mirror of
https://github.com/qodo-ai/pr-agent.git
synced 2025-07-21 04:50:39 +08:00
enable ai_metadata
This commit is contained in:
2
docs/docs/core-abilities/code_oriented_yaml.md
Normal file
2
docs/docs/core-abilities/code_oriented_yaml.md
Normal file
@ -0,0 +1,2 @@
|
||||
## Overview
|
||||
TBD
|
||||
47
docs/docs/core-abilities/compression_strategy.md
Normal file
47
docs/docs/core-abilities/compression_strategy.md
Normal file
@ -0,0 +1,47 @@
|
||||
|
||||
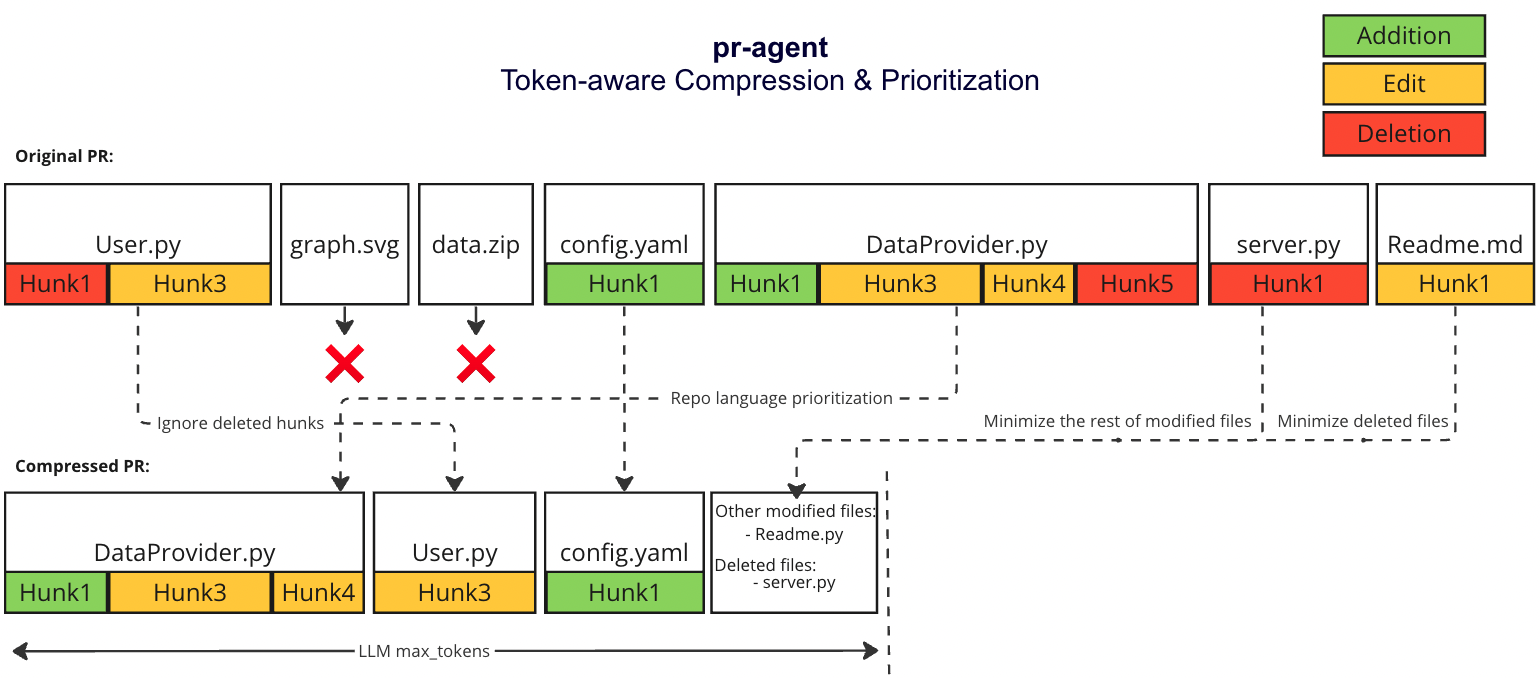
## Overview - PR Compression Strategy
|
||||
There are two scenarios:
|
||||
|
||||
1. The PR is small enough to fit in a single prompt (including system and user prompt)
|
||||
2. The PR is too large to fit in a single prompt (including system and user prompt)
|
||||
|
||||
For both scenarios, we first use the following strategy
|
||||
|
||||
#### Repo language prioritization strategy
|
||||
We prioritize the languages of the repo based on the following criteria:
|
||||
|
||||
1. Exclude binary files and non code files (e.g. images, pdfs, etc)
|
||||
2. Given the main languages used in the repo
|
||||
3. We sort the PR files by the most common languages in the repo (in descending order):
|
||||
* ```[[file.py, file2.py],[file3.js, file4.jsx],[readme.md]]```
|
||||
|
||||
|
||||
### Small PR
|
||||
In this case, we can fit the entire PR in a single prompt:
|
||||
1. Exclude binary files and non code files (e.g. images, pdfs, etc)
|
||||
2. We Expand the surrounding context of each patch to 3 lines above and below the patch
|
||||
|
||||
### Large PR
|
||||
|
||||
#### Motivation
|
||||
Pull Requests can be very long and contain a lot of information with varying degree of relevance to the pr-agent.
|
||||
We want to be able to pack as much information as possible in a single LMM prompt, while keeping the information relevant to the pr-agent.
|
||||
|
||||
#### Compression strategy
|
||||
We prioritize additions over deletions:
|
||||
- Combine all deleted files into a single list (`deleted files`)
|
||||
- File patches are a list of hunks, remove all hunks of type deletion-only from the hunks in the file patch
|
||||
|
||||
#### Adaptive and token-aware file patch fitting
|
||||
We use [tiktoken](https://github.com/openai/tiktoken) to tokenize the patches after the modifications described above, and we use the following strategy to fit the patches into the prompt:
|
||||
|
||||
1. Within each language we sort the files by the number of tokens in the file (in descending order):
|
||||
- ```[[file2.py, file.py],[file4.jsx, file3.js],[readme.md]]```
|
||||
2. Iterate through the patches in the order described above
|
||||
3. Add the patches to the prompt until the prompt reaches a certain buffer from the max token length
|
||||
4. If there are still patches left, add the remaining patches as a list called `other modified files` to the prompt until the prompt reaches the max token length (hard stop), skip the rest of the patches.
