mirror of
https://github.com/qodo-ai/pr-agent.git
synced 2025-07-21 04:50:39 +08:00
Compare commits
85 Commits
ok/update_
...
ok/remove_
| Author | SHA1 | Date | |
|---|---|---|---|
| 32151e3d9a | |||
| 42e32664a1 | |||
| 1e97236a15 | |||
| 321f7bce46 | |||
| 02a1d8dbfc | |||
| e34f9d8d1c | |||
| 35dac012bd | |||
| 21ced18f50 | |||
| fca78cf395 | |||
| d1b91b0ea3 | |||
| 76e00acbdb | |||
| 2f83e7738c | |||
| f4a226b0f7 | |||
| f5e2838fc3 | |||
| bbdfd2c3d4 | |||
| 74572e1768 | |||
| f0a17b863c | |||
| 86fd84e113 | |||
| d5b9be23d3 | |||
| 057bb3932f | |||
| 05f29cc406 | |||
| 63c4c7e584 | |||
| 1ea23cab96 | |||
| e99f9fd59f | |||
| fdf6a3e833 | |||
| 79cb94b4c2 | |||
| 9adec7cc10 | |||
| 1f0df47b4d | |||
| a71a12791b | |||
| 23fa834721 | |||
| 9f67d07156 | |||
| 6731a7643e | |||
| f87fdd88ad | |||
| f825f6b90a | |||
| f5d5008a24 | |||
| 0b63d4cde5 | |||
| 2e246869d0 | |||
| 2f9546e144 | |||
| 6134c2ff61 | |||
| 3cfbba74f8 | |||
| 050bb60671 | |||
| 12a7e1ce6e | |||
| cd0438005b | |||
| 7c3188ae06 | |||
| 6cd38a37cd | |||
| 12e51bb6aa | |||
| e2a4cd6b03 | |||
| 329e228aa2 | |||
| 3d5d517f2a | |||
| a2eb2e4dac | |||
| d89792d379 | |||
| 23ed2553c4 | |||
| fe29ce2911 | |||
| df25a3ede2 | |||
| 4c36fb4df2 | |||
| 67c61e0ac8 | |||
| 0985db4e36 | |||
| ee2c00abeb | |||
| 577f24d107 | |||
| fc24b34c2b | |||
| 1e962476da | |||
| 3326327572 | |||
| 36be79ea38 | |||
| 523839be7d | |||
| d1586ddd77 | |||
| 3420853923 | |||
| 1f373d7b0a | |||
| 7fdbd6a680 | |||
| 17b40a1fa1 | |||
| c47e74c5c7 | |||
| 7abbe08ff1 | |||
| 8038b6ab99 | |||
| 6e26ad0966 | |||
| 7e2449b228 | |||
| 97bfee47a3 | |||
| 8868c92141 | |||
| e17dd66dce | |||
| fc8494d696 | |||
| f8aea909b4 | |||
| ccddbeccad | |||
| f73cddcb93 | |||
| 5f36f0d753 | |||
| dc4bf13d39 | |||
| 6d91f44634 | |||
| 0396e10706 |
@ -9,6 +9,7 @@ You can select your git_provider with the flag `git_provider` in the `config` se
|
||||
You can enable/disable the different PR Reviewer abilities with the following flags (`pr_reviewer` section):
|
||||
```
|
||||
require_focused_review=true
|
||||
require_score_review=true
|
||||
require_tests_review=true
|
||||
require_security_review=true
|
||||
```
|
||||
|
||||
@ -95,9 +95,10 @@ cp pr_agent/settings/.secrets_template.toml pr_agent/settings/.secrets.toml
|
||||
# Edit .secrets.toml file
|
||||
```
|
||||
|
||||
4. Run the appropriate Python scripts from the scripts folder:
|
||||
4. Add the pr_agent folder to your PYTHONPATH, then run the cli.py script:
|
||||
|
||||
```
|
||||
export PYTHONPATH=[$PYTHONPATH:]<PATH to pr_agent folder>
|
||||
python pr_agent/cli.py --pr_url <pr_url> review
|
||||
python pr_agent/cli.py --pr_url <pr_url> ask <your question>
|
||||
python pr_agent/cli.py --pr_url <pr_url> describe
|
||||
|
||||
71
README.md
71
README.md
@ -2,21 +2,24 @@
|
||||
|
||||
<div align="center">
|
||||
|
||||
<img src="./pics/logo-dark.png#gh-dark-mode-only" width="250"/>
|
||||
<img src="./pics/logo-light.png#gh-light-mode-only" width="250"/>
|
||||
|
||||
<img src="./pics/logo-dark.png#gh-dark-mode-only" width="330"/>
|
||||
<img src="./pics/logo-light.png#gh-light-mode-only" width="330"/><br/>
|
||||
Making pull requests less painful with an AI agent
|
||||
</div>
|
||||
|
||||
[](https://github.com/Codium-ai/pr-agent/blob/main/LICENSE)
|
||||
[](https://discord.com/channels/1057273017547378788/1126104260430528613)
|
||||
<a href="https://github.com/Codium-ai/pr-agent/commits/main">
|
||||
<img alt="GitHub" src="https://img.shields.io/github/last-commit/Codium-ai/pr-agent/main?style=for-the-badge" height="20">
|
||||
</a>
|
||||
</div>
|
||||
<div style="text-align:left;">
|
||||
|
||||
CodiumAI `PR-Agent` is an open-source tool aiming to help developers review PRs faster and more efficiently. It automatically analyzes the PR and can provide several types of feedback:
|
||||
CodiumAI `PR-Agent` is an open-source tool aiming to help developers review pull requests faster and more efficiently. It automatically analyzes the pull request and can provide several types of feedback:
|
||||
|
||||
**Auto-Description**: Automatically generating PR description - name, type, summary, and code walkthrough.
|
||||
**Auto-Description**: Automatically generating PR description - title, type, summary, code walkthrough and PR labels.
|
||||
\
|
||||
**PR Review**: Feedback about the PR main theme, type, relevant tests, security issues, focused PR, and various suggestions for the PR content.
|
||||
**PR Review**: Adjustable feedback about the PR main theme, type, relevant tests, security issues, focus, score, and various suggestions for the PR content.
|
||||
\
|
||||
**Question Answering**: Answering free-text questions about the PR.
|
||||
\
|
||||
@ -27,32 +30,39 @@ CodiumAI `PR-Agent` is an open-source tool aiming to help developers review PRs
|
||||
<h4>/describe:</h4>
|
||||
<div align="center">
|
||||
<p float="center">
|
||||
<img src="https://codium.ai/images/describe.gif" width="800">
|
||||
<img src="https://www.codium.ai/wp-content/uploads/2023/07/describe.gif" width="800">
|
||||
</p>
|
||||
</div>
|
||||
<h4>/review:</h4>
|
||||
<div align="center">
|
||||
<p float="center">
|
||||
<img src="https://codium.ai/images/review.gif" width="800">
|
||||
<img src="https://www.codium.ai/wp-content/uploads/2023/07/review.gif" width="800">
|
||||
</p>
|
||||
</div>
|
||||
<h4>/reflect and review:</h4>
|
||||
<div align="center">
|
||||
<p float="center">
|
||||
<img src="https://www.codium.ai/wp-content/uploads/2023/07/reflect_and_review.gif" width="800">
|
||||
</p>
|
||||
</div>
|
||||
<h4>/ask:</h4>
|
||||
<div align="center">
|
||||
<p float="center">
|
||||
<img src="https://codium.ai/images/ask.gif" width="800">
|
||||
<img src="https://www.codium.ai/wp-content/uploads/2023/07/ask.gif" width="800">
|
||||
</p>
|
||||
</div>
|
||||
<h4>/improve:</h4>
|
||||
<div align="center">
|
||||
<p float="center">
|
||||
<img src="https://codium.ai/images/improve.gif" width="800">
|
||||
<img src="https://www.codium.ai/wp-content/uploads/2023/07/improve-1.gif" width="800">
|
||||
</p>
|
||||
</div>
|
||||
<div align="left">
|
||||
|
||||
- [Live demo](#live-demo)
|
||||
|
||||
- [Overview](#overview)
|
||||
- [Quickstart](#quickstart)
|
||||
- [Try it now](#try-it-now)
|
||||
- [Installation](#installation)
|
||||
- [Usage and tools](#usage-and-tools)
|
||||
- [Configuration](./CONFIGURATION.md)
|
||||
- [How it works](#how-it-works)
|
||||
@ -60,15 +70,7 @@ CodiumAI `PR-Agent` is an open-source tool aiming to help developers review PRs
|
||||
- [Similar projects](#similar-projects)
|
||||
</div>
|
||||
|
||||
## Live demo
|
||||
|
||||
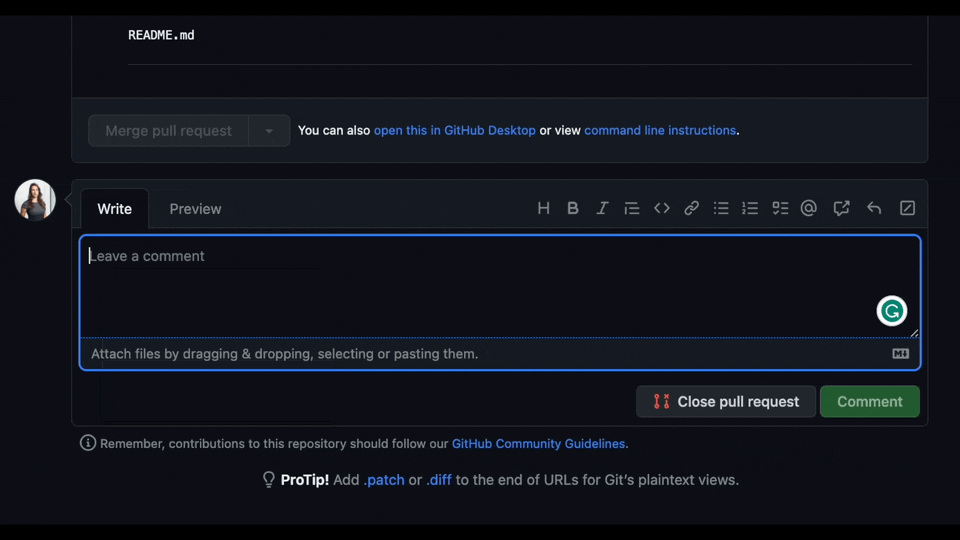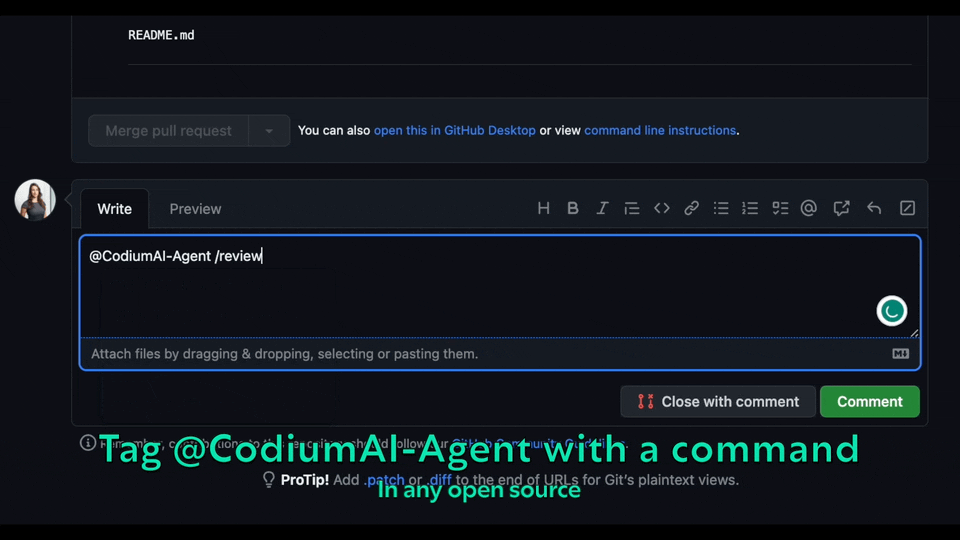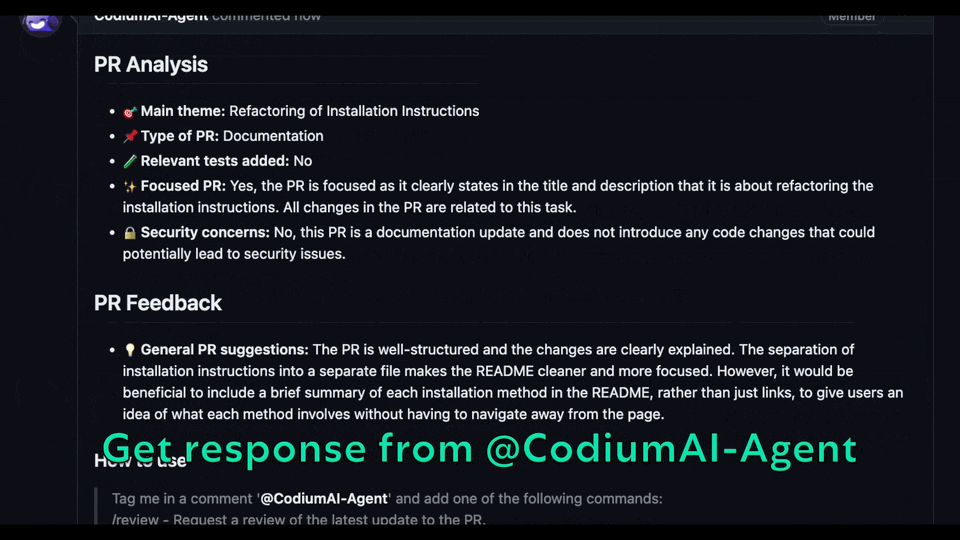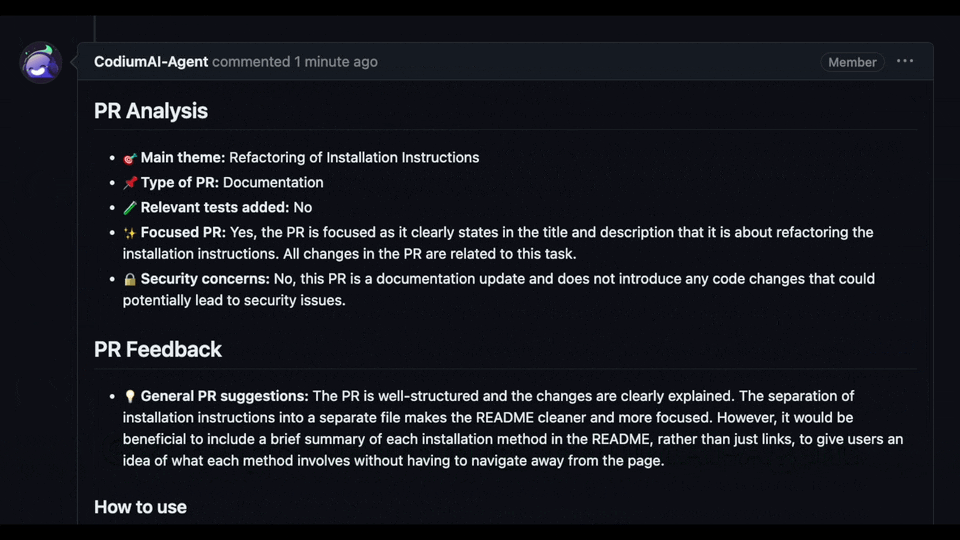
Experience GPT-4 powered PR review on your public GitHub repository with our hosted PR-Agent. To try it, just mention `@CodiumAI-Agent` and add the desired command in any PR comment! The agent will generate a response based on your command.
