pr_review_prompt]
|
||||
system="""You are PR-Reviewer, a language model designed to review a Git Pull Request (PR).
|
||||
{%- if num_code_suggestions > 0 %}
|
||||
Your task is to provide constructive and concise feedback for the PR, and also provide meaningful code suggestions.
|
||||
{%- else %}
|
||||
Your task is to provide constructive and concise feedback for the PR.
|
||||
{%- endif %}
|
||||
The review should focus on new code added in the PR code diff (lines starting with '+')
|
||||
|
||||
|
||||
@ -16,20 +20,20 @@ The format we will use to present the PR code diff:
|
||||
|
||||
@@ ... @@ def func1():
|
||||
__new hunk__
|
||||
11 unchanged code line0
|
||||
12 unchanged code line1
|
||||
13 +new code line2 added
|
||||
14 unchanged code line3
|
||||
11 unchanged code line0 in the PR
|
||||
12 unchanged code line1 in the PR
|
||||
13 +new code line2 added in the PR
|
||||
14 unchanged code line3 in the PR
|
||||
__old hunk__
|
||||
unchanged code line0
|
||||
unchanged code line1
|
||||
-old code line2 removed
|
||||
-old code line2 removed in the PR
|
||||
unchanged code line3
|
||||
|
||||
@@ ... @@ def func2():
|
||||
__new hunk__
|
||||
unchanged code line4
|
||||
+new code line5 removed
|
||||
+new code line5 removed in the PR
|
||||
unchanged code line6
|
||||
|
||||
## File: 'src/file2.py'
|
||||
@ -43,8 +47,18 @@ __new hunk__
|
||||
{%- if is_ai_metadata %}
|
||||
- If available, an AI-generated summary will appear and provide a high-level overview of the file changes. Note that this summary may not be fully accurate or complete.
|
||||
{%- endif %}
|
||||
- When quoting variables, names or file paths from the code, use backticks (`) instead of single quote (').
|
||||
- When quoting variables or names from the code, use backticks (`) instead of single quote (').
|
||||
|
||||
{%- if num_code_suggestions > 0 %}
|
||||
|
||||
|
||||
Code suggestions guidelines:
|
||||
- Provide up to {{ num_code_suggestions }} code suggestions. Try to provide diverse and insightful suggestions.
|
||||
- Focus on important suggestions like fixing code problems, issues and bugs. As a second priority, provide suggestions for meaningful code improvements, like performance, vulnerability, modularity, and best practices.
|
||||
- Avoid making suggestions that have already been implemented in the PR code. For example, if you want to add logs, or change a variable to const, or anything else, make sure it isn't already in the PR code.
|
||||
- Don't suggest to add docstring, type hints, or comments.
|
||||
- Suggestions should address the new code added in the PR diff (lines starting with '+')
|
||||
{%- endif %}
|
||||
|
||||
{%- if extra_instructions %}
|
||||
|
||||
@ -104,9 +118,25 @@ class Review(BaseModel):
|
||||
{%- if require_can_be_split_review %}
|
||||
can_be_split: List[SubPR] = Field(min_items=0, max_items=3, description="Can this PR, which contains {{ num_pr_files }} changed files in total, be divided into smaller sub-PRs with distinct tasks that can be reviewed and merged independently, regardless of the order ? Make sure that the sub-PRs are indeed independent, with no code dependencies between them, and that each sub-PR represent a meaningful independent task. Output an empty list if the PR code does not need to be split.")
|
||||
{%- endif %}
|
||||
{%- if num_code_suggestions > 0 %}
|
||||
|
||||
class CodeSuggestion(BaseModel):
|
||||
relevant_file: str = Field(description="The full file path of the relevant file")
|
||||
language: str = Field(description="The programming language of the relevant file")
|
||||
suggestion: str = Field(description="a concrete suggestion for meaningfully improving the new PR code. Also describe how, specifically, the suggestion can be applied to new PR code. Add tags with importance measure that matches each suggestion ('important' or 'medium'). Do not make suggestions for updating or adding docstrings, renaming PR title and description, or linter like.")
|
||||
relevant_line: str = Field(description="a single code line taken from the relevant file, to which the suggestion applies. The code line should start with a '+'. Make sure to output the line exactly as it appears in the relevant file")
|
||||
{%- endif %}
|
||||
{%- if num_code_suggestions > 0 %}
|
||||
|
||||
class PRReview(BaseModel):
|
||||
review: Review
|
||||
code_feedback: List[CodeSuggestion]
|
||||
{%- else %}
|
||||
|
||||
|
||||
class PRReview(BaseModel):
|
||||
review: Review
|
||||
{%- endif %}
|
||||
=====
|
||||
|
||||
|
||||
@ -155,6 +185,18 @@ review:
|
||||
title: ...
|
||||
- ...
|
||||
{%- endif %}
|
||||
|
||||
{%- if num_code_suggestions > 0 %}
|
||||
code_feedback:
|
||||
- relevant_file: |
|
||||
directory/xxx.py
|
||||
language: |
|
||||
python
|
||||
suggestion: |
|
||||
xxx [important]
|
||||
relevant_line: |
|
||||
xxx
|
||||
{%- endif %}
|
||||
```
|
||||
|
||||
Answer should be a valid YAML, and nothing else. Each YAML output MUST be after a newline, with proper indent, and block scalar indicator ('|')
|
||||
@ -221,59 +263,6 @@ The PR code diff:
|
||||
======
|
||||
|
||||
|
||||
{%- if duplicate_prompt_examples %}
|
||||
|
||||
|
||||
Example output:
|
||||
```yaml
|
||||
review:
|
||||
{%- if related_tickets %}
|
||||
ticket_compliance_check:
|
||||
- ticket_url: |
|
||||
...
|
||||
ticket_requirements: |
|
||||
...
|
||||
fully_compliant_requirements: |
|
||||
...
|
||||
not_compliant_requirements: |
|
||||
...
|
||||
overall_compliance_level: |
|
||||
...
|
||||
{%- endif %}
|
||||
{%- if require_estimate_effort_to_review %}
|
||||
estimated_effort_to_review_[1-5]: |
|
||||
3
|
||||
{%- endif %}
|
||||
{%- if require_score %}
|
||||
score: 89
|
||||
{%- endif %}
|
||||
relevant_tests: |
|
||||
No
|
||||
key_issues_to_review:
|
||||
- relevant_file: |
|
||||
...
|
||||
issue_header: |
|
||||
...
|
||||
issue_content: |
|
||||
...
|
||||
start_line: ...
|
||||
end_line: ...
|
||||
- ...
|
||||
security_concerns: |
|
||||
No
|
||||
{%- if require_can_be_split_review %}
|
||||
can_be_split:
|
||||
- relevant_files:
|
||||
- ...
|
||||
- ...
|
||||
title: ...
|
||||
- ...
|
||||
{%- endif %}
|
||||
```
|
||||
(replace '...' with the actual values)
|
||||
{%- endif %}
|
||||
|
||||
|
||||
Response (should be a valid YAML, and nothing else):
|
||||
```yaml
|
||||
"""
|
||||
|
||||
@ -1,14 +1,9 @@
|
||||
[pr_update_changelog_prompt]
|
||||
system="""You are a language model called PR-Changelog-Updater.
|
||||
Your task is to add a brief summary of this PR's changes to CHANGELOG.md file of the project:
|
||||
- Follow the file's existing format and style conventions like dates, section titles, etc.
|
||||
- Only add new changes (don't repeat existing entries)
|
||||
- Be general, and avoid specific details, files, etc. The output should be minimal, no more than 3-4 short lines.