|
||||
5. If we haven't reached the max token length, add the `deleted files` to the prompt until the prompt reaches the max token length (hard stop), skip the rest of the patches.
|
||||
|
||||
#### Example
|
||||
|
||||
{width=768}
|
||||
2
docs/docs/core-abilities/dynamic_context.md
Normal file
2
docs/docs/core-abilities/dynamic_context.md
Normal file
@ -0,0 +1,2 @@
|
||||
## Overview - Asymmetric and dynamic PR context
|
||||
TBD
|
||||
2
docs/docs/core-abilities/impact_evaluation.md
Normal file
2
docs/docs/core-abilities/impact_evaluation.md
Normal file
@ -0,0 +1,2 @@
|
||||
## Overview - Impact evaluation 💎
|
||||
TBD
|
||||
@ -1,52 +1,10 @@
|
||||
## PR Compression Strategy
|
||||
There are two scenarios:
|
||||
|
||||
1. The PR is small enough to fit in a single prompt (including system and user prompt)
|
||||
2. The PR is too large to fit in a single prompt (including system and user prompt)
|
||||
|
||||
For both scenarios, we first use the following strategy
|
||||
|
||||
#### Repo language prioritization strategy
|
||||
We prioritize the languages of the repo based on the following criteria:
|
||||
|
||||
1. Exclude binary files and non code files (e.g. images, pdfs, etc)
|
||||
2. Given the main languages used in the repo
|
||||
3. We sort the PR files by the most common languages in the repo (in descending order):
|
||||
* ```[[file.py, file2.py],[file3.js, file4.jsx],[readme.md]]```
|
||||
|
||||
|
||||
### Small PR
|
||||
In this case, we can fit the entire PR in a single prompt:
|
||||
1. Exclude binary files and non code files (e.g. images, pdfs, etc)
|
||||
2. We Expand the surrounding context of each patch to 3 lines above and below the patch
|
||||
|
||||
### Large PR
|
||||
|
||||
#### Motivation
|
||||
Pull Requests can be very long and contain a lot of information with varying degree of relevance to the pr-agent.
|
||||
We want to be able to pack as much information as possible in a single LMM prompt, while keeping the information relevant to the pr-agent.
|
||||
|
||||
#### Compression strategy
|
||||
We prioritize additions over deletions:
|
||||
- Combine all deleted files into a single list (`deleted files`)
|
||||
- File patches are a list of hunks, remove all hunks of type deletion-only from the hunks in the file patch
|
||||
|
||||
#### Adaptive and token-aware file patch fitting
|
||||
We use [tiktoken](https://github.com/openai/tiktoken) to tokenize the patches after the modifications described above, and we use the following strategy to fit the patches into the prompt:
|
||||
|
||||
1. Within each language we sort the files by the number of tokens in the file (in descending order):
|
||||
- ```[[file2.py, file.py],[file4.jsx, file3.js],[readme.md]]```
|
||||
2. Iterate through the patches in the order described above
|
||||
3. Add the patches to the prompt until the prompt reaches a certain buffer from the max token length
|
||||
4. If there are still patches left, add the remaining patches as a list called `other modified files` to the prompt until the prompt reaches the max token length (hard stop), skip the rest of the patches.
|
||||
5. If we haven't reached the max token length, add the `deleted files` to the prompt until the prompt reaches the max token length (hard stop), skip the rest of the patches.
|
||||
|
||||
#### Example
|
||||
|
||||
{width=768}
|
||||
|
||||
## YAML Prompting
|
||||
TBD
|
||||
|
||||
## Static Code Analysis 💎
|
||||
TBD
|
||||
# Core Abilities
|
||||
PR-Agent utilizes a variety of core abilities to provide a comprehensive and efficient code review experience. These abilities include:
|
||||
- [Local and global metadata](core-abilities/metadata.md)
|
||||
- [Line localization](core-abilities/line_localization.md)
|
||||
- [Dynamic context](core-abilities/dynamic_context.md)
|
||||
- [Self-reflection](core-abilities/self_reflection.md)
|
||||
- [Interactivity](core-abilities/interactivity.md)
|
||||
- [Compression strategy](core-abilities/compression_strategy.md)
|
||||
- [Code-oriented YAML](core-abilities/code_oriented_yaml.md)
|
||||
- [Static code analysis](core-abilities/static_code_analysis.md)
|
||||
2
docs/docs/core-abilities/interactivity.md
Normal file
2
docs/docs/core-abilities/interactivity.md
Normal file
@ -0,0 +1,2 @@
|
||||
## Interactive invocation 💎
|
||||
TBD
|
||||
2
docs/docs/core-abilities/line_localization.md
Normal file
2
docs/docs/core-abilities/line_localization.md
Normal file
@ -0,0 +1,2 @@
|
||||
## Overview - Line localization
|
||||
TBD
|
||||
56
docs/docs/core-abilities/metadata.md
Normal file
56
docs/docs/core-abilities/metadata.md
Normal file
@ -0,0 +1,56 @@
|
||||
## Overview - Local and global metadata injection with multi-stage analysis
|
||||
(1)
|
||||
PR-Agent initially retrieves for each PR the following data:
|
||||
- PR title and branch name
|
||||
- PR original description
|
||||
- Commit messages history
|
||||
- PR diff patches, in [hunk diff](https://loicpefferkorn.net/2014/02/diff-files-what-are-hunks-and-how-to-extract-them/) format
|
||||
- The entire content of the files that were modified in the PR
|
||||
|
||||
In addition, PR-Agent is able to receive from the user additional data, like [`extra_instructions` and `best practices`](https://pr-agent-docs.codium.ai/tools/improve/#extra-instructions-and-best-practices) that can be used to enhance the PR analysis.
|
||||
|
||||
(2)
|
||||
By default, the first command that PR-Agent executes is [`describe`](https://pr-agent-docs.codium.ai/tools/describe/), which generates three types of outputs:
|
||||
- PR Type (e.g. bug fix, feature, refactor, etc)
|
||||
- PR Description - a bullet points summary of the PR
|
||||
- Changes walkthrough - going file-by-file, PR-Agent generate a one-line summary and longer bullet points summary of the changes in the file
|
||||
|
||||
These AI-generated outputs are now considered part of the PR metadata, and can be used in subsequent commands like `review` and `improve`.