|
||||
|
||||

|
||||
|
||||
To set up your own PR-Agent, see the [Quickstart](#Quickstart) section
|
||||
|
||||
---
|
||||
## Overview
|
||||
`PR-Agent` offers extensive pull request functionalities across various git providers:
|
||||
| | | GitHub | Gitlab | Bitbucket |
|
||||
@ -81,14 +83,15 @@ To set up your own PR-Agent, see the [Quickstart](#Quickstart) section
|
||||
| | Reflect and Review | :white_check_mark: | | |
|
||||
| | | | | |
|
||||
| USAGE | CLI | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||
| | Tagging bot | :white_check_mark: | :white_check_mark: | |
|
||||
| | Tagging bot | :white_check_mark: | | |
|
||||
| | Actions | :white_check_mark: | | |
|
||||
| | | | | |
|
||||
| CORE | PR compression | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||
| | Repo language prioritization | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||
| | Adaptive and token-aware<br />file patch fitting | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||
| | Incremental PR Review | :white_check_mark: | | |
|
||||
|
||||
Examples for invoking the different tools via the [CLI](#quickstart):
|
||||
Examples for invoking the different tools via the CLI:
|
||||
- **Review**: python cli.py --pr-url=<pr_url> review
|
||||
- **Describe**: python cli.py --pr-url=<pr_url> describe
|
||||
- **Improve**: python cli.py --pr-url=<pr_url> improve
|
||||
@ -99,18 +102,24 @@ Examples for invoking the different tools via the [CLI](#quickstart):
|
||||
|
||||
In the [configuration](./CONFIGURATION.md) file you can select your git provider (GitHub, Gitlab, Bitbucket), and further configure the different tools.
|
||||
|
||||
## Quickstart
|
||||
## Try it now
|
||||
|
||||
Try GPT-4 powered PR-Agent on your public GitHub repository for free. Just mention `@CodiumAI-Agent` and add the desired command in any PR comment! The agent will generate a response based on your command.
|
||||
|
||||
|
||||
|
||||
To set up your own PR-Agent, see the [Installation](#installation) section
|
||||
|
||||
---
|
||||
|
||||
## Installation
|
||||
|
||||
To get started with PR-Agent quickly, you first need to acquire two tokens:
|
||||
|
||||
1. An OpenAI key from [here](https://platform.openai.com/), with access to GPT-4.
|
||||
2. A GitHub personal access token (classic) with the repo scope.
|
||||
|
||||
There are several ways to use PR-Agent. Let's start with the simplest one:
|
||||
|
||||
|
||||
## Install
|
||||
Here are several ways to install and run PR-Agent:
|
||||
There are several ways to use PR-Agent:
|
||||
|
||||
- [Method 1: Use Docker image (no installation required)](INSTALL.md#method-1-use-docker-image-no-installation-required)
|
||||
- [Method 2: Run as a GitHub Action](INSTALL.md#method-2-run-as-a-github-action)
|
||||
@ -128,7 +137,7 @@ Here are several ways to install and run PR-Agent:
|
||||
- The "PR Q&A" tool answers free-text questions about the PR.
|
||||
- The "PR Description" tool automatically sets the PR Title and body.
|
||||
- The "PR Code Suggestion" tool provide inline code suggestions for the PR that can be applied and committed.
|
||||
- The "PR Reflect and Review" tool first initiates a dialog with the user and asks them to reflect on the PR, and then provides a review.
|
||||
- The "PR Reflect and Review" tool initiates a dialog with the user, asks them to reflect on the PR, and then provides a more focused review.
|
||||
|
||||
## How it works
|
||||
|
||||
@ -138,9 +147,9 @@ Check out the [PR Compression strategy](./PR_COMPRESSION.md) page for more detai
|
||||
|
||||
## Roadmap
|
||||
|
||||
- [ ] Support open-source models, as a replacement for openai models. (Note - a minimal requirement for each open-source model is to have 8k+ context, and good support for generating json as an output)
|
||||
- [ ] Support open-source models, as a replacement for OpenAI models. (Note - a minimal requirement for each open-source model is to have 8k+ context, and good support for generating JSON as an output)
|
||||
- [x] Support other Git providers, such as Gitlab and Bitbucket.
|
||||
- [ ] Develop additional logics for handling large PRs, and compressing git patches
|
||||
- [ ] Develop additional logic for handling large PRs, and compressing git patches
|
||||
- [ ] Add additional context to the prompt. For example, repo (or relevant files) summarization, with tools such a [ctags](https://github.com/universal-ctags/ctags)
|
||||
- [ ] Adding more tools. Possible directions:
|
||||
- [x] PR description
|
||||
|
||||
@ -1,5 +1,8 @@
|
||||
name: 'PR Agent'
|
||||
name: 'Codium PR Agent'
|
||||
description: 'Summarize, review and suggest improvements for pull requests'
|
||||
branding:
|
||||
icon: 'award'
|
||||
color: 'green'
|
||||
runs:
|
||||
using: 'docker'
|
||||
image: 'Dockerfile.github_action_dockerhub'
|
||||
|
||||
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 20 KiB After Width: | Height: | Size: 22 KiB |
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 21 KiB After Width: | Height: | Size: 25 KiB |
@ -13,23 +13,20 @@ class PRAgent:
|
||||
pass
|
||||
|
||||
async def handle_request(self, pr_url, request) -> bool:
|
||||
if any(cmd in request for cmd in ["/answer"]):
|
||||
action, *args = request.strip().split()
|
||||
if any(cmd == action for cmd in ["/answer"]):
|
||||
await PRReviewer(pr_url, is_answer=True).review()
|
||||
elif any(cmd in request for cmd in ["/review", "/review_pr", "/reflect_and_review"]):
|
||||
elif any(cmd == action for cmd in ["/review", "/review_pr", "/reflect_and_review"]):
|
||||
if settings.pr_reviewer.ask_and_reflect or "/reflect_and_review" in request:
|
||||
await PRInformationFromUser(pr_url).generate_questions()
|
||||
else:
|
||||
await PRReviewer(pr_url).review()
|
||||
elif any(cmd in request for cmd in ["/describe", "/describe_pr"]):
|
||||
await PRReviewer(pr_url, args=args).review()
|
||||
elif any(cmd == action for cmd in ["/describe", "/describe_pr"]):
|
||||
await PRDescription(pr_url).describe()
|
||||
elif any(cmd in request for cmd in ["/improve", "/improve_code"]):
|
||||
elif any(cmd == action for cmd in ["/improve", "/improve_code"]):
|
||||
await PRCodeSuggestions(pr_url).suggest()
|
||||
elif any(cmd in request for cmd in ["/ask", "/ask_question"]):
|
||||
pattern = r'(/ask|/ask_question)\s*(.*)'
|
||||
matches = re.findall(pattern, request, re.IGNORECASE)
|
||||
if matches:
|
||||
question = matches[0][1]
|
||||
await PRQuestions(pr_url, question).answer()
|
||||
elif any(cmd == action for cmd in ["/ask", "/ask_question"]):
|
||||
await PRQuestions(pr_url, args).answer()
|
||||
else:
|
||||
return False
|
||||
|
||||
|
||||
@ -1,15 +1,25 @@
|
||||
import logging
|
||||
|
||||
import openai
|
||||
from openai.error import APIError, Timeout, TryAgain
|
||||
from openai.error import APIError, Timeout, TryAgain, RateLimitError
|
||||
from retry import retry
|
||||
|
||||
from pr_agent.config_loader import settings
|
||||
|
||||
OPENAI_RETRIES=2
|
||||
OPENAI_RETRIES=5
|
||||
|
||||
class AiHandler:
|
||||
"""
|
||||
This class handles interactions with the OpenAI API for chat completions.
|
||||
It initializes the API key and other settings from a configuration file,
|
||||
and provides a method for performing chat completions using the OpenAI ChatCompletion API.
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
"""
|
||||
Initializes the OpenAI API key and other settings from a configuration file.
|
||||
Raises a ValueError if the OpenAI key is missing.
|
||||
"""
|
||||
try:
|
||||
openai.api_key = settings.openai.key
|
||||
if settings.get("OPENAI.ORG", None):
|
||||
@ -24,9 +34,28 @@ class AiHandler:
|
||||
except AttributeError as e:
|
||||
raise ValueError("OpenAI key is required") from e
|
||||
|
||||
@retry(exceptions=(APIError, Timeout, TryAgain, AttributeError),
|
||||
@retry(exceptions=(APIError, Timeout, TryAgain, AttributeError, RateLimitError),
|
||||
tries=OPENAI_RETRIES, delay=2, backoff=2, jitter=(1, 3))
|
||||
async def chat_completion(self, model: str, temperature: float, system: str, user: str):
|
||||
"""
|
||||
Performs a chat completion using the OpenAI ChatCompletion API.
|
||||
Retries in case of API errors or timeouts.
|
||||
|
||||
Args:
|
||||
model (str): The model to use for chat completion.
|
||||
temperature (float): The temperature parameter for chat completion.
|
||||
system (str): The system message for chat completion.
|
||||
user (str): The user message for chat completion.
|
||||
|
||||
Returns:
|
||||
tuple: A tuple containing the response and finish reason from the API.
|
||||
|
||||
Raises:
|
||||
TryAgain: If the API response is empty or there are no choices in the response.
|
||||
APIError: If there is an error during OpenAI inference.
|
||||
Timeout: If there is a timeout during OpenAI inference.
|
||||
TryAgain: If there is an attribute error during OpenAI inference.
|
||||
"""
|
||||
try:
|
||||
response = await openai.ChatCompletion.acreate(
|
||||
model=model,
|
||||
@ -40,8 +69,14 @@ class AiHandler:
|
||||
except (APIError, Timeout, TryAgain) as e:
|
||||
logging.error("Error during OpenAI inference: ", e)
|
||||
raise
|
||||
except (RateLimitError) as e:
|
||||
logging.error("Rate limit error during OpenAI inference: ", e)
|
||||
raise
|
||||
except (Exception) as e:
|
||||
logging.error("Unknown error during OpenAI inference: ", e)
|
||||
raise TryAgain from e
|
||||
if response is None or len(response.choices) == 0:
|
||||
raise TryAgain
|
||||
resp = response.choices[0]['message']['content']
|
||||
finish_reason = response.choices[0].finish_reason
|
||||
return resp, finish_reason
|
||||
return resp, finish_reason
|
||||
@ -8,7 +8,15 @@ from pr_agent.config_loader import settings
|
||||
|
||||
def extend_patch(original_file_str, patch_str, num_lines) -> str:
|
||||
"""
|
||||
Extends the patch to include 'num_lines' more surrounding lines
|
||||
Extends the given patch to include a specified number of surrounding lines.
|
||||
|
||||
Args:
|
||||
original_file_str (str): The original file to which the patch will be applied.
|
||||
patch_str (str): The patch to be applied to the original file.
|
||||
num_lines (int): The number of surrounding lines to include in the extended patch.
|
||||
|
||||
Returns:
|
||||
str: The extended patch string.
|
||||
"""
|
||||
if not patch_str or num_lines == 0:
|
||||
return patch_str
|
||||
@ -61,6 +69,14 @@ def extend_patch(original_file_str, patch_str, num_lines) -> str:
|
||||
|
||||
|
||||
def omit_deletion_hunks(patch_lines) -> str:
|
||||
"""
|
||||
Omit deletion hunks from the patch and return the modified patch.
|
||||
Args:
|
||||
- patch_lines: a list of strings representing the lines of the patch
|
||||
Returns:
|
||||
- A string representing the modified patch with deletion hunks omitted
|
||||
"""
|
||||
|
||||
temp_hunk = []
|
||||
added_patched = []
|
||||
add_hunk = False
|
||||
@ -93,7 +109,20 @@ def omit_deletion_hunks(patch_lines) -> str:
|
||||
def handle_patch_deletions(patch: str, original_file_content_str: str,
|
||||
new_file_content_str: str, file_name: str) -> str:
|
||||
"""
|
||||
Handle entire file or deletion patches
|
||||
Handle entire file or deletion patches.
|
||||
|
||||
This function takes a patch, original file content, new file content, and file name as input.
|
||||
It handles entire file or deletion patches and returns the modified patch with deletion hunks omitted.
|
||||
|
||||
Args:
|
||||
patch (str): The patch to be handled.
|
||||
original_file_content_str (str): The original content of the file.
|
||||
new_file_content_str (str): The new content of the file.
|
||||
file_name (str): The name of the file.
|
||||
|
||||
Returns:
|
||||
str: The modified patch with deletion hunks omitted.
|
||||
|
||||
"""
|
||||
if not new_file_content_str:
|
||||
# logic for handling deleted files - don't show patch, just show that the file was deleted
|
||||
@ -111,20 +140,26 @@ def handle_patch_deletions(patch: str, original_file_content_str: str,
|
||||
|
||||
|
||||
def convert_to_hunks_with_lines_numbers(patch: str, file) -> str:
|
||||
# toDO: (maybe remove '-' and '+' from the beginning of the line)
|
||||
"""
|
||||
## src/file.ts
|
||||
Convert a given patch string into a string with line numbers for each hunk, indicating the new and old content of the file.
|
||||
|
||||
Args:
|
||||
patch (str): The patch string to be converted.
|
||||
file: An object containing the filename of the file being patched.
|
||||
|
||||
Returns:
|
||||
str: A string with line numbers for each hunk, indicating the new and old content of the file.
|
||||
|
||||
example output:
|
||||
## src/file.ts
|
||||
--new hunk--
|
||||
881 line1
|
||||
882 line2
|
||||
883 line3
|
||||
884 line4
|
||||
885 line6
|
||||
886 line7
|
||||
887 + line8
|
||||
888 + line9
|
||||
889 line10
|
||||
890 line11
|
||||
887 + line4
|
||||
888 + line5
|
||||
889 line6
|
||||
890 line7
|
||||
...
|
||||
--old hunk--
|
||||
line1
|
||||
@ -134,8 +169,8 @@ def convert_to_hunks_with_lines_numbers(patch: str, file) -> str:
|
||||
line5
|
||||
line6
|
||||
...
|
||||
|
||||
"""
|
||||
|
||||
patch_with_lines_str = f"## {file.filename}\n"
|
||||
import re
|
||||
patch_lines = patch.splitlines()
|
||||
|
||||
File diff suppressed because one or more lines are too long
@ -1,14 +1,15 @@
|
||||
from __future__ import annotations
|
||||
|
||||
import difflib
|
||||
import logging
|
||||
from typing import Any, Tuple, Union
|
||||
from typing import Tuple, Union, Callable, List
|
||||
|
||||
from pr_agent.algo import MAX_TOKENS
|
||||
from pr_agent.algo.git_patch_processing import convert_to_hunks_with_lines_numbers, extend_patch, handle_patch_deletions
|
||||
from pr_agent.algo.language_handler import sort_files_by_main_languages
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.utils import load_large_diff
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.git_providers import GithubProvider
|
||||
from pr_agent.git_providers.git_provider import GitProvider
|
||||
|
||||
DELETED_FILES_ = "Deleted files:\n"
|
||||
|
||||
@ -19,12 +20,22 @@ OUTPUT_BUFFER_TOKENS_HARD_THRESHOLD = 600
|
||||
PATCH_EXTRA_LINES = 3
|
||||
|
||||
|
||||
def get_pr_diff(git_provider: Union[GithubProvider, Any], token_handler: TokenHandler,
|
||||
add_line_numbers_to_hunks: bool = False, disable_extra_lines: bool =False) -> str:
|
||||
def get_pr_diff(git_provider: GitProvider, token_handler: TokenHandler, model: str,
|
||||
add_line_numbers_to_hunks: bool = False, disable_extra_lines: bool = False) -> str:
|
||||
"""
|
||||
Returns a string with the diff of the PR.
