mirror of
https://github.com/qodo-ai/pr-agent.git
synced 2025-07-02 03:40:38 +08:00
self_reflection
This commit is contained in:
@ -1,2 +1,43 @@
|
||||
## Overview - Self-reflection and suggestion cleaning and re-ranking
|
||||
TBD
|
||||
|
||||
### Introduction - fast review with hierarchical structure
|
||||
|
||||
Given that not all generated code suggestions will be relevant, it is crucial to enable users to review them in a fast and efficient way, allowing quick identification and filtering of non-applicable ones.
|
||||
|
||||
To achieve this goal, PR-Agent offers a dedicated hierarchical structure when presenting suggestions to users:
|
||||
|
||||
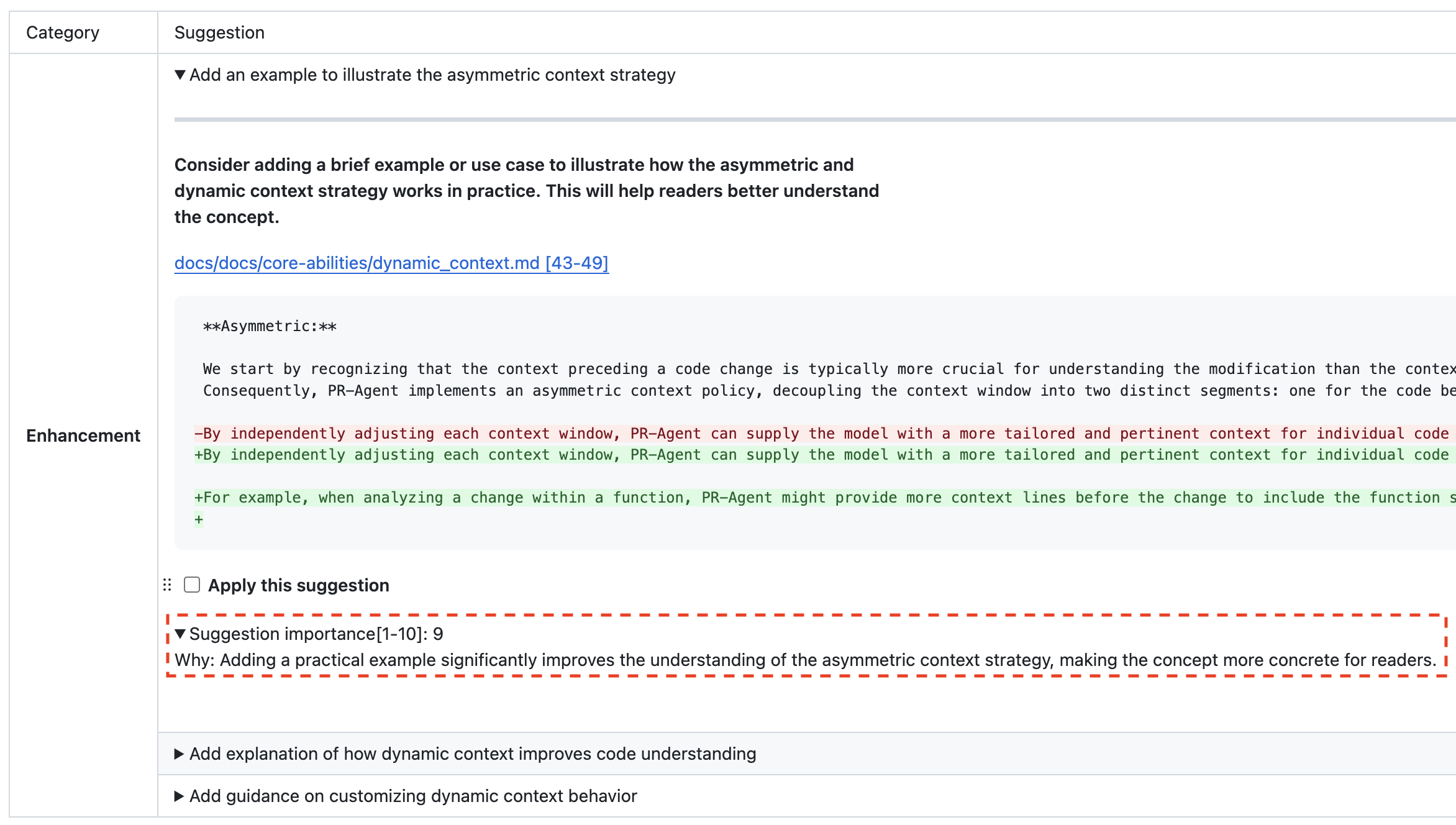
- A "category" section groups suggestions by their category, allowing users to quickly disqualify irrelevant suggestions.
|
||||
- Each suggestion is first described by a one-line summary, which can be expanded to a full description by clicking on a collapsible.
|
||||
- Upon expanding a suggestion, the user receives a more comprehensive description, and a code snippet demonstrating the recommendation.
|
||||
|
||||
This hierarchical structure is designed to facilitate rapid review of each suggestion, with users spending an average of ~5-10 seconds per item.
|
||||
|
||||
### Self-reflection and re-ranking
|
||||
|
||||
The AI model is initially tasked with generating suggestions, and outputting them in order of importance.
|
||||
However, in practice we observe that models often struggle to simultaneously generate high-quality code suggestions and rank them well in a single pass.
|
||||
Furthermore, the initial set of generated suggestions occasionally contains readily identifiable errors.
|
||||
|
||||
To address these issues, we implemented a "self-reflection" process that refines suggestion ranking and eliminates irrelevant or incorrect proposals.
|
||||
This process consists of the following steps:
|
||||
|
||||
1. Presenting the generated suggestions to the model in a follow-up call.
|
||||
2. Instructing the model to score each suggestion and provide a rationale for the assigned score.
|
||||
3. Utilizing these scores to re-rank the suggestions and filter out incorrect ones (with a score of 0).
|
||||
4. Optionally, filtering out all suggestions below a user-defined score threshold.
|
||||
|
||||
Note that presenting all generated suggestions simultaneously provides the model with a comprehensive context, enabling it to make more informed decisions compared to evaluating each suggestion individually.
|
||||
|
||||
To conclude, the self-reflection process enables PR-Agent to prioritize suggestions based on their importance, eliminate inaccurate or irrelevant proposals, and optionally exclude suggestions that fall below a specified threshold of significance.
|
||||
|
||||
### Example results
|
||||
|
||||
{width=768}
|
||||
{width=768}
|
||||
|
||||
|
||||
### Appendix - relevant configuration options
|
||||
```
|
||||
[pr_code_suggestions]
|
||||
self_reflect_on_suggestions = true # Enable self-reflection on code suggestions
|
||||
suggestions_score_threshold = 0 # Filter out suggestions with a score below this threshold (0-10)
|
||||
```
|
||||
Reference in New Issue
Block a user