|
||||
This effectively enables chain-of-thought analysis, without doing any additional API calls which will cost time and money.
|
||||
|
||||
(3)
|
||||
For example, when generating code suggestions for different files, PR-Agent can inject the AI-generated file summary in the prompt:
|
||||
|
||||
```
|
||||
## File: 'src/file1.py'
|
||||
### AI-generated file summary:
|
||||
- edited function `func1` that does X
|
||||
- Removed function `func2` that was not used
|
||||
- ....
|
||||
|
||||
@@ ... @@ def func1():
|
||||
__new hunk__
|
||||
11 unchanged code line0 in the PR
|
||||
12 unchanged code line1 in the PR
|
||||
13 +new code line2 added in the PR
|
||||
14 unchanged code line3 in the PR
|
||||
__old hunk__
|
||||
unchanged code line0
|
||||
unchanged code line1
|
||||
-old code line2 removed in the PR
|
||||
unchanged code line3
|
||||
|
||||
@@ ... @@ def func2():
|
||||
__new hunk__
|
||||
...
|
||||
__old hunk__
|
||||
...
|
||||
```
|
||||
|
||||
(4) The entire PR files that were retrieved are used to expand and enhance the PR context (see [Dynamic Context](https://pr-agent-docs.codium.ai/core-abilities/dynamic-context/)).
|
||||
|
||||
(5) All the metadata described above represent several level of analysis - from hunk level, to file level, to PR level, and enables PR-Agent AI models to generate more accurate and relevant suggestions.
|
||||
|
||||
|
||||
## Example result for prompt with metadata injection
|
||||
TBD
|
||||
2
docs/docs/core-abilities/self_reflection.md
Normal file
2
docs/docs/core-abilities/self_reflection.md
Normal file
@ -0,0 +1,2 @@
|
||||
## Overview - Self-reflection and suggestion cleaning and re-ranking
|
||||
TBD
|
||||
2
docs/docs/core-abilities/static_code_analysis.md
Normal file
2
docs/docs/core-abilities/static_code_analysis.md
Normal file
@ -0,0 +1,2 @@
|
||||
## Overview - Static Code Analysis 💎
|
||||
TBD
|
||||
@ -41,7 +41,16 @@ nav:
|
||||
- 💎 Custom Prompt: 'tools/custom_prompt.md'
|
||||
- 💎 CI Feedback: 'tools/ci_feedback.md'
|
||||
- 💎 Similar Code: 'tools/similar_code.md'
|
||||
- Core Abilities: 'core-abilities/index.md'
|
||||
- Core Abilities:
|
||||
- 'core-abilities/index.md'
|
||||
- Local and global metadata: 'core-abilities/metadata.md'
|
||||
- Line localization: 'core-abilities/line_localization.md'
|
||||
- Dynamic context: 'core-abilities/dynamic_context.md'
|
||||
- Self-reflection: 'core-abilities/self_reflection.md'
|
||||
- Interactivity: 'core-abilities/interactivity.md'
|
||||
- Compression strategy: 'core-abilities/compression_strategy.md'
|
||||
- Code-oriented YAML: 'core-abilities/code_oriented_yaml.md'
|
||||
- Static code analysis: 'core-abilities/static_code_analysis.md'
|
||||
- Chrome Extension:
|
||||
- PR-Agent Chrome Extension: 'chrome-extension/index.md'
|
||||
- Features: 'chrome-extension/features.md'
|
||||
|
||||
@ -243,7 +243,7 @@ __old hunk__
|
||||
if hasattr(file, 'edit_type') and file.edit_type == EDIT_TYPE.DELETED:
|
||||
return f"\n\n## file '{file.filename.strip()}' was deleted\n"
|
||||
|
||||
patch_with_lines_str = f"\n\n## file: '{file.filename.strip()}'\n"
|
||||
patch_with_lines_str = f"\n\n## File: '{file.filename.strip()}'\n"
|
||||
patch_lines = patch.splitlines()
|
||||
RE_HUNK_HEADER = re.compile(
|
||||
r"^@@ -(\d+)(?:,(\d+))? \+(\d+)(?:,(\d+))? @@[ ]?(.*)")
|
||||
@ -319,7 +319,7 @@ __old hunk__
|
||||
|
||||
def extract_hunk_lines_from_patch(patch: str, file_name, line_start, line_end, side) -> tuple[str, str]:
|
||||
|
||||
patch_with_lines_str = f"\n\n## file: '{file_name.strip()}'\n\n"
|
||||
patch_with_lines_str = f"\n\n## File: '{file_name.strip()}'\n\n"
|
||||
selected_lines = ""
|
||||
patch_lines = patch.splitlines()
|
||||
RE_HUNK_HEADER = re.compile(
|
||||
|
||||
@ -200,6 +200,10 @@ def pr_generate_extended_diff(pr_languages: list,
|
||||
if add_line_numbers_to_hunks:
|
||||
full_extended_patch = convert_to_hunks_with_lines_numbers(extended_patch, file)
|
||||
|
||||
# add AI-summary metadata to the patch
|
||||
if file.ai_file_summary and get_settings().get("config.enable_ai_metadata", False):
|
||||
full_extended_patch = add_ai_summary_top_patch(file, full_extended_patch)
|
||||
|
||||
patch_tokens = token_handler.count_tokens(full_extended_patch)
|
||||
file.tokens = patch_tokens
|
||||
total_tokens += patch_tokens
|
||||
@ -239,6 +243,10 @@ def pr_generate_compressed_diff(top_langs: list, token_handler: TokenHandler, mo
|
||||
if convert_hunks_to_line_numbers:
|
||||
patch = convert_to_hunks_with_lines_numbers(patch, file)
|
||||
|
||||
## add AI-summary metadata to the patch (disabled, since we are in the compressed diff)
|
||||
# if file.ai_file_summary and get_settings().config.get('config.is_auto_command', False):
|
||||
# patch = add_ai_summary_top_patch(file, patch)
|
||||
|
||||
new_patch_tokens = token_handler.count_tokens(patch)
|
||||
file_dict[file.filename] = {'patch': patch, 'tokens': new_patch_tokens, 'edit_type': file.edit_type}
|
||||
|
||||
@ -304,7 +312,7 @@ def generate_full_patch(convert_hunks_to_line_numbers, file_dict, max_tokens_mod
|
||||
|
||||
if patch:
|
||||
if not convert_hunks_to_line_numbers:
|
||||
patch_final = f"\n\n## file: '{filename.strip()}\n\n{patch.strip()}\n'"
|
||||
patch_final = f"\n\n## File: '{filename.strip()}\n\n{patch.strip()}\n'"
|
||||
else:
|
||||
patch_final = "\n\n" + patch.strip()
|
||||
patches.append(patch_final)
|
||||
@ -432,6 +440,9 @@ def get_pr_multi_diffs(git_provider: GitProvider,
|
||||
continue
|
||||
|
||||
patch = convert_to_hunks_with_lines_numbers(patch, file)
|
||||
# add AI-summary metadata to the patch
|
||||
if file.ai_file_summary and get_settings().get("config.enable_ai_metadata", False):
|
||||
patch = add_ai_summary_top_patch(file, patch)
|
||||
new_patch_tokens = token_handler.count_tokens(patch)
|
||||
|
||||
if patch and (token_handler.prompt_tokens + new_patch_tokens) > get_max_tokens(
|
||||
@ -479,3 +490,33 @@ def get_pr_multi_diffs(git_provider: GitProvider,
|
||||
final_diff_list.append(final_diff)
|
||||
|
||||
return final_diff_list
|
||||
|
||||
|
||||
def add_ai_metadata_to_diff_files(git_provider, pr_description_files):
|
||||
"""
|
||||
Adds AI metadata to the diff files based on the PR description files (FilePatchInfo.ai_file_summary).