|
||||
If needed, apply diff minimization techniques to reduce the number of tokens
|
||||
Returns a string with the diff of the pull request, applying diff minimization techniques if needed.
|
||||
|
||||
Args:
|
||||
git_provider (GitProvider): An object of the GitProvider class representing the Git provider used for the pull request.
|
||||
token_handler (TokenHandler): An object of the TokenHandler class used for handling tokens in the context of the pull request.
|
||||
model (str): The name of the model used for tokenization.
|
||||
add_line_numbers_to_hunks (bool, optional): A boolean indicating whether to add line numbers to the hunks in the diff. Defaults to False.
|
||||
disable_extra_lines (bool, optional): A boolean indicating whether to disable the extension of each patch with extra lines of context. Defaults to False.
|
||||
|
||||
Returns:
|
||||
str: A string with the diff of the pull request, applying diff minimization techniques if needed.
|
||||
"""
|
||||
|
||||
if disable_extra_lines:
|
||||
global PATCH_EXTRA_LINES
|
||||
PATCH_EXTRA_LINES = 0
|
||||
@ -39,7 +50,7 @@ def get_pr_diff(git_provider: Union[GithubProvider, Any], token_handler: TokenHa
|
||||
add_line_numbers_to_hunks)
|
||||
|
||||
# if we are under the limit, return the full diff
|
||||
if total_tokens + OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD < token_handler.limit:
|
||||
if total_tokens + OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD < MAX_TOKENS[model]:
|
||||
return "\n".join(patches_extended)
|
||||
|
||||
# if we are over the limit, start pruning
|
||||
@ -60,7 +71,16 @@ def pr_generate_extended_diff(pr_languages: list, token_handler: TokenHandler,
|
||||
add_line_numbers_to_hunks: bool) -> \
|
||||
Tuple[list, int]:
|
||||
"""
|
||||
Generate a standard diff string, with patch extension
|
||||
Generate a standard diff string with patch extension, while counting the number of tokens used and applying diff minimization techniques if needed.
|
||||
|
||||
Args:
|
||||
- pr_languages: A list of dictionaries representing the languages used in the pull request and their corresponding files.
|
||||
- token_handler: An object of the TokenHandler class used for handling tokens in the context of the pull request.
|
||||
- add_line_numbers_to_hunks: A boolean indicating whether to add line numbers to the hunks in the diff.
|
||||
|
||||
Returns:
|
||||
- patches_extended: A list of extended patches for each file in the pull request.
|
||||
- total_tokens: The total number of tokens used in the extended patches.
|
||||
"""
|
||||
total_tokens = token_handler.prompt_tokens # initial tokens
|
||||
patches_extended = []
|
||||
@ -91,14 +111,28 @@ def pr_generate_extended_diff(pr_languages: list, token_handler: TokenHandler,
|
||||
return patches_extended, total_tokens
|
||||
|
||||
|
||||
def pr_generate_compressed_diff(top_langs: list, token_handler: TokenHandler,
|
||||
def pr_generate_compressed_diff(top_langs: list, token_handler: TokenHandler, model: str,
|
||||
convert_hunks_to_line_numbers: bool) -> Tuple[list, list, list]:
|
||||
# Apply Diff Minimization techniques to reduce the number of tokens:
|
||||
# 0. Start from the largest diff patch to smaller ones
|
||||
# 1. Don't use extend context lines around diff
|
||||
# 2. Minimize deleted files
|
||||
# 3. Minimize deleted hunks
|
||||
# 4. Minimize all remaining files when you reach token limit
|
||||
"""
|
||||
Generate a compressed diff string for a pull request, using diff minimization techniques to reduce the number of tokens used.
|
||||
Args:
|
||||
top_langs (list): A list of dictionaries representing the languages used in the pull request and their corresponding files.
|
||||
token_handler (TokenHandler): An object of the TokenHandler class used for handling tokens in the context of the pull request.
|
||||
model (str): The model used for tokenization.
|
||||
convert_hunks_to_line_numbers (bool): A boolean indicating whether to convert hunks to line numbers in the diff.
|
||||
Returns:
|
||||
Tuple[list, list, list]: A tuple containing the following lists:
|
||||
- patches: A list of compressed diff patches for each file in the pull request.
|
||||
- modified_files_list: A list of file names that were skipped due to large patch size.
|
||||
- deleted_files_list: A list of file names that were deleted in the pull request.
|
||||
|
||||
Minimization techniques to reduce the number of tokens:
|
||||
0. Start from the largest diff patch to smaller ones
|
||||
1. Don't use extend context lines around diff
|
||||
2. Minimize deleted files
|
||||
3. Minimize deleted hunks
|
||||
4. Minimize all remaining files when you reach token limit
|
||||
"""
|
||||
|
||||
patches = []
|
||||
modified_files_list = []
|
||||
@ -133,12 +167,12 @@ def pr_generate_compressed_diff(top_langs: list, token_handler: TokenHandler,
|
||||
new_patch_tokens = token_handler.count_tokens(patch)
|
||||
|
||||
# Hard Stop, no more tokens
|
||||
if total_tokens > token_handler.limit - OUTPUT_BUFFER_TOKENS_HARD_THRESHOLD:
|
||||
if total_tokens > MAX_TOKENS[model] - OUTPUT_BUFFER_TOKENS_HARD_THRESHOLD:
|
||||
logging.warning(f"File was fully skipped, no more tokens: {file.filename}.")
|
||||
continue
|
||||
|
||||
# If the patch is too large, just show the file name
|
||||
if total_tokens + new_patch_tokens > token_handler.limit - OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD:
|
||||
if total_tokens + new_patch_tokens > MAX_TOKENS[model] - OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD:
|
||||
# Current logic is to skip the patch if it's too large
|
||||
# TODO: Option for alternative logic to remove hunks from the patch to reduce the number of tokens
|
||||
# until we meet the requirements
|
||||
@ -163,14 +197,16 @@ def pr_generate_compressed_diff(top_langs: list, token_handler: TokenHandler,
|
||||
return patches, modified_files_list, deleted_files_list
|
||||
|
||||
|
||||
def load_large_diff(file, new_file_content_str: str, original_file_content_str: str, patch: str) -> str:
|
||||
if not patch: # to Do - also add condition for file extension
|
||||
async def retry_with_fallback_models(f: Callable):
|
||||
model = settings.config.model
|
||||
fallback_models = settings.config.fallback_models
|
||||
if not isinstance(fallback_models, list):
|
||||
fallback_models = [fallback_models]
|
||||
all_models = [model] + fallback_models
|
||||
for i, model in enumerate(all_models):
|
||||
try:
|
||||
diff = difflib.unified_diff(original_file_content_str.splitlines(keepends=True),
|
||||
new_file_content_str.splitlines(keepends=True))
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.warning(f"File was modified, but no patch was found. Manually creating patch: {file.filename}.")
|
||||
patch = ''.join(diff)
|
||||
except Exception:
|
||||
pass
|
||||
return patch
|
||||
return await f(model)
|
||||
except Exception as e:
|
||||
logging.warning(f"Failed to generate prediction with {model}: {e}")
|
||||
if i == len(all_models) - 1: # If it's the last iteration
|
||||
raise # Re-raise the last exception
|
||||
|
||||
@ -6,12 +6,42 @@ from pr_agent.config_loader import settings
|
||||
|
||||
|
||||
class TokenHandler:
|
||||
"""
|
||||
A class for handling tokens in the context of a pull request.
|
||||
|
||||
Attributes:
|
||||
- encoder: An object of the encoding_for_model class from the tiktoken module. Used to encode strings and count the number of tokens in them.
|
||||
- limit: The maximum number of tokens allowed for the given model, as defined in the MAX_TOKENS dictionary in the pr_agent.algo module.
|
||||
- prompt_tokens: The number of tokens in the system and user strings, as calculated by the _get_system_user_tokens method.
|
||||
"""
|
||||
|
||||
def __init__(self, pr, vars: dict, system, user):
|
||||
"""
|
||||
Initializes the TokenHandler object.
|
||||
|
||||
Args:
|
||||
- pr: The pull request object.
|
||||
- vars: A dictionary of variables.
|
||||
- system: The system string.
|
||||
- user: The user string.
|
||||
"""
|
||||
self.encoder = encoding_for_model(settings.config.model)
|
||||
self.limit = MAX_TOKENS[settings.config.model]
|
||||
self.prompt_tokens = self._get_system_user_tokens(pr, self.encoder, vars, system, user)
|
||||
|
||||
def _get_system_user_tokens(self, pr, encoder, vars: dict, system, user):
|
||||
"""
|
||||
Calculates the number of tokens in the system and user strings.
|
||||
|
||||
Args:
|
||||
- pr: The pull request object.
|
||||
- encoder: An object of the encoding_for_model class from the tiktoken module.
|
||||
- vars: A dictionary of variables.
|
||||
- system: The system string.
|
||||
- user: The user string.
|
||||
|
||||
Returns:
|
||||
The sum of the number of tokens in the system and user strings.
|
||||
"""
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
system_prompt = environment.from_string(system).render(vars)
|
||||
user_prompt = environment.from_string(user).render(vars)
|
||||
@ -21,4 +51,13 @@ class TokenHandler:
|
||||
return system_prompt_tokens + user_prompt_tokens
|
||||
|
||||
def count_tokens(self, patch: str) -> int:
|
||||
"""
|
||||
Counts the number of tokens in a given patch string.
|
||||
|
||||
Args:
|
||||
- patch: The patch string.
|
||||
|
||||
Returns:
|
||||
The number of tokens in the patch string.
|
||||
"""
|
||||
return len(self.encoder.encode(patch, disallowed_special=()))
|
||||
@ -1,24 +1,36 @@
|
||||
from __future__ import annotations
|
||||
|
||||
import difflib
|
||||
from datetime import datetime
|
||||
import json
|
||||
import logging
|
||||
import re
|
||||
import textwrap
|
||||
|
||||
from pr_agent.config_loader import settings
|
||||
|
||||
|
||||
def convert_to_markdown(output_data: dict) -> str:
|
||||
"""
|
||||
Convert a dictionary of data into markdown format.
|
||||
Args:
|
||||
output_data (dict): A dictionary containing data to be converted to markdown format.
|
||||
Returns:
|
||||
str: The markdown formatted text generated from the input dictionary.
|
||||
"""
|
||||
markdown_text = ""
|
||||
|
||||
emojis = {
|
||||
"Main theme": "🎯",
|
||||
"Type of PR": "📌",
|
||||
"Score": "🏅",
|
||||
"Relevant tests added": "🧪",
|
||||
"Unrelated changes": "⚠️",
|
||||
"Focused PR": "✨",
|
||||
"Security concerns": "🔒",
|
||||
"General PR suggestions": "💡",
|
||||
"Insights from user's answers": "📝",
|
||||
"Code suggestions": "🤖"
|
||||
"Code suggestions": "🤖",
|
||||
}
|
||||
|
||||
for key, value in output_data.items():
|
||||
@ -30,7 +42,7 @@ def convert_to_markdown(output_data: dict) -> str:
|
||||
elif isinstance(value, list):
|
||||
if key.lower() == 'code suggestions':
|
||||
markdown_text += "\n" # just looks nicer with additional line breaks
|
||||
emoji = emojis.get(key, "‣") # Use a dash if no emoji is found for the key
|
||||
emoji = emojis.get(key, "")
|
||||
markdown_text += f"- {emoji} **{key}:**\n\n"
|
||||
for item in value:
|
||||
if isinstance(item, dict) and key.lower() == 'code suggestions':
|
||||
@ -38,12 +50,21 @@ def convert_to_markdown(output_data: dict) -> str:
|
||||
elif item:
|
||||
markdown_text += f" - {item}\n"
|
||||
elif value != 'n/a':
|
||||
emoji = emojis.get(key, "‣") # Use a dash if no emoji is found for the key
|
||||
emoji = emojis.get(key, "")
|
||||
markdown_text += f"- {emoji} **{key}:** {value}\n"
|
||||
return markdown_text
|
||||
|
||||
|
||||
def parse_code_suggestion(code_suggestions: dict) -> str:
|
||||
"""
|
||||
Convert a dictionary of data into markdown format.
|
||||
|
||||
Args:
|
||||
code_suggestions (dict): A dictionary containing data to be converted to markdown format.
|
||||
|
||||
Returns:
|
||||
str: A string containing the markdown formatted text generated from the input dictionary.
|
||||
"""
|
||||
markdown_text = ""
|
||||
for sub_key, sub_value in code_suggestions.items():
|
||||
if isinstance(sub_value, dict): # "code example"
|
||||
@ -63,18 +84,41 @@ def parse_code_suggestion(code_suggestions: dict) -> str:
|
||||
|
||||
|
||||
def try_fix_json(review, max_iter=10, code_suggestions=False):
|
||||
"""
|
||||
Fix broken or incomplete JSON messages and return the parsed JSON data.
|
||||
|
||||
Args:
|
||||
- review: A string containing the JSON message to be fixed.
|
||||
- max_iter: An integer representing the maximum number of iterations to try and fix the JSON message.
|
||||
- code_suggestions: A boolean indicating whether to try and fix JSON messages with code suggestions.
|
||||
|
||||
Returns:
|
||||
- data: A dictionary containing the parsed JSON data.
|
||||
|
||||
The function attempts to fix broken or incomplete JSON messages by parsing until the last valid code suggestion.
|
||||
If the JSON message ends with a closing bracket, the function calls the fix_json_escape_char function to fix the message.
|
||||
If code_suggestions is True and the JSON message contains code suggestions, the function tries to fix the JSON message by parsing until the last valid code suggestion.
|
||||
The function uses regular expressions to find the last occurrence of "}," with any number of whitespaces or newlines.
|
||||
It tries to parse the JSON message with the closing bracket and checks if it is valid.
|
||||
If the JSON message is valid, the parsed JSON data is returned.
|
||||
If the JSON message is not valid, the last code suggestion is removed and the process is repeated until a valid JSON message is obtained or the maximum number of iterations is reached.
|
||||
If a valid JSON message is not obtained, an error is logged and an empty dictionary is returned.
