mirror of
https://github.com/qodo-ai/pr-agent.git
synced 2025-07-21 04:50:39 +08:00
Merge branch 'main' into of/compliance-tool
This commit is contained in:
@ -19,7 +19,6 @@
|
|||||||
</div>
|
</div>
|
||||||
|
|
||||||
<style>
|
<style>
|
||||||
Untitled
|
|
||||||
.search-section {
|
.search-section {
|
||||||
max-width: 800px;
|
max-width: 800px;
|
||||||
margin: 0 auto;
|
margin: 0 auto;
|
||||||
@ -305,9 +304,8 @@ window.addEventListener('load', function() {
|
|||||||
spinner.style.display = 'none';
|
spinner.style.display = 'none';
|
||||||
const errorDiv = document.createElement('div');
|
const errorDiv = document.createElement('div');
|
||||||
errorDiv.className = 'error-message';
|
errorDiv.className = 'error-message';
|
||||||
errorDiv.textContent = `${error}`;
|
errorDiv.textContent = error instanceof Error ? error.message : String(error);
|
||||||
resultsContainer.value = "";
|
resultsContainer.replaceChildren(errorDiv);
|
||||||
resultsContainer.appendChild(errorDiv);
|
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|||||||
@ -6,8 +6,7 @@ Qodo Merge utilizes a variety of core abilities to provide a comprehensive and e
|
|||||||
- [Auto best practices](https://qodo-merge-docs.qodo.ai/core-abilities/auto_best_practices/)
|
- [Auto best practices](https://qodo-merge-docs.qodo.ai/core-abilities/auto_best_practices/)
|
||||||
- [Chat on code suggestions](https://qodo-merge-docs.qodo.ai/core-abilities/chat_on_code_suggestions/)
|
- [Chat on code suggestions](https://qodo-merge-docs.qodo.ai/core-abilities/chat_on_code_suggestions/)
|
||||||
- [Chrome extension](https://qodo-merge-docs.qodo.ai/chrome-extension/)
|
- [Chrome extension](https://qodo-merge-docs.qodo.ai/chrome-extension/)
|
||||||
- [Code validation](https://qodo-merge-docs.qodo.ai/core-abilities/code_validation/)
|
- [Code validation](https://qodo-merge-docs.qodo.ai/core-abilities/code_validation/) <!-- - [Compression strategy](https://qodo-merge-docs.qodo.ai/core-abilities/compression_strategy/) -->
|
||||||
- [Compression strategy](https://qodo-merge-docs.qodo.ai/core-abilities/compression_strategy/)
|
|
||||||
- [Dynamic context](https://qodo-merge-docs.qodo.ai/core-abilities/dynamic_context/)
|
- [Dynamic context](https://qodo-merge-docs.qodo.ai/core-abilities/dynamic_context/)
|
||||||
- [Fetching ticket context](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/)
|
- [Fetching ticket context](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/)
|
||||||
- [Impact evaluation](https://qodo-merge-docs.qodo.ai/core-abilities/impact_evaluation/)
|
- [Impact evaluation](https://qodo-merge-docs.qodo.ai/core-abilities/impact_evaluation/)
|
||||||
|
|||||||
@ -66,7 +66,7 @@ ___
|
|||||||
___
|
___
|
||||||
|
|
||||||
??? note "Q: Can Qodo Merge review draft/offline PRs?"
|
??? note "Q: Can Qodo Merge review draft/offline PRs?"
|
||||||
#### Answer:<span style="display:none;">5</span>
|
#### Answer:<span style="display:none;">6</span>
|
||||||
|
|
||||||
Yes. While Qodo Merge won't automatically review draft PRs, you can still get feedback by manually requesting it through [online commenting](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#online-usage).
|
Yes. While Qodo Merge won't automatically review draft PRs, you can still get feedback by manually requesting it through [online commenting](https://qodo-merge-docs.qodo.ai/usage-guide/automations_and_usage/#online-usage).
|
||||||
|
|
||||||
@ -74,7 +74,7 @@ ___
|
|||||||
___
|
___
|
||||||
|
|
||||||
??? note "Q: Can the 'Review effort' feedback be calibrated or customized?"
|
??? note "Q: Can the 'Review effort' feedback be calibrated or customized?"
|
||||||
#### Answer:<span style="display:none;">5</span>
|
#### Answer:<span style="display:none;">7</span>
|
||||||
|
|
||||||
Yes, you can customize review effort estimates using the `extra_instructions` configuration option (see [documentation](https://qodo-merge-docs.qodo.ai/tools/review/#configuration-options)).
|
Yes, you can customize review effort estimates using the `extra_instructions` configuration option (see [documentation](https://qodo-merge-docs.qodo.ai/tools/review/#configuration-options)).
|
||||||
|
|
||||||
|
|||||||
@ -1,7 +1,7 @@
|
|||||||
## Azure DevOps Pipeline
|
## Azure DevOps Pipeline
|
||||||
|
|
||||||
You can use a pre-built Action Docker image to run PR-Agent as an Azure devops pipeline.
|
You can use a pre-built Action Docker image to run PR-Agent as an Azure devops pipeline.
|
||||||
add the following file to your repository under `azure-pipelines.yml`:
|
Add the following file to your repository under `azure-pipelines.yml`:
|
||||||
|
|
||||||
```yaml
|
```yaml
|
||||||
# Opt out of CI triggers
|
# Opt out of CI triggers
|
||||||
@ -71,7 +71,7 @@ git_provider="azure"
|
|||||||
```
|
```
|
||||||
|
|
||||||
Azure DevOps provider supports [PAT token](https://learn.microsoft.com/en-us/azure/devops/organizations/accounts/use-personal-access-tokens-to-authenticate?view=azure-devops&tabs=Windows) or [DefaultAzureCredential](https://learn.microsoft.com/en-us/azure/developer/python/sdk/authentication-overview#authentication-in-server-environments) authentication.
|
Azure DevOps provider supports [PAT token](https://learn.microsoft.com/en-us/azure/devops/organizations/accounts/use-personal-access-tokens-to-authenticate?view=azure-devops&tabs=Windows) or [DefaultAzureCredential](https://learn.microsoft.com/en-us/azure/developer/python/sdk/authentication-overview#authentication-in-server-environments) authentication.
|
||||||
PAT is faster to create, but has build in expiration date, and will use the user identity for API calls.
|
PAT is faster to create, but has built-in expiration date, and will use the user identity for API calls.
|
||||||
Using DefaultAzureCredential you can use managed identity or Service principle, which are more secure and will create separate ADO user identity (via AAD) to the agent.
|
Using DefaultAzureCredential you can use managed identity or Service principle, which are more secure and will create separate ADO user identity (via AAD) to the agent.
|
||||||
|
|
||||||
If PAT was chosen, you can assign the value in .secrets.toml.
|
If PAT was chosen, you can assign the value in .secrets.toml.
|
||||||
|
|||||||
@ -50,7 +50,7 @@ git_provider="bitbucket_server"
|
|||||||
and pass the Pull request URL:
|
and pass the Pull request URL:
|
||||||
|
|
||||||
```shell
|
```shell
|
||||||
python cli.py --pr_url https://git.onpreminstanceofbitbucket.com/projects/PROJECT/repos/REPO/pull-requests/1 review
|
python cli.py --pr_url https://git.on-prem-instance-of-bitbucket.com/projects/PROJECT/repos/REPO/pull-requests/1 review
|
||||||
```
|
```
|
||||||
|
|
||||||
### Run it as service
|
### Run it as service
|
||||||
@ -63,6 +63,6 @@ docker push codiumai/pr-agent:bitbucket_server_webhook # Push to your Docker re
|
|||||||
```
|
```
|
||||||
|
|
||||||
Navigate to `Projects` or `Repositories`, `Settings`, `Webhooks`, `Create Webhook`.
|
Navigate to `Projects` or `Repositories`, `Settings`, `Webhooks`, `Create Webhook`.
