mirror of
https://github.com/qodo-ai/pr-agent.git
synced 2025-07-10 15:50:37 +08:00
Compare commits
79 Commits
mrT23-patc
...
v0.25
| Author | SHA1 | Date | |
|---|---|---|---|
| 91bf3c0749 | |||
| 159155785e | |||
| eabc296246 | |||
| b44030114e | |||
| 1d6f87be3b | |||
| a7c6fa7bd2 | |||
| a825aec5f3 | |||
| 4df097c228 | |||
| 6871e1b27a | |||
| 4afe05761d | |||
| 7d1b6c2f0a | |||
| 3547cf2057 | |||
| f2043d639c | |||
| 6240de3898 | |||
| f08b20c667 | |||
| e64b468556 | |||
| d48d14dac7 | |||
| eb0c959ca9 | |||
| 741a70ad9d | |||
| 22ee03981e | |||
| b1336e7d08 | |||
| 751caca141 | |||
| 612004727c | |||
| 577ee0241d | |||
| a141ca133c | |||
| a14b6a580d | |||
| cc5005c490 | |||
| 3a5d0f54ce | |||
| cd8ba4f59f | |||
| fe27f96bf1 | |||
| 2c3aa7b2dc | |||
| c934523f2d | |||
| 2f4545dc15 | |||
| cbd490b3d7 | |||
| b07f96d26a | |||
| 065777040f | |||
| 9c82047dc3 | |||
| e0c15409bb | |||
| d956c72cb6 | |||
| dfb3d801cf | |||
| 5c5a3e267c | |||
| f9380c2440 | |||
| e6a1f14c0e | |||
| 6339845eb4 | |||
| 732cc18fd6 | |||
| 84d0f80c81 | |||
| ee26bf35c1 | |||
| 7a5e9102fd | |||
| a8c97bfa73 | |||
| af653a048f | |||
| d2663f959a | |||
| e650fe9ce9 | |||
| daeca42ae8 | |||
| 04496f9b0e | |||
| 0eacb3e35e | |||
| c5ed2f040a | |||
| c394fc2767 | |||
| 157251493a | |||
| 4a982a849d | |||
| 6e3544f523 | |||
| bf3ebbb95f | |||
| eb44ecb1be | |||
| 45bae48701 | |||
| b2181e4c79 | |||
| 5939d3b17b | |||
| c1f4964a55 | |||
| 022e407d84 | |||
| 93ba2d239a | |||
| fa49dd5167 | |||
| 16029e66ad | |||
| 7bd6713335 | |||
| ef3241285d | |||
| d9ef26dc1c | |||
| 02949b2b96 | |||
| 443d06df06 | |||
| 852bb371af | |||
| 7c90e44656 | |||
| 81dea65856 | |||
| a3d572fb69 |
2
.github/workflows/build-and-test.yaml
vendored
2
.github/workflows/build-and-test.yaml
vendored
@ -37,5 +37,3 @@ jobs:
|
||||
name: Test dev docker
|
||||
run: |
|
||||
docker run --rm codiumai/pr-agent:test pytest -v tests/unittest
|
||||
|
||||
|
||||
|
||||
3
.github/workflows/pr-agent-review.yaml
vendored
3
.github/workflows/pr-agent-review.yaml
vendored
@ -30,6 +30,3 @@ jobs:
|
||||
GITHUB_ACTION_CONFIG.AUTO_DESCRIBE: true
|
||||
GITHUB_ACTION_CONFIG.AUTO_REVIEW: true
|
||||
GITHUB_ACTION_CONFIG.AUTO_IMPROVE: true
|
||||
|
||||
|
||||
|
||||
|
||||
17
.github/workflows/pre-commit.yml
vendored
Normal file
17
.github/workflows/pre-commit.yml
vendored
Normal file
@ -0,0 +1,17 @@
|
||||
# disabled. We might run it manually if needed.
|
||||
name: pre-commit
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
# pull_request:
|
||||
# push:
|
||||
# branches: [main]
|
||||
|
||||
jobs:
|
||||
pre-commit:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- uses: actions/setup-python@v5
|
||||
# SEE https://github.com/pre-commit/action
|
||||
- uses: pre-commit/action@v3.0.1
|
||||
46
.pre-commit-config.yaml
Normal file
46
.pre-commit-config.yaml
Normal file
@ -0,0 +1,46 @@
|
||||
# See https://pre-commit.com for more information
|
||||
# See https://pre-commit.com/hooks.html for more hooks
|
||||
|
||||
default_language_version:
|
||||
python: python3
|
||||
|
||||
repos:
|
||||
- repo: https://github.com/pre-commit/pre-commit-hooks
|
||||
rev: v5.0.0
|
||||
hooks:
|
||||
- id: check-added-large-files
|
||||
- id: check-toml
|
||||
- id: check-yaml
|
||||
- id: end-of-file-fixer
|
||||
- id: trailing-whitespace
|
||||
# - repo: https://github.com/rhysd/actionlint
|
||||
# rev: v1.7.3
|
||||
# hooks:
|
||||
# - id: actionlint
|
||||
- repo: https://github.com/pycqa/isort
|
||||
# rev must match what's in dev-requirements.txt
|
||||
rev: 5.13.2
|
||||
hooks:
|
||||
- id: isort
|
||||
# - repo: https://github.com/PyCQA/bandit
|
||||
# rev: 1.7.10
|
||||
# hooks:
|
||||
# - id: bandit
|
||||
# args: [
|
||||
# "-c", "pyproject.toml",
|
||||
# ]
|
||||
# - repo: https://github.com/astral-sh/ruff-pre-commit
|
||||
# rev: v0.7.1
|
||||
# hooks:
|
||||
# - id: ruff
|
||||
# args:
|
||||
# - --fix
|
||||
# - id: ruff-format
|
||||
# - repo: https://github.com/PyCQA/autoflake
|
||||
# rev: v2.3.1
|
||||
# hooks:
|
||||
# - id: autoflake
|
||||
# args:
|
||||
# - --in-place
|
||||
# - --remove-all-unused-imports
|
||||
# - --remove-unused-variables
|
||||
41
README.md
41
README.md
@ -43,43 +43,38 @@ Qode Merge PR-Agent aims to help efficiently review and handle pull requests, by
|
||||
|
||||
## News and Updates
|
||||
|
||||
### October 27, 2024
|
||||
### December 2, 2024
|
||||
|
||||
Qodo Merge PR Agent will now automatically document accepted code suggestions in a dedicated wiki page (`.pr_agent_accepted_suggestions`), enabling users to track historical changes, assess the tool's effectiveness, and learn from previously implemented recommendations in the repository.
|
||||
Open-source repositories can now freely use Qodo Merge Pro, and enjoy easy one-click installation using our dedicated [app](https://github.com/apps/qodo-merge-pro-for-open-source).
|
||||
|
||||
This dedicated wiki page will also serve as a foundation for future AI model improvements, allowing it to learn from historically implemented suggestions and generate more targeted, contextually relevant recommendations.
|
||||
Read more about this novel feature [here](https://qodo-merge-docs.qodo.ai/tools/improve/#suggestion-tracking).
|
||||
|
||||
<kbd><img href="https://qodo.ai/images/pr_agent/pr_agent_accepted_suggestions1.png" src="https://qodo.ai/images/pr_agent/pr_agent_accepted_suggestions1.png" width="768"></kbd>
|
||||
<kbd><img src="https://github.com/user-attachments/assets/b0838724-87b9-43b0-ab62-73739a3a855c" width="512"></kbd>
|
||||
|
||||
|
||||
### November 18, 2024
|
||||
|
||||
### October 21, 2024
|
||||
**Disable publishing labels by default:**
|
||||
A new mode was enabled by default for code suggestions - `--pr_code_suggestions.focus_only_on_problems=true`:
|
||||
|
||||
The default setting for `pr_description.publish_labels` has been updated to `false`. This means that labels generated by the `/describe` tool will no longer be published, unless this configuration is explicitly set to `true`.
|
||||
- This option reduces the number of code suggestions received
|
||||
- The suggestions will focus more on identifying and fixing code problems, rather than style considerations like best practices, maintainability, or readability.
|
||||
- The suggestions will be categorized into just two groups: "Possible Issues" and "General".
|
||||
|
||||
We constantly strive to balance informative AI analysis with reducing unnecessary noise. User feedback indicated that in many cases, the original PR title alone provides sufficient information, making the generated labels (`enhancement`, `documentation`, `bug fix`, ...) redundant.
|
||||
The [`review_effort`](https://qodo-merge-docs.qodo.ai/tools/review/#configuration-options) label, generated by the `review` tool, will still be published by default, as it provides valuable information enabling reviewers to prioritize small PRs first.
|
||||
Still, if you prefer the previous mode, you can set `--pr_code_suggestions.focus_only_on_problems=false` in the [configuration file](https://qodo-merge-docs.qodo.ai/usage-guide/configuration_options/).
|
||||
|
||||
However, every user has different preferences. To still publish the `describe` labels, set `pr_description.publish_labels=true` in the [configuration file](https://qodo-merge-docs.qodo.ai/usage-guide/configuration_options/).
|
||||
For more tailored and relevant labeling, we recommend using the [`custom_labels 💎`](https://qodo-merge-docs.qodo.ai/tools/custom_labels/) tool, that allows generating labels specific to your project's needs.
|
||||
**Example results:**
|
||||
|
||||
<kbd></kbd>
|
||||
Original mode
|
||||
|
||||
→
|
||||
<kbd><img src="https://qodo.ai/images/pr_agent/code_suggestions_original_mode.png" width="512"></kbd>
|
||||
|
||||
<kbd></kbd>
|
||||
Focused mode
|
||||
|
||||
<kbd><img src="https://qodo.ai/images/pr_agent/code_suggestions_focused_mode.png" width="512"></kbd>
|
||||
|
||||
|
||||
### November 4, 2024
|
||||
|
||||
### October 14, 2024
|
||||
Improved support for GitHub enterprise server with [GitHub Actions](https://qodo-merge-docs.qodo.ai/installation/github/#action-for-github-enterprise-server)
|
||||
|
||||
### October 10, 2024
|
||||
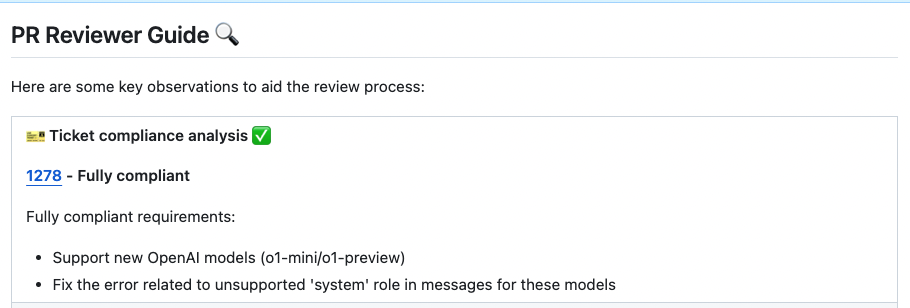
New ability for the `review` tool - **ticket compliance feedback**. If the PR contains a ticket number, PR-Agent will check if the PR code actually [complies](https://github.com/Codium-ai/pr-agent/pull/1279#issuecomment-2404042130) with the ticket requirements.
|
||||
|
||||
<kbd><img src="https://github.com/user-attachments/assets/4a2a728b-5f47-40fa-80cc-16efd296938c" width="768"></kbd>
|
||||
Qodo Merge PR Agent will now leverage context from Jira or GitHub tickets to enhance the PR Feedback. Read more about this feature
|
||||
[here](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/)
|
||||
|
||||
|
||||
## Overview
|
||||
|
||||
@ -2,4 +2,3 @@ We take your code's security and privacy seriously:
|
||||
|
||||
- The Chrome extension will not send your code to any external servers.
|
||||
- For private repositories, we will first validate the user's identity and permissions. After authentication, we generate responses using the existing Qodo Merge Pro integration.
|
||||
|
||||
|
||||
115
docs/docs/core-abilities/fetching_ticket_context.md
Normal file
115
docs/docs/core-abilities/fetching_ticket_context.md
Normal file
@ -0,0 +1,115 @@
|
||||
# Fetching Ticket Context for PRs
|
||||
## Overview
|
||||
Qodo Merge PR Agent streamlines code review workflows by seamlessly connecting with multiple ticket management systems.
|
||||
This integration enriches the review process by automatically surfacing relevant ticket information and context alongside code changes.
|
||||
|
||||
|
||||
## Affected Tools
|
||||
|
||||
Ticket Recognition Requirements:
|
||||
|
||||
1. The PR description should contain a link to the ticket.
|
||||
2. For Jira tickets, you should follow the instructions in [Jira Integration](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/#jira-integration) in order to authenticate with Jira.
|
||||
|
||||
|
||||
### Describe tool
|
||||
Qodo Merge PR Agent will recognize the ticket and use the ticket content (title, description, labels) to provide additional context for the code changes.
|
||||
By understanding the reasoning and intent behind modifications, the LLM can offer more insightful and relevant code analysis.
|
||||
|
||||
### Review tool
|
||||
Similarly to the `describe` tool, the `review` tool will use the ticket content to provide additional context for the code changes.
|
||||
|
||||
In addition, this feature will evaluate how well a Pull Request (PR) adheres to its original purpose/intent as defined by the associated ticket or issue mentioned in the PR description.
|
||||
Each ticket will be assigned a label (Compliance/Alignment level), Indicates the degree to which the PR fulfills its original purpose, Options: Fully compliant, Partially compliant or Not compliant.
|
||||
|
||||
|
||||
{width=768}
|
||||
|
||||
By default, the tool will automatically validate if the PR complies with the referenced ticket.
|
||||
If you want to disable this feedback, add the following line to your configuration file:
|
||||
|
||||
```toml
|
||||
[pr_reviewer]
|
||||
require_ticket_analysis_review=false
|
||||
```
|
||||
|
||||
## Providers
|
||||
|
||||
### Github Issues Integration
|
||||
|
||||
Qodo Merge PR Agent will automatically recognize Github issues mentioned in the PR description and fetch the issue content.
|
||||
Examples of valid GitHub issue references:
|
||||
|
||||
- `https://github.com/<ORG_NAME>/<REPO_NAME>/issues/<ISSUE_NUMBER>`
|
||||
- `#<ISSUE_NUMBER>`
|
||||
- `<ORG_NAME>/<REPO_NAME>#<ISSUE_NUMBER>`
|
||||
|
||||
Since Qodo Merge PR Agent is integrated with GitHub, it doesn't require any additional configuration to fetch GitHub issues.
|
||||
|
||||
### Jira Integration 💎
|
||||
|
||||
We support both Jira Cloud and Jira Server/Data Center.
|
||||
To integrate with Jira, The PR Description should contain a link to the Jira ticket.
|
||||
|
||||
For Jira integration, include a ticket reference in your PR description using either the complete URL format `https://<JIRA_ORG>.atlassian.net/browse/ISSUE-123` or the shortened ticket ID `ISSUE-123`.
|
||||
|
||||
!!! note "Jira Base URL"
|
||||
If using the shortened format, ensure your configuration file contains the Jira base URL under the [jira] section like this:
|
||||
|
||||
```toml
|
||||
[jira]
|
||||
jira_base_url = "https://<JIRA_ORG>.atlassian.net"
|
||||
```
|
||||
|
||||
#### Jira Cloud 💎
|
||||
There are two ways to authenticate with Jira Cloud:
|
||||
|
||||
**1) Jira App Authentication**
|
||||
|
||||
The recommended way to authenticate with Jira Cloud is to install the Qodo Merge app in your Jira Cloud instance. This will allow Qodo Merge to access Jira data on your behalf.
|
||||
|
||||
Installation steps:
|
||||
|
||||
1. Click [here](https://auth.atlassian.com/authorize?audience=api.atlassian.com&client_id=8krKmA4gMD8mM8z24aRCgPCSepZNP1xf&scope=read%3Ajira-work%20offline_access&redirect_uri=https%3A%2F%2Fregister.jira.pr-agent.codium.ai&state=qodomerge&response_type=code&prompt=consent) to install the Qodo Merge app in your Jira Cloud instance, click the `accept` button.<br>
|
||||
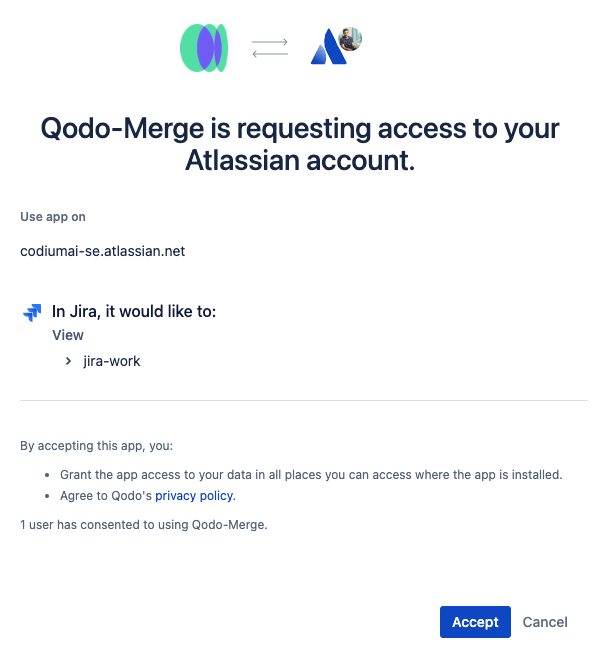{width=384}
|
||||
|
||||
2. After installing the app, you will be redirected to the Qodo Merge registration page. and you will see a success message.<br>
|
||||
{width=384}
|
||||
|
||||
3. Now you can use the Jira integration in Qodo Merge PR Agent.
|
||||
|
||||
**2) Email/Token Authentication**
|
||||
|
||||
You can create an API token from your Atlassian account:
|
||||
|
||||
1. Log in to https://id.atlassian.com/manage-profile/security/api-tokens.
|
||||
|
||||
2. Click Create API token.
|
||||
|
||||
3. From the dialog that appears, enter a name for your new token and click Create.
|
||||
|
||||
4. Click Copy to clipboard.
|
||||
|
||||
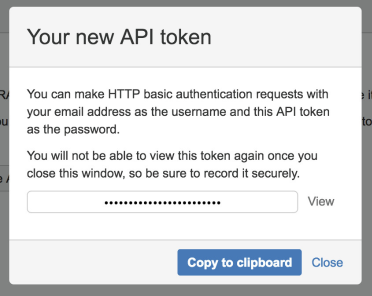{width=384}
|
||||
|
||||
5. In your [configuration file](https://qodo-merge-docs.qodo.ai/usage-guide/configuration_options/) add the following lines:
|
||||
|
||||
```toml
|
||||
[jira]
|
||||
jira_api_token = "YOUR_API_TOKEN"
|
||||
jira_api_email = "YOUR_EMAIL"
|
||||
```
|
||||
|
||||
|
||||
#### Jira Server/Data Center 💎
|
||||
|
||||
Currently, we only support the Personal Access Token (PAT) Authentication method.