|
||||
"""
|
||||
|
||||
if review.endswith("}"):
|
||||
return fix_json_escape_char(review)
|
||||
# Try to fix JSON if it is broken/incomplete: parse until the last valid code suggestion
|
||||
|
||||
data = {}
|
||||
if code_suggestions:
|
||||
closing_bracket = "]}"
|
||||
else:
|
||||
closing_bracket = "]}}"
|
||||
|
||||
if review.rfind("'Code suggestions': [") > 0 or review.rfind('"Code suggestions": [') > 0:
|
||||
last_code_suggestion_ind = [m.end() for m in re.finditer(r"\}\s*,", review)][-1] - 1
|
||||
valid_json = False
|
||||
iter_count = 0
|
||||
|
||||
while last_code_suggestion_ind > 0 and not valid_json and iter_count < max_iter:
|
||||
try:
|
||||
data = json.loads(review[:last_code_suggestion_ind] + closing_bracket)
|
||||
@ -82,16 +126,30 @@ def try_fix_json(review, max_iter=10, code_suggestions=False):
|
||||
review = review[:last_code_suggestion_ind].strip() + closing_bracket
|
||||
except json.decoder.JSONDecodeError:
|
||||
review = review[:last_code_suggestion_ind]
|
||||
# Use regular expression to find the last occurrence of "}," with any number of whitespaces or newlines
|
||||
last_code_suggestion_ind = [m.end() for m in re.finditer(r"\}\s*,", review)][-1] - 1
|
||||
iter_count += 1
|
||||
|
||||
if not valid_json:
|
||||
logging.error("Unable to decode JSON response from AI")
|
||||
data = {}
|
||||
|
||||
return data
|
||||
|
||||
|
||||
def fix_json_escape_char(json_message=None):
|
||||
"""
|
||||
Fix broken or incomplete JSON messages and return the parsed JSON data.
|
||||
|
||||
Args:
|
||||
json_message (str): A string containing the JSON message to be fixed.
|
||||
|
||||
Returns:
|
||||
dict: A dictionary containing the parsed JSON data.
|
||||
|
||||
Raises:
|
||||
None
|
||||
|
||||
"""
|
||||
try:
|
||||
result = json.loads(json_message)
|
||||
except Exception as e:
|
||||
@ -103,3 +161,53 @@ def fix_json_escape_char(json_message=None):
|
||||
new_message = ''.join(json_message)
|
||||
return fix_json_escape_char(json_message=new_message)
|
||||
return result
|
||||
|
||||
|
||||
def convert_str_to_datetime(date_str):
|
||||
"""
|
||||
Convert a string representation of a date and time into a datetime object.
|
||||
|
||||
Args:
|
||||
date_str (str): A string representation of a date and time in the format '%a, %d %b %Y %H:%M:%S %Z'
|
||||
|
||||
Returns:
|
||||
datetime: A datetime object representing the input date and time.
|
||||
|
||||
Example:
|
||||
>>> convert_str_to_datetime('Mon, 01 Jan 2022 12:00:00 UTC')
|
||||
datetime.datetime(2022, 1, 1, 12, 0, 0)
|
||||
"""
|
||||
datetime_format = '%a, %d %b %Y %H:%M:%S %Z'
|
||||
return datetime.strptime(date_str, datetime_format)
|
||||
|
||||
|
||||
def load_large_diff(file, new_file_content_str: str, original_file_content_str: str, patch: str) -> str:
|
||||
"""
|
||||
Generate a patch for a modified file by comparing the original content of the file with the new content provided as input.
|
||||
|
||||
Args:
|
||||
file: The file object for which the patch needs to be generated.
|
||||
new_file_content_str: The new content of the file as a string.
|
||||
original_file_content_str: The original content of the file as a string.
|
||||
patch: An optional patch string that can be provided as input.
|
||||
|
||||
Returns:
|
||||
The generated or provided patch string.
|
||||
|
||||
Raises:
|
||||
None.
|
||||
|
||||
Additional Information:
|
||||
- If 'patch' is not provided as input, the function generates a patch using the 'difflib' library and returns it as output.
|
||||
- If the 'settings.config.verbosity_level' is greater than or equal to 2, a warning message is logged indicating that the file was modified but no patch was found, and a patch is manually created.
|
||||
"""
|
||||
if not patch: # to Do - also add condition for file extension
|
||||
try:
|
||||
diff = difflib.unified_diff(original_file_content_str.splitlines(keepends=True),
|
||||
new_file_content_str.splitlines(keepends=True))
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.warning(f"File was modified, but no patch was found. Manually creating patch: {file.filename}.")
|
||||
patch = ''.join(diff)
|
||||
except Exception:
|
||||
pass
|
||||
return patch
|
||||
|
||||
@ -11,7 +11,8 @@ from pr_agent.tools.pr_reviewer import PRReviewer
|
||||
|
||||
|
||||
def run(args=None):
|
||||
parser = argparse.ArgumentParser(description='AI based pull request analyzer', usage="""\
|
||||
parser = argparse.ArgumentParser(description='AI based pull request analyzer', usage=
|
||||
"""\
|
||||
Usage: cli.py --pr-url <URL on supported git hosting service> <command> [<args>].
|
||||
For example:
|
||||
- cli.py --pr-url=... review
|
||||
@ -33,44 +34,68 @@ reflect - Ask the PR author questions about the PR.
|
||||
'describe', 'describe_pr',
|
||||
'improve', 'improve_code',
|
||||
'reflect', 'review_after_reflect'],
|
||||
default='review')
|
||||
default='review')
|
||||
parser.add_argument('rest', nargs=argparse.REMAINDER, default=[])
|
||||
args = parser.parse_args(args)
|
||||
logging.basicConfig(level=os.environ.get("LOGLEVEL", "INFO"))
|
||||
command = args.command.lower()
|
||||
if command in ['ask', 'ask_question']:
|
||||
question = ' '.join(args.rest).strip()
|
||||
if len(question) == 0:
|
||||
print("Please specify a question")
|
||||
parser.print_help()
|
||||
return
|
||||
print(f"Question: {question} about PR {args.pr_url}")
|
||||
reviewer = PRQuestions(args.pr_url, question)
|
||||
asyncio.run(reviewer.answer())
|
||||
elif command in ['describe', 'describe_pr']:
|
||||
print(f"PR description: {args.pr_url}")
|
||||
reviewer = PRDescription(args.pr_url)
|
||||
asyncio.run(reviewer.describe())
|
||||
elif command in ['improve', 'improve_code']:
|
||||
print(f"PR code suggestions: {args.pr_url}")
|
||||
reviewer = PRCodeSuggestions(args.pr_url)
|
||||
asyncio.run(reviewer.suggest())
|
||||
elif command in ['review', 'review_pr']:
|
||||
print(f"Reviewing PR: {args.pr_url}")
|
||||
reviewer = PRReviewer(args.pr_url, cli_mode=True)
|
||||
asyncio.run(reviewer.review())
|
||||
elif command in ['reflect']:
|
||||
print(f"Asking the PR author questions: {args.pr_url}")
|
||||
reviewer = PRInformationFromUser(args.pr_url)
|
||||
asyncio.run(reviewer.generate_questions())
|
||||
elif command in ['review_after_reflect']:
|
||||
print(f"Processing author's answers and sending review: {args.pr_url}")
|
||||
reviewer = PRReviewer(args.pr_url, cli_mode=True, is_answer=True)
|
||||
asyncio.run(reviewer.review())
|
||||
commands = {
|
||||
'ask': _handle_ask_command,
|
||||
'ask_question': _handle_ask_command,
|
||||
'describe': _handle_describe_command,
|
||||
'describe_pr': _handle_describe_command,
|
||||
'improve': _handle_improve_command,
|
||||
'improve_code': _handle_improve_command,
|
||||
'review': _handle_review_command,
|
||||
'review_pr': _handle_review_command,
|
||||
'reflect': _handle_reflect_command,
|
||||
'review_after_reflect': _handle_review_after_reflect_command
|
||||
}
|
||||
if command in commands:
|
||||
commands[command](args.pr_url, args.rest)
|
||||
else:
|
||||
print(f"Unknown command: {command}")
|
||||
parser.print_help()
|
||||
|
||||
|
||||
def _handle_ask_command(pr_url: str, rest: list):
|
||||
if len(rest) == 0:
|
||||
print("Please specify a question")
|
||||
return
|
||||
print(f"Question: {' '.join(rest)} about PR {pr_url}")
|
||||
reviewer = PRQuestions(pr_url, rest)
|
||||
asyncio.run(reviewer.answer())
|
||||
|
||||
|
||||
def _handle_describe_command(pr_url: str, rest: list):
|
||||
print(f"PR description: {pr_url}")
|
||||
reviewer = PRDescription(pr_url)
|
||||
asyncio.run(reviewer.describe())
|
||||
|
||||
|
||||
def _handle_improve_command(pr_url: str, rest: list):
|
||||
print(f"PR code suggestions: {pr_url}")
|
||||
reviewer = PRCodeSuggestions(pr_url)
|
||||
asyncio.run(reviewer.suggest())
|
||||
|
||||
|
||||
def _handle_review_command(pr_url: str, rest: list):
|
||||
print(f"Reviewing PR: {pr_url}")
|
||||
reviewer = PRReviewer(pr_url, cli_mode=True, args=rest)
|
||||
asyncio.run(reviewer.review())
|
||||
|
||||
|
||||
def _handle_reflect_command(pr_url: str, rest: list):
|
||||
print(f"Asking the PR author questions: {pr_url}")
|
||||
reviewer = PRInformationFromUser(pr_url)
|
||||
asyncio.run(reviewer.generate_questions())
|
||||
|
||||
|
||||
def _handle_review_after_reflect_command(pr_url: str, rest: list):
|
||||
print(f"Processing author's answers and sending review: {pr_url}")
|
||||
reviewer = PRReviewer(pr_url, cli_mode=True, is_answer=True)
|
||||
asyncio.run(reviewer.review())
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
run()
|
||||
|
||||
@ -9,6 +9,7 @@ settings = Dynaconf(
|
||||
settings_files=[join(current_dir, f) for f in [
|
||||
"settings/.secrets.toml",
|
||||
"settings/configuration.toml",
|
||||
"settings/language_extensions.toml",
|
||||
"settings/pr_reviewer_prompts.toml",
|
||||
"settings/pr_questions_prompts.toml",
|
||||
"settings/pr_description_prompts.toml",
|
||||
|
||||
@ -11,7 +11,7 @@ from .git_provider import FilePatchInfo
|
||||
|
||||
|
||||
class BitbucketProvider:
|
||||
def __init__(self, pr_url: Optional[str] = None):
|
||||
def __init__(self, pr_url: Optional[str] = None, incremental: Optional[bool] = False):
|
||||
s = requests.Session()
|
||||
s.headers['Authorization'] = f'Bearer {settings.get("BITBUCKET.BEARER_TOKEN", None)}'
|
||||
self.bitbucket_client = Cloud(session=s)
|
||||
@ -22,6 +22,7 @@ class BitbucketProvider:
|
||||
self.pr_num = None
|
||||
self.pr = None
|
||||
self.temp_comments = []
|
||||
self.incremental = incremental
|
||||
if pr_url:
|
||||
self.set_pr(pr_url)
|
||||
|
||||
|
||||
@ -53,8 +53,11 @@ class GitProvider(ABC):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def publish_code_suggestion(self, body: str, relevant_file: str,
|
||||
relevant_lines_start: int, relevant_lines_end: int):
|
||||
def publish_code_suggestions(self, code_suggestions: list):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def publish_labels(self, labels):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
@ -121,3 +124,11 @@ def get_main_pr_language(languages, files) -> str:
|
||||
pass
|
||||
|
||||
return main_language_str
|
||||
|
||||
|
||||
class IncrementalPR:
|
||||
def __init__(self, is_incremental: bool = False):
|
||||
self.is_incremental = is_incremental
|
||||
self.commits_range = None
|
||||
self.first_new_commit_sha = None
|
||||
self.last_seen_commit_sha = None
|
||||
|
||||
@ -7,12 +7,14 @@ from github import AppAuthentication, Github, Auth
|
||||
|
||||
from pr_agent.config_loader import settings
|
||||
|
||||
from .git_provider import FilePatchInfo, GitProvider
|
||||
from .git_provider import FilePatchInfo, GitProvider, IncrementalPR
|
||||
from ..algo.language_handler import is_valid_file
|
||||
from ..algo.utils import load_large_diff
|
||||
|
||||
|
||||
class GithubProvider(GitProvider):
|
||||
def __init__(self, pr_url: Optional[str] = None):
|
||||
def __init__(self, pr_url: Optional[str] = None, incremental=IncrementalPR(False)):
|
||||
self.repo_obj = None
|
||||
self.installation_id = settings.get("GITHUB.INSTALLATION_ID")
|
||||
self.github_client = self._get_github_client()
|
||||
self.repo = None
|
||||
@ -20,6 +22,7 @@ class GithubProvider(GitProvider):
|
||||
self.pr = None
|
||||
self.github_user_id = None
|
||||
self.diff_files = None
|
||||
self.incremental = incremental
|
||||
if pr_url:
|
||||
self.set_pr(pr_url)
|
||||
self.last_commit_id = list(self.pr.get_commits())[-1]
|
||||
@ -27,21 +30,73 @@ class GithubProvider(GitProvider):
|
||||
def is_supported(self, capability: str) -> bool:
|
||||
return True
|
||||
|
||||
def get_pr_url(self) -> str:
|
||||
return f"https://github.com/{self.repo}/pull/{self.pr_num}"
|
||||
|
||||
def set_pr(self, pr_url: str):
|
||||
self.repo, self.pr_num = self._parse_pr_url(pr_url)
|
||||
self.pr = self._get_pr()
|
||||
if self.incremental.is_incremental:
|
||||
self.get_incremental_commits()
|
||||
|
||||
def get_incremental_commits(self):
|
||||
self.commits = list(self.pr.get_commits())
|
||||
|
||||
self.get_previous_review()
|
||||
if self.previous_review:
|
||||
self.incremental.commits_range = self.get_commit_range()
|
||||
# Get all files changed during the commit range
|
||||
self.file_set = dict()
|
||||
for commit in self.incremental.commits_range:
|
||||
if commit.commit.message.startswith(f"Merge branch '{self._get_repo().default_branch}'"):
|
||||
logging.info(f"Skipping merge commit {commit.commit.message}")
|
||||
continue
|
||||
self.file_set.update({file.filename: file for file in commit.files})
|
||||
|
||||
def get_commit_range(self):
|
||||
last_review_time = self.previous_review.created_at
|
||||
first_new_commit_index = 0
|
||||
for index in range(len(self.commits) - 1, -1, -1):
|
||||
if self.commits[index].commit.author.date > last_review_time:
|
||||
self.incremental.first_new_commit_sha = self.commits[index].sha
|
||||
first_new_commit_index = index
|
||||
else:
|
||||
self.incremental.last_seen_commit_sha = self.commits[index].sha
|
||||
break
|
||||
return self.commits[first_new_commit_index:]
|
||||
|
||||
def get_previous_review(self):
|
||||
self.previous_review = None
|
||||
self.comments = list(self.pr.get_issue_comments())
|
||||
for index in range(len(self.comments) - 1, -1, -1):
|
||||
if self.comments[index].body.startswith("## PR Analysis"):
|
||||
self.previous_review = self.comments[index]
|
||||
break
|
||||
|
||||
def get_files(self):
|
||||
if self.incremental.is_incremental and self.file_set:
|
||||
return self.file_set.values()
|
||||
return self.pr.get_files()
|
||||
|
||||
def get_diff_files(self) -> list[FilePatchInfo]:
|
||||
files = self.pr.get_files()
|
||||
files = self.get_files()
|
||||
diff_files = []
|
||||
for file in files:
|
||||
if is_valid_file(file.filename):
|
||||
original_file_content_str = self._get_pr_file_content(file, self.pr.base.sha)
|
||||
new_file_content_str = self._get_pr_file_content(file, self.pr.head.sha)
|
||||
diff_files.append(FilePatchInfo(original_file_content_str, new_file_content_str, file.patch, file.filename))
|
||||
patch = file.patch
|
||||
if self.incremental.is_incremental and self.file_set:
|
||||
original_file_content_str = self._get_pr_file_content(file, self.incremental.last_seen_commit_sha)
|
||||
patch = load_large_diff(file,
|
||||
new_file_content_str,
|
||||
original_file_content_str,
|
||||
None)
|
||||
self.file_set[file.filename] = patch
|
||||
else:
|
||||
original_file_content_str = self._get_pr_file_content(file, self.pr.base.sha)
|
||||
|
||||
diff_files.append(
|
||||
FilePatchInfo(original_file_content_str, new_file_content_str, patch, file.filename))
|
||||
self.diff_files = diff_files
|
||||
return diff_files
|
||||
|
||||
@ -50,6 +105,9 @@ class GithubProvider(GitProvider):
|
||||
# self.pr.create_issue_comment(pr_comment)
|
||||
|
||||
def publish_comment(self, pr_comment: str, is_temporary: bool = False):
|
||||
if is_temporary and not settings.config.publish_output_progress:
|
||||
logging.debug(f"Skipping publish_comment for temporary comment: {pr_comment}")
|
||||
return
|
||||
response = self.pr.create_issue_comment(pr_comment)
|
||||
if hasattr(response, "user") and hasattr(response.user, "login"):
|
||||
self.github_user_id = response.user.login
|
||||
@ -91,24 +149,32 @@ class GithubProvider(GitProvider):
|
||||
def publish_inline_comments(self, comments: list[dict]):
|
||||
self.pr.create_review(commit=self.last_commit_id, comments=comments)
|
||||
|
||||
def publish_code_suggestion(self, body: str,
|
||||
relevant_file: str,
|
||||
relevant_lines_start: int,
|
||||
relevant_lines_end: int):
|
||||
if not relevant_lines_start or relevant_lines_start == -1:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.exception(f"Failed to publish code suggestion, relevant_lines_start is {relevant_lines_start}")
|
||||
return False
|
||||
def publish_code_suggestions(self, code_suggestions: list):
|
||||
"""
|
||||
Publishes code suggestions as comments on the PR.
