 ](https://www.codium.ai/images/pr_agent/pr-actions.mp4)
+
+
+
+(click on the image to see a video demonstration)
+
+### Jan 28, 2024
+- 💎 Test - A new tool, [`/test component_name`](https://github.com/Codium-ai/pr-agent/blob/main/docs/TEST.md), was added to PR-Agent Pro. The tool will generate tests for a selected component, based on the PR code changes.
+- 💎 Analyze - The [`/analyze`](https://github.com/Codium-ai/pr-agent/blob/main/docs/Analyze.md) tool was updated and simplified. It now presents a summary of the code components that were changed in the PR.
### Jan 21, 2024
- 💎 Custom suggestions - A new tool, `/custom_suggestions`, was added to PR-Agent Pro. The tool will propose only suggestions that follow specific guidelines defined by the user.
See [here](https://github.com/Codium-ai/pr-agent/blob/main/docs/CUSTOM_SUGGESTIONS.md) for more details.
-### Jan 17, 2024
-- 💎 Inline file summary - The `describe` tool has a new option `--pr_description.inline_file_summary`, which allows to add a summary of each file changes to the Diffview page. See [here](https://github.com/Codium-ai/pr-agent/blob/main/docs/DESCRIBE.md#inline-file-summary-)
-- The `improve` tool can now present suggestions in a nice collapsible format, which significantly reduces the PR footprint. See [here](https://github.com/Codium-ai/pr-agent/blob/main/docs/IMPROVE.md#summarized-vs-commitable-code-suggestions) for more details.
-- To accompany the improved interface of the `improve` tool, we change the [default automation settings](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml#L116) of our GithupApp to:
-```
-pr_commands = [
- "/describe --pr_description.add_original_user_description=true --pr_description.keep_original_user_title=true",
- "/review --pr_reviewer.num_code_suggestions=0",
- "/improve --pr_code_suggestions.summarize=true",
-]
-```
-Meaning that by default, for each PR the `describe`, `review`, and `improve` tools will be triggered automatically, and the `improve` tool will present the suggestions in a single comment.
-You can of course overwrite these defaults by adding a `.pr_agent.toml` file to your repo. See [here](https://github.com/Codium-ai/pr-agent/blob/main/Usage.md#working-with-github-app).
-
-### Jan 10, 2024
-[LanceDB](https://lancedb.com/) is now supported as a locally hosted VectorDB for the `similar_issue` tool. See [here](./docs/SIMILAR_ISSUE.md) for more details.
-
## Overview
](https://www.codium.ai/images/pr_agent/pr-actions.mp4)
+
+
+
+(click on the image to see a video demonstration)
+
+### Jan 28, 2024
+- 💎 Test - A new tool, [`/test component_name`](https://github.com/Codium-ai/pr-agent/blob/main/docs/TEST.md), was added to PR-Agent Pro. The tool will generate tests for a selected component, based on the PR code changes.
+- 💎 Analyze - The [`/analyze`](https://github.com/Codium-ai/pr-agent/blob/main/docs/Analyze.md) tool was updated and simplified. It now presents a summary of the code components that were changed in the PR.
### Jan 21, 2024
- 💎 Custom suggestions - A new tool, `/custom_suggestions`, was added to PR-Agent Pro. The tool will propose only suggestions that follow specific guidelines defined by the user.
See [here](https://github.com/Codium-ai/pr-agent/blob/main/docs/CUSTOM_SUGGESTIONS.md) for more details.
-### Jan 17, 2024
-- 💎 Inline file summary - The `describe` tool has a new option `--pr_description.inline_file_summary`, which allows to add a summary of each file changes to the Diffview page. See [here](https://github.com/Codium-ai/pr-agent/blob/main/docs/DESCRIBE.md#inline-file-summary-)
-- The `improve` tool can now present suggestions in a nice collapsible format, which significantly reduces the PR footprint. See [here](https://github.com/Codium-ai/pr-agent/blob/main/docs/IMPROVE.md#summarized-vs-commitable-code-suggestions) for more details.
-- To accompany the improved interface of the `improve` tool, we change the [default automation settings](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml#L116) of our GithupApp to:
-```
-pr_commands = [
- "/describe --pr_description.add_original_user_description=true --pr_description.keep_original_user_title=true",
- "/review --pr_reviewer.num_code_suggestions=0",
- "/improve --pr_code_suggestions.summarize=true",
-]
-```
-Meaning that by default, for each PR the `describe`, `review`, and `improve` tools will be triggered automatically, and the `improve` tool will present the suggestions in a single comment.
-You can of course overwrite these defaults by adding a `.pr_agent.toml` file to your repo. See [here](https://github.com/Codium-ai/pr-agent/blob/main/Usage.md#working-with-github-app).
-
-### Jan 10, 2024
-[LanceDB](https://lancedb.com/) is now supported as a locally hosted VectorDB for the `similar_issue` tool. See [here](./docs/SIMILAR_ISSUE.md) for more details.
-
## Overview
 +
+If you prefer to have the file summaries appear in the "Files changed" tab on every PR, change the `pr_description.inline_file_summary` parameter in the configuration file, possible values are:
+
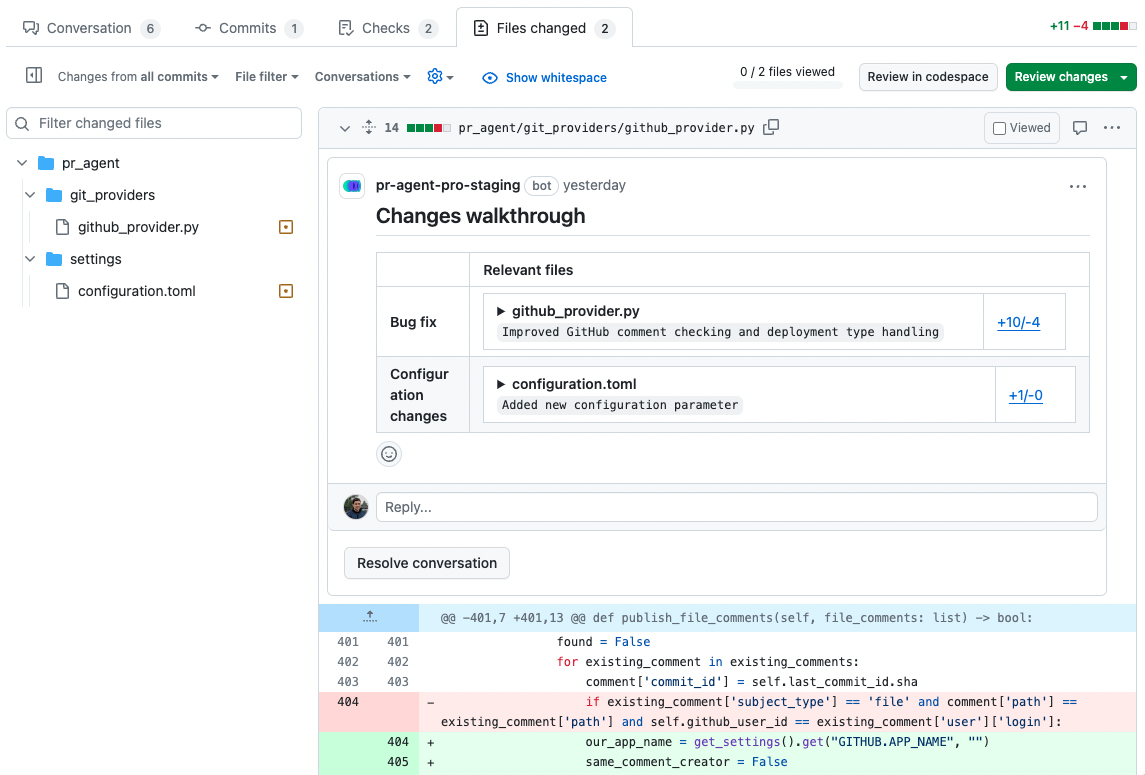
- `'table'`: File changes walkthrough table will be displayed on the top of the "Files changed" tab, in addition to the "Conversation" tab.
-
+
+If you prefer to have the file summaries appear in the "Files changed" tab on every PR, change the `pr_description.inline_file_summary` parameter in the configuration file, possible values are:
+
- `'table'`: File changes walkthrough table will be displayed on the top of the "Files changed" tab, in addition to the "Conversation" tab.
- +
+
- `true`: A collapsable file comment with changes title and a changes summary for each file in the PR.
-
+
+
- `true`: A collapsable file comment with changes title and a changes summary for each file in the PR.
- +
+
- `false` (`default`): File changes walkthrough will be added only to the "Conversation" tab.
-*Note that this feature is currently available only for GitHub.
+Note that this feature is currently available only for GitHub.