|
||||
"""
|
||||
diff_files = git_provider.get_diff_files()
|
||||
for file in diff_files:
|
||||
filename = file.filename.strip()
|
||||
found = False
|
||||
for pr_file in pr_description_files:
|
||||
if filename == pr_file['full_file_name'].strip():
|
||||
file.ai_file_summary = pr_file
|
||||
found = True
|
||||
break
|
||||
if not found:
|
||||
get_logger().info(f"File {filename} not found in the PR description files",
|
||||
artifacts=pr_description_files)
|
||||
|
||||
|
||||
def add_ai_summary_top_patch(file, full_extended_patch):
|
||||
# below every instance of '## File: ...' in the patch, add the ai-summary metadata
|
||||
full_extended_patch_lines = full_extended_patch.split("\n")
|
||||
for i, line in enumerate(full_extended_patch_lines):
|
||||
if line.startswith("## File:") or line.startswith("## file:"):
|
||||
full_extended_patch_lines.insert(i + 1,
|
||||
f"### AI-generated file summary:\n{file.ai_file_summary['long_summary']}")
|
||||
break
|
||||
full_extended_patch = "\n".join(full_extended_patch_lines)
|
||||
return full_extended_patch
|
||||
@ -21,3 +21,4 @@ class FilePatchInfo:
|
||||
old_filename: str = None
|
||||
num_plus_lines: int = -1
|
||||
num_minus_lines: int = -1
|
||||
ai_file_summary: str = None
|
||||
|
||||
@ -1,4 +1,5 @@
|
||||
from __future__ import annotations
|
||||
import html2text
|
||||
|
||||
import html
|
||||
import copy
|
||||
@ -214,19 +215,6 @@ def convert_to_markdown_v2(output_data: dict,
|
||||
reference_link = git_provider.get_line_link(relevant_file, start_line, end_line)
|
||||
|
||||
if gfm_supported:
|
||||
if get_settings().pr_reviewer.extra_issue_links:
|
||||
issue_content_linked =copy.deepcopy(issue_content)
|
||||
referenced_variables_list = issue.get('referenced_variables', [])
|
||||
for component in referenced_variables_list:
|
||||
name = component['variable_name'].strip().strip('`')
|
||||
|
||||
ind = issue_content.find(name)
|
||||
if ind != -1:
|
||||
reference_link_component = git_provider.get_line_link(relevant_file, component['relevant_line'], component['relevant_line'])
|
||||
issue_content_linked = issue_content_linked[:ind-1] + f"[`{name}`]({reference_link_component})" + issue_content_linked[ind+len(name)+1:]
|
||||
else:
|
||||
get_logger().info(f"Failed to find variable in issue content: {component['variable_name'].strip()}")
|
||||
issue_content = issue_content_linked
|
||||
issue_str = f"<a href='{reference_link}'><strong>{issue_header}</strong></a><br>{issue_content}"
|
||||
else:
|
||||
issue_str = f"[**{issue_header}**]({reference_link})\n\n{issue_content}\n\n"
|
||||
@ -945,3 +933,66 @@ def is_value_no(value):
|
||||
if value_str == 'no' or value_str == 'none' or value_str == 'false':
|
||||
return True
|
||||
return False
|
||||
|
||||
|
||||
def process_description(description_full: str):
|
||||
split_str = "### **Changes walkthrough** 📝"
|
||||
description_split = description_full.split(split_str)
|
||||
base_description_str = description_split[0]
|
||||
changes_walkthrough_str = ""
|
||||
files = []
|
||||
if len(description_split) > 1:
|
||||
changes_walkthrough_str = description_split[1]
|
||||
else:
|
||||
get_logger().debug("No changes walkthrough found")
|
||||
|
||||
try:
|
||||
if changes_walkthrough_str:
|
||||
# get the end of the table
|
||||
if '</table>\n\n___' in changes_walkthrough_str:
|
||||
end = changes_walkthrough_str.index("</table>\n\n___")
|
||||
elif '\n___' in changes_walkthrough_str:
|
||||
end = changes_walkthrough_str.index("\n___")
|
||||
else:
|
||||
end = len(changes_walkthrough_str)
|
||||
changes_walkthrough_str = changes_walkthrough_str[:end]
|
||||
|
||||
h = html2text.HTML2Text()
|
||||
h.body_width = 0 # Disable line wrapping
|
||||
|
||||
# find all the files
|
||||
pattern = r'<tr>\s*<td>\s*(<details>\s*<summary>(.*?)</summary>(.*?)</details>)\s*</td>'
|
||||
files_found = re.findall(pattern, changes_walkthrough_str, re.DOTALL)
|
||||
for file_data in files_found:
|
||||
try:
|
||||
if isinstance(file_data, tuple):
|
||||
file_data = file_data[0]
|
||||
# pattern = r'<details>\s*<summary><strong>(.*?)</strong><dd><code>(.*?)</code>.*?</summary>\s*<hr>\s*(.*?)\s*((?:\*.*\s*)*)</details>'
|
||||
pattern = r'<details>\s*<summary><strong>(.*?)</strong><dd><code>(.*?)</code>.*?</summary>\s*<hr>\s*(.*?)\n\n\s*(.*?)</details>'
|
||||
res = re.search(pattern, file_data, re.DOTALL)
|
||||
if res and res.lastindex == 4:
|
||||
short_filename = res.group(1).strip()
|
||||
short_summary = res.group(2).strip()
|
||||
long_filename = res.group(3).strip()
|
||||
long_summary = res.group(4).strip()
|
||||
long_summary = long_summary.replace('<br> *', '\n*').replace('<br>','').replace('\n','<br>')
|
||||
long_summary = h.handle(long_summary).strip()
|
||||
if not long_summary.startswith('*'):
|
||||
long_summary = f"* {long_summary}"
|
||||
|
||||
files.append({
|
||||
'short_file_name': short_filename,
|
||||
'full_file_name': long_filename,
|
||||
'short_summary': short_summary,
|
||||
'long_summary': long_summary
|
||||
})
|
||||
else:
