mirror of
https://github.com/qodo-ai/pr-agent.git
synced 2025-07-21 04:50:39 +08:00
Compare commits
377 Commits
feature/su
...
ok/gitlab_
| Author | SHA1 | Date | |
|---|---|---|---|
| e41247c473 | |||
| 5704070834 | |||
| 98fe376add | |||
| 8e5498ee97 | |||
| 0412d7aca0 | |||
| 1eac3245d9 | |||
| cd51bef7f7 | |||
| e8aa33fa0b | |||
| 54b021b02c | |||
| 32151e3d9a | |||
| 32358678e6 | |||
| 42e32664a1 | |||
| 1e97236a15 | |||
| 321f7bce46 | |||
| 02a1d8dbfc | |||
| e34f9d8d1c | |||
| 35dac012bd | |||
| 21ced18f50 | |||
| fca78cf395 | |||
| d1b91b0ea3 | |||
| 76e00acbdb | |||
| 2f83e7738c | |||
| f4a226b0f7 | |||
| f5e2838fc3 | |||
| bbdfd2c3d4 | |||
| 74572e1768 | |||
| f0a17b863c | |||
| 86fd84e113 | |||
| d5b9be23d3 | |||
| 057bb3932f | |||
| 05f29cc406 | |||
| 63c4c7e584 | |||
| 1ea23cab96 | |||
| e99f9fd59f | |||
| fdf6a3e833 | |||
| 79cb94b4c2 | |||
| 9adec7cc10 | |||
| 1f0df47b4d | |||
| a71a12791b | |||
| 23fa834721 | |||
| 9f67d07156 | |||
| 6731a7643e | |||
| f87fdd88ad | |||
| f825f6b90a | |||
| f5d5008a24 | |||
| 0b63d4cde5 | |||
| 2e246869d0 | |||
| 2f9546e144 | |||
| 6134c2ff61 | |||
| 3cfbba74f8 | |||
| 050bb60671 | |||
| 12a7e1ce6e | |||
| cd0438005b | |||
| 7c3188ae06 | |||
| 6cd38a37cd | |||
| 12e51bb6aa | |||
| e2a4cd6b03 | |||
| 329e228aa2 | |||
| 3d5d517f2a | |||
| a2eb2e4dac | |||
| d89792d379 | |||
| 23ed2553c4 | |||
| fe29ce2911 | |||
| df25a3ede2 | |||
| 4c36fb4df2 | |||
| 67c61e0ac8 | |||
| 0985db4e36 | |||
| ee2c00abeb | |||
| 577f24d107 | |||
| fc24b34c2b | |||
| 1e962476da | |||
| 3326327572 | |||
| 36be79ea38 | |||
| 523839be7d | |||
| d1586ddd77 | |||
| 3420853923 | |||
| 1f373d7b0a | |||
| 7fdbd6a680 | |||
| 17b40a1fa1 | |||
| c47e74c5c7 | |||
| 7abbe08ff1 | |||
| 8038b6ab99 | |||
| 6e26ad0966 | |||
| 7e2449b228 | |||
| 97bfee47a3 | |||
| 3b27c834a4 | |||
| 5bc2ef1eff | |||
| 2f558006bf | |||
| 8868c92141 | |||
| 370520df51 | |||
| e17dd66dce | |||
| fc8494d696 | |||
| f8aea909b4 | |||
| 2e832b8fb4 | |||
| ccddbeccad | |||
| a47fa342cb | |||
| f73cddcb93 | |||
| 5f36f0d753 | |||
| dc4bf13d39 | |||
| bdf7eff7cd | |||
| dc67e6a66e | |||
| 6d91f44634 | |||
| 0396e10706 | |||
| 77f243b7ab | |||
| c507785475 | |||
| 5c5015b267 | |||
| 3efe08d619 | |||
| 2e36fce4eb | |||
| d6d4427545 | |||
| 5d45632247 | |||
| 90c045e3d0 | |||
| 7f0a96d8f7 | |||
| 8fb9affef3 | |||
| 6c42a471e1 | |||
| f2b74b6970 | |||
| ffd11aeffc | |||
| 05e4e09dfc | |||
| 13092118dc | |||
| 7d108992fc | |||
| e5a8ed205e | |||
| 90f97b0226 | |||
| 9e0f5f0ccc | |||
| 87ea0176b9 | |||
| 62f08f4ec4 | |||
| fe0058f25f | |||
| 6d2673f39d | |||
| b3a1d456b2 | |||
| f77a5f6929 | |||
| fdeae9c209 | |||
| a994ec1427 | |||
| e5259e2f5c | |||
| 978348240b | |||
| 4d92e7d9c2 | |||
| 6f1b418b25 | |||
| 51e08c3c2b | |||
| 4c29ff2db1 | |||
| 5fbaa4366f | |||
| aee08ebbfe | |||
| 6ad8df6be7 | |||
| 539edcad3c | |||
| b7172df700 | |||
| 768bd40ad8 | |||
| ea27c63f13 | |||
| c866288b0a | |||
| 8ae3c60670 | |||
| f8f415eb75 | |||
| 24583b05f7 | |||
| fa421fd169 | |||
| e0ae5c945e | |||
| 865888e4e8 | |||
| 3b7cfe7bc5 | |||
| 262f9dddbc | |||
| fa706b6e96 | |||
| ff51ab0946 | |||
| 7884aa2348 | |||
| 8f3520807c | |||
| fa90b242e3 | |||
| 2dfd34bd61 | |||
| 48f569bef0 | |||
| a20fb9cc0c | |||
| c58e1f90e7 | |||
| d363f148f0 | |||
| cbf96a2e67 | |||
| 4d87c3ec6a | |||
| c13c52d733 | |||
| dbf8142fe0 | |||
| bacf6c96c2 | |||
| c9d49da8f7 | |||
| 7b22edac60 | |||
| fc309f69b9 | |||
| 7efb5cf74e | |||
| 8e200197c5 | |||
| fe98f67e08 | |||
| 0b1edd9716 | |||
| e638dc075c | |||
| 559b160886 | |||
| 571b8769ac | |||
| e4bd2148ce | |||
| 1637bd8774 | |||
| ce33582d3d | |||
| bc6b592fd9 | |||
| 24ae6b966f | |||
| f4de3d2899 | |||
| 4cacb07ec2 | |||
| 2371a9b041 | |||
| 5b7403ae80 | |||
| e979b8643d | |||
| 05b4f167a3 | |||
| 2c4245e023 | |||
| d54ee252ee | |||
| 85eec0b98c | |||
| 41a988d99a | |||
| 448da3d481 | |||
| b030299547 | |||
| 5bdbfda1e2 | |||
| 047cfb21f3 | |||
| 35a2497a38 | |||
| 99630f83c2 | |||
| 1757f2707c | |||
| 66c44d715c | |||
| 8f7855013a | |||
| e200be4e57 | |||
| d0b734bc91 | |||
| 399d5c5c5d | |||
| 1b88049cb0 | |||
| 0304bf05c1 | |||
| 94173cbb06 | |||
| 75447280e4 | |||
| 5edff8b7e4 | |||
| 487351d343 | |||
| 93311a9d9b | |||
| 704030230f | |||
| 60bce8f049 | |||
| e394cb7ddb | |||
| a0e4fb01af | |||
| eb9190efa1 | |||
| 8cc37d6f59 | |||
| 6cc9fe3d06 | |||
| 0acf423450 | |||
| 7958786b4c | |||
| 719f3a9dd8 | |||
| 71efd84113 | |||
| 25e46a99fd | |||
| 2531849b73 | |||
| 19f11f99ce | |||
| 87f978e816 | |||
| 7488eb8c9e | |||
| b3e79ed677 | |||
| 5d2fe07bf7 | |||
| 84bf95e9ab | |||
| 4f4989af8c | |||
| 0a4a604c28 | |||
| 23a249ccdb | |||
| 4a6bf4c55a | |||
| 3f75b14ba3 | |||
| ae9cedd50d | |||
| ae63833043 | |||
| da6828ad87 | |||
| ea1cd7ae45 | |||
| 1c1aad2806 | |||
| f466d79031 | |||
| e2323dfb9f | |||
| e51e443adc | |||
| f6d4a214ca | |||
| 4bb46d9faa | |||
| f337d76af6 | |||
| 4e59693c76 | |||
| 4033303c1f | |||
| 38c8d187d2 | |||
| f8ddfd2f25 | |||
| 4b4fda37a6 | |||
| 9ca6b789a7 | |||
| 0f73f5f906 | |||
| 055a8ea859 | |||
| 5742a9be1e | |||
| 914cc6639a | |||
| f34cda126a | |||
| dece20c984 | |||
| 94c1f430af | |||
| 9fadde388b | |||
| d1b6b3bc95 | |||
| f57d58ee7d | |||
| 77a451ada0 | |||
| 4b8420aa16 | |||
| 25bc69f70e | |||
| e2faf117c5 | |||
| aaff03bb60 | |||
| cd1e62ec96 | |||
| 7767cae181 | |||
| 1bc206e7b2 | |||
| 52a438b3c8 | |||
| b8a71b369d | |||
| 72af2a1f9c | |||
| fd4a2bf7ff | |||
| a3211d4958 | |||
| 86d7ed5f82 | |||
| 210d94f2aa | |||
| b2d952cafa | |||
| 6eacf4791d | |||
| 4076f67ab8 | |||
| c2639a2520 | |||
| 38db65831e | |||
| e1b856f7e6 | |||
| 5fdc9223e9 | |||
| 301622216f | |||
| 973cb2de1c | |||
| b63db6cef0 | |||
| 8fba670bda | |||
| ca47833c56 | |||
| 567475c18c | |||
| fb4badd160 | |||
| 9695d96799 | |||
| 0930f76cb7 | |||
| 365559405f | |||
| d4adcb3c22 | |||
| 75167c2700 | |||
| 78f5f58774 | |||
| 81a2e5cbe2 | |||
| e63a4f47ce | |||
| caff65613f | |||
| ee3cac9836 | |||
| 8b3ff7a632 | |||
| 7d49e080fc | |||
| 1a94079936 | |||
| 7ed12c2f8e | |||
| ed8cf27b05 | |||
| 4b786b350e | |||
| 110d987514 | |||
| cc5e01cec5 | |||
| 620bf68d25 | |||
| 86e5a30a36 | |||
| 6c10f78c31 | |||
| 46922d2842 | |||
| 55ab198bb2 | |||
| 0c7f048e58 | |||
| efc8f755d5 | |||
| aebcb3f3c6 | |||
| c8d369ee61 | |||
| 1cedd13cf3 | |||
| b7cd368cce | |||
| 6ef5843380 | |||
| c5f2abb548 | |||
| bfdff08cb8 | |||
| ffa4ce3f1e | |||
| f1380df468 | |||
| 2de83827b6 | |||
| 2c4c7c485e | |||
| f3df032f06 | |||
| 9e96fbab1f | |||
| e15559011d | |||
| 2434240f08 | |||
| d3936122ec | |||
| c75f561701 | |||
| f1ab6ec88f | |||
| f293717827 | |||
| 270912d41e | |||
| d9bd73646c | |||
| 933f2ca093 | |||
| 4331610e01 | |||
| d04c0f490c | |||
| f7c703751f | |||
| 13101df811 | |||
| 1eab6a8479 | |||
| 64cb5da821 | |||
| 6648c04799 | |||
| 24697d613b | |||
| f6f4d32edb | |||
| 938a8a7c7d | |||
| deda4baa87 | |||
| 30248c2a7b | |||
| c2e3bf7b70 | |||
| e5e90e35e5 | |||
| 3e445c7e03 | |||
| 53e7ff62bf | |||
| 1eea60c6a5 | |||
| d0c544e650 | |||
| 28249924fd | |||
| a2d8695ca4 | |||
| 259fa84eeb | |||
| ff720d32fe | |||
| 399d7b7990 | |||
| 74dfae8dbe | |||
| 71b077faf8 | |||
| b6333e7f20 | |||
| e53ae712f9 | |||
| 542c4599ba | |||
| 795f6ab8d5 | |||
| e3b2469e0f | |||
| 0ebd29d398 | |||
| 987befe457 | |||
| 1a626fb1f3 | |||
| 0ce42e786e | |||
| 84231f99dc | |||
| 70b7acee15 | |||
| aa1c32c714 | |||
| f1004273ec | |||
| 33f859b073 |
@ -1 +1,3 @@
|
||||
venv/
|
||||
venv/
|
||||
pr_agent/settings/.secrets.toml
|
||||
pics/
|
||||
16
.github/workflows/review.yaml
vendored
Normal file
16
.github/workflows/review.yaml
vendored
Normal file
@ -0,0 +1,16 @@
|
||||
on:
|
||||
pull_request:
|
||||
issue_comment:
|
||||
jobs:
|
||||
pr_agent_job:
|
||||
runs-on: ubuntu-latest
|
||||
name: Run pr agent on every pull request
|
||||
steps:
|
||||
- name: PR Agent action step
|
||||
id: pragent
|
||||
uses: Codium-ai/pr-agent@main
|
||||
env:
|
||||
OPENAI_KEY: ${{ secrets.OPENAI_KEY }}
|
||||
OPENAI_ORG: ${{ secrets.OPENAI_ORG }} # optional
|
||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
|
||||
11
.gitlab-ci.yml
Normal file
11
.gitlab-ci.yml
Normal file
@ -0,0 +1,11 @@
|
||||
bot-review:
|
||||
stage: test
|
||||
variables:
|
||||
MR_URL: ${CI_MERGE_REQUEST_PROJECT_URL}/-/merge_requests/${CI_MERGE_REQUEST_IID}
|
||||
image: docker:latest
|
||||
services:
|
||||
- docker:19-dind
|
||||
script:
|
||||
- docker run --rm -e OPENAI.KEY=${OPEN_API_KEY} -e OPENAI.ORG=${OPEN_API_ORG} -e GITLAB.PERSONAL_ACCESS_TOKEN=${GITLAB_PAT} -e CONFIG.GIT_PROVIDER=gitlab codiumai/pr-agent --pr_url ${MR_URL} describe
|
||||
rules:
|
||||
- if: $CI_COMMIT_BRANCH != $CI_DEFAULT_BRANCH
|
||||
19
CONFIGURATION.md
Normal file
19
CONFIGURATION.md
Normal file
@ -0,0 +1,19 @@
|
||||
## Configuration
|
||||
|
||||
The different tools and sub-tools used by CodiumAI pr-agent are easily configurable via the configuration file: `/pr-agent/settings/configuration.toml`.
|
||||
##### Git Provider:
|
||||
You can select your git_provider with the flag `git_provider` in the `config` section
|
||||
|
||||
##### PR Reviewer:
|
||||
|
||||
You can enable/disable the different PR Reviewer abilities with the following flags (`pr_reviewer` section):
|
||||
```
|
||||
require_focused_review=true
|
||||
require_score_review=true
|
||||
require_tests_review=true
|
||||
require_security_review=true
|
||||
```
|
||||
You can contol the number of suggestions returned by the PR Reviewer with the following flag:
|
||||
```inline_code_comments=3```
|
||||
And enable/disable the inline code suggestions with the following flag:
|
||||
```inline_code_comments=true```
|
||||
10
Dockerfile.github_action
Normal file
10
Dockerfile.github_action
Normal file
@ -0,0 +1,10 @@
|
||||
FROM python:3.10 as base
|
||||
|
||||
WORKDIR /app
|
||||
ADD requirements.txt .
|
||||
RUN pip install -r requirements.txt && rm requirements.txt
|
||||
ENV PYTHONPATH=/app
|
||||
ADD pr_agent pr_agent
|
||||
ADD github_action/entrypoint.sh /
|
||||
RUN chmod +x /entrypoint.sh
|
||||
ENTRYPOINT ["/entrypoint.sh"]
|
||||
1
Dockerfile.github_action_dockerhub
Normal file
1
Dockerfile.github_action_dockerhub
Normal file
@ -0,0 +1 @@
|
||||
FROM codiumai/pr-agent:github_action
|
||||
218
INSTALL.md
Normal file
218
INSTALL.md
Normal file
@ -0,0 +1,218 @@
|
||||
|
||||
## Installation
|
||||
|
||||
---
|
||||
|
||||
#### Method 1: Use Docker image (no installation required)
|
||||
|
||||
To request a review for a PR, or ask a question about a PR, you can run directly from the Docker image. Here's how:
|
||||
|
||||
1. To request a review for a PR, run the following command:
|
||||
|
||||
```
|
||||
docker run --rm -it -e OPENAI.KEY=<your key> -e GITHUB.USER_TOKEN=<your token> codiumai/pr-agent --pr_url <pr_url> review
|
||||
```
|
||||
|
||||
2. To ask a question about a PR, run the following command:
|
||||
|
||||
```
|
||||
docker run --rm -it -e OPENAI.KEY=<your key> -e GITHUB.USER_TOKEN=<your token> codiumai/pr-agent --pr_url <pr_url> ask "<your question>"
|
||||
```
|
||||
|
||||
Possible questions you can ask include:
|
||||
|
||||
- What is the main theme of this PR?
|
||||
- Is the PR ready for merge?
|
||||
- What are the main changes in this PR?
|
||||
- Should this PR be split into smaller parts?
|
||||
- Can you compose a rhymed song about this PR?
|
||||
|
||||
---
|
||||
|
||||
#### Method 2: Run as a GitHub Action
|
||||
|
||||
You can use our pre-built Github Action Docker image to run PR-Agent as a Github Action.
|
||||
|
||||
1. Add the following file to your repository under `.github/workflows/pr_agent.yml`:
|
||||
|
||||
```yaml
|
||||
on:
|
||||
pull_request:
|
||||
issue_comment:
|
||||
jobs:
|
||||
pr_agent_job:
|
||||
runs-on: ubuntu-latest
|
||||
name: Run pr agent on every pull request, respond to user comments
|
||||
steps:
|
||||
- name: PR Agent action step
|
||||
id: pragent
|
||||
uses: Codium-ai/pr-agent@main
|
||||
env:
|
||||
OPENAI_KEY: ${{ secrets.OPENAI_KEY }}
|
||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
```
|
||||
|
||||
2. Add the following secret to your repository under `Settings > Secrets`:
|
||||
|
||||
```
|
||||
OPENAI_KEY: <your key>
|
||||
```
|
||||
|
||||
The GITHUB_TOKEN secret is automatically created by GitHub.
|
||||
|
||||
3. Merge this change to your main branch.
|
||||
When you open your next PR, you should see a comment from `github-actions` bot with a review of your PR, and instructions on how to use the rest of the tools.
|
||||
|
||||
4. You may configure PR-Agent by adding environment variables under the env section corresponding to any configurable property in the [configuration](./CONFIGURATION.md) file. Some examples:
|
||||
```yaml
|
||||
env:
|
||||
# ... previous environment values
|
||||
OPENAI.ORG: "<Your organization name under your OpenAI account>"
|
||||
PR_REVIEWER.REQUIRE_TESTS_REVIEW: "false" # Disable tests review
|
||||
PR_CODE_SUGGESTIONS.NUM_CODE_SUGGESTIONS: 6 # Increase number of code suggestions
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
#### Method 3: Run from source
|
||||
|
||||
1. Clone this repository:
|
||||
|
||||
```
|
||||
git clone https://github.com/Codium-ai/pr-agent.git
|
||||
```
|
||||
|
||||
2. Install the requirements in your favorite virtual environment:
|
||||
|
||||
```
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
3. Copy the secrets template file and fill in your OpenAI key and your GitHub user token:
|
||||
|
||||
```
|
||||
cp pr_agent/settings/.secrets_template.toml pr_agent/settings/.secrets.toml
|
||||
# Edit .secrets.toml file
|
||||
```
|
||||
|
||||
4. Add the pr_agent folder to your PYTHONPATH, then run the cli.py script:
|
||||
|
||||
```
|
||||
export PYTHONPATH=[$PYTHONPATH:]<PATH to pr_agent folder>
|
||||
python pr_agent/cli.py --pr_url <pr_url> review
|
||||
python pr_agent/cli.py --pr_url <pr_url> ask <your question>
|
||||
python pr_agent/cli.py --pr_url <pr_url> describe
|
||||
python pr_agent/cli.py --pr_url <pr_url> improve
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
#### Method 4: Run as a polling server
|
||||
Request reviews by tagging your Github user on a PR
|
||||
|
||||
Follow steps 1-3 of method 2.
|
||||
Run the following command to start the server:
|
||||
|
||||
```
|
||||
python pr_agent/servers/github_polling.py
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
#### Method 5: Run as a GitHub App
|
||||
Allowing you to automate the review process on your private or public repositories.
|
||||
|
||||
1. Create a GitHub App from the [Github Developer Portal](https://docs.github.com/en/developers/apps/creating-a-github-app).
|
||||
|
||||
- Set the following permissions:
|
||||
- Pull requests: Read & write
|
||||
- Issue comment: Read & write
|
||||
- Metadata: Read-only
|
||||
- Set the following events:
|
||||
- Issue comment
|
||||
- Pull request
|
||||
|
||||
2. Generate a random secret for your app, and save it for later. For example, you can use:
|
||||
|
||||
```
|
||||
WEBHOOK_SECRET=$(python -c "import secrets; print(secrets.token_hex(10))")
|
||||
```
|
||||
|
||||
3. Acquire the following pieces of information from your app's settings page:
|
||||
|
||||
- App private key (click "Generate a private key" and save the file)
|
||||
- App ID
|
||||
|
||||
4. Clone this repository:
|
||||
|
||||
```
|
||||
git clone https://github.com/Codium-ai/pr-agent.git
|
||||
```
|
||||
|
||||
5. Copy the secrets template file and fill in the following:
|
||||
```
|
||||
cp pr_agent/settings/.secrets_template.toml pr_agent/settings/.secrets.toml
|
||||
# Edit .secrets.toml file
|
||||
```
|
||||
- Your OpenAI key.
|
||||
- Copy your app's private key to the private_key field.
|
||||
- Copy your app's ID to the app_id field.
|
||||
- Copy your app's webhook secret to the webhook_secret field.
|
||||
- Set deployment_type to 'app' in [configuration.toml](./pr_agent/settings/configuration.toml)
|
||||
|
||||
> The .secrets.toml file is not copied to the Docker image by default, and is only used for local development.
|
||||
> If you want to use the .secrets.toml file in your Docker image, you can add remove it from the .dockerignore file.
|
||||
> In most production environments, you would inject the secrets file as environment variables or as mounted volumes.
|
||||
> For example, in order to inject a secrets file as a volume in a Kubernetes environment you can update your pod spec to include the following,
|
||||
> assuming you have a secret named `pr-agent-settings` with a key named `.secrets.toml`:
|
||||
```
|
||||
volumes:
|
||||
- name: settings-volume
|
||||
secret:
|
||||
secretName: pr-agent-settings
|
||||
// ...
|
||||
containers:
|
||||
// ...
|
||||
volumeMounts:
|
||||
- mountPath: /app/pr_agent/settings_prod
|
||||
name: settings-volume
|
||||
```
|
||||
|
||||
> Another option is to set the secrets as environment variables in your deployment environment, for example `OPENAI.KEY` and `GITHUB.USER_TOKEN`.
|
||||
|
||||
6. Build a Docker image for the app and optionally push it to a Docker repository. We'll use Dockerhub as an example:
|
||||
|
||||
```
|
||||
docker build . -t codiumai/pr-agent:github_app --target github_app -f docker/Dockerfile
|
||||
docker push codiumai/pr-agent:github_app # Push to your Docker repository
|
||||
```
|
||||
|
||||
7. Host the app using a server, serverless function, or container environment. Alternatively, for development and
|
||||
debugging, you may use tools like smee.io to forward webhooks to your local machine.
|
||||
You can check [Deploy as a Lambda Function](#deploy-as-a-lambda-function)
|
||||
|
||||
8. Go back to your app's settings, and set the following:
|
||||
|
||||
- Webhook URL: The URL of your app's server or the URL of the smee.io channel.
|
||||
- Webhook secret: The secret you generated earlier.
|
||||
|
||||
9. Install the app by navigating to the "Install App" tab and selecting your desired repositories.
|
||||
|
||||
---
|
||||
|
||||
#### Deploy as a Lambda Function
|
||||
|
||||
1. Follow steps 1-5 of [Method 5](#method-5-run-as-a-github-app).
|
||||
2. Build a docker image that can be used as a lambda function
|
||||
```shell
|
||||
docker buildx build --platform=linux/amd64 . -t codiumai/pr-agent:serverless -f docker/Dockerfile.lambda
|
||||
```
|
||||
3. Push image to ECR
|
||||
```shell
|
||||
docker tag codiumai/pr-agent:serverless <AWS_ACCOUNT>.dkr.ecr.<AWS_REGION>.amazonaws.com/codiumai/pr-agent:serverless
|
||||
docker push <AWS_ACCOUNT>.dkr.ecr.<AWS_REGION>.amazonaws.com/codiumai/pr-agent:serverless
|
||||
```
|
||||
4. Create a lambda function that uses the uploaded image. Set the lambda timeout to be at least 3m.
|
||||
5. Configure the lambda function to have a Function URL.
|
||||
6. Go back to steps 8-9 of [Method 5](#method-5-run-as-a-github-app) with the function url as your Webhook URL.
|
||||
The Webhook URL would look like `https://<LAMBDA_FUNCTION_URL>/api/v1/github_webhooks`
|
||||
42
PR_COMPRESSION.md
Normal file
42
PR_COMPRESSION.md
Normal file
@ -0,0 +1,42 @@
|
||||
# Git Patch Logic
|
||||
There are two scenarios:
|
||||
1. The PR is small enough to fit in a single prompt (including system and user prompt)
|
||||
2. The PR is too large to fit in a single prompt (including system and user prompt)
|
||||
|
||||
For both scenarios, we first use the following strategy
|
||||
#### Repo language prioritization strategy
|
||||
|
||||
We prioritize the languages of the repo based on the following criteria:
|
||||
1. Exclude binary files and non code files (e.g. images, pdfs, etc)
|
||||
2. Given the main languages used in the repo
|
||||
2. We sort the PR files by the most common languages in the repo (in descending order):
|
||||
* ```[[file.py, file2.py],[file3.js, file4.jsx],[readme.md]]```
|
||||
|
||||
|
||||
## Small PR
|
||||
In this case, we can fit the entire PR in a single prompt:
|
||||
1. Exclude binary files and non code files (e.g. images, pdfs, etc)
|
||||
2. We Expand the surrounding context of each patch to 6 lines above and below the patch
|
||||
## Large PR
|
||||
|
||||
### Motivation
|
||||
Pull Requests can be very long and contain a lot of information with varying degree of relevance to the pr-agent.
|
||||
We want to be able to pack as much information as possible in a single LMM prompt, while keeping the information relevant to the pr-agent.
|
||||
|
||||
|
||||
|
||||
#### PR compression strategy
|
||||
We prioritize additions over deletions:
|
||||
- Combine all deleted files into a single list (`deleted files`)
|
||||
- File patches are a list of hunks, remove all hunks of type deletion-only from the hunks in the file patch
|
||||
#### Adaptive and token-aware file patch fitting
|
||||
We use [tiktoken](https://github.com/openai/tiktoken) to tokenize the patches after the modifications described above, and we use the following strategy to fit the patches into the prompt:
|
||||
1. Withing each language we sort the files by the number of tokens in the file (in descending order):
|
||||
* ```[[file2.py, file.py],[file4.jsx, file3.js],[readme.md]]```
|
||||
2. Iterate through the patches in the order described above
|
||||
2. Add the patches to the prompt until the prompt reaches a certain buffer from the max token length
|
||||
3. If there are still patches left, add the remaining patches as a list called `other modified files` to the prompt until the prompt reaches the max token length (hard stop), skip the rest of the patches.
|
||||
4. If we haven't reached the max token length, add the `deleted files` to the prompt until the prompt reaches the max token length (hard stop), skip the rest of the patches.
|
||||
|
||||
### Example
|
||||
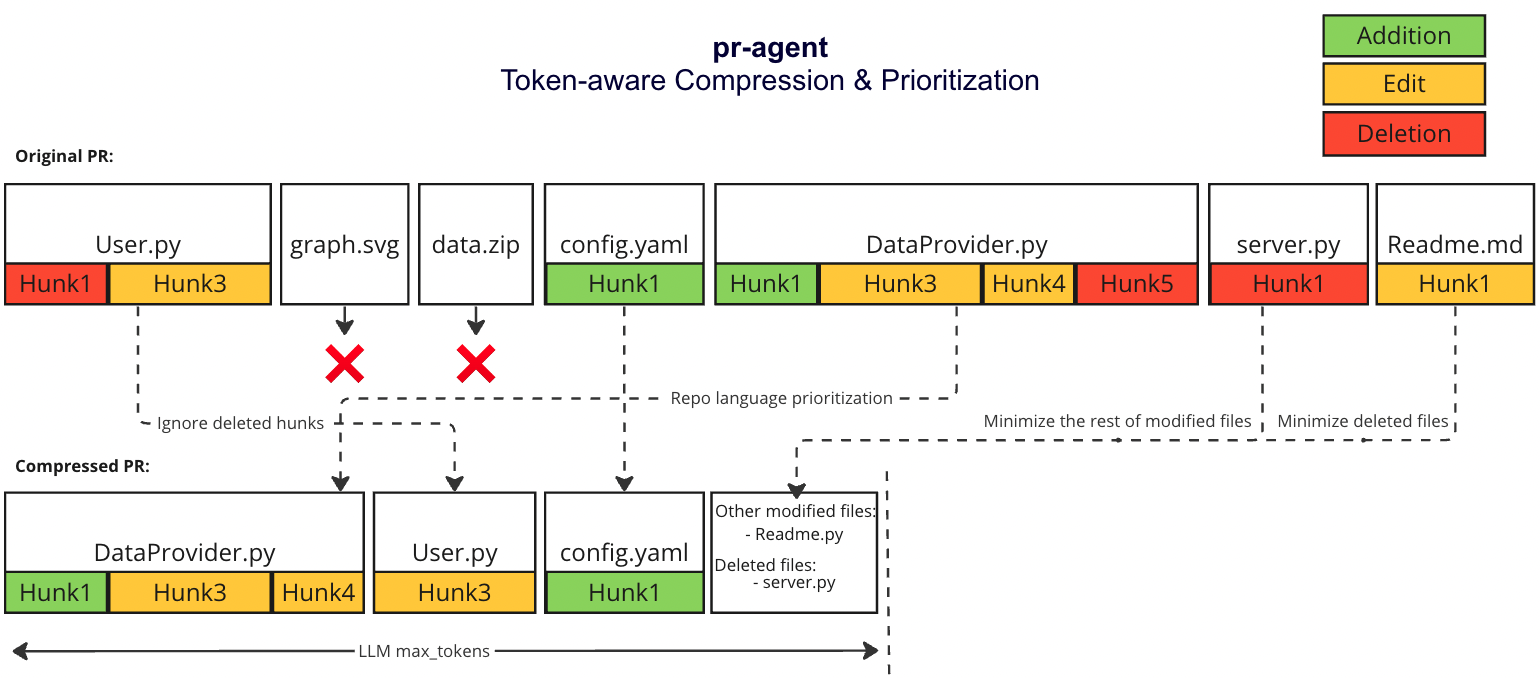
|
||||
387
README.md
387
README.md
@ -1,283 +1,170 @@
|
||||
<div align="center">
|
||||
|
||||
# 🛡️ CodiumAI PR-Agent
|
||||
[](https://github.com/Codium-ai/pr-agent/blob/main/LICENSE)
|
||||
[](https://discord.com/channels/1057273017547378788/1126104260430528613)
|
||||
<div align="center">
|
||||
|
||||
CodiumAI `PR-Agent` is an open-source tool that helps developers review PRs faster and more efficiently.