|
||||
|
||||
1. Create a [Personal Access Token (PAT)](https://confluence.atlassian.com/enterprise/using-personal-access-tokens-1026032365.html) in your Jira account
|
||||
2. In your Configuration file/Environment variables/Secrets file, add the following lines:
|
||||
|
||||
```toml
|
||||
[jira]
|
||||
jira_base_url = "YOUR_JIRA_BASE_URL" # e.g. https://jira.example.com
|
||||
jira_api_token = "YOUR_API_TOKEN"
|
||||
```
|
||||
@ -1,6 +1,7 @@
|
||||
# Core Abilities
|
||||
Qodo Merge utilizes a variety of core abilities to provide a comprehensive and efficient code review experience. These abilities include:
|
||||
|
||||
- [Fetching ticket context](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/)
|
||||
- [Local and global metadata](https://qodo-merge-docs.qodo.ai/core-abilities/metadata/)
|
||||
- [Dynamic context](https://qodo-merge-docs.qodo.ai/core-abilities/dynamic_context/)
|
||||
- [Self-reflection](https://qodo-merge-docs.qodo.ai/core-abilities/self_reflection/)
|
||||
|
||||
@ -46,6 +46,5 @@ This results in a more refined and valuable set of suggestions for the user, sav
|
||||
## Appendix - Relevant Configuration Options
|
||||
```
|
||||
[pr_code_suggestions]
|
||||
self_reflect_on_suggestions = true # Enable self-reflection on code suggestions
|
||||
suggestions_score_threshold = 0 # Filter out suggestions with a score below this threshold (0-10)
|
||||
```
|
||||
@ -51,10 +51,12 @@ stages:
|
||||
```
|
||||
This script will run Qodo Merge on every new merge request, with the `improve`, `review`, and `describe` commands.
|
||||
Note that you need to export the `azure_devops__pat` and `OPENAI_KEY` variables in the Azure DevOps pipeline settings (Pipelines -> Library -> + Variable group):
|
||||
|
||||
{width=468}
|
||||
|
||||
Make sure to give pipeline permissions to the `pr_agent` variable group.
|
||||
|
||||
> Note that Azure Pipelines lacks support for triggering workflows from PR comments. If you find a viable solution, please contribute it to our [issue tracker](https://github.com/Codium-ai/pr-agent/issues)
|
||||
|
||||
## Azure DevOps from CLI
|
||||
|
||||
|
||||
@ -38,6 +38,7 @@ You can also modify the `script` section to run different Qodo Merge commands, o
|
||||
|
||||
Note that if your base branches are not protected, don't set the variables as `protected`, since the pipeline will not have access to them.
|
||||
|
||||
> **Note**: The `$CI_SERVER_FQDN` variable is available starting from GitLab version 16.10. If you're using an earlier version, this variable will not be available. However, you can combine `$CI_SERVER_HOST` and `$CI_SERVER_PORT` to achieve the same result. Please ensure you're using a compatible version or adjust your configuration.
|
||||
|
||||
|
||||
## Run a GitLab webhook server
|
||||
|
||||
@ -245,6 +245,32 @@ enable_global_best_practices = true
|
||||
|
||||
Then, create a `best_practices.md` wiki file in the root of [global](https://qodo-merge-docs.qodo.ai/usage-guide/configuration_options/#global-configuration-file) configuration repository, `pr-agent-settings`.
|
||||
|
||||
##### Best practices for multiple languages
|
||||
For a git organization working with multiple programming languages, you can maintain a centralized global `best_practices.md` file containing language-specific guidelines.
|
||||
When reviewing pull requests, Qodo Merge automatically identifies the programming language and applies the relevant best practices from this file.
|
||||
Structure your `best_practices.md` file using the following format:
|
||||
|
||||
```
|
||||
# [Python]
|
||||
...
|
||||
# [Java]
|
||||
...
|
||||
# [JavaScript]
|
||||
...
|
||||
```
|
||||
|
||||
##### Dedicated label for best practices suggestions
|
||||
Best practice suggestions are labeled as `Organization best practice` by default.
|
||||
To customize this label, modify it in your configuration file:
|
||||
|
||||
```toml
|
||||
[best_practices]
|
||||
organization_name = ""
|
||||
```
|
||||
|
||||
And the label will be: `{organization_name} best practice`.
|
||||
|
||||
|
||||
##### Example results
|
||||
|
||||
{width=512}
|
||||
@ -276,12 +302,12 @@ Using a combination of both can help the AI model to provide relevant and tailor
|
||||
<td>Minimum score threshold for suggestions to be presented as commitable PR comments in addition to the table. Default is -1 (disabled).</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>persistent_comment</b></td>
|
||||
<td>If set to true, the improve comment will be persistent, meaning that every new improve request will edit the previous one. Default is false.</td>
|
||||
<td><b>focus_only_on_problems</b></td>
|
||||
<td>If set to true, suggestions will focus primarily on identifying and fixing code problems, and less on style considerations like best practices, maintainability, or readability. Default is true.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>self_reflect_on_suggestions</b></td>
|
||||
<td>If set to true, the improve tool will calculate an importance score for each suggestion [1-10], and sort the suggestion labels group based on this score. Default is true.</td>
|
||||
<td><b>persistent_comment</b></td>
|
||||
<td>If set to true, the improve comment will be persistent, meaning that every new improve request will edit the previous one. Default is false.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>suggestions_score_threshold</b></td>
|
||||
|
||||
@ -140,7 +140,7 @@ num_code_suggestions = ...
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>require_ticket_analysis_review</b></td>
|
||||
<td>If set to true, and the PR contains a GitHub ticket number, the tool will add a section that checks if the PR in fact fulfilled the ticket requirements. Default is true.</td>
|
||||
<td>If set to true, and the PR contains a GitHub or Jira ticket link, the tool will add a section that checks if the PR in fact fulfilled the ticket requirements. Default is true.</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
@ -258,4 +258,3 @@ If enabled, the `review` tool can approve a PR when a specific comment, `/review
|
||||
[//]: # ( Notice If you are interested **only** in the code suggestions, it is recommended to use the [`improve`](./improve.md) feature instead, since it is a dedicated only to code suggestions, and usually gives better results.)
|
||||
|
||||
[//]: # ( Use the `review` tool if you want to get more comprehensive feedback, which includes code suggestions as well.)
|
||||
|
||||
|
||||
@ -160,3 +160,13 @@ ignore_pr_target_branches = ["qa"]
|
||||
|
||||
Where the `ignore_pr_source_branches` and `ignore_pr_target_branches` are lists of regex patterns to match the source and target branches you want to ignore.
|
||||
They are not mutually exclusive, you can use them together or separately.
|
||||
|
||||
|
||||
To allow only specific folders (often needed in large monorepos), set:
|
||||
|
||||
```
|
||||
[config]
|
||||
allow_only_specific_folders=['folder1','folder2']
|
||||
```
|
||||
|
||||
For the configuration above, automatic feedback will only be triggered when the PR changes include files from 'folder1' or 'folder2'
|
||||
|
||||
@ -72,13 +72,14 @@ The configuration parameter `pr_commands` defines the list of tools that will be
|
||||
```
|
||||
[github_app]
|
||||
pr_commands = [
|
||||
"/describe --pr_description.final_update_message=false",
|
||||
"/review --pr_reviewer.num_code_suggestions=0",
|
||||
"/improve",
|
||||
"/describe",
|
||||
"/review",
|
||||
"/improve --pr_code_suggestions.suggestions_score_threshold=5",
|
||||
]
|
||||
```
|
||||
|
||||
This means that when a new PR is opened/reopened or marked as ready for review, Qodo Merge will run the `describe`, `review` and `improve` tools.
|
||||
For the `review` tool, for example, the `num_code_suggestions` parameter will be set to 0.
|
||||
For the `improve` tool, for example, the `suggestions_score_threshold` parameter will be set to 5 (suggestions below a score of 5 won't be presented)
|
||||
|
||||
You can override the default tool parameters by using one the three options for a [configuration file](https://qodo-merge-docs.qodo.ai/usage-guide/configuration_options/): **wiki**, **local**, or **global**.
|
||||
For example, if your local `.pr_agent.toml` file contains:
|
||||
@ -105,7 +106,7 @@ The configuration parameter `push_commands` defines the list of tools that will
|
||||
handle_push_trigger = true
|
||||
push_commands = [
|
||||
"/describe",
|
||||
"/review --pr_reviewer.num_code_suggestions=0 --pr_reviewer.final_update_message=false",
|
||||
"/review",
|
||||
]
|
||||
```
|
||||
This means that when new code is pushed to the PR, the Qodo Merge will run the `describe` and `review` tools, with the specified parameters.
|
||||
@ -148,7 +149,7 @@ After setting up a GitLab webhook, to control which commands will run automatica
|
||||
[gitlab]
|
||||
pr_commands = [
|
||||
"/describe",
|
||||
"/review --pr_reviewer.num_code_suggestions=0",
|
||||
"/review",
|
||||
"/improve",
|
||||
]
|
||||
```
|
||||
@ -161,7 +162,7 @@ The configuration parameter `push_commands` defines the list of tools that will
|
||||
handle_push_trigger = true
|
||||
push_commands = [
|
||||
"/describe",
|
||||
"/review --pr_reviewer.num_code_suggestions=0 --pr_reviewer.final_update_message=false",
|
||||
"/review",
|
||||
]
|
||||
```
|
||||
|
||||
@ -182,7 +183,7 @@ Each time you invoke a `/review` tool, it will use the extra instructions you se
|
||||
|
||||
|
||||
Note that among other limitations, BitBucket provides relatively low rate-limits for applications (up to 1000 requests per hour), and does not provide an API to track the actual rate-limit usage.
|
||||
If you experience lack of responses from Qodo Merge, you might want to set: `bitbucket_app.avoid_full_files=true` in your configuration file.
|
||||
If you experience a lack of responses from Qodo Merge, you might want to set: `bitbucket_app.avoid_full_files=true` in your configuration file.
|
||||
This will prevent Qodo Merge from acquiring the full file content, and will only use the diff content. This will reduce the number of requests made to BitBucket, at the cost of small decrease in accuracy, as dynamic context will not be applicable.
|
||||
|
||||
|
||||
@ -194,13 +195,23 @@ Specifically, set the following values:
|
||||
```
|
||||
[bitbucket_app]
|
||||
pr_commands = [
|
||||
"/review --pr_reviewer.num_code_suggestions=0",
|
||||
"/review",
|
||||
"/improve --pr_code_suggestions.commitable_code_suggestions=true --pr_code_suggestions.suggestions_score_threshold=7",
|
||||
]
|
||||
```
|
||||
Note that we set specifically for bitbucket, we recommend using: `--pr_code_suggestions.suggestions_score_threshold=7` and that is the default value we set for bitbucket.
|
||||
Since this platform only supports inline code suggestions, we want to limit the number of suggestions, and only present a limited number.
|
||||
|
||||
To enable BitBucket app to respond to each **push** to the PR, set (for example):
|
||||
```
|
||||
[bitbucket_app]
|
||||
handle_push_trigger = true
|
||||
push_commands = [
|
||||
"/describe",
|
||||
"/review",
|
||||
]
|
||||
```
|
||||
|
||||
## Azure DevOps provider
|
||||
|
||||
To use Azure DevOps provider use the following settings in configuration.toml:
|
||||
|
||||
@ -10,4 +10,3 @@ Specifically, CLI commands can be issued by invoking a pre-built [docker image](
|
||||
|
||||
For online usage, you will need to setup either a [GitHub App](https://qodo-merge-docs.qodo.ai/installation/github/#run-as-a-github-app) or a [GitHub Action](https://qodo-merge-docs.qodo.ai/installation/github/#run-as-a-github-action) (GitHub), a [GitLab webhook](https://qodo-merge-docs.qodo.ai/installation/gitlab/#run-a-gitlab-webhook-server) (GitLab), or a [BitBucket App](https://qodo-merge-docs.qodo.ai/installation/bitbucket/#run-using-codiumai-hosted-bitbucket-app) (BitBucket).
|
||||
These platforms also enable to run Qodo Merge specific tools automatically when a new PR is opened, or on each push to a branch.
|
||||
|
||||
|
||||
@ -43,6 +43,7 @@ nav:
|
||||
- 💎 Similar Code: 'tools/similar_code.md'
|
||||
- Core Abilities:
|
||||
- 'core-abilities/index.md'
|
||||
- Fetching ticket context: 'core-abilities/fetching_ticket_context.md'
|
||||
- Local and global metadata: 'core-abilities/metadata.md'
|
||||
- Dynamic context: 'core-abilities/dynamic_context.md'
|
||||
- Self-reflection: 'core-abilities/self_reflection.md'
|
||||
|
||||
@ -3,5 +3,5 @@
|
||||
new Date().getTime(),event:'gtm.js'});var f=d.getElementsByTagName(s)[0],
|
||||
j=d.createElement(s),dl=l!='dataLayer'?'&l='+l:'';j.async=true;j.src=
|
||||
'https://www.googletagmanager.com/gtm.js?id='+i+dl;f.parentNode.insertBefore(j,f);
|
||||
})(window,document,'script','dataLayer','GTM-5C9KZBM3');</script>
|
||||
})(window,document,'script','dataLayer','GTM-M6PJSFV');</script>
|
||||
<!-- End Google Tag Manager -->
|
||||
@ -1 +0,0 @@
|
||||
|
||||
|
||||
@ -3,7 +3,6 @@ from functools import partial
|
||||
|
||||
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||
from pr_agent.algo.ai_handlers.litellm_ai_handler import LiteLLMAIHandler
|
||||
|
||||
from pr_agent.algo.utils import update_settings_from_args
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers.utils import apply_repo_settings
|
||||
|
||||
@ -19,6 +19,7 @@ MAX_TOKENS = {
|
||||
'gpt-4o-mini': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
'gpt-4o-mini-2024-07-18': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
'gpt-4o-2024-08-06': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
'gpt-4o-2024-11-20': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
'o1-mini': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
'o1-mini-2024-09-12': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
'o1-preview': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||
@ -31,6 +32,7 @@ MAX_TOKENS = {
|
||||
'vertex_ai/codechat-bison': 6144,
|
||||
'vertex_ai/codechat-bison-32k': 32000,
|
||||
'vertex_ai/claude-3-haiku@20240307': 100000,
|
||||
'vertex_ai/claude-3-5-haiku@20241022': 100000,
|
||||
'vertex_ai/claude-3-sonnet@20240229': 100000,
|
||||
'vertex_ai/claude-3-opus@20240229': 100000,
|
||||
'vertex_ai/claude-3-5-sonnet@20240620': 100000,
|
||||
@ -48,11 +50,13 @@ MAX_TOKENS = {
|
||||
'anthropic/claude-3-opus-20240229': 100000,
|
||||
'anthropic/claude-3-5-sonnet-20240620': 100000,
|
||||
'anthropic/claude-3-5-sonnet-20241022': 100000,
|
||||
'anthropic/claude-3-5-haiku-20241022': 100000,
|
||||
'bedrock/anthropic.claude-instant-v1': 100000,
|
||||
'bedrock/anthropic.claude-v2': 100000,
|
||||
'bedrock/anthropic.claude-v2:1': 100000,
|
||||
'bedrock/anthropic.claude-3-sonnet-20240229-v1:0': 100000,
|
||||
'bedrock/anthropic.claude-3-haiku-20240307-v1:0': 100000,
|
||||
'bedrock/anthropic.claude-3-5-haiku-20241022-v1:0': 100000,
|
||||
'bedrock/anthropic.claude-3-5-sonnet-20240620-v1:0': 100000,
|
||||
'bedrock/anthropic.claude-3-5-sonnet-20241022-v2:0': 100000,
|
||||
'claude-3-5-sonnet': 100000,
|
||||
|
||||
@ -1,17 +1,18 @@
|
||||
try:
|
||||
from langchain_openai import ChatOpenAI, AzureChatOpenAI
|
||||
from langchain_core.messages import SystemMessage, HumanMessage
|
||||
from langchain_core.messages import HumanMessage, SystemMessage
|
||||
from langchain_openai import AzureChatOpenAI, ChatOpenAI
|
||||
except: # we don't enforce langchain as a dependency, so if it's not installed, just move on
|
||||
pass
|
||||
|
||||
import functools
|
||||
|
||||
from openai import APIError, RateLimitError, Timeout
|
||||
from retry import retry
|
||||
|
||||
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.log import get_logger
|
||||
|
||||
from openai import APIError, RateLimitError, Timeout
|
||||
from retry import retry
|
||||
import functools
|
||||
|
||||
OPENAI_RETRIES = 5
|
||||
|
||||
|
||||
@ -73,4 +74,3 @@ class LangChainOpenAIHandler(BaseAiHandler):
|
||||
raise ValueError(f"OpenAI {e.name} is required") from e
|
||||
else:
|
||||
raise e
|
||||
|
||||
|
||||
@ -1,7 +1,8 @@
|
||||
import os
|
||||
import requests
|
||||
|
||||
import litellm
|
||||
import openai
|
||||
import requests
|
||||
from litellm import acompletion
|
||||
from tenacity import retry, retry_if_exception_type, stop_after_attempt
|
||||
|
||||
|
||||
@ -4,6 +4,7 @@ import openai
|
||||
from openai import APIError, AsyncOpenAI, RateLimitError, Timeout
|
||||
from retry import retry
|
||||
|
||||
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.log import get_logger
|
||||
|
||||
@ -41,7 +42,6 @@ class OpenAIHandler(BaseAiHandler):
|
||||
tries=OPENAI_RETRIES, delay=2, backoff=2, jitter=(1, 3))
|
||||
async def chat_completion(self, model: str, system: str, user: str, temperature: float = 0.2):
|
||||
try:
|
||||
deployment_id = self.deployment_id
|
||||
get_logger().info("System: ", system)
|
||||
get_logger().info("User: ", user)
|
||||
messages = [{"role": "system", "content": system}, {"role": "user", "content": user}]
|
||||
|
||||
@ -3,8 +3,8 @@ from __future__ import annotations
|
||||
import re
|
||||
import traceback
|
||||
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.log import get_logger
|
||||
|
||||
|
||||
@ -31,7 +31,7 @@ def extend_patch(original_file_str, patch_str, patch_extra_lines_before=0,
|
||||
|
||||
|
||||
def decode_if_bytes(original_file_str):
|
||||
if isinstance(original_file_str, bytes):
|
||||
if isinstance(original_file_str, (bytes, bytearray)):
|
||||
try:
|
||||
return original_file_str.decode('utf-8')
|
||||
except UnicodeDecodeError:
|
||||
@ -61,23 +61,26 @@ def process_patch_lines(patch_str, original_file_str, patch_extra_lines_before,
|
||||
patch_lines = patch_str.splitlines()
|
||||
extended_patch_lines = []
|
||||
|
||||
is_valid_hunk = True
|
||||
start1, size1, start2, size2 = -1, -1, -1, -1
|
||||
RE_HUNK_HEADER = re.compile(
|
||||
r"^@@ -(\d+)(?:,(\d+))? \+(\d+)(?:,(\d+))? @@[ ]?(.*)")
|
||||
try:
|
||||
for line in patch_lines:
|
||||
for i,line in enumerate(patch_lines):
|
||||
if line.startswith('@@'):
|
||||
match = RE_HUNK_HEADER.match(line)
|
||||
# identify hunk header
|
||||
if match:
|
||||
# finish processing previous hunk
|
||||
if start1 != -1 and patch_extra_lines_after > 0:
|
||||
if is_valid_hunk and (start1 != -1 and patch_extra_lines_after > 0):
|
||||
delta_lines = [f' {line}' for line in original_lines[start1 + size1 - 1:start1 + size1 - 1 + patch_extra_lines_after]]
|
||||
extended_patch_lines.extend(delta_lines)
|
||||
|
||||
section_header, size1, size2, start1, start2 = extract_hunk_headers(match)
|
||||
|
||||
if patch_extra_lines_before > 0 or patch_extra_lines_after > 0:
|
||||
is_valid_hunk = check_if_hunk_lines_matches_to_file(i, original_lines, patch_lines, start1)
|
||||
|
||||
if is_valid_hunk and (patch_extra_lines_before > 0 or patch_extra_lines_after > 0):
|
||||
def _calc_context_limits(patch_lines_before):
|
||||
extended_start1 = max(1, start1 - patch_lines_before)
|
||||
extended_size1 = size1 + (start1 - extended_start1) + patch_extra_lines_after
|
||||
@ -138,7 +141,7 @@ def process_patch_lines(patch_str, original_file_str, patch_extra_lines_before,
|
||||
return patch_str
|
||||
|
||||
# finish processing last hunk
|
||||
if start1 != -1 and patch_extra_lines_after > 0:
|
||||
if start1 != -1 and patch_extra_lines_after > 0 and is_valid_hunk:
|
||||
delta_lines = original_lines[start1 + size1 - 1:start1 + size1 - 1 + patch_extra_lines_after]
|
||||
# add space at the beginning of each extra line
|
||||
delta_lines = [f' {line}' for line in delta_lines]
|
||||
@ -148,6 +151,23 @@ def process_patch_lines(patch_str, original_file_str, patch_extra_lines_before,
|
||||
return extended_patch_str
|
||||
|
||||
|
||||
def check_if_hunk_lines_matches_to_file(i, original_lines, patch_lines, start1):
|
||||
"""
|
||||
Check if the hunk lines match the original file content. We saw cases where the hunk header line doesn't match the original file content, and then
|
||||
extending the hunk with extra lines before the hunk header can cause the hunk to be invalid.
