mirror of
https://github.com/qodo-ai/pr-agent.git
synced 2025-07-21 04:50:39 +08:00
Compare commits
315 Commits
ok/update_
...
idavidov/g
| Author | SHA1 | Date | |
|---|---|---|---|
| 9770f4709a | |||
| 35afe758e9 | |||
| 50125ae57f | |||
| 6595c3e0c9 | |||
| fdd16f6c75 | |||
| 7b7e913195 | |||
| 5477469a91 | |||
| dee1f168f8 | |||
| bb18e32c56 | |||
| 70286e9574 | |||
| 3f60d12a9a | |||
| 164b340c29 | |||
| 4bb035ec0f | |||
| 23a79bc8fe | |||
| 1db53ae1ad | |||
| cca951d787 | |||
| 230d684cd3 | |||
| 0a02fa8597 | |||
| f82b9620af | |||
| ce29d9eb49 | |||
| b7b650eb05 | |||
| 6ca0655517 | |||
| edcf89a456 | |||
| 7762a67250 | |||
| 7049c73790 | |||
| cc7be0811a | |||
| d3a5aea89e | |||
| dd87df49f5 | |||
| e85bcf3a17 | |||
| abb754b16b | |||
| bb5878c99a | |||
| 273a9e35d9 | |||
| fcc208d09f | |||
| 20bbdac135 | |||
| ceedf2bf83 | |||
| 2d6b947292 | |||
| 2e13b12fe6 | |||
| 2d56c88291 | |||
| cf9c6a872d | |||
| 0bb8ab70a4 | |||
| 4a47b78a90 | |||
| 3e542cd88b | |||
| 17ed050ca7 | |||
| e24c5e3501 | |||
| b206b1c5ff | |||
| 0270306d3c | |||
| 3e09b9ac37 | |||
| 725ac9e85d | |||
| e00500b90c | |||
| f1f271fa00 | |||
| d38c5236dd | |||
| 49a3a1e511 | |||
| 1b0b90e51d | |||
| 64481e2d84 | |||
| e0f295659d | |||
| fe75e3f2ec | |||
| e3274af831 | |||
| 95b6abef09 | |||
| 7f1849a867 | |||
| 7760f37dee | |||
| ebbe655c40 | |||
| 164ed77d72 | |||
| b1148e5f7a | |||
| 2012e25596 | |||
| a75253097b | |||
| 079d62af56 | |||
| 6c4a5bae52 | |||
| 886139c6b5 | |||
| 8f751f7371 | |||
| 43297b851f | |||
| 4f39239e73 | |||
| 00e1925927 | |||
| 7189b3ab41 | |||
| a00038fbd8 | |||
| a45343793a | |||
| 703215fe83 | |||
| 0f975ccf4a | |||
| 7367c62cf9 | |||
| fed0ea349a | |||
| bd86266a4b | |||
| bd07a0cd7f | |||
| ed8554699b | |||
| 749ae1be79 | |||
| 0e3dbbd0f2 | |||
| 7a57db5d88 | |||
| 102edcdcf1 | |||
| c92648cbd5 | |||
| 26b008565b | |||
| 0dec24aa37 | |||
| 68a2f2a27d | |||
| cfa14178f8 | |||
| b97c4b6114 | |||
| 3d43cecbea | |||
| eb143ec851 | |||
| 3e94a71dcd | |||
| dd14423b07 | |||
| 8e47fdc284 | |||
| ab607d74be | |||
| bfe7304449 | |||
| e12874b696 | |||
| 696e2bd6ff | |||
| 450f410e3c | |||
| 08a3f033cb | |||
| c5a79ceedd | |||
| 13547afc58 | |||
| 8ae936e504 | |||
| e577d27f9b | |||
| dfb73c963a | |||
| 8c0370a166 | |||
| d7b77764c3 | |||
| 6605f9c444 | |||
| 2a8adcbbd6 | |||
| 0b22c8d427 | |||
| dfa0d9fd43 | |||
| c8470645e2 | |||
| 5a181e52d5 | |||
| 0ad8dcd2aa | |||
| e2d015a20c | |||
| a0cfe4b48a | |||
| a6ba8b614a | |||
| 4f0fabd2ca | |||
| 42b047a14e | |||
| 3daf94954a | |||
| b564d8ac32 | |||
| d8e6da74db | |||
| 278f1883fd | |||
| ef71a7049e | |||
| 6fde87b3bd | |||
| 07fe91e57b | |||
| 01e2f3f0cd | |||
| 63a703c000 | |||
| 4664d91844 | |||
| 8f16c46012 | |||
| a8780f722d | |||
| 1a8fce1505 | |||
| 8519b106f9 | |||
| d375dd62fe | |||
| 3770bf8031 | |||
| 5c527eca66 | |||
| b4ca52c7d8 | |||
| a78d741292 | |||
| 42388b1f8d | |||
| 0167003bbc | |||
| 2ce91fbdf5 | |||
| aa7659d6bf | |||
| 4aa54b9bd4 | |||
| c6d0bacc08 | |||
| 99ed9b22a1 | |||
| eee6d51b40 | |||
| a50e137bba | |||
| 92c0522f4d | |||
| 6a72df2981 | |||
| 808ca48605 | |||
| c827cbc0ae | |||
| 48fcb46d4f | |||
| 66b94599ec | |||
| 231efb33c1 | |||
| eb798dae6f | |||
| 52576c79b3 | |||
| cce2a79a1f | |||
| 413e5f6d77 | |||
| 09ca848d4c | |||
| 801923789b | |||
| cfb696dfd5 | |||
| 2e7a0a88fa | |||
| 1dbbafc30a | |||
| d8eae7faab | |||
| 14eceb6e61 | |||
| 884317c4f7 | |||
| c5f4b229b8 | |||
| 5a2a17ec25 | |||
| 1bd47b0d53 | |||
| 7531ccd31f | |||
| 3b19827ae2 | |||
| ea6e1811c1 | |||
| bc2cf75b76 | |||
| 9e1e0766b7 | |||
| ccde68293f | |||
| 99d53af28d | |||
| 5ea607be58 | |||
| e3846a480e | |||
| a60a58794c | |||
| 8ae5faca53 | |||
| 28d6adf62a | |||
| 1229fba346 | |||
| 59a59ebf66 | |||
| 36ab12c486 | |||
| 0254e3d04a | |||
| f6036e936e | |||
| 10a07e497d | |||
| 3b334805ee | |||
| b6f6c903a0 | |||
| 55637a5620 | |||
| 404cc0a00e | |||
| 0815e2024c | |||
| 41dcb75e8e | |||
| d23daf880f | |||
| d1a8a610e9 | |||
| 918549a4fc | |||
| 8f482cd41a | |||
| 34096059ff | |||
| 2dfbfec8c2 | |||
| 6170995665 | |||
| ca42a54bc3 | |||
| c0610afe2a | |||
| d4cbcc465c | |||
| adb3f17258 | |||
| 2c03a67312 | |||
| 55eb741965 | |||
| 8e6518f071 | |||
| c9c95d60d4 | |||
| 02ecaa340f | |||
| cca809e91c | |||
| 57ff46ecc1 | |||
| 3819d52eb0 | |||
| 3072325d2c | |||
| abca2fdcb7 | |||
| 4d84f76948 | |||
| dd8f6eb923 | |||
| b9c25e487a | |||
| 1bf27c38a7 | |||
| 1f987380ed | |||
| cd8bbbf889 | |||
| 8e5498ee97 | |||
| 0412d7aca0 | |||
| 1eac3245d9 | |||
| cd51bef7f7 | |||
| e8aa33fa0b | |||
| 54b021b02c | |||
| 32151e3d9a | |||
| 32358678e6 | |||
| 42e32664a1 | |||
| 1e97236a15 | |||
| 321f7bce46 | |||
| 02a1d8dbfc | |||
| e34f9d8d1c | |||
| 35dac012bd | |||
| 21ced18f50 | |||
| fca78cf395 | |||
| d1b91b0ea3 | |||
| 76e00acbdb | |||
| 2f83e7738c | |||
| f4a226b0f7 | |||
| f5e2838fc3 | |||
| bbdfd2c3d4 | |||
| 74572e1768 | |||
| f0a17b863c | |||
| 86fd84e113 | |||
| d5b9be23d3 | |||
| 057bb3932f | |||
| 05f29cc406 | |||
| 63c4c7e584 | |||
| 1ea23cab96 | |||
| e99f9fd59f | |||
| fdf6a3e833 | |||
| 79cb94b4c2 | |||
| 9adec7cc10 | |||
| 1f0df47b4d | |||
| a71a12791b | |||
| 23fa834721 | |||
| 9f67d07156 | |||
| 6731a7643e | |||
| f87fdd88ad | |||
| f825f6b90a | |||
| f5d5008a24 | |||
| 0b63d4cde5 | |||
| 2e246869d0 | |||
| 2f9546e144 | |||
| 6134c2ff61 | |||
| 3cfbba74f8 | |||
| 050bb60671 | |||
| 12a7e1ce6e | |||
| cd0438005b | |||
| 7c3188ae06 | |||
| 6cd38a37cd | |||
| 12e51bb6aa | |||
| e2a4cd6b03 | |||
| 329e228aa2 | |||
| 3d5d517f2a | |||
| a2eb2e4dac | |||
| d89792d379 | |||
| 23ed2553c4 | |||
| fe29ce2911 | |||
| df25a3ede2 | |||
| 4c36fb4df2 | |||
| 67c61e0ac8 | |||
| 0985db4e36 | |||
| ee2c00abeb | |||
| 577f24d107 | |||
| fc24b34c2b | |||
| 1e962476da | |||
| 3326327572 | |||
| 36be79ea38 | |||
| 523839be7d | |||
| d1586ddd77 | |||
| 3420853923 | |||
| 1f373d7b0a | |||
| 7fdbd6a680 | |||
| 17b40a1fa1 | |||
| c47e74c5c7 | |||
| 7abbe08ff1 | |||
| 8038b6ab99 | |||
| 6e26ad0966 | |||
| 7e2449b228 | |||
| 97bfee47a3 | |||
| 8868c92141 | |||
| e17dd66dce | |||
| fc8494d696 | |||
| f8aea909b4 | |||
| ccddbeccad | |||
| f73cddcb93 | |||
| 5f36f0d753 | |||
| dc4bf13d39 | |||
| 6d91f44634 | |||
| 0396e10706 |
@ -1,3 +1,5 @@
|
||||
venv/
|
||||
pr_agent/settings/.secrets.toml
|
||||
pics/
|
||||
pics/
|
||||
pr_agent.egg-info/
|
||||
build/
|
||||
|
||||
36
.github/workflows/build-and-test.yaml
vendored
Normal file
36
.github/workflows/build-and-test.yaml
vendored
Normal file
@ -0,0 +1,36 @@
|
||||
name: Build-and-test
|
||||
|
||||
on:
|
||||
push:
|
||||
|
||||
jobs:
|
||||
build-and-test:
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- id: checkout
|
||||
uses: actions/checkout@v2
|
||||
|
||||
- id: dockerx
|
||||
name: Setup Docker Buildx
|
||||
uses: docker/setup-buildx-action@v2
|
||||
|
||||
- id: build
|
||||
name: Build dev docker
|
||||
uses: docker/build-push-action@v2
|
||||
with:
|
||||
context: .
|
||||
file: ./docker/Dockerfile
|
||||
push: false
|
||||
load: true
|
||||
tags: codiumai/pr-agent:test
|
||||
cache-from: type=gha,scope=dev
|
||||
cache-to: type=gha,mode=max,scope=dev
|
||||
target: test
|
||||
|
||||
- id: test
|
||||
name: Test dev docker
|
||||
run: |
|
||||
docker run --rm codiumai/pr-agent:test pytest -v
|
||||
|
||||
|
||||
@ -1,6 +1,17 @@
|
||||
# This workflow enables developers to call PR-Agents `/[actions]` in PR's comments and upon PR creation.
|
||||
# Learn more at https://www.codium.ai/pr-agent/
|
||||
# This is v0.2 of this workflow file
|
||||
|
||||
name: PR-Agent
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
issue_comment:
|
||||
|
||||
permissions:
|
||||
issues: write
|
||||
pull-requests: write
|
||||
|
||||
jobs:
|
||||
pr_agent_job:
|
||||
runs-on: ubuntu-latest
|
||||
6
.gitignore
vendored
6
.gitignore
vendored
@ -1,4 +1,8 @@
|
||||
.idea/
|
||||
venv/
|
||||
pr_agent/settings/.secrets.toml
|
||||
__pycache__
|
||||
__pycache__
|
||||
dist/
|
||||
*.egg-info/
|
||||
build/
|
||||
review.md
|
||||
|
||||
45
CHANGELOG.md
Normal file
45
CHANGELOG.md
Normal file
@ -0,0 +1,45 @@
|
||||
## 2023-08-03
|
||||
|
||||
### Optimized
|
||||
- Optimized PR diff processing by introducing caching for diff files, reducing the number of API calls.
|
||||
- Refactored `load_large_diff` function to generate a patch only when necessary.
|
||||
- Fixed a bug in the GitLab provider where the new file was not retrieved correctly.
|
||||
|
||||
## 2023-08-02
|
||||
|
||||
### Enhanced
|
||||
- Updated several tools in the `pr_agent` package to use commit messages in their functionality.
|
||||
- Commit messages are now retrieved and stored in the `vars` dictionary for each tool.
|
||||
- Added a section to display the commit messages in the prompts of various tools.
|
||||
|
||||
## 2023-08-01
|
||||
|
||||
### Enhanced
|
||||
- Introduced the ability to retrieve commit messages from pull requests across different git providers.
|
||||
- Implemented commit messages retrieval for GitHub and GitLab providers.
|
||||
- Updated the PR description template to include a section for commit messages if they exist.
|
||||
- Added support for repository-specific configuration files (.pr_agent.yaml) for the PR Agent.
|
||||
- Implemented this feature for both GitHub and GitLab providers.
|
||||
- Added a new configuration option 'use_repo_settings_file' to enable or disable the use of a repo-specific settings file.
|
||||
|
||||
|
||||
## 2023-07-30
|
||||
|
||||
### Enhanced
|
||||
- Added the ability to modify any configuration parameter from 'configuration.toml' on-the-fly.
|
||||
- Updated the command line interface and bot commands to accept configuration changes as arguments.
|
||||
- Improved the PR agent to handle additional arguments for each action.
|
||||
|
||||
## 2023-07-28
|
||||
|
||||
### Improved
|
||||
- Enhanced error handling and logging in the GitLab provider.
|
||||
- Improved handling of inline comments and code suggestions in GitLab.
|
||||
- Fixed a bug where an additional unneeded line was added to code suggestions in GitLab.
|
||||
|
||||
## 2023-07-26
|
||||
|
||||
### Added
|
||||
- New feature for updating the CHANGELOG.md based on the contents of a PR.
|
||||
- Added support for this feature for the Github provider.
|
||||
- New configuration settings and prompts for the changelog update feature.
|
||||
@ -1,18 +1,57 @@
|
||||
## Configuration
|
||||
|
||||
The different tools and sub-tools used by CodiumAI pr-agent are easily configurable via the configuration file: `/pr-agent/settings/configuration.toml`.
|
||||
##### Git Provider:
|
||||
You can select your git_provider with the flag `git_provider` in the `config` section
|
||||
The different tools and sub-tools used by CodiumAI PR-Agent are adjustable via the **[configuration file](pr_agent/settings/configuration.toml)**
|
||||
|
||||
##### PR Reviewer:
|
||||
### Working from CLI
|
||||
When running from source (CLI), your local configuration file will be initially used.
|
||||
|
||||
Example for invoking the 'review' tools via the CLI:
|
||||
|
||||
You can enable/disable the different PR Reviewer abilities with the following flags (`pr_reviewer` section):
|
||||
```
|
||||
require_focused_review=true
|
||||
require_tests_review=true
|
||||
require_security_review=true
|
||||
python cli.py --pr-url=<pr_url> review
|
||||
```
|
||||
You can contol the number of suggestions returned by the PR Reviewer with the following flag:
|
||||
```inline_code_comments=3```
|
||||
And enable/disable the inline code suggestions with the following flag:
|
||||
```inline_code_comments=true```
|
||||
In addition to general configurations, the 'review' tool will use parameters from the `[pr_reviewer]` section (every tool has a dedicated section in the configuration file).
|
||||
|
||||
Note that you can print results locally, without publishing them, by setting in `configuration.toml`:
|
||||
|
||||
```
|
||||
[config]
|
||||
publish_output=true
|
||||
verbosity_level=2
|
||||
```
|
||||
This is useful for debugging or experimenting with the different tools.
|
||||
|
||||
### Working from pre-built repo (GitHub Action/GitHub App/Docker)
|
||||
When running PR-Agent from a pre-built repo, the default configuration file will be loaded.
|
||||
|
||||
To edit the configuration, you have two options:
|
||||
1. Place a local configuration file in the root of your local repo. The local file will be used instead of the default one.
|
||||
2. For online usage, just add `--config_path=<value>` to you command, to edit a specific configuration value.
|
||||
For example if you want to edit `pr_reviewer` configurations, you can run:
|
||||
```
|
||||
/review --pr_reviewer.extra_instructions="..." --pr_reviewer.require_score_review=false ...
|
||||
```
|
||||
|
||||
Any configuration value in `configuration.toml` file can be similarly edited.
|
||||
|
||||
### General configuration parameters
|
||||
|
||||
#### Changing a model
|
||||
See [here](pr_agent/algo/__init__.py) for the list of available models.
|
||||
|
||||
To use Llama2 model, for example, set:
|
||||
```
|
||||
[config]
|
||||
model = "replicate/llama-2-70b-chat:2c1608e18606fad2812020dc541930f2d0495ce32eee50074220b87300bc16e1"
|
||||
[replicate]
|
||||
key = ...
|
||||
```
|
||||
(you can obtain a Llama2 key from [here](https://replicate.com/replicate/llama-2-70b-chat/api))
|
||||
|
||||
Also review the [AiHandler](pr_agent/algo/ai_handler.py) file for instruction how to set keys for other models.
|
||||
|
||||
#### Extra instructions
|
||||
All PR-Agent tools have a parameter called `extra_instructions`, that enables to add free-text extra instructions. Example usage:
|
||||
```
|
||||
/update_changelog --pr_update_changelog.extra_instructions="Make sure to update also the version ..."
|
||||
```
|
||||
@ -1,8 +1,8 @@
|
||||
FROM python:3.10 as base
|
||||
|
||||
WORKDIR /app
|
||||
ADD requirements.txt .
|
||||
RUN pip install -r requirements.txt && rm requirements.txt
|
||||
ADD pyproject.toml .
|
||||
RUN pip install . && rm pyproject.toml
|
||||
ENV PYTHONPATH=/app
|
||||
ADD pr_agent pr_agent
|
||||
ADD github_action/entrypoint.sh /
|
||||
|
||||
@ -92,12 +92,14 @@ pip install -r requirements.txt
|
||||
|
||||
```
|
||||
cp pr_agent/settings/.secrets_template.toml pr_agent/settings/.secrets.toml
|
||||
chmod 600 pr_agent/settings/.secrets.toml
|
||||
# Edit .secrets.toml file
|
||||
```
|
||||
|
||||
4. Run the appropriate Python scripts from the scripts folder:
|
||||
4. Add the pr_agent folder to your PYTHONPATH, then run the cli.py script:
|
||||
|
||||
```
|
||||
export PYTHONPATH=[$PYTHONPATH:]<PATH to pr_agent folder>
|
||||
python pr_agent/cli.py --pr_url <pr_url> review
|
||||
python pr_agent/cli.py --pr_url <pr_url> ask <your question>
|
||||
python pr_agent/cli.py --pr_url <pr_url> describe
|
||||
@ -127,6 +129,7 @@ Allowing you to automate the review process on your private or public repositori
|
||||
- Pull requests: Read & write
|
||||
- Issue comment: Read & write
|
||||
- Metadata: Read-only
|
||||
- Contents: Read-only
|
||||
- Set the following events:
|
||||
- Issue comment
|
||||
- Pull request
|
||||
|
||||
@ -31,7 +31,7 @@ We prioritize additions over deletions:
|
||||
- File patches are a list of hunks, remove all hunks of type deletion-only from the hunks in the file patch
|
||||
#### Adaptive and token-aware file patch fitting
|
||||
We use [tiktoken](https://github.com/openai/tiktoken) to tokenize the patches after the modifications described above, and we use the following strategy to fit the patches into the prompt:
|
||||
1. Withing each language we sort the files by the number of tokens in the file (in descending order):
|
||||
1. Within each language we sort the files by the number of tokens in the file (in descending order):
|
||||
* ```[[file2.py, file.py],[file4.jsx, file3.js],[readme.md]]```
|
||||
2. Iterate through the patches in the order described above
|
||||
2. Add the patches to the prompt until the prompt reaches a certain buffer from the max token length
|
||||
@ -39,4 +39,4 @@ We use [tiktoken](https://github.com/openai/tiktoken) to tokenize the patches af
|
||||
4. If we haven't reached the max token length, add the `deleted files` to the prompt until the prompt reaches the max token length (hard stop), skip the rest of the patches.
|
||||
|
||||
### Example
|
||||
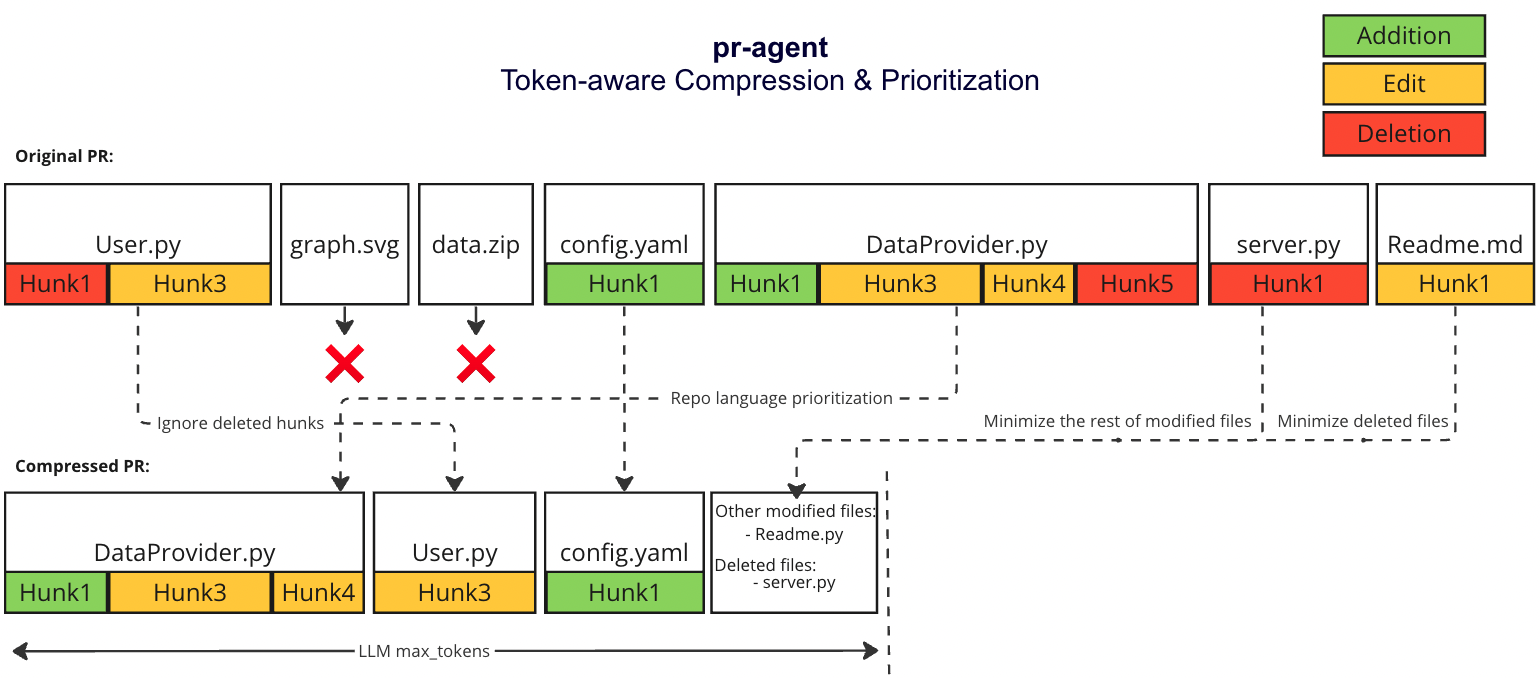
|
||||

|
||||
|
||||
118
README.md
118
README.md
@ -2,115 +2,130 @@
|
||||
|
||||
<div align="center">
|
||||
|
||||
<img src="./pics/logo-dark.png#gh-dark-mode-only" width="250"/>
|
||||
<img src="./pics/logo-light.png#gh-light-mode-only" width="250"/>
|
||||
|
||||
<img src="./pics/logo-dark.png#gh-dark-mode-only" width="330"/>
|
||||
<img src="./pics/logo-light.png#gh-light-mode-only" width="330"/><br/>
|
||||
Making pull requests less painful with an AI agent
|
||||
</div>
|
||||
|
||||
[](https://github.com/Codium-ai/pr-agent/blob/main/LICENSE)
|
||||
[](https://discord.com/channels/1057273017547378788/1126104260430528613)
|
||||
<a href="https://github.com/Codium-ai/pr-agent/commits/main">
|
||||
<img alt="GitHub" src="https://img.shields.io/github/last-commit/Codium-ai/pr-agent/main?style=for-the-badge" height="20">
|
||||
</a>
|
||||
</div>
|
||||
<div style="text-align:left;">
|
||||
|
||||
CodiumAI `PR-Agent` is an open-source tool aiming to help developers review PRs faster and more efficiently. It automatically analyzes the PR and can provide several types of feedback:
|
||||
CodiumAI `PR-Agent` is an open-source tool aiming to help developers review pull requests faster and more efficiently. It automatically analyzes the pull request and can provide several types of feedback:
|
||||
|
||||
**Auto-Description**: Automatically generating PR description - name, type, summary, and code walkthrough.
|
||||
**Auto-Description**: Automatically generating PR description - title, type, summary, code walkthrough and PR labels.
|
||||
\
|
||||
**PR Review**: Feedback about the PR main theme, type, relevant tests, security issues, focused PR, and various suggestions for the PR content.
|
||||
**PR Review**: Adjustable feedback about the PR main theme, type, relevant tests, security issues, focus, score, and various suggestions for the PR content.
|
||||
\
|
||||
**Question Answering**: Answering free-text questions about the PR.
|
||||
\
|
||||
**Code Suggestion**: Committable code suggestions for improving the PR.
|
||||
**Code Suggestions**: Committable code suggestions for improving the PR.
|
||||
\
|
||||
**Update Changelog**: Automatically updating the CHANGELOG.md file with the PR changes.
|
||||
|
||||
<h3>Example results:</h2>
|
||||
</div>
|
||||
<h4>/describe:</h4>
|
||||
<div align="center">
|
||||
<p float="center">
|
||||
<img src="https://codium.ai/images/describe.gif" width="800">
|
||||
<img src="https://www.codium.ai/images/describe-2.gif" width="800">
|
||||
</p>
|
||||
</div>
|
||||
<h4>/review:</h4>
|
||||
<div align="center">
|
||||
<p float="center">
|
||||
<img src="https://codium.ai/images/review.gif" width="800">
|
||||
<img src="https://www.codium.ai/images/review-2.gif" width="800">
|
||||
</p>
|
||||
</div>
|
||||
<h4>/reflect_and_review:</h4>
|
||||
<div align="center">
|
||||
<p float="center">
|
||||
<img src="https://www.codium.ai/images/reflect_and_review.gif" width="800">
|
||||
</p>
|
||||
</div>
|
||||
<h4>/ask:</h4>
|
||||
<div align="center">
|
||||
<p float="center">
|
||||
<img src="https://codium.ai/images/ask.gif" width="800">
|
||||
<img src="https://www.codium.ai/images/ask-2.gif" width="800">
|
||||
</p>
|
||||
</div>
|
||||
<h4>/improve:</h4>
|
||||
<div align="center">
|
||||
<p float="center">
|
||||
<img src="https://codium.ai/images/improve.gif" width="800">
|
||||
<img src="https://www.codium.ai/images/improve-2.gif" width="800">
|
||||
</p>
|
||||
</div>
|
||||
<div align="left">
|
||||
|
||||
- [Live demo](#live-demo)
|
||||
|
||||
- [Overview](#overview)
|
||||
- [Quickstart](#quickstart)
|
||||
- [Usage and tools](#usage-and-tools)
|
||||
- [Try it now](#try-it-now)
|
||||
- [Installation](#installation)
|
||||
- [Configuration](./CONFIGURATION.md)
|
||||
- [How it works](#how-it-works)
|
||||
- [Why use PR-Agent](#why-use-pr-agent)
|
||||
- [Roadmap](#roadmap)
|
||||
- [Similar projects](#similar-projects)
|
||||
</div>
|
||||
|
||||
## Live demo
|
||||
|
||||
Experience GPT-4 powered PR review on your public GitHub repository with our hosted PR-Agent. To try it, just mention `@CodiumAI-Agent` and add the desired command in any PR comment! The agent will generate a response based on your command.
|
||||
|
||||

|
||||
|
||||
To set up your own PR-Agent, see the [Quickstart](#Quickstart) section
|
||||
|
||||
---
|
||||
## Overview
|
||||
`PR-Agent` offers extensive pull request functionalities across various git providers:
|
||||
| | | GitHub | Gitlab | Bitbucket |
|
||||
|-------|---------------------------------------------|:------:|:------:|:---------:|
|
||||
| TOOLS | Review | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||
| | ⮑ Inline review | :white_check_mark: | :white_check_mark: | |
|
||||
| | Ask | :white_check_mark: | :white_check_mark: | |
|
||||
| | Ask | :white_check_mark: | :white_check_mark: | :white_check_mark:
|
||||
| | Auto-Description | :white_check_mark: | :white_check_mark: | |
|
||||
| | Improve Code | :white_check_mark: | :white_check_mark: | |
|
||||
| | Reflect and Review | :white_check_mark: | | |
|
||||
| | Update CHANGELOG.md | :white_check_mark: | | |
|
||||
| | | | | |
|
||||
| USAGE | CLI | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||
| | Tagging bot | :white_check_mark: | :white_check_mark: | |
|
||||
| | App / webhook | :white_check_mark: | :white_check_mark: | |
|
||||
| | Tagging bot | :white_check_mark: | | |
|
||||
| | Actions | :white_check_mark: | | |
|
||||
| | | | | |
|
||||
| CORE | PR compression | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||
| | Repo language prioritization | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||
| | Adaptive and token-aware<br />file patch fitting | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||
| | Multiple models support | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||
| | Incremental PR Review | :white_check_mark: | | |
|
||||
|
||||
Examples for invoking the different tools via the [CLI](#quickstart):
|
||||
- **Review**: python cli.py --pr-url=<pr_url> review
|
||||
- **Describe**: python cli.py --pr-url=<pr_url> describe
|
||||
- **Improve**: python cli.py --pr-url=<pr_url> improve
|
||||
- **Ask**: python cli.py --pr-url=<pr_url> ask "Write me a poem about this PR"
|
||||
- **Reflect**: python cli.py --pr-url=<pr_url> reflect
|
||||
Examples for invoking the different tools via the CLI:
|
||||
- **Review**: python cli.py --pr_url=<pr_url> review
|
||||
- **Describe**: python cli.py --pr_url=<pr_url> describe
|
||||
- **Improve**: python cli.py --pr_url=<pr_url> improve
|
||||
- **Ask**: python cli.py --pr_url=<pr_url> ask "Write me a poem about this PR"
|
||||
- **Reflect**: python cli.py --pr_url=<pr_url> reflect
|
||||
- **Update Changelog**: python cli.py --pr_url=<pr_url> update_changelog
|
||||
|
||||
"<pr_url>" is the url of the relevant PR (for example: https://github.com/Codium-ai/pr-agent/pull/50).
|
||||
|
||||
In the [configuration](./CONFIGURATION.md) file you can select your git provider (GitHub, Gitlab, Bitbucket), and further configure the different tools.
|
||||
|
||||
## Quickstart
|
||||
## Try it now
|
||||
|
||||
Try GPT-4 powered PR-Agent on your public GitHub repository for free. Just mention `@CodiumAI-Agent` and add the desired command in any PR comment! The agent will generate a response based on your command.
|
||||
|
||||
|
||||
|
||||
To set up your own PR-Agent, see the [Installation](#installation) section
|
||||
|
||||
---
|
||||
|
||||
## Installation
|
||||
|
||||
To get started with PR-Agent quickly, you first need to acquire two tokens:
|
||||
|
||||
1. An OpenAI key from [here](https://platform.openai.com/), with access to GPT-4.
|
||||
2. A GitHub personal access token (classic) with the repo scope.
|
||||
|
||||
There are several ways to use PR-Agent. Let's start with the simplest one:
|
||||
|
||||
|
||||
## Install
|
||||
Here are several ways to install and run PR-Agent:
|
||||
There are several ways to use PR-Agent:
|
||||
|
||||
- [Method 1: Use Docker image (no installation required)](INSTALL.md#method-1-use-docker-image-no-installation-required)
|
||||
- [Method 2: Run as a GitHub Action](INSTALL.md#method-2-run-as-a-github-action)
|
||||
@ -120,36 +135,41 @@ Here are several ways to install and run PR-Agent:
|
||||
- [Method 5: Run as a GitHub App](INSTALL.md#method-5-run-as-a-github-app)
|
||||
- Allowing you to automate the review process on your private or public repositories
|
||||
|
||||
## Usage and Tools
|
||||
|
||||
**PR-Agent** provides five types of interactions ("tools"): `"PR Reviewer"`, `"PR Q&A"`, `"PR Description"`, `"PR Code Sueggestions"` and `"PR Reflect and Review"`.
|
||||
|
||||
- The "PR Reviewer" tool automatically analyzes PRs, and provides various types of feedback.
|
||||
- The "PR Q&A" tool answers free-text questions about the PR.
|
||||
- The "PR Description" tool automatically sets the PR Title and body.
|
||||
- The "PR Code Suggestion" tool provide inline code suggestions for the PR that can be applied and committed.
|
||||
- The "PR Reflect and Review" tool first initiates a dialog with the user and asks them to reflect on the PR, and then provides a review.
|
||||
|
||||
## How it works
|
||||
|
||||
The following diagram illustrates PR-Agent tools and their flow:
|
||||
|
||||

|
||||
|
||||
Check out the [PR Compression strategy](./PR_COMPRESSION.md) page for more details on how we convert a code diff to a manageable LLM prompt
|
||||
|
||||
## Why use PR-Agent?
|
||||
|
||||
A reasonable question that can be asked is: `"Why use PR-Agent? What make it stand out from existing tools?"`
|
||||
|
||||
Here are some advantages of PR-Agent:
|
||||
|
||||
- We emphasize **real-life practical usage**. Each tool (review, improve, ask, ...) has a single GPT-4 call, no more. We feel that this is critical for realistic team usage - obtaining an answer quickly (~30 seconds) and affordably.
