mirror of
https://github.com/qodo-ai/pr-agent.git
synced 2025-07-21 04:50:39 +08:00
enable ai_metadata
This commit is contained in:
2
docs/docs/core-abilities/code_oriented_yaml.md
Normal file
2
docs/docs/core-abilities/code_oriented_yaml.md
Normal file
@ -0,0 +1,2 @@
|
||||
## Overview
|
||||
TBD
|
||||
47
docs/docs/core-abilities/compression_strategy.md
Normal file
47
docs/docs/core-abilities/compression_strategy.md
Normal file
@ -0,0 +1,47 @@
|
||||
|
||||
## Overview - PR Compression Strategy
|
||||
There are two scenarios:
|
||||
|
||||
1. The PR is small enough to fit in a single prompt (including system and user prompt)
|
||||
2. The PR is too large to fit in a single prompt (including system and user prompt)
|
||||
|
||||
For both scenarios, we first use the following strategy
|
||||
|
||||
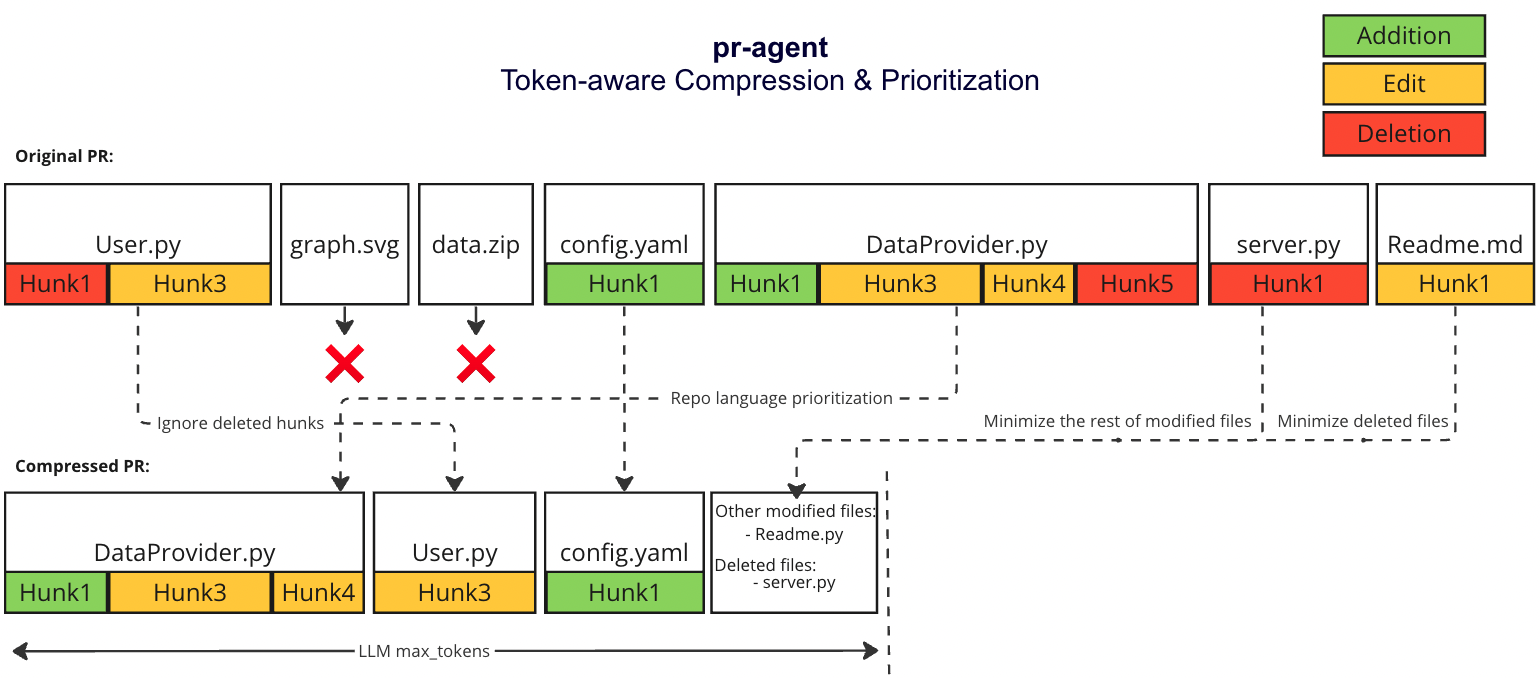
#### Repo language prioritization strategy
|
||||
We prioritize the languages of the repo based on the following criteria:
|
||||
|
||||
1. Exclude binary files and non code files (e.g. images, pdfs, etc)
|
||||
2. Given the main languages used in the repo
|
||||
3. We sort the PR files by the most common languages in the repo (in descending order):
|
||||
* ```[[file.py, file2.py],[file3.js, file4.jsx],[readme.md]]```
|
||||
|
||||
|
||||
### Small PR
|
||||
In this case, we can fit the entire PR in a single prompt:
|
||||
1. Exclude binary files and non code files (e.g. images, pdfs, etc)
|
||||
2. We Expand the surrounding context of each patch to 3 lines above and below the patch
|
||||
|
||||
### Large PR
|
||||
|
||||
#### Motivation
|
||||
Pull Requests can be very long and contain a lot of information with varying degree of relevance to the pr-agent.
|
||||
We want to be able to pack as much information as possible in a single LMM prompt, while keeping the information relevant to the pr-agent.
|
||||
|
||||
#### Compression strategy
|
||||
We prioritize additions over deletions:
|
||||
- Combine all deleted files into a single list (`deleted files`)
|
||||
- File patches are a list of hunks, remove all hunks of type deletion-only from the hunks in the file patch
|
||||
|
||||
#### Adaptive and token-aware file patch fitting
|
||||
We use [tiktoken](https://github.com/openai/tiktoken) to tokenize the patches after the modifications described above, and we use the following strategy to fit the patches into the prompt:
|
||||
|
||||