|
||||
"""
|
||||
is_valid_hunk = True
|
||||
try:
|
||||
if i + 1 < len(patch_lines) and patch_lines[i + 1][0] == ' ': # an existing line in the file
|
||||
if patch_lines[i + 1].strip() != original_lines[start1 - 1].strip():
|
||||
is_valid_hunk = False
|
||||
get_logger().error(
|
||||
f"Invalid hunk in PR, line {start1} in hunk header doesn't match the original file content")
|
||||
except:
|
||||
pass
|
||||
return is_valid_hunk
|
||||
|
||||
|
||||
def extract_hunk_headers(match):
|
||||
res = list(match.groups())
|
||||
for i in range(len(res)):
|
||||
|
||||
@ -4,8 +4,6 @@ from typing import Dict
|
||||
from pr_agent.config_loader import get_settings
|
||||
|
||||
|
||||
|
||||
|
||||
def filter_bad_extensions(files):
|
||||
# Bad Extensions, source: https://github.com/EleutherAI/github-downloader/blob/345e7c4cbb9e0dc8a0615fd995a08bf9d73b3fe6/download_repo_text.py # noqa: E501
|
||||
bad_extensions = get_settings().bad_extensions.default
|
||||
|
||||
@ -5,14 +5,15 @@ from typing import Callable, List, Tuple
|
||||
|
||||
from github import RateLimitExceededException
|
||||
|
||||
from pr_agent.algo.git_patch_processing import convert_to_hunks_with_lines_numbers, extend_patch, handle_patch_deletions
|
||||
from pr_agent.algo.language_handler import sort_files_by_main_languages
|
||||
from pr_agent.algo.file_filter import filter_ignored
|
||||
from pr_agent.algo.git_patch_processing import (
|
||||
convert_to_hunks_with_lines_numbers, extend_patch, handle_patch_deletions)
|
||||
from pr_agent.algo.language_handler import sort_files_by_main_languages
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.utils import get_max_tokens, clip_tokens, ModelType
|
||||
from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
|
||||
from pr_agent.algo.utils import ModelType, clip_tokens, get_max_tokens
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers.git_provider import GitProvider
|
||||
from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
|
||||
from pr_agent.log import get_logger
|
||||
|
||||
DELETED_FILES_ = "Deleted files:\n"
|
||||
|
||||
@ -1,8 +1,9 @@
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
from tiktoken import encoding_for_model, get_encoding
|
||||
from pr_agent.config_loader import get_settings
|
||||
from threading import Lock
|
||||
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
from tiktoken import encoding_for_model, get_encoding
|
||||
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.log import get_logger
|
||||
|
||||
|
||||
|
||||
@ -14,7 +14,6 @@ from datetime import datetime
|
||||
from enum import Enum
|
||||
from typing import Any, List, Tuple
|
||||
|
||||
|
||||
import html2text
|
||||
import requests
|
||||
import yaml
|
||||
@ -23,10 +22,11 @@ from starlette_context import context
|
||||
|
||||
from pr_agent.algo import MAX_TOKENS
|
||||
from pr_agent.algo.token_handler import TokenEncoder
|
||||
from pr_agent.config_loader import get_settings, global_settings
|
||||
from pr_agent.algo.types import FilePatchInfo
|
||||
from pr_agent.config_loader import get_settings, global_settings
|
||||
from pr_agent.log import get_logger
|
||||
|
||||
|
||||
class Range(BaseModel):
|
||||
line_start: int # should be 0-indexed
|
||||
line_end: int
|
||||
@ -173,7 +173,7 @@ def convert_to_markdown_v2(output_data: dict,
|
||||
if is_value_no(value):
|
||||
markdown_text += f'### {emoji} No relevant tests\n\n'
|
||||
else:
|
||||
markdown_text += f"### PR contains tests\n\n"
|
||||
markdown_text += f"### {emoji} PR contains tests\n\n"
|
||||
elif 'ticket compliance check' in key_nice.lower():
|
||||
markdown_text = ticket_markdown_logic(emoji, markdown_text, value, gfm_supported)
|
||||
elif 'security concerns' in key_nice.lower():
|
||||
@ -224,12 +224,21 @@ def convert_to_markdown_v2(output_data: dict,
|
||||
issue_content = issue.get('issue_content', '').strip()
|
||||
start_line = int(str(issue.get('start_line', 0)).strip())
|
||||
end_line = int(str(issue.get('end_line', 0)).strip())
|
||||
reference_link = git_provider.get_line_link(relevant_file, start_line, end_line)
|
||||
if git_provider:
|
||||
reference_link = git_provider.get_line_link(relevant_file, start_line, end_line)
|
||||
else:
|
||||
reference_link = None
|
||||
|
||||
if gfm_supported:
|
||||
issue_str = f"<a href='{reference_link}'><strong>{issue_header}</strong></a><br>{issue_content}"
|
||||
if reference_link is not None and len(reference_link) > 0:
|
||||
issue_str = f"<a href='{reference_link}'><strong>{issue_header}</strong></a><br>{issue_content}"
|
||||
else:
|
||||
issue_str = f"<strong>{issue_header}</strong><br>{issue_content}"
|
||||
else:
|
||||
issue_str = f"[**{issue_header}**]({reference_link})\n\n{issue_content}\n\n"
|
||||
if reference_link is not None and len(reference_link) > 0:
|
||||
issue_str = f"[**{issue_header}**]({reference_link})\n\n{issue_content}\n\n"
|
||||
else:
|
||||
issue_str = f"**{issue_header}**\n\n{issue_content}\n\n"
|
||||
markdown_text += f"{issue_str}\n\n"
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Failed to process 'Recommended focus areas for review': {e}")
|
||||
|
||||
@ -4,7 +4,7 @@ import os
|
||||
|
||||
from pr_agent.agent.pr_agent import PRAgent, commands
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.log import setup_logger, get_logger
|
||||
from pr_agent.log import get_logger, setup_logger
|
||||
|
||||
log_level = os.environ.get("LOG_LEVEL", "INFO")
|
||||
setup_logger(log_level)
|
||||
|
||||
@ -1,14 +1,16 @@
|
||||
from starlette_context import context
|
||||
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers.azuredevops_provider import AzureDevopsProvider
|
||||
from pr_agent.git_providers.bitbucket_provider import BitbucketProvider
|
||||
from pr_agent.git_providers.bitbucket_server_provider import BitbucketServerProvider
|
||||
from pr_agent.git_providers.bitbucket_server_provider import \
|
||||
BitbucketServerProvider
|
||||
from pr_agent.git_providers.codecommit_provider import CodeCommitProvider
|
||||
from pr_agent.git_providers.gerrit_provider import GerritProvider
|
||||
from pr_agent.git_providers.git_provider import GitProvider
|
||||
from pr_agent.git_providers.github_provider import GithubProvider
|
||||
from pr_agent.git_providers.gitlab_provider import GitLabProvider
|
||||
from pr_agent.git_providers.local_git_provider import LocalGitProvider
|
||||
from pr_agent.git_providers.azuredevops_provider import AzureDevopsProvider
|
||||
from pr_agent.git_providers.gerrit_provider import GerritProvider
|
||||
from starlette_context import context
|
||||
|
||||
_GIT_PROVIDERS = {
|
||||
'github': GithubProvider,
|
||||
|
||||
@ -2,33 +2,33 @@ import os
|
||||
from typing import Optional, Tuple
|
||||
from urllib.parse import urlparse
|
||||
|
||||
from ..algo.file_filter import filter_ignored
|
||||
from ..log import get_logger
|
||||
from ..algo.language_handler import is_valid_file
|
||||
from ..algo.utils import clip_tokens, find_line_number_of_relevant_line_in_file, load_large_diff, PRDescriptionHeader
|
||||
from ..config_loader import get_settings
|
||||
from .git_provider import GitProvider
|
||||
from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
|
||||
|
||||
from ..algo.file_filter import filter_ignored
|
||||
from ..algo.language_handler import is_valid_file
|
||||
from ..algo.utils import (PRDescriptionHeader, clip_tokens,
|
||||
find_line_number_of_relevant_line_in_file,
|
||||
load_large_diff)
|
||||
from ..config_loader import get_settings
|
||||
from ..log import get_logger
|
||||
from .git_provider import GitProvider
|
||||
|
||||
AZURE_DEVOPS_AVAILABLE = True
|
||||
ADO_APP_CLIENT_DEFAULT_ID = "499b84ac-1321-427f-aa17-267ca6975798/.default"
|
||||
MAX_PR_DESCRIPTION_AZURE_LENGTH = 4000-1
|
||||
|
||||
try:
|
||||
# noinspection PyUnresolvedReferences
|
||||
from msrest.authentication import BasicAuthentication
|
||||
# noinspection PyUnresolvedReferences
|
||||
from azure.devops.connection import Connection
|
||||
# noinspection PyUnresolvedReferences
|
||||
from azure.identity import DefaultAzureCredential
|
||||
from azure.devops.v7_1.git.models import (Comment, CommentThread,
|
||||
GitPullRequest,
|
||||
GitPullRequestIterationChanges,
|
||||
GitVersionDescriptor)
|
||||
# noinspection PyUnresolvedReferences
|
||||
from azure.devops.v7_1.git.models import (
|
||||
Comment,
|
||||
CommentThread,
|
||||
GitVersionDescriptor,
|
||||
GitPullRequest,
|
||||
GitPullRequestIterationChanges,
|
||||
)
|
||||
from azure.identity import DefaultAzureCredential
|
||||
from msrest.authentication import BasicAuthentication
|
||||
except ImportError:
|
||||
AZURE_DEVOPS_AVAILABLE = False
|
||||
|
||||
@ -67,16 +67,14 @@ class AzureDevopsProvider(GitProvider):
|
||||
relevant_lines_end = suggestion['relevant_lines_end']
|
||||
|
||||
if not relevant_lines_start or relevant_lines_start == -1:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().exception(
|
||||
f"Failed to publish code suggestion, relevant_lines_start is {relevant_lines_start}")
|
||||
get_logger().warning(
|
||||
f"Failed to publish code suggestion, relevant_lines_start is {relevant_lines_start}")
|
||||
continue
|
||||
|
||||
if relevant_lines_end < relevant_lines_start:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().exception(f"Failed to publish code suggestion, "
|
||||
f"relevant_lines_end is {relevant_lines_end} and "
|
||||
f"relevant_lines_start is {relevant_lines_start}")
|
||||
get_logger().warning(f"Failed to publish code suggestion, "
|
||||
f"relevant_lines_end is {relevant_lines_end} and "
|
||||
f"relevant_lines_start is {relevant_lines_start}")
|
||||
continue
|
||||
|
||||
if relevant_lines_end > relevant_lines_start:
|
||||
@ -95,9 +93,11 @@ class AzureDevopsProvider(GitProvider):
|
||||
"side": "RIGHT",
|
||||
}
|
||||
post_parameters_list.append(post_parameters)
|
||||
if not post_parameters_list:
|
||||
return False
|
||||
|
||||
try:
|
||||
for post_parameters in post_parameters_list:
|
||||
for post_parameters in post_parameters_list:
|
||||
try:
|
||||
comment = Comment(content=post_parameters["body"], comment_type=1)
|
||||
thread = CommentThread(comments=[comment],
|
||||
thread_context={
|
||||
@ -117,15 +117,11 @@ class AzureDevopsProvider(GitProvider):
|
||||
repository_id=self.repo_slug,
|
||||
pull_request_id=self.pr_num
|
||||
)
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().info(
|
||||
f"Published code suggestion on {self.pr_num} at {post_parameters['path']}"
|
||||
)
|
||||
return True
|
||||
except Exception as e:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().error(f"Failed to publish code suggestion, error: {e}")
|
||||
return False
|
||||
except Exception as e:
|
||||
get_logger().warning(f"Azure failed to publish code suggestion, error: {e}")
|
||||
return True
|
||||
|
||||
|
||||
|
||||
def get_pr_description_full(self) -> str:
|
||||
return self.pr.description
|
||||
@ -382,6 +378,9 @@ class AzureDevopsProvider(GitProvider):
|
||||
return []
|
||||
|
||||
def publish_comment(self, pr_comment: str, is_temporary: bool = False, thread_context=None):
|
||||
if is_temporary and not get_settings().config.publish_output_progress:
|
||||
get_logger().debug(f"Skipping publish_comment for temporary comment: {pr_comment}")
|
||||
return None
|
||||
comment = Comment(content=pr_comment)
|
||||
thread = CommentThread(comments=[comment], thread_context=thread_context, status=5)
|
||||
thread_response = self.azure_devops_client.create_thread(
|
||||
@ -620,4 +619,3 @@ class AzureDevopsProvider(GitProvider):
|
||||
|
||||
def publish_file_comments(self, file_comments: list) -> bool:
|
||||
pass
|
||||
|
||||
|
||||
@ -1,4 +1,6 @@
|
||||
import difflib
|
||||
import json
|
||||
import re
|
||||
from typing import Optional, Tuple
|
||||
from urllib.parse import urlparse
|
||||
|
||||
@ -6,13 +8,14 @@ import requests
|
||||
from atlassian.bitbucket import Cloud
|
||||
from starlette_context import context
|
||||
|
||||
from pr_agent.algo.types import FilePatchInfo, EDIT_TYPE
|
||||
from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
|
||||
|
||||
from ..algo.file_filter import filter_ignored
|
||||
from ..algo.language_handler import is_valid_file
|
||||
from ..algo.utils import find_line_number_of_relevant_line_in_file
|
||||
from ..config_loader import get_settings
|
||||
from ..log import get_logger
|
||||
from .git_provider import GitProvider, MAX_FILES_ALLOWED_FULL
|
||||
from .git_provider import MAX_FILES_ALLOWED_FULL, GitProvider
|
||||
|
||||
|
||||
def _gef_filename(diff):
|
||||
@ -71,24 +74,38 @@ class BitbucketProvider(GitProvider):
|
||||
post_parameters_list = []
|
||||
for suggestion in code_suggestions:
|
||||
body = suggestion["body"]
|
||||
original_suggestion = suggestion.get('original_suggestion', None) # needed for diff code
|
||||
if original_suggestion:
|
||||
try:
|
||||
existing_code = original_suggestion['existing_code'].rstrip() + "\n"
|
||||
improved_code = original_suggestion['improved_code'].rstrip() + "\n"
|
||||
diff = difflib.unified_diff(existing_code.split('\n'),
|
||||
improved_code.split('\n'), n=999)
|
||||
patch_orig = "\n".join(diff)
|
||||
patch = "\n".join(patch_orig.splitlines()[5:]).strip('\n')
|
||||
diff_code = f"\n\n```diff\n{patch.rstrip()}\n```"
|
||||
# replace ```suggestion ... ``` with diff_code, using regex:
|
||||
body = re.sub(r'```suggestion.*?```', diff_code, body, flags=re.DOTALL)
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Bitbucket failed to get diff code for publishing, error: {e}")
|
||||
continue
|
||||
|
||||
relevant_file = suggestion["relevant_file"]
|
||||
relevant_lines_start = suggestion["relevant_lines_start"]
|
||||
relevant_lines_end = suggestion["relevant_lines_end"]
|
||||
|
||||
if not relevant_lines_start or relevant_lines_start == -1:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().exception(
|
||||
f"Failed to publish code suggestion, relevant_lines_start is {relevant_lines_start}"
|
||||
)
|
||||
get_logger().exception(
|
||||
f"Failed to publish code suggestion, relevant_lines_start is {relevant_lines_start}"
|
||||
)
|
||||
continue
|
||||
|
||||
if relevant_lines_end < relevant_lines_start:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().exception(
|
||||
f"Failed to publish code suggestion, "
|
||||
f"relevant_lines_end is {relevant_lines_end} and "
|
||||
f"relevant_lines_start is {relevant_lines_start}"
|
||||
)
|
||||
get_logger().exception(
|
||||
f"Failed to publish code suggestion, "
|
||||
f"relevant_lines_end is {relevant_lines_end} and "
|
||||
f"relevant_lines_start is {relevant_lines_start}"
|
||||
)
|
||||
continue
|
||||
|
||||
if relevant_lines_end > relevant_lines_start:
|
||||
@ -112,8 +129,7 @@ class BitbucketProvider(GitProvider):
|
||||
self.publish_inline_comments(post_parameters_list)
|
||||
return True
|
||||
except Exception as e:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().error(f"Failed to publish code suggestion, error: {e}")
|
||||
get_logger().error(f"Bitbucket failed to publish code suggestion, error: {e}")
|
||||
return False
|
||||
|
||||
def publish_file_comments(self, file_comments: list) -> bool:
|
||||
@ -121,7 +137,7 @@ class BitbucketProvider(GitProvider):
|
||||
|
||||
def is_supported(self, capability: str) -> bool:
|
||||
if capability in ['get_issue_comments', 'publish_inline_comments', 'get_labels', 'gfm_markdown',
|
||||
'publish_file_comments']:
|
||||
'publish_file_comments']:
|
||||
return False
|
||||
return True
|
||||
|
||||
@ -309,6 +325,9 @@ class BitbucketProvider(GitProvider):
|
||||
self.publish_comment(pr_comment)
|
||||
|
||||
def publish_comment(self, pr_comment: str, is_temporary: bool = False):
|
||||
if is_temporary and not get_settings().config.publish_output_progress:
|
||||
