mirror of
https://github.com/qodo-ai/pr-agent.git
synced 2025-07-21 04:50:39 +08:00
Compare commits
43 Commits
ok/readme_
...
ok/gitlab_
| Author | SHA1 | Date | |
|---|---|---|---|
| e41247c473 | |||
| 5704070834 | |||
| 98fe376add | |||
| 8e5498ee97 | |||
| 0412d7aca0 | |||
| 1eac3245d9 | |||
| cd51bef7f7 | |||
| e8aa33fa0b | |||
| 54b021b02c | |||
| 32151e3d9a | |||
| 32358678e6 | |||
| 42e32664a1 | |||
| 1e97236a15 | |||
| 321f7bce46 | |||
| 02a1d8dbfc | |||
| e34f9d8d1c | |||
| 35dac012bd | |||
| 21ced18f50 | |||
| fca78cf395 | |||
| d1b91b0ea3 | |||
| 76e00acbdb | |||
| 2f83e7738c | |||
| f4a226b0f7 | |||
| f5e2838fc3 | |||
| bbdfd2c3d4 | |||
| 74572e1768 | |||
| f0a17b863c | |||
| 86fd84e113 | |||
| d5b9be23d3 | |||
| 057bb3932f | |||
| 05f29cc406 | |||
| 63c4c7e584 | |||
| 1ea23cab96 | |||
| e99f9fd59f | |||
| fdf6a3e833 | |||
| 79cb94b4c2 | |||
| 9adec7cc10 | |||
| 1f0df47b4d | |||
| a71a12791b | |||
| 23fa834721 | |||
| 2e246869d0 | |||
| 2f9546e144 | |||
| 6d91f44634 |
11
.gitlab-ci.yml
Normal file
11
.gitlab-ci.yml
Normal file
@ -0,0 +1,11 @@
|
||||
bot-review:
|
||||
stage: test
|
||||
variables:
|
||||
MR_URL: ${CI_MERGE_REQUEST_PROJECT_URL}/-/merge_requests/${CI_MERGE_REQUEST_IID}
|
||||
image: docker:latest
|
||||
services:
|
||||
- docker:19-dind
|
||||
script:
|
||||
- docker run --rm -e OPENAI.KEY=${OPEN_API_KEY} -e OPENAI.ORG=${OPEN_API_ORG} -e GITLAB.PERSONAL_ACCESS_TOKEN=${GITLAB_PAT} -e CONFIG.GIT_PROVIDER=gitlab codiumai/pr-agent --pr_url ${MR_URL} describe
|
||||
rules:
|
||||
- if: $CI_COMMIT_BRANCH != $CI_DEFAULT_BRANCH
|
||||
@ -95,9 +95,10 @@ cp pr_agent/settings/.secrets_template.toml pr_agent/settings/.secrets.toml
|
||||
# Edit .secrets.toml file
|
||||
```
|
||||
|
||||
4. Run the appropriate Python scripts from the scripts folder:
|
||||
4. Add the pr_agent folder to your PYTHONPATH, then run the cli.py script:
|
||||
|
||||
```
|
||||
export PYTHONPATH=[$PYTHONPATH:]<PATH to pr_agent folder>
|
||||
python pr_agent/cli.py --pr_url <pr_url> review
|
||||
python pr_agent/cli.py --pr_url <pr_url> ask <your question>
|
||||
python pr_agent/cli.py --pr_url <pr_url> describe
|
||||
|
||||
25
README.md
25
README.md
@ -4,15 +4,18 @@
|
||||
|
||||
<img src="./pics/logo-dark.png#gh-dark-mode-only" width="330"/>
|
||||
<img src="./pics/logo-light.png#gh-light-mode-only" width="330"/><br/>
|
||||
Making pull-requests less painful with an AI agent
|
||||
Making pull requests less painful with an AI agent
|
||||
</div>
|
||||
|
||||
[](https://github.com/Codium-ai/pr-agent/blob/main/LICENSE)
|
||||
[](https://discord.com/channels/1057273017547378788/1126104260430528613)
|
||||
<a href="https://github.com/Codium-ai/pr-agent/commits/main">
|
||||
<img alt="GitHub" src="https://img.shields.io/github/last-commit/Codium-ai/pr-agent/main?style=for-the-badge" height="20">
|
||||
</a>
|
||||
</div>
|
||||
<div style="text-align:left;">
|
||||
|
||||
CodiumAI `PR-Agent` is an open-source tool aiming to help developers review pull-requests faster and more efficiently. It automatically analyzes the pull-request and can provide several types of feedback:
|
||||
CodiumAI `PR-Agent` is an open-source tool aiming to help developers review pull requests faster and more efficiently. It automatically analyzes the pull request and can provide several types of feedback:
|
||||
|
||||
**Auto-Description**: Automatically generating PR description - title, type, summary, code walkthrough and PR labels.
|
||||
\
|
||||
@ -27,25 +30,31 @@ CodiumAI `PR-Agent` is an open-source tool aiming to help developers review pull
|
||||
<h4>/describe:</h4>
|
||||
<div align="center">
|
||||
<p float="center">
|
||||
<img src="https://codium.ai/images/describe.gif" width="800">
|
||||
<img src="https://www.codium.ai/images/describe-2.gif" width="800">
|
||||
</p>
|
||||
</div>
|
||||
<h4>/review:</h4>
|
||||
<div align="center">
|
||||
<p float="center">
|
||||
<img src="https://codium.ai/images/review.gif" width="800">
|
||||
<img src="https://www.codium.ai/images/review-2.gif" width="800">
|
||||
</p>
|
||||
</div>
|
||||
<h4>/reflect_and_review:</h4>
|
||||
<div align="center">
|
||||
<p float="center">
|
||||
<img src="https://www.codium.ai/images/reflect_and_review.gif" width="800">
|
||||
</p>
|
||||
</div>
|
||||
<h4>/ask:</h4>
|
||||
<div align="center">
|
||||
<p float="center">
|
||||
<img src="https://codium.ai/images/ask.gif" width="800">
|
||||
<img src="https://www.codium.ai/images/ask-2.gif" width="800">
|
||||
</p>
|
||||
</div>
|
||||
<h4>/improve:</h4>
|
||||
<div align="center">
|
||||
<p float="center">
|
||||
<img src="https://codium.ai/images/improve.gif" width="800">
|
||||
<img src="https://www.codium.ai/images/improve-2.gif" width="800">
|
||||
</p>
|
||||
</div>
|
||||
<div align="left">
|
||||
@ -74,7 +83,7 @@ CodiumAI `PR-Agent` is an open-source tool aiming to help developers review pull
|
||||
| | Reflect and Review | :white_check_mark: | | |
|
||||
| | | | | |
|
||||
| USAGE | CLI | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||
| | Tagging bot | :white_check_mark: | :white_check_mark: | |
|
||||
| | Tagging bot | :white_check_mark: | | |
|
||||
| | Actions | :white_check_mark: | | |
|
||||
| | | | | |
|
||||
| CORE | PR compression | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||
@ -97,7 +106,7 @@ In the [configuration](./CONFIGURATION.md) file you can select your git provider
|
||||
|
||||
Try GPT-4 powered PR-Agent on your public GitHub repository for free. Just mention `@CodiumAI-Agent` and add the desired command in any PR comment! The agent will generate a response based on your command.