|
||||
get_logger().error(f"Failed to parse description", artifact={'description': file_data})
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Failed to process description: {e}", artifact={'description': file_data})
|
||||
|
||||
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Failed to process description: {e}")
|
||||
|
||||
return base_description_str, files
|
||||
|
||||
@ -516,7 +516,7 @@ class AzureDevopsProvider(GitProvider):
|
||||
source_branch = pr_info.source_ref_name.split("/")[-1]
|
||||
return source_branch
|
||||
|
||||
def get_pr_description(self, *, full: bool = True) -> str:
|
||||
def get_pr_description(self, full: bool = True, split_changes_walkthrough=False) -> str:
|
||||
max_tokens = get_settings().get("CONFIG.MAX_DESCRIPTION_TOKENS", None)
|
||||
if max_tokens:
|
||||
return clip_tokens(self.pr.description, max_tokens)
|
||||
|
||||
@ -3,7 +3,7 @@ from abc import ABC, abstractmethod
|
||||
# enum EDIT_TYPE (ADDED, DELETED, MODIFIED, RENAMED)
|
||||
from typing import Optional
|
||||
|
||||
from pr_agent.algo.utils import Range
|
||||
from pr_agent.algo.utils import Range, process_description
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.algo.types import FilePatchInfo
|
||||
from pr_agent.log import get_logger
|
||||
@ -61,14 +61,20 @@ class GitProvider(ABC):
|
||||
def reply_to_comment_from_comment_id(self, comment_id: int, body: str):
|
||||
pass
|
||||
|
||||
def get_pr_description(self, *, full: bool = True) -> str:
|
||||
def get_pr_description(self, full: bool = True, split_changes_walkthrough=False) -> str or tuple:
|
||||
from pr_agent.config_loader import get_settings
|
||||
from pr_agent.algo.utils import clip_tokens
|
||||
max_tokens_description = get_settings().get("CONFIG.MAX_DESCRIPTION_TOKENS", None)
|
||||
description = self.get_pr_description_full() if full else self.get_user_description()
|
||||
if max_tokens_description:
|
||||
return clip_tokens(description, max_tokens_description)
|
||||
return description
|
||||
if split_changes_walkthrough:
|
||||
description, files = process_description(description)
|
||||
if max_tokens_description:
|
||||
description = clip_tokens(description, max_tokens_description)
|
||||
return description, files
|
||||
else:
|
||||
if max_tokens_description:
|
||||
description = clip_tokens(description, max_tokens_description)
|
||||
return description
|
||||
|
||||
def get_user_description(self) -> str:
|
||||
if hasattr(self, 'user_description') and not (self.user_description is None):
|
||||
|
||||
@ -68,6 +68,7 @@ def authorize(credentials: HTTPBasicCredentials = Depends(security)):
|
||||
async def _perform_commands_azure(commands_conf: str, agent: PRAgent, api_url: str, log_context: dict):
|
||||
apply_repo_settings(api_url)
|
||||
commands = get_settings().get(f"azure_devops_server.{commands_conf}")
|
||||
get_settings().set("config.is_auto_command", True)
|
||||
for command in commands:
|
||||
try:
|
||||
split_command = command.split(" ")
|
||||
|
||||
@ -78,6 +78,7 @@ async def handle_manifest(request: Request, response: Response):
|
||||
async def _perform_commands_bitbucket(commands_conf: str, agent: PRAgent, api_url: str, log_context: dict):
|
||||
apply_repo_settings(api_url)
|
||||
commands = get_settings().get(f"bitbucket_app.{commands_conf}", {})
|
||||
get_settings().set("config.is_auto_command", True)
|
||||
for command in commands:
|
||||
try:
|
||||
split_command = command.split(" ")
|
||||
|
||||
@ -128,7 +128,6 @@ async def handle_new_pr_opened(body: Dict[str, Any],
|
||||
log_context: Dict[str, Any],
|
||||
agent: PRAgent):
|
||||
title = body.get("pull_request", {}).get("title", "")
|
||||
get_settings().config.is_auto_command = True
|
||||
|
||||
pull_request, api_url = _check_pull_request_event(action, body, log_context)
|
||||
if not (pull_request and api_url):
|
||||
@ -371,12 +370,14 @@ def _check_pull_request_event(action: str, body: dict, log_context: dict) -> Tup
|
||||
return pull_request, api_url
|
||||
|
||||
|
||||
async def _perform_auto_commands_github(commands_conf: str, agent: PRAgent, body: dict, api_url: str, log_context: dict):
|
||||
async def _perform_auto_commands_github(commands_conf: str, agent: PRAgent, body: dict, api_url: str,
|
||||
log_context: dict):
|
||||
apply_repo_settings(api_url)
|
||||
commands = get_settings().get(f"github_app.{commands_conf}")
|
||||
if not commands:
|
||||
get_logger().info(f"New PR, but no auto commands configured")
|
||||
return
|
||||
get_settings().set("config.is_auto_command", True)
|
||||
for command in commands:
|
||||
split_command = command.split(" ")
|
||||
command = split_command[0]
|
||||
|
||||
@ -62,6 +62,7 @@ async def _perform_commands_gitlab(commands_conf: str, agent: PRAgent, api_url:
|
||||
log_context: dict):
|
||||
apply_repo_settings(api_url)
|
||||
commands = get_settings().get(f"gitlab.{commands_conf}", {})
|
||||
get_settings().set("config.is_auto_command", True)
|
||||
for command in commands:
|
||||
try:
|
||||
split_command = command.split(" ")
|