|
||||
In practice current APU enables to send only one code suggestion per comment. Might change in the future.
|
||||
"""
|
||||
post_parameters_list = []
|
||||
import github.PullRequestComment
|
||||
for suggestion in code_suggestions:
|
||||
body = suggestion['body']
|
||||
relevant_file = suggestion['relevant_file']
|
||||
relevant_lines_start = suggestion['relevant_lines_start']
|
||||
relevant_lines_end = suggestion['relevant_lines_end']
|
||||
|
||||
if relevant_lines_end<relevant_lines_start:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.exception(f"Failed to publish code suggestion, "
|
||||
f"relevant_lines_end is {relevant_lines_end} and "
|
||||
f"relevant_lines_start is {relevant_lines_start}")
|
||||
return False
|
||||
if not relevant_lines_start or relevant_lines_start == -1:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.exception(
|
||||
f"Failed to publish code suggestion, relevant_lines_start is {relevant_lines_start}")
|
||||
continue
|
||||
|
||||
if relevant_lines_end < relevant_lines_start:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.exception(f"Failed to publish code suggestion, "
|
||||
f"relevant_lines_end is {relevant_lines_end} and "
|
||||
f"relevant_lines_start is {relevant_lines_start}")
|
||||
continue
|
||||
|
||||
try:
|
||||
import github.PullRequestComment
|
||||
if relevant_lines_end > relevant_lines_start:
|
||||
post_parameters = {
|
||||
"body": body,
|
||||
@ -126,21 +192,23 @@ class GithubProvider(GitProvider):
|
||||
"line": relevant_lines_start,
|
||||
"side": "RIGHT",
|
||||
}
|
||||
headers, data = self.pr._requester.requestJsonAndCheck(
|
||||
"POST", f"{self.pr.url}/comments", input=post_parameters
|
||||
)
|
||||
github.PullRequestComment.PullRequestComment(
|
||||
self.pr._requester, headers, data, completed=True
|
||||
)
|
||||
return True
|
||||
except Exception as e:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.error(f"Failed to publish code suggestion, error: {e}")
|
||||
return False
|
||||
|
||||
try:
|
||||
headers, data = self.pr._requester.requestJsonAndCheck(
|
||||
"POST", f"{self.pr.url}/comments", input=post_parameters
|
||||
)
|
||||
github.PullRequestComment.PullRequestComment(
|
||||
self.pr._requester, headers, data, completed=True
|
||||
)
|
||||
return True
|
||||
except Exception as e:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.error(f"Failed to publish code suggestion, error: {e}")
|
||||
return False
|
||||
|
||||
def remove_initial_comment(self):
|
||||
try:
|
||||
for comment in self.pr.comments_list:
|
||||
for comment in getattr(self.pr, 'comments_list', []):
|
||||
if comment.is_temporary:
|
||||
comment.delete()
|
||||
except Exception as e:
|
||||
@ -233,7 +301,14 @@ class GithubProvider(GitProvider):
|
||||
return Github(auth=Auth.Token(token))
|
||||
|
||||
def _get_repo(self):
|
||||
return self.github_client.get_repo(self.repo)
|
||||
if hasattr(self, 'repo_obj') and \
|
||||
hasattr(self.repo_obj, 'full_name') and \
|
||||
self.repo_obj.full_name == self.repo:
|
||||
return self.repo_obj
|
||||
else:
|
||||
self.repo_obj = self.github_client.get_repo(self.repo)
|
||||
return self.repo_obj
|
||||
|
||||
|
||||
def _get_pr(self):
|
||||
return self._get_repo().get_pull(self.pr_num)
|
||||
@ -244,3 +319,16 @@ class GithubProvider(GitProvider):
|
||||
except Exception:
|
||||
file_content_str = ""
|
||||
return file_content_str
|
||||
|
||||
def publish_labels(self, pr_types):
|
||||
try:
|
||||
label_color_map = {"Bug fix": "1d76db", "Tests": "e99695", "Bug fix with tests": "c5def5", "Refactoring": "bfdadc", "Enhancement": "bfd4f2", "Documentation": "d4c5f9", "Other": "d1bcf9"}
|
||||
post_parameters = []
|
||||
for p in pr_types:
|
||||
color = label_color_map.get(p, "d1bcf9") # default to "Other" color
|
||||
post_parameters.append({"name": p, "color": color})
|
||||
headers, data = self.pr._requester.requestJsonAndCheck(
|
||||
"PUT", f"{self.pr.issue_url}/labels", input=post_parameters
|
||||
)
|
||||
except:
|
||||
logging.exception("Failed to publish labels")
|
||||
|
||||
@ -13,7 +13,7 @@ from ..algo.language_handler import is_valid_file
|
||||
|
||||
|
||||
class GitLabProvider(GitProvider):
|
||||
def __init__(self, merge_request_url: Optional[str] = None):
|
||||
def __init__(self, merge_request_url: Optional[str] = None, incremental: Optional[bool] = False):
|
||||
gitlab_url = settings.get("GITLAB.URL", None)
|
||||
if not gitlab_url:
|
||||
raise ValueError("GitLab URL is not set in the config file")
|
||||
@ -32,6 +32,7 @@ class GitLabProvider(GitProvider):
|
||||
self._set_merge_request(merge_request_url)
|
||||
self.RE_HUNK_HEADER = re.compile(
|
||||
r"^@@ -(\d+)(?:,(\d+))? \+(\d+)(?:,(\d+))? @@[ ]?(.*)")
|
||||
self.incremental = incremental
|
||||
|
||||
def is_supported(self, capability: str) -> bool:
|
||||
if capability in ['get_issue_comments', 'create_inline_comment', 'publish_inline_comments']:
|
||||
@ -134,26 +135,29 @@ class GitLabProvider(GitProvider):
|
||||
self.mr.discussions.create({'body': body,
|
||||
'position': pos_obj})
|
||||
|
||||
def publish_code_suggestion(self, body: str,
|
||||
relevant_file: str,
|
||||
relevant_lines_start: int,
|
||||
relevant_lines_end: int):
|
||||
self.diff_files = self.diff_files if self.diff_files else self.get_diff_files()
|
||||
target_file = None
|
||||
for file in self.diff_files:
|
||||
if file.filename == relevant_file:
|
||||
if file.filename == relevant_file:
|
||||
target_file = file
|
||||
break
|
||||
range = relevant_lines_end - relevant_lines_start + 1
|
||||
body = body.replace('```suggestion', f'```suggestion:-0+{range}')
|
||||
def publish_code_suggestions(self, code_suggestions: list):
|
||||
for suggestion in code_suggestions:
|
||||
body = suggestion['body']
|
||||
relevant_file = suggestion['relevant_file']
|
||||
relevant_lines_start = suggestion['relevant_lines_start']
|
||||
relevant_lines_end = suggestion['relevant_lines_end']
|
||||
|
||||
lines = target_file.head_file.splitlines()
|
||||
relevant_line_in_file = lines[relevant_lines_start - 1]
|
||||
edit_type, found, source_line_no, target_file, target_line_no = self.find_in_file(target_file,
|
||||
relevant_line_in_file)
|
||||
self.send_inline_comment(body, edit_type, found, relevant_file, relevant_line_in_file, source_line_no,
|
||||
target_file, target_line_no)
|
||||
self.diff_files = self.diff_files if self.diff_files else self.get_diff_files()
|
||||
target_file = None
|
||||
for file in self.diff_files:
|
||||
if file.filename == relevant_file:
|
||||
if file.filename == relevant_file:
|
||||
target_file = file
|
||||
break
|
||||
range = relevant_lines_end - relevant_lines_start + 1
|
||||
body = body.replace('```suggestion', f'```suggestion:-0+{range}')
|
||||
|
||||
lines = target_file.head_file.splitlines()
|
||||
relevant_line_in_file = lines[relevant_lines_start - 1]
|
||||
edit_type, found, source_line_no, target_file, target_line_no = self.find_in_file(target_file,
|
||||
relevant_line_in_file)
|
||||
self.send_inline_comment(body, edit_type, found, relevant_file, relevant_line_in_file, source_line_no,
|
||||
target_file, target_line_no)
|
||||
|
||||
def search_line(self, relevant_file, relevant_line_in_file):
|
||||
target_file = None
|
||||
@ -253,3 +257,9 @@ class GitLabProvider(GitProvider):
|
||||
|
||||
def get_user_id(self):
|
||||
return None
|
||||
|
||||
def publish_labels(self, labels):
|
||||
pass
|
||||
|
||||
def publish_inline_comments(self, comments: list[dict]):
|
||||
pass
|
||||
@ -1,64 +0,0 @@
|
||||
import asyncio
|
||||
import time
|
||||
|
||||
import gitlab
|
||||
|
||||
from pr_agent.agent.pr_agent import PRAgent
|
||||
from pr_agent.config_loader import settings
|
||||
|
||||
gl = gitlab.Gitlab(
|
||||
settings.get("GITLAB.URL"),
|
||||
private_token=settings.get("GITLAB.PERSONAL_ACCESS_TOKEN")
|
||||
)
|
||||
|
||||
# Set the list of projects to monitor
|
||||
projects_to_monitor = settings.get("GITLAB.PROJECTS_TO_MONITOR")
|
||||
magic_word = settings.get("GITLAB.MAGIC_WORD")
|
||||
|
||||
# Hold the previous seen comments
|
||||
previous_comments = set()
|
||||
|
||||
|
||||
def check_comments():
|
||||
print('Polling')
|
||||
new_comments = {}
|
||||
for project in projects_to_monitor:
|
||||
project = gl.projects.get(project)
|
||||
merge_requests = project.mergerequests.list(state='opened')
|
||||
for mr in merge_requests:
|
||||
notes = mr.notes.list(get_all=True)
|
||||
for note in notes:
|
||||
if note.id not in previous_comments and note.body.startswith(magic_word):
|
||||
new_comments[note.id] = dict(
|
||||
body=note.body[len(magic_word):],
|
||||
project=project.name,
|
||||
mr=mr
|
||||
)
|
||||
previous_comments.add(note.id)
|
||||
print(f"New comment in project {project.name}, merge request {mr.title}: {note.body}")
|
||||
|
||||
return new_comments
|
||||
|
||||
|
||||
def handle_new_comments(new_comments):
|
||||
print('Handling new comments')
|
||||
agent = PRAgent()
|
||||
for _, comment in new_comments.items():
|
||||
print(f"Handling comment: {comment['body']}")
|
||||
asyncio.run(agent.handle_request(comment['mr'].web_url, comment['body']))
|
||||
|
||||
|
||||
def run():
|
||||
assert settings.get('CONFIG.GIT_PROVIDER') == 'gitlab', 'This script is only for GitLab'
|
||||
# Initial run to populate previous_comments
|
||||
check_comments()
|
||||
|
||||
# Run the check every minute
|
||||
while True:
|
||||
time.sleep(settings.get("GITLAB.POLLING_INTERVAL_SECONDS"))
|
||||
new_comments = check_comments()
|
||||
if new_comments:
|
||||
handle_new_comments(new_comments)
|
||||
|
||||
if __name__ == '__main__':
|
||||
run()
|
||||
@ -1,8 +1,9 @@
|
||||
commands_text = "> /review - Request a review of the latest update to the PR.\n" \
|
||||
"> /describe - Modify the PR title and description based on the contents of the PR.\n" \
|
||||
"> /improve - Suggest improvements to the code in the PR. " \
|
||||
commands_text = "> **/review [-i]**: Request a review of your Pull Request. For an incremental review, which only " \
|
||||
"considers changes since the last review, include the '-i' option.\n" \
|
||||
"> **/describe**: Modify the PR title and description based on the contents of the PR.\n" \