|
||||
|
||||

|
||||
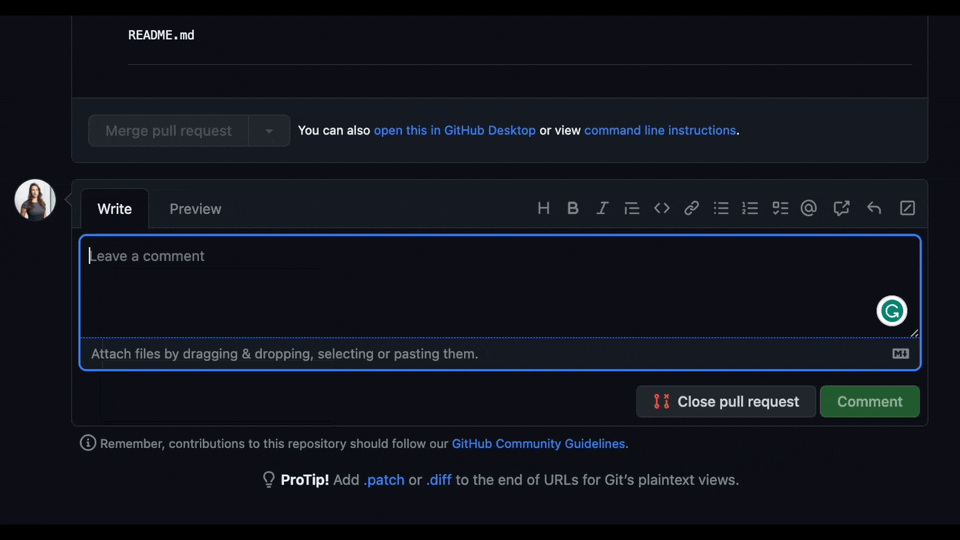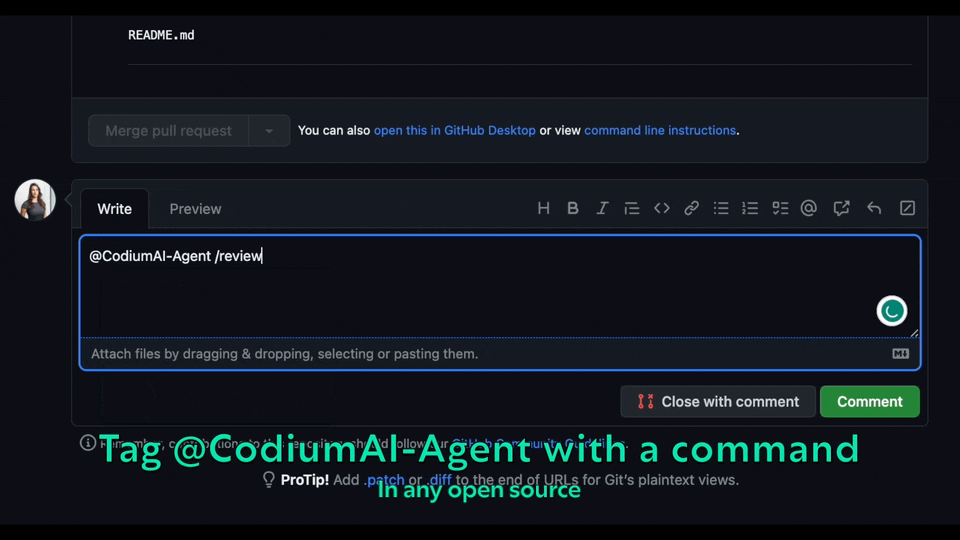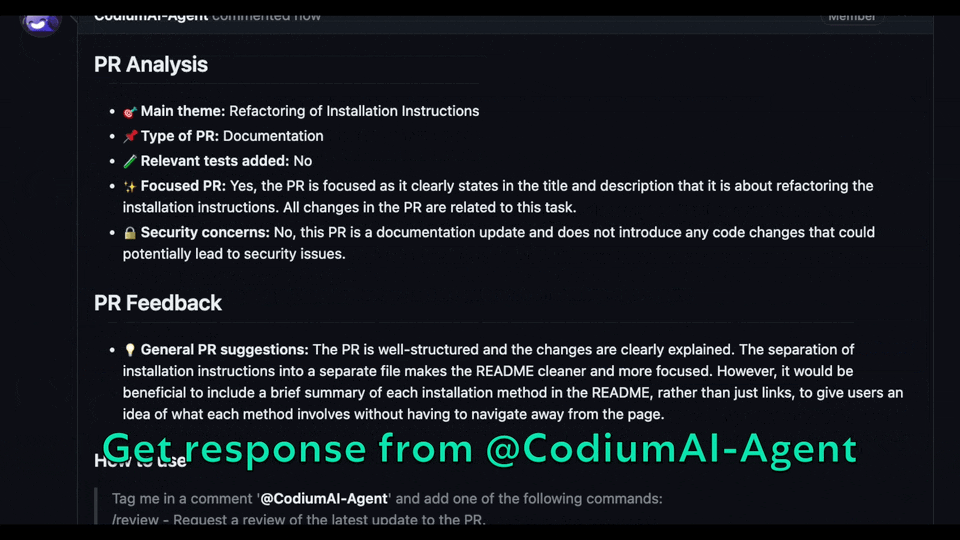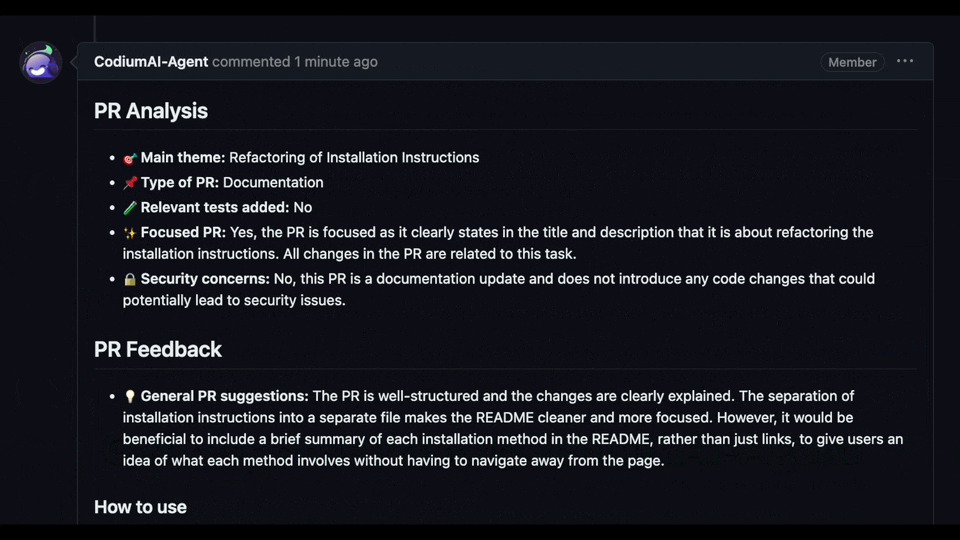
|
||||
|
||||
To set up your own PR-Agent, see the [Installation](#installation) section
|
||||
|
||||
|
||||
@ -1,5 +1,8 @@
|
||||
name: 'PR Agent'
|
||||
name: 'Codium PR Agent'
|
||||
description: 'Summarize, review and suggest improvements for pull requests'
|
||||
branding:
|
||||
icon: 'award'
|
||||
color: 'green'
|
||||
runs:
|
||||
using: 'docker'
|
||||
image: 'Dockerfile.github_action_dockerhub'
|
||||
|
||||
@ -1,12 +1,12 @@
|
||||
import logging
|
||||
|
||||
import openai
|
||||
from openai.error import APIError, Timeout, TryAgain
|
||||
from openai.error import APIError, Timeout, TryAgain, RateLimitError
|
||||
from retry import retry
|
||||
|
||||
from pr_agent.config_loader import settings
|
||||
|
||||
OPENAI_RETRIES=2
|
||||
OPENAI_RETRIES=5
|
||||
|
||||
class AiHandler:
|
||||
"""
|
||||
@ -34,7 +34,7 @@ class AiHandler:
|
||||
except AttributeError as e:
|
||||
raise ValueError("OpenAI key is required") from e
|
||||
|
||||
@retry(exceptions=(APIError, Timeout, TryAgain, AttributeError),
|
||||
@retry(exceptions=(APIError, Timeout, TryAgain, AttributeError, RateLimitError),
|
||||
tries=OPENAI_RETRIES, delay=2, backoff=2, jitter=(1, 3))
|
||||
async def chat_completion(self, model: str, temperature: float, system: str, user: str):
|
||||
"""
|
||||
@ -69,6 +69,12 @@ class AiHandler:
|
||||
except (APIError, Timeout, TryAgain) as e:
|
||||
logging.error("Error during OpenAI inference: ", e)
|
||||
raise
|
||||
except (RateLimitError) as e:
|
||||
logging.error("Rate limit error during OpenAI inference: ", e)
|
||||
raise
|
||||
except (Exception) as e:
|
||||
logging.error("Unknown error during OpenAI inference: ", e)
|
||||
raise TryAgain from e
|
||||
if response is None or len(response.choices) == 0:
|
||||
raise TryAgain
|
||||
resp = response.choices[0]['message']['content']
|
||||
|
||||
File diff suppressed because one or more lines are too long
@ -1,8 +1,9 @@
|
||||
from __future__ import annotations
|
||||
|
||||
import logging
|
||||
from typing import Tuple, Union
|
||||
from typing import Tuple, Union, Callable, List
|
||||
|
||||
from pr_agent.algo import MAX_TOKENS
|
||||
from pr_agent.algo.git_patch_processing import convert_to_hunks_with_lines_numbers, extend_patch, handle_patch_deletions
|
||||
from pr_agent.algo.language_handler import sort_files_by_main_languages
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
@ -10,7 +11,6 @@ from pr_agent.algo.utils import load_large_diff
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.git_providers.git_provider import GitProvider
|
||||
|
||||
|
||||
DELETED_FILES_ = "Deleted files:\n"
|
||||
|
||||
MORE_MODIFIED_FILES_ = "More modified files:\n"
|
||||
@ -20,14 +20,15 @@ OUTPUT_BUFFER_TOKENS_HARD_THRESHOLD = 600
|
||||
PATCH_EXTRA_LINES = 3
|
||||
|
||||
|
||||
def get_pr_diff(git_provider: GitProvider, token_handler: TokenHandler,
|
||||
add_line_numbers_to_hunks: bool = False, disable_extra_lines: bool =False) -> str:
|
||||
def get_pr_diff(git_provider: GitProvider, token_handler: TokenHandler, model: str,
|
||||
add_line_numbers_to_hunks: bool = False, disable_extra_lines: bool = False) -> str:
|
||||
"""
|
||||
Returns a string with the diff of the pull request, applying diff minimization techniques if needed.