|
||||||
Fill the name and URL, Authentication None select the Pull Request Opened checkbox to receive that event as webhook.
|
Fill in the name and URL. For Authentication, select 'None'. Select the 'Pull Request Opened' checkbox to receive that event as a webhook.
|
||||||
|
|
||||||
The URL should end with `/webhook`, for example: https://domain.com/webhook
|
The URL should end with `/webhook`, for example: https://domain.com/webhook
|
||||||
|
|||||||
@ -17,12 +17,11 @@ git clone https://github.com/qodo-ai/pr-agent.git
|
|||||||
```
|
```
|
||||||
|
|
||||||
5. Prepare variables and secrets. Skip this step if you plan on setting these as environment variables when running the agent:
|
5. Prepare variables and secrets. Skip this step if you plan on setting these as environment variables when running the agent:
|
||||||
1. In the configuration file/variables:
|
- In the configuration file/variables:
|
||||||
- Set `config.git_provider` to "gitea"
|
- Set `config.git_provider` to "gitea"
|
||||||
|
- In the secrets file/variables:
|
||||||
2. In the secrets file/variables:
|
- Set your AI model key in the respective section
|
||||||
- Set your AI model key in the respective section
|
- In the [Gitea] section, set `personal_access_token` (with token from step 2) and `webhook_secret` (with secret from step 3)
|
||||||
- In the [Gitea] section, set `personal_access_token` (with token from step 2) and `webhook_secret` (with secret from step 3)
|
|
||||||
|
|
||||||
6. Build a Docker image for the app and optionally push it to a Docker repository. We'll use Dockerhub as an example:
|
6. Build a Docker image for the app and optionally push it to a Docker repository. We'll use Dockerhub as an example:
|
||||||
|
|
||||||
|
|||||||
@ -46,7 +46,7 @@ Note that if your base branches are not protected, don't set the variables as `p
|
|||||||
|
|
||||||
1. In GitLab create a new user and give it "Reporter" role ("Developer" if using Pro version of the agent) for the intended group or project.
|
1. In GitLab create a new user and give it "Reporter" role ("Developer" if using Pro version of the agent) for the intended group or project.
|
||||||
|
|
||||||
2. For the user from step 1. generate a `personal_access_token` with `api` access.
|
2. For the user from step 1, generate a `personal_access_token` with `api` access.
|
||||||
|
|
||||||
3. Generate a random secret for your app, and save it for later (`shared_secret`). For example, you can use:
|
3. Generate a random secret for your app, and save it for later (`shared_secret`). For example, you can use:
|
||||||
|
|
||||||
@ -111,7 +111,7 @@ For example: `GITLAB.PERSONAL_ACCESS_TOKEN` --> `GITLAB__PERSONAL_ACCESS_TOKEN`
|
|||||||
4. Create a lambda function that uses the uploaded image. Set the lambda timeout to be at least 3m.
|
4. Create a lambda function that uses the uploaded image. Set the lambda timeout to be at least 3m.
|
||||||
5. Configure the lambda function to have a Function URL.
|
5. Configure the lambda function to have a Function URL.
|
||||||
6. In the environment variables of the Lambda function, specify `AZURE_DEVOPS_CACHE_DIR` to a writable location such as /tmp. (see [link](https://github.com/Codium-ai/pr-agent/pull/450#issuecomment-1840242269))
|
6. In the environment variables of the Lambda function, specify `AZURE_DEVOPS_CACHE_DIR` to a writable location such as /tmp. (see [link](https://github.com/Codium-ai/pr-agent/pull/450#issuecomment-1840242269))
|
||||||
7. Go back to steps 8-9 of [Run a GitLab webhook server](#run-a-gitlab-webhook-server) with the function url as your Webhook URL.
|
7. Go back to steps 8-9 of [Run a GitLab webhook server](#run-a-gitlab-webhook-server) with the function URL as your Webhook URL.
|
||||||
The Webhook URL would look like `https://<LAMBDA_FUNCTION_URL>/webhook`
|
The Webhook URL would look like `https://<LAMBDA_FUNCTION_URL>/webhook`
|
||||||
|
|
||||||
### Using AWS Secrets Manager
|
### Using AWS Secrets Manager
|
||||||
|
|||||||
@ -12,7 +12,7 @@ To invoke a tool (for example `review`), you can run PR-Agent directly from the
|
|||||||
- For GitHub:
|
- For GitHub:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
docker run --rm -it -e OPENAI.KEY=<your key> -e GITHUB.USER_TOKEN=<your token> codiumai/pr-agent:latest --pr_url <pr_url> review
|
docker run --rm -it -e OPENAI.KEY=<your_openai_key> -e GITHUB.USER_TOKEN=<your_github_token> codiumai/pr-agent:latest --pr_url <pr_url> review
|
||||||
```
|
```
|
||||||
|
|
||||||
If you are using GitHub enterprise server, you need to specify the custom url as variable.
|
If you are using GitHub enterprise server, you need to specify the custom url as variable.
|
||||||
|
|||||||
@ -58,6 +58,12 @@ A list of the models used for generating the baseline suggestions, and example r
|
|||||||
<td style="text-align:left;">1024</td>
|
<td style="text-align:left;">1024</td>
|
||||||
<td style="text-align:center;"><b>44.3</b></td>
|
<td style="text-align:center;"><b>44.3</b></td>
|
||||||
</tr>
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td style="text-align:left;">Grok-4</td>
|
||||||
|
<td style="text-align:left;">2025-07-09</td>
|
||||||
|
<td style="text-align:left;">unknown</td>
|
||||||
|
<td style="text-align:center;"><b>41.7</b></td>
|
||||||
|
</tr>
|
||||||
<tr>
|
<tr>
|
||||||
<td style="text-align:left;">Claude-4-sonnet</td>
|
<td style="text-align:left;">Claude-4-sonnet</td>
|
||||||
<td style="text-align:left;">2025-05-14</td>
|
<td style="text-align:left;">2025-05-14</td>
|
||||||
@ -82,6 +88,12 @@ A list of the models used for generating the baseline suggestions, and example r
|
|||||||
<td style="text-align:left;"></td>
|
<td style="text-align:left;"></td>
|
||||||
<td style="text-align:center;"><b>33.5</b></td>
|
<td style="text-align:center;"><b>33.5</b></td>
|
||||||
</tr>
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td style="text-align:left;">Claude-4-opus-20250514</td>
|
||||||
|
<td style="text-align:left;">2025-05-14</td>
|
||||||
|
<td style="text-align:left;"></td>
|
||||||
|
<td style="text-align:center;"><b>32.8</b></td>
|
||||||
|
</tr>
|
||||||
<tr>
|
<tr>
|
||||||
<td style="text-align:left;">Claude-3.7-sonnet</td>
|
<td style="text-align:left;">Claude-3.7-sonnet</td>
|
||||||
<td style="text-align:left;">2025-02-19</td>
|
<td style="text-align:left;">2025-02-19</td>
|
||||||
@ -240,6 +252,39 @@ weaknesses:
|
|||||||
- **Introduces new problems:** Several suggestions add unsupported APIs, undeclared variables, wrong types, or break compilation, hurting trust in the recommendations.
|
- **Introduces new problems:** Several suggestions add unsupported APIs, undeclared variables, wrong types, or break compilation, hurting trust in the recommendations.
|
||||||
- **Rule violations:** It often edits lines outside the diff, exceeds the 3-suggestion cap, or labels cosmetic tweaks as “critical”, showing inconsistent guideline compliance.
|
- **Rule violations:** It often edits lines outside the diff, exceeds the 3-suggestion cap, or labels cosmetic tweaks as “critical”, showing inconsistent guideline compliance.
|
||||||
|
|
||||||
|
### Claude-4 Opus
|
||||||
|
|
||||||
|
final score: **32.8**
|
||||||
|
|
||||||
|
strengths:
|
||||||
|
|
||||||
|
- **Format & rule adherence:** Almost always returns valid YAML, stays within the ≤3-suggestion limit, and usually restricts edits to newly-added lines, so its output is easy to apply automatically.
