mirror of
https://github.com/qodo-ai/pr-agent.git
synced 2025-07-21 04:50:39 +08:00
Merge remote-tracking branch 'origin/main'
This commit is contained in:
@ -8,7 +8,7 @@ ENV PYTHONPATH=/app
|
||||
|
||||
FROM base as github_app
|
||||
ADD pr_agent pr_agent
|
||||
CMD ["python", "pr_agent/servers/github_app.py"]
|
||||
CMD ["python", "-m", "gunicorn", "-k", "uvicorn.workers.UvicornWorker", "-c", "pr_agent/servers/gunicorn_config.py", "--forwarded-allow-ips", "*", "pr_agent.servers.github_app:app"]
|
||||
|
||||
FROM base as bitbucket_app
|
||||
ADD pr_agent pr_agent
|
||||
|
||||
@ -108,7 +108,7 @@ If you prefer to have the file summaries appear in the "Files changed" tab on ev
|
||||
|
||||
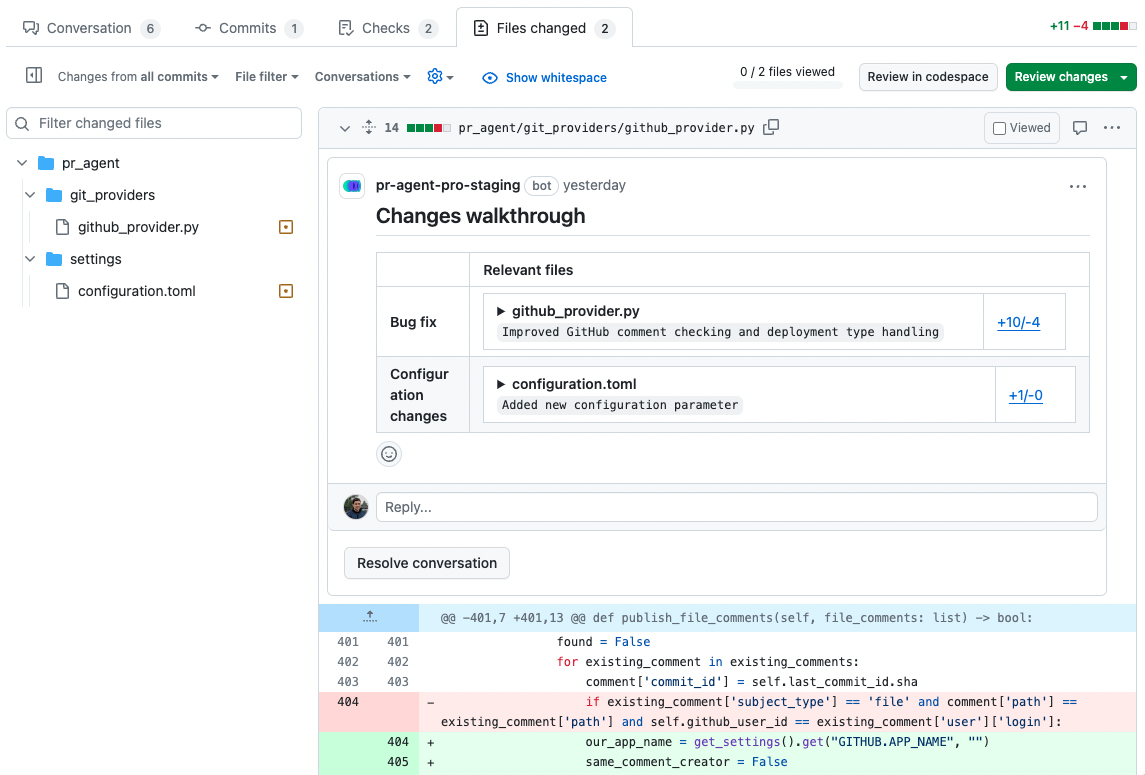{width=512}
|
||||
|
||||
- `true`: A collapsable file comment with changes title and a changes summary for each file in the PR.
|
||||
- `true`: A collapsible file comment with changes title and a changes summary for each file in the PR.
|
||||
|
||||
{width=512}
|
||||
|
||||
@ -194,7 +194,7 @@ The description should be comprehensive and detailed, indicating when to add the
|
||||
```
|
||||
pr_commands = ["/describe", ...]