1. Within each language we sort the files by the number of tokens in the file (in descending order):
|
||||
- ```[[file2.py, file.py],[file4.jsx, file3.js],[readme.md]]```
|
||||
2. Iterate through the patches in the order described above
|
||||
3. Add the patches to the prompt until the prompt reaches a certain buffer from the max token length
|
||||
4. If there are still patches left, add the remaining patches as a list called `other modified files` to the prompt until the prompt reaches the max token length (hard stop), skip the rest of the patches.
|
||||
5. If we haven't reached the max token length, add the `deleted files` to the prompt until the prompt reaches the max token length (hard stop), skip the rest of the patches.
|
||||
|
||||
#### Example
|
||||
|
||||
{width=768}
|
||||
2
docs/docs/core-abilities/dynamic_context.md
Normal file
2
docs/docs/core-abilities/dynamic_context.md
Normal file
@ -0,0 +1,2 @@
|
||||
## Overview - Asymmetric and dynamic PR context
|
||||
TBD
|
||||
2
docs/docs/core-abilities/impact_evaluation.md
Normal file
2
docs/docs/core-abilities/impact_evaluation.md
Normal file
@ -0,0 +1,2 @@
|
||||
## Overview - Impact evaluation 💎
|
||||
TBD
|
||||
@ -1,52 +1,10 @@
|
||||
## PR Compression Strategy
|
||||
There are two scenarios:
|
||||
|
||||
1. The PR is small enough to fit in a single prompt (including system and user prompt)
|
||||
2. The PR is too large to fit in a single prompt (including system and user prompt)
|
||||
|
||||
For both scenarios, we first use the following strategy
|
||||
|
||||
#### Repo language prioritization strategy
|
||||
We prioritize the languages of the repo based on the following criteria:
|
||||
|
||||
1. Exclude binary files and non code files (e.g. images, pdfs, etc)
|
||||
2. Given the main languages used in the repo
|
||||
3. We sort the PR files by the most common languages in the repo (in descending order):
|
||||
* ```[[file.py, file2.py],[file3.js, file4.jsx],[readme.md]]```
|
||||
|
||||
|
||||
### Small PR
|
||||
In this case, we can fit the entire PR in a single prompt:
|
||||
1. Exclude binary files and non code files (e.g. images, pdfs, etc)
|
||||
2. We Expand the surrounding context of each patch to 3 lines above and below the patch
|
||||
|
||||
### Large PR
|
||||
|
||||
#### Motivation
|
||||
Pull Requests can be very long and contain a lot of information with varying degree of relevance to the pr-agent.