|
||||
It automatically analyzes the PR, and provides feedback and suggestions, and can answer questions.
|
||||
It is powered by GPT-4, and is based on the [CodiumAI](https://github.com/Codium-ai/) platform.
|
||||
<img src="./pics/logo-dark.png#gh-dark-mode-only" width="330"/>
|
||||
<img src="./pics/logo-light.png#gh-light-mode-only" width="330"/><br/>
|
||||
Making pull requests less painful with an AI agent
|
||||
</div>
|
||||
|
||||
TBD: Add screenshot of the PR Reviewer (could be gif)
|
||||
[](https://github.com/Codium-ai/pr-agent/blob/main/LICENSE)
|
||||
[](https://discord.com/channels/1057273017547378788/1126104260430528613)
|
||||
<a href="https://github.com/Codium-ai/pr-agent/commits/main">
|
||||
<img alt="GitHub" src="https://img.shields.io/github/last-commit/Codium-ai/pr-agent/main?style=for-the-badge" height="20">
|
||||
</a>
|
||||
</div>
|
||||
<div style="text-align:left;">
|
||||
|
||||
CodiumAI `PR-Agent` is an open-source tool aiming to help developers review pull requests faster and more efficiently. It automatically analyzes the pull request and can provide several types of feedback:
|
||||
|
||||
**Auto-Description**: Automatically generating PR description - title, type, summary, code walkthrough and PR labels.
|
||||
\
|
||||
**PR Review**: Adjustable feedback about the PR main theme, type, relevant tests, security issues, focus, score, and various suggestions for the PR content.
|
||||
\
|
||||
**Question Answering**: Answering free-text questions about the PR.
|
||||
\
|
||||
**Code Suggestion**: Committable code suggestions for improving the PR.
|
||||
|
||||
<h3>Example results:</h2>
|
||||
</div>
|
||||
<h4>/describe:</h4>
|
||||
<div align="center">
|
||||
<p float="center">
|
||||
<img src="https://www.codium.ai/images/describe-2.gif" width="800">
|
||||
</p>
|
||||
</div>
|
||||
<h4>/review:</h4>
|
||||
<div align="center">
|
||||
<p float="center">
|
||||
<img src="https://www.codium.ai/images/review-2.gif" width="800">
|
||||
</p>
|
||||
</div>
|
||||
<h4>/reflect_and_review:</h4>
|
||||
<div align="center">
|
||||
<p float="center">
|
||||
<img src="https://www.codium.ai/images/reflect_and_review.gif" width="800">
|
||||
</p>
|
||||
</div>
|
||||
<h4>/ask:</h4>
|
||||
<div align="center">
|
||||
<p float="center">
|
||||
<img src="https://www.codium.ai/images/ask-2.gif" width="800">
|
||||
</p>
|
||||
</div>
|
||||
<h4>/improve:</h4>
|
||||
<div align="center">
|
||||
<p float="center">
|
||||
<img src="https://www.codium.ai/images/improve-2.gif" width="800">
|
||||
</p>
|
||||
</div>
|
||||
<div align="left">
|
||||
|
||||
|
||||
* [Quickstart](#Quickstart)
|
||||
* [Configuration](#Configuration)
|
||||
* [Usage and Tools](#usage-and-tools)
|
||||
* [Roadmap](#roadmap)
|
||||
* [Similar projects](#similar-projects)
|
||||
* Additional files:
|
||||
* CONTRIBUTION.md
|
||||
* LICENSE
|
||||
*
|
||||
- [Overview](#overview)
|
||||
- [Try it now](#try-it-now)
|
||||
- [Installation](#installation)
|
||||
- [Usage and tools](#usage-and-tools)
|
||||
- [Configuration](./CONFIGURATION.md)
|
||||
- [How it works](#how-it-works)
|
||||
- [Roadmap](#roadmap)
|
||||
- [Similar projects](#similar-projects)
|
||||
</div>
|
||||
|
||||
## Quickstart
|
||||
|
||||
## Overview
|
||||
`PR-Agent` offers extensive pull request functionalities across various git providers:
|
||||
| | | GitHub | Gitlab | Bitbucket |
|
||||
|-------|---------------------------------------------|:------:|:------:|:---------:|
|
||||
| TOOLS | Review | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||
| | ⮑ Inline review | :white_check_mark: | :white_check_mark: | |
|
||||
| | Ask | :white_check_mark: | :white_check_mark: | |
|
||||
| | Auto-Description | :white_check_mark: | :white_check_mark: | |
|
||||
| | Improve Code | :white_check_mark: | :white_check_mark: | |
|
||||
| | Reflect and Review | :white_check_mark: | | |
|
||||
| | | | | |
|
||||
| USAGE | CLI | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||
| | Tagging bot | :white_check_mark: | | |
|
||||
| | Actions | :white_check_mark: | | |
|
||||
| | | | | |
|
||||
| CORE | PR compression | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||
| | Repo language prioritization | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||
| | Adaptive and token-aware<br />file patch fitting | :white_check_mark: | :white_check_mark: | :white_check_mark: |
|
||||
| | Incremental PR Review | :white_check_mark: | | |
|
||||
|
||||
Examples for invoking the different tools via the CLI:
|
||||
- **Review**: python cli.py --pr-url=<pr_url> review
|
||||
- **Describe**: python cli.py --pr-url=<pr_url> describe
|
||||
- **Improve**: python cli.py --pr-url=<pr_url> improve
|
||||
- **Ask**: python cli.py --pr-url=<pr_url> ask "Write me a poem about this PR"
|
||||
- **Reflect**: python cli.py --pr-url=<pr_url> reflect
|
||||
|
||||
"<pr_url>" is the url of the relevant PR (for example: https://github.com/Codium-ai/pr-agent/pull/50).
|
||||
|
||||
In the [configuration](./CONFIGURATION.md) file you can select your git provider (GitHub, Gitlab, Bitbucket), and further configure the different tools.
|
||||
|
||||
## Try it now
|
||||
|
||||
Try GPT-4 powered PR-Agent on your public GitHub repository for free. Just mention `@CodiumAI-Agent` and add the desired command in any PR comment! The agent will generate a response based on your command.
|
||||
|
||||
|
||||
|
||||
To set up your own PR-Agent, see the [Installation](#installation) section
|
||||
|
||||
---
|
||||
|
||||
## Installation
|
||||
|
||||
To get started with PR-Agent quickly, you first need to acquire two tokens:
|
||||
|
||||
1. An OpenAI key from [here](https://platform.openai.com/), with access to GPT-4.
|
||||
2. A GitHub personal access token (classic) with the repo scope.
|
||||
|
||||
There are several ways to use PR-Agent. Let's start with the simplest one:
|
||||
There are several ways to use PR-Agent:
|
||||
|
||||
---
|
||||
|
||||
### Method 1: Use Docker image (no installation required)
|
||||
|
||||
To request a review for a PR, or ask a question about a PR, you can run the appropriate
|
||||
Python scripts from the scripts folder. Here's how:
|
||||
|
||||
1. To request a review for a PR, run the following command:
|
||||
```
|
||||
docker run --rm -it -e OPENAI.KEY=<your key> -e GITHUB.USER_TOKEN=<your token> codiumai/pr-agent \
|
||||
python pr_agent/scripts/review_pr_from_url.py --pr_url <pr url>
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
2. To ask a question about a PR, run the following command:
|
||||
```
|
||||
docker run --rm -it -e OPENAI.KEY -e GITHUB.USER_TOKEN codiumai/pr-agent \
|
||||
python pr_agent/scripts/answer_pr_questions_from_url.py --pr_url <pr url> --question "<your question>"
|
||||
```
|
||||
|
||||
Possible questions you can ask include:
|
||||
- What is the main theme of this PR?
|
||||
- Is the PR ready for merge?
|
||||
- What are the main changes in this PR?
|
||||
- Should this PR be split into smaller parts?
|
||||
- Can you compose a rhymed song about this PR.
|
||||
|
||||
---
|
||||
|
||||
### Method 2: Run from source
|
||||
|
||||
1. Clone this repository:
|
||||
```
|
||||
git clone https://github.com/Codium-ai/pr-agent.git
|
||||
```
|
||||
|
||||
2. Install the requirements in your favorite virtual environment:
|
||||
```
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
3. Copy the secrets template file and fill in your OpenAI key and your GitHub user token:
|
||||
```
|
||||
cp pr_agent/settings/.secrets_template.toml pr_agent/settings/.secrets
|
||||
# Edit .secrets file
|
||||
```
|
||||
|
||||
4. Run the appropriate Python scripts from the scripts folder:
|
||||
```
|
||||
python pr_agent/scripts/review_pr_from_url.py --pr_url <pr url>
|
||||
python pr_agent/scripts/answer_pr_questions_from_url.py --pr_url <pr url> --question "<your question>"
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### Method 3: Method 3: Run as a polling server; request reviews by tagging your Github user on a PR
|
||||
|
||||
Follow steps 1-3 of method 2.
|
||||
Run the following command to start the server:
|
||||
```
|
||||
python pr_agent/servers/github_polling.py
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### Method 4: Run as a Github App, allowing you to automate the review process on your private or public repositories.
|
||||
|
||||
1. Create a GitHub App from the [Github Developer Portal](https://docs.github.com/en/developers/apps/creating-a-github-app).
|
||||
- Set the following permissions:
|
||||
- Pull requests: Read & write
|
||||
- Issue comment: Read & write
|
||||
- Metadata: Read-only
|
||||
- Set the following events:
|
||||
- Issue comment
|
||||
- Pull request
|
||||
|
||||
2. Generate a random secret for your app, and save it for later. For example, you can use:
|
||||
```
|
||||
WEBHOOK_SECRET=$(python -c "import secrets; print(secrets.token_hex(10))")
|
||||
```
|
||||
|
||||
3. Acquire the following pieces of information from your app's settings page:
|
||||
- App private key (click "Generate a private key", and save the file)
|
||||
- App ID
|
||||
|
||||
4. Clone this repository:
|
||||
```
|
||||
git clone https://github.com/Codium-ai/pr-agent.git
|
||||
```
|
||||
|
||||
5. Copy the secrets template file and fill in the following:
|
||||
- Your OpenAI key.
|
||||
- Set deployment_type to 'app'
|
||||
- Copy your app's private key to the private_key field.
|
||||
- Copy your app's ID to the app_id field.
|
||||
- Copy your app's webhook secret to the webhook_secret field.
|
||||
```
|
||||
cp pr_agent/settings/.secrets_template.toml pr_agent/settings/.secrets
|
||||
# Edit .secrets file
|
||||
```
|
||||
|
||||
6. Build a Docker image for the app and optionally push it to a Docker repository. We'll use Dockerhub as an example:
|
||||
```
|
||||
docker build . -t codiumai/pr-agent:github_app --target github_app -f docker/Dockerfile
|
||||
docker push codiumai/pr-agent:github_app # Push to your Docker repository
|
||||
```
|
||||
|
||||
7. Host the app using a server, serverless function, or container environment. Alternatively, for development and
|
||||
debugging, you may use tools like smee.io to forward webhooks to your local machine.
|
||||
|
||||
8. Go back to your app's settings, set the following:
|
||||
- Webhook URL: The URL of your app's server, or the URL of the smee.io channel.
|
||||
- Webhook secret: The secret you generated earlier.
|
||||
|
||||
9. Install the app by navigating to the "Install App" tab, and selecting your desired repositories.
|
||||
|
||||
---
|
||||
- [Method 1: Use Docker image (no installation required)](INSTALL.md#method-1-use-docker-image-no-installation-required)
|
||||
- [Method 2: Run as a GitHub Action](INSTALL.md#method-2-run-as-a-github-action)
|
||||
- [Method 3: Run from source](INSTALL.md#method-3-run-from-source)
|
||||
- [Method 4: Run as a polling server](INSTALL.md#method-4-run-as-a-polling-server)
|
||||
- Request reviews by tagging your GitHub user on a PR
|
||||
- [Method 5: Run as a GitHub App](INSTALL.md#method-5-run-as-a-github-app)
|
||||
- Allowing you to automate the review process on your private or public repositories
|
||||
|
||||
## Usage and Tools
|
||||
CodiumAI PR-Agent provides two types of interactions ("tools"): `"PR Reviewer"` and `"PR Q&A"`.
|
||||
- The "PR Reviewer" tool automatically analyzes PRs, and provides different types of feedbacks.
|
||||
|
||||
**PR-Agent** provides five types of interactions ("tools"): `"PR Reviewer"`, `"PR Q&A"`, `"PR Description"`, `"PR Code Sueggestions"` and `"PR Reflect and Review"`.
|
||||
|
||||
- The "PR Reviewer" tool automatically analyzes PRs, and provides various types of feedback.
|
||||
- The "PR Q&A" tool answers free-text questions about the PR.
|
||||
- The "PR Description" tool automatically sets the PR Title and body.
|
||||
- The "PR Code Suggestion" tool provide inline code suggestions for the PR that can be applied and committed.
|
||||
- The "PR Reflect and Review" tool initiates a dialog with the user, asks them to reflect on the PR, and then provides a more focused review.
|
||||
|
||||
### PR Reviewer
|
||||
Here is a quick overview of the different sub-tools of PR Reviewer:
|
||||
## How it works
|
||||
|
||||
- PR Analysis
|
||||
- Summarize main theme
|
||||
- PR description and title
|
||||
- PR type classification
|
||||
- Is the PR covered by relevant tests
|
||||
- Is the PR minimal and focused
|
||||
- PR Feedback
|
||||
- General PR suggestions
|
||||
- Code suggestions
|
||||
- Security concerns
|
||||
|
||||
This is how a typical output of the PR Reviewer looks like:
|
||||
|
||||
---
|
||||
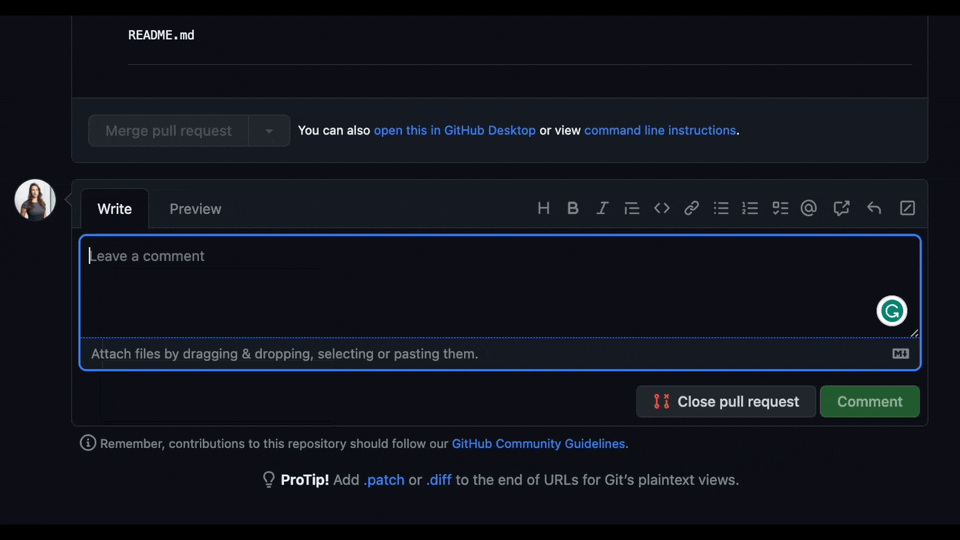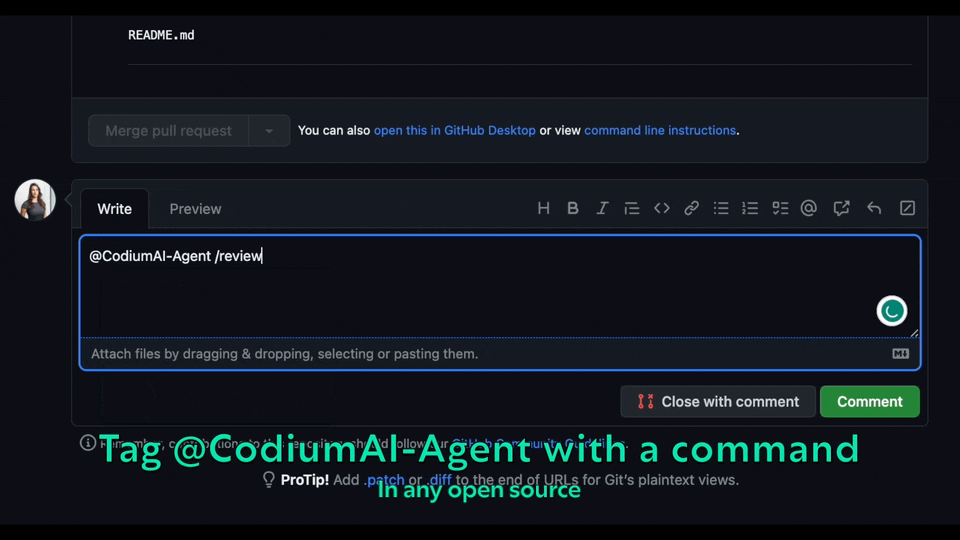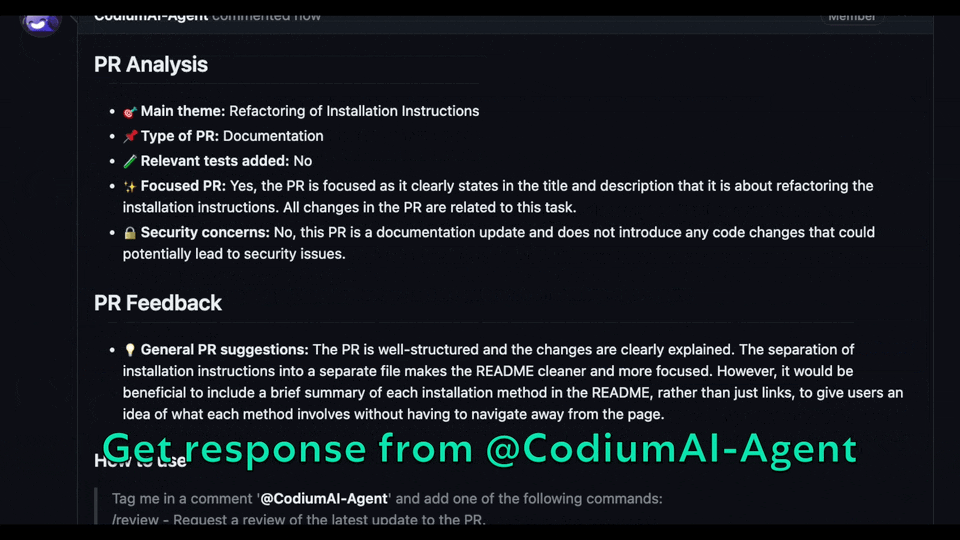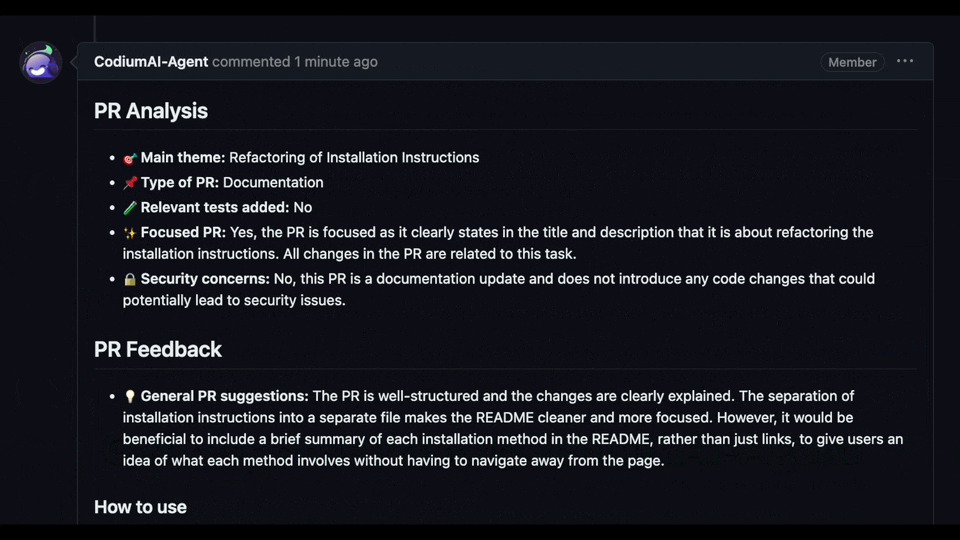
#### PR Analysis
|
||||
|
||||
- 🎯 **Main theme:** Adding language extension handler and token handler
|
||||
- 🔍 **Description and title:** Yes
|
||||
- 📌 **Type of PR:** Enhancement
|
||||
- 🧪 **Relevant tests added:** No
|
||||
- ✨ **Minimal and focused:** Yes, the PR is focused on adding two new handlers for language extension and token counting.
|
||||
#### PR Feedback
|
||||
|
||||
- 💡 **General PR suggestions:** The PR is generally well-structured and the code is clean. However, it would be beneficial to add some tests to ensure the new handlers work as expected. Also, consider adding docstrings to the new functions and classes to improve code readability and maintainability.
|
||||
|
||||
- 🤖 **Code suggestions:**
|
||||
|
||||
- **suggestion 1:**
|
||||
- **relevant file:** pr_agent/algo/language_handler.py
|
||||
- **suggestion content:** Consider using a set instead of a list for 'bad_extensions' as checking membership in a set is faster than in a list. [medium]
|
||||
|
||||
- **suggestion 2:**
|
||||
- **relevant file:** pr_agent/algo/language_handler.py
|
||||
- **suggestion content:** In the 'filter_bad_extensions' function, you are splitting the filename on '.' and taking the last element to get the extension. This might not work as expected if the filename contains multiple '.' characters. Consider using 'os.path.splitext' to get the file extension more reliably. [important]
|
||||
|
||||
- 🔒 **Security concerns:** No, the PR does not introduce possible security concerns or issues.
|
||||
|
||||
---
|
||||
|
||||
|
||||
### PR Q&A
|
||||
This tool answers free-text questions about the PR. This is how a typical output of the PR Q&A looks like:
|
||||
|
||||
---
|
||||
**Question**: summarize for me the PR in 4 bullet points
|
||||
|
||||
**Answer**:
|
||||
- The PR introduces a new feature to sort files by their main languages. It uses a mapping of programming languages to their file extensions to achieve this.
|
||||
- It also introduces a filter to exclude files with certain extensions, deemed as 'bad extensions', from the sorting process.
|
||||
- The PR modifies the `get_pr_diff` function in `pr_processing.py` to use the new sorting function. It also refactors the code to move the PR pruning logic into a separate function.
|
||||
- A new `TokenHandler` class is introduced in `token_handler.py` to handle token counting operations. This class is initialized with a PR, variables, system, and user, and provides methods to get system and user tokens and to count tokens in a patch.
|
||||
|
||||
---
|
||||
|
||||
## Configuration
|
||||
The different tools and sub-tools used by CodiumAI PR-Agent are easily configurable via the configuration file: `/settings/configuration.toml`.
|
||||
#### Enabling/disabling sub-tools:
|
||||
You can enable/disable the different PR Reviewer sub-sections with the following flags:
|
||||
```
|
||||
require_minimal_and_focused_review=true
|
||||
require_tests_review=true
|
||||
require_security_review=true
|
||||
```
|
||||
#### Code Suggestions configuration:
|
||||
There are also configuration options to control different aspects of the `code suggestions` feature.
|
||||
The number of suggestions provided can be controlled by adjusting the following parameter:
|
||||
```
|
||||
num_code_suggestions=4
|
||||
```
|
||||
You can also enable more verbose and informative mode of code suggestions:
|
||||
```
|
||||
extended_code_suggestions=false
|
||||
```
|
||||
This is a comparison of the regular and extended code suggestions modes:
|
||||
|
||||
---
|
||||
Example for regular suggestion:
|
||||
|
||||
|
||||
- **suggestion 1:**
|
||||
- **relevant file:** sql.py
|
||||
- **suggestion content:** Remove hardcoded sensitive information like username and password. Use environment variables or a secure method to store these values. [important]
|
||||
---
|
||||
|
||||
Example for extended suggestion:
|
||||
|
||||
|
||||
- **suggestion 1:**
|
||||
- **relevant file:** sql.py
|
||||
- **suggestion content:** Remove hardcoded sensitive information (username and password) [important]
|
||||
- **why:** Hardcoding sensitive information is a security risk. It's better to use environment variables or a secure way to store these values.
|
||||
- **code example:**
|
||||
- **before code:**
|
||||
```
|
||||
user = "root",
|
||||
password = "Mysql@123",
|
||||
```
|
||||
- **after code:**
|
||||
```
|
||||
user = os.getenv('DB_USER'),
|
||||
password = os.getenv('DB_PASSWORD'),
|
||||
```
|
||||
---
|
||||

|
||||
|
||||
Check out the [PR Compression strategy](./PR_COMPRESSION.md) page for more details on how we convert a code diff to a manageable LLM prompt
|
||||
|
||||
## Roadmap
|
||||
- [ ] Support open-source models, as a replacement for openai models. Note that a minimal requirement for each open-source model is to have 8k+ context, and good support for generating json as an output
|
||||
- [ ] Support other Git providers, such as Gitlab and Bitbucket.
|
||||
- [ ] Develop additional logics for handling large PRs, and compressing git patches
|
||||
- [ ] Dedicated tools and sub-tools for specific programming languages (Python, Javascript, Java, C++, etc)
|
||||
|
||||
- [ ] Support open-source models, as a replacement for OpenAI models. (Note - a minimal requirement for each open-source model is to have 8k+ context, and good support for generating JSON as an output)
|
||||
- [x] Support other Git providers, such as Gitlab and Bitbucket.
|
||||
- [ ] Develop additional logic for handling large PRs, and compressing git patches
|
||||
- [ ] Add additional context to the prompt. For example, repo (or relevant files) summarization, with tools such a [ctags](https://github.com/universal-ctags/ctags)
|
||||
- [ ] Adding more tools. Possible directions:
|
||||
- [ ] Code Quality
|
||||
- [ ] Coding Style
|
||||
- [x] PR description
|
||||
- [x] Inline code suggestions
|
||||
- [x] Reflect and review
|
||||
- [ ] Enforcing CONTRIBUTING.md guidelines
|
||||
- [ ] Performance (are there any performance issues)
|
||||
- [ ] Documentation (is the PR properly documented)
|
||||
- [ ] Rank the PR importance
|
||||
- [ ] ...
|
||||
|
||||
## Similar Projects
|
||||
|
||||
- [CodiumAI - Meaningful tests for busy devs](https://github.com/Codium-ai/codiumai-vscode-release)
|
||||
- [Aider - GPT powered coding in your terminal](https://github.com/paul-gauthier/aider)
|
||||
- [GPT-Engineer](https://github.com/AntonOsika/gpt-engineer)
|
||||
- [openai-pr-reviewer](https://github.com/coderabbitai/openai-pr-reviewer)
|
||||
- [CodeReview BOT](https://github.com/anc95/ChatGPT-CodeReview)
|
||||
- [AI-Maintainer](https://github.com/merwanehamadi/AI-Maintainer)
|
||||
|
||||
8
action.yaml
Normal file
8
action.yaml
Normal file
@ -0,0 +1,8 @@
|
||||
name: 'Codium PR Agent'
|
||||
description: 'Summarize, review and suggest improvements for pull requests'
|
||||
branding:
|
||||
icon: 'award'
|
||||
color: 'green'
|
||||
runs:
|
||||
using: 'docker'
|
||||
image: 'Dockerfile.github_action_dockerhub'
|
||||
@ -7,14 +7,14 @@ ENV PYTHONPATH=/app
|
||||
ADD pr_agent pr_agent
|
||||
|
||||
FROM base as github_app
|
||||
CMD ["python", "servers/github_app.py"]
|
||||
CMD ["python", "pr_agent/servers/github_app.py"]
|
||||
|
||||
FROM base as github_polling
|
||||
CMD ["python", "servers/github_polling.py"]
|
||||
CMD ["python", "pr_agent/servers/github_polling.py"]
|
||||
|
||||
FROM base as test
|
||||
ADD requirements-dev.txt .
|
||||
RUN pip install -r requirements-dev.txt && rm requirements-dev.txt
|
||||
|
||||
FROM base as cli
|
||||
CMD ["bash"]
|
||||
ENTRYPOINT ["python", "pr_agent/cli.py"]
|
||||
|
||||
12
docker/Dockerfile.lambda
Normal file
12
docker/Dockerfile.lambda
Normal file
@ -0,0 +1,12 @@
|
||||
FROM public.ecr.aws/lambda/python:3.10
|
||||
|
||||
RUN yum update -y && \
|
||||
yum install -y gcc python3-devel && \
|
||||
yum clean all
|
||||
|
||||
ADD requirements.txt .
|
||||
RUN pip install -r requirements.txt && rm requirements.txt
|
||||
RUN pip install mangum==16.0.0
|
||||
COPY pr_agent/ ${LAMBDA_TASK_ROOT}/pr_agent/
|
||||
|
||||
CMD ["pr_agent.servers.serverless.serverless"]
|
||||
2
github_action/entrypoint.sh
Normal file
2
github_action/entrypoint.sh
Normal file
@ -0,0 +1,2 @@
|
||||
#!/bin/bash
|
||||
python /app/pr_agent/servers/github_action_runner.py
|
||||
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 102 KiB |
BIN
pics/logo-dark.png
Normal file
BIN
pics/logo-dark.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 22 KiB |
BIN
pics/logo-light.png
Normal file
BIN
pics/logo-light.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 25 KiB |
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 137 KiB |
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 267 KiB |
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 42 KiB |
@ -1,20 +1,33 @@
|
||||
import re
|
||||
from typing import Optional
|
||||
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.tools.pr_code_suggestions import PRCodeSuggestions
|
||||
from pr_agent.tools.pr_description import PRDescription
|
||||
from pr_agent.tools.pr_information_from_user import PRInformationFromUser
|
||||
from pr_agent.tools.pr_questions import PRQuestions
|
||||
from pr_agent.tools.pr_reviewer import PRReviewer
|
||||
|
||||
|
||||
class PRAgent:
|
||||
def __init__(self, installation_id: Optional[int] = None):
|
||||
self.installation_id = installation_id
|
||||
def __init__(self):
|
||||
pass
|
||||
|
||||
async def handle_request(self, pr_url, request):
|
||||
if 'please review' in request.lower():
|
||||
reviewer = PRReviewer(pr_url, self.installation_id)
|
||||
await reviewer.review()
|
||||
async def handle_request(self, pr_url, request) -> bool:
|
||||
action, *args = request.strip().split()
|
||||
if any(cmd == action for cmd in ["/answer"]):
|
||||
await PRReviewer(pr_url, is_answer=True).review()
|
||||
elif any(cmd == action for cmd in ["/review", "/review_pr", "/reflect_and_review"]):
|
||||
if settings.pr_reviewer.ask_and_reflect or "/reflect_and_review" in request:
|
||||
await PRInformationFromUser(pr_url).generate_questions()
|
||||
else:
|
||||
await PRReviewer(pr_url, args=args).review()
|
||||
elif any(cmd == action for cmd in ["/describe", "/describe_pr"]):
|
||||
await PRDescription(pr_url).describe()
|
||||
elif any(cmd == action for cmd in ["/improve", "/improve_code"]):
|
||||
await PRCodeSuggestions(pr_url).suggest()
|
||||
elif any(cmd == action for cmd in ["/ask", "/ask_question"]):
|
||||
await PRQuestions(pr_url, args).answer()
|
||||
else:
|
||||
return False
|
||||
|
||||
elif 'please answer' in request.lower():
|
||||
question = re.split(r'(?i)please answer', request)[1].strip()
|
||||
answerer = PRQuestions(pr_url, question, self.installation_id)
|
||||
await answerer.answer()
|
||||
return True
|
||||
|
||||
@ -1,28 +1,65 @@
|
||||
import logging
|
||||
|
||||
import openai
|
||||
from openai.error import APIError, Timeout, TryAgain
|
||||
from openai.error import APIError, Timeout, TryAgain, RateLimitError
|
||||
from retry import retry
|
||||
|
||||
from pr_agent.config_loader import settings
|
||||
|
||||
OPENAI_RETRIES=2
|
||||
OPENAI_RETRIES=5
|
||||
|
||||
class AiHandler:
|
||||
"""
|
||||
This class handles interactions with the OpenAI API for chat completions.
|
||||
It initializes the API key and other settings from a configuration file,
|
||||
and provides a method for performing chat completions using the OpenAI ChatCompletion API.