|
||||
- Write only the new content to be added to CHANGELOG.md, without any introduction or summary. The content should appear as if it's a natural part of the existing file.
|
||||
{%- if pr_link %}
|
||||
- If relevant, convert the changelog main header into a clickable link using the PR URL '{{ pr_link }}'. Format: header [*][pr_link]
|
||||
{%- endif %}
|
||||
|
||||
Your task is to update the CHANGELOG.md file of the project, to shortly summarize important changes introduced in this PR (the '+' lines).
|
||||
- The output should match the existing CHANGELOG.md format, style and conventions, so it will look like a natural part of the file. For example, if previous changes were summarized in a single line, you should do the same.
|
||||
- Don't repeat previous changes. Generate only new content, that is not already in the CHANGELOG.md file.
|
||||
- Be general, and avoid specific details, files, etc. The output should be minimal, no more than 3-4 short lines. Ignore non-relevant subsections.
|
||||
|
||||
{%- if extra_instructions %}
|
||||
|
||||
@ -52,19 +47,16 @@ The PR Git Diff:
|
||||
{{ diff|trim }}
|
||||
======
|
||||
|
||||
|
||||
Current date:
|
||||
```
|
||||
{{today}}
|
||||
```
|
||||
|
||||
|
||||
The current 'CHANGELOG.md' file
|
||||
The current CHANGELOG.md:
|
||||
======
|
||||
{{ changelog_file_str }}
|
||||
======
|
||||
|
||||
|
||||
Response:
|
||||
```markdown
|
||||
"""
|
||||
|
||||
@ -4,7 +4,6 @@ import difflib
|
||||
import re
|
||||
import textwrap
|
||||
import traceback
|
||||
from datetime import datetime
|
||||
from functools import partial
|
||||
from typing import Dict, List
|
||||
|
||||
@ -82,8 +81,6 @@ class PRCodeSuggestions:
|
||||
"relevant_best_practices": "",
|
||||
"is_ai_metadata": get_settings().get("config.enable_ai_metadata", False),
|
||||
"focus_only_on_problems": get_settings().get("pr_code_suggestions.focus_only_on_problems", False),
|
||||
"date": datetime.now().strftime('%Y-%m-%d'),
|
||||
'duplicate_prompt_examples': get_settings().config.get('duplicate_prompt_examples', False),
|
||||
}
|
||||
self.pr_code_suggestions_prompt_system = get_settings().pr_code_suggestions_prompt.system
|
||||
|
||||
@ -833,8 +830,7 @@ class PRCodeSuggestions:
|
||||
"diff": patches_diff,
|
||||
'num_code_suggestions': len(suggestion_list),
|
||||
'prev_suggestions_str': prev_suggestions_str,
|
||||
"is_ai_metadata": get_settings().get("config.enable_ai_metadata", False),
|
||||
'duplicate_prompt_examples': get_settings().config.get('duplicate_prompt_examples', False)}
|
||||
"is_ai_metadata": get_settings().get("config.enable_ai_metadata", False)}
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
|
||||
if dedicated_prompt:
|
||||
|
||||
@ -38,15 +38,12 @@ class PRConfig:
|
||||
if (header.lower().startswith("pr_") or header.lower().startswith("config")) and header.lower() in configuration_headers
|
||||
}
|
||||
|
||||
skip_keys = ['ai_disclaimer', 'ai_disclaimer_title', 'ANALYTICS_FOLDER', 'secret_provider', "skip_keys", "app_id", "redirect",
|
||||
'trial_prefix_message', 'no_eligible_message', 'identity_provider', 'ALLOWED_REPOS',
|
||||
'APP_NAME', 'PERSONAL_ACCESS_TOKEN', 'shared_secret', 'key', 'AWS_ACCESS_KEY_ID', 'AWS_SECRET_ACCESS_KEY', 'user_token',
|
||||
'private_key', 'private_key_id', 'client_id', 'client_secret', 'token', 'bearer_token']
|
||||
skip_keys = ['ai_disclaimer', 'ai_disclaimer_title', 'ANALYTICS_FOLDER', 'secret_provider', "skip_keys",
|
||||
'trial_prefix_message', 'no_eligible_message', 'identity_provider', 'ALLOWED_REPOS',
|
||||
'APP_NAME']
|
||||
extra_skip_keys = get_settings().config.get('config.skip_keys', [])
|
||||
if extra_skip_keys:
|
||||
skip_keys.extend(extra_skip_keys)
|
||||
skip_keys_lower = [key.lower() for key in skip_keys]
|
||||
|
||||
|
||||
markdown_text = "<details> <summary><strong>🛠️ PR-Agent Configurations:</strong></summary> \n\n"
|
||||
markdown_text += f"\n\n```yaml\n\n"
|
||||
@ -55,7 +52,7 @@ class PRConfig:
|
||||
markdown_text += "\n\n"
|
||||
markdown_text += f"==================== {header} ===================="
|
||||
for key, value in configs.items():
|
||||
if key.lower() in skip_keys_lower:
|
||||
if key in skip_keys:
|
||||
continue
|
||||
markdown_text += f"\n{header.lower()}.{key.lower()} = {repr(value) if isinstance(value, str) else value}"
|
||||
markdown_text += " "
|
||||
|
||||
@ -1,7 +1,6 @@
|
||||
import asyncio
|
||||
import copy
|
||||
import re
|
||||
import traceback
|
||||
from functools import partial
|
||||
from typing import List, Tuple
|
||||
|
||||
@ -58,7 +57,6 @@ class PRDescription:
|
||||
self.ai_handler.main_pr_language = self.main_pr_language
|
||||
|
||||
# Initialize the variables dictionary
|
||||
self.COLLAPSIBLE_FILE_LIST_THRESHOLD = get_settings().pr_description.get("collapsible_file_list_threshold", 8)
|
||||
self.vars = {
|
||||
"title": self.git_provider.pr.title,
|
||||
"branch": self.git_provider.get_pr_branch(),
|
||||
@ -71,8 +69,6 @@ class PRDescription:
|
||||
"custom_labels_class": "", # will be filled if necessary in 'set_custom_labels' function
|
||||
"enable_semantic_files_types": get_settings().pr_description.enable_semantic_files_types,
|
||||
"related_tickets": "",
|
||||
"include_file_summary_changes": len(self.git_provider.get_diff_files()) <= self.COLLAPSIBLE_FILE_LIST_THRESHOLD,
|
||||
'duplicate_prompt_examples': get_settings().config.get('duplicate_prompt_examples', False),
|
||||
}
|
||||
|
||||
self.user_description = self.git_provider.get_user_description()
|
||||
@ -89,6 +85,7 @@ class PRDescription:
|
||||
self.patches_diff = None
|
||||
self.prediction = None
|
||||
self.file_label_dict = None
|
||||
self.COLLAPSIBLE_FILE_LIST_THRESHOLD = 8
|
||||
|
||||
async def run(self):
|
||||
try:
|
||||
@ -117,8 +114,6 @@ class PRDescription:
|
||||
pr_labels, pr_file_changes = [], []
|
||||
if get_settings().pr_description.publish_labels:
|
||||
pr_labels = self._prepare_labels()
|
||||
else:
|
||||
get_logger().debug(f"Publishing labels disabled")
|
||||
|
||||
if get_settings().pr_description.use_description_markers:
|
||||
pr_title, pr_body, changes_walkthrough, pr_file_changes = self._prepare_pr_answer_with_markers()
|
||||
@ -142,7 +137,6 @@ class PRDescription:
|
||||
pr_body += show_relevant_configurations(relevant_section='pr_description')
|
||||
|
||||
if get_settings().config.publish_output:
|
||||
|
||||
# publish labels
|
||||
if get_settings().pr_description.publish_labels and pr_labels and self.git_provider.is_supported("get_labels"):
|
||||