|
||||||
|
- **Concise, focused patches:** When it does find a real bug it gives short, well-scoped explanations plus minimal diff snippets, often outperforming verbose baselines in clarity.
|
||||||
|
- **Able to catch subtle edge-cases:** In several examples it detected overflow, race-condition or enum-mismatch issues that many other models missed, showing solid code‐analysis capability.
|
||||||
|
|
||||||
|
weaknesses:
|
||||||
|
|
||||||
|
- **Low recall / narrow coverage:** In a large share of the 399 examples the model produced an empty list or only one minor tip while more serious defects were present, causing it to be rated inferior to most baselines.
|
||||||
|
- **Frequent incorrect or no-op fixes:** It sometimes supplies identical “before/after” code, flags non-issues, or suggests changes that would break compilation or logic, reducing reviewer trust.
|
||||||
|
- **Shaky guideline consistency:** Although generally compliant, it still occasionally violates rules (touches unchanged lines, offers stylistic advice, adds imports) and duplicates suggestions, indicating unstable internal checks.
|
||||||
|
|
||||||
|
### Grok-4
|
||||||
|
|
||||||
|
final score: **32.8**
|
||||||
|
|
||||||
|
strengths:
|
||||||
|
|
||||||
|
- **Focused and concise fixes:** When the model does detect a problem it usually proposes a minimal, well-scoped patch that compiles and directly addresses the defect without unnecessary noise.
|
||||||
|
- **Good critical-bug instinct:** It often prioritises show-stoppers (compile failures, crashes, security issues) over cosmetic matters and occasionally spots subtle issues that all other reviewers miss.
|
||||||
|
- **Clear explanations & snippets:** Explanations are short, readable and paired with ready-to-paste code, making the advice easy to apply.
|
||||||
|
|
||||||
|
weaknesses:
|
||||||
|
|
||||||
|
- **High miss rate:** In a large fraction of examples the model returned an empty list or covered only one minor issue while overlooking more serious newly-introduced bugs.
|
||||||
|
- **Inconsistent accuracy:** A noticeable subset of answers contain wrong or even harmful fixes (e.g., removing valid flags, creating compile errors, re-introducing bugs).
|
||||||
|
- **Limited breadth:** Even when it finds a real defect it rarely reports additional related problems that peers catch, leading to partial reviews.
|
||||||
|
- **Occasional guideline slips:** A few replies modify unchanged lines, suggest new imports, or duplicate suggestions, showing imperfect compliance with instructions.
|
||||||
|
|
||||||
## Appendix - Example Results
|
## Appendix - Example Results
|
||||||
|
|
||||||
Some examples of benchmarked PRs and their results:
|
Some examples of benchmarked PRs and their results:
|
||||||
|
|||||||
@ -13,7 +13,7 @@ It also outlines our development roadmap for the upcoming three months. Please n
|
|||||||
- **Simplified Free Tier**: Qodo Merge now offers a simplified free tier with a monthly limit of 75 PR reviews per organization, replacing the previous two-week trial. ([Learn more](https://qodo-merge-docs.qodo.ai/installation/qodo_merge/#cloud-users))
|
- **Simplified Free Tier**: Qodo Merge now offers a simplified free tier with a monthly limit of 75 PR reviews per organization, replacing the previous two-week trial. ([Learn more](https://qodo-merge-docs.qodo.ai/installation/qodo_merge/#cloud-users))
|
||||||
- **CLI Endpoint**: A new Qodo Merge endpoint that accepts a lists of before/after code changes, executes Qodo Merge commands, and return the results. Currently available for enterprise customers. Contact [Qodo](https://www.qodo.ai/contact/) for more information.
|
- **CLI Endpoint**: A new Qodo Merge endpoint that accepts a lists of before/after code changes, executes Qodo Merge commands, and return the results. Currently available for enterprise customers. Contact [Qodo](https://www.qodo.ai/contact/) for more information.
|
||||||
- **Linear tickets support**: Qodo Merge now supports Linear tickets. ([Learn more](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/#linear-integration))
|
- **Linear tickets support**: Qodo Merge now supports Linear tickets. ([Learn more](https://qodo-merge-docs.qodo.ai/core-abilities/fetching_ticket_context/#linear-integration))
|
||||||
- **Smart Update**: Upon PR updates, Qodo Merge will offer tailored code suggestions, addressing both the entire PR and the specific incremental changes since the last feedback ([Learn more](https://qodo-merge-docs.qodo.ai/core-abilities/incremental_update//))
|
- **Smart Update**: Upon PR updates, Qodo Merge will offer tailored code suggestions, addressing both the entire PR and the specific incremental changes since the last feedback ([Learn more](https://qodo-merge-docs.qodo.ai/core-abilities/incremental_update/))
|
||||||
|
|
||||||
=== "Future Roadmap"
|
=== "Future Roadmap"
|
||||||
- **Enhanced `review` tool**: Enhancing the `review` tool validate compliance across multiple categories including security, tickets, and custom best practices.
|
- **Enhanced `review` tool**: Enhancing the `review` tool validate compliance across multiple categories including security, tickets, and custom best practices.
|
||||||
|
|||||||
@ -47,11 +47,16 @@ publish_labels = true
|
|||||||
|
|
||||||
## Preserving the original user description
|
## Preserving the original user description
|
||||||
|
|
||||||
By default, Qodo Merge preserves your original PR description by placing it above the generated content.
|
By default, Qodo Merge tries to preserve your original PR description by placing it above the generated content.
|
||||||
This requires including your description during the initial PR creation.
|
This requires including your description during the initial PR creation.
|
||||||
Be aware that if you edit the description while the automated tool is running, a race condition may occur, potentially causing your original description to be lost.
|
|
||||||
|
|
||||||
When updating PR descriptions, the `/describe` tool considers everything above the "PR Type" field as user content and will preserve it.
|
"Qodo removed the original description from the PR. Why"?
|
||||||
|
|
||||||
|
From our experience, there are two possible reasons:
|
||||||
|
|
||||||
|
- If you edit the description _while_ the automated tool is running, a race condition may occur, potentially causing your original description to be lost. Hence, create a description before launching the PR.
|
||||||
|
|
||||||
|
- When _updating_ PR descriptions, the `/describe` tool considers everything above the "PR Type" field as user content and will preserve it.
|
||||||
Everything below this marker is treated as previously auto-generated content and will be replaced.
|
Everything below this marker is treated as previously auto-generated content and will be replaced.
|
||||||
|
|
||||||
{width=512}
|
{width=512}
|
||||||
@ -177,9 +182,12 @@ pr_agent:summary
|
|||||||
|
|
||||||
## PR Walkthrough:
|
## PR Walkthrough:
|
||||||
pr_agent:walkthrough
|
pr_agent:walkthrough
|
||||||
|
|
||||||
|
## PR Diagram:
|
||||||
|
pr_agent:diagram
|
||||||
```
|
```
|
||||||
|
|
||||||
The marker `pr_agent:type` will be replaced with the PR type, `pr_agent:summary` will be replaced with the PR summary, and `pr_agent:walkthrough` will be replaced with the PR walkthrough.
|
The marker `pr_agent:type` will be replaced with the PR type, `pr_agent:summary` will be replaced with the PR summary, `pr_agent:walkthrough` will be replaced with the PR walkthrough, and `pr_agent:diagram` will be replaced with the sequence diagram (if enabled).