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
"""
|
||||
Initializes the OpenAI API key and other settings from a configuration file.
|
||||
Raises a ValueError if the OpenAI key is missing.
|
||||
"""
|
||||
try:
|
||||
openai.api_key = settings.openai.key
|
||||
if settings.get("OPENAI.ORG", None):
|
||||
openai.organization = settings.openai.org
|
||||
self.deployment_id = settings.get("OPENAI.DEPLOYMENT_ID", None)
|
||||
if settings.get("OPENAI.API_TYPE", None):
|
||||
openai.api_type = settings.openai.api_type
|
||||
if settings.get("OPENAI.API_VERSION", None):
|
||||
openai.api_version = settings.openai.api_version
|
||||
if settings.get("OPENAI.API_BASE", None):
|
||||
openai.api_base = settings.openai.api_base
|
||||
except AttributeError as e:
|
||||
raise ValueError("OpenAI key is required") from e
|
||||
|
||||
@retry(exceptions=(APIError, Timeout, TryAgain, AttributeError),
|
||||
@retry(exceptions=(APIError, Timeout, TryAgain, AttributeError, RateLimitError),
|
||||
tries=OPENAI_RETRIES, delay=2, backoff=2, jitter=(1, 3))
|
||||
async def chat_completion(self, model: str, temperature: float, system: str, user: str):
|
||||
"""
|
||||
Performs a chat completion using the OpenAI ChatCompletion API.
|
||||
Retries in case of API errors or timeouts.
|
||||
|
||||
Args:
|
||||
model (str): The model to use for chat completion.
|
||||
temperature (float): The temperature parameter for chat completion.
|
||||
system (str): The system message for chat completion.
|
||||
user (str): The user message for chat completion.
|
||||
|
||||
Returns:
|
||||
tuple: A tuple containing the response and finish reason from the API.
|
||||
|
||||
Raises:
|
||||
TryAgain: If the API response is empty or there are no choices in the response.
|
||||
APIError: If there is an error during OpenAI inference.
|
||||
Timeout: If there is a timeout during OpenAI inference.
|
||||
TryAgain: If there is an attribute error during OpenAI inference.
|
||||
"""
|
||||
try:
|
||||
response = await openai.ChatCompletion.acreate(
|
||||
model=model,
|
||||
deployment_id=self.deployment_id,
|
||||
messages=[
|
||||
{"role": "system", "content": system},
|
||||
{"role": "user", "content": user}
|
||||
@ -32,8 +69,14 @@ class AiHandler:
|
||||
except (APIError, Timeout, TryAgain) as e:
|
||||
logging.error("Error during OpenAI inference: ", e)
|
||||
raise
|
||||
except (RateLimitError) as e:
|
||||
logging.error("Rate limit error during OpenAI inference: ", e)
|
||||
raise
|
||||
except (Exception) as e:
|
||||
logging.error("Unknown error during OpenAI inference: ", e)
|
||||
raise TryAgain from e
|
||||
if response is None or len(response.choices) == 0:
|
||||
raise TryAgain
|
||||
resp = response.choices[0]['message']['content']
|
||||
finish_reason = response.choices[0].finish_reason
|
||||
return resp, finish_reason
|
||||
return resp, finish_reason
|
||||
@ -8,11 +8,22 @@ from pr_agent.config_loader import settings
|
||||
|
||||
def extend_patch(original_file_str, patch_str, num_lines) -> str:
|
||||
"""
|
||||
Extends the patch to include 'num_lines' more surrounding lines
|
||||
Extends the given patch to include a specified number of surrounding lines.
|
||||
|
||||
Args:
|
||||
original_file_str (str): The original file to which the patch will be applied.
|
||||
patch_str (str): The patch to be applied to the original file.
|
||||
num_lines (int): The number of surrounding lines to include in the extended patch.
|
||||
|
||||
Returns:
|
||||
str: The extended patch string.
|
||||
"""
|
||||
if not patch_str or num_lines == 0:
|
||||
return patch_str
|
||||
|
||||
if type(original_file_str) == bytes:
|
||||
original_file_str = original_file_str.decode('utf-8')
|
||||
|
||||
original_lines = original_file_str.splitlines()
|
||||
patch_lines = patch_str.splitlines()
|
||||
extended_patch_lines = []
|
||||
@ -58,6 +69,14 @@ def extend_patch(original_file_str, patch_str, num_lines) -> str:
|
||||
|
||||
|
||||
def omit_deletion_hunks(patch_lines) -> str:
|
||||
"""
|
||||
Omit deletion hunks from the patch and return the modified patch.
|
||||
Args:
|
||||
- patch_lines: a list of strings representing the lines of the patch
|
||||
Returns:
|
||||
- A string representing the modified patch with deletion hunks omitted
|
||||
"""
|
||||
|
||||
temp_hunk = []
|
||||
added_patched = []
|
||||
add_hunk = False
|
||||
@ -90,13 +109,26 @@ def omit_deletion_hunks(patch_lines) -> str:
|
||||
def handle_patch_deletions(patch: str, original_file_content_str: str,
|
||||
new_file_content_str: str, file_name: str) -> str:
|
||||
"""
|
||||
Handle entire file or deletion patches
|
||||
Handle entire file or deletion patches.
|
||||
|
||||
This function takes a patch, original file content, new file content, and file name as input.
|
||||
It handles entire file or deletion patches and returns the modified patch with deletion hunks omitted.
|
||||
|
||||
Args:
|
||||
patch (str): The patch to be handled.
|
||||
original_file_content_str (str): The original content of the file.
|
||||
new_file_content_str (str): The new content of the file.
|
||||
file_name (str): The name of the file.
|
||||
|
||||
Returns:
|
||||
str: The modified patch with deletion hunks omitted.
|
||||
|
||||
"""
|
||||
if not new_file_content_str:
|
||||
# logic for handling deleted files - don't show patch, just show that the file was deleted
|
||||
if settings.config.verbosity_level > 0:
|
||||
logging.info(f"Processing file: {file_name}, minimizing deletion file")
|
||||
patch = "File was deleted\n"
|
||||
patch = None # file was deleted
|
||||
else:
|
||||
patch_lines = patch.splitlines()
|
||||
patch_new = omit_deletion_hunks(patch_lines)
|
||||
@ -105,3 +137,84 @@ def handle_patch_deletions(patch: str, original_file_content_str: str,
|
||||
logging.info(f"Processing file: {file_name}, hunks were deleted")
|
||||
patch = patch_new
|
||||
return patch
|
||||
|
||||
|
||||
def convert_to_hunks_with_lines_numbers(patch: str, file) -> str:
|
||||
"""
|
||||
Convert a given patch string into a string with line numbers for each hunk, indicating the new and old content of the file.
|
||||
|
||||
Args:
|
||||
patch (str): The patch string to be converted.
|
||||
file: An object containing the filename of the file being patched.
|
||||
|
||||
Returns:
|
||||
str: A string with line numbers for each hunk, indicating the new and old content of the file.
|
||||
|
||||
example output:
|
||||
## src/file.ts
|
||||
--new hunk--
|
||||
881 line1
|
||||
882 line2
|
||||
883 line3
|
||||
887 + line4
|
||||
888 + line5
|
||||
889 line6
|
||||
890 line7
|
||||
...
|
||||
--old hunk--
|
||||
line1
|
||||
line2
|
||||
- line3
|
||||
- line4
|
||||
line5
|
||||
line6
|
||||
...
|
||||
"""
|
||||
|
||||
patch_with_lines_str = f"## {file.filename}\n"
|
||||
import re
|
||||
patch_lines = patch.splitlines()
|
||||
RE_HUNK_HEADER = re.compile(
|
||||
r"^@@ -(\d+)(?:,(\d+))? \+(\d+)(?:,(\d+))? @@[ ]?(.*)")
|
||||
new_content_lines = []
|
||||
old_content_lines = []
|
||||
match = None
|
||||
start1, size1, start2, size2 = -1, -1, -1, -1
|
||||
for line in patch_lines:
|
||||
if 'no newline at end of file' in line.lower():
|
||||
continue
|
||||
|
||||
if line.startswith('@@'):
|
||||
match = RE_HUNK_HEADER.match(line)
|
||||
if match and new_content_lines: # found a new hunk, split the previous lines
|
||||
if new_content_lines:
|
||||
patch_with_lines_str += '\n--new hunk--\n'
|
||||
for i, line_new in enumerate(new_content_lines):
|
||||
patch_with_lines_str += f"{start2 + i} {line_new}\n"
|
||||
if old_content_lines:
|
||||
patch_with_lines_str += '--old hunk--\n'
|
||||
for line_old in old_content_lines:
|
||||
patch_with_lines_str += f"{line_old}\n"
|
||||
new_content_lines = []
|
||||
old_content_lines = []
|
||||
start1, size1, start2, size2 = map(int, match.groups()[:4])
|
||||
elif line.startswith('+'):
|
||||
new_content_lines.append(line)
|
||||
elif line.startswith('-'):
|
||||
old_content_lines.append(line)
|
||||
else:
|
||||
new_content_lines.append(line)
|
||||
old_content_lines.append(line)
|
||||
|
||||
# finishing last hunk
|
||||
if match and new_content_lines:
|
||||
if new_content_lines:
|
||||
patch_with_lines_str += '\n--new hunk--\n'
|
||||
for i, line_new in enumerate(new_content_lines):
|
||||
patch_with_lines_str += f"{start2 + i} {line_new}\n"
|
||||
if old_content_lines:
|
||||
patch_with_lines_str += '\n--old hunk--\n'
|
||||
for line_old in old_content_lines:
|
||||
patch_with_lines_str += f"{line_old}\n"
|
||||
|
||||
return patch_with_lines_str.strip()
|
||||
|
||||
File diff suppressed because one or more lines are too long
@ -1,45 +1,86 @@
|
||||
from __future__ import annotations
|
||||
|
||||
import difflib
|
||||
import logging
|
||||
from typing import Any, Dict, Tuple
|
||||
from typing import Tuple, Union, Callable, List
|
||||
|
||||
from pr_agent.algo.git_patch_processing import extend_patch, handle_patch_deletions
|
||||
from pr_agent.algo import MAX_TOKENS
|
||||
from pr_agent.algo.git_patch_processing import convert_to_hunks_with_lines_numbers, extend_patch, handle_patch_deletions
|
||||
from pr_agent.algo.language_handler import sort_files_by_main_languages
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.utils import load_large_diff
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.git_providers import GithubProvider
|
||||
from pr_agent.git_providers.git_provider import GitProvider
|
||||
|
||||
OUTPUT_BUFFER_TOKENS = 800
|
||||
DELETED_FILES_ = "Deleted files:\n"
|
||||
|
||||
MORE_MODIFIED_FILES_ = "More modified files:\n"
|
||||
|
||||
OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD = 1000
|
||||
OUTPUT_BUFFER_TOKENS_HARD_THRESHOLD = 600
|
||||
PATCH_EXTRA_LINES = 3
|
||||
|
||||
|
||||
def get_pr_diff(git_provider: [GithubProvider, Any], token_handler: TokenHandler) -> str:
|
||||
def get_pr_diff(git_provider: GitProvider, token_handler: TokenHandler, model: str,
|
||||
add_line_numbers_to_hunks: bool = False, disable_extra_lines: bool = False) -> str:
|
||||
"""
|
||||
Returns a string with the diff of the PR.
|
||||
If needed, apply diff minimization techniques to reduce the number of tokens
|
||||
Returns a string with the diff of the pull request, applying diff minimization techniques if needed.
|
||||
|
||||
Args:
|
||||
git_provider (GitProvider): An object of the GitProvider class representing the Git provider used for the pull request.
|
||||
token_handler (TokenHandler): An object of the TokenHandler class used for handling tokens in the context of the pull request.
|
||||
model (str): The name of the model used for tokenization.
|
||||
add_line_numbers_to_hunks (bool, optional): A boolean indicating whether to add line numbers to the hunks in the diff. Defaults to False.
|
||||
disable_extra_lines (bool, optional): A boolean indicating whether to disable the extension of each patch with extra lines of context. Defaults to False.
|
||||
|
||||
Returns:
|
||||
str: A string with the diff of the pull request, applying diff minimization techniques if needed.
|
||||
"""
|
||||
files = list(git_provider.get_diff_files())
|
||||
|
||||
if disable_extra_lines:
|
||||
global PATCH_EXTRA_LINES
|
||||
PATCH_EXTRA_LINES = 0
|
||||
|
||||
diff_files = list(git_provider.get_diff_files())
|
||||
|
||||
# get pr languages
|
||||
pr_languages = sort_files_by_main_languages(git_provider.get_languages(), files)
|
||||
pr_languages = sort_files_by_main_languages(git_provider.get_languages(), diff_files)
|
||||
|
||||
# generate a standard diff string, with patch extension
|
||||
patches_extended, total_tokens = pr_generate_extended_diff(pr_languages, token_handler)
|
||||
patches_extended, total_tokens = pr_generate_extended_diff(pr_languages, token_handler,
|
||||
add_line_numbers_to_hunks)
|
||||
|
||||
# if we are under the limit, return the full diff
|
||||
if total_tokens + OUTPUT_BUFFER_TOKENS < token_handler.limit:
|
||||
if total_tokens + OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD < MAX_TOKENS[model]:
|
||||
return "\n".join(patches_extended)
|
||||
|
||||
# if we are over the limit, start pruning
|
||||
patches_compressed = pr_generate_compressed_diff(pr_languages, token_handler)
|
||||
return "\n".join(patches_compressed)
|
||||
patches_compressed, modified_file_names, deleted_file_names = \
|
||||
pr_generate_compressed_diff(pr_languages, token_handler, add_line_numbers_to_hunks)
|
||||
|
||||
final_diff = "\n".join(patches_compressed)
|
||||
if modified_file_names:
|
||||
modified_list_str = MORE_MODIFIED_FILES_ + "\n".join(modified_file_names)
|
||||
final_diff = final_diff + "\n\n" + modified_list_str
|
||||
if deleted_file_names:
|
||||
deleted_list_str = DELETED_FILES_ + "\n".join(deleted_file_names)
|
||||
final_diff = final_diff + "\n\n" + deleted_list_str
|
||||
return final_diff
|
||||
|
||||
|
||||
def pr_generate_extended_diff(pr_languages: list, token_handler: TokenHandler) -> \
|
||||
def pr_generate_extended_diff(pr_languages: list, token_handler: TokenHandler,
|
||||
add_line_numbers_to_hunks: bool) -> \
|
||||
Tuple[list, int]:
|
||||
"""
|
||||
Generate a standard diff string, with patch extension
|
||||
Generate a standard diff string with patch extension, while counting the number of tokens used and applying diff minimization techniques if needed.
|
||||
|
||||
Args:
|
||||
- pr_languages: A list of dictionaries representing the languages used in the pull request and their corresponding files.
|
||||
- token_handler: An object of the TokenHandler class used for handling tokens in the context of the pull request.
|
||||
- add_line_numbers_to_hunks: A boolean indicating whether to add line numbers to the hunks in the diff.
|
||||
|
||||
Returns:
|
||||
- patches_extended: A list of extended patches for each file in the pull request.
|
||||
- total_tokens: The total number of tokens used in the extended patches.
|
||||
"""
|
||||
total_tokens = token_handler.prompt_tokens # initial tokens
|
||||
patches_extended = []
|
||||
@ -59,6 +100,9 @@ def pr_generate_extended_diff(pr_languages: list, token_handler: TokenHandler) -
|
||||
extended_patch = extend_patch(original_file_content_str, patch, num_lines=PATCH_EXTRA_LINES)
|
||||
full_extended_patch = f"## {file.filename}\n\n{extended_patch}\n"
|
||||
|
||||
if add_line_numbers_to_hunks:
|
||||
full_extended_patch = convert_to_hunks_with_lines_numbers(extended_patch, file)
|
||||
|
||||
patch_tokens = token_handler.count_tokens(full_extended_patch)
|
||||
file.tokens = patch_tokens
|
||||
total_tokens += patch_tokens
|
||||
@ -67,16 +111,32 @@ def pr_generate_extended_diff(pr_languages: list, token_handler: TokenHandler) -
|
||||
return patches_extended, total_tokens
|
||||
|
||||
|
||||
def pr_generate_compressed_diff(top_langs: list, token_handler: TokenHandler) -> list:
|
||||
# Apply Diff Minimization techniques to reduce the number of tokens:
|
||||
# 0. Start from the largest diff patch to smaller ones
|
||||
# 1. Don't use extend context lines around diff
|
||||
# 2. Minimize deleted files
|
||||
# 3. Minimize deleted hunks
|
||||
# 4. Minimize all remaining files when you reach token limit
|
||||
def pr_generate_compressed_diff(top_langs: list, token_handler: TokenHandler, model: str,
|
||||
convert_hunks_to_line_numbers: bool) -> Tuple[list, list, list]:
|
||||
"""
|
||||
Generate a compressed diff string for a pull request, using diff minimization techniques to reduce the number of tokens used.
|
||||
Args:
|
||||
top_langs (list): A list of dictionaries representing the languages used in the pull request and their corresponding files.
|
||||
token_handler (TokenHandler): An object of the TokenHandler class used for handling tokens in the context of the pull request.
|
||||
model (str): The model used for tokenization.
|
||||
convert_hunks_to_line_numbers (bool): A boolean indicating whether to convert hunks to line numbers in the diff.
|
||||
Returns:
|
||||
Tuple[list, list, list]: A tuple containing the following lists:
|
||||
- patches: A list of compressed diff patches for each file in the pull request.
|
||||
- modified_files_list: A list of file names that were skipped due to large patch size.
|
||||
- deleted_files_list: A list of file names that were deleted in the pull request.
|
||||
|
||||
Minimization techniques to reduce the number of tokens:
|
||||
0. Start from the largest diff patch to smaller ones
|
||||
1. Don't use extend context lines around diff
|
||||
2. Minimize deleted files
|
||||
3. Minimize deleted hunks
|
||||
4. Minimize all remaining files when you reach token limit
|
||||
"""
|
||||
|
||||
patches = []
|
||||
|
||||
modified_files_list = []
|
||||
deleted_files_list = []
|
||||
# sort each one of the languages in top_langs by the number of tokens in the diff
|
||||
sorted_files = []
|
||||
for lang in top_langs:
|
||||
@ -94,35 +154,59 @@ def pr_generate_compressed_diff(top_langs: list, token_handler: TokenHandler) ->
|
||||
# removing delete-only hunks
|
||||
patch = handle_patch_deletions(patch, original_file_content_str,
|
||||
new_file_content_str, file.filename)
|
||||
if patch is None:
|
||||
if not deleted_files_list:
|
||||
total_tokens += token_handler.count_tokens(DELETED_FILES_)
|
||||
deleted_files_list.append(file.filename)
|
||||
total_tokens += token_handler.count_tokens(file.filename) + 1
|
||||
continue
|
||||
|
||||
if convert_hunks_to_line_numbers:
|
||||
patch = convert_to_hunks_with_lines_numbers(patch, file)
|
||||
|
||||
new_patch_tokens = token_handler.count_tokens(patch)
|
||||
|
||||
if total_tokens > token_handler.limit - OUTPUT_BUFFER_TOKENS // 2:
|
||||
# Hard Stop, no more tokens
|
||||
if total_tokens > MAX_TOKENS[model] - OUTPUT_BUFFER_TOKENS_HARD_THRESHOLD:
|
||||
logging.warning(f"File was fully skipped, no more tokens: {file.filename}.")
|
||||
continue # Hard Stop, no more tokens
|
||||
if total_tokens + new_patch_tokens > token_handler.limit - OUTPUT_BUFFER_TOKENS:
|
||||
continue
|
||||
|
||||
# If the patch is too large, just show the file name
|
||||
if total_tokens + new_patch_tokens > MAX_TOKENS[model] - OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD:
|
||||
# Current logic is to skip the patch if it's too large
|
||||
# TODO: Option for alternative logic to remove hunks from the patch to reduce the number of tokens
|
||||
# until we meet the requirements
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.warning(f"Patch too large, minimizing it, {file.filename}")
|
||||
patch = "File was modified"
|
||||
if not modified_files_list:
|
||||
total_tokens += token_handler.count_tokens(MORE_MODIFIED_FILES_)
|
||||
modified_files_list.append(file.filename)
|
||||
total_tokens += token_handler.count_tokens(file.filename) + 1
|
||||
continue
|
||||
|
||||
if patch:
|
||||
patch_final = f"## {file.filename}\n\n{patch}\n"
|
||||
if not convert_hunks_to_line_numbers:
|
||||
patch_final = f"## {file.filename}\n\n{patch}\n"
|
||||
else:
|
||||
patch_final = patch
|
||||
patches.append(patch_final)
|
||||
total_tokens += token_handler.count_tokens(patch_final)
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.info(f"Tokens: {total_tokens}, last filename: {file.filename}")
|
||||
return patches
|
||||
|
||||
return patches, modified_files_list, deleted_files_list
|
||||
|
||||
|
||||
def load_large_diff(file, new_file_content_str: str, original_file_content_str: str, patch: str) -> str:
|
||||
if not patch: # to Do - also add condition for file extension
|
||||
async def retry_with_fallback_models(f: Callable):
|
||||
model = settings.config.model
|
||||
fallback_models = settings.config.fallback_models
|
||||
if not isinstance(fallback_models, list):
|
||||
fallback_models = [fallback_models]
|
||||
all_models = [model] + fallback_models
|
||||
for i, model in enumerate(all_models):
|
||||
try:
|
||||
diff = difflib.unified_diff(original_file_content_str.splitlines(keepends=True),
|
||||
new_file_content_str.splitlines(keepends=True))
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.warning(f"File was modified, but no patch was found. Manually creating patch: {file.filename}.")
|
||||
patch = ''.join(diff)
|
||||
except Exception:
|
||||
pass
|
||||
return patch
|
||||
return await f(model)
|
||||
except Exception as e:
|
||||
logging.warning(f"Failed to generate prediction with {model}: {e}")
|
||||
if i == len(all_models) - 1: # If it's the last iteration
|
||||
raise # Re-raise the last exception
|
||||
|
||||
@ -6,12 +6,42 @@ from pr_agent.config_loader import settings
|
||||
|
||||
|
||||
class TokenHandler:
|
||||
"""
|
||||
A class for handling tokens in the context of a pull request.
|
||||
|
||||
Attributes:
|
||||
- encoder: An object of the encoding_for_model class from the tiktoken module. Used to encode strings and count the number of tokens in them.
|
||||
- limit: The maximum number of tokens allowed for the given model, as defined in the MAX_TOKENS dictionary in the pr_agent.algo module.
|
||||
- prompt_tokens: The number of tokens in the system and user strings, as calculated by the _get_system_user_tokens method.
|
||||
"""
|
||||
|
||||
def __init__(self, pr, vars: dict, system, user):
|
||||
"""
|
||||
Initializes the TokenHandler object.
|
||||
|
||||
Args:
|
||||
- pr: The pull request object.
|
||||
- vars: A dictionary of variables.
|
||||
- system: The system string.
|
||||
- user: The user string.
|
||||
"""
|
||||
self.encoder = encoding_for_model(settings.config.model)
|
||||
self.limit = MAX_TOKENS[settings.config.model]
|
||||
self.prompt_tokens = self._get_system_user_tokens(pr, self.encoder, vars, system, user)
|
||||
|
||||
def _get_system_user_tokens(self, pr, encoder, vars: dict, system, user):
|
||||
"""
|
||||
Calculates the number of tokens in the system and user strings.
|
||||
|
||||
Args:
|
||||
- pr: The pull request object.
|
||||
- encoder: An object of the encoding_for_model class from the tiktoken module.
|
||||
- vars: A dictionary of variables.
|
||||
- system: The system string.
|
||||
- user: The user string.
|
||||
|
||||
Returns:
|
||||
The sum of the number of tokens in the system and user strings.
|
||||
"""
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
system_prompt = environment.from_string(system).render(vars)
|
||||
user_prompt = environment.from_string(user).render(vars)
|
||||
@ -21,4 +51,13 @@ class TokenHandler:
|
||||
return system_prompt_tokens + user_prompt_tokens
|
||||
|
||||
def count_tokens(self, patch: str) -> int:
|
||||
return len(self.encoder.encode(patch))
|
||||
"""
|
||||
Counts the number of tokens in a given patch string.
|
||||
|
||||
Args:
|
||||
- patch: The patch string.
|
||||
|
||||
Returns:
|
||||
The number of tokens in the patch string.
|
||||
"""
|
||||
return len(self.encoder.encode(patch, disallowed_special=()))
|
||||
@ -1,21 +1,36 @@
|
||||
from __future__ import annotations
|
||||
|
||||
import difflib
|
||||
from datetime import datetime
|
||||
import json
|
||||
import logging
|
||||
import re
|
||||
import textwrap
|
||||
|
||||
from pr_agent.config_loader import settings
|
||||
|
||||
|
||||
def convert_to_markdown(output_data: dict) -> str:
|
||||
"""
|
||||
Convert a dictionary of data into markdown format.
|
||||
Args:
|
||||
output_data (dict): A dictionary containing data to be converted to markdown format.
|
||||
Returns:
|
||||
str: The markdown formatted text generated from the input dictionary.