|
||||
We want to be able to pack as much information as possible in a single LMM prompt, while keeping the information relevant to the pr-agent.
|
||||
|
||||
#### Compression strategy
|
||||
We prioritize additions over deletions:
|
||||
- Combine all deleted files into a single list (`deleted files`)
|
||||
- File patches are a list of hunks, remove all hunks of type deletion-only from the hunks in the file patch
|
||||
|
||||
#### Adaptive and token-aware file patch fitting
|
||||
We use [tiktoken](https://github.com/openai/tiktoken) to tokenize the patches after the modifications described above, and we use the following strategy to fit the patches into the prompt:
|
||||
|
||||
1. Within each language we sort the files by the number of tokens in the file (in descending order):
|
||||
- ```[[file2.py, file.py],[file4.jsx, file3.js],[readme.md]]```
|
||||
2. Iterate through the patches in the order described above
|
||||
3. Add the patches to the prompt until the prompt reaches a certain buffer from the max token length
|
||||
4. If there are still patches left, add the remaining patches as a list called `other modified files` to the prompt until the prompt reaches the max token length (hard stop), skip the rest of the patches.
|
||||
5. If we haven't reached the max token length, add the `deleted files` to the prompt until the prompt reaches the max token length (hard stop), skip the rest of the patches.
|
||||
|
||||
#### Example
|
||||
|
||||
{width=768}
|
||||
|
||||
## YAML Prompting
|
||||
TBD
|
||||
|
||||
## Static Code Analysis 💎
|
||||
TBD
|
||||
# Core Abilities
|
||||
PR-Agent utilizes a variety of core abilities to provide a comprehensive and efficient code review experience. These abilities include:
|
||||
- [Local and global metadata](core-abilities/metadata.md)
|
||||
- [Line localization](core-abilities/line_localization.md)
|
||||
- [Dynamic context](core-abilities/dynamic_context.md)
|
||||
- [Self-reflection](core-abilities/self_reflection.md)
|
||||
- [Interactivity](core-abilities/interactivity.md)
|
||||
- [Compression strategy](core-abilities/compression_strategy.md)
|
||||
- [Code-oriented YAML](core-abilities/code_oriented_yaml.md)
|
||||
- [Static code analysis](core-abilities/static_code_analysis.md)
|
||||
2
docs/docs/core-abilities/interactivity.md
Normal file
2
docs/docs/core-abilities/interactivity.md
Normal file
@ -0,0 +1,2 @@
|
||||
## Interactive invocation 💎
|
||||
TBD
|
||||
2
docs/docs/core-abilities/line_localization.md
Normal file
2
docs/docs/core-abilities/line_localization.md
Normal file
@ -0,0 +1,2 @@
|
||||
## Overview - Line localization
|
||||
TBD
|
||||
56
docs/docs/core-abilities/metadata.md
Normal file
56
docs/docs/core-abilities/metadata.md
Normal file
@ -0,0 +1,56 @@
|
||||
## Overview - Local and global metadata injection with multi-stage analysis
|
||||
(1)
|
||||
PR-Agent initially retrieves for each PR the following data:
|
||||
- PR title and branch name
|
||||
- PR original description
|
||||
- Commit messages history
|
||||
- PR diff patches, in [hunk diff](https://loicpefferkorn.net/2014/02/diff-files-what-are-hunks-and-how-to-extract-them/) format
|
||||
- The entire content of the files that were modified in the PR
|
||||
|
||||
In addition, PR-Agent is able to receive from the user additional data, like [`extra_instructions` and `best practices`](https://pr-agent-docs.codium.ai/tools/improve/#extra-instructions-and-best-practices) that can be used to enhance the PR analysis.