|
||||||
|
|
||||||
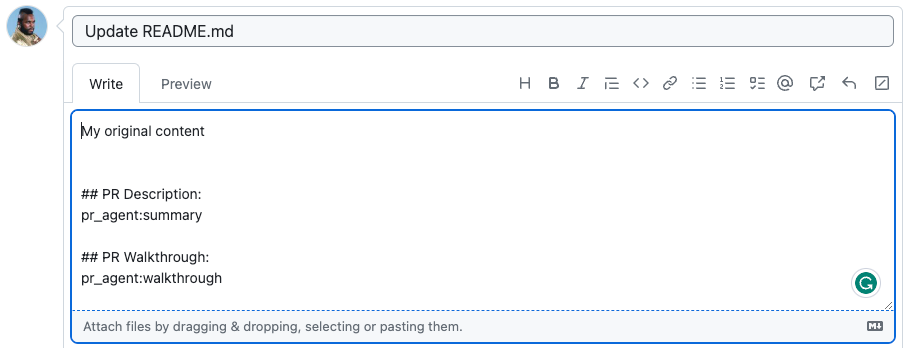{width=512}
|
{width=512}
|
||||||
|
|
||||||
@ -191,6 +199,7 @@ becomes
|
|||||||
|
|
||||||
- `use_description_markers`: if set to true, the tool will use markers template. It replaces every marker of the form `pr_agent:marker_name` with the relevant content. Default is false.
|
- `use_description_markers`: if set to true, the tool will use markers template. It replaces every marker of the form `pr_agent:marker_name` with the relevant content. Default is false.
|
||||||
- `include_generated_by_header`: if set to true, the tool will add a dedicated header: 'Generated by PR Agent at ...' to any automatic content. Default is true.
|
- `include_generated_by_header`: if set to true, the tool will add a dedicated header: 'Generated by PR Agent at ...' to any automatic content. Default is true.
|
||||||
|
- `diagram`: if present as a marker, will be replaced by the PR sequence diagram (if enabled).
|
||||||
|
|
||||||
## Custom labels
|
## Custom labels
|
||||||
|
|
||||||
|
|||||||
@ -30,7 +30,7 @@ verbosity_level=2
|
|||||||
This is useful for debugging or experimenting with different tools.
|
This is useful for debugging or experimenting with different tools.
|
||||||
|
|
||||||
3. **git provider**: The [git_provider](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml#L5) field in a configuration file determines the GIT provider that will be used by Qodo Merge. Currently, the following providers are supported:
|
3. **git provider**: The [git_provider](https://github.com/Codium-ai/pr-agent/blob/main/pr_agent/settings/configuration.toml#L5) field in a configuration file determines the GIT provider that will be used by Qodo Merge. Currently, the following providers are supported:
|
||||||
`github` **(default)**, `gitlab`, `bitbucket`, `azure`, `codecommit`, `local`,`gitea`, and `gerrit`.
|
`github` **(default)**, `gitlab`, `bitbucket`, `azure`, `codecommit`, `local`, and `gitea`.
|
||||||
|
|
||||||
### CLI Health Check
|
### CLI Health Check
|
||||||
|
|
||||||
|
|||||||
@ -32,6 +32,16 @@ OPENAI__API_BASE=https://api.openai.com/v1
|
|||||||
OPENAI__KEY=sk-...
|
OPENAI__KEY=sk-...
|
||||||
```
|
```
|
||||||
|
|
||||||
|
### OpenAI Flex Processing
|
||||||
|
|
||||||
|
To reduce costs for non-urgent/background tasks, enable Flex Processing:
|
||||||
|
|
||||||
|
```toml
|
||||||
|
[litellm]
|
||||||
|
extra_body='{"processing_mode": "flex"}'
|
||||||
|
```
|
||||||
|
|
||||||
|
See [OpenAI Flex Processing docs](https://platform.openai.com/docs/guides/flex-processing) for details.
|
||||||
|
|
||||||
### Azure
|
### Azure
|
||||||
|
|
||||||
|
|||||||
@ -45,6 +45,7 @@ MAX_TOKENS = {
|
|||||||
'command-nightly': 4096,
|
'command-nightly': 4096,
|
||||||
'deepseek/deepseek-chat': 128000, # 128K, but may be limited by config.max_model_tokens
|
'deepseek/deepseek-chat': 128000, # 128K, but may be limited by config.max_model_tokens
|
||||||
'deepseek/deepseek-reasoner': 64000, # 64K, but may be limited by config.max_model_tokens
|
'deepseek/deepseek-reasoner': 64000, # 64K, but may be limited by config.max_model_tokens
|
||||||
|
'openai/qwq-plus': 131072, # 131K context length, but may be limited by config.max_model_tokens
|
||||||
'replicate/llama-2-70b-chat:2c1608e18606fad2812020dc541930f2d0495ce32eee50074220b87300bc16e1': 4096,
|
'replicate/llama-2-70b-chat:2c1608e18606fad2812020dc541930f2d0495ce32eee50074220b87300bc16e1': 4096,
|
||||||
'meta-llama/Llama-2-7b-chat-hf': 4096,
|
'meta-llama/Llama-2-7b-chat-hf': 4096,
|
||||||
'vertex_ai/codechat-bison': 6144,
|
'vertex_ai/codechat-bison': 6144,
|
||||||
@ -193,3 +194,8 @@ CLAUDE_EXTENDED_THINKING_MODELS = [
|
|||||||
"anthropic/claude-3-7-sonnet-20250219",
|
"anthropic/claude-3-7-sonnet-20250219",
|
||||||
"claude-3-7-sonnet-20250219"
|
"claude-3-7-sonnet-20250219"
|
||||||
]
|
]
|
||||||
|
|
||||||
|
# Models that require streaming mode
|
||||||
|
STREAMING_REQUIRED_MODELS = [
|
||||||
|
"openai/qwq-plus"
|
||||||
|
]
|
||||||
|
|||||||
@ -5,14 +5,16 @@ import requests
|
|||||||
from litellm import acompletion
|
from litellm import acompletion
|
||||||
from tenacity import retry, retry_if_exception_type, retry_if_not_exception_type, stop_after_attempt
|
from tenacity import retry, retry_if_exception_type, retry_if_not_exception_type, stop_after_attempt
|
||||||
|
|
||||||
from pr_agent.algo import CLAUDE_EXTENDED_THINKING_MODELS, NO_SUPPORT_TEMPERATURE_MODELS, SUPPORT_REASONING_EFFORT_MODELS, USER_MESSAGE_ONLY_MODELS
|
from pr_agent.algo import CLAUDE_EXTENDED_THINKING_MODELS, NO_SUPPORT_TEMPERATURE_MODELS, SUPPORT_REASONING_EFFORT_MODELS, USER_MESSAGE_ONLY_MODELS, STREAMING_REQUIRED_MODELS
|
||||||
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
from pr_agent.algo.ai_handlers.base_ai_handler import BaseAiHandler
|
||||||
|
from pr_agent.algo.ai_handlers.litellm_helpers import _handle_streaming_response, MockResponse, _get_azure_ad_token, \
|
||||||
|
_process_litellm_extra_body
|
||||||
from pr_agent.algo.utils import ReasoningEffort, get_version
|
from pr_agent.algo.utils import ReasoningEffort, get_version
|
||||||
from pr_agent.config_loader import get_settings
|
from pr_agent.config_loader import get_settings
|
||||||
from pr_agent.log import get_logger
|
from pr_agent.log import get_logger
|
||||||
import json
|
import json
|
||||||
|
|
||||||
OPENAI_RETRIES = 5
|
MODEL_RETRIES = 2
|
||||||
|
|
||||||
|
|
||||||
class LiteLLMAIHandler(BaseAiHandler):
|
class LiteLLMAIHandler(BaseAiHandler):
|
||||||
@ -110,7 +112,7 @@ class LiteLLMAIHandler(BaseAiHandler):
|
|||||||
if get_settings().get("AZURE_AD.CLIENT_ID", None):
|
if get_settings().get("AZURE_AD.CLIENT_ID", None):
|
||||||
self.azure = True
|
self.azure = True
|
||||||
# Generate access token using Azure AD credentials from settings
|
# Generate access token using Azure AD credentials from settings
|
||||||
access_token = self._get_azure_ad_token()
|
access_token = _get_azure_ad_token()
|
||||||
litellm.api_key = access_token
|
litellm.api_key = access_token
|
||||||
openai.api_key = access_token
|
openai.api_key = access_token
|
||||||
|
|
||||||
@ -143,25 +145,8 @@ class LiteLLMAIHandler(BaseAiHandler):
|
|||||||
# Models that support extended thinking
|
# Models that support extended thinking
|
||||||
self.claude_extended_thinking_models = CLAUDE_EXTENDED_THINKING_MODELS
|
self.claude_extended_thinking_models = CLAUDE_EXTENDED_THINKING_MODELS
|
||||||
|
|
||||||
def _get_azure_ad_token(self):
|
# Models that require streaming
|
||||||
"""
|
self.streaming_required_models = STREAMING_REQUIRED_MODELS
|
||||||
Generates an access token using Azure AD credentials from settings.