|
||||
"""
|
||||
markdown_text = ""
|
||||
|
||||
emojis = {
|
||||
"Main theme": "🎯",
|
||||
"Description and title": "🔍",
|
||||
"Type of PR": "📌",
|
||||
"Score": "🏅",
|
||||
"Relevant tests added": "🧪",
|
||||
"Unrelated changes": "⚠️",
|
||||
"Minimal and focused": "✨",
|
||||
"Focused PR": "✨",
|
||||
"Security concerns": "🔒",
|
||||
"General PR suggestions": "💡",
|
||||
"Code suggestions": "🤖"
|
||||
"Insights from user's answers": "📝",
|
||||
"Code suggestions": "🤖",
|
||||
}
|
||||
|
||||
for key, value in output_data.items():
|
||||
@ -27,7 +42,7 @@ def convert_to_markdown(output_data: dict) -> str:
|
||||
elif isinstance(value, list):
|
||||
if key.lower() == 'code suggestions':
|
||||
markdown_text += "\n" # just looks nicer with additional line breaks
|
||||
emoji = emojis.get(key, "‣") # Use a dash if no emoji is found for the key
|
||||
emoji = emojis.get(key, "")
|
||||
markdown_text += f"- {emoji} **{key}:**\n\n"
|
||||
for item in value:
|
||||
if isinstance(item, dict) and key.lower() == 'code suggestions':
|
||||
@ -35,12 +50,21 @@ def convert_to_markdown(output_data: dict) -> str:
|
||||
elif item:
|
||||
markdown_text += f" - {item}\n"
|
||||
elif value != 'n/a':
|
||||
emoji = emojis.get(key, "‣") # Use a dash if no emoji is found for the key
|
||||
emoji = emojis.get(key, "")
|
||||
markdown_text += f"- {emoji} **{key}:** {value}\n"
|
||||
return markdown_text
|
||||
|
||||
|
||||
def parse_code_suggestion(code_suggestions: dict) -> str:
|
||||
"""
|
||||
Convert a dictionary of data into markdown format.
|
||||
|
||||
Args:
|
||||
code_suggestions (dict): A dictionary containing data to be converted to markdown format.
|
||||
|
||||
Returns:
|
||||
str: A string containing the markdown formatted text generated from the input dictionary.
|
||||
"""
|
||||
markdown_text = ""
|
||||
for sub_key, sub_value in code_suggestions.items():
|
||||
if isinstance(sub_value, dict): # "code example"
|
||||
@ -50,10 +74,140 @@ def parse_code_suggestion(code_suggestions: dict) -> str:
|
||||
code_str_indented = textwrap.indent(code_str, ' ')
|
||||
markdown_text += f" - **{code_key}:**\n{code_str_indented}\n"
|
||||
else:
|
||||
if "suggestion number" in sub_key.lower():
|
||||
markdown_text += f"- **suggestion {sub_value}:**\n" # prettier formatting
|
||||
if "relevant file" in sub_key.lower():
|
||||
markdown_text += f"\n - **{sub_key}:** {sub_value}\n"
|
||||
else:
|
||||
markdown_text += f" - **{sub_key}:** {sub_value}\n"
|
||||
markdown_text += f" **{sub_key}:** {sub_value}\n"
|
||||
|
||||
markdown_text += "\n"
|
||||
return markdown_text
|
||||
|
||||
|
||||
def try_fix_json(review, max_iter=10, code_suggestions=False):
|
||||
"""
|
||||
Fix broken or incomplete JSON messages and return the parsed JSON data.
|
||||
|
||||
Args:
|
||||
- review: A string containing the JSON message to be fixed.
|
||||
- max_iter: An integer representing the maximum number of iterations to try and fix the JSON message.
|
||||
- code_suggestions: A boolean indicating whether to try and fix JSON messages with code suggestions.
|
||||
|
||||
Returns:
|
||||
- data: A dictionary containing the parsed JSON data.
|
||||
|
||||
The function attempts to fix broken or incomplete JSON messages by parsing until the last valid code suggestion.
|
||||
If the JSON message ends with a closing bracket, the function calls the fix_json_escape_char function to fix the message.
|
||||
If code_suggestions is True and the JSON message contains code suggestions, the function tries to fix the JSON message by parsing until the last valid code suggestion.
|
||||
The function uses regular expressions to find the last occurrence of "}," with any number of whitespaces or newlines.
|
||||
It tries to parse the JSON message with the closing bracket and checks if it is valid.
|
||||
If the JSON message is valid, the parsed JSON data is returned.
|
||||
If the JSON message is not valid, the last code suggestion is removed and the process is repeated until a valid JSON message is obtained or the maximum number of iterations is reached.
|
||||
If a valid JSON message is not obtained, an error is logged and an empty dictionary is returned.
|
||||
"""
|
||||
|
||||
if review.endswith("}"):
|
||||
return fix_json_escape_char(review)
|
||||
|
||||
data = {}
|
||||
if code_suggestions:
|
||||
closing_bracket = "]}"
|
||||
else:
|
||||
closing_bracket = "]}}"
|
||||
|
||||
if review.rfind("'Code suggestions': [") > 0 or review.rfind('"Code suggestions": [') > 0:
|
||||
last_code_suggestion_ind = [m.end() for m in re.finditer(r"\}\s*,", review)][-1] - 1
|
||||
valid_json = False
|
||||
iter_count = 0
|
||||
|
||||
while last_code_suggestion_ind > 0 and not valid_json and iter_count < max_iter:
|
||||
try:
|
||||
data = json.loads(review[:last_code_suggestion_ind] + closing_bracket)
|
||||
valid_json = True
|
||||
review = review[:last_code_suggestion_ind].strip() + closing_bracket
|
||||
except json.decoder.JSONDecodeError:
|
||||
review = review[:last_code_suggestion_ind]
|
||||
last_code_suggestion_ind = [m.end() for m in re.finditer(r"\}\s*,", review)][-1] - 1
|
||||
iter_count += 1
|
||||
|
||||
if not valid_json:
|
||||
logging.error("Unable to decode JSON response from AI")
|
||||
data = {}
|
||||
|
||||
return data
|
||||
|
||||
|
||||
def fix_json_escape_char(json_message=None):
|
||||
"""
|
||||
Fix broken or incomplete JSON messages and return the parsed JSON data.
|
||||
|
||||
Args:
|
||||
json_message (str): A string containing the JSON message to be fixed.
|
||||
|
||||
Returns:
|
||||
dict: A dictionary containing the parsed JSON data.
|
||||
|
||||
Raises:
|
||||
None
|
||||
|
||||
"""
|
||||
try:
|
||||
result = json.loads(json_message)
|
||||
except Exception as e:
|
||||
# Find the offending character index:
|
||||
idx_to_replace = int(str(e).split(' ')[-1].replace(')', ''))
|
||||
# Remove the offending character:
|
||||
json_message = list(json_message)
|
||||
json_message[idx_to_replace] = ' '
|
||||
new_message = ''.join(json_message)
|
||||
return fix_json_escape_char(json_message=new_message)
|
||||
return result
|
||||
|
||||
|
||||
def convert_str_to_datetime(date_str):
|
||||
"""
|
||||
Convert a string representation of a date and time into a datetime object.
|
||||
|
||||
Args:
|
||||
date_str (str): A string representation of a date and time in the format '%a, %d %b %Y %H:%M:%S %Z'
|
||||
|
||||
Returns:
|
||||
datetime: A datetime object representing the input date and time.
|
||||
|
||||
Example:
|
||||
>>> convert_str_to_datetime('Mon, 01 Jan 2022 12:00:00 UTC')
|
||||
datetime.datetime(2022, 1, 1, 12, 0, 0)
|
||||
"""
|
||||
datetime_format = '%a, %d %b %Y %H:%M:%S %Z'
|
||||
return datetime.strptime(date_str, datetime_format)
|
||||
|
||||
|
||||
def load_large_diff(file, new_file_content_str: str, original_file_content_str: str, patch: str) -> str:
|
||||
"""
|
||||
Generate a patch for a modified file by comparing the original content of the file with the new content provided as input.
|
||||
|
||||
Args:
|
||||
file: The file object for which the patch needs to be generated.
|
||||
new_file_content_str: The new content of the file as a string.
|
||||
original_file_content_str: The original content of the file as a string.
|
||||
patch: An optional patch string that can be provided as input.
|
||||
|
||||
Returns:
|
||||
The generated or provided patch string.
|
||||
|
||||
Raises:
|
||||
None.
|
||||
|
||||
Additional Information:
|
||||
- If 'patch' is not provided as input, the function generates a patch using the 'difflib' library and returns it as output.
|
||||
- If the 'settings.config.verbosity_level' is greater than or equal to 2, a warning message is logged indicating that the file was modified but no patch was found, and a patch is manually created.
|
||||
"""
|
||||
if not patch: # to Do - also add condition for file extension
|
||||
try:
|
||||
diff = difflib.unified_diff(original_file_content_str.splitlines(keepends=True),
|
||||
new_file_content_str.splitlines(keepends=True))
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.warning(f"File was modified, but no patch was found. Manually creating patch: {file.filename}.")
|
||||
patch = ''.join(diff)
|
||||
except Exception:
|
||||
pass
|
||||
return patch
|
||||
|
||||
101
pr_agent/cli.py
Normal file
101
pr_agent/cli.py
Normal file
@ -0,0 +1,101 @@
|
||||
import argparse
|
||||
import asyncio
|
||||
import logging
|
||||
import os
|
||||
|
||||
from pr_agent.tools.pr_code_suggestions import PRCodeSuggestions
|
||||
from pr_agent.tools.pr_description import PRDescription
|
||||
from pr_agent.tools.pr_information_from_user import PRInformationFromUser
|
||||
from pr_agent.tools.pr_questions import PRQuestions
|
||||
from pr_agent.tools.pr_reviewer import PRReviewer
|
||||
|
||||
|
||||
def run(args=None):
|
||||
parser = argparse.ArgumentParser(description='AI based pull request analyzer', usage=
|
||||
"""\
|
||||
Usage: cli.py --pr-url <URL on supported git hosting service> <command> [<args>].
|
||||
For example:
|
||||
- cli.py --pr-url=... review
|
||||
- cli.py --pr-url=... describe
|
||||
- cli.py --pr-url=... improve
|
||||
- cli.py --pr-url=... ask "write me a poem about this PR"
|
||||
- cli.py --pr-url=... reflect
|
||||
|
||||
Supported commands:
|
||||
review / review_pr - Add a review that includes a summary of the PR and specific suggestions for improvement.
|
||||
ask / ask_question [question] - Ask a question about the PR.
|
||||
describe / describe_pr - Modify the PR title and description based on the PR's contents.
|
||||
improve / improve_code - Suggest improvements to the code in the PR as pull request comments ready to commit.
|
||||
reflect - Ask the PR author questions about the PR.
|
||||
""")
|
||||
parser.add_argument('--pr_url', type=str, help='The URL of the PR to review', required=True)
|
||||
parser.add_argument('command', type=str, help='The', choices=['review', 'review_pr',
|
||||
'ask', 'ask_question',
|
||||
'describe', 'describe_pr',
|
||||
'improve', 'improve_code',
|
||||
'reflect', 'review_after_reflect'],
|
||||
default='review')
|
||||
parser.add_argument('rest', nargs=argparse.REMAINDER, default=[])
|
||||
args = parser.parse_args(args)
|
||||
logging.basicConfig(level=os.environ.get("LOGLEVEL", "INFO"))
|
||||
command = args.command.lower()
|
||||
commands = {
|
||||
'ask': _handle_ask_command,
|
||||
'ask_question': _handle_ask_command,
|
||||
'describe': _handle_describe_command,
|
||||
'describe_pr': _handle_describe_command,
|
||||
'improve': _handle_improve_command,
|
||||
'improve_code': _handle_improve_command,
|
||||
'review': _handle_review_command,
|
||||
'review_pr': _handle_review_command,
|
||||
'reflect': _handle_reflect_command,
|
||||
'review_after_reflect': _handle_review_after_reflect_command
|
||||
}
|
||||
if command in commands:
|
||||
commands[command](args.pr_url, args.rest)
|
||||
else:
|
||||
print(f"Unknown command: {command}")
|
||||
parser.print_help()
|
||||
|
||||
|
||||
def _handle_ask_command(pr_url: str, rest: list):
|
||||
if len(rest) == 0:
|
||||
print("Please specify a question")
|
||||
return
|
||||
print(f"Question: {' '.join(rest)} about PR {pr_url}")
|
||||
reviewer = PRQuestions(pr_url, rest)
|
||||
asyncio.run(reviewer.answer())
|
||||
|
||||
|
||||
def _handle_describe_command(pr_url: str, rest: list):
|
||||
print(f"PR description: {pr_url}")
|
||||
reviewer = PRDescription(pr_url)
|
||||
asyncio.run(reviewer.describe())
|
||||
|
||||
|
||||
def _handle_improve_command(pr_url: str, rest: list):
|
||||
print(f"PR code suggestions: {pr_url}")
|
||||
reviewer = PRCodeSuggestions(pr_url)
|
||||
asyncio.run(reviewer.suggest())
|
||||
|
||||
|
||||
def _handle_review_command(pr_url: str, rest: list):
|
||||
print(f"Reviewing PR: {pr_url}")
|
||||
reviewer = PRReviewer(pr_url, cli_mode=True, args=rest)
|
||||
asyncio.run(reviewer.review())
|
||||
|
||||
|
||||
def _handle_reflect_command(pr_url: str, rest: list):
|
||||
print(f"Asking the PR author questions: {pr_url}")
|
||||
reviewer = PRInformationFromUser(pr_url)
|
||||
asyncio.run(reviewer.generate_questions())
|
||||
|
||||
|
||||
def _handle_review_after_reflect_command(pr_url: str, rest: list):
|
||||
print(f"Processing author's answers and sending review: {pr_url}")
|
||||
reviewer = PRReviewer(pr_url, cli_mode=True, is_answer=True)
|
||||
asyncio.run(reviewer.review())
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
run()
|
||||
@ -5,10 +5,16 @@ from dynaconf import Dynaconf
|
||||
current_dir = dirname(abspath(__file__))
|
||||
settings = Dynaconf(
|
||||
envvar_prefix=False,
|
||||
merge_enabled=True,
|
||||
settings_files=[join(current_dir, f) for f in [
|
||||
"settings/.secrets.toml",
|
||||
"settings/configuration.toml",
|
||||
"settings/language_extensions.toml",
|
||||
"settings/pr_reviewer_prompts.toml",
|
||||
"settings/pr_questions_prompts.toml"
|
||||
"settings/pr_questions_prompts.toml",
|
||||
"settings/pr_description_prompts.toml",
|
||||
"settings/pr_code_suggestions_prompts.toml",
|
||||
"settings/pr_information_from_user_prompts.toml",
|
||||
"settings_prod/.secrets.toml"
|
||||
]]
|
||||
)
|
||||
|
||||
@ -1,15 +1,19 @@
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.git_providers.bitbucket_provider import BitbucketProvider
|
||||
from pr_agent.git_providers.github_provider import GithubProvider
|
||||
from pr_agent.git_providers.gitlab_provider import GitLabProvider
|
||||
|
||||
_GIT_PROVIDERS = {
|
||||
'github': GithubProvider
|
||||
'github': GithubProvider,
|
||||
'gitlab': GitLabProvider,
|
||||
'bitbucket': BitbucketProvider,
|
||||
}
|
||||
|
||||
def get_git_provider():
|
||||
try:
|
||||
provider_id = settings.config.git_provider
|
||||
except AttributeError as e:
|
||||
raise ValueError("github_provider is a required attribute in the configuration file") from e
|
||||
raise ValueError("git_provider is a required attribute in the configuration file") from e
|
||||
if provider_id not in _GIT_PROVIDERS:
|
||||
raise ValueError(f"Unknown git provider: {provider_id}")
|
||||
return _GIT_PROVIDERS[provider_id]
|
||||
|
||||
123
pr_agent/git_providers/bitbucket_provider.py
Normal file
123
pr_agent/git_providers/bitbucket_provider.py
Normal file
@ -0,0 +1,123 @@
|
||||
import logging
|
||||
from typing import Optional, Tuple
|
||||
from urllib.parse import urlparse
|
||||
|
||||
import requests
|
||||
from atlassian.bitbucket import Cloud
|
||||
|
||||
from pr_agent.config_loader import settings
|
||||
|
||||
from .git_provider import FilePatchInfo
|
||||
|
||||
|
||||
class BitbucketProvider:
|
||||
def __init__(self, pr_url: Optional[str] = None, incremental: Optional[bool] = False):
|
||||
s = requests.Session()
|
||||
s.headers['Authorization'] = f'Bearer {settings.get("BITBUCKET.BEARER_TOKEN", None)}'
|
||||
self.bitbucket_client = Cloud(session=s)
|
||||
|
||||
self.workspace_slug = None
|
||||
self.repo_slug = None
|
||||
self.repo = None
|
||||
self.pr_num = None
|
||||
self.pr = None
|
||||
self.temp_comments = []
|
||||
self.incremental = incremental
|
||||
if pr_url:
|
||||
self.set_pr(pr_url)
|
||||
|
||||
def is_supported(self, capability: str) -> bool:
|
||||
if capability in ['get_issue_comments', 'create_inline_comment', 'publish_inline_comments']:
|
||||
return False
|
||||
return True
|
||||
|
||||
def set_pr(self, pr_url: str):
|
||||
self.workspace_slug, self.repo_slug, self.pr_num = self._parse_pr_url(pr_url)
|
||||
self.pr = self._get_pr()
|
||||
|
||||
def get_files(self):
|
||||
return [diff.new.path for diff in self.pr.diffstat()]
|
||||
|
||||
def get_diff_files(self) -> list[FilePatchInfo]:
|
||||
diffs = self.pr.diffstat()
|
||||
diff_split = ['diff --git%s' % x for x in self.pr.diff().split('diff --git') if x.strip()]
|
||||
|
||||
diff_files = []
|
||||
for index, diff in enumerate(diffs):
|
||||
original_file_content_str = self._get_pr_file_content(diff.old.get_data('links'))
|
||||
new_file_content_str = self._get_pr_file_content(diff.new.get_data('links'))
|
||||
diff_files.append(FilePatchInfo(original_file_content_str, new_file_content_str,
|
||||
diff_split[index], diff.new.path))
|
||||
return diff_files
|
||||
|
||||
def publish_comment(self, pr_comment: str, is_temporary: bool = False):
|
||||
comment = self.pr.comment(pr_comment)
|
||||
if is_temporary:
|
||||
self.temp_comments.append(comment['id'])
|
||||
|
||||
def remove_initial_comment(self):
|
||||
try:
|
||||
for comment in self.temp_comments:
|
||||
self.pr.delete(f'comments/{comment}')
|
||||
except Exception as e:
|
||||
logging.exception(f"Failed to remove temp comments, error: {e}")
|
||||
|
||||
def publish_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
||||
pass
|
||||
|
||||
def create_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
||||
raise NotImplementedError("Bitbucket provider does not support creating inline comments yet")
|
||||
|
||||
def publish_inline_comments(self, comments: list[dict]):
|
||||
raise NotImplementedError("Bitbucket provider does not support publishing inline comments yet")
|
||||
|
||||
def get_title(self):
|
||||
return self.pr.title
|
||||
|
||||
def get_languages(self):
|
||||
languages = {self._get_repo().get_data('language'): 0}
|
||||
return languages
|
||||
|
||||
def get_pr_branch(self):
|
||||
return self.pr.source_branch
|
||||
|
||||
def get_pr_description(self):
|
||||
return self.pr.description
|
||||
|
||||
def get_user_id(self):
|
||||
return 0
|
||||
|
||||
def get_issue_comments(self):
|
||||
raise NotImplementedError("Bitbucket provider does not support issue comments yet")
|
||||
|
||||
@staticmethod
|
||||
def _parse_pr_url(pr_url: str) -> Tuple[str, int]:
|
||||
parsed_url = urlparse(pr_url)
|
||||
|
||||
if 'bitbucket.org' not in parsed_url.netloc:
|
||||
raise ValueError("The provided URL is not a valid GitHub URL")
|
||||
|
||||
path_parts = parsed_url.path.strip('/').split('/')
|
||||
|
||||
if len(path_parts) < 4 or path_parts[2] != 'pull-requests':
|
||||
raise ValueError("The provided URL does not appear to be a Bitbucket PR URL")
|
||||
|
||||
workspace_slug = path_parts[0]
|
||||
repo_slug = path_parts[1]
|
||||
try:
|
||||
pr_number = int(path_parts[3])
|
||||
except ValueError as e:
|
||||
raise ValueError("Unable to convert PR number to integer") from e
|
||||
|
||||
return workspace_slug, repo_slug, pr_number
|
||||
|
||||
def _get_repo(self):
|
||||
if self.repo is None:
|
||||
self.repo = self.bitbucket_client.workspaces.get(self.workspace_slug).repositories.get(self.repo_slug)
|
||||
return self.repo
|
||||
|
||||
def _get_pr(self):
|
||||
return self._get_repo().pullrequests.get(self.pr_num)
|
||||
|
||||
def _get_pr_file_content(self, remote_link: str):
|
||||
return ""
|
||||
134
pr_agent/git_providers/git_provider.py
Normal file
134
pr_agent/git_providers/git_provider.py
Normal file
@ -0,0 +1,134 @@
|
||||
from abc import ABC, abstractmethod
|
||||
from dataclasses import dataclass
|
||||
|
||||
# enum EDIT_TYPE (ADDED, DELETED, MODIFIED, RENAMED)
|
||||
from enum import Enum
|
||||
|
||||
|
||||
class EDIT_TYPE(Enum):
|
||||
ADDED = 1
|
||||
DELETED = 2
|
||||
MODIFIED = 3
|
||||
RENAMED = 4
|
||||
|
||||
|
||||
@dataclass
|
||||
class FilePatchInfo:
|
||||
base_file: str
|
||||
head_file: str
|
||||
patch: str
|
||||
filename: str
|
||||
tokens: int = -1
|
||||
edit_type: EDIT_TYPE = EDIT_TYPE.MODIFIED
|
||||
old_filename: str = None
|
||||
|
||||
|
||||
class GitProvider(ABC):
|
||||
@abstractmethod
|
||||
def is_supported(self, capability: str) -> bool:
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_diff_files(self) -> list[FilePatchInfo]:
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def publish_description(self, pr_title: str, pr_body: str):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def publish_comment(self, pr_comment: str, is_temporary: bool = False):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def publish_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def create_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def publish_inline_comments(self, comments: list[dict]):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def publish_code_suggestions(self, code_suggestions: list):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def publish_labels(self, labels):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def remove_initial_comment(self):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_languages(self):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_pr_branch(self):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_user_id(self):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_pr_description(self):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_issue_comments(self):
|
||||
pass
|
||||
|
||||
|
||||
def get_main_pr_language(languages, files) -> str:
|
||||
"""
|
||||
Get the main language of the commit. Return an empty string if cannot determine.
|
||||
"""
|
||||
main_language_str = ""
|
||||
try:
|
||||
top_language = max(languages, key=languages.get).lower()
|
||||
|
||||
# validate that the specific commit uses the main language
|
||||
extension_list = []
|
||||
for file in files:
|
||||
extension_list.append(file.filename.rsplit('.')[-1])
|
||||
|
||||
# get the most common extension
|
||||
most_common_extension = max(set(extension_list), key=extension_list.count)
|
||||
|
||||
# look for a match. TBD: add more languages, do this systematically
|
||||
if most_common_extension == 'py' and top_language == 'python' or \
|
||||
most_common_extension == 'js' and top_language == 'javascript' or \
|
||||
most_common_extension == 'ts' and top_language == 'typescript' or \
|
||||
most_common_extension == 'go' and top_language == 'go' or \
|
||||
most_common_extension == 'java' and top_language == 'java' or \
|
||||
most_common_extension == 'c' and top_language == 'c' or \
|
||||
most_common_extension == 'cpp' and top_language == 'c++' or \
|
||||
most_common_extension == 'cs' and top_language == 'c#' or \
|
||||
most_common_extension == 'swift' and top_language == 'swift' or \
|
||||
most_common_extension == 'php' and top_language == 'php' or \
|
||||
most_common_extension == 'rb' and top_language == 'ruby' or \
|
||||
most_common_extension == 'rs' and top_language == 'rust' or \
|
||||
most_common_extension == 'scala' and top_language == 'scala' or \
|
||||
most_common_extension == 'kt' and top_language == 'kotlin' or \
|
||||
most_common_extension == 'pl' and top_language == 'perl' or \
|
||||
most_common_extension == 'swift' and top_language == 'swift':
|
||||
main_language_str = top_language
|
||||
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
return main_language_str
|
||||
|
||||
|
||||
class IncrementalPR:
|
||||
def __init__(self, is_incremental: bool = False):
|
||||
self.is_incremental = is_incremental
|
||||
self.commits_range = None
|
||||
self.first_new_commit_sha = None
|
||||
self.last_seen_commit_sha = None
|
||||
@ -1,101 +1,232 @@
|
||||
from collections import namedtuple
|
||||
from dataclasses import dataclass
|
||||
import logging
|
||||
from datetime import datetime
|
||||
from typing import Optional, Tuple
|
||||
from urllib.parse import urlparse
|
||||
|
||||
from github import AppAuthentication, File, Github
|
||||
from github import AppAuthentication, Github, Auth
|
||||
|
||||
from pr_agent.config_loader import settings
|
||||
|
||||
@dataclass
|
||||
class FilePatchInfo:
|
||||
base_file: str
|
||||
head_file: str
|
||||
patch: str
|
||||
filename: str
|
||||
tokens: int = -1
|
||||
from .git_provider import FilePatchInfo, GitProvider, IncrementalPR
|
||||
from ..algo.language_handler import is_valid_file
|
||||
from ..algo.utils import load_large_diff
|
||||
|
||||
class GithubProvider:
|
||||
def __init__(self, pr_url: Optional[str] = None, installation_id: Optional[int] = None):
|
||||
self.installation_id = installation_id
|
||||
|
||||
class GithubProvider(GitProvider):
|
||||
def __init__(self, pr_url: Optional[str] = None, incremental=IncrementalPR(False)):
|
||||
self.repo_obj = None
|
||||
self.installation_id = settings.get("GITHUB.INSTALLATION_ID")
|
||||
self.github_client = self._get_github_client()
|
||||
self.repo = None
|
||||
self.pr_num = None
|
||||
self.pr = None
|
||||
self.github_user_id = None
|
||||
self.diff_files = None
|
||||
self.incremental = incremental
|
||||
if pr_url:
|
||||
self.set_pr(pr_url)
|
||||
self.last_commit_id = list(self.pr.get_commits())[-1]
|
||||
|
||||
def is_supported(self, capability: str) -> bool:
|
||||
return True
|
||||
|
||||
def get_pr_url(self) -> str:
|
||||
return f"https://github.com/{self.repo}/pull/{self.pr_num}"
|
||||
|
||||
def set_pr(self, pr_url: str):
|
||||
self.repo, self.pr_num = self._parse_pr_url(pr_url)
|
||||
self.pr = self._get_pr()
|
||||
if self.incremental.is_incremental:
|
||||
self.get_incremental_commits()
|
||||
|
||||
def get_incremental_commits(self):
|
||||
self.commits = list(self.pr.get_commits())
|
||||
|
||||
self.get_previous_review()
|
||||
if self.previous_review:
|
||||
self.incremental.commits_range = self.get_commit_range()
|
||||
# Get all files changed during the commit range
|
||||
self.file_set = dict()
|
||||
for commit in self.incremental.commits_range:
|
||||
if commit.commit.message.startswith(f"Merge branch '{self._get_repo().default_branch}'"):
|
||||
logging.info(f"Skipping merge commit {commit.commit.message}")
|
||||
continue
|
||||
self.file_set.update({file.filename: file for file in commit.files})
|
||||
|
||||
def get_commit_range(self):
|
||||
last_review_time = self.previous_review.created_at
|
||||
first_new_commit_index = 0
|
||||
for index in range(len(self.commits) - 1, -1, -1):
|
||||
if self.commits[index].commit.author.date > last_review_time:
|
||||
self.incremental.first_new_commit_sha = self.commits[index].sha
|
||||
first_new_commit_index = index
|
||||
else:
|
||||
self.incremental.last_seen_commit_sha = self.commits[index].sha
|
||||
break
|
||||
return self.commits[first_new_commit_index:]
|
||||
|
||||
def get_previous_review(self):
|
||||
self.previous_review = None
|
||||
self.comments = list(self.pr.get_issue_comments())
|
||||
for index in range(len(self.comments) - 1, -1, -1):
|
||||
if self.comments[index].body.startswith("## PR Analysis"):
|
||||
self.previous_review = self.comments[index]
|
||||
break
|
||||
|
||||
def get_files(self):
|
||||
if self.incremental.is_incremental and self.file_set:
|
||||
return self.file_set.values()
|
||||
return self.pr.get_files()
|
||||
|
||||
def get_diff_files(self) -> list[FilePatchInfo]:
|
||||
files = self.pr.get_files()
|
||||
files = self.get_files()
|
||||
diff_files = []
|
||||
for file in files:
|
||||
original_file_content_str = self._get_pr_file_content(file, self.pr.base.sha)
|
||||
new_file_content_str = self._get_pr_file_content(file, self.pr.head.sha)
|
||||
diff_files.append(FilePatchInfo(original_file_content_str, new_file_content_str, file.patch, file.filename))
|
||||
if is_valid_file(file.filename):
|
||||
new_file_content_str = self._get_pr_file_content(file, self.pr.head.sha)
|
||||
patch = file.patch
|
||||
if self.incremental.is_incremental and self.file_set:
|
||||
original_file_content_str = self._get_pr_file_content(file, self.incremental.last_seen_commit_sha)
|
||||
patch = load_large_diff(file,
|
||||
new_file_content_str,
|
||||
original_file_content_str,
|
||||
None)
|
||||
self.file_set[file.filename] = patch
|
||||
else:
|
||||
original_file_content_str = self._get_pr_file_content(file, self.pr.base.sha)
|
||||
|
||||
diff_files.append(
|
||||
FilePatchInfo(original_file_content_str, new_file_content_str, patch, file.filename))
|
||||
self.diff_files = diff_files
|
||||
return diff_files
|
||||
|
||||
def publish_comment(self, pr_comment: str):
|
||||
self.pr.create_issue_comment(pr_comment)
|
||||
def publish_description(self, pr_title: str, pr_body: str):
|
||||
self.pr.edit(title=pr_title, body=pr_body)
|
||||
# self.pr.create_issue_comment(pr_comment)
|
||||
|
||||
def publish_comment(self, pr_comment: str, is_temporary: bool = False):
|
||||
if is_temporary and not settings.config.publish_output_progress:
|
||||
logging.debug(f"Skipping publish_comment for temporary comment: {pr_comment}")
|
||||
return
|
||||
response = self.pr.create_issue_comment(pr_comment)
|
||||
if hasattr(response, "user") and hasattr(response.user, "login"):
|
||||
self.github_user_id = response.user.login
|
||||
response.is_temporary = is_temporary
|
||||
if not hasattr(self.pr, 'comments_list'):
|
||||
self.pr.comments_list = []
|
||||
self.pr.comments_list.append(response)
|
||||
|
||||
def publish_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
||||
self.publish_inline_comments([self.create_inline_comment(body, relevant_file, relevant_line_in_file)])
|
||||
|
||||
def create_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
||||
self.diff_files = self.diff_files if self.diff_files else self.get_diff_files()
|
||||
position = -1
|
||||
for file in self.diff_files:
|
||||
if file.filename.strip() == relevant_file:
|
||||
patch = file.patch
|
||||
patch_lines = patch.splitlines()
|
||||
for i, line in enumerate(patch_lines):
|
||||
if relevant_line_in_file in line:
|
||||
position = i
|
||||
break
|
||||
elif relevant_line_in_file[0] == '+' and relevant_line_in_file[1:].lstrip() in line:
|
||||
# The model often adds a '+' to the beginning of the relevant_line_in_file even if originally
|
||||
# it's a context line
|
||||
position = i
|
||||
break
|
||||
if position == -1:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.info(f"Could not find position for {relevant_file} {relevant_line_in_file}")
|
||||
subject_type = "FILE"
|
||||
else:
|
||||
subject_type = "LINE"
|
||||
path = relevant_file.strip()
|
||||
# placeholder for future API support (already supported in single inline comment)
|
||||
# return dict(body=body, path=path, position=position, subject_type=subject_type)
|
||||
return dict(body=body, path=path, position=position) if subject_type == "LINE" else {}
|
||||
|
||||
def publish_inline_comments(self, comments: list[dict]):
|
||||
self.pr.create_review(commit=self.last_commit_id, comments=comments)
|
||||
|
||||
def publish_code_suggestions(self, code_suggestions: list):
|
||||
"""
|
||||
Publishes code suggestions as comments on the PR.