|
||||
|
||||
Args:
|
||||
git_provider (GitProvider): An object of the GitProvider class representing the Git provider used for the pull request.
|
||||
token_handler (TokenHandler): An object of the TokenHandler class used for handling tokens in the context of the pull request.
|
||||
model (str): The name of the model used for tokenization.
|
||||
add_line_numbers_to_hunks (bool, optional): A boolean indicating whether to add line numbers to the hunks in the diff. Defaults to False.
|
||||
disable_extra_lines (bool, optional): A boolean indicating whether to disable the extension of each patch with extra lines of context. Defaults to False.
|
||||
|
||||
@ -49,7 +50,7 @@ def get_pr_diff(git_provider: GitProvider, token_handler: TokenHandler,
|
||||
add_line_numbers_to_hunks)
|
||||
|
||||
# if we are under the limit, return the full diff
|
||||
if total_tokens + OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD < token_handler.limit:
|
||||
if total_tokens + OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD < MAX_TOKENS[model]:
|
||||
return "\n".join(patches_extended)
|
||||
|
||||
# if we are over the limit, start pruning
|
||||
@ -110,13 +111,14 @@ def pr_generate_extended_diff(pr_languages: list, token_handler: TokenHandler,
|
||||
return patches_extended, total_tokens
|
||||
|
||||
|
||||
def pr_generate_compressed_diff(top_langs: list, token_handler: TokenHandler,
|
||||
def pr_generate_compressed_diff(top_langs: list, token_handler: TokenHandler, model: str,
|
||||
convert_hunks_to_line_numbers: bool) -> Tuple[list, list, list]:
|
||||
"""
|
||||
Generate a compressed diff string for a pull request, using diff minimization techniques to reduce the number of tokens used.
|
||||
Args:
|
||||
top_langs (list): A list of dictionaries representing the languages used in the pull request and their corresponding files.
|
||||
token_handler (TokenHandler): An object of the TokenHandler class used for handling tokens in the context of the pull request.
|
||||
model (str): The model used for tokenization.
|
||||
convert_hunks_to_line_numbers (bool): A boolean indicating whether to convert hunks to line numbers in the diff.
|
||||
Returns:
|
||||
Tuple[list, list, list]: A tuple containing the following lists:
|
||||
@ -131,7 +133,6 @@ def pr_generate_compressed_diff(top_langs: list, token_handler: TokenHandler,
|
||||
3. Minimize deleted hunks
|
||||
4. Minimize all remaining files when you reach token limit
|
||||
"""
|
||||
|
||||
|
||||
patches = []
|
||||
modified_files_list = []
|
||||
@ -166,12 +167,12 @@ def pr_generate_compressed_diff(top_langs: list, token_handler: TokenHandler,
|
||||
new_patch_tokens = token_handler.count_tokens(patch)
|
||||
|
||||
# Hard Stop, no more tokens
|
||||
if total_tokens > token_handler.limit - OUTPUT_BUFFER_TOKENS_HARD_THRESHOLD:
|
||||
if total_tokens > MAX_TOKENS[model] - OUTPUT_BUFFER_TOKENS_HARD_THRESHOLD:
|
||||
logging.warning(f"File was fully skipped, no more tokens: {file.filename}.")
|
||||
continue
|
||||
|
||||
# If the patch is too large, just show the file name
|
||||
if total_tokens + new_patch_tokens > token_handler.limit - OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD:
|
||||
if total_tokens + new_patch_tokens > MAX_TOKENS[model] - OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD:
|
||||
# Current logic is to skip the patch if it's too large
|
||||
# TODO: Option for alternative logic to remove hunks from the patch to reduce the number of tokens
|
||||
# until we meet the requirements
|
||||
@ -196,3 +197,16 @@ def pr_generate_compressed_diff(top_langs: list, token_handler: TokenHandler,
|
||||
return patches, modified_files_list, deleted_files_list
|
||||
|
||||
|
||||
async def retry_with_fallback_models(f: Callable):
|
||||
model = settings.config.model
|
||||
fallback_models = settings.config.fallback_models
|
||||
if not isinstance(fallback_models, list):
|
||||
fallback_models = [fallback_models]
|
||||
all_models = [model] + fallback_models
|
||||
for i, model in enumerate(all_models):
|
||||
try:
|
||||
return await f(model)
|
||||
except Exception as e:
|
||||
logging.warning(f"Failed to generate prediction with {model}: {e}")
|
||||
if i == len(all_models) - 1: # If it's the last iteration
|
||||
raise # Re-raise the last exception
|
||||
|
||||
@ -26,7 +26,6 @@ class TokenHandler:
|
||||
- user: The user string.
|
||||
"""
|
||||
self.encoder = encoding_for_model(settings.config.model)
|
||||
self.limit = MAX_TOKENS[settings.config.model]
|
||||
self.prompt_tokens = self._get_system_user_tokens(pr, self.encoder, vars, system, user)
|
||||
|
||||
def _get_system_user_tokens(self, pr, encoder, vars: dict, system, user):
|
||||
|
||||
@ -11,7 +11,8 @@ from pr_agent.tools.pr_reviewer import PRReviewer
|
||||
|
||||
|
||||
def run(args=None):
|
||||
parser = argparse.ArgumentParser(description='AI based pull request analyzer', usage="""\
|
||||
parser = argparse.ArgumentParser(description='AI based pull request analyzer', usage=
|
||||
"""\
|
||||
Usage: cli.py --pr-url <URL on supported git hosting service> <command> [<args>].
|
||||
For example:
|
||||
- cli.py --pr-url=... review
|
||||
@ -33,43 +34,68 @@ reflect - Ask the PR author questions about the PR.
|
||||
'describe', 'describe_pr',
|
||||
'improve', 'improve_code',
|
||||
'reflect', 'review_after_reflect'],
|
||||
default='review')
|
||||
default='review')
|
||||
parser.add_argument('rest', nargs=argparse.REMAINDER, default=[])
|
||||
args = parser.parse_args(args)
|
||||
logging.basicConfig(level=os.environ.get("LOGLEVEL", "INFO"))
|
||||
command = args.command.lower()
|
||||
if command in ['ask', 'ask_question']:
|
||||
if len(args.rest) == 0:
|
||||
print("Please specify a question")
|
||||
parser.print_help()
|
||||
return
|
||||
print(f"Question: {' '.join(args.rest)} about PR {args.pr_url}")
|
||||
reviewer = PRQuestions(args.pr_url, args.rest)
|
||||
asyncio.run(reviewer.answer())
|
||||
elif command in ['describe', 'describe_pr']:
|
||||
print(f"PR description: {args.pr_url}")
|
||||
reviewer = PRDescription(args.pr_url)
|
||||
asyncio.run(reviewer.describe())
|
||||
elif command in ['improve', 'improve_code']:
|
||||
print(f"PR code suggestions: {args.pr_url}")
|
||||
reviewer = PRCodeSuggestions(args.pr_url)
|
||||
asyncio.run(reviewer.suggest())