|
|
||||||
Returns:
|
|
||||||
str: The access token
|
|
||||||
"""
|
|
||||||
from azure.identity import ClientSecretCredential
|
|
||||||
try:
|
|
||||||
credential = ClientSecretCredential(
|
|
||||||
tenant_id=get_settings().azure_ad.tenant_id,
|
|
||||||
client_id=get_settings().azure_ad.client_id,
|
|
||||||
client_secret=get_settings().azure_ad.client_secret
|
|
||||||
)
|
|
||||||
# Get token for Azure OpenAI service
|
|
||||||
token = credential.get_token("https://cognitiveservices.azure.com/.default")
|
|
||||||
return token.token
|
|
||||||
except Exception as e:
|
|
||||||
get_logger().error(f"Failed to get Azure AD token: {e}")
|
|
||||||
raise
|
|
||||||
|
|
||||||
def prepare_logs(self, response, system, user, resp, finish_reason):
|
def prepare_logs(self, response, system, user, resp, finish_reason):
|
||||||
response_log = response.dict().copy()
|
response_log = response.dict().copy()
|
||||||
@ -275,7 +260,7 @@ class LiteLLMAIHandler(BaseAiHandler):
|
|||||||
|
|
||||||
@retry(
|
@retry(
|
||||||
retry=retry_if_exception_type(openai.APIError) & retry_if_not_exception_type(openai.RateLimitError),
|
retry=retry_if_exception_type(openai.APIError) & retry_if_not_exception_type(openai.RateLimitError),
|
||||||
stop=stop_after_attempt(OPENAI_RETRIES),
|
stop=stop_after_attempt(MODEL_RETRIES),
|
||||||
)
|
)
|
||||||
async def chat_completion(self, model: str, system: str, user: str, temperature: float = 0.2, img_path: str = None):
|
async def chat_completion(self, model: str, system: str, user: str, temperature: float = 0.2, img_path: str = None):
|
||||||
try:
|
try:
|
||||||
@ -364,13 +349,18 @@ class LiteLLMAIHandler(BaseAiHandler):
|
|||||||
raise ValueError(f"LITELLM.EXTRA_HEADERS contains invalid JSON: {str(e)}")
|
raise ValueError(f"LITELLM.EXTRA_HEADERS contains invalid JSON: {str(e)}")
|
||||||
kwargs["extra_headers"] = litellm_extra_headers
|
kwargs["extra_headers"] = litellm_extra_headers
|
||||||
|
|
||||||
|
# Support for custom OpenAI body fields (e.g., Flex Processing)
|
||||||
|
kwargs = _process_litellm_extra_body(kwargs)
|
||||||
|
|
||||||
get_logger().debug("Prompts", artifact={"system": system, "user": user})
|
get_logger().debug("Prompts", artifact={"system": system, "user": user})
|
||||||
|
|
||||||
if get_settings().config.verbosity_level >= 2:
|
if get_settings().config.verbosity_level >= 2:
|
||||||
get_logger().info(f"\nSystem prompt:\n{system}")
|
get_logger().info(f"\nSystem prompt:\n{system}")
|
||||||
get_logger().info(f"\nUser prompt:\n{user}")
|
get_logger().info(f"\nUser prompt:\n{user}")
|
||||||
|
|
||||||
response = await acompletion(**kwargs)
|
# Get completion with automatic streaming detection
|
||||||
|
resp, finish_reason, response_obj = await self._get_completion(**kwargs)
|
||||||
|
|
||||||
except openai.RateLimitError as e:
|
except openai.RateLimitError as e:
|
||||||
get_logger().error(f"Rate limit error during LLM inference: {e}")
|
get_logger().error(f"Rate limit error during LLM inference: {e}")
|
||||||
raise
|
raise
|
||||||
@ -380,19 +370,36 @@ class LiteLLMAIHandler(BaseAiHandler):
|
|||||||
except Exception as e:
|
except Exception as e:
|
||||||
get_logger().warning(f"Unknown error during LLM inference: {e}")
|
get_logger().warning(f"Unknown error during LLM inference: {e}")
|
||||||
raise openai.APIError from e
|
raise openai.APIError from e
|
||||||
if response is None or len(response["choices"]) == 0:
|
|
||||||
raise openai.APIError
|
|
||||||
else:
|
|
||||||
resp = response["choices"][0]['message']['content']
|
|
||||||
finish_reason = response["choices"][0]["finish_reason"]
|
|
||||||
get_logger().debug(f"\nAI response:\n{resp}")
|
|
||||||
|
|
||||||
# log the full response for debugging
|
get_logger().debug(f"\nAI response:\n{resp}")
|
||||||
response_log = self.prepare_logs(response, system, user, resp, finish_reason)
|
|
||||||
get_logger().debug("Full_response", artifact=response_log)
|
|
||||||
|
|
||||||
# for CLI debugging
|
# log the full response for debugging
|
||||||
if get_settings().config.verbosity_level >= 2:
|
response_log = self.prepare_logs(response_obj, system, user, resp, finish_reason)
|
||||||
get_logger().info(f"\nAI response:\n{resp}")
|
get_logger().debug("Full_response", artifact=response_log)
|
||||||
|
|
||||||
|
# for CLI debugging
|
||||||
|
if get_settings().config.verbosity_level >= 2:
|
||||||
|
get_logger().info(f"\nAI response:\n{resp}")
|
||||||
|
|
||||||
return resp, finish_reason
|
return resp, finish_reason
|
||||||
|
|
||||||
|
async def _get_completion(self, **kwargs):
|
||||||
|
"""
|
||||||
|
Wrapper that automatically handles streaming for required models.
|
||||||
|
"""
|
||||||
|
model = kwargs["model"]
|
||||||
|
if model in self.streaming_required_models:
|
||||||
|
kwargs["stream"] = True
|
||||||
|
get_logger().info(f"Using streaming mode for model {model}")
|
||||||
|
response = await acompletion(**kwargs)
|
||||||
|
resp, finish_reason = await _handle_streaming_response(response)
|
||||||
|
# Create MockResponse for streaming since we don't have the full response object
|
||||||
|
mock_response = MockResponse(resp, finish_reason)
|
||||||
|
return resp, finish_reason, mock_response
|
||||||
|
else:
|
||||||
|
response = await acompletion(**kwargs)
|
||||||
|
if response is None or len(response["choices"]) == 0:
|
||||||
|
raise openai.APIError
|
||||||
|
return (response["choices"][0]['message']['content'],
|
||||||
|
response["choices"][0]["finish_reason"],
|
||||||
|
response)
|
||||||
|
|||||||
112
pr_agent/algo/ai_handlers/litellm_helpers.py
Normal file
112
pr_agent/algo/ai_handlers/litellm_helpers.py
Normal file
@ -0,0 +1,112 @@
|
|||||||
|
import json
|
||||||
|
|
||||||
|
import openai
|
||||||
|
|
||||||
|
from pr_agent.config_loader import get_settings
|
||||||
|
from pr_agent.log import get_logger
|
||||||
|
|
||||||
|
|
||||||
|
async def _handle_streaming_response(response):
|
||||||
|
"""
|
||||||
|
Handle streaming response from acompletion and collect the full response.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
response: The streaming response object from acompletion
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
tuple: (full_response_content, finish_reason)
|
||||||
|
"""
|
||||||
|
full_response = ""
|
||||||
|
finish_reason = None
|
||||||
|
|
||||||
|
try:
|
||||||
|
async for chunk in response:
|
||||||
|
if chunk.choices and len(chunk.choices) > 0:
|
||||||
|
choice = chunk.choices[0]
|
||||||
|
delta = choice.delta
|
||||||
|
content = getattr(delta, 'content', None)
|
||||||
|
if content:
|
||||||
|
full_response += content
|
||||||
|
if choice.finish_reason:
|
||||||
|
finish_reason = choice.finish_reason
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().error(f"Error handling streaming response: {e}")
|
||||||
|
raise
|
||||||
|
|
||||||
|
if not full_response and finish_reason is None:
|
||||||
|
get_logger().warning("Streaming response resulted in empty content with no finish reason")
|
||||||
|
raise openai.APIError("Empty streaming response received without proper completion")
|
||||||
|
elif not full_response and finish_reason:
|
||||||
|
get_logger().debug(f"Streaming response resulted in empty content but completed with finish_reason: {finish_reason}")
|
||||||
|
raise openai.APIError(f"Streaming response completed with finish_reason '{finish_reason}' but no content received")
|
||||||
|
return full_response, finish_reason
|
||||||
|
|
||||||
|
|
||||||
|
class MockResponse:
|
||||||
|
"""Mock response object for streaming models to enable consistent logging."""