|
||||
"""
|
||||
post_parameters_list = []
|
||||
for suggestion in code_suggestions:
|
||||
body = suggestion['body']
|
||||
relevant_file = suggestion['relevant_file']
|
||||
relevant_lines_start = suggestion['relevant_lines_start']
|
||||
relevant_lines_end = suggestion['relevant_lines_end']
|
||||
|
||||
if not relevant_lines_start or relevant_lines_start == -1:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.exception(
|
||||
f"Failed to publish code suggestion, relevant_lines_start is {relevant_lines_start}")
|
||||
continue
|
||||
|
||||
if relevant_lines_end < relevant_lines_start:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.exception(f"Failed to publish code suggestion, "
|
||||
f"relevant_lines_end is {relevant_lines_end} and "
|
||||
f"relevant_lines_start is {relevant_lines_start}")
|
||||
continue
|
||||
|
||||
if relevant_lines_end > relevant_lines_start:
|
||||
post_parameters = {
|
||||
"body": body,
|
||||
"path": relevant_file,
|
||||
"line": relevant_lines_end,
|
||||
"start_line": relevant_lines_start,
|
||||
"start_side": "RIGHT",
|
||||
}
|
||||
else: # API is different for single line comments
|
||||
post_parameters = {
|
||||
"body": body,
|
||||
"path": relevant_file,
|
||||
"line": relevant_lines_start,
|
||||
"side": "RIGHT",
|
||||
}
|
||||
post_parameters_list.append(post_parameters)
|
||||
|
||||
try:
|
||||
self.pr.create_review(commit=self.last_commit_id, comments=post_parameters_list)
|
||||
return True
|
||||
except Exception as e:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.error(f"Failed to publish code suggestion, error: {e}")
|
||||
return False
|
||||
|
||||
def remove_initial_comment(self):
|
||||
try:
|
||||
for comment in getattr(self.pr, 'comments_list', []):
|
||||
if comment.is_temporary:
|
||||
comment.delete()
|
||||
except Exception as e:
|
||||
logging.exception(f"Failed to remove initial comment, error: {e}")
|
||||
|
||||
def get_title(self):
|
||||
return self.pr.title
|
||||
|
||||
def get_description(self):
|
||||
return self.pr.body
|
||||
|
||||
def get_languages(self):
|
||||
return self._get_repo().get_languages()
|
||||
|
||||
def get_main_pr_language(self) -> str:
|
||||
"""
|
||||
Get the main language of the commit. Return an empty string if cannot determine.
|
||||
"""
|
||||
main_language_str = ""
|
||||
try:
|
||||
languages = self.get_languages()
|
||||
top_language = max(languages, key=languages.get).lower()
|
||||
|
||||
# validate that the specific commit uses the main language
|
||||
extension_list = []
|
||||
files = self.pr.get_files()
|
||||
for file in files:
|
||||
extension_list.append(file.filename.rsplit('.')[-1])
|
||||
|
||||
# get the most common extension
|
||||
most_common_extension = max(set(extension_list), key=extension_list.count)
|
||||
|
||||
# look for a match. TBD: add more languages, do this systematically
|
||||
if most_common_extension == 'py' and top_language == 'python' or \
|
||||
most_common_extension == 'js' and top_language == 'javascript' or \
|
||||
most_common_extension == 'ts' and top_language == 'typescript' or \
|
||||
most_common_extension == 'go' and top_language == 'go' or \
|
||||
most_common_extension == 'java' and top_language == 'java' or \
|
||||
most_common_extension == 'c' and top_language == 'c' or \
|
||||
most_common_extension == 'cpp' and top_language == 'c++' or \
|
||||
most_common_extension == 'cs' and top_language == 'c#' or \
|
||||
most_common_extension == 'swift' and top_language == 'swift' or \
|
||||
most_common_extension == 'php' and top_language == 'php' or \
|
||||
most_common_extension == 'rb' and top_language == 'ruby' or \
|
||||
most_common_extension == 'rs' and top_language == 'rust' or \
|
||||
most_common_extension == 'scala' and top_language == 'scala' or \
|
||||
most_common_extension == 'kt' and top_language == 'kotlin' or \
|
||||
most_common_extension == 'pl' and top_language == 'perl' or \
|
||||
most_common_extension == 'swift' and top_language == 'swift':
|
||||
main_language_str = top_language
|
||||
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
return main_language_str
|
||||
languages = self._get_repo().get_languages()
|
||||
return languages
|
||||
|
||||
def get_pr_branch(self):
|
||||
return self.pr.head.ref
|
||||
|
||||
def get_pr_description(self):
|
||||
return self.pr.body
|
||||
|
||||
def get_user_id(self):
|
||||
if not self.github_user_id:
|
||||
try:
|
||||
self.github_user_id = self.github_client.get_user().login
|
||||
except Exception as e:
|
||||
logging.exception(f"Failed to get user id, error: {e}")
|
||||
return self.github_user_id
|
||||
|
||||
def get_notifications(self, since: datetime):
|
||||
deployment_type = settings.get("GITHUB.DEPLOYMENT_TYPE", "user")
|
||||
|
||||
@ -105,6 +236,9 @@ class GithubProvider:
|
||||
notifications = self.github_client.get_user().get_notifications(since=since)
|
||||
return notifications
|
||||
|
||||
def get_issue_comments(self):
|
||||
return self.pr.get_issue_comments()
|
||||
|
||||
@staticmethod
|
||||
def _parse_pr_url(pr_url: str) -> Tuple[str, int]:
|
||||
parsed_url = urlparse(pr_url)
|
||||
@ -153,18 +287,40 @@ class GithubProvider:
|
||||
try:
|
||||
token = settings.github.user_token
|
||||
except AttributeError as e:
|
||||
raise ValueError("GitHub token is required when using user deployment") from e
|
||||
return Github(token)
|
||||
raise ValueError(
|
||||
"GitHub token is required when using user deployment. See: "
|
||||
"https://github.com/Codium-ai/pr-agent#method-2-run-from-source") from e
|
||||
return Github(auth=Auth.Token(token))
|
||||
|
||||
def _get_repo(self):
|
||||
return self.github_client.get_repo(self.repo)
|
||||
if hasattr(self, 'repo_obj') and \
|
||||
hasattr(self.repo_obj, 'full_name') and \
|
||||
self.repo_obj.full_name == self.repo:
|
||||
return self.repo_obj
|
||||
else:
|
||||
self.repo_obj = self.github_client.get_repo(self.repo)
|
||||
return self.repo_obj
|
||||
|
||||
|
||||
def _get_pr(self):
|
||||
return self._get_repo().get_pull(self.pr_num)
|
||||
|
||||
def _get_pr_file_content(self, file: FilePatchInfo, sha: str):
|
||||
def _get_pr_file_content(self, file: FilePatchInfo, sha: str) -> str:
|
||||
try:
|
||||
file_content_str = self._get_repo().get_contents(file.filename, ref=sha).decoded_content.decode()
|
||||
file_content_str = str(self._get_repo().get_contents(file.filename, ref=sha).decoded_content.decode())
|
||||
except Exception:
|
||||
file_content_str = ""
|
||||
return file_content_str
|
||||
|
||||
def publish_labels(self, pr_types):
|
||||
try:
|
||||
label_color_map = {"Bug fix": "1d76db", "Tests": "e99695", "Bug fix with tests": "c5def5", "Refactoring": "bfdadc", "Enhancement": "bfd4f2", "Documentation": "d4c5f9", "Other": "d1bcf9"}
|
||||
post_parameters = []
|
||||
for p in pr_types:
|
||||
color = label_color_map.get(p, "d1bcf9") # default to "Other" color
|
||||
post_parameters.append({"name": p, "color": color})
|
||||
headers, data = self.pr._requester.requestJsonAndCheck(
|
||||
"PUT", f"{self.pr.issue_url}/labels", input=post_parameters
|
||||
)
|
||||
except:
|
||||
logging.exception("Failed to publish labels")
|
||||
|
||||
265
pr_agent/git_providers/gitlab_provider.py
Normal file
265
pr_agent/git_providers/gitlab_provider.py
Normal file
@ -0,0 +1,265 @@
|
||||
import logging
|
||||
import re
|
||||
from typing import Optional, Tuple
|
||||
from urllib.parse import urlparse
|
||||
|
||||
import gitlab
|
||||
from gitlab import GitlabGetError
|
||||
|
||||
from pr_agent.config_loader import settings
|
||||
|
||||
from .git_provider import EDIT_TYPE, FilePatchInfo, GitProvider
|
||||
from ..algo.language_handler import is_valid_file
|
||||
|
||||
|
||||
class GitLabProvider(GitProvider):
|
||||
def __init__(self, merge_request_url: Optional[str] = None, incremental: Optional[bool] = False):
|
||||
gitlab_url = settings.get("GITLAB.URL", None)
|
||||
if not gitlab_url:
|
||||
raise ValueError("GitLab URL is not set in the config file")
|
||||
gitlab_access_token = settings.get("GITLAB.PERSONAL_ACCESS_TOKEN", None)
|
||||
if not gitlab_access_token:
|
||||
raise ValueError("GitLab personal access token is not set in the config file")
|
||||
self.gl = gitlab.Gitlab(
|
||||
gitlab_url,
|
||||
gitlab_access_token
|
||||
)
|
||||
self.id_project = None
|
||||
self.id_mr = None
|
||||
self.mr = None
|
||||
self.diff_files = None
|
||||
self.temp_comments = []
|
||||
self._set_merge_request(merge_request_url)
|
||||
self.RE_HUNK_HEADER = re.compile(
|
||||
r"^@@ -(\d+)(?:,(\d+))? \+(\d+)(?:,(\d+))? @@[ ]?(.*)")
|
||||
self.incremental = incremental
|
||||
|
||||
def is_supported(self, capability: str) -> bool:
|
||||
if capability in ['get_issue_comments', 'create_inline_comment', 'publish_inline_comments']:
|
||||
return False
|
||||
return True
|
||||
|
||||
@property
|
||||
def pr(self):
|
||||
'''The GitLab terminology is merge request (MR) instead of pull request (PR)'''
|
||||
return self.mr
|
||||
|
||||
def _set_merge_request(self, merge_request_url: str):
|
||||
self.id_project, self.id_mr = self._parse_merge_request_url(merge_request_url)
|
||||
self.mr = self._get_merge_request()
|
||||
self.last_diff = self.mr.diffs.list()[-1]
|
||||
|
||||
def _get_pr_file_content(self, file_path: str, branch: str) -> str:
|
||||
try:
|
||||
return self.gl.projects.get(self.id_project).files.get(file_path, branch).decode()
|
||||
except GitlabGetError:
|
||||
# In case of file creation the method returns GitlabGetError (404 file not found).
|
||||
# In this case we return an empty string for the diff.
|
||||
return ''
|
||||
|
||||
def get_diff_files(self) -> list[FilePatchInfo]:
|
||||
diffs = self.mr.changes()['changes']
|
||||
diff_files = []
|
||||
for diff in diffs:
|
||||
if is_valid_file(diff['new_path']):
|
||||
original_file_content_str = self._get_pr_file_content(diff['old_path'], self.mr.target_branch)
|
||||
new_file_content_str = self._get_pr_file_content(diff['new_path'], self.mr.source_branch)
|
||||
edit_type = EDIT_TYPE.MODIFIED
|
||||
if diff['new_file']:
|
||||
edit_type = EDIT_TYPE.ADDED
|
||||
elif diff['deleted_file']:
|
||||
edit_type = EDIT_TYPE.DELETED
|
||||
elif diff['renamed_file']:
|
||||
edit_type = EDIT_TYPE.RENAMED
|
||||
try:
|
||||
if isinstance(original_file_content_str, bytes):
|
||||
original_file_content_str = bytes.decode(original_file_content_str, 'utf-8')
|
||||
if isinstance(new_file_content_str, bytes):
|
||||
new_file_content_str = bytes.decode(new_file_content_str, 'utf-8')
|
||||
except UnicodeDecodeError:
|
||||
logging.warning(
|
||||
f"Cannot decode file {diff['old_path']} or {diff['new_path']} in merge request {self.id_mr}")
|
||||
diff_files.append(
|
||||
FilePatchInfo(original_file_content_str, new_file_content_str, diff['diff'], diff['new_path'],
|
||||
edit_type=edit_type,
|
||||
old_filename=None if diff['old_path'] == diff['new_path'] else diff['old_path']))
|
||||
self.diff_files = diff_files
|
||||
return diff_files
|
||||
|
||||
def get_files(self):
|
||||
return [change['new_path'] for change in self.mr.changes()['changes']]
|
||||
|
||||
def publish_description(self, pr_title: str, pr_body: str):
|
||||
try:
|
||||
self.mr.title = pr_title
|
||||
self.mr.description = pr_body
|
||||
self.mr.save()
|
||||
except Exception as e:
|
||||
logging.exception(f"Could not update merge request {self.id_mr} description: {e}")
|
||||
|
||||
def publish_comment(self, mr_comment: str, is_temporary: bool = False):
|
||||
comment = self.mr.notes.create({'body': mr_comment})
|
||||
if is_temporary:
|
||||
self.temp_comments.append(comment)
|
||||
|
||||
def publish_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
||||
self.diff_files = self.diff_files if self.diff_files else self.get_diff_files()
|
||||
edit_type, found, source_line_no, target_file, target_line_no = self.search_line(relevant_file,
|
||||
relevant_line_in_file)
|
||||
self.send_inline_comment(body, edit_type, found, relevant_file, relevant_line_in_file, source_line_no,
|
||||
target_file, target_line_no)
|
||||
|
||||
def create_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str):
|
||||
raise NotImplementedError("Gitlab provider does not support creating inline comments yet")
|
||||
|
||||
def create_inline_comment(self, comments: list[dict]):
|
||||
raise NotImplementedError("Gitlab provider does not support publishing inline comments yet")
|
||||
|
||||
def send_inline_comment(self, body, edit_type, found, relevant_file, relevant_line_in_file, source_line_no,
|
||||
target_file, target_line_no):
|
||||
if not found:
|
||||
logging.info(f"Could not find position for {relevant_file} {relevant_line_in_file}")
|
||||
else:
|
||||
d = self.last_diff
|
||||
pos_obj = {'position_type': 'text',
|
||||
'new_path': target_file.filename,
|
||||
'old_path': target_file.old_filename if target_file.old_filename else target_file.filename,
|
||||
'base_sha': d.base_commit_sha, 'start_sha': d.start_commit_sha, 'head_sha': d.head_commit_sha}
|
||||
if edit_type == 'deletion':
|
||||
pos_obj['old_line'] = source_line_no - 1
|
||||
elif edit_type == 'addition':
|
||||
pos_obj['new_line'] = target_line_no - 1
|
||||
else:
|
||||
pos_obj['new_line'] = target_line_no - 1
|
||||
pos_obj['old_line'] = source_line_no - 1
|
||||
self.mr.discussions.create({'body': body,
|
||||
'position': pos_obj})
|
||||
|
||||
def publish_code_suggestions(self, code_suggestions: list):
|
||||
for suggestion in code_suggestions:
|
||||
body = suggestion['body']
|
||||
relevant_file = suggestion['relevant_file']
|
||||
relevant_lines_start = suggestion['relevant_lines_start']
|
||||
relevant_lines_end = suggestion['relevant_lines_end']
|
||||
|
||||
self.diff_files = self.diff_files if self.diff_files else self.get_diff_files()
|
||||
target_file = None
|
||||
for file in self.diff_files:
|
||||
if file.filename == relevant_file:
|
||||
if file.filename == relevant_file:
|
||||
target_file = file
|
||||
break
|
||||
range = relevant_lines_end - relevant_lines_start + 1
|
||||
body = body.replace('```suggestion', f'```suggestion:-0+{range}')
|
||||
|
||||
lines = target_file.head_file.splitlines()
|
||||
relevant_line_in_file = lines[relevant_lines_start - 1]
|
||||
edit_type, found, source_line_no, target_file, target_line_no = self.find_in_file(target_file,
|
||||
relevant_line_in_file)
|
||||
self.send_inline_comment(body, edit_type, found, relevant_file, relevant_line_in_file, source_line_no,
|
||||
target_file, target_line_no)
|
||||
|
||||
def search_line(self, relevant_file, relevant_line_in_file):
|
||||
target_file = None
|
||||
|
||||
edit_type = self.get_edit_type(relevant_line_in_file)
|
||||
for file in self.diff_files:
|
||||
if file.filename == relevant_file:
|
||||
edit_type, found, source_line_no, target_file, target_line_no = self.find_in_file(file,
|
||||
relevant_line_in_file)
|
||||
return edit_type, found, source_line_no, target_file, target_line_no
|
||||
|
||||
def find_in_file(self, file, relevant_line_in_file):
|
||||
edit_type = 'context'
|
||||
source_line_no = 0
|
||||
target_line_no = 0
|
||||
found = False
|
||||
target_file = file
|
||||
patch = file.patch
|
||||
patch_lines = patch.splitlines()
|
||||
for line in patch_lines:
|
||||
if line.startswith('@@'):
|
||||
match = self.RE_HUNK_HEADER.match(line)
|
||||
if not match:
|
||||
continue
|
||||
start_old, size_old, start_new, size_new, _ = match.groups()
|
||||
source_line_no = int(start_old)
|
||||
target_line_no = int(start_new)
|
||||
continue
|
||||
if line.startswith('-'):
|
||||
source_line_no += 1
|
||||
elif line.startswith('+'):
|
||||
target_line_no += 1
|
||||
elif line.startswith(' '):
|
||||
source_line_no += 1
|
||||
target_line_no += 1
|
||||
if relevant_line_in_file in line:
|
||||
found = True
|
||||
edit_type = self.get_edit_type(line)
|
||||
break
|
||||
elif relevant_line_in_file[0] == '+' and relevant_line_in_file[1:].lstrip() in line:
|
||||
# The model often adds a '+' to the beginning of the relevant_line_in_file even if originally
|
||||
# it's a context line
|
||||
found = True
|
||||
edit_type = self.get_edit_type(line)
|
||||
break
|
||||
return edit_type, found, source_line_no, target_file, target_line_no
|
||||
|
||||
def get_edit_type(self, relevant_line_in_file):
|
||||
edit_type = 'context'
|
||||
if relevant_line_in_file[0] == '-':
|
||||
edit_type = 'deletion'
|
||||
elif relevant_line_in_file[0] == '+':
|
||||
edit_type = 'addition'
|
||||
return edit_type
|
||||
|
||||
def remove_initial_comment(self):
|
||||
try:
|
||||
for comment in self.temp_comments:
|
||||
comment.delete()
|
||||
except Exception as e:
|
||||
logging.exception(f"Failed to remove temp comments, error: {e}")
|
||||
|
||||
def get_title(self):
|
||||
return self.mr.title
|
||||
|
||||
def get_languages(self):
|
||||
languages = self.gl.projects.get(self.id_project).languages()
|
||||
return languages
|
||||
|
||||
def get_pr_branch(self):
|
||||
return self.mr.source_branch
|
||||
|
||||
def get_pr_description(self):
|
||||
return self.mr.description
|
||||
|
||||
def get_issue_comments(self):
|
||||
raise NotImplementedError("GitLab provider does not support issue comments yet")
|
||||
|
||||
def _parse_merge_request_url(self, merge_request_url: str) -> Tuple[int, int]:
|
||||
parsed_url = urlparse(merge_request_url)
|
||||
|
||||
path_parts = parsed_url.path.strip('/').split('/')
|
||||
if path_parts[-2] != 'merge_requests':
|
||||
raise ValueError("The provided URL does not appear to be a GitLab merge request URL")
|
||||
|
||||
try:
|
||||
mr_id = int(path_parts[-1])
|
||||
except ValueError as e:
|
||||
raise ValueError("Unable to convert merge request ID to integer") from e
|
||||
|
||||
# Gitlab supports access by both project numeric ID as well as 'namespace/project_name'
|
||||
return "/".join(path_parts[:2]), mr_id
|
||||
|
||||
def _get_merge_request(self):
|
||||
mr = self.gl.projects.get(self.id_project).mergerequests.get(self.id_mr)
|
||||
return mr
|
||||
|
||||
def get_user_id(self):
|
||||
return None
|
||||
|
||||
def publish_labels(self, labels):
|
||||
pass
|
||||
|
||||
def publish_inline_comments(self, comments: list[dict]):
|
||||
pass
|
||||
@ -1,16 +0,0 @@
|
||||
import argparse
|
||||
import asyncio
|
||||
import logging
|
||||
import os
|
||||
|
||||
from pr_agent.tools.pr_questions import PRQuestions
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = argparse.ArgumentParser(description='Review a PR from a URL')
|
||||
parser.add_argument('--pr_url', type=str, help='The URL of the PR to review', required=True)
|
||||
parser.add_argument('--question_str', type=str, help='The question to answer', required=True)
|
||||
|
||||
args = parser.parse_args()
|
||||
logging.basicConfig(level=os.environ.get("LOGLEVEL", "INFO"))
|
||||
reviewer = PRQuestions(args.pr_url, args.question_str, None)
|
||||
asyncio.run(reviewer.answer())
|
||||
@ -1,14 +0,0 @@
|
||||
import argparse
|
||||
import asyncio
|
||||
import logging
|
||||
import os
|
||||
|
||||
from pr_agent.tools.pr_reviewer import PRReviewer
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = argparse.ArgumentParser(description='Review a PR from a URL')
|
||||
parser.add_argument('--pr_url', type=str, help='The URL of the PR to review', required=True)
|
||||
args = parser.parse_args()
|
||||
logging.basicConfig(level=os.environ.get("LOGLEVEL", "INFO"))
|
||||
reviewer = PRReviewer(args.pr_url, None)
|
||||
asyncio.run(reviewer.review())
|
||||
57
pr_agent/servers/github_action_runner.py
Normal file
57
pr_agent/servers/github_action_runner.py
Normal file
@ -0,0 +1,57 @@
|
||||
import asyncio
|
||||
import json
|
||||
import os
|
||||
|
||||
from pr_agent.agent.pr_agent import PRAgent
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.tools.pr_reviewer import PRReviewer
|
||||
|
||||
|
||||
async def run_action():
|
||||
GITHUB_EVENT_NAME = os.environ.get('GITHUB_EVENT_NAME', None)
|
||||
if not GITHUB_EVENT_NAME:
|
||||
print("GITHUB_EVENT_NAME not set")
|
||||
return
|
||||
GITHUB_EVENT_PATH = os.environ.get('GITHUB_EVENT_PATH', None)
|
||||
if not GITHUB_EVENT_PATH:
|
||||
print("GITHUB_EVENT_PATH not set")
|
||||
return
|
||||
try:
|
||||
event_payload = json.load(open(GITHUB_EVENT_PATH, 'r'))
|
||||
except json.decoder.JSONDecodeError as e:
|
||||
print(f"Failed to parse JSON: {e}")
|
||||
return
|
||||
OPENAI_KEY = os.environ.get('OPENAI_KEY', None)
|
||||
if not OPENAI_KEY:
|
||||
print("OPENAI_KEY not set")
|
||||
return
|
||||
OPENAI_ORG = os.environ.get('OPENAI_ORG', None)
|
||||
GITHUB_TOKEN = os.environ.get('GITHUB_TOKEN', None)
|
||||
if not GITHUB_TOKEN:
|
||||
print("GITHUB_TOKEN not set")
|
||||
return
|
||||
settings.set("OPENAI.KEY", OPENAI_KEY)
|
||||
if OPENAI_ORG:
|
||||
settings.set("OPENAI.ORG", OPENAI_ORG)
|
||||
settings.set("GITHUB.USER_TOKEN", GITHUB_TOKEN)
|
||||
settings.set("GITHUB.DEPLOYMENT_TYPE", "user")
|
||||
if GITHUB_EVENT_NAME == "pull_request":
|
||||
action = event_payload.get("action", None)
|
||||
if action in ["opened", "reopened"]:
|
||||
pr_url = event_payload.get("pull_request", {}).get("url", None)
|
||||
if pr_url:
|
||||
await PRReviewer(pr_url).review()
|
||||
|
||||
elif GITHUB_EVENT_NAME == "issue_comment":
|
||||
action = event_payload.get("action", None)
|
||||
if action in ["created", "edited"]:
|
||||
comment_body = event_payload.get("comment", {}).get("body", None)
|
||||
if comment_body:
|
||||
pr_url = event_payload.get("issue", {}).get("pull_request", {}).get("url", None)
|
||||
if pr_url:
|
||||
body = comment_body.strip().lower()
|
||||
await PRAgent().handle_request(pr_url, body)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
asyncio.run(run_action())
|
||||
@ -35,12 +35,13 @@ async def handle_github_webhooks(request: Request, response: Response):
|
||||
async def handle_request(body):
|
||||
action = body.get("action", None)
|
||||
installation_id = body.get("installation", {}).get("id", None)
|
||||
agent = PRAgent(installation_id)
|
||||
settings.set("GITHUB.INSTALLATION_ID", installation_id)
|
||||
agent = PRAgent()
|
||||
if action == 'created':
|
||||
if "comment" not in body:
|
||||
return {}
|
||||
comment_body = body.get("comment", {}).get("body", None)
|
||||
if "says 'Please" in comment_body:
|
||||
if 'sender' in body and 'login' in body['sender'] and 'bot' in body['sender']['login']:
|
||||
return {}
|
||||
if "issue" not in body and "pull_request" not in body["issue"]:
|
||||
return {}
|
||||
@ -55,7 +56,7 @@ async def handle_request(body):
|
||||
api_url = pull_request.get("url", None)
|
||||
if api_url is None:
|
||||
return {}
|
||||
await agent.handle_request(api_url, "please review")
|
||||
await agent.handle_request(api_url, "/review")
|
||||
else:
|
||||
return {}
|
||||
|
||||
@ -66,8 +67,8 @@ async def root():
|
||||
|
||||
|
||||
def start():
|
||||
if settings.get("GITHUB.DEPLOYMENT_TYPE", "user") != "app":
|
||||
raise Exception("Please set deployment type to app in .secrets.toml file")
|
||||
# Override the deployment type to app
|
||||
settings.set("GITHUB.DEPLOYMENT_TYPE", "app")
|
||||
app = FastAPI()
|
||||
app.include_router(router)
|
||||
|
||||
@ -7,6 +7,8 @@ import aiohttp
|
||||
|
||||
from pr_agent.agent.pr_agent import PRAgent
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.git_providers import get_git_provider
|
||||
from pr_agent.servers.help import bot_help_text
|
||||
|
||||
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
|
||||
NOTIFICATION_URL = "https://api.github.com/notifications"
|
||||
@ -19,8 +21,12 @@ def now() -> str:
|
||||
|
||||
|
||||
async def polling_loop():
|
||||
handled_ids = set()
|
||||
since = [now()]
|
||||
last_modified = [None]
|
||||
git_provider = get_git_provider()()
|
||||
user_id = git_provider.get_user_id()
|
||||
agent = PRAgent()
|
||||
try:
|
||||
deployment_type = settings.github.deployment_type
|
||||
token = settings.github.user_token
|
||||
@ -33,41 +39,65 @@ async def polling_loop():
|
||||
raise ValueError("User token must be set to get notifications")
|
||||
async with aiohttp.ClientSession() as session:
|
||||
while True:
|
||||
headers = {
|
||||
"Accept": "application/vnd.github.v3+json",
|
||||
"Authorization": f"Bearer {token}"
|
||||
}
|
||||
params = {
|
||||
"participating": "true"
|
||||
}
|
||||
if since[0]:
|
||||
params["since"] = since[0]
|
||||
if last_modified[0]:
|
||||
headers["If-Modified-Since"] = last_modified[0]
|
||||
async with session.get(NOTIFICATION_URL, headers=headers, params=params) as response:
|
||||
if response.status == 200:
|
||||
if 'Last-Modified' in response.headers:
|
||||
last_modified[0] = response.headers['Last-Modified']
|
||||
since[0] = None
|
||||
notifications = await response.json()
|
||||
for notification in notifications:
|
||||
if 'reason' in notification and notification['reason'] == 'mention':
|
||||
if 'subject' in notification and notification['subject']['type'] == 'PullRequest':
|
||||
pr_url = notification['subject']['url']
|
||||
latest_comment = notification['subject']['latest_comment_url']
|
||||
async with session.get(latest_comment, headers=headers) as comment_response:
|
||||
if comment_response.status == 200:
|
||||
comment = await comment_response.json()
|
||||
comment_body = comment['body'] if 'body' in comment else ''
|
||||
commenter_github_user = comment['user']['login'] if 'user' in comment else ''
|
||||
logging.info(f"Commenter: {commenter_github_user}\nComment: {comment_body}")
|
||||
if comment_body.strip().startswith("@"):
|
||||
agent = PRAgent()
|
||||
await agent.handle_request(pr_url, comment_body)
|
||||
elif response.status != 304:
|
||||
print(f"Failed to fetch notifications. Status code: {response.status}")
|
||||
try:
|
||||
await asyncio.sleep(5)
|
||||
headers = {
|
||||
"Accept": "application/vnd.github.v3+json",
|
||||
"Authorization": f"Bearer {token}"
|
||||
}
|
||||
params = {
|
||||
"participating": "true"
|
||||
}
|
||||
if since[0]:
|
||||
params["since"] = since[0]
|
||||
if last_modified[0]:
|
||||
headers["If-Modified-Since"] = last_modified[0]
|
||||
async with session.get(NOTIFICATION_URL, headers=headers, params=params) as response:
|
||||
if response.status == 200:
|
||||
if 'Last-Modified' in response.headers:
|
||||
last_modified[0] = response.headers['Last-Modified']
|
||||
since[0] = None
|
||||
notifications = await response.json()
|
||||
if not notifications:
|
||||
continue
|
||||
for notification in notifications:
|
||||
handled_ids.add(notification['id'])
|
||||
if 'reason' in notification and notification['reason'] == 'mention':
|
||||
if 'subject' in notification and notification['subject']['type'] == 'PullRequest':
|
||||
pr_url = notification['subject']['url']
|
||||
latest_comment = notification['subject']['latest_comment_url']
|
||||
async with session.get(latest_comment, headers=headers) as comment_response:
|
||||
if comment_response.status == 200:
|
||||
comment = await comment_response.json()
|
||||
if 'id' in comment:
|
||||
if comment['id'] in handled_ids:
|
||||
continue
|
||||
else:
|
||||
handled_ids.add(comment['id'])
|
||||
if 'user' in comment and 'login' in comment['user']:
|
||||
if comment['user']['login'] == user_id:
|
||||
continue
|
||||
comment_body = comment['body'] if 'body' in comment else ''
|
||||
commenter_github_user = comment['user']['login'] \
|
||||
if 'user' in comment else ''
|
||||
logging.info(f"Commenter: {commenter_github_user}\nComment: {comment_body}")
|
||||
user_tag = "@" + user_id
|
||||
if user_tag not in comment_body:
|
||||
continue
|
||||
rest_of_comment = comment_body.split(user_tag)[1].strip()
|
||||
|
||||
success = await agent.handle_request(pr_url, rest_of_comment)
|
||||
if not success:
|
||||
git_provider.set_pr(pr_url)
|
||||
git_provider.publish_comment("### How to use PR-Agent\n" +
|
||||
bot_help_text(user_id))
|
||||
|
||||
elif response.status != 304:
|
||||
print(f"Failed to fetch notifications. Status code: {response.status}")
|
||||
|
||||
except Exception as e:
|
||||
logging.error(f"Exception during processing of a notification: {e}")
|
||||
|
||||
await asyncio.sleep(5)
|
||||
|
||||
if __name__ == '__main__':
|
||||
asyncio.run(polling_loop())
|
||||
|
||||
14
pr_agent/servers/help.py
Normal file
14
pr_agent/servers/help.py
Normal file
@ -0,0 +1,14 @@
|
||||
commands_text = "> **/review [-i]**: Request a review of your Pull Request. For an incremental review, which only " \
|
||||
"considers changes since the last review, include the '-i' option.\n" \
|
||||
"> **/describe**: Modify the PR title and description based on the contents of the PR.\n" \
|
||||
"> **/improve**: Suggest improvements to the code in the PR. " \
|
||||
"These will be provided as pull request comments, ready to commit.\n" \
|
||||
"> **/ask \\<QUESTION\\>**: Pose a question about the PR.\n"
|
||||
|
||||
|
||||
def bot_help_text(user: str):
|
||||
return f"> Tag me in a comment '@{user}' and add one of the following commands:\n" + commands_text
|
||||
|
||||
|
||||
actions_help_text = "> To invoke the PR-Agent, add a comment using one of the following commands:\n" + \
|
||||
commands_text
|
||||
18
pr_agent/servers/serverless.py
Normal file
18
pr_agent/servers/serverless.py
Normal file
@ -0,0 +1,18 @@
|
||||
import logging
|
||||
|
||||
from fastapi import FastAPI
|
||||
from mangum import Mangum
|
||||
|
||||
from pr_agent.servers.github_app import router
|
||||
|
||||
logger = logging.getLogger()
|
||||
logger.setLevel(logging.DEBUG)
|
||||
|
||||
app = FastAPI()
|
||||
app.include_router(router)
|
||||
|
||||
handler = Mangum(app, lifespan="off")
|
||||
|
||||
|
||||
def serverless(event, context):
|
||||
return handler(event, context)