|
||||
elif command in ['review', 'review_pr']:
|
||||
print(f"Reviewing PR: {args.pr_url}")
|
||||
reviewer = PRReviewer(args.pr_url, cli_mode=True, args=args.rest)
|
||||
asyncio.run(reviewer.review())
|
||||
elif command in ['reflect']:
|
||||
print(f"Asking the PR author questions: {args.pr_url}")
|
||||
reviewer = PRInformationFromUser(args.pr_url)
|
||||
asyncio.run(reviewer.generate_questions())
|
||||
elif command in ['review_after_reflect']:
|
||||
print(f"Processing author's answers and sending review: {args.pr_url}")
|
||||
reviewer = PRReviewer(args.pr_url, cli_mode=True, is_answer=True)
|
||||
asyncio.run(reviewer.review())
|
||||
commands = {
|
||||
'ask': _handle_ask_command,
|
||||
'ask_question': _handle_ask_command,
|
||||
'describe': _handle_describe_command,
|
||||
'describe_pr': _handle_describe_command,
|
||||
'improve': _handle_improve_command,
|
||||
'improve_code': _handle_improve_command,
|
||||
'review': _handle_review_command,
|
||||
'review_pr': _handle_review_command,
|
||||
'reflect': _handle_reflect_command,
|
||||
'review_after_reflect': _handle_review_after_reflect_command
|
||||
}
|
||||
if command in commands:
|
||||
commands[command](args.pr_url, args.rest)
|
||||
else:
|
||||
print(f"Unknown command: {command}")
|
||||
parser.print_help()
|
||||
|
||||
|
||||
def _handle_ask_command(pr_url: str, rest: list):
|
||||
if len(rest) == 0:
|
||||
print("Please specify a question")
|
||||
return
|
||||
print(f"Question: {' '.join(rest)} about PR {pr_url}")
|
||||
reviewer = PRQuestions(pr_url, rest)
|
||||
asyncio.run(reviewer.answer())
|
||||
|
||||
|
||||
def _handle_describe_command(pr_url: str, rest: list):
|
||||
print(f"PR description: {pr_url}")
|
||||
reviewer = PRDescription(pr_url)
|
||||
asyncio.run(reviewer.describe())
|
||||
|
||||
|
||||
def _handle_improve_command(pr_url: str, rest: list):
|
||||
print(f"PR code suggestions: {pr_url}")
|
||||
reviewer = PRCodeSuggestions(pr_url)
|
||||
asyncio.run(reviewer.suggest())
|
||||
|
||||
|
||||
def _handle_review_command(pr_url: str, rest: list):
|
||||
print(f"Reviewing PR: {pr_url}")
|
||||
reviewer = PRReviewer(pr_url, cli_mode=True, args=rest)
|
||||
asyncio.run(reviewer.review())
|
||||
|
||||
|
||||
def _handle_reflect_command(pr_url: str, rest: list):
|
||||
print(f"Asking the PR author questions: {pr_url}")
|
||||
reviewer = PRInformationFromUser(pr_url)
|
||||
asyncio.run(reviewer.generate_questions())
|
||||
|
||||
|
||||
def _handle_review_after_reflect_command(pr_url: str, rest: list):
|
||||
print(f"Processing author's answers and sending review: {pr_url}")
|
||||
reviewer = PRReviewer(pr_url, cli_mode=True, is_answer=True)
|
||||
asyncio.run(reviewer.review())
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
run()
|
||||
|
||||
@ -9,6 +9,7 @@ settings = Dynaconf(
|
||||
settings_files=[join(current_dir, f) for f in [
|
||||
"settings/.secrets.toml",
|
||||
"settings/configuration.toml",
|
||||
"settings/language_extensions.toml",
|
||||
"settings/pr_reviewer_prompts.toml",
|
||||
"settings/pr_questions_prompts.toml",
|
||||
"settings/pr_description_prompts.toml",
|
||||
|
||||
@ -105,6 +105,9 @@ class GithubProvider(GitProvider):
|
||||
# self.pr.create_issue_comment(pr_comment)
|
||||
|
||||
def publish_comment(self, pr_comment: str, is_temporary: bool = False):
|
||||
if is_temporary and not settings.config.publish_output_progress:
|
||||
logging.debug(f"Skipping publish_comment for temporary comment: {pr_comment}")
|
||||
return
|
||||
response = self.pr.create_issue_comment(pr_comment)
|
||||
if hasattr(response, "user") and hasattr(response.user, "login"):
|
||||
self.github_user_id = response.user.login
|
||||
@ -149,10 +152,8 @@ class GithubProvider(GitProvider):
|
||||
def publish_code_suggestions(self, code_suggestions: list):
|
||||
"""
|
||||
Publishes code suggestions as comments on the PR.
|
||||
In practice current APU enables to send only one code suggestion per comment. Might change in the future.
|
||||
"""
|
||||
post_parameters_list = []
|
||||
import github.PullRequestComment
|
||||
for suggestion in code_suggestions:
|
||||
body = suggestion['body']
|
||||
relevant_file = suggestion['relevant_file']
|
||||
@ -175,7 +176,6 @@ class GithubProvider(GitProvider):
|
||||
if relevant_lines_end > relevant_lines_start:
|
||||
post_parameters = {
|
||||
"body": body,
|
||||
"commit_id": self.last_commit_id._identity,
|
||||
"path": relevant_file,
|
||||
"line": relevant_lines_end,
|
||||
"start_line": relevant_lines_start,
|
||||
@ -184,28 +184,23 @@ class GithubProvider(GitProvider):
|
||||
else: # API is different for single line comments
|
||||
post_parameters = {
|
||||
"body": body,
|
||||
"commit_id": self.last_commit_id._identity,
|
||||
"path": relevant_file,
|
||||
"line": relevant_lines_start,
|
||||
"side": "RIGHT",
|
||||
}
|
||||
post_parameters_list.append(post_parameters)
|
||||
|
||||
try:
|
||||
headers, data = self.pr._requester.requestJsonAndCheck(
|
||||
"POST", f"{self.pr.url}/comments", input=post_parameters
|
||||
)
|
||||
github.PullRequestComment.PullRequestComment(
|
||||
self.pr._requester, headers, data, completed=True
|
||||
)
|
||||
return True
|
||||
except Exception as e:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.error(f"Failed to publish code suggestion, error: {e}")
|
||||
return False
|
||||
try:
|
||||
self.pr.create_review(commit=self.last_commit_id, comments=post_parameters_list)
|
||||
return True
|
||||
except Exception as e:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.error(f"Failed to publish code suggestion, error: {e}")
|
||||
return False
|
||||
|
||||
def remove_initial_comment(self):
|
||||
try:
|
||||
for comment in self.pr.comments_list:
|
||||
for comment in getattr(self.pr, 'comments_list', []):
|
||||
if comment.is_temporary:
|
||||
comment.delete()
|
||||
except Exception as e:
|
||||
|
||||
@ -259,4 +259,7 @@ class GitLabProvider(GitProvider):
|
||||
return None
|
||||
|
||||
def publish_labels(self, labels):
|
||||
pass
|
||||
|
||||
def publish_inline_comments(self, comments: list[dict]):
|
||||
pass
|
||||
@ -1,64 +0,0 @@
|
||||
import asyncio
|
||||
import time
|
||||
|
||||
import gitlab
|
||||
|
||||
from pr_agent.agent.pr_agent import PRAgent
|
||||
from pr_agent.config_loader import settings