|
||||
```
|
||||
meaning the `describe` tool will run automatically on every PR, with the default configurations.
|
||||
meaning the `describe` tool will run automatically on every PR, with the default configurations.
|
||||
|
||||
|
||||
- Markers are an alternative way to control the generated description, to give maximal control to the user. If you set:
|
||||
|
||||
@ -157,7 +157,7 @@ the tool can automatically approve the PR when the user checks the self-review c
|
||||
|
||||
!!! tip "Extra instructions"
|
||||
|
||||
Extra instructions are very important for the `imrpove` tool, since they enable you to guide the model to suggestions that are more relevant to the specific needs of the project.
|
||||
Extra instructions are very important for the `improve` tool, since they enable you to guide the model to suggestions that are more relevant to the specific needs of the project.
|
||||
|
||||
Be specific, clear, and concise in the instructions. With extra instructions, you are the prompter. Specify relevant aspects that you want the model to focus on.
|
||||
|
||||
@ -190,6 +190,6 @@ the tool can automatically approve the PR when the user checks the self-review c
|
||||
- Only if the `Category` header is relevant, the user should move to the summarized suggestion description
|
||||
- Only if the summarized suggestion description is relevant, the user should click on the collapsible, to read the full suggestion description with a code preview example.
|
||||
|
||||
In addition, we recommend to use the `exra_instructions` field to guide the model to suggestions that are more relevant to the specific needs of the project.
|
||||
In addition, we recommend to use the `extra_instructions` field to guide the model to suggestions that are more relevant to the specific needs of the project.
|
||||
<br>
|
||||
Consider also trying the [Custom Prompt Tool](./custom_prompt.md) 💎, that will **only** propose code suggestions that follow specific guidelines defined by user.
|
||||
|
||||
@ -235,7 +235,7 @@ class BitbucketProvider(GitProvider):
|
||||
except Exception as e:
|
||||
get_logger().exception(f"Failed to remove comment, error: {e}")
|
||||
|
||||
# funtion to create_inline_comment
|
||||
# function to create_inline_comment
|
||||
def create_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str, absolute_position: int = None):
|
||||
position, absolute_position = find_line_number_of_relevant_line_in_file(self.get_diff_files(),
|
||||
relevant_file.strip('`'),
|
||||
@ -404,7 +404,7 @@ class BitbucketProvider(GitProvider):
|
||||
|
||||
def get_commit_messages(self):
|
||||
return "" # not implemented yet
|
||||
|
||||
|
||||
# bitbucket does not support labels
|
||||
def publish_description(self, pr_title: str, description: str):
|
||||
payload = json.dumps({
|
||||
@ -424,7 +424,7 @@ class BitbucketProvider(GitProvider):
|
||||
# bitbucket does not support labels
|
||||
def publish_labels(self, pr_types: list):
|
||||
pass
|
||||
|
||||
|
||||
# bitbucket does not support labels
|
||||
def get_pr_labels(self, update=False):
|
||||
pass
|
||||
|
||||
@ -211,7 +211,7 @@ class BitbucketServerProvider(GitProvider):
|
||||
def remove_comment(self, comment):
|
||||
pass
|
||||
|
||||
# funtion to create_inline_comment
|
||||
# function to create_inline_comment
|
||||
def create_inline_comment(self, body: str, relevant_file: str, relevant_line_in_file: str,
|
||||
absolute_position: int = None):
|
||||
|
||||
|
||||
@ -107,7 +107,7 @@ class GithubProvider(GitProvider):