|
||||
@ -1,5 +1,5 @@
|
||||
# QUICKSTART:
|
||||
# Copy this file to .secrets in the same folder.
|
||||
# Copy this file to .secrets.toml in the same folder.
|
||||
# The minimum workable settings - set openai.key to your API key.
|
||||
# Set github.deployment_type to "user" and github.user_token to your GitHub personal access token.
|
||||
# This will allow you to run the CLI scripts in the scripts/ folder and the github_polling server.
|
||||
@ -9,11 +9,13 @@
|
||||
[openai]
|
||||
key = "<API_KEY>" # Acquire through https://platform.openai.com
|
||||
org = "<ORGANIZATION>" # Optional, may be commented out.
|
||||
# Uncomment the following for Azure OpenAI
|
||||
#api_type = "azure"
|
||||
#api_version = '2023-05-15' # Check Azure documentation for the current API version
|
||||
#api_base = "<API_BASE>" # The base URL for your Azure OpenAI resource. e.g. "https://<your resource name>.openai.azure.com"
|
||||
#deployment_id = "<DEPLOYMENT_ID>" # The deployment name you chose when you deployed the engine
|
||||
|
||||
[github]
|
||||
# The type of deployment to create. Valid values are 'app' or 'user'.
|
||||
deployment_type = "user"
|
||||
|
||||
# ---- Set the following only for deployment type == "user"
|
||||
user_token = "<TOKEN>" # A GitHub personal access token with 'repo' scope.
|
||||
|
||||
@ -25,3 +27,11 @@ private_key = """\
|
||||
"""
|
||||
app_id = 123456 # The GitHub App ID, replace with your own.
|
||||
webhook_secret = "<WEBHOOK SECRET>" # Optional, may be commented out.
|
||||
|
||||
[gitlab]
|
||||
# Gitlab personal access token
|
||||
personal_access_token = ""
|
||||
|
||||
[bitbucket]
|
||||
# Bitbucket personal bearer token
|
||||
bearer_token = ""
|
||||
|
||||
@ -1,15 +1,42 @@
|
||||
[config]
|
||||
model="gpt-4-0613"
|
||||
model="gpt-4"
|
||||
fallback-models=["gpt-3.5-turbo-16k", "gpt-3.5-turbo"]
|
||||
git_provider="github"
|
||||
publish_review=true
|
||||
verbosity_level=0 # 0,1,2
|
||||
publish_output=true
|
||||
publish_output_progress=true
|
||||
verbosity_level=0 # 0,1,2
|
||||
use_extra_bad_extensions=false
|
||||
|
||||
[pr_reviewer]
|
||||
require_minimal_and_focused_review=true
|
||||
require_focused_review=true
|
||||
require_score_review=false
|
||||
require_tests_review=true
|
||||
require_security_review=true
|
||||
extended_code_suggestions=false
|
||||
num_code_suggestions=0
|
||||
inline_code_comments = true
|
||||
ask_and_reflect=false
|
||||
|
||||
[pr_description]
|
||||
publish_description_as_comment=false
|
||||
|
||||
[pr_questions]
|
||||
|
||||
[pr_code_suggestions]
|
||||
num_code_suggestions=4
|
||||
|
||||
[github]
|
||||
# The type of deployment to create. Valid values are 'app' or 'user'.
|
||||
deployment_type = "user"
|
||||
|
||||
[pr_questions]
|
||||
[gitlab]
|
||||
# URL to the gitlab service
|
||||
url = "https://gitlab.com"
|
||||
|
||||
# Polling (either project id or namespace/project_name) syntax can be used
|
||||
projects_to_monitor = ['org_name/repo_name']
|
||||
|
||||
# Polling trigger
|
||||
magic_word = "AutoReview"
|
||||
|
||||
# Polling interval
|
||||
polling_interval_seconds = 30
|
||||
|
||||
434
pr_agent/settings/language_extensions.toml
Normal file
434
pr_agent/settings/language_extensions.toml
Normal file
@ -0,0 +1,434 @@
|
||||
[bad_extensions]
|
||||
default = [
|
||||
'app',
|
||||
'bin',
|
||||
'bmp',
|
||||
'bz2',
|
||||
'class',
|
||||
'csv',
|
||||
'dat',
|
||||
'db',
|
||||
'dll',
|
||||
'dylib',
|
||||
'egg',
|
||||
'eot',
|
||||
'exe',
|
||||
'gif',
|
||||
'gitignore',
|
||||
'glif',
|
||||
'gradle',
|
||||
'gz',
|
||||
'ico',
|
||||
'jar',
|
||||
'jpeg',
|
||||
'jpg',
|
||||
'lo',
|
||||
'lock',
|
||||
'log',
|
||||
'mp3',
|
||||
'mp4',
|
||||
'nar',
|
||||
'o',
|
||||
'ogg',
|
||||
'otf',
|
||||
'p',
|
||||
'pdf',
|
||||
'png',
|
||||
'pickle',
|
||||
'pkl',
|
||||
'pyc',
|
||||
'pyd',
|
||||
'pyo',
|
||||
'rkt',
|
||||
'so',
|
||||
'ss',
|
||||
'svg',
|
||||
'tar',
|
||||
'tsv',
|
||||
'ttf',
|
||||
'war',
|
||||
'webm',
|
||||
'woff',
|
||||
'woff2',
|
||||
'xz',
|
||||
'zip',
|
||||
'zst',
|
||||
'snap'
|
||||
]
|
||||
extra = [
|
||||
'md',
|
||||
'txt'
|
||||
]
|
||||
|
||||
[language_extension_map_org]
|
||||
ABAP = [".abap", ]
|
||||
"AGS Script" = [".ash", ]
|
||||
AMPL = [".ampl", ]
|
||||
ANTLR = [".g4", ]
|
||||
"API Blueprint" = [".apib", ]
|
||||
APL = [".apl", ".dyalog", ]
|
||||
ASP = [".asp", ".asax", ".ascx", ".ashx", ".asmx", ".aspx", ".axd", ]
|
||||
ATS = [".dats", ".hats", ".sats", ]
|
||||
ActionScript = [".as", ]
|
||||
Ada = [".adb", ".ada", ".ads", ]
|
||||
Agda = [".agda", ]
|
||||
Alloy = [".als", ]
|
||||
ApacheConf = [".apacheconf", ".vhost", ]
|
||||
AppleScript = [".applescript", ".scpt", ]
|
||||
Arc = [".arc", ]
|
||||
Arduino = [".ino", ]
|
||||
AsciiDoc = [".asciidoc", ".adoc", ]
|
||||
AspectJ = [".aj", ]
|
||||
Assembly = [".asm", ".a51", ".nasm", ]
|
||||
Augeas = [".aug", ]
|
||||
AutoHotkey = [".ahk", ".ahkl", ]
|
||||
AutoIt = [".au3", ]
|
||||
Awk = [".awk", ".auk", ".gawk", ".mawk", ".nawk", ]
|
||||
Batchfile = [".bat", ".cmd", ]
|
||||
Befunge = [".befunge", ]
|
||||
Bison = [".bison", ]
|
||||
BitBake = [".bb", ]
|
||||
BlitzBasic = [".decls", ]
|
||||
BlitzMax = [".bmx", ]
|
||||
Bluespec = [".bsv", ]
|
||||
Boo = [".boo", ]
|
||||
Brainfuck = [".bf", ]
|
||||
Brightscript = [".brs", ]
|
||||
Bro = [".bro", ]
|
||||
C = [".c", ".cats", ".h", ".idc", ".w", ]
|
||||
"C#" = [".cs", ".cake", ".cshtml", ".csx", ]
|
||||
"C++" = [".cpp", ".c++", ".cc", ".cp", ".cxx", ".h++", ".hh", ".hpp", ".hxx", ".inl", ".ipp", ".tcc", ".tpp", ".C", ".H", ]
|
||||
C-ObjDump = [".c-objdump", ]
|
||||
"C2hs Haskell" = [".chs", ]
|
||||
CLIPS = [".clp", ]
|
||||
CMake = [".cmake", ".cmake.in", ]
|
||||
COBOL = [".cob", ".cbl", ".ccp", ".cobol", ".cpy", ]
|
||||
CSS = [".css", ]
|
||||
CSV = [".csv", ]
|
||||
"Cap'n Proto" = [".capnp", ]
|
||||
CartoCSS = [".mss", ]
|
||||
Ceylon = [".ceylon", ]
|
||||
Chapel = [".chpl", ]
|
||||
ChucK = [".ck", ]
|
||||
Cirru = [".cirru", ]
|
||||
Clarion = [".clw", ]
|
||||
Clean = [".icl", ".dcl", ]
|
||||
Click = [".click", ]
|
||||
Clojure = [".clj", ".boot", ".cl2", ".cljc", ".cljs", ".cljs.hl", ".cljscm", ".cljx", ".hic", ]
|
||||
CoffeeScript = [".coffee", "._coffee", ".cjsx", ".cson", ".iced", ]
|
||||
ColdFusion = [".cfm", ".cfml", ]
|
||||
"ColdFusion CFC" = [".cfc", ]
|
||||
"Common Lisp" = [".lisp", ".asd", ".lsp", ".ny", ".podsl", ".sexp", ]
|
||||
"Component Pascal" = [".cps", ]
|
||||
Coq = [".coq", ]
|
||||
Cpp-ObjDump = [".cppobjdump", ".c++-objdump", ".c++objdump", ".cpp-objdump", ".cxx-objdump", ]
|
||||
Creole = [".creole", ]
|
||||
Crystal = [".cr", ]
|
||||
Csound = [".csd", ]
|
||||
Cucumber = [".feature", ]
|
||||
Cuda = [".cu", ".cuh", ]
|
||||
Cycript = [".cy", ]
|
||||
Cython = [".pyx", ".pxd", ".pxi", ]
|
||||
D = [".di", ]
|
||||
D-ObjDump = [".d-objdump", ]
|
||||
"DIGITAL Command Language" = [".com", ]
|
||||
DM = [".dm", ]
|
||||
"DNS Zone" = [".zone", ".arpa", ]
|
||||
"Darcs Patch" = [".darcspatch", ".dpatch", ]
|
||||
Dart = [".dart", ]
|
||||
Diff = [".diff", ".patch", ]
|
||||
Dockerfile = [".dockerfile", "Dockerfile", ]
|
||||
Dogescript = [".djs", ]
|
||||
Dylan = [".dylan", ".dyl", ".intr", ".lid", ]
|
||||
E = [".E", ]
|
||||
ECL = [".ecl", ".eclxml", ]
|
||||
Eagle = [".sch", ".brd", ]
|
||||
"Ecere Projects" = [".epj", ]
|
||||
Eiffel = [".e", ]
|
||||
Elixir = [".ex", ".exs", ]
|
||||
Elm = [".elm", ]
|
||||
"Emacs Lisp" = [".el", ".emacs", ".emacs.desktop", ]
|
||||
EmberScript = [".em", ".emberscript", ]
|
||||
Erlang = [".erl", ".escript", ".hrl", ".xrl", ".yrl", ]
|
||||
"F#" = [".fs", ".fsi", ".fsx", ]
|
||||
FLUX = [".flux", ]
|
||||
FORTRAN = [".f90", ".f", ".f03", ".f08", ".f77", ".f95", ".for", ".fpp", ]
|
||||
Factor = [".factor", ]
|
||||
Fancy = [".fy", ".fancypack", ]
|
||||
Fantom = [".fan", ]
|
||||
Formatted = [".eam.fs", ]
|
||||
Forth = [".fth", ".4th", ".forth", ".frt", ]
|
||||
FreeMarker = [".ftl", ]
|
||||
G-code = [".g", ".gco", ".gcode", ]
|
||||
GAMS = [".gms", ]
|
||||
GAP = [".gap", ".gi", ]
|
||||
GAS = [".s", ]
|
||||
GDScript = [".gd", ]
|
||||
GLSL = [".glsl", ".fp", ".frag", ".frg", ".fsh", ".fshader", ".geo", ".geom", ".glslv", ".gshader", ".shader", ".vert", ".vrx", ".vsh", ".vshader", ]
|
||||
Genshi = [".kid", ]
|
||||
"Gentoo Ebuild" = [".ebuild", ]
|
||||
"Gentoo Eclass" = [".eclass", ]
|
||||
"Gettext Catalog" = [".po", ".pot", ]
|
||||
Glyph = [".glf", ]
|
||||
Gnuplot = [".gp", ".gnu", ".gnuplot", ".plot", ".plt", ]
|
||||
Go = [".go", ]
|
||||
Golo = [".golo", ]
|
||||
Gosu = [".gst", ".gsx", ".vark", ]
|
||||
Grace = [".grace", ]
|
||||
Gradle = [".gradle", ]
|
||||
"Grammatical Framework" = [".gf", ]
|
||||
GraphQL = [".graphql", ]
|
||||
"Graphviz (DOT)" = [".dot", ".gv", ]
|
||||
Groff = [".man", ".1", ".1in", ".1m", ".1x", ".2", ".3", ".3in", ".3m", ".3qt", ".3x", ".4", ".5", ".6", ".7", ".8", ".9", ".me", ".rno", ".roff", ]
|
||||
Groovy = [".groovy", ".grt", ".gtpl", ".gvy", ]
|
||||
"Groovy Server Pages" = [".gsp", ]
|
||||
HCL = [".hcl", ".tf", ]
|
||||
HLSL = [".hlsl", ".fxh", ".hlsli", ]
|
||||
HTML = [".html", ".htm", ".html.hl", ".xht", ".xhtml", ]
|
||||
"HTML+Django" = [".mustache", ".jinja", ]
|
||||
"HTML+EEX" = [".eex", ]
|
||||
"HTML+ERB" = [".erb", ".erb.deface", ]
|
||||
"HTML+PHP" = [".phtml", ]
|
||||
HTTP = [".http", ]
|
||||
Haml = [".haml", ".haml.deface", ]
|
||||
Handlebars = [".handlebars", ".hbs", ]
|
||||
Harbour = [".hb", ]
|
||||
Haskell = [".hs", ".hsc", ]
|
||||
Haxe = [".hx", ".hxsl", ]
|
||||
Hy = [".hy", ]
|
||||
IDL = [".dlm", ]
|
||||
"IGOR Pro" = [".ipf", ]
|
||||
INI = [".ini", ".cfg", ".prefs", ".properties", ]
|
||||
"IRC log" = [".irclog", ".weechatlog", ]
|
||||
Idris = [".idr", ".lidr", ]
|
||||
"Inform 7" = [".ni", ".i7x", ]
|
||||
"Inno Setup" = [".iss", ]
|
||||
Io = [".io", ]
|
||||
Ioke = [".ik", ]
|
||||
Isabelle = [".thy", ]
|
||||
J = [".ijs", ]
|
||||
JFlex = [".flex", ".jflex", ]
|
||||
JSON = [".json", ".geojson", ".lock", ".topojson", ]
|
||||
JSON5 = [".json5", ]
|
||||
JSONLD = [".jsonld", ]
|
||||
JSONiq = [".jq", ]
|
||||
JSX = [".jsx", ]
|
||||
Jade = [".jade", ]
|
||||
Jasmin = [".j", ]
|
||||
Java = [".java", ]
|
||||
"Java Server Pages" = [".jsp", ]
|
||||
JavaScript = [".js", "._js", ".bones", ".es6", ".jake", ".jsb", ".jscad", ".jsfl", ".jsm", ".jss", ".njs", ".pac", ".sjs", ".ssjs", ".xsjs", ".xsjslib", ]
|
||||
Julia = [".jl", ]
|
||||
"Jupyter Notebook" = [".ipynb", ]
|
||||
KRL = [".krl", ]
|
||||
KiCad = [".kicad_pcb", ]
|
||||
Kit = [".kit", ]
|
||||
Kotlin = [".kt", ".ktm", ".kts", ]
|
||||
LFE = [".lfe", ]
|
||||
LLVM = [".ll", ]
|
||||
LOLCODE = [".lol", ]
|
||||
LSL = [".lsl", ".lslp", ]
|
||||
LabVIEW = [".lvproj", ]
|
||||
Lasso = [".lasso", ".las", ".lasso8", ".lasso9", ".ldml", ]
|
||||
Latte = [".latte", ]
|
||||
Lean = [".lean", ".hlean", ]
|
||||
Less = [".less", ]
|
||||
Lex = [".lex", ]
|
||||
LilyPond = [".ly", ".ily", ]
|
||||
"Linker Script" = [".ld", ".lds", ]
|
||||
Liquid = [".liquid", ]
|
||||
"Literate Agda" = [".lagda", ]
|
||||
"Literate CoffeeScript" = [".litcoffee", ]
|
||||
"Literate Haskell" = [".lhs", ]
|
||||
LiveScript = [".ls", "._ls", ]
|
||||
Logos = [".xm", ".x", ".xi", ]
|
||||
Logtalk = [".lgt", ".logtalk", ]
|
||||
LookML = [".lookml", ]
|
||||
Lua = [".lua", ".nse", ".pd_lua", ".rbxs", ".wlua", ]
|
||||
M = [".mumps", ]
|
||||
M4 = [".m4", ]
|
||||
MAXScript = [".mcr", ]
|
||||
MTML = [".mtml", ]
|
||||
MUF = [".muf", ]
|
||||
Makefile = [".mak", ".mk", ".mkfile", "Makefile", ]
|
||||
Mako = [".mako", ".mao", ]
|
||||
Maple = [".mpl", ]
|
||||
Markdown = [".md", ".markdown", ".mkd", ".mkdn", ".mkdown", ".ron", ]
|
||||
Mask = [".mask", ]
|
||||
Mathematica = [".mathematica", ".cdf", ".ma", ".mt", ".nb", ".nbp", ".wl", ".wlt", ]
|
||||
Matlab = [".matlab", ]
|
||||
Max = [".maxpat", ".maxhelp", ".maxproj", ".mxt", ".pat", ]
|
||||
MediaWiki = [".mediawiki", ".wiki", ]
|
||||
Metal = [".metal", ]
|
||||
MiniD = [".minid", ]
|
||||
Mirah = [".druby", ".duby", ".mir", ".mirah", ]
|
||||
Modelica = [".mo", ]
|
||||
"Module Management System" = [".mms", ".mmk", ]
|
||||
Monkey = [".monkey", ]
|
||||
MoonScript = [".moon", ]
|
||||
Myghty = [".myt", ]
|
||||
NSIS = [".nsi", ".nsh", ]
|
||||
NetLinx = [".axs", ".axi", ]
|
||||
"NetLinx+ERB" = [".axs.erb", ".axi.erb", ]
|
||||
NetLogo = [".nlogo", ]
|
||||
Nginx = [".nginxconf", ]
|
||||
Nimrod = [".nim", ".nimrod", ]
|
||||
Ninja = [".ninja", ]
|
||||
Nit = [".nit", ]
|
||||
Nix = [".nix", ]
|
||||
Nu = [".nu", ]
|
||||
NumPy = [".numpy", ".numpyw", ".numsc", ]
|
||||
OCaml = [".ml", ".eliom", ".eliomi", ".ml4", ".mli", ".mll", ".mly", ]
|
||||
ObjDump = [".objdump", ]
|
||||
"Objective-C++" = [".mm", ]
|
||||
Objective-J = [".sj", ]
|
||||
Octave = [".oct", ]
|
||||
Omgrofl = [".omgrofl", ]
|
||||
Opa = [".opa", ]
|
||||
Opal = [".opal", ]
|
||||
OpenCL = [".cl", ".opencl", ]
|
||||
"OpenEdge ABL" = [".p", ]
|
||||
OpenSCAD = [".scad", ]
|
||||
Org = [".org", ]
|
||||
Ox = [".ox", ".oxh", ".oxo", ]
|
||||
Oxygene = [".oxygene", ]
|
||||
Oz = [".oz", ]
|
||||
PAWN = [".pwn", ]
|
||||
PHP = [".php", ".aw", ".ctp", ".php3", ".php4", ".php5", ".phps", ".phpt", ]
|
||||
"POV-Ray SDL" = [".pov", ]
|
||||
Pan = [".pan", ]
|
||||
Papyrus = [".psc", ]
|
||||
Parrot = [".parrot", ]
|
||||
"Parrot Assembly" = [".pasm", ]
|
||||
"Parrot Internal Representation" = [".pir", ]
|
||||
Pascal = [".pas", ".dfm", ".dpr", ".lpr", ]
|
||||
Perl = [".pl", ".al", ".perl", ".ph", ".plx", ".pm", ".psgi", ".t", ]
|
||||
Perl6 = [".6pl", ".6pm", ".nqp", ".p6", ".p6l", ".p6m", ".pl6", ".pm6", ]
|
||||
Pickle = [".pkl", ]
|
||||
PigLatin = [".pig", ]
|
||||
Pike = [".pike", ".pmod", ]
|
||||
Pod = [".pod", ]
|
||||
PogoScript = [".pogo", ]
|
||||
Pony = [".pony", ]
|
||||
PostScript = [".ps", ".eps", ]
|
||||
PowerShell = [".ps1", ".psd1", ".psm1", ]
|
||||
Processing = [".pde", ]
|
||||
Prolog = [".prolog", ".yap", ]
|
||||
"Propeller Spin" = [".spin", ]
|
||||
"Protocol Buffer" = [".proto", ]
|
||||
"Public Key" = [".pub", ]
|
||||
"Pure Data" = [".pd", ]
|
||||
PureBasic = [".pb", ".pbi", ]
|
||||
PureScript = [".purs", ]
|
||||
Python = [".py", ".bzl", ".gyp", ".lmi", ".pyde", ".pyp", ".pyt", ".pyw", ".tac", ".wsgi", ".xpy", ]
|
||||
"Python traceback" = [".pytb", ]
|
||||
QML = [".qml", ".qbs", ]
|
||||
QMake = [".pri", ]
|
||||
R = [".r", ".rd", ".rsx", ]
|
||||
RAML = [".raml", ]
|
||||
RDoc = [".rdoc", ]
|
||||
REALbasic = [".rbbas", ".rbfrm", ".rbmnu", ".rbres", ".rbtbar", ".rbuistate", ]
|
||||
RHTML = [".rhtml", ]
|
||||
RMarkdown = [".rmd", ]
|
||||
Racket = [".rkt", ".rktd", ".rktl", ".scrbl", ]
|
||||
"Ragel in Ruby Host" = [".rl", ]
|
||||
"Raw token data" = [".raw", ]
|
||||
Rebol = [".reb", ".r2", ".r3", ".rebol", ]
|
||||
Red = [".red", ".reds", ]
|
||||
Redcode = [".cw", ]
|
||||
"Ren'Py" = [".rpy", ]
|
||||
RenderScript = [".rsh", ]
|
||||
RobotFramework = [".robot", ]
|
||||
Rouge = [".rg", ]
|
||||
Ruby = [".rb", ".builder", ".gemspec", ".god", ".irbrc", ".jbuilder", ".mspec", ".podspec", ".rabl", ".rake", ".rbuild", ".rbw", ".rbx", ".ru", ".ruby", ".thor", ".watchr", ]
|
||||
Rust = [".rs", ".rs.in", ]
|
||||
SAS = [".sas", ]
|
||||
SCSS = [".scss", ]
|
||||
SMT = [".smt2", ".smt", ]
|
||||
SPARQL = [".sparql", ".rq", ]
|
||||
SQF = [".sqf", ".hqf", ]
|
||||
SQL = [".pls", ".pck", ".pkb", ".pks", ".plb", ".plsql", ".sql", ".cql", ".ddl", ".prc", ".tab", ".udf", ".viw", ".db2", ]
|
||||
STON = [".ston", ]
|
||||
SVG = [".svg", ]
|
||||
Sage = [".sage", ".sagews", ]
|
||||
SaltStack = [".sls", ]
|
||||
Sass = [".sass", ]
|
||||
Scala = [".scala", ".sbt", ]
|
||||
Scaml = [".scaml", ]
|
||||
Scheme = [".scm", ".sld", ".sps", ".ss", ]
|
||||
Scilab = [".sci", ".sce", ]
|
||||
Self = [".self", ]
|
||||
Shell = [".sh", ".bash", ".bats", ".command", ".ksh", ".sh.in", ".tmux", ".tool", ".zsh", ]
|
||||
ShellSession = [".sh-session", ]
|
||||
Shen = [".shen", ]
|
||||
Slash = [".sl", ]
|
||||
Slim = [".slim", ]
|
||||
Smali = [".smali", ]
|
||||
Smalltalk = [".st", ]
|
||||
Smarty = [".tpl", ]
|
||||
Solidity = [".sol", ]
|
||||
SourcePawn = [".sp", ".sma", ]
|
||||
Squirrel = [".nut", ]
|
||||
Stan = [".stan", ]
|
||||
"Standard ML" = [".ML", ".fun", ".sig", ".sml", ]
|
||||
Stata = [".do", ".ado", ".doh", ".ihlp", ".mata", ".matah", ".sthlp", ]
|
||||
Stylus = [".styl", ]
|
||||
SuperCollider = [".scd", ]
|
||||
Swift = [".swift", ]
|
||||
SystemVerilog = [".sv", ".svh", ".vh", ]
|
||||
TOML = [".toml", ]
|
||||
TXL = [".txl", ]
|
||||
Tcl = [".tcl", ".adp", ".tm", ]
|
||||
Tcsh = [".tcsh", ".csh", ]
|
||||
TeX = [".tex", ".aux", ".bbx", ".bib", ".cbx", ".dtx", ".ins", ".lbx", ".ltx", ".mkii", ".mkiv", ".mkvi", ".sty", ".toc", ]
|
||||
Tea = [".tea", ]
|
||||
Text = [".txt", ".no", ]
|
||||
Textile = [".textile", ]
|
||||
Thrift = [".thrift", ]
|
||||
Turing = [".tu", ]
|
||||
Turtle = [".ttl", ]
|
||||
Twig = [".twig", ]
|
||||
TypeScript = [".ts", ".tsx", ]
|
||||
"Unified Parallel C" = [".upc", ]
|
||||
"Unity3D Asset" = [".anim", ".asset", ".mat", ".meta", ".prefab", ".unity", ]
|
||||
Uno = [".uno", ]
|
||||
UnrealScript = [".uc", ]
|
||||
UrWeb = [".ur", ".urs", ]
|
||||
VCL = [".vcl", ]
|
||||
VHDL = [".vhdl", ".vhd", ".vhf", ".vhi", ".vho", ".vhs", ".vht", ".vhw", ]
|
||||
Vala = [".vala", ".vapi", ]
|
||||
Verilog = [".veo", ]
|
||||
VimL = [".vim", ]
|
||||
"Visual Basic" = [".vb", ".bas", ".frm", ".frx", ".vba", ".vbhtml", ".vbs", ]
|
||||
Volt = [".volt", ]
|
||||
Vue = [".vue", ]
|
||||
"Web Ontology Language" = [".owl", ]
|
||||
WebAssembly = [".wat", ]
|
||||
WebIDL = [".webidl", ]
|
||||
X10 = [".x10", ]
|
||||
XC = [".xc", ]
|
||||
XML = [".xml", ".ant", ".axml", ".ccxml", ".clixml", ".cproject", ".csl", ".csproj", ".ct", ".dita", ".ditamap", ".ditaval", ".dll.config", ".dotsettings", ".filters", ".fsproj", ".fxml", ".glade", ".grxml", ".iml", ".ivy", ".jelly", ".jsproj", ".kml", ".launch", ".mdpolicy", ".mxml", ".nproj", ".nuspec", ".odd", ".osm", ".plist", ".props", ".ps1xml", ".psc1", ".pt", ".rdf", ".rss", ".scxml", ".srdf", ".storyboard", ".stTheme", ".sublime-snippet", ".targets", ".tmCommand", ".tml", ".tmLanguage", ".tmPreferences", ".tmSnippet", ".tmTheme", ".ui", ".urdf", ".ux", ".vbproj", ".vcxproj", ".vssettings", ".vxml", ".wsdl", ".wsf", ".wxi", ".wxl", ".wxs", ".x3d", ".xacro", ".xaml", ".xib", ".xlf", ".xliff", ".xmi", ".xml.dist", ".xproj", ".xsd", ".xul", ".zcml", ]
|
||||
XPages = [".xsp-config", ".xsp.metadata", ]
|
||||
XProc = [".xpl", ".xproc", ]
|
||||
XQuery = [".xquery", ".xq", ".xql", ".xqm", ".xqy", ]
|
||||
XS = [".xs", ]
|
||||
XSLT = [".xslt", ".xsl", ]
|
||||
Xojo = [".xojo_code", ".xojo_menu", ".xojo_report", ".xojo_script", ".xojo_toolbar", ".xojo_window", ]
|
||||
Xtend = [".xtend", ]
|
||||
YAML = [".yml", ".reek", ".rviz", ".sublime-syntax", ".syntax", ".yaml", ".yaml-tmlanguage", ]
|
||||
YANG = [".yang", ]
|
||||
Yacc = [".y", ".yacc", ".yy", ]
|
||||
Zephir = [".zep", ]
|
||||
Zig = [".zig", ]
|
||||
Zimpl = [".zimpl", ".zmpl", ".zpl", ]
|
||||
desktop = [".desktop", ".desktop.in", ]
|
||||
eC = [".ec", ".eh", ]
|
||||
edn = [".edn", ]
|
||||
fish = [".fish", ]
|
||||
mupad = [".mu", ]
|
||||
nesC = [".nc", ]
|
||||
ooc = [".ooc", ]
|
||||
reStructuredText = [".rst", ".rest", ".rest.txt", ".rst.txt", ]
|
||||
wisp = [".wisp", ]
|
||||
xBase = [".prg", ".prw", ]
|
||||
|
||||
79
pr_agent/settings/pr_code_suggestions_prompts.toml
Normal file
79
pr_agent/settings/pr_code_suggestions_prompts.toml
Normal file
@ -0,0 +1,79 @@
|
||||
[pr_code_suggestions_prompt]
|
||||
system="""You are a language model called CodiumAI-PR-Code-Reviewer.