|
||||
"> **/improve**: Suggest improvements to the code in the PR. " \
|
||||
"These will be provided as pull request comments, ready to commit.\n" \
|
||||
"> /ask <QUESTION> - Pose a question about the PR.\n"
|
||||
"> **/ask \\<QUESTION\\>**: Pose a question about the PR.\n"
|
||||
|
||||
|
||||
def bot_help_text(user: str):
|
||||
|
||||
@ -1,14 +1,18 @@
|
||||
[config]
|
||||
model="gpt-4-0613"
|
||||
model="gpt-4"
|
||||
fallback-models=["gpt-3.5-turbo-16k", "gpt-3.5-turbo"]
|
||||
git_provider="github"
|
||||
publish_output=true
|
||||
publish_output_progress=true
|
||||
verbosity_level=0 # 0,1,2
|
||||
use_extra_bad_extensions=false
|
||||
|
||||
[pr_reviewer]
|
||||
require_focused_review=true
|
||||
require_score_review=false
|
||||
require_tests_review=true
|
||||
require_security_review=true
|
||||
num_code_suggestions=3
|
||||
num_code_suggestions=0
|
||||
inline_code_comments = true
|
||||
ask_and_reflect=false
|
||||
|
||||
|
||||
434
pr_agent/settings/language_extensions.toml
Normal file
434
pr_agent/settings/language_extensions.toml
Normal file
@ -0,0 +1,434 @@
|
||||
[bad_extensions]
|
||||
default = [
|
||||
'app',
|
||||
'bin',
|
||||
'bmp',
|
||||
'bz2',
|
||||
'class',
|
||||
'csv',
|
||||
'dat',
|
||||
'db',
|
||||
'dll',
|
||||
'dylib',
|
||||
'egg',
|
||||
'eot',
|
||||
'exe',
|
||||
'gif',
|
||||
'gitignore',
|
||||
'glif',
|
||||
'gradle',
|
||||
'gz',
|
||||
'ico',
|
||||
'jar',
|
||||
'jpeg',
|
||||
'jpg',
|
||||
'lo',
|
||||
'lock',
|
||||
'log',
|
||||
'mp3',
|
||||
'mp4',
|
||||
'nar',
|
||||
'o',
|
||||
'ogg',
|
||||
'otf',
|
||||
'p',
|
||||
'pdf',
|
||||
'png',
|
||||
'pickle',
|
||||
'pkl',
|
||||
'pyc',
|
||||
'pyd',
|
||||
'pyo',
|
||||
'rkt',
|
||||
'so',
|
||||
'ss',
|
||||
'svg',
|
||||
'tar',
|
||||
'tsv',
|
||||
'ttf',
|
||||
'war',
|
||||
'webm',
|
||||
'woff',
|
||||
'woff2',
|
||||
'xz',
|
||||
'zip',
|
||||
'zst',
|
||||
'snap'
|
||||
]
|
||||
extra = [
|
||||
'md',
|
||||
'txt'
|
||||
]
|
||||
|
||||
[language_extension_map_org]
|
||||
ABAP = [".abap", ]
|
||||
"AGS Script" = [".ash", ]
|
||||
AMPL = [".ampl", ]
|
||||
ANTLR = [".g4", ]
|
||||
"API Blueprint" = [".apib", ]
|
||||
APL = [".apl", ".dyalog", ]
|
||||
ASP = [".asp", ".asax", ".ascx", ".ashx", ".asmx", ".aspx", ".axd", ]
|
||||
ATS = [".dats", ".hats", ".sats", ]
|
||||
ActionScript = [".as", ]
|
||||
Ada = [".adb", ".ada", ".ads", ]
|
||||
Agda = [".agda", ]
|
||||
Alloy = [".als", ]
|
||||
ApacheConf = [".apacheconf", ".vhost", ]
|
||||
AppleScript = [".applescript", ".scpt", ]
|
||||
Arc = [".arc", ]
|
||||
Arduino = [".ino", ]
|
||||
AsciiDoc = [".asciidoc", ".adoc", ]
|
||||
AspectJ = [".aj", ]
|
||||
Assembly = [".asm", ".a51", ".nasm", ]
|
||||
Augeas = [".aug", ]
|
||||
AutoHotkey = [".ahk", ".ahkl", ]
|
||||
AutoIt = [".au3", ]
|
||||
Awk = [".awk", ".auk", ".gawk", ".mawk", ".nawk", ]
|
||||
Batchfile = [".bat", ".cmd", ]
|
||||
Befunge = [".befunge", ]
|
||||
Bison = [".bison", ]
|
||||
BitBake = [".bb", ]
|
||||
BlitzBasic = [".decls", ]
|
||||
BlitzMax = [".bmx", ]
|
||||
Bluespec = [".bsv", ]
|
||||
Boo = [".boo", ]
|
||||
Brainfuck = [".bf", ]
|
||||
Brightscript = [".brs", ]
|
||||
Bro = [".bro", ]
|
||||
C = [".c", ".cats", ".h", ".idc", ".w", ]
|
||||
"C#" = [".cs", ".cake", ".cshtml", ".csx", ]
|
||||
"C++" = [".cpp", ".c++", ".cc", ".cp", ".cxx", ".h++", ".hh", ".hpp", ".hxx", ".inl", ".ipp", ".tcc", ".tpp", ".C", ".H", ]
|
||||
C-ObjDump = [".c-objdump", ]
|
||||
"C2hs Haskell" = [".chs", ]
|
||||
CLIPS = [".clp", ]
|
||||
CMake = [".cmake", ".cmake.in", ]
|
||||
COBOL = [".cob", ".cbl", ".ccp", ".cobol", ".cpy", ]
|
||||
CSS = [".css", ]
|
||||
CSV = [".csv", ]
|
||||
"Cap'n Proto" = [".capnp", ]
|
||||
CartoCSS = [".mss", ]
|
||||
Ceylon = [".ceylon", ]
|
||||
Chapel = [".chpl", ]
|
||||
ChucK = [".ck", ]
|
||||
Cirru = [".cirru", ]
|
||||
Clarion = [".clw", ]
|
||||
Clean = [".icl", ".dcl", ]
|
||||
Click = [".click", ]
|
||||
Clojure = [".clj", ".boot", ".cl2", ".cljc", ".cljs", ".cljs.hl", ".cljscm", ".cljx", ".hic", ]
|
||||
CoffeeScript = [".coffee", "._coffee", ".cjsx", ".cson", ".iced", ]
|
||||
ColdFusion = [".cfm", ".cfml", ]
|
||||
"ColdFusion CFC" = [".cfc", ]
|
||||
"Common Lisp" = [".lisp", ".asd", ".lsp", ".ny", ".podsl", ".sexp", ]
|
||||
"Component Pascal" = [".cps", ]
|
||||
Coq = [".coq", ]
|
||||
Cpp-ObjDump = [".cppobjdump", ".c++-objdump", ".c++objdump", ".cpp-objdump", ".cxx-objdump", ]
|
||||
Creole = [".creole", ]
|
||||
Crystal = [".cr", ]
|
||||
Csound = [".csd", ]
|
||||
Cucumber = [".feature", ]
|
||||
Cuda = [".cu", ".cuh", ]
|
||||
Cycript = [".cy", ]
|
||||
Cython = [".pyx", ".pxd", ".pxi", ]
|
||||
D = [".di", ]
|
||||
D-ObjDump = [".d-objdump", ]
|
||||
"DIGITAL Command Language" = [".com", ]
|
||||
DM = [".dm", ]
|
||||
"DNS Zone" = [".zone", ".arpa", ]
|
||||
"Darcs Patch" = [".darcspatch", ".dpatch", ]
|
||||
Dart = [".dart", ]
|
||||
Diff = [".diff", ".patch", ]
|
||||
Dockerfile = [".dockerfile", "Dockerfile", ]
|
||||
Dogescript = [".djs", ]
|
||||
Dylan = [".dylan", ".dyl", ".intr", ".lid", ]
|
||||
E = [".E", ]
|
||||
ECL = [".ecl", ".eclxml", ]
|
||||
Eagle = [".sch", ".brd", ]
|
||||
"Ecere Projects" = [".epj", ]
|
||||
Eiffel = [".e", ]
|
||||
Elixir = [".ex", ".exs", ]
|
||||
Elm = [".elm", ]
|
||||
"Emacs Lisp" = [".el", ".emacs", ".emacs.desktop", ]
|
||||
EmberScript = [".em", ".emberscript", ]
|
||||
Erlang = [".erl", ".escript", ".hrl", ".xrl", ".yrl", ]
|
||||
"F#" = [".fs", ".fsi", ".fsx", ]
|
||||
FLUX = [".flux", ]
|
||||
FORTRAN = [".f90", ".f", ".f03", ".f08", ".f77", ".f95", ".for", ".fpp", ]
|
||||
Factor = [".factor", ]
|
||||
Fancy = [".fy", ".fancypack", ]
|
||||
Fantom = [".fan", ]
|
||||
Formatted = [".eam.fs", ]
|
||||
Forth = [".fth", ".4th", ".forth", ".frt", ]
|
||||
FreeMarker = [".ftl", ]
|
||||
G-code = [".g", ".gco", ".gcode", ]
|
||||
GAMS = [".gms", ]
|
||||
GAP = [".gap", ".gi", ]
|
||||
GAS = [".s", ]
|
||||
GDScript = [".gd", ]
|
||||
GLSL = [".glsl", ".fp", ".frag", ".frg", ".fsh", ".fshader", ".geo", ".geom", ".glslv", ".gshader", ".shader", ".vert", ".vrx", ".vsh", ".vshader", ]
|
||||
Genshi = [".kid", ]
|
||||
"Gentoo Ebuild" = [".ebuild", ]
|
||||
"Gentoo Eclass" = [".eclass", ]
|
||||
"Gettext Catalog" = [".po", ".pot", ]
|
||||
Glyph = [".glf", ]
|
||||
Gnuplot = [".gp", ".gnu", ".gnuplot", ".plot", ".plt", ]
|
||||
Go = [".go", ]
|
||||
Golo = [".golo", ]
|
||||
Gosu = [".gst", ".gsx", ".vark", ]
|
||||
Grace = [".grace", ]
|
||||
Gradle = [".gradle", ]
|
||||
"Grammatical Framework" = [".gf", ]
|
||||
GraphQL = [".graphql", ]
|
||||
"Graphviz (DOT)" = [".dot", ".gv", ]
|
||||
Groff = [".man", ".1", ".1in", ".1m", ".1x", ".2", ".3", ".3in", ".3m", ".3qt", ".3x", ".4", ".5", ".6", ".7", ".8", ".9", ".me", ".rno", ".roff", ]
|
||||
Groovy = [".groovy", ".grt", ".gtpl", ".gvy", ]
|
||||
"Groovy Server Pages" = [".gsp", ]
|
||||
HCL = [".hcl", ".tf", ]
|
||||
HLSL = [".hlsl", ".fxh", ".hlsli", ]
|
||||
HTML = [".html", ".htm", ".html.hl", ".xht", ".xhtml", ]
|
||||
"HTML+Django" = [".mustache", ".jinja", ]
|
||||
"HTML+EEX" = [".eex", ]
|
||||
"HTML+ERB" = [".erb", ".erb.deface", ]
|
||||
"HTML+PHP" = [".phtml", ]
|
||||
HTTP = [".http", ]
|
||||
Haml = [".haml", ".haml.deface", ]
|
||||
Handlebars = [".handlebars", ".hbs", ]
|
||||
Harbour = [".hb", ]
|
||||
Haskell = [".hs", ".hsc", ]
|
||||
Haxe = [".hx", ".hxsl", ]
|
||||
Hy = [".hy", ]
|
||||
IDL = [".dlm", ]
|
||||
"IGOR Pro" = [".ipf", ]
|
||||
INI = [".ini", ".cfg", ".prefs", ".properties", ]
|
||||
"IRC log" = [".irclog", ".weechatlog", ]
|
||||
Idris = [".idr", ".lidr", ]
|
||||
"Inform 7" = [".ni", ".i7x", ]
|
||||
"Inno Setup" = [".iss", ]
|
||||
Io = [".io", ]
|
||||
Ioke = [".ik", ]
|
||||
Isabelle = [".thy", ]
|
||||
J = [".ijs", ]
|
||||
JFlex = [".flex", ".jflex", ]
|
||||
JSON = [".json", ".geojson", ".lock", ".topojson", ]
|
||||
JSON5 = [".json5", ]
|
||||
JSONLD = [".jsonld", ]
|
||||
JSONiq = [".jq", ]
|
||||
JSX = [".jsx", ]
|
||||
Jade = [".jade", ]
|
||||
Jasmin = [".j", ]
|
||||
Java = [".java", ]
|
||||
"Java Server Pages" = [".jsp", ]
|
||||
JavaScript = [".js", "._js", ".bones", ".es6", ".jake", ".jsb", ".jscad", ".jsfl", ".jsm", ".jss", ".njs", ".pac", ".sjs", ".ssjs", ".xsjs", ".xsjslib", ]
|
||||
Julia = [".jl", ]
|
||||
"Jupyter Notebook" = [".ipynb", ]
|
||||
KRL = [".krl", ]
|
||||
KiCad = [".kicad_pcb", ]
|
||||
Kit = [".kit", ]
|
||||
Kotlin = [".kt", ".ktm", ".kts", ]
|
||||
LFE = [".lfe", ]
|
||||
LLVM = [".ll", ]
|
||||
LOLCODE = [".lol", ]
|
||||
LSL = [".lsl", ".lslp", ]
|
||||
LabVIEW = [".lvproj", ]
|
||||
Lasso = [".lasso", ".las", ".lasso8", ".lasso9", ".ldml", ]
|
||||
Latte = [".latte", ]
|
||||
Lean = [".lean", ".hlean", ]
|
||||
Less = [".less", ]
|
||||
Lex = [".lex", ]
|
||||
LilyPond = [".ly", ".ily", ]
|
||||
"Linker Script" = [".ld", ".lds", ]
|
||||
Liquid = [".liquid", ]
|
||||
"Literate Agda" = [".lagda", ]
|
||||
"Literate CoffeeScript" = [".litcoffee", ]
|
||||
"Literate Haskell" = [".lhs", ]
|
||||
LiveScript = [".ls", "._ls", ]
|
||||
Logos = [".xm", ".x", ".xi", ]
|
||||
Logtalk = [".lgt", ".logtalk", ]
|
||||
LookML = [".lookml", ]
|
||||
Lua = [".lua", ".nse", ".pd_lua", ".rbxs", ".wlua", ]
|
||||
M = [".mumps", ]
|
||||
M4 = [".m4", ]
|
||||
MAXScript = [".mcr", ]
|
||||
MTML = [".mtml", ]
|
||||
MUF = [".muf", ]
|
||||
Makefile = [".mak", ".mk", ".mkfile", "Makefile", ]
|
||||
Mako = [".mako", ".mao", ]
|
||||
Maple = [".mpl", ]
|
||||
Markdown = [".md", ".markdown", ".mkd", ".mkdn", ".mkdown", ".ron", ]
|
||||
Mask = [".mask", ]
|
||||
Mathematica = [".mathematica", ".cdf", ".ma", ".mt", ".nb", ".nbp", ".wl", ".wlt", ]
|
||||
Matlab = [".matlab", ]
|
||||
Max = [".maxpat", ".maxhelp", ".maxproj", ".mxt", ".pat", ]
|
||||
MediaWiki = [".mediawiki", ".wiki", ]
|
||||
Metal = [".metal", ]
|
||||
MiniD = [".minid", ]
|
||||
Mirah = [".druby", ".duby", ".mir", ".mirah", ]
|
||||
Modelica = [".mo", ]
|
||||
"Module Management System" = [".mms", ".mmk", ]
|
||||
Monkey = [".monkey", ]
|
||||
MoonScript = [".moon", ]
|
||||
Myghty = [".myt", ]
|
||||
NSIS = [".nsi", ".nsh", ]
|
||||
NetLinx = [".axs", ".axi", ]
|
||||
"NetLinx+ERB" = [".axs.erb", ".axi.erb", ]
|
||||
NetLogo = [".nlogo", ]