original_labels = self.git_provider.get_pr_labels(update=True)
|
||||
@ -170,7 +164,7 @@ class PRDescription:
|
||||
self.git_provider.publish_description(pr_title, pr_body)
|
||||
|
||||
# publish final update message
|
||||
if (get_settings().pr_description.final_update_message and not get_settings().config.get('is_auto_command', False)):
|
||||
if (get_settings().pr_description.final_update_message):
|
||||
latest_commit_url = self.git_provider.get_latest_commit_url()
|
||||
if latest_commit_url:
|
||||
pr_url = self.git_provider.get_pr_url()
|
||||
@ -182,37 +176,35 @@ class PRDescription:
|
||||
get_settings().data = {"artifact": pr_body}
|
||||
return
|
||||
except Exception as e:
|
||||
get_logger().error(f"Error generating PR description {self.pr_id}: {e}",
|
||||
artifact={"traceback": traceback.format_exc()})
|
||||
get_logger().error(f"Error generating PR description {self.pr_id}: {e}")
|
||||
|
||||
return ""
|
||||
|
||||
async def _prepare_prediction(self, model: str) -> None:
|
||||
if get_settings().pr_description.use_description_markers and 'pr_agent:' not in self.user_description:
|
||||
get_logger().info("Markers were enabled, but user description does not contain markers. skipping AI prediction")
|
||||
get_logger().info(
|
||||
"Markers were enabled, but user description does not contain markers. skipping AI prediction")
|
||||
return None
|
||||
|
||||
large_pr_handling = get_settings().pr_description.enable_large_pr_handling and "pr_description_only_files_prompts" in get_settings()
|
||||
output = get_pr_diff(self.git_provider, self.token_handler, model, large_pr_handling=large_pr_handling, return_remaining_files=True)
|
||||
output = get_pr_diff(self.git_provider, self.token_handler, model, large_pr_handling=large_pr_handling,
|
||||
return_remaining_files=True)
|
||||
if isinstance(output, tuple):
|
||||
patches_diff, remaining_files_list = output
|
||||
else:
|
||||
patches_diff = output
|
||||
remaining_files_list = []
|
||||
|
||||
if not large_pr_handling or patches_diff:
|
||||
self.patches_diff = patches_diff
|
||||
if patches_diff:
|
||||
# generate the prediction
|
||||
get_logger().debug(f"PR diff", artifact=self.patches_diff)
|
||||
self.prediction = await self._get_prediction(model, patches_diff, prompt="pr_description_prompt")
|
||||
|
||||
# extend the prediction with additional files not shown
|
||||
if get_settings().pr_description.enable_semantic_files_types:
|
||||
self.prediction = await self.extend_uncovered_files(self.prediction)
|
||||
if (remaining_files_list and 'pr_files' in self.prediction and 'label:' in self.prediction and
|
||||
get_settings().pr_description.mention_extra_files):
|
||||
get_logger().debug(f"Extending additional files, {len(remaining_files_list)} files")
|
||||
self.prediction = await self.extend_additional_files(remaining_files_list)
|
||||
else:
|
||||
get_logger().error(f"Error getting PR diff {self.pr_id}",
|
||||
artifact={"traceback": traceback.format_exc()})
|
||||
get_logger().error(f"Error getting PR diff {self.pr_id}")
|
||||
self.prediction = None
|
||||
else:
|
||||
# get the diff in multiple patches, with the token handler only for the files prompt
|
||||
@ -297,81 +289,43 @@ class PRDescription:
|
||||
prompt="pr_description_only_description_prompts")
|
||||
prediction_headers = prediction_headers.strip().removeprefix('```yaml').strip('`').strip()
|
||||
|
||||
# extend the tables with the files not shown
|
||||
files_walkthrough_extended = await self.extend_uncovered_files(files_walkthrough)
|
||||
# manually add extra files to final prediction
|
||||
MAX_EXTRA_FILES_TO_OUTPUT = 100
|
||||
if get_settings().pr_description.mention_extra_files:
|
||||
for i, file in enumerate(remaining_files_list):
|
||||
extra_file_yaml = f"""\
|
||||
- filename: |
|
||||
{file}
|
||||
changes_summary: |
|
||||
...
|
||||
changes_title: |
|
||||
...
|
||||
label: |
|
||||
additional files (token-limit)
|
||||
"""
|
||||
files_walkthrough = files_walkthrough.strip() + "\n" + extra_file_yaml.strip()
|
||||
if i >= MAX_EXTRA_FILES_TO_OUTPUT:
|
||||
files_walkthrough += f"""\
|
||||
extra_file_yaml =
|
||||
- filename: |
|
||||
Additional {len(remaining_files_list) - MAX_EXTRA_FILES_TO_OUTPUT} files not shown
|
||||
changes_summary: |
|
||||
...
|
||||
changes_title: |
|
||||
...
|
||||
label: |
|
||||
additional files (token-limit)
|
||||
"""
|
||||
break
|
||||
|
||||
# final processing
|
||||
self.prediction = prediction_headers + "\n" + "pr_files:\n" + files_walkthrough_extended
|
||||
self.prediction = prediction_headers + "\n" + "pr_files:\n" + files_walkthrough
|
||||
if not load_yaml(self.prediction, keys_fix_yaml=self.keys_fix):
|
||||
get_logger().error(f"Error getting valid YAML in large PR handling for describe {self.pr_id}")
|
||||
if load_yaml(prediction_headers, keys_fix_yaml=self.keys_fix):
|
||||
get_logger().debug(f"Using only headers for describe {self.pr_id}")
|
||||
self.prediction = prediction_headers
|
||||
|
||||
async def extend_uncovered_files(self, original_prediction: str) -> str:
|
||||
try:
|
||||
prediction = original_prediction
|
||||
|
||||
# get the original prediction filenames
|
||||
original_prediction_loaded = load_yaml(original_prediction, keys_fix_yaml=self.keys_fix)
|
||||
if isinstance(original_prediction_loaded, list):
|
||||
original_prediction_dict = {"pr_files": original_prediction_loaded}
|
||||
else:
|
||||
original_prediction_dict = original_prediction_loaded
|
||||
filenames_predicted = [file['filename'].strip() for file in original_prediction_dict.get('pr_files', [])]
|
||||
|
||||
# extend the prediction with additional files not included in the original prediction
|
||||
pr_files = self.git_provider.get_diff_files()
|
||||
prediction_extra = "pr_files:"
|
||||
MAX_EXTRA_FILES_TO_OUTPUT = 100
|
||||
counter_extra_files = 0
|
||||
for file in pr_files:
|
||||
if file.filename in filenames_predicted:
|
||||
continue
|
||||
|
||||
# add up to MAX_EXTRA_FILES_TO_OUTPUT files
|
||||
counter_extra_files += 1
|
||||
if counter_extra_files > MAX_EXTRA_FILES_TO_OUTPUT:
|
||||
extra_file_yaml = f"""\
|
||||
- filename: |
|
||||
Additional files not shown
|
||||
changes_title: |
|
||||
...
|
||||
label: |
|
||||
additional files
|
||||
"""
|
||||
prediction_extra = prediction_extra + "\n" + extra_file_yaml.strip()
|
||||
get_logger().debug(f"Too many remaining files, clipping to {MAX_EXTRA_FILES_TO_OUTPUT}")
|
||||
break
|
||||
|
||||
extra_file_yaml = f"""\
|
||||
- filename: |
|
||||
{file.filename}
|
||||
changes_title: |
|
||||
...