|
||||
|
||||
(2)
|
||||
By default, the first command that PR-Agent executes is [`describe`](https://pr-agent-docs.codium.ai/tools/describe/), which generates three types of outputs:
|
||||
- PR Type (e.g. bug fix, feature, refactor, etc)
|
||||
- PR Description - a bullet points summary of the PR
|
||||
- Changes walkthrough - going file-by-file, PR-Agent generate a one-line summary and longer bullet points summary of the changes in the file
|
||||
|
||||
These AI-generated outputs are now considered part of the PR metadata, and can be used in subsequent commands like `review` and `improve`.
|
||||
This effectively enables chain-of-thought analysis, without doing any additional API calls which will cost time and money.
|
||||
|
||||
(3)
|
||||
For example, when generating code suggestions for different files, PR-Agent can inject the AI-generated file summary in the prompt:
|
||||
|
||||
```
|
||||
## File: 'src/file1.py'
|
||||
### AI-generated file summary:
|
||||
- edited function `func1` that does X
|
||||
- Removed function `func2` that was not used
|
||||
- ....
|
||||
|
||||
@@ ... @@ def func1():
|
||||
__new hunk__
|
||||
11 unchanged code line0 in the PR
|
||||
12 unchanged code line1 in the PR
|
||||
13 +new code line2 added in the PR
|
||||
14 unchanged code line3 in the PR
|
||||
__old hunk__
|
||||
unchanged code line0
|
||||
unchanged code line1
|
||||
-old code line2 removed in the PR
|
||||
unchanged code line3
|
||||
|
||||
@@ ... @@ def func2():
|
||||
__new hunk__
|
||||
...
|
||||
__old hunk__
|
||||
...
|
||||
```
|
||||
|
||||
(4) The entire PR files that were retrieved are used to expand and enhance the PR context (see [Dynamic Context](https://pr-agent-docs.codium.ai/core-abilities/dynamic-context/)).
|
||||
|
||||
(5) All the metadata described above represent several level of analysis - from hunk level, to file level, to PR level, and enables PR-Agent AI models to generate more accurate and relevant suggestions.
|
||||
|
||||
|
||||
## Example result for prompt with metadata injection
|
||||
TBD
|
||||
2
docs/docs/core-abilities/self_reflection.md
Normal file
2
docs/docs/core-abilities/self_reflection.md
Normal file
@ -0,0 +1,2 @@
|
||||
## Overview - Self-reflection and suggestion cleaning and re-ranking
|
||||
TBD
|
||||
2
docs/docs/core-abilities/static_code_analysis.md
Normal file
2
docs/docs/core-abilities/static_code_analysis.md
Normal file
@ -0,0 +1,2 @@
|
||||
## Overview - Static Code Analysis 💎
|
||||
TBD
|
||||
@ -41,7 +41,16 @@ nav:
|
||||
- 💎 Custom Prompt: 'tools/custom_prompt.md'
|
||||
- 💎 CI Feedback: 'tools/ci_feedback.md'
|
||||
- 💎 Similar Code: 'tools/similar_code.md'
|
||||
- Core Abilities: 'core-abilities/index.md'
|
||||
- Core Abilities:
|
||||
- 'core-abilities/index.md'
|
||||
- Local and global metadata: 'core-abilities/metadata.md'
|
||||
- Line localization: 'core-abilities/line_localization.md'
|
||||
- Dynamic context: 'core-abilities/dynamic_context.md'
|
||||
- Self-reflection: 'core-abilities/self_reflection.md'
|
||||
- Interactivity: 'core-abilities/interactivity.md'
|
||||
- Compression strategy: 'core-abilities/compression_strategy.md'
|
||||
- Code-oriented YAML: 'core-abilities/code_oriented_yaml.md'
|
||||
- Static code analysis: 'core-abilities/static_code_analysis.md'
|
||||
- Chrome Extension:
|
||||
- PR-Agent Chrome Extension: 'chrome-extension/index.md'
|
||||
- Features: 'chrome-extension/features.md'
|
||||
|
||||
Reference in New Issue
Block a user