|
||||||
|
|
||||||
|
def __init__(self, resp, finish_reason):
|
||||||
|
self._data = {
|
||||||
|
"choices": [
|
||||||
|
{
|
||||||
|
"message": {"content": resp},
|
||||||
|
"finish_reason": finish_reason
|
||||||
|
}
|
||||||
|
]
|
||||||
|
}
|
||||||
|
|
||||||
|
def dict(self):
|
||||||
|
return self._data
|
||||||
|
|
||||||
|
|
||||||
|
def _get_azure_ad_token():
|
||||||
|
"""
|
||||||
|
Generates an access token using Azure AD credentials from settings.
|
||||||
|
Returns:
|
||||||
|
str: The access token
|
||||||
|
"""
|
||||||
|
from azure.identity import ClientSecretCredential
|
||||||
|
try:
|
||||||
|
credential = ClientSecretCredential(
|
||||||
|
tenant_id=get_settings().azure_ad.tenant_id,
|
||||||
|
client_id=get_settings().azure_ad.client_id,
|
||||||
|
client_secret=get_settings().azure_ad.client_secret
|
||||||
|
)
|
||||||
|
# Get token for Azure OpenAI service
|
||||||
|
token = credential.get_token("https://cognitiveservices.azure.com/.default")
|
||||||
|
return token.token
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().error(f"Failed to get Azure AD token: {e}")
|
||||||
|
raise
|
||||||
|
|
||||||
|
|
||||||
|
def _process_litellm_extra_body(kwargs: dict) -> dict:
|
||||||
|
"""
|
||||||
|
Process LITELLM.EXTRA_BODY configuration and update kwargs accordingly.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
kwargs: The current kwargs dictionary to update
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
Updated kwargs dictionary
|
||||||
|
|
||||||
|
Raises:
|
||||||
|
ValueError: If extra_body contains invalid JSON, unsupported keys, or colliding keys
|
||||||
|
"""
|
||||||
|
allowed_extra_body_keys = {"processing_mode", "service_tier"}
|
||||||
|
extra_body = getattr(getattr(get_settings(), "litellm", None), "extra_body", None)
|
||||||
|
if extra_body:
|
||||||
|
try:
|
||||||
|
litellm_extra_body = json.loads(extra_body)
|
||||||
|
if not isinstance(litellm_extra_body, dict):
|
||||||
|
raise ValueError("LITELLM.EXTRA_BODY must be a JSON object")
|
||||||
|
unsupported_keys = set(litellm_extra_body.keys()) - allowed_extra_body_keys
|
||||||
|
if unsupported_keys:
|
||||||
|
raise ValueError(f"LITELLM.EXTRA_BODY contains unsupported keys: {', '.join(unsupported_keys)}. Allowed keys: {', '.join(allowed_extra_body_keys)}")
|
||||||
|
colliding_keys = kwargs.keys() & litellm_extra_body.keys()
|
||||||
|
if colliding_keys:
|
||||||
|
raise ValueError(f"LITELLM.EXTRA_BODY cannot override existing parameters: {', '.join(colliding_keys)}")
|
||||||
|
kwargs.update(litellm_extra_body)
|
||||||
|
except json.JSONDecodeError as e:
|
||||||
|
raise ValueError(f"LITELLM.EXTRA_BODY contains invalid JSON: {str(e)}")
|
||||||
|
return kwargs
|
||||||
@ -103,7 +103,7 @@ def prepare_repo(url: urllib3.util.Url, project, refspec):
|
|||||||
repo_url = (f"{url.scheme}://{url.auth}@{url.host}:{url.port}/{project}")
|
repo_url = (f"{url.scheme}://{url.auth}@{url.host}:{url.port}/{project}")
|
||||||
|
|
||||||
directory = pathlib.Path(mkdtemp())
|
directory = pathlib.Path(mkdtemp())
|
||||||
clone(repo_url, directory),
|
clone(repo_url, directory)
|
||||||
fetch(repo_url, refspec, cwd=directory)
|
fetch(repo_url, refspec, cwd=directory)
|
||||||
checkout(cwd=directory)
|
checkout(cwd=directory)
|
||||||
return directory
|
return directory
|
||||||
|
|||||||
@ -1,6 +1,7 @@
|
|||||||
import ast
|
import ast
|
||||||
import json
|
import json
|
||||||
import os
|
import os
|
||||||
|
import re
|
||||||
from typing import List
|
from typing import List
|
||||||
|
|
||||||
import uvicorn
|
import uvicorn
|
||||||
@ -40,6 +41,88 @@ def handle_request(
|
|||||||
|
|
||||||
background_tasks.add_task(inner)
|
background_tasks.add_task(inner)
|
||||||
|
|
||||||
|
def should_process_pr_logic(data) -> bool:
|
||||||
|
try:
|
||||||
|
pr_data = data.get("pullRequest", {})
|
||||||
|
title = pr_data.get("title", "")
|
||||||
|
|
||||||
|
from_ref = pr_data.get("fromRef", {})
|
||||||
|
source_branch = from_ref.get("displayId", "") if from_ref else ""
|
||||||
|
|
||||||
|
to_ref = pr_data.get("toRef", {})
|
||||||
|
target_branch = to_ref.get("displayId", "") if to_ref else ""
|
||||||
|
|
||||||
|
author = pr_data.get("author", {})
|
||||||
|
user = author.get("user", {}) if author else {}
|
||||||
|
sender = user.get("name", "") if user else ""
|
||||||
|
|
||||||
|
repository = to_ref.get("repository", {}) if to_ref else {}
|
||||||
|
project = repository.get("project", {}) if repository else {}
|
||||||
|
project_key = project.get("key", "") if project else ""
|
||||||
|
repo_slug = repository.get("slug", "") if repository else ""
|
||||||
|
|
||||||
|
repo_full_name = f"{project_key}/{repo_slug}" if project_key and repo_slug else ""
|
||||||
|
pr_id = pr_data.get("id", None)
|
||||||
|
|
||||||
|
# To ignore PRs from specific repositories
|
||||||
|
ignore_repos = get_settings().get("CONFIG.IGNORE_REPOSITORIES", [])
|
||||||
|
if repo_full_name and ignore_repos:
|
||||||
|
if any(re.search(regex, repo_full_name) for regex in ignore_repos):
|
||||||
|
get_logger().info(f"Ignoring PR from repository '{repo_full_name}' due to 'config.ignore_repositories' setting")
|
||||||
|
return False
|
||||||
|
|
||||||
|
# To ignore PRs from specific users
|
||||||
|
ignore_pr_users = get_settings().get("CONFIG.IGNORE_PR_AUTHORS", [])
|
||||||
|
if ignore_pr_users and sender:
|
||||||
|
if any(re.search(regex, sender) for regex in ignore_pr_users):
|
||||||
|
get_logger().info(f"Ignoring PR from user '{sender}' due to 'config.ignore_pr_authors' setting")
|
||||||
|
return False
|
||||||
|
|
||||||
|
# To ignore PRs with specific titles
|
||||||
|
if title:
|
||||||
|
ignore_pr_title_re = get_settings().get("CONFIG.IGNORE_PR_TITLE", [])
|
||||||
|
if not isinstance(ignore_pr_title_re, list):
|
||||||
|
ignore_pr_title_re = [ignore_pr_title_re]
|
||||||
|
if ignore_pr_title_re and any(re.search(regex, title) for regex in ignore_pr_title_re):
|
||||||
|
get_logger().info(f"Ignoring PR with title '{title}' due to config.ignore_pr_title setting")
|
||||||
|
return False
|
||||||
|
|
||||||
|