### Handle custom labels from the Repo's labels page :gem:
@@ -81,7 +89,7 @@ The description should be comprehensive and detailed, indicating when to add the
### Markers template
To enable markers, set `pr_description.use_description_markers=true`.
-markers enable to easily integrate user's content and auto-generated content, with a template-like mechanism.
+Markers enable to easily integrate user's content and auto-generated content, with a template-like mechanism.
For example, if the PR original description was:
```
diff --git a/docs/Full_enviroments.md b/docs/Full_environments.md
similarity index 100%
rename from docs/Full_enviroments.md
rename to docs/Full_environments.md
diff --git a/docs/REVIEW.md b/docs/REVIEW.md
index 5a35d8b9..19c4880b 100644
--- a/docs/REVIEW.md
+++ b/docs/REVIEW.md
@@ -11,6 +11,7 @@
- [Automation](#automation)
- [Auto-labels](#auto-labels)
- [Extra instructions](#extra-instructions)
+ - [Auto-approval](#auto-approval-1)
## Overview
The `review` tool scans the PR code changes, and automatically generates a PR review.
@@ -50,6 +51,9 @@ This sub-tool checks if the PR description properly contains a ticket to a proje
#### Adding PR labels
- `enable_review_labels_security`: if set to true, the tool will publish a 'possible security issue' label if it detects a security issue. Default is true.
- `enable_review_labels_effort`: if set to true, the tool will publish a 'Review effort [1-5]: x' label. Default is true.
+#### Auto-approval
+- `enable_auto_approval`: if set to true, the tool will approve the PR when invoked with the 'auto_approve' command. Default is false. This flag can be changed only from configuration file.
+- `maximal_review_effort`: maximal effort level for auto-approval. If the PR's estimated review effort is above this threshold, the auto-approval will not run. Default is 5.
### Incremental Mode
Incremental review only considers changes since the last PR-Agent review. This can be useful when working on the PR in an iterative manner, and you want to focus on the changes since the last review instead of reviewing the entire PR again.
@@ -97,6 +101,7 @@ ___
3) [Automation](#automation)
4) [Auto-labels](#auto-labels)
5) [Extra instructions](#extra-instructions)
+6) [Auto-approval](#auto-approval)
### General guidelines
The `review` tool provides a collection of possible feedbacks about a PR.
@@ -146,3 +151,27 @@ In the code feedback section, emphasize the following:
```
Use triple quotes to write multi-line instructions. Use bullet points to make the instructions more readable.
+
+### Auto-approval
+PR-Agent can approve a PR when a specific comment is invoked.
+
+To ensure safety, the auto-approval feature is disabled by default. To enable auto-approval, you need to actively set in a pre-defined configuration file the following:
+```
+[pr_reviewer]
+enable_auto_approval = true
+```
+(this specific flag cannot be set with a command line argument, only in the configuration file, committed to the repository)
+
+
+After enabling, by commenting on a PR:
+```
+/review auto_approve
+```
+PR-Agent will automatically approve the PR, and add a comment with the approval.
+
+
+You can also enable auto-approval only if the PR meets certain requirements, such as that the `estimated_review_effort` label is equal or below a certain threshold, by adjusting the flag:
+```
+[pr_reviewer]
+maximal_review_effort = 5
+```
diff --git a/docs/TEST.md b/docs/TEST.md
new file mode 100644
index 00000000..4f88c359
--- /dev/null
+++ b/docs/TEST.md
@@ -0,0 +1,30 @@
+# Test Tool 💎
+By combining LLM abilities with static code analysis, the `test` tool generate tests for a selected component, based on the PR code changes.
+It can be invoked manually by commenting on any PR:
+```
+/test component_name
+```
+where 'component_name' is the name of a specific component in the PR.
+To get a list of the components that changed in the PR, use the [`analyze`](https://github.com/Codium-ai/pr-agent/blob/main/docs/Analyze.md) tool.
+
+
+An example [result](https://github.com/Codium-ai/pr-agent/pull/598#issuecomment-1913679429):
+
+
+
+
- `false` (`default`): File changes walkthrough will be added only to the "Conversation" tab.
-*Note that this feature is currently available only for GitHub.
+Note that this feature is currently available only for GitHub.
### Handle custom labels from the Repo's labels page :gem:
@@ -81,7 +89,7 @@ The description should be comprehensive and detailed, indicating when to add the
### Markers template
To enable markers, set `pr_description.use_description_markers=true`.
-markers enable to easily integrate user's content and auto-generated content, with a template-like mechanism.
+Markers enable to easily integrate user's content and auto-generated content, with a template-like mechanism.
For example, if the PR original description was:
```
diff --git a/docs/Full_enviroments.md b/docs/Full_environments.md
similarity index 100%
rename from docs/Full_enviroments.md
rename to docs/Full_environments.md
diff --git a/docs/REVIEW.md b/docs/REVIEW.md
index 5a35d8b9..19c4880b 100644
--- a/docs/REVIEW.md
+++ b/docs/REVIEW.md
@@ -11,6 +11,7 @@
- [Automation](#automation)
- [Auto-labels](#auto-labels)
- [Extra instructions](#extra-instructions)
+ - [Auto-approval](#auto-approval-1)
## Overview
The `review` tool scans the PR code changes, and automatically generates a PR review.
@@ -50,6 +51,9 @@ This sub-tool checks if the PR description properly contains a ticket to a proje
#### Adding PR labels
- `enable_review_labels_security`: if set to true, the tool will publish a 'possible security issue' label if it detects a security issue. Default is true.
- `enable_review_labels_effort`: if set to true, the tool will publish a 'Review effort [1-5]: x' label. Default is true.
+#### Auto-approval
+- `enable_auto_approval`: if set to true, the tool will approve the PR when invoked with the 'auto_approve' command. Default is false. This flag can be changed only from configuration file.
+- `maximal_review_effort`: maximal effort level for auto-approval. If the PR's estimated review effort is above this threshold, the auto-approval will not run. Default is 5.
### Incremental Mode
Incremental review only considers changes since the last PR-Agent review. This can be useful when working on the PR in an iterative manner, and you want to focus on the changes since the last review instead of reviewing the entire PR again.
@@ -97,6 +101,7 @@ ___
3) [Automation](#automation)
4) [Auto-labels](#auto-labels)
5) [Extra instructions](#extra-instructions)
+6) [Auto-approval](#auto-approval)
### General guidelines
The `review` tool provides a collection of possible feedbacks about a PR.
@@ -146,3 +151,27 @@ In the code feedback section, emphasize the following:
```
Use triple quotes to write multi-line instructions. Use bullet points to make the instructions more readable.
+
+### Auto-approval
+PR-Agent can approve a PR when a specific comment is invoked.
+
+To ensure safety, the auto-approval feature is disabled by default. To enable auto-approval, you need to actively set in a pre-defined configuration file the following:
+```
+[pr_reviewer]
+enable_auto_approval = true
+```
+(this specific flag cannot be set with a command line argument, only in the configuration file, committed to the repository)
+
+
+After enabling, by commenting on a PR:
+```
+/review auto_approve
+```
+PR-Agent will automatically approve the PR, and add a comment with the approval.
+
+
+You can also enable auto-approval only if the PR meets certain requirements, such as that the `estimated_review_effort` label is equal or below a certain threshold, by adjusting the flag:
+```
+[pr_reviewer]
+maximal_review_effort = 5
+```
diff --git a/docs/TEST.md b/docs/TEST.md
new file mode 100644
index 00000000..4f88c359
--- /dev/null
+++ b/docs/TEST.md
@@ -0,0 +1,30 @@
+# Test Tool 💎
+By combining LLM abilities with static code analysis, the `test` tool generate tests for a selected component, based on the PR code changes.
+It can be invoked manually by commenting on any PR:
+```
+/test component_name
+```
+where 'component_name' is the name of a specific component in the PR.
+To get a list of the components that changed in the PR, use the [`analyze`](https://github.com/Codium-ai/pr-agent/blob/main/docs/Analyze.md) tool.
+
+
+An example [result](https://github.com/Codium-ai/pr-agent/pull/598#issuecomment-1913679429):
+
+ +___
+
+___
+ +___
+
+___
+ +
+Language that are currently supported by the tool: Python, Java, C++, JavaScript, TypeScript.
+
+
+
+### Configuration options
+- `num_tests`: number of tests to generate. Default is 3.
+- `testing_framework`: the testing framework to use. If not set, for Python it will use `pytest`, for Java it will use `JUnit`, for C++ it will use `Catch2`, and for JavaScript and TypeScript it will use `jest`.
+- `avoid_mocks`: if set to true, the tool will try to avoid using mocks in the generated tests. Note that even if this option is set to true, the tool might still use mocks if it cannot generate a test without them. Default is true.