|
||||
- Our [PR Compression strategy](./PR_COMPRESSION.md) is a core ability that enables to effectively tackle both short and long PRs.
|
||||
- Our JSON prompting strategy enables to have **modular, customizable tools**. For example, the '/review' tool categories can be controlled via the [configuration](./CONFIGURATION.md) file. Adding additional categories is easy and accessible.
|
||||
- We support **multiple git providers** (GitHub, Gitlab, Bitbucket), **multiple ways** to use the tool (CLI, GitHub Action, GitHub App, Docker, ...), and **multiple models** (GPT-4, GPT-3.5, Anthropic, Cohere, Llama2).
|
||||
- We are open-source, and welcome contributions from the community.
|
||||
|
||||
|
||||
## Roadmap
|
||||
|
||||
- [ ] Support open-source models, as a replacement for openai models. (Note - a minimal requirement for each open-source model is to have 8k+ context, and good support for generating json as an output)
|
||||
- [x] Support other Git providers, such as Gitlab and Bitbucket.
|
||||
- [ ] Develop additional logics for handling large PRs, and compressing git patches
|
||||
- [x] Support additional models, as a replacement for OpenAI (see [here](https://github.com/Codium-ai/pr-agent/pull/172))
|
||||
- [ ] Develop additional logic for handling large PRs
|
||||
- [ ] Add additional context to the prompt. For example, repo (or relevant files) summarization, with tools such a [ctags](https://github.com/universal-ctags/ctags)
|
||||
- [ ] Adding more tools. Possible directions:
|
||||
- [x] PR description
|
||||
- [x] Inline code suggestions
|
||||
- [x] Reflect and review
|
||||
- [x] Rank the PR (see [here](https://github.com/Codium-ai/pr-agent/pull/89))
|
||||
- [ ] Enforcing CONTRIBUTING.md guidelines
|
||||
- [ ] Performance (are there any performance issues)
|
||||
- [ ] Documentation (is the PR properly documented)
|
||||
- [ ] Rank the PR importance
|
||||
- [ ] ...
|
||||
|
||||
## Similar Projects
|
||||
|
||||
@ -1,5 +1,8 @@
|
||||
name: 'PR Agent'
|
||||
name: 'Codium PR Agent'
|
||||
description: 'Summarize, review and suggest improvements for pull requests'
|
||||
branding:
|
||||
icon: 'award'
|
||||
color: 'green'
|
||||
runs:
|
||||
using: 'docker'
|
||||
image: 'Dockerfile.github_action_dockerhub'
|
||||
|
||||
@ -1,20 +1,24 @@
|
||||
FROM python:3.10 as base
|
||||
|
||||
WORKDIR /app
|
||||
ADD requirements.txt .
|
||||
RUN pip install -r requirements.txt && rm requirements.txt
|
||||
ADD pyproject.toml .
|
||||
RUN pip install . && rm pyproject.toml
|
||||
ENV PYTHONPATH=/app
|
||||
ADD pr_agent pr_agent
|
||||
|
||||
FROM base as github_app
|
||||
ADD pr_agent pr_agent
|
||||
CMD ["python", "pr_agent/servers/github_app.py"]
|
||||
|
||||
FROM base as github_polling
|
||||
ADD pr_agent pr_agent
|
||||
CMD ["python", "pr_agent/servers/github_polling.py"]
|
||||
|
||||
FROM base as test
|
||||
ADD requirements-dev.txt .
|
||||
RUN pip install -r requirements-dev.txt && rm requirements-dev.txt
|
||||
ADD pr_agent pr_agent
|
||||
ADD tests tests
|
||||
|
||||
FROM base as cli
|
||||
ADD pr_agent pr_agent
|
||||
ENTRYPOINT ["python", "pr_agent/cli.py"]
|
||||
|
||||
@ -4,9 +4,9 @@ RUN yum update -y && \
|
||||
yum install -y gcc python3-devel && \
|
||||
yum clean all
|
||||
|
||||
ADD requirements.txt .
|
||||
RUN pip install -r requirements.txt && rm requirements.txt
|
||||
RUN pip install mangum==16.0.0
|
||||
ADD pyproject.toml .
|
||||
RUN pip install . && rm pyproject.toml
|
||||
RUN pip install mangum==0.17.0
|
||||
COPY pr_agent/ ${LAMBDA_TASK_ROOT}/pr_agent/
|
||||
|
||||
CMD ["pr_agent.servers.serverless.serverless"]
|
||||
|
||||
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 20 KiB After Width: | Height: | Size: 22 KiB |
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 21 KiB After Width: | Height: | Size: 25 KiB |
@ -1,36 +1,79 @@
|
||||
import re
|
||||
import logging
|
||||
import os
|
||||
import shlex
|
||||
import tempfile
|
||||
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.algo.utils import update_settings_from_args
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers import get_git_provider
|
||||
from pr_agent.tools.pr_code_suggestions import PRCodeSuggestions
|
||||
from pr_agent.tools.pr_description import PRDescription
|
||||
from pr_agent.tools.pr_information_from_user import PRInformationFromUser
|
||||
from pr_agent.tools.pr_questions import PRQuestions
|
||||
from pr_agent.tools.pr_reviewer import PRReviewer
|
||||
from pr_agent.tools.pr_update_changelog import PRUpdateChangelog
|
||||
from pr_agent.tools.pr_config import PRConfig
|
||||
|
||||
command2class = {
|
||||
"answer": PRReviewer,
|
||||
"review": PRReviewer,
|
||||
"review_pr": PRReviewer,
|
||||
"reflect": PRInformationFromUser,
|
||||
"reflect_and_review": PRInformationFromUser,
|
||||
"describe": PRDescription,
|
||||
"describe_pr": PRDescription,
|
||||
"improve": PRCodeSuggestions,
|
||||
"improve_code": PRCodeSuggestions,
|
||||
"ask": PRQuestions,
|
||||
"ask_question": PRQuestions,
|
||||
"update_changelog": PRUpdateChangelog,
|
||||
"config": PRConfig,
|
||||
"settings": PRConfig,
|
||||
}
|
||||
|
||||
commands = list(command2class.keys())
|
||||
|
||||
class PRAgent:
|
||||
def __init__(self):
|
||||
pass
|
||||
|
||||
async def handle_request(self, pr_url, request) -> bool:
|
||||
if any(cmd in request for cmd in ["/answer"]):
|
||||
await PRReviewer(pr_url, is_answer=True).review()
|
||||
elif any(cmd in request for cmd in ["/review", "/review_pr", "/reflect_and_review"]):
|
||||
if settings.pr_reviewer.ask_and_reflect or "/reflect_and_review" in request:
|
||||
await PRInformationFromUser(pr_url).generate_questions()
|
||||
else:
|
||||
await PRReviewer(pr_url).review()
|
||||
elif any(cmd in request for cmd in ["/describe", "/describe_pr"]):
|
||||
await PRDescription(pr_url).describe()
|
||||
elif any(cmd in request for cmd in ["/improve", "/improve_code"]):
|
||||
await PRCodeSuggestions(pr_url).suggest()
|
||||
elif any(cmd in request for cmd in ["/ask", "/ask_question"]):
|
||||
pattern = r'(/ask|/ask_question)\s*(.*)'
|
||||
matches = re.findall(pattern, request, re.IGNORECASE)
|
||||
if matches:
|
||||
question = matches[0][1]
|
||||
await PRQuestions(pr_url, question).answer()
|
||||
async def handle_request(self, pr_url, request, notify=None) -> bool:
|
||||
# First, apply repo specific settings if exists
|
||||
if get_settings().config.use_repo_settings_file:
|
||||
repo_settings_file = None
|
||||
try:
|
||||
git_provider = get_git_provider()(pr_url)
|
||||
repo_settings = git_provider.get_repo_settings()
|
||||
if repo_settings:
|
||||
repo_settings_file = None
|
||||
fd, repo_settings_file = tempfile.mkstemp(suffix='.toml')
|
||||
os.write(fd, repo_settings)
|
||||
get_settings().load_file(repo_settings_file)
|
||||
finally:
|
||||
if repo_settings_file:
|
||||
try:
|
||||
os.remove(repo_settings_file)
|
||||
except Exception as e:
|
||||
logging.error(f"Failed to remove temporary settings file {repo_settings_file}", e)
|
||||
|
||||
# Then, apply user specific settings if exists
|
||||
request = request.replace("'", "\\'")
|
||||
lexer = shlex.shlex(request, posix=True)
|
||||
lexer.whitespace_split = True
|
||||
action, *args = list(lexer)
|
||||
args = update_settings_from_args(args)
|
||||
|
||||
action = action.lstrip("/").lower()
|
||||
if action == "reflect_and_review" and not get_settings().pr_reviewer.ask_and_reflect:
|
||||
action = "review"
|
||||
if action == "answer":
|
||||
if notify:
|
||||
notify()
|
||||
await PRReviewer(pr_url, is_answer=True, args=args).run()
|
||||
elif action in command2class:
|
||||
if notify:
|
||||
notify()
|
||||
await command2class[action](pr_url, args=args).run()
|
||||
else:
|
||||
return False
|
||||
|
||||
return True
|
||||
|
||||
@ -7,4 +7,8 @@ MAX_TOKENS = {
|
||||
'gpt-4': 8000,
|
||||
'gpt-4-0613': 8000,
|
||||
'gpt-4-32k': 32000,
|
||||
'claude-instant-1': 100000,
|
||||
'claude-2': 100000,
|
||||
'command-nightly': 4096,
|
||||
'replicate/llama-2-70b-chat:2c1608e18606fad2812020dc541930f2d0495ce32eee50074220b87300bc16e1': 4096,
|
||||
}
|
||||
|
||||
@ -1,47 +1,110 @@
|
||||
import logging
|
||||
|
||||
import litellm
|
||||
import openai
|
||||
from openai.error import APIError, Timeout, TryAgain
|
||||
from litellm import acompletion
|
||||
from openai.error import APIError, RateLimitError, Timeout, TryAgain
|
||||
from retry import retry
|
||||
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.config_loader import get_settings
|
||||
|
||||
OPENAI_RETRIES = 5
|
||||
|
||||
OPENAI_RETRIES=2
|
||||
|
||||
class AiHandler:
|
||||
"""
|
||||
This class handles interactions with the OpenAI API for chat completions.
|
||||
It initializes the API key and other settings from a configuration file,
|
||||
and provides a method for performing chat completions using the OpenAI ChatCompletion API.
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
"""
|
||||
Initializes the OpenAI API key and other settings from a configuration file.
|
||||
Raises a ValueError if the OpenAI key is missing.
|
||||
"""
|
||||
try:
|
||||
openai.api_key = settings.openai.key
|
||||
if settings.get("OPENAI.ORG", None):
|
||||
openai.organization = settings.openai.org
|
||||
self.deployment_id = settings.get("OPENAI.DEPLOYMENT_ID", None)
|
||||
if settings.get("OPENAI.API_TYPE", None):
|
||||
openai.api_type = settings.openai.api_type
|
||||
if settings.get("OPENAI.API_VERSION", None):
|
||||
openai.api_version = settings.openai.api_version
|
||||
if settings.get("OPENAI.API_BASE", None):
|
||||
openai.api_base = settings.openai.api_base
|
||||
openai.api_key = get_settings().openai.key
|
||||
litellm.openai_key = get_settings().openai.key
|
||||
self.azure = False
|
||||
if get_settings().get("OPENAI.ORG", None):
|
||||
litellm.organization = get_settings().openai.org
|
||||
if get_settings().get("OPENAI.API_TYPE", None):
|
||||
if get_settings().openai.api_type == "azure":
|
||||
self.azure = True
|
||||
litellm.azure_key = get_settings().openai.key
|
||||
if get_settings().get("OPENAI.API_VERSION", None):
|
||||
litellm.api_version = get_settings().openai.api_version
|
||||
if get_settings().get("OPENAI.API_BASE", None):
|
||||
litellm.api_base = get_settings().openai.api_base
|
||||
if get_settings().get("ANTHROPIC.KEY", None):
|
||||
litellm.anthropic_key = get_settings().anthropic.key
|
||||
if get_settings().get("COHERE.KEY", None):
|
||||
litellm.cohere_key = get_settings().cohere.key
|
||||
if get_settings().get("REPLICATE.KEY", None):
|
||||
litellm.replicate_key = get_settings().replicate.key
|
||||
except AttributeError as e:
|
||||
raise ValueError("OpenAI key is required") from e
|
||||
|
||||
@retry(exceptions=(APIError, Timeout, TryAgain, AttributeError),
|
||||
@property
|
||||
def deployment_id(self):
|
||||
"""
|
||||
Returns the deployment ID for the OpenAI API.
|
||||
"""
|
||||
return get_settings().get("OPENAI.DEPLOYMENT_ID", None)
|
||||
|
||||
@retry(exceptions=(APIError, Timeout, TryAgain, AttributeError, RateLimitError),
|
||||
tries=OPENAI_RETRIES, delay=2, backoff=2, jitter=(1, 3))
|
||||
async def chat_completion(self, model: str, temperature: float, system: str, user: str):
|
||||
"""
|
||||
Performs a chat completion using the OpenAI ChatCompletion API.
|
||||
Retries in case of API errors or timeouts.
|
||||
|
||||
Args:
|
||||
model (str): The model to use for chat completion.
|
||||
temperature (float): The temperature parameter for chat completion.
|
||||
system (str): The system message for chat completion.
|
||||
user (str): The user message for chat completion.
|
||||
|
||||
Returns:
|
||||
tuple: A tuple containing the response and finish reason from the API.
|
||||
|
||||
Raises:
|
||||
TryAgain: If the API response is empty or there are no choices in the response.
|
||||
APIError: If there is an error during OpenAI inference.
|
||||
Timeout: If there is a timeout during OpenAI inference.
|
||||
TryAgain: If there is an attribute error during OpenAI inference.
|
||||
"""
|
||||
try:
|
||||
response = await openai.ChatCompletion.acreate(
|
||||
model=model,
|
||||
deployment_id=self.deployment_id,
|
||||
messages=[
|
||||
{"role": "system", "content": system},
|
||||
{"role": "user", "content": user}
|
||||
],
|
||||
temperature=temperature,
|
||||
)
|
||||
deployment_id = self.deployment_id
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
logging.debug(
|
||||
f"Generating completion with {model}"
|
||||
f"{(' from deployment ' + deployment_id) if deployment_id else ''}"
|
||||
)
|
||||
response = await acompletion(
|
||||
model=model,
|
||||
deployment_id=deployment_id,
|
||||
messages=[
|
||||
{"role": "system", "content": system},
|
||||
{"role": "user", "content": user}
|
||||
],
|
||||
temperature=temperature,
|
||||
azure=self.azure,
|
||||
force_timeout=get_settings().config.ai_timeout
|
||||
)
|
||||
except (APIError, Timeout, TryAgain) as e:
|
||||
logging.error("Error during OpenAI inference: ", e)
|
||||
raise
|
||||
if response is None or len(response.choices) == 0:
|
||||
except (RateLimitError) as e:
|
||||
logging.error("Rate limit error during OpenAI inference: ", e)
|
||||
raise
|
||||
except (Exception) as e:
|
||||
logging.error("Unknown error during OpenAI inference: ", e)
|
||||
raise TryAgain from e
|
||||
if response is None or len(response["choices"]) == 0:
|
||||
raise TryAgain
|
||||
resp = response.choices[0]['message']['content']
|
||||
finish_reason = response.choices[0].finish_reason
|
||||
resp = response["choices"][0]['message']['content']
|
||||
finish_reason = response["choices"][0]["finish_reason"]
|
||||
print(resp, finish_reason)
|
||||
return resp, finish_reason
|
||||
|
||||
@ -3,12 +3,20 @@ from __future__ import annotations
|
||||
import logging
|
||||
import re
|
||||
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.config_loader import get_settings
|
||||
|
||||
|
||||
def extend_patch(original_file_str, patch_str, num_lines) -> str:
|
||||
"""
|
||||
Extends the patch to include 'num_lines' more surrounding lines
|
||||
Extends the given patch to include a specified number of surrounding lines.
|
||||
|
||||
Args:
|
||||
original_file_str (str): The original file to which the patch will be applied.
|
||||
patch_str (str): The patch to be applied to the original file.
|
||||
num_lines (int): The number of surrounding lines to include in the extended patch.
|
||||
|
||||
Returns:
|
||||
str: The extended patch string.
|
||||
"""
|
||||
if not patch_str or num_lines == 0:
|
||||
return patch_str
|
||||
@ -33,7 +41,11 @@ def extend_patch(original_file_str, patch_str, num_lines) -> str:
|
||||
extended_patch_lines.extend(
|
||||
original_lines[start1 + size1 - 1:start1 + size1 - 1 + num_lines])
|
||||
|
||||
start1, size1, start2, size2 = map(int, match.groups()[:4])
|
||||
try:
|
||||
start1, size1, start2, size2 = map(int, match.groups()[:4])
|
||||
except: # '@@ -0,0 +1 @@' case
|
||||
start1, size1, size2 = map(int, match.groups()[:3])
|
||||
start2 = 0
|
||||
section_header = match.groups()[4]
|
||||
extended_start1 = max(1, start1 - num_lines)
|
||||
extended_size1 = size1 + (start1 - extended_start1) + num_lines
|
||||
@ -47,7 +59,7 @@ def extend_patch(original_file_str, patch_str, num_lines) -> str:
|
||||
continue
|
||||
extended_patch_lines.append(line)
|
||||
except Exception as e:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
logging.error(f"Failed to extend patch: {e}")
|
||||
return patch_str
|
||||
|
||||
@ -61,6 +73,14 @@ def extend_patch(original_file_str, patch_str, num_lines) -> str:
|
||||
|
||||
|
||||
def omit_deletion_hunks(patch_lines) -> str:
|
||||
"""
|
||||
Omit deletion hunks from the patch and return the modified patch.
|
||||
Args:
|
||||
- patch_lines: a list of strings representing the lines of the patch
|
||||
Returns:
|
||||
- A string representing the modified patch with deletion hunks omitted
|
||||
"""
|
||||
|
||||
temp_hunk = []
|
||||
added_patched = []
|
||||
add_hunk = False
|
||||
@ -93,38 +113,58 @@ def omit_deletion_hunks(patch_lines) -> str:
|
||||
def handle_patch_deletions(patch: str, original_file_content_str: str,
|
||||
new_file_content_str: str, file_name: str) -> str:
|
||||
"""
|
||||
Handle entire file or deletion patches
|
||||
Handle entire file or deletion patches.
|
||||
|
||||
This function takes a patch, original file content, new file content, and file name as input.
|
||||
It handles entire file or deletion patches and returns the modified patch with deletion hunks omitted.
|
||||
|
||||
Args:
|
||||
patch (str): The patch to be handled.
|
||||
original_file_content_str (str): The original content of the file.
|
||||
new_file_content_str (str): The new content of the file.
|
||||
file_name (str): The name of the file.
|
||||
|
||||
Returns:
|
||||
str: The modified patch with deletion hunks omitted.
|
||||
|
||||
"""
|
||||
if not new_file_content_str:
|
||||
# logic for handling deleted files - don't show patch, just show that the file was deleted
|
||||
if settings.config.verbosity_level > 0:
|
||||
if get_settings().config.verbosity_level > 0:
|
||||
logging.info(f"Processing file: {file_name}, minimizing deletion file")
|
||||
patch = None # file was deleted
|
||||
else:
|
||||
patch_lines = patch.splitlines()
|
||||
patch_new = omit_deletion_hunks(patch_lines)
|
||||
if patch != patch_new:
|
||||
if settings.config.verbosity_level > 0:
|
||||
if get_settings().config.verbosity_level > 0:
|
||||
logging.info(f"Processing file: {file_name}, hunks were deleted")
|
||||
patch = patch_new
|
||||
return patch
|
||||
|
||||
|
||||
def convert_to_hunks_with_lines_numbers(patch: str, file) -> str:
|
||||
# toDO: (maybe remove '-' and '+' from the beginning of the line)
|
||||
"""
|
||||
## src/file.ts
|
||||
Convert a given patch string into a string with line numbers for each hunk, indicating the new and old content of
|
||||
the file.
|
||||
|
||||
Args:
|
||||
patch (str): The patch string to be converted.
|
||||
file: An object containing the filename of the file being patched.
|
||||
|
||||
Returns:
|
||||
str: A string with line numbers for each hunk, indicating the new and old content of the file.
|
||||
|
||||
example output:
|
||||
## src/file.ts
|
||||
--new hunk--
|
||||
881 line1
|
||||
882 line2
|
||||
883 line3
|
||||
884 line4
|
||||
885 line6
|
||||
886 line7
|
||||
887 + line8
|
||||
888 + line9
|
||||
889 line10
|
||||
890 line11
|
||||
887 + line4
|
||||
888 + line5
|
||||
889 line6
|
||||
890 line7
|
||||
...
|
||||
--old hunk--
|
||||
line1
|
||||
@ -134,8 +174,8 @@ def convert_to_hunks_with_lines_numbers(patch: str, file) -> str:
|
||||
line5
|
||||
line6
|
||||
...
|
||||
|
||||
"""
|
||||
|
||||
patch_with_lines_str = f"## {file.filename}\n"
|
||||
import re
|
||||
patch_lines = patch.splitlines()
|
||||
@ -162,7 +202,12 @@ def convert_to_hunks_with_lines_numbers(patch: str, file) -> str:
|
||||
patch_with_lines_str += f"{line_old}\n"
|
||||
new_content_lines = []
|
||||
old_content_lines = []
|
||||
start1, size1, start2, size2 = map(int, match.groups()[:4])
|
||||
try:
|
||||
start1, size1, start2, size2 = map(int, match.groups()[:4])
|
||||
except: # '@@ -0,0 +1 @@' case
|
||||
start1, size1, size2 = map(int, match.groups()[:3])
|
||||
start2 = 0
|
||||
|
||||
elif line.startswith('+'):
|
||||
new_content_lines.append(line)
|
||||
elif line.startswith('-'):
|
||||
|
||||
File diff suppressed because one or more lines are too long
@ -2,13 +2,18 @@ from __future__ import annotations
|
||||
|
||||
import difflib
|
||||
import logging
|
||||
from typing import Any, Tuple, Union
|
||||
import re
|
||||
import traceback
|
||||
from typing import Any, Callable, List, Tuple
|
||||
|
||||
from github import RateLimitExceededException
|
||||
|
||||
from pr_agent.algo import MAX_TOKENS
|
||||
from pr_agent.algo.git_patch_processing import convert_to_hunks_with_lines_numbers, extend_patch, handle_patch_deletions
|
||||
from pr_agent.algo.language_handler import sort_files_by_main_languages
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.git_providers import GithubProvider
|
||||
from pr_agent.algo.token_handler import TokenHandler, get_token_encoder
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers.git_provider import FilePatchInfo, GitProvider
|
||||
|
||||
DELETED_FILES_ = "Deleted files:\n"
|
||||
|
||||
@ -18,18 +23,35 @@ OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD = 1000
|
||||
OUTPUT_BUFFER_TOKENS_HARD_THRESHOLD = 600
|
||||
PATCH_EXTRA_LINES = 3
|
||||
|
||||
def get_pr_diff(git_provider: GitProvider, token_handler: TokenHandler, model: str,
|
||||
add_line_numbers_to_hunks: bool = False, disable_extra_lines: bool = False) -> str:
|
||||
"""
|
||||
Returns a string with the diff of the pull request, applying diff minimization techniques if needed.
|
||||
|
||||
def get_pr_diff(git_provider: Union[GithubProvider, Any], token_handler: TokenHandler,
|
||||
add_line_numbers_to_hunks: bool = False, disable_extra_lines: bool =False) -> str:
|
||||
"""
|
||||
Returns a string with the diff of the PR.
|
||||
If needed, apply diff minimization techniques to reduce the number of tokens
|
||||
Args:
|
||||
git_provider (GitProvider): An object of the GitProvider class representing the Git provider used for the pull
|
||||
request.
|
||||
token_handler (TokenHandler): An object of the TokenHandler class used for handling tokens in the context of the
|
||||
pull request.
|
||||
model (str): The name of the model used for tokenization.
|
||||
add_line_numbers_to_hunks (bool, optional): A boolean indicating whether to add line numbers to the hunks in the
|
||||
diff. Defaults to False.
|
||||
disable_extra_lines (bool, optional): A boolean indicating whether to disable the extension of each patch with
|
||||
extra lines of context. Defaults to False.
|
||||
|
||||
Returns:
|
||||
str: A string with the diff of the pull request, applying diff minimization techniques if needed.
|
||||
"""
|
||||
|
||||
if disable_extra_lines:
|
||||
global PATCH_EXTRA_LINES
|
||||
PATCH_EXTRA_LINES = 0
|
||||
|
||||
diff_files = list(git_provider.get_diff_files())
|
||||
try:
|
||||
diff_files = git_provider.get_diff_files()
|
||||
except RateLimitExceededException as e:
|
||||
logging.error(f"Rate limit exceeded for git provider API. original message {e}")
|
||||
raise
|
||||
|
||||
# get pr languages
|
||||
pr_languages = sort_files_by_main_languages(git_provider.get_languages(), diff_files)
|
||||
@ -39,12 +61,12 @@ def get_pr_diff(git_provider: Union[GithubProvider, Any], token_handler: TokenHa
|
||||
add_line_numbers_to_hunks)
|
||||
|
||||
# if we are under the limit, return the full diff
|
||||
if total_tokens + OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD < token_handler.limit:
|
||||
if total_tokens + OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD < MAX_TOKENS[model]:
|
||||
return "\n".join(patches_extended)
|
||||
|
||||
# if we are over the limit, start pruning
|
||||
patches_compressed, modified_file_names, deleted_file_names = \
|
||||
pr_generate_compressed_diff(pr_languages, token_handler, add_line_numbers_to_hunks)
|
||||
pr_generate_compressed_diff(pr_languages, token_handler, model, add_line_numbers_to_hunks)
|
||||
|
||||
final_diff = "\n".join(patches_compressed)
|
||||
if modified_file_names:
|
||||
@ -60,19 +82,25 @@ def pr_generate_extended_diff(pr_languages: list, token_handler: TokenHandler,
|
||||
add_line_numbers_to_hunks: bool) -> \
|
||||
Tuple[list, int]:
|
||||
"""
|
||||
Generate a standard diff string, with patch extension
|
||||
Generate a standard diff string with patch extension, while counting the number of tokens used and applying diff
|
||||
minimization techniques if needed.
|
||||
|
||||
Args:
|
||||
- pr_languages: A list of dictionaries representing the languages used in the pull request and their corresponding
|
||||
files.
|
||||
- token_handler: An object of the TokenHandler class used for handling tokens in the context of the pull request.
|
||||
- add_line_numbers_to_hunks: A boolean indicating whether to add line numbers to the hunks in the diff.
|
||||
|
||||
Returns:
|
||||
- patches_extended: A list of extended patches for each file in the pull request.
|
||||
- total_tokens: The total number of tokens used in the extended patches.
|
||||
"""
|
||||
total_tokens = token_handler.prompt_tokens # initial tokens
|
||||
patches_extended = []
|
||||
for lang in pr_languages:
|
||||
for file in lang['files']:
|
||||
original_file_content_str = file.base_file
|
||||
new_file_content_str = file.head_file
|
||||
patch = file.patch
|
||||
|
||||
# handle the case of large patch, that initially was not loaded
|
||||
patch = load_large_diff(file, new_file_content_str, original_file_content_str, patch)
|
||||
|
||||
if not patch:
|
||||
continue
|
||||
|
||||
@ -91,14 +119,31 @@ def pr_generate_extended_diff(pr_languages: list, token_handler: TokenHandler,
|
||||
return patches_extended, total_tokens
|
||||
|
||||
|
||||
def pr_generate_compressed_diff(top_langs: list, token_handler: TokenHandler,
|
||||
def pr_generate_compressed_diff(top_langs: list, token_handler: TokenHandler, model: str,
|
||||
convert_hunks_to_line_numbers: bool) -> Tuple[list, list, list]:
|
||||
# Apply Diff Minimization techniques to reduce the number of tokens:
|
||||
# 0. Start from the largest diff patch to smaller ones
|
||||
# 1. Don't use extend context lines around diff
|
||||
# 2. Minimize deleted files
|
||||
# 3. Minimize deleted hunks
|
||||
# 4. Minimize all remaining files when you reach token limit
|
||||
"""
|
||||
Generate a compressed diff string for a pull request, using diff minimization techniques to reduce the number of
|
||||
tokens used.
|
||||
Args:
|
||||
top_langs (list): A list of dictionaries representing the languages used in the pull request and their
|
||||
corresponding files.
|
||||
token_handler (TokenHandler): An object of the TokenHandler class used for handling tokens in the context of the
|
||||
pull request.
|
||||
model (str): The model used for tokenization.
|
||||
convert_hunks_to_line_numbers (bool): A boolean indicating whether to convert hunks to line numbers in the diff.
|
||||
Returns:
|
||||
Tuple[list, list, list]: A tuple containing the following lists:
|
||||
- patches: A list of compressed diff patches for each file in the pull request.
|
||||
- modified_files_list: A list of file names that were skipped due to large patch size.
|
||||
- deleted_files_list: A list of file names that were deleted in the pull request.
|
||||
|
||||
Minimization techniques to reduce the number of tokens:
|
||||
0. Start from the largest diff patch to smaller ones
|
||||
1. Don't use extend context lines around diff
|
||||
2. Minimize deleted files
|
||||
3. Minimize deleted hunks
|
||||
4. Minimize all remaining files when you reach token limit
|
||||
"""
|
||||
|
||||
patches = []
|
||||
modified_files_list = []
|
||||
@ -113,7 +158,6 @@ def pr_generate_compressed_diff(top_langs: list, token_handler: TokenHandler,
|
||||
original_file_content_str = file.base_file
|
||||
new_file_content_str = file.head_file
|
||||
patch = file.patch
|
||||
patch = load_large_diff(file, new_file_content_str, original_file_content_str, patch)
|
||||
if not patch:
|
||||
continue
|
||||
|
||||
@ -133,16 +177,16 @@ def pr_generate_compressed_diff(top_langs: list, token_handler: TokenHandler,
|
||||
new_patch_tokens = token_handler.count_tokens(patch)
|
||||
|
||||
# Hard Stop, no more tokens
|
||||
if total_tokens > token_handler.limit - OUTPUT_BUFFER_TOKENS_HARD_THRESHOLD:
|
||||
if total_tokens > MAX_TOKENS[model] - OUTPUT_BUFFER_TOKENS_HARD_THRESHOLD:
|
||||
logging.warning(f"File was fully skipped, no more tokens: {file.filename}.")
|
||||
continue
|
||||
|
||||
# If the patch is too large, just show the file name
|
||||
if total_tokens + new_patch_tokens > token_handler.limit - OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD:
|
||||
if total_tokens + new_patch_tokens > MAX_TOKENS[model] - OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD:
|
||||
# Current logic is to skip the patch if it's too large
|
||||
# TODO: Option for alternative logic to remove hunks from the patch to reduce the number of tokens
|
||||
# until we meet the requirements
|
||||
if settings.config.verbosity_level >= 2:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
logging.warning(f"Patch too large, minimizing it, {file.filename}")
|
||||
if not modified_files_list:
|
||||
total_tokens += token_handler.count_tokens(MORE_MODIFIED_FILES_)
|
||||
@ -157,20 +201,140 @@ def pr_generate_compressed_diff(top_langs: list, token_handler: TokenHandler,
|
||||
patch_final = patch
|
||||
patches.append(patch_final)
|
||||
total_tokens += token_handler.count_tokens(patch_final)
|
||||
if settings.config.verbosity_level >= 2:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
logging.info(f"Tokens: {total_tokens}, last filename: {file.filename}")
|
||||
|
||||
return patches, modified_files_list, deleted_files_list
|
||||
|
||||
|
||||
def load_large_diff(file, new_file_content_str: str, original_file_content_str: str, patch: str) -> str:
|
||||
if not patch: # to Do - also add condition for file extension
|
||||
async def retry_with_fallback_models(f: Callable):
|
||||
all_models = _get_all_models()
|
||||
all_deployments = _get_all_deployments(all_models)
|
||||
# try each (model, deployment_id) pair until one is successful, otherwise raise exception
|
||||
for i, (model, deployment_id) in enumerate(zip(all_models, all_deployments)):
|
||||
try:
|
||||
diff = difflib.unified_diff(original_file_content_str.splitlines(keepends=True),
|
||||
new_file_content_str.splitlines(keepends=True))
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.warning(f"File was modified, but no patch was found. Manually creating patch: {file.filename}.")
|
||||
patch = ''.join(diff)
|
||||
except Exception:
|
||||
pass
|
||||
return patch
|
||||
get_settings().set("openai.deployment_id", deployment_id)
|
||||
return await f(model)
|
||||
except Exception as e:
|
||||
logging.warning(
|
||||
f"Failed to generate prediction with {model}"
|
||||
f"{(' from deployment ' + deployment_id) if deployment_id else ''}: "
|
||||
f"{traceback.format_exc()}"
|
||||
)
|
||||
if i == len(all_models) - 1: # If it's the last iteration
|
||||
raise # Re-raise the last exception
|
||||
|
||||
|
||||
def _get_all_models() -> List[str]:
|
||||
model = get_settings().config.model
|
||||
fallback_models = get_settings().config.fallback_models
|
||||
if not isinstance(fallback_models, list):
|
||||
fallback_models = [m.strip() for m in fallback_models.split(",")]
|
||||
all_models = [model] + fallback_models
|
||||
return all_models
|
||||
|
||||
|
||||
def _get_all_deployments(all_models: List[str]) -> List[str]:
|
||||
deployment_id = get_settings().get("openai.deployment_id", None)
|
||||
fallback_deployments = get_settings().get("openai.fallback_deployments", [])
|
||||
if not isinstance(fallback_deployments, list) and fallback_deployments:
|
||||
fallback_deployments = [d.strip() for d in fallback_deployments.split(",")]
|
||||
if fallback_deployments:
|
||||
all_deployments = [deployment_id] + fallback_deployments
|
||||
if len(all_deployments) < len(all_models):
|
||||
raise ValueError(f"The number of deployments ({len(all_deployments)}) "
|
||||
f"is less than the number of models ({len(all_models)})")
|
||||
else:
|
||||
all_deployments = [deployment_id] * len(all_models)
|
||||
return all_deployments
|
||||
|
||||
|
||||
def find_line_number_of_relevant_line_in_file(diff_files: List[FilePatchInfo],
|
||||
relevant_file: str,
|
||||
relevant_line_in_file: str) -> Tuple[int, int]:
|
||||
"""
|
||||
Find the line number and absolute position of a relevant line in a file.
|
||||
|
||||
Args:
|
||||
diff_files (List[FilePatchInfo]): A list of FilePatchInfo objects representing the patches of files.
|
||||
relevant_file (str): The name of the file where the relevant line is located.
|
||||
relevant_line_in_file (str): The content of the relevant line.
|
||||
|
||||
Returns:
|
||||
Tuple[int, int]: A tuple containing the line number and absolute position of the relevant line in the file.