|
||||
Nginx = [".nginxconf", ]
|
||||
Nimrod = [".nim", ".nimrod", ]
|
||||
Ninja = [".ninja", ]
|
||||
Nit = [".nit", ]
|
||||
Nix = [".nix", ]
|
||||
Nu = [".nu", ]
|
||||
NumPy = [".numpy", ".numpyw", ".numsc", ]
|
||||
OCaml = [".ml", ".eliom", ".eliomi", ".ml4", ".mli", ".mll", ".mly", ]
|
||||
ObjDump = [".objdump", ]
|
||||
"Objective-C++" = [".mm", ]
|
||||
Objective-J = [".sj", ]
|
||||
Octave = [".oct", ]
|
||||
Omgrofl = [".omgrofl", ]
|
||||
Opa = [".opa", ]
|
||||
Opal = [".opal", ]
|
||||
OpenCL = [".cl", ".opencl", ]
|
||||
"OpenEdge ABL" = [".p", ]
|
||||
OpenSCAD = [".scad", ]
|
||||
Org = [".org", ]
|
||||
Ox = [".ox", ".oxh", ".oxo", ]
|
||||
Oxygene = [".oxygene", ]
|
||||
Oz = [".oz", ]
|
||||
PAWN = [".pwn", ]
|
||||
PHP = [".php", ".aw", ".ctp", ".php3", ".php4", ".php5", ".phps", ".phpt", ]
|
||||
"POV-Ray SDL" = [".pov", ]
|
||||
Pan = [".pan", ]
|
||||
Papyrus = [".psc", ]
|
||||
Parrot = [".parrot", ]
|
||||
"Parrot Assembly" = [".pasm", ]
|
||||
"Parrot Internal Representation" = [".pir", ]
|
||||
Pascal = [".pas", ".dfm", ".dpr", ".lpr", ]
|
||||
Perl = [".pl", ".al", ".perl", ".ph", ".plx", ".pm", ".psgi", ".t", ]
|
||||
Perl6 = [".6pl", ".6pm", ".nqp", ".p6", ".p6l", ".p6m", ".pl6", ".pm6", ]
|
||||
Pickle = [".pkl", ]
|
||||
PigLatin = [".pig", ]
|
||||
Pike = [".pike", ".pmod", ]
|
||||
Pod = [".pod", ]
|
||||
PogoScript = [".pogo", ]
|
||||
Pony = [".pony", ]
|
||||
PostScript = [".ps", ".eps", ]
|
||||
PowerShell = [".ps1", ".psd1", ".psm1", ]
|
||||
Processing = [".pde", ]
|
||||
Prolog = [".prolog", ".yap", ]
|
||||
"Propeller Spin" = [".spin", ]
|
||||
"Protocol Buffer" = [".proto", ]
|
||||
"Public Key" = [".pub", ]
|
||||
"Pure Data" = [".pd", ]
|
||||
PureBasic = [".pb", ".pbi", ]
|
||||
PureScript = [".purs", ]
|
||||
Python = [".py", ".bzl", ".gyp", ".lmi", ".pyde", ".pyp", ".pyt", ".pyw", ".tac", ".wsgi", ".xpy", ]
|
||||
"Python traceback" = [".pytb", ]
|
||||
QML = [".qml", ".qbs", ]
|
||||
QMake = [".pri", ]
|
||||
R = [".r", ".rd", ".rsx", ]
|
||||
RAML = [".raml", ]
|
||||
RDoc = [".rdoc", ]
|
||||
REALbasic = [".rbbas", ".rbfrm", ".rbmnu", ".rbres", ".rbtbar", ".rbuistate", ]
|
||||
RHTML = [".rhtml", ]
|
||||
RMarkdown = [".rmd", ]
|
||||
Racket = [".rkt", ".rktd", ".rktl", ".scrbl", ]
|
||||
"Ragel in Ruby Host" = [".rl", ]
|
||||
"Raw token data" = [".raw", ]
|
||||
Rebol = [".reb", ".r2", ".r3", ".rebol", ]
|
||||
Red = [".red", ".reds", ]
|
||||
Redcode = [".cw", ]
|
||||
"Ren'Py" = [".rpy", ]
|
||||
RenderScript = [".rsh", ]
|
||||
RobotFramework = [".robot", ]
|
||||
Rouge = [".rg", ]
|
||||
Ruby = [".rb", ".builder", ".gemspec", ".god", ".irbrc", ".jbuilder", ".mspec", ".podspec", ".rabl", ".rake", ".rbuild", ".rbw", ".rbx", ".ru", ".ruby", ".thor", ".watchr", ]
|
||||
Rust = [".rs", ".rs.in", ]
|
||||
SAS = [".sas", ]
|
||||
SCSS = [".scss", ]
|
||||
SMT = [".smt2", ".smt", ]
|
||||
SPARQL = [".sparql", ".rq", ]
|
||||
SQF = [".sqf", ".hqf", ]
|
||||
SQL = [".pls", ".pck", ".pkb", ".pks", ".plb", ".plsql", ".sql", ".cql", ".ddl", ".prc", ".tab", ".udf", ".viw", ".db2", ]
|
||||
STON = [".ston", ]
|
||||
SVG = [".svg", ]
|
||||
Sage = [".sage", ".sagews", ]
|
||||
SaltStack = [".sls", ]
|
||||
Sass = [".sass", ]
|
||||
Scala = [".scala", ".sbt", ]
|
||||
Scaml = [".scaml", ]
|
||||
Scheme = [".scm", ".sld", ".sps", ".ss", ]
|
||||
Scilab = [".sci", ".sce", ]
|
||||
Self = [".self", ]
|
||||
Shell = [".sh", ".bash", ".bats", ".command", ".ksh", ".sh.in", ".tmux", ".tool", ".zsh", ]
|
||||
ShellSession = [".sh-session", ]
|
||||
Shen = [".shen", ]
|
||||
Slash = [".sl", ]
|
||||
Slim = [".slim", ]
|
||||
Smali = [".smali", ]
|
||||
Smalltalk = [".st", ]
|
||||
Smarty = [".tpl", ]
|
||||
Solidity = [".sol", ]
|
||||
SourcePawn = [".sp", ".sma", ]
|
||||
Squirrel = [".nut", ]
|
||||
Stan = [".stan", ]
|
||||
"Standard ML" = [".ML", ".fun", ".sig", ".sml", ]
|
||||
Stata = [".do", ".ado", ".doh", ".ihlp", ".mata", ".matah", ".sthlp", ]
|
||||
Stylus = [".styl", ]
|
||||
SuperCollider = [".scd", ]
|
||||
Swift = [".swift", ]
|
||||
SystemVerilog = [".sv", ".svh", ".vh", ]
|
||||
TOML = [".toml", ]
|
||||
TXL = [".txl", ]
|
||||
Tcl = [".tcl", ".adp", ".tm", ]
|
||||
Tcsh = [".tcsh", ".csh", ]
|
||||
TeX = [".tex", ".aux", ".bbx", ".bib", ".cbx", ".dtx", ".ins", ".lbx", ".ltx", ".mkii", ".mkiv", ".mkvi", ".sty", ".toc", ]
|
||||
Tea = [".tea", ]
|
||||
Text = [".txt", ".no", ]
|
||||
Textile = [".textile", ]
|
||||
Thrift = [".thrift", ]
|
||||
Turing = [".tu", ]
|
||||
Turtle = [".ttl", ]
|
||||
Twig = [".twig", ]
|
||||
TypeScript = [".ts", ".tsx", ]
|
||||
"Unified Parallel C" = [".upc", ]
|
||||
"Unity3D Asset" = [".anim", ".asset", ".mat", ".meta", ".prefab", ".unity", ]
|
||||
Uno = [".uno", ]
|
||||
UnrealScript = [".uc", ]
|
||||
UrWeb = [".ur", ".urs", ]
|
||||
VCL = [".vcl", ]
|
||||
VHDL = [".vhdl", ".vhd", ".vhf", ".vhi", ".vho", ".vhs", ".vht", ".vhw", ]
|
||||
Vala = [".vala", ".vapi", ]
|
||||
Verilog = [".veo", ]
|
||||
VimL = [".vim", ]
|
||||
"Visual Basic" = [".vb", ".bas", ".frm", ".frx", ".vba", ".vbhtml", ".vbs", ]
|
||||
Volt = [".volt", ]
|
||||
Vue = [".vue", ]
|
||||
"Web Ontology Language" = [".owl", ]
|
||||
WebAssembly = [".wat", ]
|
||||
WebIDL = [".webidl", ]
|
||||
X10 = [".x10", ]
|
||||
XC = [".xc", ]
|
||||
XML = [".xml", ".ant", ".axml", ".ccxml", ".clixml", ".cproject", ".csl", ".csproj", ".ct", ".dita", ".ditamap", ".ditaval", ".dll.config", ".dotsettings", ".filters", ".fsproj", ".fxml", ".glade", ".grxml", ".iml", ".ivy", ".jelly", ".jsproj", ".kml", ".launch", ".mdpolicy", ".mxml", ".nproj", ".nuspec", ".odd", ".osm", ".plist", ".props", ".ps1xml", ".psc1", ".pt", ".rdf", ".rss", ".scxml", ".srdf", ".storyboard", ".stTheme", ".sublime-snippet", ".targets", ".tmCommand", ".tml", ".tmLanguage", ".tmPreferences", ".tmSnippet", ".tmTheme", ".ui", ".urdf", ".ux", ".vbproj", ".vcxproj", ".vssettings", ".vxml", ".wsdl", ".wsf", ".wxi", ".wxl", ".wxs", ".x3d", ".xacro", ".xaml", ".xib", ".xlf", ".xliff", ".xmi", ".xml.dist", ".xproj", ".xsd", ".xul", ".zcml", ]
|
||||
XPages = [".xsp-config", ".xsp.metadata", ]
|
||||
XProc = [".xpl", ".xproc", ]
|
||||
XQuery = [".xquery", ".xq", ".xql", ".xqm", ".xqy", ]
|
||||
XS = [".xs", ]
|
||||
XSLT = [".xslt", ".xsl", ]
|
||||
Xojo = [".xojo_code", ".xojo_menu", ".xojo_report", ".xojo_script", ".xojo_toolbar", ".xojo_window", ]
|
||||
Xtend = [".xtend", ]
|
||||
YAML = [".yml", ".reek", ".rviz", ".sublime-syntax", ".syntax", ".yaml", ".yaml-tmlanguage", ]
|
||||
YANG = [".yang", ]
|
||||
Yacc = [".y", ".yacc", ".yy", ]
|
||||
Zephir = [".zep", ]
|
||||
Zig = [".zig", ]
|
||||
Zimpl = [".zimpl", ".zmpl", ".zpl", ]
|
||||
desktop = [".desktop", ".desktop.in", ]
|
||||
eC = [".ec", ".eh", ]
|
||||
edn = [".edn", ]
|
||||
fish = [".fish", ]
|
||||
mupad = [".mu", ]
|
||||
nesC = [".nc", ]
|
||||
ooc = [".ooc", ]
|
||||
reStructuredText = [".rst", ".rest", ".rest.txt", ".rst.txt", ]
|
||||
wisp = [".wisp", ]
|
||||
xBase = [".prg", ".prw", ]
|
||||
|
||||
@ -10,9 +10,9 @@ You must use the following JSON schema to format your answer:
|
||||
"type": "string",
|
||||
"description": "an informative title for the PR, describing its main theme"
|
||||
},
|
||||
"Type of PR": {
|
||||
"PR Type": {
|
||||
"type": "string",
|
||||
"enum": ["Bug fix", "Tests", "Bug fix with tests", "Refactoring", "Enhancement", "Documentation", "Other"]
|
||||
"description": possible values are: ["Bug fix", "Tests", "Bug fix with tests", "Refactoring", "Enhancement", "Documentation", "Other"]
|
||||
},
|
||||
"PR Description": {
|
||||
"type": "string",
|
||||
|
||||
@ -20,6 +20,12 @@ You must use the following JSON schema to format your answer:
|
||||
"type": "string",
|
||||
"enum": ["Bug fix", "Tests", "Bug fix with tests", "Refactoring", "Enhancement", "Documentation", "Other"]
|
||||
},
|
||||
{%- if require_score %}
|
||||
"Score": {
|
||||
"type": "int",
|
||||
"description": "Rate this PR on a scale of 0-100 (inclusive), where 0 means the worst possible PR code, and 100 means PR code of the highest quality, without any bugs or performance issues, that is ready to be merged immediately and run in production at scale."
|
||||
},
|
||||
{%- endif %}
|
||||
{%- if require_tests %}
|
||||
"Relevant tests added": {
|
||||
"type": "string",
|
||||
@ -83,6 +89,9 @@ Example output:
|
||||
{
|
||||
"Main theme": "xxx",
|
||||
"Type of PR": "Bug fix",
|
||||
{%- if require_score %}
|
||||
"Score": 89,
|
||||
{%- endif %}
|
||||
{%- if require_tests %}
|
||||
"Relevant tests added": "No",
|
||||
{%- endif %}
|
||||
@ -103,8 +112,8 @@ Example output:
|
||||
...
|
||||
]
|
||||
{%- endif %}
|
||||
{%- if require_security %},
|
||||
"Security concerns": "No, because ..."
|
||||
{%- if require_security %}
|
||||
"Security concerns": "No, because ..."
|
||||
{%- endif %}
|
||||
}
|
||||
}
|
||||
|
||||
@ -6,7 +6,7 @@ import textwrap
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
|
||||
from pr_agent.algo.ai_handler import AiHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.utils import try_fix_json
|
||||
from pr_agent.config_loader import settings
|
||||
@ -44,16 +44,7 @@ class PRCodeSuggestions:
|
||||
logging.info('Generating code suggestions for PR...')
|
||||
if settings.config.publish_output:
|
||||
self.git_provider.publish_comment("Preparing review...", is_temporary=True)
|
||||
logging.info('Getting PR diff...')
|
||||
|
||||
# we are using extended hunk with line numbers for code suggestions
|
||||
self.patches_diff = get_pr_diff(self.git_provider,
|
||||
self.token_handler,
|
||||
add_line_numbers_to_hunks=True,
|
||||
disable_extra_lines=True)
|
||||
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction()
|
||||
await retry_with_fallback_models(self._prepare_prediction)
|
||||
logging.info('Preparing PR review...')
|
||||
data = self._prepare_pr_code_suggestions()
|
||||
if settings.config.publish_output:
|
||||
@ -62,7 +53,18 @@ class PRCodeSuggestions:
|
||||
logging.info('Pushing inline code comments...')
|
||||
self.push_inline_code_suggestions(data)
|
||||
|
||||
async def _get_prediction(self):
|
||||
async def _prepare_prediction(self, model: str):
|
||||
logging.info('Getting PR diff...')