+- `extra_instructions`: Optional extra instructions to the tool. For example: "use the following mock injection scheme: ...".
+- `file`: in case there are several components with the same name, you can specify the relevant file.
+- `class_name`: in case there are several methods with the same name in the same file, you can specify the relevant class name.
+- `enable_help_text`: if set to true, the tool will add a help text to the PR comment. Default is true.
\ No newline at end of file
diff --git a/docs/TOOLS_GUIDE.md b/docs/TOOLS_GUIDE.md
index 43960531..037b4049 100644
--- a/docs/TOOLS_GUIDE.md
+++ b/docs/TOOLS_GUIDE.md
@@ -5,8 +5,9 @@
- [ASK](./ASK.md)
- [SIMILAR_ISSUE](./SIMILAR_ISSUE.md)
- [UPDATE CHANGELOG](./UPDATE_CHANGELOG.md)
-- [ADD DOCUMENTATION](./ADD_DOCUMENTATION.md)
-- [GENERATE CUSTOM LABELS](./GENERATE_CUSTOM_LABELS.md)
-- [Analyze](./Analyze.md)
+- [ADD DOCUMENTATION](./ADD_DOCUMENTATION.md) 💎
+- [GENERATE CUSTOM LABELS](./GENERATE_CUSTOM_LABELS.md) 💎
+- [Analyze](./Analyze.md) 💎
+- [Test](./TEST.md) 💎
-See the **[installation guide](/INSTALL.md)** for instructions on how to setup PR-Agent.
\ No newline at end of file
+See the **[installation guide](/INSTALL.md)** for instructions on setting up PR-Agent.
diff --git a/pr_agent/agent/pr_agent.py b/pr_agent/agent/pr_agent.py
index 3eb26841..770317fb 100644
--- a/pr_agent/agent/pr_agent.py
+++ b/pr_agent/agent/pr_agent.py
@@ -45,6 +45,7 @@ commands = list(command2class.keys())
class PRAgent:
def __init__(self, ai_handler: partial[BaseAiHandler,] = LiteLLMAIHandler):
self.ai_handler = ai_handler # will be initialized in run_action
+ self.forbidden_cli_args = ['enable_auto_approval']
async def handle_request(self, pr_url, request, notify=None) -> bool:
# First, apply repo specific settings if exists
@@ -58,6 +59,13 @@ class PRAgent:
action, *args = list(lexer)
else:
action, *args = request
+
+ if args:
+ for forbidden_arg in self.forbidden_cli_args:
+ for arg in args:
+ if forbidden_arg in arg:
+ get_logger().error(f"CLI argument '{forbidden_arg}' is forbidden")
+ return False
args = update_settings_from_args(args)
action = action.lstrip("/").lower()
diff --git a/pr_agent/algo/__init__.py b/pr_agent/algo/__init__.py
index 63a628a5..0f647bf4 100644
--- a/pr_agent/algo/__init__.py
+++ b/pr_agent/algo/__init__.py
@@ -9,6 +9,7 @@ MAX_TOKENS = {
'gpt-4-0613': 8000,
'gpt-4-32k': 32000,
'gpt-4-1106-preview': 128000, # 128K, but may be limited by config.max_model_tokens
+ 'gpt-4-0125-preview': 128000, # 128K, but may be limited by config.max_model_tokens
'claude-instant-1': 100000,
'claude-2': 100000,
'command-nightly': 4096,
diff --git a/pr_agent/algo/git_patch_processing.py b/pr_agent/algo/git_patch_processing.py
index 480387fa..72c9aebf 100644
--- a/pr_agent/algo/git_patch_processing.py
+++ b/pr_agent/algo/git_patch_processing.py
@@ -3,7 +3,7 @@ from __future__ import annotations
import re
from pr_agent.config_loader import get_settings
-from pr_agent.git_providers.git_provider import EDIT_TYPE
+from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
from pr_agent.log import get_logger
@@ -181,7 +181,7 @@ __old hunk__
...
"""
- patch_with_lines_str = f"\n\n## {file.filename}\n"
+ patch_with_lines_str = f"\n\n## file: '{file.filename.strip()}'\n"
patch_lines = patch.splitlines()
RE_HUNK_HEADER = re.compile(
r"^@@ -(\d+)(?:,(\d+))? \+(\d+)(?:,(\d+))? @@[ ]?(.*)")
@@ -202,11 +202,11 @@ __old hunk__
if new_content_lines:
if prev_header_line:
patch_with_lines_str += f'\n{prev_header_line}\n'
- patch_with_lines_str += '__new hunk__\n'
+ patch_with_lines_str = patch_with_lines_str.rstrip()+'\n__new hunk__\n'
for i, line_new in enumerate(new_content_lines):
patch_with_lines_str += f"{start2 + i} {line_new}\n"
if old_content_lines:
- patch_with_lines_str += '__old hunk__\n'
+ patch_with_lines_str = patch_with_lines_str.rstrip()+'\n__old hunk__\n'
for line_old in old_content_lines:
patch_with_lines_str += f"{line_old}\n"
new_content_lines = []
@@ -236,11 +236,11 @@ __old hunk__
if match and new_content_lines:
if new_content_lines:
patch_with_lines_str += f'\n{header_line}\n'
- patch_with_lines_str += '\n__new hunk__\n'
+ patch_with_lines_str = patch_with_lines_str.rstrip()+ '\n__new hunk__\n'
for i, line_new in enumerate(new_content_lines):
patch_with_lines_str += f"{start2 + i} {line_new}\n"
if old_content_lines:
- patch_with_lines_str += '\n__old hunk__\n'
+ patch_with_lines_str = patch_with_lines_str.rstrip() + '\n__old hunk__\n'
for line_old in old_content_lines:
patch_with_lines_str += f"{line_old}\n"
diff --git a/pr_agent/algo/pr_processing.py b/pr_agent/algo/pr_processing.py
index ecec3015..30738236 100644
--- a/pr_agent/algo/pr_processing.py
+++ b/pr_agent/algo/pr_processing.py
@@ -1,9 +1,7 @@
from __future__ import annotations
-import difflib
-import re
import traceback
-from typing import Any, Callable, List, Tuple
+from typing import Callable, List, Tuple
from github import RateLimitExceededException
@@ -11,9 +9,10 @@ from pr_agent.algo.git_patch_processing import convert_to_hunks_with_lines_numbe
from pr_agent.algo.language_handler import sort_files_by_main_languages
from pr_agent.algo.file_filter import filter_ignored
from pr_agent.algo.token_handler import TokenHandler
-from pr_agent.algo.utils import get_max_tokens
+from pr_agent.algo.utils import get_max_tokens, ModelType
from pr_agent.config_loader import get_settings
-from pr_agent.git_providers.git_provider import FilePatchInfo, GitProvider, EDIT_TYPE
+from pr_agent.git_providers.git_provider import GitProvider
+from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
from pr_agent.log import get_logger
DELETED_FILES_ = "Deleted files:\n"
@@ -209,9 +208,9 @@ def pr_generate_compressed_diff(top_langs: list, token_handler: TokenHandler, mo
if patch:
if not convert_hunks_to_line_numbers:
- patch_final = f"## {file.filename}\n\n{patch}\n"
+ patch_final = f"\n\n## file: '{file.filename.strip()}\n\n{patch.strip()}\n'"
else:
- patch_final = patch
+ patch_final = "\n\n" + patch.strip()
patches.append(patch_final)
total_tokens += token_handler.count_tokens(patch_final)
if get_settings().config.verbosity_level >= 2:
@@ -220,8 +219,8 @@ def pr_generate_compressed_diff(top_langs: list, token_handler: TokenHandler, mo
return patches, modified_files_list, deleted_files_list, added_files_list
-async def retry_with_fallback_models(f: Callable):
- all_models = _get_all_models()
+async def retry_with_fallback_models(f: Callable, model_type: ModelType = ModelType.REGULAR):
+ all_models = _get_all_models(model_type)
all_deployments = _get_all_deployments(all_models)
# try each (model, deployment_id) pair until one is successful, otherwise raise exception
for i, (model, deployment_id) in enumerate(zip(all_models, all_deployments)):
@@ -243,8 +242,11 @@ async def retry_with_fallback_models(f: Callable):
raise # Re-raise the last exception
-def _get_all_models() -> List[str]:
- model = get_settings().config.model
+def _get_all_models(model_type: ModelType = ModelType.REGULAR) -> List[str]:
+ if model_type == ModelType.TURBO:
+ model = get_settings().config.model_turbo
+ else:
+ model = get_settings().config.model