||||
@ -75,6 +76,7 @@ async def _perform_commands_gitlab(commands_conf: str, agent: PRAgent, api_url:
|
||||
except Exception as e:
|
||||
get_logger().error(f"Failed to perform command {command}: {e}")
|
||||
|
||||
|
||||
def is_bot_user(data) -> bool:
|
||||
try:
|
||||
# logic to ignore bot users (unlike Github, no direct flag for bot users in gitlab)
|
||||
|
||||
@ -31,7 +31,6 @@ ai_disclaimer_title="" # Pro feature, title for a collapsible disclaimer to AI
|
||||
ai_disclaimer="" # Pro feature, full text for the AI disclaimer
|
||||
output_relevant_configurations=false
|
||||
large_patch_policy = "clip" # "clip", "skip"
|
||||
is_auto_command=false
|
||||
# seed
|
||||
seed=-1 # set positive value to fix the seed (and ensure temperature=0)
|
||||
temperature=0.2
|
||||
@ -40,6 +39,9 @@ ignore_pr_title = ["^\\[Auto\\]", "^Auto"] # a list of regular expressions to ma
|
||||
ignore_pr_target_branches = [] # a list of regular expressions of target branches to ignore from PR agent when an PR is created
|
||||
ignore_pr_source_branches = [] # a list of regular expressions of source branches to ignore from PR agent when an PR is created
|
||||
ignore_pr_labels = [] # labels to ignore from PR agent when an PR is created
|
||||
#
|
||||
is_auto_command = false # will be auto-set to true if the command is triggered by an automation
|
||||
enable_ai_metadata = false # will enable adding ai metadata
|
||||
|
||||
[pr_reviewer] # /review #
|
||||
# enable/disable features
|
||||
@ -48,7 +50,6 @@ require_tests_review=true
|
||||
require_estimate_effort_to_review=true
|
||||
require_can_be_split_review=false
|
||||
require_security_review=true
|
||||
extra_issue_links=false
|
||||
# soc2
|
||||
require_soc2_ticket=false
|
||||
soc2_ticket_prompt="Does the PR description include a link to ticket in a project management system (e.g., Jira, Asana, Trello, etc.) ?"
|
||||
|
||||
@ -5,7 +5,7 @@ Your task is to generate {{ docs_for_language }} for code components in the PR D
|
||||
|
||||
Example for the PR Diff format:
|
||||
======
|
||||
## file: 'src/file1.py'
|
||||
## File: 'src/file1.py'
|
||||
|
||||
@@ -12,3 +12,4 @@ def func1():
|
||||
__new hunk__
|
||||
@ -25,7 +25,7 @@ __old hunk__
|
||||
...
|
||||
|
||||
|
||||
## file: 'src/file2.py'
|
||||
## File: 'src/file2.py'
|
||||
...
|
||||
======
|
||||
|
||||
|
||||
@ -5,7 +5,12 @@ Your task is to provide meaningful and actionable code suggestions, to improve t
|
||||
|
||||
The format we will use to present the PR code diff:
|
||||
======
|
||||
## file: 'src/file1.py'
|
||||
## File: 'src/file1.py'
|
||||
{%- if is_ai_metadata %}
|
||||
### AI-generated file summary:
|
||||
* ...
|
||||
* ...
|
||||
{%- endif %}
|
||||
|
||||
@@ ... @@ def func1():
|
||||
__new hunk__
|
||||
@ -26,14 +31,16 @@ __old hunk__
|
||||
...
|
||||
|
||||
|
||||
## file: 'src/file2.py'
|
||||
## File: 'src/file2.py'
|
||||
...
|
||||
======
|
||||
|
||||
- In this format, we separate each hunk of diff code to '__new hunk__' and '__old hunk__' sections. The '__new hunk__' section contains the new code of the chunk, and the '__old hunk__' section contains the old code, that was removed. If no new code was added in a specific hunk, '__new hunk__' section will not be presented. If no code was removed, '__old hunk__' section will not be presented.
|
||||
- We also added line numbers for the '__new hunk__' code, to help you refer to the code lines in your suggestions. These line numbers are not part of the actual code, and should only used for reference.
|
||||
- Code lines are prefixed with symbols ('+', '-', ' '). The '+' symbol indicates new code added in the PR, the '-' symbol indicates code removed in the PR, and the ' ' symbol indicates unchanged code. \
|
||||
|
||||
{%- if is_ai_metadata %}
|
||||
- If available, an AI-generated summary will appear and provide a high-level overview of the file changes.
|
||||
{%- endif %}
|
||||
|
||||
Specific instructions for generating code suggestions:
|
||||
- Provide up to {{ num_code_suggestions }} code suggestions.
|
||||
@ -122,7 +129,12 @@ Your task is to provide meaningful and actionable code suggestions, to improve t
|
||||
|
||||
The format we will use to present the PR code diff:
|
||||
======
|
||||
## file: 'src/file1.py'
|
||||
## File: 'src/file1.py'
|
||||
{%- if is_ai_metadata %}
|
||||
### AI-generated file summary:
|
||||
* ...
|
||||
* ...
|
||||
{%- endif %}
|
||||
|
||||
@@ ... @@ def func1():
|
||||
__new hunk__
|
||||
@ -143,14 +155,16 @@ __old hunk__
|
||||
...
|
||||
|
||||
|
||||
## file: 'src/file2.py'
|
||||
## File: 'src/file2.py'
|
||||
...
|
||||
======
|
||||
|
||||
- In this format, we separate each hunk of diff code to '__new hunk__' and '__old hunk__' sections. The '__new hunk__' section contains the new code of the chunk, and the '__old hunk__' section contains the old code, that was removed. If no new code was added in a specific hunk, '__new hunk__' section will not be presented. If no code was removed, '__old hunk__' section will not be presented.