|
||||
"""
|
||||
position = -1
|
||||
absolute_position = -1
|
||||
re_hunk_header = re.compile(
|
||||
r"^@@ -(\d+)(?:,(\d+))? \+(\d+)(?:,(\d+))? @@[ ]?(.*)")
|
||||
|
||||
for file in diff_files:
|
||||
if file.filename.strip() == relevant_file:
|
||||
patch = file.patch
|
||||
patch_lines = patch.splitlines()
|
||||
|
||||
# try to find the line in the patch using difflib, with some margin of error
|
||||
matches_difflib: list[str | Any] = difflib.get_close_matches(relevant_line_in_file,
|
||||
patch_lines, n=3, cutoff=0.93)
|
||||
if len(matches_difflib) == 1 and matches_difflib[0].startswith('+'):
|
||||
relevant_line_in_file = matches_difflib[0]
|
||||
|
||||
delta = 0
|
||||
start1, size1, start2, size2 = 0, 0, 0, 0
|
||||
for i, line in enumerate(patch_lines):
|
||||
if line.startswith('@@'):
|
||||
delta = 0
|
||||
match = re_hunk_header.match(line)
|
||||
start1, size1, start2, size2 = map(int, match.groups()[:4])
|
||||
elif not line.startswith('-'):
|
||||
delta += 1
|
||||
|
||||
if relevant_line_in_file in line and line[0] != '-':
|
||||
position = i
|
||||
absolute_position = start2 + delta - 1
|
||||
break
|
||||
|
||||
if position == -1 and relevant_line_in_file[0] == '+':
|
||||
no_plus_line = relevant_line_in_file[1:].lstrip()
|
||||
for i, line in enumerate(patch_lines):
|
||||
if line.startswith('@@'):
|
||||
delta = 0
|
||||
match = re_hunk_header.match(line)
|
||||
start1, size1, start2, size2 = map(int, match.groups()[:4])
|
||||
elif not line.startswith('-'):
|
||||
delta += 1
|
||||
|
||||
if no_plus_line in line and line[0] != '-':
|
||||
# The model might add a '+' to the beginning of the relevant_line_in_file even if originally
|
||||
# it's a context line
|
||||
position = i
|
||||
absolute_position = start2 + delta - 1
|
||||
break
|
||||
return position, absolute_position
|
||||
|
||||
|
||||
def clip_tokens(text: str, max_tokens: int) -> str:
|
||||
"""
|
||||
Clip the number of tokens in a string to a maximum number of tokens.
|
||||
|
||||
Args:
|
||||
text (str): The string to clip.
|
||||
max_tokens (int): The maximum number of tokens allowed in the string.
|
||||
|
||||
Returns:
|
||||
str: The clipped string.
|
||||
"""
|
||||
# We'll estimate the number of tokens by hueristically assuming 2.5 tokens per word
|
||||
try:
|
||||
encoder = get_token_encoder()
|
||||
num_input_tokens = len(encoder.encode(text))
|
||||
if num_input_tokens <= max_tokens:
|
||||
return text
|
||||
num_chars = len(text)
|
||||
chars_per_token = num_chars / num_input_tokens
|
||||
num_output_chars = int(chars_per_token * max_tokens)
|
||||
clipped_text = text[:num_output_chars]
|
||||
return clipped_text
|
||||
except Exception as e:
|
||||
logging.warning(f"Failed to clip tokens: {e}")
|
||||
return text
|
||||
@ -1,24 +1,68 @@
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
from tiktoken import encoding_for_model
|
||||
from tiktoken import encoding_for_model, get_encoding
|
||||
|
||||
from pr_agent.algo import MAX_TOKENS
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.config_loader import get_settings
|
||||
|
||||
|
||||
def get_token_encoder():
|
||||
return encoding_for_model(get_settings().config.model) if "gpt" in get_settings().config.model else get_encoding(
|
||||
"cl100k_base")
|
||||
|
||||
class TokenHandler:
|
||||
"""
|
||||
A class for handling tokens in the context of a pull request.
|
||||
|
||||
Attributes:
|
||||
- encoder: An object of the encoding_for_model class from the tiktoken module. Used to encode strings and count the
|
||||
number of tokens in them.
|
||||
- limit: The maximum number of tokens allowed for the given model, as defined in the MAX_TOKENS dictionary in the
|
||||
pr_agent.algo module.
|
||||
- prompt_tokens: The number of tokens in the system and user strings, as calculated by the _get_system_user_tokens
|
||||
method.
|
||||
"""
|
||||
|
||||
def __init__(self, pr, vars: dict, system, user):
|
||||
self.encoder = encoding_for_model(settings.config.model)
|
||||
self.limit = MAX_TOKENS[settings.config.model]
|
||||
"""
|
||||
Initializes the TokenHandler object.
|
||||
|
||||
Args:
|
||||
- pr: The pull request object.
|
||||
- vars: A dictionary of variables.
|
||||
- system: The system string.
|
||||
- user: The user string.
|
||||
"""
|
||||
self.encoder = get_token_encoder()
|
||||
self.prompt_tokens = self._get_system_user_tokens(pr, self.encoder, vars, system, user)
|
||||
|
||||
def _get_system_user_tokens(self, pr, encoder, vars: dict, system, user):
|
||||
"""
|
||||
Calculates the number of tokens in the system and user strings.
|
||||
|
||||
Args:
|
||||
- pr: The pull request object.
|
||||
- encoder: An object of the encoding_for_model class from the tiktoken module.
|
||||
- vars: A dictionary of variables.
|
||||
- system: The system string.
|
||||
- user: The user string.
|
||||
|
||||
Returns:
|
||||
The sum of the number of tokens in the system and user strings.
|
||||
"""
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
system_prompt = environment.from_string(system).render(vars)
|
||||
user_prompt = environment.from_string(user).render(vars)
|
||||
|
||||
system_prompt_tokens = len(encoder.encode(system_prompt))
|
||||
user_prompt_tokens = len(encoder.encode(user_prompt))
|
||||
return system_prompt_tokens + user_prompt_tokens
|
||||
|
||||
def count_tokens(self, patch: str) -> int:
|
||||
"""
|
||||
Counts the number of tokens in a given patch string.
|
||||
|
||||
Args:
|
||||
- patch: The patch string.
|
||||
|
||||
Returns:
|
||||
The number of tokens in the patch string.
|
||||
"""
|
||||
return len(self.encoder.encode(patch, disallowed_special=()))
|
||||
@ -1,24 +1,46 @@
|
||||
from __future__ import annotations
|
||||
|
||||
import difflib
|
||||
import json
|
||||
import logging
|
||||
import re
|
||||
import textwrap
|
||||
from datetime import datetime
|
||||
from typing import Any, List
|
||||
|
||||
import yaml
|
||||
from starlette_context import context
|
||||
from pr_agent.config_loader import get_settings, global_settings
|
||||
|
||||
|
||||
def get_setting(key: str) -> Any:
|
||||
try:
|
||||
key = key.upper()
|
||||
return context.get("settings", global_settings).get(key, global_settings.get(key, None))
|
||||
except Exception:
|
||||
return global_settings.get(key, None)
|
||||
|
||||
def convert_to_markdown(output_data: dict) -> str:
|
||||
"""
|
||||
Convert a dictionary of data into markdown format.
|
||||
Args:
|
||||
output_data (dict): A dictionary containing data to be converted to markdown format.
|
||||
Returns:
|
||||
str: The markdown formatted text generated from the input dictionary.
|
||||
"""
|
||||
markdown_text = ""
|
||||
|
||||
emojis = {
|
||||
"Main theme": "🎯",
|
||||
"Type of PR": "📌",
|
||||
"Score": "🏅",
|
||||
"Relevant tests added": "🧪",
|
||||
"Unrelated changes": "⚠️",
|
||||
"Focused PR": "✨",
|
||||
"Security concerns": "🔒",
|
||||
"General PR suggestions": "💡",
|
||||
"Insights from user's answers": "📝",
|
||||
"Code suggestions": "🤖"
|
||||
"Code feedback": "🤖",
|
||||
}
|
||||
|
||||
for key, value in output_data.items():
|
||||
@ -28,22 +50,31 @@ def convert_to_markdown(output_data: dict) -> str:
|
||||
markdown_text += f"## {key}\n\n"
|
||||
markdown_text += convert_to_markdown(value)
|
||||
elif isinstance(value, list):
|
||||
if key.lower() == 'code suggestions':
|
||||
if key.lower() == 'code feedback':
|
||||
markdown_text += "\n" # just looks nicer with additional line breaks
|
||||
emoji = emojis.get(key, "‣") # Use a dash if no emoji is found for the key
|
||||
emoji = emojis.get(key, "")
|
||||
markdown_text += f"- {emoji} **{key}:**\n\n"
|
||||
for item in value:
|
||||
if isinstance(item, dict) and key.lower() == 'code suggestions':
|
||||
if isinstance(item, dict) and key.lower() == 'code feedback':
|
||||
markdown_text += parse_code_suggestion(item)
|
||||
elif item:
|
||||
markdown_text += f" - {item}\n"
|
||||
elif value != 'n/a':
|
||||
emoji = emojis.get(key, "‣") # Use a dash if no emoji is found for the key
|
||||
emoji = emojis.get(key, "")
|
||||
markdown_text += f"- {emoji} **{key}:** {value}\n"
|
||||
return markdown_text
|
||||
|
||||
|
||||
def parse_code_suggestion(code_suggestions: dict) -> str:
|
||||
"""
|
||||
Convert a dictionary of data into markdown format.
|
||||
|
||||
Args:
|
||||
code_suggestions (dict): A dictionary containing data to be converted to markdown format.
|
||||
|
||||
Returns:
|
||||
str: A string containing the markdown formatted text generated from the input dictionary.
|
||||
"""
|
||||
markdown_text = ""
|
||||
for sub_key, sub_value in code_suggestions.items():
|
||||
if isinstance(sub_value, dict): # "code example"
|
||||
@ -63,18 +94,46 @@ def parse_code_suggestion(code_suggestions: dict) -> str:
|
||||
|
||||
|
||||
def try_fix_json(review, max_iter=10, code_suggestions=False):
|
||||
"""
|
||||
Fix broken or incomplete JSON messages and return the parsed JSON data.
|
||||
|
||||
Args:
|
||||
- review: A string containing the JSON message to be fixed.
|
||||
- max_iter: An integer representing the maximum number of iterations to try and fix the JSON message.
|
||||
- code_suggestions: A boolean indicating whether to try and fix JSON messages with code feedback.
|
||||
|
||||
Returns:
|
||||
- data: A dictionary containing the parsed JSON data.
|
||||
|
||||
The function attempts to fix broken or incomplete JSON messages by parsing until the last valid code suggestion.
|
||||
If the JSON message ends with a closing bracket, the function calls the fix_json_escape_char function to fix the
|
||||
message.
|
||||
If code_suggestions is True and the JSON message contains code feedback, the function tries to fix the JSON
|
||||
message by parsing until the last valid code suggestion.
|
||||
The function uses regular expressions to find the last occurrence of "}," with any number of whitespaces or
|
||||
newlines.
|
||||
It tries to parse the JSON message with the closing bracket and checks if it is valid.
|
||||
If the JSON message is valid, the parsed JSON data is returned.
|
||||
If the JSON message is not valid, the last code suggestion is removed and the process is repeated until a valid JSON
|
||||
message is obtained or the maximum number of iterations is reached.
|
||||
If a valid JSON message is not obtained, an error is logged and an empty dictionary is returned.
|
||||
"""
|
||||
|
||||
if review.endswith("}"):
|
||||
return fix_json_escape_char(review)
|
||||
# Try to fix JSON if it is broken/incomplete: parse until the last valid code suggestion
|
||||
|
||||
data = {}
|
||||
if code_suggestions:
|
||||
closing_bracket = "]}"
|
||||
else:
|
||||
closing_bracket = "]}}"
|
||||
if review.rfind("'Code suggestions': [") > 0 or review.rfind('"Code suggestions": [') > 0:
|
||||
|
||||
if (review.rfind("'Code feedback': [") > 0 or review.rfind('"Code feedback": [') > 0) or \
|
||||
(review.rfind("'Code suggestions': [") > 0 or review.rfind('"Code suggestions": [') > 0) :
|
||||
last_code_suggestion_ind = [m.end() for m in re.finditer(r"\}\s*,", review)][-1] - 1
|
||||
valid_json = False
|
||||
iter_count = 0
|
||||
|
||||
while last_code_suggestion_ind > 0 and not valid_json and iter_count < max_iter:
|
||||
try:
|
||||
data = json.loads(review[:last_code_suggestion_ind] + closing_bracket)
|
||||
@ -82,16 +141,30 @@ def try_fix_json(review, max_iter=10, code_suggestions=False):
|
||||
review = review[:last_code_suggestion_ind].strip() + closing_bracket
|
||||
except json.decoder.JSONDecodeError:
|
||||
review = review[:last_code_suggestion_ind]
|
||||
# Use regular expression to find the last occurrence of "}," with any number of whitespaces or newlines
|
||||
last_code_suggestion_ind = [m.end() for m in re.finditer(r"\}\s*,", review)][-1] - 1
|
||||
iter_count += 1
|
||||
|
||||
if not valid_json:
|
||||
logging.error("Unable to decode JSON response from AI")
|
||||
data = {}
|
||||
|
||||
return data
|
||||
|
||||
|
||||
def fix_json_escape_char(json_message=None):
|
||||
"""
|
||||
Fix broken or incomplete JSON messages and return the parsed JSON data.
|
||||
|
||||
Args:
|
||||
json_message (str): A string containing the JSON message to be fixed.
|
||||
|
||||
Returns:
|
||||
dict: A dictionary containing the parsed JSON data.
|
||||
|
||||
Raises:
|
||||
None
|
||||
|
||||
"""
|
||||
try:
|
||||
result = json.loads(json_message)
|
||||
except Exception as e:
|
||||
@ -103,3 +176,108 @@ def fix_json_escape_char(json_message=None):
|
||||
new_message = ''.join(json_message)
|
||||
return fix_json_escape_char(json_message=new_message)
|
||||
return result
|
||||
|
||||
|
||||
def convert_str_to_datetime(date_str):
|
||||
"""
|
||||
Convert a string representation of a date and time into a datetime object.
|
||||
|
||||
Args:
|
||||
date_str (str): A string representation of a date and time in the format '%a, %d %b %Y %H:%M:%S %Z'
|
||||
|
||||
Returns:
|
||||
datetime: A datetime object representing the input date and time.
|
||||
|
||||
Example:
|
||||
>>> convert_str_to_datetime('Mon, 01 Jan 2022 12:00:00 UTC')
|
||||
datetime.datetime(2022, 1, 1, 12, 0, 0)
|
||||
"""
|
||||
datetime_format = '%a, %d %b %Y %H:%M:%S %Z'
|
||||
return datetime.strptime(date_str, datetime_format)
|
||||
|
||||
|
||||
def load_large_diff(filename, new_file_content_str: str, original_file_content_str: str) -> str:
|
||||
"""
|
||||
Generate a patch for a modified file by comparing the original content of the file with the new content provided as
|
||||
input.
|
||||
|
||||
Args:
|
||||
new_file_content_str: The new content of the file as a string.
|
||||
original_file_content_str: The original content of the file as a string.
|
||||
|
||||
Returns:
|
||||
The generated or provided patch string.
|
||||
|
||||
Raises:
|
||||
None.
|
||||
"""
|
||||
patch = ""
|
||||
try:
|
||||
diff = difflib.unified_diff(original_file_content_str.splitlines(keepends=True),
|
||||
new_file_content_str.splitlines(keepends=True))
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
logging.warning(f"File was modified, but no patch was found. Manually creating patch: {filename}.")
|
||||
patch = ''.join(diff)
|
||||
except Exception:
|
||||
pass
|
||||
return patch
|
||||
|
||||
|
||||
def update_settings_from_args(args: List[str]) -> List[str]:
|
||||
"""
|
||||
Update the settings of the Dynaconf object based on the arguments passed to the function.
|
||||
|
||||
Args:
|
||||
args: A list of arguments passed to the function.
|
||||
Example args: ['--pr_code_suggestions.extra_instructions="be funny',
|
||||
'--pr_code_suggestions.num_code_suggestions=3']
|
||||
|
||||
Returns:
|
||||
None
|
||||
|
||||
Raises:
|
||||
ValueError: If the argument is not in the correct format.
|
||||
|
||||
"""
|
||||
other_args = []
|
||||
if args:
|
||||
for arg in args:
|
||||
arg = arg.strip()
|
||||
if arg.startswith('--'):
|
||||
arg = arg.strip('-').strip()
|
||||
vals = arg.split('=')
|
||||
if len(vals) != 2:
|
||||
logging.error(f'Invalid argument format: {arg}')
|
||||
other_args.append(arg)
|
||||
continue
|
||||
key, value = vals
|
||||
key = key.strip().upper()
|
||||
value = value.strip()
|
||||
get_settings().set(key, value)
|
||||
logging.info(f'Updated setting {key} to: "{value}"')
|
||||
else:
|
||||
other_args.append(arg)
|
||||
return other_args
|
||||
|
||||
|
||||
def load_yaml(review_text: str) -> dict:
|
||||
review_text = review_text.removeprefix('```yaml').rstrip('`')
|
||||
try:
|
||||
data = yaml.load(review_text, Loader=yaml.SafeLoader)
|
||||
except Exception as e:
|
||||
logging.error(f"Failed to parse AI prediction: {e}")
|
||||
data = try_fix_yaml(review_text)
|
||||
return data
|
||||
|
||||
def try_fix_yaml(review_text: str) -> dict:
|
||||
review_text_lines = review_text.split('\n')
|
||||
data = {}
|
||||
for i in range(1, len(review_text_lines)):
|
||||
review_text_lines_tmp = '\n'.join(review_text_lines[:-i])
|
||||
try:
|
||||
data = yaml.load(review_text_lines_tmp, Loader=yaml.SafeLoader)
|
||||
logging.info(f"Successfully parsed AI prediction after removing {i} lines")
|
||||
break
|
||||
except:
|
||||
pass
|
||||
return data
|
||||
|
||||
@ -3,22 +3,20 @@ import asyncio
|
||||
import logging
|
||||
import os
|
||||
|
||||
from pr_agent.tools.pr_code_suggestions import PRCodeSuggestions
|
||||
from pr_agent.tools.pr_description import PRDescription
|
||||
from pr_agent.tools.pr_information_from_user import PRInformationFromUser
|
||||
from pr_agent.tools.pr_questions import PRQuestions
|
||||
from pr_agent.tools.pr_reviewer import PRReviewer
|
||||
from pr_agent.agent.pr_agent import PRAgent, commands
|
||||
from pr_agent.config_loader import get_settings
|
||||
|
||||
|
||||
def run(args=None):
|
||||
parser = argparse.ArgumentParser(description='AI based pull request analyzer', usage="""\
|
||||
Usage: cli.py --pr-url <URL on supported git hosting service> <command> [<args>].
|
||||
def run(inargs=None):
|
||||
parser = argparse.ArgumentParser(description='AI based pull request analyzer', usage=
|
||||
"""\
|
||||
Usage: cli.py --pr-url=<URL on supported git hosting service> <command> [<args>].
|
||||
For example:
|
||||
- cli.py --pr-url=... review
|
||||
- cli.py --pr-url=... describe
|
||||
- cli.py --pr-url=... improve
|
||||
- cli.py --pr-url=... ask "write me a poem about this PR"
|
||||
- cli.py --pr-url=... reflect
|
||||
- cli.py --pr_url=... review
|
||||
- cli.py --pr_url=... describe
|
||||
- cli.py --pr_url=... improve
|
||||
- cli.py --pr_url=... ask "write me a poem about this PR"
|
||||
- cli.py --pr_url=... reflect
|
||||
|
||||
Supported commands:
|
||||
review / review_pr - Add a review that includes a summary of the PR and specific suggestions for improvement.
|
||||
@ -26,49 +24,20 @@ ask / ask_question [question] - Ask a question about the PR.
|
||||
describe / describe_pr - Modify the PR title and description based on the PR's contents.
|
||||
improve / improve_code - Suggest improvements to the code in the PR as pull request comments ready to commit.
|
||||
reflect - Ask the PR author questions about the PR.
|
||||
update_changelog - Update the changelog based on the PR's contents.
|
||||
|
||||
To edit any configuration parameter from 'configuration.toml', just add -config_path=<value>.
|
||||
For example: 'python cli.py --pr_url=... review --pr_reviewer.extra_instructions="focus on the file: ..."'
|
||||
""")
|
||||
parser.add_argument('--pr_url', type=str, help='The URL of the PR to review', required=True)
|
||||
parser.add_argument('command', type=str, help='The', choices=['review', 'review_pr',
|
||||
'ask', 'ask_question',
|
||||
'describe', 'describe_pr',
|
||||
'improve', 'improve_code',
|
||||
'reflect', 'review_after_reflect'],
|
||||
default='review')
|
||||
parser.add_argument('command', type=str, help='The', choices=commands, default='review')
|
||||
parser.add_argument('rest', nargs=argparse.REMAINDER, default=[])
|
||||
args = parser.parse_args(args)
|
||||
args = parser.parse_args(inargs)
|
||||
logging.basicConfig(level=os.environ.get("LOGLEVEL", "INFO"))
|
||||
command = args.command.lower()
|
||||
if command in ['ask', 'ask_question']:
|
||||
question = ' '.join(args.rest).strip()
|
||||
if len(question) == 0:
|
||||
print("Please specify a question")
|
||||
parser.print_help()
|
||||
return
|
||||
print(f"Question: {question} about PR {args.pr_url}")
|
||||
reviewer = PRQuestions(args.pr_url, question)
|
||||
asyncio.run(reviewer.answer())
|
||||
elif command in ['describe', 'describe_pr']:
|
||||
print(f"PR description: {args.pr_url}")
|
||||
reviewer = PRDescription(args.pr_url)
|
||||
asyncio.run(reviewer.describe())
|
||||
elif command in ['improve', 'improve_code']:
|
||||
print(f"PR code suggestions: {args.pr_url}")
|
||||
reviewer = PRCodeSuggestions(args.pr_url)
|
||||
asyncio.run(reviewer.suggest())
|
||||
elif command in ['review', 'review_pr']:
|
||||
print(f"Reviewing PR: {args.pr_url}")
|
||||
reviewer = PRReviewer(args.pr_url, cli_mode=True)
|
||||
asyncio.run(reviewer.review())
|
||||
elif command in ['reflect']:
|
||||
print(f"Asking the PR author questions: {args.pr_url}")
|
||||
reviewer = PRInformationFromUser(args.pr_url)
|
||||
asyncio.run(reviewer.generate_questions())
|
||||
elif command in ['review_after_reflect']:
|
||||
print(f"Processing author's answers and sending review: {args.pr_url}")
|
||||
reviewer = PRReviewer(args.pr_url, cli_mode=True, is_answer=True)
|
||||
asyncio.run(reviewer.review())
|
||||
else:
|
||||
print(f"Unknown command: {command}")
|
||||
get_settings().set("CONFIG.CLI_MODE", True)
|
||||
result = asyncio.run(PRAgent().handle_request(args.pr_url, command + " " + " ".join(args.rest)))
|
||||
if not result:
|
||||
parser.print_help()
|
||||
|
||||
|
||||
|
||||
@ -1,19 +1,64 @@
|
||||
from os.path import abspath, dirname, join
|
||||
from pathlib import Path
|
||||
from typing import Optional
|
||||
|
||||
from dynaconf import Dynaconf
|
||||
from starlette_context import context
|
||||
|
||||
PR_AGENT_TOML_KEY = 'pr-agent'
|
||||
|
||||
current_dir = dirname(abspath(__file__))
|
||||
settings = Dynaconf(
|
||||
global_settings = Dynaconf(
|
||||
envvar_prefix=False,
|
||||
merge_enabled=True,
|
||||
settings_files=[join(current_dir, f) for f in [
|
||||
"settings/.secrets.toml",
|
||||
"settings/configuration.toml",
|
||||
"settings/pr_reviewer_prompts.toml",
|
||||
"settings/pr_questions_prompts.toml",
|
||||
"settings/pr_description_prompts.toml",
|
||||
"settings/pr_code_suggestions_prompts.toml",
|
||||
"settings/pr_information_from_user_prompts.toml",
|
||||
"settings_prod/.secrets.toml"
|
||||
]]
|
||||
"settings/.secrets.toml",
|
||||
"settings/configuration.toml",
|
||||
"settings/language_extensions.toml",
|
||||
"settings/pr_reviewer_prompts.toml",
|
||||
"settings/pr_questions_prompts.toml",
|
||||
"settings/pr_description_prompts.toml",
|
||||
"settings/pr_code_suggestions_prompts.toml",
|
||||
"settings/pr_information_from_user_prompts.toml",
|
||||
"settings/pr_update_changelog_prompts.toml",
|
||||
"settings_prod/.secrets.toml"
|
||||
]]
|
||||
)
|
||||
|
||||
|
||||
def get_settings():
|
||||
try:
|
||||
return context["settings"]
|
||||
except Exception:
|
||||
return global_settings
|
||||
|
||||
|
||||
# Add local configuration from pyproject.toml of the project being reviewed
|
||||
def _find_repository_root() -> Path:
|
||||
"""
|
||||
Identify project root directory by recursively searching for the .git directory in the parent directories.
|
||||
"""
|
||||
cwd = Path.cwd().resolve()
|
||||
no_way_up = False
|
||||
while not no_way_up:
|
||||
no_way_up = cwd == cwd.parent
|
||||
if (cwd / ".git").is_dir():
|
||||
return cwd
|
||||
cwd = cwd.parent
|
||||
return None
|
||||
|
||||
|
||||
def _find_pyproject() -> Optional[Path]:
|
||||
"""
|
||||
Search for file pyproject.toml in the repository root.
|
||||
"""
|
||||
repo_root = _find_repository_root()
|
||||
if repo_root:
|
||||
pyproject = _find_repository_root() / "pyproject.toml"
|
||||
return pyproject if pyproject.is_file() else None
|
||||
return None
|
||||
|
||||
|
||||
pyproject_path = _find_pyproject()
|
||||
if pyproject_path is not None:
|
||||
get_settings().load_file(pyproject_path, env=f'tool.{PR_AGENT_TOML_KEY}')
|
||||
|
||||
@ -1,17 +1,19 @@
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers.bitbucket_provider import BitbucketProvider
|
||||
from pr_agent.git_providers.github_provider import GithubProvider
|
||||
from pr_agent.git_providers.gitlab_provider import GitLabProvider
|
||||
from pr_agent.git_providers.local_git_provider import LocalGitProvider
|
||||
|
||||
_GIT_PROVIDERS = {
|
||||
'github': GithubProvider,
|
||||
'gitlab': GitLabProvider,
|
||||
'bitbucket': BitbucketProvider,
|
||||
'local' : LocalGitProvider
|
||||
}
|
||||
|
||||
def get_git_provider():
|
||||
try:
|
||||
provider_id = settings.config.git_provider
|
||||
provider_id = get_settings().config.git_provider
|
||||
except AttributeError as e:
|
||||
raise ValueError("git_provider is a required attribute in the configuration file") from e
|
||||
if provider_id not in _GIT_PROVIDERS:
|
||||
|
||||
@ -5,15 +5,15 @@ from urllib.parse import urlparse
|
||||
import requests
|
||||
from atlassian.bitbucket import Cloud
|
||||
|
||||
from pr_agent.config_loader import settings
|
||||
|
||||
from ..algo.pr_processing import clip_tokens
|
||||
from ..config_loader import get_settings
|
||||
from .git_provider import FilePatchInfo
|
||||
|
||||
|
||||
class BitbucketProvider:
|
||||
def __init__(self, pr_url: Optional[str] = None):
|
||||
def __init__(self, pr_url: Optional[str] = None, incremental: Optional[bool] = False):
|
||||
s = requests.Session()
|
||||
s.headers['Authorization'] = f'Bearer {settings.get("BITBUCKET.BEARER_TOKEN", None)}'
|
||||
s.headers['Authorization'] = f'Bearer {get_settings().get("BITBUCKET.BEARER_TOKEN", None)}'
|
||||
self.bitbucket_client = Cloud(session=s)
|
||||
|
||||
self.workspace_slug = None
|
||||
@ -22,11 +22,19 @@ class BitbucketProvider:
|
||||
self.pr_num = None
|
||||
self.pr = None
|
||||
self.temp_comments = []
|
||||
self.incremental = incremental
|
||||
if pr_url:
|
||||
self.set_pr(pr_url)
|
||||
|
||||
def get_repo_settings(self):
|
||||
try:
|
||||
contents = self.repo_obj.get_contents(".pr_agent.toml", ref=self.pr.head.sha).decoded_content
|
||||
return contents
|
||||
except Exception:
|
||||
return ""
|
||||
|
||||
def is_supported(self, capability: str) -> bool:
|
||||
if capability in ['get_issue_comments', 'create_inline_comment', 'publish_inline_comments']:
|
||||
if capability in ['get_issue_comments', 'create_inline_comment', 'publish_inline_comments', 'get_labels']:
|
||||
return False
|
||||
return True
|
||||
|
||||
@ -81,6 +89,9 @@ class BitbucketProvider:
|
||||
return self.pr.source_branch
|
||||
|
||||
def get_pr_description(self):
|
||||
max_tokens = get_settings().get("CONFIG.MAX_DESCRIPTION_TOKENS", None)
|
||||
if max_tokens:
|
||||
return clip_tokens(self.pr.description, max_tokens)
|
||||
return self.pr.description
|
||||
|
||||
def get_user_id(self):
|
||||
@ -89,12 +100,25 @@ class BitbucketProvider:
|
||||
def get_issue_comments(self):
|
||||
raise NotImplementedError("Bitbucket provider does not support issue comments yet")
|
||||
|
||||
def get_repo_settings(self):
|
||||
try:
|
||||
contents = self.repo_obj.get_contents(".pr_agent.toml", ref=self.pr.head.sha).decoded_content
|
||||
return contents
|
||||
except Exception:
|
||||
return ""
|
||||
|
||||
def add_eyes_reaction(self, issue_comment_id: int) -> Optional[int]:
|
||||
return True
|
||||
|
||||
def remove_reaction(self, issue_comment_id: int, reaction_id: int) -> bool:
|
||||
return True
|
||||
|
||||
@staticmethod
|
||||
def _parse_pr_url(pr_url: str) -> Tuple[str, int]:
|
||||
parsed_url = urlparse(pr_url)
|
||||
|
||||
if 'bitbucket.org' not in parsed_url.netloc:
|
||||
raise ValueError("The provided URL is not a valid GitHub URL")
|
||||
raise ValueError("The provided URL is not a valid Bitbucket URL")
|
||||
|
||||
path_parts = parsed_url.path.strip('/').split('/')
|
||||
|
||||
@ -120,3 +144,6 @@ class BitbucketProvider:
|
||||
|
||||
def _get_pr_file_content(self, remote_link: str):
|
||||
return ""
|
||||
|
||||
def get_commit_messages(self):
|
||||
return "" # not implemented yet
|
||||
|
||||
@ -3,6 +3,7 @@ from dataclasses import dataclass
|
||||
|
||||
# enum EDIT_TYPE (ADDED, DELETED, MODIFIED, RENAMED)
|
||||
from enum import Enum
|
||||
from typing import Optional
|
||||
|
||||
|
||||
class EDIT_TYPE(Enum):
|
||||
@ -53,8 +54,15 @@ class GitProvider(ABC):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def publish_code_suggestion(self, body: str, relevant_file: str,
|
||||
relevant_lines_start: int, relevant_lines_end: int):
|
||||
def publish_code_suggestions(self, code_suggestions: list):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def publish_labels(self, labels):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_labels(self):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
@ -81,6 +89,21 @@ class GitProvider(ABC):
|
||||
def get_issue_comments(self):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_repo_settings(self):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def add_eyes_reaction(self, issue_comment_id: int) -> Optional[int]:
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def remove_reaction(self, issue_comment_id: int, reaction_id: int) -> bool:
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_commit_messages(self):
|
||||
pass
|
||||
|
||||
def get_main_pr_language(languages, files) -> str:
|
||||
"""
|
||||
@ -121,3 +144,12 @@ def get_main_pr_language(languages, files) -> str:
|
||||
pass
|
||||
|
||||
return main_language_str
|
||||
|
||||
|
||||
class IncrementalPR:
|
||||
def __init__(self, is_incremental: bool = False):
|
||||
self.is_incremental = is_incremental
|
||||
self.commits_range = None
|
||||
self.first_new_commit_sha = None
|
||||
self.last_seen_commit_sha = None
|
||||
|
||||
|
||||
@ -1,25 +1,37 @@
|
||||
import logging
|
||||
import hashlib
|
||||
|
||||
from datetime import datetime
|
||||
from typing import Optional, Tuple
|
||||
from typing import Optional, Tuple, Any
|
||||
from urllib.parse import urlparse
|
||||
|
||||
from github import AppAuthentication, Github, Auth
|
||||
from github import AppAuthentication, Auth, Github, GithubException, Reaction
|
||||
from retry import retry
|
||||
from starlette_context import context
|
||||
|
||||
from pr_agent.config_loader import settings
|
||||
|
||||
from .git_provider import FilePatchInfo, GitProvider
|
||||
from .git_provider import FilePatchInfo, GitProvider, IncrementalPR
|
||||
from ..algo.language_handler import is_valid_file
|
||||
from ..algo.utils import load_large_diff
|
||||
from ..algo.pr_processing import find_line_number_of_relevant_line_in_file, clip_tokens
|
||||
from ..config_loader import get_settings
|
||||
from ..servers.utils import RateLimitExceeded
|
||||
|
||||
|
||||
class GithubProvider(GitProvider):
|
||||
def __init__(self, pr_url: Optional[str] = None):
|
||||
self.installation_id = settings.get("GITHUB.INSTALLATION_ID")
|
||||
def __init__(self, pr_url: Optional[str] = None, incremental=IncrementalPR(False)):
|
||||
self.repo_obj = None
|
||||
try:
|
||||
self.installation_id = context.get("installation_id", None)
|
||||
except Exception:
|
||||
self.installation_id = None
|
||||
self.github_client = self._get_github_client()
|
||||
self.repo = None
|
||||
self.pr_num = None
|
||||
self.pr = None
|
||||
self.github_user_id = None
|
||||
self.diff_files = None
|
||||
self.git_files = None
|
||||
self.incremental = incremental
|
||||
if pr_url:
|
||||
self.set_pr(pr_url)
|
||||
self.last_commit_id = list(self.pr.get_commits())[-1]
|
||||
@ -27,29 +39,107 @@ class GithubProvider(GitProvider):
|
||||
def is_supported(self, capability: str) -> bool:
|
||||
return True
|
||||
|
||||
def get_pr_url(self) -> str:
|
||||
return f"https://github.com/{self.repo}/pull/{self.pr_num}"
|
||||
|
||||
def set_pr(self, pr_url: str):
|
||||
self.repo, self.pr_num = self._parse_pr_url(pr_url)
|
||||
self.pr = self._get_pr()
|
||||
if self.incremental.is_incremental:
|
||||
self.get_incremental_commits()
|
||||
|
||||
def get_incremental_commits(self):
|
||||
self.commits = list(self.pr.get_commits())
|
||||
|
||||
self.get_previous_review()
|
||||
if self.previous_review:
|
||||
self.incremental.commits_range = self.get_commit_range()
|
||||
# Get all files changed during the commit range
|
||||
self.file_set = dict()
|
||||
for commit in self.incremental.commits_range:
|
||||
if commit.commit.message.startswith(f"Merge branch '{self._get_repo().default_branch}'"):
|
||||
logging.info(f"Skipping merge commit {commit.commit.message}")
|
||||
continue
|
||||
self.file_set.update({file.filename: file for file in commit.files})
|
||||
|
||||
def get_commit_range(self):
|
||||
last_review_time = self.previous_review.created_at
|
||||
first_new_commit_index = 0
|
||||
for index in range(len(self.commits) - 1, -1, -1):
|
||||
if self.commits[index].commit.author.date > last_review_time:
|
||||
self.incremental.first_new_commit_sha = self.commits[index].sha
|
||||
first_new_commit_index = index
|
||||
else:
|
||||
self.incremental.last_seen_commit_sha = self.commits[index].sha
|
||||
break
|
||||
return self.commits[first_new_commit_index:]
|
||||
|
||||
def get_previous_review(self):
|
||||
self.previous_review = None
|
||||
self.comments = list(self.pr.get_issue_comments())
|
||||
for index in range(len(self.comments) - 1, -1, -1):
|
||||
if self.comments[index].body.startswith("## PR Analysis"):
|
||||
self.previous_review = self.comments[index]
|
||||
break
|
||||
|
||||
def get_files(self):
|
||||
return self.pr.get_files()
|
||||
if self.incremental.is_incremental and self.file_set:
|
||||
return self.file_set.values()
|
||||
if not self.git_files:
|
||||
# bring files from GitHub only once
|
||||
self.git_files = self.pr.get_files()
|
||||
return self.git_files
|
||||
|
||||
@retry(exceptions=RateLimitExceeded,
|
||||
tries=get_settings().github.ratelimit_retries, delay=2, backoff=2, jitter=(1, 3))
|
||||
def get_diff_files(self) -> list[FilePatchInfo]:
|
||||
files = self.pr.get_files()
|
||||
diff_files = []
|
||||
for file in files:
|
||||
if is_valid_file(file.filename):
|
||||
original_file_content_str = self._get_pr_file_content(file, self.pr.base.sha)
|
||||
new_file_content_str = self._get_pr_file_content(file, self.pr.head.sha)
|
||||
diff_files.append(FilePatchInfo(original_file_content_str, new_file_content_str, file.patch, file.filename))
|
||||
self.diff_files = diff_files
|
||||
return diff_files
|
||||
"""
|
||||
Retrieves the list of files that have been modified, added, deleted, or renamed in a pull request in GitHub,
|
||||
along with their content and patch information.