fallback_models = get_settings().config.fallback_models
if not isinstance(fallback_models, list):
fallback_models = [m.strip() for m in fallback_models.split(",")]
@@ -267,78 +269,6 @@ def _get_all_deployments(all_models: List[str]) -> List[str]:
return all_deployments
-def find_line_number_of_relevant_line_in_file(diff_files: List[FilePatchInfo],
- relevant_file: str,
- relevant_line_in_file: str,
- absolute_position: int = None) -> Tuple[int, int]:
- position = -1
- if absolute_position is None:
- absolute_position = -1
- re_hunk_header = re.compile(
- r"^@@ -(\d+)(?:,(\d+))? \+(\d+)(?:,(\d+))? @@[ ]?(.*)")
-
- for file in diff_files:
- if file.filename and (file.filename.strip() == relevant_file):
- patch = file.patch
- patch_lines = patch.splitlines()
- delta = 0
- start1, size1, start2, size2 = 0, 0, 0, 0
- if absolute_position != -1: # matching absolute to relative
- for i, line in enumerate(patch_lines):
- # new hunk
- if line.startswith('@@'):
- delta = 0
- match = re_hunk_header.match(line)
- start1, size1, start2, size2 = map(int, match.groups()[:4])
- elif not line.startswith('-'):
- delta += 1
-
- #
- absolute_position_curr = start2 + delta - 1
-
- if absolute_position_curr == absolute_position:
- position = i
- break
- else:
- # try to find the line in the patch using difflib, with some margin of error
- matches_difflib: list[str | Any] = difflib.get_close_matches(relevant_line_in_file,
- patch_lines, n=3, cutoff=0.93)
- if len(matches_difflib) == 1 and matches_difflib[0].startswith('+'):
- relevant_line_in_file = matches_difflib[0]
-
-
- for i, line in enumerate(patch_lines):
- if line.startswith('@@'):
- delta = 0
- match = re_hunk_header.match(line)
- start1, size1, start2, size2 = map(int, match.groups()[:4])
- elif not line.startswith('-'):
- delta += 1
-
- if relevant_line_in_file in line and line[0] != '-':
- position = i
- absolute_position = start2 + delta - 1
- break
-
- if position == -1 and relevant_line_in_file[0] == '+':
- no_plus_line = relevant_line_in_file[1:].lstrip()
- for i, line in enumerate(patch_lines):
- if line.startswith('@@'):
- delta = 0
- match = re_hunk_header.match(line)
- start1, size1, start2, size2 = map(int, match.groups()[:4])
- elif not line.startswith('-'):
- delta += 1
-
- if no_plus_line in line and line[0] != '-':
- # The model might add a '+' to the beginning of the relevant_line_in_file even if originally
- # it's a context line
- position = i
- absolute_position = start2 + delta - 1
- break
- return position, absolute_position
-
-
def get_pr_multi_diffs(git_provider: GitProvider,
token_handler: TokenHandler,
model: str,
@@ -375,6 +305,13 @@ def get_pr_multi_diffs(git_provider: GitProvider,
for lang in pr_languages:
sorted_files.extend(sorted(lang['files'], key=lambda x: x.tokens, reverse=True))
+
+ # try first a single run with standard diff string, with patch extension, and no deletions
+ patches_extended, total_tokens, patches_extended_tokens = pr_generate_extended_diff(
+ pr_languages, token_handler, add_line_numbers_to_hunks=True)
+ if total_tokens + OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD < get_max_tokens(model):
+ return ["\n".join(patches_extended)]
+
patches = []
final_diff_list = []
total_tokens = token_handler.prompt_tokens
@@ -398,6 +335,11 @@ def get_pr_multi_diffs(git_provider: GitProvider,
patch = convert_to_hunks_with_lines_numbers(patch, file)
new_patch_tokens = token_handler.count_tokens(patch)
+
+ if patch and (token_handler.prompt_tokens + new_patch_tokens) > get_max_tokens(model) - OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD:
+ get_logger().warning(f"Patch too large, skipping: {file.filename}")
+ continue
+
if patch and (total_tokens + new_patch_tokens > get_max_tokens(model) - OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD):
final_diff = "\n".join(patches)
final_diff_list.append(final_diff)
diff --git a/pr_agent/algo/types.py b/pr_agent/algo/types.py
new file mode 100644
index 00000000..045115b4
--- /dev/null
+++ b/pr_agent/algo/types.py
@@ -0,0 +1,23 @@
+from dataclasses import dataclass
+from enum import Enum
+
+
+class EDIT_TYPE(Enum):
+ ADDED = 1
+ DELETED = 2
+ MODIFIED = 3
+ RENAMED = 4
+ UNKNOWN = 5
+
+
+@dataclass
+class FilePatchInfo:
+ base_file: str
+ head_file: str
+ patch: str
+ filename: str
+ tokens: int = -1
+ edit_type: EDIT_TYPE = EDIT_TYPE.UNKNOWN
+ old_filename: str = None
+ num_plus_lines: int = -1
+ num_minus_lines: int = -1
diff --git a/pr_agent/algo/utils.py b/pr_agent/algo/utils.py
index 44e411b8..b400354c 100644
--- a/pr_agent/algo/utils.py
+++ b/pr_agent/algo/utils.py
@@ -5,7 +5,8 @@ import json
import re
import textwrap
from datetime import datetime
-from typing import Any, List
+from enum import Enum
+from typing import Any, List, Tuple
import yaml
from starlette_context import context
@@ -13,8 +14,12 @@ from starlette_context import context
from pr_agent.algo import MAX_TOKENS
from pr_agent.algo.token_handler import get_token_encoder
from pr_agent.config_loader import get_settings, global_settings
+from pr_agent.algo.types import FilePatchInfo
from pr_agent.log import get_logger
+class ModelType(str, Enum):
+ REGULAR = "regular"
+ TURBO = "turbo"
def get_setting(key: str) -> Any:
try:
@@ -489,4 +494,76 @@ def replace_code_tags(text):
parts = text.split('`')
for i in range(1, len(parts), 2):
parts[i] = '
+
+Language that are currently supported by the tool: Python, Java, C++, JavaScript, TypeScript.
+
+
+
+### Configuration options
+- `num_tests`: number of tests to generate. Default is 3.
+- `testing_framework`: the testing framework to use. If not set, for Python it will use `pytest`, for Java it will use `JUnit`, for C++ it will use `Catch2`, and for JavaScript and TypeScript it will use `jest`.
+- `avoid_mocks`: if set to true, the tool will try to avoid using mocks in the generated tests. Note that even if this option is set to true, the tool might still use mocks if it cannot generate a test without them. Default is true.
+- `extra_instructions`: Optional extra instructions to the tool. For example: "use the following mock injection scheme: ...".
+- `file`: in case there are several components with the same name, you can specify the relevant file.
+- `class_name`: in case there are several methods with the same name in the same file, you can specify the relevant class name.
+- `enable_help_text`: if set to true, the tool will add a help text to the PR comment. Default is true.
\ No newline at end of file
diff --git a/docs/TOOLS_GUIDE.md b/docs/TOOLS_GUIDE.md
index 43960531..037b4049 100644
--- a/docs/TOOLS_GUIDE.md
+++ b/docs/TOOLS_GUIDE.md
@@ -5,8 +5,9 @@
- [ASK](./ASK.md)
- [SIMILAR_ISSUE](./SIMILAR_ISSUE.md)
- [UPDATE CHANGELOG](./UPDATE_CHANGELOG.md)
-- [ADD DOCUMENTATION](./ADD_DOCUMENTATION.md)
-- [GENERATE CUSTOM LABELS](./GENERATE_CUSTOM_LABELS.md)
-- [Analyze](./Analyze.md)
+- [ADD DOCUMENTATION](./ADD_DOCUMENTATION.md) 💎
+- [GENERATE CUSTOM LABELS](./GENERATE_CUSTOM_LABELS.md) 💎
+- [Analyze](./Analyze.md) 💎
+- [Test](./TEST.md) 💎
-See the **[installation guide](/INSTALL.md)** for instructions on how to setup PR-Agent.