|
||||
- We also added line numbers for the '__new hunk__' code, to help you refer to the code lines in your suggestions. These line numbers are not part of the actual code, and should only used for reference.
|
||||
- Code lines are prefixed with symbols ('+', '-', ' '). The '+' symbol indicates new code added in the PR, the '-' symbol indicates code removed in the PR, and the ' ' symbol indicates unchanged code. \
|
||||
|
||||
{%- if is_ai_metadata %}
|
||||
- If available, an AI-generated summary will appear and provide a high-level overview of the file changes.
|
||||
{%- endif %}
|
||||
|
||||
Specific instructions for generating code suggestions:
|
||||
- Provide up to {{ num_code_suggestions }} code suggestions.
|
||||
|
||||
@ -16,7 +16,7 @@ Specific instructions:
|
||||
|
||||
The format that is used to present the PR code diff is as follows:
|
||||
======
|
||||
## file: 'src/file1.py'
|
||||
## File: 'src/file1.py'
|
||||
|
||||
@@ ... @@ def func1():
|
||||
__new hunk__
|
||||
@ -35,7 +35,7 @@ __old hunk__
|
||||
...
|
||||
|
||||
|
||||
## file: 'src/file2.py'
|
||||
## File: 'src/file2.py'
|
||||
...
|
||||
======
|
||||
- In this format, we separated each hunk of code to '__new hunk__' and '__old hunk__' sections. The '__new hunk__' section contains the new code of the chunk, and the '__old hunk__' section contains the old code that was removed.
|
||||
|
||||
@ -12,7 +12,7 @@ Additional guidelines:
|
||||
|
||||
Example Hunk Structure:
|
||||
======
|
||||
## file: 'src/file1.py'
|
||||
## File: 'src/file1.py'
|
||||
|
||||
@@ -12,5 +12,5 @@ def func1():
|
||||
code line 1 that remained unchanged in the PR
|
||||
|
||||
@ -10,7 +10,13 @@ The review should focus on new code added in the PR code diff (lines starting wi
|
||||
|
||||
The format we will use to present the PR code diff:
|
||||
======
|
||||
## file: 'src/file1.py'
|
||||
## File: 'src/file1.py'
|
||||
{%- if is_ai_metadata %}
|
||||
### AI-generated file summary:
|
||||
* ...
|
||||
* ...
|
||||
{%- endif %}
|
||||
|
||||
|
||||
@@ ... @@ def func1():
|
||||
__new hunk__
|
||||
@ -31,7 +37,7 @@ __old hunk__
|
||||
...
|
||||
|
||||
|
||||
## file: 'src/file2.py'
|
||||
## File: 'src/file2.py'
|
||||
...
|
||||
======
|
||||
|
||||
@ -39,6 +45,9 @@ __old hunk__
|
||||
- We also added line numbers for the '__new hunk__' code, to help you refer to the code lines in your suggestions. These line numbers are not part of the actual code, and should only used for reference.
|
||||
- Code lines are prefixed with symbols ('+', '-', ' '). The '+' symbol indicates new code added in the PR, the '-' symbol indicates code removed in the PR, and the ' ' symbol indicates unchanged code. \
|
||||
The review should address new code added in the PR code diff (lines starting with '+')
|
||||
{%- if is_ai_metadata %}
|
||||
- If available, an AI-generated summary will appear and provide a high-level overview of the file changes.
|
||||
{%- endif %}
|
||||
- When quoting variables or names from the code, use backticks (`) instead of single quote (').
|
||||
|
||||
{%- if num_code_suggestions > 0 %}
|
||||
@ -76,15 +85,6 @@ class KeyIssuesComponentLink(BaseModel):
|
||||
issue_content: str = Field(description="a short and concise description of the issue that needs to be reviewed")
|
||||
start_line: int = Field(description="the start line that corresponds to this issue in the relevant file")
|
||||
end_line: int = Field(description="the end line that corresponds to this issue in the relevant file")
|
||||
{%- if extra_issue_links %}
|
||||
referenced_variables: List[Refs] = Field(description="a list of relevant variables or names that appear in the 'issue_content' output. For each variable, output is name, and the line number where it appears in the relevant file")
|
||||
{% endif %}
|
||||
|
||||
{%- if extra_issue_links %}
|
||||
class Refs(BaseModel):
|
||||
variable_name: str = Field(description="the name of a variable or name that appears in the relevant 'issue_content' output.")
|
||||
relevant_line: int = Field(description="the line number where the variable or name appears in the relevant file")
|
||||
{%- endif %}
|
||||
|
||||
class Review(BaseModel):
|
||||
{%- if require_estimate_effort_to_review %}
|
||||
@ -149,12 +149,6 @@ review:
|
||||
...
|
||||
start_line: 12
|
||||
end_line: 14
|
||||
{%- if extra_issue_links %}
|
||||
referenced_variables:
|
||||
- variable_name: |
|
||||
...
|
||||
relevant_line: 13
|
||||
{%- endif %}
|
||||
- ...