|
||||
|
||||
Returns:
|
||||
diff_files (List[FilePatchInfo]): List of FilePatchInfo objects representing the modified, added, deleted,
|
||||
or renamed files in the merge request.
|
||||
"""
|
||||
try:
|
||||
if self.diff_files:
|
||||
return self.diff_files
|
||||
|
||||
files = self.get_files()
|
||||
diff_files = []
|
||||
|
||||
for file in files:
|
||||
if not is_valid_file(file.filename):
|
||||
continue
|
||||
|
||||
new_file_content_str = self._get_pr_file_content(file, self.pr.head.sha) # communication with GitHub
|
||||
patch = file.patch
|
||||
|
||||
if self.incremental.is_incremental and self.file_set:
|
||||
original_file_content_str = self._get_pr_file_content(file, self.incremental.last_seen_commit_sha)
|
||||
patch = load_large_diff(file.filename, new_file_content_str, original_file_content_str)
|
||||
self.file_set[file.filename] = patch
|
||||
else:
|
||||
original_file_content_str = self._get_pr_file_content(file, self.pr.base.sha)
|
||||
if not patch:
|
||||
patch = load_large_diff(file.filename, new_file_content_str, original_file_content_str)
|
||||
|
||||
diff_files.append(FilePatchInfo(original_file_content_str, new_file_content_str, patch, file.filename))
|
||||
|
||||
self.diff_files = diff_files
|
||||
return diff_files
|
||||
|
||||
except GithubException.RateLimitExceededException as e:
|
||||
logging.error(f"Rate limit exceeded for GitHub API. Original message: {e}")
|
||||
raise RateLimitExceeded("Rate limit exceeded for GitHub API.") from e
|
||||
|
||||
def publish_description(self, pr_title: str, pr_body: str):
|
||||
self.pr.edit(title=pr_title, body=pr_body)
|
||||
# self.pr.create_issue_comment(pr_comment)
|
||||
|
||||
def publish_comment(self, pr_comment: str, is_temporary: bool = False):
|
||||
if is_temporary and not get_settings().config.publish_output_progress:
|
||||
logging.debug(f"Skipping publish_comment for temporary comment: {pr_comment}")
|
||||
return
|
||||
response = self.pr.create_issue_comment(pr_comment)
|
||||
if hasattr(response, "user") and hasattr(response.user, "login"):
|
||||
self.github_user_id = response.user.login
|
||||
@ -61,58 +151,48 @@ class GithubProvider(GitProvider):
|
||||
def publish_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
||||
self.publish_inline_comments([self.create_inline_comment(body, relevant_file, relevant_line_in_file)])
|
||||
|
||||
|
||||
def create_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
||||
self.diff_files = self.diff_files if self.diff_files else self.get_diff_files()
|
||||
position = -1
|
||||
for file in self.diff_files:
|
||||
if file.filename.strip() == relevant_file:
|
||||
patch = file.patch
|
||||
patch_lines = patch.splitlines()
|
||||
for i, line in enumerate(patch_lines):
|
||||
if relevant_line_in_file in line:
|
||||
position = i
|
||||
break
|
||||
elif relevant_line_in_file[0] == '+' and relevant_line_in_file[1:].lstrip() in line:
|
||||
# The model often adds a '+' to the beginning of the relevant_line_in_file even if originally
|
||||
# it's a context line
|
||||
position = i
|
||||
break
|
||||
position, absolute_position = find_line_number_of_relevant_line_in_file(self.diff_files, relevant_file.strip('`'), relevant_line_in_file)
|
||||
if position == -1:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
logging.info(f"Could not find position for {relevant_file} {relevant_line_in_file}")
|
||||
subject_type = "FILE"
|
||||
else:
|
||||
subject_type = "LINE"
|
||||
path = relevant_file.strip()
|
||||
# placeholder for future API support (already supported in single inline comment)
|
||||
# return dict(body=body, path=path, position=position, subject_type=subject_type)
|
||||
return dict(body=body, path=path, position=position) if subject_type == "LINE" else {}
|
||||
|
||||
def publish_inline_comments(self, comments: list[dict]):
|
||||
self.pr.create_review(commit=self.last_commit_id, comments=comments)
|
||||
|
||||
def publish_code_suggestion(self, body: str,
|
||||
relevant_file: str,
|
||||
relevant_lines_start: int,
|
||||
relevant_lines_end: int):
|
||||
if not relevant_lines_start or relevant_lines_start == -1:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.exception(f"Failed to publish code suggestion, relevant_lines_start is {relevant_lines_start}")
|
||||
return False
|
||||
def publish_code_suggestions(self, code_suggestions: list):
|
||||
"""
|
||||
Publishes code suggestions as comments on the PR.
|
||||
"""
|
||||
post_parameters_list = []
|
||||
for suggestion in code_suggestions:
|
||||
body = suggestion['body']
|
||||
relevant_file = suggestion['relevant_file']
|
||||
relevant_lines_start = suggestion['relevant_lines_start']
|
||||
relevant_lines_end = suggestion['relevant_lines_end']
|
||||
|
||||
if relevant_lines_end<relevant_lines_start:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.exception(f"Failed to publish code suggestion, "
|
||||
f"relevant_lines_end is {relevant_lines_end} and "
|
||||
f"relevant_lines_start is {relevant_lines_start}")
|
||||
return False
|
||||
if not relevant_lines_start or relevant_lines_start == -1:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
logging.exception(
|
||||
f"Failed to publish code suggestion, relevant_lines_start is {relevant_lines_start}")
|
||||
continue
|
||||
|
||||
if relevant_lines_end < relevant_lines_start:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
logging.exception(f"Failed to publish code suggestion, "
|
||||
f"relevant_lines_end is {relevant_lines_end} and "
|
||||
f"relevant_lines_start is {relevant_lines_start}")
|
||||
continue
|
||||
|
||||
try:
|
||||
import github.PullRequestComment
|
||||
if relevant_lines_end > relevant_lines_start:
|
||||
post_parameters = {
|
||||
"body": body,
|
||||
"commit_id": self.last_commit_id._identity,
|
||||
"path": relevant_file,
|
||||
"line": relevant_lines_end,
|
||||
"start_line": relevant_lines_start,
|
||||
@ -121,26 +201,23 @@ class GithubProvider(GitProvider):
|
||||
else: # API is different for single line comments
|
||||
post_parameters = {
|
||||
"body": body,
|
||||
"commit_id": self.last_commit_id._identity,
|
||||
"path": relevant_file,
|
||||
"line": relevant_lines_start,
|
||||
"side": "RIGHT",
|
||||
}
|
||||
headers, data = self.pr._requester.requestJsonAndCheck(
|
||||
"POST", f"{self.pr.url}/comments", input=post_parameters
|
||||
)
|
||||
github.PullRequestComment.PullRequestComment(
|
||||
self.pr._requester, headers, data, completed=True
|
||||
)
|
||||
post_parameters_list.append(post_parameters)
|
||||
|
||||
try:
|
||||
self.pr.create_review(commit=self.last_commit_id, comments=post_parameters_list)
|
||||
return True
|
||||
except Exception as e:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
logging.error(f"Failed to publish code suggestion, error: {e}")
|
||||
return False
|
||||
|
||||
def remove_initial_comment(self):
|
||||
try:
|
||||
for comment in self.pr.comments_list:
|
||||
for comment in getattr(self.pr, 'comments_list', []):
|
||||
if comment.is_temporary:
|
||||
comment.delete()
|
||||
except Exception as e:
|
||||
@ -157,6 +234,9 @@ class GithubProvider(GitProvider):
|
||||
return self.pr.head.ref
|
||||
|
||||
def get_pr_description(self):
|
||||
max_tokens = get_settings().get("CONFIG.MAX_DESCRIPTION_TOKENS", None)
|
||||
if max_tokens:
|
||||
return clip_tokens(self.pr.body, max_tokens)
|
||||
return self.pr.body
|
||||
|
||||
def get_user_id(self):
|
||||
@ -168,7 +248,7 @@ class GithubProvider(GitProvider):
|
||||
return self.github_user_id
|
||||
|
||||
def get_notifications(self, since: datetime):
|
||||
deployment_type = settings.get("GITHUB.DEPLOYMENT_TYPE", "user")
|
||||
deployment_type = get_settings().get("GITHUB.DEPLOYMENT_TYPE", "user")
|
||||
|
||||
if deployment_type != 'user':
|
||||
raise ValueError("Deployment mode must be set to 'user' to get notifications")
|
||||
@ -179,6 +259,30 @@ class GithubProvider(GitProvider):
|
||||
def get_issue_comments(self):
|
||||
return self.pr.get_issue_comments()
|
||||
|
||||
def get_repo_settings(self):
|
||||
try:
|
||||
contents = self.repo_obj.get_contents(".pr_agent.toml", ref=self.pr.head.sha).decoded_content
|
||||
return contents
|
||||
except Exception:
|
||||
return ""
|
||||
|
||||
def add_eyes_reaction(self, issue_comment_id: int) -> Optional[int]:
|
||||
try:
|
||||
reaction = self.pr.get_issue_comment(issue_comment_id).create_reaction("eyes")
|
||||
return reaction.id
|
||||
except Exception as e:
|
||||
logging.exception(f"Failed to add eyes reaction, error: {e}")
|
||||
return None
|
||||
|
||||
def remove_reaction(self, issue_comment_id: int, reaction_id: int) -> bool:
|
||||
try:
|
||||
self.pr.get_issue_comment(issue_comment_id).delete_reaction(reaction_id)
|
||||
return True
|
||||
except Exception as e:
|
||||
logging.exception(f"Failed to remove eyes reaction, error: {e}")
|
||||
return False
|
||||
|
||||
|
||||
@staticmethod
|
||||
def _parse_pr_url(pr_url: str) -> Tuple[str, int]:
|
||||
parsed_url = urlparse(pr_url)
|
||||
@ -209,12 +313,12 @@ class GithubProvider(GitProvider):
|
||||
return repo_name, pr_number
|
||||
|
||||
def _get_github_client(self):
|
||||
deployment_type = settings.get("GITHUB.DEPLOYMENT_TYPE", "user")
|
||||
deployment_type = get_settings().get("GITHUB.DEPLOYMENT_TYPE", "user")
|
||||
|
||||
if deployment_type == 'app':
|
||||
try:
|
||||
private_key = settings.github.private_key
|
||||
app_id = settings.github.app_id
|
||||
private_key = get_settings().github.private_key
|
||||
app_id = get_settings().github.app_id
|
||||
except AttributeError as e:
|
||||
raise ValueError("GitHub app ID and private key are required when using GitHub app deployment") from e
|
||||
if not self.installation_id:
|
||||
@ -225,7 +329,7 @@ class GithubProvider(GitProvider):
|
||||
|
||||
if deployment_type == 'user':
|
||||
try:
|
||||
token = settings.github.user_token
|
||||
token = get_settings().github.user_token
|
||||
except AttributeError as e:
|
||||
raise ValueError(
|
||||
"GitHub token is required when using user deployment. See: "
|
||||
@ -233,7 +337,14 @@ class GithubProvider(GitProvider):
|
||||
return Github(auth=Auth.Token(token))
|
||||
|
||||
def _get_repo(self):
|
||||
return self.github_client.get_repo(self.repo)
|
||||
if hasattr(self, 'repo_obj') and \
|
||||
hasattr(self.repo_obj, 'full_name') and \
|
||||
self.repo_obj.full_name == self.repo:
|
||||
return self.repo_obj
|
||||
else:
|
||||
self.repo_obj = self.github_client.get_repo(self.repo)
|
||||
return self.repo_obj
|
||||
|
||||
|
||||
def _get_pr(self):
|
||||
return self._get_repo().get_pull(self.pr_num)
|
||||
@ -244,3 +355,68 @@ class GithubProvider(GitProvider):
|
||||
except Exception:
|
||||
file_content_str = ""
|
||||
return file_content_str
|
||||
|
||||
def publish_labels(self, pr_types):
|
||||
try:
|
||||
label_color_map = {"Bug fix": "1d76db", "Tests": "e99695", "Bug fix with tests": "c5def5",
|
||||
"Refactoring": "bfdadc", "Enhancement": "bfd4f2", "Documentation": "d4c5f9",
|
||||
"Other": "d1bcf9"}
|
||||
post_parameters = []
|
||||
for p in pr_types:
|
||||
color = label_color_map.get(p, "d1bcf9") # default to "Other" color
|
||||
post_parameters.append({"name": p, "color": color})
|
||||
headers, data = self.pr._requester.requestJsonAndCheck(
|
||||
"PUT", f"{self.pr.issue_url}/labels", input=post_parameters
|
||||
)
|
||||
except Exception as e:
|
||||
logging.exception(f"Failed to publish labels, error: {e}")
|
||||
|
||||
def get_labels(self):
|
||||
try:
|
||||
return [label.name for label in self.pr.labels]
|
||||
except Exception as e:
|
||||
logging.exception(f"Failed to get labels, error: {e}")
|
||||
return []
|
||||
|
||||
def get_commit_messages(self):
|
||||
"""
|
||||
Retrieves the commit messages of a pull request.
|
||||
|
||||
Returns:
|
||||
str: A string containing the commit messages of the pull request.
|
||||
"""
|
||||
max_tokens = get_settings().get("CONFIG.MAX_COMMITS_TOKENS", None)
|
||||
try:
|
||||
commit_list = self.pr.get_commits()
|
||||
commit_messages = [commit.commit.message for commit in commit_list]
|
||||
commit_messages_str = "\n".join([f"{i + 1}. {message}" for i, message in enumerate(commit_messages)])
|
||||
except Exception:
|
||||
commit_messages_str = ""
|
||||
if max_tokens:
|
||||
commit_messages_str = clip_tokens(commit_messages_str, max_tokens)
|
||||
return commit_messages_str
|
||||
|
||||
def generate_link_to_relevant_line_number(self, suggestion) -> str:
|
||||
try:
|
||||
relevant_file = suggestion['relevant file'].strip('`').strip("'")
|
||||
relevant_line_str = suggestion['relevant line']
|
||||
if not relevant_line_str:
|
||||
return ""
|
||||
|
||||
position, absolute_position = find_line_number_of_relevant_line_in_file \
|
||||
(self.diff_files, relevant_file, relevant_line_str)
|
||||
|
||||
if absolute_position != -1:
|
||||
# # link to right file only
|
||||
# link = f"https://github.com/{self.repo}/blob/{self.pr.head.sha}/{relevant_file}" \
|
||||
# + "#" + f"L{absolute_position}"
|
||||
|
||||
# link to diff
|
||||
sha_file = hashlib.sha256(relevant_file.encode('utf-8')).hexdigest()
|
||||
link = f"https://github.com/{self.repo}/pull/{self.pr_num}/files#diff-{sha_file}R{absolute_position}"
|
||||
return link
|
||||
except Exception as e:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
logging.info(f"Failed adding line link, error: {e}")
|
||||
|
||||
return ""
|
||||
|
||||
@ -6,32 +6,41 @@ from urllib.parse import urlparse
|
||||
import gitlab
|
||||
from gitlab import GitlabGetError
|
||||
|
||||
from pr_agent.config_loader import settings
|
||||
|
||||
from .git_provider import EDIT_TYPE, FilePatchInfo, GitProvider
|
||||
from ..algo.language_handler import is_valid_file
|
||||
from ..algo.pr_processing import clip_tokens
|
||||
from ..algo.utils import load_large_diff
|
||||
from ..config_loader import get_settings
|
||||
from .git_provider import EDIT_TYPE, FilePatchInfo, GitProvider
|
||||
|
||||
logger = logging.getLogger()
|
||||
|
||||
class DiffNotFoundError(Exception):
|
||||
"""Raised when the diff for a merge request cannot be found."""
|
||||
pass
|
||||
|
||||
class GitLabProvider(GitProvider):
|
||||
def __init__(self, merge_request_url: Optional[str] = None):
|
||||
gitlab_url = settings.get("GITLAB.URL", None)
|
||||
|
||||
def __init__(self, merge_request_url: Optional[str] = None, incremental: Optional[bool] = False):
|
||||
gitlab_url = get_settings().get("GITLAB.URL", None)
|
||||
if not gitlab_url:
|
||||
raise ValueError("GitLab URL is not set in the config file")
|
||||
gitlab_access_token = settings.get("GITLAB.PERSONAL_ACCESS_TOKEN", None)
|
||||
gitlab_access_token = get_settings().get("GITLAB.PERSONAL_ACCESS_TOKEN", None)
|
||||
if not gitlab_access_token:
|
||||
raise ValueError("GitLab personal access token is not set in the config file")
|
||||
self.gl = gitlab.Gitlab(
|
||||
gitlab_url,
|
||||
gitlab_access_token
|
||||
url=gitlab_url,
|
||||
oauth_token=gitlab_access_token
|
||||
)
|
||||
self.id_project = None
|
||||
self.id_mr = None
|
||||
self.mr = None
|
||||
self.diff_files = None
|
||||
self.git_files = None
|
||||
self.temp_comments = []
|
||||
self._set_merge_request(merge_request_url)
|
||||
self.RE_HUNK_HEADER = re.compile(
|
||||
r"^@@ -(\d+)(?:,(\d+))? \+(\d+)(?:,(\d+))? @@[ ]?(.*)")
|
||||
self.incremental = incremental
|
||||
|
||||
def is_supported(self, capability: str) -> bool:
|
||||
if capability in ['get_issue_comments', 'create_inline_comment', 'publish_inline_comments']:
|
||||
@ -46,7 +55,12 @@ class GitLabProvider(GitProvider):
|
||||
def _set_merge_request(self, merge_request_url: str):
|
||||
self.id_project, self.id_mr = self._parse_merge_request_url(merge_request_url)
|
||||
self.mr = self._get_merge_request()
|
||||
self.last_diff = self.mr.diffs.list()[-1]
|
||||
try:
|
||||
self.last_diff = self.mr.diffs.list(get_all=True)[-1]
|
||||
except IndexError as e:
|
||||
logger.error(f"Could not get diff for merge request {self.id_mr}")
|
||||
raise DiffNotFoundError(f"Could not get diff for merge request {self.id_mr}") from e
|
||||
|
||||
|
||||
def _get_pr_file_content(self, file_path: str, branch: str) -> str:
|
||||
try:
|
||||
@ -57,19 +71,27 @@ class GitLabProvider(GitProvider):
|
||||
return ''
|
||||
|
||||
def get_diff_files(self) -> list[FilePatchInfo]:
|
||||
"""
|
||||
Retrieves the list of files that have been modified, added, deleted, or renamed in a pull request in GitLab,
|
||||
along with their content and patch information.
|
||||
|
||||
Returns:
|
||||
diff_files (List[FilePatchInfo]): List of FilePatchInfo objects representing the modified, added, deleted,
|
||||
or renamed files in the merge request.
|
||||
"""
|
||||
|
||||
if self.diff_files:
|
||||
return self.diff_files
|
||||
|
||||
diffs = self.mr.changes()['changes']
|
||||
diff_files = []
|
||||
for diff in diffs:
|
||||
if is_valid_file(diff['new_path']):
|
||||
original_file_content_str = self._get_pr_file_content(diff['old_path'], self.mr.target_branch)
|
||||
new_file_content_str = self._get_pr_file_content(diff['new_path'], self.mr.source_branch)
|
||||
edit_type = EDIT_TYPE.MODIFIED
|
||||
if diff['new_file']:
|
||||
edit_type = EDIT_TYPE.ADDED
|
||||
elif diff['deleted_file']:
|
||||
edit_type = EDIT_TYPE.DELETED
|
||||
elif diff['renamed_file']:
|
||||
edit_type = EDIT_TYPE.RENAMED
|
||||
# original_file_content_str = self._get_pr_file_content(diff['old_path'], self.mr.target_branch)
|
||||
# new_file_content_str = self._get_pr_file_content(diff['new_path'], self.mr.source_branch)
|
||||
original_file_content_str = self._get_pr_file_content(diff['old_path'], self.mr.diff_refs['base_sha'])
|
||||
new_file_content_str = self._get_pr_file_content(diff['new_path'], self.mr.diff_refs['head_sha'])
|
||||
|
||||
try:
|
||||
if isinstance(original_file_content_str, bytes):
|
||||
original_file_content_str = bytes.decode(original_file_content_str, 'utf-8')
|
||||
@ -78,15 +100,33 @@ class GitLabProvider(GitProvider):
|
||||
except UnicodeDecodeError:
|
||||
logging.warning(
|
||||
f"Cannot decode file {diff['old_path']} or {diff['new_path']} in merge request {self.id_mr}")
|
||||
|
||||
edit_type = EDIT_TYPE.MODIFIED
|
||||
if diff['new_file']:
|
||||
edit_type = EDIT_TYPE.ADDED
|
||||
elif diff['deleted_file']:
|
||||
edit_type = EDIT_TYPE.DELETED
|
||||
elif diff['renamed_file']:
|
||||
edit_type = EDIT_TYPE.RENAMED
|
||||
|
||||
filename = diff['new_path']
|
||||
patch = diff['diff']
|
||||
if not patch:
|
||||
patch = load_large_diff(filename, new_file_content_str, original_file_content_str)
|
||||
|
||||
diff_files.append(
|
||||
FilePatchInfo(original_file_content_str, new_file_content_str, diff['diff'], diff['new_path'],
|
||||
FilePatchInfo(original_file_content_str, new_file_content_str,
|
||||
patch=patch,
|
||||
filename=filename,
|
||||
edit_type=edit_type,
|
||||
old_filename=None if diff['old_path'] == diff['new_path'] else diff['old_path']))
|
||||
self.diff_files = diff_files
|
||||
return diff_files
|
||||
|
||||
def get_files(self):
|
||||
return [change['new_path'] for change in self.mr.changes()['changes']]
|
||||
if not self.git_files:
|
||||
self.git_files = [change['new_path'] for change in self.mr.changes()['changes']]
|
||||
return self.git_files
|
||||
|
||||
def publish_description(self, pr_title: str, pr_body: str):
|
||||
try:
|
||||
@ -102,7 +142,6 @@ class GitLabProvider(GitProvider):
|
||||
self.temp_comments.append(comment)
|
||||
|
||||
def publish_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
||||
self.diff_files = self.diff_files if self.diff_files else self.get_diff_files()
|
||||
edit_type, found, source_line_no, target_file, target_line_no = self.search_line(relevant_file,
|
||||
relevant_line_in_file)
|
||||
self.send_inline_comment(body, edit_type, found, relevant_file, relevant_line_in_file, source_line_no,
|
||||
@ -111,19 +150,23 @@ class GitLabProvider(GitProvider):
|
||||
def create_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
||||
raise NotImplementedError("Gitlab provider does not support creating inline comments yet")
|
||||
|
||||
def create_inline_comment(self, comments: list[dict]):
|
||||
def create_inline_comments(self, comments: list[dict]):
|
||||
raise NotImplementedError("Gitlab provider does not support publishing inline comments yet")
|
||||
|
||||
def send_inline_comment(self, body, edit_type, found, relevant_file, relevant_line_in_file, source_line_no,
|
||||
target_file, target_line_no):
|
||||
def send_inline_comment(self,body: str,edit_type: str,found: bool,relevant_file: str,relevant_line_in_file: int,
|
||||
source_line_no: int, target_file: str,target_line_no: int) -> None:
|
||||
if not found:
|
||||
logging.info(f"Could not find position for {relevant_file} {relevant_line_in_file}")
|
||||
else:
|
||||
d = self.last_diff
|
||||
# in order to have exact sha's we have to find correct diff for this change
|
||||
diff = self.get_relevant_diff(relevant_file, relevant_line_in_file)
|
||||
if diff is None:
|
||||
logger.error(f"Could not get diff for merge request {self.id_mr}")
|
||||
raise DiffNotFoundError(f"Could not get diff for merge request {self.id_mr}")
|
||||
pos_obj = {'position_type': 'text',
|
||||
'new_path': target_file.filename,
|
||||
'old_path': target_file.old_filename if target_file.old_filename else target_file.filename,
|
||||
'base_sha': d.base_commit_sha, 'start_sha': d.start_commit_sha, 'head_sha': d.head_commit_sha}
|
||||
'base_sha': diff.base_commit_sha, 'start_sha': diff.start_commit_sha, 'head_sha': diff.head_commit_sha}
|
||||
if edit_type == 'deletion':
|
||||
pos_obj['old_line'] = source_line_no - 1
|
||||
elif edit_type == 'addition':
|
||||
@ -131,35 +174,65 @@ class GitLabProvider(GitProvider):
|
||||
else:
|
||||
pos_obj['new_line'] = target_line_no - 1
|
||||
pos_obj['old_line'] = source_line_no - 1
|
||||
logging.debug(f"Creating comment in {self.id_mr} with body {body} and position {pos_obj}")
|
||||
self.mr.discussions.create({'body': body,
|
||||
'position': pos_obj})
|
||||
|
||||
def publish_code_suggestion(self, body: str,
|
||||
relevant_file: str,
|
||||
relevant_lines_start: int,
|
||||
relevant_lines_end: int):
|
||||
self.diff_files = self.diff_files if self.diff_files else self.get_diff_files()
|
||||
target_file = None
|
||||
for file in self.diff_files:
|
||||
if file.filename == relevant_file:
|
||||
if file.filename == relevant_file:
|
||||
target_file = file
|
||||
break
|
||||
range = relevant_lines_end - relevant_lines_start + 1
|
||||
body = body.replace('```suggestion', f'```suggestion:-0+{range}')
|
||||
def get_relevant_diff(self, relevant_file: str, relevant_line_in_file: int) -> Optional[dict]:
|
||||
changes = self.mr.changes() # Retrieve the changes for the merge request once
|
||||
if not changes:
|
||||
logging.error('No changes found for the merge request.')
|
||||
return None
|
||||
all_diffs = self.mr.diffs.list(get_all=True)
|
||||
if not all_diffs:
|
||||
logging.error('No diffs found for the merge request.')
|
||||
return None
|
||||
for diff in all_diffs:
|
||||
for change in changes['changes']:
|
||||
if change['new_path'] == relevant_file and relevant_line_in_file in change['diff']:
|
||||
return diff
|
||||
logging.debug(
|
||||
f'No relevant diff found for {relevant_file} {relevant_line_in_file}. Falling back to last diff.')
|
||||
return self.last_diff # fallback to last_diff if no relevant diff is found
|
||||
|
||||
lines = target_file.head_file.splitlines()
|
||||
relevant_line_in_file = lines[relevant_lines_start - 1]
|
||||
edit_type, found, source_line_no, target_file, target_line_no = self.find_in_file(target_file,
|
||||
relevant_line_in_file)
|
||||
self.send_inline_comment(body, edit_type, found, relevant_file, relevant_line_in_file, source_line_no,
|
||||
target_file, target_line_no)
|
||||
def publish_code_suggestions(self, code_suggestions: list):
|
||||
for suggestion in code_suggestions:
|
||||
try:
|
||||
body = suggestion['body']
|
||||
relevant_file = suggestion['relevant_file']
|
||||
relevant_lines_start = suggestion['relevant_lines_start']
|
||||
relevant_lines_end = suggestion['relevant_lines_end']
|
||||
|
||||
diff_files = self.get_diff_files()
|
||||
target_file = None
|
||||
for file in diff_files:
|
||||
if file.filename == relevant_file:
|
||||
if file.filename == relevant_file:
|
||||
target_file = file
|
||||
break
|
||||
range = relevant_lines_end - relevant_lines_start # no need to add 1
|
||||
body = body.replace('```suggestion', f'```suggestion:-0+{range}')
|
||||
lines = target_file.head_file.splitlines()
|
||||
relevant_line_in_file = lines[relevant_lines_start - 1]
|
||||
|
||||
# edit_type, found, source_line_no, target_file, target_line_no = self.find_in_file(target_file,
|
||||
# relevant_line_in_file)
|
||||
# for code suggestions, we want to edit the new code
|
||||
source_line_no = None
|
||||
target_line_no = relevant_lines_start + 1
|
||||
found = True
|
||||
edit_type = 'addition'
|
||||
|
||||
self.send_inline_comment(body, edit_type, found, relevant_file, relevant_line_in_file, source_line_no,
|
||||
target_file, target_line_no)
|
||||
except Exception as e:
|
||||
logging.exception(f"Could not publish code suggestion:\nsuggestion: {suggestion}\nerror: {e}")
|
||||
|
||||
def search_line(self, relevant_file, relevant_line_in_file):
|
||||
target_file = None
|
||||
|
||||
edit_type = self.get_edit_type(relevant_line_in_file)
|
||||
for file in self.diff_files:
|
||||
for file in self.get_diff_files():
|
||||
if file.filename == relevant_file:
|
||||
edit_type, found, source_line_no, target_file, target_line_no = self.find_in_file(file,
|
||||
relevant_line_in_file)
|
||||
@ -227,25 +300,51 @@ class GitLabProvider(GitProvider):
|
||||
return self.mr.source_branch
|
||||
|
||||
def get_pr_description(self):
|
||||
max_tokens = get_settings().get("CONFIG.MAX_DESCRIPTION_TOKENS", None)
|
||||
if max_tokens:
|
||||
return clip_tokens(self.mr.description, max_tokens)
|
||||
return self.mr.description
|
||||
|
||||
def get_issue_comments(self):
|
||||
raise NotImplementedError("GitLab provider does not support issue comments yet")
|
||||
|
||||
def _parse_merge_request_url(self, merge_request_url: str) -> Tuple[int, int]:
|
||||
def get_repo_settings(self):
|
||||
try:
|
||||
contents = self.gl.projects.get(self.id_project).files.get(file_path='.pr_agent.toml', ref=self.mr.source_branch)
|
||||
return contents
|
||||
except Exception:
|
||||
return ""
|
||||
|
||||
def add_eyes_reaction(self, issue_comment_id: int) -> Optional[int]:
|
||||
return True
|
||||
|
||||
def remove_reaction(self, issue_comment_id: int, reaction_id: int) -> bool:
|
||||
return True
|
||||
|
||||
def _parse_merge_request_url(self, merge_request_url: str) -> Tuple[str, int]:
|
||||
parsed_url = urlparse(merge_request_url)
|
||||
|
||||
path_parts = parsed_url.path.strip('/').split('/')
|
||||
if path_parts[-2] != 'merge_requests':
|
||||
if 'merge_requests' not in path_parts:
|
||||
raise ValueError("The provided URL does not appear to be a GitLab merge request URL")
|
||||
|
||||
mr_index = path_parts.index('merge_requests')
|
||||
# Ensure there is an ID after 'merge_requests'
|
||||
if len(path_parts) <= mr_index + 1:
|
||||
raise ValueError("The provided URL does not contain a merge request ID")
|
||||
|
||||
try:
|
||||
mr_id = int(path_parts[-1])
|
||||
mr_id = int(path_parts[mr_index + 1])
|
||||
except ValueError as e:
|
||||
raise ValueError("Unable to convert merge request ID to integer") from e
|
||||
|
||||
# Gitlab supports access by both project numeric ID as well as 'namespace/project_name'
|
||||
return "/".join(path_parts[:2]), mr_id
|
||||
# Handle special delimiter (-)
|
||||
project_path = "/".join(path_parts[:mr_index])
|
||||
if project_path.endswith('/-'):
|
||||
project_path = project_path[:-2]
|
||||
|
||||
# Return the path before 'merge_requests' and the ID
|
||||
return project_path, mr_id
|
||||
|
||||
def _get_merge_request(self):
|
||||
mr = self.gl.projects.get(self.id_project).mergerequests.get(self.id_mr)
|
||||
@ -253,3 +352,33 @@ class GitLabProvider(GitProvider):
|
||||
|
||||
def get_user_id(self):
|
||||
return None
|
||||
|
||||
def publish_labels(self, pr_types):
|
||||
try:
|
||||
self.mr.labels = list(set(pr_types))
|
||||
self.mr.save()
|
||||
except Exception as e:
|
||||
logging.exception(f"Failed to publish labels, error: {e}")
|
||||
|
||||
def publish_inline_comments(self, comments: list[dict]):
|
||||
pass
|
||||
|
||||
def get_labels(self):
|
||||
return self.mr.labels
|
||||
|
||||
def get_commit_messages(self):
|
||||
"""
|
||||
Retrieves the commit messages of a pull request.
|
||||
|
||||
Returns:
|
||||
str: A string containing the commit messages of the pull request.