\ No newline at end of file
+See the **[installation guide](/INSTALL.md)** for instructions on setting up PR-Agent.
diff --git a/pr_agent/agent/pr_agent.py b/pr_agent/agent/pr_agent.py
index 3eb26841..770317fb 100644
--- a/pr_agent/agent/pr_agent.py
+++ b/pr_agent/agent/pr_agent.py
@@ -45,6 +45,7 @@ commands = list(command2class.keys())
class PRAgent:
def __init__(self, ai_handler: partial[BaseAiHandler,] = LiteLLMAIHandler):
self.ai_handler = ai_handler # will be initialized in run_action
+ self.forbidden_cli_args = ['enable_auto_approval']
async def handle_request(self, pr_url, request, notify=None) -> bool:
# First, apply repo specific settings if exists
@@ -58,6 +59,13 @@ class PRAgent:
action, *args = list(lexer)
else:
action, *args = request
+
+ if args:
+ for forbidden_arg in self.forbidden_cli_args:
+ for arg in args:
+ if forbidden_arg in arg:
+ get_logger().error(f"CLI argument '{forbidden_arg}' is forbidden")
+ return False
args = update_settings_from_args(args)
action = action.lstrip("/").lower()
diff --git a/pr_agent/algo/__init__.py b/pr_agent/algo/__init__.py
index 63a628a5..0f647bf4 100644
--- a/pr_agent/algo/__init__.py
+++ b/pr_agent/algo/__init__.py
@@ -9,6 +9,7 @@ MAX_TOKENS = {
'gpt-4-0613': 8000,
'gpt-4-32k': 32000,
'gpt-4-1106-preview': 128000, # 128K, but may be limited by config.max_model_tokens
+ 'gpt-4-0125-preview': 128000, # 128K, but may be limited by config.max_model_tokens
'claude-instant-1': 100000,
'claude-2': 100000,
'command-nightly': 4096,
diff --git a/pr_agent/algo/git_patch_processing.py b/pr_agent/algo/git_patch_processing.py
index 480387fa..72c9aebf 100644
--- a/pr_agent/algo/git_patch_processing.py
+++ b/pr_agent/algo/git_patch_processing.py
@@ -3,7 +3,7 @@ from __future__ import annotations
import re
from pr_agent.config_loader import get_settings
-from pr_agent.git_providers.git_provider import EDIT_TYPE
+from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
from pr_agent.log import get_logger
@@ -181,7 +181,7 @@ __old hunk__
...
"""
- patch_with_lines_str = f"\n\n## {file.filename}\n"
+ patch_with_lines_str = f"\n\n## file: '{file.filename.strip()}'\n"
patch_lines = patch.splitlines()
RE_HUNK_HEADER = re.compile(
r"^@@ -(\d+)(?:,(\d+))? \+(\d+)(?:,(\d+))? @@[ ]?(.*)")
@@ -202,11 +202,11 @@ __old hunk__
if new_content_lines:
if prev_header_line:
patch_with_lines_str += f'\n{prev_header_line}\n'
- patch_with_lines_str += '__new hunk__\n'
+ patch_with_lines_str = patch_with_lines_str.rstrip()+'\n__new hunk__\n'
for i, line_new in enumerate(new_content_lines):
patch_with_lines_str += f"{start2 + i} {line_new}\n"
if old_content_lines:
- patch_with_lines_str += '__old hunk__\n'
+ patch_with_lines_str = patch_with_lines_str.rstrip()+'\n__old hunk__\n'
for line_old in old_content_lines:
patch_with_lines_str += f"{line_old}\n"
new_content_lines = []
@@ -236,11 +236,11 @@ __old hunk__
if match and new_content_lines:
if new_content_lines:
patch_with_lines_str += f'\n{header_line}\n'
- patch_with_lines_str += '\n__new hunk__\n'
+ patch_with_lines_str = patch_with_lines_str.rstrip()+ '\n__new hunk__\n'
for i, line_new in enumerate(new_content_lines):
patch_with_lines_str += f"{start2 + i} {line_new}\n"
if old_content_lines:
- patch_with_lines_str += '\n__old hunk__\n'
+ patch_with_lines_str = patch_with_lines_str.rstrip() + '\n__old hunk__\n'
for line_old in old_content_lines:
patch_with_lines_str += f"{line_old}\n"
diff --git a/pr_agent/algo/pr_processing.py b/pr_agent/algo/pr_processing.py
index ecec3015..30738236 100644
--- a/pr_agent/algo/pr_processing.py
+++ b/pr_agent/algo/pr_processing.py
@@ -1,9 +1,7 @@
from __future__ import annotations
-import difflib
-import re
import traceback
-from typing import Any, Callable, List, Tuple
+from typing import Callable, List, Tuple
from github import RateLimitExceededException
@@ -11,9 +9,10 @@ from pr_agent.algo.git_patch_processing import convert_to_hunks_with_lines_numbe
from pr_agent.algo.language_handler import sort_files_by_main_languages
from pr_agent.algo.file_filter import filter_ignored
from pr_agent.algo.token_handler import TokenHandler
-from pr_agent.algo.utils import get_max_tokens
+from pr_agent.algo.utils import get_max_tokens, ModelType
from pr_agent.config_loader import get_settings
-from pr_agent.git_providers.git_provider import FilePatchInfo, GitProvider, EDIT_TYPE
+from pr_agent.git_providers.git_provider import GitProvider
+from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
from pr_agent.log import get_logger
DELETED_FILES_ = "Deleted files:\n"
@@ -209,9 +208,9 @@ def pr_generate_compressed_diff(top_langs: list, token_handler: TokenHandler, mo
if patch:
if not convert_hunks_to_line_numbers:
- patch_final = f"## {file.filename}\n\n{patch}\n"
+ patch_final = f"\n\n## file: '{file.filename.strip()}\n\n{patch.strip()}\n'"
else:
- patch_final = patch
+ patch_final = "\n\n" + patch.strip()
patches.append(patch_final)
total_tokens += token_handler.count_tokens(patch_final)
if get_settings().config.verbosity_level >= 2:
@@ -220,8 +219,8 @@ def pr_generate_compressed_diff(top_langs: list, token_handler: TokenHandler, mo
return patches, modified_files_list, deleted_files_list, added_files_list
-async def retry_with_fallback_models(f: Callable):
- all_models = _get_all_models()
+async def retry_with_fallback_models(f: Callable, model_type: ModelType = ModelType.REGULAR):
+ all_models = _get_all_models(model_type)
all_deployments = _get_all_deployments(all_models)
# try each (model, deployment_id) pair until one is successful, otherwise raise exception
for i, (model, deployment_id) in enumerate(zip(all_models, all_deployments)):
@@ -243,8 +242,11 @@ async def retry_with_fallback_models(f: Callable):
raise # Re-raise the last exception
-def _get_all_models() -> List[str]:
- model = get_settings().config.model
+def _get_all_models(model_type: ModelType = ModelType.REGULAR) -> List[str]:
+ if model_type == ModelType.TURBO:
+ model = get_settings().config.model_turbo
+ else:
+ model = get_settings().config.model
fallback_models = get_settings().config.fallback_models
if not isinstance(fallback_models, list):
fallback_models = [m.strip() for m in fallback_models.split(",")]
@@ -267,78 +269,6 @@ def _get_all_deployments(all_models: List[str]) -> List[str]:
return all_deployments
-def find_line_number_of_relevant_line_in_file(diff_files: List[FilePatchInfo],
- relevant_file: str,
- relevant_line_in_file: str,
- absolute_position: int = None) -> Tuple[int, int]:
- position = -1
- if absolute_position is None:
- absolute_position = -1
- re_hunk_header = re.compile(
- r"^@@ -(\d+)(?:,(\d+))? \+(\d+)(?:,(\d+))? @@[ ]?(.*)")
-
- for file in diff_files:
- if file.filename and (file.filename.strip() == relevant_file):
- patch = file.patch
- patch_lines = patch.splitlines()
- delta = 0
- start1, size1, start2, size2 = 0, 0, 0, 0
- if absolute_position != -1: # matching absolute to relative
- for i, line in enumerate(patch_lines):
- # new hunk
- if line.startswith('@@'):
- delta = 0
- match = re_hunk_header.match(line)
- start1, size1, start2, size2 = map(int, match.groups()[:4])
- elif not line.startswith('-'):
- delta += 1
-
- #
- absolute_position_curr = start2 + delta - 1
-
- if absolute_position_curr == absolute_position:
- position = i
- break
- else:
- # try to find the line in the patch using difflib, with some margin of error
- matches_difflib: list[str | Any] = difflib.get_close_matches(relevant_line_in_file,
- patch_lines, n=3, cutoff=0.93)
- if len(matches_difflib) == 1 and matches_difflib[0].startswith('+'):
- relevant_line_in_file = matches_difflib[0]
-
-
- for i, line in enumerate(patch_lines):
- if line.startswith('@@'):
- delta = 0
- match = re_hunk_header.match(line)
- start1, size1, start2, size2 = map(int, match.groups()[:4])
- elif not line.startswith('-'):
- delta += 1
-
- if relevant_line_in_file in line and line[0] != '-':
- position = i
- absolute_position = start2 + delta - 1
- break
-
- if position == -1 and relevant_line_in_file[0] == '+':
- no_plus_line = relevant_line_in_file[1:].lstrip()
- for i, line in enumerate(patch_lines):
- if line.startswith('@@'):
- delta = 0
- match = re_hunk_header.match(line)
- start1, size1, start2, size2 = map(int, match.groups()[:4])
- elif not line.startswith('-'):
- delta += 1
-
- if no_plus_line in line and line[0] != '-':
- # The model might add a '+' to the beginning of the relevant_line_in_file even if originally