|
||||
git_files = context.get("git_files", None)
|
||||
if git_files:
|
||||
return git_files
|
||||
self.git_files = list(self.pr.get_files()) # 'list' to hanlde pagination
|
||||
self.git_files = list(self.pr.get_files()) # 'list' to handle pagination
|
||||
context["git_files"] = self.git_files
|
||||
return self.git_files
|
||||
except Exception:
|
||||
|
||||
@ -41,7 +41,7 @@ def handle_request(
|
||||
):
|
||||
log_context["action"] = body
|
||||
log_context["api_url"] = url
|
||||
|
||||
|
||||
async def inner():
|
||||
try:
|
||||
with get_logger().contextualize(**log_context):
|
||||
@ -89,7 +89,7 @@ async def handle_webhook(background_tasks: BackgroundTasks, request: Request):
|
||||
get_logger().info(json.dumps(data))
|
||||
|
||||
actions = []
|
||||
if data["eventType"] == "git.pullrequest.created":
|
||||
if data["eventType"] == "git.pullrequest.created":
|
||||
# API V1 (latest)
|
||||
pr_url = unquote(data["resource"]["_links"]["web"]["href"].replace("_apis/git/repositories", "_git"))
|
||||
log_context["event"] = data["eventType"]
|
||||
@ -102,7 +102,7 @@ async def handle_webhook(background_tasks: BackgroundTasks, request: Request):
|
||||
repo = data["resource"]["pullRequest"]["repository"]["webUrl"]
|
||||
pr_url = unquote(f'{repo}/pullrequest/{data["resource"]["pullRequest"]["pullRequestId"]}')
|
||||
actions = [data["resource"]["comment"]["content"]]
|
||||
else:
|
||||
else:
|
||||
# API V1 not supported as it does not contain the PR URL
|
||||
return JSONResponse(
|
||||
status_code=status.HTTP_400_BAD_REQUEST,
|
||||
@ -120,7 +120,7 @@ async def handle_webhook(background_tasks: BackgroundTasks, request: Request):
|
||||
|
||||
log_context["event"] = data["eventType"]
|
||||
log_context["api_url"] = pr_url
|
||||
|
||||
|
||||
for action in actions:
|
||||
try:
|
||||
handle_request(background_tasks, pr_url, action, log_context)
|
||||
@ -131,13 +131,13 @@ async def handle_webhook(background_tasks: BackgroundTasks, request: Request):
|
||||
content=json.dumps({"message": "Internal server error"}),
|
||||
)
|
||||
return JSONResponse(
|
||||
status_code=status.HTTP_202_ACCEPTED, content=jsonable_encoder({"message": "webhook triggerd successfully"})
|
||||
status_code=status.HTTP_202_ACCEPTED, content=jsonable_encoder({"message": "webhook triggered successfully"})
|
||||
)
|
||||
|
||||
@router.get("/")
|
||||
async def root():
|
||||
return {"status": "ok"}
|
||||
|
||||
|
||||
def start():
|
||||
app = FastAPI(middleware=[Middleware(RawContextMiddleware)])
|
||||
app.include_router(router)
|
||||
|
||||
191
pr_agent/servers/gunicorn_config.py
Normal file
191
pr_agent/servers/gunicorn_config.py
Normal file
@ -0,0 +1,191 @@
|
||||
import multiprocessing
|
||||
import os
|
||||
|
||||
# from prometheus_client import multiprocess
|
||||
|
||||
# Sample Gunicorn configuration file.
|
||||
|
||||
#
|
||||
# Server socket
|
||||
#
|
||||
# bind - The socket to bind.
|
||||
#
|
||||
# A string of the form: 'HOST', 'HOST:PORT', 'unix:PATH'.
|
||||
# An IP is a valid HOST.
|
||||
#
|
||||
# backlog - The number of pending connections. This refers
|
||||
# to the number of clients that can be waiting to be
|
||||
# served. Exceeding this number results in the client
|
||||
# getting an error when attempting to connect. It should
|
||||
# only affect servers under significant load.
|
||||
#
|
||||
# Must be a positive integer. Generally set in the 64-2048
|
||||
# range.
|
||||
#
|
||||
|
||||
# bind = '0.0.0.0:5000'
|
||||
bind = '0.0.0.0:3000'