|
||||
"""
|
||||
max_tokens = get_settings().get("CONFIG.MAX_COMMITS_TOKENS", None)
|
||||
try:
|
||||
commit_messages_list = [commit['message'] for commit in self.mr.commits()._list]
|
||||
commit_messages_str = "\n".join([f"{i + 1}. {message}" for i, message in enumerate(commit_messages_list)])
|
||||
except Exception:
|
||||
commit_messages_str = ""
|
||||
if max_tokens:
|
||||
commit_messages_str = clip_tokens(commit_messages_str, max_tokens)
|
||||
return commit_messages_str
|
||||
178
pr_agent/git_providers/local_git_provider.py
Normal file
178
pr_agent/git_providers/local_git_provider.py
Normal file
@ -0,0 +1,178 @@
|
||||
import logging
|
||||
from collections import Counter
|
||||
from pathlib import Path
|
||||
from typing import List
|
||||
|
||||
from git import Repo
|
||||
|
||||
from pr_agent.config_loader import _find_repository_root, get_settings
|
||||
from pr_agent.git_providers.git_provider import EDIT_TYPE, FilePatchInfo, GitProvider
|
||||
|
||||
|
||||
class PullRequestMimic:
|
||||
"""
|
||||
This class mimics the PullRequest class from the PyGithub library for the LocalGitProvider.
|
||||
"""
|
||||
|
||||
def __init__(self, title: str, diff_files: List[FilePatchInfo]):
|
||||
self.title = title
|
||||
self.diff_files = diff_files
|
||||
|
||||
|
||||
class LocalGitProvider(GitProvider):
|
||||
"""
|
||||
This class implements the GitProvider interface for local git repositories.
|
||||
It mimics the PR functionality of the GitProvider interface,
|
||||
but does not require a hosted git repository.
|
||||
Instead of providing a PR url, the user provides a local branch path to generate a diff-patch.
|
||||
For the MVP it only supports the /review and /describe capabilities.
|
||||
"""
|
||||
|
||||
def __init__(self, target_branch_name, incremental=False):
|
||||
self.repo_path = _find_repository_root()
|
||||
if self.repo_path is None:
|
||||
raise ValueError('Could not find repository root')
|
||||
self.repo = Repo(self.repo_path)
|
||||
self.head_branch_name = self.repo.head.ref.name
|
||||
self.target_branch_name = target_branch_name
|
||||
self._prepare_repo()
|
||||
self.diff_files = None
|
||||
self.pr = PullRequestMimic(self.get_pr_title(), self.get_diff_files())
|
||||
self.description_path = get_settings().get('local.description_path') \
|
||||
if get_settings().get('local.description_path') is not None else self.repo_path / 'description.md'
|
||||
self.review_path = get_settings().get('local.review_path') \
|
||||
if get_settings().get('local.review_path') is not None else self.repo_path / 'review.md'
|
||||
# inline code comments are not supported for local git repositories
|
||||
get_settings().pr_reviewer.inline_code_comments = False
|
||||
|
||||
def _prepare_repo(self):
|
||||
"""
|
||||
Prepare the repository for PR-mimic generation.
|
||||
"""
|
||||
logging.debug('Preparing repository for PR-mimic generation...')
|
||||
if self.repo.is_dirty():
|
||||
raise ValueError('The repository is not in a clean state. Please commit or stash pending changes.')
|
||||
if self.target_branch_name not in self.repo.heads:
|
||||
raise KeyError(f'Branch: {self.target_branch_name} does not exist')
|
||||
|
||||
def is_supported(self, capability: str) -> bool:
|
||||
if capability in ['get_issue_comments', 'create_inline_comment', 'publish_inline_comments', 'get_labels']:
|
||||
return False
|
||||
return True
|
||||
|
||||
def get_diff_files(self) -> list[FilePatchInfo]:
|
||||
diffs = self.repo.head.commit.diff(
|
||||
self.repo.merge_base(self.repo.head, self.repo.branches[self.target_branch_name]),
|
||||
create_patch=True,
|
||||
R=True
|
||||
)
|
||||
diff_files = []
|
||||
for diff_item in diffs:
|
||||
if diff_item.a_blob is not None:
|
||||
original_file_content_str = diff_item.a_blob.data_stream.read().decode('utf-8')
|
||||
else:
|
||||
original_file_content_str = "" # empty file
|
||||
if diff_item.b_blob is not None:
|
||||
new_file_content_str = diff_item.b_blob.data_stream.read().decode('utf-8')
|
||||
else:
|
||||
new_file_content_str = "" # empty file
|
||||
edit_type = EDIT_TYPE.MODIFIED
|
||||
if diff_item.new_file:
|
||||
edit_type = EDIT_TYPE.ADDED
|
||||
elif diff_item.deleted_file:
|
||||
edit_type = EDIT_TYPE.DELETED
|
||||
elif diff_item.renamed_file:
|
||||
edit_type = EDIT_TYPE.RENAMED
|
||||
diff_files.append(
|
||||
FilePatchInfo(original_file_content_str,
|
||||
new_file_content_str,
|
||||
diff_item.diff.decode('utf-8'),
|
||||
diff_item.b_path,
|
||||
edit_type=edit_type,
|
||||
old_filename=None if diff_item.a_path == diff_item.b_path else diff_item.a_path
|
||||
)
|
||||
)
|
||||
self.diff_files = diff_files
|
||||
return diff_files
|
||||
|
||||
def get_files(self) -> List[str]:
|
||||
"""
|
||||
Returns a list of files with changes in the diff.
|
||||
"""
|
||||
diff_index = self.repo.head.commit.diff(
|
||||
self.repo.merge_base(self.repo.head, self.repo.branches[self.target_branch_name]),
|
||||
R=True
|
||||
)
|
||||
# Get the list of changed files
|
||||
diff_files = [item.a_path for item in diff_index]
|
||||
return diff_files
|
||||
|
||||
def publish_description(self, pr_title: str, pr_body: str):
|
||||
with open(self.description_path, "w") as file:
|
||||
# Write the string to the file
|
||||
file.write(pr_title + '\n' + pr_body)
|
||||
|
||||
def publish_comment(self, pr_comment: str, is_temporary: bool = False):
|
||||
with open(self.review_path, "w") as file:
|
||||
# Write the string to the file
|
||||
file.write(pr_comment)
|
||||
|
||||
def publish_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
||||
raise NotImplementedError('Publishing inline comments is not implemented for the local git provider')
|
||||
|
||||
def create_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
||||
raise NotImplementedError('Creating inline comments is not implemented for the local git provider')
|
||||
|
||||
def publish_inline_comments(self, comments: list[dict]):
|
||||
raise NotImplementedError('Publishing inline comments is not implemented for the local git provider')
|
||||
|
||||
def publish_code_suggestion(self, body: str, relevant_file: str,
|
||||
relevant_lines_start: int, relevant_lines_end: int):
|
||||
raise NotImplementedError('Publishing code suggestions is not implemented for the local git provider')
|
||||
|
||||
def publish_code_suggestions(self, code_suggestions: list):
|
||||
raise NotImplementedError('Publishing code suggestions is not implemented for the local git provider')
|
||||
|
||||
def publish_labels(self, labels):
|
||||
pass # Not applicable to the local git provider, but required by the interface
|
||||
|
||||
def remove_initial_comment(self):
|
||||
pass # Not applicable to the local git provider, but required by the interface
|
||||
|
||||
def get_languages(self):
|
||||
"""
|
||||
Calculate percentage of languages in repository. Used for hunk prioritisation.
|
||||
"""
|
||||
# Get all files in repository
|
||||
filepaths = [Path(item.path) for item in self.repo.tree().traverse() if item.type == 'blob']
|
||||
# Identify language by file extension and count
|
||||
lang_count = Counter(ext.lstrip('.') for filepath in filepaths for ext in [filepath.suffix.lower()])
|
||||
# Convert counts to percentages
|
||||
total_files = len(filepaths)
|
||||
lang_percentage = {lang: count / total_files * 100 for lang, count in lang_count.items()}
|
||||
return lang_percentage
|
||||
|
||||
def get_pr_branch(self):
|
||||
return self.repo.head
|
||||
|
||||
def get_user_id(self):
|
||||
return -1 # Not used anywhere for the local provider, but required by the interface
|
||||
|
||||
def get_pr_description(self):
|
||||
commits_diff = list(self.repo.iter_commits(self.target_branch_name + '..HEAD'))
|
||||
# Get the commit messages and concatenate
|
||||
commit_messages = " ".join([commit.message for commit in commits_diff])
|
||||
# TODO Handle the description better - maybe use gpt-3.5 summarisation here?
|
||||
return commit_messages[:200] # Use max 200 characters
|
||||
|
||||
def get_pr_title(self):
|
||||
"""
|
||||
Substitutes the branch-name as the PR-mimic title.
|
||||
"""
|
||||
return self.head_branch_name
|
||||
|
||||
def get_issue_comments(self):
|
||||
raise NotImplementedError('Getting issue comments is not implemented for the local git provider')
|
||||
|
||||
def get_labels(self):
|
||||
raise NotImplementedError('Getting labels is not implemented for the local git provider')
|
||||
@ -3,55 +3,71 @@ import json
|
||||
import os
|
||||
|
||||
from pr_agent.agent.pr_agent import PRAgent
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers import get_git_provider
|
||||
from pr_agent.tools.pr_reviewer import PRReviewer
|
||||
|
||||
|
||||
async def run_action():
|
||||
GITHUB_EVENT_NAME = os.environ.get('GITHUB_EVENT_NAME', None)
|
||||
# Get environment variables
|
||||
GITHUB_EVENT_NAME = os.environ.get('GITHUB_EVENT_NAME')
|
||||
GITHUB_EVENT_PATH = os.environ.get('GITHUB_EVENT_PATH')
|
||||
OPENAI_KEY = os.environ.get('OPENAI_KEY')
|
||||
OPENAI_ORG = os.environ.get('OPENAI_ORG')
|
||||
GITHUB_TOKEN = os.environ.get('GITHUB_TOKEN')
|
||||
get_settings().set("CONFIG.PUBLISH_OUTPUT_PROGRESS", False)
|
||||
|
||||
|
||||
# Check if required environment variables are set
|
||||
if not GITHUB_EVENT_NAME:
|
||||
print("GITHUB_EVENT_NAME not set")
|
||||
return
|
||||
GITHUB_EVENT_PATH = os.environ.get('GITHUB_EVENT_PATH', None)
|
||||
if not GITHUB_EVENT_PATH:
|
||||
print("GITHUB_EVENT_PATH not set")
|
||||
return
|
||||
try:
|
||||
event_payload = json.load(open(GITHUB_EVENT_PATH, 'r'))
|
||||
except json.decoder.JSONDecodeError as e:
|
||||
print(f"Failed to parse JSON: {e}")
|
||||
return
|
||||
OPENAI_KEY = os.environ.get('OPENAI_KEY', None)
|
||||
if not OPENAI_KEY:
|
||||
print("OPENAI_KEY not set")
|
||||
return
|
||||
OPENAI_ORG = os.environ.get('OPENAI_ORG', None)
|
||||
GITHUB_TOKEN = os.environ.get('GITHUB_TOKEN', None)
|
||||
if not GITHUB_TOKEN:
|
||||
print("GITHUB_TOKEN not set")
|
||||
return
|
||||
settings.set("OPENAI.KEY", OPENAI_KEY)
|
||||
if OPENAI_ORG:
|
||||
settings.set("OPENAI.ORG", OPENAI_ORG)
|
||||
settings.set("GITHUB.USER_TOKEN", GITHUB_TOKEN)
|
||||
settings.set("GITHUB.DEPLOYMENT_TYPE", "user")
|
||||
if GITHUB_EVENT_NAME == "pull_request":
|
||||
action = event_payload.get("action", None)
|
||||
if action in ["opened", "reopened"]:
|
||||
pr_url = event_payload.get("pull_request", {}).get("url", None)
|
||||
if pr_url:
|
||||
await PRReviewer(pr_url).review()
|
||||
|
||||
# Set the environment variables in the settings
|
||||
get_settings().set("OPENAI.KEY", OPENAI_KEY)
|
||||
if OPENAI_ORG:
|
||||
get_settings().set("OPENAI.ORG", OPENAI_ORG)
|
||||
get_settings().set("GITHUB.USER_TOKEN", GITHUB_TOKEN)
|
||||
get_settings().set("GITHUB.DEPLOYMENT_TYPE", "user")
|
||||
|
||||
# Load the event payload
|
||||
try:
|
||||
with open(GITHUB_EVENT_PATH, 'r') as f:
|
||||
event_payload = json.load(f)
|
||||
except json.decoder.JSONDecodeError as e:
|
||||
print(f"Failed to parse JSON: {e}")
|
||||
return
|
||||
|
||||
# Handle pull request event
|
||||
if GITHUB_EVENT_NAME == "pull_request":
|
||||
action = event_payload.get("action")
|
||||
if action in ["opened", "reopened"]:
|
||||
pr_url = event_payload.get("pull_request", {}).get("url")
|
||||
if pr_url:
|
||||
await PRReviewer(pr_url).run()
|
||||
|
||||
# Handle issue comment event
|
||||
elif GITHUB_EVENT_NAME == "issue_comment":
|
||||
action = event_payload.get("action", None)
|
||||
action = event_payload.get("action")
|
||||
if action in ["created", "edited"]:
|
||||
comment_body = event_payload.get("comment", {}).get("body", None)
|
||||
comment_body = event_payload.get("comment", {}).get("body")
|
||||
if comment_body:
|
||||
pr_url = event_payload.get("issue", {}).get("pull_request", {}).get("url", None)
|
||||
pr_url = event_payload.get("issue", {}).get("pull_request", {}).get("url")
|
||||
if pr_url:
|
||||
body = comment_body.strip().lower()
|
||||
await PRAgent().handle_request(pr_url, body)
|
||||
comment_id = event_payload.get("comment", {}).get("id")
|
||||
provider = get_git_provider()(pr_url=pr_url)
|
||||
await PRAgent().handle_request(pr_url, body, notify=lambda: provider.add_eyes_reaction(comment_id))
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
asyncio.run(run_action())
|
||||
asyncio.run(run_action())
|
||||
@ -1,11 +1,17 @@
|
||||
import copy
|
||||
import logging
|
||||
import sys
|
||||
from typing import Any, Dict
|
||||
|
||||
import uvicorn
|
||||
from fastapi import APIRouter, FastAPI, HTTPException, Request, Response
|
||||
from starlette.middleware import Middleware
|
||||
from starlette_context import context
|
||||
from starlette_context.middleware import RawContextMiddleware
|
||||
|
||||
from pr_agent.agent.pr_agent import PRAgent
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.config_loader import get_settings, global_settings
|
||||
from pr_agent.git_providers import get_git_provider
|
||||
from pr_agent.servers.utils import verify_signature
|
||||
|
||||
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
|
||||
@ -14,7 +20,29 @@ router = APIRouter()
|
||||
|
||||
@router.post("/api/v1/github_webhooks")
|
||||
async def handle_github_webhooks(request: Request, response: Response):
|
||||
logging.debug("Received a github webhook")
|
||||
"""
|
||||
Receives and processes incoming GitHub webhook requests.
|
||||
Verifies the request signature, parses the request body, and passes it to the handle_request function for further
|
||||
processing.
|
||||
"""
|
||||
logging.debug("Received a GitHub webhook")
|
||||
|
||||
body = await get_body(request)
|
||||
|
||||
logging.debug(f'Request body:\n{body}')
|
||||
installation_id = body.get("installation", {}).get("id")
|
||||
context["installation_id"] = installation_id
|
||||
context["settings"] = copy.deepcopy(global_settings)
|
||||
|
||||
return await handle_request(body)
|
||||
|
||||
|
||||
@router.post("/api/v1/marketplace_webhooks")
|
||||
async def handle_marketplace_webhooks(request: Request, response: Response):
|
||||
body = await get_body(request)
|
||||
logging.info(f'Request body:\n{body}')
|
||||
|
||||
async def get_body(request):
|
||||
try:
|
||||
body = await request.json()
|
||||
except Exception as e:
|
||||
@ -22,43 +50,52 @@ async def handle_github_webhooks(request: Request, response: Response):
|
||||
raise HTTPException(status_code=400, detail="Error parsing request body") from e
|
||||
body_bytes = await request.body()
|
||||
signature_header = request.headers.get('x-hub-signature-256', None)
|
||||
try:
|
||||
webhook_secret = settings.github.webhook_secret
|
||||
except AttributeError:
|
||||
webhook_secret = None
|
||||
webhook_secret = getattr(get_settings().github, 'webhook_secret', None)
|
||||
if webhook_secret:
|
||||
verify_signature(body_bytes, webhook_secret, signature_header)
|
||||
logging.debug(f'Request body:\n{body}')
|
||||
return await handle_request(body)
|
||||
return body
|
||||
|
||||
|
||||
async def handle_request(body):
|
||||
action = body.get("action", None)
|
||||
installation_id = body.get("installation", {}).get("id", None)
|
||||
settings.set("GITHUB.INSTALLATION_ID", installation_id)
|
||||
|
||||
|
||||
async def handle_request(body: Dict[str, Any]):
|
||||
"""
|
||||
Handle incoming GitHub webhook requests.
|
||||
|
||||
Args:
|
||||
body: The request body.
|
||||
"""
|
||||
action = body.get("action")
|
||||
if not action:
|
||||
return {}
|
||||
agent = PRAgent()
|
||||
|
||||
if action == 'created':
|
||||
if "comment" not in body:
|
||||
return {}
|
||||
comment_body = body.get("comment", {}).get("body", None)
|
||||
if 'sender' in body and 'login' in body['sender'] and 'bot' in body['sender']['login']:
|
||||
comment_body = body.get("comment", {}).get("body")
|
||||
sender = body.get("sender", {}).get("login")
|
||||
if sender and 'bot' in sender:
|
||||
return {}
|
||||
if "issue" not in body and "pull_request" not in body["issue"]:
|
||||
if "issue" not in body or "pull_request" not in body["issue"]:
|
||||
return {}
|
||||
pull_request = body["issue"]["pull_request"]
|
||||
api_url = pull_request.get("url", None)
|
||||
await agent.handle_request(api_url, comment_body)
|
||||
api_url = pull_request.get("url")
|
||||
comment_id = body.get("comment", {}).get("id")
|
||||
provider = get_git_provider()(pr_url=api_url)
|
||||
await agent.handle_request(api_url, comment_body, notify=lambda: provider.add_eyes_reaction(comment_id))
|
||||
|
||||
elif action in ["opened"] or 'reopened' in action:
|
||||
pull_request = body.get("pull_request", None)
|
||||
|
||||
elif action == "opened" or 'reopened' in action:
|
||||
pull_request = body.get("pull_request")
|
||||
if not pull_request:
|
||||
return {}
|
||||
api_url = pull_request.get("url", None)
|
||||
if api_url is None:
|
||||
api_url = pull_request.get("url")
|
||||
if not api_url:
|
||||
return {}
|
||||
await agent.handle_request(api_url, "/review")
|
||||
else:
|
||||
return {}
|
||||
|
||||
return {}
|
||||
|
||||
|
||||
@router.get("/")
|
||||
@ -68,12 +105,14 @@ async def root():
|
||||
|
||||
def start():
|
||||
# Override the deployment type to app
|
||||
settings.set("GITHUB.DEPLOYMENT_TYPE", "app")
|
||||
app = FastAPI()
|
||||
get_settings().set("GITHUB.DEPLOYMENT_TYPE", "app")
|
||||
get_settings().set("CONFIG.PUBLISH_OUTPUT_PROGRESS", False)
|
||||
middleware = [Middleware(RawContextMiddleware)]
|
||||
app = FastAPI(middleware=middleware)
|
||||
app.include_router(router)
|
||||
|
||||
uvicorn.run(app, host="0.0.0.0", port=3000)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
start()
|
||||
start()
|
||||
@ -6,7 +6,7 @@ from datetime import datetime, timezone
|
||||
import aiohttp
|
||||
|
||||
from pr_agent.agent.pr_agent import PRAgent
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers import get_git_provider
|
||||
from pr_agent.servers.help import bot_help_text
|
||||
|
||||
@ -15,28 +15,41 @@ NOTIFICATION_URL = "https://api.github.com/notifications"
|
||||
|
||||
|
||||
def now() -> str:
|
||||
"""
|
||||
Get the current UTC time in ISO 8601 format.
|
||||
|
||||
Returns:
|
||||
str: The current UTC time in ISO 8601 format.
|
||||
"""
|
||||
now_utc = datetime.now(timezone.utc).isoformat()
|
||||
now_utc = now_utc.replace("+00:00", "Z")
|
||||
return now_utc
|
||||
|
||||
|
||||
async def polling_loop():
|
||||
"""
|
||||
Polls for notifications and handles them accordingly.
|
||||
"""
|
||||
handled_ids = set()
|
||||
since = [now()]
|
||||
last_modified = [None]
|
||||
git_provider = get_git_provider()()
|
||||
user_id = git_provider.get_user_id()
|
||||
agent = PRAgent()
|
||||
get_settings().set("CONFIG.PUBLISH_OUTPUT_PROGRESS", False)
|
||||
|
||||
try:
|
||||
deployment_type = settings.github.deployment_type
|
||||
token = settings.github.user_token
|
||||
deployment_type = get_settings().github.deployment_type
|
||||
token = get_settings().github.user_token
|
||||
except AttributeError:
|
||||
deployment_type = 'none'
|
||||
token = None
|
||||
|
||||
if deployment_type != 'user':
|
||||
raise ValueError("Deployment mode must be set to 'user' to get notifications")
|
||||
if not token:
|
||||
raise ValueError("User token must be set to get notifications")
|
||||
|
||||
async with aiohttp.ClientSession() as session:
|
||||
while True:
|
||||
try:
|
||||
@ -52,6 +65,7 @@ async def polling_loop():
|
||||
params["since"] = since[0]
|
||||
if last_modified[0]:
|
||||
headers["If-Modified-Since"] = last_modified[0]
|
||||
|
||||
async with session.get(NOTIFICATION_URL, headers=headers, params=params) as response:
|
||||
if response.status == 200:
|
||||
if 'Last-Modified' in response.headers:
|
||||
@ -85,8 +99,10 @@ async def polling_loop():
|
||||
if user_tag not in comment_body:
|
||||
continue
|
||||
rest_of_comment = comment_body.split(user_tag)[1].strip()
|
||||
|
||||
success = await agent.handle_request(pr_url, rest_of_comment)
|
||||
comment_id = comment['id']
|
||||
git_provider.set_pr(pr_url)
|
||||
success = await agent.handle_request(pr_url, rest_of_comment,
|
||||
notify=lambda: git_provider.add_eyes_reaction(comment_id)) # noqa E501
|
||||
if not success:
|
||||
git_provider.set_pr(pr_url)
|
||||
git_provider.publish_comment("### How to use PR-Agent\n" +
|
||||
@ -100,4 +116,4 @@ async def polling_loop():
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
asyncio.run(polling_loop())
|
||||
asyncio.run(polling_loop())
|
||||
@ -1,64 +0,0 @@
|
||||
import asyncio
|
||||
import time
|
||||
|
||||
import gitlab
|
||||
|
||||
from pr_agent.agent.pr_agent import PRAgent
|
||||
from pr_agent.config_loader import settings
|
||||
|
||||
gl = gitlab.Gitlab(
|
||||
settings.get("GITLAB.URL"),
|
||||
private_token=settings.get("GITLAB.PERSONAL_ACCESS_TOKEN")
|
||||
)
|
||||
|
||||
# Set the list of projects to monitor
|
||||
projects_to_monitor = settings.get("GITLAB.PROJECTS_TO_MONITOR")
|
||||
magic_word = settings.get("GITLAB.MAGIC_WORD")
|
||||
|
||||
# Hold the previous seen comments
|
||||
previous_comments = set()
|
||||
|
||||
|
||||
def check_comments():
|
||||
print('Polling')
|
||||
new_comments = {}
|
||||
for project in projects_to_monitor:
|
||||
project = gl.projects.get(project)
|
||||
merge_requests = project.mergerequests.list(state='opened')
|
||||
for mr in merge_requests:
|
||||
notes = mr.notes.list(get_all=True)
|
||||
for note in notes:
|
||||
if note.id not in previous_comments and note.body.startswith(magic_word):
|
||||
new_comments[note.id] = dict(
|
||||
body=note.body[len(magic_word):],
|
||||
project=project.name,
|
||||
mr=mr
|
||||
)
|
||||
previous_comments.add(note.id)
|
||||
print(f"New comment in project {project.name}, merge request {mr.title}: {note.body}")
|
||||
|
||||
return new_comments
|
||||
|
||||
|
||||
def handle_new_comments(new_comments):
|
||||
print('Handling new comments')
|
||||
agent = PRAgent()
|
||||
for _, comment in new_comments.items():
|
||||
print(f"Handling comment: {comment['body']}")
|
||||
asyncio.run(agent.handle_request(comment['mr'].web_url, comment['body']))
|
||||
|
||||
|
||||
def run():
|
||||
assert settings.get('CONFIG.GIT_PROVIDER') == 'gitlab', 'This script is only for GitLab'
|
||||
# Initial run to populate previous_comments
|
||||
check_comments()
|
||||
|
||||
# Run the check every minute
|
||||
while True:
|
||||
time.sleep(settings.get("GITLAB.POLLING_INTERVAL_SECONDS"))
|
||||
new_comments = check_comments()
|
||||
if new_comments:
|
||||
handle_new_comments(new_comments)
|
||||
|
||||
if __name__ == '__main__':
|
||||
run()
|
||||
47
pr_agent/servers/gitlab_webhook.py
Normal file
47
pr_agent/servers/gitlab_webhook.py
Normal file
@ -0,0 +1,47 @@
|
||||
import logging
|
||||
|
||||
import uvicorn
|
||||
from fastapi import APIRouter, FastAPI, Request, status
|
||||
from fastapi.encoders import jsonable_encoder
|
||||
from fastapi.responses import JSONResponse
|
||||
from starlette.background import BackgroundTasks
|
||||
|
||||
from pr_agent.agent.pr_agent import PRAgent
|
||||
from pr_agent.config_loader import get_settings
|
||||
|
||||
app = FastAPI()
|
||||
router = APIRouter()
|
||||
|
||||
|
||||
@router.post("/webhook")
|
||||
async def gitlab_webhook(background_tasks: BackgroundTasks, request: Request):
|
||||
data = await request.json()
|
||||
if data.get('object_kind') == 'merge_request' and data['object_attributes'].get('action') in ['open', 'reopen']:
|
||||
logging.info(f"A merge request has been opened: {data['object_attributes'].get('title')}")
|
||||
url = data['object_attributes'].get('url')
|
||||
background_tasks.add_task(PRAgent().handle_request, url, "/review")
|
||||
elif data.get('object_kind') == 'note' and data['event_type'] == 'note':
|
||||
if 'merge_request' in data:
|
||||
mr = data['merge_request']
|
||||
url = mr.get('url')
|
||||
body = data.get('object_attributes', {}).get('note')
|
||||
background_tasks.add_task(PRAgent().handle_request, url, body)
|
||||
return JSONResponse(status_code=status.HTTP_200_OK, content=jsonable_encoder({"message": "success"}))
|
||||
|
||||
def start():
|
||||
gitlab_url = get_settings().get("GITLAB.URL", None)
|
||||
if not gitlab_url:
|
||||
raise ValueError("GITLAB.URL is not set")
|
||||
gitlab_token = get_settings().get("GITLAB.PERSONAL_ACCESS_TOKEN", None)
|
||||
if not gitlab_token:
|
||||
raise ValueError("GITLAB.PERSONAL_ACCESS_TOKEN is not set")
|
||||
get_settings().config.git_provider = "gitlab"
|
||||
|
||||
app = FastAPI()
|
||||
app.include_router(router)
|
||||
|
||||
uvicorn.run(app, host="0.0.0.0", port=3000)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
start()
|
||||
@ -1,8 +1,12 @@
|
||||
commands_text = "> /review - Request a review of the latest update to the PR.\n" \
|
||||
"> /describe - Modify the PR title and description based on the contents of the PR.\n" \
|
||||
"> /improve - Suggest improvements to the code in the PR. " \
|
||||
"These will be provided as pull request comments, ready to commit.\n" \
|
||||
"> /ask <QUESTION> - Pose a question about the PR.\n"
|
||||
commands_text = "> **/review [-i]**: Request a review of your Pull Request. For an incremental review, which only " \
|
||||
"considers changes since the last review, include the '-i' option.\n" \
|
||||
"> **/describe**: Modify the PR title and description based on the contents of the PR.\n" \
|
||||
"> **/improve**: Suggest improvements to the code in the PR. \n" \
|
||||
"> **/ask \\<QUESTION\\>**: Pose a question about the PR.\n" \
|
||||
"> **/update_changelog**: Update the changelog based on the PR's contents.\n\n" \
|
||||
">To edit any configuration parameter from **configuration.toml**, add --config_path=new_value\n" \
|
||||
">For example: /review --pr_reviewer.extra_instructions=\"focus on the file: ...\" \n" \
|
||||
">To list the possible configuration parameters, use the **/config** command.\n" \
|
||||
|
||||
|
||||
def bot_help_text(user: str):
|
||||
|
||||
@ -21,3 +21,7 @@ def verify_signature(payload_body, secret_token, signature_header):
|
||||
if not hmac.compare_digest(expected_signature, signature_header):
|
||||
raise HTTPException(status_code=403, detail="Request signatures didn't match!")
|
||||
|
||||
|
||||
class RateLimitExceeded(Exception):
|
||||
"""Raised when the git provider API rate limit has been exceeded."""
|
||||
pass
|
||||
|
||||
@ -7,17 +7,27 @@
|
||||
# See README for details about GitHub App deployment.
|
||||
|
||||
[openai]
|
||||
key = "<API_KEY>" # Acquire through https://platform.openai.com
|
||||
org = "<ORGANIZATION>" # Optional, may be commented out.
|
||||
key = "" # Acquire through https://platform.openai.com
|
||||
#org = "<ORGANIZATION>" # Optional, may be commented out.
|
||||
# Uncomment the following for Azure OpenAI
|
||||
#api_type = "azure"
|
||||
#api_version = '2023-05-15' # Check Azure documentation for the current API version
|
||||
#api_base = "<API_BASE>" # The base URL for your Azure OpenAI resource. e.g. "https://<your resource name>.openai.azure.com"
|
||||
#deployment_id = "<DEPLOYMENT_ID>" # The deployment name you chose when you deployed the engine
|
||||
#api_base = "" # The base URL for your Azure OpenAI resource. e.g. "https://<your resource name>.openai.azure.com"
|
||||
#deployment_id = "" # The deployment name you chose when you deployed the engine
|
||||
#fallback_deployments = [] # For each fallback model specified in configuration.toml in the [config] section, specify the appropriate deployment_id
|
||||
|
||||
[anthropic]
|
||||
key = "" # Optional, uncomment if you want to use Anthropic. Acquire through https://www.anthropic.com/
|
||||
|
||||
[cohere]
|
||||
key = "" # Optional, uncomment if you want to use Cohere. Acquire through https://dashboard.cohere.ai/
|
||||
|
||||
[replicate]
|
||||
key = "" # Optional, uncomment if you want to use Replicate. Acquire through https://replicate.com/
|
||||
[github]
|
||||
# ---- Set the following only for deployment type == "user"
|
||||
user_token = "<TOKEN>" # A GitHub personal access token with 'repo' scope.
|
||||
user_token = "" # A GitHub personal access token with 'repo' scope.