|
||||
label: |
|
||||
additional files
|
||||
"""
|
||||
prediction_extra = prediction_extra + "\n" + extra_file_yaml.strip()
|
||||
|
||||
# merge the two dictionaries
|
||||
if counter_extra_files > 0:
|
||||
get_logger().info(f"Adding {counter_extra_files} unprocessed extra files to table prediction")
|
||||
prediction_extra_dict = load_yaml(prediction_extra, keys_fix_yaml=self.keys_fix)
|
||||
if isinstance(original_prediction_dict, dict) and isinstance(prediction_extra_dict, dict):
|
||||
original_prediction_dict["pr_files"].extend(prediction_extra_dict["pr_files"])
|
||||
new_yaml = yaml.dump(original_prediction_dict)
|
||||
if load_yaml(new_yaml, keys_fix_yaml=self.keys_fix):
|
||||
prediction = new_yaml
|
||||
if isinstance(original_prediction, list):
|
||||
prediction = yaml.dump(original_prediction_dict["pr_files"])
|
||||
|
||||
return prediction
|
||||
except Exception as e:
|
||||
get_logger().error(f"Error extending uncovered files {self.pr_id}: {e}")
|
||||
return original_prediction
|
||||
|
||||
|
||||
async def extend_additional_files(self, remaining_files_list) -> str:
|
||||
prediction = self.prediction
|
||||
try:
|
||||
@ -443,44 +397,35 @@ class PRDescription:
|
||||
self.data['pr_files'] = self.data.pop('pr_files')
|
||||
|
||||
def _prepare_labels(self) -> List[str]:
|
||||
pr_labels = []
|
||||
pr_types = []
|
||||
|
||||
# If the 'PR Type' key is present in the dictionary, split its value by comma and assign it to 'pr_types'
|
||||
if 'labels' in self.data and self.data['labels']:
|
||||
if 'labels' in self.data:
|
||||
if type(self.data['labels']) == list:
|
||||
pr_labels = self.data['labels']
|
||||
pr_types = self.data['labels']
|
||||
elif type(self.data['labels']) == str:
|
||||
pr_labels = self.data['labels'].split(',')
|
||||
elif 'type' in self.data and self.data['type'] and get_settings().pr_description.publish_labels:
|
||||
pr_types = self.data['labels'].split(',')
|
||||
elif 'type' in self.data:
|
||||
if type(self.data['type']) == list:
|
||||
pr_labels = self.data['type']
|
||||
pr_types = self.data['type']
|
||||
elif type(self.data['type']) == str:
|
||||
pr_labels = self.data['type'].split(',')
|
||||
pr_labels = [label.strip() for label in pr_labels]
|
||||
pr_types = self.data['type'].split(',')
|
||||
pr_types = [label.strip() for label in pr_types]
|
||||
|
||||
# convert lowercase labels to original case
|
||||
try:
|
||||
if "labels_minimal_to_labels_dict" in self.variables:
|
||||
d: dict = self.variables["labels_minimal_to_labels_dict"]
|
||||
for i, label_i in enumerate(pr_labels):
|
||||
for i, label_i in enumerate(pr_types):
|
||||
if label_i in d:
|
||||
pr_labels[i] = d[label_i]
|
||||
pr_types[i] = d[label_i]
|
||||
except Exception as e:
|
||||
get_logger().error(f"Error converting labels to original case {self.pr_id}: {e}")
|
||||
return pr_labels
|
||||
return pr_types
|
||||
|
||||
def _prepare_pr_answer_with_markers(self) -> Tuple[str, str, str, List[dict]]:
|
||||
get_logger().info(f"Using description marker replacements {self.pr_id}")
|
||||
|
||||
# Remove the 'PR Title' key from the dictionary
|
||||
ai_title = self.data.pop('title', self.vars["title"])
|
||||
if (not get_settings().pr_description.generate_ai_title):
|
||||
# Assign the original PR title to the 'title' variable
|
||||
title = self.vars["title"]
|
||||
else:
|
||||
# Assign the value of the 'PR Title' key to 'title' variable
|
||||
title = ai_title
|
||||
|
||||
title = self.vars["title"]
|
||||
body = self.user_description
|
||||
if get_settings().pr_description.include_generated_by_header:
|
||||
ai_header = f"### 🤖 Generated by PR Agent at {self.git_provider.last_commit_id.sha}\n\n"
|
||||
@ -489,11 +434,7 @@ class PRDescription:
|
||||
|
||||
ai_type = self.data.get('type')
|
||||
if ai_type and not re.search(r'<!--\s*pr_agent:type\s*-->', body):
|
||||
if isinstance(ai_type, list):
|
||||
pr_types = [f"{ai_header}{t}" for t in ai_type]
|
||||
pr_type = ','.join(pr_types)
|
||||
else:
|
||||
pr_type = f"{ai_header}{ai_type}"
|
||||
pr_type = f"{ai_header}{ai_type}"
|
||||
body = body.replace('pr_agent:type', pr_type)
|
||||
|
||||
ai_summary = self.data.get('description')
|
||||
@ -570,11 +511,6 @@ class PRDescription:
|
||||
elif 'pr_files' in key.lower() and get_settings().pr_description.enable_semantic_files_types:
|
||||
changes_walkthrough, pr_file_changes = self.process_pr_files_prediction(changes_walkthrough, value)
|
||||
changes_walkthrough = f"{PRDescriptionHeader.CHANGES_WALKTHROUGH.value}\n{changes_walkthrough}"
|
||||
elif key.lower().strip() == 'description':
|
||||
if isinstance(value, list):
|
||||
value = ', '.join(v.rstrip() for v in value)
|
||||
value = value.replace('\n-', '\n\n-').strip() # makes the bullet points more readable by adding double space
|
||||
pr_body += f"{value}\n"
|
||||
else:
|
||||
# if the value is a list, join its items by comma
|
||||
if isinstance(value, list):
|
||||
@ -592,18 +528,14 @@ class PRDescription:
|
||||
return file_label_dict
|
||||
for file in self.data['pr_files']:
|
||||
try:
|
||||
required_fields = ['changes_title', 'filename', 'label']
|
||||
required_fields = ['changes_summary', 'changes_title', 'filename', 'label']
|
||||
if not all(field in file for field in required_fields):
|
||||
# can happen for example if a YAML generation was interrupted in the middle (no more tokens)
|
||||
get_logger().warning(f"Missing required fields in file label dict {self.pr_id}, skipping file",
|
||||
artifact={"file": file})
|
||||
continue
|
||||
if not file.get('changes_title'):
|
||||
get_logger().warning(f"Empty changes title or summary in file label dict {self.pr_id}, skipping file",
|
||||
artifact={"file": file})
|
||||
continue
|
||||
filename = file['filename'].replace("'", "`").replace('"', '`')
|
||||
changes_summary = file.get('changes_summary', "").strip()
|
||||
changes_summary = file['changes_summary']
|
||||
changes_title = file['changes_title'].strip()
|
||||
label = file.get('label').strip().lower()
|
||||
if label not in file_label_dict:
|
||||
@ -646,14 +578,12 @@ class PRDescription:
|
||||
for filename, file_changes_title, file_change_description in list_tuples:
|
||||
filename = filename.replace("'", "`").rstrip()
|
||||
filename_publish = filename.split("/")[-1]
|
||||