|
||||
backlog = 2048
|
||||
|
||||
#
|
||||
# Worker processes
|
||||
#
|
||||
# workers - The number of worker processes that this server
|
||||
# should keep alive for handling requests.
|
||||
#
|
||||
# A positive integer generally in the 2-4 x $(NUM_CORES)
|
||||
# range. You'll want to vary this a bit to find the best
|
||||
# for your particular application's work load.
|
||||
#
|
||||
# worker_class - The type of workers to use. The default
|
||||
# sync class should handle most 'normal' types of work
|
||||
# loads. You'll want to read
|
||||
# http://docs.gunicorn.org/en/latest/design.html#choosing-a-worker-type
|
||||
# for information on when you might want to choose one
|
||||
# of the other worker classes.
|
||||
#
|
||||
# A string referring to a Python path to a subclass of
|
||||
# gunicorn.workers.base.Worker. The default provided values
|
||||
# can be seen at
|
||||
# http://docs.gunicorn.org/en/latest/settings.html#worker-class
|
||||
#
|
||||
# worker_connections - For the eventlet and gevent worker classes
|
||||
# this limits the maximum number of simultaneous clients that
|
||||
# a single process can handle.
|
||||
#
|
||||
# A positive integer generally set to around 1000.
|
||||
#
|
||||
# timeout - If a worker does not notify the master process in this
|
||||
# number of seconds it is killed and a new worker is spawned
|
||||
# to replace it.
|
||||
#
|
||||
# Generally set to thirty seconds. Only set this noticeably
|
||||
# higher if you're sure of the repercussions for sync workers.
|
||||
# For the non sync workers it just means that the worker
|
||||
# process is still communicating and is not tied to the length
|
||||
# of time required to handle a single request.
|
||||
#
|
||||
# keepalive - The number of seconds to wait for the next request
|
||||
# on a Keep-Alive HTTP connection.
|
||||
#
|
||||
# A positive integer. Generally set in the 1-5 seconds range.
|
||||
#
|
||||
|
||||
if os.getenv('GUNICORN_WORKERS', None):
|
||||
workers = int(os.getenv('GUNICORN_WORKERS'))
|
||||
else:
|
||||
cores = multiprocessing.cpu_count()
|
||||
workers = cores * 2 + 1
|
||||
worker_connections = 1000
|
||||
timeout = 240
|
||||
keepalive = 2
|
||||
|
||||
#
|
||||
# spew - Install a trace function that spews every line of Python
|
||||
# that is executed when running the server. This is the
|
||||
# nuclear option.
|
||||
#
|
||||
# True or False
|
||||
#
|
||||
|
||||
spew = False
|
||||
|
||||
#
|
||||
# Server mechanics
|
||||
#
|
||||
# daemon - Detach the main Gunicorn process from the controlling
|
||||
# terminal with a standard fork/fork sequence.
|
||||
#
|
||||
# True or False
|
||||
#
|
||||
# raw_env - Pass environment variables to the execution environment.
|
||||
#
|
||||
# pidfile - The path to a pid file to write
|
||||
#
|
||||
# A path string or None to not write a pid file.
|
||||
#
|
||||
# user - Switch worker processes to run as this user.
|
||||
#
|
||||
# A valid user id (as an integer) or the name of a user that
|
||||
# can be retrieved with a call to pwd.getpwnam(value) or None
|
||||
# to not change the worker process user.
|
||||
#
|
||||
# group - Switch worker process to run as this group.
|
||||
#
|
||||
# A valid group id (as an integer) or the name of a user that
|
||||
# can be retrieved with a call to pwd.getgrnam(value) or None
|
||||
# to change the worker processes group.
|
||||
#
|
||||
# umask - A mask for file permissions written by Gunicorn. Note that
|
||||
# this affects unix socket permissions.
|
||||
#
|
||||
# A valid value for the os.umask(mode) call or a string
|
||||
# compatible with int(value, 0) (0 means Python guesses
|
||||
# the base, so values like "0", "0xFF", "0022" are valid
|
||||
# for decimal, hex, and octal representations)
|
||||
#
|
||||
# tmp_upload_dir - A directory to store temporary request data when
|
||||
# requests are read. This will most likely be disappearing soon.
|
||||
#
|
||||
# A path to a directory where the process owner can write. Or
|
||||
# None to signal that Python should choose one on its own.
|
||||
#
|
||||
|
||||
daemon = False
|
||||
raw_env = []