|
||||
# we are using extended hunk with line numbers for code suggestions
|
||||
self.patches_diff = get_pr_diff(self.git_provider,
|
||||
self.token_handler,
|
||||
model,
|
||||
add_line_numbers_to_hunks=True,
|
||||
disable_extra_lines=True)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction(model)
|
||||
|
||||
async def _get_prediction(self, model: str):
|
||||
variables = copy.deepcopy(self.vars)
|
||||
variables["diff"] = self.patches_diff # update diff
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
@ -71,7 +73,6 @@ class PRCodeSuggestions:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.info(f"\nSystem prompt:\n{system_prompt}")
|
||||
logging.info(f"\nUser prompt:\n{user_prompt}")
|
||||
model = settings.config.model
|
||||
response, finish_reason = await self.ai_handler.chat_completion(model=model, temperature=0.2,
|
||||
system=system_prompt, user=user_prompt)
|
||||
|
||||
@ -79,7 +80,6 @@ class PRCodeSuggestions:
|
||||
|
||||
def _prepare_pr_code_suggestions(self) -> str:
|
||||
review = self.prediction.strip()
|
||||
data = None
|
||||
try:
|
||||
data = json.loads(review)
|
||||
except json.decoder.JSONDecodeError:
|
||||
@ -89,6 +89,7 @@ class PRCodeSuggestions:
|
||||
return data
|
||||
|
||||
def push_inline_code_suggestions(self, data):
|
||||
code_suggestions = []
|
||||
for d in data['Code suggestions']:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.info(f"suggestion: {d}")
|
||||
@ -100,27 +101,33 @@ class PRCodeSuggestions:
|
||||
new_code_snippet = d['improved code']
|
||||
|
||||
if new_code_snippet:
|
||||
try: # dedent code snippet
|
||||
self.diff_files = self.git_provider.diff_files if self.git_provider.diff_files \
|
||||
else self.git_provider.get_diff_files()
|
||||
original_initial_line = None
|
||||
for file in self.diff_files:
|
||||
if file.filename.strip() == relevant_file:
|
||||
original_initial_line = file.head_file.splitlines()[relevant_lines_start - 1]
|
||||
break
|
||||
if original_initial_line:
|
||||
suggested_initial_line = new_code_snippet.splitlines()[0]
|
||||
original_initial_spaces = len(original_initial_line) - len(original_initial_line.lstrip())
|
||||
suggested_initial_spaces = len(suggested_initial_line) - len(suggested_initial_line.lstrip())
|
||||
delta_spaces = original_initial_spaces - suggested_initial_spaces
|
||||
if delta_spaces > 0:
|
||||
new_code_snippet = textwrap.indent(new_code_snippet, delta_spaces * " ").rstrip('\n')
|
||||
except Exception as e:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.info(f"Could not dedent code snippet for file {relevant_file}, error: {e}")
|
||||
new_code_snippet = self.dedent_code(relevant_file, relevant_lines_start, new_code_snippet)
|
||||
|
||||
body = f"**Suggestion:** {content}\n```suggestion\n" + new_code_snippet + "\n```"
|
||||
self.git_provider.publish_code_suggestion(body=body,
|
||||
relevant_file=relevant_file,
|
||||
relevant_lines_start=relevant_lines_start,
|
||||
relevant_lines_end=relevant_lines_end)
|
||||
code_suggestions.append({'body': body,'relevant_file': relevant_file,
|
||||
'relevant_lines_start': relevant_lines_start,
|
||||
'relevant_lines_end': relevant_lines_end})
|
||||
|
||||
self.git_provider.publish_code_suggestions(code_suggestions)
|
||||
|
||||
def dedent_code(self, relevant_file, relevant_lines_start, new_code_snippet):
|
||||
try: # dedent code snippet
|
||||
self.diff_files = self.git_provider.diff_files if self.git_provider.diff_files \
|
||||
else self.git_provider.get_diff_files()
|
||||
original_initial_line = None
|
||||
for file in self.diff_files:
|
||||
if file.filename.strip() == relevant_file:
|
||||
original_initial_line = file.head_file.splitlines()[relevant_lines_start - 1]
|
||||
break
|
||||
if original_initial_line:
|
||||
suggested_initial_line = new_code_snippet.splitlines()[0]
|
||||
original_initial_spaces = len(original_initial_line) - len(original_initial_line.lstrip())
|
||||
suggested_initial_spaces = len(suggested_initial_line) - len(suggested_initial_line.lstrip())
|
||||
delta_spaces = original_initial_spaces - suggested_initial_spaces
|
||||
if delta_spaces > 0:
|
||||
new_code_snippet = textwrap.indent(new_code_snippet, delta_spaces * " ").rstrip('\n')
|
||||
except Exception as e:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.info(f"Could not dedent code snippet for file {relevant_file}, error: {e}")
|
||||
|
||||
return new_code_snippet
|
||||
|
||||
@ -5,7 +5,7 @@ import logging
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
|
||||
from pr_agent.algo.ai_handler import AiHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.git_providers import get_git_provider
|
||||
@ -37,22 +37,26 @@ class PRDescription:
|
||||
logging.info('Generating a PR description...')
|
||||
if settings.config.publish_output:
|
||||
self.git_provider.publish_comment("Preparing pr description...", is_temporary=True)
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction()
|
||||
await retry_with_fallback_models(self._prepare_prediction)
|
||||
logging.info('Preparing answer...')
|
||||
pr_title, pr_body, markdown_text = self._prepare_pr_answer()
|
||||
pr_title, pr_body, pr_types, markdown_text = self._prepare_pr_answer()
|
||||
if settings.config.publish_output:
|
||||
logging.info('Pushing answer...')
|
||||
if settings.pr_description.publish_description_as_comment:
|
||||
self.git_provider.publish_comment(markdown_text)
|
||||
else:
|
||||
self.git_provider.publish_description(pr_title, pr_body)
|
||||
self.git_provider.publish_labels(pr_types)
|
||||
self.git_provider.remove_initial_comment()
|
||||
return ""
|
||||
|
||||
async def _get_prediction(self):
|
||||
async def _prepare_prediction(self, model: str):
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler, model)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction(model)
|
||||
|
||||
async def _get_prediction(self, model: str):
|
||||
variables = copy.deepcopy(self.vars)
|
||||
variables["diff"] = self.patches_diff # update diff
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
@ -61,7 +65,6 @@ class PRDescription:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.info(f"\nSystem prompt:\n{system_prompt}")
|
||||
logging.info(f"\nUser prompt:\n{user_prompt}")
|
||||
model = settings.config.model
|
||||
response, finish_reason = await self.ai_handler.chat_completion(model=model, temperature=0.2,
|
||||
system=system_prompt, user=user_prompt)
|
||||
return response
|
||||
@ -73,6 +76,9 @@ class PRDescription:
|
||||
markdown_text += f"## {key}\n\n"
|
||||
markdown_text += f"{value}\n\n"
|
||||
pr_body = ""
|
||||
pr_types = []
|
||||
if 'PR Type' in data:
|
||||
pr_types = data['PR Type'].split(',')
|
||||
title = data['PR Title']
|
||||
del data['PR Title']
|
||||
for key, value in data.items():
|
||||
@ -83,4 +89,4 @@ class PRDescription:
|
||||
pr_body += f"**{value}**\n\n___\n"
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.info(f"title:\n{title}\n{pr_body}")
|
||||
return title, pr_body, markdown_text
|
||||
return title, pr_body, pr_types, markdown_text
|
||||
|
||||
@ -4,13 +4,15 @@ import logging
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
|
||||
from pr_agent.algo.ai_handler import AiHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.git_providers import get_git_provider
|
||||
from pr_agent.git_providers.git_provider import get_main_pr_language
|
||||
|
||||
|
||||
|
||||
|
||||
class PRInformationFromUser:
|
||||
def __init__(self, pr_url: str):
|
||||
self.git_provider = get_git_provider()(pr_url)
|
||||
@ -36,10 +38,7 @@ class PRInformationFromUser:
|
||||
logging.info('Generating question to the user...')
|
||||
if settings.config.publish_output:
|
||||
self.git_provider.publish_comment("Preparing questions...", is_temporary=True)
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction()
|
||||
await retry_with_fallback_models(self._prepare_prediction)
|
||||
logging.info('Preparing questions...')
|
||||
pr_comment = self._prepare_pr_answer()
|
||||
if settings.config.publish_output:
|
||||
@ -48,7 +47,13 @@ class PRInformationFromUser:
|
||||
self.git_provider.remove_initial_comment()
|
||||
return ""
|
||||
|
||||
async def _get_prediction(self):
|
||||
async def _prepare_prediction(self, model):
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler, model)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction(model)
|
||||
|
||||
async def _get_prediction(self, model: str):
|
||||
variables = copy.deepcopy(self.vars)
|
||||
variables["diff"] = self.patches_diff # update diff
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
@ -57,7 +62,6 @@ class PRInformationFromUser:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.info(f"\nSystem prompt:\n{system_prompt}")
|
||||
logging.info(f"\nUser prompt:\n{user_prompt}")
|
||||
model = settings.config.model
|
||||
response, finish_reason = await self.ai_handler.chat_completion(model=model, temperature=0.2,
|
||||
system=system_prompt, user=user_prompt)
|
||||
return response
|
||||
|
||||
@ -4,7 +4,7 @@ import logging
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
|
||||
from pr_agent.algo.ai_handler import AiHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.git_providers import get_git_provider
|
||||
@ -12,7 +12,8 @@ from pr_agent.git_providers.git_provider import get_main_pr_language
|
||||
|
||||
|
||||
class PRQuestions:
|
||||
def __init__(self, pr_url: str, question_str: str):
|
||||
def __init__(self, pr_url: str, args=None):
|
||||
question_str = self.parse_args(args)
|
||||
self.git_provider = get_git_provider()(pr_url)
|
||||
self.main_pr_language = get_main_pr_language(
|
||||
self.git_provider.get_languages(), self.git_provider.get_files()
|
||||
@ -34,14 +35,18 @@ class PRQuestions:
|
||||
self.patches_diff = None
|
||||
self.prediction = None
|
||||
|
||||
def parse_args(self, args):
|
||||
if args and len(args) > 0:
|
||||
question_str = " ".join(args)
|
||||
else:
|
||||
question_str = ""
|
||||
return question_str
|
||||
|
||||
async def answer(self):
|
||||
logging.info('Answering a PR question...')
|
||||
if settings.config.publish_output:
|
||||
self.git_provider.publish_comment("Preparing answer...", is_temporary=True)
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction()
|
||||
await retry_with_fallback_models(self._prepare_prediction)
|
||||
logging.info('Preparing answer...')
|
||||
pr_comment = self._prepare_pr_answer()
|
||||
if settings.config.publish_output:
|
||||
@ -50,7 +55,13 @@ class PRQuestions:
|
||||
self.git_provider.remove_initial_comment()
|
||||
return ""
|
||||
|
||||
async def _get_prediction(self):
|
||||
async def _prepare_prediction(self, model: str):
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler, model)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction(model)
|
||||
|
||||
async def _get_prediction(self, model: str):
|
||||
variables = copy.deepcopy(self.vars)
|
||||
variables["diff"] = self.patches_diff # update diff
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
@ -59,7 +70,6 @@ class PRQuestions:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.info(f"\nSystem prompt:\n{system_prompt}")
|
||||
logging.info(f"\nUser prompt:\n{user_prompt}")
|
||||
model = settings.config.model
|
||||
response, finish_reason = await self.ai_handler.chat_completion(model=model, temperature=0.2,
|
||||
system=system_prompt, user=user_prompt)
|
||||
return response
|
||||
|
||||
@ -1,26 +1,29 @@
|
||||
import copy
|
||||
import json
|
||||
import logging
|
||||
from collections import OrderedDict
|
||||
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
|
||||
from pr_agent.algo.ai_handler import AiHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.utils import convert_to_markdown, try_fix_json
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.git_providers import get_git_provider
|
||||
from pr_agent.git_providers.git_provider import get_main_pr_language
|
||||
from pr_agent.git_providers.git_provider import get_main_pr_language, IncrementalPR
|
||||
from pr_agent.servers.help import actions_help_text, bot_help_text
|
||||
|
||||
|
||||
class PRReviewer:
|
||||
def __init__(self, pr_url: str, cli_mode=False, is_answer: bool = False):
|
||||
def __init__(self, pr_url: str, cli_mode=False, is_answer: bool = False, args=None):
|
||||
self.parse_args(args)
|
||||
|
||||
self.git_provider = get_git_provider()(pr_url)
|
||||
self.git_provider = get_git_provider()(pr_url, incremental=self.incremental)
|
||||
self.main_language = get_main_pr_language(
|
||||
self.git_provider.get_languages(), self.git_provider.get_files()
|
||||
)
|
||||
self.pr_url = pr_url
|
||||
self.is_answer = is_answer
|
||||
if self.is_answer and not self.git_provider.is_supported("get_issue_comments"):
|
||||
raise Exception(f"Answer mode is not supported for {settings.config.git_provider} for now")
|
||||
@ -35,6 +38,7 @@ class PRReviewer:
|
||||
"description": self.git_provider.get_pr_description(),
|
||||
"language": self.main_language,
|
||||
"diff": "", # empty diff for initial calculation
|
||||
"require_score": settings.pr_reviewer.require_score_review,
|
||||
"require_tests": settings.pr_reviewer.require_tests_review,
|
||||
"require_security": settings.pr_reviewer.require_security_review,
|
||||
"require_focused": settings.pr_reviewer.require_focused_review,
|
||||
@ -48,14 +52,19 @@ class PRReviewer:
|
||||
settings.pr_review_prompt.system,
|
||||
settings.pr_review_prompt.user)
|
||||
|
||||
def parse_args(self, args):
|
||||
is_incremental = False
|
||||
if args and len(args) >= 1:
|
||||
arg = args[0]
|
||||
if arg == "-i":
|
||||
is_incremental = True
|
||||
self.incremental = IncrementalPR(is_incremental)
|
||||
|
||||
async def review(self):
|
||||
logging.info('Reviewing PR...')
|
||||
if settings.config.publish_output:
|
||||
self.git_provider.publish_comment("Preparing review...", is_temporary=True)
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction()
|
||||
await retry_with_fallback_models(self._prepare_prediction)
|
||||
logging.info('Preparing PR review...')
|
||||
pr_comment = self._prepare_pr_review()
|
||||
if settings.config.publish_output:
|
||||
@ -67,7 +76,13 @@ class PRReviewer:
|
||||
self._publish_inline_code_comments()
|
||||
return ""
|
||||
|
||||
async def _get_prediction(self):
|
||||
async def _prepare_prediction(self, model: str):
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler, model)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction(model)
|
||||
|
||||
async def _get_prediction(self, model: str):
|
||||
variables = copy.deepcopy(self.vars)
|
||||
variables["diff"] = self.patches_diff # update diff
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
@ -76,7 +91,6 @@ class PRReviewer:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.info(f"\nSystem prompt:\n{system_prompt}")
|
||||
logging.info(f"\nUser prompt:\n{user_prompt}")
|
||||
model = settings.config.model
|
||||
response, finish_reason = await self.ai_handler.chat_completion(model=model, temperature=0.2,
|
||||
system=system_prompt, user=user_prompt)
|
||||
|
||||
@ -107,6 +121,14 @@ class PRReviewer:
|
||||
if not data['PR Feedback']['Code suggestions']:
|
||||
del data['PR Feedback']['Code suggestions']
|
||||
|
||||
if self.incremental.is_incremental:
|
||||
# Rename title when incremental review - Add to the beginning of the dict
|
||||
last_commit_url = f"{self.git_provider.get_pr_url()}/commits/{self.git_provider.incremental.first_new_commit_sha}"
|
||||
data = OrderedDict(data)
|
||||
data.update({'Incremental PR Review': {
|
||||
"⏮️ Review for commits since previous PR-Agent review": f"Starting from commit {last_commit_url}"}})
|
||||
data.move_to_end('Incremental PR Review', last=False)
|
||||
|
||||
markdown_text = convert_to_markdown(data)
|
||||
user = self.git_provider.get_user_id()
|
||||
|
||||
|
||||
Reference in New Issue
Block a user