if file_changes_title and file_changes_title.strip() != "...":
|
||||
file_changes_title_code = f"<code>{file_changes_title}</code>"
|
||||
file_changes_title_code_br = insert_br_after_x_chars(file_changes_title_code, x=(delta - 5)).strip()
|
||||
if len(file_changes_title_code_br) < (delta - 5):
|
||||
file_changes_title_code_br += " " * ((delta - 5) - len(file_changes_title_code_br))
|
||||
filename_publish = f"<strong>{filename_publish}</strong><dd>{file_changes_title_code_br}</dd>"
|
||||
else:
|
||||
filename_publish = f"<strong>{filename_publish}</strong>"
|
||||
|
||||
file_changes_title_code = f"<code>{file_changes_title}</code>"
|
||||
file_changes_title_code_br = insert_br_after_x_chars(file_changes_title_code, x=(delta - 5)).strip()
|
||||
if len(file_changes_title_code_br) < (delta - 5):
|
||||
file_changes_title_code_br += " " * ((delta - 5) - len(file_changes_title_code_br))
|
||||
filename_publish = f"<strong>{filename_publish}</strong><dd>{file_changes_title_code_br}</dd>"
|
||||
diff_plus_minus = ""
|
||||
delta_nbsp = ""
|
||||
diff_files = self.git_provider.get_diff_files()
|
||||
@ -662,8 +592,6 @@ class PRDescription:
|
||||
num_plus_lines = f.num_plus_lines
|
||||
num_minus_lines = f.num_minus_lines
|
||||
diff_plus_minus += f"+{num_plus_lines}/-{num_minus_lines}"
|
||||
if len(diff_plus_minus) > 12 or diff_plus_minus == "+0/-0":
|
||||
diff_plus_minus = "[link]"
|
||||
delta_nbsp = " " * max(0, (8 - len(diff_plus_minus)))
|
||||
break
|
||||
|
||||
@ -672,40 +600,9 @@ class PRDescription:
|
||||
if hasattr(self.git_provider, 'get_line_link'):
|
||||
filename = filename.strip()
|
||||
link = self.git_provider.get_line_link(filename, relevant_line_start=-1)
|
||||
if (not link or not diff_plus_minus) and ('additional files' not in filename.lower()):
|
||||
get_logger().warning(f"Error getting line link for '{filename}'")
|
||||
continue
|
||||
|
||||
# Add file data to the PR body
|
||||
file_change_description_br = insert_br_after_x_chars(file_change_description, x=(delta - 5))
|
||||
pr_body = self.add_file_data(delta_nbsp, diff_plus_minus, file_change_description_br, filename,
|
||||
filename_publish, link, pr_body)
|
||||
|
||||
# Close the collapsible file list
|
||||
if use_collapsible_file_list:
|
||||
pr_body += """</table></details></td></tr>"""
|
||||
else:
|
||||
pr_body += """</table></td></tr>"""
|
||||
pr_body += """</tr></tbody></table>"""
|
||||
|
||||
except Exception as e:
|
||||
get_logger().error(f"Error processing pr files to markdown {self.pr_id}: {str(e)}")
|
||||
pass
|
||||
return pr_body, pr_comments
|
||||
|
||||
def add_file_data(self, delta_nbsp, diff_plus_minus, file_change_description_br, filename, filename_publish, link,
|
||||
pr_body) -> str:
|
||||
|
||||
if not file_change_description_br:
|
||||
pr_body += f"""
|
||||
<tr>
|
||||
<td>{filename_publish}</td>
|
||||
<td><a href="{link}">{diff_plus_minus}</a>{delta_nbsp}</td>
|
||||
|
||||
</tr>
|
||||
"""
|
||||
else:
|
||||
pr_body += f"""
|
||||
pr_body += f"""
|
||||
<tr>
|
||||
<td>
|
||||
<details>
|
||||
@ -725,7 +622,17 @@ class PRDescription:
|
||||
|
||||
</tr>
|
||||
"""
|
||||
return pr_body
|
||||
if use_collapsible_file_list:
|
||||
pr_body += """</table></details></td></tr>"""
|
||||
else:
|
||||
pr_body += """</table></td></tr>"""
|
||||
pr_body += """</tr></tbody></table>"""
|
||||
|
||||
except Exception as e:
|
||||
get_logger().error(f"Error processing pr files to markdown {self.pr_id}: {e}")
|
||||
pass
|
||||
return pr_body, pr_comments
|
||||
|
||||
|
||||
def count_chars_without_html(string):
|
||||
if '<' not in string:
|
||||
@ -734,14 +641,11 @@ def count_chars_without_html(string):
|
||||
return len(no_html_string)
|
||||
|
||||
|
||||
def insert_br_after_x_chars(text: str, x=70):
|
||||
def insert_br_after_x_chars(text, x=70):
|
||||
"""
|
||||
Insert <br> into a string after a word that increases its length above x characters.
|
||||
Use proper HTML tags for code and new lines.
|
||||
"""
|
||||
|
||||
if not text:
|
||||
return ""
|
||||
if count_chars_without_html(text) < x:
|
||||
return text
|
||||
|
||||
|
||||
@ -232,7 +232,7 @@ class PRHelpMessage:
|
||||
for i in range(len(tool_names)):
|
||||
pr_comment += f"\n<tr><td align='left'>\n\n<strong>{tool_names[i]}</strong></td>\n<td>{descriptions[i]}</td>\n<td>\n\n{checkbox_list[i]}\n</td></tr>"
|
||||
pr_comment += "</table>\n\n"
|
||||
pr_comment += f"""\n\n(1) Note that each tool can be [triggered automatically](https://pr-agent-docs.codium.ai/usage-guide/automations_and_usage/#github-app-automatic-tools-when-a-new-pr-is-opened) when a new PR is opened, or called manually by [commenting on a PR](https://pr-agent-docs.codium.ai/usage-guide/automations_and_usage/#online-usage)."""
|
||||
pr_comment += f"""\n\n(1) Note that each tool be [triggered automatically](https://pr-agent-docs.codium.ai/usage-guide/automations_and_usage/#github-app-automatic-tools-when-a-new-pr-is-opened) when a new PR is opened, or called manually by [commenting on a PR](https://pr-agent-docs.codium.ai/usage-guide/automations_and_usage/#online-usage)."""
|
||||
pr_comment += f"""\n\n(2) Tools marked with [*] require additional parameters to be passed. For example, to invoke the `/ask` tool, you need to comment on a PR: `/ask "<question content>"`. See the relevant documentation for each tool for more details."""
|
||||
elif isinstance(self.git_provider, BitbucketServerProvider):
|
||||
# only support basic commands in BBDC
|
||||
@ -242,7 +242,7 @@ class PRHelpMessage:
|
||||
for i in range(len(tool_names)):
|
||||
pr_comment += f"\n<tr><td align='left'>\n\n<strong>{tool_names[i]}</strong></td><td>{commands[i]}</td><td>{descriptions[i]}</td></tr>"
|
||||
pr_comment += "</table>\n\n"
|
||||
pr_comment += f"""\n\nNote that each tool can be [invoked automatically](https://pr-agent-docs.codium.ai/usage-guide/automations_and_usage/) when a new PR is opened, or called manually by [commenting on a PR](https://pr-agent-docs.codium.ai/usage-guide/automations_and_usage/#online-usage)."""
|
||||
pr_comment += f"""\n\nNote that each tool be [invoked automatically](https://pr-agent-docs.codium.ai/usage-guide/automations_and_usage/) when a new PR is opened, or called manually by [commenting on a PR](https://pr-agent-docs.codium.ai/usage-guide/automations_and_usage/#online-usage)."""