- # it's a context line
- position = i
- absolute_position = start2 + delta - 1
- break
- return position, absolute_position
-
-
def get_pr_multi_diffs(git_provider: GitProvider,
token_handler: TokenHandler,
model: str,
@@ -375,6 +305,13 @@ def get_pr_multi_diffs(git_provider: GitProvider,
for lang in pr_languages:
sorted_files.extend(sorted(lang['files'], key=lambda x: x.tokens, reverse=True))
+
+ # try first a single run with standard diff string, with patch extension, and no deletions
+ patches_extended, total_tokens, patches_extended_tokens = pr_generate_extended_diff(
+ pr_languages, token_handler, add_line_numbers_to_hunks=True)
+ if total_tokens + OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD < get_max_tokens(model):
+ return ["\n".join(patches_extended)]
+
patches = []
final_diff_list = []
total_tokens = token_handler.prompt_tokens
@@ -398,6 +335,11 @@ def get_pr_multi_diffs(git_provider: GitProvider,
patch = convert_to_hunks_with_lines_numbers(patch, file)
new_patch_tokens = token_handler.count_tokens(patch)
+
+ if patch and (token_handler.prompt_tokens + new_patch_tokens) > get_max_tokens(model) - OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD:
+ get_logger().warning(f"Patch too large, skipping: {file.filename}")
+ continue
+
if patch and (total_tokens + new_patch_tokens > get_max_tokens(model) - OUTPUT_BUFFER_TOKENS_SOFT_THRESHOLD):
final_diff = "\n".join(patches)
final_diff_list.append(final_diff)
diff --git a/pr_agent/algo/types.py b/pr_agent/algo/types.py
new file mode 100644
index 00000000..045115b4
--- /dev/null
+++ b/pr_agent/algo/types.py
@@ -0,0 +1,23 @@
+from dataclasses import dataclass
+from enum import Enum
+
+
+class EDIT_TYPE(Enum):
+ ADDED = 1
+ DELETED = 2
+ MODIFIED = 3
+ RENAMED = 4
+ UNKNOWN = 5
+
+
+@dataclass
+class FilePatchInfo:
+ base_file: str
+ head_file: str
+ patch: str
+ filename: str
+ tokens: int = -1
+ edit_type: EDIT_TYPE = EDIT_TYPE.UNKNOWN
+ old_filename: str = None
+ num_plus_lines: int = -1
+ num_minus_lines: int = -1
diff --git a/pr_agent/algo/utils.py b/pr_agent/algo/utils.py
index 44e411b8..b400354c 100644
--- a/pr_agent/algo/utils.py
+++ b/pr_agent/algo/utils.py
@@ -5,7 +5,8 @@ import json
import re
import textwrap
from datetime import datetime
-from typing import Any, List
+from enum import Enum
+from typing import Any, List, Tuple
import yaml
from starlette_context import context
@@ -13,8 +14,12 @@ from starlette_context import context
from pr_agent.algo import MAX_TOKENS
from pr_agent.algo.token_handler import get_token_encoder
from pr_agent.config_loader import get_settings, global_settings
+from pr_agent.algo.types import FilePatchInfo
from pr_agent.log import get_logger
+class ModelType(str, Enum):
+ REGULAR = "regular"
+ TURBO = "turbo"
def get_setting(key: str) -> Any:
try:
@@ -489,4 +494,76 @@ def replace_code_tags(text):
parts = text.split('`')
for i in range(1, len(parts), 2):
parts[i] = '' + parts[i] + ''
- return ''.join(parts)
\ No newline at end of file
+ return ''.join(parts)
+
+
+def find_line_number_of_relevant_line_in_file(diff_files: List[FilePatchInfo],
+ relevant_file: str,
+ relevant_line_in_file: str,
+ absolute_position: int = None) -> Tuple[int, int]:
+ position = -1
+ if absolute_position is None:
+ absolute_position = -1
+ re_hunk_header = re.compile(
+ r"^@@ -(\d+)(?:,(\d+))? \+(\d+)(?:,(\d+))? @@[ ]?(.*)")
+
+ for file in diff_files:
+ if file.filename and (file.filename.strip() == relevant_file):
+ patch = file.patch
+ patch_lines = patch.splitlines()
+ delta = 0
+ start1, size1, start2, size2 = 0, 0, 0, 0
+ if absolute_position != -1: # matching absolute to relative
+ for i, line in enumerate(patch_lines):
+ # new hunk
+ if line.startswith('@@'):
+ delta = 0
+ match = re_hunk_header.match(line)
+ start1, size1, start2, size2 = map(int, match.groups()[:4])
+ elif not line.startswith('-'):
+ delta += 1
+
+ #
+ absolute_position_curr = start2 + delta - 1
+
+ if absolute_position_curr == absolute_position:
+ position = i
+ break
+ else:
+ # try to find the line in the patch using difflib, with some margin of error
+ matches_difflib: list[str | Any] = difflib.get_close_matches(relevant_line_in_file,
+ patch_lines, n=3, cutoff=0.93)
+ if len(matches_difflib) == 1 and matches_difflib[0].startswith('+'):
+ relevant_line_in_file = matches_difflib[0]
+
+
+ for i, line in enumerate(patch_lines):
+ if line.startswith('@@'):
+ delta = 0
+ match = re_hunk_header.match(line)
+ start1, size1, start2, size2 = map(int, match.groups()[:4])
+ elif not line.startswith('-'):
+ delta += 1
+
+ if relevant_line_in_file in line and line[0] != '-':
+ position = i
+ absolute_position = start2 + delta - 1
+ break
+
+ if position == -1 and relevant_line_in_file[0] == '+':
+ no_plus_line = relevant_line_in_file[1:].lstrip()
+ for i, line in enumerate(patch_lines):
+ if line.startswith('@@'):
+ delta = 0
+ match = re_hunk_header.match(line)
+ start1, size1, start2, size2 = map(int, match.groups()[:4])
+ elif not line.startswith('-'):
+ delta += 1
+
+ if no_plus_line in line and line[0] != '-':
+ # The model might add a '+' to the beginning of the relevant_line_in_file even if originally
+ # it's a context line
+ position = i
+ absolute_position = start2 + delta - 1
+ break
+ return position, absolute_position
diff --git a/pr_agent/git_providers/azuredevops_provider.py b/pr_agent/git_providers/azuredevops_provider.py
index 17d87488..a46c0ab2 100644
--- a/pr_agent/git_providers/azuredevops_provider.py
+++ b/pr_agent/git_providers/azuredevops_provider.py
@@ -6,7 +6,8 @@ from ..log import get_logger
from ..algo.language_handler import is_valid_file
from ..algo.utils import clip_tokens, load_large_diff
from ..config_loader import get_settings
-from .git_provider import EDIT_TYPE, FilePatchInfo, GitProvider
+from .git_provider import GitProvider
+from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
AZURE_DEVOPS_AVAILABLE = True
diff --git a/pr_agent/git_providers/bitbucket_provider.py b/pr_agent/git_providers/bitbucket_provider.py
index c98ebc05..c761d10b 100644
--- a/pr_agent/git_providers/bitbucket_provider.py
+++ b/pr_agent/git_providers/bitbucket_provider.py
@@ -6,10 +6,11 @@ import requests
from atlassian.bitbucket import Cloud
from starlette_context import context
-from ..algo.pr_processing import find_line_number_of_relevant_line_in_file
+from pr_agent.algo.types import FilePatchInfo, EDIT_TYPE
+from ..algo.utils import find_line_number_of_relevant_line_in_file
from ..config_loader import get_settings
from ..log import get_logger
-from .git_provider import FilePatchInfo, GitProvider, EDIT_TYPE
+from .git_provider import GitProvider
class BitbucketProvider(GitProvider):
diff --git a/pr_agent/git_providers/bitbucket_server_provider.py b/pr_agent/git_providers/bitbucket_server_provider.py
index 2d96120b..9798cd5e 100644
--- a/pr_agent/git_providers/bitbucket_server_provider.py
+++ b/pr_agent/git_providers/bitbucket_server_provider.py
@@ -6,9 +6,9 @@ import requests
from atlassian.bitbucket import Bitbucket
from starlette_context import context
-from .git_provider import FilePatchInfo, GitProvider, EDIT_TYPE
-from ..algo.pr_processing import find_line_number_of_relevant_line_in_file
-from ..algo.utils import load_large_diff
+from .git_provider import GitProvider
+from pr_agent.algo.types import FilePatchInfo
+from ..algo.utils import load_large_diff, find_line_number_of_relevant_line_in_file
from ..config_loader import get_settings
from ..log import get_logger
diff --git a/pr_agent/git_providers/codecommit_provider.py b/pr_agent/git_providers/codecommit_provider.py
index 3c7b7697..50398c17 100644
--- a/pr_agent/git_providers/codecommit_provider.py
+++ b/pr_agent/git_providers/codecommit_provider.py
@@ -5,9 +5,9 @@ from typing import List, Optional, Tuple
from urllib.parse import urlparse
from pr_agent.git_providers.codecommit_client import CodeCommitClient
-
+from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
from ..algo.utils import load_large_diff
-from .git_provider import EDIT_TYPE, FilePatchInfo, GitProvider
+from .git_provider import GitProvider
from ..config_loader import get_settings
from ..log import get_logger
diff --git a/pr_agent/git_providers/gerrit_provider.py b/pr_agent/git_providers/gerrit_provider.py
index f7dd05ac..a1491c78 100644
--- a/pr_agent/git_providers/gerrit_provider.py