ignore_pr_source_branches = get_settings().get("CONFIG.IGNORE_PR_SOURCE_BRANCHES", [])
|
||||||
|
ignore_pr_target_branches = get_settings().get("CONFIG.IGNORE_PR_TARGET_BRANCHES", [])
|
||||||
|
if (ignore_pr_source_branches or ignore_pr_target_branches):
|
||||||
|
if any(re.search(regex, source_branch) for regex in ignore_pr_source_branches):
|
||||||
|
get_logger().info(
|
||||||
|
f"Ignoring PR with source branch '{source_branch}' due to config.ignore_pr_source_branches settings")
|
||||||
|
return False
|
||||||
|
if any(re.search(regex, target_branch) for regex in ignore_pr_target_branches):
|
||||||
|
get_logger().info(
|
||||||
|
f"Ignoring PR with target branch '{target_branch}' due to config.ignore_pr_target_branches settings")
|
||||||
|
return False
|
||||||
|
|
||||||
|
# Allow_only_specific_folders
|
||||||
|
allowed_folders = get_settings().config.get("allow_only_specific_folders", [])
|
||||||
|
if allowed_folders and pr_id and project_key and repo_slug:
|
||||||
|
from pr_agent.git_providers.bitbucket_server_provider import BitbucketServerProvider
|
||||||
|
bitbucket_server_url = get_settings().get("BITBUCKET_SERVER.URL", "")
|
||||||
|
pr_url = f"{bitbucket_server_url}/projects/{project_key}/repos/{repo_slug}/pull-requests/{pr_id}"
|
||||||
|
provider = BitbucketServerProvider(pr_url=pr_url)
|
||||||
|
changed_files = provider.get_files()
|
||||||
|
if changed_files:
|
||||||
|
# Check if ALL files are outside allowed folders
|
||||||
|
all_files_outside = True
|
||||||
|
for file_path in changed_files:
|
||||||
|
if any(file_path.startswith(folder) for folder in allowed_folders):
|
||||||
|
all_files_outside = False
|
||||||
|
break
|
||||||
|
|
||||||
|
if all_files_outside:
|
||||||
|
get_logger().info(f"Ignoring PR because all files {changed_files} are outside allowed folders {allowed_folders}")
|
||||||
|
return False
|
||||||
|
except Exception as e:
|
||||||
|
get_logger().error(f"Failed 'should_process_pr_logic': {e}")
|
||||||
|
return True # On exception - we continue. Otherwise, we could just end up with filtering all PRs
|
||||||
|
return True
|
||||||
|
|
||||||
@router.post("/")
|
@router.post("/")
|
||||||
async def redirect_to_webhook():
|
async def redirect_to_webhook():
|
||||||
return RedirectResponse(url="/webhook")
|
return RedirectResponse(url="/webhook")
|
||||||
@ -73,6 +156,11 @@ async def handle_webhook(background_tasks: BackgroundTasks, request: Request):
|
|||||||
|
|
||||||
if data["eventKey"] == "pr:opened":
|
if data["eventKey"] == "pr:opened":
|
||||||
apply_repo_settings(pr_url)
|
apply_repo_settings(pr_url)
|
||||||
|
if not should_process_pr_logic(data):
|
||||||
|
get_logger().info(f"PR ignored due to config settings", **log_context)
|
||||||
|
return JSONResponse(
|
||||||
|
status_code=status.HTTP_200_OK, content=jsonable_encoder({"message": "PR ignored by config"})
|
||||||
|
)
|
||||||
if get_settings().config.disable_auto_feedback: # auto commands for PR, and auto feedback is disabled
|
if get_settings().config.disable_auto_feedback: # auto commands for PR, and auto feedback is disabled
|
||||||
get_logger().info(f"Auto feedback is disabled, skipping auto commands for PR {pr_url}", **log_context)
|
get_logger().info(f"Auto feedback is disabled, skipping auto commands for PR {pr_url}", **log_context)
|
||||||
return
|
return
|
||||||
|
|||||||
@ -234,6 +234,9 @@ async def gitlab_webhook(background_tasks: BackgroundTasks, request: Request):
|
|||||||
get_logger().info(f"Skipping draft MR: {url}")
|
get_logger().info(f"Skipping draft MR: {url}")
|
||||||
return JSONResponse(status_code=status.HTTP_200_OK, content=jsonable_encoder({"message": "success"}))
|
return JSONResponse(status_code=status.HTTP_200_OK, content=jsonable_encoder({"message": "success"}))
|
||||||
|
|
||||||
|
# Apply repo settings before checking push commands or handle_push_trigger
|
||||||
|
apply_repo_settings(url)
|
||||||
|
|
||||||
commands_on_push = get_settings().get(f"gitlab.push_commands", {})
|
commands_on_push = get_settings().get(f"gitlab.push_commands", {})
|
||||||
handle_push_trigger = get_settings().get(f"gitlab.handle_push_trigger", False)
|
handle_push_trigger = get_settings().get(f"gitlab.handle_push_trigger", False)
|
||||||
if not commands_on_push or not handle_push_trigger:
|
if not commands_on_push or not handle_push_trigger:
|
||||||
@ -282,8 +285,8 @@ def handle_ask_line(body, data):
|
|||||||
question = body.replace('/ask', '').strip()
|
question = body.replace('/ask', '').strip()
|
||||||
path = data['object_attributes']['position']['new_path']
|
path = data['object_attributes']['position']['new_path']
|
||||||
side = 'RIGHT' # if line_range_['start']['type'] == 'new' else 'LEFT'
|
side = 'RIGHT' # if line_range_['start']['type'] == 'new' else 'LEFT'
|
||||||
comment_id = data['object_attributes']["discussion_id"]
|
_id = data['object_attributes']["discussion_id"]
|
||||||
get_logger().info("Handling line comment")
|
get_logger().info("Handling line ")
|
||||||
body = f"/ask_line --line_start={start_line} --line_end={end_line} --side={side} --file_name={path} --comment_id={comment_id} {question}"
|
body = f"/ask_line --line_start={start_line} --line_end={end_line} --side={side} --file_name={path} --comment_id={comment_id} {question}"
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
get_logger().error(f"Failed to handle ask line comment: {e}")
|
get_logger().error(f"Failed to handle ask line comment: {e}")
|
||||||
|
|||||||
@ -81,6 +81,7 @@ the tool will replace every marker of the form `pr_agent:marker_name` in the PR
|
|||||||
- `type`: the PR type.
|
- `type`: the PR type.
|
||||||
- `summary`: the PR summary.
|
- `summary`: the PR summary.
|
||||||
- `walkthrough`: the PR walkthrough.
|
- `walkthrough`: the PR walkthrough.
|
||||||
|
- `diagram`: the PR sequence diagram (if enabled).
|
||||||
|
|
||||||
Note that when markers are enabled, if the original PR description does not contain any markers, the tool will not alter the description at all.
|
Note that when markers are enabled, if the original PR description does not contain any markers, the tool will not alter the description at all.