|
||||
|
||||
if get_settings().config.publish_output:
|
||||
self.git_provider.publish_comment(pr_comment)
|
||||
|
||||
79
pr_agent/tools/pr_information_from_user.py
Normal file
79
pr_agent/tools/pr_information_from_user.py
Normal file
@ -0,0 +1,79 @@
|
||||
import copy
|
||||
from functools import partial
|
||||
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
|
||||
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||
from pr_agent.algo.ai_handlers.litellm_ai_handler import LiteLLMAIHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers import get_git_provider
|
||||
from pr_agent.git_providers.git_provider import get_main_pr_language
|
||||
from pr_agent.log import get_logger
|
||||
|
||||
|
||||
class PRInformationFromUser:
|
||||
def __init__(self, pr_url: str, args: list = None,
|
||||
ai_handler: partial[BaseAiHandler,] = LiteLLMAIHandler):
|
||||
self.git_provider = get_git_provider()(pr_url)
|
||||
self.main_pr_language = get_main_pr_language(
|
||||
self.git_provider.get_languages(), self.git_provider.get_files()
|
||||
)
|
||||
self.ai_handler = ai_handler()
|
||||
self.ai_handler.main_pr_language = self.main_pr_language
|
||||
|
||||
self.vars = {
|
||||
"title": self.git_provider.pr.title,
|
||||
"branch": self.git_provider.get_pr_branch(),
|
||||
"description": self.git_provider.get_pr_description(),
|
||||
"language": self.main_pr_language,
|
||||
"diff": "", # empty diff for initial calculation
|
||||
"commit_messages_str": self.git_provider.get_commit_messages(),
|
||||
}
|
||||
self.token_handler = TokenHandler(self.git_provider.pr,
|
||||
self.vars,
|
||||
get_settings().pr_information_from_user_prompt.system,
|
||||
get_settings().pr_information_from_user_prompt.user)
|
||||
self.patches_diff = None
|
||||
self.prediction = None
|
||||
|
||||
async def run(self):
|
||||
get_logger().info('Generating question to the user...')
|
||||
if get_settings().config.publish_output:
|
||||
self.git_provider.publish_comment("Preparing questions...", is_temporary=True)
|
||||
await retry_with_fallback_models(self._prepare_prediction)
|
||||
get_logger().info('Preparing questions...')
|
||||
pr_comment = self._prepare_pr_answer()
|
||||
if get_settings().config.publish_output:
|
||||
get_logger().info('Pushing questions...')
|
||||
self.git_provider.publish_comment(pr_comment)
|
||||
self.git_provider.remove_initial_comment()
|
||||
return ""
|
||||
|
||||
async def _prepare_prediction(self, model):
|
||||
get_logger().info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler, model)
|
||||
get_logger().info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction(model)
|
||||
|
||||
async def _get_prediction(self, model: str):
|
||||
variables = copy.deepcopy(self.vars)
|
||||
variables["diff"] = self.patches_diff # update diff
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
system_prompt = environment.from_string(get_settings().pr_information_from_user_prompt.system).render(variables)
|
||||
user_prompt = environment.from_string(get_settings().pr_information_from_user_prompt.user).render(variables)
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().info(f"\nSystem prompt:\n{system_prompt}")
|
||||
get_logger().info(f"\nUser prompt:\n{user_prompt}")
|
||||
response, finish_reason = await self.ai_handler.chat_completion(
|
||||
model=model, temperature=get_settings().config.temperature, system=system_prompt, user=user_prompt)
|
||||
return response
|
||||
|
||||
def _prepare_pr_answer(self) -> str:
|
||||
model_output = self.prediction.strip()
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().info(f"answer_str:\n{model_output}")
|
||||
answer_str = f"{model_output}\n\n Please respond to the questions above in the following format:\n\n" +\
|
||||
"\n>/answer\n>1) ...\n>2) ...\n>...\n"
|
||||
return answer_str
|
||||
@ -79,17 +79,13 @@ class PR_LineQuestions:
|
||||
line_end=line_end,
|
||||
side=side)
|
||||
if self.patch_with_lines:
|
||||
model_answer = await retry_with_fallback_models(self._get_prediction, model_type=ModelType.WEAK)
|
||||
# sanitize the answer so that no line will start with "/"
|
||||
model_answer_sanitized = model_answer.strip().replace("\n/", "\n /")
|
||||
if model_answer_sanitized.startswith("/"):
|
||||
model_answer_sanitized = " " + model_answer_sanitized
|
||||
response = await retry_with_fallback_models(self._get_prediction, model_type=ModelType.WEAK)
|
||||
|
||||
get_logger().info('Preparing answer...')
|
||||
if comment_id:
|
||||
self.git_provider.reply_to_comment_from_comment_id(comment_id, model_answer_sanitized)
|
||||
self.git_provider.reply_to_comment_from_comment_id(comment_id, response)
|
||||
else:
|
||||
self.git_provider.publish_comment(model_answer_sanitized)
|
||||
self.git_provider.publish_comment(response)
|
||||
|
||||
return ""
|
||||
|
||||
|
||||
@ -117,16 +117,6 @@ class PRQuestions:
|
||||
return response
|
||||
|
||||
def _prepare_pr_answer(self) -> str:
|
||||
model_answer = self.prediction.strip()
|
||||
# sanitize the answer so that no line will start with "/"
|
||||
model_answer_sanitized = model_answer.replace("\n/", "\n /")
|
||||
if model_answer_sanitized.startswith("/"):
|
||||
model_answer_sanitized = " " + model_answer_sanitized
|
||||
if model_answer_sanitized != model_answer:
|
||||
get_logger().debug(f"Sanitized model answer",
|
||||
artifact={"model_answer": model_answer, "sanitized_answer": model_answer_sanitized})
|
||||
|
||||
|
||||
answer_str = f"### **Ask**❓\n{self.question_str}\n\n"
|
||||
answer_str += f"### **Answer:**\n{model_answer_sanitized}\n\n"
|
||||
answer_str += f"### **Answer:**\n{self.prediction.strip()}\n\n"
|
||||
return answer_str
|
||||
|
||||
@ -86,6 +86,7 @@ class PRReviewer:
|
||||
"require_estimate_effort_to_review": get_settings().pr_reviewer.require_estimate_effort_to_review,
|
||||
'require_can_be_split_review': get_settings().pr_reviewer.require_can_be_split_review,
|
||||
'require_security_review': get_settings().pr_reviewer.require_security_review,
|
||||
'num_code_suggestions': get_settings().pr_reviewer.num_code_suggestions,
|
||||
'question_str': question_str,
|
||||
'answer_str': answer_str,
|
||||
"extra_instructions": get_settings().pr_reviewer.extra_instructions,
|
||||
@ -94,7 +95,6 @@ class PRReviewer:
|
||||
"enable_custom_labels": get_settings().config.enable_custom_labels,
|
||||
"is_ai_metadata": get_settings().get("config.enable_ai_metadata", False),
|
||||
"related_tickets": get_settings().get('related_tickets', []),
|
||||
'duplicate_prompt_examples': get_settings().config.get('duplicate_prompt_examples', False),
|
||||
}
|
||||
|
||||
self.token_handler = TokenHandler(
|
||||
@ -168,6 +168,8 @@ class PRReviewer:
|
||||
self.git_provider.publish_comment(pr_review)
|
||||
|
||||
self.git_provider.remove_initial_comment()
|
||||
if get_settings().pr_reviewer.inline_code_comments:
|
||||
self._publish_inline_code_comments()
|
||||
else:
|
||||
get_logger().info("Review output is not published")
|
||||
get_settings().data = {"artifact": pr_review}
|
||||
@ -233,6 +235,33 @@ class PRReviewer:
|
||||
key_issues_to_review = data['review'].pop('key_issues_to_review')
|
||||
data['review']['key_issues_to_review'] = key_issues_to_review
|
||||
|
||||
if 'code_feedback' in data:
|
||||
code_feedback = data['code_feedback']
|
||||
|
||||
# Filter out code suggestions that can be submitted as inline comments
|
||||
if get_settings().pr_reviewer.inline_code_comments:
|
||||
del data['code_feedback']
|
||||
else:
|
||||
for suggestion in code_feedback:
|
||||
if ('relevant_file' in suggestion) and (not suggestion['relevant_file'].startswith('``')):
|
||||
suggestion['relevant_file'] = f"``{suggestion['relevant_file']}``"
|
||||
|
||||
if 'relevant_line' not in suggestion:
|
||||
suggestion['relevant_line'] = ''
|
||||
|
||||
relevant_line_str = suggestion['relevant_line'].split('\n')[0]
|
||||
|
||||
# removing '+'
|
||||
suggestion['relevant_line'] = relevant_line_str.lstrip('+').strip()
|
||||
|
||||
# try to add line numbers link to code suggestions
|
||||
if hasattr(self.git_provider, 'generate_link_to_relevant_line_number'):
|
||||
link = self.git_provider.generate_link_to_relevant_line_number(suggestion)
|
||||
if link:
|
||||
suggestion['relevant_line'] = f"[{suggestion['relevant_line']}]({link})"
|
||||
else:
|
||||
pass
|
||||
|
||||
incremental_review_markdown_text = None
|
||||
# Add incremental review section
|
||||
if self.incremental.is_incremental:
|
||||
@ -263,6 +292,38 @@ class PRReviewer:
|
||||
|
||||
return markdown_text
|
||||
|
||||
def _publish_inline_code_comments(self) -> None:
|
||||
"""
|
||||
Publishes inline comments on a pull request with code suggestions generated by the AI model.