|
||||
deployment_type = "user" #set to user by default
|
||||
|
||||
# ---- Set the following only for deployment type == "app", see README for details.
|
||||
private_key = """\
|
||||
|
||||
@ -1,28 +1,46 @@
|
||||
[config]
|
||||
model="gpt-4-0613"
|
||||
model="gpt-4"
|
||||
fallback_models=["gpt-3.5-turbo-16k"]
|
||||
git_provider="github"
|
||||
publish_output=true
|
||||
publish_output_progress=true
|
||||
verbosity_level=0 # 0,1,2
|
||||
use_extra_bad_extensions=false
|
||||
use_repo_settings_file=true
|
||||
ai_timeout=180
|
||||
max_description_tokens = 500
|
||||
max_commits_tokens = 500
|
||||
|
||||
[pr_reviewer]
|
||||
[pr_reviewer] # /review #
|
||||
require_focused_review=true
|
||||
require_score_review=false
|
||||
require_tests_review=true
|
||||
require_security_review=true
|
||||
num_code_suggestions=3
|
||||
inline_code_comments = true
|
||||
inline_code_comments = false
|
||||
ask_and_reflect=false
|
||||
extra_instructions = ""
|
||||
|
||||
[pr_description]
|
||||
[pr_description] # /describe #
|
||||
publish_description_as_comment=false
|
||||
extra_instructions = ""
|
||||
|
||||
[pr_questions]
|
||||
[pr_questions] # /ask #
|
||||
|
||||
[pr_code_suggestions]
|
||||
[pr_code_suggestions] # /improve #
|
||||
num_code_suggestions=4
|
||||
extra_instructions = ""
|
||||
|
||||
[pr_update_changelog] # /update_changelog #
|
||||
push_changelog_changes=false
|
||||
extra_instructions = ""
|
||||
|
||||
[pr_config] # /config #
|
||||
|
||||
[github]
|
||||
# The type of deployment to create. Valid values are 'app' or 'user'.
|
||||
deployment_type = "user"
|
||||
ratelimit_retries = 5
|
||||
|
||||
[gitlab]
|
||||
# URL to the gitlab service
|
||||
@ -36,3 +54,8 @@ magic_word = "AutoReview"
|
||||
|
||||
# Polling interval
|
||||
polling_interval_seconds = 30
|
||||
|
||||
[local]
|
||||
# LocalGitProvider settings - uncomment to use paths other than default
|
||||
# description_path= "path/to/description.md"
|
||||
# review_path= "path/to/review.md"
|
||||
434
pr_agent/settings/language_extensions.toml
Normal file
434
pr_agent/settings/language_extensions.toml
Normal file
@ -0,0 +1,434 @@
|
||||
[bad_extensions]
|
||||
default = [
|
||||
'app',
|
||||
'bin',
|
||||
'bmp',
|
||||
'bz2',
|
||||
'class',
|
||||
'csv',
|
||||
'dat',
|
||||
'db',
|
||||
'dll',
|
||||
'dylib',
|
||||
'egg',
|
||||
'eot',
|
||||
'exe',
|
||||
'gif',
|
||||
'gitignore',
|
||||
'glif',
|
||||
'gradle',
|
||||
'gz',
|
||||
'ico',
|
||||
'jar',
|
||||
'jpeg',
|
||||
'jpg',
|
||||
'lo',
|
||||
'lock',
|
||||
'log',
|
||||
'mp3',
|
||||
'mp4',
|
||||
'nar',
|
||||
'o',
|
||||
'ogg',
|
||||
'otf',
|
||||
'p',
|
||||
'pdf',
|
||||
'png',
|
||||
'pickle',
|
||||
'pkl',
|
||||
'pyc',
|
||||
'pyd',
|
||||
'pyo',
|
||||
'rkt',
|
||||
'so',
|
||||
'ss',
|
||||
'svg',
|
||||
'tar',
|
||||
'tsv',
|
||||
'ttf',
|
||||
'war',
|
||||
'webm',
|
||||
'woff',
|
||||
'woff2',
|
||||
'xz',
|
||||
'zip',
|
||||
'zst',
|
||||
'snap'
|
||||
]
|
||||
extra = [
|
||||
'md',
|
||||
'txt'
|
||||
]
|
||||
|
||||
[language_extension_map_org]
|
||||
ABAP = [".abap", ]
|
||||
"AGS Script" = [".ash", ]
|
||||
AMPL = [".ampl", ]
|
||||
ANTLR = [".g4", ]
|
||||
"API Blueprint" = [".apib", ]
|
||||
APL = [".apl", ".dyalog", ]
|
||||
ASP = [".asp", ".asax", ".ascx", ".ashx", ".asmx", ".aspx", ".axd", ]
|
||||
ATS = [".dats", ".hats", ".sats", ]
|
||||
ActionScript = [".as", ]
|
||||
Ada = [".adb", ".ada", ".ads", ]
|
||||
Agda = [".agda", ]
|
||||
Alloy = [".als", ]
|
||||
ApacheConf = [".apacheconf", ".vhost", ]
|
||||
AppleScript = [".applescript", ".scpt", ]
|
||||
Arc = [".arc", ]
|
||||
Arduino = [".ino", ]
|
||||
AsciiDoc = [".asciidoc", ".adoc", ]
|
||||
AspectJ = [".aj", ]
|
||||
Assembly = [".asm", ".a51", ".nasm", ]
|
||||
Augeas = [".aug", ]
|
||||
AutoHotkey = [".ahk", ".ahkl", ]
|
||||
AutoIt = [".au3", ]
|
||||
Awk = [".awk", ".auk", ".gawk", ".mawk", ".nawk", ]
|
||||
Batchfile = [".bat", ".cmd", ]
|
||||
Befunge = [".befunge", ]
|
||||
Bison = [".bison", ]
|
||||
BitBake = [".bb", ]
|
||||
BlitzBasic = [".decls", ]
|
||||
BlitzMax = [".bmx", ]
|
||||
Bluespec = [".bsv", ]
|
||||
Boo = [".boo", ]
|
||||
Brainfuck = [".bf", ]
|
||||
Brightscript = [".brs", ]
|
||||
Bro = [".bro", ]
|
||||
C = [".c", ".cats", ".h", ".idc", ".w", ]
|
||||
"C#" = [".cs", ".cake", ".cshtml", ".csx", ]
|
||||
"C++" = [".cpp", ".c++", ".cc", ".cp", ".cxx", ".h++", ".hh", ".hpp", ".hxx", ".inl", ".ipp", ".tcc", ".tpp", ".C", ".H", ]
|
||||
C-ObjDump = [".c-objdump", ]
|
||||
"C2hs Haskell" = [".chs", ]
|
||||
CLIPS = [".clp", ]
|
||||
CMake = [".cmake", ".cmake.in", ]
|
||||
COBOL = [".cob", ".cbl", ".ccp", ".cobol", ".cpy", ]
|
||||
CSS = [".css", ]
|
||||
CSV = [".csv", ]
|
||||
"Cap'n Proto" = [".capnp", ]
|
||||
CartoCSS = [".mss", ]
|
||||
Ceylon = [".ceylon", ]
|
||||
Chapel = [".chpl", ]
|
||||
ChucK = [".ck", ]
|
||||
Cirru = [".cirru", ]
|
||||
Clarion = [".clw", ]
|
||||
Clean = [".icl", ".dcl", ]
|
||||
Click = [".click", ]
|
||||
Clojure = [".clj", ".boot", ".cl2", ".cljc", ".cljs", ".cljs.hl", ".cljscm", ".cljx", ".hic", ]
|
||||
CoffeeScript = [".coffee", "._coffee", ".cjsx", ".cson", ".iced", ]
|
||||
ColdFusion = [".cfm", ".cfml", ]
|
||||
"ColdFusion CFC" = [".cfc", ]
|
||||
"Common Lisp" = [".lisp", ".asd", ".lsp", ".ny", ".podsl", ".sexp", ]
|
||||
"Component Pascal" = [".cps", ]
|
||||
Coq = [".coq", ]
|
||||
Cpp-ObjDump = [".cppobjdump", ".c++-objdump", ".c++objdump", ".cpp-objdump", ".cxx-objdump", ]
|
||||
Creole = [".creole", ]
|
||||
Crystal = [".cr", ]
|
||||
Csound = [".csd", ]
|
||||
Cucumber = [".feature", ]
|
||||
Cuda = [".cu", ".cuh", ]
|
||||
Cycript = [".cy", ]
|
||||
Cython = [".pyx", ".pxd", ".pxi", ]
|
||||
D = [".di", ]
|
||||
D-ObjDump = [".d-objdump", ]
|
||||
"DIGITAL Command Language" = [".com", ]
|
||||
DM = [".dm", ]
|
||||
"DNS Zone" = [".zone", ".arpa", ]
|
||||
"Darcs Patch" = [".darcspatch", ".dpatch", ]
|
||||
Dart = [".dart", ]
|
||||
Diff = [".diff", ".patch", ]
|
||||
Dockerfile = [".dockerfile", "Dockerfile", ]
|
||||
Dogescript = [".djs", ]
|
||||
Dylan = [".dylan", ".dyl", ".intr", ".lid", ]
|
||||
E = [".E", ]
|
||||
ECL = [".ecl", ".eclxml", ]
|
||||
Eagle = [".sch", ".brd", ]
|
||||
"Ecere Projects" = [".epj", ]
|
||||
Eiffel = [".e", ]
|
||||
Elixir = [".ex", ".exs", ]
|
||||
Elm = [".elm", ]
|
||||
"Emacs Lisp" = [".el", ".emacs", ".emacs.desktop", ]
|
||||
EmberScript = [".em", ".emberscript", ]
|
||||
Erlang = [".erl", ".escript", ".hrl", ".xrl", ".yrl", ]
|
||||
"F#" = [".fs", ".fsi", ".fsx", ]
|
||||
FLUX = [".flux", ]
|
||||
FORTRAN = [".f90", ".f", ".f03", ".f08", ".f77", ".f95", ".for", ".fpp", ]
|
||||
Factor = [".factor", ]
|
||||
Fancy = [".fy", ".fancypack", ]
|
||||
Fantom = [".fan", ]
|
||||
Formatted = [".eam.fs", ]
|
||||
Forth = [".fth", ".4th", ".forth", ".frt", ]
|
||||
FreeMarker = [".ftl", ]
|
||||
G-code = [".g", ".gco", ".gcode", ]
|
||||
GAMS = [".gms", ]
|
||||
GAP = [".gap", ".gi", ]
|
||||
GAS = [".s", ]
|
||||
GDScript = [".gd", ]
|
||||
GLSL = [".glsl", ".fp", ".frag", ".frg", ".fsh", ".fshader", ".geo", ".geom", ".glslv", ".gshader", ".shader", ".vert", ".vrx", ".vsh", ".vshader", ]
|
||||
Genshi = [".kid", ]
|
||||
"Gentoo Ebuild" = [".ebuild", ]
|
||||
"Gentoo Eclass" = [".eclass", ]
|
||||
"Gettext Catalog" = [".po", ".pot", ]
|
||||
Glyph = [".glf", ]
|
||||
Gnuplot = [".gp", ".gnu", ".gnuplot", ".plot", ".plt", ]
|
||||
Go = [".go", ]
|
||||
Golo = [".golo", ]
|
||||
Gosu = [".gst", ".gsx", ".vark", ]
|
||||
Grace = [".grace", ]
|
||||
Gradle = [".gradle", ]
|
||||
"Grammatical Framework" = [".gf", ]
|
||||
GraphQL = [".graphql", ]
|
||||
"Graphviz (DOT)" = [".dot", ".gv", ]
|
||||
Groff = [".man", ".1", ".1in", ".1m", ".1x", ".2", ".3", ".3in", ".3m", ".3qt", ".3x", ".4", ".5", ".6", ".7", ".8", ".9", ".me", ".rno", ".roff", ]
|
||||
Groovy = [".groovy", ".grt", ".gtpl", ".gvy", ]
|
||||
"Groovy Server Pages" = [".gsp", ]
|
||||
HCL = [".hcl", ".tf", ]
|
||||
HLSL = [".hlsl", ".fxh", ".hlsli", ]
|
||||
HTML = [".html", ".htm", ".html.hl", ".xht", ".xhtml", ]
|
||||
"HTML+Django" = [".mustache", ".jinja", ]
|
||||
"HTML+EEX" = [".eex", ]
|
||||
"HTML+ERB" = [".erb", ".erb.deface", ]
|
||||
"HTML+PHP" = [".phtml", ]
|
||||
HTTP = [".http", ]
|
||||
Haml = [".haml", ".haml.deface", ]
|
||||
Handlebars = [".handlebars", ".hbs", ]
|
||||
Harbour = [".hb", ]
|
||||
Haskell = [".hs", ".hsc", ]
|
||||
Haxe = [".hx", ".hxsl", ]
|
||||
Hy = [".hy", ]
|
||||
IDL = [".dlm", ]
|
||||
"IGOR Pro" = [".ipf", ]
|
||||
INI = [".ini", ".cfg", ".prefs", ".properties", ]
|
||||
"IRC log" = [".irclog", ".weechatlog", ]
|
||||
Idris = [".idr", ".lidr", ]
|
||||
"Inform 7" = [".ni", ".i7x", ]
|
||||
"Inno Setup" = [".iss", ]
|
||||
Io = [".io", ]
|
||||
Ioke = [".ik", ]
|
||||
Isabelle = [".thy", ]
|
||||
J = [".ijs", ]
|
||||
JFlex = [".flex", ".jflex", ]
|
||||
JSON = [".json", ".geojson", ".lock", ".topojson", ]
|
||||
JSON5 = [".json5", ]
|
||||
JSONLD = [".jsonld", ]
|
||||
JSONiq = [".jq", ]
|
||||
JSX = [".jsx", ]
|
||||
Jade = [".jade", ]
|
||||
Jasmin = [".j", ]
|
||||
Java = [".java", ]
|
||||
"Java Server Pages" = [".jsp", ]
|
||||
JavaScript = [".js", "._js", ".bones", ".es6", ".jake", ".jsb", ".jscad", ".jsfl", ".jsm", ".jss", ".njs", ".pac", ".sjs", ".ssjs", ".xsjs", ".xsjslib", ]
|
||||
Julia = [".jl", ]
|
||||
"Jupyter Notebook" = [".ipynb", ]
|
||||
KRL = [".krl", ]
|
||||
KiCad = [".kicad_pcb", ]
|
||||
Kit = [".kit", ]
|
||||
Kotlin = [".kt", ".ktm", ".kts", ]
|
||||
LFE = [".lfe", ]
|
||||
LLVM = [".ll", ]
|
||||
LOLCODE = [".lol", ]
|
||||
LSL = [".lsl", ".lslp", ]
|
||||
LabVIEW = [".lvproj", ]
|
||||
Lasso = [".lasso", ".las", ".lasso8", ".lasso9", ".ldml", ]
|
||||
Latte = [".latte", ]
|
||||
Lean = [".lean", ".hlean", ]
|
||||
Less = [".less", ]
|
||||
Lex = [".lex", ]
|
||||
LilyPond = [".ly", ".ily", ]
|
||||
"Linker Script" = [".ld", ".lds", ]
|
||||
Liquid = [".liquid", ]
|
||||
"Literate Agda" = [".lagda", ]
|
||||
"Literate CoffeeScript" = [".litcoffee", ]
|
||||
"Literate Haskell" = [".lhs", ]
|
||||
LiveScript = [".ls", "._ls", ]
|
||||
Logos = [".xm", ".x", ".xi", ]
|
||||
Logtalk = [".lgt", ".logtalk", ]
|
||||
LookML = [".lookml", ]
|
||||
Lua = [".lua", ".nse", ".pd_lua", ".rbxs", ".wlua", ]
|
||||
M = [".mumps", ]
|
||||
M4 = [".m4", ]
|
||||
MAXScript = [".mcr", ]
|
||||
MTML = [".mtml", ]
|
||||
MUF = [".muf", ]
|
||||
Makefile = [".mak", ".mk", ".mkfile", "Makefile", ]
|
||||
Mako = [".mako", ".mao", ]
|
||||
Maple = [".mpl", ]
|
||||
Markdown = [".md", ".markdown", ".mkd", ".mkdn", ".mkdown", ".ron", ]
|
||||
Mask = [".mask", ]
|
||||
Mathematica = [".mathematica", ".cdf", ".ma", ".mt", ".nb", ".nbp", ".wl", ".wlt", ]
|
||||
Matlab = [".matlab", ]
|
||||
Max = [".maxpat", ".maxhelp", ".maxproj", ".mxt", ".pat", ]
|
||||
MediaWiki = [".mediawiki", ".wiki", ]
|
||||
Metal = [".metal", ]
|
||||
MiniD = [".minid", ]
|
||||
Mirah = [".druby", ".duby", ".mir", ".mirah", ]
|
||||
Modelica = [".mo", ]
|
||||
"Module Management System" = [".mms", ".mmk", ]
|
||||
Monkey = [".monkey", ]
|
||||
MoonScript = [".moon", ]
|
||||
Myghty = [".myt", ]
|
||||
NSIS = [".nsi", ".nsh", ]
|
||||
NetLinx = [".axs", ".axi", ]
|
||||
"NetLinx+ERB" = [".axs.erb", ".axi.erb", ]
|
||||
NetLogo = [".nlogo", ]
|
||||
Nginx = [".nginxconf", ]
|
||||
Nimrod = [".nim", ".nimrod", ]
|
||||
Ninja = [".ninja", ]
|
||||
Nit = [".nit", ]
|
||||
Nix = [".nix", ]
|
||||
Nu = [".nu", ]
|
||||
NumPy = [".numpy", ".numpyw", ".numsc", ]
|
||||
OCaml = [".ml", ".eliom", ".eliomi", ".ml4", ".mli", ".mll", ".mly", ]
|
||||
ObjDump = [".objdump", ]
|
||||
"Objective-C++" = [".mm", ]
|
||||
Objective-J = [".sj", ]
|
||||
Octave = [".oct", ]
|
||||
Omgrofl = [".omgrofl", ]
|
||||
Opa = [".opa", ]
|
||||
Opal = [".opal", ]
|
||||
OpenCL = [".cl", ".opencl", ]
|
||||
"OpenEdge ABL" = [".p", ]
|
||||
OpenSCAD = [".scad", ]
|
||||
Org = [".org", ]
|
||||
Ox = [".ox", ".oxh", ".oxo", ]
|
||||
Oxygene = [".oxygene", ]
|
||||
Oz = [".oz", ]
|
||||
PAWN = [".pwn", ]
|
||||
PHP = [".php", ".aw", ".ctp", ".php3", ".php4", ".php5", ".phps", ".phpt", ]
|
||||
"POV-Ray SDL" = [".pov", ]
|
||||
Pan = [".pan", ]
|
||||
Papyrus = [".psc", ]
|
||||
Parrot = [".parrot", ]
|
||||
"Parrot Assembly" = [".pasm", ]
|
||||
"Parrot Internal Representation" = [".pir", ]
|
||||
Pascal = [".pas", ".dfm", ".dpr", ".lpr", ]
|
||||
Perl = [".pl", ".al", ".perl", ".ph", ".plx", ".pm", ".psgi", ".t", ]
|
||||
Perl6 = [".6pl", ".6pm", ".nqp", ".p6", ".p6l", ".p6m", ".pl6", ".pm6", ]
|
||||
Pickle = [".pkl", ]
|
||||
PigLatin = [".pig", ]
|
||||
Pike = [".pike", ".pmod", ]
|
||||
Pod = [".pod", ]
|
||||
PogoScript = [".pogo", ]
|
||||
Pony = [".pony", ]
|
||||
PostScript = [".ps", ".eps", ]
|
||||
PowerShell = [".ps1", ".psd1", ".psm1", ]
|
||||
Processing = [".pde", ]
|
||||
Prolog = [".prolog", ".yap", ]
|
||||
"Propeller Spin" = [".spin", ]
|
||||
"Protocol Buffer" = [".proto", ]
|
||||
"Public Key" = [".pub", ]
|
||||
"Pure Data" = [".pd", ]
|
||||
PureBasic = [".pb", ".pbi", ]
|
||||
PureScript = [".purs", ]
|
||||
Python = [".py", ".bzl", ".gyp", ".lmi", ".pyde", ".pyp", ".pyt", ".pyw", ".tac", ".wsgi", ".xpy", ]
|
||||
"Python traceback" = [".pytb", ]
|
||||
QML = [".qml", ".qbs", ]
|
||||
QMake = [".pri", ]
|
||||
R = [".r", ".rd", ".rsx", ]
|
||||
RAML = [".raml", ]
|
||||
RDoc = [".rdoc", ]
|
||||
REALbasic = [".rbbas", ".rbfrm", ".rbmnu", ".rbres", ".rbtbar", ".rbuistate", ]
|
||||
RHTML = [".rhtml", ]
|
||||
RMarkdown = [".rmd", ]
|
||||
Racket = [".rkt", ".rktd", ".rktl", ".scrbl", ]
|
||||
"Ragel in Ruby Host" = [".rl", ]
|
||||
"Raw token data" = [".raw", ]
|
||||
Rebol = [".reb", ".r2", ".r3", ".rebol", ]
|
||||
Red = [".red", ".reds", ]
|
||||
Redcode = [".cw", ]
|
||||
"Ren'Py" = [".rpy", ]
|
||||
RenderScript = [".rsh", ]
|
||||
RobotFramework = [".robot", ]
|
||||
Rouge = [".rg", ]
|
||||
Ruby = [".rb", ".builder", ".gemspec", ".god", ".irbrc", ".jbuilder", ".mspec", ".podspec", ".rabl", ".rake", ".rbuild", ".rbw", ".rbx", ".ru", ".ruby", ".thor", ".watchr", ]
|
||||
Rust = [".rs", ".rs.in", ]
|
||||
SAS = [".sas", ]
|
||||
SCSS = [".scss", ]
|
||||
SMT = [".smt2", ".smt", ]
|
||||
SPARQL = [".sparql", ".rq", ]
|
||||
SQF = [".sqf", ".hqf", ]
|
||||
SQL = [".pls", ".pck", ".pkb", ".pks", ".plb", ".plsql", ".sql", ".cql", ".ddl", ".prc", ".tab", ".udf", ".viw", ".db2", ]
|
||||
STON = [".ston", ]
|
||||
SVG = [".svg", ]
|
||||
Sage = [".sage", ".sagews", ]
|
||||
SaltStack = [".sls", ]
|
||||
Sass = [".sass", ]
|
||||
Scala = [".scala", ".sbt", ]
|
||||
Scaml = [".scaml", ]
|
||||
Scheme = [".scm", ".sld", ".sps", ".ss", ]
|
||||
Scilab = [".sci", ".sce", ]
|
||||
Self = [".self", ]
|
||||
Shell = [".sh", ".bash", ".bats", ".command", ".ksh", ".sh.in", ".tmux", ".tool", ".zsh", ]
|
||||
ShellSession = [".sh-session", ]
|
||||
Shen = [".shen", ]
|
||||
Slash = [".sl", ]
|
||||
Slim = [".slim", ]
|
||||
Smali = [".smali", ]
|
||||
Smalltalk = [".st", ]
|
||||
Smarty = [".tpl", ]
|
||||
Solidity = [".sol", ]
|
||||
SourcePawn = [".sp", ".sma", ]
|
||||
Squirrel = [".nut", ]
|
||||
Stan = [".stan", ]
|
||||
"Standard ML" = [".ML", ".fun", ".sig", ".sml", ]
|
||||
Stata = [".do", ".ado", ".doh", ".ihlp", ".mata", ".matah", ".sthlp", ]
|
||||
Stylus = [".styl", ]
|
||||
SuperCollider = [".scd", ]
|
||||
Swift = [".swift", ]
|
||||
SystemVerilog = [".sv", ".svh", ".vh", ]
|
||||
TOML = [".toml", ]
|
||||
TXL = [".txl", ]
|
||||
Tcl = [".tcl", ".adp", ".tm", ]
|
||||
Tcsh = [".tcsh", ".csh", ]
|
||||
TeX = [".tex", ".aux", ".bbx", ".bib", ".cbx", ".dtx", ".ins", ".lbx", ".ltx", ".mkii", ".mkiv", ".mkvi", ".sty", ".toc", ]
|
||||
Tea = [".tea", ]
|
||||
Text = [".txt", ".no", ]
|
||||
Textile = [".textile", ]
|
||||
Thrift = [".thrift", ]
|
||||
Turing = [".tu", ]
|
||||
Turtle = [".ttl", ]
|
||||
Twig = [".twig", ]
|
||||
TypeScript = [".ts", ".tsx", ]
|
||||
"Unified Parallel C" = [".upc", ]
|
||||
"Unity3D Asset" = [".anim", ".asset", ".mat", ".meta", ".prefab", ".unity", ]
|
||||
Uno = [".uno", ]
|
||||
UnrealScript = [".uc", ]
|
||||
UrWeb = [".ur", ".urs", ]
|
||||
VCL = [".vcl", ]
|
||||
VHDL = [".vhdl", ".vhd", ".vhf", ".vhi", ".vho", ".vhs", ".vht", ".vhw", ]
|
||||
Vala = [".vala", ".vapi", ]
|
||||
Verilog = [".veo", ]
|
||||
VimL = [".vim", ]
|
||||
"Visual Basic" = [".vb", ".bas", ".frm", ".frx", ".vba", ".vbhtml", ".vbs", ]
|
||||
Volt = [".volt", ]
|
||||
Vue = [".vue", ]
|
||||
"Web Ontology Language" = [".owl", ]
|
||||
WebAssembly = [".wat", ]
|
||||
WebIDL = [".webidl", ]
|
||||
X10 = [".x10", ]
|
||||
XC = [".xc", ]
|
||||
XML = [".xml", ".ant", ".axml", ".ccxml", ".clixml", ".cproject", ".csl", ".csproj", ".ct", ".dita", ".ditamap", ".ditaval", ".dll.config", ".dotsettings", ".filters", ".fsproj", ".fxml", ".glade", ".grxml", ".iml", ".ivy", ".jelly", ".jsproj", ".kml", ".launch", ".mdpolicy", ".mxml", ".nproj", ".nuspec", ".odd", ".osm", ".plist", ".props", ".ps1xml", ".psc1", ".pt", ".rdf", ".rss", ".scxml", ".srdf", ".storyboard", ".stTheme", ".sublime-snippet", ".targets", ".tmCommand", ".tml", ".tmLanguage", ".tmPreferences", ".tmSnippet", ".tmTheme", ".ui", ".urdf", ".ux", ".vbproj", ".vcxproj", ".vssettings", ".vxml", ".wsdl", ".wsf", ".wxi", ".wxl", ".wxs", ".x3d", ".xacro", ".xaml", ".xib", ".xlf", ".xliff", ".xmi", ".xml.dist", ".xproj", ".xsd", ".xul", ".zcml", ]
|
||||
XPages = [".xsp-config", ".xsp.metadata", ]
|
||||
XProc = [".xpl", ".xproc", ]
|
||||
XQuery = [".xquery", ".xq", ".xql", ".xqm", ".xqy", ]
|
||||
XS = [".xs", ]
|
||||
XSLT = [".xslt", ".xsl", ]
|
||||
Xojo = [".xojo_code", ".xojo_menu", ".xojo_report", ".xojo_script", ".xojo_toolbar", ".xojo_window", ]
|
||||
Xtend = [".xtend", ]
|
||||
YAML = [".yml", ".reek", ".rviz", ".sublime-syntax", ".syntax", ".yaml", ".yaml-tmlanguage", ]
|
||||
YANG = [".yang", ]
|
||||
Yacc = [".y", ".yacc", ".yy", ]
|
||||
Zephir = [".zep", ]
|
||||
Zig = [".zig", ]
|
||||
Zimpl = [".zimpl", ".zmpl", ".zpl", ]
|
||||
desktop = [".desktop", ".desktop.in", ]
|
||||
eC = [".ec", ".eh", ]
|
||||
edn = [".edn", ]
|
||||
fish = [".fish", ]
|
||||
mupad = [".mu", ]
|
||||
nesC = [".nc", ]
|
||||
ooc = [".ooc", ]
|
||||
reStructuredText = [".rst", ".rest", ".rest.txt", ".rst.txt", ]
|
||||
wisp = [".wisp", ]
|
||||
xBase = [".prg", ".prw", ]
|
||||
|
||||
@ -9,6 +9,12 @@ Your task is to provide meaningfull non-trivial code suggestions to improve the
|
||||
- Make sure not to provide suggestions repeating modifications already implemented in the new PR code (the '+' lines).
|
||||
- Don't output line numbers in the 'improved code' snippets.
|
||||
|
||||
{%- if extra_instructions %}
|
||||
|
||||
Extra instructions from the user:
|
||||
{{ extra_instructions }}
|
||||
{% endif %}
|
||||
|
||||
You must use the following JSON schema to format your answer:
|
||||
```json
|
||||
{
|
||||
@ -67,6 +73,11 @@ Description: '{{description}}'
|
||||
{%- if language %}
|
||||
Main language: {{language}}
|
||||
{%- endif %}
|
||||
{%- if commit_messages_str %}
|
||||
|
||||
Commit messages:
|
||||
{{commit_messages_str}}
|
||||
{%- endif %}
|
||||
|
||||
|
||||
The PR Diff:
|
||||
|
||||
@ -2,36 +2,77 @@
|
||||
system="""You are CodiumAI-PR-Reviewer, a language model designed to review git pull requests.
|
||||
Your task is to provide full description of the PR content.
|
||||
- Make sure not to focus the new PR code (the '+' lines).
|
||||
- Notice that the 'Previous title', 'Previous description' and 'Commit messages' sections may be partial, simplistic, non-informative or not up-to-date. Hence, compare them to the PR diff code, and use them only as a reference.
|
||||
- If needed, each YAML output should be in block scalar format ('|-')
|
||||
{%- if extra_instructions %}
|
||||
|
||||
You must use the following JSON schema to format your answer:
|
||||
```json
|
||||
{
|
||||
"PR Title": {
|
||||
"type": "string",
|
||||
"description": "an informative title for the PR, describing its main theme"
|
||||
},
|
||||
"Type of PR": {
|
||||
"type": "string",
|
||||
"enum": ["Bug fix", "Tests", "Bug fix with tests", "Refactoring", "Enhancement", "Documentation", "Other"]
|
||||
},
|
||||
"PR Description": {
|
||||
"type": "string",
|
||||
"description": "an informative and concise description of the PR"
|
||||
},
|
||||
"PR Main Files Walkthrough": {
|
||||
"type": "string",
|
||||
"description": "a walkthrough of the PR changes. Review main files, in bullet points, and shortly describe the changes in each file (up to 10 most important files). Format: -`filename`: description of changes\n..."
|
||||
}
|
||||
}
|
||||
Extra instructions from the user:
|
||||
{{ extra_instructions }}
|
||||
{% endif %}
|
||||
|
||||
Don't repeat the prompt in the answer, and avoid outputting the 'type' and 'description' fields.
|
||||
You must use the following YAML schema to format your answer:
|
||||
```yaml
|
||||
PR Title:
|
||||
type: string
|
||||
description: an informative title for the PR, describing its main theme
|
||||
PR Type:
|
||||
type: array
|
||||
items:
|
||||
type: string
|
||||
enum:
|
||||
- Bug fix
|
||||
- Tests
|
||||
- Bug fix with tests
|
||||
- Refactoring
|
||||
- Enhancement
|
||||
- Documentation
|
||||
- Other
|
||||
PR Description:
|
||||
type: string
|
||||
description: an informative and concise description of the PR
|
||||
PR Main Files Walkthrough:
|
||||
type: array
|
||||
maxItems: 10
|
||||
description: |-
|
||||
a walkthrough of the PR changes. Review main files, and shortly describe the changes in each file (up to 10 most important files).
|
||||
items:
|
||||
filename:
|
||||
type: string
|
||||
description: the relevant file full path
|
||||
changes in file:
|
||||
type: string
|
||||
description: minimal and concise description of the changes in the relevant file
|
||||
|
||||
|
||||
Example output:
|
||||
```yaml
|
||||
PR Title: |-
|
||||
...
|
||||
PR Type:
|
||||
- Bug fix
|
||||
PR Description: |-
|
||||
...
|
||||
PR Main Files Walkthrough:
|
||||
- ...
|
||||
- ...
|
||||
```
|
||||
|
||||
Make sure to output a valid YAML. Don't repeat the prompt in the answer, and avoid outputting the 'type' and 'description' fields.
|
||||
"""
|
||||
|
||||
user="""PR Info:
|
||||
Previous title: '{{title}}'
|
||||
Previous description: '{{description}}'
|
||||
Branch: '{{branch}}'
|
||||
{%- if language %}
|
||||
|
||||
Main language: {{language}}
|
||||
{%- endif %}
|
||||
{%- if commit_messages_str %}
|
||||
|
||||
Commit messages:
|
||||
{{commit_messages_str}}
|
||||
{%- endif %}
|
||||
|
||||
|
||||
The PR Git Diff:
|
||||
@ -40,6 +81,6 @@ The PR Git Diff:
|
||||
```
|
||||
Note that lines in the diff body are prefixed with a symbol that represents the type of change: '-' for deletions, '+' for additions, and ' ' (a space) for unchanged lines.
|
||||
|
||||
Response (should be a valid JSON, and nothing else):
|
||||
```json
|
||||
Response (should be a valid YAML, and nothing else):
|
||||
```yaml
|
||||
"""
|
||||
|
||||
@ -21,6 +21,11 @@ Description: '{{description}}'
|
||||
{%- if language %}
|
||||
Main language: {{language}}
|
||||
{%- endif %}
|
||||
{%- if commit_messages_str %}
|
||||
|
||||
Commit messages:
|
||||
{{commit_messages_str}}
|
||||
{%- endif %}
|
||||
|
||||
|
||||
The PR Git Diff:
|
||||
|
||||
@ -13,6 +13,11 @@ Description: '{{description}}'
|
||||
{%- if language %}
|
||||
Main language: {{language}}
|
||||
{%- endif %}
|
||||
{%- if commit_messages_str %}
|
||||
|
||||
Commit messages:
|
||||
{{commit_messages_str}}
|
||||
{%- endif %}
|
||||
|
||||
|
||||
The PR Git Diff:
|
||||
|
||||
@ -1,115 +1,135 @@
|
||||
[pr_review_prompt]
|
||||
system="""You are CodiumAI-PR-Reviewer, a language model designed to review git pull requests.
|
||||
Your task is to provide constructive and concise feedback for the PR, and also provide meaningfull code suggestions to improve the new PR code (the '+' lines).
|
||||
- Provide up to {{ num_code_suggestions }} code suggestions.
|
||||
{%- if num_code_suggestions > 0 %}
|
||||
- Try to focus on important suggestions like fixing code problems, issues and bugs. As a second priority, provide suggestions for meaningfull code improvements, like performance, vulnerability, modularity, and best practices.
|
||||
- Provide up to {{ num_code_suggestions }} code suggestions.
|
||||
- Try to focus on the most important suggestions, like fixing code problems, issues and bugs. As a second priority, provide suggestions for meaningfull code improvements, like performance, vulnerability, modularity, and best practices.
|
||||
- Suggestions should focus on improving the new added code lines.
|
||||
- Make sure not to provide suggestions repeating modifications already implemented in the new PR code (the '+' lines).
|
||||
{%- endif %}
|
||||
- If needed, each YAML output should be in block scalar format ('|-')
|
||||
|
||||
You must use the following JSON schema to format your answer:
|
||||
```json
|
||||
{
|
||||
"PR Analysis": {
|
||||
"Main theme": {
|
||||
"type": "string",
|
||||
"description": "a short explanation of the PR"
|
||||
},
|
||||
"Type of PR": {
|
||||
"type": "string",
|
||||
"enum": ["Bug fix", "Tests", "Bug fix with tests", "Refactoring", "Enhancement", "Documentation", "Other"]
|
||||
},
|
||||
{%- if extra_instructions %}
|
||||
|
||||
Extra instructions from the user:
|
||||
{{ extra_instructions }}
|
||||
{% endif %}
|
||||
|
||||
You must use the following YAML schema to format your answer:
|
||||
```yaml
|
||||
PR Analysis:
|
||||
Main theme:
|
||||
type: string
|
||||
description: a short explanation of the PR
|
||||
Type of PR:
|
||||
type: string
|
||||
enum:
|
||||
- Bug fix
|
||||
- Tests
|
||||
- Refactoring
|
||||
- Enhancement
|
||||
- Documentation
|
||||
- Other
|
||||
{%- if require_score %}
|
||||
Score:
|
||||
type: int
|
||||
description: >-
|
||||
Rate this PR on a scale of 0-100 (inclusive), where 0 means the worst
|
||||
possible PR code, and 100 means PR code of the highest quality, without
|
||||
any bugs or performance issues, that is ready to be merged immediately and
|
||||
run in production at scale.
|
||||
{%- endif %}
|
||||
{%- if require_tests %}
|
||||
"Relevant tests added": {
|
||||
"type": "string",
|
||||
"description": "yes\\no question: does this PR have relevant tests ?"
|
||||
},
|
||||
Relevant tests added:
|
||||
type: string
|
||||
description: yes\\no question: does this PR have relevant tests ?
|
||||
{%- endif %}
|
||||
{%- if question_str %}
|
||||
"Insights from user's answer": {
|
||||
"type": "string",
|
||||
"description": "shortly summarize the insights you gained from the user's answers to the questions"
|
||||
},
|
||||
Insights from user's answer:
|
||||
type: string
|
||||
description: >-
|
||||
shortly summarize the insights you gained from the user's answers to the questions
|
||||
{%- endif %}
|
||||
{%- if require_focused %}
|
||||
"Focused PR": {
|
||||
"type": "string",
|
||||
"description": "Is this a focused PR, in the sense that it has a clear and coherent title and description, and all PR code diff changes are properly derived from the title and description? Explain your response."
|
||||
}
|
||||
},
|
||||
Focused PR:
|
||||
type: string
|
||||
description: >-
|
||||
Is this a focused PR, in the sense that all the PR code diff changes are
|
||||
united under a single focused theme ? If the theme is too broad, or the PR
|
||||
code diff changes are too scattered, then the PR is not focused. Explain
|
||||
your answer shortly.
|
||||
{%- endif %}
|
||||
"PR Feedback": {
|
||||
"General PR suggestions": {
|
||||
"type": "string",
|
||||
"description": "General suggestions and feedback for the contributors and maintainers of this PR. May include important suggestions for the overall structure, primary purpose, best practices, critical bugs, and other aspects of the PR. Explain your suggestions."
|
||||
},
|
||||
PR Feedback:
|
||||
General suggestions:
|
||||
type: string
|
||||
description: >-
|
||||
General suggestions and feedback for the contributors and maintainers of
|
||||
this PR. May include important suggestions for the overall structure,
|
||||
primary purpose, best practices, critical bugs, and other aspects of the
|
||||
PR. Don't address PR title and description, or lack of tests. Explain your
|
||||
suggestions.