+++ b/pr_agent/git_providers/gerrit_provider.py
@@ -13,7 +13,8 @@ import urllib3.util
from git import Repo
from pr_agent.config_loader import get_settings
-from pr_agent.git_providers.git_provider import EDIT_TYPE, FilePatchInfo, GitProvider
+from pr_agent.git_providers.git_provider import GitProvider
+from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
from pr_agent.git_providers.local_git_provider import PullRequestMimic
from pr_agent.log import get_logger
diff --git a/pr_agent/git_providers/git_provider.py b/pr_agent/git_providers/git_provider.py
index f981d863..a3237dac 100644
--- a/pr_agent/git_providers/git_provider.py
+++ b/pr_agent/git_providers/git_provider.py
@@ -1,35 +1,13 @@
from abc import ABC, abstractmethod
-from dataclasses import dataclass
# enum EDIT_TYPE (ADDED, DELETED, MODIFIED, RENAMED)
-from enum import Enum
from typing import Optional
from pr_agent.config_loader import get_settings
+from pr_agent.algo.types import FilePatchInfo
from pr_agent.log import get_logger
-class EDIT_TYPE(Enum):
- ADDED = 1
- DELETED = 2
- MODIFIED = 3
- RENAMED = 4
- UNKNOWN = 5
-
-
-@dataclass
-class FilePatchInfo:
- base_file: str
- head_file: str
- patch: str
- filename: str
- tokens: int = -1
- edit_type: EDIT_TYPE = EDIT_TYPE.UNKNOWN
- old_filename: str = None
- num_plus_lines: int = -1
- num_minus_lines: int = -1
-
-
class GitProvider(ABC):
@abstractmethod
def is_supported(self, capability: str) -> bool:
@@ -193,6 +171,11 @@ class GitProvider(ABC):
def get_latest_commit_url(self) -> str:
return ""
+ def auto_approve(self) -> bool:
+ return False
+
+
+
def get_main_pr_language(languages, files) -> str:
"""
Get the main language of the commit. Return an empty string if cannot determine.
@@ -261,7 +244,6 @@ def get_main_pr_language(languages, files) -> str:
return main_language_str
-
class IncrementalPR:
def __init__(self, is_incremental: bool = False):
self.is_incremental = is_incremental
diff --git a/pr_agent/git_providers/github_provider.py b/pr_agent/git_providers/github_provider.py
index aaf1f386..8dd8a87f 100644
--- a/pr_agent/git_providers/github_provider.py
+++ b/pr_agent/git_providers/github_provider.py
@@ -9,12 +9,12 @@ from retry import retry
from starlette_context import context
from ..algo.language_handler import is_valid_file
-from ..algo.pr_processing import find_line_number_of_relevant_line_in_file
-from ..algo.utils import load_large_diff, clip_tokens
+from ..algo.utils import load_large_diff, clip_tokens, find_line_number_of_relevant_line_in_file
from ..config_loader import get_settings
from ..log import get_logger
from ..servers.utils import RateLimitExceeded
-from .git_provider import FilePatchInfo, GitProvider, IncrementalPR, EDIT_TYPE
+from .git_provider import GitProvider, IncrementalPR
+from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
class GithubProvider(GitProvider):
@@ -643,3 +643,13 @@ class GithubProvider(GitProvider):
return pr_id
except:
return ""
+
+ def auto_approve(self) -> bool:
+ try:
+ res = self.pr.create_review(event="APPROVE")
+ if res.state == "APPROVED":
+ return True
+ return False
+ except Exception as e:
+ get_logger().exception(f"Failed to auto-approve, error: {e}")
+ return False
\ No newline at end of file
diff --git a/pr_agent/git_providers/gitlab_provider.py b/pr_agent/git_providers/gitlab_provider.py
index 4db37305..85525e6c 100644
--- a/pr_agent/git_providers/gitlab_provider.py
+++ b/pr_agent/git_providers/gitlab_provider.py
@@ -7,10 +7,10 @@ import gitlab
from gitlab import GitlabGetError
from ..algo.language_handler import is_valid_file
-from ..algo.pr_processing import find_line_number_of_relevant_line_in_file
-from ..algo.utils import load_large_diff, clip_tokens
+from ..algo.utils import load_large_diff, clip_tokens, find_line_number_of_relevant_line_in_file
from ..config_loader import get_settings
-from .git_provider import EDIT_TYPE, FilePatchInfo, GitProvider
+from .git_provider import GitProvider
+from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
from ..log import get_logger
diff --git a/pr_agent/git_providers/local_git_provider.py b/pr_agent/git_providers/local_git_provider.py
index 3d45d35c..83c50791 100644
--- a/pr_agent/git_providers/local_git_provider.py
+++ b/pr_agent/git_providers/local_git_provider.py
@@ -5,7 +5,8 @@ from typing import List
from git import Repo
from pr_agent.config_loader import _find_repository_root, get_settings
-from pr_agent.git_providers.git_provider import EDIT_TYPE, FilePatchInfo, GitProvider
+from pr_agent.git_providers.git_provider import GitProvider
+from pr_agent.algo.types import EDIT_TYPE, FilePatchInfo
from pr_agent.log import get_logger
diff --git a/pr_agent/secret_providers/__init__.py b/pr_agent/secret_providers/__init__.py
index 1cc3ea7b..020ed16c 100644
--- a/pr_agent/secret_providers/__init__.py
+++ b/pr_agent/secret_providers/__init__.py
@@ -2,15 +2,18 @@ from pr_agent.config_loader import get_settings
def get_secret_provider():
- try:
- provider_id = get_settings().config.secret_provider
- except AttributeError as e:
- raise ValueError("secret_provider is a required attribute in the configuration file") from e
- try:
- if provider_id == 'google_cloud_storage':
+ if not get_settings().get("CONFIG.SECRET_PROVIDER"):
+ return None
+
+ provider_id = get_settings().config.secret_provider
+ if provider_id == 'google_cloud_storage':
+ try:
from pr_agent.secret_providers.google_cloud_storage_secret_provider import GoogleCloudStorageSecretProvider
return GoogleCloudStorageSecretProvider()
- else:
- raise ValueError(f"Unknown secret provider: {provider_id}")
- except Exception as e:
- raise ValueError(f"Failed to initialize secret provider {provider_id}") from e
+ except Exception as e:
+ raise ValueError(f"Failed to initialize google_cloud_storage secret provider {provider_id}") from e
+ else:
+ raise ValueError("Unknown SECRET_PROVIDER")
+
+
+
diff --git a/pr_agent/servers/bitbucket_app.py b/pr_agent/servers/bitbucket_app.py
index bdb972c7..d2cae362 100644
--- a/pr_agent/servers/bitbucket_app.py
+++ b/pr_agent/servers/bitbucket_app.py
@@ -26,7 +26,8 @@ from pr_agent.tools.pr_reviewer import PRReviewer
setup_logger(fmt=LoggingFormat.JSON)
router = APIRouter()
-secret_provider = get_secret_provider()
+secret_provider = get_secret_provider() if get_settings().get("CONFIG.SECRET_PROVIDER") else None
+
async def get_bearer_token(shared_secret: str, client_key: str):
try:
diff --git a/pr_agent/servers/github_action_runner.py b/pr_agent/servers/github_action_runner.py
index 45f9c712..b56eeb07 100644
--- a/pr_agent/servers/github_action_runner.py
+++ b/pr_agent/servers/github_action_runner.py
@@ -82,14 +82,23 @@ async def run_action():
if action in ["opened", "reopened"]:
pr_url = event_payload.get("pull_request", {}).get("url")
if pr_url:
+ # legacy - supporting both GITHUB_ACTION and GITHUB_ACTION_CONFIG
auto_review = get_setting_or_env("GITHUB_ACTION.AUTO_REVIEW", None)
+ if auto_review is None:
+ auto_review = get_setting_or_env("GITHUB_ACTION_CONFIG.AUTO_REVIEW", None)
+ auto_describe = get_setting_or_env("GITHUB_ACTION.AUTO_DESCRIBE", None)
+ if auto_describe is None:
+ auto_describe = get_setting_or_env("GITHUB_ACTION_CONFIG.AUTO_DESCRIBE", None)
+ auto_improve = get_setting_or_env("GITHUB_ACTION.AUTO_IMPROVE", None)
+ if auto_improve is None:
+ auto_improve = get_setting_or_env("GITHUB_ACTION_CONFIG.AUTO_IMPROVE", None)
+
+ # invoke by default all three tools
+ if auto_describe is None or is_true(auto_describe):
+ await PRDescription(pr_url).run()
if auto_review is None or is_true(auto_review):
await PRReviewer(pr_url).run()
- auto_describe = get_setting_or_env("GITHUB_ACTION.AUTO_DESCRIBE", None)
- if is_true(auto_describe):
- await PRDescription(pr_url).run()
- auto_improve = get_setting_or_env("GITHUB_ACTION.AUTO_IMPROVE", None)
- if is_true(auto_improve):
+ if auto_improve is None or is_true(auto_improve):
await PRCodeSuggestions(pr_url).run()
# Handle issue comment event
diff --git a/pr_agent/servers/help.py b/pr_agent/servers/help.py
index 376475fe..36bd0db5 100644
--- a/pr_agent/servers/help.py
+++ b/pr_agent/servers/help.py
@@ -48,7 +48,7 @@ Examples for extra instructions:
```
[pr_reviewer] # /review #
extra_instructions="""
-In the code feedback section, emphasize the following:
+In the 'general suggestions' section, emphasize the following:
- Does the code logic cover relevant edge cases?