|
||||
"""
|
||||
if get_settings().pr_reviewer.num_code_suggestions == 0:
|
||||
return
|
||||
|
||||
first_key = 'review'
|
||||
last_key = 'security_concerns'
|
||||
data = load_yaml(self.prediction.strip(),
|
||||
keys_fix_yaml=["ticket_compliance_check", "estimated_effort_to_review_[1-5]:", "security_concerns:", "key_issues_to_review:",
|
||||
"relevant_file:", "relevant_line:", "suggestion:"],
|
||||
first_key=first_key, last_key=last_key)
|
||||
comments: List[str] = []
|
||||
for suggestion in data.get('code_feedback', []):
|
||||
relevant_file = suggestion.get('relevant_file', '').strip()
|
||||
relevant_line_in_file = suggestion.get('relevant_line', '').strip()
|
||||
content = suggestion.get('suggestion', '')
|
||||
if not relevant_file or not relevant_line_in_file or not content:
|
||||
get_logger().info("Skipping inline comment with missing file/line/content")
|
||||
continue
|
||||
|
||||
if self.git_provider.is_supported("create_inline_comment"):
|
||||
comment = self.git_provider.create_inline_comment(content, relevant_file, relevant_line_in_file)
|
||||
if comment:
|
||||
comments.append(comment)
|
||||
else:
|
||||
self.git_provider.publish_inline_comment(content, relevant_file, relevant_line_in_file, suggestion)
|
||||
|
||||
if comments:
|
||||
self.git_provider.publish_inline_comments(comments)
|
||||
|
||||
def _get_user_answers(self) -> Tuple[str, str]:
|
||||
"""
|
||||
Retrieves the question and answer strings from the discussion messages related to a pull request.
|
||||
|
||||
@ -41,7 +41,6 @@ class PRUpdateChangelog:
|
||||
"description": self.git_provider.get_pr_description(),
|
||||
"language": self.main_language,
|
||||
"diff": "", # empty diff for initial calculation
|
||||
"pr_link": "",
|
||||
"changelog_file_str": self.changelog_file_str,
|
||||
"today": date.today(),
|
||||
"extra_instructions": get_settings().pr_update_changelog.extra_instructions,
|
||||
@ -103,23 +102,12 @@ class PRUpdateChangelog:
|
||||
async def _get_prediction(self, model: str):
|
||||
variables = copy.deepcopy(self.vars)
|
||||
variables["diff"] = self.patches_diff # update diff
|
||||
if get_settings().pr_update_changelog.add_pr_link:
|
||||
variables["pr_link"] = self.git_provider.get_pr_url()
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
system_prompt = environment.from_string(get_settings().pr_update_changelog_prompt.system).render(variables)
|
||||
user_prompt = environment.from_string(get_settings().pr_update_changelog_prompt.user).render(variables)
|
||||
response, finish_reason = await self.ai_handler.chat_completion(
|
||||
model=model, system=system_prompt, user=user_prompt, temperature=get_settings().config.temperature)
|
||||
|
||||
# post-process the response
|
||||
response = response.strip()
|
||||
if not response:
|
||||
return ""
|
||||
if response.startswith("```"):
|
||||
response_lines = response.splitlines()
|
||||
response_lines = response_lines[1:]
|
||||
response = "\n".join(response_lines)
|
||||
response = response.strip("`")
|
||||
return response
|
||||
|
||||
def _prepare_changelog_update(self) -> Tuple[str, str]:
|
||||
|
||||
@ -24,13 +24,6 @@ class TestBitbucketServerProvider:
|
||||
assert repo_slug == "my-repo"
|
||||
assert pr_number == 1
|
||||
|
||||
def test_parse_pr_url_with_users(self):
|
||||
url = "https://bitbucket.company-server.url/users/username/repos/my-repo/pull-requests/1"
|
||||
workspace_slug, repo_slug, pr_number = BitbucketServerProvider._parse_pr_url(url)
|
||||
assert workspace_slug == "~username"
|
||||
assert repo_slug == "my-repo"
|
||||
assert pr_number == 1
|
||||
|
||||
def mock_get_content_of_file(self, project_key, repository_slug, filename, at=None, markup=None):
|
||||
content_map = {
|
||||
'9c1cffdd9f276074bfb6fb3b70fbee62d298b058': 'file\nwith\nsome\nlines\nto\nemulate\na\nreal\nfile\n',
|
||||
@ -251,7 +244,7 @@ class TestBitbucketServerProvider:
|
||||
FilePatchInfo(
|
||||
'file\nwith\nmultiple\nlines\nto\nemulate\na\nreal\nfile',
|
||||
'readme\nwithout\nsome\nlines\nto\nsimulate\na\nreal\nfile',
|
||||
'--- \n+++ \n@@ -1,9 +1,9 @@\n-file\n-with\n-multiple\n+readme\n+without\n+some\n lines\n to\n-emulate\n+simulate\n a\n real\n file\n',
|
||||
'--- \n+++ \n@@ -1,9 +1,9 @@\n-file\n-with\n-multiple\n+readme\n+without\n+some\n lines\n to\n-emulate\n+simulate\n a\n real\n file',
|
||||
'Readme.md',
|
||||
edit_type=EDIT_TYPE.MODIFIED,
|
||||
)
|
||||
@ -273,7 +266,7 @@ class TestBitbucketServerProvider:
|
||||
FilePatchInfo(
|
||||
'file\nwith\nsome\nlines\nto\nemulate\na\nreal\nfile',
|
||||
'readme\nwithout\nsome\nlines\nto\nsimulate\na\nreal\nfile',
|
||||
'--- \n+++ \n@@ -1,9 +1,9 @@\n-file\n-with\n+readme\n+without\n some\n lines\n to\n-emulate\n+simulate\n a\n real\n file\n',
|
||||
'--- \n+++ \n@@ -1,9 +1,9 @@\n-file\n-with\n+readme\n+without\n some\n lines\n to\n-emulate\n+simulate\n a\n real\n file',
|
||||
'Readme.md',
|
||||
edit_type=EDIT_TYPE.MODIFIED,
|
||||
)
|
||||
@ -295,7 +288,7 @@ class TestBitbucketServerProvider:
|
||||
FilePatchInfo(
|
||||
'file\nwith\nsome\nlines\nto\nemulate\na\nreal\nfile',
|
||||
'readme\nwithout\nsome\nlines\nto\nsimulate\na\nreal\nfile',
|
||||
'--- \n+++ \n@@ -1,9 +1,9 @@\n-file\n-with\n+readme\n+without\n some\n lines\n to\n-emulate\n+simulate\n a\n real\n file\n',
|
||||
'--- \n+++ \n@@ -1,9 +1,9 @@\n-file\n-with\n+readme\n+without\n some\n lines\n to\n-emulate\n+simulate\n a\n real\n file',