|
||||
|
||||
gl = gitlab.Gitlab(
|
||||
settings.get("GITLAB.URL"),
|
||||
private_token=settings.get("GITLAB.PERSONAL_ACCESS_TOKEN")
|
||||
)
|
||||
|
||||
# Set the list of projects to monitor
|
||||
projects_to_monitor = settings.get("GITLAB.PROJECTS_TO_MONITOR")
|
||||
magic_word = settings.get("GITLAB.MAGIC_WORD")
|
||||
|
||||
# Hold the previous seen comments
|
||||
previous_comments = set()
|
||||
|
||||
|
||||
def check_comments():
|
||||
print('Polling')
|
||||
new_comments = {}
|
||||
for project in projects_to_monitor:
|
||||
project = gl.projects.get(project)
|
||||
merge_requests = project.mergerequests.list(state='opened')
|
||||
for mr in merge_requests:
|
||||
notes = mr.notes.list(get_all=True)
|
||||
for note in notes:
|
||||
if note.id not in previous_comments and note.body.startswith(magic_word):
|
||||
new_comments[note.id] = dict(
|
||||
body=note.body[len(magic_word):],
|
||||
project=project.name,
|
||||
mr=mr
|
||||
)
|
||||
previous_comments.add(note.id)
|
||||
print(f"New comment in project {project.name}, merge request {mr.title}: {note.body}")
|
||||
|
||||
return new_comments
|
||||
|
||||
|
||||
def handle_new_comments(new_comments):
|
||||
print('Handling new comments')
|
||||
agent = PRAgent()
|
||||
for _, comment in new_comments.items():
|
||||
print(f"Handling comment: {comment['body']}")
|
||||
asyncio.run(agent.handle_request(comment['mr'].web_url, comment['body']))
|
||||
|
||||
|
||||
def run():
|
||||
assert settings.get('CONFIG.GIT_PROVIDER') == 'gitlab', 'This script is only for GitLab'
|
||||
# Initial run to populate previous_comments
|
||||
check_comments()
|
||||
|
||||
# Run the check every minute
|
||||
while True:
|
||||
time.sleep(settings.get("GITLAB.POLLING_INTERVAL_SECONDS"))
|
||||
new_comments = check_comments()
|
||||
if new_comments:
|
||||
handle_new_comments(new_comments)
|
||||
|
||||
if __name__ == '__main__':
|
||||
run()
|
||||
@ -1,8 +1,11 @@
|
||||
[config]
|
||||
model="gpt-4-0613"
|
||||
model="gpt-4"
|
||||
fallback-models=["gpt-3.5-turbo-16k", "gpt-3.5-turbo"]
|
||||
git_provider="github"
|
||||
publish_output=true
|
||||
publish_output_progress=true
|
||||
verbosity_level=0 # 0,1,2
|
||||
use_extra_bad_extensions=false
|
||||
|
||||
[pr_reviewer]
|
||||
require_focused_review=true
|
||||
|
||||
434
pr_agent/settings/language_extensions.toml
Normal file
434
pr_agent/settings/language_extensions.toml
Normal file
@ -0,0 +1,434 @@
|
||||
[bad_extensions]
|
||||
default = [
|
||||
'app',
|
||||
'bin',
|
||||
'bmp',
|
||||
'bz2',
|
||||
'class',
|
||||
'csv',
|
||||
'dat',
|
||||
'db',
|
||||
'dll',
|
||||
'dylib',
|
||||
'egg',
|
||||
'eot',
|
||||
'exe',
|
||||
'gif',
|
||||
'gitignore',
|
||||
'glif',
|
||||
'gradle',
|
||||
'gz',
|
||||
'ico',
|
||||
'jar',
|
||||
'jpeg',
|
||||
'jpg',
|
||||
'lo',
|
||||
'lock',
|
||||
'log',
|
||||
'mp3',
|
||||
'mp4',
|
||||
'nar',
|
||||
'o',
|
||||
'ogg',
|
||||
'otf',
|
||||
'p',
|
||||
'pdf',
|
||||
'png',
|
||||
'pickle',
|
||||
'pkl',
|
||||
'pyc',
|
||||
'pyd',
|
||||
'pyo',
|
||||
'rkt',
|
||||
'so',
|
||||
'ss',
|
||||
'svg',
|
||||
'tar',
|
||||
'tsv',
|
||||
'ttf',
|
||||
'war',
|
||||
'webm',
|
||||
'woff',
|
||||
'woff2',
|
||||
'xz',
|
||||
'zip',
|
||||
'zst',
|
||||
'snap'
|
||||
]
|
||||
extra = [
|
||||
'md',
|
||||
'txt'
|
||||
]
|
||||
|
||||
[language_extension_map_org]
|
||||
ABAP = [".abap", ]
|
||||
"AGS Script" = [".ash", ]
|
||||
AMPL = [".ampl", ]
|
||||
ANTLR = [".g4", ]
|
||||
"API Blueprint" = [".apib", ]
|
||||
APL = [".apl", ".dyalog", ]
|
||||
ASP = [".asp", ".asax", ".ascx", ".ashx", ".asmx", ".aspx", ".axd", ]
|
||||
ATS = [".dats", ".hats", ".sats", ]
|
||||
ActionScript = [".as", ]
|
||||
Ada = [".adb", ".ada", ".ads", ]
|
||||
Agda = [".agda", ]
|
||||
Alloy = [".als", ]
|
||||
ApacheConf = [".apacheconf", ".vhost", ]
|
||||
AppleScript = [".applescript", ".scpt", ]
|
||||
Arc = [".arc", ]
|
||||
Arduino = [".ino", ]
|
||||
AsciiDoc = [".asciidoc", ".adoc", ]
|
||||
AspectJ = [".aj", ]
|
||||
Assembly = [".asm", ".a51", ".nasm", ]
|
||||
Augeas = [".aug", ]
|
||||
AutoHotkey = [".ahk", ".ahkl", ]
|
||||
AutoIt = [".au3", ]
|
||||
Awk = [".awk", ".auk", ".gawk", ".mawk", ".nawk", ]
|
||||
Batchfile = [".bat", ".cmd", ]
|
||||
Befunge = [".befunge", ]
|
||||
Bison = [".bison", ]
|
||||
BitBake = [".bb", ]
|
||||
BlitzBasic = [".decls", ]
|
||||
BlitzMax = [".bmx", ]
|
||||
Bluespec = [".bsv", ]
|
||||
Boo = [".boo", ]
|
||||
Brainfuck = [".bf", ]
|
||||
Brightscript = [".brs", ]
|
||||
Bro = [".bro", ]
|
||||
C = [".c", ".cats", ".h", ".idc", ".w", ]
|
||||
"C#" = [".cs", ".cake", ".cshtml", ".csx", ]
|
||||
"C++" = [".cpp", ".c++", ".cc", ".cp", ".cxx", ".h++", ".hh", ".hpp", ".hxx", ".inl", ".ipp", ".tcc", ".tpp", ".C", ".H", ]
|
||||
C-ObjDump = [".c-objdump", ]
|
||||
"C2hs Haskell" = [".chs", ]
|
||||
CLIPS = [".clp", ]
|
||||
CMake = [".cmake", ".cmake.in", ]
|
||||
COBOL = [".cob", ".cbl", ".ccp", ".cobol", ".cpy", ]
|
||||
CSS = [".css", ]
|
||||
CSV = [".csv", ]
|
||||
"Cap'n Proto" = [".capnp", ]
|
||||
CartoCSS = [".mss", ]
|
||||
Ceylon = [".ceylon", ]
|
||||
Chapel = [".chpl", ]
|
||||
ChucK = [".ck", ]
|
||||
Cirru = [".cirru", ]
|
||||
Clarion = [".clw", ]
|
||||
Clean = [".icl", ".dcl", ]
|
||||
Click = [".click", ]
|
||||
Clojure = [".clj", ".boot", ".cl2", ".cljc", ".cljs", ".cljs.hl", ".cljscm", ".cljx", ".hic", ]
|
||||
CoffeeScript = [".coffee", "._coffee", ".cjsx", ".cson", ".iced", ]
|
||||
ColdFusion = [".cfm", ".cfml", ]
|
||||
"ColdFusion CFC" = [".cfc", ]
|
||||
"Common Lisp" = [".lisp", ".asd", ".lsp", ".ny", ".podsl", ".sexp", ]
|
||||
"Component Pascal" = [".cps", ]
|
||||
Coq = [".coq", ]
|
||||
Cpp-ObjDump = [".cppobjdump", ".c++-objdump", ".c++objdump", ".cpp-objdump", ".cxx-objdump", ]
|
||||
Creole = [".creole", ]
|
||||
Crystal = [".cr", ]
|
||||
Csound = [".csd", ]
|
||||
Cucumber = [".feature", ]
|
||||
Cuda = [".cu", ".cuh", ]
|
||||
Cycript = [".cy", ]
|
||||
Cython = [".pyx", ".pxd", ".pxi", ]
|
||||
D = [".di", ]
|
||||
D-ObjDump = [".d-objdump", ]
|
||||
"DIGITAL Command Language" = [".com", ]
|
||||
DM = [".dm", ]
|
||||
"DNS Zone" = [".zone", ".arpa", ]
|
||||
"Darcs Patch" = [".darcspatch", ".dpatch", ]
|
||||
Dart = [".dart", ]
|
||||
Diff = [".diff", ".patch", ]
|
||||
Dockerfile = [".dockerfile", "Dockerfile", ]