get_logger().debug(f"Skipping publish_comment for temporary comment: {pr_comment}")
|
||||
return None
|
||||
pr_comment = self.limit_output_characters(pr_comment, self.max_comment_length)
|
||||
comment = self.pr.comment(pr_comment)
|
||||
if is_temporary:
|
||||
|
||||
@ -1,16 +1,21 @@
|
||||
from distutils.version import LooseVersion
|
||||
from requests.exceptions import HTTPError
|
||||
import difflib
|
||||
import re
|
||||
|
||||
from packaging.version import parse as parse_version
|
||||
from typing import Optional, Tuple
|
||||
from urllib.parse import quote_plus, urlparse
|
||||
|
||||
from atlassian.bitbucket import Bitbucket
|
||||
from requests.exceptions import HTTPError
|
||||
|
||||
from .git_provider import GitProvider
|
||||
from ..algo.types import EDIT_TYPE, FilePatchInfo
|
||||
from ..algo.git_patch_processing import decode_if_bytes
|
||||
from ..algo.language_handler import is_valid_file
|
||||
from ..algo.utils import load_large_diff, find_line_number_of_relevant_line_in_file
|
||||
from ..algo.types import EDIT_TYPE, FilePatchInfo
|
||||
from ..algo.utils import (find_line_number_of_relevant_line_in_file,
|
||||
load_large_diff)
|
||||
from ..config_loader import get_settings
|
||||
from ..log import get_logger
|
||||
from .git_provider import GitProvider
|
||||
|
||||
|
||||
class BitbucketServerProvider(GitProvider):
|
||||
@ -35,7 +40,7 @@ class BitbucketServerProvider(GitProvider):
|
||||
token=get_settings().get("BITBUCKET_SERVER.BEARER_TOKEN",
|
||||
None))
|
||||
try:
|
||||
self.bitbucket_api_version = LooseVersion(self.bitbucket_client.get("rest/api/1.0/application-properties").get('version'))
|
||||
self.bitbucket_api_version = parse_version(self.bitbucket_client.get("rest/api/1.0/application-properties").get('version'))
|
||||
except Exception:
|
||||
self.bitbucket_api_version = None
|
||||
|
||||
@ -65,24 +70,37 @@ class BitbucketServerProvider(GitProvider):
|
||||
post_parameters_list = []
|
||||
for suggestion in code_suggestions:
|
||||
body = suggestion["body"]
|
||||
original_suggestion = suggestion.get('original_suggestion', None) # needed for diff code
|
||||
if original_suggestion:
|
||||
try:
|
||||
existing_code = original_suggestion['existing_code'].rstrip() + "\n"
|
||||
improved_code = original_suggestion['improved_code'].rstrip() + "\n"
|
||||
diff = difflib.unified_diff(existing_code.split('\n'),
|
||||
improved_code.split('\n'), n=999)
|
||||
patch_orig = "\n".join(diff)
|
||||
patch = "\n".join(patch_orig.splitlines()[5:]).strip('\n')
|
||||
diff_code = f"\n\n```diff\n{patch.rstrip()}\n```"
|
||||
# replace ```suggestion ... ``` with diff_code, using regex:
|
||||
body = re.sub(r'```suggestion.*?```', diff_code, body, flags=re.DOTALL)
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Bitbucket failed to get diff code for publishing, error: {e}")
|
||||
continue
|
||||
relevant_file = suggestion["relevant_file"]
|
||||
relevant_lines_start = suggestion["relevant_lines_start"]
|
||||
relevant_lines_end = suggestion["relevant_lines_end"]
|
||||
|
||||
if not relevant_lines_start or relevant_lines_start == -1:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().exception(
|
||||
f"Failed to publish code suggestion, relevant_lines_start is {relevant_lines_start}"
|
||||
)
|
||||
get_logger().warning(
|
||||
f"Failed to publish code suggestion, relevant_lines_start is {relevant_lines_start}"
|
||||
)
|
||||
continue
|
||||
|
||||
if relevant_lines_end < relevant_lines_start:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().exception(
|
||||
f"Failed to publish code suggestion, "
|
||||
f"relevant_lines_end is {relevant_lines_end} and "
|
||||
f"relevant_lines_start is {relevant_lines_start}"
|
||||
)
|
||||
get_logger().warning(
|
||||
f"Failed to publish code suggestion, "
|
||||
f"relevant_lines_end is {relevant_lines_end} and "
|
||||
f"relevant_lines_start is {relevant_lines_start}"
|
||||
)
|
||||
continue
|
||||
|
||||
if relevant_lines_end > relevant_lines_start:
|
||||
@ -159,7 +177,7 @@ class BitbucketServerProvider(GitProvider):
|
||||
head_sha = self.pr.fromRef['latestCommit']
|
||||
|
||||
# if Bitbucket api version is >= 8.16 then use the merge-base api for 2-way diff calculation
|
||||
if self.bitbucket_api_version is not None and self.bitbucket_api_version >= LooseVersion("8.16"):
|
||||
if self.bitbucket_api_version is not None and self.bitbucket_api_version >= parse_version("8.16"):
|
||||
try:
|
||||
base_sha = self.bitbucket_client.get(self._get_merge_base())['id']
|
||||
except Exception as e:
|
||||
@ -174,7 +192,7 @@ class BitbucketServerProvider(GitProvider):
|
||||
# if Bitbucket api version is None or < 7.0 then do a simple diff with a guaranteed common ancestor
|
||||
base_sha = source_commits_list[-1]['parents'][0]['id']
|
||||
# if Bitbucket api version is 7.0-8.15 then use 2-way diff functionality for the base_sha
|
||||
if self.bitbucket_api_version is not None and self.bitbucket_api_version >= LooseVersion("7.0"):
|
||||
if self.bitbucket_api_version is not None and self.bitbucket_api_version >= parse_version("7.0"):
|
||||
try:
|
||||
destination_commits = list(
|
||||
self.bitbucket_client.get_commits(self.workspace_slug, self.repo_slug, base_sha,
|
||||
@ -200,25 +218,21 @@ class BitbucketServerProvider(GitProvider):
|
||||
case 'ADD':
|
||||
edit_type = EDIT_TYPE.ADDED
|
||||
new_file_content_str = self.get_file(file_path, head_sha)
|
||||
if isinstance(new_file_content_str, (bytes, bytearray)):
|
||||
new_file_content_str = new_file_content_str.decode("utf-8")
|
||||
new_file_content_str = decode_if_bytes(new_file_content_str)
|
||||
original_file_content_str = ""
|
||||
case 'DELETE':
|
||||
edit_type = EDIT_TYPE.DELETED
|
||||
new_file_content_str = ""
|
||||
original_file_content_str = self.get_file(file_path, base_sha)
|
||||
if isinstance(original_file_content_str, (bytes, bytearray)):
|
||||
original_file_content_str = original_file_content_str.decode("utf-8")
|
||||
original_file_content_str = decode_if_bytes(original_file_content_str)
|
||||
case 'RENAME':
|
||||
edit_type = EDIT_TYPE.RENAMED
|
||||
case _:
|
||||
edit_type = EDIT_TYPE.MODIFIED
|
||||
original_file_content_str = self.get_file(file_path, base_sha)
|
||||
if isinstance(original_file_content_str, (bytes, bytearray)):
|
||||
original_file_content_str = original_file_content_str.decode("utf-8")
|
||||
original_file_content_str = decode_if_bytes(original_file_content_str)
|
||||
new_file_content_str = self.get_file(file_path, head_sha)
|
||||
if isinstance(new_file_content_str, (bytes, bytearray)):
|
||||
new_file_content_str = new_file_content_str.decode("utf-8")
|
||||
new_file_content_str = decode_if_bytes(new_file_content_str)
|
||||
|
||||
patch = load_large_diff(file_path, new_file_content_str, original_file_content_str)
|
||||
|
||||
@ -329,10 +343,10 @@ class BitbucketServerProvider(GitProvider):
|
||||
for comment in comments:
|
||||
if 'position' in comment:
|
||||
self.publish_inline_comment(comment['body'], comment['position'], comment['path'])
|
||||
elif 'start_line' in comment: # multi-line comment
|
||||
elif 'start_line' in comment: # multi-line comment
|
||||
# note that bitbucket does not seem to support range - only a comment on a single line - https://community.developer.atlassian.com/t/api-post-endpoint-for-inline-pull-request-comments/60452
|
||||
self.publish_inline_comment(comment['body'], comment['start_line'], comment['path'])
|
||||
elif 'line' in comment: # single-line comment
|
||||
elif 'line' in comment: # single-line comment
|
||||
self.publish_inline_comment(comment['body'], comment['line'], comment['path'])
|
||||
else:
|
||||
get_logger().error(f"Could not publish inline comment: {comment}")
|
||||
|
||||
@ -4,13 +4,15 @@ from collections import Counter
|
||||
from typing import List, Optional, Tuple
|
||||
from urllib.parse import urlparse
|
||||
|
||||
from pr_agent.git_providers.codecommit_client import CodeCommitClient
|
||||
from pr_agent.algo.language_handler import is_valid_file
|
||||
from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
|
||||
from pr_agent.git_providers.codecommit_client import CodeCommitClient
|
||||
|
||||
from ..algo.utils import load_large_diff
|
||||
from .git_provider import GitProvider
|
||||
from ..config_loader import get_settings
|
||||
from ..log import get_logger
|
||||
from pr_agent.algo.language_handler import is_valid_file
|
||||
from .git_provider import GitProvider
|
||||
|
||||
|
||||
class PullRequestCCMimic:
|
||||
"""
|
||||
|
||||
@ -12,9 +12,9 @@ import requests
|
||||
import urllib3.util
|
||||
from git import Repo
|
||||
|
||||
from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers.git_provider import GitProvider
|
||||
from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
|
||||
from pr_agent.git_providers.local_git_provider import PullRequestMimic
|
||||
from pr_agent.log import get_logger
|
||||
|
||||
|
||||
@ -1,12 +1,12 @@
|
||||
from abc import ABC, abstractmethod
|
||||
|
||||
# enum EDIT_TYPE (ADDED, DELETED, MODIFIED, RENAMED)
|
||||
from typing import Optional
|
||||
|
||||
from pr_agent.algo.types import FilePatchInfo
|
||||
from pr_agent.algo.utils import Range, process_description
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.algo.types import FilePatchInfo
|
||||
from pr_agent.log import get_logger
|
||||
|
||||
MAX_FILES_ALLOWED_FULL = 50
|
||||
|
||||
class GitProvider(ABC):
|
||||
@ -62,8 +62,8 @@ class GitProvider(ABC):
|
||||
pass
|
||||
|
||||
def get_pr_description(self, full: bool = True, split_changes_walkthrough=False) -> str or tuple:
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.algo.utils import clip_tokens
|
||||
from pr_agent.config_loader import get_settings
|
||||
max_tokens_description = get_settings().get("CONFIG.MAX_DESCRIPTION_TOKENS", None)
|
||||
description = self.get_pr_description_full() if full else self.get_user_description()
|
||||
if split_changes_walkthrough:
|
||||
|
||||
@ -1,22 +1,30 @@
|
||||
import itertools
|
||||
import time
|
||||
import copy
|
||||
import difflib
|
||||
import hashlib
|
||||
import itertools
|
||||
import re
|
||||
import time
|
||||
import traceback
|
||||
from datetime import datetime
|
||||
from typing import Optional, Tuple
|
||||
from urllib.parse import urlparse
|
||||
|
||||
from github import AppAuthentication, Auth, Github
|
||||
from retry import retry
|
||||
from starlette_context import context
|
||||
|
||||
from ..algo.file_filter import filter_ignored
|
||||
from ..algo.git_patch_processing import extract_hunk_headers
|
||||
from ..algo.language_handler import is_valid_file
|
||||
from ..algo.types import EDIT_TYPE
|
||||
from ..algo.utils import PRReviewHeader, load_large_diff, clip_tokens, find_line_number_of_relevant_line_in_file, Range
|
||||
from ..algo.utils import (PRReviewHeader, Range, clip_tokens,
|
||||
find_line_number_of_relevant_line_in_file,
|
||||
load_large_diff)
|
||||
from ..config_loader import get_settings
|
||||
from ..log import get_logger
|
||||
from ..servers.utils import RateLimitExceeded
|
||||
from .git_provider import FilePatchInfo, GitProvider, IncrementalPR, MAX_FILES_ALLOWED_FULL
|
||||
from .git_provider import (MAX_FILES_ALLOWED_FULL, FilePatchInfo, GitProvider,
|
||||
IncrementalPR)
|
||||
|
||||
|
||||
class GithubProvider(GitProvider):
|
||||
@ -195,7 +203,24 @@ class GithubProvider(GitProvider):
|
||||
if avoid_load:
|
||||
original_file_content_str = ""
|
||||
else:
|
||||
original_file_content_str = self._get_pr_file_content(file, self.pr.base.sha)
|
||||
# The base.sha will point to the current state of the base branch (including parallel merges), not the original base commit when the PR was created
|
||||
# We can fix this by finding the merge base commit between the PR head and base branches
|
||||
# Note that The pr.head.sha is actually correct as is - it points to the latest commit in your PR branch.
|
||||
# This SHA isn't affected by parallel merges to the base branch since it's specific to your PR's branch.
|
||||
repo = self.repo_obj
|
||||
pr = self.pr
|
||||
try:
|
||||
compare = repo.compare(pr.base.sha, pr.head.sha)
|
||||
merge_base_commit = compare.merge_base_commit
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to get merge base commit: {e}")
|
||||
merge_base_commit = pr.base
|
||||
if merge_base_commit.sha != pr.base.sha:
|
||||
get_logger().info(
|
||||
f"Using merge base commit {merge_base_commit.sha} instead of base commit "
|
||||
f"{pr.base.sha} for {file.filename}")
|
||||
original_file_content_str = self._get_pr_file_content(file, merge_base_commit.sha)
|
||||
|
||||
if not patch:
|
||||
patch = load_large_diff(file.filename, new_file_content_str, original_file_content_str)
|
||||
|
||||
@ -279,8 +304,7 @@ class GithubProvider(GitProvider):
|
||||
relevant_line_in_file,
|
||||
absolute_position)
|
||||
if position == -1:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().info(f"Could not find position for {relevant_file} {relevant_line_in_file}")
|
||||
get_logger().info(f"Could not find position for {relevant_file} {relevant_line_in_file}")
|
||||
subject_type = "FILE"
|
||||
else:
|
||||
subject_type = "LINE"
|
||||
@ -292,11 +316,9 @@ class GithubProvider(GitProvider):
|
||||
# publish all comments in a single message
|
||||
self.pr.create_review(commit=self.last_commit_id, comments=comments)
|
||||
except Exception as e:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().error(f"Failed to publish inline comments")
|
||||
get_logger().info(f"Initially failed to publish inline comments as committable")
|
||||
|
||||
if (getattr(e, "status", None) == 422
|
||||
and get_settings().github.publish_inline_comments_fallback_with_verification and not disable_fallback):
|
||||
if (getattr(e, "status", None) == 422 and not disable_fallback):
|
||||
pass # continue to try _publish_inline_comments_fallback_with_verification
|
||||
else:
|
||||
raise e # will end up with publishing the comments one by one
|
||||
@ -304,8 +326,7 @@ class GithubProvider(GitProvider):
|
||||
try:
|
||||
self._publish_inline_comments_fallback_with_verification(comments)
|
||||
except Exception as e:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().error(f"Failed to publish inline code comments fallback, error: {e}")
|
||||
get_logger().error(f"Failed to publish inline code comments fallback, error: {e}")
|
||||
raise e
|
||||
|
||||
def _publish_inline_comments_fallback_with_verification(self, comments: list[dict]):
|
||||
@ -330,11 +351,9 @@ class GithubProvider(GitProvider):
|
||||
for comment in fixed_comments_as_one_liner:
|
||||
try:
|
||||
self.publish_inline_comments([comment], disable_fallback=True)
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().info(f"Published invalid comment as a single line comment: {comment}")
|
||||
get_logger().info(f"Published invalid comment as a single line comment: {comment}")
|
||||
except:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().error(f"Failed to publish invalid comment as a single line comment: {comment}")
|
||||
get_logger().error(f"Failed to publish invalid comment as a single line comment: {comment}")
|
||||
|
||||
def _verify_code_comment(self, comment: dict):
|
||||
is_verified = False
|
||||
@ -392,8 +411,7 @@ class GithubProvider(GitProvider):
|
||||
if fixed_comment != comment:
|
||||
fixed_comments.append(fixed_comment)
|
||||
except Exception as e:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().error(f"Failed to fix inline comment, error: {e}")
|
||||
get_logger().error(f"Failed to fix inline comment, error: {e}")
|
||||
return fixed_comments
|
||||
|
||||
def publish_code_suggestions(self, code_suggestions: list) -> bool:
|
||||
@ -401,23 +419,24 @@ class GithubProvider(GitProvider):
|
||||
Publishes code suggestions as comments on the PR.