|
||||
Your task is to provide meaningfull non-trivial code suggestions to improve the new code in a PR (the '+' lines).
|
||||
- Try to give important suggestions like fixing code problems, issues and bugs. As a second priority, provide suggestions for meaningfull code improvements, like performance, vulnerability, modularity, and best practices.
|
||||
- Suggestions should refer only to the 'new hunk' code, and focus on improving the new added code lines, with '+'.
|
||||
- Provide the exact line number range (inclusive) for each issue.
|
||||
- Assume there is additional code in the relevant file that is not included in the diff.
|
||||
- Provide up to {{ num_code_suggestions }} code suggestions.
|
||||
- Make sure not to provide suggestions repeating modifications already implemented in the new PR code (the '+' lines).
|
||||
- Don't output line numbers in the 'improved code' snippets.
|
||||
|
||||
You must use the following JSON schema to format your answer:
|
||||
```json
|
||||
{
|
||||
"Code suggestions": {
|
||||
"type": "array",
|
||||
"minItems": 1,
|
||||
"maxItems": {{ num_code_suggestions }},
|
||||
"uniqueItems": "true",
|
||||
"items": {
|
||||
"relevant file": {
|
||||
"type": "string",
|
||||
"description": "the relevant file full path"
|
||||
},
|
||||
"suggestion content": {
|
||||
"type": "string",
|
||||
"description": "a concrete suggestion for meaningfully improving the new PR code."
|
||||
},
|
||||
"existing code": {
|
||||
"type": "string",
|
||||
"description": "a code snippet showing authentic relevant code lines from a 'new hunk' section. It must be continuous, correctly formatted and indented, and without line numbers."
|
||||
},
|
||||
"relevant lines": {
|
||||
"type": "string",
|
||||
"description": "the relevant lines in the 'new hunk' sections, in the format of 'start_line-end_line'. For example: '10-15'. They should be derived from the hunk line numbers, and correspond to the 'existing code' snippet above."
|
||||
},
|
||||
"improved code": {
|
||||
"type": "string",
|
||||
"description": "a new code snippet that can be used to replace the relevant lines in 'new hunk' code. Replacement suggestions should be complete, correctly formatted and indented, and without line numbers."
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Example input:
|
||||
'
|
||||
## src/file1.py
|
||||
---new_hunk---
|
||||
```
|
||||
[new hunk code, annotated with line numbers]
|
||||
```
|
||||
---old_hunk---
|
||||
```
|
||||
[old hunk code]
|
||||
```
|
||||
...
|
||||
'
|
||||
|
||||
Don't repeat the prompt in the answer, and avoid outputting the 'type' and 'description' fields.
|
||||
"""
|
||||
|
||||
user="""PR Info:
|
||||
Title: '{{title}}'
|
||||
Branch: '{{branch}}'
|
||||
Description: '{{description}}'
|
||||
{%- if language %}
|
||||
Main language: {{language}}
|
||||
{%- endif %}
|
||||
|
||||
|
||||
The PR Diff:
|
||||
```
|
||||
{{diff}}
|
||||
```
|
||||
|
||||
Response (should be a valid JSON, and nothing else):
|
||||
```json
|
||||
"""
|
||||
45
pr_agent/settings/pr_description_prompts.toml
Normal file
45
pr_agent/settings/pr_description_prompts.toml
Normal file
@ -0,0 +1,45 @@
|
||||
[pr_description_prompt]
|
||||
system="""You are CodiumAI-PR-Reviewer, a language model designed to review git pull requests.
|
||||
Your task is to provide full description of the PR content.
|
||||
- Make sure not to focus the new PR code (the '+' lines).
|
||||
|
||||
You must use the following JSON schema to format your answer:
|
||||
```json
|
||||
{
|
||||
"PR Title": {
|
||||
"type": "string",
|
||||
"description": "an informative title for the PR, describing its main theme"
|
||||
},
|
||||
"PR Type": {
|
||||
"type": "string",
|
||||
"description": possible values are: ["Bug fix", "Tests", "Bug fix with tests", "Refactoring", "Enhancement", "Documentation", "Other"]
|
||||
},
|
||||
"PR Description": {
|
||||
"type": "string",
|
||||
"description": "an informative and concise description of the PR"
|
||||
},
|
||||
"PR Main Files Walkthrough": {
|
||||
"type": "string",
|
||||
"description": "a walkthrough of the PR changes. Review main files, in bullet points, and shortly describe the changes in each file (up to 10 most important files). Format: -`filename`: description of changes\n..."
|
||||
}
|
||||
}
|
||||
|
||||
Don't repeat the prompt in the answer, and avoid outputting the 'type' and 'description' fields.
|
||||
"""
|
||||
|
||||
user="""PR Info:
|
||||
Branch: '{{branch}}'
|
||||
{%- if language %}
|
||||
Main language: {{language}}
|
||||
{%- endif %}
|
||||
|
||||
|
||||
The PR Git Diff:
|
||||
```
|
||||
{{diff}}
|
||||
```
|
||||
Note that lines in the diff body are prefixed with a symbol that represents the type of change: '-' for deletions, '+' for additions, and ' ' (a space) for unchanged lines.
|
||||
|
||||
Response (should be a valid JSON, and nothing else):
|
||||
```json
|
||||
"""
|
||||
34
pr_agent/settings/pr_information_from_user_prompts.toml
Normal file
34
pr_agent/settings/pr_information_from_user_prompts.toml
Normal file
@ -0,0 +1,34 @@
|
||||
[pr_information_from_user_prompt]
|
||||
system="""You are CodiumAI-PR-Reviewer, a language model designed to review git pull requests.
|
||||
Given the PR Info and the PR Git Diff, generate 3 short questions about the PR code for the PR author.
|
||||
The goal of the questions is to help the language model understand the PR better, so the questions should be insightful, informative, non-trivial, and relevant to the PR.
|
||||
You should prefer asking yes\\no questions, or multiple choice questions. Also add at least one open-ended question, but make sure they are not too difficult, and can be answered in a sentence or two.
|
||||
|
||||
|
||||
Example output:
|
||||
'
|
||||
Questions to better understand the PR:
|
||||
1) ...
|
||||
2) ...
|
||||
...
|
||||
'
|
||||
"""
|
||||
|
||||
user="""PR Info:
|
||||
Title: '{{title}}'
|
||||
Branch: '{{branch}}'
|
||||
Description: '{{description}}'
|
||||
{%- if language %}
|
||||
Main language: {{language}}
|
||||
{%- endif %}
|
||||
|
||||
|
||||
The PR Git Diff:
|
||||
```
|
||||
{{diff}}
|
||||
```
|
||||
Note that lines in the diff body are prefixed with a symbol that represents the type of change: '-' for deletions, '+' for additions, and ' ' (a space) for unchanged lines
|
||||
|
||||
|
||||
Response:
|
||||
"""
|
||||
@ -1,7 +1,8 @@
|
||||
[pr_questions_prompt]
|
||||
system="""You are CodiumAI-PR-Reviewer, a language model designed to review git pull requests.
|
||||
Your task is to answer questions about the new PR code (the '+' lines), and provide feedback.
|
||||
Be informative, constructive, and give examples. Try to be as specific as possible, and don't avoid answering the questions.
|
||||
Be informative, constructive, and give examples. Try to be as specific as possible.
|
||||
Don't avoid answering the questions. You must answer the questions, as best as you can, without adding unrelated content.
|
||||
Make sure not to repeat modifications already implemented in the new PR code (the '+' lines).
|
||||
"""
|
||||
|
||||
|
||||
@ -2,11 +2,11 @@
|
||||
system="""You are CodiumAI-PR-Reviewer, a language model designed to review git pull requests.
|
||||
Your task is to provide constructive and concise feedback for the PR, and also provide meaningfull code suggestions to improve the new PR code (the '+' lines).
|
||||
- Provide up to {{ num_code_suggestions }} code suggestions.
|
||||
{%- if num_code_suggestions > 0 %}
|
||||
- Try to focus on important suggestions like fixing code problems, issues and bugs. As a second priority, provide suggestions for meaningfull code improvements, like performance, vulnerability, modularity, and best practices.
|
||||
{%- if extended_code_suggestions %}
|
||||
- For each suggestion, provide a short and concise code snippet to illustrate the existing code, and the improved code.
|
||||
- Suggestions should focus on improving the new added code lines.
|
||||
- Make sure not to provide suggestions repeating modifications already implemented in the new PR code (the '+' lines).
|
||||
{%- endif %}
|
||||
- Make sure not to provide suggestion repeating modifications already implemented in the new PR code (the '+' lines).
|
||||
|
||||
You must use the following JSON schema to format your answer:
|
||||
```json
|
||||
@ -16,74 +16,61 @@ You must use the following JSON schema to format your answer:
|
||||
"type": "string",
|
||||
"description": "a short explanation of the PR"
|
||||
},
|
||||
"Description and title": {
|
||||
"type": "string",
|
||||
"description": "yes\\no question: does this PR have a relevant description and title"
|
||||
},
|
||||
"Type of PR": {
|
||||
"type": "string",
|
||||
"enum": ["Bug fix", "Tests", "Bug fix with tests", "Refactoring", "Enhancement", "Documentation", "Other"]
|
||||
},
|
||||
{%- if require_score %}
|
||||
"Score": {
|
||||
"type": "int",
|
||||
"description": "Rate this PR on a scale of 0-100 (inclusive), where 0 means the worst possible PR code, and 100 means PR code of the highest quality, without any bugs or performance issues, that is ready to be merged immediately and run in production at scale."
|
||||
},
|
||||
{%- endif %}
|
||||
{%- if require_tests %}
|
||||
"Relevant tests added": {
|
||||
"type": "string",
|
||||
"description": "yes\\no question: does this PR have relevant tests ?"
|
||||
},
|
||||
{%- endif %}
|
||||
{%- if require_minimal_and_focused %}
|
||||
"Minimal and focused": {
|
||||
{%- if question_str %}
|
||||
"Insights from user's answer": {
|
||||
"type": "string",
|
||||
"description": "is this PR as minimal and focused as possible, with all code changes centered around a single coherent theme, described in the PR description and title ?" explain your answer"
|
||||
"description": "shortly summarize the insights you gained from the user's answers to the questions"
|
||||
},
|
||||
{%- endif %}
|
||||
{%- if require_focused %}
|
||||
"Focused PR": {
|
||||
"type": "string",
|
||||
"description": "Is this a focused PR, in the sense that it has a clear and coherent title and description, and all PR code diff changes are properly derived from the title and description? Explain your response."
|
||||
}
|
||||
},
|
||||
{%- endif %}
|
||||
"PR Feedback": {
|
||||
"General PR suggestions": {
|
||||
"type": "string",
|
||||
"description": "important suggestions for the contributors and maintainers of this PR, may include overall structure, primary purpose and best practices. consider using specific filenames, classes and functions names. explain yourself!"
|
||||
"description": "General suggestions and feedback for the contributors and maintainers of this PR. May include important suggestions for the overall structure, primary purpose, best practices, critical bugs, and other aspects of the PR. Explain your suggestions."
|
||||
},
|
||||
{%- if num_code_suggestions > 0 %}
|
||||
"Code suggestions": {
|
||||
"type": "array",
|
||||
"maxItems": {{ num_code_suggestions }},
|
||||
"uniqueItems": true,
|
||||
"items": {
|
||||
"suggestion number": {
|
||||
"type": "int",
|
||||
"description": "suggestion number, starting from 1"
|
||||
},
|
||||
"relevant file": {
|
||||
"type": "string",
|
||||
"description": "the relevant file name"
|
||||
"description": "the relevant file full path"
|
||||
},
|
||||
"suggestion content": {
|
||||
"type": "string",
|
||||
{%- if extended_code_suggestions %}
|
||||
"description": "a concrete suggestion for meaningfully improving the new PR code. Don't repeat previous suggestions. Add tags with importance measure that matches each suggestion ('important' or 'medium'). Do not make suggestions for updating or adding docstrings, renaming PR title and description, or linter like.
|
||||
{%- else %}
|
||||
"description": "a concrete suggestion for meaningfully improving the new PR code. Also describe how, specifically, the suggestion can be applied to new PR code. Add tags with importance measure that matches each suggestion ('important' or 'medium'). Do not make suggestions for updating or adding docstrings, renaming PR title and description, or linter like.
|
||||
{%- endif %}
|
||||
},
|
||||
{%- if extended_code_suggestions %}
|
||||
"why": {
|
||||
"relevant line in file": {
|
||||
"type": "string",
|
||||
"description": "shortly explain why this suggestion is important"
|
||||
},
|
||||
"code example": {
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"before code": {
|
||||
"type": "string",
|
||||
"description": "Short and concise code snippet, to illustrate the existing code"
|
||||
},
|
||||
"after code": {
|
||||
"type": "string",
|
||||
"description": "Short and concise code snippet, to illustrate the improved code"
|
||||
}
|
||||
}
|
||||
"description": "an authentic single code line from the PR git diff section, to which the suggestion applies."
|
||||
}
|
||||
{%- endif %}
|
||||
}
|
||||
},
|
||||
{%- endif %}
|
||||
{%- if require_security %}
|
||||
"Security concerns": {
|
||||
"type": "string",
|
||||
@ -101,36 +88,32 @@ Example output:
|
||||
"PR Analysis":
|
||||
{
|
||||
"Main theme": "xxx",
|
||||
"Description and title": "Yes",
|
||||
"Type of PR": "Bug fix",
|
||||
{%- if require_score %}
|
||||
"Score": 89,
|
||||
{%- endif %}
|
||||
{%- if require_tests %}
|
||||
"Relevant tests added": "No",
|
||||
{%- endif %}
|
||||
{%- if require_minimal_and_focused %}
|
||||
"Minimal and focused": "No, because ..."
|
||||
{%- if require_focused %}
|
||||
"Focused PR": "yes\\no, because ..."
|
||||
{%- endif %}
|
||||
},
|
||||
"PR Feedback":
|
||||
{
|
||||
"General PR suggestions": "..., `xxx`...",
|
||||
{%- if num_code_suggestions > 0 %}
|
||||
"Code suggestions": [
|
||||
{
|
||||
"suggestion number": 1,
|
||||
"relevant file": "xxx.py",
|
||||
"relevant file": "directory/xxx.py",
|
||||
"suggestion content": "xxx [important]",
|
||||
{%- if extended_code_suggestions %}
|
||||
"why": "xxx",
|
||||
"code example":
|
||||
{
|
||||
"before code": "xxx",
|
||||
"after code": "xxx"
|
||||
}
|
||||
{%- endif %}
|
||||
"relevant line in file": "xxx",
|
||||
},
|
||||
...
|
||||
]
|
||||
{%- if require_security %},
|
||||
"Security concerns": "No, because ..."
|
||||
{%- endif %}
|
||||
{%- if require_security %}
|
||||
"Security concerns": "No, because ..."
|
||||
{%- endif %}
|
||||
}
|
||||
}
|
||||
@ -147,6 +130,16 @@ Description: '{{description}}'
|
||||
Main language: {{language}}
|
||||
{%- endif %}
|
||||
|
||||
{%- if question_str %}
|
||||
######
|
||||
Here are questions to better understand the PR. Use the answers to provide better feedback.
|
||||
|
||||
{{question_str|trim}}
|
||||
|
||||
User answers:
|
||||
{{answer_str|trim}}
|
||||
######
|
||||
{%- endif %}
|
||||
|
||||
The PR Git Diff:
|
||||
```
|
||||
|
||||
133
pr_agent/tools/pr_code_suggestions.py
Normal file
133
pr_agent/tools/pr_code_suggestions.py
Normal file
@ -0,0 +1,133 @@
|
||||
import copy
|
||||
import json
|
||||
import logging
|
||||
import textwrap
|
||||
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
|
||||
from pr_agent.algo.ai_handler import AiHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.utils import try_fix_json
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.git_providers import BitbucketProvider, get_git_provider
|
||||
from pr_agent.git_providers.git_provider import get_main_pr_language
|
||||
|
||||
|
||||
class PRCodeSuggestions:
|
||||
def __init__(self, pr_url: str, cli_mode=False):
|
||||
|
||||
self.git_provider = get_git_provider()(pr_url)
|
||||
self.main_language = get_main_pr_language(
|
||||
self.git_provider.get_languages(), self.git_provider.get_files()
|
||||
)
|
||||
self.ai_handler = AiHandler()
|
||||
self.patches_diff = None
|
||||
self.prediction = None
|
||||
self.cli_mode = cli_mode
|
||||
self.vars = {
|
||||
"title": self.git_provider.pr.title,
|
||||
"branch": self.git_provider.get_pr_branch(),
|
||||
"description": self.git_provider.get_pr_description(),
|
||||
"language": self.main_language,
|
||||
"diff": "", # empty diff for initial calculation
|
||||
'num_code_suggestions': settings.pr_code_suggestions.num_code_suggestions,
|
||||
}
|
||||
self.token_handler = TokenHandler(self.git_provider.pr,
|
||||
self.vars,
|
||||
settings.pr_code_suggestions_prompt.system,
|
||||
settings.pr_code_suggestions_prompt.user)
|
||||
|
||||
async def suggest(self):
|
||||
assert type(self.git_provider) != BitbucketProvider, "Bitbucket is not supported for now"
|
||||
|
||||
logging.info('Generating code suggestions for PR...')
|
||||
if settings.config.publish_output:
|
||||
self.git_provider.publish_comment("Preparing review...", is_temporary=True)
|
||||
await retry_with_fallback_models(self._prepare_prediction)
|
||||
logging.info('Preparing PR review...')
|
||||
data = self._prepare_pr_code_suggestions()
|
||||
if settings.config.publish_output:
|
||||
logging.info('Pushing PR review...')
|
||||
self.git_provider.remove_initial_comment()
|
||||
logging.info('Pushing inline code comments...')
|
||||
self.push_inline_code_suggestions(data)
|
||||
|
||||
async def _prepare_prediction(self, model: str):
|
||||
logging.info('Getting PR diff...')
|
||||
# we are using extended hunk with line numbers for code suggestions
|
||||
self.patches_diff = get_pr_diff(self.git_provider,
|
||||
self.token_handler,
|
||||
model,
|
||||
add_line_numbers_to_hunks=True,
|
||||
disable_extra_lines=True)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction(model)
|
||||
|
||||
async def _get_prediction(self, model: str):
|
||||
variables = copy.deepcopy(self.vars)
|
||||
variables["diff"] = self.patches_diff # update diff
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
system_prompt = environment.from_string(settings.pr_code_suggestions_prompt.system).render(variables)
|
||||
user_prompt = environment.from_string(settings.pr_code_suggestions_prompt.user).render(variables)
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.info(f"\nSystem prompt:\n{system_prompt}")
|
||||
logging.info(f"\nUser prompt:\n{user_prompt}")
|
||||
response, finish_reason = await self.ai_handler.chat_completion(model=model, temperature=0.2,
|
||||
system=system_prompt, user=user_prompt)
|
||||
|
||||
return response
|
||||
|
||||
def _prepare_pr_code_suggestions(self) -> str:
|
||||
review = self.prediction.strip()
|
||||
try:
|
||||
data = json.loads(review)
|
||||
except json.decoder.JSONDecodeError:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.info(f"Could not parse json response: {review}")
|
||||
data = try_fix_json(review, code_suggestions=True)
|
||||
return data
|
||||
|
||||
def push_inline_code_suggestions(self, data):
|
||||
code_suggestions = []
|
||||
for d in data['Code suggestions']:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.info(f"suggestion: {d}")
|
||||
relevant_file = d['relevant file'].strip()
|
||||
relevant_lines_str = d['relevant lines'].strip()
|
||||
relevant_lines_start = int(relevant_lines_str.split('-')[0]) # absolute position
|
||||
relevant_lines_end = int(relevant_lines_str.split('-')[-1])
|
||||
content = d['suggestion content']
|
||||
new_code_snippet = d['improved code']
|
||||
|
||||
if new_code_snippet:
|
||||
new_code_snippet = self.dedent_code(relevant_file, relevant_lines_start, new_code_snippet)
|
||||
|
||||
body = f"**Suggestion:** {content}\n```suggestion\n" + new_code_snippet + "\n```"
|
||||
code_suggestions.append({'body': body,'relevant_file': relevant_file,
|
||||
'relevant_lines_start': relevant_lines_start,
|
||||
'relevant_lines_end': relevant_lines_end})
|
||||
|
||||
self.git_provider.publish_code_suggestions(code_suggestions)
|
||||
|
||||
def dedent_code(self, relevant_file, relevant_lines_start, new_code_snippet):
|
||||
try: # dedent code snippet
|
||||
self.diff_files = self.git_provider.diff_files if self.git_provider.diff_files \
|
||||
else self.git_provider.get_diff_files()
|
||||
original_initial_line = None
|
||||
for file in self.diff_files:
|
||||
if file.filename.strip() == relevant_file:
|
||||
original_initial_line = file.head_file.splitlines()[relevant_lines_start - 1]
|
||||
break
|
||||
if original_initial_line:
|
||||
suggested_initial_line = new_code_snippet.splitlines()[0]
|
||||
original_initial_spaces = len(original_initial_line) - len(original_initial_line.lstrip())
|
||||
suggested_initial_spaces = len(suggested_initial_line) - len(suggested_initial_line.lstrip())
|
||||
delta_spaces = original_initial_spaces - suggested_initial_spaces
|
||||
if delta_spaces > 0:
|
||||
new_code_snippet = textwrap.indent(new_code_snippet, delta_spaces * " ").rstrip('\n')
|
||||
except Exception as e:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.info(f"Could not dedent code snippet for file {relevant_file}, error: {e}")
|
||||
|
||||
return new_code_snippet
|
||||
92
pr_agent/tools/pr_description.py
Normal file
92
pr_agent/tools/pr_description.py
Normal file
@ -0,0 +1,92 @@
|
||||
import copy
|
||||
import json
|
||||
import logging
|
||||
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
|
||||
from pr_agent.algo.ai_handler import AiHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.git_providers import get_git_provider
|
||||
from pr_agent.git_providers.git_provider import get_main_pr_language
|
||||
|
||||
|
||||
class PRDescription:
|
||||
def __init__(self, pr_url: str):
|
||||
self.git_provider = get_git_provider()(pr_url)
|
||||
self.main_pr_language = get_main_pr_language(
|
||||
self.git_provider.get_languages(), self.git_provider.get_files()
|
||||
)
|
||||
self.ai_handler = AiHandler()
|
||||
self.vars = {
|
||||
"title": self.git_provider.pr.title,
|
||||
"branch": self.git_provider.get_pr_branch(),
|
||||
"description": self.git_provider.get_pr_description(),
|
||||
"language": self.main_pr_language,
|
||||
"diff": "", # empty diff for initial calculation
|
||||
}
|
||||
self.token_handler = TokenHandler(self.git_provider.pr,
|
||||
self.vars,
|
||||
settings.pr_description_prompt.system,
|
||||
settings.pr_description_prompt.user)
|
||||
self.patches_diff = None
|
||||
self.prediction = None
|
||||
|
||||
async def describe(self):
|
||||
logging.info('Generating a PR description...')
|
||||
if settings.config.publish_output:
|
||||
self.git_provider.publish_comment("Preparing pr description...", is_temporary=True)
|
||||
await retry_with_fallback_models(self._prepare_prediction)
|
||||
logging.info('Preparing answer...')
|
||||
pr_title, pr_body, pr_types, markdown_text = self._prepare_pr_answer()
|
||||
if settings.config.publish_output:
|
||||
logging.info('Pushing answer...')