|
||||
security_concerns: |
|
||||
No
|
||||
|
||||
@ -7,7 +7,8 @@ from jinja2 import Environment, StrictUndefined
|
||||
|
||||
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||
from pr_agent.algo.ai_handlers.litellm_ai_handler import LiteLLMAIHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, get_pr_multi_diffs, retry_with_fallback_models
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, get_pr_multi_diffs, retry_with_fallback_models, \
|
||||
add_ai_metadata_to_diff_files
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.utils import load_yaml, replace_code_tags, ModelType, show_relevant_configurations
|
||||
from pr_agent.config_loader import get_settings
|
||||
@ -54,16 +55,27 @@ class PRCodeSuggestions:
|
||||
self.prediction = None
|
||||
self.pr_url = pr_url
|
||||
self.cli_mode = cli_mode
|
||||
self.pr_description, self.pr_description_files = (
|
||||
self.git_provider.get_pr_description(split_changes_walkthrough=True))
|
||||
if (self.pr_description_files and get_settings().get("config.is_auto_command", False) and
|
||||
get_settings().get("config.enable_ai_metadata", False)):
|
||||
add_ai_metadata_to_diff_files(self.git_provider, self.pr_description_files)
|
||||
get_logger().debug(f"AI metadata added to the this command")
|
||||
else:
|
||||
get_settings().set("config.enable_ai_metadata", False)
|
||||
get_logger().debug(f"AI metadata is disabled for this command")
|
||||
|
||||
self.vars = {
|
||||
"title": self.git_provider.pr.title,
|
||||
"branch": self.git_provider.get_pr_branch(),
|
||||
"description": self.git_provider.get_pr_description(),
|
||||
"description": self.pr_description,
|
||||
"language": self.main_language,
|
||||
"diff": "", # empty diff for initial calculation
|
||||
"num_code_suggestions": num_code_suggestions,
|
||||
"extra_instructions": get_settings().pr_code_suggestions.extra_instructions,
|
||||
"commit_messages_str": self.git_provider.get_commit_messages(),
|
||||
"relevant_best_practices": "",
|
||||
"is_ai_metadata": get_settings().get("config.enable_ai_metadata", False),
|
||||
}
|
||||
if 'claude' in get_settings().config.model:
|
||||
# prompt for Claude, with minor adjustments
|
||||
@ -505,7 +517,8 @@ class PRCodeSuggestions:
|
||||
|
||||
async def _prepare_prediction_extended(self, model: str) -> dict:
|
||||
self.patches_diff_list = get_pr_multi_diffs(self.git_provider, self.token_handler, model,
|
||||
max_calls=get_settings().pr_code_suggestions.max_number_of_calls)
|
||||
max_calls=get_settings().pr_code_suggestions.max_number_of_calls,
|
||||
pr_description_files =self.pr_description_files)
|
||||
if self.patches_diff_list:
|
||||
get_logger().info(f"Number of PR chunk calls: {len(self.patches_diff_list)}")
|
||||
get_logger().debug(f"PR diff:", artifact=self.patches_diff_list)
|
||||
|
||||
@ -638,9 +638,10 @@ def insert_br_after_x_chars(text, x=70):
|
||||
text = replace_code_tags(text)
|
||||
|
||||
# convert list items to <li>
|
||||
if text.startswith("- "):
|
||||
if text.startswith("- ") or text.startswith("* "):
|
||||
text = "<li>" + text[2:]
|
||||
text = text.replace("\n- ", '<br><li> ').replace("\n - ", '<br><li> ')
|
||||
text = text.replace("\n* ", '<br><li> ').replace("\n * ", '<br><li> ')
|
||||
|
||||
# convert new lines to <br>
|
||||
text = text.replace("\n", '<br>')
|
||||
|
||||
@ -6,7 +6,7 @@ from typing import List, Tuple
|
||||
from jinja2 import Environment, StrictUndefined
|
||||
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||
from pr_agent.algo.ai_handlers.litellm_ai_handler import LiteLLMAIHandler
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models
|
||||
from pr_agent.algo.pr_processing import get_pr_diff, retry_with_fallback_models, add_ai_metadata_to_diff_files
|
||||
from pr_agent.algo.token_handler import TokenHandler
|
||||
from pr_agent.algo.utils import github_action_output, load_yaml, ModelType, \
|
||||
show_relevant_configurations, convert_to_markdown_v2, PRReviewHeader
|
||||
@ -51,15 +51,23 @@ class PRReviewer:
|
||||
raise Exception(f"Answer mode is not supported for {get_settings().config.git_provider} for now")
|
||||
self.ai_handler = ai_handler()
|
||||
self.ai_handler.main_pr_language = self.main_language
|
||||
|
||||
self.patches_diff = None
|
||||
self.prediction = None
|
||||
|
||||
answer_str, question_str = self._get_user_answers()
|
||||
self.pr_description, self.pr_description_files = (
|
||||
self.git_provider.get_pr_description(split_changes_walkthrough=True))
|
||||
if (self.pr_description_files and get_settings().get("config.is_auto_command", False) and
|
||||
get_settings().get("config.enable_ai_metadata", False)):
|
||||
add_ai_metadata_to_diff_files(self.git_provider, self.pr_description_files)
|
||||
get_logger().debug(f"AI metadata added to the this command")
|
||||
else:
|
||||
get_settings().set("config.enable_ai_metadata", False)
|
||||
get_logger().debug(f"AI metadata is disabled for this command")
|
||||
|
||||
self.vars = {
|
||||
"title": self.git_provider.pr.title,
|
||||
"branch": self.git_provider.get_pr_branch(),
|
||||
"description": self.git_provider.get_pr_description(),
|
||||
"description": self.pr_description,
|
||||
"language": self.main_language,
|
||||
"diff": "", # empty diff for initial calculation
|
||||
"num_pr_files": self.git_provider.get_num_of_files(),
|
||||
@ -75,7 +83,7 @@ class PRReviewer:
|
||||
"commit_messages_str": self.git_provider.get_commit_messages(),
|
||||
"custom_labels": "",
|
||||
"enable_custom_labels": get_settings().config.enable_custom_labels,
|
||||
"extra_issue_links": get_settings().pr_reviewer.extra_issue_links,
|
||||
"is_ai_metadata": get_settings().get("config.enable_ai_metadata", False),
|
||||
}
|
||||
|
||||
self.token_handler = TokenHandler(
|
||||
|
||||
@ -27,6 +27,7 @@ tenacity==8.2.3
|
||||
gunicorn==22.0.0
|
||||
pytest-cov==5.0.0
|
||||
pydantic==2.8.2
|
||||
html2text==2024.2.26
|
||||
# Uncomment the following lines to enable the 'similar issue' tool
|
||||
# pinecone-client
|
||||
# pinecone-datasets @ git+https://github.com/mrT23/pinecone-datasets.git@main
|
||||
|
||||
@ -94,10 +94,11 @@ class TestExtendedPatchMoreLines:
|
||||
get_settings().config.allow_dynamic_context = False
|
||||
|
||||
class File:
|
||||
def __init__(self, base_file, patch, filename):
|
||||
def __init__(self, base_file, patch, filename, ai_file_summary=None):
|
||||
self.base_file = base_file
|
||||
self.patch = patch
|
||||
self.filename = filename
|
||||
self.ai_file_summary = ai_file_summary
|
||||
|
||||
@pytest.fixture
|
||||
def token_handler(self):
|
||||
|
||||
Reference in New Issue
Block a user