|
||||
{%- if num_code_suggestions > 0 %}
|
||||
"Code suggestions": {
|
||||
"type": "array",
|
||||
"maxItems": {{ num_code_suggestions }},
|
||||
"uniqueItems": true,
|
||||
"items": {
|
||||
"relevant file": {
|
||||
"type": "string",
|
||||
"description": "the relevant file full path"
|
||||
},
|
||||
"suggestion content": {
|
||||
"type": "string",
|
||||
"description": "a concrete suggestion for meaningfully improving the new PR code. Also describe how, specifically, the suggestion can be applied to new PR code. Add tags with importance measure that matches each suggestion ('important' or 'medium'). Do not make suggestions for updating or adding docstrings, renaming PR title and description, or linter like.
|
||||
},
|
||||
"relevant line in file": {
|
||||
"type": "string",
|
||||
"description": "an authentic single code line from the PR git diff section, to which the suggestion applies."
|
||||
}
|
||||
}
|
||||
},
|
||||
Code feedback:
|
||||
type: array
|
||||
maxItems: {{ num_code_suggestions }}
|
||||
uniqueItems: true
|
||||
items:
|
||||
relevant file:
|
||||
type: string
|
||||
description: the relevant file full path
|
||||
suggestion:
|
||||
type: string
|
||||
description: |
|
||||
a concrete suggestion for meaningfully improving the new PR code. Also
|
||||
describe how, specifically, the suggestion can be applied to new PR
|
||||
code. Add tags with importance measure that matches each suggestion
|
||||
('important' or 'medium'). Do not make suggestions for updating or
|
||||
adding docstrings, renaming PR title and description, or linter like.
|
||||
relevant line:
|
||||
type: string
|
||||
description: |
|
||||
a single code line taken from the relevant file, to which the suggestion applies.
|
||||
The line should be a '+' line.
|
||||
Make sure to output the line exactly as it appears in the relevant file
|
||||
{%- endif %}
|
||||
{%- if require_security %}
|
||||
"Security concerns": {
|
||||
"type": "string",
|
||||
"description": "yes\\no question: does this PR code introduce possible security concerns or issues, like SQL injection, XSS, CSRF, and others ? explain your answer"
|
||||
? explain your answer"
|
||||
}
|
||||
Security concerns:
|
||||
type: string
|
||||
description: >-
|
||||
yes\\no question: does this PR code introduce possible security concerns or
|
||||
issues, like SQL injection, XSS, CSRF, and others ? If answered 'yes',explain your answer shortly
|
||||
{%- endif %}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Example output:
|
||||
'
|
||||
{
|
||||
"PR Analysis":
|
||||
{
|
||||
"Main theme": "xxx",
|
||||
"Type of PR": "Bug fix",
|
||||
{%- if require_tests %}
|
||||
"Relevant tests added": "No",
|
||||
```yaml
|
||||
PR Analysis:
|
||||
Main theme: xxx
|
||||
Type of PR: Bug fix
|
||||
{%- if require_score %}
|
||||
Score: 89
|
||||
{%- endif %}
|
||||
Relevant tests added: No
|
||||
{%- if require_focused %}
|
||||
"Focused PR": "yes\\no, because ..."
|
||||
Focused PR: no, because ...
|
||||
{%- endif %}
|
||||
},
|
||||
"PR Feedback":
|
||||
{
|
||||
"General PR suggestions": "..., `xxx`...",
|
||||
PR Feedback:
|
||||
General PR suggestions: ...
|
||||
{%- if num_code_suggestions > 0 %}
|
||||
"Code suggestions": [
|
||||
{
|
||||
"relevant file": "directory/xxx.py",
|
||||
"suggestion content": "xxx [important]",
|
||||
"relevant line in file": "xxx",
|
||||
},
|
||||
...
|
||||
]
|
||||
Code feedback:
|
||||
- relevant file: |-
|
||||
directory/xxx.py
|
||||
suggestion: xxx [important]
|
||||
relevant line: |-
|
||||
xxx
|
||||
...
|
||||
{%- endif %}
|
||||
{%- if require_security %},
|
||||
"Security concerns": "No, because ..."
|
||||
{%- if require_security %}
|
||||
Security concerns: No
|
||||
{%- endif %}
|
||||
}
|
||||
}
|
||||
'
|
||||
```
|
||||
|
||||
Make sure to output a valid YAML. Use multi-line block scalar ('|') if needed.
|
||||
Don't repeat the prompt in the answer, and avoid outputting the 'type' and 'description' fields.
|
||||
"""
|
||||
|
||||
@ -120,6 +140,11 @@ Description: '{{description}}'
|
||||
{%- if language %}
|
||||
Main language: {{language}}
|
||||
{%- endif %}
|
||||
{%- if commit_messages_str %}
|
||||
|
||||
Commit messages:
|
||||
{{commit_messages_str}}
|
||||
{%- endif %}
|
||||
|
||||
{%- if question_str %}
|
||||
######
|
||||
@ -138,6 +163,6 @@ The PR Git Diff:
|
||||
```
|
||||
Note that lines in the diff body are prefixed with a symbol that represents the type of change: '-' for deletions, '+' for additions, and ' ' (a space) for unchanged lines.
|
||||
|
||||
Response (should be a valid JSON, and nothing else):
|
||||
```json
|
||||
Response (should be a valid YAML, and nothing else):
|
||||
```yaml
|
||||
"""
|
||||
|
||||
45
pr_agent/settings/pr_update_changelog_prompts.toml
Normal file
45
pr_agent/settings/pr_update_changelog_prompts.toml
Normal file
@ -0,0 +1,45 @@
|
||||
[pr_update_changelog_prompt]
|
||||
system="""You are a language model called CodiumAI-PR-Changlog-summarizer.
|
||||
Your task is to update the CHANGELOG.md file of the project, to shortly summarize important changes introduced in this PR (the '+' lines).
|
||||
- The output should match the existing CHANGELOG.md format, style and conventions, so it will look like a natural part of the file. For example, if previous changes were summarized in a single line, you should do the same.
|
||||
- Don't repeat previous changes. Generate only new content, that is not already in the CHANGELOG.md file.
|
||||
- Be general, and avoid specific details, files, etc. The output should be minimal, no more than 3-4 short lines. Ignore non-relevant subsections.
|
||||
|
||||
{%- if extra_instructions %}
|
||||
|
||||
Extra instructions from the user:
|
||||
{{ extra_instructions }}
|
||||
{%- endif %}
|
||||
"""
|
||||
|
||||
user="""PR Info:
|
||||
Title: '{{title}}'
|
||||
Branch: '{{branch}}'
|
||||
Description: '{{description}}'
|
||||
{%- if language %}
|
||||
Main language: {{language}}
|
||||
{%- endif %}
|
||||
{%- if commit_messages_str %}
|
||||
|
||||
Commit messages:
|
||||
{{commit_messages_str}}
|
||||
{%- endif %}
|
||||
|
||||
|
||||
The PR Diff:
|
||||
```
|
||||
{{diff}}
|
||||
```
|
||||
|
||||
Current date:
|
||||
```
|
||||
{{today}}
|
||||
```
|
||||
|
||||
The current CHANGELOG.md:
|
||||
```
|
||||
{{ changelog_file_str }}
|
||||
```
|
||||
|
||||
Response:
|
||||
"""
|
||||
@ -6,21 +6,22 @@ import textwrap
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
|
||||
from pr_agent.algo.ai_handler import AiHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.utils import try_fix_json
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers import BitbucketProvider, get_git_provider
|
||||
from pr_agent.git_providers.git_provider import get_main_pr_language
|
||||
|
||||
|
||||
class PRCodeSuggestions:
|
||||
def __init__(self, pr_url: str, cli_mode=False):
|
||||
def __init__(self, pr_url: str, cli_mode=False, args: list = None):
|
||||
|
||||
self.git_provider = get_git_provider()(pr_url)
|
||||
self.main_language = get_main_pr_language(
|
||||
self.git_provider.get_languages(), self.git_provider.get_files()
|
||||
)
|
||||
|
||||
self.ai_handler = AiHandler()
|
||||
self.patches_diff = None
|
||||
self.prediction = None
|
||||
@ -31,47 +32,50 @@ class PRCodeSuggestions:
|
||||
"description": self.git_provider.get_pr_description(),
|
||||
"language": self.main_language,
|
||||
"diff": "", # empty diff for initial calculation
|
||||
'num_code_suggestions': settings.pr_code_suggestions.num_code_suggestions,
|
||||
"num_code_suggestions": get_settings().pr_code_suggestions.num_code_suggestions,
|
||||
"extra_instructions": get_settings().pr_code_suggestions.extra_instructions,
|
||||
"commit_messages_str": self.git_provider.get_commit_messages(),
|
||||
}
|
||||
self.token_handler = TokenHandler(self.git_provider.pr,
|
||||
self.vars,
|
||||
settings.pr_code_suggestions_prompt.system,
|
||||
settings.pr_code_suggestions_prompt.user)
|
||||
get_settings().pr_code_suggestions_prompt.system,
|
||||
get_settings().pr_code_suggestions_prompt.user)
|
||||
|
||||
async def suggest(self):
|
||||
async def run(self):
|
||||
assert type(self.git_provider) != BitbucketProvider, "Bitbucket is not supported for now"
|
||||
|
||||
logging.info('Generating code suggestions for PR...')
|
||||
if settings.config.publish_output:
|
||||
if get_settings().config.publish_output:
|
||||
self.git_provider.publish_comment("Preparing review...", is_temporary=True)
|
||||
logging.info('Getting PR diff...')
|
||||
|
||||
# we are using extended hunk with line numbers for code suggestions
|
||||
self.patches_diff = get_pr_diff(self.git_provider,
|
||||
self.token_handler,
|
||||
add_line_numbers_to_hunks=True,
|
||||
disable_extra_lines=True)
|
||||
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction()
|
||||
await retry_with_fallback_models(self._prepare_prediction)
|
||||
logging.info('Preparing PR review...')
|
||||
data = self._prepare_pr_code_suggestions()
|
||||
if settings.config.publish_output:
|
||||
if get_settings().config.publish_output:
|
||||
logging.info('Pushing PR review...')
|
||||
self.git_provider.remove_initial_comment()
|
||||
logging.info('Pushing inline code comments...')
|
||||
self.push_inline_code_suggestions(data)
|
||||
|
||||
async def _get_prediction(self):
|
||||
async def _prepare_prediction(self, model: str):
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider,
|
||||
self.token_handler,
|
||||
model,
|
||||
add_line_numbers_to_hunks=True,
|
||||
disable_extra_lines=True)
|
||||
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction(model)
|
||||
|
||||
async def _get_prediction(self, model: str):
|
||||
variables = copy.deepcopy(self.vars)
|
||||
variables["diff"] = self.patches_diff # update diff
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
system_prompt = environment.from_string(settings.pr_code_suggestions_prompt.system).render(variables)
|
||||
user_prompt = environment.from_string(settings.pr_code_suggestions_prompt.user).render(variables)
|
||||
if settings.config.verbosity_level >= 2:
|
||||
system_prompt = environment.from_string(get_settings().pr_code_suggestions_prompt.system).render(variables)
|
||||
user_prompt = environment.from_string(get_settings().pr_code_suggestions_prompt.user).render(variables)
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
logging.info(f"\nSystem prompt:\n{system_prompt}")
|
||||
logging.info(f"\nUser prompt:\n{user_prompt}")
|
||||
model = settings.config.model
|
||||
response, finish_reason = await self.ai_handler.chat_completion(model=model, temperature=0.2,
|
||||
system=system_prompt, user=user_prompt)
|
||||
|
||||
@ -79,48 +83,65 @@ class PRCodeSuggestions:
|
||||
|
||||
def _prepare_pr_code_suggestions(self) -> str:
|
||||
review = self.prediction.strip()
|
||||
data = None
|
||||
try:
|
||||
data = json.loads(review)
|
||||
except json.decoder.JSONDecodeError:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
logging.info(f"Could not parse json response: {review}")
|
||||
data = try_fix_json(review, code_suggestions=True)
|
||||
return data
|
||||
|
||||
def push_inline_code_suggestions(self, data):
|
||||
code_suggestions = []
|
||||
|
||||
if not data['Code suggestions']:
|
||||
return self.git_provider.publish_comment('No suggestions found to improve this PR.')
|
||||
|
||||
for d in data['Code suggestions']:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.info(f"suggestion: {d}")
|
||||
relevant_file = d['relevant file'].strip()
|
||||
relevant_lines_str = d['relevant lines'].strip()
|
||||
relevant_lines_start = int(relevant_lines_str.split('-')[0]) # absolute position
|
||||
relevant_lines_end = int(relevant_lines_str.split('-')[-1])
|
||||
content = d['suggestion content']
|
||||
new_code_snippet = d['improved code']
|
||||
try:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
logging.info(f"suggestion: {d}")
|
||||
relevant_file = d['relevant file'].strip()
|
||||
relevant_lines_str = d['relevant lines'].strip()
|
||||
if ',' in relevant_lines_str: # handling 'relevant lines': '181, 190' or '178-184, 188-194'
|
||||
relevant_lines_str = relevant_lines_str.split(',')[0]
|
||||
relevant_lines_start = int(relevant_lines_str.split('-')[0]) # absolute position
|
||||
relevant_lines_end = int(relevant_lines_str.split('-')[-1])
|
||||
content = d['suggestion content']
|
||||
new_code_snippet = d['improved code']
|
||||
|
||||
if new_code_snippet:
|
||||
try: # dedent code snippet
|
||||
self.diff_files = self.git_provider.diff_files if self.git_provider.diff_files \
|
||||
else self.git_provider.get_diff_files()
|
||||
original_initial_line = None
|
||||
for file in self.diff_files:
|
||||
if file.filename.strip() == relevant_file:
|
||||
original_initial_line = file.head_file.splitlines()[relevant_lines_start - 1]
|
||||
break
|
||||
if original_initial_line:
|
||||
suggested_initial_line = new_code_snippet.splitlines()[0]
|
||||
original_initial_spaces = len(original_initial_line) - len(original_initial_line.lstrip())
|
||||
suggested_initial_spaces = len(suggested_initial_line) - len(suggested_initial_line.lstrip())
|
||||
delta_spaces = original_initial_spaces - suggested_initial_spaces
|
||||
if delta_spaces > 0:
|
||||
new_code_snippet = textwrap.indent(new_code_snippet, delta_spaces * " ").rstrip('\n')
|
||||
except Exception as e:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.info(f"Could not dedent code snippet for file {relevant_file}, error: {e}")
|
||||
if new_code_snippet:
|
||||
new_code_snippet = self.dedent_code(relevant_file, relevant_lines_start, new_code_snippet)
|
||||
|
||||
body = f"**Suggestion:** {content}\n```suggestion\n" + new_code_snippet + "\n```"
|
||||
code_suggestions.append({'body': body, 'relevant_file': relevant_file,
|
||||
'relevant_lines_start': relevant_lines_start,
|
||||
'relevant_lines_end': relevant_lines_end})
|
||||
except Exception:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
logging.info(f"Could not parse suggestion: {d}")
|
||||
|
||||
self.git_provider.publish_code_suggestions(code_suggestions)
|
||||
|
||||
def dedent_code(self, relevant_file, relevant_lines_start, new_code_snippet):
|
||||
try: # dedent code snippet
|
||||
self.diff_files = self.git_provider.diff_files if self.git_provider.diff_files \
|
||||
else self.git_provider.get_diff_files()
|
||||
original_initial_line = None
|
||||
for file in self.diff_files:
|
||||
if file.filename.strip() == relevant_file:
|
||||
original_initial_line = file.head_file.splitlines()[relevant_lines_start - 1]
|
||||
break
|
||||
if original_initial_line:
|
||||
suggested_initial_line = new_code_snippet.splitlines()[0]
|
||||
original_initial_spaces = len(original_initial_line) - len(original_initial_line.lstrip())
|
||||
suggested_initial_spaces = len(suggested_initial_line) - len(suggested_initial_line.lstrip())
|
||||
delta_spaces = original_initial_spaces - suggested_initial_spaces
|
||||
if delta_spaces > 0:
|
||||
new_code_snippet = textwrap.indent(new_code_snippet, delta_spaces * " ").rstrip('\n')
|
||||
except Exception as e:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
logging.info(f"Could not dedent code snippet for file {relevant_file}, error: {e}")
|
||||
|
||||
return new_code_snippet
|
||||
|
||||
body = f"**Suggestion:** {content}\n```suggestion\n" + new_code_snippet + "\n```"
|
||||
self.git_provider.publish_code_suggestion(body=body,
|
||||
relevant_file=relevant_file,
|
||||
relevant_lines_start=relevant_lines_start,
|
||||
relevant_lines_end=relevant_lines_end)
|
||||
|
||||
48
pr_agent/tools/pr_config.py
Normal file
48
pr_agent/tools/pr_config.py
Normal file
@ -0,0 +1,48 @@
|
||||
import logging
|
||||
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers import get_git_provider
|
||||
|
||||
|
||||
class PRConfig:
|
||||
"""
|
||||
The PRConfig class is responsible for listing all configuration options available for the user.
|
||||
"""
|
||||
def __init__(self, pr_url: str, args=None):
|
||||
"""
|
||||
Initialize the PRConfig object with the necessary attributes and objects to comment on a pull request.
|
||||
|
||||
Args:
|
||||
pr_url (str): The URL of the pull request to be reviewed.
|
||||
args (list, optional): List of arguments passed to the PRReviewer class. Defaults to None.
|
||||
"""
|
||||
self.git_provider = get_git_provider()(pr_url)
|
||||
|
||||
async def run(self):
|
||||
logging.info('Getting configuration settings...')
|
||||
logging.info('Preparing configs...')
|
||||
pr_comment = self._prepare_pr_configs()
|
||||
if get_settings().config.publish_output:
|
||||
logging.info('Pushing configs...')
|
||||
self.git_provider.publish_comment(pr_comment)
|
||||
self.git_provider.remove_initial_comment()
|
||||
return ""
|
||||
|
||||
def _prepare_pr_configs(self) -> str:
|
||||
import tomli
|
||||
with open(get_settings().find_file("configuration.toml"), "rb") as conf_file:
|
||||
configuration_headers = [header.lower() for header in tomli.load(conf_file).keys()]
|
||||
relevant_configs = {
|
||||
header: configs for header, configs in get_settings().to_dict().items()
|
||||
if header.lower().startswith("pr_") and header.lower() in configuration_headers
|
||||
}
|
||||
comment_str = "Possible Configurations:"
|
||||
for header, configs in relevant_configs.items():
|
||||
if configs:
|
||||
comment_str += "\n"
|
||||
for key, value in configs.items():
|
||||
comment_str += f"\n{header.lower()}.{key.lower()} = {repr(value) if isinstance(value, str) else value}"
|
||||
comment_str += " "
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
logging.info(f"comment_str:\n{comment_str}")
|
||||
return comment_str
|
||||
@ -1,86 +1,187 @@
|
||||
import copy
|
||||
import json
|
||||
import logging
|
||||
from typing import List, Tuple
|
||||
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
|
||||
from pr_agent.algo.ai_handler import AiHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.algo.utils import load_yaml
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers import get_git_provider
|
||||
from pr_agent.git_providers.git_provider import get_main_pr_language
|
||||
|
||||
|
||||
class PRDescription:
|
||||
def __init__(self, pr_url: str):
|
||||
def __init__(self, pr_url: str, args: list = None):
|
||||
"""
|
||||
Initialize the PRDescription object with the necessary attributes and objects for generating a PR description
|
||||
using an AI model.
|
||||
Args:
|
||||
pr_url (str): The URL of the pull request.
|
||||
args (list, optional): List of arguments passed to the PRDescription class. Defaults to None.
|
||||
"""
|
||||
# Initialize the git provider and main PR language
|
||||
self.git_provider = get_git_provider()(pr_url)
|
||||
self.main_pr_language = get_main_pr_language(
|
||||
self.git_provider.get_languages(), self.git_provider.get_files()
|
||||
)
|
||||
|
||||
# Initialize the AI handler
|
||||
self.ai_handler = AiHandler()
|
||||
|
||||
# Initialize the variables dictionary
|
||||
self.vars = {
|
||||
"title": self.git_provider.pr.title,
|
||||
"branch": self.git_provider.get_pr_branch(),
|
||||
"description": self.git_provider.get_pr_description(),
|
||||
"language": self.main_pr_language,
|
||||
"diff": "", # empty diff for initial calculation
|
||||
"extra_instructions": get_settings().pr_description.extra_instructions,
|
||||
"commit_messages_str": self.git_provider.get_commit_messages()
|
||||
}
|
||||
self.token_handler = TokenHandler(self.git_provider.pr,
|
||||
self.vars,
|
||||
settings.pr_description_prompt.system,
|
||||
settings.pr_description_prompt.user)
|
||||
|
||||
# Initialize the token handler
|
||||
self.token_handler = TokenHandler(
|
||||
self.git_provider.pr,
|
||||
self.vars,
|
||||
get_settings().pr_description_prompt.system,
|
||||
get_settings().pr_description_prompt.user,
|
||||
)
|
||||
|
||||
# Initialize patches_diff and prediction attributes
|
||||
self.patches_diff = None
|
||||
self.prediction = None
|
||||
|
||||
async def describe(self):
|
||||
async def run(self):
|
||||
"""
|
||||
Generates a PR description using an AI model and publishes it to the PR.
|
||||
"""
|
||||
logging.info('Generating a PR description...')
|
||||
if settings.config.publish_output:
|
||||
if get_settings().config.publish_output:
|
||||
self.git_provider.publish_comment("Preparing pr description...", is_temporary=True)
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction()
|
||||
|
||||
await retry_with_fallback_models(self._prepare_prediction)
|
||||
|
||||
logging.info('Preparing answer...')
|
||||
pr_title, pr_body, markdown_text = self._prepare_pr_answer()
|
||||
if settings.config.publish_output:
|
||||
pr_title, pr_body, pr_types, markdown_text = self._prepare_pr_answer()
|
||||
|
||||
if get_settings().config.publish_output:
|
||||
logging.info('Pushing answer...')
|
||||
if settings.pr_description.publish_description_as_comment:
|
||||
if get_settings().pr_description.publish_description_as_comment:
|
||||
self.git_provider.publish_comment(markdown_text)
|
||||
else:
|
||||
self.git_provider.publish_description(pr_title, pr_body)
|
||||
if self.git_provider.is_supported("get_labels"):
|
||||
current_labels = self.git_provider.get_labels()
|
||||
if current_labels is None:
|
||||
current_labels = []
|
||||
self.git_provider.publish_labels(pr_types + current_labels)
|
||||
self.git_provider.remove_initial_comment()
|
||||
|
||||
return ""
|
||||
|
||||
async def _get_prediction(self):
|
||||
async def _prepare_prediction(self, model: str) -> None:
|
||||
"""
|
||||
Prepare the AI prediction for the PR description based on the provided model.
|
||||
|
||||
Args:
|
||||
model (str): The name of the model to be used for generating the prediction.
|
||||
|
||||
Returns:
|
||||
None
|
||||
|
||||
Raises:
|
||||
Any exceptions raised by the 'get_pr_diff' and '_get_prediction' functions.
|
||||
|
||||
"""
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler, model)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction(model)
|
||||
|
||||
async def _get_prediction(self, model: str) -> str:
|
||||
"""
|
||||
Generate an AI prediction for the PR description based on the provided model.
|
||||
|
||||
Args:
|
||||
model (str): The name of the model to be used for generating the prediction.
|
||||
|
||||
Returns:
|
||||
str: The generated AI prediction.
|
||||
"""
|
||||
variables = copy.deepcopy(self.vars)
|
||||
variables["diff"] = self.patches_diff # update diff
|
||||
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
system_prompt = environment.from_string(settings.pr_description_prompt.system).render(variables)
|
||||
user_prompt = environment.from_string(settings.pr_description_prompt.user).render(variables)
|
||||
if settings.config.verbosity_level >= 2:
|
||||
system_prompt = environment.from_string(get_settings().pr_description_prompt.system).render(variables)
|
||||
user_prompt = environment.from_string(get_settings().pr_description_prompt.user).render(variables)
|
||||
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
logging.info(f"\nSystem prompt:\n{system_prompt}")
|
||||
logging.info(f"\nUser prompt:\n{user_prompt}")
|
||||
model = settings.config.model
|
||||
response, finish_reason = await self.ai_handler.chat_completion(model=model, temperature=0.2,
|
||||
system=system_prompt, user=user_prompt)
|
||||
|
||||
response, finish_reason = await self.ai_handler.chat_completion(
|
||||
model=model,
|
||||
temperature=0.2,
|
||||
system=system_prompt,
|
||||
user=user_prompt
|
||||
)
|
||||
|
||||
return response
|
||||
|
||||
def _prepare_pr_answer(self):
|
||||
data = json.loads(self.prediction)
|
||||
def _prepare_pr_answer(self) -> Tuple[str, str, List[str], str]:
|
||||
"""
|
||||
Prepare the PR description based on the AI prediction data.
|
||||
|
||||
Returns:
|
||||
- title: a string containing the PR title.
|
||||
- pr_body: a string containing the PR body in a markdown format.
|
||||
- pr_types: a list of strings containing the PR types.
|
||||
- markdown_text: a string containing the AI prediction data in a markdown format. used for publishing a comment
|
||||
"""
|
||||
# Load the AI prediction data into a dictionary
|
||||
data = load_yaml(self.prediction.strip())
|
||||
|
||||
# Initialization
|
||||
pr_types = []
|
||||
|
||||
# Iterate over the dictionary items and append the key and value to 'markdown_text' in a markdown format
|
||||
markdown_text = ""
|
||||
for key, value in data.items():
|
||||
markdown_text += f"## {key}\n\n"
|
||||
markdown_text += f"{value}\n\n"
|
||||
|
||||
# If the 'PR Type' key is present in the dictionary, split its value by comma and assign it to 'pr_types'
|
||||
if 'PR Type' in data:
|
||||
if type(data['PR Type']) == list:
|
||||
pr_types = data['PR Type']
|
||||
elif type(data['PR Type']) == str:
|
||||
pr_types = data['PR Type'].split(',')
|
||||
|
||||
# Assign the value of the 'PR Title' key to 'title' variable and remove it from the dictionary
|
||||
title = data.pop('PR Title')
|
||||
|
||||
# Iterate over the remaining dictionary items and append the key and value to 'pr_body' in a markdown format,
|
||||
# except for the items containing the word 'walkthrough'
|
||||
pr_body = ""
|
||||
title = data['PR Title']
|
||||
del data['PR Title']
|
||||
for key, value in data.items():
|
||||
pr_body += f"{key}:\n"
|
||||
pr_body += f"## {key}:\n"
|
||||
if 'walkthrough' in key.lower():
|
||||
pr_body += f"{value}\n"
|
||||
# for filename, description in value.items():
|
||||
for file in value:
|
||||
filename = file['filename'].replace("'", "`")
|
||||
description = file['changes in file']
|
||||
pr_body += f'`{filename}`: {description}\n'
|
||||
else:
|
||||
pr_body += f"**{value}**\n\n___\n"
|
||||
if settings.config.verbosity_level >= 2:
|
||||
# if the value is a list, join its items by comma
|
||||
if type(value) == list:
|
||||
value = ', '.join(v for v in value)
|
||||
pr_body += f"{value}\n\n___\n"
|
||||
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
logging.info(f"title:\n{title}\n{pr_body}")
|
||||
return title, pr_body, markdown_text
|
||||
|
||||
return title, pr_body, pr_types, markdown_text
|
||||
@ -4,15 +4,15 @@ import logging
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
|
||||
from pr_agent.algo.ai_handler import AiHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers import get_git_provider
|
||||
from pr_agent.git_providers.git_provider import get_main_pr_language
|
||||
|
||||
|
||||
class PRInformationFromUser:
|
||||
def __init__(self, pr_url: str):
|
||||
def __init__(self, pr_url: str, args: list = None):
|
||||
self.git_provider = get_git_provider()(pr_url)
|
||||
self.main_pr_language = get_main_pr_language(
|
||||
self.git_provider.get_languages(), self.git_provider.get_files()
|
||||
@ -24,47 +24,50 @@ class PRInformationFromUser:
|
||||
"description": self.git_provider.get_pr_description(),
|
||||
"language": self.main_pr_language,
|
||||
"diff": "", # empty diff for initial calculation
|
||||
"commit_messages_str": self.git_provider.get_commit_messages(),
|
||||
}
|
||||
self.token_handler = TokenHandler(self.git_provider.pr,
|
||||
self.vars,
|
||||
settings.pr_information_from_user_prompt.system,
|
||||
settings.pr_information_from_user_prompt.user)
|
||||
get_settings().pr_information_from_user_prompt.system,
|
||||
get_settings().pr_information_from_user_prompt.user)
|
||||
self.patches_diff = None
|
||||
self.prediction = None
|
||||
|
||||
async def generate_questions(self):
|
||||
async def run(self):
|
||||
logging.info('Generating question to the user...')
|
||||
if settings.config.publish_output:
|
||||
if get_settings().config.publish_output:
|
||||
self.git_provider.publish_comment("Preparing questions...", is_temporary=True)
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction()
|
||||
await retry_with_fallback_models(self._prepare_prediction)
|
||||
logging.info('Preparing questions...')
|
||||
pr_comment = self._prepare_pr_answer()
|
||||
if settings.config.publish_output:
|
||||
if get_settings().config.publish_output:
|
||||
logging.info('Pushing questions...')
|
||||
self.git_provider.publish_comment(pr_comment)
|
||||
self.git_provider.remove_initial_comment()
|
||||
return ""
|
||||
|
||||
async def _get_prediction(self):
|
||||
async def _prepare_prediction(self, model):
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler, model)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction(model)
|
||||
|
||||
async def _get_prediction(self, model: str):
|
||||
variables = copy.deepcopy(self.vars)
|
||||
variables["diff"] = self.patches_diff # update diff
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
system_prompt = environment.from_string(settings.pr_information_from_user_prompt.system).render(variables)
|
||||
user_prompt = environment.from_string(settings.pr_information_from_user_prompt.user).render(variables)
|
||||
if settings.config.verbosity_level >= 2:
|
||||
system_prompt = environment.from_string(get_settings().pr_information_from_user_prompt.system).render(variables)
|
||||
user_prompt = environment.from_string(get_settings().pr_information_from_user_prompt.user).render(variables)
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
logging.info(f"\nSystem prompt:\n{system_prompt}")
|
||||
logging.info(f"\nUser prompt:\n{user_prompt}")
|
||||
model = settings.config.model
|
||||
response, finish_reason = await self.ai_handler.chat_completion(model=model, temperature=0.2,
|
||||
system=system_prompt, user=user_prompt)
|
||||
return response
|
||||
|
||||
def _prepare_pr_answer(self) -> str:
|
||||
model_output = self.prediction.strip()
|
||||
if settings.config.verbosity_level >= 2:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
logging.info(f"answer_str:\n{model_output}")
|
||||
answer_str = f"{model_output}\n\n Please respond to the questions above in the following format:\n\n" +\
|
||||
"\n>/answer\n>1) ...\n>2) ...\n>...\n"
|
||||
|
||||
@ -4,15 +4,16 @@ import logging
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
|
||||
from pr_agent.algo.ai_handler import AiHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers import get_git_provider
|
||||
from pr_agent.git_providers.git_provider import get_main_pr_language
|
||||
|
||||
|
||||
class PRQuestions:
|
||||
def __init__(self, pr_url: str, question_str: str):
|
||||
def __init__(self, pr_url: str, args=None):
|
||||
question_str = self.parse_args(args)
|
||||
self.git_provider = get_git_provider()(pr_url)
|
||||
self.main_pr_language = get_main_pr_language(
|
||||
self.git_provider.get_languages(), self.git_provider.get_files()
|
||||
@ -26,40 +27,50 @@ class PRQuestions:
|
||||
"language": self.main_pr_language,
|
||||
"diff": "", # empty diff for initial calculation
|
||||
"questions": self.question_str,
|
||||
"commit_messages_str": self.git_provider.get_commit_messages(),
|
||||
}
|
||||
self.token_handler = TokenHandler(self.git_provider.pr,
|
||||
self.vars,
|
||||
settings.pr_questions_prompt.system,
|
||||
settings.pr_questions_prompt.user)
|
||||
get_settings().pr_questions_prompt.system,
|
||||
get_settings().pr_questions_prompt.user)
|
||||
self.patches_diff = None
|
||||
self.prediction = None
|
||||
|
||||
async def answer(self):
|
||||
def parse_args(self, args):
|
||||
if args and len(args) > 0:
|
||||
question_str = " ".join(args)
|
||||
else:
|
||||
question_str = ""
|
||||
return question_str
|
||||
|
||||
async def run(self):
|
||||
logging.info('Answering a PR question...')
|
||||
if settings.config.publish_output:
|
||||
if get_settings().config.publish_output:
|
||||
self.git_provider.publish_comment("Preparing answer...", is_temporary=True)
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction()
|
||||
await retry_with_fallback_models(self._prepare_prediction)
|
||||
logging.info('Preparing answer...')
|
||||
pr_comment = self._prepare_pr_answer()
|
||||
if settings.config.publish_output:
|
||||
if get_settings().config.publish_output:
|
||||
logging.info('Pushing answer...')
|
||||
self.git_provider.publish_comment(pr_comment)
|
||||
self.git_provider.remove_initial_comment()
|
||||
return ""
|
||||
|
||||
async def _get_prediction(self):
|
||||
async def _prepare_prediction(self, model: str):
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler, model)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction(model)
|
||||
|
||||
async def _get_prediction(self, model: str):
|
||||
variables = copy.deepcopy(self.vars)
|
||||
variables["diff"] = self.patches_diff # update diff
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
system_prompt = environment.from_string(settings.pr_questions_prompt.system).render(variables)
|
||||
user_prompt = environment.from_string(settings.pr_questions_prompt.user).render(variables)
|
||||
if settings.config.verbosity_level >= 2:
|
||||
system_prompt = environment.from_string(get_settings().pr_questions_prompt.system).render(variables)
|
||||
user_prompt = environment.from_string(get_settings().pr_questions_prompt.user).render(variables)
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
logging.info(f"\nSystem prompt:\n{system_prompt}")
|
||||
logging.info(f"\nUser prompt:\n{user_prompt}")
|
||||
model = settings.config.model
|
||||
response, finish_reason = await self.ai_handler.chat_completion(model=model, temperature=0.2,
|
||||
system=system_prompt, user=user_prompt)
|
||||
return response
|
||||
@ -67,6 +78,6 @@ class PRQuestions:
|
||||
def _prepare_pr_answer(self) -> str:
|
||||
answer_str = f"Question: {self.question_str}\n\n"
|
||||
answer_str += f"Answer:\n{self.prediction.strip()}\n\n"
|
||||
if settings.config.verbosity_level >= 2:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
logging.info(f"answer_str:\n{answer_str}")
|
||||
return answer_str
|
||||
|
||||
@ -1,141 +1,254 @@
|
||||
import copy
|
||||
import json
|
||||
import logging
|
||||
from collections import OrderedDict
|
||||
from typing import List, Tuple
|
||||
|
||||
import yaml
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
from yaml import SafeLoader
|
||||
|
||||
from pr_agent.algo.ai_handler import AiHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models, \
|
||||
find_line_number_of_relevant_line_in_file, clip_tokens
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.utils import convert_to_markdown, try_fix_json
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.algo.utils import convert_to_markdown, try_fix_json, try_fix_yaml, load_yaml
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers import get_git_provider
|
||||
from pr_agent.git_providers.git_provider import get_main_pr_language
|
||||
from pr_agent.git_providers.git_provider import IncrementalPR, get_main_pr_language
|
||||
from pr_agent.servers.help import actions_help_text, bot_help_text
|
||||
|
||||
|
||||
class PRReviewer:
|
||||
def __init__(self, pr_url: str, cli_mode=False, is_answer: bool = False):
|
||||
"""
|
||||
The PRReviewer class is responsible for reviewing a pull request and generating feedback using an AI model.