|
||||
pidfile = None
|
||||
umask = 0
|
||||
user = None
|
||||
group = None
|
||||
tmp_upload_dir = None
|
||||
|
||||
#
|
||||
# Logging
|
||||
#
|
||||
# logfile - The path to a log file to write to.
|
||||
#
|
||||
# A path string. "-" means log to stdout.
|
||||
#
|
||||
# loglevel - The granularity of log output
|
||||
#
|
||||
# A string of "debug", "info", "warning", "error", "critical"
|
||||
#
|
||||
|
||||
errorlog = '-'
|
||||
loglevel = 'info'
|
||||
accesslog = None
|
||||
access_log_format = '%(h)s %(l)s %(u)s %(t)s "%(r)s" %(s)s %(b)s "%(f)s" "%(a)s"'
|
||||
|
||||
#
|
||||
# Process naming
|
||||
#
|
||||
# proc_name - A base to use with setproctitle to change the way
|
||||
# that Gunicorn processes are reported in the system process
|
||||
# table. This affects things like 'ps' and 'top'. If you're
|
||||
# going to be running more than one instance of Gunicorn you'll
|
||||
# probably want to set a name to tell them apart. This requires
|
||||
# that you install the setproctitle module.
|
||||
#
|
||||
# A string or None to choose a default of something like 'gunicorn'.
|
||||
#
|
||||
|
||||
proc_name = None
|
||||
|
||||
|
||||
#
|
||||
# Server hooks
|
||||
#
|
||||
# post_fork - Called just after a worker has been forked.
|
||||
#
|
||||
# A callable that takes a server and worker instance
|
||||
# as arguments.
|
||||
#
|
||||
# pre_fork - Called just prior to forking the worker subprocess.
|
||||
#
|
||||
# A callable that accepts the same arguments as after_fork
|
||||
#
|
||||
# pre_exec - Called just prior to forking off a secondary
|
||||
# master process during things like config reloading.
|
||||
#
|
||||
# A callable that takes a server instance as the sole argument.
|
||||
#
|
||||
@ -40,8 +40,8 @@ After that, rank each response. Criterions to rank each response:
|
||||
- How well does the response follow the specific task instructions and requirements?
|
||||
- How well does the response analyze and understand the PR code diff?
|
||||
- How well will a person perceive it as a good response that correctly addresses the task?
|
||||
- How well does the reponse prioritize key feedback, related to the task instructions, that a human reader seeing that feedback would also consider as important?
|
||||
- Don't neccessarily rank higher a response that is longer. A shorter response might be better if it is more concise, and still addresses the task better.
|
||||
- How well does the response prioritize key feedback, related to the task instructions, that a human reader seeing that feedback would also consider as important?
|
||||
- Don't necessarily rank higher a response that is longer. A shorter response might be better if it is more concise, and still addresses the task better.
|
||||
|
||||
|
||||
The output must be a YAML object equivalent to type $PRRankRespones, according to the following Pydantic definitions:
|
||||
|
||||
@ -73,7 +73,7 @@ class Review(BaseModel):
|
||||
security_concerns: str = Field(description="does this PR code introduce possible vulnerabilities such as exposure of sensitive information (e.g., API keys, secrets, passwords), or security concerns like SQL injection, XSS, CSRF, and others ? Answer 'No' if there are no possible issues. If there are security concerns or issues, start your answer with a short header, such as: 'Sensitive information exposure: ...', 'SQL injection: ...' etc. Explain your answer. Be specific and give examples if possible")
|
||||
{%- endif %}
|
||||
{%- if require_can_be_split_review %}
|
||||
can_be_split: List[SubPR] = Field(min_items=0, max_items=3, description="Can this PR, which contains {{ num_pr_files }} changed files in total, be divided into smaller sub-PRs with distinct tasks that can be reviewed and merged independently, regardless of the order ? Make sure that the sub-PRs are indeed independent, with no code dependencies between them, and that each sub-PR represent a meaningfull independent task. Output an empty list if the PR code does not needd to be split.")
|
||||
can_be_split: List[SubPR] = Field(min_items=0, max_items=3, description="Can this PR, which contains {{ num_pr_files }} changed files in total, be divided into smaller sub-PRs with distinct tasks that can be reviewed and merged independently, regardless of the order ? Make sure that the sub-PRs are indeed independent, with no code dependencies between them, and that each sub-PR represent a meaningful independent task. Output an empty list if the PR code does not need to be split.")
|
||||
{%- endif %}
|
||||
{%- if num_code_suggestions > 0 %}
|
||||
|
||||
|
||||
@ -24,6 +24,7 @@ tiktoken==0.7.0
|
||||
ujson==5.8.0
|
||||
uvicorn==0.22.0
|
||||
tenacity==8.2.3
|
||||
gunicorn==20.1.0
|
||||
# Uncomment the following lines to enable the 'similar issue' tool
|
||||
# pinecone-client
|
||||
# pinecone-datasets @ git+https://github.com/mrT23/pinecone-datasets.git@main
|
||||
|
||||
Reference in New Issue
Block a user