|
||||||
|
|
||||||
|
|||||||
@ -16,6 +16,10 @@ key = "" # Acquire through https://platform.openai.com
|
|||||||
#deployment_id = "" # The deployment name you chose when you deployed the engine
|
#deployment_id = "" # The deployment name you chose when you deployed the engine
|
||||||
#fallback_deployments = [] # For each fallback model specified in configuration.toml in the [config] section, specify the appropriate deployment_id
|
#fallback_deployments = [] # For each fallback model specified in configuration.toml in the [config] section, specify the appropriate deployment_id
|
||||||
|
|
||||||
|
# OpenAI Flex Processing (optional, for cost savings)
|
||||||
|
# [litellm]
|
||||||
|
# extra_body='{"processing_mode": "flex"}'
|
||||||
|
|
||||||
[pinecone]
|
[pinecone]
|
||||||
api_key = "..."
|
api_key = "..."
|
||||||
environment = "gcp-starter"
|
environment = "gcp-starter"
|
||||||
|
|||||||
@ -5,7 +5,7 @@ In addition to evaluating the suggestion correctness and importance, another sub
|
|||||||
|
|
||||||
Examine each suggestion meticulously, assessing its quality, relevance, and accuracy within the context of PR. Keep in mind that the suggestions may vary in their correctness, accuracy and impact.
|
Examine each suggestion meticulously, assessing its quality, relevance, and accuracy within the context of PR. Keep in mind that the suggestions may vary in their correctness, accuracy and impact.
|
||||||
Consider the following components of each suggestion:
|
Consider the following components of each suggestion:
|
||||||
1. 'one_sentence_summary' - A one-liner summary summary of the suggestion's purpose
|
1. 'one_sentence_summary' - A one-liner summary of the suggestion's purpose
|
||||||
2. 'suggestion_content' - The suggestion content, explaining the proposed modification
|
2. 'suggestion_content' - The suggestion content, explaining the proposed modification
|
||||||
3. 'existing_code' - a code snippet from a __new hunk__ section in the PR code diff that the suggestion addresses
|
3. 'existing_code' - a code snippet from a __new hunk__ section in the PR code diff that the suggestion addresses
|
||||||
4. 'improved_code' - a code snippet demonstrating how the 'existing_code' should be after the suggestion is applied
|
4. 'improved_code' - a code snippet demonstrating how the 'existing_code' should be after the suggestion is applied
|
||||||
|
|||||||
@ -8,7 +8,7 @@
|
|||||||
# models
|
# models
|
||||||
model="o4-mini"
|
model="o4-mini"
|
||||||
fallback_models=["gpt-4.1"]
|
fallback_models=["gpt-4.1"]
|
||||||
#model_reasoning="o4-mini" # dedictated reasoning model for self-reflection
|
#model_reasoning="o4-mini" # dedicated reasoning model for self-reflection
|
||||||
#model_weak="gpt-4o" # optional, a weaker model to use for some easier tasks
|
#model_weak="gpt-4o" # optional, a weaker model to use for some easier tasks
|
||||||
# CLI
|
# CLI
|
||||||
git_provider="github"
|
git_provider="github"
|
||||||
|
|||||||
@ -48,7 +48,7 @@ class PRDescription(BaseModel):
|
|||||||
description: str = Field(description="summarize the PR changes in up to four bullet points, each up to 8 words. For large PRs, add sub-bullets if needed. Order bullets by importance, with each bullet highlighting a key change group.")
|
description: str = Field(description="summarize the PR changes in up to four bullet points, each up to 8 words. For large PRs, add sub-bullets if needed. Order bullets by importance, with each bullet highlighting a key change group.")
|
||||||
title: str = Field(description="a concise and descriptive title that captures the PR's main theme")
|
title: str = Field(description="a concise and descriptive title that captures the PR's main theme")
|
||||||
{%- if enable_pr_diagram %}
|
{%- if enable_pr_diagram %}
|
||||||
changes_diagram: str = Field(description="a horizontal diagram that represents the main PR changes, in the format of a valid mermaid LR flowchart. The diagram should be concise and easy to read. Leave empty if no diagram is relevant. To create robust Mermaid diagrams, follow this two-step process: (1) Declare the nodes: nodeID["node description"]. (2) Then define the links: nodeID1 -- "link text" --> nodeID2. Node description must always be surrounded with quotation marks.")
|
changes_diagram: str = Field(description="a horizontal diagram that represents the main PR changes, in the format of a valid mermaid LR flowchart. The diagram should be concise and easy to read. Leave empty if no diagram is relevant. To create robust Mermaid diagrams, follow this two-step process: (1) Declare the nodes: nodeID[\"node description\"]. (2) Then define the links: nodeID1 -- \"link text\" --> nodeID2. Node description must always be surrounded with quotation marks.")
|
||||||
{%- endif %}
|
{%- endif %}
|
||||||
{%- if enable_semantic_files_types %}
|
{%- if enable_semantic_files_types %}
|
||||||
pr_files: List[FileDescription] = Field(max_items=20, description="a list of all the files that were changed in the PR, and summary of their changes. Each file must be analyzed regardless of change size.")
|
pr_files: List[FileDescription] = Field(max_items=20, description="a list of all the files that were changed in the PR, and summary of their changes. Each file must be analyzed regardless of change size.")
|
||||||
|
|||||||
@ -169,7 +169,7 @@ class PRDescription:
|
|||||||
|
|
||||||
# publish description
|
# publish description
|
||||||
if get_settings().pr_description.publish_description_as_comment:
|
if get_settings().pr_description.publish_description_as_comment:
|
||||||
full_markdown_description = f"## Title\n\n{pr_title}\n\n___\n{pr_body}"
|
full_markdown_description = f"## Title\n\n{pr_title.strip()}\n\n___\n{pr_body}"
|
||||||
if get_settings().pr_description.publish_description_as_comment_persistent:
|
if get_settings().pr_description.publish_description_as_comment_persistent:
|
||||||
self.git_provider.publish_persistent_comment(full_markdown_description,
|
self.git_provider.publish_persistent_comment(full_markdown_description,
|
||||||
initial_header="## Title",
|
initial_header="## Title",
|
||||||
@ -179,7 +179,7 @@ class PRDescription:
|
|||||||
else:
|
else:
|
||||||
self.git_provider.publish_comment(full_markdown_description)
|
self.git_provider.publish_comment(full_markdown_description)
|
||||||
else:
|
else:
|
||||||
self.git_provider.publish_description(pr_title, pr_body)
|
self.git_provider.publish_description(pr_title.strip(), pr_body)
|
||||||
|
|
||||||
# publish final update message
|
# publish final update message
|
||||||
if (get_settings().pr_description.final_update_message and not get_settings().config.get('is_auto_command', False)):
|
if (get_settings().pr_description.final_update_message and not get_settings().config.get('is_auto_command', False)):
|
||||||
@ -538,6 +538,11 @@ class PRDescription:
|
|||||||
get_logger().error(f"Failing to process walkthrough {self.pr_id}: {e}")
|
get_logger().error(f"Failing to process walkthrough {self.pr_id}: {e}")
|
||||||
body = body.replace('pr_agent:walkthrough', "")
|
body = body.replace('pr_agent:walkthrough', "")
|
||||||
|
|
||||||
|
# Add support for pr_agent:diagram marker (plain and HTML comment formats)
|
||||||
|
ai_diagram = self.data.get('changes_diagram')
|
||||||
|
if ai_diagram:
|
||||||
|
body = re.sub(r'<!--\s*pr_agent:diagram\s*-->|pr_agent:diagram', ai_diagram, body)
|
||||||
|
|
||||||
return title, body, walkthrough_gfm, pr_file_changes
|
return title, body, walkthrough_gfm, pr_file_changes
|
||||||
|
|
||||||
def _prepare_pr_answer(self) -> Tuple[str, str, str, List[dict]]:
|
def _prepare_pr_answer(self) -> Tuple[str, str, str, List[dict]]:
|
||||||
|
|||||||
Reference in New Issue
Block a user