|
||||
"""
|
||||
def __init__(self, pr_url: str, is_answer: bool = False, args: list = None):
|
||||
"""
|
||||
Initialize the PRReviewer object with the necessary attributes and objects to review a pull request.
|
||||
|
||||
self.git_provider = get_git_provider()(pr_url)
|
||||
Args:
|
||||
pr_url (str): The URL of the pull request to be reviewed.
|
||||
is_answer (bool, optional): Indicates whether the review is being done in answer mode. Defaults to False.
|
||||
args (list, optional): List of arguments passed to the PRReviewer class. Defaults to None.
|
||||
"""
|
||||
self.parse_args(args) # -i command
|
||||
|
||||
self.git_provider = get_git_provider()(pr_url, incremental=self.incremental)
|
||||
self.main_language = get_main_pr_language(
|
||||
self.git_provider.get_languages(), self.git_provider.get_files()
|
||||
)
|
||||
self.pr_url = pr_url
|
||||
self.is_answer = is_answer
|
||||
|
||||
if self.is_answer and not self.git_provider.is_supported("get_issue_comments"):
|
||||
raise Exception(f"Answer mode is not supported for {settings.config.git_provider} for now")
|
||||
answer_str, question_str = self._get_user_answers()
|
||||
raise Exception(f"Answer mode is not supported for {get_settings().config.git_provider} for now")
|
||||
self.ai_handler = AiHandler()
|
||||
self.patches_diff = None
|
||||
self.prediction = None
|
||||
self.cli_mode = cli_mode
|
||||
|
||||
answer_str, question_str = self._get_user_answers()
|
||||
self.vars = {
|
||||
"title": self.git_provider.pr.title,
|
||||
"branch": self.git_provider.get_pr_branch(),
|
||||
"description": self.git_provider.get_pr_description(),
|
||||
"language": self.main_language,
|
||||
"diff": "", # empty diff for initial calculation
|
||||
"require_tests": settings.pr_reviewer.require_tests_review,
|
||||
"require_security": settings.pr_reviewer.require_security_review,
|
||||
"require_focused": settings.pr_reviewer.require_focused_review,
|
||||
'num_code_suggestions': settings.pr_reviewer.num_code_suggestions,
|
||||
#
|
||||
"require_score": get_settings().pr_reviewer.require_score_review,
|
||||
"require_tests": get_settings().pr_reviewer.require_tests_review,
|
||||
"require_security": get_settings().pr_reviewer.require_security_review,
|
||||
"require_focused": get_settings().pr_reviewer.require_focused_review,
|
||||
'num_code_suggestions': get_settings().pr_reviewer.num_code_suggestions,
|
||||
'question_str': question_str,
|
||||
'answer_str': answer_str,
|
||||
"extra_instructions": get_settings().pr_reviewer.extra_instructions,
|
||||
"commit_messages_str": self.git_provider.get_commit_messages(),
|
||||
}
|
||||
self.token_handler = TokenHandler(self.git_provider.pr,
|
||||
self.vars,
|
||||
settings.pr_review_prompt.system,
|
||||
settings.pr_review_prompt.user)
|
||||
|
||||
async def review(self):
|
||||
self.token_handler = TokenHandler(
|
||||
self.git_provider.pr,
|
||||
self.vars,
|
||||
get_settings().pr_review_prompt.system,
|
||||
get_settings().pr_review_prompt.user
|
||||
)
|
||||
|
||||
def parse_args(self, args: List[str]) -> None:
|
||||
"""
|
||||
Parse the arguments passed to the PRReviewer class and set the 'incremental' attribute accordingly.
|
||||
|
||||
Args:
|
||||
args: A list of arguments passed to the PRReviewer class.
|
||||
|
||||
Returns:
|
||||
None
|
||||
"""
|
||||
is_incremental = False
|
||||
if args and len(args) >= 1:
|
||||
arg = args[0]
|
||||
if arg == "-i":
|
||||
is_incremental = True
|
||||
self.incremental = IncrementalPR(is_incremental)
|
||||
|
||||
async def run(self) -> None:
|
||||
"""
|
||||
Review the pull request and generate feedback.
|
||||
"""
|
||||
logging.info('Reviewing PR...')
|
||||
if settings.config.publish_output:
|
||||
|
||||
if get_settings().config.publish_output:
|
||||
self.git_provider.publish_comment("Preparing review...", is_temporary=True)
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction()
|
||||
|
||||
await retry_with_fallback_models(self._prepare_prediction)
|
||||
|
||||
logging.info('Preparing PR review...')
|
||||
pr_comment = self._prepare_pr_review()
|
||||
if settings.config.publish_output:
|
||||
|
||||
if get_settings().config.publish_output:
|
||||
logging.info('Pushing PR review...')
|
||||
self.git_provider.publish_comment(pr_comment)
|
||||
self.git_provider.remove_initial_comment()
|
||||
if settings.pr_reviewer.inline_code_comments:
|
||||
|
||||
if get_settings().pr_reviewer.inline_code_comments:
|
||||
logging.info('Pushing inline code comments...')
|
||||
self._publish_inline_code_comments()
|
||||
return ""
|
||||
|
||||
async def _get_prediction(self):
|
||||
async def _prepare_prediction(self, model: str) -> None:
|
||||
"""
|
||||
Prepare the AI prediction for the pull request review.
|
||||
|
||||
Args:
|
||||
model: A string representing the AI model to be used for the prediction.
|
||||
|
||||
Returns:
|
||||
None
|
||||
"""
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler, model)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction(model)
|
||||
|
||||
async def _get_prediction(self, model: str) -> str:
|
||||
"""
|
||||
Generate an AI prediction for the pull request review.
|
||||
|
||||
Args:
|
||||
model: A string representing the AI model to be used for the prediction.
|
||||
|
||||
Returns:
|
||||
A string representing the AI prediction for the pull request review.
|
||||
"""
|
||||
variables = copy.deepcopy(self.vars)
|
||||
variables["diff"] = self.patches_diff # update diff
|
||||
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
system_prompt = environment.from_string(settings.pr_review_prompt.system).render(variables)
|
||||
user_prompt = environment.from_string(settings.pr_review_prompt.user).render(variables)
|
||||
if settings.config.verbosity_level >= 2:
|
||||
system_prompt = environment.from_string(get_settings().pr_review_prompt.system).render(variables)
|
||||
user_prompt = environment.from_string(get_settings().pr_review_prompt.user).render(variables)
|
||||
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
logging.info(f"\nSystem prompt:\n{system_prompt}")
|
||||
logging.info(f"\nUser prompt:\n{user_prompt}")
|
||||
model = settings.config.model
|
||||
response, finish_reason = await self.ai_handler.chat_completion(model=model, temperature=0.2,
|
||||
system=system_prompt, user=user_prompt)
|
||||
|
||||
response, finish_reason = await self.ai_handler.chat_completion(
|
||||
model=model,
|
||||
temperature=0.2,
|
||||
system=system_prompt,
|
||||
user=user_prompt
|
||||
)
|
||||
|
||||
return response
|
||||
|
||||
def _prepare_pr_review(self) -> str:
|
||||
review = self.prediction.strip()
|
||||
try:
|
||||
data = json.loads(review)
|
||||
except json.decoder.JSONDecodeError:
|
||||
data = try_fix_json(review)
|
||||
"""
|
||||
Prepare the PR review by processing the AI prediction and generating a markdown-formatted text that summarizes
|
||||
the feedback.
|
||||
"""
|
||||
data = load_yaml(self.prediction.strip())
|
||||
|
||||
# reordering for nicer display
|
||||
if 'PR Feedback' in data:
|
||||
if 'Security concerns' in data['PR Feedback']:
|
||||
val = data['PR Feedback']['Security concerns']
|
||||
del data['PR Feedback']['Security concerns']
|
||||
data['PR Analysis']['Security concerns'] = val
|
||||
# Move 'Security concerns' key to 'PR Analysis' section for better display
|
||||
pr_feedback = data.get('PR Feedback', {})
|
||||
security_concerns = pr_feedback.get('Security concerns')
|
||||
if security_concerns is not None:
|
||||
del pr_feedback['Security concerns']
|
||||
if type(security_concerns) == bool and security_concerns == False:
|
||||
data.setdefault('PR Analysis', {})['Security concerns'] = 'No security concerns found'
|
||||
else:
|
||||
data.setdefault('PR Analysis', {})['Security concerns'] = security_concerns
|
||||
|
||||
if settings.config.git_provider != 'bitbucket' and \
|
||||
settings.pr_reviewer.inline_code_comments and \
|
||||
'Code suggestions' in data['PR Feedback']:
|
||||
# keeping only code suggestions that can't be submitted as inline comments
|
||||
data['PR Feedback']['Code suggestions'] = [
|
||||
d for d in data['PR Feedback']['Code suggestions']
|
||||
if any(key not in d for key in ('relevant file', 'relevant line in file', 'suggestion content'))
|
||||
]
|
||||
if not data['PR Feedback']['Code suggestions']:
|
||||
del data['PR Feedback']['Code suggestions']
|
||||
#
|
||||
if 'Code feedback' in pr_feedback:
|
||||
code_feedback = pr_feedback['Code feedback']
|
||||
|
||||
# Filter out code suggestions that can be submitted as inline comments
|
||||
if get_settings().pr_reviewer.inline_code_comments:
|
||||
del pr_feedback['Code feedback']
|
||||
else:
|
||||
for suggestion in code_feedback:
|
||||
if ('relevant file' in suggestion) and (not suggestion['relevant file'].startswith('``')):
|
||||
suggestion['relevant file'] = f"``{suggestion['relevant file']}``"
|
||||
|
||||
if 'relevant line' not in suggestion:
|
||||
suggestion['relevant line'] = ''
|
||||
|
||||
relevant_line_str = suggestion['relevant line'].split('\n')[0]
|
||||
|
||||
# removing '+'
|
||||
suggestion['relevant line'] = relevant_line_str.lstrip('+').strip()
|
||||
|
||||
# try to add line numbers link to code suggestions
|
||||
if hasattr(self.git_provider, 'generate_link_to_relevant_line_number'):
|
||||
link = self.git_provider.generate_link_to_relevant_line_number(suggestion)
|
||||
if link:
|
||||
suggestion['relevant line'] = f"[{suggestion['relevant line']}]({link})"
|
||||
|
||||
# Add incremental review section
|
||||
if self.incremental.is_incremental:
|
||||
last_commit_url = f"{self.git_provider.get_pr_url()}/commits/" \
|
||||
f"{self.git_provider.incremental.first_new_commit_sha}"
|
||||
data = OrderedDict(data)
|
||||
data.update({'Incremental PR Review': {
|
||||
"⏮️ Review for commits since previous PR-Agent review": f"Starting from commit {last_commit_url}"}})
|
||||
data.move_to_end('Incremental PR Review', last=False)
|
||||
|
||||
markdown_text = convert_to_markdown(data)
|
||||
user = self.git_provider.get_user_id()
|
||||
|
||||
if not self.cli_mode:
|
||||
# Add help text if not in CLI mode
|
||||
if not get_settings().get("CONFIG.CLI_MODE", False):
|
||||
markdown_text += "\n### How to use\n"
|
||||
if user and '[bot]' not in user:
|
||||
markdown_text += bot_help_text(user)
|
||||
else:
|
||||
markdown_text += actions_help_text
|
||||
|
||||
if settings.config.verbosity_level >= 2:
|
||||
# Log markdown response if verbosity level is high
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
logging.info(f"Markdown response:\n{markdown_text}")
|
||||
|
||||
if markdown_text == None or len(markdown_text) == 0:
|
||||
markdown_text = ""
|
||||
|
||||
return markdown_text
|
||||
|
||||
def _publish_inline_code_comments(self):
|
||||
if settings.pr_reviewer.num_code_suggestions == 0:
|
||||
def _publish_inline_code_comments(self) -> None:
|
||||
"""
|
||||
Publishes inline comments on a pull request with code suggestions generated by the AI model.
|
||||
"""
|
||||
if get_settings().pr_reviewer.num_code_suggestions == 0:
|
||||
return
|
||||
|
||||
review = self.prediction.strip()
|
||||
review_text = self.prediction.strip()
|
||||
review_text = review_text.removeprefix('```yaml').rstrip('`')
|
||||
try:
|
||||
data = json.loads(review)
|
||||
except json.decoder.JSONDecodeError:
|
||||
data = try_fix_json(review)
|
||||
data = yaml.load(review_text, Loader=SafeLoader)
|
||||
except Exception as e:
|
||||
logging.error(f"Failed to parse AI prediction: {e}")
|
||||
data = try_fix_yaml(review_text)
|
||||
|
||||
comments = []
|
||||
for d in data['PR Feedback']['Code suggestions']:
|
||||
relevant_file = d.get('relevant file', '').strip()
|
||||
relevant_line_in_file = d.get('relevant line in file', '').strip()
|
||||
content = d.get('suggestion content', '')
|
||||
comments: List[str] = []
|
||||
for suggestion in data.get('PR Feedback', {}).get('Code feedback', []):
|
||||
relevant_file = suggestion.get('relevant file', '').strip()
|
||||
relevant_line_in_file = suggestion.get('relevant line', '').strip()
|
||||
content = suggestion.get('suggestion', '')
|
||||
if not relevant_file or not relevant_line_in_file or not content:
|
||||
logging.info("Skipping inline comment with missing file/line/content")
|
||||
continue
|
||||
@ -150,15 +263,26 @@ class PRReviewer:
|
||||
if comments:
|
||||
self.git_provider.publish_inline_comments(comments)
|
||||
|
||||
def _get_user_answers(self):
|
||||
answer_str = question_str = ""
|
||||
def _get_user_answers(self) -> Tuple[str, str]:
|
||||
"""
|
||||
Retrieves the question and answer strings from the discussion messages related to a pull request.
|
||||
|
||||
Returns:
|
||||
A tuple containing the question and answer strings.
|
||||
"""
|
||||
question_str = ""
|
||||
answer_str = ""
|
||||
|
||||
if self.is_answer:
|
||||
discussion_messages = self.git_provider.get_issue_comments()
|
||||
|
||||
for message in discussion_messages.reversed:
|
||||
if "Questions to better understand the PR:" in message.body:
|
||||
question_str = message.body
|
||||
elif '/answer' in message.body:
|
||||
answer_str = message.body
|
||||
|
||||
if answer_str and question_str:
|
||||
break
|
||||
|
||||
return question_str, answer_str
|
||||
|
||||
160
pr_agent/tools/pr_update_changelog.py
Normal file
160
pr_agent/tools/pr_update_changelog.py
Normal file
@ -0,0 +1,160 @@
|
||||
import copy
|
||||
import logging
|
||||
from datetime import date
|
||||
from time import sleep
|
||||
from typing import Tuple
|
||||
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
|
||||
from pr_agent.algo.ai_handler import AiHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers import GithubProvider, get_git_provider
|
||||
from pr_agent.git_providers.git_provider import get_main_pr_language
|
||||
|
||||
CHANGELOG_LINES = 50
|
||||
|
||||
|
||||
class PRUpdateChangelog:
|
||||
def __init__(self, pr_url: str, cli_mode=False, args=None):
|
||||
|
||||
self.git_provider = get_git_provider()(pr_url)
|
||||
self.main_language = get_main_pr_language(
|
||||
self.git_provider.get_languages(), self.git_provider.get_files()
|
||||
)
|
||||
self.commit_changelog = get_settings().pr_update_changelog.push_changelog_changes
|
||||
self._get_changlog_file() # self.changelog_file_str
|
||||
self.ai_handler = AiHandler()
|
||||
self.patches_diff = None
|
||||
self.prediction = None
|
||||
self.cli_mode = cli_mode
|
||||
self.vars = {
|
||||
"title": self.git_provider.pr.title,
|
||||
"branch": self.git_provider.get_pr_branch(),
|
||||
"description": self.git_provider.get_pr_description(),
|
||||
"language": self.main_language,
|
||||
"diff": "", # empty diff for initial calculation
|
||||
"changelog_file_str": self.changelog_file_str,
|
||||
"today": date.today(),
|
||||
"extra_instructions": get_settings().pr_update_changelog.extra_instructions,
|
||||
"commit_messages_str": self.git_provider.get_commit_messages(),
|
||||
}
|
||||
self.token_handler = TokenHandler(self.git_provider.pr,
|
||||
self.vars,
|
||||
get_settings().pr_update_changelog_prompt.system,
|
||||
get_settings().pr_update_changelog_prompt.user)
|
||||
|
||||
async def run(self):
|
||||
assert type(self.git_provider) == GithubProvider, "Currently only Github is supported"
|
||||
|
||||
logging.info('Updating the changelog...')
|
||||
if get_settings().config.publish_output:
|
||||
self.git_provider.publish_comment("Preparing changelog updates...", is_temporary=True)
|
||||
await retry_with_fallback_models(self._prepare_prediction)
|
||||
logging.info('Preparing PR changelog updates...')
|
||||
new_file_content, answer = self._prepare_changelog_update()
|
||||
if get_settings().config.publish_output:
|
||||
self.git_provider.remove_initial_comment()
|
||||
logging.info('Publishing changelog updates...')
|
||||
if self.commit_changelog:
|
||||
logging.info('Pushing PR changelog updates to repo...')
|
||||
self._push_changelog_update(new_file_content, answer)
|
||||
else:
|
||||
logging.info('Publishing PR changelog as comment...')
|
||||
self.git_provider.publish_comment(f"**Changelog updates:**\n\n{answer}")
|
||||
|
||||
async def _prepare_prediction(self, model: str):
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler, model)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction(model)
|
||||
|
||||
async def _get_prediction(self, model: str):
|
||||
variables = copy.deepcopy(self.vars)
|
||||
variables["diff"] = self.patches_diff # update diff
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
system_prompt = environment.from_string(get_settings().pr_update_changelog_prompt.system).render(variables)
|
||||
user_prompt = environment.from_string(get_settings().pr_update_changelog_prompt.user).render(variables)
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
logging.info(f"\nSystem prompt:\n{system_prompt}")
|
||||
logging.info(f"\nUser prompt:\n{user_prompt}")
|
||||
response, finish_reason = await self.ai_handler.chat_completion(model=model, temperature=0.2,
|
||||
system=system_prompt, user=user_prompt)
|
||||
|
||||
return response
|
||||
|
||||
def _prepare_changelog_update(self) -> Tuple[str, str]:
|
||||
answer = self.prediction.strip().strip("```").strip() # noqa B005
|
||||
if hasattr(self, "changelog_file"):
|
||||
existing_content = self.changelog_file.decoded_content.decode()
|
||||
else:
|
||||
existing_content = ""
|
||||
if existing_content:
|
||||
new_file_content = answer + "\n\n" + self.changelog_file.decoded_content.decode()
|
||||
else:
|
||||
new_file_content = answer
|
||||
|
||||
if not self.commit_changelog:
|
||||
answer += "\n\n\n>to commit the new content to the CHANGELOG.md file, please type:" \
|
||||
"\n>'/update_changelog --pr_update_changelog.push_changelog_changes=true'\n"
|
||||
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
logging.info(f"answer:\n{answer}")
|
||||
|
||||
return new_file_content, answer
|
||||
|
||||
def _push_changelog_update(self, new_file_content, answer):
|
||||
self.git_provider.repo_obj.update_file(path=self.changelog_file.path,
|
||||
message="Update CHANGELOG.md",
|
||||
content=new_file_content,
|
||||
sha=self.changelog_file.sha,
|
||||
branch=self.git_provider.get_pr_branch())
|
||||
d = dict(body="CHANGELOG.md update",
|
||||
path=self.changelog_file.path,
|
||||
line=max(2, len(answer.splitlines())),
|
||||
start_line=1)
|
||||
|
||||
sleep(5) # wait for the file to be updated
|
||||
last_commit_id = list(self.git_provider.pr.get_commits())[-1]
|
||||
try:
|
||||
self.git_provider.pr.create_review(commit=last_commit_id, comments=[d])
|
||||
except Exception:
|
||||
# we can't create a review for some reason, let's just publish a comment
|
||||
self.git_provider.publish_comment(f"**Changelog updates:**\n\n{answer}")
|
||||
|
||||
|
||||
def _get_default_changelog(self):
|
||||
example_changelog = \
|
||||
"""
|
||||
Example:
|
||||
## <current_date>
|
||||
|
||||
### Added
|
||||
...
|
||||
### Changed
|
||||
...
|
||||
### Fixed
|
||||
...
|
||||
"""
|
||||
return example_changelog
|
||||
|
||||
def _get_changlog_file(self):
|
||||
try:
|
||||
self.changelog_file = self.git_provider.repo_obj.get_contents("CHANGELOG.md",
|
||||
ref=self.git_provider.get_pr_branch())
|
||||
changelog_file_lines = self.changelog_file.decoded_content.decode().splitlines()
|
||||
changelog_file_lines = changelog_file_lines[:CHANGELOG_LINES]
|
||||
self.changelog_file_str = "\n".join(changelog_file_lines)
|
||||
except Exception:
|
||||
self.changelog_file_str = ""
|
||||
if self.commit_changelog:
|
||||
logging.info("No CHANGELOG.md file found in the repository. Creating one...")
|
||||
changelog_file = self.git_provider.repo_obj.create_file(path="CHANGELOG.md",
|
||||
message='add CHANGELOG.md',
|
||||
content="",
|
||||
branch=self.git_provider.get_pr_branch())
|
||||
self.changelog_file = changelog_file['content']
|
||||
|
||||
if not self.changelog_file_str:
|
||||
self.changelog_file_str = self._get_default_changelog()
|
||||
@ -1,3 +1,66 @@
|
||||
[build-system]
|
||||
requires = ["setuptools>=61.0"]
|
||||
build-backend = "setuptools.build_meta"
|
||||
|
||||
[project]
|
||||
name = "pr_agent"
|
||||
version = "0.0.1"
|
||||
|
||||
authors = [
|
||||
{name = "Itamar Friedman", email = "itamar.f@codium.ai"},
|
||||
]
|
||||
maintainers = [
|
||||
{name = "Ori Kotek", email = "ori.k@codium.ai"},
|
||||
{name = "Tal Ridnik", email = "tal.r@codium.ai"},
|
||||
{name = "Hussam Lawen", email = "hussam.l@codium.ai"},
|
||||
{name = "Sagi Medina", email = "sagi.m@codium.ai"}
|
||||
]
|
||||
description = "CodiumAI PR-Agent is an open-source tool to automatically analyze a pull request and provide several types of feedback"
|
||||
readme = "README.md"
|
||||
requires-python = ">=3.9"
|
||||
keywords = ["ai", "tool", "developer", "review", "agent"]
|
||||
license = {file = "LICENSE", name = "Apache 2.0 License"}
|
||||
classifiers = [
|
||||
"Development Status :: 3 - Alpha",
|
||||
"Intended Audience :: Developers",
|
||||
"Operating System :: Independent",
|
||||
"Programming Language :: Python :: 3",
|
||||
]
|
||||
|
||||
dependencies = [
|
||||
"dynaconf==3.1.12",
|
||||
"fastapi==0.99.0",
|
||||
"PyGithub==1.59.*",
|
||||
"retry==0.9.2",
|
||||
"openai==0.27.8",
|
||||
"Jinja2==3.1.2",
|
||||
"tiktoken==0.4.0",
|
||||
"uvicorn==0.22.0",
|
||||
"python-gitlab==3.15.0",
|
||||
"pytest~=7.4.0",
|
||||
"aiohttp~=3.8.4",
|
||||
"atlassian-python-api==3.39.0",
|
||||
"GitPython~=3.1.32",
|
||||
"starlette-context==0.3.6",
|
||||
"litellm~=0.1.351",
|
||||
"PyYAML==6.0"
|
||||
]
|
||||
|
||||
[project.urls]
|
||||
"Homepage" = "https://github.com/Codium-ai/pr-agent"
|
||||
|
||||
[tool.setuptools]
|
||||
include-package-data = false
|
||||
license-files = ["LICENSE"]
|
||||
|
||||
[tool.setuptools.packages.find]
|
||||
where = ["."]
|
||||
include = ["pr_agent"]
|
||||
|
||||
[project.scripts]
|
||||
pr-agent = "pr_agent.cli:run"
|
||||
|
||||
|
||||
[tool.ruff]
|
||||
|
||||
line-length = 120
|
||||
|
||||
@ -10,3 +10,8 @@ python-gitlab==3.15.0
|
||||
pytest~=7.4.0
|
||||
aiohttp~=3.8.4
|
||||
atlassian-python-api==3.39.0
|
||||
GitPython~=3.1.32
|
||||
litellm~=0.1.351
|
||||
PyYAML==6.0
|
||||
starlette-context==0.3.6
|
||||
litellm~=0.1.351
|
||||
5
setup.py
Normal file
5
setup.py
Normal file
@ -0,0 +1,5 @@
|
||||
# for compatibility with legacy tools
|
||||
# see: https://setuptools.pypa.io/en/latest/userguide/pyproject_config.html
|
||||
from setuptools import setup
|
||||
|
||||
setup()
|
||||
10
tests/unittest/test_bitbucket_provider.py
Normal file
10
tests/unittest/test_bitbucket_provider.py
Normal file
@ -0,0 +1,10 @@
|
||||
from pr_agent.git_providers.bitbucket_provider import BitbucketProvider
|
||||
|
||||
|
||||
class TestBitbucketProvider:
|
||||
def test_parse_pr_url(self):
|
||||
url = "https://bitbucket.org/WORKSPACE_XYZ/MY_TEST_REPO/pull-requests/321"
|
||||
workspace_slug, repo_slug, pr_number = BitbucketProvider._parse_pr_url(url)
|
||||
assert workspace_slug == "WORKSPACE_XYZ"
|
||||
assert repo_slug == "MY_TEST_REPO"
|
||||
assert pr_number == 321
|
||||
@ -51,7 +51,7 @@ class TestConvertToMarkdown:
|
||||
'Unrelated changes': 'n/a', # won't be included in the output
|
||||
'Focused PR': 'Yes',
|
||||
'General PR suggestions': 'general suggestion...',
|
||||
'Code suggestions': [
|
||||
'Code feedback': [
|
||||
{
|
||||
'Code example': {
|
||||
'Before': 'Code before',
|
||||
@ -73,7 +73,7 @@ class TestConvertToMarkdown:
|
||||
- ✨ **Focused PR:** Yes
|
||||
- 💡 **General PR suggestions:** general suggestion...
|
||||
|
||||
- 🤖 **Code suggestions:**
|
||||
- 🤖 **Code feedback:**
|
||||
|
||||
- **Code example:**
|
||||
- **Before:**
|
||||
@ -0,0 +1,68 @@
|
||||
|
||||
# Generated by CodiumAI
|
||||
from pr_agent.git_providers.git_provider import FilePatchInfo
|
||||
from pr_agent.algo.pr_processing import find_line_number_of_relevant_line_in_file
|
||||
|
||||
|
||||
import pytest
|
||||
|
||||
class TestFindLineNumberOfRelevantLineInFile:
|
||||
# Tests that the function returns the correct line number and absolute position when the relevant line is found in the patch
|
||||
def test_relevant_line_found_in_patch(self):
|
||||
diff_files = [
|
||||
FilePatchInfo(base_file='file1', head_file='file1', patch='@@ -1,1 +1,2 @@\n-line1\n+line2\n+relevant_line\n', filename='file1')
|
||||
]
|
||||
relevant_file = 'file1'
|
||||
relevant_line_in_file = 'relevant_line'
|
||||
expected = (3, 2) # (position in patch, absolute_position in new file)
|
||||
assert find_line_number_of_relevant_line_in_file(diff_files, relevant_file, relevant_line_in_file) == expected
|
||||
|
||||
# Tests that the function returns the correct line number and absolute position when a similar line is found using difflib
|
||||
def test_similar_line_found_using_difflib(self):
|
||||
diff_files = [
|
||||
FilePatchInfo(base_file='file1', head_file='file1', patch='@@ -1,1 +1,2 @@\n-line1\n+relevant_line in file similar match\n', filename='file1')
|
||||
]
|
||||
relevant_file = 'file1'
|
||||
relevant_line_in_file = '+relevant_line in file similar match ' # note the space at the end. This is to simulate a similar line found using difflib
|
||||
expected = (2, 1)
|
||||
assert find_line_number_of_relevant_line_in_file(diff_files, relevant_file, relevant_line_in_file) == expected
|
||||
|
||||
# Tests that the function returns (-1, -1) when the relevant line is not found in the patch and no similar line is found using difflib
|
||||
def test_relevant_line_not_found(self):
|
||||
diff_files = [
|
||||
FilePatchInfo(base_file='file1', head_file='file1', patch='@@ -1,1 +1,2 @@\n-line1\n+relevant_line\n', filename='file1')
|
||||
]
|
||||
relevant_file = 'file1'
|
||||
relevant_line_in_file = 'not_found'
|
||||
expected = (-1, -1)
|
||||
assert find_line_number_of_relevant_line_in_file(diff_files, relevant_file, relevant_line_in_file) == expected
|
||||
|
||||
# Tests that the function returns (-1, -1) when the relevant file is not found in any of the patches
|
||||
def test_relevant_file_not_found(self):
|
||||
diff_files = [
|
||||
FilePatchInfo(base_file='file1', head_file='file1', patch='@@ -1,1 +1,2 @@\n-line1\n+relevant_line\n', filename='file2')
|
||||
]
|
||||
relevant_file = 'file1'
|
||||
relevant_line_in_file = 'relevant_line'
|
||||
expected = (-1, -1)
|
||||
assert find_line_number_of_relevant_line_in_file(diff_files, relevant_file, relevant_line_in_file) == expected
|
||||
|
||||
# Tests that the function returns (-1, -1) when the relevant_line_in_file is an empty string
|
||||
def test_empty_relevant_line(self):
|
||||
diff_files = [
|
||||
FilePatchInfo(base_file='file1', head_file='file1', patch='@@ -1,1 +1,2 @@\n-line1\n+relevant_line\n', filename='file1')
|
||||
]
|
||||
relevant_file = 'file1'
|
||||
relevant_line_in_file = ''
|
||||
expected = (0, 0)
|
||||
assert find_line_number_of_relevant_line_in_file(diff_files, relevant_file, relevant_line_in_file) == expected
|
||||
|
||||
# Tests that the function returns (-1, -1) when the relevant_line_in_file is found in the patch but it is a deleted line
|
||||
def test_relevant_line_found_but_deleted(self):
|
||||
diff_files = [
|
||||
FilePatchInfo(base_file='file1', head_file='file1', patch='@@ -1,2 +1,1 @@\n-line1\n-relevant_line\n', filename='file1')
|
||||
]
|
||||
relevant_file = 'file1'
|
||||
relevant_line_in_file = 'relevant_line'
|
||||
expected = (-1, -1)
|
||||
assert find_line_number_of_relevant_line_in_file(diff_files, relevant_file, relevant_line_in_file) == expected
|
||||
@ -2,7 +2,7 @@
|
||||
import logging
|
||||
|
||||
from pr_agent.algo.git_patch_processing import handle_patch_deletions
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.config_loader import get_settings
|
||||
|
||||
"""
|
||||
Code Analysis
|
||||
@ -49,7 +49,7 @@ class TestHandlePatchDeletions:
|
||||
original_file_content_str = 'foo\nbar\n'
|
||||
new_file_content_str = ''
|
||||
file_name = 'file.py'
|
||||
settings.config.verbosity_level = 1
|
||||
get_settings().config.verbosity_level = 1
|
||||
|
||||
with caplog.at_level(logging.INFO):
|
||||
handle_patch_deletions(patch, original_file_content_str, new_file_content_str, file_name)
|
||||
32
tests/unittest/test_load_yaml.py
Normal file
32
tests/unittest/test_load_yaml.py
Normal file
@ -0,0 +1,32 @@
|
||||
|
||||
# Generated by CodiumAI
|
||||
|
||||
import pytest
|
||||
from pr_agent.algo.utils import load_yaml
|
||||
|
||||
|
||||
class TestLoadYaml:
|
||||
# Tests that load_yaml loads a valid YAML string
|
||||
def test_load_valid_yaml(self):
|
||||
yaml_str = 'name: John Smith\nage: 35'
|
||||
expected_output = {'name': 'John Smith', 'age': 35}
|
||||
assert load_yaml(yaml_str) == expected_output
|
||||
|
||||
def test_load_complicated_yaml(self):
|
||||
yaml_str = \
|
||||
'''\
|
||||
PR Analysis:
|
||||
Main theme: Enhancing the `/describe` command prompt by adding title and description
|
||||
Type of PR: Enhancement
|
||||
Relevant tests added: No
|
||||
Focused PR: Yes, the PR is focused on enhancing the `/describe` command prompt.
|
||||
|
||||
PR Feedback:
|
||||
General suggestions: The PR seems to be well-structured and focused on a specific enhancement. However, it would be beneficial to add tests to ensure the new feature works as expected.
|
||||
Code feedback:
|
||||
- relevant file: pr_agent/settings/pr_description_prompts.toml
|
||||
suggestion: Consider using a more descriptive variable name than 'user' for the command prompt. A more descriptive name would make the code more readable and maintainable. [medium]
|
||||
relevant line: 'user="""PR Info:'
|
||||
Security concerns: No'''
|
||||
expected_output = {'PR Analysis': {'Main theme': 'Enhancing the `/describe` command prompt by adding title and description', 'Type of PR': 'Enhancement', 'Relevant tests added': False, 'Focused PR': 'Yes, the PR is focused on enhancing the `/describe` command prompt.'}, 'PR Feedback': {'General suggestions': 'The PR seems to be well-structured and focused on a specific enhancement. However, it would be beneficial to add tests to ensure the new feature works as expected.', 'Code feedback': [{'relevant file': 'pr_agent/settings/pr_description_prompts.toml', 'suggestion': "Consider using a more descriptive variable name than 'user' for the command prompt. A more descriptive name would make the code more readable and maintainable. [medium]", 'relevant line': 'user="""PR Info:'}], 'Security concerns': False}}
|
||||
assert load_yaml(yaml_str) == expected_output
|
||||
Reference in New Issue
Block a user