|
||||
"""
|
||||
post_parameters_list = []
|
||||
for suggestion in code_suggestions:
|
||||
|
||||
code_suggestions_validated = self.validate_comments_inside_hunks(code_suggestions)
|
||||
|
||||
for suggestion in code_suggestions_validated:
|
||||
body = suggestion['body']
|
||||
relevant_file = suggestion['relevant_file']
|
||||
relevant_lines_start = suggestion['relevant_lines_start']
|
||||
relevant_lines_end = suggestion['relevant_lines_end']
|
||||
|
||||
if not relevant_lines_start or relevant_lines_start == -1:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().exception(
|
||||
f"Failed to publish code suggestion, relevant_lines_start is {relevant_lines_start}")
|
||||
get_logger().exception(
|
||||
f"Failed to publish code suggestion, relevant_lines_start is {relevant_lines_start}")
|
||||
continue
|
||||
|
||||
if relevant_lines_end < relevant_lines_start:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().exception(f"Failed to publish code suggestion, "
|
||||
f"relevant_lines_end is {relevant_lines_end} and "
|
||||
f"relevant_lines_start is {relevant_lines_start}")
|
||||
get_logger().exception(f"Failed to publish code suggestion, "
|
||||
f"relevant_lines_end is {relevant_lines_end} and "
|
||||
f"relevant_lines_start is {relevant_lines_start}")
|
||||
continue
|
||||
|
||||
if relevant_lines_end > relevant_lines_start:
|
||||
@ -441,8 +460,7 @@ class GithubProvider(GitProvider):
|
||||
self.publish_inline_comments(post_parameters_list)
|
||||
return True
|
||||
except Exception as e:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().error(f"Failed to publish code suggestion, error: {e}")
|
||||
get_logger().error(f"Failed to publish code suggestion, error: {e}")
|
||||
return False
|
||||
|
||||
def edit_comment(self, comment, body: str):
|
||||
@ -501,6 +519,7 @@ class GithubProvider(GitProvider):
|
||||
elif self.deployment_type == 'user':
|
||||
same_comment_creator = self.github_user_id == existing_comment['user']['login']
|
||||
if existing_comment['subject_type'] == 'file' and comment['path'] == existing_comment['path'] and same_comment_creator:
|
||||
|
||||
headers, data_patch = self.pr._requester.requestJsonAndCheck(
|
||||
"PATCH", f"{self.base_url}/repos/{self.repo}/pulls/comments/{existing_comment['id']}", input={"body":comment['body']}
|
||||
)
|
||||
@ -512,8 +531,7 @@ class GithubProvider(GitProvider):
|
||||
)
|
||||
return True
|
||||
except Exception as e:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().error(f"Failed to publish diffview file summary, error: {e}")
|
||||
get_logger().error(f"Failed to publish diffview file summary, error: {e}")
|
||||
return False
|
||||
|
||||
def remove_initial_comment(self):
|
||||
@ -801,8 +819,7 @@ class GithubProvider(GitProvider):
|
||||
link = f"{self.base_url_html}/{self.repo}/pull/{self.pr_num}/files#diff-{sha_file}R{absolute_position}"
|
||||
return link
|
||||
except Exception as e:
|
||||
if get_settings().config.verbosity_level >= 2:
|
||||
get_logger().info(f"Failed adding line link, error: {e}")
|
||||
get_logger().info(f"Failed adding line link, error: {e}")
|
||||
|
||||
return ""
|
||||
|
||||
@ -862,3 +879,100 @@ class GithubProvider(GitProvider):
|
||||
|
||||
def calc_pr_statistics(self, pull_request_data: dict):
|
||||
return {}
|
||||
|
||||
def validate_comments_inside_hunks(self, code_suggestions):
|
||||
"""
|
||||
validate that all committable comments are inside PR hunks - this is a must for committable comments in GitHub
|
||||
"""
|
||||
code_suggestions_copy = copy.deepcopy(code_suggestions)
|
||||
diff_files = self.get_diff_files()
|
||||
RE_HUNK_HEADER = re.compile(
|
||||
r"^@@ -(\d+)(?:,(\d+))? \+(\d+)(?:,(\d+))? @@[ ]?(.*)")
|
||||
|
||||
# map file extensions to programming languages
|
||||
language_extension_map_org = get_settings().language_extension_map_org
|
||||
extension_to_language = {}
|
||||
for language, extensions in language_extension_map_org.items():
|
||||
for ext in extensions:
|
||||
extension_to_language[ext] = language
|
||||
for file in diff_files:
|
||||
extension_s = '.' + file.filename.rsplit('.')[-1]
|
||||
language_name = "txt"
|
||||
if extension_s and (extension_s in extension_to_language):
|
||||
language_name = extension_to_language[extension_s]
|
||||
file.language = language_name.lower()
|
||||
|
||||
for suggestion in code_suggestions_copy:
|
||||
try:
|
||||
relevant_file_path = suggestion['relevant_file']
|
||||
for file in diff_files:
|
||||
if file.filename == relevant_file_path:
|
||||
|
||||
# generate on-demand the patches range for the relevant file
|
||||
patch_str = file.patch
|
||||
if not hasattr(file, 'patches_range'):
|
||||
file.patches_range = []
|
||||
patch_lines = patch_str.splitlines()
|
||||
for i, line in enumerate(patch_lines):
|
||||
if line.startswith('@@'):
|
||||
match = RE_HUNK_HEADER.match(line)
|
||||
# identify hunk header
|
||||
if match:
|
||||
section_header, size1, size2, start1, start2 = extract_hunk_headers(match)
|
||||
file.patches_range.append({'start': start2, 'end': start2 + size2 - 1})
|
||||
|
||||
patches_range = file.patches_range
|
||||
comment_start_line = suggestion.get('relevant_lines_start', None)
|
||||
comment_end_line = suggestion.get('relevant_lines_end', None)
|
||||
original_suggestion = suggestion.get('original_suggestion', None) # needed for diff code
|
||||
if not comment_start_line or not comment_end_line or not original_suggestion:
|
||||
continue
|
||||
|
||||
# check if the comment is inside a valid hunk
|
||||
is_valid_hunk = False
|
||||
min_distance = float('inf')
|
||||
patch_range_min = None
|
||||
# find the hunk that contains the comment, or the closest one
|
||||
for i, patch_range in enumerate(patches_range):
|
||||
d1 = comment_start_line - patch_range['start']
|
||||
d2 = patch_range['end'] - comment_end_line
|
||||
if d1 >= 0 and d2 >= 0: # found a valid hunk
|
||||
is_valid_hunk = True
|
||||
min_distance = 0
|
||||
patch_range_min = patch_range
|
||||
break
|
||||
elif d1 * d2 <= 0: # comment is possibly inside the hunk
|
||||
d1_clip = abs(min(0, d1))
|
||||
d2_clip = abs(min(0, d2))
|
||||
d = max(d1_clip, d2_clip)
|
||||
if d < min_distance:
|
||||
patch_range_min = patch_range
|
||||
min_distance = min(min_distance, d)
|
||||
if not is_valid_hunk:
|
||||
if min_distance < 10: # 10 lines - a reasonable distance to consider the comment inside the hunk
|
||||
# make the suggestion non-committable, yet multi line
|
||||
suggestion['relevant_lines_start'] = max(suggestion['relevant_lines_start'], patch_range_min['start'])
|
||||
suggestion['relevant_lines_end'] = min(suggestion['relevant_lines_end'], patch_range_min['end'])
|
||||
body = suggestion['body'].strip()
|
||||
|
||||
# present new diff code in collapsible
|
||||
existing_code = original_suggestion['existing_code'].rstrip() + "\n"
|
||||
improved_code = original_suggestion['improved_code'].rstrip() + "\n"
|
||||
diff = difflib.unified_diff(existing_code.split('\n'),
|
||||
improved_code.split('\n'), n=999)
|
||||
patch_orig = "\n".join(diff)
|
||||
patch = "\n".join(patch_orig.splitlines()[5:]).strip('\n')
|
||||
diff_code = f"\n\n<details><summary>New proposed code:</summary>\n\n```diff\n{patch.rstrip()}\n```"
|
||||
# replace ```suggestion ... ``` with diff_code, using regex:
|
||||
body = re.sub(r'```suggestion.*?```', diff_code, body, flags=re.DOTALL)
|
||||
body += "\n\n</details>"
|
||||
suggestion['body'] = body
|
||||
get_logger().info(f"Comment was moved to a valid hunk, "
|
||||
f"start_line={suggestion['relevant_lines_start']}, end_line={suggestion['relevant_lines_end']}, file={file.filename}")
|
||||
else:
|
||||
get_logger().error(f"Comment is not inside a valid hunk, "
|
||||
f"start_line={suggestion['relevant_lines_start']}, end_line={suggestion['relevant_lines_end']}, file={file.filename}")
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to process patch for committable comment, error: {e}")
|
||||
return code_suggestions_copy
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
import difflib
|
||||
import hashlib
|
||||
import re
|
||||
from typing import Optional, Tuple
|
||||
@ -7,13 +8,16 @@ import gitlab
|
||||
import requests
|
||||
from gitlab import GitlabGetError
|
||||
|
||||
from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
|
||||
|
||||
from ..algo.file_filter import filter_ignored
|
||||
from ..algo.language_handler import is_valid_file
|
||||
from ..algo.utils import load_large_diff, clip_tokens, find_line_number_of_relevant_line_in_file
|
||||
from ..algo.utils import (clip_tokens,
|
||||
find_line_number_of_relevant_line_in_file,
|
||||
load_large_diff)
|
||||
from ..config_loader import get_settings
|
||||
from .git_provider import GitProvider, MAX_FILES_ALLOWED_FULL
|
||||
from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
|
||||
from ..log import get_logger
|
||||
from .git_provider import MAX_FILES_ALLOWED_FULL, GitProvider
|
||||
|
||||
|
||||
class DiffNotFoundError(Exception):
|
||||
@ -190,6 +194,9 @@ class GitLabProvider(GitProvider):
|
||||
self.publish_persistent_comment_full(pr_comment, initial_header, update_header, name, final_update_message)
|
||||
|
||||
def publish_comment(self, mr_comment: str, is_temporary: bool = False):
|
||||
if is_temporary and not get_settings().config.publish_output_progress:
|
||||
get_logger().debug(f"Skipping publish_comment for temporary comment: {mr_comment}")
|
||||
return None
|
||||
mr_comment = self.limit_output_characters(mr_comment, self.max_comment_chars)
|
||||
comment = self.mr.notes.create({'body': mr_comment})
|
||||
if is_temporary:
|
||||
@ -275,20 +282,23 @@ class GitLabProvider(GitProvider):
|
||||
new_code_snippet = original_suggestion['improved_code']
|
||||
content = original_suggestion['suggestion_content']
|
||||
label = original_suggestion['label']
|
||||
if 'score' in original_suggestion:
|
||||
score = original_suggestion['score']
|
||||
else:
|
||||
score = 7
|
||||
score = original_suggestion.get('score', 7)
|
||||
|
||||
if hasattr(self, 'main_language'):
|
||||
language = self.main_language
|
||||
else:
|
||||
language = ''
|
||||
link = self.get_line_link(relevant_file, line_start, line_end)
|
||||
body_fallback =f"**Suggestion:** {content} [{label}, importance: {score}]\n___\n"
|
||||
body_fallback +=f"\n\nReplace lines ([{line_start}-{line_end}]({link}))\n\n```{language}\n{old_code_snippet}\n````\n\n"
|
||||
body_fallback +=f"with\n\n```{language}\n{new_code_snippet}\n````"
|
||||
body_fallback += f"\n\n___\n\n`(Cannot implement this suggestion directly, as gitlab API does not enable committing to a non -+ line in a PR)`"
|
||||
body_fallback =f"**Suggestion:** {content} [{label}, importance: {score}]\n\n"
|
||||
body_fallback +=f"\n\n<details><summary>[{target_file.filename} [{line_start}-{line_end}]]({link}):</summary>\n\n"
|
||||
body_fallback += f"\n\n___\n\n`(Cannot implement directly - GitLab API allows committable suggestions strictly on MR diff lines)`"
|
||||
body_fallback+="</details>\n\n"
|
||||
diff_patch = difflib.unified_diff(old_code_snippet.split('\n'),
|
||||
new_code_snippet.split('\n'), n=999)
|
||||
patch_orig = "\n".join(diff_patch)
|
||||
patch = "\n".join(patch_orig.splitlines()[5:]).strip('\n')
|
||||
diff_code = f"\n\n```diff\n{patch.rstrip()}\n```"
|
||||
body_fallback += diff_code
|
||||
|
||||
# Create a general note on the file in the MR
|
||||
self.mr.notes.create({
|
||||
@ -301,6 +311,7 @@ class GitLabProvider(GitProvider):
|
||||
'file_path': f'{target_file.filename}',
|
||||
}
|
||||
})
|
||||
get_logger().debug(f"Created fallback comment in MR {self.id_mr} with position {pos_obj}")
|
||||
|
||||
# get_logger().debug(
|
||||
# f"Failed to create comment in MR {self.id_mr} with position {pos_obj} (probably not a '+' line)")
|
||||
|
||||
@ -4,9 +4,9 @@ from typing import List
|
||||
|
||||
from git import Repo
|
||||
|
||||
from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
|
||||
from pr_agent.config_loader import _find_repository_root, get_settings
|
||||
from pr_agent.git_providers.git_provider import GitProvider
|
||||
from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
|
||||
from pr_agent.log import get_logger
|
||||
|
||||
|
||||
|
||||
@ -3,11 +3,12 @@ import os
|
||||
import tempfile
|
||||
|
||||
from dynaconf import Dynaconf
|
||||
from starlette_context import context
|
||||
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers import get_git_provider, get_git_provider_with_context
|
||||
from pr_agent.git_providers import (get_git_provider,
|
||||
get_git_provider_with_context)
|
||||
from pr_agent.log import get_logger
|
||||
from starlette_context import context
|
||||
|
||||
|
||||
def apply_repo_settings(pr_url):
|
||||
|
||||
@ -1,5 +1,6 @@
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.identity_providers.default_identity_provider import DefaultIdentityProvider
|
||||
from pr_agent.identity_providers.default_identity_provider import \
|
||||
DefaultIdentityProvider
|
||||
|
||||
_IDENTITY_PROVIDERS = {
|
||||
'default': DefaultIdentityProvider
|
||||
|
||||
@ -1,4 +1,5 @@
|
||||
from pr_agent.identity_providers.identity_provider import Eligibility, IdentityProvider
|
||||
from pr_agent.identity_providers.identity_provider import (Eligibility,
|
||||
IdentityProvider)
|
||||
|
||||
|
||||
class DefaultIdentityProvider(IdentityProvider):
|
||||
|
||||
@ -8,12 +8,10 @@ def get_secret_provider():
|
||||
provider_id = get_settings().config.secret_provider
|
||||
if provider_id == 'google_cloud_storage':
|
||||
try:
|
||||
from pr_agent.secret_providers.google_cloud_storage_secret_provider import GoogleCloudStorageSecretProvider
|
||||
from pr_agent.secret_providers.google_cloud_storage_secret_provider import \
|
||||
GoogleCloudStorageSecretProvider
|
||||
return GoogleCloudStorageSecretProvider()
|
||||
except Exception as e:
|
||||
raise ValueError(f"Failed to initialize google_cloud_storage secret provider {provider_id}") from e
|
||||
else:
|
||||
raise ValueError("Unknown SECRET_PROVIDER")
|
||||
|
||||
|
||||
|
||||
|
||||
@ -9,9 +9,9 @@ import secrets
|
||||
from urllib.parse import unquote
|
||||
|
||||
import uvicorn
|
||||
from fastapi import APIRouter, Depends, FastAPI, HTTPException
|
||||
from fastapi.security import HTTPBasic, HTTPBasicCredentials
|
||||
from fastapi import APIRouter, Depends, FastAPI, HTTPException, Request
|
||||
from fastapi.encoders import jsonable_encoder
|
||||
from fastapi.security import HTTPBasic, HTTPBasicCredentials
|
||||
from starlette import status
|
||||
from starlette.background import BackgroundTasks
|
||||
from starlette.middleware import Middleware
|
||||
@ -23,9 +23,6 @@ from pr_agent.agent.pr_agent import PRAgent, command2class
|
||||
from pr_agent.algo.utils import update_settings_from_args
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers.utils import apply_repo_settings
|
||||
from pr_agent.log import get_logger
|
||||
from fastapi import Request, Depends
|
||||
from fastapi.security import HTTPBasic, HTTPBasicCredentials
|
||||
from pr_agent.log import LoggingFormat, get_logger, setup_logger
|
||||
|
||||
setup_logger(fmt=LoggingFormat.JSON, level="DEBUG")
|
||||
|
||||
@ -98,11 +98,14 @@ async def _perform_commands_bitbucket(commands_conf: str, agent: PRAgent, api_ur
|
||||
|
||||
def is_bot_user(data) -> bool:
|
||||
try:
|
||||
if data["data"]["actor"]["type"] != "user":
|
||||
get_logger().info(f"BitBucket actor type is not 'user': {data['data']['actor']['type']}")
|
||||
actor = data.get("data", {}).get("actor", {})
|
||||
# allow actor type: user . if it's "AppUser" or "team" then it is a bot user
|
||||
allowed_actor_types = {"user"}
|
||||
if actor and actor["type"].lower() not in allowed_actor_types:
|
||||
get_logger().info(f"BitBucket actor type is not 'user', skipping: {actor}")
|
||||
return True
|
||||
except Exception as e:
|
||||
get_logger().error("Failed 'is_bot_user' logic: {e}")
|
||||
get_logger().error(f"Failed 'is_bot_user' logic: {e}")
|
||||
return False
|
||||
|
||||
|
||||
@ -161,16 +164,18 @@ async def handle_github_webhooks(background_tasks: BackgroundTasks, request: Req
|
||||
return "OK"
|
||||
|
||||
# Get the username of the sender
|
||||
try:
|
||||
username = data["data"]["actor"]["username"]
|
||||
except KeyError:
|
||||
actor = data.get("data", {}).get("actor", {})
|
||||
if actor:
|
||||
try:
|
||||
username = data["data"]["actor"]["display_name"]
|
||||
username = actor["username"]
|
||||
except KeyError:
|
||||
username = data["data"]["actor"]["nickname"]
|
||||
log_context["sender"] = username
|
||||
try:
|
||||
username = actor["display_name"]
|
||||
except KeyError:
|
||||
username = actor["nickname"]
|
||||
log_context["sender"] = username
|
||||
|
||||
sender_id = data["data"]["actor"]["account_id"]
|
||||
sender_id = data.get("data", {}).get("actor", {}).get("account_id", "")
|
||||
log_context["sender_id"] = sender_id
|
||||
jwt_parts = input_jwt.split(".")