|
||||
Dogescript = [".djs", ]
|
||||
Dylan = [".dylan", ".dyl", ".intr", ".lid", ]
|
||||
E = [".E", ]
|
||||
ECL = [".ecl", ".eclxml", ]
|
||||
Eagle = [".sch", ".brd", ]
|
||||
"Ecere Projects" = [".epj", ]
|
||||
Eiffel = [".e", ]
|
||||
Elixir = [".ex", ".exs", ]
|
||||
Elm = [".elm", ]
|
||||
"Emacs Lisp" = [".el", ".emacs", ".emacs.desktop", ]
|
||||
EmberScript = [".em", ".emberscript", ]
|
||||
Erlang = [".erl", ".escript", ".hrl", ".xrl", ".yrl", ]
|
||||
"F#" = [".fs", ".fsi", ".fsx", ]
|
||||
FLUX = [".flux", ]
|
||||
FORTRAN = [".f90", ".f", ".f03", ".f08", ".f77", ".f95", ".for", ".fpp", ]
|
||||
Factor = [".factor", ]
|
||||
Fancy = [".fy", ".fancypack", ]
|
||||
Fantom = [".fan", ]
|
||||
Formatted = [".eam.fs", ]
|
||||
Forth = [".fth", ".4th", ".forth", ".frt", ]
|
||||
FreeMarker = [".ftl", ]
|
||||
G-code = [".g", ".gco", ".gcode", ]
|
||||
GAMS = [".gms", ]
|
||||
GAP = [".gap", ".gi", ]
|
||||
GAS = [".s", ]
|
||||
GDScript = [".gd", ]
|
||||
GLSL = [".glsl", ".fp", ".frag", ".frg", ".fsh", ".fshader", ".geo", ".geom", ".glslv", ".gshader", ".shader", ".vert", ".vrx", ".vsh", ".vshader", ]
|
||||
Genshi = [".kid", ]
|
||||
"Gentoo Ebuild" = [".ebuild", ]
|
||||
"Gentoo Eclass" = [".eclass", ]
|
||||
"Gettext Catalog" = [".po", ".pot", ]
|
||||
Glyph = [".glf", ]
|
||||
Gnuplot = [".gp", ".gnu", ".gnuplot", ".plot", ".plt", ]
|
||||
Go = [".go", ]
|
||||
Golo = [".golo", ]
|
||||
Gosu = [".gst", ".gsx", ".vark", ]
|
||||
Grace = [".grace", ]
|
||||
Gradle = [".gradle", ]
|
||||
"Grammatical Framework" = [".gf", ]
|
||||
GraphQL = [".graphql", ]
|
||||
"Graphviz (DOT)" = [".dot", ".gv", ]
|
||||
Groff = [".man", ".1", ".1in", ".1m", ".1x", ".2", ".3", ".3in", ".3m", ".3qt", ".3x", ".4", ".5", ".6", ".7", ".8", ".9", ".me", ".rno", ".roff", ]
|
||||
Groovy = [".groovy", ".grt", ".gtpl", ".gvy", ]
|
||||
"Groovy Server Pages" = [".gsp", ]
|
||||
HCL = [".hcl", ".tf", ]
|
||||
HLSL = [".hlsl", ".fxh", ".hlsli", ]
|
||||
HTML = [".html", ".htm", ".html.hl", ".xht", ".xhtml", ]
|
||||
"HTML+Django" = [".mustache", ".jinja", ]
|
||||
"HTML+EEX" = [".eex", ]
|
||||
"HTML+ERB" = [".erb", ".erb.deface", ]
|
||||
"HTML+PHP" = [".phtml", ]
|
||||
HTTP = [".http", ]
|
||||
Haml = [".haml", ".haml.deface", ]
|
||||
Handlebars = [".handlebars", ".hbs", ]
|
||||
Harbour = [".hb", ]
|
||||
Haskell = [".hs", ".hsc", ]
|
||||
Haxe = [".hx", ".hxsl", ]
|
||||
Hy = [".hy", ]
|
||||
IDL = [".dlm", ]
|
||||
"IGOR Pro" = [".ipf", ]
|
||||
INI = [".ini", ".cfg", ".prefs", ".properties", ]
|
||||
"IRC log" = [".irclog", ".weechatlog", ]
|
||||
Idris = [".idr", ".lidr", ]
|
||||
"Inform 7" = [".ni", ".i7x", ]
|
||||
"Inno Setup" = [".iss", ]
|
||||
Io = [".io", ]
|
||||
Ioke = [".ik", ]
|
||||
Isabelle = [".thy", ]
|
||||
J = [".ijs", ]
|
||||
JFlex = [".flex", ".jflex", ]
|
||||
JSON = [".json", ".geojson", ".lock", ".topojson", ]
|
||||
JSON5 = [".json5", ]
|
||||
JSONLD = [".jsonld", ]
|
||||
JSONiq = [".jq", ]
|
||||
JSX = [".jsx", ]
|
||||
Jade = [".jade", ]
|
||||
Jasmin = [".j", ]
|
||||
Java = [".java", ]
|
||||
"Java Server Pages" = [".jsp", ]
|
||||
JavaScript = [".js", "._js", ".bones", ".es6", ".jake", ".jsb", ".jscad", ".jsfl", ".jsm", ".jss", ".njs", ".pac", ".sjs", ".ssjs", ".xsjs", ".xsjslib", ]
|
||||
Julia = [".jl", ]
|
||||
"Jupyter Notebook" = [".ipynb", ]
|
||||
KRL = [".krl", ]
|
||||
KiCad = [".kicad_pcb", ]
|
||||
Kit = [".kit", ]
|
||||
Kotlin = [".kt", ".ktm", ".kts", ]
|
||||
LFE = [".lfe", ]
|
||||
LLVM = [".ll", ]
|
||||
LOLCODE = [".lol", ]
|
||||
LSL = [".lsl", ".lslp", ]
|
||||
LabVIEW = [".lvproj", ]
|
||||
Lasso = [".lasso", ".las", ".lasso8", ".lasso9", ".ldml", ]
|
||||
Latte = [".latte", ]
|
||||
Lean = [".lean", ".hlean", ]
|
||||
Less = [".less", ]
|
||||
Lex = [".lex", ]
|
||||
LilyPond = [".ly", ".ily", ]
|
||||
"Linker Script" = [".ld", ".lds", ]
|
||||
Liquid = [".liquid", ]
|
||||
"Literate Agda" = [".lagda", ]
|
||||
"Literate CoffeeScript" = [".litcoffee", ]
|
||||
"Literate Haskell" = [".lhs", ]
|
||||
LiveScript = [".ls", "._ls", ]
|
||||
Logos = [".xm", ".x", ".xi", ]
|
||||
Logtalk = [".lgt", ".logtalk", ]
|
||||
LookML = [".lookml", ]
|
||||
Lua = [".lua", ".nse", ".pd_lua", ".rbxs", ".wlua", ]
|
||||
M = [".mumps", ]
|
||||
M4 = [".m4", ]
|
||||
MAXScript = [".mcr", ]
|
||||
MTML = [".mtml", ]
|
||||
MUF = [".muf", ]
|
||||
Makefile = [".mak", ".mk", ".mkfile", "Makefile", ]
|
||||
Mako = [".mako", ".mao", ]
|
||||
Maple = [".mpl", ]
|
||||
Markdown = [".md", ".markdown", ".mkd", ".mkdn", ".mkdown", ".ron", ]
|
||||
Mask = [".mask", ]
|
||||
Mathematica = [".mathematica", ".cdf", ".ma", ".mt", ".nb", ".nbp", ".wl", ".wlt", ]
|
||||
Matlab = [".matlab", ]
|
||||
Max = [".maxpat", ".maxhelp", ".maxproj", ".mxt", ".pat", ]
|
||||
MediaWiki = [".mediawiki", ".wiki", ]
|
||||
Metal = [".metal", ]
|
||||
MiniD = [".minid", ]
|
||||
Mirah = [".druby", ".duby", ".mir", ".mirah", ]
|
||||
Modelica = [".mo", ]
|
||||
"Module Management System" = [".mms", ".mmk", ]
|
||||
Monkey = [".monkey", ]
|
||||
MoonScript = [".moon", ]
|
||||
Myghty = [".myt", ]
|
||||
NSIS = [".nsi", ".nsh", ]
|
||||
NetLinx = [".axs", ".axi", ]
|
||||
"NetLinx+ERB" = [".axs.erb", ".axi.erb", ]
|
||||
NetLogo = [".nlogo", ]
|
||||
Nginx = [".nginxconf", ]
|
||||
Nimrod = [".nim", ".nimrod", ]
|
||||
Ninja = [".ninja", ]
|
||||
Nit = [".nit", ]
|
||||
Nix = [".nix", ]
|
||||
Nu = [".nu", ]
|
||||
NumPy = [".numpy", ".numpyw", ".numsc", ]
|
||||
OCaml = [".ml", ".eliom", ".eliomi", ".ml4", ".mli", ".mll", ".mly", ]
|
||||
ObjDump = [".objdump", ]
|
||||
"Objective-C++" = [".mm", ]
|
||||
Objective-J = [".sj", ]
|
||||
Octave = [".oct", ]
|
||||
Omgrofl = [".omgrofl", ]
|
||||
Opa = [".opa", ]
|
||||
Opal = [".opal", ]
|
||||
OpenCL = [".cl", ".opencl", ]
|
||||
"OpenEdge ABL" = [".p", ]
|
||||
OpenSCAD = [".scad", ]
|
||||
Org = [".org", ]
|
||||
Ox = [".ox", ".oxh", ".oxo", ]
|
||||
Oxygene = [".oxygene", ]
|
||||
Oz = [".oz", ]
|
||||
PAWN = [".pwn", ]
|
||||
PHP = [".php", ".aw", ".ctp", ".php3", ".php4", ".php5", ".phps", ".phpt", ]
|
||||
"POV-Ray SDL" = [".pov", ]
|
||||
Pan = [".pan", ]
|
||||
Papyrus = [".psc", ]
|
||||
Parrot = [".parrot", ]
|
||||
"Parrot Assembly" = [".pasm", ]
|
||||
"Parrot Internal Representation" = [".pir", ]
|
||||
Pascal = [".pas", ".dfm", ".dpr", ".lpr", ]