|
||||
if settings.pr_description.publish_description_as_comment:
|
||||
self.git_provider.publish_comment(markdown_text)
|
||||
else:
|
||||
self.git_provider.publish_description(pr_title, pr_body)
|
||||
self.git_provider.publish_labels(pr_types)
|
||||
self.git_provider.remove_initial_comment()
|
||||
return ""
|
||||
|
||||
async def _prepare_prediction(self, model: str):
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler, model)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction(model)
|
||||
|
||||
async def _get_prediction(self, model: str):
|
||||
variables = copy.deepcopy(self.vars)
|
||||
variables["diff"] = self.patches_diff # update diff
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
system_prompt = environment.from_string(settings.pr_description_prompt.system).render(variables)
|
||||
user_prompt = environment.from_string(settings.pr_description_prompt.user).render(variables)
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.info(f"\nSystem prompt:\n{system_prompt}")
|
||||
logging.info(f"\nUser prompt:\n{user_prompt}")
|
||||
response, finish_reason = await self.ai_handler.chat_completion(model=model, temperature=0.2,
|
||||
system=system_prompt, user=user_prompt)
|
||||
return response
|
||||
|
||||
def _prepare_pr_answer(self):
|
||||
data = json.loads(self.prediction)
|
||||
markdown_text = ""
|
||||
for key, value in data.items():
|
||||
markdown_text += f"## {key}\n\n"
|
||||
markdown_text += f"{value}\n\n"
|
||||
pr_body = ""
|
||||
pr_types = []
|
||||
if 'PR Type' in data:
|
||||
pr_types = data['PR Type'].split(',')
|
||||
title = data['PR Title']
|
||||
del data['PR Title']
|
||||
for key, value in data.items():
|
||||
pr_body += f"{key}:\n"
|
||||
if 'walkthrough' in key.lower():
|
||||
pr_body += f"{value}\n"
|
||||
else:
|
||||
pr_body += f"**{value}**\n\n___\n"
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.info(f"title:\n{title}\n{pr_body}")
|
||||
return title, pr_body, pr_types, markdown_text
|
||||
75
pr_agent/tools/pr_information_from_user.py
Normal file
75
pr_agent/tools/pr_information_from_user.py
Normal file
@ -0,0 +1,75 @@
|
||||
import copy
|
||||
import logging
|
||||
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
|
||||
from pr_agent.algo.ai_handler import AiHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.git_providers import get_git_provider
|
||||
from pr_agent.git_providers.git_provider import get_main_pr_language
|
||||
|
||||
|
||||
|
||||
|
||||
class PRInformationFromUser:
|
||||
def __init__(self, pr_url: str):
|
||||
self.git_provider = get_git_provider()(pr_url)
|
||||
self.main_pr_language = get_main_pr_language(
|
||||
self.git_provider.get_languages(), self.git_provider.get_files()
|
||||
)
|
||||
self.ai_handler = AiHandler()
|
||||
self.vars = {
|
||||
"title": self.git_provider.pr.title,
|
||||
"branch": self.git_provider.get_pr_branch(),
|
||||
"description": self.git_provider.get_pr_description(),
|
||||
"language": self.main_pr_language,
|
||||
"diff": "", # empty diff for initial calculation
|
||||
}
|
||||
self.token_handler = TokenHandler(self.git_provider.pr,
|
||||
self.vars,
|
||||
settings.pr_information_from_user_prompt.system,
|
||||
settings.pr_information_from_user_prompt.user)
|
||||
self.patches_diff = None
|
||||
self.prediction = None
|
||||
|
||||
async def generate_questions(self):
|
||||
logging.info('Generating question to the user...')
|
||||
if settings.config.publish_output:
|
||||
self.git_provider.publish_comment("Preparing questions...", is_temporary=True)
|
||||
await retry_with_fallback_models(self._prepare_prediction)
|
||||
logging.info('Preparing questions...')
|
||||
pr_comment = self._prepare_pr_answer()
|
||||
if settings.config.publish_output:
|
||||
logging.info('Pushing questions...')
|
||||
self.git_provider.publish_comment(pr_comment)
|
||||
self.git_provider.remove_initial_comment()
|
||||
return ""
|
||||
|
||||
async def _prepare_prediction(self, model):
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler, model)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction(model)
|
||||
|
||||
async def _get_prediction(self, model: str):
|
||||
variables = copy.deepcopy(self.vars)
|
||||
variables["diff"] = self.patches_diff # update diff
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
system_prompt = environment.from_string(settings.pr_information_from_user_prompt.system).render(variables)
|
||||
user_prompt = environment.from_string(settings.pr_information_from_user_prompt.user).render(variables)
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.info(f"\nSystem prompt:\n{system_prompt}")
|
||||
logging.info(f"\nUser prompt:\n{user_prompt}")
|
||||
response, finish_reason = await self.ai_handler.chat_completion(model=model, temperature=0.2,
|
||||
system=system_prompt, user=user_prompt)
|
||||
return response
|
||||
|
||||
def _prepare_pr_answer(self) -> str:
|
||||
model_output = self.prediction.strip()
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.info(f"answer_str:\n{model_output}")
|
||||
answer_str = f"{model_output}\n\n Please respond to the questions above in the following format:\n\n" +\
|
||||
"\n>/answer\n>1) ...\n>2) ...\n>...\n"
|
||||
return answer_str
|
||||
@ -1,29 +1,31 @@
|
||||
import copy
|
||||
import logging
|
||||
from typing import Optional
|
||||
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
|
||||
from pr_agent.algo.ai_handler import AiHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.git_providers import get_git_provider
|
||||
from pr_agent.git_providers.git_provider import get_main_pr_language
|
||||
|
||||
|
||||
class PRQuestions:
|
||||
def __init__(self, pr_url: str, question_str: str, installation_id: Optional[int] = None):
|
||||
self.git_provider = get_git_provider()(pr_url, installation_id)
|
||||
self.main_pr_language = self.git_provider.get_main_pr_language()
|
||||
self.installation_id = installation_id
|
||||
def __init__(self, pr_url: str, args=None):
|
||||
question_str = self.parse_args(args)
|
||||
self.git_provider = get_git_provider()(pr_url)
|
||||
self.main_pr_language = get_main_pr_language(
|
||||
self.git_provider.get_languages(), self.git_provider.get_files()
|
||||
)
|
||||
self.ai_handler = AiHandler()
|
||||
self.question_str = question_str
|
||||
self.vars = {
|
||||
"title": self.git_provider.pr.title,
|
||||
"branch": self.git_provider.get_pr_branch(),
|
||||
"description": self.git_provider.pr.body,
|
||||
"language": self.git_provider.get_main_pr_language(),
|
||||
"diff": "", # empty diff for initial calculation
|
||||
"description": self.git_provider.get_pr_description(),
|
||||
"language": self.main_pr_language,
|
||||
"diff": "", # empty diff for initial calculation
|
||||
"questions": self.question_str,
|
||||
}
|
||||
self.token_handler = TokenHandler(self.git_provider.pr,
|
||||
@ -33,21 +35,33 @@ class PRQuestions:
|
||||
self.patches_diff = None
|
||||
self.prediction = None
|
||||
|
||||
def parse_args(self, args):
|
||||
if args and len(args) > 0:
|
||||
question_str = " ".join(args)
|
||||
else:
|
||||
question_str = ""
|
||||
return question_str
|
||||
|
||||
async def answer(self):
|
||||
logging.info('Answering a PR question...')
|
||||
self.git_provider.publish_comment("Preparing answer...")
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction()
|
||||
if settings.config.publish_output:
|
||||
self.git_provider.publish_comment("Preparing answer...", is_temporary=True)
|
||||
await retry_with_fallback_models(self._prepare_prediction)
|
||||
logging.info('Preparing answer...')
|
||||
pr_comment = self._prepare_pr_answer()
|
||||
if settings.config.publish_review:
|
||||
if settings.config.publish_output:
|
||||
logging.info('Pushing answer...')
|
||||
self.git_provider.publish_comment(pr_comment)
|
||||
self.git_provider.remove_initial_comment()
|
||||
return ""
|
||||
|
||||
async def _get_prediction(self):
|
||||
async def _prepare_prediction(self, model: str):
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler, model)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction(model)
|
||||
|
||||
async def _get_prediction(self, model: str):
|
||||
variables = copy.deepcopy(self.vars)
|
||||
variables["diff"] = self.patches_diff # update diff
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
@ -56,12 +70,13 @@ class PRQuestions:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.info(f"\nSystem prompt:\n{system_prompt}")
|
||||
logging.info(f"\nUser prompt:\n{user_prompt}")
|
||||
model = settings.config.model
|
||||
response, finish_reason = await self.ai_handler.chat_completion(model=model, temperature=0.2,
|
||||
system=system_prompt, user=user_prompt)
|
||||
return response
|
||||
|
||||
def _prepare_pr_answer(self) -> str:
|
||||
answer_str = f"Questions: {self.question_str}\n\n"
|
||||
answer_str += f"Answer: {self.prediction.strip()}\n\n"
|
||||
answer_str = f"Question: {self.question_str}\n\n"
|
||||
answer_str += f"Answer:\n{self.prediction.strip()}\n\n"
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.info(f"answer_str:\n{answer_str}")
|
||||
return answer_str
|
||||
|
||||
@ -1,60 +1,88 @@
|
||||
import copy
|
||||
import json
|
||||
import logging
|
||||
from typing import Optional
|
||||
from collections import OrderedDict
|
||||
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
|
||||
from pr_agent.algo.ai_handler import AiHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.utils import convert_to_markdown
|
||||
from pr_agent.algo.utils import convert_to_markdown, try_fix_json
|
||||
from pr_agent.config_loader import settings
|
||||
from pr_agent.git_providers import get_git_provider
|
||||
from pr_agent.git_providers.git_provider import get_main_pr_language, IncrementalPR
|
||||
from pr_agent.servers.help import actions_help_text, bot_help_text
|
||||
|
||||
|
||||
class PRReviewer:
|
||||
def __init__(self, pr_url: str, installation_id: Optional[int] = None):
|
||||
def __init__(self, pr_url: str, cli_mode=False, is_answer: bool = False, args=None):
|
||||
self.parse_args(args)
|
||||
|
||||
self.git_provider = get_git_provider()(pr_url, installation_id)
|
||||
self.main_language = self.git_provider.get_main_pr_language()
|
||||
self.installation_id = installation_id
|
||||
self.git_provider = get_git_provider()(pr_url, incremental=self.incremental)
|
||||
self.main_language = get_main_pr_language(
|
||||
self.git_provider.get_languages(), self.git_provider.get_files()
|
||||
)
|
||||
self.pr_url = pr_url
|
||||
self.is_answer = is_answer
|
||||
if self.is_answer and not self.git_provider.is_supported("get_issue_comments"):
|
||||
raise Exception(f"Answer mode is not supported for {settings.config.git_provider} for now")
|
||||
answer_str, question_str = self._get_user_answers()
|
||||
self.ai_handler = AiHandler()
|
||||
self.patches_diff = None
|
||||
self.prediction = None
|
||||
self.cli_mode = cli_mode
|
||||
self.vars = {
|
||||
"title": self.git_provider.pr.title,
|
||||
"branch": self.git_provider.get_pr_branch(),
|
||||
"description": self.git_provider.pr.body,
|
||||
"language": self.git_provider.get_main_pr_language(),
|
||||
"description": self.git_provider.get_pr_description(),
|
||||
"language": self.main_language,
|
||||
"diff": "", # empty diff for initial calculation
|
||||
"require_score": settings.pr_reviewer.require_score_review,
|
||||
"require_tests": settings.pr_reviewer.require_tests_review,
|
||||
"require_security": settings.pr_reviewer.require_security_review,
|
||||
"require_minimal_and_focused": settings.pr_reviewer.require_minimal_and_focused_review,
|
||||
'extended_code_suggestions': settings.pr_reviewer.extended_code_suggestions,
|
||||
"require_focused": settings.pr_reviewer.require_focused_review,
|
||||
'num_code_suggestions': settings.pr_reviewer.num_code_suggestions,
|
||||
#
|
||||
'question_str': question_str,
|
||||
'answer_str': answer_str,
|
||||
}
|
||||
self.token_handler = TokenHandler(self.git_provider.pr,
|
||||
self.vars,
|
||||
settings.pr_review_prompt.system,
|
||||
settings.pr_review_prompt.user)
|
||||
|
||||
def parse_args(self, args):
|
||||
is_incremental = False
|
||||
if args and len(args) >= 1:
|
||||
arg = args[0]
|
||||
if arg == "-i":
|
||||
is_incremental = True
|
||||
self.incremental = IncrementalPR(is_incremental)
|
||||
|
||||
async def review(self):
|
||||
logging.info('Reviewing PR...')
|
||||
if settings.config.publish_review:
|
||||
self.git_provider.publish_comment("Preparing review...")
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction()
|
||||
if settings.config.publish_output:
|
||||
self.git_provider.publish_comment("Preparing review...", is_temporary=True)
|
||||
await retry_with_fallback_models(self._prepare_prediction)
|
||||
logging.info('Preparing PR review...')
|
||||
pr_comment = self._prepare_pr_review()
|
||||
if settings.config.publish_review:
|
||||
if settings.config.publish_output:
|
||||
logging.info('Pushing PR review...')
|
||||
self.git_provider.publish_comment(pr_comment)
|
||||
self.git_provider.remove_initial_comment()
|
||||
if settings.pr_reviewer.inline_code_comments:
|
||||
logging.info('Pushing inline code comments...')
|
||||
self._publish_inline_code_comments()
|
||||
return ""
|
||||
|
||||
async def _get_prediction(self):
|
||||
async def _prepare_prediction(self, model: str):
|
||||
logging.info('Getting PR diff...')
|
||||
self.patches_diff = get_pr_diff(self.git_provider, self.token_handler, model)
|
||||
logging.info('Getting AI prediction...')
|
||||
self.prediction = await self._get_prediction(model)
|
||||
|
||||
async def _get_prediction(self, model: str):
|
||||
variables = copy.deepcopy(self.vars)
|
||||
variables["diff"] = self.patches_diff # update diff
|
||||
environment = Environment(undefined=StrictUndefined)
|
||||
@ -63,14 +91,9 @@ class PRReviewer:
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.info(f"\nSystem prompt:\n{system_prompt}")
|
||||
logging.info(f"\nUser prompt:\n{user_prompt}")
|
||||
model = settings.config.model
|
||||
response, finish_reason = await self.ai_handler.chat_completion(model=model, temperature=0.2,
|
||||
system=system_prompt, user=user_prompt)
|
||||
try:
|
||||
json.loads(response)
|
||||
except json.decoder.JSONDecodeError:
|
||||
logging.warning("Could not decode JSON")
|
||||
response = {}
|
||||
|
||||
return response
|
||||
|
||||
def _prepare_pr_review(self) -> str:
|
||||
@ -78,11 +101,86 @@ class PRReviewer:
|
||||
try:
|
||||
data = json.loads(review)
|
||||
except json.decoder.JSONDecodeError:
|
||||
logging.error("Unable to decode JSON response from AI")
|
||||
data = {}
|
||||
data = try_fix_json(review)
|
||||
|
||||
# reordering for nicer display
|
||||
if 'PR Feedback' in data:
|
||||
if 'Security concerns' in data['PR Feedback']:
|
||||
val = data['PR Feedback']['Security concerns']
|
||||
del data['PR Feedback']['Security concerns']
|
||||
data['PR Analysis']['Security concerns'] = val
|
||||
|
||||
if settings.config.git_provider != 'bitbucket' and \
|
||||
settings.pr_reviewer.inline_code_comments and \
|
||||
'Code suggestions' in data['PR Feedback']:
|
||||
# keeping only code suggestions that can't be submitted as inline comments
|
||||
data['PR Feedback']['Code suggestions'] = [
|
||||
d for d in data['PR Feedback']['Code suggestions']
|
||||
if any(key not in d for key in ('relevant file', 'relevant line in file', 'suggestion content'))
|
||||
]
|
||||
if not data['PR Feedback']['Code suggestions']:
|
||||
del data['PR Feedback']['Code suggestions']
|
||||
|
||||
if self.incremental.is_incremental:
|
||||
# Rename title when incremental review - Add to the beginning of the dict
|
||||
last_commit_url = f"{self.git_provider.get_pr_url()}/commits/{self.git_provider.incremental.first_new_commit_sha}"
|
||||
data = OrderedDict(data)
|
||||
data.update({'Incremental PR Review': {
|
||||
"⏮️ Review for commits since previous PR-Agent review": f"Starting from commit {last_commit_url}"}})
|
||||
data.move_to_end('Incremental PR Review', last=False)
|
||||
|
||||
markdown_text = convert_to_markdown(data)
|
||||
markdown_text += "\nAdd a comment that says 'Please review' to ask for a new review after you update the PR.\n"
|
||||
markdown_text += "Add a comment that says 'Please answer <QUESTION...>' to ask a question about this PR.\n"
|
||||
user = self.git_provider.get_user_id()
|
||||
|
||||
if not self.cli_mode:
|
||||
markdown_text += "\n### How to use\n"
|
||||
if user and '[bot]' not in user:
|
||||
markdown_text += bot_help_text(user)
|
||||
else:
|
||||
markdown_text += actions_help_text
|
||||
|
||||
if settings.config.verbosity_level >= 2:
|
||||
logging.info(f"Markdown response:\n{markdown_text}")
|
||||
return markdown_text
|
||||
|
||||
def _publish_inline_code_comments(self):
|
||||
if settings.pr_reviewer.num_code_suggestions == 0:
|
||||
return
|
||||
|
||||
review = self.prediction.strip()
|
||||
try:
|
||||
data = json.loads(review)
|
||||
except json.decoder.JSONDecodeError:
|
||||
data = try_fix_json(review)
|
||||
|
||||
comments = []
|
||||
for d in data['PR Feedback']['Code suggestions']:
|
||||
relevant_file = d.get('relevant file', '').strip()
|
||||
relevant_line_in_file = d.get('relevant line in file', '').strip()
|
||||
content = d.get('suggestion content', '')
|
||||
if not relevant_file or not relevant_line_in_file or not content:
|
||||
logging.info("Skipping inline comment with missing file/line/content")
|
||||
continue
|
||||
|
||||
if self.git_provider.is_supported("create_inline_comment"):
|
||||
comment = self.git_provider.create_inline_comment(content, relevant_file, relevant_line_in_file)
|
||||
if comment:
|
||||
comments.append(comment)
|
||||
else:
|
||||
self.git_provider.publish_inline_comment(content, relevant_file, relevant_line_in_file)
|
||||
|
||||
if comments:
|
||||
self.git_provider.publish_inline_comments(comments)
|
||||
|
||||
def _get_user_answers(self):
|
||||
answer_str = question_str = ""
|
||||
if self.is_answer:
|
||||
discussion_messages = self.git_provider.get_issue_comments()
|
||||
for message in discussion_messages.reversed:
|
||||
if "Questions to better understand the PR:" in message.body:
|
||||
question_str = message.body
|
||||
elif '/answer' in message.body:
|
||||
answer_str = message.body
|
||||
if answer_str and question_str:
|
||||
break
|
||||
return question_str, answer_str
|
||||
|
||||
@ -1,8 +1,12 @@
|
||||
dynaconf==3.1.12
|
||||
fastapi==0.99.0
|
||||
PyGithub==1.58.2
|
||||
PyGithub==1.59.*
|
||||
retry==0.9.2
|
||||
openai==0.27.8
|
||||
Jinja2==3.1.2
|
||||
tiktoken==0.4.0
|
||||
uvicorn==0.22.0
|
||||
python-gitlab==3.15.0
|
||||
pytest~=7.4.0
|
||||
aiohttp~=3.8.4
|
||||
atlassian-python-api==3.39.0
|
||||
|
||||
@ -46,22 +46,19 @@ class TestConvertToMarkdown:
|
||||
def test_simple_dictionary_input(self):
|
||||
input_data = {
|
||||
'Main theme': 'Test',
|
||||
'Description and title': 'Test description',
|
||||
'Type of PR': 'Test type',
|
||||
'Relevant tests added': 'no',
|
||||
'Unrelated changes': 'n/a', # won't be included in the output
|
||||
'Minimal and focused': 'Yes',
|
||||
'Focused PR': 'Yes',
|
||||
'General PR suggestions': 'general suggestion...',
|
||||
'Code suggestions': [
|
||||
{
|
||||
'Suggestion number': 1,
|
||||
'Code example': {
|
||||
'Before': 'Code before',
|
||||
'After': 'Code after'
|
||||
}
|
||||
},
|
||||
{
|
||||
'Suggestion number': 2,
|
||||
'Code example': {
|
||||
'Before': 'Code before 2',
|
||||
'After': 'Code after 2'
|
||||
@ -71,15 +68,13 @@ class TestConvertToMarkdown:
|
||||
}
|
||||
expected_output = """\
|
||||
- 🎯 **Main theme:** Test
|
||||
- 🔍 **Description and title:** Test description
|
||||
- 📌 **Type of PR:** Test type
|
||||
- 🧪 **Relevant tests added:** no
|
||||
- ✨ **Minimal and focused:** Yes
|
||||
- ✨ **Focused PR:** Yes
|
||||
- 💡 **General PR suggestions:** general suggestion...
|
||||
|
||||
- 🤖 **Code suggestions:**
|
||||
|
||||
- **suggestion 1:**
|
||||
- **Code example:**
|
||||
- **Before:**
|
||||
```
|
||||
@ -90,7 +85,6 @@ class TestConvertToMarkdown:
|
||||
Code after
|
||||
```
|
||||
|
||||
- **suggestion 2:**
|
||||
- **Code example:**
|
||||
- **Before:**
|
||||
```
|
||||
@ -112,11 +106,10 @@ class TestConvertToMarkdown:
|
||||
def test_dictionary_input_containing_only_empty_dictionaries(self):
|
||||
input_data = {
|
||||
'Main theme': {},
|
||||
'Description and title': {},
|
||||
'Type of PR': {},
|
||||
'Relevant tests added': {},
|
||||
'Unrelated changes': {},
|
||||
'Minimal and focused': {},
|
||||
'Focused PR': {},
|
||||
'General PR suggestions': {},
|
||||
'Code suggestions': {}
|
||||
}
|
||||
|
||||
82
tests/unit/test_fix_output.py
Normal file
82
tests/unit/test_fix_output.py
Normal file
@ -0,0 +1,82 @@
|
||||
# Generated by CodiumAI
|
||||
|
||||
from pr_agent.algo.utils import try_fix_json
|
||||
|
||||
|
||||
class TestTryFixJson:
|
||||
# Tests that JSON with complete 'Code suggestions' section returns expected output
|
||||
def test_incomplete_code_suggestions(self):
|
||||
review = '{"PR Analysis": {"Main theme": "xxx", "Type of PR": "Bug fix"}, "PR Feedback": {"General PR suggestions": "..., `xxx`...", "Code suggestions": [{"relevant file": "xxx.py", "suggestion content": "xxx [important]"}, {"suggestion number": 2, "relevant file": "yyy.py", "suggestion content": "yyy [incomp...' # noqa: E501
|
||||
expected_output = {
|
||||
'PR Analysis': {
|
||||
'Main theme': 'xxx',
|
||||
'Type of PR': 'Bug fix'
|
||||
},
|
||||
'PR Feedback': {
|
||||
'General PR suggestions': '..., `xxx`...',
|
||||
'Code suggestions': [
|
||||
{
|
||||
'relevant file': 'xxx.py',
|
||||
'suggestion content': 'xxx [important]'
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
assert try_fix_json(review) == expected_output
|
||||
|
||||
def test_incomplete_code_suggestions_new_line(self):
|
||||
review = '{"PR Analysis": {"Main theme": "xxx", "Type of PR": "Bug fix"}, "PR Feedback": {"General PR suggestions": "..., `xxx`...", "Code suggestions": [{"relevant file": "xxx.py", "suggestion content": "xxx [important]"} \n\t, {"suggestion number": 2, "relevant file": "yyy.py", "suggestion content": "yyy [incomp...' # noqa: E501
|
||||
expected_output = {
|
||||
'PR Analysis': {
|
||||
'Main theme': 'xxx',
|
||||
'Type of PR': 'Bug fix'
|
||||
},
|
||||
'PR Feedback': {
|
||||
'General PR suggestions': '..., `xxx`...',
|
||||
'Code suggestions': [
|
||||
{
|
||||
'relevant file': 'xxx.py',
|
||||
'suggestion content': 'xxx [important]'
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
assert try_fix_json(review) == expected_output
|
||||
|
||||
def test_incomplete_code_suggestions_many_close_brackets(self):
|
||||
review = '{"PR Analysis": {"Main theme": "xxx", "Type of PR": "Bug fix"}, "PR Feedback": {"General PR suggestions": "..., `xxx`...", "Code suggestions": [{"relevant file": "xxx.py", "suggestion content": "xxx [important]"} \n, {"suggestion number": 2, "relevant file": "yyy.py", "suggestion content": "yyy }, [}\n ,incomp.} ,..' # noqa: E501
|
||||
expected_output = {
|
||||
'PR Analysis': {
|
||||
'Main theme': 'xxx',
|
||||
'Type of PR': 'Bug fix'
|
||||
},
|
||||
'PR Feedback': {
|
||||
'General PR suggestions': '..., `xxx`...',
|
||||
'Code suggestions': [
|
||||
{
|
||||
'relevant file': 'xxx.py',
|
||||
'suggestion content': 'xxx [important]'
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
assert try_fix_json(review) == expected_output
|
||||
|
||||
def test_incomplete_code_suggestions_relevant_file(self):
|
||||
review = '{"PR Analysis": {"Main theme": "xxx", "Type of PR": "Bug fix"}, "PR Feedback": {"General PR suggestions": "..., `xxx`...", "Code suggestions": [{"relevant file": "xxx.py", "suggestion content": "xxx [important]"}, {"suggestion number": 2, "relevant file": "yyy.p' # noqa: E501
|
||||
expected_output = {
|
||||
'PR Analysis': {
|
||||
'Main theme': 'xxx',
|
||||
'Type of PR': 'Bug fix'
|
||||
},
|
||||
'PR Feedback': {
|
||||
'General PR suggestions': '..., `xxx`...',
|
||||
'Code suggestions': [
|
||||
{
|
||||
'relevant file': 'xxx.py',
|
||||
'suggestion content': 'xxx [important]'
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
assert try_fix_json(review) == expected_output
|
||||
@ -62,7 +62,7 @@ class TestHandlePatchDeletions:
|
||||
new_file_content_str = ''
|
||||
file_name = 'file.py'
|
||||
assert handle_patch_deletions(patch, original_file_content_str, new_file_content_str,
|
||||
file_name) == 'File was deleted\n'
|
||||
file_name) is None
|
||||
|
||||
# Tests that handle_patch_deletions returns the original patch when patch and patch_new are equal
|
||||
def test_handle_patch_deletions_edge_case_patch_and_patch_new_are_equal(self):
|
||||
|
||||
@ -1,15 +1,15 @@
|
||||
|
||||
# Generated by CodiumAI
|
||||
|
||||
from pr_agent.algo.language_handler import sort_files_by_main_languages
|
||||
|
||||
|
||||
import pytest
|
||||
|
||||
"""
|
||||
Code Analysis
|
||||
|
||||
Objective:
|
||||
The objective of the function is to sort a list of files by their main language, putting the files that are in the main language first and the rest of the files after. It takes in a dictionary of languages and their sizes, and a list of files.
|
||||
The objective of the function is to sort a list of files by their main language, putting the files that are in the main
|
||||
language first and the rest of the files after. It takes in a dictionary of languages and their sizes, and a list of
|
||||
files.
|
||||
|
||||
Inputs:
|
||||
- languages: a dictionary containing the languages and their sizes
|
||||
@ -33,6 +33,8 @@ Additional aspects:
|
||||
- The function uses the filter_bad_extensions function to filter out files with bad extensions
|
||||
- The function uses a rest_files dictionary to store the files that do not belong to any of the main extensions
|
||||
"""
|
||||
|
||||
|
||||
class TestSortFilesByMainLanguages:
|
||||
# Tests that files are sorted by main language, with files in main language first and the rest after
|
||||
def test_happy_path_sort_files_by_main_languages(self):
|
||||
@ -118,4 +120,4 @@ class TestSortFilesByMainLanguages:
|
||||
{'language': 'C++', 'files': [files[2], files[7]]},
|
||||
{'language': 'Other', 'files': []}
|
||||
]
|
||||
assert sort_files_by_main_languages(languages, files) == expected_output
|
||||
assert sort_files_by_main_languages(languages, files) == expected_output
|
||||
@ -41,14 +41,6 @@ class TestParseCodeSuggestion:
|
||||
expected_output = "\n" # modified to expect a newline character
|
||||
assert parse_code_suggestion(input_data) == expected_output
|
||||
|
||||
# Tests that function returns correct output when 'suggestion number' key has a non-integer value
|
||||
def test_non_integer_suggestion_number(self):
|
||||
input_data = {
|
||||
"Suggestion number": "one",
|
||||
"Description": "This is a suggestion"
|
||||
}
|
||||
expected_output = "- **suggestion one:**\n - **Description:** This is a suggestion\n\n"
|
||||
assert parse_code_suggestion(input_data) == expected_output
|
||||
|
||||
# Tests that function returns correct output when 'before' or 'after' key has a non-string value
|
||||
def test_non_string_before_or_after(self):
|
||||
@ -64,19 +56,17 @@ class TestParseCodeSuggestion:
|
||||
# Tests that function returns correct output when input dictionary does not have 'code example' key
|
||||
def test_no_code_example_key(self):
|
||||
code_suggestions = {
|
||||
'suggestion number': 1,
|
||||
'suggestion': 'Suggestion 1',
|
||||
'description': 'Description 1',
|
||||
'before': 'Before 1',
|
||||
'after': 'After 1'
|
||||
}
|
||||
expected_output = "- **suggestion 1:**\n - **suggestion:** Suggestion 1\n - **description:** Description 1\n - **before:** Before 1\n - **after:** After 1\n\n" # noqa: E501
|
||||
expected_output = " **suggestion:** Suggestion 1\n **description:** Description 1\n **before:** Before 1\n **after:** After 1\n\n" # noqa: E501
|
||||
assert parse_code_suggestion(code_suggestions) == expected_output
|
||||
|
||||
# Tests that function returns correct output when input dictionary has 'code example' key
|
||||
def test_with_code_example_key(self):
|
||||
code_suggestions = {
|
||||
'suggestion number': 2,
|
||||
'suggestion': 'Suggestion 2',
|
||||
'description': 'Description 2',
|
||||
'code example': {
|
||||
@ -84,5 +74,5 @@ class TestParseCodeSuggestion:
|
||||
'after': 'After 2'
|
||||
}
|
||||
}
|
||||
expected_output = "- **suggestion 2:**\n - **suggestion:** Suggestion 2\n - **description:** Description 2\n - **code example:**\n - **before:**\n ```\n Before 2\n ```\n - **after:**\n ```\n After 2\n ```\n\n" # noqa: E501
|
||||
expected_output = " **suggestion:** Suggestion 2\n **description:** Description 2\n - **code example:**\n - **before:**\n ```\n Before 2\n ```\n - **after:**\n ```\n After 2\n ```\n\n" # noqa: E501
|
||||
assert parse_code_suggestion(code_suggestions) == expected_output
|
||||
|
||||
Reference in New Issue
Block a user