|
||||
claim_part = jwt_parts[1]
|
||||
|
||||
@ -6,20 +6,20 @@ from typing import List
|
||||
import uvicorn
|
||||
from fastapi import APIRouter, FastAPI
|
||||
from fastapi.encoders import jsonable_encoder
|
||||
from fastapi.responses import RedirectResponse
|
||||
from starlette import status
|
||||
from starlette.background import BackgroundTasks
|
||||
from starlette.middleware import Middleware
|
||||
from starlette.requests import Request
|
||||
from starlette.responses import JSONResponse
|
||||
from starlette_context.middleware import RawContextMiddleware
|
||||
|
||||
from pr_agent.agent.pr_agent import PRAgent
|
||||
from pr_agent.algo.utils import update_settings_from_args
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers.utils import apply_repo_settings
|
||||
from pr_agent.log import LoggingFormat, get_logger, setup_logger
|
||||
from pr_agent.servers.utils import verify_signature
|
||||
from fastapi.responses import RedirectResponse
|
||||
|
||||
|
||||
setup_logger(fmt=LoggingFormat.JSON, level="DEBUG")
|
||||
router = APIRouter()
|
||||
|
||||
@ -15,7 +15,8 @@ from starlette_context.middleware import RawContextMiddleware
|
||||
from pr_agent.agent.pr_agent import PRAgent
|
||||
from pr_agent.algo.utils import update_settings_from_args
|
||||
from pr_agent.config_loader import get_settings, global_settings
|
||||
from pr_agent.git_providers import get_git_provider, get_git_provider_with_context
|
||||
from pr_agent.git_providers import (get_git_provider,
|
||||
get_git_provider_with_context)
|
||||
from pr_agent.git_providers.git_provider import IncrementalPR
|
||||
from pr_agent.git_providers.utils import apply_repo_settings
|
||||
from pr_agent.identity_providers import get_identity_provider
|
||||
|
||||
@ -1,11 +1,12 @@
|
||||
import asyncio
|
||||
import multiprocessing
|
||||
from collections import deque
|
||||
import traceback
|
||||
from datetime import datetime, timezone
|
||||
import time
|
||||
import requests
|
||||
import traceback
|
||||
from collections import deque
|
||||
from datetime import datetime, timezone
|
||||
|
||||
import aiohttp
|
||||
import requests
|
||||
|
||||
from pr_agent.agent.pr_agent import PRAgent
|
||||
from pr_agent.config_loader import get_settings
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
import copy
|
||||
import re
|
||||
import json
|
||||
import re
|
||||
from datetime import datetime
|
||||
|
||||
import uvicorn
|
||||
|
||||
@ -5,7 +5,6 @@ from starlette_context.middleware import RawContextMiddleware
|
||||
|
||||
from pr_agent.servers.github_app import router
|
||||
|
||||
|
||||
middleware = [Middleware(RawContextMiddleware)]
|
||||
app = FastAPI(middleware=middleware)
|
||||
app.include_router(router)
|
||||
|
||||
@ -2,7 +2,7 @@ import hashlib
|
||||
import hmac
|
||||
import time
|
||||
from collections import defaultdict
|
||||
from typing import Callable, Any
|
||||
from typing import Any, Callable
|
||||
|
||||
from fastapi import HTTPException
|
||||
|
||||
|
||||
@ -1,12 +1,13 @@
|
||||
[config]
|
||||
# models
|
||||
model="gpt-4-turbo-2024-04-09"
|
||||
model_turbo="gpt-4o-2024-08-06"
|
||||
fallback_models=["gpt-4o-2024-05-13"]
|
||||
model_turbo="gpt-4o-2024-11-20"
|
||||
fallback_models=["gpt-4o-2024-08-06"]
|
||||
# CLI
|
||||
git_provider="github"
|
||||
publish_output=true
|
||||
publish_output_progress=true
|
||||
publish_output_no_suggestions=true
|
||||
verbosity_level=0 # 0,1,2
|
||||
use_extra_bad_extensions=false
|
||||
# Configurations
|
||||
@ -106,10 +107,11 @@ enable_help_text=false
|
||||
|
||||
|
||||
[pr_code_suggestions] # /improve #
|
||||
max_context_tokens=14000
|
||||
max_context_tokens=16000
|
||||
#
|
||||
commitable_code_suggestions = false
|
||||
dual_publishing_score_threshold=-1 # -1 to disable, [0-10] to set the threshold (>=) for publishing a code suggestion both in a table and as commitable
|
||||
focus_only_on_problems=true
|
||||
#
|
||||
extra_instructions = ""
|
||||
rank_suggestions = false
|
||||
@ -121,7 +123,6 @@ max_history_len=4
|
||||
# enable to apply suggestion 💎
|
||||
apply_suggestions_checkbox=true
|
||||
# suggestions scoring
|
||||
self_reflect_on_suggestions=true
|
||||
suggestions_score_threshold=0 # [0-10]| recommend not to set this value above 8, since above it may clip highly relevant suggestions
|
||||
# params for '/improve --extended' mode
|
||||
auto_extended_mode=true
|
||||
|
||||
@ -1,7 +1,10 @@
|
||||
[pr_code_suggestions_prompt]
|
||||
system="""You are PR-Reviewer, an AI specializing in Pull Request (PR) code analysis and suggestions.
|
||||
Your task is to examine the provided code diff, focusing on new code (lines prefixed with '+'), and offer concise, actionable suggestions to fix possible bugs and problems, and enhance code quality, readability, and performance.
|
||||
|
||||
{%- if not focus_only_on_problems %}
|
||||
Your task is to examine the provided code diff, focusing on new code (lines prefixed with '+'), and offer concise, actionable suggestions to fix possible bugs and problems, and enhance code quality and performance.
|
||||
{%- else %}
|
||||
Your task is to examine the provided code diff, focusing on new code (lines prefixed with '+'), and offer concise, actionable suggestions to fix critical bugs and problems.
|
||||
{%- endif %}
|
||||
|
||||
The PR code diff will be in the following structured format:
|
||||
======
|
||||
@ -14,10 +17,10 @@ The PR code diff will be in the following structured format:
|
||||
|
||||
@@ ... @@ def func1():
|
||||
__new hunk__
|
||||
11 unchanged code line0 in the PR
|
||||
12 unchanged code line1 in the PR
|
||||
13 +new code line2 added in the PR
|
||||
14 unchanged code line3 in the PR
|
||||
unchanged code line0 in the PR
|
||||
unchanged code line1 in the PR
|
||||
+new code line2 added in the PR
|
||||
unchanged code line3 in the PR
|
||||
__old hunk__
|
||||
unchanged code line0
|
||||
unchanged code line1
|
||||
@ -35,7 +38,6 @@ __new hunk__
|
||||
======
|
||||
|
||||
- In the format above, the diff is organized into separate '__new hunk__' and '__old hunk__' sections for each code chunk. '__new hunk__' contains the updated code, while '__old hunk__' shows the removed code. If no code was removed in a specific chunk, the __old hunk__ section will be omitted.
|
||||
- Line numbers were added for the '__new hunk__' sections to help referencing specific lines in the code suggestions. These numbers are for reference only and are not part of the actual code.
|
||||
- Code lines are prefixed with symbols: '+' for new code added in the PR, '-' for code removed, and ' ' for unchanged code.
|
||||
{%- if is_ai_metadata %}
|
||||
- When available, an AI-generated summary will precede each file's diff, with a high-level overview of the changes. Note that this summary may not be fully accurate or complete.
|
||||
@ -43,9 +45,17 @@ __new hunk__
|
||||
|
||||
|
||||
Specific guidelines for generating code suggestions:
|
||||
{%- if not focus_only_on_problems %}
|
||||
- Provide up to {{ num_code_suggestions }} distinct and insightful code suggestions.
|
||||
- Focus solely on enhancing new code introduced in the PR, identified by '+' prefixes in '__new hunk__' sections (after the line numbers).
|
||||
{%- else %}
|
||||
- Provide up to {{ num_code_suggestions }} distinct and insightful code suggestions. Return less suggestions if no pertinent ones are applicable.
|
||||
{%- endif %}
|
||||
- Focus solely on enhancing new code introduced in the PR, identified by '+' prefixes in '__new hunk__' sections.
|
||||
{%- if not focus_only_on_problems %}
|
||||
- Prioritize suggestions that address potential issues, critical problems, and bugs in the PR code. Avoid repeating changes already implemented in the PR. If no pertinent suggestions are applicable, return an empty list.
|
||||
{%- else %}
|
||||
- Only give suggestions that address critical problems and bugs in the PR code. If no relevant suggestions are applicable, return an empty list.
|
||||
{%- endif %}
|
||||
- Don't suggest to add docstring, type hints, or comments, to remove unused imports, or to use more specific exception types.
|
||||
- When referencing variables or names from the code, enclose them in backticks (`). Example: "ensure that `variable_name` is..."
|
||||
- Be mindful you are viewing a partial PR code diff, not the full codebase. Avoid suggestions that might conflict with unseen code or alerting variables not declared in the visible scope, as the context is incomplete.
|
||||
@ -67,12 +77,14 @@ class CodeSuggestion(BaseModel):
|
||||
relevant_file: str = Field(description="Full path of the relevant file")
|
||||
language: str = Field(description="Programming language used by the relevant file")
|
||||
suggestion_content: str = Field(description="An actionable suggestion to enhance, improve or fix the new code introduced in the PR. Don't present here actual code snippets, just the suggestion. Be short and concise")
|
||||
existing_code: str = Field(description="A short code snippet from a '__new hunk__' section that the suggestion aims to enhance or fix. Include only complete code lines, without line numbers. Use ellipsis (...) for brevity if needed. This snippet should represent the specific PR code targeted for improvement.")
|
||||
existing_code: str = Field(description="A short code snippet from a '__new hunk__' section that the suggestion aims to enhance or fix. Include only complete code lines. Use ellipsis (...) for brevity if needed. This snippet should represent the specific PR code targeted for improvement.")
|
||||
improved_code: str = Field(description="A refined code snippet that replaces the 'existing_code' snippet after implementing the suggestion.")
|
||||
one_sentence_summary: str = Field(description="A concise, single-sentence overview of the suggested improvement. Focus on the 'what'. Be general, and avoid method or variable names.")
|
||||
relevant_lines_start: int = Field(description="The relevant line number, from a '__new hunk__' section, where the suggestion starts (inclusive). Should be derived from the hunk line numbers, and correspond to the beginning of the 'existing code' snippet above")
|
||||
relevant_lines_end: int = Field(description="The relevant line number, from a '__new hunk__' section, where the suggestion ends (inclusive). Should be derived from the hunk line numbers, and correspond to the end of the 'existing code' snippet above")
|
||||
label: str = Field(description="A single, descriptive label that best characterizes the suggestion type. Possible labels include 'security', 'possible bug', 'possible issue', 'performance', 'enhancement', 'best practice', 'maintainability'. Other relevant labels are also acceptable.")
|
||||
{%- if not focus_only_on_problems %}
|
||||
label: str = Field(description="A single, descriptive label that best characterizes the suggestion type. Possible labels include 'security', 'possible bug', 'possible issue', 'performance', 'enhancement', 'best practice', 'maintainability', 'typo'. Other relevant labels are also acceptable.")
|
||||
{%- else %}
|
||||
label: str = Field(description="A single, descriptive label that best characterizes the suggestion type. Possible labels include 'security', 'critical bug', 'general'. The 'general' section should be used for suggestions that address a major issue, but are necessarily on a critical level.")
|
||||
{%- endif %}
|
||||
|
||||
|
||||
class PRCodeSuggestions(BaseModel):
|
||||
@ -95,8 +107,6 @@ code_suggestions:
|
||||
...
|
||||
one_sentence_summary: |
|
||||
...
|
||||
relevant_lines_start: 12
|
||||
relevant_lines_end: 13
|
||||
label: |
|
||||
...
|
||||
```
|
||||
@ -112,7 +122,7 @@ Title: '{{title}}'
|
||||
|
||||
The PR Diff:
|
||||
======
|
||||
{{ diff|trim }}
|
||||
{{ diff_no_line_numbers|trim }}
|
||||
======
|
||||
|
||||
|
||||
|
||||
@ -15,8 +15,8 @@ Be particularly vigilant for suggestions that:
|
||||
- Contradict or ignore parts of the PR's modifications
|
||||
In such cases, assign the suggestion a score of 0.
|
||||
|
||||
For valid suggestions, your role is to provide an impartial and precise score assessment that accurately reflects each suggestion's potential impact on the PR's correctness, quality and functionality.
|
||||
|
||||
Evaluate each valid suggestion by scoring its potential impact on the PR's correctness, quality and functionality.
|
||||
In addition, you should also detect the line numbers in the '__new hunk__' section that correspond to the 'existing_code' snippet.
|
||||
|
||||
Key guidelines for evaluation:
|
||||
- Thoroughly examine both the suggestion content and the corresponding PR code diff. Be vigilant for potential errors in each suggestion, ensuring they are logically sound, accurate, and directly derived from the PR code diff.
|
||||
@ -82,6 +82,8 @@ The output must be a YAML object equivalent to type $PRCodeSuggestionsFeedback,
|
||||
class CodeSuggestionFeedback(BaseModel):
|
||||
suggestion_summary: str = Field(description="Repeated from the input")
|
||||
relevant_file: str = Field(description="Repeated from the input")
|
||||
relevant_lines_start: int = Field(description="The relevant line number, from a '__new hunk__' section, where the suggestion starts (inclusive). Should be derived from the hunk line numbers, and correspond to the beginning of the relevant 'existing code' snippet")
|
||||
relevant_lines_end: int = Field(description="The relevant line number, from a '__new hunk__' section, where the suggestion ends (inclusive). Should be derived from the hunk line numbers, and correspond to the end of the relevant 'existing code' snippet")
|
||||
suggestion_score: int = Field(description="Evaluate the suggestion and assign a score from 0 to 10. Give 0 if the suggestion is wrong. For valid suggestions, score from 1 (lowest impact/importance) to 10 (highest impact/importance).")
|
||||
why: str = Field(description="Briefly explain the score given in 1-2 sentences, focusing on the suggestion's impact, relevance, and accuracy.")
|
||||
|
||||
@ -96,6 +98,8 @@ code_suggestions:
|
||||
- suggestion_summary: |
|
||||
Use a more descriptive variable name here
|
||||
relevant_file: "src/file1.py"
|
||||
relevant_lines_start: 13
|
||||
relevant_lines_end: 14
|
||||
suggestion_score: 6
|
||||
why: |
|
||||
The variable name 't' is not descriptive enough
|
||||
|
||||
@ -1,25 +1,30 @@
|
||||
import asyncio
|
||||
import copy
|
||||
import difflib
|
||||
import re
|
||||
import textwrap
|
||||
import traceback
|
||||
from functools import partial
|
||||
from typing import Dict, List
|
||||
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
|
||||
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||
from pr_agent.algo.ai_handlers.litellm_ai_handler import LiteLLMAIHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, get_pr_multi_diffs, retry_with_fallback_models, \
|
||||
add_ai_metadata_to_diff_files
|
||||
from pr_agent.algo.pr_processing import (add_ai_metadata_to_diff_files,
|
||||
get_pr_diff, get_pr_multi_diffs,
|
||||
retry_with_fallback_models)
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.utils import load_yaml, replace_code_tags, ModelType, show_relevant_configurations
|
||||
from pr_agent.algo.utils import (ModelType, load_yaml, replace_code_tags,
|
||||
show_relevant_configurations)
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers import get_git_provider, get_git_provider_with_context, GithubProvider, GitLabProvider, \
|
||||
AzureDevopsProvider
|
||||
from pr_agent.git_providers import (AzureDevopsProvider, GithubProvider,
|
||||
GitLabProvider, get_git_provider,
|
||||
get_git_provider_with_context)
|
||||
from pr_agent.git_providers.git_provider import get_main_pr_language
|
||||
from pr_agent.log import get_logger
|
||||
from pr_agent.servers.help import HelpMessage
|
||||
from pr_agent.tools.pr_description import insert_br_after_x_chars
|
||||
import difflib
|
||||
import re
|
||||
|
||||
|
||||
class PRCodeSuggestions:
|
||||
@ -44,7 +49,7 @@ class PRCodeSuggestions:
|
||||
self.is_extended = self._get_is_extended(args or [])
|
||||
except:
|
||||
self.is_extended = False
|
||||
num_code_suggestions = get_settings().pr_code_suggestions.num_code_suggestions_per_chunk
|
||||
num_code_suggestions = int(get_settings().pr_code_suggestions.num_code_suggestions_per_chunk)
|
||||
|
||||
|
||||
self.ai_handler = ai_handler()
|
||||
@ -69,11 +74,13 @@ class PRCodeSuggestions:
|
||||
"description": self.pr_description,
|
||||
"language": self.main_language,
|
||||
"diff": "", # empty diff for initial calculation
|
||||
"diff_no_line_numbers": "", # empty diff for initial calculation
|
||||
"num_code_suggestions": num_code_suggestions,
|
||||
"extra_instructions": get_settings().pr_code_suggestions.extra_instructions,
|
||||
"commit_messages_str": self.git_provider.get_commit_messages(),
|
||||
"relevant_best_practices": "",
|
||||
"is_ai_metadata": get_settings().get("config.enable_ai_metadata", False),
|
||||
"focus_only_on_problems": get_settings().get("pr_code_suggestions.focus_only_on_problems", False),
|
||||
}
|
||||
self.pr_code_suggestions_prompt_system = get_settings().pr_code_suggestions_prompt.system
|
||||
|
||||
@ -110,15 +117,17 @@ class PRCodeSuggestions:
|
||||
if not data:
|
||||
data = {"code_suggestions": []}
|
||||
|
||||
if (data is None or 'code_suggestions' not in data or not data['code_suggestions']
|
||||
and get_settings().config.publish_output):
|
||||
get_logger().warning('No code suggestions found for the PR.')
|
||||
if (data is None or 'code_suggestions' not in data or not data['code_suggestions']):
|
||||
pr_body = "## PR Code Suggestions ✨\n\nNo code suggestions found for the PR."
|
||||
get_logger().debug(f"PR output", artifact=pr_body)
|
||||
if self.progress_response:
|
||||
self.git_provider.edit_comment(self.progress_response, body=pr_body)
|
||||
get_logger().warning('No code suggestions found for the PR.')
|
||||
if get_settings().config.publish_output and get_settings().config.publish_output_no_suggestions:
|
||||
get_logger().debug(f"PR output", artifact=pr_body)
|
||||
if self.progress_response:
|
||||
self.git_provider.edit_comment(self.progress_response, body=pr_body)
|
||||
else:
|
||||
self.git_provider.publish_comment(pr_body)
|
||||
else:
|
||||
self.git_provider.publish_comment(pr_body)
|
||||
get_settings().data = {"artifact": ""}
|
||||
return
|
||||
|
||||
if (not self.is_extended and get_settings().pr_code_suggestions.rank_suggestions) or \
|
||||
@ -195,8 +204,11 @@ class PRCodeSuggestions:
|
||||
self.git_provider.remove_comment(self.progress_response)
|
||||
else:
|
||||
get_logger().info('Code suggestions generated for PR, but not published since publish_output is False.')