|
||||
Perl = [".pl", ".al", ".perl", ".ph", ".plx", ".pm", ".psgi", ".t", ]
|
||||
Perl6 = [".6pl", ".6pm", ".nqp", ".p6", ".p6l", ".p6m", ".pl6", ".pm6", ]
|
||||
Pickle = [".pkl", ]
|
||||
PigLatin = [".pig", ]
|
||||
Pike = [".pike", ".pmod", ]
|
||||
Pod = [".pod", ]
|
||||
PogoScript = [".pogo", ]
|
||||
Pony = [".pony", ]
|
||||
PostScript = [".ps", ".eps", ]
|
||||
PowerShell = [".ps1", ".psd1", ".psm1", ]
|
||||
Processing = [".pde", ]
|
||||
Prolog = [".prolog", ".yap", ]
|
||||
"Propeller Spin" = [".spin", ]
|
||||
"Protocol Buffer" = [".proto", ]
|
||||
"Public Key" = [".pub", ]
|
||||
"Pure Data" = [".pd", ]
|
||||
PureBasic = [".pb", ".pbi", ]
|
||||
PureScript = [".purs", ]
|
||||
Python = [".py", ".bzl", ".gyp", ".lmi", ".pyde", ".pyp", ".pyt", ".pyw", ".tac", ".wsgi", ".xpy", ]
|
||||
"Python traceback" = [".pytb", ]
|
||||
QML = [".qml", ".qbs", ]
|
||||
QMake = [".pri", ]
|
||||
R = [".r", ".rd", ".rsx", ]
|
||||
RAML = [".raml", ]
|
||||
RDoc = [".rdoc", ]
|
||||
REALbasic = [".rbbas", ".rbfrm", ".rbmnu", ".rbres", ".rbtbar", ".rbuistate", ]
|
||||
RHTML = [".rhtml", ]
|
||||
RMarkdown = [".rmd", ]
|
||||
Racket = [".rkt", ".rktd", ".rktl", ".scrbl", ]
|
||||
"Ragel in Ruby Host" = [".rl", ]
|
||||
"Raw token data" = [".raw", ]
|
||||
Rebol = [".reb", ".r2", ".r3", ".rebol", ]
|
||||
Red = [".red", ".reds", ]
|
||||
Redcode = [".cw", ]
|
||||
"Ren'Py" = [".rpy", ]
|
||||
RenderScript = [".rsh", ]
|
||||
RobotFramework = [".robot", ]
|
||||
Rouge = [".rg", ]
|
||||
Ruby = [".rb", ".builder", ".gemspec", ".god", ".irbrc", ".jbuilder", ".mspec", ".podspec", ".rabl", ".rake", ".rbuild", ".rbw", ".rbx", ".ru", ".ruby", ".thor", ".watchr", ]
|
||||
Rust = [".rs", ".rs.in", ]
|
||||
SAS = [".sas", ]
|
||||
SCSS = [".scss", ]
|
||||
SMT = [".smt2", ".smt", ]
|
||||
SPARQL = [".sparql", ".rq", ]
|
||||
SQF = [".sqf", ".hqf", ]
|
||||
SQL = [".pls", ".pck", ".pkb", ".pks", ".plb", ".plsql", ".sql", ".cql", ".ddl", ".prc", ".tab", ".udf", ".viw", ".db2", ]
|
||||
STON = [".ston", ]
|
||||
SVG = [".svg", ]
|
||||
Sage = [".sage", ".sagews", ]
|
||||
SaltStack = [".sls", ]
|
||||
Sass = [".sass", ]
|
||||
Scala = [".scala", ".sbt", ]
|
||||
Scaml = [".scaml", ]
|
||||
Scheme = [".scm", ".sld", ".sps", ".ss", ]
|
||||
Scilab = [".sci", ".sce", ]
|
||||
Self = [".self", ]
|
||||
Shell = [".sh", ".bash", ".bats", ".command", ".ksh", ".sh.in", ".tmux", ".tool", ".zsh", ]
|
||||
ShellSession = [".sh-session", ]
|
||||
Shen = [".shen", ]
|
||||
Slash = [".sl", ]
|
||||
Slim = [".slim", ]
|
||||
Smali = [".smali", ]
|
||||
Smalltalk = [".st", ]
|
||||
Smarty = [".tpl", ]
|
||||
Solidity = [".sol", ]
|
||||
SourcePawn = [".sp", ".sma", ]
|
||||
Squirrel = [".nut", ]
|
||||
Stan = [".stan", ]
|
||||
"Standard ML" = [".ML", ".fun", ".sig", ".sml", ]
|
||||
Stata = [".do", ".ado", ".doh", ".ihlp", ".mata", ".matah", ".sthlp", ]
|
||||
Stylus = [".styl", ]
|
||||
SuperCollider = [".scd", ]
|
||||
Swift = [".swift", ]
|
||||
SystemVerilog = [".sv", ".svh", ".vh", ]
|
||||
TOML = [".toml", ]
|
||||
TXL = [".txl", ]
|
||||
Tcl = [".tcl", ".adp", ".tm", ]
|
||||
Tcsh = [".tcsh", ".csh", ]
|
||||
TeX = [".tex", ".aux", ".bbx", ".bib", ".cbx", ".dtx", ".ins", ".lbx", ".ltx", ".mkii", ".mkiv", ".mkvi", ".sty", ".toc", ]
|
||||
Tea = [".tea", ]
|
||||
Text = [".txt", ".no", ]
|
||||
Textile = [".textile", ]
|
||||
Thrift = [".thrift", ]
|
||||
Turing = [".tu", ]
|
||||
Turtle = [".ttl", ]
|
||||
Twig = [".twig", ]
|
||||
TypeScript = [".ts", ".tsx", ]
|
||||
"Unified Parallel C" = [".upc", ]
|
||||
"Unity3D Asset" = [".anim", ".asset", ".mat", ".meta", ".prefab", ".unity", ]
|
||||
Uno = [".uno", ]
|
||||
UnrealScript = [".uc", ]
|
||||
UrWeb = [".ur", ".urs", ]
|
||||
VCL = [".vcl", ]
|
||||
VHDL = [".vhdl", ".vhd", ".vhf", ".vhi", ".vho", ".vhs", ".vht", ".vhw", ]
|
||||
Vala = [".vala", ".vapi", ]
|
||||
Verilog = [".veo", ]
|
||||
VimL = [".vim", ]
|
||||
"Visual Basic" = [".vb", ".bas", ".frm", ".frx", ".vba", ".vbhtml", ".vbs", ]
|
||||
Volt = [".volt", ]
|
||||
Vue = [".vue", ]
|
||||
"Web Ontology Language" = [".owl", ]
|
||||
WebAssembly = [".wat", ]
|
||||
WebIDL = [".webidl", ]
|
||||
X10 = [".x10", ]
|
||||
XC = [".xc", ]
|
||||
XML = [".xml", ".ant", ".axml", ".ccxml", ".clixml", ".cproject", ".csl", ".csproj", ".ct", ".dita", ".ditamap", ".ditaval", ".dll.config", ".dotsettings", ".filters", ".fsproj", ".fxml", ".glade", ".grxml", ".iml", ".ivy", ".jelly", ".jsproj", ".kml", ".launch", ".mdpolicy", ".mxml", ".nproj", ".nuspec", ".odd", ".osm", ".plist", ".props", ".ps1xml", ".psc1", ".pt", ".rdf", ".rss", ".scxml", ".srdf", ".storyboard", ".stTheme", ".sublime-snippet", ".targets", ".tmCommand", ".tml", ".tmLanguage", ".tmPreferences", ".tmSnippet", ".tmTheme", ".ui", ".urdf", ".ux", ".vbproj", ".vcxproj", ".vssettings", ".vxml", ".wsdl", ".wsf", ".wxi", ".wxl", ".wxs", ".x3d", ".xacro", ".xaml", ".xib", ".xlf", ".xliff", ".xmi", ".xml.dist", ".xproj", ".xsd", ".xul", ".zcml", ]
|
||||
XPages = [".xsp-config", ".xsp.metadata", ]
|
||||
XProc = [".xpl", ".xproc", ]
|
||||
XQuery = [".xquery", ".xq", ".xql", ".xqm", ".xqy", ]
|
||||
XS = [".xs", ]
|
||||
XSLT = [".xslt", ".xsl", ]
|
||||
Xojo = [".xojo_code", ".xojo_menu", ".xojo_report", ".xojo_script", ".xojo_toolbar", ".xojo_window", ]
|
||||
Xtend = [".xtend", ]
|
||||
YAML = [".yml", ".reek", ".rviz", ".sublime-syntax", ".syntax", ".yaml", ".yaml-tmlanguage", ]
|
||||
YANG = [".yang", ]
|
||||
Yacc = [".y", ".yacc", ".yy", ]
|
||||
Zephir = [".zep", ]
|
||||
Zig = [".zig", ]
|
||||
Zimpl = [".zimpl", ".zmpl", ".zpl", ]
|
||||
desktop = [".desktop", ".desktop.in", ]
|
||||
eC = [".ec", ".eh", ]
|
||||
edn = [".edn", ]
|
||||
fish = [".fish", ]
|
||||
mupad = [".mu", ]
|
||||
nesC = [".nc", ]
|
||||
ooc = [".ooc", ]
|
||||
reStructuredText = [".rst", ".rest", ".rest.txt", ".rst.txt", ]
|
||||
wisp = [".wisp", ]
|
||||
xBase = [".prg", ".prw", ]
|
||||
|
||||
@ -6,7 +6,7 @@ import textwrap
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
|
||||
from pr_agent.algo.ai_handler import AiHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.utils import try_fix_json
|
||||
from pr_agent.config_loader import settings
|
||||
@ -44,16 +44,7 @@ class PRCodeSuggestions:
|
||||
logging.info('Generating code suggestions for PR...')
