mirror of
https://github.com/qodo-ai/pr-agent.git
synced 2025-07-21 04:50:39 +08:00
Format files by pre-commit run -a
Signed-off-by: Yu Ishikawa <yu-iskw@users.noreply.github.com>
This commit is contained in:
@ -1,2 +1,2 @@
|
||||
## Overview
|
||||
TBD
|
||||
TBD
|
||||
|
||||
@ -12,9 +12,9 @@ We prioritize the languages of the repo based on the following criteria:
|
||||
|
||||
1. Exclude binary files and non code files (e.g. images, pdfs, etc)
|
||||
2. Given the main languages used in the repo
|
||||
3. We sort the PR files by the most common languages in the repo (in descending order):
|
||||
3. We sort the PR files by the most common languages in the repo (in descending order):
|
||||
* ```[[file.py, file2.py],[file3.js, file4.jsx],[readme.md]]```
|
||||
|
||||
|
||||
|
||||
### Small PR
|
||||
In this case, we can fit the entire PR in a single prompt:
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
## TL;DR
|
||||
|
||||
Qodo Merge uses an **asymmetric and dynamic context strategy** to improve AI analysis of code changes in pull requests.
|
||||
It provides more context before changes than after, and dynamically adjusts the context based on code structure (e.g., enclosing functions or classes).
|
||||
Qodo Merge uses an **asymmetric and dynamic context strategy** to improve AI analysis of code changes in pull requests.
|
||||
It provides more context before changes than after, and dynamically adjusts the context based on code structure (e.g., enclosing functions or classes).
|
||||
This approach balances providing sufficient context for accurate analysis, while avoiding needle-in-the-haystack information overload that could degrade AI performance or exceed token limits.
|
||||
|
||||
## Introduction
|
||||
@ -17,12 +17,12 @@ Pull request code changes are retrieved in a unified diff format, showing three
|
||||
code line that already existed in the file...
|
||||
code line that already existed in the file...
|
||||
code line that already existed in the file...
|
||||
|
||||
|
||||
@@ -26,2 +26,4 @@ def func2():
|
||||
...
|
||||
```
|
||||
|
||||
This unified diff format can be challenging for AI models to interpret accurately, as it provides limited context for understanding the full scope of code changes.
|
||||
This unified diff format can be challenging for AI models to interpret accurately, as it provides limited context for understanding the full scope of code changes.
|
||||
The presentation of code using '+', '-', and ' ' symbols to indicate additions, deletions, and unchanged lines respectively also differs from the standard code formatting typically used to train AI models.
|
||||
|
||||
|
||||
@ -37,7 +37,7 @@ Pros:
|
||||
Cons:
|
||||
|
||||
- Excessive context may overwhelm the model with extraneous information, creating a "needle in a haystack" scenario where focusing on the relevant details (the code that actually changed) becomes challenging.
|
||||
LLM quality is known to degrade when the context gets larger.
|
||||
LLM quality is known to degrade when the context gets larger.
|
||||
Pull requests often encompass multiple changes across many files, potentially spanning hundreds of lines of modified code. This complexity presents a genuine risk of overwhelming the model with excessive context.
|
||||
|
||||
- Increased context expands the token count, increasing processing time and cost, and may prevent the model from processing the entire pull request in a single pass.
|
||||
@ -47,18 +47,18 @@ To address these challenges, Qodo Merge employs an **asymmetric** and **dynamic*
|
||||
|
||||
**Asymmetric:**
|
||||
|
||||
We start by recognizing that the context preceding a code change is typically more crucial for understanding the modification than the context following it.
|
||||
We start by recognizing that the context preceding a code change is typically more crucial for understanding the modification than the context following it.
|
||||
Consequently, Qodo Merge implements an asymmetric context policy, decoupling the context window into two distinct segments: one for the code before the change and another for the code after.
|
||||
|
||||
By independently adjusting each context window, Qodo Merge can supply the model with a more tailored and pertinent context for individual code changes.
|
||||
By independently adjusting each context window, Qodo Merge can supply the model with a more tailored and pertinent context for individual code changes.
|
||||
|
||||
**Dynamic:**
|
||||
|
||||
We also employ a "dynamic" context strategy.
|
||||
We start by recognizing that the optimal context for a code change often corresponds to its enclosing code component (e.g., function, class), rather than a fixed number of lines.
|
||||
We start by recognizing that the optimal context for a code change often corresponds to its enclosing code component (e.g., function, class), rather than a fixed number of lines.
|
||||
Consequently, we dynamically adjust the context window based on the code's structure, ensuring the model receives the most pertinent information for each modification.
|
||||
|
||||
To prevent overwhelming the model with excessive context, we impose a limit on the number of lines searched when identifying the enclosing component.
|
||||
To prevent overwhelming the model with excessive context, we impose a limit on the number of lines searched when identifying the enclosing component.
|
||||
This balance allows for comprehensive understanding while maintaining efficiency and limiting context token usage.