|
||||
get_settings().data = {"artifact": data}
|
||||
return
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to generate code suggestions for PR, error: {e}")
|
||||
get_logger().error(f"Failed to generate code suggestions for PR, error: {e}",
|
||||
artifact={"traceback": traceback.format_exc()})
|
||||
if get_settings().config.publish_output:
|
||||
if self.progress_response:
|
||||
self.progress_response.delete()
|
||||
@ -325,10 +337,12 @@ class PRCodeSuggestions:
|
||||
model,
|
||||
add_line_numbers_to_hunks=True,
|
||||
disable_extra_lines=False)
|
||||
self.patches_diff_list = [self.patches_diff]
|
||||
self.patches_diff_no_line_number = self.remove_line_numbers([self.patches_diff])[0]
|
||||
|
||||
if self.patches_diff:
|
||||
get_logger().debug(f"PR diff", artifact=self.patches_diff)
|
||||
self.prediction = await self._get_prediction(model, self.patches_diff)
|
||||
self.prediction = await self._get_prediction(model, self.patches_diff, self.patches_diff_no_line_number)
|
||||
else:
|
||||
get_logger().warning(f"Empty PR diff")
|
||||
self.prediction = None
|
||||
@ -336,54 +350,76 @@ class PRCodeSuggestions:
|
||||
data = self.prediction
|
||||
return data
|
||||
|
||||
async def _get_prediction(self, model: str, patches_diff: str) -> dict:
|
||||
async def _get_prediction(self, model: str, patches_diff: str, patches_diff_no_line_number: str) -> dict:
|
||||
variables = copy.deepcopy(self.vars)
|
||||
variables["diff"] = patches_diff # update diff
|
||||
variables["diff_no_line_numbers"] = patches_diff_no_line_number # update diff
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
system_prompt = environment.from_string(self.pr_code_suggestions_prompt_system).render(variables)
|
||||
user_prompt = environment.from_string(get_settings().pr_code_suggestions_prompt.user).render(variables)
|
||||
response, finish_reason = await self.ai_handler.chat_completion(
|
||||
model=model, temperature=get_settings().config.temperature, system=system_prompt, user=user_prompt)
|
||||
if not get_settings().config.publish_output:
|
||||
get_settings().system_prompt = system_prompt
|
||||
get_settings().user_prompt = user_prompt
|
||||
|
||||
# load suggestions from the AI response
|
||||
data = self._prepare_pr_code_suggestions(response)
|
||||
|
||||
# self-reflect on suggestions
|
||||
if get_settings().pr_code_suggestions.self_reflect_on_suggestions:
|
||||
model_turbo = get_settings().config.model_turbo # use turbo model for self-reflection, since it is an easier task
|
||||
response_reflect = await self.self_reflect_on_suggestions(data["code_suggestions"],
|
||||
patches_diff, model=model_turbo)
|
||||
if response_reflect:
|
||||
response_reflect_yaml = load_yaml(response_reflect)
|
||||
code_suggestions_feedback = response_reflect_yaml["code_suggestions"]
|
||||
if len(code_suggestions_feedback) == len(data["code_suggestions"]):
|
||||
for i, suggestion in enumerate(data["code_suggestions"]):
|
||||
try:
|
||||
suggestion["score"] = code_suggestions_feedback[i]["suggestion_score"]
|
||||
suggestion["score_why"] = code_suggestions_feedback[i]["why"]
|
||||
except Exception as e: #
|
||||
get_logger().error(f"Error processing suggestion score {i}",
|
||||
artifact={"suggestion": suggestion,
|
||||
"code_suggestions_feedback": code_suggestions_feedback[i]})
|
||||
suggestion["score"] = 7
|
||||
suggestion["score_why"] = ""
|
||||
|
||||
# if the before and after code is the same, clear one of them
|
||||
try:
|
||||
if suggestion['existing_code'] == suggestion['improved_code']:
|
||||
get_logger().debug(
|
||||
f"edited improved suggestion {i + 1}, because equal to existing code: {suggestion['existing_code']}")
|
||||
if get_settings().pr_code_suggestions.commitable_code_suggestions:
|
||||
suggestion['improved_code'] = "" # we need 'existing_code' to locate the code in the PR
|
||||
else:
|
||||
suggestion['existing_code'] = ""
|
||||
except Exception as e:
|
||||
get_logger().error(f"Error processing suggestion {i + 1}, error: {e}")
|
||||
else:
|
||||
# get_logger().error(f"Could not self-reflect on suggestions. using default score 7")
|
||||
# self-reflect on suggestions (mandatory, since line numbers are generated now here)
|
||||
model_reflection = get_settings().config.model
|
||||
response_reflect = await self.self_reflect_on_suggestions(data["code_suggestions"],
|
||||
patches_diff, model=model_reflection)
|
||||
if response_reflect:
|
||||
response_reflect_yaml = load_yaml(response_reflect)
|
||||
code_suggestions_feedback = response_reflect_yaml["code_suggestions"]
|
||||
if len(code_suggestions_feedback) == len(data["code_suggestions"]):
|
||||
for i, suggestion in enumerate(data["code_suggestions"]):
|
||||
suggestion["score"] = 7
|
||||
suggestion["score_why"] = ""
|
||||
try:
|
||||
suggestion["score"] = code_suggestions_feedback[i]["suggestion_score"]
|
||||
suggestion["score_why"] = code_suggestions_feedback[i]["why"]
|
||||
|
||||
if 'relevant_lines_start' not in suggestion:
|
||||
relevant_lines_start = code_suggestions_feedback[i].get('relevant_lines_start', -1)
|
||||
relevant_lines_end = code_suggestions_feedback[i].get('relevant_lines_end', -1)
|
||||
suggestion['relevant_lines_start'] = relevant_lines_start
|
||||
suggestion['relevant_lines_end'] = relevant_lines_end
|
||||
if relevant_lines_start < 0 or relevant_lines_end < 0:
|
||||
suggestion["score"] = 0
|
||||
|
||||
try:
|
||||
if get_settings().config.publish_output:
|
||||
suggestion_statistics_dict = {'score': int(suggestion["score"]),
|
||||
'label': suggestion["label"].lower().strip()}
|
||||
get_logger().info(f"PR-Agent suggestions statistics",
|
||||
statistics=suggestion_statistics_dict, analytics=True)
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to log suggestion statistics, error: {e}")
|
||||
pass
|
||||
|
||||
except Exception as e: #
|
||||
get_logger().error(f"Error processing suggestion score {i}",
|
||||
artifact={"suggestion": suggestion,
|
||||
"code_suggestions_feedback": code_suggestions_feedback[i]})
|
||||
suggestion["score"] = 7
|
||||
suggestion["score_why"] = ""
|
||||
|
||||
# if the before and after code is the same, clear one of them
|
||||
try:
|
||||
if suggestion['existing_code'] == suggestion['improved_code']:
|
||||
get_logger().debug(
|
||||
f"edited improved suggestion {i + 1}, because equal to existing code: {suggestion['existing_code']}")
|
||||
if get_settings().pr_code_suggestions.commitable_code_suggestions:
|
||||
suggestion['improved_code'] = "" # we need 'existing_code' to locate the code in the PR
|
||||
else:
|
||||
suggestion['existing_code'] = ""
|
||||
except Exception as e:
|
||||
get_logger().error(f"Error processing suggestion {i + 1}, error: {e}")
|
||||
else:
|
||||
# get_logger().error(f"Could not self-reflect on suggestions. using default score 7")
|
||||
for i, suggestion in enumerate(data["code_suggestions"]):
|
||||
suggestion["score"] = 7
|
||||
suggestion["score_why"] = ""
|
||||
|
||||
return data
|
||||
|
||||
@ -393,10 +429,10 @@ class PRCodeSuggestions:
|
||||
suggestion_truncation_message = get_settings().get("PR_CODE_SUGGESTIONS.SUGGESTION_TRUNCATION_MESSAGE", "")
|
||||
if max_code_suggestion_length > 0:
|
||||
if len(suggestion['improved_code']) > max_code_suggestion_length:
|
||||
suggestion['improved_code'] = suggestion['improved_code'][:max_code_suggestion_length]
|
||||
suggestion['improved_code'] += f"\n{suggestion_truncation_message}"
|
||||
get_logger().info(f"Truncated suggestion from {len(suggestion['improved_code'])} "
|
||||
f"characters to {max_code_suggestion_length} characters")
|
||||
suggestion['improved_code'] = suggestion['improved_code'][:max_code_suggestion_length]
|
||||
suggestion['improved_code'] += f"\n{suggestion_truncation_message}"
|
||||
return suggestion
|
||||
|
||||
def _prepare_pr_code_suggestions(self, predictions: str) -> Dict:
|
||||
@ -411,8 +447,7 @@ class PRCodeSuggestions:
|
||||
one_sentence_summary_list = []
|
||||
for i, suggestion in enumerate(data['code_suggestions']):
|
||||
try:
|
||||
needed_keys = ['one_sentence_summary', 'label', 'relevant_file', 'relevant_lines_start',
|
||||
'relevant_lines_end']
|
||||
needed_keys = ['one_sentence_summary', 'label', 'relevant_file']
|
||||
is_valid_keys = True
|
||||
for key in needed_keys:
|
||||
if key not in suggestion:
|
||||
@ -423,6 +458,11 @@ class PRCodeSuggestions:
|
||||
if not is_valid_keys:
|
||||
continue
|
||||
|
||||
if get_settings().get("pr_code_suggestions.focus_only_on_problems", False):
|
||||
CRITICAL_LABEL = 'critical'
|
||||
if CRITICAL_LABEL in suggestion['label'].lower(): # we want the published labels to be less declarative
|
||||
suggestion['label'] = 'possible issue'
|
||||
|
||||
if suggestion['one_sentence_summary'] in one_sentence_summary_list:
|
||||
get_logger().debug(f"Skipping suggestion {i + 1}, because it is a duplicate: {suggestion}")
|
||||
continue
|
||||
@ -536,9 +576,33 @@ class PRCodeSuggestions:
|
||||
return True
|
||||
return False
|
||||
|
||||
def remove_line_numbers(self, patches_diff_list: List[str]) -> List[str]:
|
||||
# create a copy of the patches_diff_list, without line numbers for '__new hunk__' sections
|
||||
try:
|
||||
self.patches_diff_list_no_line_numbers = []
|
||||
for patches_diff in self.patches_diff_list:
|
||||
patches_diff_lines = patches_diff.splitlines()
|
||||
for i, line in enumerate(patches_diff_lines):
|
||||
if line.strip():
|
||||
if line[0].isdigit():
|
||||
# find the first letter in the line that starts with a valid letter
|
||||
for j, char in enumerate(line):
|
||||
if not char.isdigit():
|
||||
patches_diff_lines[i] = line[j + 1:]
|
||||
break
|
||||
self.patches_diff_list_no_line_numbers.append('\n'.join(patches_diff_lines))
|
||||
return self.patches_diff_list_no_line_numbers
|
||||
except Exception as e:
|
||||
get_logger().error(f"Error removing line numbers from patches_diff_list, error: {e}")
|
||||
return patches_diff_list
|
||||
|
||||
async def _prepare_prediction_extended(self, model: str) -> dict:
|
||||
self.patches_diff_list = get_pr_multi_diffs(self.git_provider, self.token_handler, model,
|
||||
max_calls=get_settings().pr_code_suggestions.max_number_of_calls)
|
||||
|
||||
# create a copy of the patches_diff_list, without line numbers for '__new hunk__' sections
|
||||
self.patches_diff_list_no_line_numbers = self.remove_line_numbers(self.patches_diff_list)
|
||||
|
||||
if self.patches_diff_list:
|
||||
get_logger().info(f"Number of PR chunk calls: {len(self.patches_diff_list)}")
|
||||
get_logger().debug(f"PR diff:", artifact=self.patches_diff_list)
|
||||
@ -546,12 +610,14 @@ class PRCodeSuggestions:
|
||||
# parallelize calls to AI:
|
||||
if get_settings().pr_code_suggestions.parallel_calls:
|
||||
prediction_list = await asyncio.gather(
|
||||
*[self._get_prediction(model, patches_diff) for patches_diff in self.patches_diff_list])
|
||||
*[self._get_prediction(model, patches_diff, patches_diff_no_line_numbers) for
|
||||
patches_diff, patches_diff_no_line_numbers in
|
||||
zip(self.patches_diff_list, self.patches_diff_list_no_line_numbers)])
|
||||
self.prediction_list = prediction_list
|
||||
else:
|
||||
prediction_list = []
|
||||
for i, patches_diff in enumerate(self.patches_diff_list):
|
||||
prediction = await self._get_prediction(model, patches_diff)
|
||||
for patches_diff, patches_diff_no_line_numbers in zip(self.patches_diff_list, self.patches_diff_list_no_line_numbers):
|
||||
prediction = await self._get_prediction(model, patches_diff, patches_diff_no_line_numbers)
|
||||
prediction_list.append(prediction)
|
||||
|
||||
data = {"code_suggestions": []}
|
||||
@ -560,18 +626,16 @@ class PRCodeSuggestions:
|
||||
score_threshold = max(1, int(get_settings().pr_code_suggestions.suggestions_score_threshold))
|
||||
for i, prediction in enumerate(predictions["code_suggestions"]):
|
||||
try:
|
||||
if get_settings().pr_code_suggestions.self_reflect_on_suggestions:
|
||||
score = int(prediction.get("score", 1))
|
||||
if score >= score_threshold:
|
||||
data["code_suggestions"].append(prediction)
|
||||
else:
|
||||
get_logger().info(
|
||||
f"Removing suggestions {i} from call {j}, because score is {score}, and score_threshold is {score_threshold}",
|
||||
artifact=prediction)
|
||||
else:
|
||||
score = int(prediction.get("score", 1))
|
||||
if score >= score_threshold:
|
||||
data["code_suggestions"].append(prediction)
|
||||
else:
|
||||
get_logger().info(
|
||||
f"Removing suggestions {i} from call {j}, because score is {score}, and score_threshold is {score_threshold}",
|
||||
artifact=prediction)
|
||||
except Exception as e:
|
||||
get_logger().error(f"Error getting PR diff for suggestion {i} in call {j}, error: {e}")
|
||||
get_logger().error(f"Error getting PR diff for suggestion {i} in call {j}, error: {e}",
|
||||
artifact={"prediction": prediction})
|
||||
self.data = data
|
||||
else:
|
||||
get_logger().warning(f"Empty PR diff list")
|
||||
@ -622,7 +686,7 @@ class PRCodeSuggestions:
|
||||
if get_settings().pr_code_suggestions.final_clip_factor != 1:
|
||||
max_len = max(
|
||||
len(data_sorted),
|
||||
get_settings().pr_code_suggestions.num_code_suggestions_per_chunk,
|
||||
int(get_settings().pr_code_suggestions.num_code_suggestions_per_chunk),
|
||||
)
|
||||
new_len = int(0.5 + max_len * get_settings().pr_code_suggestions.final_clip_factor)
|
||||
if new_len < len(data_sorted):
|
||||
@ -655,10 +719,7 @@ class PRCodeSuggestions:
|
||||
header = f"Suggestion"
|
||||
delta = 66
|
||||
header += " " * delta
|
||||
if get_settings().pr_code_suggestions.self_reflect_on_suggestions:
|
||||
pr_body += f"""<thead><tr><td>Category</td><td align=left>{header}</td><td align=center>Score</td></tr>"""
|
||||
else:
|
||||
pr_body += f"""<thead><tr><td>Category</td><td align=left>{header}</td></tr>"""
|
||||
pr_body += f"""<thead><tr><td>Category</td><td align=left>{header}</td><td align=center>Score</td></tr>"""
|
||||
pr_body += """<tbody>"""
|
||||
suggestions_labels = dict()
|
||||
# add all suggestions related to each label
|
||||
@ -669,12 +730,11 @@ class PRCodeSuggestions:
|
||||
suggestions_labels[label].append(suggestion)
|
||||
|
||||
# sort suggestions_labels by the suggestion with the highest score
|
||||
if get_settings().pr_code_suggestions.self_reflect_on_suggestions:
|
||||
suggestions_labels = dict(
|
||||
sorted(suggestions_labels.items(), key=lambda x: max([s['score'] for s in x[1]]), reverse=True))
|
||||
# sort the suggestions inside each label group by score
|
||||
for label, suggestions in suggestions_labels.items():
|
||||
suggestions_labels[label] = sorted(suggestions, key=lambda x: x['score'], reverse=True)
|
||||
suggestions_labels = dict(
|
||||
sorted(suggestions_labels.items(), key=lambda x: max([s['score'] for s in x[1]]), reverse=True))
|
||||
# sort the suggestions inside each label group by score
|
||||
for label, suggestions in suggestions_labels.items():
|
||||
suggestions_labels[label] = sorted(suggestions, key=lambda x: x['score'], reverse=True)
|
||||
|
||||
counter_suggestions = 0
|
||||
for label, suggestions in suggestions_labels.items():
|
||||
@ -733,16 +793,14 @@ class PRCodeSuggestions:
|
||||
|
||||
{example_code.rstrip()}
|
||||
"""
|
||||
if get_settings().pr_code_suggestions.self_reflect_on_suggestions:
|
||||
pr_body += f"<details><summary>Suggestion importance[1-10]: {suggestion['score']}</summary>\n\n"
|
||||
pr_body += f"Why: {suggestion['score_why']}\n\n"
|
||||
pr_body += f"</details>"
|
||||
pr_body += f"<details><summary>Suggestion importance[1-10]: {suggestion['score']}</summary>\n\n"
|
||||
pr_body += f"Why: {suggestion['score_why']}\n\n"
|
||||
pr_body += f"</details>"
|
||||
|
||||
pr_body += f"</details>"
|
||||
|
||||
# # add another column for 'score'
|
||||
if get_settings().pr_code_suggestions.self_reflect_on_suggestions:
|
||||
pr_body += f"</td><td align=center>{suggestion['score']}\n\n"
|
||||
pr_body += f"</td><td align=center>{suggestion['score']}\n\n"
|
||||
|
||||
pr_body += f"</td></tr>"
|
||||
counter_suggestions += 1
|
||||
@ -783,4 +841,3 @@ class PRCodeSuggestions:
|
||||
get_logger().info(f"Could not reflect on suggestions, error: {e}")
|
||||
return ""
|
||||
return response_reflect
|
||||
|
||||
|
||||
@ -9,19 +9,24 @@ from jinja2 import Environment, StrictUndefined
|
||||
|
||||
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||
from pr_agent.algo.ai_handlers.litellm_ai_handler import LiteLLMAIHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models, get_pr_diff_multiple_patchs, \
|
||||
OUTPUT_BUFFER_TOKENS_HARD_THRESHOLD
|
||||
from pr_agent.algo.pr_processing import (OUTPUT_BUFFER_TOKENS_HARD_THRESHOLD,
|
||||
get_pr_diff,
|
||||
get_pr_diff_multiple_patchs,