|
||||
if settings.config.publish_output:
|
||||
self.git_provider.publish_comment("Preparing review...", is_temporary=True)
|
||||
logging.info('Getting PR diff...')
|
||||
|
||||
# we are using extended hunk with line numbers for code suggestions
|
||||
self.patches_diff = get_pr_diff(self.git_provider,
|
||||
self.token_handler,
|
||||
add_line_numbers_to_hunks=True,
|
||||
disable_extra_lines=True)
|
||||
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction()
|
||||
await retry_with_fallback_models(self._prepare_prediction)
|
||||
logging.info('Preparing PR review...')
|
||||
data = self._prepare_pr_code_suggestions()
|
||||
if settings.config.publish_output:
|
||||
@ -62,7 +53,18 @@ class PRCodeSuggestions:
|
||||
logging.info('Pushing inline code comments...')
|
||||
self.push_inline_code_suggestions(data)
|
||||
|
||||
async def _get_prediction(self):
|
||||
async def _prepare_prediction(self, model: str):
|
||||
logging.info('Getting PR diff...')
|
||||
# we are using extended hunk with line numbers for code suggestions
|
||||
self.patches_diff = get_pr_diff(self.git_provider,
|
||||
self.token_handler,
|
||||
model,
|
||||
add_line_numbers_to_hunks=True,
|
||||
disable_extra_lines=True)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction(model)
|
||||
|
||||
async def _get_prediction(self, model: str):
|
||||
variables = copy.deepcopy(self.vars)
|
||||
variables["diff"] = self.patches_diff # update diff
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
@ -71,7 +73,6 @@ class PRCodeSuggestions:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.info(f"\nSystem prompt:\n{system_prompt}")
|
||||
logging.info(f"\nUser prompt:\n{user_prompt}")
|
||||
model = settings.config.model
|
||||
response, finish_reason = await self.ai_handler.chat_completion(model=model, temperature=0.2,
|
||||
system=system_prompt, user=user_prompt)
|
||||
|
||||
|
||||
@ -5,7 +5,7 @@ import logging
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
|
||||
from pr_agent.algo.ai_handler import AiHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.git_providers import get_git_provider
|
||||
@ -37,10 +37,7 @@ class PRDescription:
|
||||
logging.info('Generating a PR description...')
|
||||
if settings.config.publish_output:
|
||||
self.git_provider.publish_comment("Preparing pr description...", is_temporary=True)
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction()
|
||||
await retry_with_fallback_models(self._prepare_prediction)
|
||||
logging.info('Preparing answer...')
|
||||
pr_title, pr_body, pr_types, markdown_text = self._prepare_pr_answer()
|
||||
if settings.config.publish_output:
|
||||
@ -53,7 +50,13 @@ class PRDescription:
|
||||
self.git_provider.remove_initial_comment()
|
||||
return ""
|
||||
|
||||
async def _get_prediction(self):
|
||||
async def _prepare_prediction(self, model: str):
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler, model)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction(model)
|
||||
|
||||
async def _get_prediction(self, model: str):
|
||||
variables = copy.deepcopy(self.vars)
|
||||
variables["diff"] = self.patches_diff # update diff
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
@ -62,7 +65,6 @@ class PRDescription:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.info(f"\nSystem prompt:\n{system_prompt}")
|
||||
logging.info(f"\nUser prompt:\n{user_prompt}")
|
||||
model = settings.config.model
|
||||
response, finish_reason = await self.ai_handler.chat_completion(model=model, temperature=0.2,
|
||||
system=system_prompt, user=user_prompt)
|
||||
return response
|
||||
|
||||
@ -4,13 +4,15 @@ import logging
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
|
||||
from pr_agent.algo.ai_handler import AiHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.git_providers import get_git_provider
|
||||
from pr_agent.git_providers.git_provider import get_main_pr_language
|
||||
|
||||
|
||||
|
||||
|
||||
class PRInformationFromUser:
|
||||
def __init__(self, pr_url: str):
|
||||
self.git_provider = get_git_provider()(pr_url)
|
||||
@ -36,10 +38,7 @@ class PRInformationFromUser:
|
||||
logging.info('Generating question to the user...')
|
||||
if settings.config.publish_output:
|
||||
self.git_provider.publish_comment("Preparing questions...", is_temporary=True)
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction()
|
||||
await retry_with_fallback_models(self._prepare_prediction)
|
||||
logging.info('Preparing questions...')
|
||||
pr_comment = self._prepare_pr_answer()
|
||||
if settings.config.publish_output:
|
||||
@ -48,7 +47,13 @@ class PRInformationFromUser:
|
||||
self.git_provider.remove_initial_comment()
|
||||
return ""
|
||||
|
||||
async def _get_prediction(self):
|
||||
async def _prepare_prediction(self, model):
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler, model)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction(model)
|
||||
|
||||
async def _get_prediction(self, model: str):
|
||||
variables = copy.deepcopy(self.vars)
|
||||
variables["diff"] = self.patches_diff # update diff
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
@ -57,7 +62,6 @@ class PRInformationFromUser:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.info(f"\nSystem prompt:\n{system_prompt}")
|
||||
logging.info(f"\nUser prompt:\n{user_prompt}")
|
||||
model = settings.config.model
|
||||
response, finish_reason = await self.ai_handler.chat_completion(model=model, temperature=0.2,
|
||||
system=system_prompt, user=user_prompt)
|
||||
return response
|
||||
|
||||
@ -4,7 +4,7 @@ import logging
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
|
||||
from pr_agent.algo.ai_handler import AiHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.git_providers import get_git_provider
|
||||
@ -46,10 +46,7 @@ class PRQuestions:
|
||||
logging.info('Answering a PR question...')
|
||||
if settings.config.publish_output:
|
||||
self.git_provider.publish_comment("Preparing answer...", is_temporary=True)
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction()
|
||||
await retry_with_fallback_models(self._prepare_prediction)
|
||||
logging.info('Preparing answer...')
|
||||
pr_comment = self._prepare_pr_answer()
|
||||
if settings.config.publish_output:
|
||||
@ -58,7 +55,13 @@ class PRQuestions:
|
||||
self.git_provider.remove_initial_comment()
|
||||
return ""
|
||||
|
||||
async def _get_prediction(self):
|
||||
async def _prepare_prediction(self, model: str):
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler, model)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction(model)
|
||||
|
||||
async def _get_prediction(self, model: str):
|
||||
variables = copy.deepcopy(self.vars)
|
||||
variables["diff"] = self.patches_diff # update diff
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
@ -67,7 +70,6 @@ class PRQuestions:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.info(f"\nSystem prompt:\n{system_prompt}")
|
||||
logging.info(f"\nUser prompt:\n{user_prompt}")
|
||||
model = settings.config.model
|
||||
response, finish_reason = await self.ai_handler.chat_completion(model=model, temperature=0.2,
|
||||
system=system_prompt, user=user_prompt)
|
||||
return response
|
||||
|
||||
@ -6,7 +6,7 @@ from collections import OrderedDict
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
|
||||
from pr_agent.algo.ai_handler import AiHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.utils import convert_to_markdown, try_fix_json
|
||||
from pr_agent.config_loader import settings
|
||||
@ -64,10 +64,7 @@ class PRReviewer:
|
||||
logging.info('Reviewing PR...')
|
||||
if settings.config.publish_output:
|
||||
self.git_provider.publish_comment("Preparing review...", is_temporary=True)
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction()
|
||||
await retry_with_fallback_models(self._prepare_prediction)
|
||||
logging.info('Preparing PR review...')
|
||||
pr_comment = self._prepare_pr_review()
|
||||
if settings.config.publish_output:
|
||||
@ -79,7 +76,13 @@ class PRReviewer:
|
||||
self._publish_inline_code_comments()
|
||||
return ""
|
||||
|
||||
async def _get_prediction(self):
|
||||
async def _prepare_prediction(self, model: str):
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler, model)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction(model)
|
||||
|
||||
async def _get_prediction(self, model: str):
|
||||
variables = copy.deepcopy(self.vars)
|
||||
variables["diff"] = self.patches_diff # update diff
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
@ -88,7 +91,6 @@ class PRReviewer:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.info(f"\nSystem prompt:\n{system_prompt}")
|
||||
logging.info(f"\nUser prompt:\n{user_prompt}")
|
||||
model = settings.config.model
|
||||
response, finish_reason = await self.ai_handler.chat_completion(model=model, temperature=0.2,
|
||||
system=system_prompt, user=user_prompt)
|
||||
|
||||
|
||||
Reference in New Issue
Block a user