- Is the code logic clear and easy to understand?
- Is the code logic efficient?
@@ -71,14 +71,14 @@ Edit this field to enable/disable the tool, or to change the used configurations
"""
output += "\n\n\n\n"
- # code feedback
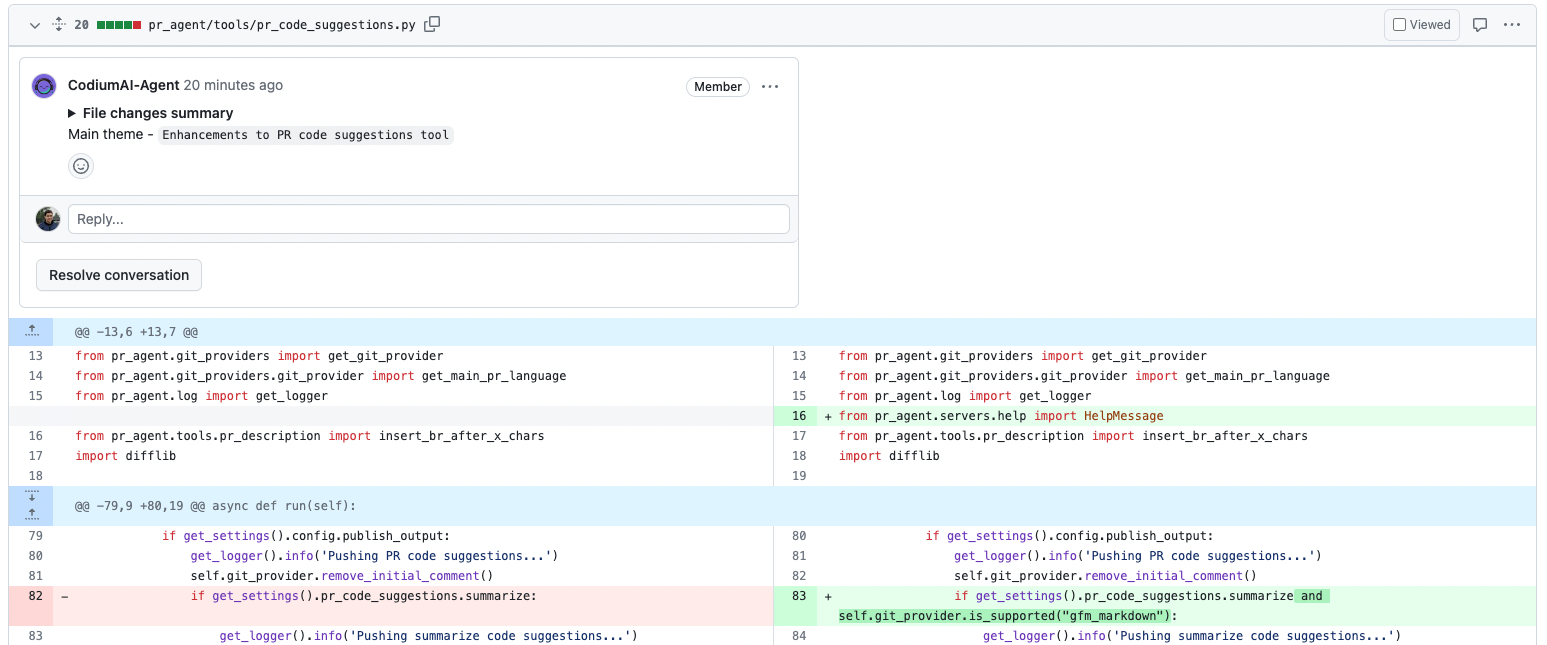
- output += "About the 'Code feedback' section
\n\n" - output+="""\ -The `review` tool provides several type of feedbacks, one of them is code suggestions. -If you are interested **only** in the code suggestions, it is recommended to use the [`improve`](https://github.com/Codium-ai/pr-agent/blob/main/docs/IMPROVE.md) feature instead, since it dedicated only to code suggestions, and usually gives better results. -Use the `review` tool if you want to get a more comprehensive feedback, which includes code suggestions as well. -""" - output += "\n\n
About the 'Code feedback' section
\n\n" +# output+="""\ +# The `review` tool provides several type of feedbacks, one of them is code suggestions. +# If you are interested **only** in the code suggestions, it is recommended to use the [`improve`](https://github.com/Codium-ai/pr-agent/blob/main/docs/IMPROVE.md) feature instead, since it dedicated only to code suggestions, and usually gives better results. +# Use the `review` tool if you want to get a more comprehensive feedback, which includes code suggestions as well. +# """ +# output += "\n\n
Auto-labels
\n\n" @@ -99,6 +99,31 @@ Some of the feature that are disabled by default are quite useful, and should be """ output += "\n\n
Auto-approve PRs
\n\n" + output += '''\ +By invoking: +``` +/review auto_approve +``` +The tool will automatically approve the PR, and add a comment with the approval. + + +To ensure safety, the auto-approval feature is disabled by default. To enable auto-approval, you need to actively set in a pre-defined configuration file the following: +``` +[pr_reviewer] +enable_auto_approval = true +``` +(this specific flag cannot be set with a command line argument, only in the configuration file, committed to the repository) + + +You can also enable auto-approval only if the PR meets certain requirements, such as that the `estimated_review_effort` is equal or below a certain threshold, by adjusting the flag: +``` +[pr_reviewer] +maximal_review_effort = 5 +``` +''' + output += "\n\n
More PR-Agent commands
\n\n" output += HelpMessage.get_general_bot_help_text() @@ -186,6 +211,7 @@ To enable inline file summary, set `pr_description.inline_file_summary` in the c - `true`: A collapsable file comment with changes title and a changes summary for each file in the PR. - `false` (default): File changes walkthrough will be added only to the "Conversation" tab. """ + # extra instructions output += "
Utilizing extra instructions
\n\n" output += '''\ @@ -309,8 +335,9 @@ Use triple quotes to write multi-line instructions. Use bullet points to make th output += """\ - While the current AI for code is getting better and better (GPT-4), it's not flawless. Not all the suggestions will be perfect, and a user should not accept all of them automatically. - Suggestions are not meant to be simplistic. Instead, they aim to give deep feedback and raise questions, ideas and thoughts to the user, who can then use his judgment, experience, and understanding of the code base. -- Recommended to use the 'extra_instructions' field to guide the model to suggestions that are more relevant to the specific needs of the project. -- Best quality will be obtained by using 'improve --extended' mode. +- Recommended to use the 'extra_instructions' field to guide the model to suggestions that are more relevant to the specific needs of the project, or use the [custom suggestions :gem:](https://github.com/Codium-ai/pr-agent/blob/main/docs/CUSTOM_SUGGESTIONS.md) tool +- With large PRs, best quality will be obtained by using 'improve --extended' mode. + """ output += "\n\n
| {header} |
|---|
| {header} | {diff_plus_minus}{delta_nbsp} | @@ -423,48 +431,74 @@ class PRDescription: pass return pr_body -def insert_br_after_x_chars(text, x=70, new_line_char="
|---|