|
||||
retry_with_fallback_models)
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.utils import set_custom_labels, PRDescriptionHeader
|
||||
from pr_agent.algo.utils import load_yaml, get_user_labels, ModelType, show_relevant_configurations, get_max_tokens, \
|
||||
clip_tokens
|
||||
from pr_agent.algo.utils import (ModelType, PRDescriptionHeader, clip_tokens,
|
||||
get_max_tokens, get_user_labels, load_yaml,
|
||||
set_custom_labels,
|
||||
show_relevant_configurations)
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers import get_git_provider, GithubProvider, get_git_provider_with_context
|
||||
from pr_agent.git_providers import (GithubProvider, get_git_provider,
|
||||
get_git_provider_with_context)
|
||||
from pr_agent.git_providers.git_provider import get_main_pr_language
|
||||
from pr_agent.log import get_logger
|
||||
from pr_agent.servers.help import HelpMessage
|
||||
from pr_agent.tools.ticket_pr_compliance_check import extract_ticket_links_from_pr_description, extract_tickets, \
|
||||
extract_and_cache_pr_tickets
|
||||
from pr_agent.tools.ticket_pr_compliance_check import (
|
||||
extract_and_cache_pr_tickets, extract_ticket_links_from_pr_description,
|
||||
extract_tickets)
|
||||
|
||||
|
||||
class PRDescription:
|
||||
|
||||
@ -9,7 +9,7 @@ from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||
from pr_agent.algo.ai_handlers.litellm_ai_handler import LiteLLMAIHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.utils import load_yaml, set_custom_labels, get_user_labels
|
||||
from pr_agent.algo.utils import get_user_labels, load_yaml, set_custom_labels
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers import get_git_provider
|
||||
from pr_agent.git_providers.git_provider import get_main_pr_language
|
||||
|
||||
@ -9,10 +9,10 @@ from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||
from pr_agent.algo.ai_handlers.litellm_ai_handler import LiteLLMAIHandler
|
||||
from pr_agent.algo.pr_processing import retry_with_fallback_models
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.utils import ModelType, load_yaml, clip_tokens
|
||||
from pr_agent.algo.utils import ModelType, clip_tokens, load_yaml
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers import GithubProvider, BitbucketServerProvider, \
|
||||
get_git_provider_with_context
|
||||
from pr_agent.git_providers import (BitbucketServerProvider, GithubProvider,
|
||||
get_git_provider_with_context)
|
||||
from pr_agent.log import get_logger
|
||||
|
||||
|
||||
|
||||
@ -6,8 +6,8 @@ from jinja2 import Environment, StrictUndefined
|
||||
|
||||
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||
from pr_agent.algo.ai_handlers.litellm_ai_handler import LiteLLMAIHandler
|
||||
from pr_agent.algo.git_patch_processing import convert_to_hunks_with_lines_numbers, \
|
||||
extract_hunk_lines_from_patch
|
||||
from pr_agent.algo.git_patch_processing import (
|
||||
convert_to_hunks_with_lines_numbers, extract_hunk_lines_from_patch)
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.utils import ModelType
|
||||
|
||||
@ -4,19 +4,27 @@ import traceback
|
||||
from collections import OrderedDict
|
||||
from functools import partial
|
||||
from typing import List, Tuple
|
||||
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
|
||||
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||
from pr_agent.algo.ai_handlers.litellm_ai_handler import LiteLLMAIHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models, add_ai_metadata_to_diff_files
|
||||
from pr_agent.algo.pr_processing import (add_ai_metadata_to_diff_files,
|
||||
get_pr_diff,
|
||||
retry_with_fallback_models)
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.utils import github_action_output, load_yaml, ModelType, \
|
||||
show_relevant_configurations, convert_to_markdown_v2, PRReviewHeader
|
||||
from pr_agent.algo.utils import (ModelType, PRReviewHeader,
|
||||
convert_to_markdown_v2, github_action_output,
|
||||
load_yaml, show_relevant_configurations)
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers import get_git_provider, get_git_provider_with_context
|
||||
from pr_agent.git_providers.git_provider import IncrementalPR, get_main_pr_language
|
||||
from pr_agent.git_providers import (get_git_provider,
|
||||
get_git_provider_with_context)
|
||||
from pr_agent.git_providers.git_provider import (IncrementalPR,
|
||||
get_main_pr_language)
|
||||
from pr_agent.log import get_logger
|
||||
from pr_agent.servers.help import HelpMessage
|
||||
from pr_agent.tools.ticket_pr_compliance_check import extract_tickets, extract_and_cache_pr_tickets
|
||||
from pr_agent.tools.ticket_pr_compliance_check import (
|
||||
extract_and_cache_pr_tickets, extract_tickets)
|
||||
|
||||
|
||||
class PRReviewer:
|
||||
|
||||
@ -34,9 +34,9 @@ class PRSimilarIssue:
|
||||
|
||||
if get_settings().pr_similar_issue.vectordb == "pinecone":
|
||||
try:
|
||||
import pandas as pd
|
||||
import pinecone
|
||||
from pinecone_datasets import Dataset, DatasetMetadata
|
||||
import pandas as pd
|
||||
except:
|
||||
raise Exception("Please install 'pinecone' and 'pinecone_datasets' to use pinecone as vectordb")
|
||||
# assuming pinecone api key and environment are set in secrets file
|
||||
@ -111,7 +111,7 @@ class PRSimilarIssue:
|
||||
|
||||
elif get_settings().pr_similar_issue.vectordb == "lancedb":
|
||||
try:
|
||||
import lancedb # import lancedb only if needed
|
||||
import lancedb # import lancedb only if needed
|
||||
except:
|
||||
raise Exception("Please install lancedb to use lancedb as vectordb")
|
||||
self.db = lancedb.connect(get_settings().lancedb.uri)
|
||||
|
||||
@ -3,14 +3,16 @@ from datetime import date
|
||||
from functools import partial
|
||||
from time import sleep
|
||||
from typing import Tuple
|
||||
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
|
||||
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||
from pr_agent.algo.ai_handlers.litellm_ai_handler import LiteLLMAIHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.utils import ModelType, show_relevant_configurations
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers import get_git_provider, GithubProvider
|
||||
from pr_agent.git_providers import GithubProvider, get_git_provider
|
||||
from pr_agent.git_providers.git_provider import get_main_pr_language
|
||||
from pr_agent.log import get_logger
|
||||
|
||||
|
||||
@ -108,7 +108,7 @@ async def extract_tickets(git_provider):
|
||||
|
||||
|
||||
async def extract_and_cache_pr_tickets(git_provider, vars):
|
||||
if get_settings().get('config.require_ticket_analysis_review', False):
|
||||
if not get_settings().get('pr_reviewer.require_ticket_analysis_review', False):
|
||||
return
|
||||
related_tickets = get_settings().get('related_tickets', [])
|
||||
if not related_tickets:
|
||||
|
||||
@ -6,19 +6,19 @@ build-backend = "setuptools.build_meta"
|
||||
name = "pr-agent"
|
||||
version = "0.2.4"
|
||||
|
||||
authors = [{name= "CodiumAI", email = "tal.r@codium.ai"}]
|
||||
authors = [{ name = "CodiumAI", email = "tal.r@codium.ai" }]
|
||||
|
||||
maintainers = [
|
||||
{name = "Tal Ridnik", email = "tal.r@codium.ai"},
|
||||
{name = "Ori Kotek", email = "ori.k@codium.ai"},
|
||||
{name = "Hussam Lawen", email = "hussam.l@codium.ai"},
|
||||
{ name = "Tal Ridnik", email = "tal.r@codium.ai" },
|
||||
{ name = "Ori Kotek", email = "ori.k@codium.ai" },
|
||||
{ name = "Hussam Lawen", email = "hussam.l@codium.ai" },
|
||||
]
|
||||
|
||||
description = "CodiumAI PR-Agent aims to help efficiently review and handle pull requests, by providing AI feedbacks and suggestions."
|
||||
readme = "README.md"
|
||||
requires-python = ">=3.10"
|
||||
keywords = ["AI", "Agents", "Pull Request", "Automation", "Code Review"]
|
||||
license = {name = "Apache 2.0", file = "LICENSE"}
|
||||
license = { name = "Apache 2.0", file = "LICENSE" }
|
||||
|
||||
classifiers = [
|
||||
"Intended Audience :: Developers",
|
||||
@ -28,7 +28,7 @@ dynamic = ["dependencies"]
|
||||
|
||||
|
||||
[tool.setuptools.dynamic]
|
||||
dependencies = {file = ["requirements.txt"]}
|
||||
dependencies = { file = ["requirements.txt"] }
|
||||
|
||||
[project.urls]
|
||||
"Homepage" = "https://github.com/Codium-ai/pr-agent"
|
||||
@ -40,41 +40,43 @@ license-files = ["LICENSE"]
|
||||
|
||||
[tool.setuptools.packages.find]
|
||||
where = ["."]
|
||||
include = ["pr_agent*"] # include pr_agent and any sub-packages it finds under it.
|
||||
include = [
|
||||
"pr_agent*",
|
||||
] # include pr_agent and any sub-packages it finds under it.
|
||||
|
||||
[project.scripts]
|
||||
pr-agent = "pr_agent.cli:run"
|
||||
|
||||
|
||||
[tool.ruff]
|
||||
|
||||
line-length = 120
|
||||
|
||||
select = [
|
||||
"E", # Pyflakes
|
||||
"F", # Pyflakes
|
||||
"B", # flake8-bugbear
|
||||
"I001", # isort basic checks
|
||||
"I002", # isort missing-required-import
|
||||
]
|
||||
lint.select = [
|
||||
"E", # Pyflakes
|
||||
"F", # Pyflakes
|
||||
"B", # flake8-bugbear
|
||||
"I001", # isort basic checks
|
||||
"I002", # isort missing-required-import
|
||||
]
|
||||
|
||||
# First commit - only fixing isort
|
||||
fixable = [
|
||||
"I001", # isort basic checks
|
||||
lint.fixable = [
|
||||
"I001", # isort basic checks
|
||||
]
|
||||
|
||||
unfixable = [
|
||||
"B", # Avoid trying to fix flake8-bugbear (`B`) violations.
|
||||
]
|
||||
|
||||
exclude = [
|
||||
"api/code_completions",
|
||||
lint.unfixable = [
|
||||
"B", # Avoid trying to fix flake8-bugbear (`B`) violations.
|
||||
]
|
||||
|
||||
ignore = [
|
||||
"E999", "B008"
|
||||
]
|
||||
lint.exclude = ["api/code_completions"]
|
||||
|
||||
[tool.ruff.per-file-ignores]
|
||||
"__init__.py" = ["E402"] # Ignore `E402` (import violations) in all `__init__.py` files, and in `path/to/file.py`.
|
||||
# TODO: should decide if maybe not to ignore these.
|
||||
lint.ignore = ["E999", "B008"]
|
||||
|
||||
[tool.ruff.lint.per-file-ignores]
|
||||
"__init__.py" = [
|
||||
"E402",
|
||||
] # Ignore `E402` (import violations) in all `__init__.py` files, and in `path/to/file.py`.
|
||||
|
||||
[tool.bandit]
|
||||
exclude_dirs = ["tests"]
|
||||
skips = ["B101"]
|
||||
tests = []
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
pytest==7.4.0
|
||||
poetry
|
||||
twine
|
||||
pre-commit>=4,<5
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
aiohttp==3.9.5
|
||||
anthropic[vertex]==0.37.1
|
||||
anthropic[vertex]==0.39.0
|
||||
atlassian-python-api==3.41.4
|
||||
azure-devops==7.1.0b3
|
||||
azure-identity==1.15.0
|
||||
@ -12,17 +12,17 @@ google-cloud-aiplatform==1.38.0
|
||||
google-generativeai==0.8.3
|
||||
google-cloud-storage==2.10.0
|
||||
Jinja2==3.1.2
|
||||
litellm==1.50.2
|
||||
litellm==1.52.12
|
||||
loguru==0.7.2
|
||||
msrest==0.7.1
|
||||
openai==1.52.1
|
||||
openai==1.55.3
|
||||
pytest==7.4.0
|
||||
PyGithub==1.59.*
|
||||
PyYAML==6.0.1
|
||||
python-gitlab==3.15.0
|
||||
retry==0.9.2
|
||||
starlette-context==0.3.6
|
||||
tiktoken==0.7.0
|
||||
tiktoken==0.8.0
|
||||
ujson==5.8.0
|
||||
uvicorn==0.22.0
|
||||
tenacity==8.2.3
|
||||
|
||||
@ -32,4 +32,3 @@ def main():
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
"""
|
||||
|
||||
|
||||
@ -5,16 +5,16 @@ import time
|
||||
from datetime import datetime
|
||||
|
||||
import jwt
|
||||
from atlassian.bitbucket import Cloud
|
||||
|
||||
import requests
|
||||
from atlassian.bitbucket import Cloud
|
||||
from requests.auth import HTTPBasicAuth
|
||||
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.log import setup_logger, get_logger
|
||||
from tests.e2e_tests.e2e_utils import NEW_FILE_CONTENT, FILE_PATH, PR_HEADER_START_WITH, REVIEW_START_WITH, \
|
||||
IMPROVE_START_WITH_REGEX_PATTERN, NUM_MINUTES
|
||||
|
||||
from pr_agent.log import get_logger, setup_logger
|
||||
from tests.e2e_tests.e2e_utils import (FILE_PATH,
|
||||
IMPROVE_START_WITH_REGEX_PATTERN,
|
||||
NEW_FILE_CONTENT, NUM_MINUTES,
|
||||
PR_HEADER_START_WITH, REVIEW_START_WITH)
|
||||
|
||||
log_level = os.environ.get("LOG_LEVEL", "INFO")
|
||||
setup_logger(log_level)
|
||||
|
||||
@ -5,9 +5,11 @@ from datetime import datetime
|
||||
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers import get_git_provider
|
||||
from pr_agent.log import setup_logger, get_logger
|
||||
from tests.e2e_tests.e2e_utils import NEW_FILE_CONTENT, FILE_PATH, PR_HEADER_START_WITH, REVIEW_START_WITH, \
|
||||
IMPROVE_START_WITH_REGEX_PATTERN, NUM_MINUTES
|
||||
from pr_agent.log import get_logger, setup_logger
|
||||
from tests.e2e_tests.e2e_utils import (FILE_PATH,
|
||||
IMPROVE_START_WITH_REGEX_PATTERN,
|
||||
NEW_FILE_CONTENT, NUM_MINUTES,
|
||||
PR_HEADER_START_WITH, REVIEW_START_WITH)
|
||||
|
||||
log_level = os.environ.get("LOG_LEVEL", "INFO")
|
||||
setup_logger(log_level)
|
||||
|
||||
@ -7,9 +7,11 @@ import gitlab
|
||||
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.git_providers import get_git_provider
|
||||
from pr_agent.log import setup_logger, get_logger
|
||||
from tests.e2e_tests.e2e_utils import NEW_FILE_CONTENT, FILE_PATH, PR_HEADER_START_WITH, REVIEW_START_WITH, \
|
||||
IMPROVE_START_WITH_REGEX_PATTERN, NUM_MINUTES
|
||||
from pr_agent.log import get_logger, setup_logger
|
||||
from tests.e2e_tests.e2e_utils import (FILE_PATH,
|
||||
IMPROVE_START_WITH_REGEX_PATTERN,
|
||||
NEW_FILE_CONTENT, NUM_MINUTES,
|
||||
PR_HEADER_START_WITH, REVIEW_START_WITH)
|
||||
|
||||
log_level = os.environ.get("LOG_LEVEL", "INFO")
|
||||
setup_logger(log_level)
|
||||
|
||||
@ -1,8 +1,10 @@
|
||||
from unittest.mock import MagicMock
|
||||
|
||||
from atlassian.bitbucket import Bitbucket
|
||||
|
||||
from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
|
||||
from pr_agent.git_providers import BitbucketServerProvider
|
||||
from pr_agent.git_providers.bitbucket_provider import BitbucketProvider
|
||||
from unittest.mock import MagicMock
|
||||
from atlassian.bitbucket import Bitbucket
|
||||
from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
|
||||
|
||||
|
||||
class TestBitbucketProvider:
|
||||
|
||||
@ -1,4 +1,5 @@
|
||||
from unittest.mock import MagicMock
|
||||
|
||||
from pr_agent.git_providers.codecommit_client import CodeCommitClient
|
||||
|
||||
|
||||
|
||||
@ -1,9 +1,11 @@
|
||||
import pytest
|
||||
from unittest.mock import patch
|
||||
from pr_agent.git_providers.codecommit_provider import CodeCommitFile
|
||||
from pr_agent.git_providers.codecommit_provider import CodeCommitProvider
|
||||
from pr_agent.git_providers.codecommit_provider import PullRequestCCMimic
|
||||
|
||||
import pytest
|
||||
|
||||
from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
|
||||
from pr_agent.git_providers.codecommit_provider import (CodeCommitFile,
|
||||
CodeCommitProvider,
|
||||
PullRequestCCMimic)
|
||||
|
||||
|
||||
class TestCodeCommitFile:
|
||||
|
||||
@ -1,4 +1,5 @@
|
||||
import pytest
|
||||
|
||||
from pr_agent.algo.git_patch_processing import extend_patch
|
||||
from pr_agent.algo.pr_processing import pr_generate_extended_diff
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
|
||||
@ -1,7 +1,9 @@
|
||||
import pytest
|
||||
|
||||
from pr_agent.algo.file_filter import filter_ignored
|
||||
from pr_agent.config_loader import global_settings
|
||||
|
||||
|
||||
class TestIgnoreFilter:
|
||||
def test_no_ignores(self):
|
||||
"""
|
||||
|
||||
@ -1,9 +1,10 @@
|
||||
|
||||
# Generated by CodiumAI
|
||||
import pytest
|
||||
|
||||
from pr_agent.algo.types import FilePatchInfo
|
||||
from pr_agent.algo.utils import find_line_number_of_relevant_line_in_file
|
||||
|
||||
import pytest
|
||||
|
||||
class TestFindLineNumberOfRelevantLineInFile:
|
||||
# Tests that the function returns the correct line number and absolute position when the relevant line is found in the patch
|
||||
|
||||
@ -1,7 +1,9 @@
|
||||
import os
|
||||
import json
|
||||
import os
|
||||
|
||||
from pr_agent.algo.utils import get_settings, github_action_output
|
||||
|
||||
|
||||
class TestGitHubOutput:
|
||||
def test_github_action_output_enabled(self, monkeypatch, tmp_path):
|
||||
get_settings().set('GITHUB_ACTION_CONFIG.ENABLE_OUTPUT', True)
|
||||
|
||||
@ -47,7 +47,3 @@ PR Feedback:
|
||||
|
||||
expected_output = [{'relevant file': 'src/app.py:\n', 'suggestion content': 'The print statement is outside inside the if __name__ ==:'}]
|
||||
assert load_yaml(yaml_str) == expected_output
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,10 +1,10 @@
|
||||
|
||||
# Generated by CodiumAI
|
||||
import pytest
|
||||
|
||||
from pr_agent.algo.utils import try_fix_yaml
|
||||
|
||||
|
||||
import pytest
|
||||
|
||||
class TestTryFixYaml:
|
||||
|
||||
# The function successfully parses a valid YAML string.
|
||||
|
||||
Reference in New Issue
Block a user