|
||||
|
||||
## Appendix - relevant configuration options
|
||||
@ -69,4 +69,4 @@ allow_dynamic_context=true # Allow dynamic context extension
|
||||
max_extra_lines_before_dynamic_context = 8 # will try to include up to X extra lines before the hunk in the patch, until we reach an enclosing function or class
|
||||
patch_extra_lines_before = 3 # Number of extra lines (+3 default ones) to include before each hunk in the patch
|
||||
patch_extra_lines_after = 1 # Number of extra lines (+3 default ones) to include after each hunk in the patch
|
||||
```
|
||||
```
|
||||
|
||||
@ -41,4 +41,4 @@ Here are key metrics that the dashboard tracks:
|
||||
|
||||
#### Suggestion Score Distribution
|
||||
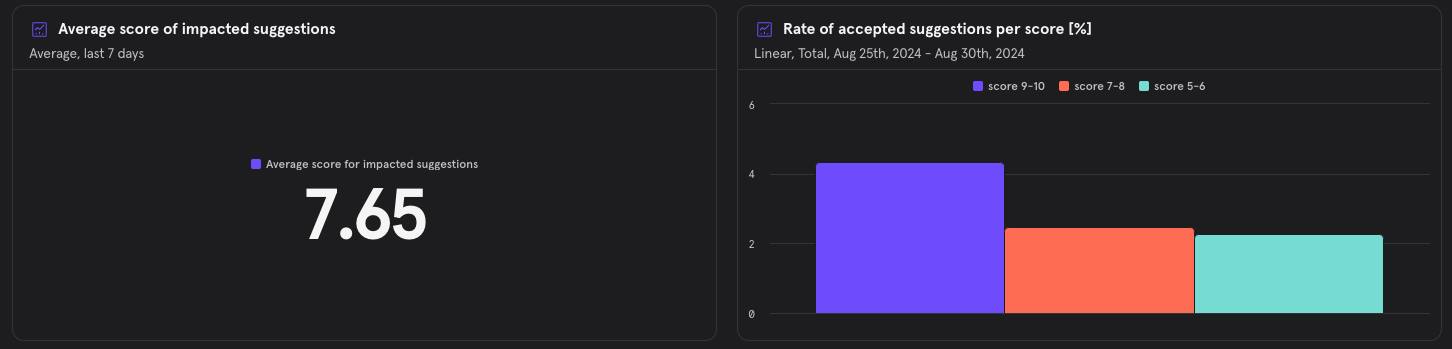{width=512}
|
||||
> Explanation: The distribution of the suggestion score for the implemented suggestions, ensuring that higher-scored suggestions truly represent more significant improvements.
|
||||
> Explanation: The distribution of the suggestion score for the implemented suggestions, ensuring that higher-scored suggestions truly represent more significant improvements.
|
||||
|
||||
@ -13,7 +13,7 @@ Qodo Merge utilizes a variety of core abilities to provide a comprehensive and e
|
||||
|
||||
## Blogs
|
||||
|
||||
Here are some additional technical blogs from Qodo, that delve deeper into the core capabilities and features of Large Language Models (LLMs) when applied to coding tasks.
|
||||
Here are some additional technical blogs from Qodo, that delve deeper into the core capabilities and features of Large Language Models (LLMs) when applied to coding tasks.
|
||||
These resources provide more comprehensive insights into leveraging LLMs for software development.
|
||||
|
||||
### Code Generation and LLMs
|
||||
@ -25,4 +25,4 @@ These resources provide more comprehensive insights into leveraging LLMs for sof
|
||||
- [Introduction to Code Coverage Testing](https://www.qodo.ai/blog/introduction-to-code-coverage-testing/)
|
||||
|
||||
### Cost Optimization
|
||||
- [Reduce Your Costs by 30% When Using GPT for Python Code](https://www.qodo.ai/blog/reduce-your-costs-by-30-when-using-gpt-3-for-python-code/)
|
||||
- [Reduce Your Costs by 30% When Using GPT for Python Code](https://www.qodo.ai/blog/reduce-your-costs-by-30-when-using-gpt-3-for-python-code/)
|
||||
|
||||
@ -1,2 +1,2 @@
|
||||
## Interactive invocation 💎
|
||||
TBD
|
||||
TBD
|
||||
|
||||
@ -53,4 +53,4 @@ __old hunk__
|
||||
|
||||
|
||||
(4) All the metadata described above represents several level of cumulative analysis - ranging from hunk level, to file level, to PR level, to organization level.
|
||||
This comprehensive approach enables Qodo Merge AI models to generate more precise and contextually relevant suggestions and feedback.
|
||||
This comprehensive approach enables Qodo Merge AI models to generate more precise and contextually relevant suggestions and feedback.
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
## TL;DR
|
||||
|
||||
Qodo Merge implements a **self-reflection** process where the AI model reflects, scores, and re-ranks its own suggestions, eliminating irrelevant or incorrect ones.
|
||||
This approach improves the quality and relevance of suggestions, saving users time and enhancing their experience.
|
||||
Qodo Merge implements a **self-reflection** process where the AI model reflects, scores, and re-ranks its own suggestions, eliminating irrelevant or incorrect ones.
|
||||
This approach improves the quality and relevance of suggestions, saving users time and enhancing their experience.
|
||||
Configuration options allow users to set a score threshold for further filtering out suggestions.
|
||||
|
||||
## Introduction - Efficient Review with Hierarchical Presentation
|
||||
@ -24,7 +24,7 @@ The AI model is initially tasked with generating suggestions, and outputting the
|
||||
However, in practice we observe that models often struggle to simultaneously generate high-quality code suggestions and rank them well in a single pass.
|
||||
Furthermore, the initial set of generated suggestions sometimes contains easily identifiable errors.
|
||||
|
||||
To address these issues, we implemented a "self-reflection" process that refines suggestion ranking and eliminates irrelevant or incorrect proposals.
|
||||
To address these issues, we implemented a "self-reflection" process that refines suggestion ranking and eliminates irrelevant or incorrect proposals.
|
||||
This process consists of the following steps:
|
||||
|
||||
1. Presenting the generated suggestions to the model in a follow-up call.
|
||||
@ -48,4 +48,4 @@ This results in a more refined and valuable set of suggestions for the user, sav
|
||||
[pr_code_suggestions]
|
||||
self_reflect_on_suggestions = true # Enable self-reflection on code suggestions
|
||||
suggestions_score_threshold = 0 # Filter out suggestions with a score below this threshold (0-10)
|
||||
```
|
||||
```
|
||||
|
||||
Reference in New Issue
Block a user