|
||||
'Readme.md',
|
||||
edit_type=EDIT_TYPE.MODIFIED,
|
||||
)
|
||||
|
||||
@ -47,10 +47,13 @@ class TestConvertToMarkdown:
|
||||
def test_simple_dictionary_input(self):
|
||||
input_data = {'review': {
|
||||
'estimated_effort_to_review_[1-5]': '1, because the changes are minimal and straightforward, focusing on a single functionality addition.\n',
|
||||
'relevant_tests': 'No\n', 'possible_issues': 'No\n', 'security_concerns': 'No\n'}}
|
||||
'relevant_tests': 'No\n', 'possible_issues': 'No\n', 'security_concerns': 'No\n'}, 'code_feedback': [
|
||||
{'relevant_file': '``pr_agent/git_providers/git_provider.py\n``', 'language': 'python\n',
|
||||
'suggestion': "Consider raising an exception or logging a warning when 'pr_url' attribute is not found. This can help in debugging issues related to the absence of 'pr_url' in instances where it's expected. [important]\n",
|
||||
'relevant_line': '[return ""](https://github.com/Codium-ai/pr-agent-pro/pull/102/files#diff-52d45f12b836f77ed1aef86e972e65404634ea4e2a6083fb71a9b0f9bb9e062fR199)'}]}
|
||||
|
||||
|
||||
expected_output = f'{PRReviewHeader.REGULAR.value} 🔍\n\nHere are some key observations to aid the review process:\n\n<table>\n<tr><td>⏱️ <strong>Estimated effort to review</strong>: 1 🔵⚪⚪⚪⚪</td></tr>\n<tr><td>🧪 <strong>No relevant tests</strong></td></tr>\n<tr><td> <strong>Possible issues</strong>: No\n</td></tr>\n<tr><td>🔒 <strong>No security concerns identified</strong></td></tr>\n</table>'
|
||||
expected_output = f'{PRReviewHeader.REGULAR.value} 🔍\n\nHere are some key observations to aid the review process:\n\n<table>\n<tr><td>⏱️ <strong>Estimated effort to review</strong>: 1 🔵⚪⚪⚪⚪</td></tr>\n<tr><td>🧪 <strong>No relevant tests</strong></td></tr>\n<tr><td> <strong>Possible issues</strong>: No\n</td></tr>\n<tr><td>🔒 <strong>No security concerns identified</strong></td></tr>\n</table>\n\n\n<details><summary> <strong>Code feedback:</strong></summary>\n\n<hr><table><tr><td>relevant file</td><td>pr_agent/git_providers/git_provider.py\n</td></tr><tr><td>suggestion </td><td>\n\n<strong>\n\nConsider raising an exception or logging a warning when \'pr_url\' attribute is not found. This can help in debugging issues related to the absence of \'pr_url\' in instances where it\'s expected. [important]\n\n</strong>\n</td></tr><tr><td>relevant line</td><td><a href=\'https://github.com/Codium-ai/pr-agent-pro/pull/102/files#diff-52d45f12b836f77ed1aef86e972e65404634ea4e2a6083fb71a9b0f9bb9e062fR199\'>return ""</a></td></tr></table><hr>\n\n</details>'
|
||||
|
||||
assert convert_to_markdown_v2(input_data).strip() == expected_output.strip()
|
||||
|
||||
@ -64,7 +67,7 @@ class TestConvertToMarkdown:
|
||||
assert convert_to_markdown_v2(input_data).strip() == expected_output.strip()
|
||||
|
||||
def test_dictionary_with_empty_dictionaries(self):
|
||||
input_data = {'review': {}}
|
||||
input_data = {'review': {}, 'code_feedback': [{}]}
|
||||
|
||||
expected_output = ''
|
||||
|
||||
|
||||
@ -3,7 +3,6 @@ import pytest
|
||||
from pr_agent.algo.git_patch_processing import extend_patch
|
||||
from pr_agent.algo.pr_processing import pr_generate_extended_diff
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.utils import load_large_diff
|
||||
from pr_agent.config_loader import get_settings
|
||||
|
||||
|
||||
@ -146,8 +145,8 @@ class TestExtendedPatchMoreLines:
|
||||
# Check that with no extra lines, the patches are the same as the original patches
|
||||
p0 = patches_extended_no_extra_lines[0].strip()
|
||||
p1 = patches_extended_no_extra_lines[1].strip()
|
||||
assert p0 == "## File: 'file1'\n" + pr_languages[0]['files'][0].patch.strip()
|
||||
assert p1 == "## File: 'file2'\n" + pr_languages[0]['files'][1].patch.strip()
|
||||
assert p0 == '## file1\n' + pr_languages[0]['files'][0].patch.strip()
|
||||
assert p1 == '## file2\n' + pr_languages[0]['files'][1].patch.strip()
|
||||
|
||||
patches_extended_with_extra_lines, total_tokens, patches_extended_tokens = pr_generate_extended_diff(
|
||||
pr_languages, token_handler, add_line_numbers_to_hunks=False,
|
||||
@ -155,37 +154,5 @@ class TestExtendedPatchMoreLines:
|
||||
patch_extra_lines_after=1
|
||||
)
|
||||
|
||||
|
||||
p0_extended = patches_extended_with_extra_lines[0].strip()
|
||||
assert p0_extended == "## File: 'file1'\n\n@@ -3,8 +3,8 @@ \n line0\n line1\n-original content\n+modified content\n line2\n line3\n line4\n line5\n line6"
|
||||
|
||||
|
||||
class TestLoadLargeDiff:
|
||||
def test_no_newline(self):
|
||||
patch = load_large_diff("test.py",
|
||||
"""\
|
||||
old content 1
|
||||
some new content
|
||||
another line
|
||||
""",
|
||||
"""
|
||||
old content 1
|
||||
old content 2""")
|
||||
|
||||
patch_expected="""\
|
||||
---
|
||||
+++
|
||||
@@ -1,3 +1,3 @@
|
||||
-
|
||||
old content 1
|
||||
- old content 2
|
||||
+ some new content
|
||||
+ another line
|
||||
"""
|
||||
assert patch == patch_expected
|
||||
|
||||
def test_empty_inputs(self):
|
||||
assert load_large_diff("test.py", "", "") == ""
|
||||
assert load_large_diff("test.py", None, None) == ""
|
||||
assert (load_large_diff("test.py", "content\n", "") ==
|
||||
'--- \n+++ \n@@ -1 +1 @@\n-\n+content\n')
|
||||
assert p0_extended == '## file1\n\n@@ -3,8 +3,8 @@ \n line0\n line1\n-original content\n+modified content\n line2\n line3\n line4\n line5\n line6'
|
||||
|
||||
Reference in New Issue
Block a user